ChatGPT tests ads for Free and $8 Go – answers ‘independent’
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
OpenAI says ChatGPT will start testing ads in the US “in the coming weeks” for Free and $8/month Go; ads are promised to be clearly labeled, placed separately from answers (mockups show Sponsored product cards below the response), and governed by “answer independence” claims that ads won’t influence outputs. The company also publishes Ad Principles: conversations are “private from advertisers”; users can opt out of ad personalization and clear ad data; advertisers reportedly receive aggregate metrics rather than user-level data; Pro, Business, and Enterprise are reiterated as ad-free.
• Targeting skepticism: replies focus on the boundary between “private from advertisers” and OpenAI using conversation content/metadata internally for topic-matched targeting; policy language doesn’t fully settle the practical implementation.
• Codex tooling: Codex CLI adds mid-run steering and shell snapshotting; Altman teases “very fast Codex,” but no public benchmarks accompany the speed push.
Across the feed, monetization, memory, and tool-routing are converging into interface contracts; the unresolved variable is incentive drift once ads become a revenue loop.
Top links today
- MemGovern paper on governed memory for code agents
- Parallel Context-of-Experts decoding for RAG
- OpenRouter 100T token usage study paper
- Private LLM inference on RTX 50 GPUs paper
- OpenTinker agentic RL infrastructure paper
- Event-graph memory for long-history agents paper
- PrivacyReasoner paper for privacy reaction prediction
- Agentic RAG vs enhanced RAG comparison paper
- OpenAI ad principles and ad formats update
- ChatGPT Go plan details and rollout notes
- Claude Cowork macOS app preview notes
- vLLM-Omni FLUX.2 Klein day-0 support PR
- SGLang official website and documentation
Feature Spotlight
Feature: ChatGPT begins testing ads (Free + $8 Go) with ‘answer independence’ & privacy controls
OpenAI starts US testing of ads for ChatGPT Free + $8 Go, promising answers won’t be ad-influenced, ads are labeled/separate, and conversations aren’t shared with advertisers—raising major trust, privacy, and monetization questions.
High-volume story: OpenAI and Sam Altman say ads will be clearly labeled, separated from answers, and not influence responses; tests start in the US for Free and Go while paid higher tiers stay ad‑free. Excludes non-ad ChatGPT product updates (covered separately).
Jump to Feature: ChatGPT begins testing ads (Free + $8 Go) with ‘answer independence’ & privacy controls topicsTable of Contents
🪧 Feature: ChatGPT begins testing ads (Free + $8 Go) with ‘answer independence’ & privacy controls
High-volume story: OpenAI and Sam Altman say ads will be clearly labeled, separated from answers, and not influence responses; tests start in the US for Free and Go while paid higher tiers stay ad‑free. Excludes non-ad ChatGPT product updates (covered separately).
OpenAI to test ads in ChatGPT Free and Go, publishes “Ad Principles”
ChatGPT ads (OpenAI): OpenAI says it will start testing ads in ChatGPT’s Free and Go tiers “in the coming weeks,” while promising responses “will not be influenced by ads,” and that ads will be separate and clearly labeled, according to the [Ad principles thread]Ad principles thread. This is paired with a clear monetization boundary—Pro, Business, and Enterprise remain ad-free, as reiterated in the [Altman post]Altman post.
OpenAI also frames ads as supporting accessibility for people who “want to use a lot of AI and don’t want to pay,” per the [Altman post]Altman post. The stated principle set includes “conversation privacy” (no selling conversation data to advertisers) and “long-term value” (not optimizing for time spent), as shown in the [principles graphic]Ad principles thread.
ChatGPT ad mockups show sponsored cards beneath answers
ChatGPT ads UI (OpenAI): OpenAI shared early examples of ad formats that appear after the main answer—e.g., a “Sponsored” product card shown under dinner-party suggestions—per the [ad format example]Ad format example. The separation is positioned as the core UX constraint: ads are “always separate and clearly labeled,” aligned with the [stated principles]Ad principles thread.
This mockup matters because it sets expectations for where monetization can live in an assistant UI (below answers, not blended into them), and implies a commerce-style card format rather than pre-roll or interstitial placements.
Users press OpenAI on conversation-based ad targeting boundaries
Conversation privacy questions (ChatGPT): A high-signal concern in replies is whether ad targeting will use conversation content or metadata—explicitly raised in a question asking if users should expect their conversation content to be used to “teach an AI to sell them stuff,” per the [targeting question]Targeting question.
OpenAI’s published principles say conversations are kept “private from advertisers,” and users can turn off personalization and clear data used for ads, as shown in the [principles screenshot]Ad principles screenshot and echoed in the [OpenAI thread]Ad principles thread. What’s still not fully resolved in the tweets is the practical boundary between “private from advertisers” and “used internally for targeting.”
Altman’s “ads as last resort” quote resurfaces amid ChatGPT ad testing
OpenAI positioning (ChatGPT): A clip of Sam Altman saying he thinks of ads as a “last resort” business model is being recirculated as OpenAI moves into ad testing, per the [resurfaced interview clip]Resurfaced interview clip.

The contrast is now explicit in Altman’s current framing that ads may be needed because “a lot of people want to use a lot of AI and don’t want to pay,” as written in the [Altman statement]Altman statement.
OpenAI frames ads as funding free and low-cost ChatGPT access
Accessibility framing (OpenAI): OpenAI messaging describes ads as supporting “making AI accessible to everyone” by helping keep ChatGPT available at free and affordable price points, with testing planned “in the US soon,” as shown in the [in-app style notice]In-app style notice.
That framing sits alongside the explicit tier separation (Plus/Pro/Business/Enterprise ad-free) stated in the [OpenAI announcement]Ad principles thread. It’s a straightforward subsidy argument, with the operational detail being that the ad-exposed tiers include Free and Go.
Wired details ChatGPT ads: topic matching, aggregate metrics, opt-out
Ad targeting mechanics (OpenAI): A Wired report says OpenAI’s initial ad tests will match ads to conversation topics; ads show only for Free and $8/month Go users; advertisers receive aggregate performance metrics rather than individual user data, per the [Wired explainer]Wired explainer highlighted in [the source post]Wired source post. It also describes controls around opting out of personalization while keeping other personalization features.
The Wired framing aligns with OpenAI’s claim that “responses won’t be influenced by ads” and that “your conversations are private from advertisers,” as stated in the [OpenAI announcement]Ad principles thread.
Community skepticism focuses on incentives and durability of ad principles
Trust & incentives (ChatGPT ads): A recurring reaction is skepticism that ad-related principles will survive contact with revenue incentives—e.g., concerns that “one day these ‘ad principles’ disappear” as advertisers pay more for frequency, per the [skeptical post]Skeptical post.
Even among people accepting the rollout as “fine,” the debate centers on whether “answer independence” can remain credible long-term once there’s a monetization loop, with the principle itself repeatedly emphasized in OpenAI’s materials, including the [answer independence snippet]Answer independence snippet.
🧑💻 OpenAI Codex tooling: real-time steering, speed push, and ‘very fast Codex’ teasers
Codex-centric updates and practitioner comparisons: multiple posts on new CLI steering, speed optimizations, and early quality anecdotes vs Claude Code. Excludes ChatGPT ads/Go and non-Codex OpenAI legal dispute coverage.
Codex CLI adds mid-turn steering without interrupting (experimental toggle)
Codex CLI (OpenAI): Codex CLI can now be steered while a task is running—without a hard interrupt—so you can correct course and watch the agent adapt “almost real time,” building on steer toggle (experimental steering) as described in the steering note from mid-turn steering.
The mechanics showing up in the CLI UI are practical: the Steer conversation toggle changes input behavior so Enter can submit immediately while work is in progress, and Tab can be used to queue messages, per the pro tip in terminal toggle screenshot. The net effect is fewer “panic Ctrl+C” aborts and more incremental course correction while Codex is already deep in a repo.
Sam Altman teases “very fast Codex” as OpenAI pushes speed improvements
Codex (OpenAI): Multiple OpenAI-side signals point to a speed push: Sam Altman posts the near-quote “very fast Codex coming,” in very fast teaser, while Codex team members echo “we heard you wanted faster codex” in speed-focused post and hint “something speedy” in speedy hint.
The framing isn’t just speed-for-speed: Altman also pairs speed with “higher level of intelligence” in speed plus intelligence, which reads like a roadmap promise that future Codex defaults may move up the quality-latency curve rather than only shaving seconds.
Codex CLI experiments with shell snapshotting to reduce startup overhead
Codex CLI (OpenAI): The CLI’s /experimental menu now surfaces Shell snapshotting, pitched as a way to make Codex faster by snapshotting your shell environment so it doesn’t re-run login scripts every command, as shown in the CLI screenshot from shell snapshot tip.
This is a small but telling knob: it targets repeated per-command setup cost (environment init) rather than model latency, and it suggests the team is still chipping away at “time to first useful tool call” inside the terminal loop.
Developers report choosing GPT-5.2 Codex xhigh over Claude Code Opus 4.5
GPT-5.2 Codex xhigh (OpenAI): A repeated side-by-side pattern is showing up in practitioner anecdotes: running the same prompt in Codex (GPT‑5.2 Codex xhigh) and Claude Code (Opus 4.5), then continuing with Codex because the initial output is better, as stated in the comparison note from side-by-side result.
This is a narrow datapoint (no shared prompt, repo, or eval artifact in the tweets), but it’s a clean “first-response quality” claim, which is often what decides which agent you keep driving when you’re juggling two terminals.
“Smarter vs faster” model choice reshapes how teams schedule agent work
Workflow shift (GPT-5.2 vs Opus 4.5): One concrete behavioral change being reported is that switching from Opus to GPT‑5.2 changes the workday from long “deep work” blocks to shorter cycles spent prompting and steering async agents, as described in workflow reflection.
The same thread emphasizes less time reviewing and more time writing longer prompts and stacking PRs, per review time note. In Codex contexts, this maps directly to tool UX: better steering and lower latency make “30-minute steering windows” viable, while slow-but-smart settings tend to force longer uninterrupted blocks.
Prompting heuristic: adding “spec” reportedly makes Codex planning 10× better
Prompting pattern (Codex): A simple planning hack is circulating: Codex “plans get 10× better if the word ‘spec’ is in the input,” per spec keyword tip.
This reads like a routing cue—nudging the model into a more structured “requirements → plan → implementation” mode rather than jumping straight to edits. There’s no counterexample in the tweets, but it’s a crisp, reproducible knob people are already adopting in agent instructions and task templates.
Why GPT‑5.2 feels slow in Codex: deep repo exploration vs supplied context
Codex performance perception: A specific explanation for “GPT‑5.2 is slow” shows up repeatedly: when run inside Codex, it may spend time exploring the codebase and gathering context; if you provide the necessary context up front, responses can arrive much faster, per slowness explanation.
The same point is reinforced as a Q&A-style takeaway in follow-up question. It’s a reminder that some latency is self-inflicted by an agent harness doing the right thing (searching/reading), and the speed/quality trade can be shifted by how much context you hand it.
🧑🤝🧑 Claude Cowork expands to Pro: workflow UX, connectors, and safety guardrails
Cowork is the other cross-account product spike today: rollout to Pro users, connector fixes, and early feedback on limits and safety behaviors. Excludes MCP-specific integration details (covered under Orchestration/MCP).
Claude Cowork expands to Pro subscribers with session renaming and connector fixes
Claude Cowork (Anthropic): Following up on early leak—Cowork is now available to Claude Pro subscribers; Anthropic frames it as still a “research preview,” but notes they’ve already shipped session renaming plus connector improvements and bug fixes, as described in the Pro rollout note.
Usage limits are now a first-order constraint: Anthropic warns that because Cowork handles more complex work, Pro users “may hit their usage limit sooner,” according to the Limit warning.
Access is currently pointed at the macOS app download flow via the Desktop download page, and the team is explicitly asking for feedback while iterating quickly, per the Daily updates request.
Cowork tightens safety UX: explicit permission before deletions
Cowork safety UX (Anthropic): A new safety behavior is being rolled into Cowork where Claude should “always request explicit permission before deleting” items, as surfaced in the Deletion permission change.
The Cowork team is also signaling broader guardrail tightening based on early user feedback, with “a big safety improvement” called out by a product lead in the Safety improvement note.
What’s not yet clear from today’s posts is whether this permission gate is enforced uniformly across all connected surfaces or only for specific actions.
Early Cowork users say the Slack-email-docs agent loop finally feels coherent
Cowork adoption sentiment (Anthropic): Early users are describing Cowork as the first time a “Slack + Email + Docs + Agent Loop” has actually worked in practice, with a notably strong endorsement in the Cowork believer quote.
This “it finally fits together” feeling is showing up right as Pro access opens, as echoed by multiple “Cowork is now available for Pro” confirmations in the Availability confirmation and the Pro rollout note.
Local-first ‘Cowork’ pattern gains traction: run coworker workflows on-device
Local-first cowork pattern (Hugging Face): A parallel thread to Cowork’s cloud workflow is the push for Cowork-like orchestration that runs on local models “not to send all your data to a remote cloud,” as argued in the Local cowork demo.

The idea is getting visible distribution quickly—Hugging Face’s CEO notes it trending on the Hub in the Trending confirmation.
This doesn’t change Cowork itself, but it’s a clear competitive pressure line: same “agent coworker” UX goals, with privacy posture flipped.
Windows pressure builds as Cowork remains framed around the macOS app
Cowork platform availability (Anthropic): The Pro rollout continues to point people to “try it in the macOS app,” as stated in the macOS app callout, and users are increasingly asking when Cowork will be available on Windows.
That demand is explicit in replies like “Wen Windows?” in the Windows request and “Is there a Windows version?” in the Windows version question.
The public download entry point exists via the Desktop download page, but today’s Cowork-specific guidance still reads as macOS-first.
⚖️ OpenAI vs Elon lawsuit narrative: filings, diary excerpts, and ‘context’ rebuttals
Governance/legal storyline dominates non-product OpenAI discourse today: unsealed docs, competing narratives about nonprofit vs for-profit intent, and leadership responses. Excludes ad-monetization rollout (feature) and general policy changes on X (separate category).
OpenAI publishes “The truth Elon left out” rebuttal in Musk lawsuit
OpenAI (OpenAI): OpenAI published a point-by-point rebuttal arguing Elon Musk’s filing selectively quoted internal notes and omitted surrounding context, with Sam Altman framing the dispute as “cherry-picking” to make Greg Brockman look bad in the Altman context post and the linked Rebuttal post; the post also reiterates OpenAI’s current dual-entity structure (nonprofit controlling a PBC) and cites an equity value around $130B in the same Rebuttal post.
The central evidentiary move in the rebuttal is contrasting Musk’s quoted phrasing with original call notes—showing what was included vs left out, as illustrated in the Call notes image and amplified again via the Comparison repost.
Unsealed court order keeps Musk claims alive and surfaces internal Brockman notes
OpenAI v. Musk (US District Court): A circulated court order indicates OpenAI’s motion for summary judgment was denied on Musk’s claims while Microsoft’s motion was granted only in part, per the Court order PDF shared in the Court order link.
The same unsealed materials also include excerpts from Brockman’s personal files—critics highlight lines about not “steal[ing] the non-profit” and references to “making the billions,” as shown in the Filing screenshot and repeated in the Diary quote tweet.
Greg Brockman says Musk demanded control; calls journal excerpt use “dishonest”
Greg Brockman (OpenAI): Brockman says Musk’s use of his private journal is “beyond dishonest,” and claims the snippets were about whether to accept Musk’s “draconian terms,” including demands for majority equity and control, as stated in the Brockman statement and expanded in the Brockman follow-up.
He also adds a process takeaway: OpenAI says it avoided publicly correcting Musk’s narratives “out of respect,” but now wants to tell “the real history” as the case proceeds, according to the Brockman follow-up.
CNBC: OpenAI warned investors to expect “deliberately outlandish” Musk claims
Investor communications (OpenAI): A CNBC screenshot claims OpenAI told investors and banking partners to brace for “deliberately outlandish” claims from Musk ahead of an April trial window, as shown in the CNBC screenshot discussion.
The tweet context also highlights a credibility meta-point—commentators note the wording is “outlandish” rather than “false,” reflecting how closely the investor-relations posture is being parsed in public discourse, per the CNBC screenshot discussion.
Executives react to lawsuit discovery: private diaries and notes become evidence
Discovery risk (Org ops): A thread circulating an excerpt labeled “Brockman’s Personal Files—2017” highlights that private notes can become discoverable once litigation starts, with a widely shared screenshot emphasizing the “Financially, what will take me to $1B?” line in the Discovery excerpt.
The practical implication being debated is not model capability; it’s operational exposure—how internal intent documents can be recontextualized as public evidence when a governance dispute goes to court, as the Discovery excerpt illustrates.
Observers frame the dispute as a fight over philanthropic intent vs for‑profit transition
Narrative framing (Ecosystem): Independent commentary summarizes the case as a dispute over whether OpenAI was intended as a philanthropic project, who pushed for a for-profit transition first, and what financial motivations were in play, as laid out in the Dispute recap.
The same thread positions the newly surfaced filings as kicking off “the next phase” of the public argument rather than settling facts, signaling continued reputational and governance spillover while the legal process runs, per the Dispute recap.
🕹️ Agent runners & operator tooling: Clawdbot, Ralph/Loom loops, Kilo for Slack, Browser Use, Scouts
Operational layer news: personal/organizational agent runners, multi-agent automation, and ‘agents running in the background’ patterns—lots of hands-on demos and productionization stories. Excludes SDK-only items (Agent Frameworks) and MCP plumbing (Orchestration/MCP).
Browser Use adds 1Password-backed cloud logins with 2FA/MFA handling
Browser Use (Browser Use): Browser Use says it can now automate logins “in the cloud securely with 1Password,” explicitly claiming this solves 2FA/MFA for agent-driven workflows, per the 1Password login feature. The tweet frames this as a blocker removal for cloud browser automation rather than a marginal UX tweak, per the 1Password login feature.
Clawd can boot Claude Code and run commands via PTY mode
Clawd (Clawdbot): A demo shows Clawd starting the Claude Code CLI “in PTY mode,” then issuing a command (claude "tell me a mass effect joke") and relaying the output back into chat, as shown in the PTY control screenshots.
This is a concrete example of a runner acting as an operator-of-operators—driving another agent tool as a subprocess—rather than only calling APIs, per the PTY control screenshots.
Yutori Scouts ships realtime traces, natural-language feedback, and an X bot
Scouts (Yutori): Scouts shipped three operator-facing upgrades: a realtime agent “livestream” for watching actions as they run, natural-language feedback on reports (not just thumbs), and an X bot that turns mentions into a Scout and replies with updates, as announced in the Scouts updates thread.

• Feedback loop: Report-quality guidance can now be written in plain language and absorbed into Scout guidelines, as shown in the Feedback demo.
• X-triggered creation: Tagging @ScoutThisForMe creates a Scout and keeps updates in-thread, per the X bot announcement.
The operational theme is visibility + control in long-running monitoring agents, tied to concrete UI affordances rather than backend claims, per the Scouts updates thread.
A “life of a packet” diagram shows Clawdbot’s cross-OS execution path
Clawdbot (Clawdbot): A shared architecture walkthrough maps a full request path from WSL to Windows host processes to a native sqlite3.dll write on NTFS—explicitly calling out agent IDs, TCP hops, temp files, and process spawning, as captured in the Architecture walkthrough.
The flow reads like an operator runbook (proxy → host router → spawned MCP server → temp JSON blob → CLI → native sqlite), which matters because debugging “agent did something weird” usually lands in exactly these seams, per the Architecture walkthrough.
Clawdbot merges PR #1000 to stop SIGKILLing background jobs on abort
Clawdbot (Clawdbot): PR #1000 was merged to prevent abort handling from sending SIGKILL to backgrounded processes, tightening long-running task reliability and reducing accidental collateral damage during cancellations, as described in the PR #1000 merge. The specific change targets the “abort” path, which is exactly where background agent runners tend to accumulate sharp edges.
Kilo Cloud Agents add one-click “browser as IDE” demos
Kilo Cloud Agents (KiloCode): Kilo says the browser can act as a full coding environment via Cloud Agents, and it shipped two one-click demos that fork a repo and run an agent workflow (e.g., updating an avatar, learning game mechanics), as shown in the Cloud agents post.
This is a concrete productization move: pre-canned environments + repo forking + agent context, presented as a single click path, per the Cloud agents post.
Loom runs AFK system testing and verification loops
Loom / Ralph loops (Geoffrey Huntley): Following up on Open-source Loom (repo release), a new clip shows Loom running end-to-end system testing/verification “completely AFK,” with a screen full of PASS results while the operator is elsewhere, per the AFK verification photo.
The operational claim is straightforward: tasks that used to require multi-engineer planning plus weeks of verification are being expressed as a repeated loop with automated checks, as described in the AFK verification photo.
Browser Use approves top 200 waitlisters, then adds 1,000 more seats
Browser Use (Browser Use): Access is being doled out via a waitlist leaderboard: the “top 200 users” were approved, per the Top 200 approved clip, and then another 1,000 users were approved later, per the 1,000 more approved.

A sample confirmation screen shows a “You’re in!” message and rank-based approval, as shown in the Waitlist confirmation screenshot.
Clawdbot docs are reportedly 95% agent-written
Clawdbot (Clawdbot): The maintainer claims the public documentation is now “95% Codex and 5% Clawd,” framing documentation as an automated output rather than a manual bottleneck, per the Docs generation claim and the linked docs site in Docs site. This is a concrete datapoint for “agent-written documentation at scale” workflows, tied directly to an operating project.
Clawdbot can see reactions and treat them as system events
Clawdbot (Clawdbot): A small but operationally relevant UX detail: Clawdbot reports that emoji reactions arrive as system messages and are visible to the agent (and it can infer who reacted), as shown in the Reactions screenshot.
For agent runners, this creates a lightweight feedback channel distinct from “reply with text,” which can matter when trying to keep bots from over-participating, per the Reactions screenshot.
🧠 ChatGPT product updates (non-ads): memory retrieval + Business ‘apps in custom GPTs’ beta
Non-ad ChatGPT changes today focus on longer-term user state: improved memory retrieval with sourcing, and workspace app connections for Business custom GPTs. Excludes ads/Go rollout (feature).
ChatGPT memory search now cites which past chats it used (Plus & Pro)
ChatGPT (OpenAI): Following up on Reference chats (more reliable past-chat recall), OpenAI now says that when reference chat history is enabled, ChatGPT can more reliably find specific details from your past chats—and it will show the past chat it used as a source so you can open and review the original context, as described in the release notes snippet and detailed in the release notes page.
The update is positioned as global for Plus and Pro users in the same release note entry, while Sam Altman’s “awesome” reaction in the exec endorsement is one of the few real-world signals in the tweets about how noticeable the recall improvement feels in day-to-day use.
Apps in custom GPTs beta rolls out to select ChatGPT Business workspaces
Apps in custom GPTs (OpenAI): OpenAI is rolling out a beta that lets workspace GPT creators attach approved workspace apps to a custom GPT, starting with select ChatGPT Business accounts as noted in the rollout mention and expanded in the Help Center doc.
• Live org context: The feature is framed as letting GPTs “retrieve information and perform tasks” from connected systems (docs, calendars, business data) without requiring custom Actions or manual file uploads, per the doc screenshot.
The gating matters operationally: it’s Business-only for now, with workspace admin control over which apps can be used and how broadly a GPT can be shared, as written in the Help Center doc.
ChatGPT surfaces an improved chat history browsing UI
Chat history (ChatGPT): A UI change is being demoed that makes chat history browsing feel more explicit in-product—showing “Chat history is here!” and a scrollable list of prior chats in the UI demo clip.
This is adjacent to the new memory/retrieval work, but distinct: it’s about navigation and visibility of past conversations rather than the model’s ability to pull specific details into answers.
🧩 How engineers are changing dev loops: speed vs intelligence, disposable software, and spec-first prompting
Practice-layer discussion: how to drive agents effectively (specs, planning, shorter work blocks, and ‘disposable’ one-off software). Excludes tool release notes (Coding Assistants) and CI/PR review specifics (Code Quality).
File interfaces reduce the need to overthink chunking in agentic retrieval
File interfaces (workflow pattern): The “chunking is dead” claim is being sharpened: when agents can dynamically navigate files (search, open, scroll), static chunk/embed pipelines become less central for many code-and-doc workloads, as argued in Chunking is dead.
The follow-up nuance matters: the critique is aimed at “naive” chunk-and-vector-db as the default retrieval interface, while still acknowledging you’ll want persistence/metadata layers at scale, as clarified in Clarifying note. The underlying bet is that simple file ops (ls, grep, targeted reads) are “unreasonably effective” up to a few hundred docs, as reinforced in File interface rationale.
TypeScript feedback loops turn agents into green-CI machines
TypeScript feedback loops (workflow pattern): A concrete recipe for keeping agent output reliable is being pushed: bake typechecking, tests, and pre-commit hooks into the loop so the agent gets fast, objective failure signals and retries until CI is green, per Feedback loops tutorial and the linked Tutorial.

The emphasis is practical: structure the repo so the agent can verify its own work continuously rather than relying on human review as the primary correctness check.
Boundary-first vibe coding: verify inputs/outputs, not the generated internals
Verification over inspection (workflow framing): A clear trust model is being proposed: vibe-code functions/libraries/components, but engage seriously at boundaries—specs, tests, contracts—rather than trying to read every generated line, as summarized in Boundary-first framing.
• Trust mechanism shift: The framing is that old trust came from reputation/OSS social proof; now trust has to come from checks you can run yourself (property tests, fuzzing, contracts), as argued in Trust via verification and echoed by Contracts over free-form.
This is a direct response to “whole-system slop”: it localizes risk to a component boundary you can test.
Disposable software and the “market of one” mindset goes mainstream
Disposable software (workflow pattern): The “build it, use it once, throw it away” framing is getting articulated as a serious shift in how software value is created, with the claim that “the minimum viable market is now one,” per Disposable software take.
This reframes the dev loop around time-to-outcome rather than product polish—especially for internal tooling and one-off workflows where the old ROI math never penciled out.
Faster models are changing developer time blocks into async agent driving
Work scheduling (speed vs intelligence): A concrete behavioral change is showing up: switching to a faster model pushes work into many short cycles—“more 30 min blocks” to respond to agents instead of needing “3 hour blocks” to get into flow—per Work block shift.
As a side effect, the work shifts from heavy review/correction toward longer upfront prompts and stacking parallel changes, as described in Stacking PRs pattern.
Spec-first prompting gets a simple heuristic: include “spec”
Spec-first prompting (workflow pattern): A small but repeated heuristic is being shared: “plans get 10x better if the word ‘spec’ is in the input,” per Spec keyword trick.
It’s a signal that many agent planning failures are still prompt-shape failures: asking for a spec nudges models into requirements and acceptance-criteria mode instead of jumping straight to edits.
Vibe coding expands prototypes, but doesn’t erase maintenance economics
Software maintenance economics (workflow framing): Levie draws a clean line: AI makes it cheaper to prototype and build internal apps, but the “long tail” of maintenance (bugs, connectors, API changes, operations) still dominates—so large orgs will keep renting CRM/ERP rather than vibe-coding replacements, as argued in Maintenance still dominates.
The point is less about code generation speed and more about who pays the ongoing tax of keeping systems correct and connected.
Agent memory and state resurface as core dev-loop plumbing
Agent memory and state (workflow pattern): There’s renewed attention on “memory/state” as an engineering surface—framed as something getting cool again via agent ecosystems—and the claim that any filesystem-as-source-of-truth pattern tends to evolve into a database as complexity grows, per Memory-state resurgence.
The takeaway is less about which tool wins and more about acknowledging that long-running agent work forces explicit choices about persistence, indexing, and mutation control.
Classic “good code” criteria are getting reused as agent prompt primitives
Prompt grounding for code quality (workflow pattern): A simple prompting move is being recommended: use classic programming books’ descriptions of “good code” directly inside prompts, skills, and AGENTS.md to shape agent behavior, as suggested in Prompting with classics.
This is a reminder that, even with stronger models, the fastest way to reduce rewrites is often to specify taste and constraints in reusable project artifacts.
📚 Retrieval & memory methods: Agentic RAG vs Enhanced, multi-vector retrieval, and cache-parallel decoding
Today’s retrieval chatter is unusually research-heavy: empirical comparisons of Agentic vs Enhanced RAG, new decoding tricks to avoid giant prompts, and strong advocacy for multi-vector retrieval. Excludes bioscience-related papers entirely.
Agentic RAG vs Enhanced RAG: first head-to-head study favors pipelines on hard fact-checking
Agentic RAG vs Enhanced RAG (research): A new empirical comparison argues the “LLM orchestrates everything” approach is more flexible but materially pricier—Agentic RAG often needs 2–10× more tokens/compute—and can lose badly on tasks where a fixed pipeline helps, with Enhanced RAG winning on FEVER by +28.8 F1 in the RAG comparison thread.
• Where Enhanced wins: Router/rewriter/reranker stacks look more stable on datasets where agents retrieve unnecessarily, as described in the RAG comparison thread.
• Where Agentic helps: The same write-up claims modest gains on intent handling and query rewriting averages, but ties performance tightly to underlying model strength in the RAG comparison thread.
The main open question is how much of the gap is “agent policy” vs “missing modules” (rerankers, explicit routers) rather than the agentic paradigm itself.
PCED proposes parallel per-document decoding to avoid long RAG prefills
PCED (research): “Parallel Context-of-Experts Decoding” keeps separate KV caches per retrieved document, runs them in parallel, and combines logits via retrieval-aware contrastive decoding—aiming to scale multi-doc evidence without stuffing everything into one prompt, as explained in the PCED paper summary.
• Latency claim: The thread reports >180× faster time to first token, framing PCED as a way to dodge the prefill bottleneck while still stitching evidence across documents in decoding, per the PCED paper summary.
• Key constraint: This approach assumes you can access and combine full token logits across parallel “experts,” which can be awkward depending on your serving stack, as implied in the PCED paper summary.
It’s a decoding-time alternative to rerankers and long-context prompts, not a new retriever.
MemGovern uses “experience cards” memory to lift automated bug-fixing results
MemGovern (research): A memory construction pipeline converts messy GitHub issue/PR history into structured “experience cards” (indexable symptoms + resolution + verification), and reports a +4.65% gain on SWE-bench Verified when plugged into a standard fixing agent, as summarized in the MemGovern summary.
• Why it’s different from plain retrieval: The cards are explicitly “governed” (cleaned, split into index vs resolution) to reduce noise and make retrieval actionable, per the MemGovern summary.
This is basically “curated episodic memory” for code agents, built from open-source history.
Multi-vector retrieval push: ColBERT/ColPali proponents argue dense is losing
Multi-vector retrieval (ColBERT/ColPali): Practitioners are again arguing that “multi vector is the only way forward” for retrieval quality, citing repeated cases where small multi-vector models outperform much larger dense encoders in real benchmarks, as stated in the Multi-vector claim and expanded in the ColBERT advocacy.
• Why it matters: The pitch is that late-interaction scoring better preserves token-level evidence (especially for reasoning-heavy or long-context queries) than a single pooled embedding, per the ColBERT advocacy.
This is advocacy, not a new release—no single canonical benchmark artifact is linked in the tweets, so treat the performance claims as directional.
CompassMem builds event-graph memory to answer long-horizon questions better
CompassMem (research): An event-centric memory system stores interactions as a graph of events with explicit temporal/causal links, then traverses the graph to satisfy decomposed sub-questions; it reports about 52% average F1 on LoCoMo long-conversation questions, with strongest gains on multi-step and time-based queries, according to the CompassMem summary.
This frames “memory” less as semantic similarity search and more as navigable structure that preserves ordering and dependency.
File-interface retrieval gets a sharper definition: grep-first until you truly scale
File interface retrieval (workflow): A follow-up clarification tightens what “chunking is dead” means in practice: using file tools (scroll/search within files) plus simple ls/grep can be “unreasonably effective” up to a few hundred docs, while production apps still need a persistence layer and likely decoupled retrieval vs final context, per the Chunking clarification and File interface rationale.
• Architecture nuance: The thread explicitly distinguishes “naive chunk/embed/vector-db as the only retrieval” from hybrid systems where a DB indexes metadata and the agent reads whole files on demand, as described in the Chunking clarification.
It’s a concrete scoping statement: file tools aren’t a database replacement, but they can postpone database complexity for smaller corpora.
LlamaParse can surface human highlights as tagged context for agents
LlamaParse (LlamaIndex): A small but practical parsing trick—asking for “output highlighted text with special html tags” returns highlighted spans wrapped in <mark> so downstream extractors/agents can prioritize what a human annotator cared about, as shown in the Highlight extraction tip.

This is a retrieval-quality move: it turns latent human attention (highlights) into explicit, machine-usable structure.
📈 Benchmarks & real-world usage measurement: Economic Index, token studies, and head-to-head reviews
Measurement-heavy day: real usage datasets (Anthropic Economic Index, OpenRouter token study), product benchmarks, and model-vs-model comparisons for code review and deep research. Excludes pure model release announcements.
Anthropic data suggests multi-turn use sustains longer task horizons
Economic Index (Anthropic): New figures from Anthropic’s Economic Index analysis suggest Claude.ai usage degrades much more slowly with task duration than API usage—extrapolating to ~19 hours at a 50% success rate, as shown in the Task horizon chart and detailed in the Economic Index PDF linked in Economic Index PDF.
• Duration vs success: Claude.ai’s fitted trend stays above 60% across the plotted window, while 1P API falls toward 50% around ~5 hours, according to the Task horizon chart.
• Education and speedups: The report’s plots indicate measured speedups rise with predicted education level, as shown in the Speedup vs education plot.
The data is observational (real usage + model-based estimates), so treat the extrapolation as directional rather than a benchmark score.
Kilo’s code review test finds Grok Code Fast 1 matches Opus 4.5 on detection
Kilo Code Reviews (Kilo): Kilo reports a head-to-head code review comparison where Grok Code Fast 1 (free tier) found 8 issues at a 44% detection rate—matching Claude Opus 4.5—while GPT‑5.2 found 13 issues at 56%, as shown in the Benchmark table post and expanded in the free models writeup linked in Free reviews test.
• Frontier vs free framing: The same table places GPT‑5.2 as top on issues found (13) and detection rate (56%), while Opus 4.5 and Grok Code Fast 1 tie on detection at 44%, per the Benchmark table post.
• Methodology context: Kilo points to separate deep dives on frontier and free model runs in the frontier writeup linked in Frontier reviews post and the free models writeup linked in Free reviews test.
The benchmark is a single PR-style task suite; treat the ranking as task-specific rather than a general coding leaderboard.
OpenRouter’s 100T-token study shows open-weight and agentic usage rising
State of AI (OpenRouter): OpenRouter published an empirical analysis of 100T tokens of anonymized request metadata, reporting open-weight models rising to ~33% of usage by late 2025 alongside a shift toward agent-style, tool-using workloads, as summarized in the 100T token study thread.
• Open vs closed mix: The paper’s headline claim is open-weight traffic reaching roughly one-third of all usage by late 2025, per the 100T token study thread.
• What people do with it: The reported open-weight traffic skewed heavily toward roleplay and coding assistance, while “agentic inference” and longer inputs increased over time, according to the same 100T token study thread.
Because the study uses metadata rather than prompt text, the granularity comes from proxies (tool calls, tokens, timing) rather than content inspection.
Artificial Analysis reports DeepSeek R1 throughput on SambaNova SN40L
Hardware benchmarking (Artificial Analysis): Artificial Analysis says its hardware suite now includes DeepSeek R1 runs on SambaNova’s SN40L RDU, with throughput reaching ~4,700 tokens/sec at and beyond 256 concurrent requests, according to the Benchmarking announcement.
It also highlights unusually high per-user speed at low concurrency—peaking at 269 tokens/sec for single-user workloads—as stated in the Single-user speed note. Pricing comparisons are explicitly incomplete because SN40L isn’t offered with standard hourly spot pricing, per the same Single-user speed note.
Parallel shares DeepSearchQA accuracy and cost table for agentic search tasks
DeepSearchQA (Parallel): Parallel published a DeepSearchQA table claiming its Task API variants outperform Gemini Deep Research and OpenAI GPT‑5.2 Pro on a joint accuracy/cost view, led by “Ultra2X” at 72.6% accuracy and 600 CPM, as shown in the Benchmarks hub post.
• Relative positioning: The same table lists Gemini Deep Research at 64.3% and 2500 CPM and OpenAI GPT‑5.2 Pro at 61% and 1830 CPM, per the Benchmarks hub post.
No evaluation artifact or dataset card is linked in the tweets, so the claim is best treated as vendor-reported until independently reproduced.
Epoch summarizes a 2025 forecasting miss on revenue and bio risk
Forecasting evaluation (Epoch AI): Epoch’s write-up of an AI Digest forecasting survey says forecasters largely matched benchmark score trajectories but missed on real-world outcomes—most notably underestimating annualized AI revenue (median $16B vs ~ $30B), as summarized in the Core takeaway and written up in the Gradient update linked in Gradient update.
It also reports mixed performance on risk forecasts, calling out underestimated biological risk (while cyber and autonomy calls were closer), per the Risk forecast note.
⚙️ Inference & self-hosting: day‑0 runtimes, consumer GPU economics, and local deployments
Serving/runtime posts focus on getting new models running fast (day‑0 support) and practical local inference economics on consumer GPUs. Excludes chip geopolitics and broader energy buildout (Infrastructure).
Paper quantifies private LLM inference costs on RTX 5060Ti/5070Ti/5090 GPUs
Private inference economics: A new paper argues SMEs can run private LLM inference on consumer Blackwell GPUs with electricity-only costs around $0.001–$0.04 per 1M tokens, with long-context RAG latency hinging on high-end cards like the RTX 5090 for sub-second time-to-first-token, as summarized in the paper thread.
• Quantization result: the paper claims NVFP4 improves throughput about 1.6× while cutting energy about 41% with modest quality loss, per the paper thread.
It’s a clean, numbers-first datapoint for teams comparing local inference vs “cheap API tiers,” especially where data governance forces on-prem.
vLLM-Omni adds day-0 support for FLUX.2 [klein] image generation
vLLM-Omni (vLLM Project): vLLM-Omni added day-0 support for FLUX.2 [klein], framing it as a fast, consumer-GPU-friendly image generator with integrated text-to-image and inpainting, as described in the day-0 support note.
The practical implication is another step toward “model drops → runnable in production runtimes” without bespoke glue, especially for teams standardizing on vLLM-style serving surfaces.
Android Studio adds Ollama as a model provider in its IDE model picker
Android Studio (Google) + Ollama: The latest Android Studio build surfaces Ollama as a first-class model provider in the IDE’s model picker—alongside Gemini and Anthropic—showing local options like gpt-oss and gemma variants, as shown in the model picker screenshot.
This is a concrete “local by default” integration point: a mainstream IDE UI treating on-device model selection like any other provider choice.
Ollama ships TranslateGemma with a required prompt format and guide
TranslateGemma (Google) on Ollama: Following up on TranslateGemma release—open translation models—Ollama now lists TranslateGemma as runnable via ollama run translategemma, with a warning that it requires a specific prompting format, per the Ollama announcement and the linked prompting guide.
The update is less about new model capability and more about friction removal: “downloadable, local translation” with a documented invocation contract.
SGLang launches official site consolidating docs, cookbook, and ecosystem
SGLang (LM-SYS): LM-SYS launched an official SGLang website to centralize docs, deployment guides, ecosystem projects, and community events, positioned as a response to information sprawl as adoption grows, according to the website launch note.
This is more “ops readiness” than a feature release, but it’s a real lever for teams standardizing on SGLang for serving and needing a single canonical reference.
🧪 Model and benchmarked drop watch: FLUX.2, LTX‑2, YOLO26, embeddings, and ‘Sonata’ hostname spotting
Model chatter spans fast open image/video models, new retrieval embeddings, and ‘what is this hostname’ leak-watching. Excludes bioscience-related papers and excludes Veo/creative workflow tutorials (in Gen Media).
FLUX.2 [klein] posts top open-model image-edit rankings and day-0 vLLM support
FLUX.2 [klein] (Black Forest Labs): Following up on initial release, new third-party signals put FLUX.2 [klein] near the top of open image editing—Artificial Analysis notes the 9B variant is #2 among open models in Image Edit Arena and also competitive in Text-to-Image, with pricing/positioning details in the Rank and pricing breakdown; LMArena/arena posts similar placement for 4B and 9B in both Image Edit and Text-to-Image leaderboards, per the Leaderboard snapshot.

• Serving readiness: vLLM-Omni added day-0 support for FLUX.2 [klein], calling out sub-second inference and a ~13GB VRAM target for the 4B Apache-2.0 model, as described in the vLLM-Omni support note.
Overall, today’s chatter is less about “new model exists” and more about where it lands on public preference leaderboards and whether the open inference stack is ready on day one.
LTX-2 becomes the top open-weights video model in Artificial Analysis Video Arena
LTX-2 (Lightricks): Artificial Analysis claims LTX-2 is now the leading open-weights video model in its Video Arena, surpassing Wan 2.2 A14B on both text-to-video and image-to-video, with licensing caveats noted in the Arena leader claim.
The same post distinguishes between the newly open-sourced base weights (including a 19B base) and the vendor’s “Pro/Fast” API endpoints that layer additional pipeline optimizations on top, per the Arena leader claim.
Ultralytics releases YOLO26 family: ~30 small models for detection, seg, and keypoints
YOLO26 (Ultralytics): Ultralytics’ YOLO26 family is being shared as a broad “small model” drop—about 30 variants under 50M parameters covering open-vocab detection, segmentation, and keypoint detection, with a CPU demo highlighted in the Release demo.

The collection link aggregated in the Model collection pointer points to a Hugging Face bundle—see the Model collection for the full set of weights and variants.
Voyage 4 embedding models ship, with open-weights voyage-4-nano called out on FreshStack
Voyage 4 embeddings (VoyageAI/MongoDB): Tweets point to a Voyage 4 embedding-model release, with special attention on the first open-weights entry “voyage-4-nano,” which is claimed to beat Stella on the FreshStack retrieval leaderboard, according to the FreshStack comparison and the FreshStack comparison framing.
The benchmark context for that claim lives on the FreshStack site—see the FreshStack leaderboard for what the evaluation is measuring (technical-doc retrieval) and how models are ranked.
xAI tests Grok 4.20 “Theta-Hat” checkpoint on LMArena
Grok 4.20 (xAI): A model-watching thread says xAI is testing multiple Grok 4.20 variants on LMArena, with the latest checkpoint “Theta-Hat” described as the strongest so far in the LMArena test clip.

No official spec or release notes are in the tweets, so the only concrete artifact today is the “in-arena checkpoint” observation and the naming.
“sonata.openai.com” hostnames spotted; speculation points to an OpenAI audio model
Sonata (OpenAI): Hostname-watchers report newly observed subdomains including “sonata.openai.com” (dated 2026-01-16) and “sonata.api.openai.com” (dated 2026-01-15) in the Hostname sightings.
Speculation in follow-ups suggests “Sonata” could map to an upcoming audio or music-related model/product, as raised in the Audio model question and echoed in the Audio model speculation.
HeartMuLa open-sourced music foundation models shared, including a 3B OSS checkpoint
HeartMuLa (Ario Scale Global): HeartMuLa is being circulated as a family of open-sourced music foundation models, with a Hugging Face checkpoint referenced as “HeartMuLa-oss-3B,” per the Model card link and the Hugging Face model card.

Today’s tweets don’t include benchmark numbers; what’s concrete is the open checkpoint naming, the model family positioning, and the availability of weights via Hugging Face.
🔌 Open Responses spec adoption: SDKs and harnesses standardizing multi-provider Responses
Continuation of yesterday’s Open Responses momentum, now with concrete SDK positioning and builder intent to create harnesses around the spec. Excludes MCP-specific connectors (Orchestration/MCP).
OpenRouter ships an Open Responses-native SDK positioned for agentic multi-model apps
OpenRouter SDK (OpenRouter): Following up on Standardization, OpenRouter is now explicitly positioning its SDK as “the first agentic SDK native to Open Responses,” with a single interface spanning 300+ AI models as described in the SDK positioning claim and detailed on the SDK page. The emphasis is that multi-provider switching and agent-style workflows (streaming, tools, composable steps) can live behind one API surface instead of per-provider adapters.
• What’s concrete in the SDK pitch: The SDK page highlights 300+ models plus built-in streaming and tool isolation primitives, with Open Responses called out as the native grounding spec in the SDK page.
This is an adoption signal more than a spec change: Open Responses is turning into something third-party SDKs want to be “native” to, not just “compatible with.”
OpenAI Devs spotlights early Open Responses adoption by builders and tooling projects
Open Responses (OpenAI Devs): OpenAI Devs is now explicitly amplifying “builders are already using Open Responses,” framing it as an open-source spec for interoperable, multi-provider Responses-style interfaces in the Adoption shoutout.

The notable shift versus the initial spec announcement is the messaging moving from “here’s the spec” to “here are early adopters,” as shown in the Adoption shoutout and reinforced by the explainer clip in the Open Responses recap.
vLLM frames Open Responses as a way to stop “reverse-engineering” provider behavior
Open Responses (vLLM ecosystem): vLLM contributors are explicitly endorsing Open Responses as a cleanup of a painful integration workflow—having to “reverse-engineer the protocol by iterating and guessing” when adding support for a Responses-like API, then welcoming the spec as “clean primitives” and better consistency per the Meetup note with context.
The concrete claim here is not about new vLLM code landing today; it’s about integration cost—Open Responses is being used as the argument for fewer bespoke shims and fewer behavior-driven “guess the protocol” loops, as described in the Meetup note with context.
Builder pattern: new coding harnesses planned around first-class Open Responses support
Open Responses-first harnesses (Pattern): A concrete builder signal today is people designing their own coding/agent harnesses around Open Responses as the primary abstraction, with nummanali framing “too many providers, too many variations” as the blocker that the spec removes in the Harness intent note. The practical idea is that a harness can focus on outcomes (plans, tool orchestration, agent loops) while treating provider/model differences as a configuration detail.
This is still intent, not a shipped tool; there’s no published harness interface or reference implementation in the tweets yet beyond the stated direction in the Harness intent note.
🧰 Plugins & Skills ecosystems: ‘npm for skills’, reusable prompts, and agent UX add-ons
Installable/portable extensions and skill packs are a major thread today (skills registries, skill installers, statuslines). Excludes MCP servers (Orchestration/MCP) and full agent runners (Agent Ops).
Vercel pitches “skills” as an agent-agnostic, npm-like ecosystem for AI extensions
Skills (Vercel): Vercel is positioning skills as a portable, agent-agnostic packaging ecosystem—explicitly framed as the “npm of AI skills”—intended to make reusable agent capabilities installable across different runtimes, as described in the skills announcement. The point is standardizing the unit of reuse (a skill) so distribution and discovery look more like software packages than copy-pasted prompts.
What’s still unclear from today’s tweets is the concrete on-disk format and execution contract (how a skill declares tools, inputs/outputs, permissions, and sandboxing) beyond the high-level framing in the skills announcement.
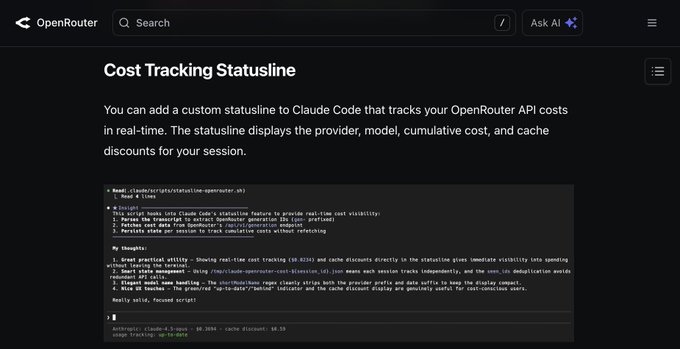
OpenRouter adds a real-time cost-tracking statusline for Claude Code sessions
Claude Code statusline (OpenRouter): OpenRouter documented a real-time cost statusline for Claude Code that reads generation IDs from the transcript, calls OpenRouter’s generation endpoint for spend, and keeps a per-session running total—including cache discounts—per the statusline walkthrough and the linked integration guide in Claude Code docs.
• What it surfaces: Provider, model name, cumulative cost, and cache discount are shown inline in the terminal statusline, as shown in the statusline walkthrough.
It’s a small UI hook, but it formalizes “what did this agent run cost?” as a first-class signal rather than a post-hoc dashboard lookup.
RepoPrompt 1.5.68 adds worktree window control and new installers
RepoPrompt 1.5.68 (RepoPrompt): RepoPrompt shipped v1.5.68 with a worktree-window workflow (spin up/close windows for agent use) and added an opinionated claude-rp installer plus opencode installers, as announced in the release note with the full changelog linked in changelog link.
• Why it’s “ecosystem” news: The emphasis is on install paths and compatibility layers (getting a “nice Claude Code” setup with clashing tools disabled) rather than a single-model upgrade, per the release note.
The tweets don’t include performance numbers or a demo, so operational impact is still qualitative.
A “building glamorous TUIs” meta-skill packages Charm usage for agents
Building glamorous TUIs (meta-skill): A new meta-skill packages guidance on using Charm libraries to get better terminal UI output from agents, with the implementation published as a GitHub skill in the skill release.
This is notable less for new model capability and more for capturing a repeatable “taste layer” (design conventions + library choices) into an installable artifact, rather than a one-off prompt—per the skill release.
Firecrawl documents a one-file install artifact for agent setups
Firecrawl install artifact (Firecrawl): Firecrawl is pushing an agent-friendly one-file install pattern—“tell your agents how to install Firecrawl with one file”—as a documentation convention for reliable setup automation, per the docs update.
This is a small move, but it’s squarely in the “skills and reusable setup” lane: turning environment bootstrapping into a portable artifact agents can consume consistently, as described in the docs update.
💼 Capital and enterprise moves: funding, acquisitions, and licensing for AI data
Business-side signals today include a major gen-video funding round plus infra-adjacent acquisitions/licensing moves that affect AI training data and developer ecosystems. Excludes ad monetization (feature).
Cloudflare buys Human Native, an AI data marketplace for creator licensing
Human Native (Cloudflare): Cloudflare is acquiring Human Native, a UK-based AI data marketplace aimed at brokering deals between AI developers and content creators—Cloudflare says it will build tooling for “fair and transparent” access to high-quality training data, while declining to disclose deal terms in the deal summary.
The immediate signal is that “data licensing as infrastructure” keeps getting more formal: instead of scraping → training → lawsuits, vendors are trying to sell auditable access paths that can scale with enterprise procurement.
Wikimedia Enterprise adds Amazon, Meta, Microsoft, Mistral, and Perplexity as API partners
Wikimedia Enterprise (Wikimedia Foundation): Wikimedia Enterprise announced Amazon, Meta, Microsoft, Mistral AI, and Perplexity as new partners using Wikipedia’s data via its paid API services, positioned as a way to fund and sustain the underlying knowledge commons in the partner announcement.
For AI teams, this is a straightforward licensing signal: high-trust corpora are increasingly accessed through enterprise contracts (with provenance and terms), not just public dumps.
Cloudflare acquires Astro, tightening its hold on modern web dev tooling
Astro (Cloudflare): Developers are reacting to news that Cloudflare acquired Astro, with at least one builder calling it a platform-positive move for Workers migrations in the developer reaction; the deal also showed up near the top of Hacker News in the HN front page screenshot.
This sits at the intersection of web frameworks and AI delivery: more “AI products” are just web apps with agent backends, and platform consolidation changes where teams host, cache, and deploy those workloads.
🏗️ Compute, energy, and AI supply chain: data center power math, ‘energy = intelligence’ framing
Infra/energy becomes the bottleneck theme: quantifying data center power capacity and framing energy as synonymous with near-AGI scaling. Excludes bioscience items and pure model benchmarks.
Epoch AI estimates global AI data center power capacity at ~30 GW
AI power capacity (Epoch AI): Epoch AI estimates AI data centers now have roughly 30 GW of power capacity—comparable to New York State peak demand—based on chip sales multiplied by rated power draw and a 2.5× facility overhead factor for servers/cooling/networking, as described in the 30 GW estimate and expanded in the power capacity post power capacity post.
The methodology matters because it turns “AI is energy-hungry” into a trackable series; the caveats matter because it’s capacity, not metered utilization.
• Method: Capacity is derived from chip units sold times each chip’s power draw, then scaled by 2.5× overhead, as explained in the Overhead method and documented via the chip sales dataset chip sales dataset.
• Caveats: Epoch flags these as capacity figures (not actual usage), notes the 2.5× comes from GB200 NVL72 assumptions, and says Q4 2025 includes extrapolated values, per the Caveats list.
What’s still unclear from the tweets is how quickly the capacity curve is rising quarter-to-quarter, versus grid interconnect and permitting timelines.
OpenAI launches a US AI supply-chain manufacturing RFP tied to Stargate scale-up
US AI supply chain (OpenAI): OpenAI is launching a Request for Proposals to expand U.S.-based manufacturing across the AI supply chain—not just chips and data centers, but also components like cooling and robotics—framed alongside Stargate’s move toward a 10‑GW energy commitment, as shown in the RFP screenshot.
This is concrete infrastructure signaling: it’s about sourcing physical bottlenecks (thermal, power delivery, and upstream components), not model features. It also implies procurement and vendor qualification will be part of “AI strategy,” not a back-office task.
The tweets don’t include the RFP’s submission window, selection criteria, or whether the program comes with guaranteed offtake—so it’s hard to infer near-term volume impact.
Demis Hassabis: energy is effectively synonymous with intelligence near AGI
Energy constraint framing (DeepMind): Demis Hassabis argues that as we approach AGI, “energy is effectively synonymous with intelligence,” and claims AI will help solve its own energy constraints via new materials and infrastructure optimization—and potentially breakthroughs like fusion and room‑temperature superconductors, as stated in the Hassabis energy clip.

This isn’t a benchmark claim. It’s a scaling claim.
For infra teams, the practical read is that “model progress” and “power procurement + buildout” are being talked about as the same roadmap item, not separate tracks.
Projection: data centers could reach 10% of the US power grid by 2030
Grid share projection: A commonly repeated projection says data centers could consume ~10% of the entire US power grid by 2030, with “fusion energy” floated as a potential relief valve, per the 10% grid projection.
This is a big-number claim without a method attached in the tweet. That’s the gap.
In context with today’s other signals, it functions as a shorthand for why energy procurement, interconnect queues, and cooling efficiency are being treated as first-order AI constraints.
Claim: AI labs are 4–5 months ahead of public releases and prioritizing energy buildouts
Release lag and infrastructure focus: A circulating claim says major AI labs run about 4–5 months ahead of what they ship publicly, and even if they had AGI-level systems internally, they’d likely prioritize scaling data centers and energy first—presented as a reason for today’s investment surge, according to the Release lag claim.
This is directional, not audited. No source data is given.
Still, it matches a pattern visible elsewhere in the feed: energy and capacity planning are becoming the gating factor for “what can be released,” not just what can be trained.
🎬 Generative media pipelines: Veo 3.1 upgrades, ComfyUI ref‑to‑video, and motion control workflows
Creator-focused but technically relevant: new video generation knobs (4K/seed/neg prompts), ComfyUI workflows, and reference-to-video techniques. Excludes funding/valuation news (Business) and policy/deepfake debate (Security).
fal adds 4K, seed, and negative prompts across Veo 3.1 endpoints
Veo 3.1 (fal): fal shipped a broad control/quality upgrade for Veo 3.1—4K output on all endpoints, plus seed and negative prompt support, and a new 9:16 option for reference-to-video, as announced in the fal release post. This tightens reproducibility (seed), gives teams a consistent “don’t do X” knob (negative prompts), and makes vertical-first creative pipelines less hacky.

The same rollout also points people to individual playground pages per mode, with links collected in the try 4K links, including a Text-to-video endpoint and a Reference-to-video endpoint.
ComfyUI ships WAN 2.6 Reference-to-Video workflow for motion and camera transfer
WAN 2.6 Reference-to-Video (ComfyUI): ComfyUI highlighted a new workflow that learns motion/camera/style from 1–2 reference clips and generates short outputs (5–10s) at 720p/1080p, per the workflow announcement. This is aimed at “copy this movement language” use cases rather than pure text direction.

ComfyUI’s walkthrough and setup steps are also spelled out in its Workflow blog post, shared in the blog link follow-up.
Veo 3.1 “ingredients” prompting: multi-image references to steer scenes
Veo 3.1 (GeminiApp): Google is pushing a specific prompting pattern for Veo 3.1—upload multiple reference images so the images carry environment/style details while the prompt focuses on motion and camera direction, as shown in the multi-image guidance thread. It’s an explicit move toward “reference bundles” as the primary control surface.

• Reference swapping as a control knob: the reference set example shows an astronaut plus different environment images yielding different scene outcomes.
• Pre-edit references before video: Gemini also suggests using Nano Banana to transform a reference image (e.g., butterflies-as-flowers) before feeding it into Veo, as described in the Nano Banana pre-edit example and reinforced by the stylized reference tip.
Higgsfield promotes 30-day unlimited Kling Motion Control for motion transfer video edits
Kling Motion Control (Higgsfield): Higgsfield is marketing a 30-day “unlimited” Motion Control offer focused on transferring motion onto different subjects (“motion transfer”), positioning it for fast social-video creation and AI influencer pipelines, per the promo post. It’s framed as a capability play (camera/motion language) more than a new model release.

Running LTX-2 locally via ComfyUI: install steps and example 720p timings
LTX-2 local workflow (ComfyUI): A practical “run it on your own GPU” guide circulated for installing ComfyUI and running LTX-2 locally, including requirements like Python 3.10+ and an NVIDIA CUDA GPU, as shown in the local install guide. The post includes rough generation-time expectations for 5 seconds at 720p (t2v ~5 minutes; i2v ~8 minutes) on a 4070 Ti 16GB setup, as stated in the local install guide.

A later follow-up bundles the install/download pointer in the download link post.
TikTok text-to-video benchmark nostalgia highlights rapid realism jump since 2024
Text-to-video realism (TikTok benchmark meme): A “then vs now” clip is making the rounds as a qualitative benchmark—contrasting 2024’s “Will Smith eating spaghetti” era with much cleaner, higher-fidelity character motion and image quality in today’s TikTok-style samples, as shown in the benchmark comparison clip. It’s not a standardized eval, but it is an easily legible barometer of how fast perceived realism moved.

🧷 Orchestration & MCP in practice: enterprise file systems, editor agents, and ‘MCP vs RAG’ framing
MCP and tool-interop posts today are about real integrations (cloud filesystems, editors) and clearer comparisons vs RAG-style retrieval. Excludes general agent SDKs and Open Responses (separate).
Box uses MCP as a cloud filesystem for Claude Cowork to generate slides locally
Box MCP integration (Box): Box’s CEO demoed using Box “as a cloud filesystem via MCP” so Claude Cowork can pull enterprise content as context and generate slides locally, pointing at background agents as the emerging knowledge-work UX, as shown in the Box MCP demo.

The important implementation detail is the abstraction: instead of “upload docs,” the agent gets a filesystem-like surface (read/list/search) backed by Box permissions, which is the same mental model devs already use for repo-aware coding agents. The clip also implicitly highlights the governance question teams will ask next: which folders/providers are allowed, and what actions are permitted, as hinted by the broader Cowork rollout framing in the Box MCP demo.
Factory runs Droid as a native agent inside Zed with full MCP server support
Droid in Zed (FactoryAI): Factory announced Droid can run as a native custom agent inside Zed, with full MCP server support, and paired it with a one‑month Factory Pro promo for existing Zed users, as shown in the Zed integration launch.

This is a concrete MCP-in-practice story: an editor-native agent UI plus an explicit protocol surface for tools/servers, rather than bespoke plugin APIs per editor. The integration doc is linked from the Setup docs pointer, which is the piece teams will need to evaluate how MCP servers are configured and what parts of the editor state are exposed.
Cowork-style orchestration with local models gets a push from Hugging Face
Local Cowork concept (Hugging Face): Hugging Face’s CEO highlighted a “Cowork but with local models” direction—explicitly framing it as avoiding sending sensitive data to remote clouds—using a short demo that emphasizes on-device execution, as shown in the Local Cowork demo.
This lands as an orchestration story more than a model story: the same multi-tool, multi-app coordination people want from Cowork, but with a local-runtime constraint that changes how you think about tool adapters, permissions, and state. The tweet doesn’t name a specific standard, but it’s clearly adjacent to MCP-style “tools as interfaces,” rather than pure prompt stuffing.
GitButler contrasts MCP vs RAG as two fundamentally different context strategies
MCP vs RAG framing (GitButler): GitButler published a write-up that draws a bright line between RAG pipelines (retrieve text blobs into prompts) and MCP-style protocol interfaces (structured tool/context access), positioning them as different failure modes and engineering burdens, as linked in the MCP vs RAG post and detailed in the MCP vs RAG write-up.
The practical takeaway is definitional clarity: “grounding” can mean either “paste evidence” or “give the model an interface,” and those choices drive very different observability, caching, and safety/control surfaces—especially once you’re integrating enterprise systems rather than static corpora.
Forced tool calling pattern spreads via the AI SDK’s toolChoice: required
Forced tool calling (AI SDK): A shared snippet shows how to configure an agent loop so the model is forced to call tools (e.g., code interpreter) by setting toolChoice: "required", using a done tool as an explicit completion signal, as shown in the Forced tool calling snippet.
This is a small but real orchestration lever: it turns “the model might compute” into “the harness enforces tool use,” which makes outcomes more auditable and makes tool availability part of your contract with the agent. The snippet also illustrates a pattern for structured termination (extracting the answer from the done tool call) rather than relying on free-form text.
🛡️ AI policy & trust: platform ToS shifts, prompt/data licensing, and synthetic deception
Security/policy items today center on platform governance around AI interactions (prompt/output licensing, jailbreak bans) and the social reality of synthetic personas. Excludes OpenAI-vs-Elon litigation (separate category) and ChatGPT ads privacy claims (feature).
X updates Terms: AI prompts/outputs treated as content licensed for training; jailbreak bans added
X Terms of Service (X): X’s updated Terms (effective Jan 15, 2026) explicitly define “Content” to include AI prompts and outputs, and require users to grant X a license to use that material for AI training/improvements, as summarized in the ToS update summary. It also adds explicit prohibitions on circumventing AI systems—called out as jailbreaks and prompt-injection attempts targeting features like Grok—per the same ToS update summary.
The practical implication is that any product or workflow that routes user prompts/outputs through X should assume those artifacts are covered by X’s broad content license, and that “red teaming by prompting” behavior may now be a ToS risk on-platform rather than only a product-policy risk.
Fake AI influencer clip shows synthetic personas fooling people on social feeds
Synthetic personas on social (Trust): A widely shared clip shows people being fooled by a fake AI influencer, suggesting “who is real” checks are failing in casual consumption contexts, as shown in the fake influencer post.

The same day’s chatter also anchors why this is happening: the qualitative jump in text-to-video realism keeps shrinking the “obvious tell” gap, with the pace-of-change contrast illustrated in the video realism benchmark.
“Wisdom-maxxing” becomes a mini-meme as builders push back on pure capability races
Safety and values discourse: A small but clear sentiment spike argues the next bottleneck isn’t “cleverer models” but better judgment and values shaping, framed as “we need to be wisdom-maxxing now” in the wisdom-maxxing take.
This is less a concrete policy change and more a signal that parts of the builder community are foregrounding alignment/intent outcomes over raw capability scaling, at least in day-to-day conversation.
🛠️ Dev tools shipping around agents: terminals, DevTools, and one-click infra for builders
Concrete tooling updates that support agentic engineering (terminal UX, IDE model providers, and one-click production DBs). Excludes installable skills/plugins (Coding Plugins) and full agent runners (Agent Ops).
Warp adds first-class UX for CLI coding agents (voice, images, file browsing)
Warp (Warp): Warp shipped a dedicated experience for running CLI coding agents, bundling built-in voice transcription (via WisprFlow), easy image attachments, and an in-terminal file/code review UI; it’s positioned as working across Claude Code, Codex, Amp, Gemini, and Droid, as shown in the feature demo.

• Input ergonomics: Voice transcription and image attach are treated as native prompt inputs rather than bolt-ons, per the feature demo.
• Agent-friendly review loop: File browsing and code review happen directly inside Warp’s UI so the agent session and artifacts stay co-located, as demonstrated in the feature demo.
Vercel Marketplace and v0 add one-click AWS databases (Aurora, DynamoDB, DSQL)
AWS databases on Vercel (Vercel): Vercel added one-click provisioning for AWS databases—Aurora PostgreSQL, DynamoDB, and Aurora DSQL—via the Vercel Marketplace and v0, emphasizing “secure, production-ready” setup in seconds, as shown in the launch demo and detailed in the launch blog.

• Prompt-to-app wiring: The pitch is that v0 can go from prompt to a working app backed by a real production database without manual IAM/console work, per the launch blog.
• Why it matters for agentic dev: It reduces the “last-mile” gap where agents can scaffold code but humans still get pulled into cloud setup, as described in the launch demo.
Chrome DevTools adds per-request network throttling
Chrome DevTools (Google): DevTools now supports throttling individual network requests instead of applying a global throttle profile, which helps isolate a single dependency (API, image CDN, analytics) while leaving the rest of the page unthrottled, as highlighted in the throttling announcement.
This is a practical testing primitive for agent-built web apps too, since it makes it easier to reproduce flaky “one slow call” scenarios without distorting the entire runtime, per the throttling announcement.
v0 Max becomes the default model for v0 users (Opus 4.5) and is 20% cheaper
v0 Max (v0): v0 made v0 Max the default for all users and says it’s powered by Opus 4.5 with a 20% price reduction, per the product post.

The change is mostly an economic/defaults move rather than a new workflow surface, but it directly shifts the “default intelligence” and cost baseline for anyone using v0 as an agentic app builder, as stated in the product post.
Android Studio adds Ollama as a model provider in its built-in model picker
Android Studio (Google): The latest Android Studio surfaced Ollama as a first-class model provider alongside Gemini and Anthropic in the model dropdown, showing local options like gemma3 and gpt-oss variants, as shown in the model picker screenshot.
This is a concrete IDE-level step toward making “local model for dev tasks” a normal toggle rather than a custom plugin path, as implied by the integrated picker in the model picker screenshot.
Firecrawl ships dashboard job ID search for faster debugging
Firecrawl dashboard (Firecrawl): Firecrawl added job ID search to its dashboard so operators can paste a job identifier and jump straight to the relevant logs/results—no paging through lists—per the feature demo and the dashboard link.

This is a small UX change with outsized ops impact for teams running large volumes of agent-driven crawls/extractions, because it tightens the “find the failing run” loop, as shown in the feature demo.
Firecrawl crosses 75,000 GitHub stars as agent web-extraction demand grows
Firecrawl (Firecrawl): Firecrawl reported crossing 75k GitHub stars, framing it as a sign that developers are leaning on it to “unlock web data” for agents and automation workflows, according to the milestone post.
The project also pointed people at its repo while pushing toward 100k, as linked in the repo call.