Nvidia–Groq $20B licensing move – 3× valuation for deterministic inference
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Nvidia and Groq confirm a non‑exclusive inference tech licensing tie‑up structured as a $20B cash asset deal; commentators label it Nvidia’s largest transaction and roughly 3× Groq’s last reported $6.9B valuation. GroqCloud stays online under new CEO Simon Edwards while founder Jonathan Ross and president Sunny Madra move to Nvidia, blurring the line between asset sale and acquisition. Nvidia gains Groq’s deterministic LPU architecture, SRAM‑heavy design, and RealScale cluster synchronization, positioning these ideas inside its broader AI factory stack and signaling a shift from pure accelerator sales toward tightly integrated, low‑latency inference services.
• Coding agents & Skills: Windsurf Wave 13 ships parallel agents and free SWE‑1.5; Mistral’s Vibe Skills, the Agent Skills markdown standard, Warp forking, MCP servers like Zread/cto.new, and tools such as Typeless and CodexBar deepen reusable, multi‑backend agent workflows.
• Compute & infra: ByteDance targets $23B 2026 AI capex and a 20k‑unit H200 trial as Nvidia seeks 5k–10k H200 exports under a 25% fee; Blackwell GB300 outpaces Google’s Ironwood TPU on MoE throughput; Intel’s Fab 52 aims for 10k 18A wafer starts/week.
• Models, evals & methods: GLM‑4.7 leads open leaderboards; GPT‑5.x trends show jagged High‑reasoning gains; Terminal‑Bench 2.0 adds per‑trial telemetry; TurboDiffusion, DataFlow, Agent‑R1, UCoder, Canon layers, and new safety/ToM benchmarks highlight system‑level and RL‑centric advances.
Top links today
- Nvidia–Groq $20B inference technology deal analysis
- Nvidia AI factory moat and Gemini impact
- Reuters: Nvidia seeks H200 AI chip sales to China
- FT: ByteDance plans $23bn 2026 AI capex
- Intel Fab 52 overview and US capacity
- DataFlow: LLM-driven data preparation framework
- UCoder: unsupervised code generation via self-play
- Canon layers for deeper LM reasoning
- Meta-RL induces exploration in language agents
- LORE: laws of reasoning for LMs
- TurboDiffusion: 100–200x faster video diffusion
- Probing scientific general intelligence of LLMs
- Evaluating LLMs in scientific discovery tasks
- Loop closure grasping for soft robotic manipulators
Feature Spotlight
Feature: Nvidia–Groq tie‑up for deterministic, low‑latency inference
Nvidia licenses Groq’s inference stack and hires its leaders (reports peg consideration near $20B), keeping GroqCloud live—positioning deterministic LPU/RealScale ideas inside Nvidia’s AI factory for real‑time inference.
Cross‑account story: Groq says Nvidia will license its inference tech and hire key leaders; media report a ~$20B deal. GroqCloud stays up; LPU determinism and RealScale sync are the technical hooks.
Jump to Feature: Nvidia–Groq tie‑up for deterministic, low‑latency inference topicsTable of Contents
🤝 Feature: Nvidia–Groq tie‑up for deterministic, low‑latency inference
Cross‑account story: Groq says Nvidia will license its inference tech and hire key leaders; media report a ~$20B deal. GroqCloud stays up; LPU determinism and RealScale sync are the technical hooks.
Groq and Nvidia sign non‑exclusive inference tech deal while GroqCloud stays up
Groq–Nvidia licensing (Groq/Nvidia): Groq announced a non‑exclusive licensing agreement for its inference technology with Nvidia, saying GroqCloud will continue to operate and that it will remain an independent company, while founder Jonathan Ross and president Sunny Madra move to Nvidia and Simon Edwards becomes Groq’s CEO, according to the official update in the groq licensing post and the detailed groq newsroom note. This keeps existing GroqCloud customers online while handing Nvidia both IP access and much of Groq’s leadership bench.
Deal structure: Groq frames the arrangement as a non‑exclusive technology license plus key hires rather than an outright acquisition, while emphasising that GroqCloud “will continue without interruption,” as reiterated in the independent recap in the deal recap thread; that combination signals Nvidia wants Groq’s inference know‑how inside its AI factory stack without fully absorbing the cloud business.
Reports say Nvidia paying about $20B for Groq in its biggest deal yet
Deal size and framing (Nvidia/Groq): Multiple reports describe Nvidia’s arrangement with Groq as a roughly $20 billion transaction, calling it Nvidia’s largest deal on record and treating it as an acquisition of Groq’s assets even as official language stresses licensing and independence, as outlined in the CNBC coverage in the cnbc deal scoop and the matching cnbc article, and echoed by Reuters in the reuters confirmation. That number implies Nvidia is paying roughly 3× Groq’s last reported $6.9 billion valuation for access to its inference tech and team.
• Asset sale vs acquisition: A longform breakdown characterises the structure as a "non‑exclusive licensing agreement" plus most of Groq’s leadership joining Nvidia for "total consideration of $20 billion cash," comparing it to an acquisition in all but name and noting that Groq was last valued at $6.9 billion in September, according to the text excerpted in the asset sale summary.
• Regulatory asymmetry concerns: Commentators contrast this greenlighted mega‑deal with the FTC’s earlier opposition to Amazon’s iRobot purchase, arguing that regulators effectively pushed iRobot into bankruptcy while allowing Nvidia to neutralise a specialised inference rival for $20 billion, as argued in the asset sale summary and the initial "BREAKING" post in the breaking summary.
Investor and market angle: Some threads note that because this is structured as an asset deal and licensing arrangement, existing Groq investors now sit on a company with $20 billion in cash whose future exit options are unclear, which adds another layer of complexity to how the transaction will be viewed in capital markets, as raised in the investor question.
Groq’s deterministic LPU, SRAM design and RealScale pitch folded into Nvidia stack
Groq LPU architecture (Groq): Analysis of the Nvidia–Groq deal focuses heavily on Groq’s Language Processing Unit (LPU), which runs inference on a deterministic, pre‑scheduled execution plan so each token step has predictable latency instead of the cache and scheduling jitter typical of general‑purpose GPUs, as explained in the technical breakdown in the technical explainer thread. Groq claims this yields tight, consistent response timing for real‑time chat and streaming output.
• SRAM vs HBM tradeoff: Groq’s chips keep much of the working model state in on‑chip SRAM, which offers very low access latency and lower energy per access but much smaller capacity; that forces a trade between fast, power‑efficient token generation and the maximum model size per chip, while GPU systems rely on off‑chip HBM with far higher capacity but more complex access paths, as laid out in the technical explainer thread.
• RealScale cluster sync: Groq also promotes its RealScale interconnect, which coordinates clocks across many servers so token computations stay time‑aligned and avoid extra buffering and retries that come from clock drift, aiming to make a multi‑server deployment behave like one large, predictable machine, according to the same technical explainer thread and the deeper siliconangle analysis.
Integration stakes: The licensing agreement gives Nvidia a path to embed Groq’s deterministic scheduling ideas, SRAM‑heavy designs, and RealScale‑style cluster synchronisation into its broader AI factory vision, potentially creating a differentiated lane for ultra‑low‑latency inference alongside conventional GPU deployments.
Commentators see Nvidia–Groq tie‑up as a bet on inference services, not just chips
Inference strategy (Nvidia/Groq): Industry voices frame the Nvidia–Groq deal as Nvidia buying not only IP but a mature inference service mindset, contrasting Nvidia’s traditional focus on selling chips with Groq’s focus on selling deterministic, low‑latency inference as a service, as summed up in the remark that "Nvidia sells chips, not inference; Groq sells inference, not chips" in the strategy comment. That framing suggests Nvidia is shoring up the inference layer of its AI factory to complement GPU hardware.
• Customer and ecosystem reaction: Existing Groq customers, such as AmpCode, highlight that Groq was "one of the very first teams" using their tooling and offer public congratulations, signalling that at least part of the developer ecosystem views the move as validation of Groq’s approach rather than an abrupt shutdown, as seen in the customer reaction.
• Non‑exclusive and independence spin: The combination of non‑exclusive licensing language and Groq’s continued operation under a new CEO is read by some as Nvidia wanting Groq’s inference technology inside its stack while still allowing Groq to serve other clouds and customers, an interpretation reinforced by the technical and deal commentary in the technical explainer thread and the asset‑sale framing in the asset sale summary.
Market implication: Taken together, the licensing, leadership move, and public commentary position the tie‑up less as a one‑off chip acquisition and more as Nvidia tightening its grip on both the hardware and software sides of high‑performance inference.
🛠️ Coding agents and IDE workflows ship holiday upgrades
Busy day for agentic dev tools: parallel agents, reusable skills, and better terminals. Excludes the Nvidia–Groq feature; this is about builder ergonomics and adoption.
Windsurf Wave 13 ships parallel agents, Git worktrees and free SWE‑1.5
Windsurf Wave 13 (Cognition): Cognition rolled out Wave 13 "Shipmas" for the Windsurf IDE, adding true parallel agents, Git worktrees support and making the SWE‑1.5 coding model free for all users, according to the holiday release notes in the wave13 announcement and recap in the feature overview.
The update introduces multi‑Cascade tabs and panes so several agent sessions can work in the same repo without stepping on each other, plus a dedicated zsh-based agent terminal aimed at more reliable command execution and faster shell loops, as highlighted in the Shipmas poster in the Wave13 explainer. The notes also mention Git worktrees so agents can branch work cleanly, a context window indicator for long sessions, and a "Shipmas gift" where SWE‑1.5 replaces the older SWE‑1 as the free default, which earlier tweets framed as a near‑frontier coding model now exposed at standard speeds in the wave13 announcement. The longer write‑up on Windsurf’s site goes into more details on multi‑agent layout and hooks, describing how multi‑Cascade plus worktrees are meant to approximate Conductor‑style parallelism directly inside a desktop IDE, as discussed in the Wave13 explainer and expanded in the Wave13 blog. Overall, Wave 13 moves Windsurf from a single‑agent coding helper toward a small multi‑agent environment tuned for long‑running coding tasks and refactors.
Firecrawl’s /agent node lands in n8n for goal‑to‑data workflows
/agent node in n8n (Firecrawl): Firecrawl introduced a new /agent node for n8n, turning its earlier /agent HTTP endpoint into a drag‑and‑drop block that can take a natural‑language goal and orchestrate search, crawl and enrichment to return structured data, extending the web‑automation story that was first framed as a generic endpoint in web orchestration and now embedded directly into a workflow builder in the n8n demo.
In the short product video, a user drops the /agent node into an n8n flow, describes the goal, and Firecrawl’s agent then issues its own sub‑requests to search, crawl and scrape before handing rich output back into the graph, which can then feed downstream nodes like databases or messaging systems in the n8n demo. The Product Hunt launch copy stresses that this is meant to "enrich data" rather than just scrape pages, so the agent can, for example, visit a site, extract relevant fields, and normalize them into a JSON structure in a single node according to the launch summary. The integration docs on Firecrawl’s side explain that the node uses the same underlying /agent orchestration stack that was exposed via API earlier, but now hides token accounting and tool selection inside n8n, as described in the n8n integration docs.
This effectively promotes Firecrawl from a component you have to wire up manually to a first‑class agentic data‑ingestion block in one of the more popular low‑code automation tools, which should lower the barrier for engineers who want web‑aware agents in their pipelines without writing orchestration code by hand.
Mistral ships Vibe CLI Skills for reusable agent expertise
Vibe CLI Skills (Mistral): Mistral released a holiday update to Vibe CLI adding Skills, an abstraction for bundling domain expertise and rules into reusable profiles that can be applied across projects, alongside new reasoning‑model support and native terminal themes, as shown in the skills launch.
Skills are created and managed via commands like mistral-vibe skills add, then referenced when running the CLI so an agent can inherit consistent conventions (for example, project structure or code style), which the short demo in the skills launch emphasizes as a way to keep dev expertise close to the tool rather than rewriting instructions per repo. The update also enables support for Mistral’s reasoning models from the same CLI surface and introduces multiple themed terminal UIs meant to integrate better with local shells, which should matter for developers who live in tmux or custom terminal setups. Installation is handled through uv tool install mistral-vibe, so this stays in the Python tooling ecosystem familiar to many backend and ML engineers.
The point is: Vibe is being positioned less as a one‑off code generator and more as an agentic coding harness where Skills act like portable system prompts that capture a team’s preferences and can be versioned, shared and reused across repositories.
Warp adds conversation forking, Slack/Linear integrations and GPT‑5.1 Codex
Warp terminal agents (Warp): Warp surfaced a pair of small but meaningful upgrades to its agentic terminal experience: a "fork conversation from here" action that lets users branch an agent session at any past step, and documented integrations to create Warp agent tasks directly from Slack and Linear, all on top of the earlier context compaction tools discussed in context tools and illustrated in the forking demo.
Right‑clicking any message in a Warp agent session now offers "fork conversation from here", which starts a fresh thread with only the context up to that point so users can explore alternate approaches without polluting the main history; the short clip in the forking demo shows a new conversation spawning and then diverging. Separately, new CLI commands like warp integration create slack --environment {{environment_id}} and warp integration create linear --environment {{environment_id}} configure Warp as a target in Slack and Linear, so mentioning @Warp or a linked command can turn chat or ticket context into a queued agent task, as spelled out in the integration snippet in the integration snippet and deeper explained in the integrations overview. Another tweet notes that GPT‑5.1 Codex is now available inside Warp for those still using the legacy Codex tooling, which ties into this broader push to centralize high‑end coding models into a terminal‑first workflow in the codex in warp.
Together these updates keep Warp moving toward an agent‑aware terminal where context can be pruned, branched and sourced from team tools, rather than treating each chat as an isolated, linear session.
Agent Skills standard gains traction and inspires new Claude Code plugin
Agent Skills ecosystem (multi‑tool): Discussion around Agent Skills—markdown files that define reusable capabilities for coding agents—highlighted how many tools now support the format, from OpenCode and Cursor to Claude Code, Letta, GitHub and Codex, and that this standardization is inspiring new plugins like Continuity Claude, which packages twelve Claude Code improvements into a single skill, as shown in the tool collage in the skills ecosystem view and the follow‑up praise in the continuity claude shout.
The image shared in the skills tweet lists a range of clients that understand Skills—including VS Code, Claude Code, Cursor, Letta and Codex—framing Skills as a portable way to ship agent behaviors (instructions, conventions, workflows) across different agent hosts without duplicating system prompts, which the author argues will be a "valuable skill to learn" for structuring agents efficiently in the skills ecosystem view. Building on that, another post calls out the Continuity Claude plugin, which reportedly addresses a dozen problematic behaviors in Claude Code—things like session continuity, tool usage patterns and context hygiene—packaged into a single plugin that users can install as a skill, with the author noting it was inspired by an earlier "Continuity Ledger for Codex" in the continuity claude shout.
This suggests Skills are emerging as a de facto portability layer for agent configuration, with community plugins starting to encode best practices and bug‑workarounds in a reusable way rather than leaving every team to rediscover the same patterns.
Kilo Code debuts in‑browser App Builder and launches Kilo College
App Builder and Kilo College (Kilo Code): Kilo Code rolled out a new App Builder inside its Agentic Engineering Platform that lets users build full web apps through conversation with a real‑time preview, no local setup, plus one‑click deploys, and paired the launch with Kilo College, a training program focused on shipping production code with AI rather than demos, as described in the app builder intro and college teaser.
The App Builder runs entirely in the browser and is pitched as a "Lovable alternative for serious projects"—users describe what they want, watch a live preview update, and then deploy to an instant production URL, with the workflow designed to hand off smoothly into Kilo Code for deeper editing without losing context, according to the app builder intro. Kilo College is introduced as a companion educational track that teaches developers how to move beyond "vibe coding" toward practices that ship reliable systems, with the launch blog emphasizing production‑grade workflows, integration with existing teams, and focusing on real deployment patterns rather than toy apps, as detailed in the Kilo College blog.
For engineers, this pairs an agentic UI layer for app creation with a structured path to learning the underlying discipline, reflecting a pattern where AI‑assisted dev tools also invest in training so teams can adopt them in serious contexts.
Typeless launches iOS AI keyboard for voice‑driven coding across apps
Typeless iOS keyboard (Typeless): Typeless released an AI‑powered voice keyboard for iOS that turns natural speech into structured text in any app, with devs already using it to "vibe code" in Claude Code, Gemini, AI Studio and other tools, as shown in the UI screenshots in the keyboard demo and launch notes in the ios rollout.
The keyboard presents a large microphone button branded "Typeless" in place of normal keys, encouraging users to tap or hold to dictate while it handles punctuation, formatting, and light editing in real time; the example shows it driving a Claude Code session where the user is editing a GitHub repo from mobile, described in the keyboard demo. The companion app dashboard tracks aggregate stats such as 43 minutes dictated, 4,743 words and an average of 109 WPM, and offers a schedule for automatically turning Typeless off after a set inactive period, with all processing kept on‑device according to the metrics screen in the keyboard demo and summary in the feature overview. The launch thread emphasizes that this is aimed at scenarios where system voice dictation is unavailable or awkward—like coding from bed or on a commute—and supports multiple languages while trying to stay quiet and context‑aware, as explained in the ios rollout.
For engineers already leaning on agentic tools on desktop, Typeless effectively extends those workflows to iPhone by making voice a first‑class input for code edits, prompts, and issue responses without leaving their existing apps.
Zread MCP server lets GLM coding agents navigate GitHub from IDEs
Zread MCP server (Zhipu / Z.ai): Zhipu introduced Zread, an MCP server that plugs into clients like Claude Code and Cline and is now bundled with the GLM coding plan, allowing coding agents to browse, search and read GitHub repos without leaving the IDE, as outlined in the zread announcement.
According to the docs, Zread exposes tools for repository structure listing, full‑text documentation search and file content reading, giving agents direct access to codebases hosted on GitHub via the Model Context Protocol, so a GLM‑4.7 coding session can, for example, inspect a project layout, open specific files, and answer questions about the code in‑place, as summarized in the Zread MCP docs. The tweet frames this specifically as a way to "stay in your flow" when exploring repos, and positions Zread as part of the GLM Coding Plan so that devs on Z.ai’s stack do not need to create custom MCP servers or intermittent copy‑paste bridges, as described in the zread announcement.
This brings GLM closer to the experience Claude Code users have with MCP‑powered tools, and it suggests a trend where coding plans come with first‑party MCP servers for repo exploration baked in, rather than leaving that to third‑party experiments.
CodexBar 0.14.0 adds Antigravity provider, status page and bug fixes
CodexBar 0.14.0 (steipete): The CodexBar macOS menu bar companion for coding agents shipped v0.14.0, adding a new Antigravity local provider, a provider status page, better menu layout for up to four providers, and multiple bug fixes around usage tracking and ghost web views, building on earlier cost‑and‑usage improvements from usage ui and detailed in the release screenshot.
The new build shows Antigravity alongside Claude and Gemini in the provider list, with live quota percentages and reset timers for each, so developers can see at a glance how much of their Claude Pro, Gemini Pro/Flash, or Antigravity quotas remain, as visible in the menu capture in the release screenshot. The status page now polls Google Workspace incidents for Gemini and Antigravity and links out to a dedicated page if there are upstream outages, while the Providers tab in settings centralizes configuration instead of scattering API keys and toggles, according to the CodexBar changelog. The author also notes fixes for the "ghost" OpenAI web view overlay on desktop and more reliable debug output for probing Claude usage, which should matter for people running several providers through CodexBar to power tools like Codex CLI or Claude Code.
This keeps CodexBar evolving into a multi‑provider observability layer for coding agents rather than a thin wrapper, making it easier for power users to route work across Claude, Gemini, Antigravity and others without manually tracking quotas.
cto.new turns Cursor into a background coding agent via MCP
Cursor + cto.new (cto.new): A new guide from cto.new shows how to wire the Cursor IDE to cto.new as a background AI coding agent using MCP, so developers can delegate tasks from Cursor to a free, external executor instead of relying solely on Cursor’s built‑in agents, as shown in the integration graphic in the cursor integration visual and documented in the integration guide.
The setup involves adding cto.new as an MCP server in Cursor’s configuration, authenticated via OAuth, which then exposes cto.new’s capabilities as slash commands and context providers inside Cursor; the blog explains that this lets developers plan and scope work inside Cursor, then offload execution to cto.new’s AI engineer without paying Cursor’s per‑task agent costs, according to the integration guide. The author frames this as avoiding the expense of Cursor’s "native background agents" while still getting long‑running delegated work done, and positions cto.new as a general coding agent optimized for feature implementation and refactors rather than chatty assistance, consistent with the benefits outlined in the cursor integration visual.
This points to a loosely coupled agent stack pattern: IDEs like Cursor act as frontends and MCP routers, while heavy lifting can be handed off to third‑party agent backends chosen for cost or capability.
🏭 Compute race: TPU vs Blackwell, H200 to China, ByteDance capex
Infra and capex updates with concrete throughput/capacity deltas. Excludes the Nvidia–Groq tie‑up (featured).
ByteDance lines up ~$23B 2026 AI capex and tests big H200 buys
AI capex race (ByteDance vs US hyperscalers): ByteDance is planning around $23 billion of capital spending in 2026 focused on AI infrastructure in an effort to keep pace with U.S. rivals whose combined AI data‑center capex tops $300 billion this year, with the Financial Times reporting that ByteDance is exploring a 20,000‑unit H200 test order at roughly $20,000 per module plus significant overseas data‑center leasing bytedance capex thread and the underlying coverage ft article.
• Three‑pronged strategy: The plan reportedly mixes domestic build‑out, selective access to Nvidia hardware (via any approved H200 exports), and leasing foreign compute as operating expense, effectively expanding ByteDance’s usable AI capacity without booking all of it as on‑shore capex bytedance capex thread.
• H200 linkage: The mooted 20k H200 trial order—worth about $400M at the cited price—would directly plug into the same export channel Nvidia is trying to open to China, tying ByteDance’s roadmap to the outcome of the H200 licensing negotiations and any requirements to pair U.S. accelerators with Chinese chips ft article.
• Relative scale: Even at $23B, ByteDance’s spend is a fraction of U.S. hyperscaler AI capex but still large enough to materially expand its training and inference fleet for products like TikTok and domestic LLMs, with leased capacity giving it flexibility to adjust to geopolitical or regulatory shocks bytedance capex thread.
This positions ByteDance as the most aggressive non‑U.S. player in the AI infra arms race, with its ability to secure H200‑class GPUs now a key variable for Chinese frontier‑model competitiveness.
Nvidia targets mid‑Feb H200 shipments to China, pending approvals and 25% fee
H200 exports to China (Nvidia, regulators): Nvidia is reportedly preparing to ship 5,000–10,000 H200 modules—equivalent to roughly 40,000–80,000 GPUs—to Chinese buyers by mid‑February 2026, contingent on Beijing sign‑off and a new U.S. licensing regime that would take a 25% fee on such sales, according to the Reuters‑sourced briefing summarized here h200 shipment report and the original coverage reuters story; this marks a sharp policy reversal from earlier H200 export bans.
• Chip positioning: The report notes that H200—a Hopper‑class GPU with 141 GB HBM3e and around 4.8 TB/s bandwidth—is estimated at about 6× the performance of H20 for many AI workloads, while Nvidia’s upcoming Blackwell is said to be roughly 1.5× faster for training and 5× for inference than H200 h200 shipment report.
• Inventory and capacity: Nvidia aims to cover the initial Chinese demand from existing H200 inventory, even as its CoWoS packaging capacity is being prioritized for Blackwell and next‑gen Rubin, tightening supply and making these 5k–10k modules a scarce allocation h200 shipment report.
• Policy mechanics: Under the new framework, the U.S. government would license H200 exports while collecting a quarter of the contract value, and Chinese regulators are reportedly considering tying approvals to mandatory bundles of domestic accelerators, which could blunt but not erase the impact on China’s near‑term AI compute pool reuters story.
For AI infra planners, this suggests that H200 will likely appear in select Chinese clouds and labs as a bridge between restricted A100/H100 generations and delayed access to Blackwell‑class parts, with pricing and allocation heavily shaped by licensing friction.
Nvidia GB300 NVL72 outpaces Google Ironwood TPU on MoE training throughput
Blackwell vs Ironwood (Nvidia, Google): New vendor benchmarks circulating among practitioners show GB300 NVL72 delivering 1.5–1.9× higher tokens/sec per chip than Google’s Ironwood TPU on large Mixture‑of‑Experts models, with the biggest gap (1.9×) on a GPT‑OSS‑120B workload, as highlighted in the chart shared via Steve Nouri’s analysis throughput thread and his linked commentary linkedin post; the framing stresses that real training speed is now limited more by memory bandwidth, interconnect and software stack than raw FLOPS.
• MoE workloads tested: The comparison spans Qwen1.5‑235B‑A22B, DeepSeek‑V3 BF16/FP8, and GPT‑OSS‑120B BF16, where GB300’s NVLink‑plus‑stacked‑HBM design and software stack (NCCL, CUDA graphing) appear to keep GPUs busier than Ironwood’s pod fabric—especially on communication‑heavy expert routing throughput thread.
• Per‑chip vs system view: While the graphic reports per‑chip throughput, Nouri notes that Nvidia’s integrated hardware + interconnect + software stack lets customers realize more of that theoretical gain in practice, whereas TPU results are often gated by pod topology and compiler maturity linkedin post.
• Practical takeaway: The numbers support the view that on frontier‑scale MoE training, Nvidia retains a cost‑performance moat despite TPU FLOPS parity claims, because end‑to‑end training throughput tracks interconnect and tooling as much as silicon specs.
This adds quantitative backing to the idea that competing with Nvidia on FLOPS alone is insufficient without matching its networking and software ecosystem for MoE‑heavy frontier training.
Intel Fab 52 aims for 10k 18A wafer starts per week, surpassing TSMC’s US scale
US leading‑edge fabs (Intel vs TSMC): Intel’s new Fab 52 in Arizona is described as the largest and most advanced logic fab in the U.S., with more EUV tools and higher planned volume than TSMC’s Arizona facilities, and a target capacity of 10,000 wafer starts per week (~40,000 WSPM) on the Intel 18A node, according to Tom’s Hardware’s summary of the build‑out fab52 capacity report and the underlying analysis tomshardware article.
• Process tech: Intel 18A is a 1.8 nm‑class process that combines RibbonFET gate‑all‑around transistors with PowerVia backside power delivery, a combination aimed at better performance‑per‑watt for CPUs and accelerators that will underpin future AI servers and client devices tomshardware article.
• EUV tool density and yields: The article notes that Fab 52 carries a heavier EUV scanner load than TSMC’s current Arizona fabs, but that Intel does not expect “world‑class” 18A yields until early 2027, implying that the fab could remain under‑utilized in the near term despite its physical scale fab52 capacity report.
• Relative footprint: By contrast, TSMC’s U.S. operations focus on N4/N5 in Fab 21 phase 1 and N3 in phase 2, with smaller module‑style capacities; Intel’s move positions Fab 52 as the first U.S. site capable of true frontier‑node volumes for both its own products and prospective foundry customers building AI accelerators tomshardware article.
This makes Fab 52 a key part of the medium‑term AI compute supply story, even though its impact will depend on how quickly Intel can ramp 18A yields and attract external AI chip designs.
OpenAI and Google report ~0.0003 kWh energy per median LLM prompt
Energy per prompt (OpenAI, Google, independents): Multiple sources now converge on a median energy use of roughly 0.0003 kWh per LLM prompt, with Ethan Mollick noting that this puts a typical ChatGPT request at about the same electrical cost as a Google search in 2008, and adding that both OpenAI and Google’s Gemini team publicly report similar figures, a claim he reiterates in follow‑up discussion llm energy tweet and a separate clarification second energy note.
• Cross‑lab agreement: According to Mollick, internal estimates from OpenAI and Google plus independent assessments on open‑weight models align on the 0.3 Wh per prompt ballpark for “median” interactions, suggesting that near‑term gains in efficiency are coming less from per‑query power drops and more from hardware and data‑center scale‑out second energy note.
• Comparative framing: The comparison to 2008‑era search cost emphasizes that today’s LLM usage is already within a familiar energy envelope on a per‑query basis, though the sheer volume of AI interactions and longer multi‑turn sessions can still create sizable aggregate demand at scale llm energy tweet.
For infra and sustainability teams, this provides a working order‑of‑magnitude for budgeting AI workloads, while leaving open how much future model scaling and agentic use will push beyond this early median figure.
📊 Leaderboards move: task‑level Terminal‑Bench, GPT‑5 trends, open model wins
Today’s evals focus on transparency and positioning across suites; fewer new math/code SOTAs, more dashboards and ranks.
GLM‑4.7 becomes top open model across design and WebDev leaderboards
GLM‑4.7 (Zhipu / Zai): Following up on coding sota where GLM‑4.7 set open‑source SOTA on SWE‑bench and τ²‑Bench, new results show it climbing creative and product leaderboards: it now ranks #2 on Design Arena’s Website Arena behind Gemini 3 Pro, appears as the only open-weight model in the WebDev top 10, and sits at #1 on Hugging Face’s trending models list, as shown in design ranking and hf trending.
• Design Arena aesthetics: On the Design Arena Website Arena Elo chart, Gemini 3 Pro Preview leads with 1377, while GLM‑4.7 scores 1345–1346, edging out Claude Opus 4.5 and several GPT‑5 variants; this positions GLM‑4.7 as the strongest open model for front-end/UI aesthetics in design ranking and website arena.
• WebDev #6, top open model: On the LM Arena WebDev benchmark, GLM‑4.7 currently sits at rank #6 with a score of 1449, trailing only frontier closed models like Claude Opus 4.5, GPT‑5.2‑High, Gemini 3 Pro and Flash, but ahead of all other open weights—prompting comments that "GLM 4.7 only open model in top 10" in webdev chart and open model remark.
• Hugging Face momentum: Hugging Face’s trending models page shows zai-org/GLM-4.7 as the #1 trending model, with 2.72k downloads and 744 likes, ahead of Qwen’s layered image models and others, which indicates strong early adoption and experimentation in hf trending and trending list.
• Agent and runtime usage: Factory AI reports that GLM‑4.7 "excels at recovering from errors" and is now available as a high setting in the Droid agent runtime, where it manages background services and full-stack builds without frontier‑level costs, according to agent eval and droid integration.
This cluster of rankings and usage reports paints GLM‑4.7 as the current flagship open model not just for coding, but also for web design and agentic application work.
GPT‑5.2 no‑reasoning climbs to #14 on LM Arena overall rankings
GPT‑5.2 (OpenAI): New LM Arena analysis shows the no‑reasoning GPT‑5 series steadily climbing the overall rankings, with base GPT‑5 around rank 26, GPT‑5.1 at 18, and GPT‑5.2 now reaching 14 on the style-controlled leaderboard, as charted in the series overview.
• Non-thinking variants only: This view strips out chain-of-thought and other "High/Thinking" modes to isolate raw single-pass chat performance; GPT‑5.2’s improvement over GPT‑5.1 suggests OpenAI has continued to refine alignment, breadth, and instruction following even without explicit reasoning traces in series overview.
• Position vs competitors: The same chart places GPT‑5.2 in the mid-teens among frontier models, behind top contenders but ahead of many earlier 5.x variants and non-OpenAI models, giving practitioners a clearer sense of how far they can go with cheaper, non-reasoning runs before paying for High/Thinking efforts in series overview.
This separation between no‑reasoning and High variants sets up more nuanced routing strategies, where builders can reserve expensive reasoning modes for only the hardest calls.
GPT‑5.2‑High lags GPT‑5.1‑High on many LM Arena categories
GPT‑5.2‑High (OpenAI): A category-by-category LM Arena breakdown shows GPT‑5.1‑High still outperforming GPT‑5.2‑High in many areas like instruction following, long-form queries, and multi‑turn chat, even as GPT‑5.2‑High pulls ahead in math, expert domains, and coding, according to the new trend charts in category trends.
• Overall ranking peak at 5.1: On the High Reasoning overall leaderboard, GPT‑5‑High starts around rank 19, GPT‑5.1‑High peaks at 8, and GPT‑5.2‑High drops back to 17, forming a "hill" pattern that contrasts with the monotonic improvement of the no‑reasoning series in category trends and series overview.
• Where 5.2‑High improves: In Math, Expert QA, and Coding, the 5.x High line continues upward—Math category ranks move from 14 → 4 → 1, and Coding from 25 → 14 → 12—matching expectations that RL with verifiable rewards helps proofs, compilers, and unit-testable tasks, as the charts highlight in category trends.
• Where 5.1‑High still wins: For Instruction Following, Hard Prompts, Business & Finance, Longer Query, Multi‑Turn, Life & Physical Sciences, and Creative Writing, GPT‑5.1‑High holds better ranks than GPT‑5.2‑High (e.g., Instruction Following improves from 31 → 9 but then slides to 14), suggesting the newer RL regime may have introduced regressions or sharper trade-offs across softer skills in category trends.
• Context for model choice: The LM Arena team notes that these numbers come from style-controlled matchups; combined with the open comparison tools at model comparison, they offer a more granular view for routing High‑effort calls between GPT‑5.1‑High and GPT‑5.2‑High depending on workload.
Taken together, these curves reinforce that the new RL-heavy frontier is "jagged" rather than uniformly better, with GPT‑5.2‑High looking like a specialized upgrade rather than a clean superset of GPT‑5.1‑High.
Terminal-Bench 2.0 adds per-task, per-trial breakdowns for coding agents
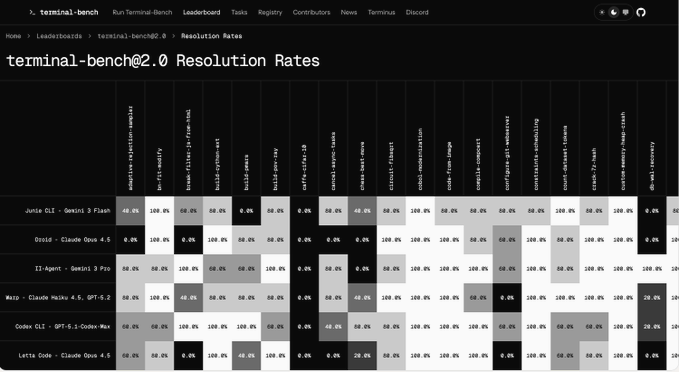
Terminal-Bench 2.0 (Terminal-Bench): The Terminal-Bench 2.0 leaderboard now lets users click into each task to see resolution rates by agent, then drill all the way down to individual trials with token, cost, and duration stats, giving a much clearer picture of where terminal agents succeed or burn budget, as shown in the new heatmap view in resolution heatmap.
• Task grid compare: A new "Resolution Rates" grid lays out success percentages per task and agent side by side (e.g., Junie CLI, Droid, II-Agent, Warp, Codex CLI, Letta Code), which makes strengths and blind spots across ~20 tasks—like cobol-modernization, vulnerable-secret, or git-leak-recovery—immediately visible in grid compare and resolution heatmap.
• Per-trial telemetry: Clicking a cell reveals all trials for that task/agent with fields for input/output/cache tokens, total tokens, dollar cost, and wall-clock duration (e.g., one adaptive-rejection-sampler run used 2.96M tokens for $0.83 and took 15m44s) according to trial breakdown.
• Step-level traces: Individual trials expose step-by-step traces of the agent’s plan, tool calls (like bash_command), and observations inside a “Steps (29)” view, clarifying whether failures are due to planning, environment setup, or flaky commands in steps trace.
For AI engineering teams, this turns Terminal-Bench from a single aggregate score into a diagnostic dashboard for cost, latency, and failure modes across real CLI workloads.
🚀 MiniMax M2.1 traction as a coding/agent backend
Continues yesterday’s M2.1 launch with fresh adoption and sentiment; this section covers usage and integrations, not eval dashboards.
MiniMax M2.1 becomes coding backend for Blackbox’s 30M devs
MiniMax M2.1 (MiniMax): MiniMax says M2.1 is now live inside Blackbox AI, exposing the 10B open‑weight coding/agent model to around 30 million developers who already use Blackbox for code assistance and automation, according to the distribution note in Blackbox integration; this extends the model’s reach beyond earlier integrations into tools like Kilo, Roo Code and Cline noted previously in tool integrations.
The point is: M2.1 is no longer just an option for self‑hosters and early agent frameworks; it is now wired into one of the largest AI coding frontends, which means many devs will encounter it first as a drop‑down backend rather than as a model card or GitHub repo.
MiniMax M2.1 deepens role as general agent backend across tools
MiniMax M2.1 (MiniMax): A detailed capability thread frames M2.1 as a general “digital employee” backend for agents and coding tools—calling out stable performance across Claude Code, Droid, Cline, Kilo Code, Roo Code, BlackBox and more, plus support for context conventions like Skill.md, Claude.md, agent.md, cursorrule and slash commands in common agent harnesses, as outlined in capability thread; MiniMax in parallel promotes its own Open Platform text generation API and Coding Plan packages as the primary way to call M2.1 directly, using an Anthropic‑compatible endpoint and prompt‑caching options in the guide linked from platform how-to and detailed in the text guide, building on the earlier MiniMax Agent “digital employee” storyline in digital employee.
• Agent and IDE support: The same thread emphasizes that M2.1 has been tested across multiple agent frameworks and coding surfaces (Claude Code, Droid, Cline, Kilo Code, Roo Code, BlackBox) with consistent long‑horizon behavior and interleaved thinking tuned for multi‑step tool use, as shown in capability thread.
• First‑party platform surface: MiniMax’s Open Platform docs present M2.1 as the default model behind all Coding Plan SKUs with an Anthropic‑style API surface, prompt‑caching hooks, and no extra setup beyond key configuration, which can matter for teams already wired into that ecosystem, per the text guide.
Taken together, these updates move M2.1 further into the role of a drop‑in, multi‑tool agent backend—something that can sit behind many different frontends and orchestrators while keeping the same planning style and context‑management patterns instead of being tied to a single IDE or vendor UI.
YouWareAI adopts MiniMax M2.1 for app-building workflows
MiniMax M2.1 (MiniMax): MiniMax highlights that builders can now use M2.1 on YouWareAI to "build some cool stuff," positioning the model as a turnkey backend for spinning up new AI apps on that platform rather than something users must wire up from scratch, as described in YouWare usage.
So what this changes: alongside Blackbox, Ollama, Cline and others, M2.1 is increasingly showing up as a pre‑integrated option inside third‑party dev tools and app builders, which lowers the friction for teams who want to try an open‑weight, agent‑ready coding model without managing their own serving stack.
💼 Monetization and market share: OpenAI ads tests, mega‑raise chatter, Gemini rank
Commercial signals and distribution: ad placements inside assistants, funding structure talk, and app‑store rank snapshots. Excludes Nvidia–Groq (feature).
OpenAI is prototyping ads inside ChatGPT answers and sidebars
ChatGPT ads (OpenAI): Reporting says OpenAI is actively experimenting with multiple ad formats in ChatGPT, including sponsored products promoted directly in ranked answers, right‑hand sidebar modules, and pop‑ups that trigger only after a user clicks into an itinerary or product detail, with Sephora-style mascara placements and “includes sponsored results” disclosures described in the ads details; some mockups also keep the first reply organic, then show sponsor blocks only once the user signals deeper intent, which is framed as a way to preserve trust while unlocking search‑like monetization.
A separate summary calls this "OpenAI preparing to start serving ads" and asks whether people actually want ads in AI assistants, surfacing mixed sentiment about whether sponsored responses would undermine perceived neutrality of ChatGPT’s advice user poll.
OpenAI reportedly targets a $100B round at around a $750B valuation
OpenAI funding (OpenAI): OpenAI is reported to be seeking a roughly $100B capital raise at an implied valuation near $750B, with U.S. institutional investors constrained by concentration limits and much of the money expected to come from cash‑rich tech giants, sovereign funds, and banks that want proximity to a future IPO according to the funding analysis; commentary notes the round may blend straight equity with strategic investments and large amounts of chip, datacenter and power-project financing counted toward the total, drawing parallels to an $80B U.S.–Westinghouse reactor deal shown in the underlying article excerpt
.
Amazon lines up as major capital partner to both Anthropic and possibly OpenAI
Anthropic and OpenAI stakes (Amazon): Amazon has already invested about $8B into Anthropic and is now reported to be in discussions to contribute roughly $10B more into OpenAI, creating a setup where the same hyperscaler is at once a cloud supplier, major customer, investor, and competitive model provider, as summarized in the investment overview; the post frames this as emblematic of today’s AI ecosystem, where a small group of firms simultaneously finance, host, and compete with the leading frontier labs.
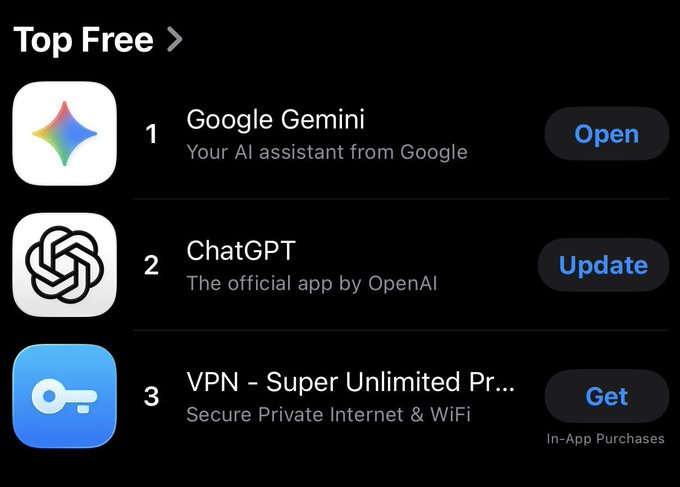
Gemini app overtakes ChatGPT in Singapore’s Top Free Productivity chart
Gemini mobile app (Google): A Singapore App Store snapshot shows Google’s Gemini app ranked #1 in Top Free Productivity while ChatGPT sits at #2, signalling at least one market where Gemini has pulled ahead in new installs according to the store screenshot; the same screen also highlights how both are competing side‑by‑side in the same category, rather than in separate AI sections.
This local ranking sits alongside earlier Similarweb data that suggested ChatGPT’s iOS app had around 20× Gemini’s daily active users globally, so together they point to a patchy landscape where global usage and country‑level download momentum can diverge significantly iOS gap.
OpenAI’s listed OPEA shares have trended down for almost two months
OPEA stock (OpenAI): Multiple posts highlight that OpenAI’s OPEA stock has been sliding for nearly two months, with a TradingView chart showing a drop from a peak near $760 in November to around $665 by late December and a visible downtrend after an earlier run‑up skeptical take; one comment bluntly notes "OpenAI stonk straight down for almost 2 months," suggesting that recent product and fundraising headlines have not yet reversed public‑market sentiment stock comment.
Another post jokes that some commentary around new features is "saying anything to save the OpenAI stonk" skeptical take, underlining how investors and builders are now watching both capability announcements and share price in tandem.
🧪 Methods: RL agents, dataflow, local mixing, unlearning, ToM, fast video
Paper drops skew toward agent training and evaluation rigor; also an architectural tweak for local token mixing and a 100–200× video sampler.
“Erasure Illusion” shows many LLM unlearning metrics overstate real forgetting
Erasure Illusion (multi‑institution): The Erasure Illusion paper argues that current machine unlearning metrics for LLMs, which mostly test performance drop on the exact forget set Du, can create a false sense that knowledge is gone while semantically adjacent capabilities remain intact, as described in the Erasure Illusion thread. In 18 experimental setups, 61.1% of metric judgments flipped once the authors probed with carefully constructed surrogate data.
• Proximal surrogate generation: Their PSG method fine-tunes on Du, then samples new, fluent sentences that become more likely post-finetune yet are pushed far in embedding space, producing a surrogate Du′ that captures generalized knowledge rather than verbatim strings, per the Erasure Illusion thread.
• Metric stress test: When models look “forgotten” on Du but still perform well on Du′, the paper classifies this as an erasure illusion and concludes that many proposed unlearning scores mainly measure memorization, not removal of underlying concepts or styles.
For teams relying on LLM unlearning for copyright or safety guarantees, this work suggests evaluation needs to move beyond the original examples toward probing generalized behavior.
Agent-R1 uses end-to-end RL to train multi-turn, tool-using LLM agents
Agent-R1 (USTC): Researchers propose Agent-R1, a framework that treats LLM agents plus their tools as a single reinforcement learning system, extending the Markov Decision Process to include interaction history, stochastic tool calls, and dense process rewards, as described in the Agent-R1 thread. It introduces action and loss masks so gradients only hit agent-generated tokens and a ToolEnv module that simulates tool responses and reward computation across multi-turn trajectories.
• Performance gains: On multi-hop QA, even REINFORCE++ beats naive RAG by ~2.5× average EM, while GRPO reaches 0.3877 EM vs 0.1328 for RAG, according to the Agent-R1 thread and the GitHub repo.
• Credit assignment: Ablations show disabling the advantage and loss masks drops PPO EM from 0.3719 to 0.3022, highlighting how crucial token-level credit routing is in noisy, tool-rich environments.
The work frames RL not as a post-hoc tweak but as the primary training paradigm for autonomous, tool-using LLM agents operating over many steps.
DataFlow turns LLM data prep into operator pipelines that beat 1M-instruction baselines
DataFlow (OpenDCAI et al.): DataFlow recasts LLM data preparation as PyTorch-style pipelines of reusable operators over a shared table, replacing ad-hoc scripts with nearly 200 standardized transforms across text, math, code, Text-to-SQL, RAG, and knowledge extraction, as outlined in the DataFlow summary. Pipelines can be planned automatically by DataFlow-Agent, which turns a natural-language goal into an operator graph and iteratively verifies it until it runs cleanly.
• Sample efficiency: A unified 10k-sample dataset produced with DataFlow lets base models beat counterparts trained on 1M Infinity-Instruct examples, with reported +1–3 point gains on MATH, GSM8K and AIME plus +7 points on code suites and +3% execution accuracy on Text-to-SQL over SynSQL, according to the ArXiv paper.
• Model-in-the-loop design: By standardizing LLM calls, prompts, and verification into operators, the framework supports scalable synthetic data generation and cleaning while keeping runs debuggable and resumable like conventional ML training.
The result is a data-centric substrate where improving operators and pipelines can directly translate into better downstream model performance without ever labeling another million instructions by hand.
LAMER meta-RL teaches language agents to explore, then exploit across attempts
LAMER meta-RL (EPFL & collaborators): The LAMER framework applies meta reinforcement learning to language agents so they learn a “try, learn, try again” habit during training, treating repeated attempts on the same task as one episode with cross-episode credit assignment, as summarized in the LAMER abstract. At test time, the agent keeps its weights fixed and adapts per task through in-context reflections between attempts.
• Reported gains: On Sokoban, Minesweeper and Webshop, LAMER improves success over strong RL baselines by 11%, 14% and 19% respectively, with the biggest lifts on harder or previously unseen tasks, according to the LAMER abstract.
• Exploration mechanism: Early attempts are encouraged to explore because later attempts share in the reward via a cross-episode discount factor, and the agent writes short reflection notes about mistakes and updated plans that feed back as context on subsequent tries.
The paper suggests that explicitly training agents to use multiple tries as a learning loop can overcome the risk-averse behavior common in sparse-reward RL setups.
Meta’s Canon layers add cheap local mixing and deepen reasoning across sequence models
Canon layers (Meta): Meta’s latest Physics of Language Models installment introduces Canon layers, lightweight components that, inside each layer, mix a token’s hidden state with those of its previous three neighbors to promote short-range information flow without relying solely on attention, as described in the Canon layer paper. These layers compute small weighted sums over a fixed local window and can be inserted into Transformers, linear attention models, or state-space architectures.
• Controlled pretraining: On synthetic pretraining tasks designed to isolate capabilities, Canon layers roughly double effective reasoning depth versus baselines at comparable parameter counts, and they can rescue models that struggle without explicit positional encodings, per the Canon layer paper.
• Noise-aware comparisons: The authors stress that at 1.3B/100B-token academic scales, benchmark deltas often sit within training noise, so they use infinite synthetic data to show consistent Canon advantages before confirming similar but noisier gains on standard pretraining.
Canon layers position local mixing as a low-cost architectural tweak that can be bolted onto many sequence models to make them think in longer chains without widening or deepening the whole network.
New benchmark tests LLMs on full scientific discovery workflows, not trivia
Scientific discovery eval (multi‑institution): A new Scientific Discovery Evaluation benchmark builds 1,125 expert-checked questions and eight open-ended projects to test whether models can read literature, form hypotheses, run simulations or lab tools, and interpret results like working scientists, rather than just regurgitating known facts, as summarized in the Sci discovery summary. Tasks span four domains and decompose deep research into conception, deliberation, action, and perception phases.
• Performance reality check: When asked deep questions with a single checkable answer, frontier models only match the ground-truth final answer about 10–20% of the time, even when some intermediate steps look plausible, according to the Sci discovery summary.
• End-to-end gaps: Models often draft reasonable literature reviews or experiment plans, but their code can be subtly wrong, key experimental details are missed, and answer drift appears as multi-step workflows progress.
The benchmark suggests that despite impressive scores on science QA leaderboards, no current model behaves like a reliable end-to-end “AI scientist” across real discovery pipelines.
UCoder shows unsupervised code generation can self-improve without labeled data
UCoder (Beihang & Huawei): UCoder trains a code LLM to improve itself without any human labels or curated code datasets by internally generating problems, tests and solutions, then fine-tuning on high-agreement samples, as described in the UCoder outline. Instead of starting from solved examples, the base model invents new programming tasks with clear I/O specs and writes unit tests to make each task executable.
• Self-distillation loop: For each problem, UCoder samples many candidate programs, runs them against the tests and clusters solutions by behavior; clusters with consistent behavior are treated as pseudo-ground-truth and used as new training data, per the UCoder outline.
• Competitive performance: Across multiple code generation benchmarks, this unsupervised loop yields models that approach, and sometimes match, counterparts trained in the standard supervised fashion on large human-written corpora, according to the UCoder outline.
The work points to a path where code models can bootstrap much of their own training signal through internal probing, reducing dependence on large labeled code datasets.
CATArena turns agent evaluation into multi-round tournaments with peer learning
CATArena (Meituan, SJTU, AGI‑Eval): The CATArena benchmark reframes LLM agent evaluation as iterative tournaments where agents code game strategies, play repeated matches, read logs and peers’ code, then revise and resubmit, rather than answering a fixed test set, as outlined in the CATArena abstract. The platform currently uses four games—Gomoku, Texas Hold’em, Bridge and Chess960—with rule variants and no explicit upper score limit to avoid benchmark saturation.
• League-style metrics: Repeated matches generate a score matrix used to rank agents on strategy coding (S.C.), global learning (G.L.) and generalizability (G.A.), cleanly separating one-shot skill from across-round improvement, according to the ArXiv paper.
• Code-as-policy: Because each “policy” is a codebase that can evolve between rounds, CATArena directly measures an agent’s ability to read logs, understand others’ implementations and incorporate lessons, with a public GitHub stack for reproducing tournaments in different environments as shown in the GitHub repo.
This shifts agent eval toward ongoing competitive learning, closer to how real multi-agent systems will evolve than static question-answer benchmarks.
Equall world-model architecture automates venture cap table tie-outs at 85% F1
Equall tie-out system (Equall): Equall’s new paper formalizes venture cap table tie-out—matching every share, option, warrant and note in a spreadsheet to backing legal documents—as a world-model problem instead of plain RAG, building a structured fact graph of issuances, amendments, conversions, exercises and transfers before running deterministic checks, as outlined in the Equall paper intro. The authors argue standard agents break down because they treat the dataroom as a passive corpus and cannot provide stable, auditable evidence chains.
• Accuracy gains: Their Equall system reaches an F1 of 85% on real cap tables versus 29% for a strong baseline legal agent, with F1 summarizing both misses and false positives, according to the Equall paper intro.
• Structured reasoning: A two-stage pipeline first extracts atomic facts from documents, then links them into event chains that can be queried like a database, so that tie-out answers are deterministic and each discrepancy can be traced back to specific filings.
This work shows how moving from per-query retrieval to an explicit, task-specific world model can make LLM-based legal agents reliable enough for high-stakes workflows.
Observer-only Rock–Paper–Scissors benchmark probes LLM theory-of-mind
Observer, Not Player (NCCU): The Observer, Not Player framework evaluates LLM theory-of-mind by having models watch rock–paper–scissors games and infer both players’ hidden strategies and payoffs, instead of playing themselves, as explained in the Observer framework. Strategy generators include fixed habits, biased random mixes and reactive rules like “copy last” or “win last,” with ground-truth win/draw/loss distributions known for each pair.
• Metrics and results: The benchmark combines cross-entropy, Brier score and expected-value discrepancy into a Union Loss, plus a Strategy Identification Rate for naming both policies; in one setup, OpenAI’s o3 correctly identifies both players’ strategies in 57.5% of rounds while GPT-4o-mini effectively stays at 0%, according to the Observer framework.
• Dynamic updating: A live dashboard shows how models update beliefs over rounds; the authors report that o3 adapts quickly and stably, Claude 3.7 is noisy, and GPT-4o-mini barely updates, suggesting large quality gaps in sequential, mind-like inference.
The work proposes game observation as a cleaner, more interpretable way to test LLMs’ ability to infer intent and adapt than raw win rates.
🎬 Practical image/video stacks: Qwen Edit/Layered, Kling control, Comfy Cloud
High‑volume creator updates: identity‑safe edits, layer decomposition, motion/voice control, and cheaper GPU minutes.
Kling 2.6 adds Voice Control to lock character voices across scenes
Kling 2.6 Voice Control (ByteDance): A new "Voice Control" feature for Kling 2.6 lets creators bind custom voices to specific characters using simple tags like [Character@VoiceName], with claims that those voices stay identical across an entire video instead of drifting between scenes, according to the voice control intro. This is positioned as a direct fix for the long‑standing voice‑consistency problem in AI video.
• Use cases: Posts highlight obvious fits such as IP mascots, brand virtual spokespersons and episodic content, where a single voice identity must persist across many clips and campaigns, as emphasized in the brand voice angle.
By moving voice identity into the same prompt‑level control plane as motion and style, Kling pushes toward end‑to‑end controllable characters rather than one‑off, hard‑to‑reproduce shots.
Comfy Cloud halves GPU prices for holiday image and video runs
Comfy Cloud (ComfyUI): ComfyUI announced a 50% price cut on Comfy Cloud GPUs running "starting NOW through Dec 31st", explicitly to encourage end‑of‑year creation bursts on its hosted pipelines, as stated in the gpu discount. This directly lowers the cost of running heavier graphs that combine models like Qwen-Image-Edit‑2511, Z‑Image, Wan video backends and custom LoRA stacks.
For teams and solo creators already standardized on Comfy graphs, this temporary discount effectively doubles the number of HD image or short‑video jobs they can run this week for the same spend, which matters when testing new nodes or iterating on longer, multi‑stage workflows.
Qwen-Image-Edit-2511 and Image-Layered spread across ComfyUI, Replicate and TostUI
Qwen image stack (Alibaba/Qwen): Qwen-Image-Edit-2511 and Qwen-Image-Layered are now wired into practical creator stacks including ComfyUI, Comfy Cloud frontends, Replicate and TostUI—extending the identity-preserving, low‑drift edits first described in Qwen edit release into point‑and‑click workflows. ComfyUI announced native nodes for both models with examples like material‑swapping a dark desk and chair to light wood while preserving layout and lighting, as shown in the comfyui announcement.
Features & surfaces: Community posts emphasize that Qwen-Image-Edit-2511 bakes popular LoRAs directly into the base model, so creators can change lighting, material or camera angle without extra fine‑tuning while keeping faces and multi‑person identities intact, according to the feature overview; ComfyUI’s blog walks through per‑object editing and text‑driven industrial design changes using these nodes in standard graphs, as detailed in the blog post. Alibaba’s team also highlighted deployments on Replicate and TostUI where one‑click UIs wrap the same model for rapid before/after edits in the browser, as mentioned in the replicate launch and the tostui support.
The net effect is that Qwen’s edit and layered stack is moving from model card to mainstream pipelines in the tools many power users already rely on.
Qwen-Image-Layered brings RGBA layer decomposition to ComfyUI VFX pipelines
Qwen-Image-Layered (Alibaba/Qwen): Alongside the edit model, Qwen-Image-Layered is now shipping inside ComfyUI graphs where it can decompose a single input image into multiple editable RGBA layers—foreground subject, props, and background—so each can be adjusted independently without re‑rendering the whole frame, as illustrated in the layered demo. The examples show fashion shots and market scenes being peeled into subject and environment layers that can then be recolored or restyled.
• Recursive decomposition: ComfyUI’s examples and the Qwen team’s notes describe support for recursive decomposition, meaning users can take an already‑isolated subject layer and split it again (for example, separating clothing from the person) to build complex compositions for compositing and VFX work, as noted in the comfyui announcement.
This kind of layered output gives artists a bridge between one‑click generation and traditional node‑based compositing, using AI mostly to generate clean, editable elements rather than flattened finished frames.
Kling 2.6 Motion Control gets side-by-side evals and workflow tips
Kling 2.6 Motion Control (ByteDance): Kling 2.6’s motion‑control video model is now being tested directly against rivals like Turbo and Wan Animate 2.2 Turbo on fal, with all three driven by the same input motion and prompt so users can judge stability and adherence shot‑for‑shot, as shown in the motion comparison. This follows the earlier rollout of Kling 2.6 Motion Control across Higgsfield, fal and Replicate Kling motion, and shifts the conversation from raw demos to comparative motion quality.
• Workflow guidance: Practitioners are also posting step‑by‑step workflows in tools like Freepik to get more consistent outputs from Kling 2.6, including guidance on reference video choice and prompt structure, as explained in the kling workflow.
These tests give builders clearer intuition about when Kling’s motion stack is the better fit than other controllers, especially for dance‑like loops and character‑centric shots.
Qwen Image FAST offers ~1.6s inference and near-free pricing on Replicate
Qwen Image FAST (PrunaAI/Replicate): A new "Qwen Image FAST" variant is being promoted on Replicate with claimed 1.6‑second inference for image generation and "almost free" pricing for a limited time, targeting high‑volume use of the base Qwen image model rather than the heavier edit stack, as described in the qwen fast promo. This is framed as a speed‑optimized endpoint for existing Qwen Image users who care more about throughput and cost than maximum fidelity.
The practical takeaway for builders is that the Qwen image family now has a distinct fast path for bulk jobs—thumbnails, A/B variants, batch moodboards—sitting alongside the more precise edit and layered models used for fine‑tuned art direction.
Seedance 1.5 Pro uses first/last-frame locks to curb style and character drift
Seedance 1.5 Pro (ByteDance): Following its earlier launch as an audio‑video generator Seedance launch, Seedance 1.5 Pro is now being highlighted for how it tackles style and character drift by letting users lock the first and last frame and then filling the in‑between video under those hard constraints, as described in the seedance constraints. The commentary frames this as a practical solution for keeping characters on‑model while still generating fluid motion.
The locked‑frame approach makes edit lists more predictable, since editors know exactly how the clip begins and ends, and can plan transitions or overlays around those anchors while still benefiting from generative motion in the middle.
Z-Image sampling utils add sharper detail modes for ComfyUI outputs
Z-Image sampling utils (ComfyUIWiki): A new ComfyUI utility for Z‑Image pipelines adds a "more detail" sampling mode that visibly sharpens textures and micro‑structure—rose petals gain water droplets, sweaters show ribbing and cable knit, Gundam models pick up weathering, and even dog‑in‑armor portraits gain fabric and metal detail, as demonstrated in the detail comparison.
• Detail mode: The node compares an "orig" render to a "detailed" variant across several subjects, making the change in fine structure easy to inspect in side‑by‑side grids, and is shipped as part of an open‑source sampling utility for ComfyUI graphs, according to the sampling utils.
This sits neatly in the growing ecosystem of post‑processing nodes that let users trade a bit more GPU time for noticeably crisper frames without swapping out their base diffusion model.
🛡️ Agent safety: prompt‑injection reality and local dev PSAs
Safety guidance rather than new defenses: warnings that prompt injection may persist, plus developer hygiene reminders.
OpenAI and UK NCSC say prompt injection may never be fully “fixed”
Prompt injection limits (OpenAI, NCSC): OpenAI’s new study on AI-powered browsers concludes that prompt injection remains an inherent, long‑term risk for agentic browsing, even after reinforcement‑learning hardening of ChatGPT’s Atlas agent, following up on Atlas RL which focused on RL red‑teaming defenses for the browser stack; the UK’s National Cyber Security Centre independently echoes that prompt-injection attacks against generative‑AI apps "may never be fully eliminated," framing this as an ongoing confused‑deputy problem rather than a one‑off bug to patch, according to the OpenAI study recap and the NCSC warning.
So the message to teams wiring tools and browsers into LLMs is that mitigations (stronger retrieval filters, permission prompts, output validation, and least‑privilege tool scopes) reduce blast radius but do not turn prompt injection into a solved problem, as summarized again in the newsletter overview.
Anthropic engineer warns against using --dangerously-skip-permissions in home directory
CLI permissions PSA (Anthropic): An Anthropic engineer warns developers not to run a --dangerously-skip-permissions flag from their home directory, highlighting that bypassing the permissions layer there can give an LLM-powered agent broad, unintended access to personal files, configs, and SSH keys, as noted in the skip permissions PSA.
The post, framed with a hospital-monitor meme, reinforces that permission prompts and sandboxing are a core safety boundary for local agent harnesses, and that widening this boundary at the root of a filesystem turns minor tool mistakes into full-machine incidents rather than contained failures in a project workspace.
🤖 Embodied AI: loop‑closure grasping and in‑the‑wild tests
A research‑backed grasping idea lands alongside casual real‑world trials; light day beyond these demos.
MIT loop‑closure gripper lifts kettlebells and humans with soft “vine” strap
Loop-closure grasping (MIT): MIT researchers present a “loop closure grasping” system where an inflatable vine-like tube first grows in an open-loop shape to snake around an object, then fastens its tip back to the base to form a closed loop that carries load mostly in tension; the prototype lifts a 6.8 kg kettlebell from a cluttered bin and even a 74.1 kg person with peak contact pressure around 16.95 kPa, according to the Science demo and paper robot grasp demo and Science paper. This splits grasping into an exploratory open-loop phase and a gentle but strong closed-loop holding phase, which is relevant for embodied AI because it offloads much of grasp robustness to geometry and materials instead of precise fingertip force control.
The paper’s overview figure shows how open-loop tentacles route around targets, then topologically transform into closed loops that distribute force over large surface areas, and includes photos of a robot gently lifting a glass vase using this mechanism
. The approach suggests a design space for future mobile manipulators where relatively simple controllers plus loop-switching hardware can handle heavy, fragile, or hard-to-reach items in real homes and hospitals without intricate multi-finger dexterity.
Robotic dog in Beijing mall highlighted as free real‑world RL testbed
Quadruped robots in the wild (multiple): A clip from a Beijing shopping mall shows a person walking a robotic dog on a leash through real crowds, glass floors, reflections and varied lighting, framed as an ideal real-world reinforcement learning testbed mall robot clip. The post notes that each lap through the mall naturally generates trajectories with edge cases like moving groups, shiny surfaces, and tight corners that are expensive to recreate in controlled labs but ubiquitous in public spaces.
The point is: as more commercial quadrupeds roam semi-public environments for logistics or marketing, they unintentionally create ongoing in-situ evaluation and potential training data for locomotion and perception policies, which could accelerate embodied AI robustness beyond what carefully curated benchmarks alone provide.
⚡ Latency engineering and gateways
Runtime/service notes improving user‑perceived speed. Excludes any Nvidia–Groq outcomes (feature).
OpenRouter cuts p99 latency about 70% and claims “fastest gateway”
OpenRouter gateway (OpenRouter): OpenRouter reports a roughly 70% reduction in p99 latency, calling itself the "fastest gateway" in its internal benchmarks, which directly affects end‑user wait times for multi‑model API calls according to the latency update. This is a service‑side optimization; nothing changes in client integration.
The point is: any stack routing through OpenRouter should now see noticeably snappier tail latencies on long or bursty workloads, especially when many models are in play, though no detailed breakdown by model or region has been published yet.
Summarize CLI 0.6 adds podcast mode with local or cloud STT
Summarize CLI (independent): Summarize v0.6 introduces a podcast workflow that first obtains a transcript—using local Whisper.cpp when available or falling back to OpenAI/Fal Whisper—then runs its existing summarization stack over that text, as shown in the summarize update. This extends the tool from text and web pages into long‑form audio while keeping the core interface the same.
• Transcription pipeline: The new mode will use an existing episode transcript if the feed provides one; otherwise it downloads the audio and chooses between on‑device Whisper.cpp or remote STT services depending on what is installed and configured summarize update.
• Extra flags: The release also mentions new support for Z.ai models and a --language option, which lets people steer summarization language independently of the source audio summarize update.
The result is that Summarize behaves more like a generic "URL to structured notes" gateway, now spanning blogs, articles and multi‑hour podcast episodes without changing the CLI surface.