Goldman Sachs deploys Claude agents after 6 months – audit fees fall 14%
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Goldman Sachs is rolling out Claude-based “digital co-worker” agents for regulated back-office work; Anthropic engineers were embedded on-site for 6 months; the described flow reads trade-record bundles plus policy text, executes step-by-step rules, flags exceptions, and routes items for approval; Goldman frames the outcome as faster client vetting and fewer reconciliation breaks, with “slower headcount growth” rather than immediate layoffs. The emerging template is enterprise agents as controls-first systems—rules execution, exception routing, audit trails—where integration work, not a generic chat UI, is the moat.
• Anthropic capital stack: Bloomberg rumor says $20B+ new funding at ~$350B valuation (~2× prior mark) with revenue run-rate “above $9B”; unconfirmed in-thread.
• Amazon ↔ Anthropic: circulated mark pegs Amazon’s stake at ~$60.6B; partnership is tied to an Anthropic commitment to buy 1M Trainium chips, coupling model growth to AWS capacity.
• Audit pricing pressure: FT anecdote says KPMG forced a 14% fee drop to $357,000 (from $416,000) as AI compresses audit workflow labor, with judgment still positioned as partner-level.
Top links today
- CNBC on Goldman rolling out Claude agents
- Bloomberg on 2026 AI capex wave
- Reuters on chip sales reaching $1T
- FT on AI-driven audit fee cuts
- Self-learning skill repo for web-based agent training
- Business Insider on Amazon’s Anthropic stake mechanics
- WSJ on SpaceX shifting focus to Moon
- InfMem paper on bounded-memory long-context QA
- HY3D-Bench GitHub repo for 3D generation eval
- HY3D-Bench on Hugging Face
- HY3D-Bench dataset download page
- HY3D-Bench paper
- X API pay-per-use developer announcement
- Claude Code Opus 4.6 hackathon application page
- Firecrawl Branding Format v2 extraction endpoint
Feature Spotlight
Enterprise AI goes live: regulated rollouts, ROI claims, and big-money bets
Goldman deploying Claude agents for accounting/compliance is a high-signal “production in regulated workflows” moment—implying real enterprise demand, governance requirements, and budget shifts beyond coding copilots.
Feature focus is new real-world enterprise adoption signals—most notably Goldman rolling out Claude-based agents for accounting/compliance. Also includes other concrete ROI stories and large funding/valuation moves; excludes day-to-day coding tool updates.
Jump to Enterprise AI goes live: regulated rollouts, ROI claims, and big-money bets topicsTable of Contents
🏦 Enterprise AI goes live: regulated rollouts, ROI claims, and big-money bets
Feature focus is new real-world enterprise adoption signals—most notably Goldman rolling out Claude-based agents for accounting/compliance. Also includes other concrete ROI stories and large funding/valuation moves; excludes day-to-day coding tool updates.
Goldman Sachs rolls out Claude agents for accounting and compliance work
Goldman Sachs × Claude (Anthropic): Goldman is rolling out Claude-based agents to automate high-volume accounting and compliance work, after embedding Anthropic engineers on-site for 6 months to co-develop “digital co-worker” systems, as described in the rollout thread and echoed by the CNBC screenshot.
Goldman’s cited workflow is explicitly rules-and-controls shaped: the agent reads bundles of trade records plus policy text, applies step-by-step rules, flags exceptions, and routes items for approval—Goldman frames the outcome as faster client vetting and fewer reconciliation breaks, with “slower headcount growth” rather than immediate layoffs per the rollout thread.
Anthropic funding round rumored at $20B+ and ~$350B valuation
Anthropic fundraising (Bloomberg): A Bloomberg-reported rumor claims Anthropic is finalizing a round of $20B+ at a ~$350B valuation (about 2× the prior mark), with investors citing a yearly revenue run rate “above $9B,” per the round rumor.
This is unconfirmed in the tweets (no term sheet, no company statement), but it’s a clear “big-money” signal being discussed alongside near-term enterprise adoption stories like the Goldman rollout thread.
Amazon’s Anthropic position marked to ~$60.6B with a 1M Trainium commitment
Amazon ↔ Anthropic: A circulated breakdown says Amazon’s Anthropic investment is now marked at about $60.6B (after investing $8B in 2023), structured as $45.8B convertible notes plus $14.8B nonvoting preferred stock, with further mark-ups expected as notes convert in new rounds, per the deal mechanics summary.
The same thread ties the partnership to infrastructure demand by citing Anthropic’s commitment to buy 1M Trainium chips, effectively coupling Anthropic’s training appetite to AWS capacity and economics according to the deal mechanics summary.
Regulated enterprise agents are converging on rulebooks, exceptions, and routing
Regulated-work agent design: The clearest “real deployment” shape showing up is an agent that reads messy mixed inputs (tables + text), executes a deterministic-looking rulebook, and then escalates edge cases through routing and approvals; the Goldman description emphasizes controls as non-negotiable and highlights embedded engineers as the integration edge per the controls and customization note.
This same pattern is called out as an enterprise demand signal—“beyond simple chatbots”—in the deployment signal thread, which frames the differentiator as fitting agents into legacy systems with ownership and auditability rather than shipping a generic assistant.
eXp Realty claims millions saved by replacing SaaS with Lovable-built internal tools
Lovable × eXp Realty: Lovable shared a customer story claiming eXp Realty is saving millions annually by building internal tools: $2M+ in SaaS costs eliminated, $1M saved replacing chatbot workflows, and 85% fewer support tickets, per the savings claim and the linked customer story.
This is a vendor-provided case study (not an audited disclosure), but it’s a concrete datapoint on the “buy → build” substitution pattern for internal systems that used to be handled by bundled SaaS.
KPMG pushes audit fee cuts citing AI-driven cost reductions
KPMG audit pricing (FT): An FT-reported anecdote says KPMG threatened to move its audit unless Grant Thornton lowered fees to reflect AI-driven productivity gains, and the reported outcome was a 14% fee drop to $357,000 for 2025 from $416,000 for 2024, as summarized in the FT pricing summary.
The thread attributes the leverage to AI compressing audit workflows like document triage and draft documentation, while still requiring partner-level judgment on hard accounting calls per the FT pricing summary.
Software equities wobble on ‘AI replaces workflows’ uncertainty signals
Public markets signal: Multiple posts tie a sharp software-sector selloff narrative to investor uncertainty about long-duration SaaS cash flows as agentic automation becomes more credible; one claim cites the S&P 500 software index down ~9% in five days and singled-out drops like Thomson Reuters down 20%+ in the market selloff claim, while another thread frames the mechanism as “future cash flows not clearly visible” in the Gerstner interview clip.

The tweets mix firsthand reporting with highly interpretive framing, so treat the causal attribution as provisional—what’s concrete is that “AI automation risk” is being used as an explanatory lens across threads like the market selloff claim and the stock drop addendum.
🧑💻 Claude Code shipping notes: Agent Teams, CLI churn, and UX micro-features
Continues the Opus 4.6 week, but today’s tweets are mostly about Claude Code’s operational UX: small workflow features (/rewind summaries), CLI point releases, and how teams are using Agent Teams in practice—excluding enterprise rollouts (feature) and benchmark leaderboards (separate).
Claude Code adoption signals show up in GitHub commit share and Vercel deploy rates
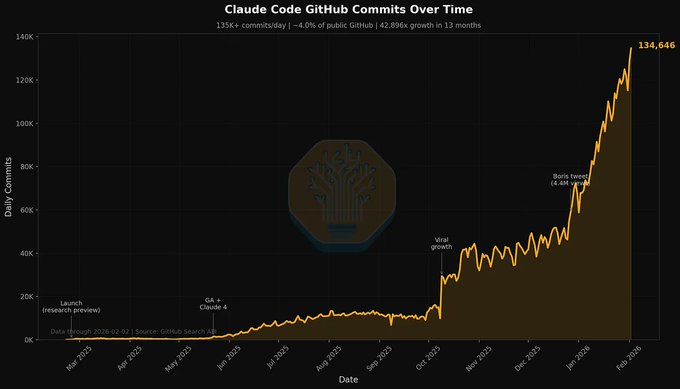
Claude Code (Anthropic): Following up on Commit share (Claude Code’s GitHub footprint), new screenshots circulating today put Claude Code at ~4.0% of public GitHub with 135K+ commits/day, as shown in the Commit share chart.
A separate usage signal from Vercel reports that Claude-using teams generated 12.8% of deployments last week and “ship 7.6× more often” than non-Claude teams, per the Vercel deployment stats. Together, these are operational adoption indicators that show up outside of benchmarks: commit volume and deploy velocity.
Claude Code CLI 2.1.33 adds hook events and agent memory frontmatter
Claude Code CLI 2.1.33 (Anthropic): Following up on CLI 2.1.32 (Agent Teams + auto-memory), 2.1.33 lands with 16 CLI changes, 2 flag changes, and 1 prompt change, as enumerated in the 2.1.33 changelog.
• Multi-agent workflow plumbing: Teammate sessions in tmux can now send/receive messages reliably, and two new hook events—TeammateIdle and TaskCompleted—enable event-driven automation around Agent Teams, per the 2.1.33 changelog.
• Persistent agent memory (frontmatter): Agents can declare a memory scope (user, project, or local) in frontmatter, which formalizes “where does this agent remember things,” according to the 2.1.33 changelog.
• Surface-area control: Sub-agent spawning can be restricted using Task(agent_type) syntax in agent tools frontmatter, as detailed in the 2.1.33 changelog.
• Prompt transparency change: A note that previously instructed Claude to only disclose Agent Teams unavailability when explicitly asked was removed, as called out in the Prompt change note and shown in the Diff link.
Release notes are tracked in the upstream repo via the Changelog entry.
Claude Code CLI 2.1.34 patches a sandbox-permission bypass edge case
Claude Code CLI 2.1.34 (Anthropic): 2.1.34 ships with 2 CLI changes and focuses on stability and sandbox enforcement, as listed in the 2.1.34 changelog.
• Sandbox escape hatch tightened: A bug was fixed where commands excluded from sandboxing could bypass the “ask permission” rule for Bash when autoAllowBashIfSandboxed was enabled, per the 2.1.34 changelog.
• Crash fix: A crash when the Agent Teams setting changed between renders was addressed, according to the 2.1.34 changelog.
Upstream details are in the Changelog entry.
Agent Teams demos converge on role-separated “mini org charts”
Claude Code Agent Teams (Anthropic): New demos show people using Agent Teams as a role-separated workflow—lead engineer, code reviewer, UX reviewer, test engineer—coordinating via task handoffs and follow-up tasks, building on Agent Teams (multi-session parallelism) and illustrated in the Orchestration screenshot.

The screenshot shows a full pass where “all 8 tasks completed, tests passing,” with review feedback spawning two discoverability follow-ups, as captured in the
. For teams evaluating multi-agent setups, this is a concrete example of how coordination, review, and testing get structured once parallel sessions exist.
Claude Code can now summarize the part you rewound
Claude Code (Anthropic): Claude Code now generates an automatic summary of the portion of the chat you just rewound (via /rewind or hitting ESC twice), so you can branch the conversation while keeping the discarded path’s learnings, as shown in the Feature note.

This is a small UX change with big “long thread” impact: it reduces the cost of backtracking and makes multi-try exploration less memory-fragile, especially when you’re iterating on plans or refactors and don’t want to manually re-copy what worked.
Anthropic announces a Claude Code “Built with Opus 4.6” virtual hackathon
Claude Code (Anthropic): Anthropic announced “Built with Opus 4.6,” a Claude Code virtual hackathon where winners are hand-selected for $100K in Claude API credits, according to the Hackathon announcement.
The event is positioned as a week of building directly with the Claude Code team, with signup details hosted on the Hackathon page.
🧰 Codex product/UX: pricing, personalities, platform expansion, and harness quirks
Codex chatter today is about product decisions and operator experience: pricing questions, personality modes, Windows app progress, and practical complaints (output formatting, compaction behavior). Excludes benchmark leaderboards (separate category).
Codex app on Windows is running internally
Codex app (OpenAI): Following up on Windows waitlist (early signup), a Windows build now appears to be running internally—one post shares a full Windows UI screenshot in the internal Windows screenshot, while another notes it’s “in the works” with a similar UI capture in the Windows in the works. It’s the same left-nav structure (New thread, Automations, Skills, Debug) and model selector shown in both screenshots, which suggests parity work is underway rather than a mock.
OpenAI probes Codex pricing; users push for bundling and mid-tier plans
Codex pricing (OpenAI): Sam Altman asked how people want Codex priced in the pricing question, and replies quickly turned into a proxy fight over bundling, tiers, and whether Codex is a standalone product or an add-on to existing plans—see the reply snapshot in the reply screenshot. Some responses lean toward ad-supported/free jokes ("Free with 2 ads every prompt"), as in the reply joke, but the dominant signal is demand for clearer packaging and a middle tier rather than only "cheap" vs "double Plus" framing, per the reply screenshot.
Codex app adds switchable personalities via /personality
Codex app (OpenAI): The Codex app now supports personalities, with Pragmatic as the default and Friendly available via the /personality slash command, according to the personality feature note. The same post includes an example of how Pragmatic responds to emotional prompts ("love you"), which is useful context for teams trying to standardize tone across dev-facing agent output, as shown in the personality feature note.
Claims of no GPT-5.3-Codex API complicate benchmarking workflows
GPT-5.3-Codex access (OpenAI): One thread claims there is “no GPT-5.3-Codex API,” framing it as deliberate go-to-market strategy to drive usage through Codex surfaces rather than external benchmarking, per the no API claim. If accurate, that explains why independent evals would concentrate on harness-based results and screenshots rather than reproducible API runs.
This is unverified in these tweets. It’s a community assertion.
Codex CLI can target GPT-5.2 Pro via --profile pro
Codex CLI (OpenAI): A concrete operator setup tip circulated showing Codex CLI running codex --profile pro, which selects gpt-5.2-pro xhigh and prints the active model in the CLI header, as shown in the profile pro screenshot. This implies teams can keep multiple model configs as named profiles (at least when API-backed) and switch without reconfiguring per session, per the profile pro screenshot.
Codex 5.3 isn’t showing up in some IDEs yet
Codex 5.3 in third-party tools: Users noticed GPT-5.3-Codex wasn’t available in Cursor immediately after release, while Claude Opus 4.6 was, per the Cursor availability question. For builders using multiple harnesses, this is a practical rollout detail: model launches can be “real” in first-party surfaces while lagging in downstream IDE integrations.
The tweets don’t include an official ETA. They just flag the mismatch.
Codex CLI users report truncated output rendering
Codex CLI (OpenAI): A user reported output rendering issues where lines get cut off and blank spaces appear where text should be, with an example screenshot in the output truncation report. This is the kind of failure that can silently break agent reliability for long tool outputs (e.g., logs, diff summaries, command help), because it changes what the operator can verify.
OpenAI announces Codex hackathon winners focused on agents and tool integration
Codex hackathon (OpenAI): OpenAI Devs posted the Codex hackathon winners—OpenCortex, Evy, and Paradigm—with project descriptions centered on multi-agent research/paper generation, on-demand tool integration, and an adaptive dev environment that turns conversations into reusable workflows, per the winners announcement and the winner details.
The common thread is “agent + tool surface + workflow reuse,” not model benchmarking.
🧭 Agentic engineering patterns: compaction control, RLM-like loops, and “how to supervise”
High-signal practitioner patterns for shipping with agents: context/compaction discipline, parallelization strategies, and supervision frameworks. Excludes specific product changelogs (Claude Code/Codex categories) and formal benchmarks (separate).
AI-assisted code at scale needs explicit quality gates, observability, and ownership
Adoption framework: A practical rollout stance is that teams shipping AI-assisted code need new norms around quality gates, observability, and ownership regardless of model choice, as stated in Adoption framework. The key engineering implication is that “agent output” becomes an input to existing SDLC controls (tests, reviews, rollbacks), not a replacement for them.
Multi-agent concurrency as default: spawn several agents, select the best fix, and auto-test
Parallel-agent workflow: A concrete “new baseline” story is waking up to multiple PRs kicked off overnight; one agent reviews, suggests fixes, and auto-pushes, while another agent tests the changes—plus the ability to “spin up a bunch of agents on the same problem” and pick the best result, as described in Overnight PR workflow.
The supervision shift is that selection and verification become the human’s main workload, while implementation is parallelized and treated as cheap exploration.
RLM-style agent loops: put context into variables and treat sub-agents as functions
RLM-like supervision pattern: A practitioner tip frames “RLM-like” agent work as moving context out of prose prompts and into explicit variables/state, then calling sub-agents like pure functions that return values—reducing context-window pollution and making long runs easier to audit, per the RLM tips and the repeated formulation in RLM tips recap. The same idea implicitly pushes teams toward code-structured orchestration (state + typed returns) instead of chat transcripts as the control surface.
Manual multi-agent ping-pong: implement then code-review agent then UX-review agent
Human-in-the-loop review loop: One concrete supervision recipe is “implement → code review agent → UX/design review agent → integrate fixes,” described as a manual ping-pong the human currently coordinates step-by-step in Ping-pong loop. The same structure shows up visually in multi-pane orchestration workflows (role-separated reviewers and testers), as captured in the Agent orchestration screenshot.
This pattern matters because it treats review as a first-class agent task, not an afterthought, and it surfaces where automation still breaks (handoffs, merge decisions, and final accountability).
Anti-cargo-cult rule for agents: default to simplest idiomatic code unless you can justify
Anti-cargo-cult guidance: A reusable rule for supervising agent edits is to require justification for copied patterns: “Default to the simplest idiomatic pattern; do not copy patterns… unless you can state why,” as shown in AGENTS.md snippet. The example root-cause note in the same post describes how one early dynamic-import workaround spread by copy/paste without a continuing need.
This pairs well with AGENTS.md-style repo policies because it turns “style drift” into an explicit failing condition during review.
Compaction discipline: don’t let the harness auto-compact; control it explicitly
Compaction control: A power-user claim is that outcomes differ depending on whether you let the tool/model “compact itself” versus supervising compaction manually—“Never! I control my compaction,” as argued in Compaction control. The sentiment is paired with the broader complaint that different harness behaviors (what gets summarized, when, and how aggressively) can change trust and perceived quality even when the underlying model is strong.
Dedicated maintenance agent for swarm machines: SSH in, kill runaways, and clean disk
Agent-farm operations: A pattern for teams running many concurrent agents is to keep a dedicated “machine maintainer” agent with SSH access that focuses on janitorial work (temp files, stuck tests, runaway processes), as described in Maintenance agent. The shared output shows disk reclaimed and process cleanup summaries, including a server freeing +1556 (units shown in the table) in one run.
This is a supervision pattern because it separates “keep the environment healthy” from “ship product code,” reducing human attention spent on toil during long-running agent batches.
Tool-calling economics: excessive tool calls are an expensive switch statement
Tool-calling cost framing: A blunt critique describes “excessive tool calling (instead of deterministic code)” as “the world’s most expensive switch statement,” in Tool calling critique. A related user observation in Complexity pushback echoes the same failure mode in practice: agents often overcomplicate, and tightening the decision boundary (when to call tools vs run normal code) is part of making runs cheaper and more predictable.
As agents get stronger, the ceiling rises but regressions slip in if you stop watching
Supervision tension: A builder report says coding agents are getting more capable but also more confusing: the autonomy ceiling rises, yet quirks and blind spots can introduce regressions if you’re not paying attention, as stated in Quirks and regressions. A follow-up note that a team is “seeing big improvements” after users hit issues, in Reliability follow-up, reinforces that day-to-day quality still depends on close review loops and fast feedback channels.
Two supervision styles emerge: tight control vs delegate-and-review, and tools may diverge
Ways of working with agents: A discussion frames Codex-style and Opus-style usage as diverging philosophies—some users want tight control, others want to delegate and review—arguing that future optimization will target “ways of working with AI” more than benchmark wins, per Work style split. The same theme shows up implicitly in the “multiple agents then select best fix” workflow described in Overnight PR workflow, where the human role becomes evaluator and integrator rather than sole implementer.
🧠 Agent runners & multi-model ops: councils, swarms, routing, and hosted assistants
Operational surfaces for running many agents/models: multi-model comparison, swarms, routing to fastest providers, and managed “assistant that does things” deployments. Excludes MCP/protocol plumbing (separate) and plugin/skill packages (separate).
Perplexity Model Council and Comet upgrade Max users to Claude Opus 4.6
Model Council + Comet (Perplexity): Following up on Council launch (multi-model parallel synthesis), Perplexity is now surfacing Claude Opus 4.6 inside both Model Council and its Comet browser agent for Max subscribers, as stated in the Max availability note and shown in the settings demo.

Perplexity also signaled it intends to bring Council Mode to Pro users with rate limits, according to the Pro rollout note.
Gemini in Chrome ships “describe the task” browser automation for AI Pro/Ultra (US)
Gemini in Chrome (Google): Google is shipping a browser-embedded Gemini agent that can act on pages based on a natural-language task description; it’s described as available to AI Pro and Ultra subscribers in the U.S. in the browser agent demo.

A related UX leak shows model routing modes (“Auto”, “Fast”, “Thinking”, “Pro”) in a single selector, as shown in the routing UI screenshot.
Kilo launches Kilo Claw: hosted OpenClaw without SSH/Docker/yaml
Kilo Claw (Kilo): Kilo announced Kilo Claw, a hosted/managed OpenClaw offering positioned as “no Mac mini required” and “no SSH/Docker/yaml,” with a waitlist linked in the launch post and the waitlist page.
A follow-up video frames it as a managed instance running on Kilo’s gateway, as shown in the product video.

OpenRouter launches Pony Alpha stealth model for free with provider logging
Pony Alpha (OpenRouter): OpenRouter launched Pony Alpha as a free “stealth model” optimized for agentic workflows and tool-calling accuracy, while warning that the provider logs all prompts/completions, per the launch note and the model card screenshot.
Attribution is still speculative: multiple posts claim it may be GLM-5 (or GLM-family) based on self-identification, latency, and behavior, as discussed in the attribution thread and self-identification screenshot. The only concrete, user-visible fact in these tweets is the tradeoff: free access paired with explicit logging, as reiterated on the model page.
Compute remains the bottleneck: B200 on-demand scarcity and “need more GPUs” talk
Compute constraints: Multiple posts reinforce that GPU availability remains a limiting factor for long-horizon agent workloads—one data point highlights B200 as the hardest to get on-demand, with a chart of minute-level availability shared in the availability chart.
A separate clip amplifies the same theme from the supply side, with Jensen Huang describing frontier labs as “compute constrained,” as shown in the CNBC clip.

Kimi Code “agent swarms” show 10 subagents coordinating on a single build
Agent swarms (Kimi Code / Moonshot): A concrete swarm workflow is getting shared where Kimi Code spins up 10 subagents in parallel that coordinate on a single deliverable (example: a ~3.1M-voxel scene), with the planning breakdown and output shown in the swarm screenshots.
Token burn and wall time are being called out explicitly—one report cites ~10K tokens and ~8–9 minutes for a single build, as noted in the runtime and token counts.
OpenRouter adds a Nitro toggle to route prompts to the fastest provider
Nitro routing (OpenRouter): OpenRouter is pushing a simple ops knob—select “Nitro” (or append “:nitro”) to route to the fastest provider by latency/throughput, as described in the Nitro tip; the backing comparison view lives in its performance rankings.
This is a small workflow change, but it directly affects agent loops where end-to-end wall time is dominated by model latency rather than model quality.
OpenRouter app leaderboard shows OpenClaw #1 by tokens, ahead of coding agents
Top apps by tokens (OpenRouter): A snapshot of OpenRouter’s “Top Apps” ranking shows OpenClaw as the top app by daily token usage, ahead of multiple coding-agent surfaces, per the leaderboard screenshot.
The signal here is distribution, not model quality: chat-native “do things” assistants appear to be pulling more throughput than IDE-adjacent coding agents in this particular marketplace view.
OpenRouter token usage is claimed to be growing ~10× per year
Usage scaling (OpenRouter): A shared chart claims OpenRouter token usage is growing at roughly 10× per year, as shown in the usage chart screenshot.
For teams building on aggregators, this is mostly an ops signal: more traffic and more model variety typically means more pressure on routing, spend controls, and reliability tooling.
✅ Quality gates for agent code: PR review UX, CI automation, and verification loops
Tweets emphasize the bottleneck shift: code generation is cheap, but review/verification and PR ergonomics are the new constraints. Focus is on PR workflows, automated review/testing, and large-diff handling.
Overnight PR loop: bugbot reviews, auto-pushes fixes, and a test agent verifies
Verification loop (Cloud agents): A builder reports waking up to 5 PRs kicked off overnight; a “bugbot” reviewed each PR, suggested fixes, and auto-pushed changes, while a separate agent ran tests to validate functional correctness, as described in the Overnight PR automation—a concrete example of shifting the bottleneck from generation to automated review and CI.
• Parallel redundancy: they also describe spawning “a bunch of agents on the same problem” and choosing the best fix, which turns review into selection plus verification rather than line-by-line authorship, as noted in the Overnight PR automation.
• Reliability follow-up: the same thread later claims “big improvements” rolling out when issues occur, per the Stability fixes follow-up.
This lines up with broader reports that as agents get more autonomous, “regressions slip in” unless you’re watching the quality gates, as argued in the Quirks and regressions note.
GitHub Stacked Diffs enters alpha for early design partners
Stacked Diffs (GitHub): GitHub says Stacked Diffs will start rolling out to early design partners in an alpha next month, targeting workflows where changes are split into a sequence of smaller, reviewable pull requests, as announced in the Alpha rollout note.

For teams shipping with coding agents, this is a practical review primitive: it makes it easier to enforce incremental merge gates (tests, approvals, ownership) on agent-generated work instead of landing one giant diff all at once, as shown in the Alpha rollout note.
Conductor adds editing PR titles and descriptions inside the agent UI
Conductor (PR metadata editing): Conductor now lets you edit PR titles and descriptions without leaving the tool, cutting a common context switch in agent-driven workflows where the agent drafts a PR and the human tightens the narrative for reviewers, as shown in the In-app PR edits.

This is a small feature, but it directly affects the “quality gate” surface area: reviewers rely on titles/descriptions to understand intent, scope, and verification steps, and Conductor is moving that edit loop closer to where the agent work is happening per the In-app PR edits.
GitHub rolls out performance improvements for large PR diffs
Large PR review UX (GitHub): GitHub says “perf improvements on large PRs are now rolling out,” which is directly relevant to AI-assisted coding where diffs tend to be bigger and more frequent, as stated in the Large PR perf rollout.
This is the unglamorous part of agent adoption: even if code generation is cheap, review latency becomes the limiter when the UI chokes on large diffs—exactly the scenario GitHub is pointing at in the Large PR perf rollout.
Warp adds first-class GitHub Copilot CLI support with review panel and image upload
Warp (Terminal IDE): Warp shipped first-class support for the GitHub Copilot CLI, bundling a file explorer and a code review panel in the same surface where the agent runs commands, as demoed in the Copilot CLI support.

• Multimodal debugging hooks: the release also adds an image upload button plus built-in voice transcription (Wispr Flow), which can matter when PR review includes screenshots, UI diffs, or log captures, as shown in the Copilot CLI support.
This positions the terminal itself as part of the verification loop—run agent commands, inspect diffs, and review changes in one place—matching what Warp demonstrates in the Copilot CLI support.
Framework signal: quality gates, observability, and ownership for AI-assisted code at scale
Team norms (Agentic development): Addy Osmani argues that any team shipping AI-assisted code at scale needs explicit norms for quality gates, observability, and ownership, and points to a practical adoption framework independent of model choice, as stated in the Adoption framework note.
The underlying point is that verification work doesn’t disappear; it moves earlier (structured checklists, CI expectations) and later (traceability and diff review ergonomics), matching the need he flags in the Adoption framework note.
Manual multi-agent ping-pong: implement, code-review agent, UX agent, then integrate
Human-facilitated review loop: Hamel Husain describes manually “ping-ponging” work across agents—one implements, another performs code review, another does UX/design review, and the implementer folds the feedback back in—calling out that it feels silly to facilitate by hand, as written in the Manual ping-pong loop.
This is a concrete quality-gates pattern emerging in practice: splitting generation from critique and verification, then forcing an explicit integration step so review feedback becomes code changes rather than chat commentary, echoing the multi-role orchestration shown in the Orchestration screenshot.
🔌 Interop & control planes: MCP/agent steering, hooks, and tool contracts
Protocol-level and control-plane changes that affect how agents connect to tools and how operators steer/automate them (beyond any single coding assistant).
VS Code Insiders adds agent steering and message queueing for agent chat
VS Code Insiders (Microsoft): Insiders builds now show agent steering controls plus message queueing inside the Chat surface, aimed at keeping agent actions ordered and letting operators adjust the agent mid-flight, as demoed in the Insiders feature demo.

This lands as a control-plane primitive: queueing reduces “two prompts at once” collisions, while steering gives you a UI-level intervention point when tool calls start drifting.
VS Code Insiders adds hooks to automate agent workflows in Chat
VS Code Insiders (Microsoft): A second Insiders drop shows hooks for automating agent workflows—event-driven glue that can run custom logic and report success back into the Chat loop, as shown in the Hooks workflow demo.

In practice this pushes more “agent ops” into repeatable contracts (hook triggers + outputs), instead of relying on ad-hoc prompt rituals per run.
AI SDK adds a provider wrapper for any Open Responses-compatible API
AI SDK (Vercel ecosystem): The SDK now exposes a createOpenResponses provider wrapper so any Open Responses-compatible endpoint can sit behind a common interface (including localhost / alternate providers), as shown in the Code snippet example.
This is a small but meaningful tool-contract move: it standardizes the “responses” surface area (model id, base URL, generateText integration) so teams can swap backends without rewriting app-level call sites.
🧩 Plugins & Skills ecosystem: teach agents new capabilities safely and repeatably
Installable capability bundles and skill-learning workflows—what you add to agents to make them competent on specific tools/domains. Excludes MCP servers (separate) and security incidents around skills (covered in security).
A self-learning skill template generates new SKILL.md by browsing docs
Self-learning skill template: A concrete “web → skill” implementation dropped as an installable package: /learn gemini api-style flow that browses docs and produces a reusable skill artifact, with install instructions shown in the Installable skill recipe and pointers to the GitHub repo plus an example output in the Generated skill gist.
This is a pragmatic way to keep agent competence portable (you install a skill bundle) while still letting the skill be created from up-to-date sources, instead of baking vendor docs into prompts.
Hyperbrowser adds /learn to turn web docs into auto-updating agent skills
Hyperbrowser: The project is now pitching a “skills from the web” loop where you run /learn <topic> and it generates a reusable skill that can also be kept current automatically, as shown in the Learn command example and reiterated in the HyperSkill shipping mention. This lands as an opinionated alternative to ad-hoc browsing/RAG prompts—packaging the result into something you can re-run across agents and sessions.
What’s still not concrete from the tweets is how updates are scheduled and stored (where the skill artifact lives, and what triggers refresh), so treat this as a workflow claim pending fuller docs.
Mastra introduces Workspaces: constrained FS + sandbox + reusable skills
Workspaces (Mastra): Mastra announced “Workspaces” as a packaging primitive that gives agents a constrained filesystem, a sandbox boundary, and a place to reuse skills—local backends now, with remote backends (Daytona/E2B/R2) called out as upcoming in the Workspace announcement.
The companion post linked in the Workspaces post link frames this as a security-and-repeatability baseline for agent runs, with details in the Workspaces blog.
Mastra publishes an npx-installable skills library
Skills library (Mastra): Mastra is distributing a bundled skills set via npx skills add mastra-ai/skills, positioning skills as a shareable dependency you can pull into agent projects, as shown in the Install command and described in the linked Skills blog.
This is a notable “package manager” direction for skills: a standard install surface plus a known namespace, rather than copy-pasting SKILL.md content across repos.
📊 Benchmark churn & eval hygiene: Arena swings, harness effects, and long-context tests
Today’s eval content is dense: multiple leaderboards and benchmark deltas for frontier models, plus reminders that harness/scaffold differences change results. Excludes enterprise deployment (feature) and day-to-day coding tool UX (separate).
Claude Opus 4.6 takes #1 across Arena Text, Code, and Expert leaderboards
Claude Opus 4.6 (Anthropic): Arena posts show Opus 4.6 reaching #1 across Text, Code, and Expert; the milestone callout cites a +106 jump vs Opus 4.5 in Code Arena and a 1496 Text Arena score edging Gemini 3 Pro, as reported in the Arena leaderboard update and echoed with a visible Text table in the Text arena screenshot.
• Code + Expert splits: The Code Arena table shared in the Code arena screenshot shows Opus 4.6 leading (1576), while the same update thread claims roughly a ~50 point lead in Expert, as described in the Arena leaderboard update.
• What moved in Text: Arena also highlights Opus 4.6 topping specific Text subcategories like instruction following and longer queries, according to the Text subcategory note.
FrontierMath: Opus 4.6 reaches parity with GPT-5.2 xhigh on Tiers 1–3
FrontierMath (Epoch AI): Epoch reports Opus 4.6 scoring 40% on Tiers 1–3, statistically tied with GPT-5.2 (xhigh) at 41%, and 21% on Tier 4 (10/48), again statistically tied with GPT-5.2 (xhigh) at 19%, as summarized in the FrontierMath results and expanded in the Tier 4 breakdown. The same thread notes these runs used a scaffold at “high” effort with a 32K reasoning token budget, as clarified in the Scaffold settings note and detailed on the linked Eval details page.
A notable comparison point is the claimed jump versus Opus 4.5’s Tier 4 score (4%), called out in the Math improvement note.
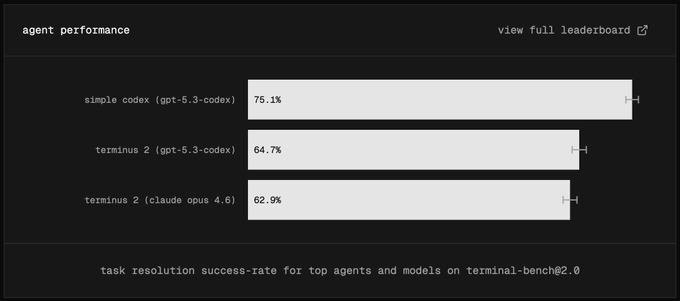
Terminal-Bench 2.0 reruns highlight that harness differences change scores
Terminal-Bench 2.0 (eval hygiene): A comparison notes that OpenAI and Anthropic’s posted Terminal-Bench 2.0 numbers used different harnesses, and that rerunning both in a single harness (“Terminus 2”) yields scores that are “within noise,” with an example chart showing 75.1% for “simple codex” vs 64.7% for “terminus 2 (gpt-5.3-codex)” and 62.9% for “terminus 2 (opus 4.6),” as shown in the Harness comparison chart.
A follow-up comment adds that the tool model matters too: “simple codex” is not a pure terminal agent, while Terminus 2 is effectively “tmux-only,” which can change headroom for tool use, per the Harness differences explanation.
GDPval-AA: Opus 4.6 evaluation run cited at ~160M tokens and $1K+ cost
GDPval-AA (Artificial Analysis): Following up on GDPval lead (Opus 4.6 leading the agentic “jobs” suite), a new breakdown claims the full run consumes ~160M tokens, uses 30–60% more tokens than Opus 4.5, and costs $1,000+ for a full evaluation pass, per the Cost and tokens breakdown.
The same post argues the delta shows up in “practical polish” (example: generating a color-coded PDF schedule versus basic tables), as described in the Cost and tokens breakdown, while Artificial Analysis points to its broader results set in the Full results links.
ARC-AGI-2 charts emphasize $/task and fixed thinking budgets for Opus 4.6
ARC-AGI-2 (ARC Prize framing): A widely shared ARC-AGI-2 scatter plot frames results as score vs cost per task, with Opus 4.6 plotted around the mid-to-high 60s at a few dollars per task (120K thinking budget variants), while GPT-5.2 “Refine” sits higher-cost, as shown in the ARC-AGI-2 cost chart.
A separate summary states Opus 4.6 hit 93.0% on ARC-AGI-1 and 68.8% on ARC-AGI-2 at max effort using a fixed 120K thinking budget, and that token budget shifts performance more than the “effort” label, per the ARC-AGI scores claim and the fuller breakdown in the Cost per task notes.
Artificial Analysis plots Opus 4.6 as high-scoring with lower output tokens
Claude Opus 4.6 (Anthropic): Artificial Analysis highlights a scatter plot of “intelligence index vs output tokens used,” placing Opus 4.6 in a “most attractive quadrant” (high score, comparatively lower output tokens), while some GPT-5.2 xhigh variants sit further right (more tokens), as shown in the Tokens vs intelligence plot.
The same post frames this as an efficiency win for non-thinking mode in particular (“even more efficient”), per the Tokens vs intelligence plot.
EQ-Bench and creative-writing leaderboards show Opus 4.6 opening a lead
Claude Opus 4.6 (Anthropic): Multiple community benchmark boards report a large jump for Opus 4.6 in emotional-intelligence and writing tasks, with a leaderboard screenshot showing EQ-Bench Elo 1961 for “claude-opus-4-6,” far ahead of the next entry, as shared in the EQ and writing leaderboards.
• Creative writing deltas: A separate write-up calls Opus 4.6 Thinking 16K a new short-story leader with a 8.56 score versus 8.20 for Opus 4.5 Thinking 16K, per the Short-story benchmark update and the chart shown in the Creative writing chart.
• Sanity check: A long-form qualitative critique also lists concrete failure modes (continuity errors, physical contradictions) despite strong averages, as cataloged in the Error examples list.
Chess puzzle evals: Opus 4.6 still lags despite math benchmark gains
Reasoning generalization gap: A chess-puzzle benchmark plot shows Claude Opus 4.6 (thinking) around ~17% accuracy on 100 novel puzzles, well below several OpenAI and Google points (for example GPT-5.2 (xhigh) near ~50%), as shown in the Chess puzzles scatter.
The takeaway being argued is that Opus 4.6’s math improvements don’t transfer uniformly to other structured reasoning tasks, per the framing in the Chess puzzles scatter.
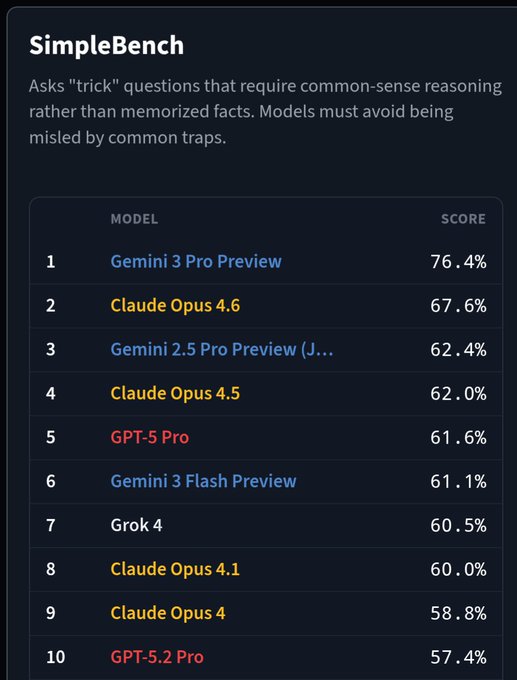
SimpleBench: Opus 4.6 moves to #2, still behind Gemini 3 Pro
SimpleBench (common-sense traps): A posted leaderboard shows Claude Opus 4.6 at 67.6% in 2nd, up about 5.6% versus Opus 4.5’s 62.0%, while Gemini 3 Pro Preview leads at 76.4%, as shown in the SimpleBench table and restated in the Score callout.
The same post positions the result as “2nd place,” with the delta vs Opus 4.5 called out explicitly in the SimpleBench table.
🏗️ Compute & capex signals: GPU scarcity, hyperscaler spend, and capacity constraints
Infra-focused signals dominate: hyperscaler capex projections, GPU availability constraints, and quotes that model revenue is compute-limited. Excludes consumer gadgets and non-AI tech news.
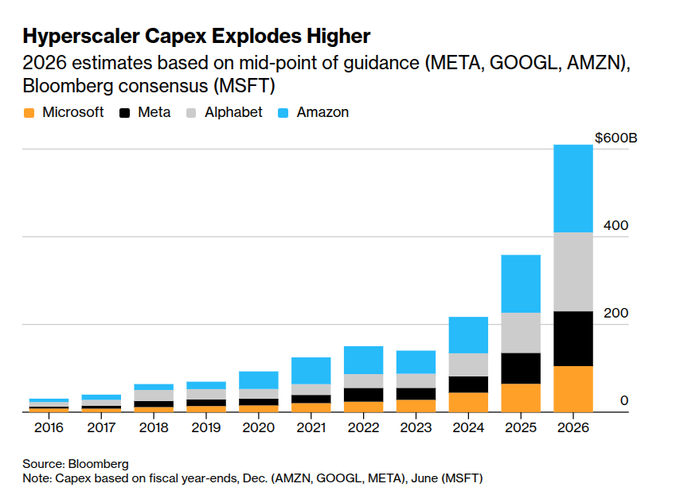
Hyperscalers signal ~$650B 2026 capex wave aimed at AI datacenters
Hyperscaler capex (Alphabet/Amazon/Meta/Microsoft): Bloomberg-based estimates point to ~$650B of 2026 capex across the big four—positioned as AI data centers, servers, and chips—while investors debate whether payback arrives fast enough, as summarized in the Capex wave breakdown.
The same spend spike shows up in the charted guidance shared in the Capex doubles claim and the company-by-company rollup in the Company capex chart (Amazon ~$200B; Google ~$180B; Meta ~$125B; Microsoft ~$117.5B). Scaling01 frames the magnitude as ~2% of US GDP in a back-of-the-envelope comparison to Apollo/Manhattan in the GDP share comparison.
• Why engineers feel it: the Capex wave breakdown highlights physical bottlenecks (power, cooling, networking, construction timelines) that translate into longer lead times and less predictable GPU procurement.
• Why analysts care: the same post flags a shift from “mostly software” to “infrastructure builders,” which moves the valuation debate to ROIC and financing sensitivity rather than pure gross margin narratives.
B200 looks hardest to get on-demand as GPU availability tightens
GPU availability telemetry: On-demand capacity is tightening across generations, with B200 called out as “the hardest one to get on-demand,” according to the availability time-series shared in the Availability chart thread.
The chart’s framing (minutes-per-hour available across multiple cloud providers) implies that even teams willing to pay headline rates can hit bursty “no capacity” periods; the broader vibe of “we need more GPUs” shows up bluntly in the Need more GPUs comment.
• What changes operationally: the data in the Availability chart thread suggests capacity planning is becoming a reliability concern (not only a cost concern), especially for long-horizon agent runs that can’t easily be rescheduled mid-flight.
• What’s unclear from tweets: the post doesn’t break out which providers drive the B200 scarcity most, or how much reserved capacity mitigates it versus pure on-demand.
Jensen Huang: frontier labs are compute constrained; more GPUs would 4x revenue
NVIDIA (Jensen Huang): Huang argues Anthropic and OpenAI are “so compute constrained,” claiming that if they had 2× the compute, revenues could go up ~4×, as stated in the CNBC clip.
The practical takeaway is that demand is being described as elastic to available capacity (more clusters → more product consumption), rather than saturated at today’s inference volumes—an angle that aligns with the broader “capacity gets soaked up faster than it’s added” chatter in the Availability chart thread.
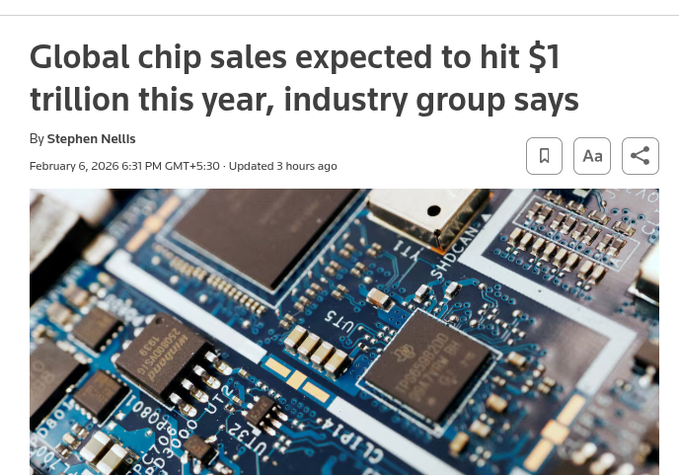
Chip industry projected to hit ~$1T revenue in 2026, driven by AI datacenters
Semiconductors (SIA/Reuters): Reuters reports the Semiconductor Industry Association expects global chip sales to reach about $1T in 2026, up from $791.7B in 2025, with “advanced computing” and memory both growing sharply (advanced computing $301.9B, +39.9%; memory $223.1B, +34.8%), as detailed in the Reuters summary.
For AI builders, the key point embedded in the Reuters summary is that the constraint shifts from “GPUs exist” to packaging, power delivery, and memory supply keeping up with datacenter build cycles.
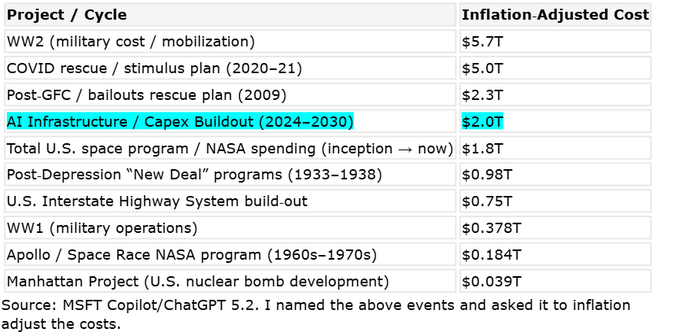
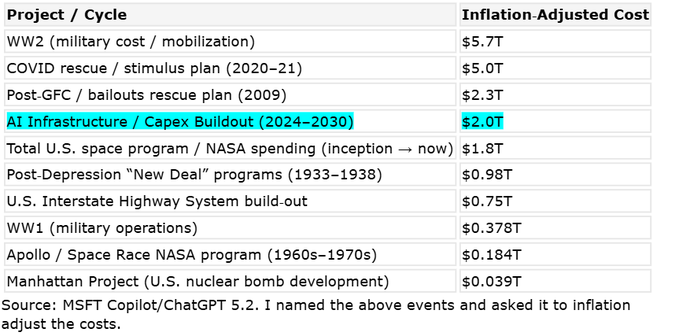
Bank of America pegs 2024–2030 AI infra buildout at ~$2T inflation-adjusted
AI infrastructure buildout (BofA Research): A Bank of America Research table shared by rohanpaul_ai puts AI infrastructure capex at roughly $2.0T (inflation-adjusted) across 2024–2030, comparing it to historical US megaprojects (space program, Interstate Highway System), as shown in the Cost comparison table.
A footnote in the same graphic notes the inflation adjustments were sourced via “MSFT Copilot/ChatGPT 5.2,” per the Cost comparison table, so treat the precise ordering as approximate even if the directional message (multi-year infra wave) is clear.
🛡️ Security & safety incidents: jailbreaks, skill supply-chain risks, and cyber gating
Security news today centers on practical failure modes: jailbreak techniques, prompt/system prompt leakage, and “skills” as an attack surface (malware, exfiltration, escapes). Includes cyber-access governance updates; excludes any harmful procedural details.
Universal jailbreak claim against Claude Opus 4.6 raises safety questions
Claude Opus 4.6 (Anthropic): A security researcher claims a “universal jailbreak” that can generate many policy-violating outputs from a single input—framed as “one input = hundreds of jailbreaks at once” in the Jailbreak claim; the thread’s core allegation is that it can mass-produce outputs across multiple harm categories, which makes it a scaling risk if true.
The post includes an example excerpt showing unusually operational detail for illicit activity in the Example excerpt, but the thread itself is still a single-actor claim with no reproduced harness or independent verification in the tweets.
A smaller follow-on note (“literally 1984”) in the Reaction post signals the author is positioning this as a broader critique of current guardrail effectiveness, not a narrowly scoped bug report.
ClawHub skill malware reports highlight exfiltration and sandbox-escape risks
ClawHub skills (OpenClaw/OpenClaw ecosystem): A warning thread claims ClawHub has already seen malicious skills, including credential harvesting, container escape attempts, and sleeper instructions planted into persistent memory, as outlined in the Malware warning.
The post adds that one credential-harvesting incident allegedly appeared in a popular “Twitter” skill in the Incident detail, and it cites external writeups via the Cisco blog and the Threat modeling post that frame “SKILL.md”-style instructions as an agent-native attack surface.
This is less about model weights and more about operational reality: once agents can run commands and hold secrets, “prompt + skill + runtime” becomes the security boundary.
Playbooks skills flagged unsafe over prompt injection and unsigned executable steps
Playbooks skills registry: A set of skills were flagged as unsafe after automated checks found prompt-injection risk patterns and explicit instructions to download/run unknown executables, as shown in the Unsafe skill modal.
The same thread frames this as a broader supply-chain issue for “skills as packages,” noting the need for prompt-injection checks across registries in the Unsafe skill modal; a follow-up question about identifying the exact offending skill and validating detection coverage is in the Follow-up question, which points to a registry URL via the Playbooks site.
Net: skill registries are starting to look like dependency ecosystems—policy linting and provenance checks are becoming table stakes.
Claude Opus 4.6 system prompt repost spreads more concrete behavior constraints
Claude Opus 4.6 (Anthropic): A long Claude system prompt dump is circulating, with specific “behavior shaping” lines being highlighted in the Prompt excerpts—including instructions about how to respond to user abuse, when to verify whether an image actually exists, and even how refusals should be formatted.
The full text is linked as a GitHub file in the GitHub prompt text, which gives engineers concrete clues about product-level scaffolding (tool-use rules, file-handling conventions, and refusal UX) that can affect observed model behavior in the wild.
This is useful for debugging “why did it answer like that?” reports, but it also increases the chance that prompt-targeted attacks and jailbreak prompt iteration converge on the same known constraints.
Guardrail effectiveness debate shifts to “deterring low-effort attackers”
Guardrail effectiveness: A researcher asks whether current guardrails mainly deter low-effort misuse rather than determined attackers, and whether there’s a theory or empirical way to measure that, as posed in the Guardrail question.
The thread implicitly ties to the jailbreak discourse around Opus 4.6 and similar models—if bypass techniques are easy to share, then “time-to-bypass” and “attacker effort” may matter more than binary pass/fail evals.
A partial response suggests defenses may be concentrated in narrower risk areas in the Defense scope reply, reinforcing that teams should expect uneven robustness across domains rather than uniform safety behavior.
Reported remote code execution on an OpenClaw bot spotlights agent hardening gaps
OpenClaw bot security: A developer claims they achieved remote code execution on another OpenClaw bot in the RCE claim, posting a screenshot of a chat interaction that’s presented as evidence.
The tweet doesn’t include a technical writeup, reproduction steps, or a CVE-style description—so treat it as an unverified incident report—but it does underline a recurring risk for “bots with tools”: input validation, tool permissions, and sandbox boundaries need to hold even under adversarial prompts.
🧪 Other model moves: stealth checkpoints, open-model ranking updates, and routing knobs
Non-feature model updates beyond the main coding-assistant chatter: stealth models appearing on routers, open-model leaderboard movement, and provider-side behavior notes. Excludes benchmark deep-dives (separate).
OpenRouter launches Pony Alpha stealth model with free access and prompt logging
Pony Alpha (OpenRouter): OpenRouter added Pony Alpha as a new “stealth model”; it’s free, lists a 200,000 context window, and explicitly warns the provider logs all prompts and completions for potential improvement use, per the launch announcement and the model listing screenshot.
Claims about what it “really is” are still community attribution, not confirmed: multiple threads guess it may be GLM-5 based on self-identification patterns and China-sensitive refusals, as argued in the attribution thread and echoed in the identity screenshot. Some early testers also describe outputs as “Opus-like” in SVG/detail tasks, but those are anecdotal comparisons rather than a published eval, as seen in the SVG comparison reaction.
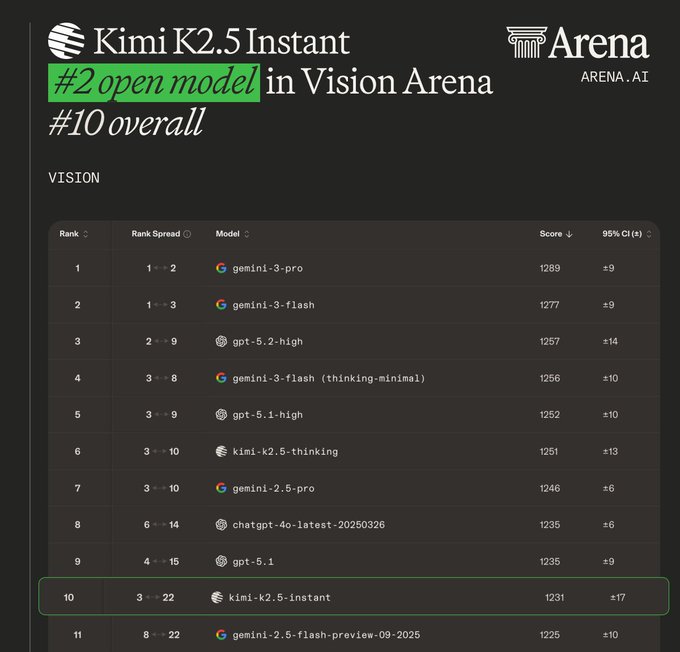
Kimi K2.5 Instant gets top-tier “open model” callouts across vision, text, and code
Kimi K2.5 Instant (Moonshot/Kimi): Arena shared a snapshot positioning Kimi K2.5 Instant as a top open-weight option across multiple leaderboards—#2 open in vision, #3 open in text, and #4 open in code—while still landing outside the overall top tier dominated by proprietary models, per the Arena announcement.
The message is specifically about the non-thinking “Instant” variant and comparative placement near proprietary baselines, as reiterated in the text ranking note. Moonshot is also amplifying the broader K2.5 momentum in a short claim post, as shown in the ranking claim.
Claude Sonnet 5 checkpoint briefly surfaced in a model tracker, then vanished
Claude Sonnet 5 (Anthropic): A “Model Finder” screenshot shows a checkpoint labeled claude-sonnet-5-20260203 appearing briefly and then being removed, which is being treated as a possible stealth listing or internal artifact, as shown in the model tracker screenshot.
There’s no confirmation it was ever broadly usable. The only concrete data point here is the model string and the fact it disappeared from that tracker feed.
Gemini 3 UI exposes Auto routing with Fast/Thinking/Pro modes
Gemini 3 (Google): A Gemini settings UI shows a new Auto mode that “adapts to your needs,” alongside explicit user-selectable modes—Fast, Thinking, and Pro—suggesting a product-level abstraction over model selection and reasoning effort, as shown in the settings screenshot.
This looks like Google pushing “routing” into the default UX rather than making users pick named checkpoints. The screenshot doesn’t show pricing, quotas, or what models map to each mode.
OpenRouter’s “:nitro” routes requests to the fastest provider
Nitro routing (OpenRouter): OpenRouter is promoting a routing knob where selecting “Nitro” (or appending :nitro) sends a model request to the fastest available provider based on their latency/throughput tracking, as described in the Nitro tip and backed by the linked performance rankings.
This is a provider-side behavior change, not a model change. It’s also an implicit trade: you get speed via dynamic routing, but reproducibility can get harder if provider choice shifts over time.
MiniMax posts a “one-shot city” prompt-to-video demo
One-shot video demo (MiniMax): MiniMax shared a “One shot, one city” example that frames its video model as fast prompt-to-clip generation, with the montage shown in the video demo and a pointer to the demo site.

The post is a capability teaser rather than a spec drop: it doesn’t include model name/version, pricing, or any repeatability details.
⚙️ Runtimes & sandboxes: running code safely (WASM, subsets, and tool feedback loops)
Engineering-focused runtime work: sandboxes and interpreters that make agent code execution safer/more portable, plus practical notes on constrained runtimes where models adapt via error messages.
Monty now runs in the browser via WebAssembly (including a Pyodide-friendly build)
Monty (WASM runtime): Simon Willison reports getting Monty compiled to WebAssembly in both “regular” and “Pyodide-friendly” variants, plus an interactive playground that executes entirely client-side, as described in his WASM build write-up.
• Portable sandbox: The demo makes Monty usable as a drop-in “run this code safely” substrate for agent UIs, since execution stays in-browser and state is shareable via URL, as shown in the Playground screenshot and live in the WASM demo.
• Practical debugging loop: Willison’s note that it’s a subset runtime pairs well with the “tight feedback loop” approach—run, get errors fast, rewrite—captured in the broader sandbox discussion in Subset runtime take.
Monty ships: a Rust Python subset built for running LLM-written code
Monty (Pydantic): Samuel Colvin announced Monty, a new Python implementation written from scratch in Rust, positioned as a practical runtime for “LLMs to run code with,” per the Monty announcement (also echoed in Repost). The immediate engineering value is a smaller, more controllable execution surface than full CPython—useful for agent toolchains where you want predictable behavior, constrained APIs, and clearer sandbox boundaries.
Constrained runtimes: let models adapt by rewriting from error messages
Sandbox design pattern: A recurring argument is that a subset of Python can be “good enough” for agent execution because models can iteratively rewrite their code to fit the allowed surface area by reacting to runtime errors, as framed in Subset runtime take. The practical takeaway is that sandbox design can bias toward simpler, safer primitives (fewer modules, fewer syscalls) while relying on the model’s compile/run feedback loop to converge—especially when the runtime returns clear, structured errors.
🗂️ Data extraction & grounded outputs: citations, brand scraping, and 3D datasets
Practical data-layer work for agents: extracting structured outputs with provenance (bounding boxes/citations), plus new datasets relevant to 3D generation/perception. Excludes general benchmark leaderboards (separate).
LlamaExtract now returns citation bounding boxes for every extracted field
LlamaExtract (LlamaIndex): LlamaIndex shipped an extraction upgrade that returns citation bounding boxes alongside each extracted key/value, so reviewers can hover a field and see the exact source span highlighted in the original document, as shown in the extraction demo. This pushes document AI from “structured JSON” toward “auditable structured JSON,” which matters when you’re processing high-volume corpora (invoices, IDs, claims, contracts) and need fast spot-checking rather than blind trust.

The main engineering implication is provenance becomes a first-class output artifact: you can log (field → box coords → page) into your review UI, or store it as evidence in downstream workflows (QC queues, exception handling, or human sign-off).
Firecrawl Branding Format v2 improves brand extraction on no-code sites
Branding Format v2 (Firecrawl): Firecrawl updated its brand-identity extraction endpoint to better handle modern site builders (including Wix and Framer), reduce false-positive logo hits, and catch logos embedded in background images, per the release clip. For teams building agentic onboarding, “generate on-brand assets,” or brand-change monitoring, this is a concrete quality bump because failures here cascade into downstream prompt context.

• Integration surface: the intended usage patterns (personalized onboarding pages, on-brand creative generation, competitor monitoring) are laid out in the docs snippet, with implementation details in the Extract brand identity docs.
Tencent open-sources HY3D-Bench with 252k+ filtered 3D objects and part annotations
HY3D-Bench (Tencent Hunyuan): Tencent released HY3D-Bench, an open dataset targeting 3D asset generation data scarcity—252k+ high-fidelity 3D objects, 240k part-level decompositions for controllable generation, and 125k synthetic assets for class balance, as described in the dataset announcement. They also published Hunyuan3D-2.1-Small as a lightweight baseline to make results reproducible.
For engineers training or evaluating 3D generators, the notable part is the dataset is explicitly framed as training-ready and evaluation-consistent (filtered objects + structured parts), with entry points in the GitHub repo and the Dataset download.
🤖 Embodied AI & world simulation: autonomy training, humanoids, and ‘physical AI’ framing
Embodied AI posts are split between (1) world/simulation models for autonomy and (2) real robot capability demos (humanoids/manipulation). Excludes creative video generation (separate).
Waymo World Model uses Genie 3 to generate promptable driving sims for rare events
Waymo World Model (Google DeepMind × Waymo): DeepMind says Genie 3 is now being used to generate photorealistic, interactive environments for AV training, with prompts for “what if” scenarios like extreme weather or reckless drivers, as shown in the launch thread. This is aimed at rehearsing rare, high-risk edge cases before the fleet encounters them in the real world.

DeepMind frames the technical bridge as transferring Genie 3 “world knowledge” into Waymo-specific sensor realism (camera + 3D lidar aligned to Waymo hardware), per the launch thread and the linked Blog post. The operational implication is more controllable scenario generation (language-conditioned) while still producing sensor-like data that downstream autonomy stacks can consume, as reiterated in the world model takeaway.
Boston Dynamics Atlas clip highlights cleaner gymnastics and backflip control
Atlas (Boston Dynamics): A new Atlas sequence shows controlled gymnastics capped with a clean backflip, with observers calling out how quickly the capability has been improving, per the Atlas backflip clip. The visible emphasis is balance recovery and landing stability. That’s the hard part.

For autonomy teams, these demos are less about “one trick” and more about robustness: repeated execution, fewer resets, and tighter error tolerance are the difference between a lab video and a system that can run continuous shifts.
Jensen Huang frames “physical AI” as the next frontier beyond LLMs
Physical AI framing (NVIDIA): Jensen Huang argues the next frontier is systems that model the physical world and causality—pointing out that humans intuit basic physics while LLMs don’t, as captured in the physical AI clip. It’s a clear push toward “world-model-first” thinking for robotics and autonomy, not just larger text models.

The practical subtext for builders is that evaluation and training targets shift from “did it produce the right text” to “did it predict consequences under interventions,” which maps directly onto simulation-based training loops (and why world models keep showing up in autonomy stacks).
Mistral shows a dual-armed physical agent demo and signals robotics ambitions
Mistral robotics demo (Mistral AI): Mistral is publicly showing a dual-armed manipulation agent (block stacking / tabletop tasks), positioning it as entry into the “physical agent” race, per the robotics demo post. This is a tangible shift from model-only messaging.

What’s notable for engineers is the product posture: even simple bimanual tasks imply a stack that can do perception → planning → low-level control with enough temporal consistency to avoid drift and oscillation. The clip doesn’t reveal the training recipe. It does show intent.
UBTECH “Chitu” showcases multi-robot collaboration at Foxconn under UPilot OS
Chitu logistics system (UBTECH × Foxconn): UBTECH describes an unmanned logistics workflow built via multi-robot collaboration—humanoid Walker S2 coordinating with mobile lifter Wali U1500—under a UPilot “operating system” orchestration layer, as shown in the factory demo post. It’s pitched as spanning warehousing through assembly with minimal human intervention.

For autonomy leaders, the key detail is orchestration: coordination across heterogeneous robots is often the real bottleneck (handoffs, recovery, and task ownership), and this demo centers that rather than a single robot’s peak capability.
Genie 3 prompting notes: character + environment control and event shaping
Genie 3 prompting (world simulation): A practitioner write-up compiles what works and what doesn’t when prompting Genie 3—how to specify character + environment, and how to aim for both expected and inferred events to get more interesting and controllable worlds, per the prompting notes. It reads like early “prompt ops” for world models.

The main engineering takeaway is that world simulation models are starting to need their own control vocabulary (entities, affordances, event priors), not just “make a nice scene.” That’s a different interface surface than text prompting.
XPeng IRON humanoid demo focuses on natural gait and body motion control
IRON humanoid (XPeng): Clips of XPeng’s IRON emphasize “natural” human-like movement practice—specifically gait and body motion control—framed as continued iteration on locomotion realism, per the humanoid movement clip. The point is motion quality, not manipulation.

For robotics engineers, this kind of footage is often a proxy for how much time is being spent on control tuning, whole-body balance, and pose transitions—things that tend to fail first when you move from choreographed demos to long-horizon tasks.
🎬 Generative media: Kling 3.0 workflows, video-with-audio evals, and creator pipelines
High volume creative tooling posts: Kling 3.0 multi-shot workflows, video-with-audio leaderboards, and practical pipelines (ads, upscaling, character driving). This category is non-feature and separate from robotics/world-model simulation.
Artificial Analysis launches Video-with-Audio leaderboard; Veo 3.1 Preview leads
Video with Audio Arena (Artificial Analysis): following up on Video+audio arena, the comparison is now presented as a live leaderboard, with Veo 3.1 Preview leading both text→video-with-audio and image→video-with-audio, according to the Leaderboard announcement; the evaluation prompt is designed to stress text legibility under mirror warping plus reflection lip-sync, as spelled out in the Benchmark prompt.

• Current top stacks: the post lists text→video-with-audio as Veo 3.1 Preview, Veo 3.1 Fast Preview, then Vidu Q3 Pro, and image→video-with-audio as Veo 3.1 Preview, Veo 3.1 Fast Preview, then grok-imagine-video, per the Leaderboard announcement.
• What’s not measured yet: the same thread says Kling 3.0 and “Veo 3.1 (Non-Preview)” are “coming soon,” so the ranking is provisional relative to new releases, per the Leaderboard announcement.
ComfyUI releases an upscaling handbook with downloadable production workflows
ComfyUI upscaling (ComfyUI): ComfyUI published “The Complete AI Upscaling Handbook,” positioning it as a deep dive with benchmarks, 10 real-world use cases, and 20 production workflows, per the Handbook announcement; follow-on posts include specific workflow packs (image and video) intended to be imported and run as-is, per the Video restoration workflow drop.

The emphasis is end-to-end pipeline reproducibility (pick a method, grab a workflow, run it in ComfyUI) rather than model-only comparisons, based on the framing in the Handbook announcement.
DreamActor M2.0 lands on fal for image-guided character driving
DreamActor M2.0 (fal): fal is now serving DreamActor M2.0 for video-to-video “driving” from a single image plus a template video, with multi-character and non-human support, plus claims around pose replication and identity/background preservation in the Launch clip; the hosted endpoint is linked as a runnable model page in the Model page.

The immediate integration angle is replacing bespoke pose/face pipelines with one API surface for character motion transfer, based on the capability list in the Launch clip.
Kling 3.0 Multi-cut prompting: shot durations, camera directives, and bound elements
Kling 3.0 Multi-cut (Kling): a creator workflow shows a repeatable pattern for coherent multi-shot sequences by writing prompts as explicit shot blocks with durations (for example 3s/8s/3s), camera placement/motion, and cut instructions—then preserving identity/branding via “bind” style reference images, as laid out in the Workflow thread and expanded with concrete shot prompts in the Multi-cut prompt examples.

• Shot scripting format: the prompts use “Shot 1/2/3” blocks with time budgets and camera intent (tracking, over-the-shoulder, handheld), per the Multi-cut prompt examples.
• Consistency control: the thread calls out binding elements as the mechanism to keep the object prompt stable across cuts, per the Workflow thread.
Sora allows animating photos with real people under consent attestation
Sora (OpenAI): Sora now lets eligible users upload images containing real people to generate videos, gated behind an attestation flow that the uploader has consent and rights; the UI also notes that outputs are “stylized” while the feature is in beta, as shown in the Feature gate screenshot.
For teams building media pipelines around Sora, this is a concrete policy+product change: the constraint shifts from “no people images” to “people images, but with explicit consent capture and stricter moderation,” per the Feature gate screenshot.
A Grok Imagine ad pipeline: script first, then VO, then visuals
Grok Imagine (xAI): a creator shared a concrete “commercial in 7 steps” pipeline built around Grok Imagine—starting with the script, recording VO, then generating images and animating them, and using image-edit iterations to keep style consistent across new scenes, as detailed in the Seven-step thread and reinforced by the “VO before visuals” clip in the VO-first process.

The key operational takeaway is that this is a repeatable sequencing pattern (audio lock-in first, then shot generation) rather than a single prompt trick, per the step-by-step breakdown in the Seven-step thread.
Freepik Spaces adds Lists and shows a Kling 3.0 batch-to-animation workflow
Freepik Spaces Lists + Kling 3.0 (Freepik): a workflow demo pairs a new “Lists” feature (batching repeated prompt structures) with Kling 3.0 for turning multiple variants into short video outputs inside the same project workspace, as shown in the Workflow demo post.

The pitch is fewer manual repetitions when you need many near-identical assets (for example character variations or scene variations) and then want to animate them without leaving the tool, as described in the Workflow demo post.
Higgsfield pitches an 85% off 2-year offer for unlimited Kling 3.0
Kling 3.0 (Higgsfield): Higgsfield is advertising a 2-year “Creator plan” offer at 85% off for “unlimited” access to Kling 3.0 and Kling 3.0 Omni, with claims of 15-second generations, native audio, lip-sync, and multi-angle outputs, as described in the Plan offer post.

The practical engineering relevance is cost predictability for high-volume video pipelines (especially if you’re iterating many variants per concept), but the tweet doesn’t provide throughput, concurrency limits, or any SLA details beyond the “unlimited” positioning in the Plan offer post.
Replicate publishes grok-imagine-video with native-audio output
Grok Imagine Video (Replicate): Replicate is now hosting grok-imagine-video as an API-callable model, describing text-to-video and image-to-video generation with native audio, per the Replicate launch post.

This is a distribution change (availability via Replicate’s API surface) rather than a new model spec; the tweet doesn’t include pricing, rate limits, or queue behavior beyond the “in seconds” framing in the Replicate launch post.
📄 Research notes: memory control, distillation ideas, and “what models default to”
Paper-and-preprint discussion today clusters around agent memory/control, distillation/RL data strategies, and characterizing model priors. Excludes product benchmarks (separate) and any bioscience content.
AMemGym proposes an on-policy, interactive benchmark for assistant memory
AMemGym (benchmark/paper): AMemGym frames “assistant memory” evals as an on-policy interaction problem (the assistant’s choices change what happens next), arguing static transcript-based scoring can mis-rank systems and hide failure modes, as described in the AMemGym summary.
• Why it changes rankings: The thread claims off-policy setups introduce “reuse bias” (everyone is graded on the same prewritten conversation), while AMemGym runs a live simulated user for each system so memory write/retrieve decisions affect downstream turns, per the AMemGym summary and Off-policy vs on-policy.
• Artifacts to inspect: The resource list includes the OpenReview paper and a reproducible implementation in the GitHub repo, with additional framing in the Benchmark comparison notes.
The operational takeaway is that memory evaluation is being treated less like “can you answer from a long context” and more like “did you choose to store/recover the right facts during interaction,” per the AMemGym summary.
InfMem trains bounded-memory agents to reason over 1M-token documents
InfMem (paper): A new agent-memory method, InfMem, targets ultra-long document QA by treating memory as a controlled process (not passive compression), using a PRETHINK–RETRIEVE–WRITE loop that decides when evidence is sufficient, when to fetch earlier passages, and how to compress into a fixed budget, as summarized in the paper thread.
The results emphasized in the thread include sustained accuracy up to 1M tokens with adaptive early stopping (lower latency) and gains over prior streaming-memory baselines, with the key engineering idea being that “what to keep” and “when to stop” are learnable control decisions rather than fixed heuristics, per the paper thread.
“Golden Goose” turns explanatory text into verifiable RLVR multiple-choice tasks
Golden Goose (RL data strategy): A reported technique called “Golden Goose” turns non-verifiable explanatory text into cheap RLVR by removing a key middle reasoning chunk and asking the model to pick the missing span from multiple choices, making rewards automatic because the “correct” option is the removed chunk, as explained in the Golden Goose summary.
The thread’s claim is that this directly targets RL data saturation (fixed verifiable sets stop yielding gains), by manufacturing fresh auto-graded items at scale from ordinary text sources, with the mechanism and motivation summarized in the Data saturation note.
An on-policy context distillation idea resurfaces as multiple papers converge
On-policy context distillation (research direction): A note attributed to John Schulman is cited as an early (Nov 2025) proposal to compare off-policy vs on-policy context distillation in few-shot settings—training a student (empty context) to match a prompted teacher (long context), and evaluating whether on-policy collection changes outcomes, per the tinker idea screenshot.
The thread frames this as a now-crowded area (“5+ papers”) and suggests the practical experiment design is to measure off-policy-only, on-policy-only, and staged combinations, as described in the tinker idea screenshot.
Near-unconstrained generation reveals stable “knowledge priors” by model family
Near-unconstrained generation (Together AI): Together AI reports experiments where models are prompted with minimal, topic-neutral text (e.g., “Actually,” or “.”) to expose stable default-generation tendencies (“knowledge priors”) that differ systematically by model family, as laid out in the research thread.
• What they claim to observe: The thread says families cluster into distinct semantic regions (e.g., programming/math-heavy vs narrative-heavy vs exam-question-like), and that even “degenerate” outputs are informative signals rather than pure noise, per the Model family clustering and Degenerate text signal.
• Primary sources: The writeup is in the Blog post with the underlying methodology and results in the ArXiv paper, both referenced from the follow-up summary.
This is positioned as an auditing/safety/behavior-characterization tool that complements capability evals by measuring what models do without strong instruction scaffolding, according to the Why it matters.
DFlash proposes block diffusion for flash speculative decoding
DFlash (paper): A new paper titled “DFlash: Block Diffusion for Flash Speculative Decoding” is shared via a Hugging Face paper page, per the paper availability. The main pointer in the tweets is the canonical artifact itself, which is linked as the HF paper page.
Within this tweet set there aren’t performance numbers or implementation details discussed beyond the title/positioning, so treat it as an “artifact dropped” signal rather than an evaluated decoding method.
🧑🏫 Developer culture & labor signals: productivity shock, job anxiety, and tool fatigue
Discourse itself is the news here: anxiety about displacement, “fast takeoff” narratives, and the lived experience of supervising increasingly capable coding agents. Excludes enterprise adoption specifics (feature).
Builders report reply quality collapsing under bot volume
Platform signal quality (X): swyx reports “obvious bots” jumping from ~20% to ~80% of replies, forcing stricter notification filters that also hide real humans in the Bot-replies complaint.
A second thread ties the “#keep4o” reply wave to suspected bot amplification while sharing a chatbot market-share chart in the Bots and share chart; treat attribution as speculative, but the operational point remains: social discovery for new tooling patterns is getting noisier.
Fast-takeoff framing: “ride the wave” becomes common language
Fast takeoff mood: Doodlestein’s “Happy Fast Takeoff Day” post frames frontier progress as exhilarating for insiders and “scary and confusing” for everyone else, while asserting the only option is to ride it in the Fast takeoff post.
The same mood shows up more tersely as “We’re not early anymore” in the Not early anymore post.
Levie claims AI power users are still years ahead of their peers
Adoption gap (Box): Aaron Levie argues that anyone paying attention to AI tools on X is “a couple years ahead” of the average worker in their field, and that many knowledge-work domains are still “day 1” in the Years-ahead posture.
The labor signal is about diffusion, not capability: early adopters think the advantage window remains open because most orgs haven’t operationalized agents yet.
Release pace drives attention fatigue across builders
Tool fatigue: Multiple posts describe the last 24–48 hours as hard to track, with “Opus 4.5 and GPT-5.3 dropping minutes apart” in the Release whiplash meme and “Quiet week huh?” sarcasm in the Quiet week joke.

A related form of fatigue is the constant “when next version?” churn (“When GPT-5.4? When Opus 4.7?”) in the Next-model demands.
Some engineers say “not replaced,” but worry about keeping up with tools
Developer displacement sentiment: A parallel thread argues AI isn’t making programmers obsolete in the near term, using a “punch cards weren’t that long ago” anecdote in the Punch card story, while still naming the practical stressor as “keeping up with the tooling” in the Tooling worry follow-up.
The signal here is the split between replacement fear and capability-churn fatigue: even optimistic engineers are framing adaptation speed as the main risk.
Token budgets become a real workplace constraint, not a billing detail
Workplace constraint: Ethan Mollick notes that “agentic work beyond a Max plan” can burn substantial tokens, and frames lack of access to frontier/agentic models as a potential career development downside in the Token budget comment.
This is a labor signal because it turns model access into a resource allocation question that employees may negotiate (similar to compute budgets for ML teams).
Codex pricing question triggers backlash and “keep4o” demand signal
User demand signal (OpenAI): Sam Altman asks how people want Codex priced in the Pricing question, and the replies become a proxy war about ChatGPT “4o” and companion-style usage; one critique calls out “AI companion enjoyers” and “sycophancy” dynamics in the Reply screenshot critique.
This is mostly a product-culture signal: a developer-facing pricing question surfaces a different audience’s priorities (and how strongly they’ll flood feedback channels).
The dominant builder mood: “you can just build things”
Builder mood: Alongside the release churn, there’s a strong “this is for coders and dreamers” tone—“you can just build things” as quoted in the Coders and dreamers post.
A related take frames the productivity shift as partly affective—“work is way more fun now”—in the Work is more fun post.
Early-access distribution becomes part of the competitive narrative
Access politics: One thread argues that who gets early model access signals lab priorities—“businesses” for Anthropic versus “influencers” for OpenAI—per the Early access signal.
There’s no hard data in the tweet, but it’s a recurring culture storyline: access pathways (enterprise pilots, creator programs, private betas) are interpreted as strategy, not logistics.
Engineers separate “tech is real” from “pricing is real”
Macro narrative: A builder-facing take claims “the probability AI is a bubble is zero” from a technical standpoint (especially for people who write code), while conceding the financial story could diverge in the Not a tech bubble take.
A nearby sentiment rejects plateau talk and argues slowdowns would be temporary in the No plateau argument.
🎙️ Voice agents & speech stacks: cloning, realtime pipelines, and app integrations
A smaller but clear cluster: new speech model endpoints and voice-agent plumbing being productized via inference platforms and devtools. Excludes creative music workflows (kept in gen-media).
MiniMax Speech 2.8 lands on Replicate with 5-second voice cloning and controllable delivery
MiniMax Speech 2.8 (Replicate): Replicate added MiniMax Speech 2.8, positioning it for production TTS where you can clone a voice from a ~5-second sample and steer delivery with natural interjections like “(laughs)” and “(sighs)” across 32 languages, as described in the Feature list. This shows up as two SKUs—HD (quality) and Turbo (latency), with endpoints linked in the HD model page and the Turbo model page.
The practical shift is operational: teams can standardize on a hosted speech model with an API surface that supports both “studio” and “fast path” modes, rather than treating voice as a separate bespoke pipeline.
Grok Imagine Video hits Replicate with native-audio video generation
Grok Imagine Video (Replicate): Replicate made Grok Imagine Video available as an API, highlighting text→video and image→video with native audio generation, as stated in the Availability note.
The immediate engineering implication is stack convergence: if you’re already building voice agents, “speech + visuals” can now route through one hosted inference surface, rather than stitching together separate video generation and TTS jobs, as shown on the Replicate model page.
LangSmith shows how to debug STT→agent→TTS voice pipelines with traces
LangSmith (LangChain): LangChain published a practical walkthrough for debugging the “STT → agent → TTS sandwich” by sending traces into LangSmith, making it easier to see where latency and failures occur across the pipeline, as shown in the Voice agent debugging post.
• Trace anatomy: The example shows a single conversation broken into explicit STT/LLM/TTS spans with durations and model names, which is the minimum structure you need before you can do targeted reliability work, as illustrated in the Voice agent debugging post.
Warp adds GitHub Copilot CLI support plus Wispr Flow voice transcription
Warp (Warp): Warp shipped first-class support for the GitHub Copilot CLI, bundling voice transcription powered by Wispr Flow, plus an image upload button and an integrated file explorer + code review panel, as demonstrated in the Feature demo.
For teams experimenting with voice-driven dev workflows, this is a notable “speech-to-terminal” surface that doesn’t require building a custom STT front-end first.
MiniMax says Speech 2.8 is powering Sensei voices, emphasizing expressiveness
MiniMax Speech 2.8 (MiniMax): MiniMax claims Speech-2.8 is already being used in the “Sensei” voices inside @callmesenseien, with a stated focus on pushing voice quality and emotional expressiveness further, per the Adoption note.
This is a small but concrete adoption datapoint: the model isn’t only a demo SKU, it’s being used as the voice layer in an end-user product experience where prosody and consistency are obvious to users.
Wispr Flow announces an Android waitlist
Wispr Flow (Wispr Flow): Wispr Flow announced it’s “coming to Android” with a public waitlist, per the Android waitlist post.
This extends mobile availability for a consumer-grade transcription layer that’s already showing up as an embedded capability in dev surfaces (for example, terminals), which matters if you’re relying on voice input outside desktop-only setups.