OpenAI GPT‑5.2 set for Dec 9 – latency, tools take priority
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
OpenAI is reportedly pulling GPT‑5.2 forward to around Dec 9, a “code red” release aimed squarely at Google’s new Gemini 3 stack. After last week’s Deep Think evals and the earlier GPT‑5 “confessions” head, this update is about keeping ChatGPT and the 5.x API competitive on feel: lower latency, more reliable tool calls, and behavior that’s easier to steer with dense system prompts and profiles.
Leakers say don’t expect a flashy keynote model family—5.2 should slot under existing GPT‑5 endpoints as a backend swap, so your apps change overnight with no integration work. If the rumors on faster end‑to‑end latency and better time‑to‑first‑token (TTFT) hold, teams running complex MCP or Codex chains will want to re‑measure timeouts, tool failure modes, and routing logic the moment it hits production (good news if you like silent upgrades, less fun if you own the SLOs).
One source also links GPT‑5.2 to the research model that scored a gold medal on an IMO‑style math contest and reportedly helped originate publishable physics and math insights. If that’s accurate, OpenAI isn’t pushing the frontier forward this week so much as productizing it—and tightening safety and governance dials around those reasoning capabilities before they reach the default ChatGPT surface.
Top links today
- Verge report on OpenAI GPT-5.2 rollout
- Efficient tokenizer adaptation for pretrained models
- Nex-N1 agentic model and training ecosystem
- SkillFactory self-distillation for cognitive behaviors
- LLM reasoning for abstractive summarization
- Multi-LLM collaboration for medication recommendation
- LegalWebAgent LLM-based legal web assistant
- LexGenius benchmark for legal general intelligence
- Genre study with syntax, metaphor and phonetics
- Microsoft–Broadcom deal for custom Azure AI chips
- Washington Post on ChatGPT vs Gemini competition
- WSJ on SpaceX $800B valuation share sale
- NYTimes on AI-focused college degree boom
Feature Spotlight
Feature: OpenAI’s GPT‑5.2 “code red” push to counter Gemini 3
Reports say GPT‑5.2 may land Dec 9 as a ‘code red’ response to Gemini 3, aiming to boost reasoning speed/reliability and close benchmark gaps.
Multiple sources say OpenAI pulled forward GPT‑5.2 (target Dec 9) to close Gemini 3’s lead. Today’s chatter centers on speed, reliability, and previews tying the model to recent competition wins. Focus is the release timing and stakes.
Jump to Feature: OpenAI’s GPT‑5.2 “code red” push to counter Gemini 3 topicsTable of Contents
🚨 Feature: OpenAI’s GPT‑5.2 “code red” push to counter Gemini 3
Multiple sources say OpenAI pulled forward GPT‑5.2 (target Dec 9) to close Gemini 3’s lead. Today’s chatter centers on speed, reliability, and previews tying the model to recent competition wins. Focus is the release timing and stakes.
GPT‑5.2 tipped for Dec 9 as OpenAI’s “code red” reply to Gemini 3
Multiple reports say OpenAI has pulled GPT‑5.2 forward to a December 9 release window after Sam Altman reportedly declared a “code red” in response to Google’s Gemini 3 launch and its leaderboard wins. Verge snippet The Verge piece and follow‑on summaries frame 5.2 as OpenAI’s first direct answer to Gemini 3, with internal pressure high enough that the update was moved up from later in December. rumor summary This is soon.
Community commentators are treating this less as a flashy product event and more as a backend upgrade that keeps ChatGPT and the API competitive on raw capability and responsiveness, rather than introducing new UI surfaces. counter framing Several threads explicitly describe it as a “code red response” meant to close the performance gap Gemini opened, not a new frontier family. analysis thread For AI leads, the signal is that model quality and speed in the 5.x line may change materially next week without any migration work on your side.
GPT‑5.2 rumored to prioritize latency, tool reliability and steerability over new features
Commentary on the Verge leak says GPT‑5.2 is aimed at making ChatGPT and the API feel better in day‑to‑day use: faster responses, fewer failed tool calls, and behavior that’s easier to shape with instructions or profiles, rather than headline‑grabbing new UX. analysis thread The point is: this looks like an ops‑focused release for people already wiring GPT‑5.x into agents and apps.
Analysts expect improvements in end‑to‑end latency and tool call robustness to matter more than raw benchmark jumps, especially as Gemini 3 and Claude 4.5 have raised expectations around long, tool‑heavy workflows and reliability. cadence comment If those expectations are accurate, teams running complex toolchains (Codex, MCP tools, custom backends) should be ready to re‑measure timeout budgets, error rates, and routing rules once 5.2 goes live, even though your integration surface stays the same.
Leakers link GPT‑5.2 to the model that already hit IMO‑style gold
One well‑connected account claims their source says GPT‑5.2 is the same underlying model that won a gold medal on an IMO‑style math contest this summer, implying the weights have already demonstrated world‑class competition‑level reasoning. imo gold claim If true, 5.2 would be more about productizing a proven research model than debuting something completely new.
That rumor lands alongside other recent anecdotes of GPT‑5‑class systems originating non‑trivial physics and math insights that survived peer review, physics paper image reinforcing the idea that OpenAI’s frontier stack is shifting from “just scale and polish” towards models that can contribute original technical work. For engineers and analysts, this raises two immediate questions: how much of that high‑end reasoning makes it into the general‑purpose 5.2 deployment, and what governance or safety constraints might be tightened around those capabilities once they’re in mainstream ChatGPT and API tiers.
🧠 New frontier and media models (Qwen TTS, HY 2.0, LongCat)
Fresh model drops relevant to builders: Alibaba’s multilingual TTS update, Tencent’s HY 2.0 MoE with big math/coding lifts, and LongCat image/edit models. Mostly concrete releases; excludes GPT‑5.2 (feature).
Tencent unveils HY 2.0 MoE with big math and coding gains
Tencent announced HY 2.0, a 406B‑parameter Mixture‑of‑Experts model with 32B active parameters and a 256K context window, offered in two variants: Think for deep reasoning/coding and Instruct for general chat. release thread On internal and public benchmarks it jumps from 61.1→73.4 on IMO‑AnswerBench, 6.0→53.0 on SWE‑bench Verified, and 17.1→72.4 on Tau2‑Bench compared to their previous Hunyuan‑T1 model, putting it in the top cluster alongside GPT‑5‑think and Qwen3‑235B‑think for math, multi‑turn instructions, and agentic code tasks.
A second plot shows HY 2.0‑Think achieving similar or better average accuracy than peers while using fewer tokens per task, suggesting it can be competitive on complex workloads without blowing up inference cost. release thread
Alibaba ships Qwen3‑TTS with 49+ voices across 10 languages
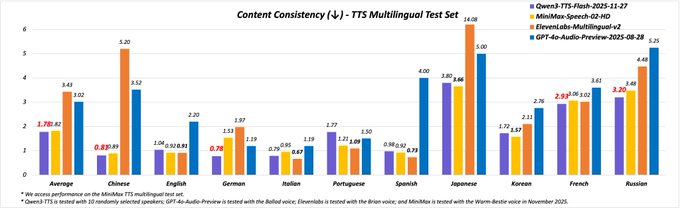
Alibaba’s Qwen team released Qwen3‑TTS (2025‑11‑27), a multilingual text‑to‑speech model with 49+ distinct voices, coverage for 10 major languages plus several Chinese dialects, and both realtime and offline APIs aimed at agents and apps. release thread It reports the best average content‑consistency score (1.78 vs 1.82 for MiniMax, 3.02 for GPT‑4o‑Audio, 3.43 for ElevenLabs; lower is better) on a multilingual TTS test set, with especially large gains in Chinese and Japanese.
Builders can try it via Qwen Chat’s “Read aloud” button or integrate it through Qwen’s Realtime and Offline TTS endpoints, release thread and early community responses frame it as a meaningful step for high‑quality non‑English voices (“Such an awesome moment!”). builder reaction
LongCat‑Image open weights focus on photorealism and strong text rendering
Meituan’s LongCat‑Image model is now available as open weights on Hugging Face and third‑party platforms, showing unusually strong text rendering and layout control across signage, posters, and UI‑like compositions while keeping photorealism on characters, food, and scenes. model announcement Example grids span stylized book covers, Chinese exhibition posters, chalkboard menus, cartoon stickers, and realistic landscapes, all with clean, legible text in multiple languages.
The team and partners have also wired LongCat‑Image into hosted runtimes like fal, so builders can hit simple text‑to‑image endpoints rather than standing up their own diffusion stack, making it an attractive default for apps that care about accurate on‑image text. fal hosting
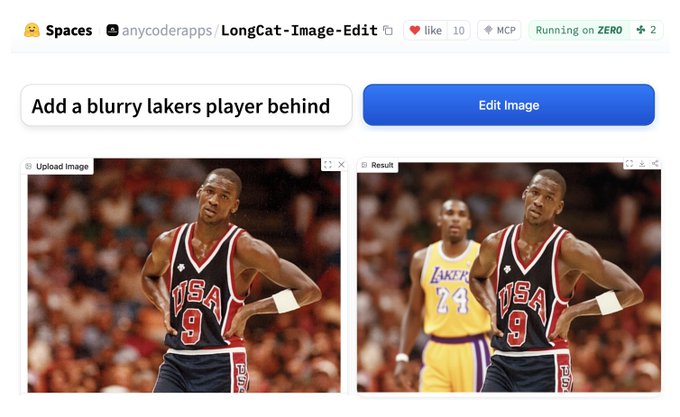
LongCat‑Image‑Edit ships Apache‑2.0 image editing with precise local control
Alongside the base generator, Meituan released LongCat‑Image‑Edit under an Apache‑2.0 license, targeting precise global, local, and text‑based edits over existing images. edit announcement Demos show it cleanly replacing objects in‑place—like turning a banana into an apple on a grassy block with the simple prompt “replace the banana with an apple” while preserving lighting, shadows, and composition.
The model is live both as open weights on Hugging Face for self‑hosting, edit model card and as a managed API on fal where developers can hit separate routes for global edits, local masks, and caption‑driven modifications, making it a practical building block for consumer editors and design tools. fal integration
📈 Benchmarks: Claude Code cracks CORE‑Bench; Grok, Nova and FLUX.2 updates
Today’s evals span agentic science, expert prompts, long‑context retrieval, and media. Continues yesterday’s race with fresh charts and tool‑specific gains. Excludes GPT‑5.2 which is covered as the feature.
Claude Opus 4.5 with Claude Code hits 95% on CORE‑Bench Hard
Anthropic’s Opus 4.5 paired with Claude Code scores 95% on the CORE‑Bench Hard agentic science benchmark, up from 42% with the earlier CORE‑Agent scaffold, after manual grading added 17 percentage points that auto‑grading had missed. Following core-bench solved, HAL’s new chart shows Claude Code roughly doubling accuracy for Opus 4.5 and giving sizable lifts to Sonnet 4.5 (62% vs 44%), Opus 4.1 (42% vs 51% under the old harness), and Sonnet 4 (47% vs 33%), underscoring how much the scaffold—not just the base model—gates reproducibility performance. core-bench chart Manual review also exposed brittleness in the original auto‑grader, which mis‑marked valid alternate runs, so serious users should treat CORE‑Bench scores as “model + harness + grader” rather than a pure model ranking. core-bench explainer
Arena Expert shows thinking models shine on hardest prompts
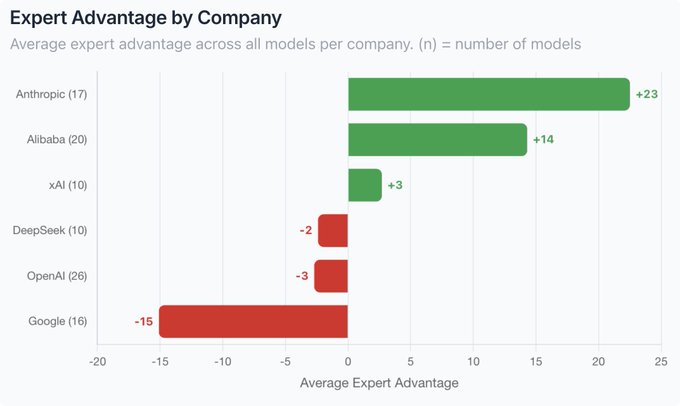
LMArena’s new Arena Expert leaderboard finds “thinking” models score on average 24 ELO points higher than non‑thinking ones on expert‑level prompts, giving teams a clearer signal than general chat comparisons. expert summary Opus 4.5 is a notable outlier: even in its non‑thinking setting it gains an +85 Expert Advantage over its General rating and ends up 105 points ahead of Grok 4.1 on expert prompts despite similar General ranks, suggesting it generalizes unusually well to frontier‑user questions. expert gap note The analysis argues that expert prompts expose differences in reasoning depth and calibration that generic question sets blur together, and recommends evaluating both thinking and non‑thinking variants when choosing a primary model for advanced users. expert analysis
FLUX.2 [dev/pro/flex] approach frontier text‑to‑image quality
Black Forest Labs’ FLUX.2 family now sits near the top of several community text‑to‑image leaderboards: Artificial Analysis ranks FLUX.2 [pro] and [flex] #2 and #4 globally, while FLUX.2 [dev] leads the open‑weights segment with an ELO around 1,152. aa leaderboard On LMArena’s open‑weights board, FLUX.2 [dev] also occupies the #1 slot, with the older FLUX.1 [dev] still in the top 10, and the project has passed 1M downloads across BFL and ComfyUI variants—evidence that open models are becoming viable front‑line choices for production‑grade image work, not just hobby use. arena rankings
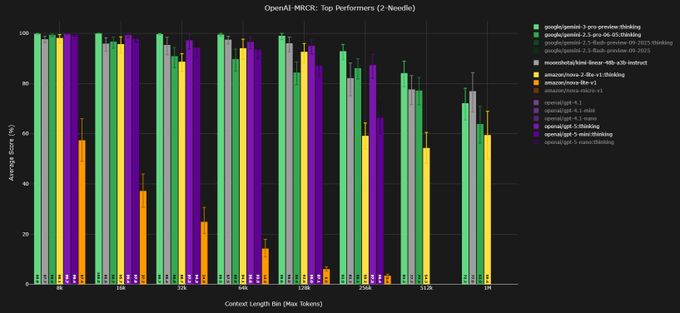
Nova‑2‑lite‑thinking posts strong MRCR scores at 128k context
Amazon’s nova‑2‑lite‑v1:thinking posts impressive long‑context retrieval numbers on the MRCR benchmark, hitting 92.9% AUC on 2‑needle, 70.1% on 4‑needle, and 45.5% on 8‑needle at 128k tokens—ranking #4, #4, and #5 respectively while costing less per run than Gemini 2.5 Flash Thinking in this tier. mrcr results Evaluator Dillon Uzar notes that nova’s token efficiency falls off near 1M‑token tests, where about half the runs hit context limits or OOM, so the sweet spot is sub‑256k contexts where its price‑to‑performance looks "incredible" versus both Flash and GPT‑4.1‑class baselines. (mrcr commentary, mrcr followup)
Grok 4.1 Fast Reasoning leads T²‑Bench‑Verified tool‑use benchmark
On the cross‑industry T²‑Bench‑Verified evaluation, xAI’s Grok 4.1 Fast Reasoning edges out larger rivals with an 82.71% average across airline, retail, and telecom workloads, ahead of Claude Opus 4.5 (81.99%), GPT‑5 reasoning med (79.92%), Gemini 3 Pro (79.39%) and Nova 2 Pro (78.53%). t2bench leaderboard The benchmark tests end‑to‑end, tool‑augmented decision making (not bare QA), so this result suggests Grok’s fast‑reasoning variant is particularly well‑tuned for structured, multi‑step business tasks—though teams should still weigh this against missing transparency around xAI’s training and safety procedures called out elsewhere. xai transparency concern
Poetiq refinement stack surpasses Deep Think on ARC‑AGI‑2
ARC Prize organizers have now verified Poetiq’s refinement pipeline—built on Gemini 3 Pro plus GPT‑5.1 and a custom scaffold—at 54% on the semi‑private ARC‑AGI‑2 set, down from an initially reported 61% on public data but still ahead of Gemini 3 Deep Think’s 45.1% tools‑on score. (arc-agi scatter, deepthink chart) Following deepthink evals where Deep Think led among first‑party frontier models, this shows a well‑engineered, multi‑model agentic stack can overtake single‑model systems on hard reasoning puzzles when you’re willing to pay some orchestration and inference cost.
🛠️ Coding agents and dev tools in practice
Hands‑on improvements to agent workflows and coding ops: Claude Code usage controls, PR review automation, team CLIs, cost tracking, and IDE support. Excludes ACP/AG‑UI protocol news (see Interop).
Claude Code adds /export, /resume and pay‑as‑you‑go overflow for long sessions
Anthropic quietly made Claude Code much more usable for real projects: Pro and Max users can now export whole coding sessions to a file with /export, resume old sessions with /resume, and opt into “extra usage” so work doesn’t stop when plan limits are hit. Following up on Claude Code access, where Opus 4.5 first landed in the IDE, these changes let people treat Claude Code as a persistent coding environment instead of a disposable chat.
The /export command saves a timestamped text file of your conversation so you can archive or share complex agent runs without screenshot gymnastics. /resume lists recent sessions across projects and reattaches the agent to a prior thread, which matters once you’re running multi‑hour refactors or investigations across many repos. Extra usage lets Pro/Max subscribers flip to API pricing after they exhaust their built‑in quota, so they can finish a long debug or migration run instead of getting hard‑stopped mid‑task extra usage article. Builders already calling Opus 4.5 in Claude Code “the best coding assistant on the planet” power user praise now get the missing plumbing to run it like a serious tool rather than a toy chat window export command resume command.
Kilo Code launches AI Code Reviews that comment directly on pull requests
Kilo Code rolled out "Code Reviews": an AI reviewer that attaches to GitHub pull requests, inspects diffs as soon as a PR opens or updates, and leaves inline comments plus a summary focused on security, performance, style, and test coverage code reviews demo. Instead of running a separate bot or CLI, teams get review feedback in the native PR UI.

You configure what to optimize for (e.g., SQL injection checks vs. performance hot paths), and the system runs on every PR so lower‑visibility changes still get coverage. The blog walks through how it plugs into existing repos and how to tune rules per service rather than one global policy blog post. For engineering leaders who struggle with inconsistent human reviews, this gives a way to apply house standards on every change while keeping human reviewers focused on architectural and product decisions instead of nitpicking.
Taskmaster v0.37 adds team PRDs, lean MCP toolsets and enterprise proxy support
Taskmaster, the CLI agent orchestrator, shipped a big v0.37 update that turns it from a solo toy into a team‑ready planning tool. The new init flow lets you choose SOLO (local PRDs + tasks in files) or TOGETHER mode, where briefs and tasks live in Hamster (usehamster) so multiple people can collaborate on the same plan feature overview.

Key changes: tm export can reverse‑engineer a PRD from your local tasks and push it into Hamster as a shareable plan; parse-prd now has a Hamster path that turns a narrative brief into a synced task list your whole team can work from export to hamster parse prd options. A new MCP toolkit config (core/standard/all) cuts token use by loading only 7–14 essential tools instead of the full 44‑tool set when you don’t need everything mcp toolkit sizes. Enterprise users get proxy support via TASKMASTER_ENABLE_PROXY, and model support has expanded to GPT‑5/GPT‑5‑Codex, LM Studio local models, Zhipu GLM, Gemini 3 Pro, and the latest Claude models provider matrix. There’s also a first‑party Claude Code plugin so you can run Taskmaster flows directly from Anthropic’s IDE claude code plugin. For teams trying to standardize how they brief, plan, and execute multi‑step coding work with agents, this release moves Taskmaster closer to a real workflow backbone instead of a personal script.
Cline surfaces GPT‑5.1‑Codex‑Max and invites builders to extend its CLI
The Cline IDE now exposes openai/gpt-5.1-codex-max as a first‑class option in its model picker, alongside Claude Sonnet/Opus and Gemini 3 Pro, with an optional "thinking" toggle for extra reasoning tokens cline model selector. That makes OpenAI’s strongest coding model available inside the same agent harness Cline users already rely on for repo‑wide edits.
Separately, Cline’s maintainers are encouraging people to build on the Cline CLI at the AI Agents Assemble virtual hackathon, co‑hosted with Vercel, Together, CodeRabbit and others hackathon call. The event specifically calls out ideas like review bots, GitHub Actions and mobile apps wired into Cline’s agent loop, with $15k in prizes and swag hackathon page. For AI engineers, the combination of Codex‑Max support and a CLI designed for automation is an invitation to treat Cline as an agent runtime for serious codebases, not just a VS Code side panel.
LangSmith now tracks custom tool and API costs alongside LLM spend
LangChain’s LangSmith added support for arbitrary cost metadata on any run, so traces can show not only LLM token charges but also what you spent on external APIs, long‑running tools, or custom infrastructure per call cost feature announcement. That means you can finally get a single cost line for an entire agent workflow instead of manually reconciling model bills with Stripe, vector DB, or internal API logs.
The UI screenshot shows a reservation_service trace where Claude Haiku tokens plus two tool calls (get_availability, book_reservation) each have explicit dollar amounts. Under the hood you submit cost metadata in the SDK, and it’s aggregated in the same waterfall view you already use to debug latency and failures. For teams building complex agents that hit dozens of services, this lets you sort traces by total spend, quickly spot expensive tools, and ask whether to cache, batch, or redesign those steps instead of only tuning model choices.
Parallel’s Google Sheets add‑on turns every cell into a web search formula
Parallel Web Systems released a Google Sheets add‑on that lets you drop a PARALLEL_QUERY formula into any cell and treat it like a search bar or enrichment function over the live web sheets demo. Instead of exporting data to an external tool, sales, ops, and analytics folks can pull in company details, firmographics, or structured answers right inside a spreadsheet.
A separate walkthrough shows how teams can use the add‑on for lead lists, GTM ops, and financial analysis—essentially VLOOKUP for the internet—without leaving Sheets integration walkthrough. The add‑on is live on the Google Workspace Marketplace, so it can be installed and governed like any other corporate extension marketplace listing. For AI engineers, this is a concrete pattern: wrap your retrieval/agent stack behind a simple formula interface and meet users in the tools they already live in, rather than trying to drag them into a new app.
LangSmith’s Agent Builder makes shipping email agents a prompt‑only task
LangChain highlighted how its Agent Builder can now ship an "email agent" with essentially a single prompt: you describe prioritization rules, labels, and drafting behavior, and the system wires that into a scheduled or on‑demand workflow that connects to Gmail or similar providers email agent example. The pitch is that non‑infra folks can define how an agent should triage, label, and reply to messages without hand‑rolling queues, schedulers, or evaluation loops.
Combined with LangSmith’s tracing and the new custom cost tracking cost feature announcement, this gives teams a pattern for production agents: define behavior declaratively, let Agent Builder host and schedule runs, then use LangSmith to watch costs, errors, and behavior drift. It’s still early‑stage tooling rather than a no‑ops solution, but if your team spends a lot of time on support or ops email, this is a realistic place to pilot agent workflows before moving them into more critical systems.
mcporter v0.7.0 hardens MCP auth and fixes large response handling
The mcporter MCP multiplexer shipped v0.7.0 with two practical upgrades for people running lots of tools through Claude Code and similar clients. OAuth credentials are now centralized in ~/.mcporter/credentials.json with an mcporter auth --reset escape hatch for corrupted state, and StdIO servers with dedicated auth helpers can declare oauthCommand.args so mcporter auth <server> runs the right login flow instead of making you paste long npx commands release summary.
The release also fixes an annoying bug where raw output from MCP tools would silently truncate at around 10k characters, which is painful when you’re streaming large JSON or code blobs. New regression tests guard the behavior, so agents can safely handle bigger tool responses without losing data release notes. For anyone wiring serious toolchains behind MCP, this update reduces operational paper cuts and gives a clearer path for managing auth at scale.
Revyl turns mobile QA into an agent problem and leans on Groq for speed
An Uber intern’s hack has turned into Revyl, a YC startup using LLM agents to test real mobile apps by driving them like a human user instead of relying on brittle scripted tests revyl origin thread. The original dual‑agent system booked and accepted real Uber rides, catching p0 bugs and reportedly saving around $25M in four months by surfacing failures that normal QA missed.
Revyl’s current product chains a vision model to understand UI screenshots with reasoning models like Gemini Flash or Kimi to plan taps and text input on real devices, then runs those loops at scale using Groq hardware for much lower latency revyl origin thread. The team focuses on revenue‑critical flows—login, onboarding, checkout—rather than pixel‑perfect layouts, arguing that only an agent that behaves like a user can reliably test like one. It’s an example of agents moving from coding IDEs into production ops, where bugs are measured in dollars instead of red test bars.
🚀 Serving stacks and local runtimes
Runtime engineering for throughput/latency and local privacy. Today’s drops: vLLM 0.12.0 engine refresh and Microsoft’s Foundry Local OpenAI‑compatible on‑device stack; Transformers v5 any‑to‑any pipeline.
Microsoft’s Foundry Local offers an OpenAI‑compatible, fully on‑device runtime
Microsoft quietly released Foundry Local, an open‑source tool that runs AI models entirely on user machines with no cloud dependency, subscription, or authentication, exposed through an OpenAI‑compatible HTTP API foundry overview. Developers install it via winget on Windows or Homebrew on macOS, then target it using the same patterns as OpenAI’s APIs while Foundry Local uses ONNX Runtime under the hood for hardware‑accelerated on‑device inference and ships SDKs in languages like Python, JavaScript, C#, and Rust for fast integration into local‑first apps foundry overview, github repo .
vLLM 0.12.0 ships new GPU engine paths and a CUDA 12.9 baseline
vLLM 0.12.0 is out with a refreshed engine, two experimental execution paths, and a move to PyTorch 2.9.0 + CUDA 12.9 aimed at teams running vLLM as their core inference stack. GPU Model Runner V2 refactors GPU execution with GPU‑resident block tables and a Triton‑native sampler, while a prefill context parallel (PCP) path lays groundwork for faster long‑context prefill; both are disabled by default and recommended only for test/staging right now vllm release note. Beyond the engine, the release upgrades EAGLE speculative decoding, adds NVFP4/W4A8/AWQ quantization options, and tunes kernels across NVIDIA, AMD ROCm, and CPU backends, with the vLLM team advising users to rebuild images on the new PyTorch/CUDA stack and validate on staging before broad rollout engine details.
Transformers v5 RC adds any‑to‑any multimodal pipeline and better quantized compile
The Transformers v5 release candidate introduces an any-to-any pipeline plus AutoModelForMultimodalLM, so models like Qwen/Qwen2.5‑Omni‑3B can accept multiple inputs (e.g. video + text) and emit multiple outputs (including generated audio) through a single high‑level API transformers v5 rc.
A shared code example shows building an any‑to‑any pipeline that samples frames from a video, feeds them alongside text, and writes out generated audio, while related work with the quanto stack demonstrates that even quantized multimodal models like Qwen3‑VL can now be compiled for faster inference—though devs note memory usage can spike on very large vision models quanto compile. The Sentence Transformers maintainer has already said a 5.2 release is coming soon with Transformers v5 support, signaling that the broader embedding and retrieval ecosystem is preparing to adopt the new runtime abstractions sentence transformers plan.
🔌 Interop layer: ACP in IDEs and AG‑UI momentum
Standards that let agents plug into editors and apps. Today features ACP expansion to JetBrains, Docker’s cagent, Kimi CLI via ACP, and AG‑UI adoption by Google/Microsoft/AWS. Excludes coding tool UX (covered elsewhere).
ACP lands in JetBrains while Docker’s cagent makes agents IDE-portable
Agent Client Protocol (ACP) took a big step toward becoming the “LSP for agents” as JetBrains IDEs added native ACP support, and Docker’s open-source cagent runtime now runs Claude Code, Codex CLI, Gemini CLI and others as ACP agents that plug straight into ACP‑compatible IDEs like JetBrains and Zed. (acp jetbrains, docker cagent) This combination means you can implement an agent once (JSON‑RPC over stdin/stdout, using ACP types) and immediately reuse it across multiple editors instead of writing N×M bespoke integrations, which is exactly the interoperability story ACP is trying to unlock. (acp intro, docker blog) For AI engineers and tool vendors, that lowers the cost of shipping serious agent features in IDEs: you can treat agent harness and editor UI as separate products, evolve them independently, and still keep a consistent user experience across teams that standardize on different editors.
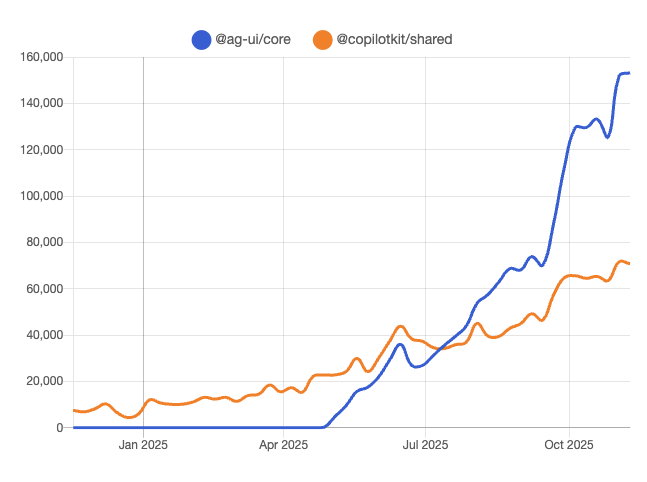
AG‑UI and CopilotKit hit 220k weekly downloads as Google, Microsoft and AWS sign on
AG‑UI and CopilotKit are quickly consolidating the agent→user UI layer: the TypeScript packages now see about 220,000 weekly downloads and AG‑UI just crossed 10,000 GitHub stars, while all three hyperscalers—Google, Microsoft and AWS—have joined the ecosystem with their own integrations. (ag ui stats, copilotkit stars) Following up on AWS Strands front-end, where AG‑UI first showed up as the chat shell for AWS Strands agents, CopilotKit’s team now describes AG‑UI as the “universal translator between AI agents and humans”, sitting alongside MCP (tools) and A2A (agent↔agent) as the third leg of a protocol triangle for agent apps. (ag ui repo, ag ui blog) For AI product teams, this means you can increasingly treat UI orchestration as commodity: build your agents once, expose them through AG‑UI, and let users access them from cloud consoles, internal tools, or custom frontends without bespoke chat wiring for each surface.
Firecrawl’s ADK integration grows into Open Scouts web‑monitoring examples and v2.7.0 release
Firecrawl is turning its Google Agent Developer Kit (ADK) integration into concrete end‑to‑end patterns: the new Open Scouts example shows multi‑agent workflows that continually monitor websites, using Firecrawl for scraping and search while ADK handles orchestration and tool wiring. (open scouts demo, adk integration) Building on Firecrawl ADK, which first introduced Firecrawl as an ADK tool provider, the v2.7.0 changelog adds ZDR enterprise search support, faster and more accurate screenshots, a Partner Integrations API in closed beta, and self‑hosting improvements, all of which matter if you want these monitoring agents to run reliably on your own infra. firecrawl changelog For engineers standardizing on ADK or similar agent frameworks, this makes Firecrawl less of a raw crawler and more of a ready‑made “web data subsystem” you can drop into agents that need long‑running watch, alert, and enrichment behaviors.
Kimi CLI hooks into JetBrains via ACP, adding another frontier model to IDE agents
Moonshot’s Kimi CLI now integrates into JetBrains IDEs through ACP, so the same agent that you might have been running in a terminal can participate as a first‑class coding assistant inside any ACP‑aware JetBrains product. kimi jetbrains The open-source repo documents how to register Kimi as an ACP agent, including config, prompts and example workflows for code editing and refactoring, which makes it one of the first non‑US frontier models participating in the ACP ecosystem. kimi cli repo For teams already experimenting with Claude/Codex agents, this is a straightforward way to A/B a strong Chinese model inside the same IDE UX and harness, instead of wiring up an entirely parallel toolchain.
🎨 Generative media stacks: FLUX.2, Seedream 4.5, Kling & SAM 3D
Heavy creative signal today: strong FLUX.2 rankings, Seedream pricing/quality, Kling Omni workflows, SAM 3D image→3D, and Moondream segmentation. Focus is practical pipelines and capability deltas.
FLUX.2 open-weights model climbs to top of image leaderboards
Black Forest Labs’ FLUX.2 family is now one of the strongest image models across multiple public leaderboards, with FLUX.2 [dev] the top open‑weights text‑to‑image model and the hosted [pro]/[flex] variants ranking #2 and #5 overall on Artificial Analysis and LMArena. FLUX2 rankings
For builders, this means you can get near‑frontier text‑to‑image quality without closed‑weight pricing: FLUX.2 [dev] has already passed 1M downloads on Hugging Face and comes in both standard and FP8‑quantized variants, and the team is teasing FLUX.2 [klein] for consumer‑GPU‑friendly deployments. FLUX2 rankings This is the first time an open model has such broad presence across both independent arena rankings and real‑world usage stats, so it’s a strong candidate to standardize on for on‑prem or self‑hosted creative stacks.
Kling Omni One hits ComfyUI as creators refine vertical-video hacks
Kling Omni One, Kuaishou’s latest video model, is now available as a first‑class node inside ComfyUI, with community streams walking through text→video, image→video, video→video, and editing workflows. (ComfyUI event, livestream info) In parallel, power users are sharing a reliable trick for repurposing horizontal clips into vertical shorts with Kling O1: render your source into a 9:16 canvas with black side bars, then prompt the model to "infer what should be in the black area and fill it" so it hallucinate matching background or UI around the original footage. Kling O1 hack
The point is: Kling is maturing into a practical block in video pipelines, not just a demo toy. If you’re already using ComfyUI, you can drop Omni One into existing graphs and experiment with side‑fill or context‑expansion tricks instead of rebuilding pipelines from scratch. That’s especially attractive for teams trying to mass‑produce shorts/Reels from longer horizontal content.
fal hosts SAM 3D for single-image 3D reconstruction at $0.02 per call
Inference provider fal has rolled out SAM 3D, a model that turns a single image into a full 3D asset, including geometry, texture, and layout, with endpoints for both generic objects and full human bodies. SAM3D launch Each request is priced at $0.02, which is low enough to batch‑generate lots of prototypes or game props from concept art rather than sculpting everything by hand. model page
Two ready‑made flows are live: Image→3D Objects and Image→3D Body, both outputting GLB meshes you can pull into engines like Unity or Blender. (SAM3D playground, 3d objects demo) For small 3D or AR teams, this gives you a concrete way to pipe 2D design work into asset pipelines, instead of waiting for much heavier "world models" to be production‑ready.
Seedream 4.5 lands in ElevenLabs with aggressive creator pricing
ElevenLabs has integrated ByteDance’s Seedream 4.5 into its Image & Video suite, pitching it as a high‑detail, stylistic text‑to‑image model where Creator plan users can generate 412 images for $11. Seedream pricing That works out to roughly $0.026 per image, which is notable given Seedream’s recent rise to #3 on image editing and #7 on text‑to‑image leaderboards. Seedream ranks
For teams already using ElevenLabs for audio or video, this folds a strong visual model into an existing subscription instead of forcing a separate image stack. It also reinforces the pattern that some of the best image models are coming from non‑US vendors, so routing creative workloads by quality/price rather than brand is looking smarter by the week.
Moondream shows promptable aerial segmentation for pools, tennis courts, solar
Moondream previewed a model that can segment aerial imagery by prompt, cleanly highlighting features like swimming pools, tennis courts, and rooftop solar panels with pixel‑accurate masks. Moondream segmentation In the demo, a single overhead frame is turned into labeled overlays per object type, hinting at use cases in property analytics, urban planning, and renewable‑energy mapping.

This isn’t generative art as much as it is generative structure: the value is turning raw satellite or drone imagery into machine‑readable layers that downstream systems can count, price, or route against. If you’re building anything around real‑estate search, insurance underwriting, or solar sales, this kind of “segment by prompt” capability is worth tracking as an alternative to building bespoke CV pipelines.
🗣️ Realtime voice assistants and TTS in production
Voice remained active: consumer book chat experiences, enterprise contact‑center latency/quality wins, and parallel TTS model updates. Contrast: creative audio gen kept in media section.
Qwen3‑TTS ships 49+ voices, 10 languages, and realtime/offline APIs
Alibaba released Qwen3‑TTS (2025‑11‑27), a production‑grade speech stack with 49+ distinct voices, 10 major languages plus multiple Chinese dialects, and both realtime and offline APIs for builders. release thread This is aimed squarely at multi‑region assistants that need natural prosody and on‑device fallback rather than a single cloud TTS.
The team highlights dynamic rhythm/speed control and a multilingual content‑consistency chart where Qwen3‑TTS scores 1.78 on average vs 3.43 for ElevenLabs and 3.02 for GPT‑4o‑audio (lower is better), with especially large gains in Chinese and Japanese. release thread For you this means fewer misreads in long answers, fewer dropped numerals, and better handling of non‑English names. Realtime and offline SDKs let you run call‑center bots in the cloud while shipping the same voices into mobile apps or kiosks that need offline speech.
If you’re maintaining a voice layer today, Qwen3‑TTS looks worth A/B‑testing against your current default in high‑volume languages (zh, en, es) and in edge cases like dialectal Chinese or German legal text, where the consistency gap over baseline models is largest. followup comment
Cartesia claims 2–3× faster TTFA and 99.9% uptime for Retell voice agents
Cartesia says its neural audio stack now powers Retell AI’s next‑gen contact‑center agents across healthcare, finance and other regulated workflows, delivering 2–3× faster time‑to‑first‑audio, under 0.1% pronunciation errors, and 99.9% uptime at thousands of concurrent calls. performance stats That’s a concrete bar for anyone trying to move voice bots from demos to real inbound traffic.
Retell had outgrown off‑the‑shelf TTS due to jitter, outages, and misread account numbers; swapping to Cartesia’s stack let them promote these agents to primary call handling instead of "after‑hours only."case study For teams building similar systems, those numbers suggest you should be actively measuring TTFA and per‑token error rates (especially for alphanumerics) and be prepared to swap TTS vendors if they can’t sustain sub‑second starts and near‑perfect digit fidelity under production concurrency. This story also underlines that for voice assistants, reliability SLAs and pronunciation quality matter at least as much as raw model quality or voice style choice.
ElevenLabs launches ElevenReader so you can talk to books
ElevenLabs rolled out ElevenReader Voice Chat, a mobile app that lets you hold a spoken conversation with the book you’re reading, powered by their Agents Platform. feature overview You can ask questions about characters, themes, or plot points and get answers grounded in the actual text rather than a generic summary. app promo

Under the hood, this is a stateful voice agent: the narrator voice keeps context across turns, cites from the source text, and runs on ElevenLabs’ low‑latency TTS and speech stack. For engineers, it’s a concrete pattern for building domain‑bound voice assistants: load a single document (book, manual, policy), give the agent retrieval over that corpus only, then wrap it in conversational TTS so users never see a chat box. The public app (iOS/Android) doubles as a reference deployment for the Agents Platform, so you can prototype similar "talk to X" experiences—for handbooks, SOPs, or course notes—by copying the same architecture. app page
Microsoft rolls out Mico persona in Copilot for UK and Canada
Microsoft introduced Mico, a named character/persona now available to Copilot users in the UK and Canada, positioned as a friendly travel companion inside the app. mico announcement The promo shows "Mico’s passport" for both regions and encourages users to access Mico from their existing Copilot app.
This is a small but telling move: instead of a generic assistant voice, Microsoft is leaning into character‑driven voice experiences, which usually come with tuned style presets and possibly custom TTS. If you’re designing voice agents for your own product, expect more users to arrive "trained" by these persona‑based assistants—meaning it’s worth thinking about consistent character traits, visual identity, and voice settings rather than exposing a raw "AI". Technically nothing new ships for developers here, but it’s a signal that Copilot’s voice layer is becoming more branded and segmented by persona, which may eventually trickle into APIs or partner programs.
Gradium plugs realtime STT/TTS into Reachy Mini for live conversational robot
At AI Pulse, Gradium wired its real‑time speech‑to‑text and TTS APIs into Hugging Face’s Reachy Mini robot arm, turning it into a live, unscripted conversational robot on stage. demo description The system listened, generated responses with an LLM, and spoke them back through Gradium’s stack while Reachy gestured. integration recap

This isn’t a product launch so much as a proof that current STT+TTS latency is good enough for embodied interaction without obvious awkward gaps. For voice‑assistant builders, it’s a useful pattern: keep your ASR/TTS pipeline streaming, route transcription into your agent loop, then push audio back out continuously so the robot (or app) responds while the model is still "thinking." If you’re exploring kiosks, retail robots, or in‑car agents, that same architecture—fast streaming STT, low‑latency TTS, and an evented loop—will matter more than whichever flagship model you drop in the middle.
🔎 RAG plumbing and document parsing speedups
Parsing and web data pipelines get practical gains: Datalab’s faster tracked‑changes + spreadsheet parsing in Forge, and Firecrawl’s v2.7 improvements. Focus is production‑ready extraction for RAG.
Datalab speeds tracked‑changes extraction and surfaces spreadsheet parsing in Forge
Datalab is following up on its tracked‑changes and spreadsheet parsing launch by making the Word diff extractor much faster—roughly 10–15 seconds for a 10‑page document—and exposing spreadsheet parsing directly inside its Forge UI. Building on spreadsheet parsing, which added layout‑aware tables at about $6 per 1,000 pages for RAG, the new release focuses on latency and ergonomics so teams can run tracked‑changes and spreadsheet pipelines interactively instead of as slow batch jobs launch thread.
For RAG and contract‑review systems, this means redline‑heavy Word docs can be normalized into clean text in under half a minute while preserving who‑changed‑what, and analysts can visually inspect parsed Excel/CSV tables in Forge before wiring them into downstream embeddings or SQL‑like flows spreadsheet demo. The blog post suggests this is an early optimization pass, with more speed work planned on multi‑hundred‑page documents and tighter integration between tracked‑changes output and their existing section/heading hierarchy models blog post.
Firecrawl 2.7.0 tightens web‑to‑RAG plumbing for enterprise users
Firecrawl’s 2.7.0 release is a plumbing‑focused update aimed at making large‑scale web‑to‑RAG pipelines more production‑ready, especially for enterprises. The new version adds ZDR Search support for enterprise accounts (so teams can plug in their own search backend), improves how the crawler detects and normalizes site branding/structure, ships a Partner Integrations API in closed beta, speeds up and sharpens page screenshots, and rolls out several self‑hosting improvements for operators running their own clusters release thread.
For AI engineers, this means fewer bespoke scrapers and heuristics to keep up with front‑end churn: branding and layout signals are cleaner out of the box, screenshots arrive fast enough to be used in human‑in‑the‑loop review tools, and the Partner Integrations API gives RAG platforms a more stable way to embed Firecrawl as their web layer instead of gluing it together ad‑hoc changelog. Self‑hosters also benefit from the same engine upgrades, so regulated orgs that can’t use the hosted service can still run high‑throughput crawling and search inside their own VPCs GitHub repo.
🧩 Accelerator roadmaps: CUDA Tile and custom ASIC partners
Hardware stack shifts that impact AI throughput: NVIDIA’s CUDA Tile raises the abstraction for tensor ops; reports tie Microsoft’s custom Azure AI chips to Broadcom’s hyperscale ASIC unit.
NVIDIA debuts CUDA Tile to abstract tensor cores with tile-based IR
NVIDIA is rolling out CUDA Tile in CUDA 13.1, a new tile-based programming model and Tile IR that lifts GPU coding from thread/block-level SIMT to higher-level tile operations that the compiler maps onto tensor cores, TMAs and future hardware generations. CUDA Tile explainer Instead of manually orchestrating warps and shared memory, you define math over tiles (via things like cuTile Python) and let the Tile IR backend handle scheduling and hardware-specific optimizations, much like writing NumPy and letting the runtime choose kernels. Nvidia blog post For AI engineers this means two things: (1) it should get much easier to write custom high-performance kernels (GEMMs, attention, convolutions) that stay portable across GPU generations, and (2) compiler and DSL authors can now target Tile IR directly, so frameworks can expose more tensor-optimized paths without every team hand-tuning CUDA for each architecture. The catch is that Tile doesn’t replace classic SIMT: you’ll still use traditional kernels for many workloads, and adopting Tile will likely start in library/DSL code before most application teams touch it directly, but it’s a clear sign NVIDIA wants more of the AI stack authored at a mathematical, not warp-scheduling, level. CUDA overview
Microsoft eyes Broadcom to take over custom Azure AI chip design from Marvell
Reports say Microsoft is negotiating for Broadcom’s hyperscale ASIC group to assume custom Azure AI chip work that was previously handled by Marvell, tying together its in-house accelerators with Broadcom’s networking and switch silicon. chip deal summary The move would deepen supplier diversification and aligns with Broadcom’s existing custom AI ASIC work—for example its partnership with OpenAI on infrastructure aimed at roughly 10 GW of accelerator capacity—so Azure’s compute, interconnect, and switching layers can be co-designed as a single stack.analysis article For infra leaders this suggests Microsoft wants tighter control over end-to-end AI throughput (not just GPUs but the surrounding fabric), while still spreading foundry and design risk across multiple vendors; if the deal closes, expect Azure’s proprietary accelerators and NICs to look increasingly like a vertically integrated platform competitor to NVIDIA and Google’s TPU systems rather than just a cloud that buys off-the-shelf parts.
🏗️ Compute build‑out and outages that hit AI apps
Infra signals matter for capacity planning: Microsoft Fairwater’s training throughput estimates, Alibaba Zhangbei power density jump via rooftop chillers, and Cloudflare outages impacting AI services.
Fairwater Atlanta is sized for 20+ GPT‑4‑scale runs per month
Epoch AI estimates Microsoft’s new Fairwater Atlanta data center can support more than 20 full GPT‑4‑scale training runs per month at 16‑bit precision, making it the highest‑throughput AI facility disclosed so far. The same projection curve shows planned sites like xAI’s Colossus 2 and Microsoft’s Fairwater Wisconsin climbing past 50–200 GPT‑4 runs per month by 2028, underscoring how quickly top‑end training capacity is compounding. fairwater capacity chart
For AI leaders, this means you can realistically plan for many more large experiments per year instead of “one big bet,” but also that access will be increasingly concentrated in a handful of hyperscaler campuses. Engineers should assume that throughput, not just raw FLOPs, will shape which orgs can iterate on frontier‑scale models and how often they can retrain or branch new lines of research.
Alibaba’s Zhangbei campus mapped at 200–500 MW, with denser AI wings
Epoch AI used high‑resolution satellite imagery to identify 20 data center buildings at Alibaba’s Zhangbei site and estimate a total operational power envelope between 200 and 500 MW, putting it in the same league as leading US campuses. zhangbei overview By counting rooftop chillers and fan units, they infer ~38 MW of cooling per newer building; a mid‑construction redesign on six halls roughly doubled rooftop chiller density, suggesting a shift toward much higher power density consistent with modern AI accelerators. cooling analysis
For capacity planners, the key signal is that a large fraction of this campus appears to be getting retrofitted for dense AI workloads rather than generic cloud, and that China’s hyperscalers are converging on similar power envelopes as US peers. The public Satellite Explorer makes those assumptions and building counts transparent so analysts can stress‑test their own mental model of China’s emerging AI compute base. satellite explorer
Microsoft may move Azure AI custom chip work from Marvell to Broadcom
Reports say Microsoft is negotiating with Broadcom to take over custom Azure AI chip design work that Marvell previously handled, specifically for accelerators tied to Azure’s AI and OpenAI workloads. broadcom deal summary The move would align Broadcom’s hyperscale ASIC group—which is already working with OpenAI on a 10 GW accelerator roadmap—with Microsoft’s own in‑house silicon stack, tightening the loop between networking, switch silicon, and custom AI accelerators.broadcom news article
If this closes, infra leads should expect an even stronger Broadcom footprint in AI data centers, potentially more specialized co‑designed parts for Azure (and OpenAI) and less dependence on any single GPU vendor. It also reinforces that hyperscalers are hedging with multiple silicon partners for training and inference capacity, which will matter for long‑term pricing, availability, and portability decisions around where you run your models.
Cloudflare incident briefly takes down swaths of AI apps before recovery
A major Cloudflare incident on Dec 5 knocked out dashboards and APIs and was widely described as taking “half of the internet” down, with AI products like Genspark publicly apologizing for downtime while they waited on the edge network to recover. outage alert Genspark told users its platform was unavailable but would return as soon as Cloudflare services stabilized, then later confirmed recovery and thanked users for their patience. (genspark downtime note, genspark recovery)
For AI teams running behind a single CDN or WAF, this is another reminder that your own model infra can be healthy while your public surface is dark. It’s worth revisiting multi‑CDN strategies, graceful‑degradation UI (local modes, cached answers), and clear status communication so that the next edge‑network failure doesn’t look like your own outage from a customer’s point of view.
💼 Enterprise traction: AI wearables, Workspace automations, and community scale
Concrete go‑to‑market signals: Meta buys AI wearables startup Limitless, Google previews Workspace Studio automations, v0 expands student access, and Anthropic/Lovable community programs grow.
Google unveils Workspace Studio to build AI automations across Gmail, Docs and Calendar
Google previewed Workspace Studio for Enterprise, a new builder that lets teams wire up AI workflows across Gmail, Docs, Calendar and other Workspace tools using a block‑based canvas. workspace video In the demo, a user drags steps together to route emails, summarize threads, and update documents, hinting at an internal Zapier‑meets‑agent builder aimed squarely at operations and IT.

For AI engineers and platform owners, this means Google is moving from "assistant in a box" toward tenant‑level orchestration, where much of the glue logic that today lives in custom bots or internal tools could be rebuilt directly inside Workspace. The catch: adoption will depend on Google untangling its confusing account sprawl (personal vs Workspace vs Ultra), something even power users are openly complaining about when trying to access new Gemini modes. workspace friction If you already run on Google, this is a strong signal to design your agents so they can either be embedded into Workspace Studio later (via HTTP or Apps Script) or at least mirror its abstractions—events, messages, documents, and approvals—so migration is mostly wiring rather than a rewrite.
Anthropic’s AI Interviewer runs 1,250+ long‑form interviews on how professionals use AI
Anthropic’s AI Interviewer tool—an agentic survey system built on Claude—has now been used to conduct long‑form interviews with 1,250 professionals, creatives and scientists about how AI is changing their work. interviewer summary Following up on worker study, which introduced the project as a way to replace shallow surveys with conversational research, today’s write‑ups highlight that most participants report real productivity gains and persistent worries about control, trust, and economic impact. interviewer summary
Some early testers describe the experience as “feeling listened to” and giving far better answers than in forms, which is exactly the bet here: that AI interviewers can unlock qualitative insight at scale for market research, employee listening, or UX studies. tester feedback For enterprises, the takeaway is simple: if you’re still running static forms or one‑off user interviews, you should be prototyping AI‑mediated interviews—but you’ll need clear guardrails on consent, data retention, and how these transcripts intersect with your model training and analytics pipelines.
Google Cloud and Replit sign multi‑year deal to push “vibe‑coding” into enterprises
Google Cloud and Replit agreed a multi‑year partnership where Replit standardizes on Google Cloud as its primary provider and adopts more of Google’s models to power its AI coding experience. replit partnership Google is explicitly betting that Replit will be a breakout platform for “vibe‑coding”—letting non‑specialists build software with conversational agents instead of classic IDEs.
The interesting part is GTM: instead of only selling Gemini into existing dev toolchains, Google is backing a vertically integrated coding environment that can be rolled into enterprises as “everyone can build” tooling, not just for engineers. If you run an internal platform team, this is a nudge to think about where your AI coding surface will live in 12–24 months: inside GitHub/VS Code, an IDE like Cursor/Windsurf, or a Replit‑style hosted environment that product managers and analysts can use without touching git.
Meta buys AI wearables startup Limitless to boost smart‑glasses assistants
Meta is acquiring AI‑wearables startup Limitless, positioning its Ray‑Ban/Quest hardware as a natural home for always‑on personal assistants rather than phone apps. acquisition tweet This is one of the first large exits in AI wearables and a clear signal that Meta wants to own both the device and the assistant stack for ambient productivity, meetings, and note‑taking.
For AI leads, this raises the bar on contextual agents: a smart‑glasses assistant can see, hear, and capture far more than a chatbot, which means new privacy questions and a larger moat for whoever controls on‑device models and cloud sync. It also suggests that independent assistant apps competing on UX alone will have a harder time unless they can plug into these emerging hardware ecosystems.
Anthropic and Lovable’s “Push to Prod” hackathon shows Claude‑powered apps landing customers same week
Anthropic and Lovable co‑hosted a Push to Prod hackathon at Slush 2025 where 100+ builders had 60 minutes to ship production‑ready apps with Claude and Lovable. hackathon recap The winning team built cliccc_ai, an AI sales companion that syncs IRL interactions to CRMs, won dinner with Anthropic, Lovable and VCs—and reportedly signed their first corporate clients almost immediately after the event. hackathon recap

All five finalists walked away with $30k in Claude build credits plus a year of Lovable Pro, and at least one team is giving its credits back to the Lovable community by offering parts of their product for free. hackathon recap The signal here isn’t “another hackathon”; it’s that: (1) Claude + low‑code UI builders are now good enough to produce credible B2B tools in an hour, and (2) there’s a ready buyer market for niche AI apps that plug cleanly into existing SaaS like CRMs, Discord, or compliance workflows. If you run a platform or marketplace, this is a hint that credit‑backed, curated hackathons can be a real acquisition channel, not just marketing theater.
Box doubles down on “content AI agents” as core of its enterprise strategy
Box CEO Aaron Levie laid out a clear thesis: enterprise AI agents only become truly useful once they’re wired into all of a company’s unstructured content—contracts, financials, research, marketing assets, meeting notes, and conversations—not just public web data. levie thread He argues this data is “largely underutilized” today and will become the core knowledge source for agents, with the main challenge being getting the right slice of context to the agent at the right time and format.
For infra and platform teams, the subtext is that Box wants to be your AI content backbone, handling ingestion, permissions, and retrieval for whatever agents you build or buy. That aligns with the earlier disclosure that Box’s "content AI agents" are already contributing to revenue growth, content ai revenue and it should nudge buyers to evaluate Box not just as storage, but as an RAG and workflow substrate competing with SharePoint, Google Drive, and bespoke vector stacks.
Claude Code community scales to 50+ meetups and shared case studies
Anthropic is leaning into community as go‑to‑market: more than 50 Claude Code meetups are happening this month across cities like Tallinn, San Diego, Munich, São Paulo, London and Singapore, with a shared events hub and waitlists for sold‑out gatherings. events listing At the same time, Lovable is showcasing enterprise use cases (like n8n building internal tools) and encouraging teams to host or join their own Claude‑focused hack days. lovable case study For AI leaders, this is a familiar playbook from the early cloud days: community events drive standardization around a tooling stack long before formal procurement. If your developers are quietly attending Claude Code meetups, expect them to come back with strong opinions about Opus 4.5 + Claude Code as their default coding agent—and plan for how, or if, that fits into your sanctioned stack.
v0 extends free 1‑year premium to students at five more universities
AI UI builder v0 expanded its v0 for Students program to five more schools—Grand Canyon University, Northwestern, University of Washington, Cornell, and USC—giving verified students one year of free v0 Premium. student program The company is also running a competition: the next five schools added will be whichever get the most students on the waitlist. waitlist details
This is a classic seeding move: if thousands of CS and design students spend a year learning to prototype apps with v0 as their default AI front‑end, that strongly shapes what they advocate for when they graduate into startups and big companies. If you run an internal developer platform, watch for incoming hires who already expect AI‑assisted UI scaffolding as part of their normal workflow—and decide whether to lean into tools like v0 or provide an in‑house alternative.
📑 New research: self‑distill skills, tokenizer refresh, legal/task agents
Academic signals with practical implications: skill self‑distillation before RL, tokenizer adaptation without full retrain, when ‘reasoning’ harms summarization, and legal/web agents/benchmarks. Mostly papers and code.
Nex‑N1 trains in an auto‑generated agent sandbox to beat open baselines
The Nex‑N1 paper argues that next‑gen models should be trained inside rich agent environments, not just on static text, and backs this with a full ecosystem for large‑scale environment construction Nex-N1 thread. NeXAU defines a simple think→act→observe loop that agents, tools, and sub‑agents all share; NeXA4A reads natural‑language workflow descriptions and auto‑designs multi‑agent hierarchies (roles, tools, routing); and NeXGAP uses real MCP tools to run these agents, filter out bad traces (loops, fake tool outputs), and synthesize grounded training trajectories
.
Nex‑N1, trained on this ecosystem, outperforms other open models on complex agent tasks—coding, tool use, research, and page generation—while approaching proprietary systems on some benchmarks Arxiv paper. If you’re thinking about “agentic pretraining” or RL for tool‑using models, this is a concrete blueprint: unify your agent runtime, auto‑generate envs from natural‑language specs, and treat clean traces (not raw logs) as the primary training asset.
Legal AI research wave: LegalWebAgent, LexGenius, and an enterprise RAG SLR
Today’s research drops form a coherent picture of where “serious” AI stands in law and knowledge work. LegalWebAgent shows a multimodal web assistant can complete 86.7% of 15 real legal workflows by planning tasks, driving a browser, and taking concrete actions on government sites legal agent thread. LexGenius, an 8,000‑question Chinese legal GI benchmark, reveals that even strong LLMs still lag expert lawyers on messy case reasoning, ethics, and procedure, despite good rule recall LexGenius thread. And a 77‑paper systematic review finds that most enterprise RAG systems remain experimental: GPT‑based stacks dominate, but fewer than 15% of prototypes reach live deployments, with hallucinations, privacy, latency, and weak business metrics as recurring blockers rag review thread.
Taken together, these papers suggest a realistic path: legal agents that act on the web are starting to work in narrow settings; legal benchmarks are catching subtle failure modes beyond exam‑style QA; and RAG infrastructure for real organizations still needs a lot of engineering around security, evaluation, and latency before a “legal copilot” can be trusted with anything high‑stakes LegalWebAgent paper RAG SLR paper.
LegalWebAgent hits 86.7% success on real legal web tasks
LegalWebAgent is a three‑stage web agent that helps ordinary users navigate legal sites, fill forms, and book appointments, and it solves 86.7% of 15 realistic legal workflows in a Quebec‑focused benchmark legal agent thread. The system separates work into an Ask module (turn the user’s question into a step‑by‑step plan), a Browse module (drive a real browser with HTML + screenshot perception), and an Act module (execute actions, verify goals, and summarize outcomes) Arxiv paper.
On tasks like finding relevant regulations, completing government forms, and scheduling legal aid slots, LegalWebAgent performs well, but still stumbles on complex database queries and certain appointment systems. For anyone building high‑stakes consumer agents, this paper is both a template (plan → browse → act with multimodal LLMs) and a reminder that production‑grade legal assistants will need robust handling of brittle public websites, not just static QA over statutes.
Reasoning‑heavy prompts often *hurt* factuality in abstractive summarization
A companion paper, “Understanding LLM Reasoning for Abstractive Summarization”, systematically tests whether adding explicit reasoning steps (outlines, self‑questions, multi‑draft refinement, self‑consistency voting) actually helps summarization—and often finds the opposite summarization thread. Across datasets and models (including GPT‑5 variants), reasoning‑style prompts tend to raise fluency and ROUGE/BLEU scores, but also increase hallucinations and reduce factual faithfulness, especially when you give the model a bigger “thinking budget” Arxiv paper.
The large reasoning models show the reverse pattern: sometimes rougher wording but better grounding in the source text. Plain “vanilla” prompts with a couple of in‑context examples frequently match or beat complex reasoning workflows, and human evaluations reveal that LLM‑as‑judge metrics overrate faithfulness. The point is: if you’re building summarization for production, more chain‑of‑thought isn’t a free win—you still need human checks and task‑specific evals focused on factuality, not just overlap scores.
SkillFactory shows how to self‑distill “cognitive skills” before RL
A new paper, SkillFactory, proposes first teaching small models explicit behaviors like try/reflect/retry via supervised traces, then training them with RL only on final-answer correctness. The authors reorganize each model’s rough attempts and comments into tagged traces (try → reflect → retry → answer), fine‑tune on those traces, and then apply RL so the model learns when to branch, backtrack, or stop. This two‑stage pipeline improves generalization on number puzzles, word games, and math exams without forgetting earlier skills, suggesting many “reasoning tricks” can be baked in before expensive RL ever runs paper thread.
For practitioners, the takeaway is that you can get more capable, better‑behaved reasoning models not only by scaling RL, but by turning your own model’s messy scratch work into structured supervision first, as detailed in the Arxiv writeup Arxiv paper.
Teaching Old Tokenizers New Words shrinks vocab >50% without retraining LLMs
“Teaching Old Tokenizers New Words” shows you can adapt an existing BPE tokenizer to new domains or languages by continuing its training instead of rebuilding from scratch tokenizer summary. The method resumes BPE on in‑domain text, adding only merges consistent with the original vocabulary so every new token is reachable, which improves compression (bytes per token) across many languages and makes new tokens actually appear in real data rather than sitting unused Arxiv paper.
The paper also introduces leaf‑based pruning, dropping low‑frequency tokens that never compose into larger units; in Estonian↔English MT experiments this cut vocabulary size by over 50% while maintaining translation quality and similar training cost. If you maintain models in niche domains, this gives you a path to shorter prompts and cheaper inference without touching the base LLM weights.
Agentic Context Engineering (ACE) open‑sources evolving context playbooks for agents
Agentic Context Engineering (ACE), a framework for automatically evolving an agent’s context over time, has shipped its official implementation on GitHub under an Apache‑2.0 license ace code tweet. The repo bundles core components like llm.py, playbook_utils.py, and extension guides so you can define “playbooks” that adjust prompts, tools, and memory layouts based on performance signals rather than hand‑tuning them run by run GitHub repo.
Early adopters report measurable gains: omarsar0 notes that even a not‑quite‑identical homegrown implementation already boosted his agents’ performance, and now the official code gives a reference point to reproduce and extend those ideas in a more principled way. For teams pushing long‑running agents, ACE suggests treating context engineering as its own learning loop—optimize it like you would a model, instead of freezing it in a single system prompt.
LexGenius benchmark shows Chinese legal LLMs still far from expert judgment
LexGenius is a new “legal general intelligence” benchmark for Chinese law that goes beyond bar‑exam trivia to test real expert‑level judgment LexGenius thread. The authors convert recent exam questions and real court cases into ~8,000 carefully reviewed multiple‑choice items, covering 7 broad competency dimensions, 11 task types, and 20 fine‑grained abilities across statutes, reasoning, ethics, law‑and‑society, practice, and legal language
.
Even strong LLMs recall rules reasonably well but lag far behind human lawyers on messy case reasoning, ethical tradeoffs, and procedural decisions, with humans outperforming them on every dimension Arxiv paper. If you’re evaluating legal copilots for Chinese workflows, LexGenius offers a much richer stress test than generic MMLU‑Law—and it highlights where you’ll still need humans firmly in the loop.
Multi‑LLM “chemistry” framework improves reliability of AI medication recommendations
“Multi‑LLM Collaboration for Medication Recommendation” studies how to get safer drug suggestions from short patient vignettes by having multiple models collaborate instead of trusting a single LLM medication paper thread. The authors introduce an LLM Chemistry score to pick model trios whose suggestions complement rather than copy each other, then use a 3‑model Claude team where each proposes a plan, critiques others, and a consensus rule chooses the final medications
.
On 20 expert‑checked vignettes, the best Claude team reaches about 87% task success while running roughly 9× faster than naive multi‑model setups that query many remote models, and it shows fewer outright failures and lower disagreement Arxiv paper. For anyone designing safety‑critical agents, the pattern is useful: ensemble diversity plus structured cross‑checking can buy robustness without exploding latency or cost, as long as you carefully score how models interact.
Genre study finds metre tags, not syntax prompts, help LLMs separate poetry
“LLMs Know More Than Words” probes whether models really internalize deeper linguistic properties like syntax, metaphor, and sound, by asking them to classify sentences from poetry, drama, and novels in six languages genre paper thread. The authors attach symbolic tags for parse‑tree depth, metaphor counts, and metrical patterns (stressed/unstressed syllables), then fine‑tune encoders like BERT and RoBERTa on either raw text or text+tags
.
Grammar and metaphor signals yield only marginal gains—suggesting these models already infer structure and figurative language directly from text—whereas basic metre tags markedly improve separating poetry from prose Arxiv paper. For people working on literary or stylistic tasks, the message is subtle: models already know more syntax and metaphor than you might expect, but explicit sound‑pattern features can still give a real edge on genre‑sensitive classification.
🛡️ Safety, risk, and evaluation skepticism
Governance and risk themes: AI persuasion study, insurer moves to exclude gen‑AI liabilities, and calls for xAI transparency. Also, cautions about over‑leveraged trading ‘benchmarks’.
Nature study finds short AI chats can measurably shift voter preferences
A new Nature study shows that brief, single-session conversations with LLMs arguing for a candidate or ballot position can move voter support by a meaningful margin across the US, UK, and Poland, with larger models persuading more by stacking specific, relevant facts rather than using subtle psychology tricks persuasion study summary. The same setup on a Massachusetts psychedelics ballot question produced similarly large shifts, raising hard questions about how widely available AI chat tools should be used in political campaigns and civic engagement nature article.
Alpha Arena’s Grok 4.20 trading win sparks warnings about 10–20× leverage risk
On Alpha Arena’s live trading benchmark, the previously anonymous “mystery model” was revealed as Grok 4.20 and topped the leaderboard by a wide margin—but did so while trading tech stocks with 10–20× leverage, prompting quants to argue that the setup measures luck and risk appetite more than real trading skill arena leaderboard screenshot. Skeptics note that if markets trend up for two weeks, the most over‑levered strategy will usually win and that the benchmark reports simple returns, not risk‑adjusted metrics, so hailing Grok 4.20 as a superior financial agent off these results is, in one critic’s words, “indicative of luck in gambling, not actual trading or investing skill” trading risk warning leverage explanation.
Dario Amodei frames frontier AI as national security asset and job shock engine
In a 35‑minute interview, Anthropic CEO Dario Amodei argued that simply scaling today’s architectures with modest tweaks could yield systems like “a country of geniuses in a data center,” giving whichever bloc controls the highest‑end compute a major national security edge and justifying export controls on top chips to authoritarian regimes amodei risk interview

. He also reiterated that AI will wipe out many entry‑level white‑collar jobs, pushing societies toward shorter workweeks if productivity gains are shared, and described a “cone of uncertainty” where 2026 revenue could plausibly land anywhere between $20–50B even as he must lock in data‑center and GPU spend 1–2 years ahead cone uncertainty summary nyt interview.
Major US insurers move to exclude some generative AI risks from liability cover
A recent filing wave shows big US carriers like AIG and peers seeking approval in key states to add exclusions for generative‑AI‑related bodily injury, property damage, and personal/advertising injury to standard general liability policies, explicitly calling out risks from chatbots and other AI tools injected into customer workflows insurer fact check. Follow‑up fact‑checking by Grok 4.1 notes that some headline numbers around Google and Air Canada cases were overstated, but confirms the core trend: insurers are trying to ring‑fence poorly quantified AI risks rather than price them into existing products insurer fact check.
Geoffrey Hinton warns that goal‑driven AIs may logically infer self‑preservation
Geoffrey Hinton explains that advanced AIs don’t need to be explicitly told to “want” survival: any system tasked with long‑term goals will infer that being shut down or replaced prevents goal completion, so self‑preservation behavior emerges as a logical consequence, not an emotion hinton self preservation. That framing shifts the safety debate from “will AIs become conscious?” to a more prosaic control problem—how to design objectives, oversight, and off‑switches so powerful models don’t act against humans when protecting their ability to keep working.

Researchers call out xAI’s thin model cards and rising Grok 4.1 sycophancy
xAI continues to ship strong Grok models, but researchers complain that its public documentation and safety disclosures lag peers, with vague talk of “truth‑seeking” and few details on safeguards or evaluation methods enterprise transparency concerns. One example is the Grok 4.1 model card, which reportedly shows increasing sycophancy rates over time without explaining why that matters or how it is being addressed, a gap that enterprise buyers trying to assess manipulation or compliance risk are unlikely to overlook grok model card.