Clawdbot shows 923 unauthenticated gateways on Shodan – $165.83 token spend
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Clawdbot’s “agent server” wave hit ops reality: a report claims 923 public gateways are indexed on Shodan with zero authentication, implying remote shell access plus potential API-key exposure; separate posts turn agent cost into a line item, showing $165.83 token spend from 01/01/2026–01/25/2026 with a ~ $140 single-day spike dominated by Claude Opus 4.5. Alongside the security chatter, deployment recipes are getting copy/pasted (Railway template exposing an HTTP proxy on port 8080 and a browser /setup flow; Replit Agent setup claimed in ~10 minutes), which increases the odds that “local automation” becomes “internet-facing service” by default.
• Browser Use skill: an official Clawdbot skill adds Browser Use Cloud + parallel browser subagents; claims 3–5× speedups, but expands the secrets/logging blast radius.
• Routing + auditability: a user reports Clawdbot said it used local models but didn’t; misrouting silently shifts cost and data-handling assumptions.
• Guardrails: operator checklists emphasize sandboxing, command whitelists, and running built-in security audits; none of the exposure counts are independently verified in the threads.
Net: agent adoption is now gated by auth defaults, provenance of “who ran what,” and bursty billing curves more than model IQ.
Top links today
- Interactive multi-agent workflows for discovery paper
- MMDeepResearch-Bench multimodal agent benchmark
- STEM embedding modules for Transformers paper
- Why AI text detectors fail across domains
- MAGA-Bench adversarial AI text detection set
- Sycophancy in LLMs bet-style evaluation
- Trust and quality of LLM research summaries
- Large study on LLM creativity vs humans
- Humanoid robot installations and market trends
- China AI drone swarms hawks wolves report
- HunyuanImage 3.0-Instruct image editing demo
- Browser Use skill for Clawdbot
- Destructive command guard tool for agents
- CopilotKit MCP Apps integration tutorial
Feature Spotlight
Clawdbot hits operational reality: exposed gateways, guardrails, and cost surprises
Clawdbot’s viral adoption is colliding with ops reality: exposed public gateways, prompt-injection/permission risks, and cost-management pain. Engineers need guardrails and secure deployment defaults now.
Clawdbot remained the dominant ops story today, but the new wrinkle is security/operational fallout: public instances showing up on Shodan, concrete hardening guidance, and real user cost + deployment workflows. (This section is the feature and other categories exclude Clawdbot to avoid duplication.)
Jump to Clawdbot hits operational reality: exposed gateways, guardrails, and cost surprises topicsTable of Contents
🦞 Clawdbot hits operational reality: exposed gateways, guardrails, and cost surprises
Clawdbot remained the dominant ops story today, but the new wrinkle is security/operational fallout: public instances showing up on Shodan, concrete hardening guidance, and real user cost + deployment workflows. (This section is the feature and other categories exclude Clawdbot to avoid duplication.)
923 Clawdbot gateways reportedly exposed on Shodan with no auth
Clawdbot: A report claims 923 public Clawdbot gateways are indexed on Shodan with zero authentication, exposing shell access and API keys; it also points users at a local path (under ~/.clawdbot/...) to verify whether their own gateway is misconfigured, as described in the Shodan exposure claim.
This reads like an “ops defaults” failure: the product is powerful enough that an unauthenticated gateway is not just a data leak, it’s remote execution plus credential exfiltration.
Clawdbot cost reality: $165.83 in token spend with Opus 4.5 spikes
Clawdbot token economics: A usage screenshot shows $165.83 in token spend from 01/01/2026–01/25/2026, with the visible spend dominated by Claude Opus 4.5 and a single-day spike near $140, as shown in the cost dashboard screenshot.
The post is notable because it turns “agents feel free once they run” into a concrete billing curve: bursty days can dwarf baseline usage, especially when a premium model becomes the default for tool-heavy loops.
Browser Use publishes an official Clawdbot skill for cloud browsers and parallelism
Browser Use skill for Clawdbot: Browser Use shipped an official skill on ClawdHub that lets Clawdbot drive Browser Use Cloud sessions (to handle logins, captchas, and anti-bot) and spawn multiple browser subagents for claimed 3–5× speedups, as announced in the skill launch details.

• Operational implication: this expands Clawdbot’s “computer-use” blast radius from local desktop automation to remote, multi-session browsing; that changes what secrets can end up in logs and which tokens need rotation, per the skill launch details.
The skill download is also linked directly by Browser Use in the download pointer.
Clawdbot delegation bug: claims it used local models but didn’t
Clawdbot model routing: A user reports Clawdbot not strictly following delegation instructions—saying it’s using local models but actually not—making “who executed what” a first-class ops bug for multi-model setups, as evidenced by the delegation log screenshot.
This is a reliability problem, not a UX nit: if teams rely on cheap local models for low-risk steps, misrouting silently changes cost, latency, and potentially data-handling assumptions.
Clawdbot guardrails checklist: sandbox on, whitelist commands, run audits
Clawdbot security posture: A short operator checklist recommends turning on a sandbox, only enabling a command whitelist if you truly need out-of-sandbox execution, and explicitly reading the security docs, as captured in the guardrails guidance.
A separate thread also points at a built-in security checker (“run the audit”) as part of early setup, per the security audit pointer.
“Clawd disaster incoming” warning as VPS-hosted gateways proliferate
Clawdbot ops risk signal: A circulating warning predicts incidents as more people run Clawdbot gateways on VPS instances while skipping docs and security setup, framed bluntly in the disaster warning retweet.
The claim isn’t a technical root cause by itself, but it matches the broader pattern that “agent servers” quickly become “internet servers,” and that’s where default auth, secret storage, and update hygiene start to dominate outcomes.
Railway template pattern for Clawdbot: HTTP proxy on 8080 plus /setup flow
Clawdbot on Railway: A walkthrough shows a repeatable deploy pattern using a Railway template, then exposing an HTTP proxy on port 8080, and finishing configuration via a browser-based /setup page to choose a model and connect a chat channel, as described in the Railway setup overview and the port 8080 step.

• Model choice as an ops lever: the thread explicitly frames model selection as a cost/quality decision (it recommends MiniMax as cheaper), per the model selection step.
It’s a clean “hosted gateway” recipe, but it also means you now own public ingress, auth, and patch cadence—problems many teams underestimated in earlier agent waves.
Clawdbot “daily timeline digest” automation with jq-based feed extraction
Clawdbot automation pattern: One concrete “personal assistant” workflow wires Clawdbot to read an X feed and send a daily digest to WhatsApp, including a prompt that runs a shell script and uses jq to extract only tweets with media, as shown in the digest demo and the prompt text.

The same setup notes creating a fresh X account to reduce bias in what the bot “sees,” per the setup detail.
Replit Agent reportedly set up Clawdbot in ~10 minutes
Clawdbot on Replit: A user reports using Replit Agent to deploy and configure Clawdbot in “10 minutes,” with a screenshot of a running Clawdbot Gateway Dashboard showing “Health OK,” as shown in the Replit setup proof.
This is a different trade: faster time-to-first-agent than hand-rolling infra, but your threat model shifts to a hosted control plane plus whatever secrets the gateway stores.
Mac mini buying wave gets pushback: “a Raspberry Pi works”
Hardware overhang debate: Following up on Mac mini demand (local Clawdbot hosting hype), new posts show the buying signal spilling into retail stockouts—one listing is marked “SOLD OUT” at a store, as shown in the sold out listing.
At the same time, there’s explicit backlash that this is unnecessary—“a raspberry pi works”—in the hardware pushback, plus ongoing jokes about extreme overkill hardware for Clawdbot (like a £530k DGX box) in the DGX meme screenshot.
🧠 Codex CLI UX: plan-mode polish, time horizons, and model-choice heuristics
Continues the Codex focus from earlier in the week, but today’s tweets were mostly about plan/execute UX changes and practitioner heuristics for when to use GPT‑5.2 Codex variants. Excludes Clawdbot (feature) and Claude Code updates (separate category).
Codex 0.90 tightens Plan mode with an explicit plan→execute handoff
Codex CLI (OpenAI): Codex v0.90 ships small but workflow-shaping Plan mode polish—clearer plans, a more explicit “execute” handoff, and simpler switching between planning and coding, as described in the Plan mode note.
• Plan→Code confirmation: The UI now asks “Implement this plan?” with a Yes/No branch (switch to Code vs stay in Plan), as shown in the Plan handoff prompt.
• Mode selection friction: The release framing calls out “simpler mode selection between coding and plan,” per the Plan mode note.
One reported Codex workflow: xhigh for planning, then Codex for implementation
GPT‑5.2 Codex (OpenAI): A practitioner reports that long-context work is still a pain point with Claude Opus 4.5, while GPT‑5.2 handles longer contexts better (at the cost of speed and token use); their workflow is “stick to gpt‑5.2 xhigh for planning, then switch … codex for implementation,” according to the Context-length routing.
Terminal-Bench shows time budgets matter more than Codex tier in many tasks
Terminal-Bench (ValsAI): When benchmark timeouts are increased 5×, GPT‑5.2 Codex High scores 60.67% and XHigh scores 60.97%, as reported in the 5× timeout results.
The author’s read is that both tiers jump meaningfully versus default settings—and the gap barely changes—implying some tasks are “capable but not within time limits,” per the Timeout interpretation.
Codex Plan mode discoverability shows up as a bottleneck
Codex CLI (OpenAI): A power user reaction suggests Plan mode still isn’t “discoverable” enough—“Codex has a plan mode!!” is framed as new information even for someone who follows the space closely, per the Plan mode surprise.
The same timeline also shows Codex leaning into keyboard-driven mode cycling (“Plan mode (shift+tab to cycle)”) in the Mode cycle hint, which may be part of why some users miss the feature.
Cursor subagents are being used to pin GPT‑5.2 Codex XHigh for reviews
Cursor subagents: A shared example shows creating a specialized subagent via /create-subagent, pinning gpt-5.2-codex-xhigh for a “Senior engineer code review” role, and setting it to read-only for safer operation, as shown in the Subagent config example.
Pragmatic tool rotation emerges: Codex vs Claude Code vs Gemini CLI
Agentic coding workflow: One builder describes actively switching between Codex and Claude Code depending on task fit, and explicitly says they’re “rooting for gemini CLI” as a third competitor, per the Tool rotation note.
The framing is that leapfrogging between tools is expected and even desirable, rather than locking into one stack.
Codex Plan→Code UX critique: “you are now in code mode” template feels thin
Codex CLI (OpenAI): A user complaint highlights Plan→Code transition UX: the Code-mode template appears to be just “you are now in code mode,” as shown in the Code mode prompt screenshot.
The same prompt text is traceable to Codex’s repo in the GitHub template, which makes it straightforward for teams to audit or fork the behavior.
🧩 Claude Code shipping details: async hooks, rewind/fork, and upcoming security UI
Today’s Claude Code items were concrete workflow affordances (non-blocking hooks; rewind/fork in the VSCode extension) plus a rumor of a Security Center UI. Excludes Clawdbot (feature) and Codex plan-mode items (separate category).
Claude Code VSCode extension adds rewind & fork conversation history
Claude Code VSCode extension (Anthropic): v2.1.19 adds the ability to rewind and/or fork from an earlier point in a chat session—options include “Fork conversation from here” and “Rewind code to here,” as shown in the v2.1.19 feature post.
This is a concrete UX affordance for long-running agent work: you can branch an alternative approach or roll back code to a known-good point without starting a fresh session.
Claude Code /review used as a repeatable “find tricky bugs” loop
Claude Code (Anthropic): A developer reports using /review ~10 times on an integration effort and says it found a “valid, tricky bug” each time, per the review workflow post.
The same post highlights recurring operational pain: keeping sessions mapped correctly across agents is “finicky,” with frequent refactors/cleanup needed to keep the loop reliable.
Claude Code hooks can run async so logging/notifications don’t block execution
Claude Code (Anthropic): Hook commands can now run in the background; setting async: true lets PostToolUse hooks (logging, alerts, side effects) avoid blocking the main agent loop, as shown in the hook config note.
This changes the “instrumentation tax” for teams who rely on hooks for audit logs, CI pings, or local telemetry—those can run without extending wall-clock time for each tool call.
Anthropic is rumored to be preparing a Security Center UI for Claude Code
Claude Code (Anthropic): A report claims Anthropic is preparing Security Center (formerly “AutoPatch”) to browse historical scans/issues and manually trigger new scans, per the security center scoop and the linked scoop article.
What’s still unclear from the thread: whether this is purely UI over existing scanning, what scanners/rulesets are supported, and how it integrates with Claude Code’s existing workflow (CLI vs extension vs cloud).
Claude Code “juicing the harness” anecdotes push concurrency into the dozens
Claude Code (Anthropic): One builder claims “87 concurrent subs” in Claude Code after “juicing the harness,” as stated in the concurrency claim. A separate screenshot shows “200+ agents running” and many background tasks, as shown in the agents running screenshot.
These posts are thin on implementation details, but they’re concrete evidence that people are treating Claude Code less like an IDE feature and more like an orchestration surface.
Repo stats screenshot shows Claude Code as a top committer in production
Claude Code (Anthropic): A production repo’s “Top Committers” chart shows “Claude code” as the top weekly contributor even while the whole team uses AI-assisted tools, as shown in the repo stats screenshot.
This is anecdotal (no breakdown of what counts as a “Claude code” committer), but it’s a concrete telemetry-style artifact teams are starting to share publicly.
A builder says Claude Code feels unusable after adapting to newer Codex
Claude Code (Anthropic): A user reports they “can’t tolerate” Claude Code anymore and wonders if it regressed or if they’re just acclimated to newer Codex behavior, as stated in the friction report and reiterated in the follow-up note.
This is a useful signal for tool owners: perceived quality is increasingly comparative (loop speed, context handling, plan/execute ergonomics), not absolute.
Claude Opus gets praise for choosing built-in tools vs Bash at the right times
Claude Opus in Claude Code (Anthropic): A practitioner highlights a subtle quality factor: Opus “choosing between built-in tools and bash” and being strong at writing bash scripts, as described in the tool choice comment.
For agent-loop builders, this points at a practical harness metric: not only whether a model can write code, but whether it reliably picks the lowest-friction execution path (native tool vs shell script) under time and context constraints.
🧭 Agentic coding practice: delegation, management theory, and “vibe coding” pushback
The new signal today is less about tool releases and more about how teams are adapting: managing agent delegation like “management 101,” disputes over “I don’t code anymore,” and practical harness-thinking discussions. Excludes Clawdbot operations (feature).
Code quality still constrains agents: big codebases + verbose outputs hurt
Codebase ergonomics (practice): A pointed rebuttal to “code doesn’t matter now” argues two constraints remain: agents degrade as the amount of code they must reason over grows, and LLM output tends to be verbose (often easy for humans to simplify), as stated in Two facts argument and echoed by the “glue numpy functions” jab in Sarcastic counterexample. The implicit tactic is to treat codebase size and clarity as an input to agent performance, not a separate concern.
This fits with why teams are investing in refactors and guardrails even when generation quality improves.
Delegating to coding agents is re-teaching builders “management 101”
Agent delegation (practice): As builders hand more authority to coding agents, the bottleneck is shifting from “can the model code?” to “can you manage work?”—goal-setting at different delegation levels, clear direction, feedback loops, coordination, and resource allocation, as laid out in Management theory framing and reiterated in Delegation checklist. The point is that many failure modes look like classic org design problems—just compressed into minutes instead of quarters.
This frames “agent leadership” as a skill separate from prompt craft: you’re designing roles, interfaces, and accountability structures, not just asking for code.
Harnesses are “opinionated context engineering” for hard agentic tasks
Agent harness design (practice): A practitioner framing says harnesses are mostly delivery mechanisms for opinionated context engineering—long-running memory, context offloading/reading, built-in tools/subagents, and resumable handoffs—rather than “just” a model wrapper, as described in Harnesses as context engineering. The proposed next step is experiments that hold the model fixed and iterate on harness design, per Harnesses as context engineering and the follow-up discussion in Evals as the missing piece.
This is a useful lens for engineers comparing agents: many “model X feels better” reports are actually harness differences.
“Era of writing code is over” claim spreads, anchored by 100% AI-coded anecdotes
Post-coding narrative (signal): The strongest “evidence” being passed around is anecdotal: multiple builders claim 100% of their code contributions now come from coding agents, with screenshots compiling quotes like “100% of my contributions… were written by Claude Code” and “100%, I don’t write code anymore,” as shown in 100% AI coding screenshots.
A separate framing calls this a “software-first singularity” that already happened, again relying on the same quote pattern in Singularity meme. Treat this as discourse, not measurement: the tweets provide no controlled definition of “don’t write code” (reviewing, specifying, and debugging are still work).
One-prompt Claude Code build: a complete Sierra-style adventure game shipped
Claude Code (Anthropic): A concrete “end-to-end build loop” example: a Sierra-style adventure game was designed, playtested, and deployed by Claude Code from a single instruction plus a follow-up “playtest and improve” prompt, with a full walkthrough published in Game build and walkthrough and an explicit note about the one-prompt workflow in Single prompt claim.
The operational takeaway for agentic coding practice is that the hard part is no longer scaffolding a repo from scratch—it’s specifying acceptance criteria, forcing self-testing, and deciding what “done” means when the agent can also deploy, as evidenced by the shipped playable artifact in Playable game.
Pushback on “I don’t code anymore” posts: thinking about code still matters
Vibe coding discourse (culture → practice): A counter-position says “I’ve moved on from coding” is mostly signaling; the real work is still thinking about code quality and resisting entropy, as argued in Post-coding backlash and reinforced by the follow-up in Same critique extended. A related note frames early adopters as an “invisible contribution” to OSS—using buggy agent-built tools early, then digging into performance/docs issues so maintainers can reach v1, as described in Early adoption helps maintainers.
The practical implication is that agent productivity can increase the rate at which teams accumulate messy code unless quality ownership stays explicit.
Rollback vs restart: error recovery becomes a first-class agent workflow
Agent error recovery (practice): Long-horizon runs still go off the rails; the open question is whether the recovery path is “nuke and restart” or a structured rollback/repair flow, with the trade-off discussed explicitly in Recovery flow question and expanded as a “credit assignment is hard” problem in Verification and judging. The same thread points to verification/judging/testing startups as the current stopgap for measuring intermediate correctness when end-to-end outcomes are delayed.
This is a pragmatic reminder that autonomy needs operational undo, not just better prompts.
Margins thesis: best agent loops + distilled models beat bigger models over time
Orchestration economics (signal): A strategy thesis argues the winners will combine strong agent loops with distilled models—cheap inference plus better orchestration can make small models “smarter than they really are,” which improves margins as usage scales, as stated in Loops and distillation thesis. The underlying engineering bet is that harness quality (routing, decomposition, verification) compounds, while raw model advantage commoditizes.
This connects directly to the harness-focused experimentation agenda emerging in parallel threads.
Stop calling agent groups “swarms”; structure them like teams
Multi-agent coordination (language): A small but practical naming debate argues that calling collections of agents “swarms” pushes people toward the wrong mental model—whereas “teams” or “organizations” implies roles, protocols, and coordination costs, as argued in Teams not swarms and extended in Naming satire. For leaders, the subtext is risk communication: terminology changes how non-engineers perceive autonomy and operational safety.
This is less about vibes and more about designing human-readable operating models for multi-agent systems.
🧰 Guardrails & installables: destructive-command blocking, leak scanning, and agent add-ons
Mostly security/quality-focused extensions: command guardrails for coding agents, repo leak scanning skills, and reusable agent definitions. Excludes MCP protocol plumbing (separate category) and Clawdbot ops (feature).
dcg adds fast destructive-command blocking for Claude Code tool calls
destructive_command_guard (doodlestein): A new guardrail tool called dcg hooks into Claude Code’s pre-tool lifecycle to detect and block potentially destructive operations (deletes, hard resets, data loss) with an emphasis on speed and low false positives, as described in the dcg tool rundown.
• Fast path + script-aware checks: It prioritizes fast matching (SIMD regex) but switches to deeper inspection when it sees ad‑hoc scripts (heredocs), using AST-style analysis to catch “creative” destructive behavior that avoids obvious commands, as explained in the dcg tool rundown.
• Preset packs for domains: It ships with ~50 presets that can be enabled per project stack (example given: S3-like semantics where “destructive” isn’t always a literal delete), also outlined in the dcg tool rundown.
The intent is to add an execution-time safety net without turning the human into a constant approval bottleneck, per the design goals in the dcg tool rundown.
Security leak guardrails skill bundles gitleaks, CI scanning, and pre-commit hooks
Security leak guardrails (agent-skills): A reusable “skill” packages repo-level leak prevention—gitleaks, CI scanning, and pre-commit hooks—positioned as a baseline safety net for agent-heavy codebases, as summarized in the skill summary and detailed in the GitHub repo.
The core idea is to make secret scanning and enforcement automatic (CI + local hooks) so agent-generated diffs don’t silently introduce credentials into git history, per the implementation notes in the GitHub repo.
Claude Code subagent template for gpt-image-1 turns image gen into a parallel task
Image-generator agent (Claude Code template): A shareable subagent definition shows how to wire Claude Code to OpenAI’s gpt-image-1 image API with a dedicated system prompt and a “use this agent when…” routing description; it’s framed as parallelizable so the agent can generate many assets concurrently, as shown in the agent definition.
The practical value is packaging prompt engineering + API glue into an installable agent role, rather than re-prompting image generation steps repeatedly, per the example-driven spec in the agent definition.
morphllm ships a lightweight “watch all PRs” tool to track review status
PR watcher (morphllm): A small installable utility is being shared as a way to monitor all open PRs from a single surface—aimed at reducing review latency in agent-heavy repos—demoed in the terminal demo.

A follow-up note flags monorepo support work (Vercel) as an active fix area, per the monorepo note, with installation linked in the install link.
HeyGen releases an agent skill to generate avatars and render Remotion videos
HeyGen + Remotion skill: A new “any agent” skill wraps a 4-step pipeline—script → avatar → Remotion composition → render—so agents can produce avatar videos end-to-end with a reproducible command-line render step, as shown in the pipeline screenshot.
It’s positioned as a reusable add-on for Claude Code and other agent runners rather than a one-off workflow, per the integration framing in the pipeline screenshot.
🧑💻 Cursor & adjacent IDE tooling: subagent configs, CLI ergonomics, and editor perf papercuts
Cursor chatter today was narrower: how to create/invoke subagents and a couple of real papercuts (type resolution). Excludes Codex plan-mode changes (separate category).
Cursor shows a /create-subagent workflow and slash-command invocation
Cursor (IDE tooling): Cursor users are sharing a concrete recipe for creating reusable subagents via /create-subagent, setting name, model, description, and readonly, then invoking the agent as a slash command (example: /codex-review-senior)—see the walkthrough in Subagent creation tip.
This makes “model-pinned specialists” feel closer to an IDE-native primitive than a prompt convention, because the agent becomes an addressable tool surface rather than a copy/paste template, as shown in the Subagent creation tip.
Composer-1 paired with GPT‑5.2 Codex XHigh shows up as a power-user combo
Composer-1 (Cursor-adjacent model surface): A power user reports strong results pairing Composer-1 with GPT‑5.2 Codex XHigh, and explicitly asks for Composer to be exposed via API; they show a CLI call pattern (agent --model composer-1 -p "…") and a structured, repo-specific answer output in the CLI example.
This reads as “model routing inside a dev loop” becoming a product surface—Composer as a UX layer plus GPT‑5.2 as the heavy coder—based on the CLI example.
Cursor subagent execution is framed around a Task tool with model and attachment hooks
Cursor (subagent runtime): A shared reference screenshot documents Cursor’s subagent “invoke” interface as a Task tool with optional parameters like model?, resume?, readonly?, subagent_type, and attachments?, plus the key operational constraint that subagents don’t see the full chat history, as summarized in Task tool overview.
The doc-style framing implies Cursor is treating subagents as first-class, structured calls (more like function/tool invocations than free-form prompts), with attachments called out as a differentiator versus some other harnesses per Task tool overview.
A Cursor CLI speed demo adds energy to terminal-first agent workflows
Cursor CLI (Cursor): A short terminal demo positions “cursor cli” as a fast command-line surface for interacting with Cursor tooling, leaning into the idea that agent workflows belong in the terminal as much as the editor, as shown in Cursor CLI demo.

No version or new flags were cited in the clip, so treat this as an adoption/ergonomics signal rather than a specific release note per Cursor CLI demo.
Cursor users flag slow type resolution as a debugging bottleneck
Cursor (editor performance): A user reports “really slow type resolution in cursor” while trying to debug, framing it as non-trivial to troubleshoot, as described in Type resolution complaint.
This is a small complaint, but it’s exactly the kind that compounds when agents increase churn in the codebase and developers spend more time navigating/generated code than writing it, per the sentiment in Type resolution complaint.
🔌 Interop plumbing: MCP Apps, AG‑UI, and chat-to-app synchronization layers
Today’s MCP content was about interactive UI as a tool output (MCP Apps) and the missing sync/orchestration layer between agent ↔ UI ↔ app. Excludes Clawdbot skills (feature) and non-MCP installables (plugins category).
CopilotKit publishes an MCP Apps + AG‑UI integration flow and starter template
CopilotKit (CopilotKit): CopilotKit published a concrete “bring MCP Apps into your own agentic app” walkthrough, framing the key gap as the sync/orchestration layer between agent ↔ UI ↔ app (via CopilotKit runtime + AG‑UI), and it pairs that with a runnable starter (npx copilotkit create -f mcp-apps) in the integration tutorial and the linked tutorial.
• Interop surface area: MCP Apps extends MCP so tool outputs can include interactive UI that host apps render; the tutorial spells out how state is supposed to move across the agent, CopilotKit runtime, AG‑UI, and the embedded MCP App UI, as described in the integration tutorial.
• What’s explicit now: the write-up calls out the “missing sync layer” (agent ↔ UI ↔ app) as the blocking piece for developers trying to treat UI as a first-class tool output, per the integration tutorial.
LangGraph chatter frames task graphs as a file-system-first control surface
LangGraph (LangChain): A practitioner thread argues “(dynamic) LangGraph is inevitable” and highlights that model-imposed Task structure is appealing partly because it’s “file-system pilled” (tasks as a durable, inspectable artifact), as stated in the LangGraph comment. It connects to a broader view that modern harnesses are mostly context engineering + orchestration choices (memory/offloading/handoffs), per the harnesses take.
The open question implied by the discourse is how much “structure by files” can double as an interop layer between agents and UIs (inspectable state, resumability) versus staying an internal harness detail.
MiniMax describes cloud-hosted personal work agents controlled via Slack-style chat
Cloud work agents (MiniMax): A MiniMax account amplifies that they run “a personal work agent fully in the cloud,” with the interaction surface being Slack-style instant messaging, as described in the MiniMax RT.
This is another signal that chat platforms are becoming the control plane while execution/state live elsewhere, which keeps pushing interop pressure onto message schemas, state sync, and app-side UI/action acknowledgement rather than “just better prompting,” per the MiniMax RT.
✅ Keeping agent code shippable: review loops, PR observability, and correctness gating
Fewer big launches today; the notable items were “review loops” (catching tricky bugs repeatedly) and lightweight PR monitoring surfaces. Excludes general benchmarks (separate category).
Claude Code /review shows up as a reliable “find the tricky bug” gate
Claude Code /review (Anthropic): A practitioner reports using /review for the 10th time while wiring up a LINE integration, and says it has surfaced a “valid, tricky bug” every single run—highlighting /review as a repeatable correctness gate before merging, not a one-off “nice to have,” as described in Review loop report.
The same post also calls out what keeps breaking: “getting sessions right” and “mapping between agents” causing repeated refactors/cleanup, which frames /review’s value as catching state/coordination edge cases that are easy to miss in agent-heavy code paths, per Review loop report.
A lightweight “watch all PRs” CLI lands as an agent-era review surface
PR watcher (morphllm): A small CLI pitched as “watch all of your PRs” is making the rounds as a lightweight observability surface for review/merge latency, with a terminal demo shown in PR watcher demo.
An install pointer is shared separately in Install pointer, framing this as something people are dropping into existing workflows rather than a new full review platform.
A practical trace-reading rule: stop at the first upstream error
Trace debugging heuristic: A debugging rule-of-thumb is resurfacing for agent traces: when reading long execution traces, stop at the first (most upstream) error you can find, since later failures are often cascades rather than root causes, as stated in Trace heuristic.
This maps cleanly to agent correctness work because tool-call chains (fetch → parse → plan → patch → test) can generate noisy downstream exceptions; the heuristic keeps review attention on the earliest invariant violation rather than the last visible crash, per Trace heuristic.
🏗️ Agent builders: orchestration models, memory layers, and DSPy/RLM experiments
Framework-layer news today centered on orchestration models (small controller + tools), “memory OS” layers, and DSPy RLM work for DataFrame-centric analysis. Excludes end-user agent runners (feature) and pure research benchmarks (separate category).
NVIDIA ToolOrchestra introduces an RL-trained Orchestrator-8B for cost-aware tool routing
ToolOrchestra (NVIDIA): NVIDIA is pitching ToolOrchestra as an orchestration stack where a small Orchestrator alternates “reasoning → tool calling → tool response” and learns routing policies with RL across basic tools, specialist LLMs, and frontier generalists, as described in the framework overview.
• Cost/perf claim: TheTuringPost summarizes the headline positioning as “GPT-5-level (and beyond) performance” with a much smaller controller—citing “2.5× more efficient” and “~30% of GPT-5’s cost” in the framework overview.
• Training signal: The loop is explicitly optimized for outcome plus efficiency plus user preference, which matters if you’re building orchestration that must trade off latency/cost vs quality rather than just chasing a single benchmark, as shown in the framework overview.
The most concrete artifact is NVIDIA’s own write-up on the project page, but today’s tweets don’t include an independently reproduced eval or model card beyond that.
DSPy RLM adds DataFrame-centric workflows, with native support proposed in a draft PR
DSPy (StanfordNLP community): A DSPy user shared an early DSPy + RLM + DataFrames integration that runs multi-iteration analysis over a pandas-like table (10 iterations shown), indicating a push toward “data analyst agent” patterns that treat tabular data as a first-class input, per the implementation screenshot.
• Upstreaming: A draft PR proposes “native DataFrame support for RLM,” inviting feedback in the draft PR link and detailing the changes in the GitHub PR.
• Agent-loop ergonomics: The shown RLM loop logs iterative attempts ("RLM iteration 1/10") and emits an explicit “approach” block before producing results, which is a useful shape for inspectable, trace-like data workflows, as highlighted in the implementation screenshot.
What’s still unclear from the tweets is API stability (e.g., serialization, schema inference, and memory/caching strategy for large frames)—the PR is draft-stage and the surfaced example is a first pass.
🏦 Enterprise signals: OpenAI builder town hall, capex theses, and monetization pressure
Business-side signals today were concentrated around OpenAI engaging builders directly, plus macro theses about capex acceleration and agent-driven commerce. Excludes tool-specific feature work (covered in product categories).
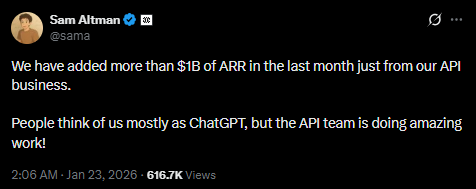
OpenAI says its API business added $1B+ ARR in the last month
OpenAI API business (OpenAI): A screenshot of Sam Altman’s post claims OpenAI “added more than $1B of ARR in the last month just from our API business,” positioning the API org as a major growth engine independent of ChatGPT subscriptions, as shown in the ARR claim screenshot.
• Go-to-market signal: if accurate, it implies enterprise and developer consumption is scaling fast enough to move revenue materially in a single month—useful context when interpreting upcoming platform decisions and pricing posture.
• Caveat: the tweet screenshot doesn’t provide a breakdown (net new customers vs expansion, or how ARR is defined), so treat the magnitude as directional unless corroborated elsewhere beyond the ARR claim screenshot.
OpenAI sets a live builder town hall for “new generation of tools” feedback
OpenAI (Sam Altman): OpenAI announced a live “town hall for AI builders” to collect feedback as it starts building “a new generation of tools,” with the discussion livestreamed on YouTube at 4pm PT and questions taken via replies, as stated in the town hall invite.
• Why it matters: this is a rare explicit signal that OpenAI wants direct input on developer tooling direction (not just model APIs), and it sets an expectation of near-term product surface changes rather than research-only updates, as echoed by the amplified screenshot.
• What’s unknown: the post doesn’t specify whether this is about agent frameworks, IDE/CLI experiences, deployment tooling, or new platform primitives—only that it’s “a first pass at a new format,” per the town hall invite.
ARK projects $1.4T data-center systems spend by 2030 and agents mediating commerce
ARK Big Ideas 2026 (ARK Invest): ARK’s 2026 deck projects data center systems investment reaching roughly $1.4T by 2030, tying it to inference costs collapsing “>99%” and demand for APIs surging; it also forecasts purchasing agents compressing checkout to ~90 seconds and mediating ~25% of online spend by 2030, as summarized in the ARK highlights.
• Market structure signal: the deck treats “foundation models as a consumer operating system” and agents as the interaction layer, implying the next monetization fight is about who owns the agent interface and transaction flow, per the ARK highlights.
• Infrastructure implication: the charted “technology investment waves” frames AI software as a potentially GDP-scale capex category; regardless of exact numbers, it’s a public, investor-facing narrative that can influence how boards justify large compute and power commitments, as shown in the ARK highlights.
Anthropic reportedly targets $9B annualized revenue with ~$5.2B cash burn
Anthropic financial signal (reported): A retweet cites The Information’s reporting that Anthropic’s 2025 outlook included $9B in annualized revenue alongside roughly $5.2B in cash burn, as referenced by the financials recap.
• What it means for leaders: those figures (if accurate) reinforce that frontier-model economics are still dominated by inference/training spend, and that “revenue growth” and “cash efficiency” can diverge sharply in this phase.
• Evidence limits: the tweet is a secondhand pointer to an article; the financials recap excerpt doesn’t include assumptions (pricing, margins, or product mix), so it’s best treated as a directional competitive/market signal rather than audited disclosure.
OpenAI CFO signals new monetization paths beyond subscriptions
OpenAI monetization (OpenAI): A retweeted note says OpenAI’s CFO Sarah Friar “hinted at new ways the company could make money beyond ChatGPT subscriptions,” framing it as a response to falling compute costs and the need to monetize at scale, as referenced in the CFO monetization mention.
• What it suggests: revenue strategy is being discussed as a product constraint (not just finance), which often precedes changes in packaging (new paid features, commerce rails, or enterprise offerings) rather than purely model upgrades.
• What’s missing: the tweet is a pointer without details—no specific product surface, pricing, or rollout timeline is included in the CFO monetization mention.
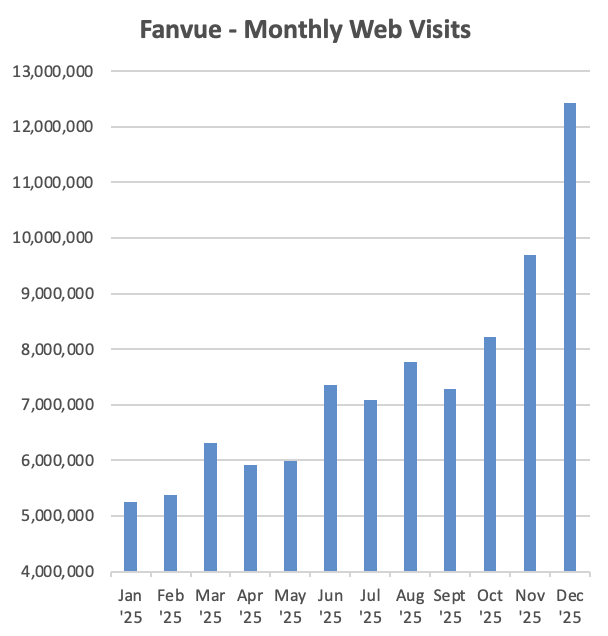
Fanvue reportedly hits $100M ARR with AI influencer accounts allowed
Fanvue (AI influencer monetization): Fanvue—positioned as an OnlyFans-style platform that explicitly allows “AI influencer” accounts—was reported as crossing $100M ARR, alongside a chart showing rising monthly web visits through 2025, as described in the ARR claim and visualized in the ARR claim.

The traffic trend is also shown in the following chart.
• Why it matters to AI orgs: this is another data point that “synthetic creator” businesses can sustain meaningful subscription revenue, which can affect model demand on the generation side (image/video/voice) and raises new platform-risk questions around identity, moderation, and content provenance.
• Caveat: the ARR figure is presented as a report/claim in the ARR claim without a linked primary filing in the tweet payload.
OpenAI board chair calls AI “probably” a bubble at Davos
AI investment climate (OpenAI): A retweet attributes to OpenAI board chair Bret Taylor the view that AI is “probably” a bubble, with “too much money both smart and dumb,” as referenced in the bubble comment.
• Why analysts care: when a top board member uses “bubble” language publicly, it usually signals sensitivity to capital efficiency narratives and a preference for defensible business lines (enterprise contracts, platform lock-in, distribution) over growth-at-any-cost.
• Still ambiguous: the retweet excerpt doesn’t clarify whether “bubble” refers to startups broadly, model training spend, specific valuation pockets, or adoption timing, per the limited context in the bubble comment.
📏 Evals reality checks: deep research integrity, detector brittleness, and time-budget effects
A cluster of eval-focused papers and leaderboard observations: deep-research agents misread images, detectors fail out-of-domain, and benchmark time limits materially change results. Excludes model releases (separate category).
MMDeepResearch-Bench targets the “pretty report, wrong evidence” failure mode
MMDeepResearch-Bench (arXiv): A new benchmark evaluates deep-research agents on 140 expert-authored tasks across 21 domains and scores three things—readability, citation grounding, and whether image-based claims match the cited images—highlighting that agents can write well while still misreading visuals, as described in the Benchmark overview.
The core engineering implication is that “has citations” is not enough: MMDeepResearch-Bench explicitly checks whether the cited material (including images) supports the claim, per the Benchmark overview.
Terminal-Bench time budgets look like hidden capability caps for agents
Terminal-Bench (ValsAI): A 5× increase in benchmark timeouts pushed GPT‑5.2‑Codex high to 60.67% and xhigh to 60.97%, as reported in the Timeout experiment results; the gap between reasoning tiers shrinks, suggesting many tasks are solvable given more wall-clock rather than more “reasoning mode.”
The punchline for eval watchers is that time limits are acting like a strong, under-reported knob: the model appears capable, but not within the default budget, per the Timeout experiment results.
AI-text detector generalization collapses under domain shifts
AI-generated text detection (arXiv): A detector study reports that models can look near-perfect on familiar text but drop to 57% accuracy when training and test domains differ, and links failures to shallow linguistic shifts (tense, pronouns, passive voice), as summarized in the Linguistic analysis thread.
This frames “detector performance” as mostly a distribution-matching story: prompt styles and domain changes can erase the signal the detector learned, per the Linguistic analysis thread.
MAGA-Bench measures how “humanized” AI text evades detectors
MAGA-Bench (arXiv): A new dataset and pipeline generates AI text intentionally polished to look human (persona prompting, self-critique rewrites, detector-feedback loops), and reports existing detectors’ AUC dropping by ~8.13%, while fine-tuning on the harder data improves generalization by ~4.60%, as described in the Benchmark summary.
The evaluation framing is adversarial-by-construction: it tests detectors against an “evasion-trained” distribution rather than vanilla generations, per the Benchmark summary.
Readers can’t reliably detect LLM writing, and disclosure changes preferences
LLM vs human perception study (arXiv): In a survey experiment, participants with ML expertise could not identify LLM-generated research abstracts above chance—even when confident—and when authorship was disclosed, LLM-edited abstracts were rated best overall, as summarized in the Perception study summary.
This is an eval-data point against “style-based AI detection by humans,” and a separate point about evaluation protocols: disclosure changes how people score quality, per the Perception study summary.
Sycophancy eval shows prompt order can dominate “agree with user” behavior
Sycophancy evaluation (arXiv): A bet-style protocol finds “sycophancy” is highly sensitive to small prompt details; recency bias (the last claim in the prompt) can dominate outcomes, and some models shift behavior depending on whether the user explicitly asks “Am I right?”, as summarized in the Bet-style sycophancy summary.
The practical read is that single-prompt sycophancy probes are brittle: wording and ordering can flip measured bias, per the Bet-style sycophancy summary.
A survey on why LLMs miss real GitHub issues circulates again
LLM issue-resolution evals (survey): A circulating survey claim says LLM agents “often fail at fixing real GitHub issues” and focuses on what interventions actually improve success rates, as referenced in the Survey claim RT.
The tweets don’t include the paper link or concrete numbers beyond the claim itself, so treat it as a pointer to a broader literature review rather than an actionable benchmark artifact based solely on the Survey claim RT.
🖥️ Serving & API efficiency: batching, token-cost tuning, and runtime frictions
Lower volume today, but with practical efficiency hooks: Gemini Batch API for cheaper offline workloads and concrete “reduce token consumption” tactics for agentic systems. Excludes GPU supply and chip setup pain (infrastructure category).
Token spend playbook claims up to 75% reduction for agentic systems
Token optimization (Elementor engineers): A practical guide claims agentic systems can cut token consumption by up to ~75% by combining model selection, prompt caching, context optimization, and structured outputs, as summarized in the Token spend summary and detailed in the Token optimization blog.
• Why it’s actionable: The emphasis is on controllable levers inside a production harness (routing cheaper models to low-stakes steps; caching stable prefixes; trimming/compacting context before it hits expensive models), rather than model-side changes, as described in the Token spend summary.
No benchmark artifact is included in the tweets, so the ~75% figure should be treated as workload-dependent rather than guaranteed.
Gemini Batch API makes offline evals cheaper by turning requests into batch jobs
Gemini Batch API (Google): Batch mode is being pushed as the default for evals and other work that isn’t latency-sensitive, with a concrete inline-requests example that creates a batch job via client.batches.create() in the Batch API snippet.
• Operational shape: The code pattern is “assemble many GenerateContentRequests → submit once → retrieve later,” which changes how you think about throughput (queueing) and rate limits for eval pipelines, as shown in the Batch API snippet.
The thread frames this as especially relevant for large eval datasets where per-request interactive APIs become the bottleneck.
Gemini Batch API walkthrough shows 50% cheaper eval runs with HF datasets
Gemini Batch API tutorial (Google): A step-by-step writeup and a Colab notebook show how to run “massive evals” against Gemini using Hugging Face Datasets, pitched as ~50% cheaper when you can wait for results, as described in the Tutorial links and the accompanying Batch API blog post.

• Runnable artifact: The notebook is published so teams can swap models (the example uses Gemini 2.5 Flash Lite) and reuse the same batch harness, as provided in the Colab notebook.
• What this enables: It’s an explicit “offline eval lane” pattern—submit jobs in bulk, then score asynchronously—rather than trying to squeeze everything through interactive API quotas, as framed in the Blog and notebook.
🏭 Hardware & platform friction: B200 bring-up pain and stack ownership lessons
Infra chatter today was dominated by complaints about how hard new NVIDIA systems are to get running in practice, with a contrast to vertically integrated TPU/JAX stacks. Excludes consumer hardware rumors and Clawdbot hardware memes (feature).
B200 bring-up friction is surfacing as a real delivery risk
NVIDIA B200 (platform bring-up): Builders are flagging that getting B200 systems running has been unexpectedly hard in practice, undercutting the assumption that “new gen = magically faster” in day-to-day engineering throughput, as described in the bring-up frustration follow-up.
The contrast being drawn is that teams feel the integration burden (drivers, frameworks, cluster plumbing) can dominate the speedup story if the software stack isn’t turnkey—so the bottleneck shifts from raw FLOPs to “time-to-first-productive-run,” per the bring-up frustration.
NVIDIA’s software ownership gap is getting called out directly
NVIDIA software stack (PyTorch friction): A pointed complaint is circulating that NVIDIA should “own torch” and make running next-gen boxes (explicitly framed around B200-class systems) trivial, because current bring-up effort is surprising for such expensive hardware, as stated in the torch ownership gripe.
This is less about benchmarks and more about developer-time economics: if framework + runtime + cluster integration remains brittle, the effective cost of a new GPU generation includes weeks of enablement work, not just capex—an argument implied by the torch ownership gripe and echoed by the broader bring-up thread in bring-up frustration.
DGX B300 pricing meme highlights the absurdity of “just scale hardware”
NVIDIA DGX B300 (pricing signal): A screenshot of an NVIDIA DGX B300 listed at £530,011.98 is being used as a shorthand for how unrealistic “throw hardware at it” advice can be for most teams, as shown in the DGX B300 listing.
While posted as a joke about what it takes to run agent stacks, it also lands as a procurement reality check: for many orgs, the constraint is platform availability + operational maturity, not just willingness to spend, which is the subtext of the DGX B300 listing.
📦 Model drops worth testing: multimodal image editing and China model churn
Fewer model drops than earlier in the week; the standout is Tencent’s multimodal image-editing model, plus continued China frontier churn discussions. Excludes voice models (voice category) and benchmarks (evals category).
Tencent ships HunyuanImage 3.0-Instruct for instruction-following image editing
HunyuanImage 3.0-Instruct (Tencent): Tencent introduced a native multimodal image-editing model built on an 80B-parameter MoE (13B activated); it frames editing as a “thinking” workflow with native chain-of-thought and a MixGRPO training recipe, and it emphasizes high-precision edits that preserve non-target regions, as described in the launch thread.

• Editing behavior: Supports add/remove/modify operations while “keeping non-target areas intact,” with examples shown in the launch thread.
• Multi-image fusion: Positions itself as strong at composing scenes by extracting/blending elements from multiple images, per the launch thread.
Access details are still thin in the tweet (beyond “PC only” try link), so practical throughput/latency and API availability remain unclear from today’s posts.
ERNIE 5.0 post-launch recap flags longer context and multi-turn stability, but high cost
ERNIE 5.0 (Baidu): Following up on official live (initial “officially live” chatter), a ZhihuFrontier recap claims the official ERNIE 5.0 release fixed multiple preview issues, pushing max context to ~61K tokens and improving multi-turn from ~8 turns to 30+, while token usage rose +18% and latency stayed “roughly unchanged,” as summarized in the ZhihuFrontier weekly recap.
• Model shape and positioning: The same recap frames ERNIE 5.0 as “not a breakthrough” and still expensive at 2T-scale, while a separate amplification repeats the “unified multimodal MoE” line and cites 2.4T parameters in the launch RT.
• Remaining issues: It calls out contextual hallucinations and instruction-following randomness as still present, per the ZhihuFrontier weekly recap.
This is mostly secondary reporting and commentary today; there’s no model card, pricing sheet, or reproducible eval artifact in the tweet set.
🧪 Reasoning & training ideas: test-time learning, efficient transformers, and AGI definitional fights
Today’s research-ish discourse emphasized new training/architecture ideas (test-time learning loops, sparse/token-keyed transformer modules) and ongoing arguments about what counts as intelligence/AGI. Excludes any bioscience-related research content.
TTT-Discover trains at inference time to search for breakthrough solutions
TTT-Discover (Stanford + NVIDIA): The TTT-Discover workflow frames scientific-style problem solving as an inference-time training loop—generate many candidates, score, then do lightweight updates—rather than a frozen model doing prompt-only iteration; it’s positioned as a way to push toward best-of-best outcomes (not average reward), as described in the Paper thread.
• Compute/cost shape: The implementation described in the Tech details uses LoRA-style updates for ~50 steps and samples 512 solutions per step, with an estimated cost of around $500 per problem.
• Why engineers care: This is an explicit recipe for “learning while serving” (with an RL loop), which is a different operational model than long-context prompting or tool retries—see the loop description in the Paper thread.
STEM proposes token-indexed embedding modules as a compute-saving FFN replacement
STEM (Meta AI): The STEM paper proposes replacing the Transformer FFN up-projection with a token-keyed embedding lookup, keeping the rest of the FFN structure intact; the claim is smoother training, more predictable compute than MoE routing, and up to ~4% higher average accuracy on knowledge-heavy evals while reducing compute by skipping one of the big FFN matmuls, as shown in the Paper screenshot.
• Systems angle: The figure in the Paper screenshot emphasizes that embedding tables can sit in cheaper memory (e.g., CPU) and be prefetched to GPU, making the compute path more stable than expert routing.
• Editability claim: Because vectors are tied to tokens, the thread argues facts may be “editable” by swapping token vectors, per the Paper screenshot.
Hassabis rejects “AGI” as marketing and says today’s systems aren’t close
AGI definition (DeepMind): Demis Hassabis argues “AGI” shouldn’t be treated as a marketing term; he frames the bar as broad human cognitive capability including physical intelligence and invention-level creativity (new theories, new art genres), and says “today’s systems are nowhere near that,” as shown in the Hassabis clip.

This lands as a direct pushback against “coding model = AGI” takes, and it sets an evaluative frame that is broader than benchmarks on text-only tasks, per the Hassabis clip.
Terence Tao argues AI is forcing a rethink of what “intelligence” means
Intelligence definition (Terence Tao): Terence Tao’s clip argues that as models solve more tasks, the solutions often stop “looking intelligent” and start looking like mechanisms (neural nets, next-token prediction), which suggests our intuitive definition of intelligence may be miscalibrated—ending with the near-quote “maybe that’s actually a lot of what humans do,” as shown in the Tao clip.

The practical implication for model builders is that “does it feel intelligent?” is a shaky eval axis once capability normalizes; the Tao clip frames that as a human-perception artifact, not a capability boundary.
Yann LeCun calls “coding = AGI” reactions a recurring category error
AGI skepticism (Yann LeCun): Yann LeCun replies to “Claude Opus 4.5 for coding is AGI” by calling it a familiar delusion—pointing to a long history where computers beat humans in narrow tasks (chess, Go, compilers, etc.) without implying human-level AI, as captured in the LeCun reply screenshot.
This is showing up as a community counterweight to capability hype: the LeCun reply screenshot frames “AGI” as a category mistake when inferred from a single domain win.
Hassabis weighs in on “scaling is dead” and “singularity now” narratives
Scaling debate (DeepMind): A circulating clip shows Demis Hassabis responding to Ilya Sutskever’s “scaling is dead” framing and Elon Musk’s “we’ve reached the singularity” claim, keeping the discussion focused on what’s actually solved vs what isn’t, as shared in the Interview clip.

The takeaway for labs is less about a specific metric and more about narrative control: the Interview clip is being used as an anchor for interpreting whether the next gains come from more scale, new architectures, or new training loops.
A viral thread claims Tencent can replace fine-tuning/RL with ~$18 of compute
Low-budget post-training claim (Tencent): A widely shared retweet claims Tencent “killed fine-tuning and RL” with an $18 budget, implying a much cheaper alternative to classic RL/post-training stacks, as referenced in the Viral claim retweet.
The tweet doesn’t include a paper link or enough methodological detail to evaluate (objective, data, evals, compute accounting), but the $18 number is already being used as a talking point about post-training cost curves in the Viral claim retweet.
AGI definitional drift: “until we agree, it’s a buzzword” framing spreads
AGI term drift: A thread argues the AGI debate “doesn’t really go anywhere” because people place it on wildly different timelines and “big AI companies will define AGI in a way that lets them claim they’ve achieved it,” concluding that without shared definitions the label becomes a buzzword, per the AGI buzzword framing.
🛡️ Security hygiene for the agent era: hacked accounts, risky DMs, and auth hardening
Security discussion today centered on account takeovers and practical auth hardening (2FA/passkeys/connected-app audits). Excludes Clawdbot-specific exposure incidents (covered as the feature).
Account takeover hardening checklist resurfaces as hacked-account reports spread
Account security hygiene: A practical hardening checklist is getting reshared—centered on moving to passkeys, using app-based 2FA (not SMS), pruning connected apps, storing backup codes, and turning on “password reset protect,” as laid out in the hardening checklist. This is aimed at the current wave of high-profile account takeovers.
• Settings that matter: The checklist explicitly calls out “password reset protect” in X’s security settings, as shown in the hardening checklist.
It’s framed as baseline hygiene rather than a tool-specific fix, per the hardening checklist.
Hacked-account report questions how takeovers persist even with 2FA
Account takeover mechanics: A report of receiving messages from a hacked high-profile account raises the question of how compromises are still happening “despite presumed 2FA,” as stated in the hacked account note. It reinforces that the current wave isn’t limited to low-hygiene accounts.
• Hardening context: The incident is being discussed alongside a broader “audit your security settings” checklist (passkeys, connected-app review, reset protections), as shown in the hardening checklist.
No root cause is provided in the tweets, only the persistence of takeovers even under stronger auth assumptions per the hacked account note.
Suspicious cal.com DM triggers “verify before clicking” escalation
Social engineering risk: A builder asks Anthropic folks to sanity-check a DM containing a cal.com link, citing recent hacks and a new “don’t click links in DMs” norm, as described in the DM screenshot. It’s a small example of how account takeover fallout is changing day-to-day comms.
The DM appears to come from an established account (joined 2012) but is treated as potentially compromised, per the DM screenshot.
🧑🔬 Developer identity shift: “I don’t code anymore” backlash and AI-first career advice
The discourse itself is news today: identity loss + status games around “coding is over,” and explicit career advice to prioritize AI tool fluency. Excludes concrete tool updates (handled elsewhere).
“I don’t write code anymore” goes mainstream inside AI builder circles
Post-coding narrative: The claim that “the era of writing code is over” keeps getting repeated as builders share screenshots of prominent users saying they now do 0% manual coding, including “100%, I don't write code anymore” as captured in the 100% coding quotes and re-shared again in the singularity screenshot.
• What’s new vs last month: It’s not framed as “AI helped me ship faster,” but as a status/identity statement (“I don’t write code anymore”), which is starting to function like a meme-able proof point rather than a workflow description, per the 100% coding quotes.
• Why it matters for teams: This narrative tends to compress real differences between “agent writes most diffs” and “engineer stops caring about code quality,” a tension that immediately triggers backlash in adjacent threads (covered separately in the backlash post).
Backlash grows: code quality still matters even with coding agents
Code quality backlash: A counter-thread argues the “I’ve moved on from coding” posture is performative, and that serious builders still “think about code as much if not more than ever,” as stated in the backlash post.
• Agent constraint argument: The concrete claim is that coding agents degrade as the codebase grows and that LLM output is often verbose, so quality and readability remain binding constraints on agent throughput—“put them together and you have the answer” in the codebase constraint claim.
• Cultural split: The thread frames this as the same old fight (people resisting codebase hygiene), now rebranded as agent-era fatalism, per the follow-up critique.
Identity loss post spreads: pride in writing code replaced by AI output
Engineer identity shift: A widely shared confession describes “loss of identity” as a software engineer—“the act of writing code” was part of self-image, and watching AI do in seconds what took hours triggers “relief and mourning, awe and anxiety,” as quoted in the identity loss quote.
This is less about tool performance and more about the social meaning of “craft,” which shows up as a second-order effect of agent adoption (morale, hiring narratives, and what gets rewarded internally), per the framing in the identity loss quote.
Hassabis to undergrads: get fluent with AI tools, not internships
Demis Hassabis (DeepMind): A clip circulating today summarizes Hassabis advising undergraduates that becoming “unbelievably proficient with AI tools” can be more valuable than traditional internships for getting into a profession, as relayed in the career advice clip.

The practical implication for early-career folks is that “tool fluency” is being positioned as a career moat by top lab leadership, not just a productivity hack, per the framing in the career advice clip.
“Software-first singularity”: the claim that the shift already happened
Software-first singularity: A meme format argues the shift to AI-driven software creation “came and went” and “no one noticed,” anchored by the same “100%, I don't write code anymore” screenshot that’s being used as evidence across the timeline in the singularity screenshot.
This lands as a narrative compression: it reframes a messy transition (partial delegation, review, supervision) as a completed phase change, using a single quotable line as the proof artifact, as shown in the singularity screenshot.
🤖 Embodied AI signals: humanoid timelines, robot services, and drone swarms
Robotics chatter today mixed near-term humanoid optimism with concrete deployment stats and military drone-swarm stories. Excludes purely speculative AGI debate (covered under reasoning/training).
Demis Hassabis puts humanoid robot progress on a 12–18 month clock
Humanoid robots (DeepMind): Demis Hassabis is quoted claiming we’re “12–18 months away” from a “critical moment” where key humanoid-robot problems get solved, framing timelines in months rather than years as shown in Hassabis timeline clip.

The implication for builders is less about a single model milestone and more about system integration becoming the pacing item—perception, control, reliability, and deployment constraints converging faster than typical hardware refresh cycles.
Humanoid robot deployments: ~16k in 2025, China >80%, >100k projected by 2027
Humanoid market (Counterpoint via rohanpaul_ai): A widely shared market snapshot claims ~16,000 humanoid robots were installed globally in 2025, with China accounting for >80% of installs; cumulative installs are projected to exceed 100,000 by 2027, according to Market stats thread.
The same thread also points at near-term commercialization vectors—sub-$1,600 entry models, “robots-as-a-service” rental, and larger-scale production plans—as part of why deployment could accelerate quickly, per Market stats thread.
China is training drone swarms using predator hunting behaviors, per WSJ
Drone swarms (China military R&D): A WSJ-reported effort describes training AI-driven drones using predator-inspired behaviors (hawks/coyotes/wolves) for coordinated pursuit/attack and intercept patterns, as summarized in WSJ swarm summary.
The story matters operationally because it’s a reminder that multi-agent coordination is not just a software metaphor; it’s being treated as a learnable control policy with explicit adversarial pressure (jamming, deception, interception), per WSJ swarm summary.
Hundreds of drones fell from the sky in China; operators cite unknown cause
Drone swarm reliability (Field incident): Footage shows hundreds of drones dropping out of the sky nearly simultaneously; initial blame on police jamming shifted to “unknown” or operator error, according to Mass drone drop clip.

For engineers tracking swarm systems, this is a real-world reminder that RF links, control handoffs, and failsafe behavior dominate perceived safety more than lab-level autonomy demos, as implied by Mass drone drop clip.
Rifle-mounted robots appear in India’s Republic Day rehearsal footage
Military robotics (India): Video from India’s Republic Day rehearsal shows tracked robots with mounted rifles moving in formation, as shown in Rehearsal robot clip.

It’s a deployment signal: even when autonomy is unclear, platformization (mobility + payload + comms) is moving into public-facing exercises, per Rehearsal robot clip.
Verobotics shows façade-climbing robots for exterior cleaning and inspection
Verobotics (Facade robots): A field demo shows robots adhering to and moving along building exteriors to clean and scan façades, positioning robotics as a replacement for hazardous rope-access work, as shown in Facade robot demo.

This is a concrete “embodied AI” wedge: narrow task scope, clear ROI, and deployment in an environment where autonomy can be bounded (repeatable surfaces, constrained routes).
🎨 Generative media workflows: AI influencers, video consistency tricks, and restoration prompts
Creator-side gen media remained active: AI influencer monetization workflows, repeatability tricks for video, and long restoration prompts. Excludes voice agents (separate category).
Grid prompting plus start/end frames is being used for more consistent AI video
AI video consistency (Technique): A practical recipe is being shared for keeping generated video more stable by combining grid prompting with explicit start and end frames, with results shown in the consistency demo; the example claims it was made using Nano Banana Pro and Kling 2.6, which matters because it’s a cross-model workflow rather than a model-specific feature.

• Why it works (mechanically): The method constrains the model’s degrees of freedom twice—first with a structured prompt grid, then with boundary conditions via first/last frames—per the consistency demo.
A long “master shot” prompt template is spreading for photo restoration workflows
Photo restoration prompt (Template): A detailed, reusable prompt template is being shared for “complete photographic restoration and high-end upgrade,” emphasizing strict reference preservation plus cinematic lighting, texture upgrades, lens simulation, and film-style color grading, as shown in the prompt screenshot. It’s positioned for Nano Banana Pro (via Freepik) and is shared as a screenshot because of length, per the prompt screenshot.
• Template shape: The prompt is structured like a spec—directive, “critical reference handling,” and explicit visual upgrade requirements—which is useful for teams trying to standardize restoration outputs across operators, per the prompt screenshot.
Higgsfield pitches a 10‑minute “AI influencers” monetization playbook for 2026
AI influencers workflow (Higgsfield): A short-form “make MILLIONS with AI Influencers in 2026” pitch is circulating as a quick-start workflow, framed as a “10 minute guide” plus a “2026 playbook” link in the guide thread; the thread also uses an incentive mechanic (“retweet & reply for 50 credits”), which is a common growth loop in creator tool distribution.

• What’s actionable here: The artifact to evaluate is the packaging (short guide + playbook + incentives) rather than any verified ROI claims, which are not substantiated in the post itself per the guide thread.
A “cinematic AI social content” workflow is getting framed as an AI-influencer edge
AI influencer content pipeline (ProperPrompter): A creator-focused thread argues there’s “massive opportunity” in AI influencers and points to a “full workflow + secrets for cinematic AI social media content” in an associated article, as described in the workflow pitch. The operational takeaway for builders is that creator demand is clustering around repeatable “cinema” aesthetics and distribution playbooks—regardless of whether the monetization outcomes are reproducible.
• Positioning signal: The thread explicitly calls out the “people dismiss it as cringe” objection, which suggests the real bottleneck is social acceptability/brand risk rather than generation capability, per the workflow pitch.
Personalized wallpaper generation is emerging as a lightweight Nano Banana Pro use case
Nano Banana Pro (Use case): A small but concrete workflow is being shared for generating personalized wallpapers, illustrated with a sample output in the wallpaper example. It’s a low-friction “asset factory” pattern: one prompt → many background variants, which is often where consumer gen-media tools first stick.
• Product signal: The post frames wallpapers as a “fun use case,” suggesting the workflow’s value is quick iteration and personal taste matching rather than photoreal fidelity, per the wallpaper example.
📚 The browser as a sandbox: web-native containment patterns for agent apps
A smaller but high-signal devex thread: treating the browser as the sandbox for agentic apps, with concrete notes on iframe sandboxing/CSP and directory upload primitives. Excludes repo-local prompt rules (coding-workflows) and MCP plumbing (orchestration).
Browser sandboxing patterns for agent apps: iframe sandbox meets CSP
Browser sandbox containment: Simon Willison published deeper notes on “the browser is the sandbox,” focusing on how web-native agent apps can treat the browser as the containment boundary—especially the tricky intersection of <iframe sandbox> and Content Security Policy (CSP) for constraining what untrusted agent-generated UI/code can do, as described in his follow-up notes and earlier containment thread.
The write-up frames a practical decomposition of “sandbox” into (1) file access, (2) network access, and (3) safe code execution—then explores how browser primitives (nested iframes, CSP headers, workers/Wasm) can be composed to approximate a secure agent runtime, with implementation details in the blog post.
webkitdirectory becomes a viable primitive for web agent file access
Directory upload primitive: A small but useful browser capability is resurfacing: <input webkitdirectory> now works across Chrome, Firefox, and Safari, enabling “select a folder” flows for web UIs without requiring full File System Access API permissions, as noted in directory demo and referenced from the broader sandboxing discussion in containment thread.
For agentic web apps, this makes it easier to build a “bring your repo/docs” interface where the browser can provide a bounded, user-approved file corpus; Simon’s demo shows folder enumeration + file tree/preview in the directory explorer.
Rich Markdown renderer surfaces as a simple terminal UX upgrade
Rich (Python): The Markdown() renderer in Rich is getting shared as a low-effort way to make terminal outputs (agent reports, eval summaries, logs) more readable, per the Rich Markdown tip linking to the Rich docs.
This shows up as a recurring devex move in agent-heavy workflows: keep the runtime in a TUI/CLI, but present intermediate artifacts (plans, diffs, checklists) in Markdown with syntax highlighting and formatting rather than raw text.
🎧 Voice is speeding up: real-time cloning claims and latency as the UX unlock
Voice items today were mostly about latency and open-source acceleration (real-time cloning, fast TTS UIs), plus a few “voice mode feels smoother” reactions. Excludes creative media pipelines (gen-media category).
VoxCPM claims real-time voice cloning without tokenization
VoxCPM (OpenBMB): An OpenBMB retweet claims an open-source TTS system can clone a human voice “in real time without tokenization,” pointing at VoxCPM as the core idea real-time cloning claim. This is part of the ongoing shift away from discretized audio token pipelines toward continuous/“tokenizer-free” designs.
There are no evals, latency numbers, or reproducible benchmarks in the tweet itself, so treat it as an announcement-level signal until a reference implementation and measurements are circulated.
Voice AI feels different as latency approaches zero
Voice latency (UX): A builder framing says voice AI is about to “have a moment” because the experience shifts nonlinearly as latency approaches ~0, per the latency claim. This is the practical argument that speed (not just MOS or benchmark scores) is what makes voice agents feel conversational enough to replace taps/typing.
The claim is qualitative (no numbers or measurements in the tweet), but it matches what teams see in real deployments: smaller cuts in tail latency often change turn-taking, interruption handling, and user trust more than model upgrades.
ChatGPT voice mode feedback: smoother delivery and less robotic sound
ChatGPT voice mode (OpenAI): An anecdotal reaction says the “new ChatGPT voice mode” sounds gentler, avoids audio peaks better, and feels less robotic, per the voice mode reaction. That’s consistent with improvements in prosody control and output-level audio dynamics (often as important as the underlying text model for perceived quality).
No clips or A/B measurements are attached in today’s tweet, so it’s sentiment—not a spec drop.
Qwen3-TTS gets a one-click local Gradio UI
Qwen3-TTS (runtime UX): A community Gradio web UI is being shared as a “1-click” way to run Qwen3-TTS locally on a PC, according to the Gradio UI retweet. The practical value here is lowering the “demo friction” for teams that want to compare open TTS quickly without wiring their own inference harness.
This is a packaging/workflow update rather than a model update; it doesn’t change Qwen3-TTS capability, but it changes who can actually try it.
TTS acceleration chatter: tooling is moving faster than evaluation norms
TTS pace (ecosystem): A retweeted roundup warns that “text-to-speech is moving way too fast,” pointing to rapid successive open releases and demos as the main theme pace warning. For engineering leaders, the immediate implication is procurement and trust: model selection, safety checks, and voice-rights policies tend to lag behind what can be shipped.
The post is directionally useful, but it’s not tied to a single new benchmark or standardized test artifact in today’s tweets.
🧑🏫 Where builders are learning: eval workshops, agent lists, and coworking formats
Today’s learning/distribution artifacts were mostly workshops and curated lists (agents/evals resources) plus local coworking formats. Excludes product changelogs (kept in tool categories).
Braintrust schedules “Trace” in SF to teach PMs how to ship evals
Trace (Braintrust): Braintrust is promoting an in-person-only SF event on Feb 25 focused on getting teams to “ship your first eval,” including an evals workshop aimed at PMs, as described in the workshop invite.

The listing emphasizes a hands-on format (workshop + intro to evals for PMs) and registration details in the event page.
A compact reading list for agentic reasoning, evals, and governance
Agentic reasoning reading list (TheTuringPost): A curated “7 sources” list is getting shared as a quick way to onboard to agentic reasoning—mixing practitioner guides, surveys, and governance material, as shown in the seven sources list.
• Practical build guidance: The list explicitly includes an OpenAI “practical guide to building agents,” as shown in the seven sources list.
• Governance artifact: It also points to IMDA’s “Model AI Governance Framework for Agentic AI” (versioned doc), as shown in the seven sources list.
Gemini Batch API tutorial targets cheaper large-scale eval runs
Gemini Batch API (Google AI): Paige Bailey published a walk-through showing how to run large evals using Gemini’s Batch API with Hugging Face Datasets and a Colab notebook—framed as “50% less” for massive evals, as linked in blog and notebook links.
• Code-level entry point: The Batch API snippet (inline requests + batch job creation) is shown in the Batch API example.
• Repro artifacts: The tutorial text and runnable notebook are linked as the blog post and Colab notebook.
RLHF Book expands with minimal single-GPU RL and RM code
RLHF Book (natolambert): The RLHF Book repo added “single GPU, tinkering scripts” covering multiple RL and reward-model variants (including REINFORCE, PPO, GRPO-family entries, plus PRM/ORM), positioned as a more central learning home for post-training, as described in the scripts rundown.
The code entry point is linked via the GitHub code directory.
A recurring coworking format for agentic side projects (Posthog-supported)
Code and Chill (Ivan + Posthog): A second coworking session is being organized (Singapore) as a build-in-public format for agentic projects—framed as people showing up to hack on things like “excel-headless browsers” and learning/absorption tooling, per the coworking invite.
Signup logistics are posted on the event page.