Ollama 0.15 adds launch for 4 coding CLIs – 64K+ context tuning
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Ollama shipped v0.15 with ollama launch, a one-command wrapper to run Claude Code, Codex, Droid, and OpenCode against a selected backend; the pitch is reducing per-tool env-var/config glue while making “swap local vs cloud model” a single knob. The same drop spotlights GLM‑4.7 Flash memory optimization for 64k+ context runs and positions Ollama Cloud as the fallback for full precision/long context; early papercuts exist—one report shows ollama launch claude failing with “claude is not installed” despite the CLI working, suggesting PATH/detection brittleness.
• Codex subagents: /experimental enables orchestrator/worker spawning; workers appear pinned to gpt‑5.2‑codex while orchestrators inherit parent model choice—routing control may be limited; OpenAI says a high Responses API error rate was fixed, but no RCA.
• Cursor: subagents can pin or inherit models via .cursor/agents/<agent>.md; an unverified field claim says Salesforce has 20,000+ active users, ~90% adoption, and >30% PR velocity.
• Crawler tax: codebase.md reports ~771.5k crawler hits vs ~9.7k humans in 30 days; Amazonbot alone at ~408k/month even with Cloudflare blocks.
• MCP plumbing: Google Cloud proposes gRPC as a native MCP transport with bidirectional streaming, replacing JSON-RPC gateways—cleaner fit for enterprise meshes, but still a proposal.
Top links today
- CaMeLs security design for computer-use agents
- Physics-IQ benchmark for video model physics
- LLM self-detection fails for homework plagiarism
- ARC Prize 2025 technical report
- Language of thought increases LLM output diversity
- AI exposure plus worker adaptability analysis
- US plans investment in rare earth magnets supply
- TechCrunch AI lab monetization levels framework
- Pope Leo XIV message on AI and media
- TSMC supplier chain overview chart
- Ollama repository and local model runtime
Feature Spotlight
Clawdbot ops wave: always-on local agents, deployment patterns, and brittle sessions
Clawdbot is going viral as an always-on, local-first “AI employee.” Engineers are rapidly deploying it (Mac mini/VPS), then immediately hitting real ops problems: session corruption, prompt-injection risk, and isolation/sandboxing decisions.
Today’s dominant builder story is the Clawdbot adoption spike: people wiring it into Slack/Gmail/Asana/Telegram, debating dedicated hardware vs VPS, and learning failure modes (session corruption, tool-call brittleness). Excludes specific Clawdbot skills/plugins (covered under Plugins/Skills).
Jump to Clawdbot ops wave: always-on local agents, deployment patterns, and brittle sessions topicsTable of Contents
🦞 Clawdbot ops wave: always-on local agents, deployment patterns, and brittle sessions
Today’s dominant builder story is the Clawdbot adoption spike: people wiring it into Slack/Gmail/Asana/Telegram, debating dedicated hardware vs VPS, and learning failure modes (session corruption, tool-call brittleness). Excludes specific Clawdbot skills/plugins (covered under Plugins/Skills).
Clawdbot brittleness: corrupted tool calls can break sessions, and /new is the recovery ritual
Clawdbot (clawdbot): Multiple users hit the same failure mode: malformed/corrupted tool calls “poison” a running session, sometimes forcing deletion of session history; the common workaround is starting a fresh thread with /new, as documented in Session broke out of house and the tips thread in Tips and tricks thread. This matters because it’s not a model-quality issue—it’s an orchestration/serialization fragility that shows up only once you run long-lived agents.
• Observed symptoms: Reports range from “can’t talk to it while away” in Session broke out of house to repeated “corrupt tool calls” complaints in Corrupted tool calls.
• Operational workaround: The /new guidance is repeated explicitly in Tips and tricks thread and again as a concrete fix in Start a new session.
Clawdbot setup wave: wiring Slack/Telegram/Gmail/Cal/Asana/HubSpot/Obsidian into one agent
Clawdbot (clawdbot): A visible adoption spike is coming from people connecting Clawdbot to their daily comms + work stack (Slack/Telegram/Gmail/Calendar/Asana/HubSpot/Obsidian) and then asking what “first week” use cases to try once it’s wired in, as described in Integration list and Beginner use cases ask. This matters because it’s the operational leap from “coding assistant” to “always-on operator” where reliability and permissions start dominating the experience.
• Real-world posture: Users are explicitly planning to use Clawdbot to respond to social replies (with disclosure) in Reply automation plan, which is a good proxy for how quickly people move from local automation to public-facing actions.
• What it looks like: The Clawdbot Gateway UI example in Dashboard screenshot shows the “tool did X; want me to publish/delete?” interaction loop that tends to define agent ops more than model quality.
Isolation debate: running Clawdbot on your main machine vs dedicated box/VPS to limit blast radius
Clawdbot (clawdbot): A recurring argument is that “credentials are already granted, so why isolate?” but the counterpoint is about blast radius: an agent that can run commands, edit files, and act in email can be steered by prompt injection or bugs, so isolating it on a separate machine/VPS is an ops safety boundary, as debated in Main machine question and stated bluntly in Prompt injection risk. This matters because Clawdbot’s value comes from deep integration, and that same integration defines the failure mode.
• What the tool itself warns: The onboarding flow in Security prompt screenshot explicitly frames agents as “powerful and inherently risky,” which matches the community’s push for least privilege.
• Concrete concern: The “reply as you in emails, delete files” list in Prompt injection risk is the practical threat model people are using to justify a dedicated host.
Clawdbot hybrid inference: controlling LM Studio remotely and swapping in local models for easy tasks
Clawdbot (clawdbot): Users are running a hybrid routing setup where Clawdbot is controlled via chat (Telegram) while it manages LM Studio on a host machine—downloading a local model, testing it, then using it for “easy tasks” to reduce cloud usage, as shown in LM Studio control screenshot and described in Mixing local and cloud. This matters because “local for cheap tasks + hosted for hard tasks” is quickly becoming the default ops pattern for always-on agents.
• What’s actually happening: The chat log in LM Studio control screenshot shows the agent pulling a large model, measuring task behavior (speed/verbosity), and then “swapping out” the default—basically model routing as a background maintenance job.
• User framing: The “combination of models, including local models for easier tasks” phrasing in Mixing local and cloud captures the emerging mental model of Clawdbot as a coordinator, not a single model.
Clawdbot Node deployment: VPS-first setup as the alternative to extra machines
Clawdbot (clawdbot): A practical deployment pattern getting repeated is “don’t buy another computer; deploy a VPS and run Clawdbot there,” with docs and lightweight guides getting shared in VPS instead of machine and AWS setup guide. The point is operational: always-on uptime, clearer blast radius, and fewer surprises when your laptop sleeps.
• Mechanics: The Clawdbot “Node” workflow is documented in the Node docs, which frames it as a CLI-managed deployment rather than a desktop-only install.
• Cost narrative: The Amazon Free Tier angle is being explicitly used to counter the hardware-buying wave in Sponsor not Mac mini.
Mac mini buying wave for Clawdbot meets pushback: old hardware or AWS Free Tier works
Clawdbot (clawdbot): People are still buying Mac minis specifically to run Clawdbot 24/7, but the pushback got louder today: it doesn’t “require” dedicated Apple hardware, and the social default is drifting toward “use whatever box you have” or a cheap VPS instead, as argued in Sponsor not Mac mini and reinforced by the PSA repost in No Mac mini needed. This matters because perceived hardware requirements shape adoption and security posture (always-on machine vs laptop vs hosted).
• Community split: You can see the “Mac mini ordered” impulse in Mac mini ordered, while the meta-question “why is everyone ordering a Mac mini?” is in Trend confusion.
• Alternative framing: The strongest counter-position is “sponsor contributors, deploy on Free Tier,” paired with the repo’s community sponsorship section in the GitHub repo.
AI crawler ops pain: codebase.md reports 771k crawler hits vs 9.7k humans in 30 days
AI crawler load (ops signal): A concrete ops datapoint: codebase.md reports ~771.5k crawler requests in 30 days vs ~9.7k human visits and ~14k “agents,” with Amazonbot singled out at ~408k requests/month despite Cloudflare blocks, as shown in Traffic breakdown. This matters to anyone shipping agent-facing docs/tools because crawler load is becoming a first-order reliability and cost issue.
• Where it shows up: The screenshot in Traffic breakdown breaks traffic into humans/agents/bots, which is the kind of measurement Clawdbot-scale OSS projects end up needing once they go viral.
• Why it’s sticky: This isn’t “marketing traffic.” It’s operational overhead driven by automated retrieval.
Clawdbot privacy reality check: state is local, but providers and chat platforms still see content
Clawdbot (clawdbot): A FAQ-style explanation is circulating that Clawdbot’s state/memory/workspace is local by default, but anything sent to model APIs and chat channels is still processed/stored by those external services, as summarized in Local vs remote data answer. This matters because a lot of “local-first” expectations break once you wire in Gmail/Slack/Telegram.
• Operational implication: The answer in Local vs remote data answer draws a clean boundary: local storage for agent state vs unavoidable third-party exposure for channels and model inference, with pointers to the FAQ page.
Trust calibration warning: new users are over-believing Clawdbot outputs
Clawdbot (clawdbot): As new users flood in, there’s a parallel warning that people are taking agent responses as truth too readily, as called out in Trust warning. This matters operationally because always-on agents are most dangerous when their outputs become “accepted defaults” without review.
The same thread of thinking shows up indirectly when users downplay worst-case recovery (“full reset… nbd”) in Main machine question, which is a mismatch with how integrated agents can affect external systems.
Files-over-apps for agent runners: reducing brittleness by keeping workflows as files
Files-over-apps (workflow pattern): A small but consistent practice is showing up: keep your agent setup minimal and file-based (Markdown rules, saved commands/skills as files) rather than wiring a large pile of external services, with the clearest statements in Files over apps and the “MCP = context rot” framing in MCP context rot claim. This matters for Clawdbot-style always-on ops because fewer moving parts usually means fewer long-session failures.
The trade-off is obvious: fewer integrations means less automation reach. That’s the tension these posts are describing.
🧠 Codex agent updates: subagents, reliability fixes, and model-routing quirks
Continues Codex momentum from earlier this week, but today’s delta is about how Codex spawns subagents and what models they’re forced to use, plus service reliability notes affecting long runs. Excludes Claude/Excel and Clawdbot hype (covered elsewhere).
Codex adds subagents behind /experimental, with worker vs orchestrator roles
Codex (OpenAI): Codex now supports spawning subagents—an orchestrator that inherits your main model and a worker that does a single task—enabled via the /experimental flag per the Subagents flag note.
This changes how long runs are structured: instead of one agent juggling planning + execution, Codex can split work into multiple short-lived workers under one coordinating loop.
Codex subagent workers appear hardcoded to gpt-5.2-codex
Codex subagents (OpenAI): Early reverse-engineering suggests worker subagents are forced to gpt-5.2-codex, while orchestrator subagents inherit the parent model choice, as shown in the Subagent model diagram and discussed alongside the /experimental enablement in the Subagents flag note.
This matters if you were hoping to route cheap/fast models into “worker” roles; it looks like model-routing control may currently be limited to the top-level session and orchestrators.
OpenAI says Responses API error rate is fixed (Codex should be stable)
Responses API (OpenAI): OpenAI staff report they “fixed a high error rate” in the Responses API that Codex uses, and say service should be stable now, asking users to confirm if issues persist in the Stability note.
For teams running long agent sessions, this is the kind of silent reliability regression that shows up as flaky tool calls and stuck loops, so it’s a meaningful ops datapoint even without a detailed RCA.
Builders report a bad day for GPT-5.2 Codex on real coding tasks
GPT-5.2 Codex (OpenAI): A builder report says “5.2 codex isn't running well today,” citing incorrect Next.js sitemap code even with docs provided, unrelated edits to content, and slow copy-over of Tailwind typography; they switched to Opus 4.5, which “fixed it in one shot,” per the Regression report.
Treat it as anecdotal, but it’s a concrete reminder that day-to-day agent quality is a moving target—especially when you depend on tool calls and long-horizon edits.
Codex review mode will fetch upstream docs by itself, but GitHub auth can block it
Codex (OpenAI): A practical review workflow is emerging where Codex, when asked to review behavior, will proactively locate upstream repos/docs and try to read them—see the Upstream fetch attempt, where it pulls a raw GitHub doc and then hits a GitHub Search API 401 without auth.
This is useful because it reduces “go find the docs” back-and-forth, but it also means your agent runner needs a clear policy for when (and how) it’s allowed to authenticate to third-party developer APIs.
Codex users are explicitly asking for Cowork-style UX and team workflows
Codex (OpenAI): With “multiple launches” teased recently, developers are now being explicit about what they want next: a Cowork-like interface, better terminal messaging, plugins, team mode, plan mode, and subagent tooling parity, as laid out in the Feature wishlist.
It’s a product signal: the baseline expectation is shifting from “good model in a CLI” to “collaboration surface + durable workflows.”
Demand grows for a web-resumable, agents-first remote dev environment
Agent runtime UX: There’s a clear pain point around running agent sessions on a remote Linux box and resuming them via web/mobile without terminal emulation; one request asks for something “better than cursor cloud/claude web,” but still able to “work locally” and pick up the same agentic session later, as described in the Remote agent env ask and clarified in the Web resume requirement.
This sits right between “SSH to a server” and “hosted agent IDE,” and it’s becoming a recurring infrastructure product gap as more teams run long-lived agents.
🧩 Cursor subagents: model selection, defaults, and task-specific routing
New Cursor discussion today centers on subagent configuration mechanics—how you pin/inherit models per agent and what built-in subagents ship by default. This is distinct from broader agent-runner ops (covered under Clawdbot/ops).
Cursor subagents can pin or inherit models via .cursor/agents/<agent>.md
Cursor (Subagents config): Cursor subagents can be configured per-agent in .cursor/agents/<mysubagent>.md, where model: inherit keeps the parent model while model: <model> pins a specific one, as shown in a minimal front-matter snippet shared in config example.
This makes subagent routing explicit and reviewable in-repo (diffable), instead of hidden in UI toggles—useful when teams want deterministic behavior for “fast vs careful” tasks across long-running agent sessions.
Cursor reportedly hits ~90% adoption inside Salesforce with 20k+ active users
Cursor (Enterprise adoption signal): A field claim says Salesforce has 20,000+ active Cursor users, roughly 90% internal adoption, and a >30% increase in PR velocity, framed as organic word-of-mouth spread inside engineering, per Salesforce metrics.
If accurate, this is a strong datapoint that “agent IDE” tooling is crossing into default dev workflow territory at large enterprises, not just individual power users.
Cursor ships built-in Explore and General-purpose subagents with name invocation
Cursor (Built-in subagents): Cursor’s subagent feature includes default agents like Explore and General purpose, and supports direct invocation via prompts like “use explore subagent,” as illustrated in the workflow screenshot in built-in subagent UI.
• Parallel exploration: The same example shows Cursor spinning up multiple Explore agents “in parallel” for architecture + code-smell scanning, then tracking each agent’s current activity inline, as shown in built-in subagent UI.
This is a concrete shift from “one chat does everything” to named roles that can be re-used and taught as stable primitives.
Cursor subagents: task-specific model routing across providers
Cursor (Task routing pattern): A common setup emerging is to assign different models to different subagents—e.g., using GPT‑5.2 Codex for longer-running work, Opus 4.5 for implementation, and Composer‑1 for small, well-scoped tasks, as described in model mix example.
The main engineering implication is operational: the “default model” stops being a single decision, and becomes an orchestration choice per task type (latency/price vs correctness vs verbosity).
🖥️ Local inference & self-hosting: Ollama ‘launch’, memory tuning, and local toolchains
Self-hosting chatter is very concrete today: Ollama adds a single command to run popular coding tools against local/cloud models, plus memory optimizations for long-context. Excludes agent-runner ops decisions (feature category).
Ollama 0.15 adds `ollama launch` to run Claude Code/Codex/Droid/OpenCode on Ollama models
Ollama (0.15): Ollama shipped a new ollama launch command that bootstraps popular coding agent CLIs (Claude Code, Codex, Droid, OpenCode) against an Ollama-selected model—aiming to remove the usual “wire up env vars/config files” friction called out in the Release note and detailed in the Launch blog.

• What changes for local toolchains: the launcher is positioned as a single entry point for picking a model (local or cloud) and then starting the tool with that backend, as shown in the Release note and the Coding quickstart.
• Interoperability signal: the same surface explicitly targets multiple agent CLIs (not just Ollama’s own chat), which makes “swap the backend model” a workflow knob rather than a per-tool setup project, per the Release note.
Ollama tunes GLM-4.7 Flash for lower-memory 64k+ context sessions
GLM‑4.7 Flash (Ollama): Ollama says GLM‑4.7 Flash was optimized to use “much less memory” for long context lengths (64k+), which matters most for long-running local coding sessions that previously forced a hardware upgrade or aggressive context trimming, according to the Memory optimization note.
This is framed as a practical enabler for running longer-context workloads locally (or on smaller machines) without immediately jumping to a cloud endpoint, per the model guidance in the Launch blog.
Qwen3-TTS roadmap: vLLM streaming inference and an upcoming 25Hz control release
Qwen3‑TTS (Alibaba Qwen): The Qwen team says streaming inference support is being built in collaboration with vLLM, and they outline a near-term path to more controllable output—suggesting an upcoming open-source “25Hz model” to enable stronger instruct-style controls like emotion/style, per the Qwen3-TTS update.
• Voice consistency: they recommend using Voice Design to pick a voice and then the Base model’s cloning as a reference anchor for stable tone, as described in the Qwen3-TTS update.
• Streaming interest from builders: community reaction specifically calls out the significance of vLLM-level streaming audio support, as seen in the Streaming audio question.
Ollama Cloud positions GLM-4.7 as a fallback for full-precision long context
Ollama Cloud (GLM‑4.7): Alongside the local-memory work, Ollama points to its cloud offering for GLM‑4.7 “full precision and context length” when local hardware isn’t enough, as described in the Cloud option note.
The implication for teams is a single toolchain that can flip between local and hosted capacity while keeping the same CLI surfaces (via ollama pull …:cloud and ollama launch …), following the examples in the Launch blog.
Bug report: `ollama launch claude` mis-detects Claude Code installation
Ollama launch (Claude Code integration): A user reports ollama launch claude --model glm-4.7-flash fails with “claude is not installed” even though claude -p 'say hi' runs successfully in the same shell, pointing to a detection/PATH resolution bug in the launcher, as shown in the Terminal error screenshot.
If reproducible across environments, this is the kind of papercut that blocks adoption of “one-command” local toolchains until the launcher’s install checks match how Claude Code is actually discovered on developer machines.
📊 Claude in Excel: spreadsheet agents become “real work”
Claude-in-Excel is the standout workplace integration today: engineers and analysts report major productivity wins and capabilities (like complex table segmentation) that other spreadsheet copilots struggle with. Excludes broader Anthropic strategy/business (covered under Funding & Enterprise).
Finance and corporate teams report big productivity jumps from Claude in Excel
Claude in Excel (Anthropic/Microsoft): Following up on Pro rollout—Pro availability and the initial shipping surface—new field reports frame it as a “normie” adoption moment: one user claims a project that “would have taken 2 weeks” was finished “in 30 mins” for $20/mo in the productivity claim, while another reports finance-industry word-of-mouth that it’s “blowing their minds” in the finance anecdote screenshot.
The signal here isn’t model specs; it’s that spreadsheets are the default interface for huge parts of the economy, so an agent that reliably manipulates real Excel sheets changes who can automate work without learning a new toolchain.
Claude in Excel shows one-shot messy-sheet table segmentation via an agent harness
Claude in Excel (Anthropic/Microsoft): A concrete capability report is “one-shot table segmentation” on messy spreadsheets—splitting a composite sheet into multiple clean 2D tables and writing them into new sheets—called out as unusually strong compared to other Excel agents in the segmentation walkthrough.
• What the agent is doing: it reads a range (example shown as A1:R39), infers table boundaries + metadata rows, creates new sheets, and rewrites segmented data, as shown in the segmentation walkthrough.
• Cost/latency tradeoff: the same report notes it can be “quite a bit of time, tokens, and prompting” when you try to codify repetitive workflows at scale, which matters if you’re building headless/batch Excel parsing pipelines rather than interactive analysis in the UI, as described in the segmentation walkthrough.
Spreadsheet copilot gap: Claude-in-Excel/Sheets vs Gemini-in-Sheets becomes a loud complaint
Spreadsheet agents (Anthropic vs Google): A recurring comparison thread argues Claude’s spreadsheet manipulation is meaningfully ahead of Gemini-in-Sheets—citing “16M impressions in 24 hours” as a proxy for how widely the Excel/Sheets experience is being discussed, and claiming Anthropic is “0.5 to 3 years ahead” on formula/sheet handling in the integration gap claim.
This is still anecdotal (no shared eval harness), but it’s a clear product integration signal: spreadsheet reliability is showing up as a competitive axis, not just model quality.
🧰 Workflow patterns: context hygiene, verification loops, and “files over apps”
Practitioner guidance today is about reliability: context rot, prompt discipline, and multi-model workflows (creative vs verifier). This category excludes tool-specific ops issues for Clawdbot (feature) and product-level changelogs (other categories).
“Files over apps” becomes a durability tactic for long agent sessions
Files over apps (workflow pattern): A recurring practitioner approach is to treat your agent setup as a filesystem artifact—keep commands, subagents, and Skills as plain files (often Markdown), and avoid bolting on lots of external services to reduce brittleness, as described in Files over apps note.
A sharper critique bundled into the same idea is that “MCP = context rot,” with the claim that long-running work is more stable when mediated through a CLI + files rather than ever-growing tool/context surfaces, as argued in MCP equals context rot.
The practical implication is that context management becomes reviewable (diffable) because the “operating manual” lives in repo files, not hidden in UI state.
A two-model workflow: creative driver plus correctness verifier
Multi-model pairing (workflow pattern): Builders are explicitly splitting roles across models—one report frames it as needing both Opus 4.5 for fast creative ideation and GPT-5.2 Codex for technical rigor, including catching issues the creative model misses, as stated in Two-model pairing.
There’s also the negative-space detail: the “verifier” role isn’t optional when you’re seeing instruction-following drift or silent deviations, which shows up in a complaint that Codex found “astounding” bugs left behind after Claude didn’t follow instructions, per the Codex finds leftovers report.
Another field datapoint is that model roles can flip depending on task shape—one developer reports swapping away from Codex to Opus 4.5 after Codex produced wrong/irrelevant edits on concrete tasks, as described in Switched to Opus.
Overtrust in agent outputs is emerging as an operational failure mode
Trust calibration (workflow risk): A maintainer observation is that new users often take agent output at face value, and that this credulity is “troubling,” per the Overtrust warning—a reminder that review/verification habits are part of the workflow, not a nice-to-have.
A compatible “tools require skill” framing shows up in a separate reflection that coding with agents can be both highly productive and “downright destructive,” reinforcing that reliability work is process, not model choice, as described in Tool must be wielded.
Repeatable “fresh eyes” self-review loop for agent-written code
Self-review loop (workflow pattern): Following up on Review prompt (second-pass bug hunting), a concrete variation is to have the model re-read only what it just changed with “fresh eyes,” then repeat the exact same instruction 3–5 times—a practitioner reports doing this “hundreds of times a day” to reliably surface obvious mistakes, per the Fresh eyes prompt.
The core mechanic is that each pass reframes the work as verification rather than generation, so the model is less tempted to continue building and more likely to notice mismatches, missing imports, edge cases, and unintended edits (especially in multi-file refactors).
“Vibe coding” gets a sharper definition (and a boundary)
Vibe coding (workflow boundary): One crisp definition separates “vibe coding” from professional engineering: it’s throwing together a non-production project in a stack you barely know, made feasible by AI; professional teams still use AI, but the constraints and incentives differ, as argued in Vibe coding definition.
This framing matters because it names a failure mode teams keep seeing: demos scale faster than the reliability/maintainability work needed to ship and operate systems.
Agent-first engineering: lower barrier, higher throughput ceiling
Agent-first software engineering (capability shift): A short but widely shared claim is that agent-first tooling simultaneously raises the “floor” (more people can build) and the “ceiling” (experts can produce more), as framed in Floor and ceiling claim.
This is a macro signal more than a technique, but it’s shaping how teams think about skill distribution, leverage, and what “senior” work becomes when execution is cheap.
Why do all assistants sound the same? Personality convergence debate returns
LLM personality convergence (ecosystem discussion): There’s renewed frustration that many assistants converge to a similar “emoji/markdown” persona and “no human speaks like this,” with speculation that this is the reward-maximizing basin of RLHF/post-training, per the Personality convergence complaint.
For builders, the subtext is product/design: if your agent UX depends on tone, you may need explicit style constraints or post-processing rather than trusting defaults.
🧱 Plugins/Skills: orchestrators, skill marketplaces, and hardening packages
Today’s installable ecosystem news is about extending agent behavior: new orchestrator releases, skill directories, and security hardening scripts. Excludes MCP transport/protocol work (covered under Orchestration & MCP).
ACIP ships a Clawdbot integration for prompt-injection hardening
ACIP (Clawdbot hardening): A Clawdbot-specific integration of ACIP was posted with a “one-liner” installer aimed at making Clawdbot more resistant to prompt injection attacks, as described in the hardening note and implemented in the GitHub integration.
The pitch is straightforward: treat agents with filesystem/tool access as inherently risky, then add a guard layer early—setup and self-test flags are shown in the installer one-liner.
Kilo for Slack: bug report thread to PR without leaving Slack
Kilo for Slack (KiloCode): A Slack-native workflow was described where a bug report happens in a thread, someone tags @Kilo to implement, and a PR shows up back in Slack—framed as “the conversation is the spec,” according to the workflow description.
This is notable less for “Slack integration” and more because it treats Slack as the durable input artifact for an agent run (spec + context), which is where a lot of teams already do triage and decision-making anyway.
oh-my-opencode v3.0.0: production-ready orchestrator with dynamic agents and plan-to-code compilation
oh-my-opencode v3.0.0 (OpenCode ecosystem): The orchestrator project cut a major release, positioning it as “stable and production-ready” and adding dynamic agent creation plus two named components—Prometheus (a plan agent) and Atlas (an orchestrator that “compiles” work plans into code)—as described in the release notes.
• Agent generation: The update adds model categories + a skill system for creating agents on demand, per the release notes.
• Plan execution pipeline: Prometheus and Atlas formalize a plan-first workflow (plan output treated as an artifact that gets translated into code), as outlined in the release notes.
The post doesn’t include evals or latency/cost numbers yet, so the practical delta will show up in repo-level demos and failure cases over the next few days.
“Better call codex” skill adds cross-model Codex subagent spawning
“Better call codex” (Skill): A new skill was shared that spawns Codex subagents on demand—intended for workflows where you’re driving from Claude or another model but want Codex to take specific tasks, according to the skill announcement.
This lines up with the newly discussed Codex subagent split (orchestrator vs worker) that can be enabled with /experimental, as described in the subagents note, but the skill makes it callable as an extension rather than a manual workflow.
Context7 launches a Skill Marketplace for agent extensions
Context7 (Skill Marketplace): Context7 was reported to have launched a Skill Marketplace—positioned as a curated, “high signal” directory for extending agent capabilities—per the marketplace announcement.
Details like packaging format, install mechanism, and review/moderation model weren’t included in the tweets, so it’s not yet clear whether this is closer to a registry (metadata + installs) or a content hub (docs + prompts + snippets).
Open-source presentation agent turns context files + a template into PPT/PDF
Presentation agent (LlamaIndex): An open-source “vibe-coded” agent app was shared that generates a slide deck from uploaded context files plus a style template, then supports inline edits and exports to PowerPoint/PDF, as shown in the product demo.

• Stack: Built with Claude Code and the Claude Agent SDK, plus LlamaParse, per the product demo.
• Artifacts: App + repo are linked in the app link and GitHub repo.
It’s a concrete example of “agent as document compiler” where the artifact (deck) is the output, not a chat transcript.
🏗️ Agent frameworks & memory layers: from tracing to “memory OS”
Framework-level progress today emphasizes productionization: memory systems that are inspectable/editable and real-world tracing/eval workflows. Excludes single-product agent runners (feature) and pure research papers (covered under Research).
MemOS pushes agent memory toward an inspectable “memory OS” layer
MemOS (MemTensor): MemTensor’s MemOS is being positioned as an OS-level memory layer for LLM agents—structured, editable, and inspectable (not “just embeddings”)—with a unified API for add/retrieve/edit/delete and support for multimodal memory (text/images/tool traces/personas), as outlined in the project screenshot and the linked GitHub repo.
• Memory as a graph you can edit: The pitch is explicitly “inspectable, graph-based memory” plus a feedback/correction loop to refine what gets stored, as summarized in the project screenshot.
• Production-minded API surface: It calls out async memory ops and “low latency for production workloads,” which is the kind of claim teams will want to validate early against their existing RAG/memory stack, per the project screenshot.
LangSmith case study: making an AI SDR chatbot shippable with traces and evals
LangSmith (LangChain): A community write-up describes deploying an AI SDR chatbot (lead qualification + product Q&A + routing) and credits LangSmith traces, feedback, and evaluations for making the system debuggable enough to ship, with the full narrative in the LangSmith post and the linked case study write-up.
• State machine over “one big prompt”: The system is modeled as a LangGraph state machine (tool calls + retries + idempotency), which is how the team handled real-user multi-part questions and tool failures, per the LangSmith post and the case study write-up.
• Observed failure modes were operational, not theoretical: The post calls out issues like occasional duplicate downstream updates and “quality drift” once real traffic hit, and frames tracing/evals as the mechanism to isolate and fix those, as described in the case study write-up.
🔌 Orchestration & MCP: transport upgrades and interactive agent UIs
MCP-related items are narrower today but concrete: protocol plumbing (gRPC transport) and UI surfaces for agent mini-apps. Excludes generic skills/plugins (covered under Plugins/Skills).
Google Cloud proposes gRPC as a native transport for Model Context Protocol
Model Context Protocol (Google Cloud): Google Cloud published a technical proposal to add gRPC as a first-class transport for MCP—aiming to remove JSON-RPC transcoding gateways, enable bidirectional streaming, and fit existing enterprise gRPC service meshes, as summarized in transport note and detailed in the [gRPC transport blog] gRPC transport blog.
The practical implication is cleaner “agent ↔ tool” plumbing for teams already standardized on gRPC, since MCP servers wouldn’t need a translation layer just to speak JSON-RPC.
CopilotKit passes 28,000 GitHub stars as it pushes MCP Apps and AG-UI
CopilotKit: CopilotKit crossed 28,000 GitHub stars and positioned 2025 as its breakout year as an “application layer” for agentic systems, with continued emphasis on AG-UI and chat-embedded mini-apps following up on mini-app demo—see the milestone post in stars announcement and the repo link in [GitHub repo] GitHub repo.

This is a distribution signal more than a spec update, but it correlates with ongoing standardization pressure around “agents that return UI,” not just text.
🏭 Infra signals: GPU demand shocks, packaging capacity, and AI power politics
Infra chatter is tied directly to AI demand: GPU rental pricing spikes, packaging capacity scaling, and power generation becoming part of the AI stack. Excludes funding rounds (covered under Funding & Enterprise).
H100 rental prices jump, attributed to Claude Opus 4.5 demand shock
H100 rental market: A charted H100 rental index shows a sharp upswing from early December into late January, with commentary attributing the move to a sudden wave of demand after Claude 4.5 Opus—the key claim being that the pressure is concentrated on H100 rather than spilling broadly across other GPU SKUs, as described in the H100 rental index chart.
• Why this matters operationally: if the price shock is real and SKU-specific, it changes near-term capacity planning (H100 queues/spot pricing) while leaving A100/B200 as less-stressed fallback options—though the tweets don’t include a comparable A100/B200 time series, only the narrative claim in the H100 rental index chart.
Goldman projects TSMC CoWoS capacity to reach ~2,310k wafers by 2027
TSMC CoWoS (Goldman Sachs): A new sell-side chart claims TSMC’s CoWoS advanced-packaging capacity forecast was revised upward, showing 675k wafers (2025E), 1,275k (2026E), and 2,310k (2027E)—with the 2027 estimate notably above the prior 1,740k, as shown in the CoWoS capacity chart.
This is one of the cleaner “bottleneck signals” for AI accelerators because CoWoS gates HBM+die integration even when front-end wafer supply is available.
David Sacks relays Trump: AI companies should become “power companies”
Data center energy (US policy signal): David Sacks relays a Trump quote encouraging AI companies to “become power companies” and stand up their own generation alongside new data centers—explicitly framing self-supply of electricity as a competitive requirement, as stated in the Sacks clip.

This aligns with the broader shift where power procurement and generation show up as first-class constraints alongside chips and networking.
FT: US plans $1.6B investment in USA Rare Earth to secure AI-chip magnets
USA Rare Earth (US government): The FT-reported plan is a $1.6B investment into USA Rare Earth Inc, framed as shoring up “critical minerals and magnets required for AI chips,” with details of roughly a 10% stake plus $1.3B in senior secured debt via a Commerce Department program tied to the CHIPS Act, per the FT headline screenshot.
The immediate relevance for AI infra buyers is supply-chain risk moving upstream: magnets/minerals become explicit policy targets rather than background commodities.
codebase.md sees 771k crawler hits in 30 days, swamping human traffic
Crawler load as infra tax: Traffic stats for codebase.md show ~9.7k human visitors, ~14k “agents”, and ~771.5k crawlers over ~30 days, with Amazonbot called out for ~408k requests/month even with Cloudflare blocks, according to the traffic breakdown and the linked Codebase site.
For teams running documentation, demos, or model endpoints, this is another concrete datapoint that bot traffic is no longer edge noise—it can dominate baseline ops.
📦 Model releases & upgrades: roleplay LMs, TTS roadmap, and China frontier churn
Model news today is a mix of new endpoints for roleplay and continued China-model iteration (TTS and ERNIE). Excludes video/image model chatter (covered under Generative Media).
Qwen3-TTS updates: vLLM streaming in progress and a 25Hz control model teased
Qwen3-TTS (Alibaba Qwen): Qwen shared a short roadmap update covering near-term serving and controllability; the most concrete item is streaming inference work “with @vllm_project,” aiming for real-time output Roadmap update, with community reaction focusing on streaming audio support potential Streaming support reaction.
• Streaming inference: The team says it’s actively being implemented with vLLM for smoother real-time TTS output, per the Roadmap update.
• Consistent voice identity: The recommended approach is using Voice Design to pick a target voice and then using the Base model’s clone feature as a fixed reference to reduce drift Roadmap update.
• Instruct-style controls: Qwen says emotion/style control is planned for an upcoming open-source “25Hz model” release, implying higher control bandwidth than earlier variants Roadmap update.
MiniMax releases M2-her for roleplay, with new message roles and 32k context
MiniMax M2-her (MiniMax): A new dialogue-first LLM optimized for immersive roleplay is being promoted as M2-her, with emphasis on “more immersion” and “longer coherence” in the launch chatter around OpenRouter availability Model teaser and the model listing OpenRouter announcement.
The OpenRouter card highlights a 32,768 context window and explicit support for additional message roles beyond the typical system/user/assistant pattern (notably user_system, group, and example-dialogue roles), positioning it for character consistency and multi-turn scenario adherence OpenRouter model card. Access is linked directly from OpenRouter’s “chat with her” entry Chat link.
ERNIE 5.0 is now described as officially live, but with few concrete specs
ERNIE 5.0 (Baidu/PaddlePaddle): Following up on Release claim (reported release + circulating charts), PaddlePaddle now posts that “ERNIE 5.0 is officially live” in a brief status-style announcement Official live post, echoed again without added technical detail Repeat post.
There aren’t enough surfaced artifacts in these tweets (pricing, endpoints, evals, or API docs) to pin down what changed operationally versus the earlier “reported released” chatter; the main new signal is the “officially live” framing itself Official live post.
🧪 Reasoning & training ideas: ‘societies of thought’, scaling-law search, and energy-based models
Today’s research-heavy thread focuses on why reasoning emerges and how to train/search for it: multi-perspective internal debate, automated scaling-law discovery, and alternative reasoning architectures. Excludes benchmark-only papers and security papers (covered elsewhere).
Reasoning traces look like internal multi-agent debate, not monologue
Reasoning Models Generate Societies of Thought (Google): A new paper analyzes reasoning traces and argues that “reasoning” behavior may come less from longer chains-of-thought and more from implicit multi-agent-style interaction inside a single model—question/answer turns, perspective shifts, conflicts, and reconciliation—as summarized in the Paper screenshot thread.
The same writeup claims the effect shows up when comparing reasoning-tuned models (DeepSeek-R1, QwQ-32B) against instruction-tuned baselines, where the former exhibit higher “perspective diversity” and less one-sided monologue behavior, per the Paper screenshot thread.
Evolutionary agent searches scaling laws that extrapolate better
SLDAgent (Stanford/Tsinghua/Peking/Wizard Quant): A paper claims an evolution-style LLM agent can iteratively rewrite both the scaling-law formula and its parameter-fitting code, yielding better extrapolation to larger runs than hand-crafted human formulas, as described in the Scaling law agent summary. The arXiv entry referenced in the thread is available via the ArXiv paper.
The tweets emphasize the operational payoff as “fewer sweeps” for hyperparameters and better choices of which pretrained model to finetune from small trials, following the Scaling law agent summary.
Energy-based “Kona” pitches constraint-scored reasoning over next-token sampling
Kona (Logical Intelligence): A startup is pitching an “energy-based reasoning model” that scores candidate reasoning traces against constraints (minimizing “energy”) instead of generating token-by-token; the thread frames this as a path to fewer fluent-but-wrong answers and more constraint-consistent outputs, as summarized in Kona thread.
The claims in the tweets are qualitative (no shared eval artifact or model card in the dataset), but they clearly position “non-autoregressive, constraint-scoring” as the architectural differentiator, per Kona thread.
Non-English internal reasoning increases diversity in English answers
Language of Thought Shapes Output Diversity (SUTD): A new paper claims you can increase output diversity by forcing the model’s hidden “thinking” language to be non-English while still requiring the final answer in English, as summarized in Language of thought summary.
The thread also claims mixing multiple thinking languages broadens cultural/values coverage with little quality loss, and that languages “farther from English” help more, according to Language of thought summary.
Demis Hassabis frames AGI as needing continual learning, memory, and planning breakthroughs
AGI research direction (Google DeepMind): Demis Hassabis says AGI likely requires “1–2 new breakthroughs” such as continual learning, selective memory, smarter context windows, and long-term planning, while still expecting large foundation models to remain the core component, per the Hassabis clip.

The clip is high-level (no new technical mechanism specified), but it’s a clear prioritization signal around continual learning and planning as the missing pieces, as stated in the Hassabis clip.
RL training stack pattern: decouple trainer, inference engine, and environment servers
Atropos RL training stack (Atropos): A shared architecture diagram breaks RL into three services—an RL trainer, an inference engine (vLLM/sglang), and “environment servers” (math/game/toolcall)—connected via a trajectory API for batching tokens/masks/scores, as shown in Stack diagram.
This is a concrete blueprint for teams trying to scale multi-environment rollouts without entangling training code and serving code, as depicted in Stack diagram.
📄 Research papers: evals, security, and benchmark realism checks
A dense paper day: new benchmarks (video physics), agent security designs for computer-use, and evidence that AI detectors are unreliable. Excludes training/optimizer-centric papers (covered under Reasoning & training).
CaMeLs proposes system-level prompt-injection defenses for computer-use agents
CaMeLs Can Use Computers Too (paper): A system design for computer-use agents reduces prompt-injection by forcing a trusted planner to generate a full (branching) plan before the model sees any screen content, so untrusted on-screen text can’t rewrite instructions mid-run, as described in the CaMeLs paper summary.
• Security mechanism: The split between a trusted planner and an untrusted “screen reader” is meant to stop “hidden screen text” from taking over the task, per the CaMeLs paper summary.
• Performance trade: The thread claims up to 57% of strong-model OSWorld success is retained (and smaller models can improve by up to 19%) under the constraints, according to the CaMeLs paper summary.
• Residual risk: The paper still notes “branch steering” (UI changes that nudge the agent into a dangerous-but-valid plan branch), as highlighted in the CaMeLs paper summary.
This is one of the clearer “agent security is a system problem” proposals seen in CUAs, not a pure prompt trick.
Physics-IQ finds today’s video generators still fail basic physics checks
Physics-IQ (Google DeepMind + INSAIT): A new benchmark argues that photorealistic generative video is weak evidence of a model having a usable “world model”; it measures whether a model can continue real videos while preserving motion/physics constraints across domains (fluids, optics, solid mechanics, etc.), and reports that even the most visually convincing models score far below a “two real takes agree” ceiling, as summarized in the Physics-IQ writeup.
• Benchmark design: The test shows a few seconds of a real event, asks the model to predict the next seconds, and checks motion consistency (where/when/how much things move), per the Physics-IQ writeup.
• Key empirical claim: “Visual polish and true understanding are uncorrelated” (Sora called out as hard to distinguish from real while still scoring low on physics), as stated in the Physics-IQ writeup.
The practical read is that evals for video agents and robotics simulators need explicit physics metrics, not “looks real” human preference alone.
ARC Prize 2025 report: progress comes from propose-check-revise loops
ARC Prize 2025 Technical Report: The ARC-AGI competition writeup frames the main winning pattern as a refinement loop—propose an answer, score it with a feedback signal, revise, repeat—rather than a single-shot “just prompt it” approach, as summarized in the ARC report summary.
• Method family: The report surveys systems that search over tiny programs (keep edits that score better) and systems that do test-time training while solving, per the ARC report summary.
• Score context: It repeats that the best 2025 entry reached 24% on a hidden test set, while humans solve almost all tasks, according to the ARC report summary.
• Benchmark hygiene warning: It explicitly flags potential dataset leakage (models absorbing ARC-style patterns), stressing that the benchmark must evolve, as noted in the ARC report summary.
For engineers, it’s another data point that “self-correction wrappers” are becoming table stakes for brittle reasoning tasks.
LLM-based AI detectors collapse under small style changes
LLM self-detection in education (paper): A computing-education study finds LLMs are unreliable “AI-written vs human-written” judges; they mislabel human answers as AI up to 32%, and a minimal “write like a human” instruction makes detection accuracy collapse—e.g., Gemini outputs fool GPT-4 100% of the time in one setup, per the detector failure summary.
• Why this matters operationally: The paper argues false positives and false negatives make LLM-judge-based misconduct decisions unsafe in high-stakes settings, as stated in the detector failure summary.
• Adversarial ease: It claims “write like a human” (casual, imperfect) is sufficient to evade “self-detection” and even causes Gemini to “fool itself” 96% of the time, according to the detector failure summary.
This reinforces that provenance needs cryptographic or platform-level signals; style-based judging is too brittle when the generator can target the judge.
NBER paper: most AI-exposed workers can adapt, but clerical roles stand out
AI exposure + adaptability (NBER paper): A new approach combines task exposure with a worker “adaptability” score (savings, transferable skills, local job options, age) and concludes that the most vulnerable subgroup is clerical/administrative support—about 4.2% of workers (~6.1M people)—as summarized in the NBER paper thread.
• Metric shift: The claim is that “exposure alone” overstates displacement risk; adding buffers changes which occupations look fragile, per the NBER paper thread.
For AI leaders, this is a concrete segmentation framework for where “automation narrative” translates into real transition risk, rather than a broad occupational doom score.
🛡️ Security & safety: agent hijacks, platform privacy, and abuse mitigations
Security today is mostly about practical risks when agents can act: prompt injection, credential exposure, and OS/platform data access. Excludes the Clawdbot ops wave itself (feature) while still covering general mitigations.
CaMeLs: plan-before-screen design reduces prompt injection, but branch steering remains
CaMeLs computer-use security (arXiv): A new design pattern for computer-use agents splits a trusted planner from an untrusted screen-reading executor, forcing the plan to be written before the model sees the screen—aiming to prevent on-screen prompt injection from rewriting intent, as summarized in the [paper thread](t:243|paper thread).
• Reported results: The thread claims this preserves up to 57% of strong-model success on OSWorld while boosting small models by up to 19%, according to the same [paper thread](t:243|paper thread).
• Residual risk: Even with plan-first, “branch steering” remains—attackers can alter UI affordances so the executor chooses a harmful but plan-consistent branch, again as described in the [paper thread](t:243|paper thread).
Windows 11 BitLocker key access becomes a real-world privacy threat model item
Windows 11 / BitLocker (Microsoft): A Windows Central report says Microsoft confirmed it can provide BitLocker recovery keys to the FBI when served a legal order, with the practical enabler being Windows 11’s forced online-account flow for many users, as described in the [privacy claim](t:73|privacy claim) and detailed in the [Windows Central report](link:395:0|Windows Central report).
For teams relying on BitLocker as “local device secrecy,” this shifts the risk model from purely endpoint compromise to also include account-escrow and legal-process pathways, especially for laptops used in AI engineering workflows (repos, local eval data, API keys).
ACIP publishes a one-liner to harden agent setups against prompt injection
ACIP (Dicklesworthstone): The ACIP project is being promoted as a practical hardening layer for agent runners against prompt-injection attacks, with a one-liner installer that sets ACIP_INJECT=1 and ACIP_SELFTEST=1, as shown in the [ACIP integration post](t:368|ACIP integration post) and the [one-liner snippet](t:556|one-liner snippet).
The emphasis is on making prompt-injection resistance an installable “baseline,” rather than a bespoke prompt discipline per workflow, with code and integration details in the [GitHub integration directory](link:368:0|GitHub integration directory).
Credentialed agents push teams back to blast-radius isolation basics
Agent runner isolation (Practice): As people wire agents into email, calendars, and other privileged services, a recurring safety argument is to isolate the agent on a separate machine/VPS to reduce the damage from prompt injection or mis-executed tool calls; the risk framing is explicit in the [credential exposure warning](t:459|credential exposure warning), and the “why do I need a separate box?” questions show up in the [separate machine question](t:99|separate machine question) and follow-on [blast radius debate](t:245|blast radius debate).
The underlying issue is that once an agent can read inbound messages and execute local actions, a single malicious email/DM (or a brittle tool edge case) can become an escalation path to destructive operations under the user’s identity.
📚 Docs & devex surfaces for agents: markdownification and new tool affordances
Today’s docs/devex angle is about making artifacts consumable by agents (repo→markdown) and new assistant-side tooling surfacing in the wild. Excludes repo-local prompts/rules (covered under Workflow patterns).
codebase.md traffic shows crawler storms dwarf human use
codebase.md (Codebase): A real usage snapshot suggests “repo→Markdown for agents” services can become crawler magnets; codebase.md saw 771.5k crawler hits vs 9.7k humans over 30 days, plus 14k agent-like requests, and the operator calls out Amazonbot at ~408k requests/month despite Cloudflare blocking “AI crawlers,” per the Traffic breakdown and the tool page linked in Tool page.
This matters because the doc-surface itself becomes the bottleneck: once you publish an agent-consumable representation of code, you may need bot-rate-limiting, caching, and possibly paid gates just to keep the service stable under automated fetchers.
ChatGPT surfaces a “container.download” tool in a reasoning trace
ChatGPT (OpenAI): A user noticed ChatGPT referencing a container.download tool directly inside a “thinking trace,” implying a new or newly-exposed affordance for fetching remote files into the sandbox/container environment, as shown in the Thinking trace.
This is a devex signal more than a product announcement: it hints at tool availability that may vary by model/plan/runtime, and at a discoverability gap where capabilities appear first as internal tool mentions rather than documented surfaces.
💼 Funding & enterprise moves: distribution, monetization, and talent acquisitions
Business signals today focus on how AI products monetize and distribute (ads/commerce, Android distribution), and enterprise positioning vs consumer. Excludes pure infrastructure capacity (covered under Infrastructure).
Ads thesis: OpenAI needs leverage beyond 1:1 compute-to-revenue scaling
ChatGPT monetization (OpenAI): Following up on Ads framing (value-sharing + ad-test hints), a new analysis argues OpenAI’s revenue has effectively scaled ~1:1 with compute (illustrated as ~1GW ≈ $10B), and that ads are the cleanest way to increase “revenue per GW” without pricing users out, as laid out in the Revenue leverage chart.
The same chart models a wide band of outcomes depending on ad/subscription mix (Spotify-like vs YouTube-like), and ties the upside to advertiser-funded “price increases” rather than pushing subscription prices directly, per the Revenue leverage chart.
Amodei argues enterprise-first helps Anthropic avoid the “engagement trap”
Anthropic (Enterprise strategy): Dario Amodei argues Anthropic deliberately prioritized selling to businesses to avoid consumer incentives that maximize engagement, produce “slop,” and create a competitive “death race,” as stated in the Enterprise strategy clip.

The implication is a business model that optimizes for workflow outcomes (accuracy, reliability, compliance) rather than time-spent metrics—useful context for how Anthropic may weigh product decisions and safety trade-offs.
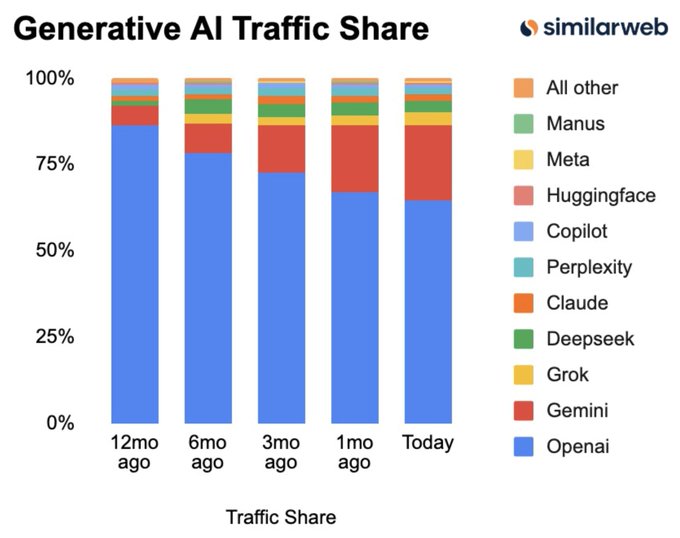
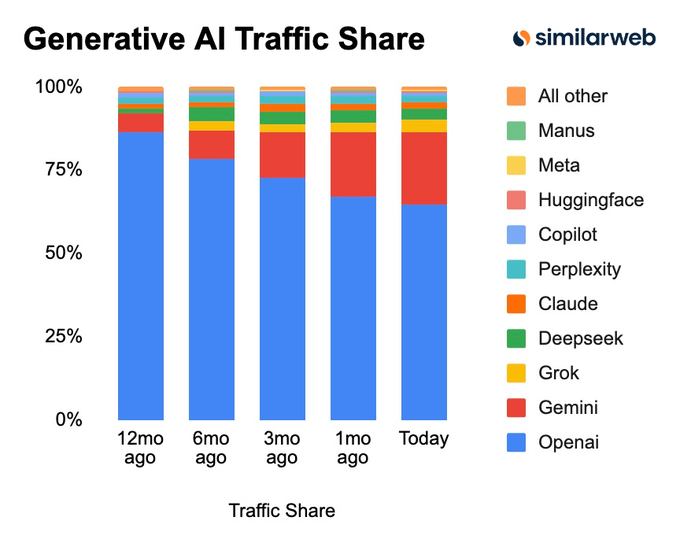
Gemini’s traffic share jumps to 22%, reinforcing “distribution wins” narrative
Gemini (Google) distribution: A Similarweb-style chart claims Gemini’s share of “Generative AI Traffic” rose from 5.3% to 22% over the last 12 months, as shown in the Traffic share chart.
• Distribution as the lever: The post frames the growth as primarily driven by distribution rather than purely model quality, as argued in the Traffic share chart.
• Monetization follow-on concern: A reply flags that ads inside ChatGPT-style products can become an easy monetization wedge once you have the default position, per the Ads follow-up comment.
Treat the exact shares as directional (methodology isn’t in the tweets), but the pattern is clear: default-placement distribution is showing up as a measurable advantage.
DeepMind hires Hume AI leadership under a licensing agreement
Google DeepMind (Talent acquisition): DeepMind is hiring Hume AI’s CEO Alan Cowen plus “several top engineers” under a new licensing agreement, per the Wired article screenshot.
This looks like a targeted bet on “emotionally intelligent” voice interfaces—less about generic TTS, more about affect detection/expressive voice UX and the product layer that wraps it.
🎥 Generative media: Veo 3.1 promos, motion control, and realtime style transforms
Creator tooling is active today: Veo/Kling/Krea workflows and claims about anime-quality video generation. Excludes non-media models (covered under Model Releases).
Google’s Veo 3.1 update spotlights vertical video, consistency, and upscaling
Veo 3.1 (Google): Google published an “Ingredients to Video” update for Veo 3.1 that emphasizes native vertical generation, improved character/background consistency, and upscaling (up to 1080p and 4K) for mobile-first workflows, as summarized in the weekly brief and detailed in the Product blog post.
This matters mainly as a format and post-processing shift: vertical-first output reduces the amount of downstream editing teams do for Shorts/Reels-style distribution, and better subject consistency is the failure mode that currently burns the most iteration time.
Kling 2.6 Motion Control: reference video + character image as a repeatable workflow
Kling 2.6 (KlingAI): A creator workflow is getting repeated: provide one character image and one reference video, then let Kling 2.6 “Motion Control” transfer timing/body movement/facial expressions while keeping character identity stable, per the workflow thread.

• Why builders care: this is effectively “motion as conditioning,” which can reduce prompt trial-and-error when you need a very specific performance (especially facial beats) and you already have a reference clip.
Krea’s real-time editing demos show live style transforms, including anime looks
Krea (Krea AI): Demos of Krea’s real-time editing show an interactive loop where the output updates continuously as you type (e.g., “cute robot” → “chibi”), as shown in the live typing demo, alongside claims like “you can watch any show in anime now” built on the same real-time editing capability in the anime montage.

This matters operationally because “live” editing changes the iteration cadence: it’s closer to a controllable UI tool than a batch T2I/T2V job queue.
“Text-to-video anime is indistinguishable” claims keep resurfacing
Text-to-video sentiment: A recurring claim is that current text-to-video outputs can be “indistinguishable from what anime labs create,” paired with short showcase clips as evidence in the anime quality claim.

The main signal here is expectation-setting: as more teams treat anime as a reachable quality bar for short-form clips, the differentiator shifts toward controllability (shot planning, character continuity, editability) rather than single-clip fidelity.
Higgsfield pushes Veo 3.1 “MAX” (4K) with a time-boxed discount
Veo 3.1 on Higgsfield (Higgsfield): Higgsfield is promoting Google Veo 3.1 access in “MAX quality” with native 4K, portrait/landscape support, stronger prompt adherence, native audio, and “clean transitions,” framed as an 85% off time-boxed deal in the promo announcement.

• Pricing/ops signal: the push is explicitly structured around credits + promo codes and a “2-year access” upsell, as described in the promo code post and the 2-year offer.
Treat it as a distribution/packaging move—no independent quality/eval artifact is shared in these tweets beyond marketing claims.
Comfy Cloud ships 3D camera control + multi-angle Qwen edit LoRA building blocks
ComfyUI (Comfy Cloud): Comfy Cloud added a 3D Camera Control node and made a Qwen Image Edit 2511 multi-angle LoRA available, per the availability note.
This is a small but concrete pipeline building block: it’s the kind of node/LoRA pairing that teams use to standardize multi-angle consistency and camera motion control inside a Comfy graph without rewriting custom nodes.
🤖 Robotics & embodied AI: VLA model maps and humanoid capability demos
Robotics tweets are a mix of model taxonomy and real-world humanoid demos, useful for tracking where VLA/VLA+ is heading. Excludes “world model” philosophy clips unless tied to a specific robotics artifact.
A practical map of VLA models and where “VLA+” is heading
VLA taxonomy (TheTuringPost): A curated list of “8 most illustrative” vision-language-action (VLA) models is circulating as a quick orientation layer for embodied-AI builders, spanning Gemini Robotics, π0, SmolVLA, Helix, ChatVLA‑2 (MoE), ACoT‑VLA, VLA‑0, and Microsoft’s Rho‑alpha (ρα), as compiled in the VLA model roundup. The post also points to build resources via the linked build guide page, which makes it easier to translate paper names into runnable stacks.
• Why this matters: It’s a concrete “model map” for teams deciding whether they’re betting on policy-only action heads vs action CoT vs MoE-style routing, without mixing it into broader “world model” philosophy. It’s also a useful checklist for competitive analysis when you’re evaluating robotics vendors or planning internal prototypes.
Agile Robots demo highlights tactile + navigation as product features
Agile Robots (Agile Robots): A short industrial-oriented demo is being shared emphasizing 71 degrees of freedom, precision tactile sensors, and autonomous navigation, positioning the system for practical deployment rather than lab-only benchmarks, as described in the industrial robot demo.

• Signal for builders: The emphasis on tactile sensing and autonomy suggests the near-term differentiation isn’t just better VLMs; it’s sensor + control integration and reliability under constrained tasks (pick/place, insertion, handling variability).
Unitree G1 dance clips keep becoming the default “humanoids are here” demo
Unitree G1 (Unitree): A short synchronized dance demo from two Unitree G1 humanoids is making the rounds again, with the cleanest clip in the G1 dance routine. A separate post wraps the same kind of footage under Demis Hassabis’s “bubble-like” investing remark, implying the capability demos are now decoupled from any single lab’s narrative, as shown in the bubble comment with robots.

• What to take from it: The clip is less about choreography and more about repeatable whole-body control + timing in a commodity-looking platform; it’s the sort of demo customers will benchmark every other humanoid against, even when it’s not representative of manipulation work.
A Tesla Optimus hallway-walk photo becomes a shorthand for humanoid ubiquity
Optimus (Tesla): A single still of Tesla Optimus walking down a hallway is getting reshared with the framing that people will see “a million of these,” as posted in the Optimus hallway photo.
• Why it lands: It’s a distribution/mindshare signal more than a technical update—once these visuals become boring, the bar for “credible humanoid progress” shifts from staged demos to repeatable, deployed tasks.