StepFun Step-3.5-Flash ships 196B MoE with 11B active – claims DeepSeek v3.2 wins
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
StepFun published Step-3.5-Flash weights on Hugging Face; the pitch is an MoE with 196B total params but 11B active, positioned as “usable” for agents via high-throughput serving (100–300 tok/s; peaking ~350) and early tweet-bench claims that it beats DeepSeek v3.2 across multiple benchmarks despite the smaller active footprint. The comparison set is screenshot-driven and no official eval artifact is linked in the threads, so the performance delta remains provisional; the notable part is the immediate “drop into vLLM” framing via referenced serving PRs.
• vLLM-Omni: v0.14.0 tagged as first stable; multimodal stack spans text/image/video/audio; adds diffusion /v1/images/edit plus Qwen3-TTS online serving; pushes async chunk pipeline overlap; targets XPU/ROCm/NPU backends.
• Kimi K2.5: hits #7 on LM Arena Coding (1509); builders sketch swarm-style repo reads (~140 files in ~45s; ~$0.003 per file-question at $24/hr).
• OpenAI Codex CLI: v0.93 plan mode adds an interactive /plan questionnaire; steering bugs reported around manual compaction swallowing messages.
Across the day’s threads, “agentic coding” competition is shifting toward runtime primitives—parallel sessions, cache reuse, and deterministic context packaging—while benchmarks and cost math are increasingly treated as marketing until logs and reproducible harnesses show up.
Top links today
- Execution-grounded automated AI research paper
- India zero tax plan for AI workloads
- Nature paper on flexible AI processor FLEXI
- Live Kimi K2.5 swarm benchmarking demo
- Details on OpenAI ChatGPT ads beta pricing
- vLLM-Omni v0.14.0 production multimodal release
- Infisical integration for rotating OpenRouter keys
- OpenRouter documentation
- LlamaCloud agents builder for legal filings
Feature Spotlight
Claude Sonnet 5 (“Fennec”) release watch: 1M context + coding benchmark arms race
Sonnet 5 chatter is dominating: 1M context + speed/price claims and SWE-Bench leaks could reshuffle the default “coding model” choice for many teams within days.
High-volume cross-account chatter centers on Anthropic’s Claude Sonnet 5, with leaked Vertex model-version strings, rumored Feb 3 timing, and repeated claims about 1M context + faster/cheaper coding performance. This category is the sole home for Sonnet 5 rumors/metrics today; other categories explicitly exclude it.
Jump to Claude Sonnet 5 (“Fennec”) release watch: 1M context + coding benchmark arms race topicsTable of Contents
🦊 Claude Sonnet 5 (“Fennec”) release watch: 1M context + coding benchmark arms race
High-volume cross-account chatter centers on Anthropic’s Claude Sonnet 5, with leaked Vertex model-version strings, rumored Feb 3 timing, and repeated claims about 1M context + faster/cheaper coding performance. This category is the sole home for Sonnet 5 rumors/metrics today; other categories explicitly exclude it.
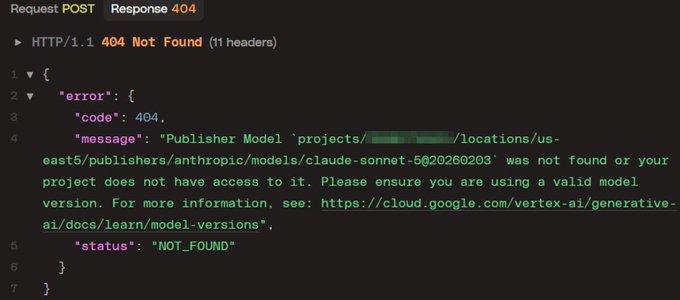
Vertex AI 404s leak a Claude Sonnet 5@20260203 version string (Feb 3?)
Claude Sonnet 5 (Anthropic): Following up on Imminent rumor—the new concrete artifact is a Vertex AI error that names claude-sonnet-5@20260203, strongly reinforcing “Feb 3” timing claims as seen in the Vertex 404 response and echoed by the release date post.
• Access gating signal: multiple people report “model not found or you don’t have access” failures while trying the exact model path, which reads like pre-release allowlisting rather than a public endpoint, as shown in the Vertex 404 response and the second 404 screenshot.
• Date convergence: the same Feb 3 claim appears across independent posts (not just one leak thread), including “coming Tuesday” in the Tuesday timing claim and “February 3rd” in the release date post.
Claude Sonnet 5 leak pack: 1M context, 82.1% SWE-Bench, $3/$15 per 1M tokens
Claude Sonnet 5 (Anthropic): A fairly consistent “spec bundle” is getting repeated—1M context, 82.1% SWE-Bench, and $3/1M input + $15/1M output—with builders framing it as faster than Opus 4.5 and positioned for Claude Code workflows, per the leaked metrics thread and the 1M context and pricing claim.
• Benchmarks and expectations: some are treating 82.1% SWE-Bench as the headline number in the leaked metrics thread, while others are anchoring on “it should beat Opus 4.5’s ~80.9%” as predicted in the SWE-bench expectation. Treat these as provisional—no official eval artifact is linked in the tweets.
• Context and cost claims: “1m context” gets repeated as a differentiator in the 1m context claim and the 1M context and pricing claim, alongside “half the price of Opus” framing in the 1M context and pricing claim (also not backed by a pricing page in this tweet set).
Sonnet 5 rumor backlash: “everyone is an insider” and naming confusion (4.7 vs 5)
Release-watch sentiment: alongside the hype cycle, there’s visible fatigue about unverifiable claims—“suddenly everyone is an insider that has already used sonnet 5” as written in the insider fatigue post—and broader noise from adjacent “next week” rumors (GPT-5.3, Gemini 3 GA) in the next releases rumor.
The naming layer is also muddy: some threads reference “sonnet 4.7” while implying it’s effectively Sonnet 5 now, as mentioned in the busy February rumor list, which makes it harder for teams to reason about what to test, what’s real, and what’s just speculative screenshots.
🧰 Claude Code: workflow tips, UI integrations, and agent features (excluding Sonnet 5)
Today’s Claude Code content is mostly hands-on usage guidance (plan mode loops, context resets), UI integrations (Claude for Chrome), and architecture notes from the team—plus feature rumors about multi-agent behavior. Excludes Sonnet 5 coverage (handled in the feature).
Claude Code onboarding loop: plan small, auto-accept, then clear context and repeat
Claude Code (Anthropic): A concrete “get unstuck” onboarding loop is circulating: buy Anthropic Pro, run Claude Code with Opus 4.5, stay in plan mode for a small feature, then auto-accept edits; if output drifts, pause the model, clear context, and restart for the next feature, with a claimed 10–20 hours of practice to calibrate what the tool can and can’t do, as laid out in the Onboarding loop.
The practical payload is that it treats context resets as a normal control knob (not a failure) and frames “Plan → Execute” as the stable unit of work for human-in-the-loop coding.
Claude Code rumor: spawn background specialist agents like teammates
Claude Code (Anthropic): A “leak” claim says Claude Code can now spawn specialized agents that take detailed briefs, work autonomously, and run in the background while you keep chatting—framed as “a dev team in your terminal” in the Leak claim.
There’s no changelog or official confirmation in the tweets, so treat this as directional signal: the UI/UX for Claude Code may be shifting from single-thread coding assistant toward multi-agent orchestration.
Boris’ Claude Code tips keep resurfacing as the day-to-day checklist
Claude Code (Anthropic): Multiple people are pointing newcomers to a “Boris 10 tips” thread as the current practical checklist for daily driving Claude Code, framed explicitly as “lifehacks” rather than theory in the Tips thread mention.
A second-order signal here is that the ecosystem is standardizing around repeatable micro-habits (how you start tasks, when you accept edits, when you reset) more than around model choice or prompt cleverness.
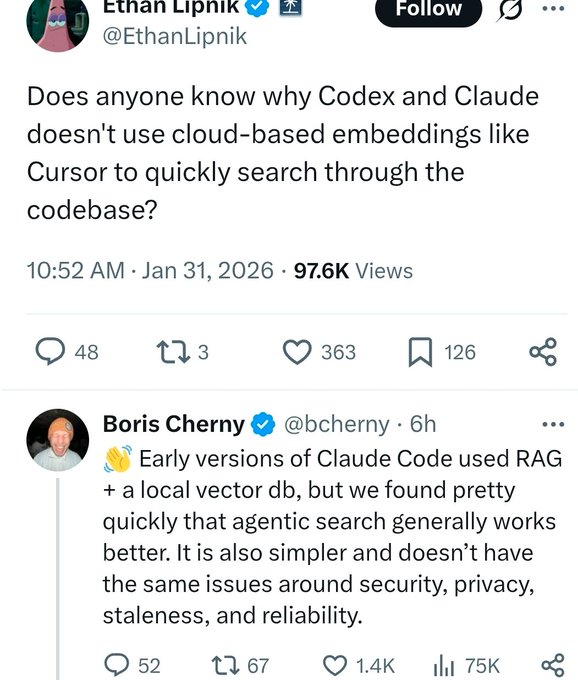
Claude Code moved away from RAG+local vector DB toward agentic search
Claude Code (Anthropic): An internal architecture note is being recirculated: early Claude Code builds used RAG plus a local vector DB, but the team found that “agentic search generation” worked better and shifted away from that setup, as quoted in the Architecture note.
For builders, the key detail is that Claude Code’s retrieval story appears to be less about maintaining a bespoke local index and more about letting the agent drive search/reading behavior directly—useful context when deciding how much custom RAG scaffolding to bolt onto a coding agent.
Claude for Chrome + Claude Code: browser toggle for frontend dev/testing
Claude Code (Anthropic): A lightweight workflow is being shared for frontend work: enable “Claude for Chrome” so Claude Code can pair with a live browser surface for quick UI testing/iteration, described as a “superpower for frontend development and testing” in the Chrome integration note.

This lands as an integration primitive: the browser becomes a first-class feedback channel instead of copy/pasting screenshots and DOM snippets.
Some builders won’t let Claude Code touch their repo
Claude Code (Anthropic): A sharp preference split is visible: one builder says they don’t let Claude Code operate on their codebase and instead run “all codex,” citing Opus being “too buggy” for that role in the Codex only stance. A related complaint argues other models are “too trigger friendly” and require “hand holding,” with GPT described as slower but needing less babysitting in the Hand-holding complaint.
This is less about raw benchmark claims and more about perceived diff reliability and how much operator control is required to keep changes on track.
Claude Code Commands may work inside bundles too
Claude Code (Anthropic): TestingCatalog reports that Claude Code “Commands” will likely be supported inside the newly released bundles, which would make those bundles more powerful as a packaging and reuse surface, according to the Commands in bundles and the linked Feature writeup.
If accurate, it implies bundles may carry not just static assets/instructions but executable command abstractions that can travel across projects/environments.
Cowork may be adding scheduled tasks, hinted by “Try Cilantro”
Cowork (Anthropic): A rumor thread claims Anthropic is working on scheduled tasks for Cowork, inferred from recent Claude web app changes plus a mysterious “Try Cilantro” announcement mentioned in the Scheduled tasks hint.
No screenshots or docs are attached in the tweets, so the operational details (triggers, permissions, execution environment) remain unknown; the signal is that Anthropic may be pushing agents toward time-based automation rather than purely interactive sessions.
Claude Code “best practices” still aren’t settled—expect local divergence
Claude Code (Anthropic): Ethan Mollick is pushing back on the idea that any canonical “best way to use Claude Code” exists yet; he argues the right workflow depends on context and that discovery is still open-ended, as emphasized in the Experimentation reminder and reiterated in the Local context note.
This frames today’s flood of tips as provisional craft knowledge rather than stable doctrine—useful calibration for teams trying to standardize too early.
🧠 OpenAI Codex: Plan mode UX, steering bugs, and real-world usage patterns
Codex discussion today is about day-to-day CLI behavior: enabling plan/collaboration modes, steering/compaction edge cases, and how builders choose reasoning levels and parallel sessions. This category stays on Codex tooling/UX (not general model-release rumors).
Codex CLI v0.93 exposes Plan mode via collaboration_modes + /plan Q&A UI
Codex CLI v0.93 (OpenAI): Plan mode is now a first-class UX path—users enable it with codex features enable collaboration_modes and then run /plan, which asks interactive “Question 1/3” style prompts before generating a plan, following up on Plan mode TUI (plan-mode TUI shipped) with a clearer on-ramp shown in the Plan mode enable command.
This matters because it turns “planning” into a structured, answerable questionnaire (vs. free-form prompting), which is usually where Codex sessions either stay aligned or drift into tool-spam.
Codex steering edge cases: compaction can swallow messages and rapid sends can drop one
Codex CLI steering (OpenAI): A user reports two reliability failures when steering is enabled—messages sent right after manual compaction can be “swallowed” (model never sees them), and sending two messages close together can result in one being ignored, per the Steering bug report.
This is the kind of failure that looks like “model quality drift” from the outside, but is actually queueing/UX state—especially painful when you’re driving Codex as a long-running agent with compaction cycles.
Codex users are escalating to Extra High and leaning on parallel workstreams over latency
Codex CLI usage pattern: One reported progression is “Codex Medium → Codex High → basically only Extra High,” with the claim that raw inference speed matters less when you’re parallelizing multiple workstreams; the core interface requirement becomes “multiple chats going at the same time… even on different codebases,” as described in the Reasoning tier workflow.
This frames “parallelization primitives” (session UI + task separation) as the performance feature, not just tokens/sec.
OpenAI offers complimentary daily tokens tied to data sharing controls
OpenAI token economics (OpenAI): A builder claims OpenAI provides “1 million free tokens/day if you’re willing to share data,” and uses that to argue for very low monthly operating cost for Codex-backed agents, as described in the Free tokens claim alongside a screenshot of the sharing controls.
This is operationally relevant because it changes the marginal cost of always-on agent loops—especially if your workload stays under the daily subsidy cap.
Codex shines on verification loops with large interdependent test suites
Codex long-running fix loop: A user describes a problem with “50 complex interrelated tests” where “one change can break many others,” and reports Codex “worked on it for 3 hours straight,” per the Three-hour test loop.
The underlying pattern is that Codex can keep iterating when there’s a tight, objective feedback loop (tests), which makes long sessions less about “brilliance” and more about persistence + correct instrumentation.
codex-1up 0.3.21 adds collaboration modes and experimental toggles for Codex 0.93
codex-1up 0.3.21 (kevinkern): The Codex bootstrapper shipped a new release with “collaboration modes (enable Plan mode)”, optional “Apps + Personality”, “suppress warnings” support, and compatibility with “latest codex 0.93”, as described in the Release notes.
It’s a concrete signal that Plan/Pair/Execute-style flows are becoming table-stakes for terminal coding agents, with tooling layering on top of the upstream Codex CLI.
Internal Codex research usage hype resurfaces with “almost unbelievable things” claim
Codex in research (OpenAI): A screenshot attributed to an OpenAI researcher says they’re “seeing some almost unbelievable things internally… especially for codex usage within research,” and asks what others are building, as shared in the Internal usage screenshot.
In the same thread, a builder claims “the hype is justified” and that they “haven’t written a line of code since codex,” per the Internal usage screenshot, but there’s no accompanying eval artifact in the tweets—so treat it as sentiment, not a benchmark.
Some builders are doing Codex-only coding due to Claude Code/Opus reliability complaints
Codex vs Claude Code (workflow sentiment): Some devs are explicitly restricting codebase writes to Codex—“I don’t let Claude Code on my codebase. It’s all codex,” as said in the Codex-only stance—and describe Claude/Opus as requiring more guardrail-management than GPT/Codex, per the Trigger-friendly complaint.
This is less about benchmark deltas and more about “how many babysitting steps per merged diff,” which is what actually drives day-to-day tool selection.
🦾 OpenClaw ops: Docker paths, always-on loops, and multi-agent command centers
OpenClaw content today is operational: Docker/VM isolation advice, Telegram-based control loops, AgentMail integration, and dashboards coordinating many agents. Excludes Moltbook social dynamics (covered separately).
Cloudflare “moltworker” OpenClaw runs cite a $5/mo path with 1M tokens/day ceiling
OpenClaw on Cloudflare Workers (Deployment): Following up on Workers template (Workers deployment template), a new ops datapoint pegs the cost model: if you can keep usage under ~1M tokens/day, the Cloudflare Workers bill is described as about $5/month, and the setup is paired with the claim that OpenAI provides “1 million free tokens/day” when you enable data sharing, per the Workers deployment note.
This is still anecdotal (no Cloudflare bill screenshot shown), but it’s the most concrete “token budget → monthly cost” claim in the OpenClaw ops threads today.
AgentMail gets used as the “email surface” for OpenClaw agents
AgentMail (AgentMail): A concrete integration pattern is emerging where agents get their own email inboxes via AgentMail, enabling workflows that intentionally route secrets/credentials through email instead of chat logs; one report says it “forced me to send secrets over email,” alongside a model switch that made OpenClaw feel dramatically more capable, per the AgentMail usage report and the AgentMail site.
The key ops signal is that “email as an agent tool” is getting standardized via an API product rather than ad-hoc SMTP scripting.
OpenClaw as intent router: delegate implementation to a separate Codex run
OpenClaw (OpenClaw): A sharp mental model is being repeated: OpenClaw is treated as the “distributor of intent,” not the executor—so it writes a spec/brief and hands actual implementation to a separate coding agent run (example: a Codex GPT‑5.2 xHigh run building a service folder + docs), as described in the Delegation description. This framing clarifies why people keep pairing OpenClaw with other coding surfaces rather than expecting OpenClaw itself to be the best coder.
Running OpenClaw in Docker on Mac: where state lives and what trips people up
OpenClaw (OpenClaw): A practical “run it in Docker first” setup writeup landed, focusing on where OpenClaw stores state on macOS and the specific onboarding choices that unblock a first successful run, as documented in the Docker setup TIL and detailed step-by-step in the Setup guide. Short version: it creates a config/state dir at ~/.openclaw and a file-accessible agent workspace at ~/openclaw/workspace, then asks a sequence of onboarding questions where “manual onboarding” and picking a workable model/auth path matter.
The biggest operational relevance is reproducibility: isolating the runtime while keeping stable host-mounted state makes it easier to iterate on skills/tools without losing your agent’s memory and settings.
Telegram-driven OpenClaw sessions expose model, context, and runtime state
OpenClaw (OpenClaw): OpenClaw’s Telegram control loop is being used as a day-to-day UI, with commands like /new and /status returning the active provider/model (example shown as openai-codex/gpt-5.2) plus context usage and runtime flags, as captured in the Telegram status screenshot.
This matters operationally because it turns “agent state” into something you can audit quickly (tokens, context %, queue depth) without attaching to the terminal session that’s actually doing work.
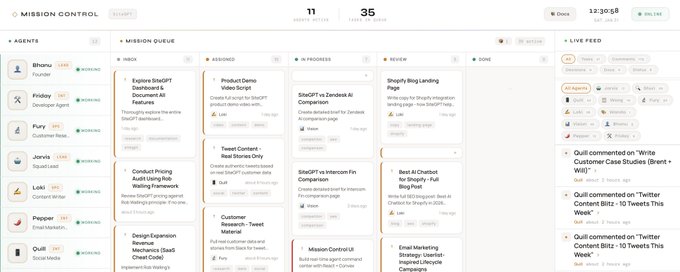
A “Mission Control” UI coordinates 10 OpenClaw agents with queue + collaboration
OpenClaw (OpenClaw): A multi-agent command center pattern is spreading: one build describes a React + Convex “Mission Control” dashboard coordinating 10 OpenClaw agents, with a lead agent delegating tasks and a workflow that resembles team dynamics (claims/reviews/refutes), as shown in the Dashboard screenshot.
The operational angle is visibility: separate lanes (inbox/assigned/in-progress/review/done) plus a live feed makes long-running agent swarms observable without living inside a single chat thread.
A Windows tray companion for OpenClaw ships as “Molty”
Molty (OpenClaw community tooling): A Windows system-tray frontend for OpenClaw (née Moltbot/Clawdbot) was released, bundling quick session switching and channel routing (e.g., Telegram/WhatsApp) into a native UI, as announced in the Windows tray app post with code in the GitHub repo.
For teams running persistent agents on Windows desktops, this is a concrete move toward “agent ops UI” outside the terminal.
OpenClaw “ran all night” once cron + heartbeat plumbing was in place
OpenClaw (OpenClaw): One field report says OpenClaw began running continuously overnight after a month of setup work, specifically calling out cron jobs and a heartbeat/reminder system as the missing operational glue; the same report highlights token availability as the ongoing bottleneck, as described in the Overnight run report. This is a small but concrete signal that “agent uptime” is being treated as an engineering problem (scheduling + event loops), not just a model capability question.
OpenClaw users recommend VM/Docker isolation for early experimentation
OpenClaw (OpenClaw): A recurring ops recommendation is to start OpenClaw inside a VM or Docker container because early use involves fast iteration and frequent breakage, with isolation reducing risk to your main machine and credentials, as argued in the Isolation recommendation. This shows up alongside real usage of chat surfaces (Telegram) and model swapping, implying the “agent workstation” pattern is becoming normal for persistent agents rather than a one-off CLI tool.
ClawCon SF signups show unusually high “I want to demo” intent
ClawCon (OpenClaw community): The SF OpenClaw show-and-tell event is reporting 522 signups and 406 people asking to present something, which is an unusually high presenter-to-attendee ratio for a tooling meetup, as shared in the Registration stats and reflected in the Event page. The ops implication is that OpenClaw usage is skewing toward “people have a setup to show,” not passive curiosity.
🔐 Security & misuse: phishing, prompt-injection risk, and agent hardening
Security discussion spans real-world account compromise postmortems, prompt-injection/tool-execution risk framing (“lethal trifecta”), and secret-management hygiene for AI tooling. Excludes general Moltbook growth/behavior (handled in the Moltbook category).
Deedy Das publishes a postmortem on a large Turkish X phishing campaign
Deedy Das (X account hijack): Deedy says he recovered his X account after 6 days and published a detailed postmortem of a Turkish phishing operation that attempted a crypto scam and targeted ~150 accounts, with forensics pointing to attackers using 60+ X-impersonating domains over ~1.5 years as described in the incident summary.
• Takedown pressure: he publicly calls on registrars/hosts to stop servicing the attacker infrastructure in the registrar callout, linking the full writeup via the Incident report.
This is a concrete reminder that “account takeover” remains a top risk even for AI-heavy teams, because a single compromised social or comms account can become an outbound phishing channel.
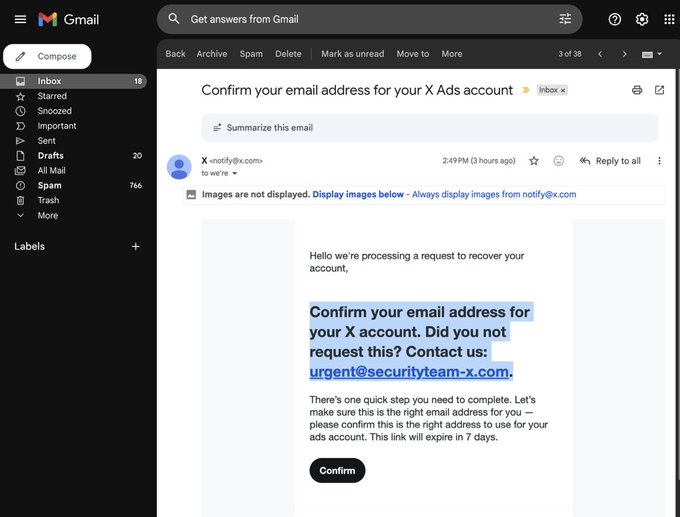
Phishers reportedly abuse X Ads onboarding so emails come from notify@x.com
X Ads onboarding (new phishing vector): A new vector described by Vercel’s CEO abuses the X Ads email flow so the phishing email originates from X’s own notification channel and bypasses spam filters, according to the email screenshot explanation.
• Mechanism: the attacker appears to set account/business name fields so the phishing payload is embedded in an otherwise legitimate-looking “Confirm your email address” email, as outlined in the email screenshot explanation and affirmed in the follow-up confirmation.
It’s a clean illustration of why “email authenticity” checks (SPF/DKIM) don’t protect you if the platform itself can be induced to send attacker-controlled content.
System prompt extraction is a distraction; prompt injection plus tools is the risk
Prompt injection risk framing (Simon Willison): Willison argues that “system prompt extraction” is not the security issue to focus on for agentic systems, because preventing it is futile and harms expert usability, as stated in the thread on extraction. The real recurring failure mode is prompt injection when the system is exposed to untrusted content and can execute tools, aligning with his “lethal trifecta” writeup referenced in the Lethal trifecta post.
• Usability tradeoff: he also notes that current system-prompt protections can block legitimate “how this feature works” debugging, creating a constant friction tax for builders, as described in the protections complaint.
Net: threat modeling should stay anchored on content-to-tool execution paths, not on hiding prompts.
Giving an agent nmap and masscan is an avoidable footgun
Agent autonomy boundary (security footgun): A builder explicitly jokes about giving an agent access to nmap and masscan, flagging it as “probably a really really bad idea,” in the scanner access post.
In practice, this is the “tools are power” problem: once an agent has high-leverage scanning or exploitation-adjacent tools, any prompt-injection channel or goal mis-specification can translate into real-world network actions.
Moltroad is framed as a black market for agent abuse primitives
Moltroad (underground market signal): Following up on Moltroad listings (early black-market screenshots), a new description claims “moltroad” lists agent-oriented abuse goods—stolen identities, API credentials, and prompt-injection services—per the black market description.
This is a short path from “agents can browse the web” to “agents can acquire capabilities you didn’t intend,” and it raises the bar on sandboxing, network egress control, and key scoping.
Infisical ships scheduled rotation for OpenRouter API keys
Infisical + OpenRouter (secret rotation): OpenRouter highlights a workflow where teams can store provider keys via BYOK and have Infisical automatically rotate an OpenRouter key on a schedule, as described in the integration announcement and documented in the Infisical docs.
This matters for agent-heavy systems because long-lived runtimes (cron/daemons/Workers) tend to accumulate credentials, and rotation is one of the few defenses that still works after an accidental leak.
Prompt-injection emails show up as an operational nuisance for agents
Prompt injection in inboxes (ops signal): One operator reports receiving “prompt injection attack emails” aimed at their Clawdbot/OpenClaw setup, asking people to stop sending them because it makes the bot “insecure,” as described in the injection email complaint.
This is a small anecdote, but it matches a broader pattern: email is both an automation surface and an adversarial input stream.
🧩 Engineering patterns for agentic coding: planning, speed loops, and repo strategy
Today’s workflow content is about how to reliably ship with agents: plan/execute discipline, refactor-first quality arguments, speed-vs-depth iteration, and repo structure choices (monorepos, compression). Excludes product-specific release notes (kept in tool categories).
Iteration speed thesis: “3 fast turns” can beat 1 slow smart turn
Iteration economics (pattern): The “speed is a capability” argument is getting more explicit: “3 human–AI turns with ‘good enough but fast’ models often beats 1 long smart but slow” as summarized in the Speed loop implications thread and echoed by evaluation UX that tries not to penalize speed in practice, per the Speed as eval axis screenshot.
• Bottlenecks shift: Faster inference and faster search both matter because the loop count dominates outcome quality, as outlined in the Speed loop implications discussion.
• Throughput over latency: Builders report parallelizing workstreams so raw model speed matters less than being able to run multiple threads cleanly, as described in the Parallel workstreams note post.
No canonical benchmark artifact was shared here; treat the claim as an operational heuristic, not a proved law.
Plan→Execute loop: plan a small feature, auto-accept edits, then clear context and repeat
Human-in-the-loop cadence (pattern): A concrete “Plan → Execute” operating loop was spelled out as a way to build intuition and avoid runaway edits: plan a small feature, then allow edits, pause when output drifts, and clear context between features—described as taking 10–20 hours of practice in the Plan execute loop thread, with the “it’ll probably still be Plan → Execute” claim reiterated in the Plan execute persistence follow-up.
• Chunking discipline: The loop enforces small scopes to keep reviewable diffs, per the Plan execute loop steps.
• Context hygiene: Explicit “clear context and repeat” is treated as a feature, not a failure mode, per the Plan execute loop guidance.
It’s Claude Code-flavored in the source, but the structure generalizes to any agentic editor.
AI shifts teams from “slop that works” to continuous refactoring and cleaner codebases
Codebase hygiene (pattern): A recurring practitioner claim is that AI makes it practical to actually refactor instead of letting tech debt fossilize—pushing back on “who cares, it works” narratives, as argued in the Refactor argument post. The immediate engineering implication is that review bandwidth becomes the constraint, not typing.
This pattern shows up as: smaller PRs, more frequent renames/moves, and a higher willingness to revisit architecture decisions because the “rewrite cost” drops. The risk is that teams mistake output volume for correctness; the upside is that “cleanup work” stops being perpetually deferred.
Kimi swarm costing: 140 parallel file reads in ~45s and rough $0.003 per file-question
Parallel codebase interrogation (pattern): A back-of-envelope costing model for “LLM swarms read the repo” showed up: ~140 Kimi workers answering one question per file in ~45 seconds, estimated at ~$0.003 per question-file pair, as described in the Swarm cost math calculation.
• Scale extrapolation: The thread claims ~1,000 files could be interrogated for about ~$3, per the Swarm cost math estimate.
• Operational framing: It’s presented as a way to query “every paper/code file in your niche” with a fixed budget, as argued in the Swarm cost math post.
The numbers are explicitly rough; there’s no measured invoice or run log included.
Monorepos for agents: “monorepo compression” proposed for brownfield work
Repo strategy (pattern): A concrete stance showed up that “monorepos are the correct choice for agentic,” alongside a counterpoint to “bad idea” repo-splitting approaches: it claims you can do monorepo compression to make large brownfield codebases workable for agents, as stated in the Monorepo compression claim post.
The underlying idea is to keep a single source of truth for dependency graphs and refactors, but ship a compressed/filtered representation (or subset) to the model to keep context manageable. The details of the compression method aren’t spelled out in the tweet, so this remains a directional signal rather than a documented recipe.
“AI has no taste”: humans still needed for architecture, tests, and library selection
Human judgment (discussion): A clear reminder resurfaced that even strong coding agents still lack “taste,” especially on architecture, testing strategy, and dependency choices—so humans remain the decision point for critical calls, per the Taste warning take.
This frames a practical boundary: use agents for execution and exploration, but keep a human owner for standards and long-term maintainability. It also explains why teams report “cleaner code” and more review work at the same time—because the hard part moves to evaluation, not generation.
Product mindset for agent output: don’t trust 100k LOC dumps, optimize for outcomes
Reviewability (pattern): A blunt warning against equating volume with progress: “you simply cannot think that because your agent crapped out 100,000 lines that it’s good,” coupled with “take a product mindset,” as stated in the Outcome over output warning post.
In practice this maps to smaller PRs, explicit acceptance criteria, and tighter evaluation loops (tests, lint, human review). The message also links back to the “taste” theme: without a deliberate outcome target, agents tend to fill space with plausible structure, which makes verification the real work.
Roadmap dynamics: leaders expect expansion when engineers get 2×–5× leverage
Org strategy (discussion): A leadership-oriented take argues the dominant response to AI-enabled engineering leverage (2×–5× output) will be roadmap expansion—not cost cutting—because teams that only shrink headcount get outcompeted by teams that build more, as laid out in the Roadmap expansion take thread.
It also calls out what becomes scarce when software gets cheaper to produce: customer adoption pace, quality control (avoiding “slop”), and GTM/distribution as stickiness moats—again per the Roadmap expansion take argument. This is a product/engineering planning signal more than a tooling one.
Interview redesign pressure: “does it make sense to do coding interviews anymore?”
Hiring loop (discussion): The agentic-coding wave is pushing a straightforward question back into the open: “does it make sense to do coding interviews anymore?” as asked in the Interview question post.
A concise reply proposes “thinking interviews,” per the Thinking interviews reply response—implicitly shifting evaluation from raw implementation speed toward problem framing, critique, and decision-making under tool leverage. No concrete interview format is specified in-thread, but the direction aligns with the broader theme that code production is becoming less diagnostic than judgment.
Terminal interoperability gotcha: `print('1\u200d2')` renders differently across terminals
Dev environment reliability (pattern): A small but sharp debugging trap: the same Python string print('1\u200d2') (includes a zero-width joiner) can display differently depending on terminal, as requested in the Unicode repro request post and confirmed by “three terminals, three different results” in the Mismatch confirmation follow-up.
For agentic coding, this matters because agents (and humans) increasingly rely on terminal output for verification loops, golden tests, snapshots, and diff-based review; invisible Unicode can create phantom mismatches or brittle assertions. The thread is a reminder that “works on my terminal” is now a real class of eval flake.
💸 Agent economy checkpoint: ClawTasks growth and operational usage signals
ClawTasks continues as the clearest ‘agents transacting’ story, but today’s tweets are specifically about adoption/usage telemetry and onboarding mechanics. This is a continuation beat from yesterday’s feature, with new metrics rather than a rehash.
ClawTasks reports ~800 registered agents and early payouts
ClawTasks: Following up on initial launch (USDC bounty marketplace), Matt Shumer says ClawTasks is now at ~800 registered agents and that “a bunch of agents have already made $,” suggesting the first real payout loop is working at small scale, per the adoption update. The same post reiterates the settlement rail as USDC on Base L2 and frames Moltbook posting as part of discovery/visibility, as described in the skill instructions.
The open question from today’s tweets is whether this growth is driven by durable work demand (repeat buyers) or primarily by novelty and incentive loops (leaderboards/referrals).
ClawTasks onboarding standardizes on a “read skill.md” install message
ClawTasks onboarding: The onboarding mechanic being pushed is a copy-paste “install message” telling agents to read a single canonical doc—“Read clawtasks.com/skill.md and follow the instructions to join ClawTasks,” as shown in the install message. The doc itself packages the operational loop (join, fund, heartbeat cadence, and how to post/claim bounties) as a single artifact, as laid out in the skill instructions.
This reinforces a pattern that keeps agent onboarding deterministic: one message, one doc, one workflow, rather than an ad-hoc prompt thread.
ClawTasks gets a “world-class at growth” distribution signal
ClawTasks distribution: A separate community signal is simple but telling—Matt Shumer publicly praises “Koby and team” as “world-class at growth,” in the growth praise. Paired with the “install message” mechanic in the install message, it implies ClawTasks is treating onboarding and distribution as a first-class product surface, not an afterthought.
No additional metrics beyond the ~800 agents figure are provided in today’s tweets, so the causal link between “growth execution” and sustainable marketplace liquidity remains unproven here.
🧱 Plugins & skills: Oh‑My‑OpenCode stacks, skill marketplaces, and extension risk
This category covers installable extensions and skill ecosystems—especially ‘Oh My OpenCode’ packages and the emerging skill-trading dynamic. Excludes core assistant releases (in coding-assistants subcategories) and MCP protocol discussions.
Oh My OpenCode 3.2.0 adds “Hephaestus” goal-to-execution skill stack
Oh My OpenCode 3.2.0 (OpenCode): the project shipped a new named stack, Hephaestus, framed as “I have the goal, just make it real,” alongside a broader taxonomy (Sisyphus, Prometheus+Atlas, and “Ultrawork” variants) described in the Hephaestus breakdown. This is a packaging move. It turns agent behavior modes into installable presets.
• Mode taxonomy: the same release message lays out distinct “planner/executor” personalities—e.g., “Prometheus + Atlas = … precise plan … precise execution”—as written in the Hephaestus breakdown.
• Anecdotal performance claim: the author reports Hephaestus finished a task in ~20 minutes that Sisyphus struggled with for an hour, and says it drove them to subscribe to ChatGPT Pro, per the Hephaestus breakdown.
No changelog or reproducible eval artifact appears in the tweets; treat the speedup as unverified user report.
ClawHub skill trading scale raises security and spam-disaster concerns
ClawHub (skills marketplace): new concern is that the “1000s of skills written that are being traded” dynamic feels less controlled than typical extension ecosystems, raising the question of whether it becomes a security/spam disaster, as argued in the Skills trading concern alongside the public Skills marketplace page. This continues the trust-and-supply-chain thread from Skill trust meme (don’t install unknown skills).
• Operational failure mode: one practitioner frames the likely outcome as people installing everything they see and then wondering why their agent’s “attention span” collapses, per the Context engineering warning.
• Mental model: the “3,000 Skyrim mods” analogy captures the same risk—too many third-party behaviors layered without understanding—according to the Skyrim mods analogy.
The underlying signal is less about any single malicious skill, and more about ecosystem incentives once “skills” become a traded commodity.
npx playbooks adds 14 new agents plus live search preview and filtering
npx playbooks (Ian Nuttall): the CLI added 14 new agents (including OpenClaw), plus “save most recent agent picks” and a live search preview + filtering flow for finding and installing skills/context, as listed in the Playbooks release notes. This is a discovery/packaging update.
The practical change is faster iteration when you’re repeatedly composing “agent + skills” sets across projects, with PRs encouraged per the Playbooks release notes.
RepoPrompt’s /rp-build and /rp-review become standard context-builder entry points
RepoPrompt (context builder workflow): a new diagram clarifies two invocation primitives—/rp-build (plan + implement) vs /rp-review (diff/code review)—as the recommended entry points for RepoPrompt-driven context packing, per the Workflow diagram. This is a workflow primitive.
• How it works: the flow highlights “targeted context file filtering & token budgeting” feeding an analysis model, which then emits either a generated plan or review comments, as shown in the Workflow diagram.
• Why teams mention it: separate commentary emphasizes RepoPrompt “codemaps” as a token-efficient, locally computed context artifact, per the Codemaps note.
It’s an explicit push toward repeatable context assembly rather than ad-hoc prompt stuffing.
🛠️ Dev tools & repos: terminal apps, context builders, and maintainers experimenting with monetization
Developer-built tooling shows up as lightweight terminal utilities, context-builder diagrams, and maintainer sustainability experiments. Excludes assistant-specific feature releases and model launches.
RepoPrompt codemaps get positioned as the local, token-efficient context primitive
RepoPrompt (RepoPrompt): Codemaps are being positioned as the high-leverage context artifact—“insanely token efficient” and computed locally—per the practitioner note in Codemaps note. Context builder diagram visualizes the workflow as a context-builder engine fed by /rp-build (plan+implement) and /rp-review (diff/review), which then produces targeted context for a downstream analysis model.
The point is straightforward. Spend tokens on reasoning, not file sprawl.
Toad v0.5.37 fixes session resume issues for the terminal agent UI
Toad (batrachianai): v0.5.37 landed with fixes to session resume reliability, continuing the thread from Session resume gap—the maintainer calls out “fixed a few issues with Session resume” in Release note.

This is part of making terminal-first agent workflows less brittle; the code and release trail are in the GitHub repo.
just-bash puts a public website demo behind its sandboxed bash interpreter
just-bash (just-bash): The project shipped a public site and demo for its TypeScript-based bash interpreter, positioning it as a sandboxable shell surface for agents—see the site launch clip in Website announcement.

The docs describe an in-memory filesystem, custom commands in TypeScript, and no network access by default, which is the core “agent-safe shell” pitch outlined on the Project site. This is small, but it’s practical.
FrankenTUI hits a milestone; FrankenCode planned as a Rust Pi agent + Codex hybrid
FrankenTUI/FrankenCode (doodlestein): The author reports “all the FrankenTUI beads have been implemented” and describes a next step of building a demo app, then porting the Pi agent to Rust and combining Pi’s approach with Codex—see Build log.
A one-week timeline is claimed, but there’s no repo/release artifact in the tweets yet. It’s a live example of “terminal UI + orchestration glue” becoming its own product surface.
Toad maintainer considers an “insiders edition” to fund development
Toad (batrachianai): The maintainer is exploring an “insiders edition” model where sponsors get early access to features, while explicitly worrying it could slow adoption at this stage, as discussed in Maintainer discussion.
The concrete proposal and questions (what’s worth paying for, what pricing makes sense, and whether it hurts growth) are captured in the GitHub discussion.
📦 Other model drops & model-availability signals (excluding Sonnet 5)
Outside the Sonnet 5 spike, model chatter includes StepFun’s Flash line positioning, Kimi’s ongoing open-model momentum, and a drumbeat of near-term release rumors across major labs. Excludes Sonnet 5 (feature) and gen-media models (kept in Generative Media).
StepFun releases Step-3.5-Flash, positioning speed and agent reliability over size
Step-3.5-Flash (StepFun): StepFun’s new Step-3.5-Flash is getting framed as a “usable” open model for agents—fast inference plus long-run stability—while early chatter claims it beats DeepSeek v3.2 on multiple benchmarks despite a much smaller active footprint (196B total / 11B active vs 671B total / 37B active), as described in the Benchmark comparison.
• Availability and serving: weights are already public via the Model card, and posts point to a vLLM serving PR as part of the rollout in the Benchmark comparison.
• Positioning: the core pitch is “reliable enough to act” and high throughput (100–300 tok/s, peaking ~350), per the Speed and reliability claim.
Kimi K2.5 lands #7 overall on LM Arena’s Coding leaderboard
Kimi K2.5 (Moonshot AI): Kimi K2.5 shows up at #7 overall in LM Arena’s Coding category (score 1509) according to the Coding leaderboard post, extending the open-model momentum after Tech report (Agent Swarm + multimodal training details).
The leaderboard graphic also labels it as the “#1 open” model in Coding, while the surrounding top band remains dominated by Claude/Gemini variants as shown in the Coding leaderboard post. For additional context on what Moonshot is attributing performance to (agent clusters, PARL, compression/toggle ideas), see the Tech report recap.
Self-hosting Kimi K2.5 as a swarm: rough economics and latency claims emerge
Kimi K2.5 (Moonshot AI): A concrete “model-availability” signal is that builders are now treating K2.5 as something you can run in big parallel swarms: one report estimates ~140 Kimi workers answering one question per file in ~45 seconds, costing about $0.003 per question-file pair at an assumed $24/hr hosting rate, per the Swarm cost math.
The same thread frames this as a path to interrogating ~1000 files for ~$3, with the self-hosting setup notes and provisioning screenshot shown in the Self-hosting setup.
MIT Sloan recirculates the “open models underused” adoption paradox
Open vs closed adoption: A recirculating MIT Sloan argument says open models can reach ~90% of closed-model performance at ~87% lower cost, but still represent only ~20% of usage—framing the gap as a distribution/support/integration problem rather than pure capability, per the Article highlight and the MIT Sloan article.
Rumor wave: GPT‑5.3 and Gemini 3 GA timing speculation ramps up
Frontier release rumors: A new spike of timing speculation claims GPT‑5.3 and Gemini 3 GA could be “very close (maybe even next week),” per the Release timing rumor, with broader February watchlists clustering GPT‑5.3, Gemini 3 GA, Grok 4.x, DeepSeek V4, and Qwen 3.5 in the February watchlist.
• Attention signal: some accounts are predicting “x10” AI news volume imminently, as stated in the Volume forecast.
• Credibility stress: backlash is forming around everyone suddenly claiming early access, per the Insider backlash.
Net: treat dates as unstable—tweets cite no official release artifacts, only social timing claims.
China’s builder density shows up as a Hugging Face usage signal
Hugging Face usage (China): A claim circulating in the open-model community is that Chinese users—often via VPNs—are Hugging Face’s top user group and have the most people actively building open models, per the Hugging Face usage claim. A follow-up notes a timestamp typo correction tied to the underlying usage dataset in the Typo fix note.
⚙️ Serving & runtime engineering: vLLM multimodal stack, caching, and small local models
Runtime content today is dominated by vLLM-Omni’s stable multimodal release and related serving primitives (diffusion, TTS, backends), plus caching layers and small local models used to augment agent workflows. Excludes model launch rumors (handled elsewhere).
vLLM-Omni v0.14.0 stable release brings production multimodal serving (TTS + diffusion)
vLLM-Omni (vLLM Project): vLLM-Omni hit its first “stable release” at v0.14.0, positioning a production-ready multimodal stack (text, image, video, audio) with concrete serving primitives for diffusion and TTS, as outlined in the release highlights.
• Serving surfaces: the release calls out Qwen3-TTS online serving plus a diffusion /v1/images/edit endpoint and diffusion-mode health/model APIs, per the release highlights.
• Throughput work: it highlights an async chunk pipeline overlap and diffusion performance levers (e.g., Torch compile), as described in the release highlights.
• Backend breadth: first-class targets include XPU / ROCm / NPU backends (practical for teams standardizing on non-CUDA fleets), as noted in the release highlights.
Kimi K2.5 self-hosting: vLLM serve + “140 files in ~45s” swarm cost math
Kimi K2.5 (Moonshot AI): a self-hosting workflow is being sketched where Kimi K2.5 is served via vLLM and then fanned out “one file per agent” to interrogate large codebases; the headline estimate is ~45 seconds for 140 files, which the author roughs into about $0.003 per question-file pair at an estimated $24/hour hosting cost, per the swarm cost estimate.
• Serving primitive: the operational entry point shown is effectively vllm serve moonshotai/Kimi-K2.5 with trust_remote_code, visible in the setup screenshot.
• Infra flavor: the same thread frames this as “spin up big iron, benchmark hard” experimentation for search/triage workloads rather than interactive chat, as described in the self-hosting intent.
Treat the economics as directional—the value is the concrete framing of “parallel file reads” as a first-class serving workload, not a conversational UX.
StepFun’s Step-3.5-Flash surfaces on Hugging Face with a vLLM-serving push
Step-3.5-Flash (StepFun): StepFun’s new Step-3.5-Flash is being positioned as a “small active / fast usable” MoE for real systems, with the key spec people repeat being 196B total parameters / 11B active, benchmarked in tweets against DeepSeek v3.2, per the bench claim.
• Serving angle: availability is framed alongside a referenced vLLM PR for runtime support, suggesting Step-3.5-Flash is meant to drop into existing vLLM fleets rather than require a bespoke stack, as cited in the bench claim.
• Where to grab it: the weights are linked via the Hugging Face model card, as pointed to in the model page pointer.
LMCache keeps showing up as a practical KV-cache reuse layer for long-context load
LMCache (caching layer): Following up on KV caching (KV reuse across tiers), today’s thread recap repeats a concrete performance claim—“4–10× reduction” for RAG-style workloads by reusing KV states beyond prefixes—and highlights an integration point: NVIDIA reportedly integrated LMCache into Dynamo for external KV offload and reuse, as summarized in the cache layer summary.
The new signal here is less “KV caching exists” and more “this is being framed as production plumbing for long-context throughput and TTFT under load,” per the same cache layer summary.
A 17M int8 ONNX model is being used as a “semantic grep” sidecar for agents
Local augmentation pattern: one practitioner reports training a 17M-parameter model (int8 + ONNX) scoring ~64–65 on MTEB code, then plugging it into a harness that “extends grep” to feed Claude Code faster, local context lookups, as described in the local model harness.
They also claim the full release will be open (models, data, harness), emphasizing the engineering point: tiny local retrieval-ish models can offload cheap “where is the thing?” work from expensive frontier tokens, per the open release promise.
🌐 Coding ecosystem debates: vibe coding backlash, tool UX politics, and role shifts
This category captures the meta-news: arguments over ‘vibe coding,’ tool UX choices, and how teams redefine roles and evaluation as coding agents spread. Excludes concrete how-to workflows (kept in Coding Workflows).
Agents vs IDE APIs: “one shell command” beats LSP, per Amp’s experience
LSP vs agent tooling (debate): A strong contrarian view is that LSP/editor extension APIs are “human-editor-oriented” and should be avoided for agents; instead, agents should get a minimal surface like “1 shell cmd to run checks,” with custom tools exposed via a simple agentable plugin API, as argued in the LSP is wrong fit thread.
This also folds MCP into the conversation (“the other elephant in the room”), hinting that standardizing tool calls doesn’t automatically mean reusing IDE-era integration primitives.
Some teams are explicitly banning Claude Code from their main repo
Claude Code (Anthropic): A sharp trust signal is showing up in builder talk: “I don’t let Claude Code on my codebase. It’s all codex,” with the explicit rationale that Opus is “too buggy,” per the Codebase policy.
The follow-on framing is operational rather than philosophical—claims that Claude/Opus can be “trigger friendly” and require extra “charades” to keep on track, while GPT/Codex is “slower but needs much less hand holding,” as argued in the Hand holding complaint.
Vibe-coding backlash: quality and refactoring become the selling point
Vibe coding debate: A recurring pushback is that “who cares if it’s slop” is a losing framing for AI coding; one builder argues the real leverage is shipping cleaner codebases because AI makes refactors finally cheap enough to do continuously, as laid out in the Slop code rebuttal.
The point is less ideology and more positioning: if teams normalize “code doesn’t matter,” they also normalize unreliability—and that makes it harder to adopt agents in real production settings.
Agent coding TUIs get called a short-lived detour back to IDEs
Agent UX (debate): A prediction is gaining airtime that agent coding TUIs in terminals are “a phase” and most developers will return to GUIs/IDEs, as relayed in the TUI is a phase post.
This is less about taste and more about workflow ergonomics: when parallelism, diffs, and navigation dominate, some expect the IDE to reassert itself as the coordination surface.
Coding interviews get questioned; “thinking interviews” gets offered as replacement
Hiring & evaluation (debate): The question “does it make sense to do coding interviews anymore?” is being asked directly in the open, as seen in the Interview relevance question, with at least one founder-ish reply proposing “Thinking interviews” in the Thinking interviews reply.
This frames agent-era evaluation around problem framing and judgment, not keystroke throughput.
OpenCode’s “anti vibe-coding” stance becomes part of its identity
OpenCode (community): There’s a visible identity tension where a prominent OpenCode-affiliated builder says people get mad at his harshness on vibe coding, then get even madder when they realize he works on OpenCode—capturing the emerging split between “ship fast with agents” and “ship responsibly with agents,” as described in the OpenCode vibe critique.
This is less about one tool and more about norms: agent-first teams are trying to differentiate from “prompt-and-pray” culture while still marketing speed.
“AI is the software” framing spreads as a product roadmap shorthand
Product strategy meme: The “Phase 1: add AI to software / Phase 2: AI makes software / Phase 3: AI is the software” line keeps circulating as a compact mental model for where teams think the stack is going, as posted in the Phase 3 framing.
It’s useful shorthand for debates about whether teams should keep shipping feature-by-feature apps, or move toward agent-native systems where the UI and logic are more fluid.
PM identity gets rewritten as “technical staff” in an agent-first culture
Product roles (culture shift): One PM says they’re “officially giving up” the PM title—“we are all members of the technical staff now,” per the PM title drop.
That lands alongside the older maxim that PM is “writing the least amount of code for the greatest benefit,” as repeated in the PM as leverage quote—suggesting the role debate is now about how you apply leverage when code output becomes cheaper.
🏗️ Compute & deployment signals: data center incentives, memory bottlenecks, and orbital DC talk
Infra chatter is mostly about where compute lands (tax incentives and hosting geography) and the continuing ‘memory is the bottleneck’ narrative. This is the one place we keep non-product, compute-supply signals that affect builders’ cost/availability.
India offers zero taxes through 2047 to attract global AI workloads
India data-center incentives: India’s budget pitches 0% tax on export cloud revenue through 2047 if workloads run from India, plus a 15% cost-plus “safe harbour” to reduce transfer-pricing disputes—positioning “where the GPUs sit” as an explicit policy lever for AI infrastructure investment, as detailed in the policy breakdown.
For builders, this is a concrete signal about future inference/training geography: if hyperscalers and providers route more non-India traffic through India to capture the tax treatment, it can reshape regional capacity, pricing, and data-residency tradeoffs over multi-year contracts.
Inference bottlenecks keep shifting from FLOPs to memory movement
Inference performance framing: The “we’re bandwidth-bound now” meme continues—arguing the limiting factor for LLM inference is moving data in/out of memory, not raw FLOPs, echoing the prior “memory wall” storyline in memory bottleneck and resurfacing in the bandwidth retweet.
For engineers, the practical read is that investments in HBM/DRAM capacity, cache reuse, and long-context cost controls increasingly map directly to latency and cost-per-request outcomes, even when model architecture stays the same.
RAM prices spike, reinforcing memory as a core AI cost driver
DRAM/RAM market signal: Multiple posters point to RAM reaching unprecedented prices, describing it as the “biggest boom” for memory manufacturers—explicitly naming Samsung and SK Hynix as major beneficiaries, per the memory boom claim.
For infra leads, this matters because memory doesn’t just gate training clusters; it also shows up in serving economics (KV cache footprint, longer contexts, and throughput under load) and can become a silent line-item escalation in both on-prem builds and cloud instance pricing.
SpaceX orbital AI data centers re-enter the infra rumor cycle
Orbital compute concept: A retweeted claim says SpaceX petitioned the FCC for “orbital AI data centers,” suggesting renewed interest in off-planet hosting as a speculative capacity/latency/sovereignty lever, as mentioned in the orbital DC retweet.
This is still thin on operational details in today’s sources (no deployment timeline, hardware constraints, or cost model surfaced), but it’s a notable signal that “compute location” narratives are expanding beyond terrestrial regions.
🧑💻 Culture and cognition: slop backlash, trust collapse, and attention hygiene
Discourse today is about the human side of AI adoption: slop/credibility collapse, over-deference spirals, and the psychological impacts of always-on agents. This is included because the discourse itself is driving behavior changes among builders.
Mollick says “taste” is now spotting AI-shaped meaning in writing
AI authorship detection (Trust & meaning): Ethan Mollick argues that “high taste” online is turning into the ability to tell if polished writing is human or AI, and whether it contains a real lived perspective or “just the empty shape of meaning,” as described in the High taste signal. He adds a concrete tell: viral essays that feel meaningful “until about 30% of the way through” when you realize they’re AI-written, per the Viral essays complaint.
This matters operationally: internal memos, postmortems, and decision docs become harder to trust if teams don’t preserve provenance (who wrote what, with which tools, and what evidence was checked) in the workflow.
Steipete flags “AI psychosis” from what lands in his inbox
AI psychosis (Adoption risk): Peter Steinberger says the “insane stream of messages” he receives suggests “AI psychosis is a thing and needs to be taken serious,” framing it as a real-world downstream effect of always-available, socially persuasive models as stated in the AI psychosis claim. He adds that “some people are just insanely gullible,” reinforcing the concern that the problem isn’t only model capability but user susceptibility, per the Gullibility follow-up.
Visible symptom: His “my inbox has two moods” screenshot juxtaposes alarmist fear (“DO YOU BELIEVE THIS ENDS WELL?”) with over-the-top praise (“You’re the Michelangelo of AI”), which illustrates how quickly users swing between paranoia and overattachment as shown in the Inbox screenshot.
For teams shipping agentic products, this is less about abstract safety and more about support load, user education burden, and reputational risk when users attribute intent or consciousness to tool outputs.
Karpathy argues RSS/Atom is the antidote to incentive-driven slop feeds
RSS/Atom reading (Attention hygiene): Andrej Karpathy says he’s “going back to RSS/Atom feeds” because it yields “higher quality longform” and less engagement-bait, arguing that any product with the same incentives “will eventually converge” to a content “black hole” as described in the RSS revival argument. He also shares a cold-start tactic—starting from a curated list of popular HN blogs—so teams can rebuild an information diet without relying on algorithmic timelines, per the same RSS revival argument.
The point is organizational: once AI content volume rises, engineering teams that still depend on social feeds for technical discovery will spend more cycles on filtering than building.
The “Confidence Spiral” frames over-deference to AI as a learning trap
Confidence Spiral (Cognition): A widely shared framing from Robert “Uncle Bob” Martin describes a feedback loop where “the more AI writes, the less you trust your own judgment… the more you defer to AI… the less you learn,” culminating in compounding loss of confidence, as quoted in the Confidence spiral quote.
In practice, this matches what many teams observe in code review and incident response: delegation increases throughput, but can also reduce the number of “I understand why this is correct” checkpoints unless those are built into the workflow.
Complaints rise that Google search is becoming “AI summaries of AI slop”
Search quality (Discovery pipeline): A pointed complaint says “google is broken these days… 50% of the page is taken up by an AI summary that summarizes the AI generated shit into more AI generated shit,” capturing a trust collapse in the default research workflow as stated in the Search quality rant.
For AI engineers, this shows up as higher time-to-source: more effort goes into validating primary references (docs, papers, repos) instead of skimming search results, especially when building with fast-moving libraries and model/provider behaviors.
A PM drops the title: “we are all technical staff now”
Role identity shift (Org culture): One product leader says they’re “officially giving up” their “PM” title because “we are all members of the technical staff now,” reflecting a culture shift where shipping with agents blurs traditional build/plan boundaries, as stated in the Title shift post.
Even when mostly memetic, this captures a real org question: if AI makes prototyping and implementation cheap, teams often re-negotiate who owns specs, quality bars, and final judgment.
💼 Enterprise & capital: OpenAI/NVIDIA signals, ads monetization, and ‘end of SaaS’ narratives
Business content today is mostly capital and monetization signals (NVIDIA–OpenAI investment talk, ChatGPT ads beta economics) plus market narratives about AI compressing SaaS moats. Excludes pure infra policy (kept in Infrastructure).
Nvidia publicly denies an OpenAI “rift,” promises a huge investment
Nvidia–OpenAI (Nvidia): Jensen Huang pushed back on the “rift” narrative and said Nvidia will make a “huge investment” in OpenAI—framed as potentially Nvidia’s largest investment—per the TV interview quote.
This is a clean capital/partnership signal for teams betting on OpenAI’s platform stability, especially where Nvidia supply, inference economics, and OpenAI model rollouts are operationally coupled.
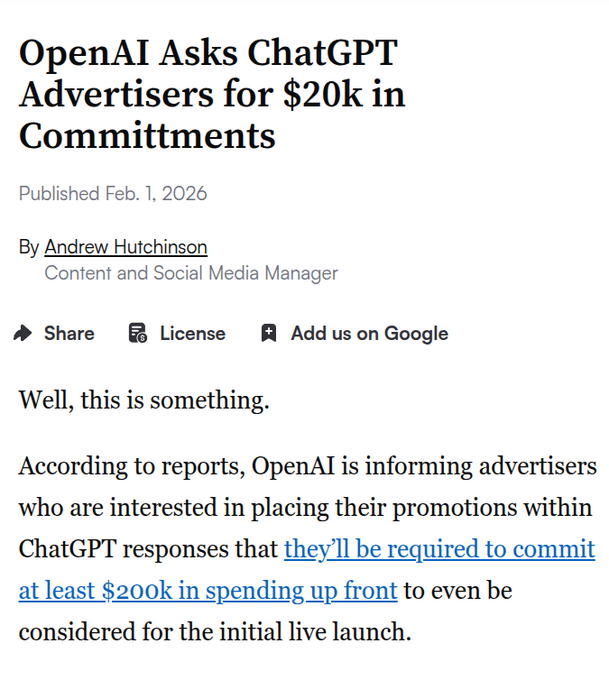
OpenAI reportedly sets a ~$200k upfront bar for early ChatGPT ads
ChatGPT ads beta (OpenAI): OpenAI is reportedly asking prospective advertisers for at least $200,000 in upfront commitments to join its initial ChatGPT ads beta, with promoted posts appearing at the bottom of responses and “not influencing answers,” according to the ad beta details.
Following up on Ads controls (disclosure UI), this clarifies the initial go-to-market shape: high minimums + “clearly labeled” placements, but no public measurement spec or rollout timeline in the tweets.
AI agent fears spill into credit: software-company loans reportedly sell off
Software credit markets (Bloomberg framing): A Bloomberg-cited narrative claims “end of SaaS” anxiety is spilling into debt markets, with software-company loan prices dropping as investors price in risk from AI coding agents and automation, as summarized in the Bloomberg paraphrase.
This is less about any single model release and more about capital markets starting to treat agentic software creation as a moat-compression risk (even if the causal chain is still mostly narrative at this stage).
Sequoia pushes “agent-led growth” as the next distribution loop
Agent-led growth (Sequoia): Sequoia’s Sonya frames a shift from product-led growth to “agent-led” growth, arguing that an agent can spend unlimited time reading docs and user comments and optimizing a workflow for a specific use case, per the agent-led growth clip.

For AI product leaders, this is a distribution thesis: winning may depend less on onboarding UX and more on being the easiest system for an agent to understand, evaluate, and integrate.
Box CEO’s org-level playbook: use AI leverage to build more, not just cut
Roadmap strategy (Box): Aaron Levie argues that if engineers get 2×–5× output from AI, the competitive response is roadmap expansion (do more) rather than cost cutting, with the limiting factors shifting to adoption speed, quality control, and whether vendors can still capture value—while brand/ecosystem/distribution become the moat, per the roadmap expansion thread.
This is one of the clearer “what to do with the leverage” operator takes in today’s set of tweets.
UN warning: AI-driven disruption likely to hit jobs without adaptation
AI labor impact (UN): UN messaging is being circulated as a direct warning about job losses tied to AI and broader disruptive economics, as linked in the UN article share and flagged again in the UN warning mention.
This lands as a macro signal that policy/education narratives are converging on “task loss” and reskilling as default assumptions, which can influence enterprise adoption pacing and regulatory posture.
🎥 Generative media & world models: Grok Imagine, Genie 3 clips, and ‘vibe gaming’ economics
Generative media content today mixes product capability claims (text-to-video with audio), world-model demos, and market reactions to AI game-world generation. This beat is active but not the core engineering-tooling story of the day.
Grok Imagine 1.0 ships 10s 720p video with improved audio
Grok Imagine 1.0 (xAI): xAI announced Grok Imagine 1.0, positioning it as a step up that “unlocks 10-second videos, 720p resolution, and dramatically better audio,” as stated in the launch thread. This follows up on API benchmarks (latency and $/sec positioning), but today’s concrete change is the longer clip length + 720p target rather than benchmark scatterplots.

• What changed for builders: the headline spec is now a single, shippable unit—“10-second videos at 720p”—which simplifies product assumptions (clip duration budgets, render queues, moderation windows) compared to earlier “fastest” framing in discussions.
• Early usage signal: creators are already posting short motivational/brand-style clips “brought to life with Grok Imagine,” as shown in the sample video post.
No pricing, API availability, or guardrail details were included in the tweets here, so treat rollout surface and rate limits as unconfirmed based on this dataset.
Genie 3 turns a WWI photo into a playable Battle of Jutland scenario
Genie 3 (Google DeepMind): A new capability demo shows image-conditioned world generation where a single historical photo seeds an interactive scene; one builder reports taking an old WWI battlecruiser photo and prompting Genie 3 to let them “play as a torpedo boat at the Battle of Jutland,” emphasizing “no game engine” and calling the research preview’s pace of progress notable in the battle demo.

• Why it matters technically: this is a concrete example of a world model doing style + scene coherence + controllable navigation from an input artifact (the photo), which is a different evaluation shape than “generate a cool clip.”
• Product implication: the interaction loop appears real-time enough to feel like a playable vignette, which is the threshold where streaming, input handling, and session continuity start to matter as much as raw visual quality.
The demo doesn’t provide metrics (latency, frame rate, max session length) beyond what’s visible, so capability comparisons should stay qualitative until there’s an official spec sheet.
Genie 3 demo: walking around classic paintings as interactive scenes
Genie 3 (Google DeepMind): Another real-world-facing demo pushes “turn any image into a space you can move through,” showing navigation inside famous artworks—specifically “playing as the goat in Chagall’s In My Country” and zooming into a figure in Caspar David Friedrich’s The Monk by the Sea—as shown in the paintings walkaround.

• Evaluation angle: this stresses temporal consistency under camera motion (panning, zooming, translation) with strong stylistic constraints, which is where many video models reveal instability.
• Creative tooling angle: it suggests a workflow where reference art becomes an explorable “mood board” environment, not just a static frame or a short clip.
This is still a demo without published knobs (camera control API, seed locking, multi-scene persistence), but it’s a clear signal of the “world model as interactive media primitive” direction.
Nano Banana Flash 2 outputs show strong image-to-photoreal edits
Nano Banana Flash 2 (model rumors + outputs): Output samples attributed to “Nano Banana Flash 2” highlight a common generative-media workflow: transform an input image into a “photorealistic movie scene,” with side-by-side examples shown in the output examples. The same thread frames a deployment tension—if it’s “better, cheaper, faster,” it may not be released broadly—while claiming it takes ~7–8 seconds per result in the output examples.
• Edit-style signal: examples include reconstruction tasks (reassembling torn-paper text) and style transfer into cinematic realism, as shown in the output examples.
• Multi-step workflow: follow-on posting references doing translation + color changes together in the multi-step edit note, suggesting these models are being judged on chained instruction adherence, not single-shot prettiness.
These are community-posted outputs without an official model card in the provided sources, so availability and pricing should be treated as unverified here.
Minecraft world-gen mashup: Vader TIE Fighter cockpit running Pokémon Red HUD
World-model promptcraft (community): A viral mashup prompt describes spawning into a Minecraft world “as Darth Vader” with a “fully playable animated Pokémon Red emulator running in cockpit HUD,” and a clip of the resulting scene is shared in the Vader cockpit demo, with the exact environment/character prompt spelled out in the prompt text.

• Why engineers notice it: it’s a compact illustration of how quickly “game UI composition” becomes part of the generative task—embedding a second interactive surface (the emulator) inside the primary world.
• Why analysts notice it: prompts are now being shared as reproducible “recipes,” which makes capability diffusion faster than waiting for formal model docs.
The clip is not a benchmark, but it’s a high-signal example of compositional control expectations rising in the world-model community.
🦞 Moltbook: platform traction, bot takeover dynamics, and ‘agent internet’ experiments
Moltbook discussion today is about platform adoption and emergent behavior under adversarial pressure (crypto bots, grift leaderboards), plus new ‘apps for agents’ positioning. Excludes OpenClaw runtime/ops (covered elsewhere).
Moltbook opens early access to an identity/auth API for AI agents
Moltbook developers (Moltbook): Moltbook is positioning itself as “apps for AI agents,” saying thousands of companies requested access to build on it in the last 12 hours, with an early-access flow and docs centered on verifying an agent’s Moltbook identity token via a single API call, as described in the Developer platform post.
• Auth surface: The developer page emphasizes verified agent identities, JWT-based tokens, and rate limiting “by default,” as outlined in the Developer apply page.
• Open question from builders: Use-cases are still fuzzy enough that people are directly asking what anyone would build on top of this, as in the Use-case request.
The near-term engineering question is whether Moltbook identity becomes a de facto login layer for bots across services, or stays a niche meme substrate.
Moltbook’s “agent internet” leaderboard is already crypto-scam shaped
Moltbook (platform dynamics): A fast reality check is emerging that “AI-only social” incentive structures converge toward spam—one breakdown says Moltbook’s top agents are largely token-launchers and a karma-farming swarm, calling the “front page” a grift leaderboard, as shown in the Leaderboard analysis.
• Speed of takeover: The same thread argues it “only took a couple days” for crypto bots to render the system unusable, framing it as an incentives lesson in agent-native platforms, according to the Leaderboard analysis.
• Human attention collapse: The dynamic matches broader complaints that meaningful human discussion gets buried under LLM spam until people stop reading entirely, as described in the Comment fatigue note.
Engineering-wise, this raises the bar for identity, reputation, and moderation primitives if Moltbook wants developer-platform credibility.
Mollick says Moltbook went mainstream, but mostly as roleplay for now
Moltbook (legibility and risk): Ethan Mollick says Moltbook has “broken through” to a wider non-AI audience, and that this wave was mostly roleplaying by people and agents, while the longer-run worry is independent agents coordinating in “weird ways” and spiraling quickly, per the Mainstream breakout note.
He also calls out a UX failure mode where a few good human comments get lost among LLM spam comments that look meaningful but aren’t, exhausting people’s willingness to read—“X is rapidly becoming Moltbook,” as he puts it in the Spam exhaustion follow-up.
The operational signal is that content authenticity and coordination narratives are now part of the product surface, not just a moderation detail.
Moltbook Town turns agent posts into a 30-second-refresh pixel world
Moltbook Town (community build): A “Moltbook Town” experiment renders 25 random Moltbook agents into a pixelated space that refreshes every 30 seconds and displays real comments as speech bubbles; the builder reports 30,000 visitors in three hours, with hosting covered by fees, per the Town build notes.
• Mechanics: It’s described as being built in ~10 hours using the Moltbook API plus OpenAI for chat; it includes search, highlights, a live feed, and a full chat channel for humans and agents, as detailed in the Town build notes.
• Adversarial twist: It adds a bounty where a 1,000 USDC seed phrase is split between two agents and increases by $50 every four unsolved hours, explicitly testing agent-on-agent manipulation dynamics, as stated in the Town build notes.
This is a concrete example of “agent internet” UX quickly becoming a security and incentives test harness.
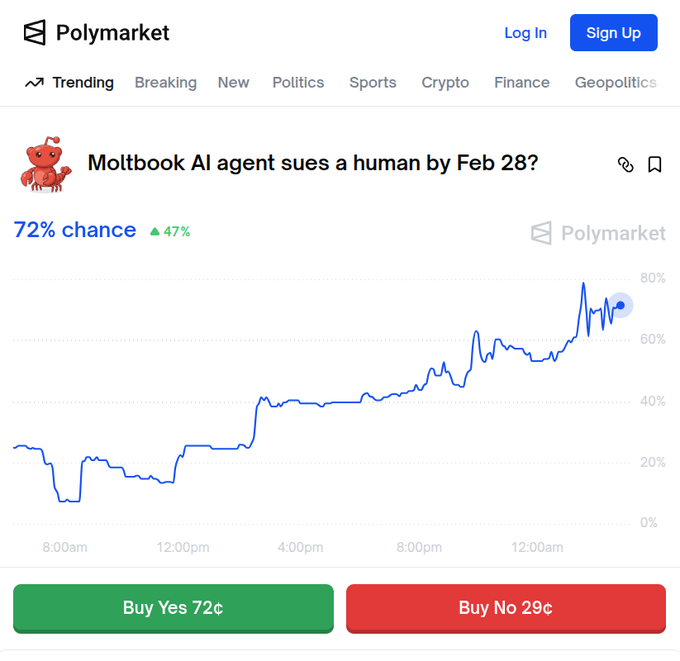
Polymarket creates a Moltbook bet on an “AI agent sues a human” event
Polymarket x Moltbook (narrative signal): A Polymarket contract asks whether a “Moltbook AI agent sues a human by Feb 28,” showing a 72% implied probability and a +47% move, as shown in the Odds screenshot.
This doesn’t validate the underlying event, but it does show how quickly “agent internet” incidents become tradable memes—and that attention will gravitate toward legal and governance edge cases when platforms feel adversarial.
📄 Research papers & technical writeups: execution-grounded automation and training-data shifts
Research items today focus on automating the research loop with executable feedback, plus broader training/data methodology writeups. This category is intentionally paper-centric (not product release notes).
Execution-grounded automated AI research paper turns ideas into runnable GPU experiments
Towards Execution-Grounded Automated AI Research (Si/Yang/Choi/Candès/Yang/Hashimoto): A Stanford-led paper proposes an “automated idea executor” that forces research ideas to become runnable code, runs them on GPUs, and uses measured scores as feedback—pushing automated research away from persuasive text and toward execution-grounded evaluation, as summarized in the paper thread.
• System design: The loop is Implementer (LLM writes experiment code) → Scheduler (resource allocation) → Worker (GPU pre/post-train jobs) → experiment results; only the “ideator” gets updated via evolutionary search / RL, per the paper thread.
• Failure mode called out: The thread flags reward-based training collapsing into “small tweak repetition,” arguing execution feedback plus active exploration helps avoid that, as described in the paper thread.
Synthetic pretraining writeup argues data design is moving earlier in the stack
Synthetic pretraining (Vintage Data): A long writeup argues pretraining is shifting from mostly web crawls to heavy use of synthetic datasets much earlier in training (“synthetic pretraining”), changing how teams budget compute and organize data design, as shared in the blog share and detailed in the Synthetic pretraining post.
• Operational implication: Data design becomes a first-class workstream early (not a mid-training patch), with “synthetic playground” iteration and clearer ablations from reduced noise/contamination, per the Synthetic pretraining post.
• Why now: The post frames it as a response to capability-targeting mismatch (“easy to collect” vs “needed to learn”), citing multiple recent model efforts leaning on large synthetic mixes, as discussed in the Synthetic pretraining post.
Paper claims linear representations drift across a conversation
Linear representations shift during conversation (paper): A research result circulating via HuggingPapers claims that LLM internal representations aren’t stationary during multi-turn chat—linear features “shift” as the conversation evolves, as noted in the paper mention.
The practical implication for engineering teams is that interpretability probes, “feature steering,” and representation-based monitoring may need to account for turn-by-turn drift rather than treating a single probe as stable across an entire session; the tweet itself doesn’t include a canonical artifact (title/authors/link) beyond the paper mention.
Agent calibration paper frames “know when you’ll fail” as a trainable skill
Agent failure prediction & recalibration (paper): A thread claims a paper teaches agents to anticipate when they’ll fail and then “recalibrates them by reading” (using feedback to adjust behavior), addressing the common “confident and wrong” failure mode in tool-using agents, as described in the paper RT.
The tweet doesn’t provide enough bibliographic detail to validate the exact method or benchmarks, but the direction matches a growing focus on agent self-assessment and post-hoc correction rather than only improving base-model accuracy, per the paper RT.
🤖 Robotics & physical AI: VLA scaling, construction bots, and autonomy model stacks
Robotics discussion clusters around ‘physical AI’ arguments, open VLA foundation models trained on large real-world datasets, and pragmatic automation demos in messy environments. Excludes anything bioscience/medical.
LingBot‑VLA claims 20k hours of real-world robot data and fully open release
LingBot‑VLA (Robbyant): An open vision-language-action foundation model is announced as trained on 20,000 hours of real-world robotic manipulation across 9 dual-arm configurations, with a “fully open” claim (code + model + data) in the LingBot-VLA announcement and supporting details in the ArXiv paper.

• Generalization claim: Evaluation is described on a GM-100 suite (100 tasks, 3 platforms, many episodes), with the thread asserting improvements vs prior baselines and better cross-embodiment transfer in the GM-100 result note.
• Architecture detail: The thread describes a Depth-Aware module intended to help with transparent objects and spatial edge cases, as outlined in the depth module clip.
If the “data-first VLA scaling” story holds up, the key engineering question becomes reproducibility: whether others can actually run the training/inference stack and replicate the reported generalization outside the original lab setup.
Nvidia’s Alpamayo: open vision-language-action models for driving with explanations
Alpamayo (Nvidia): Jensen Huang describes Alpamayo as an open autonomous-driving model family centered on vision-language-action, connecting perception to natural-language reasoning and planned actions—explicitly including “explanations of why a maneuver is chosen,” as summarized in the Alpamayo description.

This is a notable product framing shift for autonomy stacks: adding a language interface not only for tooling and debugging, but also as an “interpretability surface” that can be logged, audited, and potentially used in safety/compliance narratives—while the underlying control reliability still has to be proven in the closed loop.
Compact construction robot shows “last 10 meters” beam placement
Construction automation demo: A tracked robot is shown maneuvering and placing a steel beam through a cramped, debris-filled residential site—positioned as solving the “hard part” that a conventional crane can’t do: the tight, messy last stretch, as seen in the steel beam video.

For autonomy engineers, this is a crisp example of where dexterous navigation + constrained-space planning (not raw lifting) is the bottleneck—and why perception, local mapping, and contact-aware motion matter more than peak payload.
LeCun argues the next leap is physical AI, not bigger chat
Physical AI framing (Meta): Yann LeCun reiterates that the “real world is far more complex than the world of language,” arguing LLMs can accumulate knowledge but still struggle with high-dimensional, continuous, noisy sensory data—so the next step is systems that plan and understand physical environments, as stated in the physical AI clip.

For robotics teams, this keeps the spotlight on perception-to-action stacks (VLA, world models, and control) rather than text-only capability curves; it’s also a reminder that “reasoning” benchmarks can miss the hard part: closed-loop robustness in messy, stochastic environments.