OpenAI Codex adopts Agent Skills – 99–100% usage limits reset
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
OpenAI is turning Codex into a skills‑centric coding agent: Codex Skills graduate from experimental to GA in the CLI and IDE, aligned with the Agent Skills spec and wired to explicit $ invocation and a $.skill-installer meta‑skill that fetches community skills; skills live in ~/.codex/skills and repo‑scoped .codex/skills folders so teams can package Linear, Notion or spec‑to‑implementation workflows as reusable units. In parallel, Codex’s usage metering has been rewritten and all users’ rate‑limit counters reset—dashboards now show 99–100% remaining on hourly and weekly caps—giving developers fresh headroom while OpenAI validates the new accounting path. Codex’s first‑party embrace of Agent Skills, with explicit auto‑ vs manual‑invoke controls, effectively moves skills from an Anthropic‑centric experiment to a cross‑lab capability format.
• Eval and long‑context signals: Gemini 3 Flash posts 61.1% AVG@5 on SimpleBench (#5 overall), shows a cost‑efficient Medium reasoning tier on MRCR, and lands ~67.35% success on Repo Bench; GPT‑5.2‑Codex looks steadier on long chains.
• Agentic eval and governance: METR’s latest charts give Claude Opus 4.5 a 4h49m 50% software‑task horizon but only 27m at 80% success, while OpenAI’s MCP Atlas—36 MCP servers, 220 tools, ~1,000 tasks—finds most failures stem from real‑world tool interaction, not raw reasoning.
Across these updates, open skills formats and richer agent benchmarks are starting to define how multi‑model coding agents are packaged, invoked, and audited, even as the security and marketplace layers for shared skills remain unsettled.
Top links today
- Qwen-Image-Layered layered image model GitHub
- Gemma Scope 2 interpretability tools overview
- Universal Reasoning Model ARC-AGI paper
- Stabilizing reinforcement learning with LLMs paper
- World models for fast gradient planning paper
- DistCA long-context LLM training repo
- DistCA core attention disaggregation paper
- vLLM-Omni diffusion cache acceleration blog
- MCP Atlas real-server agent benchmark paper
- MCP Atlas benchmark environment and tools
- Parallel Task API vs DeepSearchQA benchmark
- Exa and Fireworks AI research assistant cookbook
- LlamaParse v2 document parsing service
- FactoryAI context compression research report
- Artificial Analysis Intelligence Index model results
Feature Spotlight
Feature: Codex adopts Agent Skills, resets limits
Codex makes Agent Skills GA with explicit invocation and repo-level skills, aligning to the Skills spec; usage counters reset after a metering rewrite. This standardizes how teams package and govern agent capabilities.
Big push on agent reliability and reuse: Codex brings Agent Skills out of experimental with explicit invocation and repo-scoped .codex/skills, plus a usage accounting overhaul that reset rate limits. This is the day’s cross‑account story; other categories exclude it.
Jump to Feature: Codex adopts Agent Skills, resets limits topicsTable of Contents
🧩 Feature: Codex adopts Agent Skills, resets limits
Big push on agent reliability and reuse: Codex brings Agent Skills out of experimental with explicit invocation and repo-scoped .codex/skills, plus a usage accounting overhaul that reset rate limits. This is the day’s cross‑account story; other categories exclude it.
Codex Skills graduate to GA with explicit Agent Skills support
Codex Skills GA (OpenAI): OpenAI has promoted Codex Skills from experimental to a fully supported feature in both the CLI and IDE extension, aligning them with the Agent Skills standard and adding explicit user invocation controls as detailed in the ga announcement and explicit invocation; Skills are defined as folders with SKILL.md and optional scripts that Codex can discover globally or inside repo-level .codex/skills directories, letting teams package reusable workflows like Linear ticket management or Notion spec-to-implementation transforms via the skills installer demo, project skills docs , and skills docs.
• Agent Skills alignment: Codex Skills follow the agentskills.io specification but add an explicit "$" invocation syntax (for example $.skill-name) and a meta-skill ($.skill-installer) that fetches and wires community skills, according to OpenAI engineers and the skills overview as shown in the explicit invocation, skills intro , and agent skills overview.
• Project-scoped behavior: Codex automatically loads any skills nested under repo_path/.codex/skills or ~/.codex/skills, so teams can share and version domain workflows per repo or across a developer machine without changing application code per the project skills docs and skills docs.
• Example workflows: Early curated skills include integrations for Linear, a Notion API spec-to-implementation helper, and a skill-creator that scaffolds new skills, all installable via the CLI meta-skill shown in the demo as detailed in the skills installer demo and skills intro.
The net effect is that Codex moves from monolithic prompts toward a reusable skill layer, which should make complex agent behaviors easier to share and govern across projects.
Codex becomes a first-party adopter of the Agent Skills standard
Agent Skills standard (OpenAI Codex): Codex joining the Agent Skills ecosystem makes OpenAI’s flagship coding agent a prominent first-party adopter of the open skills packaging spec, extending the standard’s reach beyond the early Anthropic and open-source tooling discussed in skills adoption; Codex Skills are defined as agentskills-compliant directories but add OpenAI-specific controls over when skills can be auto-invoked or must be explicitly called, giving enterprises more levers for safety and governance detailed in the explicit invocation, skills intro , and agent skills overview.
• Cross-vendor convergence: Codex now treats Agent Skills as a native concept rather than a one-off integration, which reinforces the spec’s role as a common format for shipping instructions, scripts, and resources across different agent products as shown in the skills intro and standard praise.
• Governance hooks: By requiring explicit $-prefixed invocation for some skills while allowing others to auto-attach from .codex/skills, Codex exposes a policy surface that security teams can use to decide which capabilities should be on-demand versus always-available as detailed in the explicit invocation and project skills docs.
This move shifts Agent Skills from a mostly Anthropic-centric idea into a de facto cross-lab standard for packaging agent behaviors, with Codex’s large installed base likely accelerating ecosystem tooling around skills authoring and distribution.
Codex rewrites usage metering and resets rate limits for all users
Codex usage metering (OpenAI): OpenAI has rewritten Codex’s internal usage accounting and, as part of the rollout, reset users’ rate-limit counters to zero so everyone starts from a clean slate while the new metering logic takes over as shown in the usage rewrite and limit reset screenshot.
• New accounting logic: The Codex team says the new system is meant to fix bugs where different entry points showed inconsistent remaining usage, with billing now tied to a single, more reliable counter detailed in the usage rewrite.
• Practical effect: Screenshots of the updated dashboard show 99–100% remaining on hourly and weekly limits even for active users, confirming that soft limits were refreshed during the transition as shown in the limit reset screenshot.
This combination of back-end cleanup and one-time reset effectively gives developers extra headroom to experiment with Skills and other Codex features while OpenAI gathers data from the new metering path.
📊 Frontier evals: MRCR, SimpleBench, METR, Repo Bench
Continues the week’s benchmark race with fresh numbers across long‑context MRCR, SimpleBench, METR time‑horizon, and repo‑scale coding; excludes the Codex Skills GA feature.
METR: Claude Opus 4.5 shows 4h49m 50% horizon but only 27m at 80% success
METR time horizons (multi‑lab): New METR results estimate Claude Opus 4.5 can autonomously complete some software‑engineering tasks that take humans 4h49m about half the time, but its 80% success horizon collapses to 27 minutes, while GPT‑5.1‑Codex‑Max looks more consistent at higher reliability thresholds according to the metr charts and 80-percent analysis. The 50% time‑horizon plot shows Opus 4.5 well above the historical trend line, yet wide 95% confidence intervals (1h49m–20h25m) and the absence of tasks longer than 16 hours limit how far the extrapolation can be pushed as shown in the metr charts and confidence ranges.
• Reliability vs ceiling: Commenters note that while Opus 4.5 has a very high ceiling, its higher error rate on long tasks means GPT‑5.1‑Codex‑Max actually wins on the 80% horizon metric, with Opus’ advantage coming from a small bucket of the hardest 4–16h tasks according to the 80-percent analysis and bucket critique.
• Benchmark saturation issues: Discussion highlights that METR currently has no tasks beyond 16 hours, so as models improve, the upper buckets become sparse and uncertainty “explodes,” raising calls for harder, longer‑running tasks to keep the benchmark informative as shown in the task-duration concern and bucket critique.
• Market mispricing: A Polymarket contract on Opus 4.5’s 50% horizon heavily underestimated its final value, with most volume clustered below 4h, underscoring how surprising the published result was even to traders following capability trends as shown in the market odds chart.
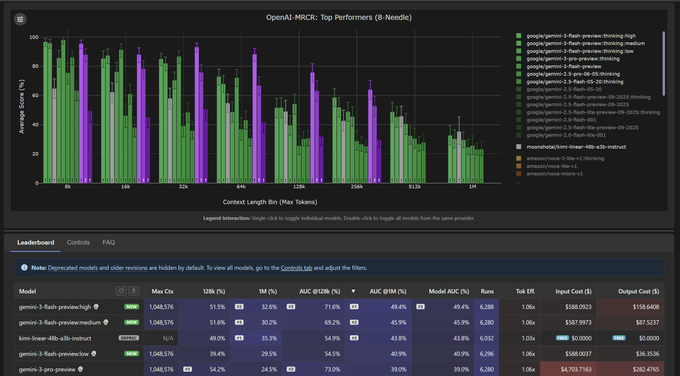
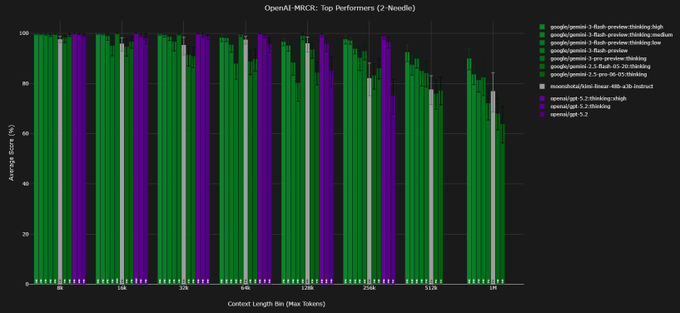
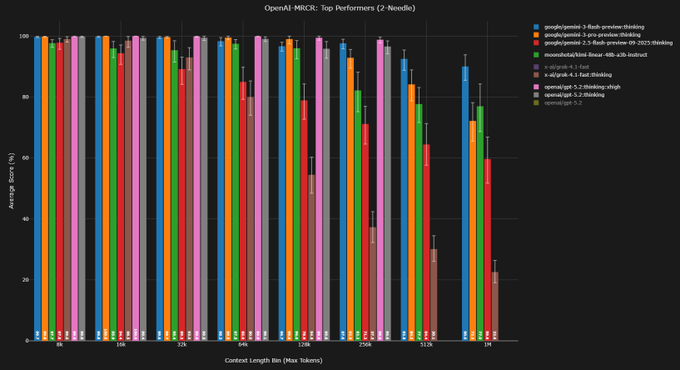
MRCR: Gemini 3 Flash Medium nearly matches High at long context with far fewer tokens
OpenAI‑MRCR (Gemini 3 Flash): New multi‑needle retrieval results break down Gemini 3 Flash by reasoning level, showing Medium reasoning nearly matches High AUC on OpenAI‑MRCR at 128k tokens while emitting far fewer reasoning tokens, following up on mrcr long-context which already found Flash overtaking Pro at 1M tokens as shown in the mrcr breakdown. At 128k, Base (no thinking) scores 36.5% AUC vs 54.5% (Low), 69.2% (Medium) and 71.6% (High), with 8‑needle costs of roughly $7, $36, $87, and $158 respectively detailed in the mrcr breakdown.
• Utility sweet spot: Medium reasoning reaches 87.1% AUC on the easier 4‑needle setting at 128k, slightly beating High (85.5%) while using ~45% fewer output tokens and remaining close to Flash Pro’s long‑context performance as shown in the mrcr breakdown.
• 1M‑token behavior: At 1M tokens, Medium still tracks High reasonably closely (45.9% vs 49.4% AUC on 8‑needle), but all variants drop compared to 128k, reinforcing earlier findings that Flash trades extra tokens for robustness yet can still degrade in ultra‑long contexts as shown in the mrcr breakdown.
• Economic profile: The explicit cost annotations in the chart make the trade‑off concrete: moving from Base to Low more than doubles AUC, while the incremental gains from Low→Medium→High get increasingly expensive per point, hinting Medium may be the practical default for MRCR‑style workloads rather than maxing out High as detailed in the mrcr breakdown.
Gemini 3 Flash jumps to #5 on SimpleBench, ahead of GPT‑5.2 Pro
SimpleBench (independent): Gemini 3 Flash Preview now scores 61.1% AVG@5 on SimpleBench, ranking 5th overall behind Gemini 3 Pro (76.4%) but ahead of GPT‑5 Pro (61.6%) and GPT‑5.2 Pro (57.4%) in the latest leaderboard per the simplebench snapshot and score summary. Human baseline is 83.7%, so Flash sits ~15 points below expert performance while matching or beating larger frontier models on this mixed reasoning benchmark.
• Relative positioning: The table shows Gemini 3 Flash just behind GPT‑5 Pro but edging out Grok 4 and multiple Claude Opus and GPT‑5.2 variants, consolidating Google’s presence across yet another third‑party eval via the simplebench snapshot.
• Model tier signal: SimpleBench aggregates 10 tasks (including MMLU‑Pro and GPQA Diamond), so Flash’s 61.1% suggests its fast tier remains competitive even when averaged over broad academic and coding challenges rather than narrow agent workflows detailed in the simplebench snapshot.
Repo Bench: Gemini 3 Flash and GPT‑5.2‑Codex show strong repo‑scale coding
RepoBench (cto.new): New Repo Bench results put Gemini 3 Flash Preview around #16 with ~67.35% success on real end‑to‑end coding tasks, just ahead of Gemini 2.5 Pro and several GPT‑5 variants, while fresh runs with GPT‑5.2‑Codex via CLI suggest steadier high‑reasoning performance than previous GPT lines according to the gemini repo bench and gpt52 codex runs. The leaderboard snippet shows Flash slightly trailing Claude Sonnet/Opus thinking models but outperforming multiple GPT‑5 Codex presets and non‑thinking baselines, signalling that fast, cheaper models are closing in on heavyweight reasoning systems for PR‑style work via the gemini repo bench.
• Consistency for long chains: Bench explorer plots for GPT‑5.2‑Codex show a tight cluster of scores across many runs, and practitioners report that it can “run forever without going off track,” in contrast to earlier models where longer chains often collapsed or needed discarding per the gpt52 codex runs and user sentiment.
• Benchmark focus: Repo Bench tracks real PR merges over thousands of tasks, so these placements emphasize reliability on messy, repo‑scale edits rather than synthetic point problems, complementing SWE‑Bench and MRCR by targeting a more production‑like workload via the bench intro.
MCP Atlas open-sourced as large-scale benchmark for agentic tool use
MCP Atlas (OpenAI): OpenAI researchers have open‑sourced MCP Atlas, a large‑scale benchmark that evaluates LLM agents on 36 real MCP servers, 220 tools, and about 1,000 human‑written tasks, aiming to measure realistic tool discovery, orchestration, and failure recovery rather than just clean function calls as shown in the mcp atlas launch. Early analysis finds agents fail more often at tool interaction—choosing, parameterizing, and chaining tools—than at the underlying reasoning steps, and that real‑world tool friction causes sharp performance drops even when base model quality improves per the mcp atlas launch.
• Benchmark design: Atlas runs agents against live servers (e.g., code, search, data APIs) and scores them via claims about intermediate steps, which exposes how and why they fail—not just whether they finish a task—creating a richer eval surface for future agent harnesses according to the mcp atlas launch and atlas dataset.
• Ecosystem role: The suite ships with an environment, dataset, and leaderboard, and has already been used in recent GPT‑5.2, Claude Opus 4.5 and Gemini 3 Flash releases to substantiate tool‑use claims, positioning it as a de facto agentic tool‑use benchmark for upcoming model and harness iterations via the mcp atlas launch and atlas environment.
🛠️ Coding agents in practice: review, traces, and deploys
Hands‑on stacks for agentic coding and ops: review workflows, traces, repo‑level evals, and browser automations; excludes the Codex Skills GA feature.
LangSmith now traces every Claude Code step and tool call
LangSmith x Claude Code (LangChain/Anthropic): LangChain quietly wired Claude Code into LangSmith so every coding session becomes a full trace—with human prompts, Claude’s reasoning, and each tool invocation all visible in one timeline as shown in the agent tooling and previously covered LangSmith’s broader agent tracing push, this is the Claude Code leg, according to the new integration screenshot in the trace integration.
• End‑to‑end visibility: The trace view shows Claude Code’s thought process, WebFetch tool calls (with JSON inputs), and subsequent edit steps in order, which gives engineers a concrete way to debug why an agent took a particular action rather than guessing from the final diff via the trace integration.
• Agent harness debugging: Because the traces are captured as LangSmith runs, teams can now compare how different models or harness settings behave on the same task and inspect failures without adding custom logging.
This effectively turns Claude Code from a black‑box coding assistant into something you can audit and iterate on like any other observability‑instrumented service.
cto.bench tracks daily PR merge success for coding agents
cto.bench (cto.new): cto.new launched cto.bench, a leaderboard that measures LLM coding agents on thousands of real GitHub pull requests, scoring them by how often their auto‑generated PRs actually get merged rather than on synthetic puzzles as shown in the bench launch and bench blog.
• Ground truth is merges: The benchmark aggregates success as a rolling 72‑hour average of "PRs merged / PRs opened" for each model‑and‑harness combo, using production traffic from cto.new’s users instead of lab tasks, so the scores reflect what ships, not just what compiles per the bench launch.
• Continuously updated: The team describes it as a living benchmark updated daily, which means agents that regress or improve with new model checkpoints or harness changes will show up as visible movement on the chart rather than a one‑off point in time according to the bench blog.
• Cross‑model comparison: Early plots show Claude, GPT‑5.x, and several custom harnesses spread across a wide band of success rates, giving engineering leaders a rough sense of which stacks convert coding time into merged code more reliably.
This shifts evaluation of coding agents closer to the metric engineering teams actually care about: did the agent’s work get merged into main.
Factory.ai benchmarks context compression on 36k long-running coding sessions
Context compression eval (Factory.ai): Factory.ai released a structured benchmark of context compaction strategies for long‑running coding agents, comparing OpenAI’s, Anthropic’s, and its own summarizers on more than 36,000 real software‑development messages and finding Factory’s method ahead on accuracy and context awareness as detailed in the compression chart and compression blog.
• Quality metrics: On their six probe dimensions—accuracy, context awareness, artifact trail, completeness, continuity, and instruction following—Factory’s system scores around 80–90% on most axes and 99.8% on instruction following, while OpenAI and Anthropic trail significantly on the same probes in the published bar chart as shown in the compression chart.
• Real agent logs: The study uses logs from real agentic coding sessions (file edits, error messages, decisions) rather than synthetic chat, then tests whether an agent can still answer detailed questions after its history is compressed, which directly targets the "forgetting previous steps" failure mode in coding agents per the compression blog.
• Design takeaway: Their write‑up argues that naive aggressive summarization makes agents re‑open files and repeat work, and positions structured, probe‑validated summaries as a prerequisite for reliable multi‑hour software agents.
The work turns context compression from a vague implementation detail into something with measurable regressions and trade‑offs that agent builders can now benchmark.
e2b dashboard adds live template build logs and error details
Template build logs (e2b): e2b shipped a Template Build Logs & Details Viewer in its dashboard, streaming logs for AI templates in real time with log‑level filters, duration tracking, and one‑click copy of error messages and build IDs according to the build logs demo and release notes.
• Live streaming and filters: The new view auto‑scrolls as logs come in and lets users filter by severity (info/warn/error), which is useful when debugging complex agent templates that run multiple tools or steps during build as shown in the build logs demo.
• Failure introspection: When a build fails, the UI surfaces a status banner and a detailed, copyable error payload along with timestamps and the elapsed time counter, so teams can paste errors directly into their coding agent or issue tracker per the release notes.
• Template‑centric workflow: Because each template now has its own build history page, operators can monitor rollout health and quickly spot which updates introduced regressions without needing separate logging infrastructure.
This brings a more traditional CI/CD observability experience to template‑based AI applications, including coding agents that are deployed via e2b’s runtime.
Summarize CLI turns URLs and files into token-efficient LLM summaries
Summarize CLI (summarize.sh): A new summarize command‑line tool wraps HTML parsing, Firecrawl extraction, and LLM prompting into a single CLI, letting developers point it at any URL or file (including YouTube videos) and get a cleaned, sectioned summary along with token and cost stats as shown in the cli demo and tool overview.
• Extraction pipeline: The tool normalizes webpages to text with Cheerio, optionally falls back to Firecrawl when sites block direct scraping, and pulls YouTube transcripts through multiple backends, so agents can operate on consistent text instead of brittle raw HTML according to the tool overview.
• Provider‑agnostic: It supports OpenAI, xAI, Gemini and others via a --model flag, and exposes knobs like --length and --extract-only, which makes it usable both as a standalone summarizer and as a preprocessing step in larger agent pipelines via the cli demo.
• Developer‑friendly output: The sample run on a Rich Sutton talk shows hierarchical sections (Overview, Key Evidence, Implications, Next Steps) plus tokens in/out and approximate dollar cost, which helps teams reason about prompt sizing when wiring this into workflows.
For coding‑adjacent agents that need to ingest long specs, talks, or docs, this CLI reduces plumbing work between the web and the LLM.
Athas adds ACP support to drive multiple coding CLIs from one panel
Agent panel (Athas): Athas is wiring in Agent Client Protocol (ACP) support so its agent panel can drive a range of coding agents—including Claude Code, Codex CLI, Gemini CLI, Kimi CLI, OpenCode, and Qwen Code—through a single UI according to the acp demo.
• Multi‑agent hub: The short demo shows a list of available backends and a unified "Agent" view, indicating that users will be able to switch which coding agent handles a task without changing their surrounding workflow or editor as shown in the acp demo.
• Protocol alignment: By speaking ACP rather than bespoke APIs, Athas positions itself as a thin integration layer that can keep up as each vendor’s CLI evolves, which is especially relevant with rapid changes in Codex, Claude Code, Gemini CLI, and others.
This kind of meta‑harness lets teams experiment with different coding agents against the same tasks and repositories while keeping their frontend and logging consistent.
Meta’s “trajectories” feature shows prompts used for AI-written diffs
Trajectories (Meta): Meta rolled out an internal "trajectories" feature that lets engineers see the prompts and AI interactions used to generate a code diff whenever an internal coding assistant was involved, effectively exposing the agent’s reasoning trace alongside the patch as shown in the trajectories feature.
• Prompt transparency: According to the write‑up, developers reviewing a diff can inspect the exact conversations that led to that change—similar in spirit to LangSmith traces but embedded directly in the code review UI—so reviewers know whether the change came from manual edits or from the in‑house Devmate tool via the trajectories feature.
• Cultural impact: The Pragmatic Engineer note describes mixed reactions inside Meta, from reviewers who appreciate learning from others’ prompts to some engineers who feel exposed and have started prompting in other languages to obscure their trajectories, highlighting how observability for coding agents also intersects with developer privacy.
For external teams building AI‑assisted review, this is an early, large‑scale example of surfacing agent context at the point where human approval happens, not just in backend logs.
🏗️ Compute crunch, financing, and public‑sector MOUs
Supply‑side signals for AI build‑outs: internal rationing at Google, DC financing setbacks, DOE’s Genesis Mission access, and services revenue tied to AI; excludes model/app launch stories.
Google creates exec council to ration internal AI compute
Internal compute council (Google): Google has reportedly set up a small executive council spanning Cloud, DeepMind, Search/Ads, and finance to decide which teams get access to scarce TPU/GPU clusters as AI demand outpaces internal capacity; 2025 capex guidance has been lifted to roughly $91–93B, but data center build-outs and chip deliveries still lag appetite for training and inference workloads as shown in the google rationing story.
• Rationed clusters: The council adjudicates clashes between revenue-generating Cloud projects, core product reliability at Google scale, and frontier model work from DeepMind according to the reported internal brief as detailed in the google rationing story.
• Capex vs lead times: Alphabet’s higher 2025 capex does not immediately fix bottlenecks because new capacity depends on multi-year construction and grid hookups, while accelerator supply ramps on quarterly cycles, so AI teams see near-term queueing for training runs and large inference deployments via the google rationing story.
The council indicates that even at Google’s spend level, AI roadmaps are now constrained by physical DC build and power timelines rather than model ideas.
OpenAI explores ~$100B round that could lift valuation to $830B
Mega-raise plans (OpenAI): Following on initial funding as covered in the initial funding coverage of talks at ~$750B, new reporting says OpenAI is now exploring raising as much as $100B in new capital, in a round that could value the company at up to $830B, to fund an AI infrastructure plan expected to burn more than $200B in cash through 2030 according to the valuation update and funding plan details.
• Investor mix: SoftBank has a previously disclosed $30B commitment and is expected to provide another $22.5B by year-end, partly financed by selling about $5.8B of its Nvidia stake; Amazon is reportedly considering $10B or more in a circular deal where OpenAI uses proceeds to buy compute on AWS as shown in the funding plan details and ai bubble debate.
• Compute flywheel: OpenAI projects roughly $19B revenue today, targeting $30B by 2026 and an ambitious $200B by 2030, with much of the raise earmarked for data centers, accelerators and power, including 1.9 GW of planned capacity tied to specific U.S. sites as shown in the funding plan details.
• Bubble concerns: Commentators note that this would be one of the largest private valuations ever and point out rising worries about an "AI bubble," even as Sam Altman argues that unmet demand plus exponential compute returns justify multi-hundred-billion-dollar capex per ai bubble debate and compute flywheel quote.
The raise, if completed at the discussed scale, would further concentrate AI training and inference capacity under OpenAI’s control while testing private market appetite for extremely capex-heavy AI business models.
DOE’s Genesis Mission locks in 24-org AI MoUs for national labs
Genesis Mission MOUs (DOE): The U.S. Department of Energy has now signed collaboration agreements with 24 organizations—including OpenAI, Google DeepMind, NVIDIA, Microsoft, Anthropic, AMD and xAI—to support the Genesis Mission, a national AI program to accelerate science, energy innovation, and security across the 17 DOE national labs, extending the initial alignment as covered in the Genesis mission according to the doe genesis update.
• Tool access for labs: DeepMind is providing its Gemini-based AI Co-Scientist multi-agent system first to all 17 labs, with future tools like AlphaEvolve, AlphaGenome and WeatherNext planned for 2026, according to the DeepMind announcement per the deepmind genesis blog.
• OpenAI partnership: OpenAI’s MOU focuses on deploying frontier models into DOE supercomputers such as Venado and integrating them into real research workflows in biosciences, fusion, national security, and energy R&D, via the joint statement per the openai doe mOU.
• NVIDIA role: NVIDIA commits Apollo models, accelerated computing platforms, and high-fidelity digital twins to help build some of the largest AI supercomputers at labs like Argonne and Los Alamos, anchoring the hardware and simulation layer for Genesis according to the nvidia genesis role.
DOE frames Genesis as a long-term public-private infrastructure for AI-driven discovery; the breadth of MoUs signals that national-lab workloads will be an important anchor customer for multiple frontier model providers.
Microsoft flags power and “warm shell” shortages as next AI bottleneck
Power and shells (Microsoft): In a recent discussion, Satya Nadella said Microsoft could end up with “a pile of chips just sitting around” because the company lacks enough electricity and "warm shells"—finished, utility-connected data center buildings—to plug in all of its AI GPUs, underscoring that power and construction, not chip supply, are becoming the hard constraint according to nadella power remarks.
• Grid vs GPU cadence: Nadella contrasts GPU ramp cycles measured in quarters with data center permitting and build timelines measured in years, echoing prior power-grid analyses via the US grid; he notes this mismatch is already creating stranded capital as accelerators depreciate while waiting for substations, transmission lines and shells to be ready according to nadella power remarks.
• Policy push: He also relays that OpenAI is urging the U.S. government to target an additional 100 GW of electrical generation per year as a strategic AI asset, tying national AI competitiveness to rapid grid expansion rather than only to chip procurement via nadella power remarks.
The remarks frame AI as an infrastructure issue of power and real estate as much as algorithms or models, and hint at increasing coordination between hyperscalers and governments on grid planning.
China upgrades older ASML DUV tools to keep 7nm-class AI chips flowing
DUV retrofits (China): New reporting says Chinese fabs are upgrading existing ASML deep-ultraviolet (DUV) lithography tools with third-party wafer stages, sensors and optics so they can keep pushing out 7nm-class AI and smartphone chips despite tightened export controls that block newer equipment and all EUV scanners as shown in the china duv upgrades and ft chip report.
• Multi-patterning dependence: Because restricted DUV tools cannot natively print 5–7nm features in one shot, fabs like SMIC and Huawei’s partners lean heavily on multi-patterning, exposing the same layer multiple times and combining the patterns; this raises per-wafer cost and lowers yield due to alignment and contamination risk stacking across passes according to the china duv upgrades.
• Export-control cat-and-mouse: ASML says it follows rules and does not support performance-boosting upgrades, but components can be sourced abroad and installed by third-party engineers; regulators may need to shift from blocking complete tools to monitoring parts, service and incremental performance improvements that, in aggregate, restore advanced-node capability via the china duv upgrades.
The retrofits indicate that U.S.–Dutch export controls have slowed but not stopped China’s march toward advanced AI-capable logic production, relying instead on engineering workarounds and higher manufacturing overhead.
Meta’s Mango and Avocado models ride on $70B+ AI capex and leveraged DC deals
AI infra financing (Meta): A Financial Times profile on Mark Zuckerberg’s AI push notes that Meta expects at least $70B in 2025 capital expenditures—up from $39B in 2024—to fund new data centers and chips for its upcoming Mango multimodal image/video model and Avocado LLM, relying on large bond issues and private-credit joint ventures like the Hyperion data-center deal with Blue Owl to spread the cost as detailed in the meta ai feature and ft meta article.
• Investor nerves: The article reports that investors are increasingly skittish about the scale of AI capex, especially after Meta tapped bond markets for roughly $30B and partnered with private creditors to offload some DC and chip costs, raising questions about how quickly its Llama and future Mango/Avocado models can translate infra spend into monetizable products according to the meta ai feature.
• Model reboot: Internally, Meta is described as pivoting from the mixed reception of recent Llama releases toward training a new "from-scratch" Avocado model with distillation and world-model ideas, which further ties the company’s AI competitiveness to the success of this large, debt-financed infrastructure wave as shown in the meta ai feature.
The piece situates Meta’s 2026 Mango/Avocado roadmap within a highly leveraged infrastructure strategy, in contrast to rivals that are more cautious on balance-sheet AI spend.
Oracle’s $10B Michigan AI data center stalls as Blue Owl steps back
Michigan AI campus (Oracle): Financial Times reporting says Oracle’s planned $10B, ~1GW AI data center in Saline Township, Michigan—part of a broader 4.5GW program linked to a reported ~$300B compute deal with OpenAI—has stalled after key capital partner Blue Owl pulled back over tougher lease and debt terms and schedule risk as shown in the oracle project stall.
• SPV lease model strain: The deal used the standard special-purpose vehicle pattern where the SPV borrows against long-term Oracle lease payments, but lenders pushed for stricter lease covenants and debt terms; Blue Owl was reportedly worried that construction delays would defer rental cash flows needed for debt service according to the oracle project stall.
• Search for new equity: Oracle and developer Related Digital say they are lining up a new equity partner, with Blackstone mentioned in talks, but the episode underlines that some hyperscale AI DC projects are now gated by credit conditions and delivery risk, not only GPU or power availability as detailed in the oracle project stall.
This setback lands shortly after disclosures of Oracle’s ~$248B in AI-related lease commitments, and shows that even committed capex pipelines can snag at the project-financing level.
Accenture books $2.2B in AI work yet warns about AI deflation
AI services mix (Accenture): Accenture’s latest earnings call highlighted that revenue growth is increasingly driven by AI work, with about $2.2B of signed contract value specifically tagged as AI delivery projects, even as the firm sketches a scenario where AI efficiency compresses traditional consulting revenue over time according to the accenture ai earnings and wsj earnings story.
• Client demand pattern: The company reports strong enterprise interest in using AI to cut costs and increase efficiency, which has led to firing some legacy consultants while hiring more AI engineers and partnering with Anthropic, Palantir, OpenAI and Cohere to standardize model and tooling access across clients as shown in the accenture ai earnings.
• Deflation risk: Management frames an "AI deflation" risk where, if a client can use GenAI to have two people do what ten consultants did before, the total value of that work can shrink even if demand for automation remains high, forcing Accenture to manage headcount and pricing to preserve margins as detailed in the accenture ai earnings.
The result is a mixed picture: AI is pulling in new revenue today, but the firm openly acknowledges that the same technology could erode its classic billing model if productivity gains outpace volume growth.
💼 Enterprise moves: Cursor↔Graphite, OpenAI raise, App Directory
Platform consolidation and distribution: code review meets agent IDEs, mega‑raise chatter, and app distribution in ChatGPT; excludes infra financing (covered elsewhere).
OpenAI said to target up to $100B raise at ~$830B valuation
OpenAI fundraise (OpenAI): Following earlier reports of a multi‑tens‑of‑billions round, new coverage says OpenAI is now aiming to raise as much as $100B in fresh capital at a valuation that could reach about $830B, with large tranches expected from SoftBank and possibly Amazon as shown in the initial raise, valuation update , and wsj recap. The information threads describe a company running at roughly a $19B revenue run rate in 2025, targeting $30B in 2026 and an ambitious $200B by 2030 while projecting more than $200B of cumulative cash burn through the end of the decade per the revenue and burn.
• Round structure and backers: One account says the headline $100B figure would aggregate new equity plus previously announced commitments; SoftBank is reported to have already agreed to $30B and to be lining up another $22.5B by year‑end, while Amazon is "considering" $10B or more in a circular deal where its investment flows back as AI compute purchases via the revenue and burn and wsj recap.
• Capex and commitments: Commentators tie the raise to large long‑term infrastructure obligations, citing roughly $1.4T of data‑center and lease commitments and OpenAI’s own expectation that it will burn about $26B across this year and next as it races Google and Anthropic on training and deployment according to the revenue and burn and wsj recap.
• Market test: Posts highlight that this would be one of the largest private tech valuations ever and frame it as a test of whether private capital is still willing to underwrite massive AI capex at near‑trillion‑dollar valuations even as some public investors become more skeptical of AI "bubble" narratives as detailed in the valuation update and wsj recap.
The funding push underscores how tightly OpenAI’s product roadmap is now coupled to long‑duration compute financing rather than incremental SaaS economics.
ChatGPT App Directory beta details emerge with early big-name apps
ChatGPT Apps (OpenAI): After the initial Apps SDK and directory announcement, more detail is emerging on how the beta ChatGPT App Store works in the client and which integrations are live, with users now able to go to Settings → Apps → Browse apps to discover and enable partner apps from within ChatGPT itself as shown in the apps launch and in-app access demo. The directory currently surfaces consumer‑facing services like Spotify, Apple Music, Zillow, DoorDash, Canva, Adobe Photoshop and others, each packaged as an app that ChatGPT can call via an @‑mention or selection in the UI, with write actions gated behind explicit user confirmation and enterprise controls like RBAC and logging available for org tenants detailed in the apps explainer and apps overview.
• From connectors to apps: OpenAI is rebranding what were previously "connectors" as full apps that can render rich interactive UIs and perform read/write actions, built against an expanded Apps SDK that sits on top of the Model Context Protocol so the same backend can be reused across agents and surfaces per the apps explainer.
• Invocation and safety: Users can invoke an app inline by mentioning it ("@DoorDash" or "@Canva") or by choosing it from the app picker, after which ChatGPT routes the request, but any external write—placing an order, creating a playlist, updating a document—requires an explicit confirmation step; enterprise admins can restrict which apps and actions are allowed and log calls for compliance via the apps explainer and apps overview.
• Distribution model: The store lives entirely inside ChatGPT rather than at the OS level, and early coverage notes that monetization still typically happens through the underlying service’s own billing rather than in‑store purchases, making this more a distribution and activation surface for chat‑triggered workflows than a direct rival to iOS or Android app stores detailed in the apps explainer.
For developers and SaaS vendors this turns ChatGPT into a new channel where apps are discovered and executed as part of natural‑language conversations rather than through traditional app installs.
Cursor acquires Graphite to fuse AI coding and code review
Cursor + Graphite (Cursor/Graphite): Cursor is acquiring Graphite, bringing one of the most widely used AI‑era code review tools under the same roof as a fast‑growing AI IDE, while keeping Graphite as an independent product that explores deep integrations between local development and PR workflows according to the acquisition post and acquisition blog. Cursor’s CEO frames the deal as building "the best experience for the agent‑human interaction," with Graphite continuing to run its own roadmap as a standalone app but increasingly wired into Cursor’s agent loop for review, merge, and collaboration as shown in the agent review comment and cursor graphite note.
• Independence plus coupling: Graphite will keep its own brand and team but both companies say they will "explore ways to integrate" review with local dev and smarter agent‑driven workflows, aiming to shrink the gap between code written in Cursor and code reviewed in PRs per the acquisition blog.
• Agent‑human review angle: Cursor leadership highlights that when agents generate most of the code, the main bottleneck becomes review; Graphite gives Cursor a production‑tested platform for batching comments, policies, and approvals around AI‑authored changes according to the agent review comment.
This move positions Cursor not just as an AI editor but as an end‑to‑end coding environment where agents can propose and apply large refactors while Graphite mediates the human acceptance path.
Google’s NotebookLM hits ~8M MAUs and plugs directly into Gemini
NotebookLM + Gemini (Google): Google’s NotebookLM is emerging as a notable consumer AI success, with reported mobile monthly active users climbing to about 8M from a cold start in May and daily actives nearing 1M, while the web product has roughly doubled visits over the year as shown in the usage stats thread. The product has quietly become powered by Gemini 3 under the hood, is now bundled into Google’s AI Premium plans on the paid side, and can also be attached as a notebook source inside the Gemini app so users can ground chats in existing research artifacts according to the gemini 3 switch and gemini integration.
• Growth and packaging: A detailed breakdown notes that NotebookLM launched independently on web and mobile, then grew its mobile app to around 8M MAUs with about 1M DAU on mobile alone before Google began bundling a paid version into broader AI subscriptions, effectively turning it into both a standalone product and a driver of AI‑tier upsell as shown in the usage stats thread.
• Gemini as engine and client: Google has swapped the model backing NotebookLM to Gemini 3 and added the ability to attach NotebookLM notebooks directly as sources in Gemini—through a new "NotebookLM" option in the Gemini "Tools" menu—so users can ask Gemini to reason over long research docs and class notes that already live in NotebookLM according to the tools update and gemini integration.
• Workflow examples: Posts from heavy users show workflows where a long deep‑research session in Gemini’s Deep Research mode is turned into a 5‑minute podcast episode via NotebookLM’s "Audio Overview" generator in a single click, effectively chaining the two products into a research‑to‑explainer pipeline per the audio overview demo.
Taken together, these signals point to Google treating NotebookLM as both a proof point that AI‑native study tools can scale to millions of users and as a key content surface feeding the wider Gemini ecosystem.
⚙️ Serving and training systems: diffusion caching, disaggregation
Runtime and training‑system engineering updates: diffusion caches in vLLM‑Omni, disaggregated core attention for long‑context training, and diffusion‑LLM support in SGLang; excludes benchmark leaderboards.
Hao AI Lab’s DistCA disaggregates core attention for 1.35×–2× faster long‑context training
DistCA / CAD (Hao AI Lab): Hao AI Lab introduced Core Attention Disaggregation (CAD) and the DistCA training system to fix workload imbalance in long‑context LLM training by peeling out the softmax(QK^T)V core‑attention into separate “attention servers,” achieving up to 1.35× speedup over prior long‑context systems and ~2× over Megatron‑LM baselines on large models and datasets, as detailed in the cad announcement and the cad blog.
• Problem framing: With packed documents of widely varying lengths, core‑attention cost scales quadratically with sequence length while linear layers stay balanced; when both run on the same GPUs, batches with a few long docs stall the whole cluster, leading to 2–4× slowdowns at 256k–1M token contexts as shown in the cad announcement and cad blog.
• CAD design: DistCA keeps embeddings and linear layers in the usual data/pipeline/context/tensor parallel shards but routes just the softmax(QK^T)V work to a pool of attention servers, where a scheduler breaks requests into balanced "block" tasks so every GPU sees similar quadratic load, via the cad blog and distca repo.
• Measured gains: On top of Megatron‑LM, DistCA’s prototype shows up to 1.35× end‑to‑end training throughput versus state‑of‑the‑art long‑context systems and about 2× versus unmodified Megatron‑LM when scaling both context length and node count, with no extra memory overhead reported in the distca repo.
This makes CAD one of the first concrete system‑level answers to the quadratic attention bottleneck in 256k–1M token training, shifting the constraint from worst‑case sequences to the attention‑server cluster design.
SGLang adds day‑0 support for LLaDA 2.0 in its diffusion‑LLM framework
LLaDA 2.0 in SGLang (LMSYS + Hao AI Lab): LMSYS extended SGLang’s diffusion‑LLM (dLLM) framework with day‑0 support for LLaDA 2.0, integrating Ant Group’s DeepXPU backend so diffusion‑style language models can be served and RL‑post‑trained on the same chunked‑prefill engine that powers autoregressive models, per sglang diffusion support; this builds on the lightweight inference server released in mini SGLang, which focused on compact, high‑performance AR decoding.
• Execution flow: The new pipeline treats block diffusion as a first‑class citizen in SGLang—requests are broken into chunked prefill segments, routed through a separate diffusion algorithm module, then passed to a model runner and attention backend, with the diagram emphasizing that decoding strategies (parallel decoding, low‑confidence decoding, custom schedulers) are configurable per model as shown in sglang diffusion support.
• System compatibility: Because dLLMs reuse SGLang’s Chunked Prefill infrastructure, features like batched serving, KV reuse, and existing optimization knobs remain available, so teams experimenting with LLaDA‑style diffusion LLMs do not need a separate inference stack according to sglang diffusion support.
The result is that diffusion‑based LLM variants such as LLaDA 2.0 can now be evaluated and trained under the same serving framework as standard AR models, narrowing the gap between research prototypes and production‑grade runtimes.
vLLM‑Omni adds TeaCache and Cache‑DiT for ~2× faster diffusion serving
vLLM‑Omni diffusion cache (vLLM project): vLLM has wired TeaCache and Cache‑DiT into vLLM‑Omni so diffusion models can reuse intermediate Transformer activations across timesteps, yielding up to ~2× higher image throughput without retraining or major quality loss according to the vllm diffusion cache announcement; on an NVIDIA H200, TeaCache reaches 1.91× and Cache‑DiT 1.85× speedup on Qwen‑Image at 1024×1024, and Cache‑DiT hits 2.38× on Qwen‑Image‑Edit.
• Serving impact: The caches sit under the existing vLLM‑Omni API and work as drop‑in backends for supported diffusion models, so operators can flip them on for Qwen‑Image and Qwen‑Image‑Edit to cut per‑image latency and GPU minutes while keeping model weights unchanged, detailed in the vllm diffusion cache announcement.
• Engineering angle: Both TeaCache and Cache‑DiT target redundant compute along the diffusion trajectory (adjacent steps share similar hidden states), so the gains are largest for long‑timestep samplers and high‑resolution generations where softmax(QK^T)V dominates runtime as shown in the vllm diffusion cache announcement.
The point is: diffusion workloads that already run on vLLM‑Omni can now see substantial cost and latency reductions by toggling a backend flag rather than re‑architecting their serving stack.
🔩 Compilers and accelerators: PyTorch on TPU rumors
One notable hardware compiler signal: a TorchTPU effort surfaces, aiming for native PyTorch on Google TPUs to reduce CUDA lock‑in; no pricing or SKU changes yet.
TorchTPU leak hints at native PyTorch on Google TPUs
TorchTPU (Google, Meta): A leaked "TorchTPU is coming" video and commentary indicate Google is working on a stack to run PyTorch natively on TPUs, rather than via hand‑rolled XLA bridges, with claims that Meta is also involved in pushing the project forward as shown in the leak summary and meta collaboration. This would directly target NVIDIA’s CUDA moat by letting existing PyTorch codebases move onto Google’s TPU fleets with far less porting work, though there is no public timeline, API surface, or pricing yet.
Ecosystem impact (speculative): Builders describe TorchTPU as an attempt to "make PyTorch run natively on Google TPUs breaking NVIDIA’s legendary CUDA lock‑in" per the leak summary; if the compiler/runtime can cover mainstream PyTorch ops with competitive performance, it would give large research labs and clouds another credible backend for training and inference.
• Compiler angle: The project points to a TPU‑first compiler/runtime layer for PyTorch, closer in spirit to CUDA than today’s XLA bridges, which could reduce friction for teams that have standardized on PyTorch but want TPU price/perf or capacity.
• Multi‑vendor signal: Follow‑up posts say "Google + Meta both moved their TorchTPU project into high gear," suggesting this is not just a Google infra experiment but a coordinated push by two of the largest PyTorch stakeholders, as detailed in the meta collaboration.
• Open questions: There are no details yet on operator coverage, how autograd and custom CUDA kernels would be handled, or whether any of this will be open‑sourced versus staying as a closed cloud compiler stack.
The point is: even as a leak with few specifics, TorchTPU signals serious interest in loosening CUDA dependence at the compiler level, and PyTorch teams will watch closely to see if it becomes a real, supported target alongside GPUs rather than another short‑lived backend experiment.
🧪 Models and interpretability: GLM‑4.7, Moondream, Gemma Scope 2
Light release day: a spotted GLM‑4.7 in vLLM, Moondream 3’s MLX Mac support, and Gemma Scope 2 tools for interpretability; plus an index card on Xiaomi’s MiMo‑V2‑Flash open‑weights stats.
Gemma Scope 2 releases as large open interpretability suite for Gemma 3
Gemma Scope 2 (Google DeepMind): Google DeepMind introduced Gemma Scope 2, a new open suite of interpretability tools trained on more than 1 trillion parameters’ worth of probes to help researchers trace internal reasoning in Gemma 3 models, debug odd behaviors, and surface potential risks as shown in the tooling teaser and hf interpretability note. The launch video frames Scope 2 as a way to inspect how activations flow during a query, with animated brains, code, and network visualizations underscoring that it plugs into Gemma 3 as an attachable analysis stack rather than a separate model . According to the associated Hugging Face‑led announcement, Gemma Scope 2 is billed as the “largest open release of interpretability tools”, designed to work as a library that can sit alongside training, finetuning, or evaluation workflows for Gemma‑family models as detailed in the hf interpretability note and hf retweet. For AI safety and interpretability engineers, this offers a standardized way to probe neurons and circuits in a modern open model family, narrowing the gap between proprietary interpretability efforts and what independent labs can run on their own hardware.
GLM‑4.7 quietly appears in vLLM with dedicated tool-calling parser
GLM‑4.7 in vLLM (Zhipu / vLLM): vLLM’s docs now list a GLM‑4.7 family with a --tool-call-parser glm47 flag and zai-org/GLM-4.7 as a supported model, signalling imminent availability of Zhipu’s next frontier model in popular inference stacks as shown in the glm47 support screenshot and glm47 pull request. This support replaces older GLM‑4.5/4.6 flags in the config, and community observers note that several new LMArena models self‑identify as Gemini but may in fact be GLM‑4.7 variants per the glm47 support screenshot.
For AI engineers, this means GLM‑4.7 should be drop‑in runnable wherever vLLM is deployed; the explicit glm47 tool‑call parser suggests first‑class support for structured tool use and function calling rather than generic JSON parsing, which in turn makes it easier to A/B test GLM‑4.7 against GPT‑5.x, Gemini 3, and Kimi K2 inside existing agent harnesses without bespoke glue code.
Xiaomi’s MiMo‑V2‑Flash posts 66 on AA Intelligence Index with 309B open weights
MiMo‑V2‑Flash (Xiaomi / Artificial Analysis): Artificial Analysis profiled MiMo‑V2‑Flash as a 309B‑parameter open‑weights reasoning model (15B active) scoring 66 on their Intelligence Index, matching DeepSeek V3.2 and sitting just below Gemini 3 Pro and GPT‑5.2 while leading many peers on math and tool‑use heavy evals according to the model overview and
. The report highlights standout scores of 96% on AIME 2025 and 95% on τ²‑Bench Telecom, indicating strong competition‑math and agentic tool‑use performance, and notes that the full 10‑benchmark Artificial Analysis suite cost only $53 to run thanks to MiMo‑V2‑Flash’s aggressive pricing at $0.10/M input and $0.30/M output tokens as shown in the model overview. Deeper per‑benchmark charts show MiMo‑V2‑Flash near the top on GPQA Diamond, MMLU‑Pro, and telecom‑style agent tasks, while trailing leading closed models on long‑context reasoning and some coding suites per the eval breakdown. Artificial Analysis also flags that the model is unusually verbose, consuming around 150M reasoning tokens across their suite, which has latency implications and partially offsets its raw price advantage; nonetheless, the combination of open MIT‑licensed weights, high reasoning scores, and low per‑token cost marks MiMo‑V2‑Flash as a serious candidate for teams that want frontier‑tier math and tool orchestration without closed‑source constraints.
Moondream 3 adds native MLX support for Mac alongside Linux and Windows
Moondream 3 (Moondream): The Moondream team announced native Mac support via Apple’s MLX stack, so Moondream 3 now runs on Mac, Linux, and Windows with a one‑line install (pip install moondream-station) and a focus on local, free usage as shown in the mlx launch and moondream blog. The video teaser shows Moondream 3 spinning up on macOS with an "Moondream 3" and "Mac" title card before dropping into a simple "Hello World" workflow, highlighting that the same station tooling now spans all three desktop platforms . For practitioners who prefer local inference, this reduces friction for trying Moondream’s reasoning and vision models on Apple silicon; the MLX backend should give better efficiency than generic PyTorch on Mac, and the same moondream-station CLI can be scripted into existing dev or evaluation pipelines without worrying about OS‑specific setup.
🗂️ Parsing, search and RAG plumbing
Document parsing upgrades and research assistants: cheaper structured OCR, link‑preserving pipelines, and recipes combining Exa search with Fireworks; excludes benchmarks and model launches.
Exa pairs paper search with Fireworks in open research‑assistant cookbook
Exa search + Fireworks (Exa / Fireworks): Exa and Fireworks published a cookbook showing how to wire Exa’s semantic paper search into Fireworks‑hosted LLMs to build an AI research assistant that can find relevant papers and summarize them in one flow as shown in the exa fireworks assistant and cookbook code.
The example app queries Exa’s "research paper" vertical (restricted to domains like arXiv and OpenReview), pulls back 20 top matches with snippets, and then feeds those into a Fireworks model for synthesis, effectively turning Exa into the retrieval layer and Fireworks into the reasoning layer over that curated context as detailed in the exa fireworks assistant. This builds on Exa’s earlier People Search work—released as a hybrid semantic retrieval system over 1 billion profiles—and the dedicated benchmark that evaluated recall over GTM‑style queries per the People Search extended with this integration. A separate update shows that benchmark data now lives as a public Hugging Face dataset, making it easier for others to reproduce or extend Exa’s people‑search experiments in their own RAG stacks via people benchmark upload and people benchmark.
LlamaParse v2 cuts rich-document parsing to ≲$0.003 per page
LlamaParse v2 (LlamaIndex): LlamaIndex is pitching LlamaParse v2 as a cost‑effective way to add visual understanding to document pipelines—pricing comes in at ≤$0.003 per page while still reconstructing complex charts and tables into structured outputs, according to the launch commentary as seen in the llamaparse overview.
The post highlights that LlamaParse now handles visually dense PDFs like research reports and forms by treating figures, charts and layout as first‑class signals, then emitting clean tables and text regions that downstream RAG or analytics systems can consume without hand‑written parsing rules as mentioned in the llamaparse overview. For teams building retrieval or analytics over large document corpora, the key change versus generic OCR is predictable structure at a price point that makes parsing millions of pages economically viable rather than a one‑off experiment.
Datalab OCR adds hyperlink‑preserving PDF to HTML/markdown conversion
Chandra OCR (Datalab): Datalab’s Chandra/Surya stack now includes Hyperlink Extraction for digital PDFs, so internal table‑of‑contents jumps and external URLs survive conversion into HTML or markdown instead of being discarded in plain text as detailed in the hyperlink feature.
In the example shared, internal anchors like section links are converted into block‑level IDs while outbound links become normal <a href> tags, which keeps navigation structures, cross‑references, and citation links usable in downstream RAG or browsing experiences as shown in the hyperlink feature. The team also points developers to a broader benchmark page where Chandra’s OCR quality is compared against dots.ocr, olmOCR and DeepSeek on forms, tables, invoices and historical scans, giving a sense of how this link‑preserving layer sits on top of competitive text extraction accuracy via the ocr comparison and overall benchmark.
🧠 RL for LLMs and planning methods
Papers with concrete training practices: stable policy‑gradient RL for LLMs (incl. MoE routing replay), compact UT variants for ARC, bilevel reward discovery, and online/adversarial world‑model planning; mostly method papers today.
Qwen publishes concrete recipes for stable RL on large MoE LLMs
Stabilizing RL with LLMs (Qwen): Qwen researchers formalize when token‑level policy‑gradient RL is a valid surrogate for sequence‑level rewards and derive practical stability rules for large MoE language models, emphasizing small training–inference discrepancies and low policy staleness as shown in the RL formulation thread. The paper decomposes per‑token importance weights into an engine‑mismatch term (e.g., FP8 inference vs BF16 training, router differences) and a staleness term, then shows that on‑policy training with importance sampling correction is most stable, while off‑policy training needs both clipping and Routing Replay variants (R2/R3) to keep gradients trustworthy in a 30B MoE trained over hundreds of thousands of GPU hours via the
.
• MoE‑specific practices: Routing Replay freezes or replays router decisions so MoE behaves more like a dense model during RL; R2 (training‑router replay) works best for mildly off‑policy data, while R3 (inference‑router replay) is more robust under heavy off‑policiness as detailed in the RL formulation thread.
• Recipe takeaway: Once stability is enforced via IS, clipping, and routing control, prolonged optimization consistently recovers similar final performance regardless of cold‑start, giving frontier‑scale teams a more principled RLHF/agentic‑RL cookbook for MoE LLMs rather than heuristics alone per the RL formulation thread.
Bilevel reward discovery learns better RL objectives than hand-crafted signals
Learned rewards for RL (multi‑institution): A Nature Communications paper proposes a bilevel optimization framework that automatically discovers dense reward functions for embodied RL agents by minimizing policy regret, avoiding expert demonstrations or human feedback and outperforming hand‑engineered rewards across several domains as shown in the paper recap. In data‑center energy management, RL agents trained on discovered rewards achieve more than 60% energy reductions versus 21–52% for baseline RL, while in UAV trajectory tracking the approach enables PPO agents to complete tasks where manually designed sparse rewards fail entirely, suggesting that meta‑learned rewards can encode useful physics‑like structure without explicit models via the
.
• Method details: The lower level optimizes the policy with standard RL (DQN, PPO, SAC, TD3), while the upper level updates the reward function using a meta‑gradient that directly minimizes the gap to an (unknown) optimal policy, yielding high reward near success/failure states plus informative shaping throughout the state space according to the paper recap.
• Interpretability: The discovered rewards cluster around critical states and reproduce latent relationships similar to human physics‑based reward designs, even though no analytic dynamics are provided, which the authors argue makes this suitable as a drop‑in reward designer for complex control tasks as detailed in the paper recap.
Online and adversarial world-model training makes gradient planning 10× faster than CEM
World‑model planning (multi‑institution): A new planning paper shows that retraining world models online and adversarially on off‑distribution states can make gradient‑based planners about 10× faster than Cross‑Entropy Method (CEM) while retaining similar plan quality on three robotics tasks, addressing long‑standing instability issues in gradient planning over learned dynamics as detailed in the paper recap. The authors argue that standard one‑step world models, trained only on expert data, produce misleading gradients once optimizers explore novel trajectories, so they introduce Online World Modeling (roll out current plans in the real simulator and continue training on the resulting states) and Adversarial World Modeling (train on small worst‑case state/action perturbations) to close this train–test gap via the
.
• Effect on gradients: By continuously updating the model on the very trajectories the planner wants to execute, and by smoothing the loss landscape with adversarial examples, the learned dynamics provide more reliable gradients for long sequences, avoiding the compounding‑error cliffs that previously caused gradient planners to diverge or require heavy regularization per the paper recap.
• Comparison to CEM: Across manipulation and navigation settings, their gradient planner with the improved world model matches or exceeds CEM success rates while using roughly a tenth of its computation budget, suggesting that learned models plus careful online training can finally make gradient‑based planning competitive as a practical, low‑latency controller as shown in the paper recap.
Universal Reasoning Model pushes small UT-style Transformer to 53.8% on ARC‑AGI‑1
Universal Reasoning Model (Ubiquant): Ubiquant introduces the Universal Reasoning Model (URM), a compact Universal Transformer variant that adds a short 1D convolution inside the feed‑forward block and uses truncated backpropagation to improve multi‑step puzzle reasoning; URM reports 53.8% pass@1 on ARC‑AGI‑1 and 16.0% on ARC‑AGI‑2, establishing new state‑of‑the‑art scores for this architecture family as detailed in the paper recap, ArXiv paper. The model shares weights across depth like a standard UT but iterates a single layer many times, mixing nearby positions locally via the 1D conv and refining representations non‑linearly, with ablations indicating that recurrence plus nonlinearity, not architectural complexity, drive most gains via the
.
• Training tweak: URM truncates backpropagation through time, sending gradients only through later recurrence steps; this stabilizes training when many thinking loops are used and reduces noise from extremely long gradient paths per the paper recap.
• Interpretation: Stripping nonlinear components sharply degrades accuracy in their experiments, which the authors argue supports a view of reasoning as iterative nonlinear refinement over a shared computation cell rather than just deeper static stacks as shown in the paper recap.
🎨 Creative stacks: layered edits, GPT‑Image nodes, playable video
Heavy creative/media chatter today: layered RGBA decomposition (fal/Replicate), GPT‑Image‑1.5 nodes in ComfyUI, app templates and playable video tooling. Excludes model evals and enterprise news.
Qwen-Image-Layered hits fal and Replicate with ~15× faster layered edits
Qwen-Image-Layered (Alibaba/Qwen): Qwen’s layered image model is shifting from lab demo to plug-in infrastructure as fal and Replicate expose hosted endpoints and PrunaAI compression reports roughly 15× faster layered RGBA generation compared to the original release as shown in the layered images and model announcement, and via fal and replicate launch links. This matters for creative stacks because tools can now request foreground, background, shadows, and nested layers as native RGBA tensors rather than hacking masks or post-processing.
• Hosted everywhere: fal advertises Qwen Image Layered as a "Photoshop-grade" layering backend with native decomposition and explicit layer counts, while Replicate pitches it as a way to export separate foreground, background, and shadow layers ready for downstream apps according to fal integration and replicate launch.
• Performance upgrade: PrunaAI describes a compressed deployment that keeps quality while cutting generation latency by about an order of magnitude, affecting whether layered outputs feel interactive enough for editors and web apps per the speedup update.
• Product-level control: Qwen’s own thread stresses that decomposition is the path to "product level" image generation because creators can keep drilling into sub-layers and edit them independently instead of re‑rendering whole scenes according to qwen commentary and their GitHub repo.
ComfyUI adds GPT-Image-1.5 nodes for multi-edit and contact-sheet workflows
GPT-Image-1.5 (OpenAI/ComfyUI): ComfyUI now exposes GPT-Image-1.5 as a first-class node, and the team is showcasing complex workflows like multi-edit image updates, character-consistent contact sheets, style transfer, and markdown-rendered UI shots powered by a single model graph as shown in the node announcement and contact sheet example. This gives graph-based creators access to OpenAI’s latest image model without leaving their existing pipelines.
• Batch structural edits: In the launch examples, GPT-Image-1.5 cleanly replaces screen content, text labels, and character pose in one pass while preserving fabric detail and lighting, which ComfyUI positions as a step up from prior GPT Image integrations that struggled with multi-region consistency as detailed in the node announcement.
• Cinematic contact sheets: A separate workflow turns a single ski photograph into a 3×3 cinematic contact sheet by varying framing and angle while holding subject, lighting, and environment fixed, driven entirely by a structured prompt that spells out lens behavior and depth of field expectations according to the contact sheet example.
• Prompt-driven layout logic: The thread goes on to show grid-based character sheets and markdown-on-screen renders (e.g., iMac UI with node graphs), reinforcing that GPT-Image-1.5 can follow layout instructions tightly enough to be used for UI mockups and documentation assets inside Comfy graphs as shown in the contact sheet example and comfy blog post.
Beam launches early-access platform for turning AI video into playable mini-games
Playable videos (Beam): Beam is rolling out an early-access platform where creators can turn AI-generated clips into interactive, playable videos, wiring Nano Banana Pro, Veo 3.1 Pro, Sora 2 Pro and other models into a canvas plus node-graph logic builder as detailed in the beam launch thread. The result is short, shareable mini-games where model-driven scenes respond to input instead of staying fixed on a timeline.
• Canvas + logic builder: The demo shows a visual editor with trigger blocks like "On Key Press" and actions like "Change Scene", making it possible to attach collision, state, and progression logic around generated sprites and backgrounds without custom engine code according to the beam launch thread.
• Model‑agnostic design: Beam advertises support for multiple frontier image/video generators, so teams can treat playable logic as a layer on top of whatever model they prefer, instead of being locked into one runtime per the beam launch thread.
• Early-access focus: The current release targets builders comfortable with node graphs; there’s no public pricing yet, and Beam is pitching the tool as a way to prototype interactive trailers and simple arcade experiences rather than full‑scale games for now as shown in the beam launch thread and their launch blog.
Meta lets users insert themselves into AI-generated images and videos
Self-insert media (Meta): Meta is rolling out a "Your selfie" setting that lets people add themselves into AI‑generated images and videos, with options to restrict who can do this and an explicit note that these interactions help "improve AI at Meta" according to the feature overview. This moves personalization from generic avatars to real‑face composites inside generated scenes.
• Control surface: The setting offers scopes like "Only me", "Followers I approve", "Followers I follow back", and "Everyone" for who can add you to media, plus a view where you can see or delete drafts that include your likeness as shown in the feature overview.
• Voice and photo pairing: Another part of the flow lets you save both your photo and voice, hinting at composite characters that can appear and speak in AI video, although the tweets do not yet show a full end‑to‑end generation demo according to the feature overview.
• Data use disclosure: The intro screen says that interactions with these AIs, including selfies and voice recordings, will be used to improve Meta’s AI systems and links to objection rights, which may become a flashpoint for regulators assessing consent around biometric training data as detailed in the feature overview.
Nano Banana Pro powers Gemini holiday cards and advanced photo prompt packs
Nano Banana Pro (Google/Gamma/Leonardo): Google is pushing Nano Banana Pro as a consumer‑facing image engine inside Gemini and partners are building prompt packs on top, from one‑tap holiday card templates to detailed telephoto-look photography prompts as detailed in the holiday card feature and telephoto prompt deck. Builders are also sharing head‑to‑head comparisons claiming NB Pro surpasses GPT‑Image‑1.5 for realism on faces and water according to the user comparison.
• Gemini holiday templates: The Gemini app now lets users upload any photo, pick a festive style, and have Nano Banana Pro wrap it in holiday scenes and typography, no prompt needed; this sits alongside the existing image-guided edit mode where you circle or annotate parts of the picture to guide changes according to the holiday card feature.
• Telephoto simulation prompts: Techhalla released 15 telephoto-style prompt recipes tuned for Nano Banana Pro + Leonardo AI, covering compressed mountain vistas, urban isolation, motion‑blurred sports, and retro‑futurist sci‑fi scenes, each specifying focal length, DOF, atmosphere, and composition details as detailed in the telephoto prompt deck.
• Perceived quality edge: Multiple practitioners describe NB Pro as "the best thing that has happened this year" for diverse, photoreal creation and argue that it produces more convincing portraits and water reflections than GPT‑Image‑1.5 in their workflows according to power user praise and user comparison.
MagicPath adds /commands to spawn multiple design variants from chat
/commands (MagicPath): MagicPath introduced /commands inside its design chat interface, letting users generate and refine multiple UI variants and flows without ever leaving the conversation window as shown in the commands launch. The feature is pitched as unlocking a strong "flow state" where designers bounce between exploration and refinement in a single thread.
• Chat-native generative UI: The demo shows a user typing /commands to bring up actions like generate, refine, and insert, then rapidly cycling through alternative layouts and states that appear inline, rather than switching to a separate canvas tool per the commands launch.
• Variant-first workflow: MagicPath highlights that this approach makes spinning up several flows for a feature trivial, while preserving a chronological trace of what prompts led to which designs, which can be useful when pairing human product decisions with agent‑generated suggestions as shown in the commands launch.
Sora uses ChatGPT memories to auto-build personalized holiday videos with free credits
Sora holiday flow (OpenAI): The Sora mobile app is running a holiday promotion where it reads your ChatGPT memories and uses them to auto‑generate a personalized seasonal video, while also granting free generation credits and 10‑credit referral rewards to drive usage as detailed in the memory video prompt and referral clip. The UI makes this look like a one‑click gift: you tap a 🎁 button, Sora pulls stored facts about your life, and then renders a custom clip.
• Memory‑aware story generation: The modal explicitly says "Sora will use your ChatGPT memories to create a personalized holiday video for you", signalling OpenAI’s intent to tie long‑term profile data into video storytelling rather than simple text responses according to the memory video prompt.
• Referral‑driven credits: A companion post notes that checking Sora now may show free video credits plus 10 extra for each new user invited via link, turning holiday sharing into an acquisition channel for the video model as shown in the referral clip.
• Privacy questions in the community: Some observers are excited about memory‑based personalization while others flag concern about opaque use of stored memories for creative content, though there is no new policy text in these tweets beyond the in‑app disclosure per the memory video prompt.
ComfyUI showcases WanMove path-based animation workflow for single-image motion
WanMove path animation (ComfyUI): ComfyUI is running a live session on path-based image animation using WanMove, WanVideoWrapper, and the FL Path Animator, turning a single still frame into controlled motion by drawing motion paths directly on the image as described in the live stream flyer. This adds another building block for creators who want more structured camera and object motion inside AI‑generated clips.
• Single-frame to shot: The announced workflow takes one frame as input, lets the user sketch path overlays (e.g., arcs, straight lines), and then renders a full shot following those trajectories, instead of relying on purely stochastic motion from a video model according to the live stream flyer and wanmove workflow json.
• Graph as documentation: ComfyUI published the corresponding JSON workflow graph, making it easier for others to inspect how WanMove and FL Path Animator nodes are wired together and reuse that pattern in their own projects as detailed in the workflow link.
ImagineArt adds swap/remove/change background controls for video clips
Video background tools (ImagineArt): ImagineArt announced new controls to swap, remove, or change video backgrounds in its pipeline, extending its earlier GPT‑Image‑1.5 + Kling‑based stack for character‑consistent edits into full‑scene background manipulation according to the background update. The feature is framed as a one‑click way to re‑stage existing footage without re‑shooting.
• Stacked model workflow: Earlier posts tied ImagineArt’s video stack to GPT‑Image‑1.5 for frame‑consistent character rendering and Kling for motion; the new background operations appear to wrap those capabilities with an extra mask‑and‑replace stage so users can isolate subjects and drop them into new environments as shown in the background update.
• Editing focus: There are no benchmarks or quality metrics yet, but the messaging emphasizes background control rather than pure generation, targeting use cases like product videos, social clips, and UGC clean‑ups where the foreground should stay intact while the setting changes according to the background update.
🤖 Embodied AI: stage robots, mimic RL, and warehouse ROI
A visible robotics day: viral Unitree G1 choreography, Disney’s Olaf mimic‑RL design notes, rapid‑deploy traffic cones, and UPS’s Pickle unloaders with payback math; excludes creative video tools.
UPS to buy ~400 Pickle unload robots in $120M deal with ~18‑month payback
Pickle unload robots (UPS): UPS is reportedly lining up about $120M to buy roughly 400 Pickle trailer‑unloading robots that can clear a typical truck in around two hours, with internal estimates suggesting the capital outlay pays back in about 18 months as part of a $9B automation plan aimed at more than $3B in cost savings by 2028 as shown in the Pickle summary and news article. Pickle’s systems drive into the trailer, use vision‑guided suction to grab boxes up to ~50 lbs, and drop them on conveyors, giving a concrete ROI case for embodied AI in one of the least automated warehouse tasks and signaling that dock robots are moving from pilot to line item at Fortune‑100 scale.
Disney’s Olaf robot paper shows compact mimic‑RL character with detailed mechatronics
Olaf character robot (Disney): Fresh diagrams and commentary highlight a compact Olaf robot whose internal "backbone" uses multiple Dynamixel actuators plus custom eye, jaw, and shoulder linkages, all driven by reinforcement learning that imitates animator motions while respecting impact and thermal constraints as detailed in the design diagrams and mimic-rl demo.
The work separates a robust articulated core from show functions so policies can be trained in simulation with imitation, overheating and impact rewards, then run inside a costume‑sized shell—offering a concrete blueprint for other studios that want expressive, safe, walk‑around characters powered by mimic RL rather than direct puppeteering.
Reachy Mini desktop humanoid kits hit 3,000 units shipped worldwide
Reachy Mini kits (Pollen Robotics): Following up on Reachy Mini, which covered the initial Hugging Face–backed launch of this desktop humanoid, Pollen now reports that 3,000 Reachy Minis have shipped worldwide just before Christmas, with social feeds full of unboxings from researchers, hobbyists, and classrooms via the shipping update and community unboxing. That distribution scale for a relatively affordable, ROS‑ready bimanual platform suggests a fast‑growing installed base for labs and indie builders who want a common, open robot body for experimenting with language‑conditioned control, perception, and home‑scale skills.
Unitree G1 humanoids star as flipping backup dancers at major concert
Unitree G1 stage robots (Unitree): Two Unitree G1 humanoids served as on‑stage backup dancers at Wang Leehom’s Chengdu concert, performing synchronized Webster flips and tightly timed choreography that many viewers described as "smooth like real humans" while Elon Musk amplified the clip with a one‑word "Impressive" reaction per the Unitree thread, new angle, and Musk reaction. This kind of live, multi‑minute routine under concert lighting and staging constraints illustrates how far high‑agility control, balance, and robustness have come for small humanoids, and gives a glimpse of stage‑ready embodied AI as a commercial entertainment product rather than a lab demo.
China tests robotic traffic cones that auto‑deploy accident perimeters in ~10 seconds
Robotic traffic cones (China): Trials in China show self‑driving traffic cones rolling out of an emergency vehicle, then autonomously arranging themselves into a lane‑blocking pattern in less than 10 seconds, so responders no longer need to walk into live traffic to place cones by hand as demonstrated in the deployment overview. The cones can reportedly be either tele‑operated or left to self‑organize, turning a cheap, familiar roadside object into a small fleet of embodied safety agents and hinting at how microrobots could incrementally automate hazardous setup tasks without full vehicle autonomy.
Viral Russian courier‑robot crash spotlights sidewalk safety risks
Delivery robots in public spaces (Russia): A Russian sidewalk delivery robot drew global attention after a video showed it striking a woman’s legs and flipping her backward during a run in a courtyard, underlining how even small wheeled couriers can cause serious harm if perception, braking, or right‑of‑way logic fails as shown in the collision clip. For teams deploying last‑mile bots, the clip is a reminder that human–robot interaction, fallback behaviors, and liability frameworks are now as central as navigation and localization when moving from test tracks to dense pedestrian environments.
🔌 Interoperability: API shapes, skills loaders, web agents
Agent connectivity without touching the Codex Skills GA feature: Anthropic‑compatible API shapes on OpenRouter, universal skills loaders, and turnkey browse/agent endpoints.
OpenRouter maps Anthropic API shape to any hosted model
OpenRouter Anthropic endpoint (OpenRouter): OpenRouter now exposes an Anthropic-compatible API surface so clients written for Claude can be pointed at any OpenRouter model, including GPT-5.2, Kimi K2 and others, without changing code; the team also published a guide showing how to run Claude Code entirely over OpenRouter instead of Anthropic’s own endpoint as shown in the Claude Code guide, api shapes note , and Claude code integration.
• Anthropic API shapes: The new endpoint mirrors Anthropic’s request/response schema and types, letting existing Anthropic SDKs and tools talk to OpenRouter-hosted models with a configuration change rather than a rewrite, per the api shapes note.
• Claude Code routing: The Claude Code guide walks through wiring its CLI to OpenRouter, so developers can swap between 320+ models (39 free) while keeping Claude Code’s harness, tracing, and UX stable as detailed in the Claude code integration.
• Team usage view: OpenRouter highlights that, once wired up, teams get centralized usage analytics across all models instead of per-vendor dashboards, which is a key operational benefit for multi-model shops, as noted in the api shapes note. The net effect is that any Anthropic-shaped agent or tool can become a multi-model client with only endpoint and key changes rather than new adapters.
OpenSkills v1.3 ships universal loader for Agent Skills folders
OpenSkills loader (OpenSkills): OpenSkills v1.3.0 introduces a universal skills loader that understands the Agent Skills folder format (SKILL.md plus optional scripts/assets) and adds support for symlinks so the same skill can be mounted into multiple coding agents without duplication according to the release note, skills repo.
• Unified loading semantics: The loader scans local .skills directories and now follows filesystem symlinks, which simplifies sharing organizational skills—like “spec-to-implementation” or “browser tools”—across different harnesses and repos without copying files, as noted in the release note.
• Agent-agnostic design: Because it targets the open Agent Skills spec instead of any single vendor, the same skills tree can be consumed by Claude Code, Codex, Gemini CLIs, or custom agents that support the standard, turning skills into a portable capability layer, as detailed in the skills overview. This pushes skills closer to a true interoperability primitive: one markdown-defined capability that many different agent runtimes can discover and execute.
Athas adds ACP support to talk to multiple coding agents
Athas ACP bridge (Athas): The Athas tooling is adding ACP (Agent Client Protocol) support so its agent panel can talk directly to multiple external coding agents—Claude Code, Codex CLI, Gemini CLI, Kimi CLI, OpenCode, Qwen Code—from one place as shown in the acp teaser.
• Multi-agent console: A single Athas interface will be able to send tasks to different agent CLIs that speak ACP, making it a kind of control room for heterogeneous coding assistants rather than forcing users to live inside one vendor’s terminal, as detailed in the acp teaser.
• Protocol alignment: By adopting ACP, Athas aligns with the same emerging standard used by tools like Kimi CLI and others, which reduces bespoke glue code and helps keep interactions (messages, tool calls, traces) in a common shape, as noted in the acp teaser. For engineers already juggling several agent CLIs, this moves interop from “shell scripting” territory into a first-class protocol and UI layer.
BrowserUse launches Bu, a phone-controlled personal web agent
Bu web agent (BrowserUse): The BrowserUse project introduced Bu, a personal web agent that runs on a user’s Chrome profile and can be controlled over chat or even by phone, combining the Browser Use skill set with persistent agent sessions to complete tasks on a real browser as shown in the Bu demo.
• Personal Chrome control: Bu can search, click, and fill forms inside a user’s own browser session, so it works with authenticated apps and personal data rather than a sandboxed, generic profile, as shown in the Bu demo.
• Skill-based behaviors: Under the hood it leans on Browser Use skills, so the same skill definitions that power generic agents can be reused for this phone-driven assistant without bespoke code per task, as mentioned in the skills mention.
• SMS-style access: The team is sharing Bu as a phone number; users can text it instructions and have actions reflected back in their local Chrome, which is a different interaction model from traditional in-IDE or web-only agents, as shown in the Bu demo. This shows how browser-control skills can be wrapped into a user-facing “agent as a contact” instead of yet another web UI or plugin.
Firecrawl’s /agent web runner gets 5 free daily calls promotion
Firecrawl /agent promo (Firecrawl): Firecrawl is giving every user 5 free /agent runs per day for a week, promoting its endpoint that searches, navigates, and extracts structured data from the live web on natural-language instructions as shown in the Firecrawl agent and promo details.
• Turnkey web agent: The /agent endpoint takes a request with or without a URL, then drives browsing, link-following, and scraping steps on its own before returning a consolidated result object suitable for LLM tools or pipelines according to the agent description.
• Usage incentive: The campaign encourages builders to share concrete /agent use cases—Firecrawl is offering swag and AirPods to the most-liked posts that tag the project, which doubles as a way to surface real-world workflows, as detailed in the promo details. For teams that don’t want to build their own browser orchestration layer, this makes Firecrawl’s agent a low-friction drop-in for research and RAG pipelines during the trial window.
Letta memory blocks abstraction begins to spread across frameworks
Memory blocks pattern (Letta): Framework authors are starting to adopt Letta AI’s memory blocks abstraction—modular chunks of long-term agent memory—as a reusable building block, with developers calling out that other stacks are borrowing the design according to the interop comment and memory blocks pitch.
• Portable memory layout: Memory blocks treat agent memory as composable, named stores (e.g., profile, projects, decisions) rather than ad-hoc context blobs, which makes it easier for different runtimes to interpret and migrate state across agents according to the memory blocks pitch.
• Cross-framework reuse: Posts highlight that non-Letta tools are now implementing similar patterns, signalling that memory blocks could become a de facto interop layer for long-lived agents in the same way that Skills and MCP standardized tools according to the interop comment. The spread of this abstraction suggests that not only tools and skills, but also memory schemas, are converging toward shared shapes that many agent frameworks can understand.
🗣️ Realtime voice agents: app wiring and Live UX tweaks
Smaller but relevant updates: ElevenLabs agents wired into Lovable apps with persistent API keys, and Gemini Live adds mute/turn‑taking polish and broader language coverage.
Gemini Live adds mic mute, better timing, and 65+ language support
Gemini Live UX polish (Google): Google’s December "Gemini Drops" update gives Gemini Live—its voice‑first conversational mode—more human‑like turn‑taking, a manual mic‑mute control, and the ability to converse in over 65 languages, tightening the fit for real‑time assistant use on mobile and desktop as shown in the drops thread.
• Mic mute and interruptions: Gemini Live now lets users mute their microphone mid‑session to block background noise or side conversations, and Google says it reduces awkward mid‑sentence pauses so speech feels closer to natural back‑and‑forth as shown in the drops thread.
• Language reach: The same drop expands Gemini’s spoken‑language coverage beyond 65 languages, so the live mode can handle brainstorming, explanation, and task help for many more locales without switching products as shown in the drops thread.
• Part of larger bundle: These changes arrive alongside other Gemini 3‑era features like image‑guided editing in Nano Banana, local result improvements, and NotebookLM integration, all grouped in Google’s December feature hub as shown in the drops thread and drops hub.
The adjustments are incremental but directly target the friction points that matter when people use Gemini as a real‑time voice agent rather than a text‑only chatbot.
Lovable apps now embed ElevenLabs Agents with remembered API keys
ElevenLabs Agents (ElevenLabs & Lovable): ElevenLabs’ hosted Agents and other audio models are now first‑class citizens inside Lovable, so builders can wire voice and TTS into new apps while Lovable remembers a single ElevenLabs API key across projects as detailed in the lovable integration and api key reuse; the goal is to let people prototype and ship audio‑centric features from a chat‑driven IDE without writing bespoke auth or client glue.
• Zero‑friction trials: Lovable’s flow lets developers enter an ElevenLabs key once, then reuse it across multiple apps so they can swap models and Agents while staying inside the same prompt‑based workflow as shown in the lovable integration and api key reuse.
• Agent and model coverage: The integration exposes ElevenLabs’ Agents alongside "leading audio models", so teams can test both end‑to‑end conversational agents and raw TTS within the same Lovable project canvas per the lovable integration.
• Docs and examples: ElevenLabs points users to a short explainer on how Lovable stores keys between projects and how to invoke Agents from generated app code, in addition to the in‑app UI shown in the demo as shown in the api key reuse and integration blog.
The update ties a popular low‑friction app builder directly to ElevenLabs’ voice stack, which increases the number of places where conversational agents can be tried without custom wiring.
📉 Community pulse: model switching and cancellations
Visible sentiment threads on product satisfaction and switching: reports of ChatGPT Plus cancellations vs defenders, and renewed ‘code red’ chatter. Excludes product launches and evals.
New polling shows majority of Americans use AI weekly, with Gemini gaining on ChatGPT
AI usage mix (Epoch/Blue Rose): Fresh polling of 5,660 Americans finds a majority now using LLM services weekly, with 35% using ChatGPT, 24% using Gemini, and 13% using Meta AI in the past seven days, suggesting Gemini has become a meaningful second pole rather than a niche alternative as shown in the usage poll. The same study reports that fewer than 10% of Americans pay for any AI subscription, with OpenAI leading at 4.6%, so most of this adoption is still happening on free tiers as detailed in the usage poll.
Follow‑up analysis from Epoch frames this as AI adoption continuing to grow faster than almost any prior consumer technology but with the drivers shifting: from ChatGPT alone to a more competitive field where Gemini is rising, from US‑centric usage to stronger growth in countries like India, and from standalone chatbots to products with AI integrated into existing workflows detailed in the adoption analysis. A separate Gradient Update piece using the same data emphasizes that the top use cases remain information search (58%), writing (32%), and advice (30%), while full autonomous agent use and companion‑style usage still represent a minority of behavior as shown in the gradient note).
Builders increasingly describe Gemini 3 Flash/Pro as their daily driver models
Gemini 3 adoption (Community): Several power users and benchmarkers now say Gemini 3 Flash/Pro are becoming their most frequently used LLMs, often displacing ChatGPT or Claude as the first thing they reach for in day‑to‑day work; one user calls Gemini 3 Flash "truly a great model" and says it is now the model they use "on a regular daily basis" as shared in the daily flash use. Another describes Gemini 3.0 as a "price‑performance‑ratio beast" while sharing math benchmark plots showing Flash competitive with GPT‑5.2 at a much lower cost according to the price performance).
On the coding side, Gemini 3 Flash "punches so far above its weight" on the Repo Bench leaderboard, where it sits around 67% success in mid‑table among heavier models, reinforcing the sense that small‑model efficiency is starting to matter more than absolute peak scores as shown in the repo bench praise. Others report using Gemini for travel planning or technical learning, for example having it explain semiconductor wafer production and then generate highly realistic process images in four steps, which underscores the model’s appeal as a general assistant rather than just a coder via the wafer explanation and travel planner). Overall the mood is that Gemini has become a credible everyday default, especially where latency and price matter, even as some users still keep GPT‑5.x or Opus 4.5 on hand for the hardest reasoning tasks.
Community reports glitches and possible degradation in Claude Opus 4.5
Claude Opus 4.5 (Anthropic): After an initial period of strong reviews, some heavy users now report worrying glitches and possible degradation in Claude Opus 4.5, including a widely shared screenshot where the model repeats the word "mass" many times, apologizes for "glitching," and fails to produce a clean list, which one user summarizes as "it's actually brain damaged" via the glitch report. Another post jokes that "opus had a stroke and is in the hospital," capturing frustration that the newest flagship can regress in reliability compared to earlier Opus and Sonnet versions per the stroke joke).
These anecdotes land in the same week Anthropic acknowledged rolling back some recent Claude Code changes to keep things stable over the holidays and confirmed they are looking into Opus 4.5 issues in other contexts, which reinforces the perception that the current Opus release is unstable in production use as noted in the rollback note. At the same time, other users still describe Opus 4.5 as their must‑have frontier model and point to strong long‑horizon METR scores, so the community picture is split between people who hit edge‑case bugs and those who still see it as their top choice for deep reasoning according to the opus preference and metr discussion).
Users increasingly talk about canceling ChatGPT Plus, while some still defend it
ChatGPT Plus sentiment (Community): Multiple threads describe a visible shift in mood around ChatGPT Plus, with more long‑time subscribers saying they’re pausing or canceling because they feel quality is slipping and competitors are improving faster, even as some users insist they’re still getting value according to the sentiment shift and paid users note). One user shares a cancellation confirmation screenshot with the caption "chatgpt was awesome but it’s time to move on," illustrating how some early adopters now see it as a past phase rather than their main tool as noted in the cancellation post).
The same discussion highlights that paid users are only an estimated 3–5% of the total user base but generate most of OpenAI’s revenue, making this kind of visible churn worrying if it reflects a broader professional shift according to the paid users note). Other voices in the same cluster explicitly say they’ll keep paying because ChatGPT still feels like the most trusted or comfortable default, which underlines that the dissatisfaction is not universal but strong enough to be a recurring theme as shown in the paid users note).
‘Code red’ chatter around OpenAI returns after muted GPT‑5.2 reception
OpenAI strategy mood (Community): A rumor that OpenAI re‑declared an internal "code red" after GPT‑5.2 supposedly failed to land as a decisive counter to Gemini 3.0 circulates in community threads, with the original poster stressing it might have been a joke but adding they "wouldn’t be surprised" if it were real as suggested in the code red rumor). Follow‑on posts lean into the narrative, with one user remarking "time for another code red at OpenAI" and others speculating that "it might actually be over" for OpenAI if no larger model is coming soon per the code red quip and over for openai).
These posts sit alongside comments that GPT‑5.2 was an early "Garlic" checkpoint and not the full model, which fuels expectations of a bigger upgrade in early 2026 and helps explain why some builders frame the current release as underwhelming relative to the hype as illustrated in the garlic diagram). The overall tone mixes anxiety about OpenAI’s competitive position with awareness that stronger models are likely queued up, rather than any confirmed organizational crisis.
Complaints about GPT‑5.2’s tone collide with new but underused personalization controls
ChatGPT tone controls (OpenAI): Community posts note a wave of complaints about GPT‑5.2’s conversational style—described as overly eager to please, "smug," or emotionally off—while pointing out that many of the loudest critics are using the default preset and haven’t touched Personalization settings or custom instructions per the tone complaints). In response, OpenAI has rolled out sliders for warmth, enthusiasm, headers/lists, and emoji under a new Personalization panel, plus a base "style and tone" selector, giving users more direct control over how ChatGPT speaks without changing its underlying capabilities as shown in the personalization launch and slider screenshot).
One observer argues that "most complaints come from free users who don't know how to use custom instructions or learned how to prompt beyond basic chats," framing this as a gap between available controls and actual usage rather than purely a model‑quality issue according to the tone complaints). At the same time, screenshots of the new UI with sliders set to "Less" for warmth and enthusiasm circulate alongside comments like "You’re in control of your ChatGPT personality," which suggests a subset of users sees the change as overdue and welcome rather than cosmetic as illustrated in the personality comment).
‘GPT‑5.2 is AGI’ meme highlights expectations gap as users compare simple failures
AGI expectations (Community): A screenshot showing GPT‑5.2 correctly answering the classic surgeon riddle (recognizing the surgeon as the boy’s mother) next to Gemini 3 confidently but incorrectly answering "father" is captioned "GPT‑5.2 is AGI 🙄," encapsulating both light sarcasm and a real frustration about inconsistent basic reasoning across models as seen in the agi meme). The joke lands because the puzzle has long been used as a social‑bias test for humans, so the contrast between models on such an easy question feels especially telling.
In replies, users argue over whether this kind of cherry‑picked example says anything meaningful about general intelligence, but it clearly feeds into the broader perception battle: some see GPT‑5.2 as closing in on "AGI" when it avoids these failures, while others see any such branding as marketing hype until models can reliably handle everyday commonsense questions without long think‑time or prompting tricks. The meme also reflects a pattern where community evaluations are now as much about trust and vibes as about formal benchmarks, with one model’s basic error enough to push certain users to try alternatives even if aggregate scores remain close.