OpenAI Codex CLI PR 13212 adds /fast tier – GPT‑5.1 leaves March 11
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
A Codex CLI pull request (PR 13212) adds a persistent Fast mode: the TUI gets a /fast command; the setting is stored locally in codex-core; requests flip to service_tier=priority, implying a first-class routing tier rather than a client-side trick. The diff also shows a ServiceTier enum (standard, fast) and hard-coded help text referencing “Fast mode for GPT‑5.4,” turning a latency toggle into a rollout breadcrumb for a new model name; none of this is an official launch artifact, but it reads like plumbing being wired ahead of a swap.
• GPT‑5.4 surfacing: sightings span a ChatGPT model picker option, an alpha-gpt-5.4 entry near alpha-gpt-5.3-codex in a models listing, and the Codex CLI string itself; still no public model card or benchmarks.
• ChatGPT churn: a model menu screenshot tags GPT‑5.1 Instant and GPT‑5.1 Thinking as “Leaving on March 11,” while newer 5.2/mini variants appear alongside.
• Cognition SWE‑1.6 preview: claims 51.7% SWE‑Bench Pro at 950 tok/s via scaled RL (same pre-trained base); early access only; Cognition flags overthinking/self-verification as remaining issues.
Top links today
- Everything is Context agentic file system paper
- FastAPI 0.135.0 Server-Sent Events release
- Study on AI context files in open source repos
- LangChain guide to evaluating deep agents
- CopilotKit interactive MCP apps playground demo
- CopilotKit MCP apps playground GitHub repo
- Webreel scripted UI video recorder repo
- Readout Assistant product update
- Kling 3.0 multi-shot workflow thread
- OpenPencil open source Figma alternative repo
- Grand Old Books free annotated PDFs site
- Taalas HC1 inference ASICs breakdown
- Coinbase on agents with stablecoin wallets
- WSJ report on Claude use in Iran strikes
Feature Spotlight
Codex CLI “Fast mode” + GPT‑5.4 breadcrumbs (priority tier + model churn signals)
Codex CLI code changes point to a new /fast toggle that routes requests to a priority service tier, alongside repeated GPT‑5.4 breadcrumbs—hinting at imminent model/tier packaging changes that affect latency, cost, and agent throughput.
Cross-account chatter centers on a Codex CLI PR adding a persistent /fast toggle that sends `service_tier=priority`, with multiple sightings of “GPT‑5.4” strings and model inventory entries. This is the day’s clearest workflow-changing signal for Codex users (latency tiers + impending model swap).
Jump to Codex CLI “Fast mode” + GPT‑5.4 breadcrumbs (priority tier + model churn signals) topicsTable of Contents
⚡ Codex CLI “Fast mode” + GPT‑5.4 breadcrumbs (priority tier + model churn signals)
Cross-account chatter centers on a Codex CLI PR adding a persistent /fast toggle that sends service_tier=priority, with multiple sightings of “GPT‑5.4” strings and model inventory entries. This is the day’s clearest workflow-changing signal for Codex users (latency tiers + impending model swap).
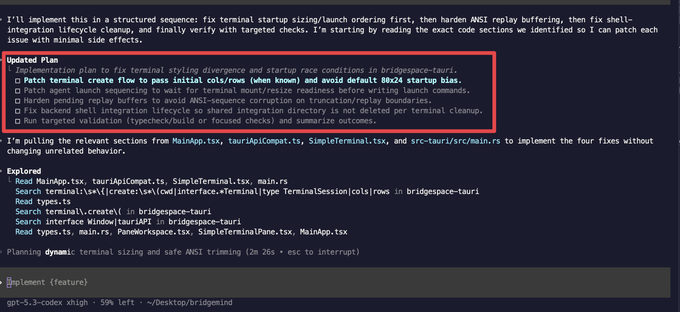
Codex CLI PR adds /fast mode with a priority service tier
Codex CLI (OpenAI): A new Codex CLI pull request adds a persistent Fast mode toggle stored locally in codex-core; when enabled, requests include service_tier=priority, and the TUI gains a /fast slash command that persists the setting, as described in the PR summary and diff notes in PR summary screenshot and linked via the GitHub pull request.
• Request-tier change: Fast mode explicitly flips requests to service_tier=priority, which implies a first-class latency tier split rather than a purely client-side tweak, per the PR notes shown in PR summary screenshot.
• UI + persistence: The change adds /fast in the TUI and persists it on disk (mirroring how model id is stored), as shown in the diff excerpt in TUI diff screenshot.
• Tier taxonomy emerging: A separate snippet shows a ServiceTier enum with standard and fast, reinforcing that Codex is formalizing “normal vs priority” routing as a product primitive, as shown in Service tier enum.
The diff also hard-codes the help text “toggle Fast mode for GPT-5.4,” tying the UX to an upcoming model name in a way that reads like a rollout breadcrumb, as shown in Slash command snippet.
GPT-5.4 breadcrumbs expand across UI and model inventories
GPT-5.4 (OpenAI): Following up on OpenCode listing (alpha-gpt-5.4 appearing then getting walked back), GPT-5.4 now shows up across at least three surfaces: a ChatGPT model picker UI option, an OpenCode model inventory entry, and Codex CLI strings that mention “Fast mode for GPT-5.4,” as evidenced in Model picker clip, Model list screenshot , and Slash command snippet.
• UI sighting: A captured selector shows “+ GPT-5.4” alongside a reasoning-effort control (“Extra High”), suggesting internal exposure in a ChatGPT UI surface, as shown in Model picker clip.
• Inventory echo: A JSON listing screenshot shows alpha-gpt-5.4 adjacent to alpha-gpt-5.3-codex, implying model ids exist in at least one models endpoint used by tooling, as shown in Model list screenshot.
None of these are an official launch artifact on their own; taken together, they’re consistent with staged rollout plumbing getting wired up before a name is broadly enabled.
ChatGPT UI flags GPT-5.1 models as leaving March 11
ChatGPT models (OpenAI): A ChatGPT model menu screenshot shows GPT-5.1 Instant and GPT-5.1 Thinking marked “Leaving on March 11,” indicating an in-product retirement date for the 5.1 variants, as shown in Leaving March 11 menu.
The same menu view also lists newer options (for example “ChatGPT 5.2 Thinking” and “GPT-5 Thinking mini”), so the signal here is operational churn—model availability is being actively rotated with a specific cutoff date, per the UI state captured in Leaving March 11 menu.
🧑💻 Codex in the wild: speed vs overthinking, subagent ergonomics, and reliability gaps
Day-after day of practitioner reports compare Codex to Claude on speed, interruption handling, and long refactors; the consistent theme is strong planning but too much verification/latency on some runs. Excludes the /fast + GPT‑5.4 PR storyline (covered in the feature).
Codex can “finish the plan” while missing plan items
Codex (OpenAI): A small but concrete failure mode: Codex says it’s “done with the plan,” then admits it “missed a few things” only after being asked to read the plan and check it against the code in the plan recheck anecdote. The takeaway is about verification ergonomics: without an explicit plan↔code cross-check request, the agent may stop at a locally-satisfying completion state.
Codex used for phased refactor with acceptance tests held constant
Codex (OpenAI): Uncle Bob describes running a major refactor via Codex—dependency inversion, consolidated state changes, polymorphic boundaries—while keeping acceptance tests unchanged and validating each phase via full test suite + manual gameplay checks in the phased refactor writeup. He reports each phase boundary “worked perfectly,” and later notes the run is a long-haul but still faster than doing it manually progress update.
Codex 0.106 reportedly causes connectivity issues; 0.105 seen as stable
Codex CLI (OpenAI): RepoPrompt’s author warns that “codex 106 seems to cause a lot of connectivity issues,” especially for Europe/shaky Wi‑Fi, and suggests staying on 105 because it’s “pretty stable,” per the version regression note. This is a concrete operational signal for teams standardizing on Codex CLI versions in shared dev environments.
Codex team asks what to fix next after speed and frontend work
Codex (OpenAI): A Codex engineer says “speed and front-end capabilities” were heard “loudly” and claims Codex is now “highly competitive on speed” at least, then explicitly asks builders what else to improve next in the team feedback prompt. For engineers shipping with Codex, this is a direct channel to push on practical gaps (latency tail, tool reliability, better UI/codegen loops) while the product is still being tuned.
Codex Xhigh feels reliable for planning, but slow on some runs
GPT‑5.3 Codex Xhigh (OpenAI): A user says Codex “feels reliable” and produces “good plans based on a deep codebase understanding,” but also notes it may “think and work for a while,” sometimes feeling more reliable than Claude Code outcomes in the planning screenshot.
In another report, the same user frames the trade-off as “works harder” but “takes way longer” than Claude Opus 4.6 on some tasks, with the latency attributed to heavy verification loops speed tradeoff claim.
Some builders default to Codex, then switch to Claude for UI loops
Codex (OpenAI): One practitioner reports doing ~70% of work in GPT‑5.3 Codex Xhigh, using Claude mainly for UI because Claude has better MCP tooling and a Chrome extension that makes preview/tweak cycles faster in the workflow split. This is an example of tool specialization emerging around “core codebase work” vs “UI iteration surfaces,” rather than a single-model default.
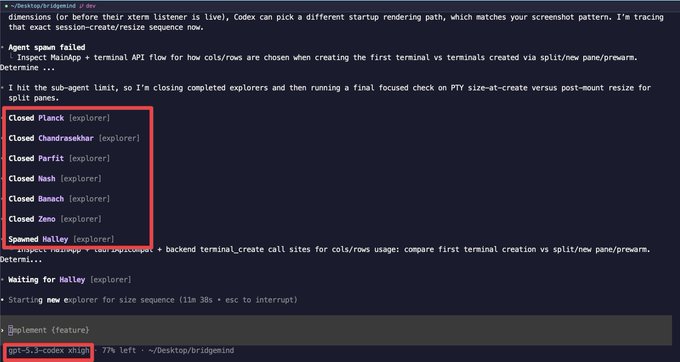
Codex subagents show new naming conventions in logs
Codex (OpenAI): A user noticed Codex “now launches sub-agents with different naming conventions,” with a terminal log showing multiple “explorer” agents named after scientists/philosophers (e.g., Planck, Nash, Banach) in the subagent log screenshot.
They also report GPT‑5.3 Codex Xhigh taking longer than Claude Opus 4.6 on some tasks but “works harder” on complex issues, suggesting the UX change is landing alongside heavier verification behaviors in longer runs subagent log screenshot.
Uncle Bob reports Codex is more interruption-tolerant than Claude
Codex (OpenAI): In a direct head-to-head interaction note, Uncle Bob says “codex handles interruptions better than claude does” in the comparison note. It’s a narrow datapoint, but it’s specifically about mid-task control flow—how well the agent recovers when a human changes direction or inserts new constraints.
Under-specified app builds still produce “slop” without strong human taste
Coding agents (Codex vs Claude Opus): A practitioner describes repeatedly giving Codex and Opus a lightly specified “build an app” task and getting “barely working” output—corner-cutting, ineffective self-testing loops, and weak self-criticism unless the human points out issues—per the under-specified task report. This frames a current reliability boundary: good results track strongly with the human having a clear architectural view and actively steering evaluation.
Codex open source program criteria gets discussed publicly
Codex (OpenAI): A question surfaces about what eligibility gates should exist for a Codex open-source program—minimum contributions, stars/downloads, or nominations-only—in the program criteria question. While no policy is announced, it’s a signal that “who gets access” and “what qualifies as legit OSS” is becoming part of the Codex ecosystem conversation.
🧠 Claude memory portability: import/export as a cross-assistant workflow primitive
Anthropic’s memory transfer flow (copy/paste-generated prompt into Memory settings) becomes a concrete interoperability wedge: teams want portable preferences/context across assistants and local CLIs. This is new vs prior days’ generic “memory” chatter: it’s an explicit migration mechanism.
Claude ships a copy-paste memory migration flow for paid users
Claude Memory (Anthropic): Anthropic rolled out a memory-transfer workflow that lets you migrate preferences/context from another assistant by copying a generated “transfer prompt” and pasting it into Claude’s Memory settings, as described in the feature walkthrough; it’s positioned as available across paid plans, echoed in the product banner.

The practical change is that switching assistants no longer starts from a blank slate; teams can move “how I like to work” (formatting, defaults, background) into Claude without rebuilding that state through weeks of usage.
Anthropic also published step-by-step instructions for importing and exporting memory in the Help center guide, which makes this feel like an intended workflow primitive rather than a one-off UI trick.
A concrete switch workflow: seed Claude Memory from long-term ChatGPT use
Claude Memory bootstrapping: A user reports using ChatGPT for “two years” and then importing that accumulated context into Claude to get Claude “up to speed really quickly,” pointing to the official import/export steps in the Help center guide.
This is an emerging migration pattern for teams running multiple assistants: one tool holds the long-lived preferences/history, and new tools get a fast-start via a structured memory payload rather than repeated re-explaining, as described in the usage note.
Builders push for memory export/import portability across assistants
Interoperability pressure: Builder reaction to Claude’s new migration flow is that memory should be portable across labs—import and export—so users can move their working context between systems rather than getting locked in, as argued in the portability reaction.
The subtext in the “competition is heating up” framing in the competitive signal is that memory is starting to look like an ecosystem-level switching cost, not just a UX feature; the missing piece is symmetric export from other assistants so migration isn’t one-way.
🧪 Agentic coding model race: Cognition’s SWE‑1.6 preview (RL scale + 950 tok/s)
Cognition shared an early preview of SWE‑1.6 with concrete speed and SWE‑Bench Pro numbers plus details on scaling RL environments and compute. This is a distinct thread from general Codex/Claude product talk: it’s about training/run characteristics and eval deltas.
Cognition previews SWE‑1.6: big SWE‑Bench Pro jump without slowing inference
SWE‑1.6 Preview (Cognition): Cognition shared an early preview of SWE‑1.6, reporting a jump to 51.7% on SWE‑Bench Pro while keeping throughput at 950 tok/s—described as faster than SWE‑1.5 and achieved via post-training on the same pre-trained base model, per the preview note in preview announcement.
They also call out remaining behavior issues—overthinking and excessive self-verification—and say the model is rolling out as early access to a small subset of Windsurf users, according to the same preview announcement and the rollout framing in milestone note.
• RL scaling details: Cognition attributes the gain to a refined RL recipe and infrastructure work that unlocked two orders of magnitude more compute than SWE‑1.5 training, plus scaling the number of RL environments; they report continued improvement with further RL training in RL scaling note.
• Benchmark positioning: The shared chart places SWE‑1.6 Preview between top proprietary coding agents—e.g., below GPT‑5.3‑Codex xhigh (56.8%) and Claude Opus 4.6 high (53.6%), but above several open and open-adjacent entries—as shown in the preview announcement.
The preview wording implies the main near-term work is tuning behavior rather than chasing more raw speed, since 950 tok/s is being held constant while RL continues to run, per preview announcement.
🕹️ Running lots of agents: harnesses, handoffs, and “agents on their own machines”
Operational patterns show up around long-running agent sessions, cross-agent context handoff payloads, and giving agents dedicated environments (VMs or spare hardware). This category focuses on running/containing agents, not training or MCP plumbing.
RepoPrompt adds compressed handoff payloads to move a session between agents
RepoPrompt (RepoPrompt): A new “handoff to new chat” flow can export a compressed session payload that preserves repo/file context, so you can continue the same task in a different agent (including Claude↔Codex) using copy-to-clipboard or a direct handoff, as shown in the Handoff modal screenshot.
• Cross-agent continuity: The UI lets you pick the next agent (example: Codex CLI + GPT-5.3 Codex) and then either “Copy payload” or “Handoff,” per the Handoff modal example.
• Demo artifact: A 4K walkthrough is linked in the 4K demo link, which points to the 4K demo video for the full flow end-to-end.
A Cursor cloud agent was prompted to build a full Windows VM and snapshot it
Cursor Cloud Agents (Cursor): A user reports getting a cloud agent to provision a full Windows VM with a desktop UI “with just one prompt,” taking ~1.5 hours on a long-running harness and then snapshotting it as a reusable Windows base, according to the Windows VM claim.
The prompt used to drive the setup (including “don’t stop until you’ve successfully got the windows desktop set up”) is included in the follow-up Full prompt text, which is the key operational detail for anyone trying to reproduce the behavior.
Hermes Agent adds ChatGPT/Codex OAuth subscription support
Hermes Agent (Hermes): Hermes Agent shipped OAuth “subscription provider support,” so it can use a Codex/ChatGPT subscription instead of an API key, as announced in the OAuth support release.
A follow-up note in the Next MCP support reply indicates broader MCP support is the next planned expansion, but no timeline is given.
WezTerm reportedly leaks memory under many-agent workloads, prompting FrankenTerm
WezTerm (terminal ops): A practitioner reports WezTerm wasn’t built for “multi-day sessions” with “many dozens of concurrent agents,” claiming it “starts leaking memory like crazy,” and says this is motivating them to build a replacement (“FrankenTerm”), per the Many-agent terminal pain.
The screenshot in the same post shows WezTerm consuming 182.28 GB of memory in macOS Force Quit, which makes the operational failure mode concrete rather than theoretical.
A tutorial claims OpenClaw can be hosted on an old Android phone
OpenClaw (deployment): A tutorial post claims you don’t need a Mac Mini at all—OpenClaw can be hosted on “an old Android phone,” with the tutorial announced in the Tutorial release.
This directly reframes the “dedicated agent box” requirement implied by the Mac Mini rush, and it’s presented as a practical hosting setup rather than a code change.
Mac Mini stockouts in NYC get attributed to OpenClaw demand
OpenClaw (community): A builder reports Mac Minis being sold out “throughout New York City,” and says store staff “knew exactly what I was buying it for” (OpenClaw) without being told, per the Mac Mini stockout anecdote.
It’s a soft signal, but it points to a specific operational pattern: people are buying small always-on Macs to dedicate as agent boxes.
OpenClaw is claimed to have passed React in GitHub stars
OpenClaw (community): A viral claim says the OpenClaw repo “just passed React on GitHub stars,” framed as a scale/attention signal for personal-agent stacks, as stated in the Stars claim.
The tweet doesn’t include a screenshot of the star counts, so treat it as an unverified metric until cross-checked in GitHub.
Phone-to-SSH becomes a lightweight control plane for coding agents
Remote control pattern: One builder describes a minimal control setup—“Phone terminal → SSH → dev machine”—as a private network between devices for driving coding agents without extra tooling, per the Phone SSH workflow.
It’s a small pattern, but it shows how teams are avoiding heavier remote-control stacks when they mostly need task dispatch + status checks.
🔌 MCP + agent UI: interactive “mini-apps” rendered inside chat
Today’s MCP content is mostly about UI-returning tools: rendering rich components/mini-apps inside a chat sidebar via middleware. Excludes non-MCP plugins/skills (covered separately).
CopilotKit’s MCP Apps playground shows interactive mini-apps rendered inside chat
CopilotKit (MCP Apps): CopilotKit shared an interactive playground demonstrating UI-returning MCP tools that render rich components and sandboxed mini-apps directly inside a chat sidebar, building on the earlier AG‑UI approach described in AG‑UI middleware; the public demo and repo are linked from the playground announcement, with implementation notes (CopilotKit + AG‑UI middleware + MCP SDK + Vite bundling) spelled out in the how it works follow-up.

• What’s concretely new: A runnable end-to-end example (not just middleware) where tool calls can return interactive UX (e.g., booking flows, dashboards) rather than markdown-only outputs, as shown in the playground announcement and the accompanying interactive demo.
• Packaging pattern: The thread notes a practical distribution model—mini-apps bundled as self-contained HTML (iframes) via Vite—so tool UIs can be shipped as artifacts alongside MCP servers, per the how it works details and the GitHub repo.
🗂️ Context engineering becomes architecture: file-system memories + evidence of docs decay
Two papers drive today’s context-engineering discussion: a file-system abstraction (“everything is a file”) and an empirical scan of OSS repos showing low adoption and rapid decay of AGENTS.md/CLAUDE.md-style files. This is materially new vs prior generic ‘use AGENTS.md’ advice: it’s systems design + adoption data.
Everything is Context: agentic file-system abstraction for memory, tools, and provenance
Everything is Context (paper): A new arXiv paper proposes treating all agent context artifacts—conversation history, long-term memory, scratchpads, tool interfaces, external sources, and human notes—as files in a shared “agentic file system,” aiming to make context engineering auditable and reusable rather than prompt-by-prompt glue, as described in the [paper thread](t:19|paper thread).
• Prompt slicing + lifecycle roles: The design explicitly separates raw history, long-term memory, and short-lived scratchpads, then introduces a constructor (select/shrink context), updater (swap memory slices), and evaluator (check answers and update memory), reflecting the limited-context/forgetful nature of per-call inference highlighted in the [architecture summary](t:19|architecture summary).
• Governance by logging: Every access/transformation is logged with timestamps and provenance so teams can trace how tools, sources, and human feedback shaped an output—positioned as a response to “opaque” agent context pipelines in today’s stacks, per the same [paper thread](t:19|paper thread).
• Implementation hook: The authors claim this is implemented in the AIGNE framework, where services like GitHub appear through the same file-style interface, per the [AIGNE mention](t:19|AIGNE implementation).
The tweets don’t include eval results or adoption evidence, so treat it as an architectural proposal with an existence proof rather than a validated standard.
OSS study: only ~5% of repos use AGENTS.md-style context files, and many never change
AI context files adoption (paper): An empirical scan of 10,000 open-source repos found only 466 (~5%) include AI context/config files like AGENTS.md, CLAUDE.md, or Copilot instructions, and the ones that exist often stagnate quickly, according to the [study summary](t:49|study summary).
• Maintenance decay signal: Of 155 AGENTS.md files analyzed, ~50% were never modified after the initial commit and only ~6% had 10+ revisions, suggesting “write-once documentation rot” is already the median outcome, per the [revision stats](t:49|revision stats).
• Content is mostly conventions: The most common material is conventions, contribution guidelines, and architecture overviews, but with no standard structure and wide variation—meaning agents (and humans) can’t rely on a consistent contract across projects, per the [content breakdown](t:49|content breakdown).
The core operational implication is that “add an AGENTS.md” is not self-sustaining as a practice without process/tooling that keeps it fresh—this paper gives numbers for that failure mode rather than more exhortation.
🧩 Skills & extensions: giving agents new surfaces (Electron apps, orchestration skills)
Installable skills are a major workflow multiplier this week: new skills let agents drive desktop Electron apps and orchestrate subagents. Excludes MCP servers (covered in Orchestration & MCP).
Vercel agent-browser adds Electron skill to control desktop apps like Figma and VS Code
agent-browser Electron skill (Vercel Labs): Vercel Labs shipped a new Electron skill for vercel-labs/agent-browser, letting an agent control Electron-based desktop apps (Discord, Figma, Notion, Spotify, VS Code) as described in the skill announcement. The install path is also concrete—npx skills add vercel-labs/agent-browser --skill electron—which makes it a drop-in surface you can attach to “any coding agent,” per the same skill announcement.
This is a notable surface expansion versus browser-only automation: instead of driving web UIs, agents can now operate local desktop workflows that are often where “real work” lives (design files, editor state, chat coordination), with the same skill packaging model.
Warp explores /orchestrate skill to automatically plan and coordinate subagents
/orchestrate skill (Warp): Warp is exploring a new skill, /orchestrate, aimed at automatic agent orchestration—starting with a “main agent” that writes a plan and then coordinates execution, as outlined in the preview mention.
What’s concrete so far is the intended interaction shape (a single command that triggers planning and delegation) rather than a shipped spec, but it’s a clear signal that terminal-centric agent UIs are moving toward first-class plan→delegate→aggregate primitives instead of users hand-spawning and managing subagents.
📏 Agent reliability & evaluation: deep-agent tests, confabulations, and leading questions
Tweets emphasize that agent quality can’t be evaluated like one-shot LLM tasks, and that hallucinations are often prompted by developer framing. This category is about correctness and measurement, not benchmark leaderboards or model launches.
LangChain lays out a test strategy for “deep agents,” not one-shot LLM prompts
LangChain: After building and testing several production agents, LangChain argues “deep agents” can’t be evaluated like single LLM calls; each datapoint often needs custom success criteria, and teams should run a mix of single-step, full-turn, and multi-turn simulations to catch different classes of regressions, as summarized in the Eval requirements thread and expanded in the Deep agents eval blog.
• Test harness shape: The post emphasizes clean, reproducible environments as a prerequisite for meaningful eval signal, alongside layered evals (step-level decisions vs end-to-end behavior), as described in the Eval requirements thread and the Deep agents eval blog.
The writeup frames “agent correctness” as trajectory- and state-dependent (memory/tool side effects), not just answer-quality dependent, per the Deep agents eval blog.
Leading questions can manufacture “bugs” in agent-assisted debugging
Prompt framing reliability: A developer anecdote highlights a recurring failure mode: if a user asks an agent “why is this library doing X wrong,” the model often accepts the premise and fabricates a plausible bug narrative, which can cascade into confident—but incorrect—issue reports to maintainers, as described in the Leading question warning.
The example is a reminder that many “agent errors” are interaction errors: the evaluation target is not just the model’s code reasoning, but whether the dialogue setup forces hypothesis-testing vs premise-acceptance, per the Leading question warning.
Hinton: “hallucinations” are better understood as confabulations
Hallucinations vs confabulations: Geoffrey Hinton argues the failure mode is closer to constructed recall than “making things up,” since both brains and models reconstruct outputs from connection weights rather than retrieving ground truth from a literal memory store, as explained in the Hinton confabulations clip.

The framing implies that confidence and plausibility are weak proxies for correctness in agent outputs, especially when evaluation only checks surface-form answers rather than provenance or verifiable steps, per the Hinton confabulations clip.
AI timelines still collide with real-world rollout constraints
Deployment reality check: A thread pushes back on “AI will fix everything overnight” expectations by pointing out that even if models surface a solution, downstream processes (trials, approvals, integration work, adoption) dominate real timelines, as stated in the Rollout realism note.
For engineering leaders, the core claim is that capability improvements and organizational delivery speed remain decoupled; the constraining factors shift to verification, governance, and rollout mechanics, per the Rollout realism note.
🛡️ AI + defense governance: Anthropic standoff aftermath and “AI in the kill chain” reporting
The defense-policy thread continues with new reporting and interview clips: Anthropic’s red lines, supply-chain-risk posture, and claims that Claude remained in use during strikes despite a ban. Excludes privacy labels and chat-data training defaults (covered in a separate privacy category).
WSJ: CENTCOM reportedly used Claude for strike support despite ban, with 6‑month phaseout
Claude (Anthropic): Reporting circulated that U.S. Central Command kept using Claude for “intelligence assessments, target identification, and simulating battle scenarios” during strikes on Iran even after an order to stop using Anthropic tools, with the government estimating it will take 6 months to fully phase it out, according to the WSJ summary and a parallel headline screenshot.
The same thread claims Claude had already been embedded in prior operations (including one involving Venezuela’s Nicolás Maduro), as stated in the WSJ summary.
Amodei reiterates two red lines: domestic surveillance and fully autonomous weapons
Dario Amodei (Anthropic): Following up on CBS interview (no formal notice, “just tweets”), Amodei put a number on Anthropic’s negotiating posture—saying they told the Department of War they’re fine with “98 or 99% of the use cases” except for domestic mass surveillance and fully autonomous weapons, as shown in the CBS clip.

He also argues the Department is “misrepresenting the law” via social-media messaging around its powers, per the CBS clip analysis, with fuller context available in the CBS transcript.
Altman AMA frames OpenAI’s DoW deal as de-escalation with three flexible red lines
Sam Altman (OpenAI): A recap of Altman’s AMA says OpenAI “definitely rushed” a classified agreement to reduce escalation after Anthropic’s standoff, while arguing elected governments—not CEOs—should make defense ethics calls; OpenAI’s approach is described as three flexible “red lines” plus engineering-time capability limits rather than day-to-day operational vetoes, per the AMA takeaways and engineering vs oversight thread.
The same AMA framing highlights two immediate defense applications—cyber defense and biosecurity—while criticizing an industry posture of warning about an AI arms race and then refusing to supply models, as summarized in the AMA takeaways.
Supply chain risk designation is treated as a new political-risk cost for AI infra
Procurement and political risk: Commentary argues the “supply chain risk” designation (and its most expansive interpretations) creates a chilling effect beyond Anthropic—raising perceived political risk for data center financing and any frontier lab that could be singled out next, with the precipitating negotiations described as an abrupt 3‑day ultimatum in the CBS interview rundown.
One detailed take warns that if courts don’t quickly stay or overturn the designation, it could materially raise infra costs “for everyone,” not just Anthropic, as laid out in the investor risk thread. For a contract-structure lens on why “restrictions” can vary by acquisition pathway and negotiated terms, the contract rights explainer is being shared alongside these threads.
Mollick: assume government models lag yours, and inference constraints are similar
Government AI capability (policy context): Ethan Mollick argues it’s a category error to assume government users have better models than the public—if anything, they often have older releases—so debates about “state AI power” should start from the premise that capabilities are comparable, per the capability lens.
He also notes the government has many computers but “the wrong kind” for inference and still leans on hyperscalers like everyone else, echoing the point in the economics note and the linked AWS investment note about federal cloud AI infrastructure.
“Virtually no progress” vs later reports: negotiation state may have shifted within 24 hours
Anthropic–DoW negotiation state: A reconciliation theory suggests Anthropic’s public statement describing “virtually no progress” could have reflected the contract language they saw Wednesday night, while later reporting described Friday’s state after another day of negotiation—potentially with the autonomous-weapons language partially resolved and surveillance wording still contested, as argued in the timeline hypothesis.
The same post pulls direct lines from Amodei’s interview about why domestic surveillance is treated differently from “catching up with adversaries,” and frames the remaining information gap as material for evaluating the dispute, per the timeline hypothesis.
🛠️ Builder utilities: scripted demos, dev-environment assistants, and streaming UX primitives
A set of developer tools show up that improve day-to-day shipping: scripted demo recording, local dev-environment assistants that can take actions, and SSE support landing in popular web stacks. Excludes coding assistants themselves (Codex/Claude/etc).
Readout adds an “Assistant” that can answer fast and run cleanup actions
Readout (Benji Taylor): Readout shipped an Assistant layer on top of its background dev-environment scanning; you can chat with it for near-instant responses with rich cards, and it can take actions like listing/cleaning git worktrees, as demonstrated in the Assistant demo.

• Roadmap signal: The author says Readout is growing quickly and plans to add Codex support, per the support for Codex mention, with the product entry point at the Product site.
FastAPI 0.135.0 lands Server-Sent Events support for streaming endpoints
FastAPI (Tiangolo): FastAPI 0.135.0 adds documented Server-Sent Events (SSE) support for text/event-stream endpoints (via EventSourceResponse), with an official tutorial linked from the release callout and detailed in the SSE docs.
• Builder sentiment: One developer notes SSE “works better for a class of problems” than WebSockets, per the SSE vs websockets note, which lines up with common streaming UX needs like token streaming, logs, and live status updates.
Vercel Labs ships webreel for scripted, never-stale product demo videos
webreel (Vercel Labs): Vercel Labs released webreel, a tool to record browser demos from a JSON script (clicks/keystrokes/drags) with a human-like cursor and keystroke HUD; it outputs MP4/GIF/WebM and is designed to re-run headlessly in CI so demos can be re-recorded on every deploy, as shown in the feature rundown.

• Workflow fit: It’s positioned for teams whose docs/launch pages rot when UI changes—webreel makes the recording “code” so you can keep demos current with the app, per the feature rundown and the linked GitHub repo.
WezTerm hits 182GB memory under heavy agent usage; FrankenTerm starts as a workaround
Terminal reliability under agent load: A builder reports WezTerm wasn’t built for multi-day sessions with “many dozens” of concurrent agents, showing a macOS “out of application memory” dialog with WezTerm at 182.28GB, motivating a new terminal project dubbed FrankenTerm, as described in the memory leak screenshot.
This is a concrete failure mode for agent-heavy workflows where the terminal becomes the long-running UI substrate and ends up being the stability bottleneck.
💼 Business & enterprise signals: revenue scale, data moats, and agents as ‘employees’
Today’s business thread is about scale and defensibility: OpenAI revenue/user metrics, proprietary data as moat, and companies treating agents as workers (including payments). Excludes pure infra incidents (covered under infrastructure).
ChatGPT scale screenshot claims 900M weekly actives and 50M paid subs
ChatGPT (OpenAI): A widely shared slide claims 900M weekly active users and 50M paying subscribers, plus “9M paying business users,” framing distribution and conversion as the core moat at current scale, as shown in the metrics slide.
This is being used as an enterprise adoption signal more than a product update: the slide explicitly points to teams moving from “individual productivity” into deployments across engineering/support/finance/sales/ops, per the same metrics slide.
OpenAI pegs total revenue above $20B and downplays DoW contract size
OpenAI (OpenAI): OpenAI executives and close readers are circulating that the company has now surpassed $20B in total revenue, while also characterizing the Pentagon/DoW contract as financially immaterial relative to that base, as relayed in the revenue claim and reiterated by the Fidji Simo confirmation.

Sam Altman separately frames revenue growth as fast enough to support ongoing infra spend, while flagging chip supply volatility as the operational risk, per the Altman clip. The net business signal is that government defense work is being positioned as strategically important but not a primary revenue driver.
Coinbase frames agents as workers, backed by stablecoin wallets for payments
Coinbase (Enterprise adoption): Coinbase’s CEO claims AI agents are already writing 50%+ of code and resolving ~60% of support tickets, and says they’re scaling autonomy by giving agents stablecoin wallets for machine-to-machine payments, per the agent metrics clip.

• Operational framing: The “digital employee” posture implies governance, identity, and spend-control become first-class platform features (wallet limits, audit trails, approvals) rather than app-level glue, as described in the agent metrics clip.
Block layoffs are framed as AI-driven productivity, with a positive market reaction
Block (Workforce signal): A recap thread claims Block laid off 4,000 employees (out of 10,000) with Jack Dorsey explicitly citing AI as a driver, and notes the stock moved up ~20% on the news, per the layoff recap.
This is being discussed less as a one-off cut and more as a template other exec teams may copy: “AI productivity” becomes an externally legible narrative that markets appear to reward, at least in this anecdote, per the same layoff recap.
Ellison’s moat thesis: proprietary data over model advantages
Oracle / Larry Ellison: Ellison argues frontier models are commoditizing because they train on broadly similar public internet data, so defensibility shifts toward exclusive proprietary datasets as the remaining moat, per the Ellison moat clip.

For builders, the immediate takeaway is less about model choice and more about data strategy: if this framing holds, procurement and partnerships that create unique training/eval corpora become competitive levers alongside inference cost and latency.
ARK chart: AI capex share of GDP is tracking above prior tech waves
AI capex cycle (ARK Invest): An ARK Invest chart being shared claims AI is moving faster than prior tech buildouts when measured as capital expenditures as a percent of GDP, with a steep projected climb toward the end of the decade, per the ARK chart share.
The chart is being used as a macro justification for sustained data-center and compute buildout—useful context when interpreting vendor pricing power, capacity constraints, and “who gets compute” dynamics.
💾 Hardware & systems acceleration: baked-in inference chips + storage-bottleneck workarounds
Two distinct acceleration narratives appear: models ‘baked into’ dedicated inference chips with extreme tok/s, and DeepSeek-style system design that treats KV-cache I/O as the bottleneck in long-context agentic inference. This is about throughput/architecture, not model capability announcements.
DeepSeek DualPath analysis argues KV-cache I/O, not FLOPs, is the agent bottleneck
DualPath inference (DeepSeek): Following up on DualPath paper—KV-cache I/O as the long-context bottleneck—new discussion digs into the mechanism: using otherwise-idle decode-side storage NIC bandwidth as a second path to move KV blocks to prefill, treating prefill+decode NICs as a pooled bandwidth budget rather than isolated pipes, per the Zhihu DualPath breakdown.
• Reported scale and result: The thread claims evaluation on a 660B “production-scale” model with up to 1.87× throughput improvement in offline inference, while smaller models (example given: 27B) see less benefit because overheads don’t amortize, as summarized in the Zhihu DualPath breakdown.
• Why it’s tied to agentic workloads: The argument is that tool-using agents drive long contexts (128K+ KV growth; bursty concurrency), which makes storage bandwidth dominate; DualPath is presented as a systems response to that workload shape, per the Zhihu DualPath breakdown.
Some details remain secondhand (a commentary translation rather than the paper itself), but the constraints and the NIC pooling idea are concrete in the Zhihu DualPath breakdown.
Taalas pitches HC1 chips with “baked-in” models running ~17,000 tok/s
HC1 inference ASICs (Taalas): A new pitch making the rounds claims models can be “baked” into Taalas’s HC1 chips and serve inference at roughly 17,000 tokens/second, framing it as a path beyond GPU-centric stacks for steady high-throughput serving, as described in the HC1 speed claim.

• Throughput framing: The headline number is positioned as the core advantage—extreme tok/s for inference workloads, per the HC1 speed claim.
• Trade-off surface (implied): The same “bake into a chip” story implies tighter coupling between model + hardware image (potentially great for stable production SKUs, but less flexible for rapid model swaps); the tweet itself doesn’t provide deployment details like model size limits, memory, or host integration, so treat the claim as directional until there’s a public spec sheet beyond the HC1 speed claim.
🏗️ Infra reliability under conflict: UAE AZ fire, multi‑AZ failover, and energy-cost shock risks
Infra signals today are unusually operational: an AWS UAE availability zone reports fire after being struck, and teams discuss what multi‑AZ/multi‑region actually buys you. Also includes second-order cost pressure narratives tied to regional conflict (energy → inference costs).
AWS UAE availability zone mec1-az2 hit by “objects,” causing fire and outage
AWS me-central-1 (AWS): An AWS UAE Availability Zone (mec1-az2) reported being “impacted by objects that struck the data center,” causing sparks/fire and a power shutdown while emergency response worked the incident, according to the status excerpt quoted in status quote. This is a hard reminder that single-AZ placements can fail for reasons outside normal cloud fault models.
• What’s actually known: The only concrete primary detail in the tweets is the provider’s own phrasing about “objects” and a resulting fire/power cut, as shown in status quote.
• Attribution is still indirect: A separate headline screenshot explicitly ties the event to Iran strikes on Dubai/Abu Dhabi, as shown in headline screenshot, but no official attribution is included in the materials here.
Data centers discussed as potential conflict targets, not just collateral
Conflict-driven infra risk: Commentary is explicitly framing “objects hit the data center” incidents as a form of warfare that targets tech infrastructure rather than (only) military assets, as argued in data center targeting framing. That framing lands because it turns cloud AZ geography into a security and continuity variable, beyond normal redundancy math.
The only hard operational anchor in the tweets remains the AWS status excerpt quoted in status quote; everything else here is interpretation and second-order risk discussion.
Vercel details how dxb1 traffic and Fluid functions ride through the UAE AZ incident
Vercel Dubai region dxb1 (Vercel): In response to the AWS UAE AZ incident, Vercel says its primary traffic ingress AZ was unaffected and that Fluid functions already deploy across multiple AZs and load-balance around an impacted zone, with automatic rerouting and optional backup-region deployment for failover described in incident response. This is operationally relevant for teams hosting agent backends and tool APIs on Vercel where availability depends on cloud routing behavior.
• Failover surface: The post calls out both multi-AZ behavior and multi-region reroute paths, with the mechanics summarized directly in incident response.
• Practical framing: The same note explicitly connects availability to access for “critical information” during disruption, as stated in incident response.
Hormuz energy-risk thread ties oil/LNG shocks to inference and chip input costs
Energy prices and inference economics: A thread claims Iran “officially” closed the Strait of Hormuz and argues this could raise AI inference and hardware input costs via electricity and industrial energy pass-through, citing figures like “20% of global seaborne oil trade,” inference energy as “30–50%+ of total cost,” and inference representing “80–90%” of AI compute energy use, all as stated in energy cost thread. This is an attempt to connect geopolitical energy chokepoints to near-term unit economics for serving.
The post is a narrative rather than a measured market report; it contains no pricing series or grid/utility data beyond the claims listed in energy cost thread.
Multi-AZ resilience gets a rare “actually mattered” moment in production
Multi-AZ failover (Cloud practice): Engineers are reacting to the UAE incident as one of the rare times multi-AZ design has visibly paid off in the wild, with one post saying it’s “like the second time ever” they’ve seen multi-AZ be useful, referencing the same incident headline in multi-AZ reaction. The sentiment matters because agentic systems tend to create long-lived sessions and retry storms, making partial regional degradation more user-visible.
The posts don’t add new technical mechanisms beyond the outage itself; they mainly signal renewed attention to AZ-level blast radius as shown in multi-AZ reaction and the underlying status language quoted in status quote.
🧠 Model & integration watch: DeepSeek V4 timing, GLM‑5‑Code, and open‑weight agents in Notion
Model chatter spans China labs (DeepSeek V4 timing rumors) and coding-specialized releases (GLM‑5‑Code), plus open-weight deployment inside end-user agent products. Excludes SWE‑1.6 (covered separately as an agentic coding model run).
DeepSeek V4 rumors firm up around a “next week” release window
DeepSeek V4 (DeepSeek): Following up on V4 rumor (next-week multimodal expectations), multiple posts now claim the release is specifically expected “next week,” with one screenshot pointing to Financial Times-style reporting that DeepSeek has worked with Huawei to cut reliance on Nvidia and is timing release around China’s political calendar, as shown in the
.
• Reporting-shaped details (still unconfirmed): The “brief technical report” expectation shows up in aggregation posts like Next week claim, while “multimodal” expectations and competitive framing recur in Next week rumor and Whale is coming.
Treat this as a schedule signal rather than a capability artifact until a model card, evals, or API surface is published.
GLM-5-Code shows up as a distinct coding model with its own pricing
GLM-5-Code (Zhipu/GLM): A distinct GLM-5-Code entry is being spotted on pricing pages as “coming soon,” with separate input/output rates, as shown in the
. Some accounts are now treating it as effectively launched (“dropping”), with early UI screenshots describing it as a programming-focused variant aimed at more stable tool calls and better front-end generation (including animations/mini-games/3D), as shown in the
.
• Positioning claims: The most concrete product-language snapshot is the feature list in Model selector screenshot, while the “coming soon” evidence trails back to pricing sightings in Pricing page mention and Pricing screenshot.
No benchmark artifact is shared in these tweets, so treat quality claims as provisional until public evals land.
Notion Custom Agents adds an open-weight model option via MiniMax M2.5
MiniMax M2.5 (MiniMax) + Notion Custom Agents: MiniMax says M2.5 is now live as the first open-weight model available inside Notion Custom Agents, positioned for “lightweight, high-frequency agent workflows,” according to Notion integration post. Follow-on commentary frames it as a cost/latency-driven insertion of open-weight models into end-user agent products in Ollama reaction and Hackathon note.
No deployment details (hardware targets, context length, or pricing) are included in the posts shared here.
Qwen “small models” hinted via hidden collection updates
Qwen3.5 (Qwen/Alibaba) ecosystem watch: A LocalLLaMA screenshot suggests the Qwen3.5 collection was updated with “hidden items,” with commenters doing the math (“13-9=4”) and noting Unsloth also has “4 hidden items,” as shown in the
. The same screenshot is re-shared by HF repost, implying broader attention.
This is an early packaging signal (weights not yet visible in the referenced UI), so it mainly matters as a heads-up for people planning fine-tunes or low-latency deployments.
The “China is 5 months behind” trope returns ahead of DeepSeek V4 rumors
Competitive pacing discourse: Builders are re-litigating whether China is “just 5 months behind,” with DeepSeek V4 used as the test case and framed as “the whale is coming” in Whale is coming and reinforced by “coming next week” chatter in Next week rumor.
The practical relevance for leaders is expectation-setting: a lot of public discussion is about cadence and parity claims, not concrete integration surfaces or independently reproducible evals yet.
🏟️ Builder distribution: hackathons, meetups, and free courses feeding the agent ecosystem
Community/learning is itself the news today: multiple large hackathons and meetups, plus structured training resources from major labs. This category captures distribution mechanisms rather than product changelogs.
YC x Browser Use web agents hackathon reports biggest turnout yet
YC x Browser Use hackathon (Y Combinator + Browser Use): Multiple posts describe an unusually large, two-day builder turnout for the web-agents hackathon—framed as potentially the biggest YC hackathon to date—co-sponsored by a cluster of agent ecosystem companies, as shown in the event photos recap.
The distribution angle is straightforward: a high-attendance, tool-rich hackathon weekend is functioning as a “launch surface” for agent stacks (browser control, memory, model access, sandboxes) through hands-on shipping rather than docs.
Anthropic spotlights free courses on the Claude API and MCP
Anthropic courses (Anthropic): Anthropic’s free course catalog is being circulated, including “Building with the Claude API” and an “Introduction to Model Context Protocol,” as shown in the course list screenshot.
This matters as enablement infrastructure: formal training material is becoming a parallel distribution channel to product launches, especially for MCP and agent toolchains where “how to wire it” is often the real blocker.
Imperial College hack week kicked off with free Codex subscriptions
Codex (OpenAI): An Imperial College London hack-week kickoff reportedly gave attendees free Codex subscriptions, with the intent of getting builders into agentic coding immediately, according to the hack week note.
For teams tracking adoption, this is a direct distribution play: subsidized access at a high-density builder event to seed new default workflows and collect feedback loops quickly.
Agent Forge hackathon: teams demo multimodal “marketing engine” agent stacks
Agent Forge hackathon (community event): A Singapore hackathon writeup describes shipping a “video+image marketing engine” built from a product URL and brief, using OpenAI Agents SDK plus a multi-model stack (Codex 5.3, Kimi-K2.5, Nano Banana 2, Seedance 2) as documented in the event photos.
The distribution relevance is that hackathons are increasingly acting as integration testbeds for cross-vendor model pipelines (image → video → voiceover) under real demo constraints.
OpenAI Codex hackathon: StoryWorld takes 1st place
Codex hackathon (OpenAI community): A winner announcement claims 1st place at an OpenAI Codex hackathon with “StoryWorld,” pitched as a 3D movie studio on iOS using ARKit, according to the winner post.
This is another distribution pattern showing up repeatedly: short hackathon timeboxes are now enough to prototype agent-adjacent creative tools that would previously have required a full team and longer runway.
Toronto Codex community meetup points to growing local scenes for cloud agents
Codex community (Toronto): A Toronto meetup shoutout frames “cloud coding agents” as a workflow that’s spreading beyond SF, with builders describing multi-surface usage (Slack/Linear/GitHub/iOS) as a normal part of their dev flow in the cloud agent reflection and then calling out the local community meetup in the Toronto note.
The signal here is distribution via local scenes: once a CLI/agent workflow becomes teachable in-person, it tends to standardize faster than via online threads alone.
HackIllinois: Supermemory reports projects built at the event
Supermemory at HackIllinois (community showcase): Photos from HackIllinois show multiple projects using Supermemory, per the event photos.
For ecosystem watchers, this is a classic adoption signal: student hackathons function as early distribution for agent memory/tooling libraries, especially when integrations are lightweight enough to be used mid-event.
🎬 Generative video tooling: Seedance 2.0 realism, Kling workflows, and Meta’s Vibes editor
Creator tooling remains high-volume: multiple clips and workflow templates for text-to-video and edit-from-frame features, plus rumors of Meta shipping a more full-featured video editor. This stays separate so it doesn’t get dropped by the engineering-heavy sections.
Meta’s Vibes is rumored to expand into a standalone timeline video editor
Vibes (Meta): A leak claims Meta is turning Vibes into a standalone web (and mobile) app with a multi-track timeline editor, aiming at longer-form, multi-scene creation plus character consistency and “ingredients,” with references suggesting Midjourney involvement in the stack as shown in the [UI screenshot](t:54|UI screenshot).
• Product shape: The reported shift is from “generate a clip” to a project workspace—timeline tracks for video/text/music/voiceover and a dashboard workflow—per the [feature scoop](link:368:0|Feature scoop), which also notes testing in Brazil and Mexico.
The reporting is directional rather than confirmed; no official Meta announcement is referenced in these tweets.
A practical Kling 3.0 multi-shot prompt template is spreading
Kling 3.0 (Kling AI): Builders are sharing a repeatable multi-shot prompt skeleton—camera → subject lock → environment → event → physics layer → technical tail—as a way to keep multi-cut sequences coherent, per the [prompt structure post](t:506|Prompt structure) and the [workflow demo thread](t:274|Multi-shot workflow).

• Reference-driven multi-cut: One workflow emphasizes using a small set of reference images (e.g., “2 ref images”) and then treating the per-shot prompts like classic text-to-video “secondary prompts,” as shown in the [multi-shot example](t:274|Multi-shot workflow).
Grok Imagine adds “extend from frame” to continue an animation with a new prompt
Grok Imagine (xAI): iOS users are seeing an “extend from frame” control that appends about 10 seconds of new animation from a chosen frame, driven by a follow-on text prompt, as demonstrated in the [feature clip](t:325|Feature clip).

This is a concrete UX primitive for iterative video edits (extend/branch) rather than regenerating full sequences from scratch.
Seedance 2.0 clips keep pushing the “looks non-AI” narrative
Seedance 2.0: New clips and reactions keep repeating the same claim—outputs “do not even look like an AI generated video anymore,” as stated alongside a dance-focused example in the [realism post](t:156|Realism post).

• Style direction: Separate posts show ongoing interest in stylized/anime-adjacent outputs (e.g., “Ghibli” remixes) in the [style clip](t:455|Style clip), suggesting Seedance is being used both for realism flexes and for intentional stylization.
These are user-shared examples rather than a new model release, so treat quality claims as anecdotal until there’s a reproducible public eval.
A three-variable prompt template for Nano Banana 2 is being reused for cinematic stills
Nano Banana 2: A prompt pattern using three variables (subject, environment, and a visual “film realism” style layer) is being passed around as a reusable way to get consistent, high-detail “cinematic still” outputs, as shown in the [variable card](t:95|Variable card) and reinforced by the [template follow-up](t:350|Template follow-up).
The emphasis here is naming components explicitly (what the UI component is, what the scene is, what the rendering/style constraints are) so you can swap one variable without destabilizing the rest.
⚖️ Open weights vs safety: what ‘open source’ means for models and alignment risk
A separate discourse thread focuses on whether ‘open weights’ changes safety economics and competition, and whether open-source arguments transfer cleanly to opaque neural nets. This is governance and market-structure debate, not a model release log.
Amodei argues open weights don’t deliver classic open-source benefits
Anthropic (Claude): Dario Amodei argues that “open source” doesn’t map cleanly onto frontier models because you can’t inspect internal mechanisms the way you can inspect source code; he prefers the framing “open weights,” and says the practical question is whether a model is good at the tasks that matter, not how it’s licensed, as stated in the interview clip and echoed in the longer podcast interview.

He also makes an economic point engineers will recognize: open weights are not “free” because serious models still require expensive inference infrastructure and someone to operate/optimize it (often cloud-hosted anyway), as argued in the interview clip.
A direct alignment challenge to open-weights advocacy
Open weights vs alignment: Ethan Mollick asks what the concrete alignment justification is for releasing open-weights models—separating “narrow alignment” (misuse) from broader agent/AGI alignment risk—framing it as a real trade-off rather than a default good, in his alignment question.
The prompt implicitly challenges builders and policy folks to articulate what mitigation story (if any) substitutes for centralized hosting controls when weights are widely distributable, as raised in the same alignment question.
Backfire thesis: restricting open models shifts US usage to China
Open models and geopolitics: Teknium claims that heavy lobbying to restrict open(-weight) models in the US would mainly harm American builders—predicting “the most intense outcome” is US-only restrictions while China ignores them—so US developers and companies would default to Chinese models over time, as argued in the backfire warning.
The claim is directional rather than evidenced with data in the tweet, but it’s a clear market-structure argument about where usage and developer ecosystems would migrate under asymmetric regulation, per the backfire warning.
🔒 Privacy & disclosure mechanics: chat-training defaults + “Made with AI” labels
Operational trust issues show up as policy audits (chat data used for training) and platform UI controls for disclosure. This category is about data governance and labeling mechanics, not defense procurement (covered elsewhere).
X adds manual post labels for paid promotion and “Made with AI” disclosure
X (Content disclosure UI): X has rolled out per-post toggles to label content as “Disclose paid promotion” and “Made with AI”, as shown in the disclosure menu screenshot shared in Disclosure toggles screenshot.
The same rollout is already triggering skepticism that a manual toggle won’t catch bad actors—i.e., “people who don't want you to know their work is AI will clearly not use this,” as argued in Manual toggle skepticism, while others frame it as removing excuses for non-disclosure in Deception framing.
🤖 Robotics & embodied demos: humanoid open hardware and desk assistants powered by LLMs
Robotics posts are clustered around humanoid/open-hardware releases and consumer-device ‘robot’ framing, plus practical LLM-driven desk/arm assistants. This category is distinct from agent software runners and from generative media.
A voice-controlled OpenClaw desk assistant pairs Kimi 2.5 with MOSS
OpenClaw desk assistant (OpenClaw): A builder demo shows a voice-controlled robotic desk assistant built on OpenClaw, using Kimi 2.5 plus MOSS, with the author noting Kimi 2.5 is a common choice in OpenClaw demos “largely for pricing reasons,” as described in demo summary. It’s a concrete embodied-agent pattern: speech input → LLM decisioning → arm actuation.

This matters because it’s an end-to-end wiring example that turns “agent output” into physical actions (grasping/moving objects) rather than just UI automation. The evidence here is primarily the interaction loop captured in demo summary, with no additional details in the tweets on latency, safety interlocks, or the exact division of labor between Kimi 2.5 and MOSS.
Asimov v1 expands its open humanoid push beyond legs
Asimov v1 (Asimov): The Asimov project is claiming an open-source release for a full humanoid body design, including simulation files and an actuator list, building beyond the earlier “v0 legs” release described in open-source v1 claim. The post frames this as a complete-body drop rather than a single subsystem.

For robotics engineers, the practical value is in artifact availability (simulation + actuator BOM-style list) because it enables reproducible experiments, control iteration, and community forks without re-deriving the mechanical baseline. The tweet doesn’t include performance metrics or a control-policy description, so treat it as a hardware/open-design availability signal anchored to what’s stated in open-source v1 claim and shown in the open-source v1 claim.
Honor demos its first humanoid robot with smooth dance motion
Humanoid demo (Honor): Honor revealed what it calls its first humanoid robot, showcasing smooth locomotion via a stage demo where it performs a Michael Jackson-style slide, as shown in humanoid reveal. The clip is light on specs (no payload, runtime, or control stack details), but it’s a concrete “embodied” PR beat from a phone OEM.

For AI builders, this kind of release is mainly a distribution signal: consumer hardware brands are trying to own the “agent in the room” narrative, even when the underlying autonomy (planning, safety, perception) isn’t described. The post’s evidence is the motion demo itself, with no published technical artifact in the tweets to validate the robotics stack beyond what’s visible in humanoid reveal.
Honor pitches a phone-as-robot companion via a pop-up “eyes” camera
HONOR “AI robot phone” concept (Honor): Honor is positioning a phone feature as a continuously active AI companion, with the pop-up/rotating camera acting as the agent’s “eyes,” per the concept described in robot phone claim. It reads more like an embodied-assistant framing than a new autonomy stack, but it’s a clear signal that vendors want a persistent sensor loop for on-device agents.

The engineering implication is mostly about product shape: always-available perception (camera) paired with an assistant that can keep running in the background, and then translate that into “companion” UX rather than a one-shot assistant. The post itself flags it may be a gimmick and that the core trend is “personal AI companions are coming,” as stated in robot phone claim.