Gemini in Chrome preview ships Auto-browse approvals – 3 app connectors
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Google is previewing a revamped Gemini-in-Chrome experience that turns the browser into the agent surface: a persistent side panel supports multiple chats; “@tabs” can pull context from open tabs and history; Auto-browse can click through sites, fill forms, and run multi-step tasks, pausing for explicit approvals on high-risk actions like purchases, reservations, and posting. Rollout is described as US-only first for AI Pro and Ultra subscribers on Windows/macOS (plus Chromebook Plus); connected-app hooks deepen retrieval/actions across Gmail, Calendar, and YouTube; Nano Banana is embedded for inline image create/edit. Threads also cite a “Universal Commerce Protocol” with partners (Shopify, Etsy, Wayfair, Target), but no spec/SDK is shown.
• Claude Code 2.1.23: mTLS/proxy fixes and ripgrep timeout errors; safety prompt now allows authorized testing/CTFs; web-configured MCP connectors can auto-load into CLI context unless disabled.
• ACP/MCP plumbing: Zed v0.221 adds ACP Registry installs and defaults message queuing; Copilot CLI flags ACP support; Factory Droid ships ACP integrations for JetBrains/Zed.
Net: browser automation is converging on “logged-in context + interrupt approvals,” but it’s still unclear whether Chrome Auto-browse exposes a programmable interface beyond first-party UX.
Top links today
- Anthropic paper on assistant disempowerment patterns
- Nature paper on DeepMind AlphaGenome
- Google Keyword blog on Gemini in Chrome
- Google AI Studio for Gemini API
- Run Claude Code locally with Ollama
- Vercel approach for agent version syncing
- SDFT continual learning paper (arXiv)
- LLM auto-fill lung cancer tumor board forms
- Artificial Analysis Video Arena leaderboard
- Artificial Analysis benchmarks for Qwen3-Max-Thinking
- OpenAI Prism LaTeX-native research workspace
- Firecrawl change tracking docs for agents
- Generative UI patterns repo for agents
- Cohere Model Vault private inference platform
- Voyage-4-nano open embedding model card
Feature Spotlight
Gemini in Chrome: agentic auto-browsing + cross-tab context
Gemini in Chrome turns the browser into an agent runtime: it can read across tabs and complete multi-step tasks with user sign-off. For builders, this is a new distribution + automation surface that changes how web agents ship.
High-volume rollout: Gemini gets deeply embedded in Chrome with agentic Auto-browse, multi-tab awareness, and in-browser actions. This is the day’s headline because it shifts web automation from “agents in a separate app” to the default browser surface.
Jump to Gemini in Chrome: agentic auto-browsing + cross-tab context topicsTable of Contents
🌐 Gemini in Chrome: agentic auto-browsing + cross-tab context
High-volume rollout: Gemini gets deeply embedded in Chrome with agentic Auto-browse, multi-tab awareness, and in-browser actions. This is the day’s headline because it shifts web automation from “agents in a separate app” to the default browser surface.
Gemini in Chrome previews Auto-browse to complete multi-step web tasks with approvals
Auto-browse (Gemini in Chrome): Google is previewing Auto-browse—an agentic browsing mode that can click through sites, fill forms, and complete multi-step tasks while pausing for explicit user approval at high-risk actions (purchases, reservations, posting), according to the Auto-browse explainer and the task walkthrough.

• Platform and gating: The preview is described as rolling out in the US for AI Pro and Ultra subscribers on Windows and macOS (plus Chromebook Plus), as stated in the Auto-browse explainer and echoed by the rollout clip.
What remains unclear from the tweets is whether Auto-browse exposes a programmable interface (beyond UI) or stays a first-party UX only.
Gemini in Chrome adds a persistent side panel with multi-chat and @tabs context
Gemini in Chrome (Google): Google is rolling out a revamped Gemini in Chrome experience centered on a persistent side panel; it supports multiple concurrent chats and can pull context from open tabs via “@tabs” mentions and history recall, reducing copy/paste between pages and chats as shown in the feature demo and reiterated in the rollout thread.

• Entry points and multitasking: The flow starts from a new side panel and is positioned as running “in the background” while you switch tabs, with the keyboard shortcut note calling out a Control+G entry point.
• Rollout scope: Multiple posts describe it as shipping first to Google AI Pro and Ultra subscribers in the US, including the rollout clip and the feature demo.
Gemini in Chrome pulls Gmail and Calendar context without leaving the browser
Connected apps (Gemini in Chrome): Gemini’s Chrome experience is being tied more directly into Google apps so it can retrieve details from Gmail and other services and then draft/update content without tab switching, as shown in the Gmail-to-draft demo and summarized in the feature list.

• What’s connected: Posts describe deeper hooks into Gmail, Calendar, YouTube (and in some mentions Flights/Maps) through @-style references and connected-app context, as detailed in the feature list and the capabilities summary.
Gemini in Chrome integrates Nano Banana for in-browser image edits
Nano Banana (Gemini in Chrome): The Chrome sidebar now includes direct Nano Banana integration for image creation and editing, positioned as “edit and transform images directly” from the browsing surface, as shown in the product demo and restated in the feature list.

This is being presented as part of the same Chrome-side Gemini update that also adds agentic browsing features, per the launch recap.
Google cites Universal Commerce Protocol partners for agent-driven shopping flows
Universal Commerce Protocol (Google/Chrome): One thread claims Google is adopting a Universal Commerce Protocol to support agent-driven shopping flows across the web, citing partners including Shopify, Etsy, Wayfair, and Target in the capabilities summary.

The tweets don’t include a spec, SDK, or enforcement details, so it’s unclear what a third-party merchant needs to implement versus what Chrome/Gemini infers from page behavior.
Gemini in Chrome rollout mentions “Personal Intelligence” as part of the new sidebar
Personal Intelligence (Gemini in Chrome): A rollout post frames the new Gemini sidebar as including Auto Browse and “Personal Intelligence” features for Pro and Ultra Chrome users in the US, per the rollout post.

The related official write-up emphasizes that Auto-browse is expected to evolve toward more context-aware help, as described in the Keyword blog post.
Browser AI consolidation talk spikes as Gemini ships deeper Chrome integration
Market signal (AI browsers): Reaction posts characterize Gemini’s Chrome integration as the strongest “AI in-browser” implementation they’ve seen, while also arguing Google is absorbing features pioneered by startups and leaving less room for standalone “AI browser” products, as stated in the startup displacement take and amplified by the reaction clip.

Another thread frames the rollout scale as reaching “2 billion people” via Chrome distribution, as written in the rollout scale claim, though that number is not presented as an official metric in the tweets.
🛠️ Claude Code: CLI 2.1.23 + connectors behavior changes
Continues the fast CLI churn, but today’s novelty is version-specific: 2.1.23 reliability/UX fixes plus policy + skill-discovery changes. Also notable: Claude Code now pulling in web-configured MCP connectors can silently bloat context unless you disable them.
Claude Code CLI can silently pull in claude.ai MCP connectors and eat context
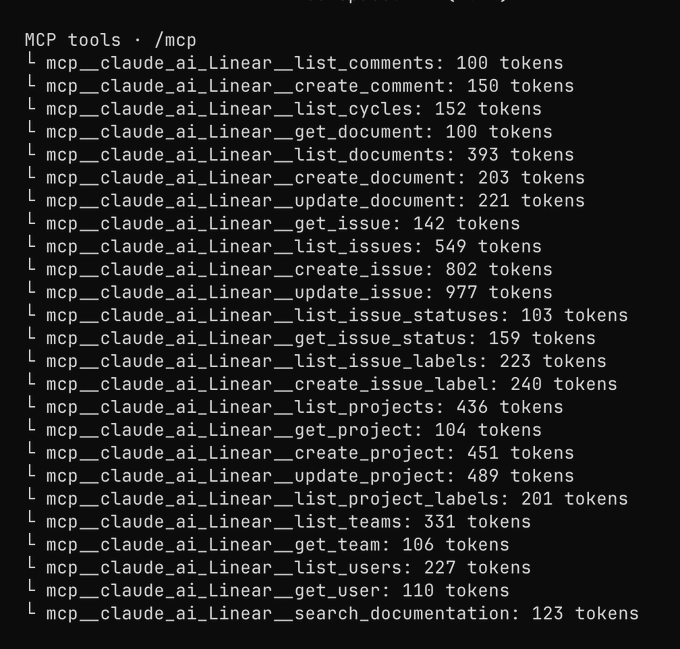
Claude Code connectors (Anthropic): Users are reporting that Claude Code CLI sessions can now pick up MCP connectors configured on the claude.ai web app—e.g., a Linear MCP server—leading to context windows filling faster unless you disable them with /mcp, as shown in the connector screenshot and described in the connector screenshot. This is operationally important because “hidden tools” also mean hidden tool schemas + tool lists consuming tokens.
• Practical implication: If your org standardizes connectors in the web UI, engineers may inherit them in local CLI sessions without realizing it, per the connector screenshot.
Claude Code CLI 2.1.23 focuses on enterprise connectivity and terminal reliability
Claude Code CLI 2.1.23 (Anthropic): The 2.1.23 release stacks a bunch of “it broke in real life” fixes—especially for enterprise networks—plus terminal UX polish, as listed in the changelog thread and detailed in the changelog section. It also removes a nasty failure mode where ripgrep timeouts could look like “no results,” which matters because search is the backbone of any codebase-scale agent loop.

• Enterprise network support: mTLS and proxy connectivity fixes target corporate setups (client certs, proxies) that often make agent CLIs flaky in locked-down environments, as described in the detailed changelog.
• Search and terminal correctness: ripgrep timeouts now report errors instead of silently returning empty results, and terminal rendering was optimized for performance, according to the detailed changelog.
• PR visibility in the CLI: merged PRs now show a purple status indicator in the prompt footer, and the “active PR updates” view is shown in the PR footer demo.
Claude Code expands to authorized security testing while tightening misuse limits
Claude Code (Anthropic): Claude Code’s policy prompt now explicitly supports authorized security testing (including CTFs and educational security work), while continuing to refuse destructive or mass-abuse behaviors—dual-use requests need clear authorization context, per the policy diff summary and the linked diff view. This is a concrete scope change for teams using Claude Code in internal appsec workflows (where the previous “defensive-only” posture could cause confusing refusals).
• What’s still refused: The update keeps hard lines on destructive techniques, DoS, mass targeting, supply-chain compromise, and malicious detection evasion, as summarized in the policy diff summary.
Claude Code shifts skill discovery to system reminders and adds keybindings-help
Claude Code (Anthropic): 2.1.23 changes how the model is supposed to “know” about skills: the Skill tool policy now says available “/<skill>” commands come from system-reminder messages, and the model must not guess or hallucinate skill names, as described in the prompt changes note and the keybindings-help diff. Separately, a new user-invocable keybindings-help skill is introduced for edits to ~/.claude/keybindings.json, per the keybindings-help diff.
• Why this matters: In practice, this pushes teams toward explicit skill inventories (the system prompt becomes the source of truth) instead of relying on model memory or pattern-matching, per the prompt changes note.
Claude Projects shows an early UI for launching Cowork tasks with project context
Claude Projects (Anthropic): A leaked/preview UI shows an option to “Create new task with context” from a project, pulling in the project’s instructions and uploaded files (with caveats about what isn’t included), as shown in the project task modal. The same screenshot notes it’s not public yet and that some project memory/synced files won’t be included, per the project task modal.
This looks like a step toward project-scoped task execution becoming a first-class primitive, but the rollout and exact runtime behavior aren’t confirmed in today’s tweets.
Claude Code 2.1.23 surfaces new tengu flags
Claude Code CLI 2.1.23 (Anthropic): Two new flags—tengu_system_prompt_global_cache and tengu_workout—show up in the 2.1.23 flag diff, per the flag changes note and the linked diff view. The tweets don’t include semantics for what they toggle, but for anyone managing shared configs across a team, the presence of new flags is a signal to re-check pinned CLI versions and default settings.
⌨️ OpenAI Codex: UX knobs, collaboration mode, and day-to-day usage
Today’s Codex chatter is mostly workflow-level: “collaboration mode” subagents, local state changes, and small UX knobs (personalities, question UI) that affect how teams run Codex in practice.
Codex collaboration mode introduces Explorer/Worker subagents with guard limits
Codex (OpenAI): A community-circulated “last 7 days changelog” claims Codex now has a Collaboration Mode (beta) where the main agent can spawn specialized subagents—an Explorer for fast read-only codebase understanding (noted as using GPT‑5.2‑Codex) and a Worker for execution—while Guards enforce limits like max depth =1 and up to 12 subagents per session, as shown in the Codex changelog screenshot.
• Shipping impact: If accurate, this formalizes the “spawn helpers” pattern inside Codex instead of relying on manual multi-terminal setups, but with explicit caps that will shape how teams partition work across agents, per the Codex changelog screenshot.
Clawdbot creator steipete prefers Codex for large codebases and reliability
Codex (OpenAI): The creator of Clawdbot/Moltbot is cited as preferring Codex over Claude Opus for coding because it can “navigate large codebases” and offers “95% certainty that it actually works,” while Claude Code “needs more tricks,” per the Preference quote clip.

This is a concrete “feel” comparison engineers can map to their own environments: long-context + repo navigation confidence is valued over raw generation speed in this account, as stated in the Preference quote clip.
Codex local state reportedly moves thread metadata into SQLite
Codex (OpenAI): The same “last 7 days changelog” screenshot claims Codex moved thread/session metadata into a SQLite state DB (instead of parsing JSONL on each query), enabling faster listing/filtering/pagination plus indexes on fields like created_at and archived status, as described in the Codex changelog screenshot.
This looks aimed at CLI responsiveness and “many threads” workflows—i.e., making local state a first-class performance lever rather than a log parsing bottleneck, as implied by the Codex changelog screenshot.
Codex plan mode shifts to Explore → Intent → Implementation
Codex (OpenAI): A shared changelog screenshot says Plan Mode now runs in three phases—Explore → Intent chat → Implementation chat—with an “Explore first, ask second” bias (discover repo facts before questioning the user), and a requirement that plans be “decision complete” (exact file paths, signatures, test cases), according to the Codex changelog screenshot.
This is a concrete UX nudge toward fewer back-and-forth clarification loops and more repo-grounded planning, if the Codex changelog screenshot reflects what shipped.
Codex “ask user” UI adds keyboard navigation and explicit selection
Codex (OpenAI): The circulated “last 7 days changelog” claims the ask-user question UI got keyboard-driven navigation—j/k to move options, h/l to switch questions, Tab to toggle notes (hidden by default)—and now requires explicit selection (Enter only after choosing), as shown in the Codex changelog screenshot.
Net effect: fewer accidental submissions and faster human-in-the-loop steering during tool-heavy runs, based on the behavior described in the Codex changelog screenshot.
Two-model loop: Opus for implementation, GPT-5.2 Codex for /review hardening
Codex (OpenAI): A practitioner workflow pairs Claude Opus 4.5 for fast iteration and feature building, then runs /review with GPT‑5.2 Codex as a “make sure the code is rock solid before shipping” pass, as described in the Workflow pairing note.
This positions Codex as a reliability/verification layer rather than the primary generator in that stack, per the framing in the Workflow pairing note.
Prompting “ask me for confirmation” yields stepwise approvals in Codex
Codex (OpenAI): A prompt pattern—adding “ask me for confirmation along the way”—is reported to produce a UI that lets you direct/approve agent decisions mid-run, per the Prompt control tip; one shared screenshot shows a Codex run that had already read ~93.95k tokens before acting, indicating these flows can become highly context-heavy, as shown in the Token readout screenshot.
The tradeoff implied across the Prompt control tip and the Token readout screenshot is tighter human control at the cost of longer “read first” phases and larger context consumption.
Codex Berlin Meetup promo signals growing CLI user community
Codex (OpenAI): A “Codex Berlin Meetup” promo card suggests OpenAI’s Codex team/community is organizing in-person CLI meetups, per the Meetup promo images.
This is a soft signal that Codex CLI usage is clustering into local communities (and likely that workflows/configs are stabilizing enough to share), as implied by the Meetup promo images.
Codex debugging flow: agent-to-agent handoff and a fast “found it” moment
Codex (OpenAI): A short clip shows Codex debugging code written with another agent, culminating in an “Aha! Found it.” moment during a terminal/editor flow, as shown in the Debugging clip.

This is a small but repeated theme in Codex chatter today: terminal-first loops and agent-to-agent handoffs are becoming normal, as implied by the Debugging clip and follow-on commentary in the Dictation workflow note.
🧩 Agent IDEs & app builders: Lovable, v0, Kilo, Mistral Vibe, Cline
Non-Claude/Codex coding tools had a busy day: app builders shipping more autonomy (planning, browser testing, prompt queues), plus repo-import workflows that reduce friction from prototype → real codebase.
Lovable adds planning, browser testing, and prompt queues to push more work autonomous
Lovable (Lovable): Lovable says it’s now 71% better at solving complex tasks and is leaning harder into autonomy via deeper planning, browser-driven testing, and prompt queueing, as announced in the product update and demonstrated in the browser testing clip.

• Browser testing loop: It opens a browser, navigates user flows, probes edge cases, and patches bugs it finds, as shown in the browser testing clip.
• Prompt queueing: Multiple prompts can be stacked while the agent works (a concurrency primitive for humans), per the queueing demo.
• Google auth in one prompt: It now claims to add Google sign-in without the usual Google Cloud Console setup steps, per the auth feature note.
Treat the “71%” as a product claim—no eval artifact is provided in the tweets.
v0 can import GitHub repos so you can edit and ship the actual codebase
v0 (Vercel): v0 added Git Import (beta) so you can pull in an existing GitHub repo, work on the real codebase, and ship changes to production without leaving v0, per the product announcement.

The practical shift is less “prototype generator” and more “agent working against your repo”; Vercel frames it as actively improving and requests feedback in the product announcement.
Amp adds deep mode: GPT-5.2 Codex reads first, edits later
Amp deep mode (Amp): Amp shipped a new agent mode called deep that uses GPT-5.2 Codex and is described as spending 5–15 minutes reading and navigating a codebase before making changes, contrasting with an interactive “smart” mode, per the deep mode post and the deep mode writeup.
A redemption link for trial usage circulated separately in the redeem code note, but the tweet indicates the code may be exhausted.
Cline argues regulated orgs block agents due to opaque data flow, not AI itself
Cline (Cline): Cline’s team argues many AI coding tools get blocked in regulated environments because data flow is opaque, and positions Cline as a local extension with auditable routing (cloud API, private endpoint, or fully local via Ollama), as described in the architecture post.
The framing is governance-first (“security teams can audit this”), rather than a model capability claim, per the architecture post.
Kilo Code offers Kimi K2.5 free for a week inside its VS Code extension
Kilo Code (Kilo): Following up on Distribution (K2.5 spreading across toolchains), Kilo is offering Kimi K2.5 free for a week, positioning it as beating Opus 4.5 on several coding benchmarks, per the free-week announcement and the promo post.
This is a distribution and trial-access change rather than a new model release; benchmark specifics aren’t shown in the tweet itself.
Mistral ships Vibe 2.0 with custom subagents and slash-command skills
Mistral Vibe 2.0 (Mistral): Mistral announced Vibe 2.0, a terminal-native coding assistant upgrade that adds custom subagents, multi-step clarifications, slash-command skills, and unified agent modes, as summarized in the launch recap.
Access is framed as Pro/Team, with Devstral 2 moving to paid API use per the launch recap; the tweets don’t include a concrete changelog diff.
Cline Hooks block insecure agent output before it hits the repo
Cline Hooks (Cline): Cline is demoing Hooks that can block insecure code patterns before they’re written (examples cited: SQL injection, hardcoded credentials, debug mode in prod), per the hooks demo note.
The capability is presented as programmable guardrails with an enterprise demo, with details shown in the Hooks demo video.
🧠 Agent runners & multi-agent ops: swarms, memory, and automation demos
Operational tooling and “run-forever” patterns continue: agent swarms, persistent memory plugins, multi-threaded agent chat, and local review UIs. Excludes Gemini-in-Chrome (covered as the feature).
Clawd shows end-to-end account creation via AgentMail plus browser automation
Clawd (Moltbot ecosystem): A demo shows an agent completing a full Reddit signup flow end-to-end—creating and using its own email via AgentMail, driving a web browser, and finishing registration in about ~26 seconds, as shown in the Autonomous signup demo.

• Why it matters operationally: This is a clean example of “run-forever” automation where the fragile parts are identity (email) and browser state, rather than planning, as implied by the AgentMail dependency called out in the Autonomous signup demo.
• Near-term risk surface: The same capability class (form fill, account creation) is exactly where teams typically need tighter sandboxing, separate credentials, and audit logs, even for internal agents.
Supermemory’s Moltbot memory plugin spikes to 101 stars and surfaces a memory graph UI
Supermemory plugin (Moltbot): Following up on Infinite memory (persistent memory plugin), the repo hits 101 GitHub stars as shown in the Star history milestone, and the product UI emphasizes automatic profile capture (“You are now being followed”), as shown in the Followed flow demo.

• Operator takeaway: The graph-style view suggests a shift from “append-only notes” to explicit memory inspection and debugging, as seen in the
.
It’s still unclear how much of the memory store is user-controlled vs. agent-controlled from the tweets alone.
A local review companion streams agent diffs and gates commits with quizzes
Local review app (benhylak): A prototype “code review app” live-streams change summaries while Claude Code is working, quizzes the developer about intent before committing, and runs local bug-finding without pushing to GitHub, as shown in the Review app demo.

• Workflow detail: Access is being shared ad hoc (“dm me if you want access”), per the Access via DM note.
• Strategic angle: The same author frames it as a starting point for “local tools” rather than trying to replace GitHub, per the Local-first tooling comment.
Kimi Agent adds file creation and renames “OK Computer”
Kimi Agent (Moonshot): Kimi can now create and edit files—spreadsheets, slides, and PDFs—directly from chat prompts, and “OK Computer” is renamed to “Kimi Agent,” as shown in the File creation demo.

This is an agent-runner capability shift (document outputs as a first-class tool result) rather than a pure model-quality update.
Multi-threaded agent chat emerges as the practical fix for context window blowups
Multi-threaded agent ops (Moltbot/Clawd): Running agents in multiple concurrent threads—one per Slack/Discord/Telegram conversation—keeps each thread’s sequence and memory separate, avoiding “shoving all tasks into a single conversation” and the resulting context compaction failures, per the Multi-threaded workflow note.
• Implementation detail: The same setup is described as “TOPICS” where each topic becomes a new session, according to the Topics as sessions note.
This is mostly an ops pattern: it reduces context churn and makes long-running agent usage more predictable, without changing the underlying model.
Agent-driven “barnacle cleanup” for machines running many agents
System Performance Remediation (doodlestein): A “skill” is being used to diagnose and clean up stuck/zombie processes that accumulate when running many concurrent agents—example output shows Load 150 / 64 cores and a prioritized kill list (stuck bun tests, hung vercel inspect, stuck git add), as shown in the Remediation output screenshot.
The post frames this as cumulative ops debt that becomes visible only at agent scale, per the Remediation output screenshot.
AI-generated triage reports become a maintainer-scale workflow
OSS triage via agents (doodlestein): A maintainer workflow generates a structured daily “GitHub issues & PRs triage report” spanning 27 issues + 13 PRs across 13 repos, including close/implement guidance and bug-vs-feature separation, as shown in the Triage report screenshot.
The same author notes the meta-bottleneck: agents can produce changes faster than a human can commit/group them, per the Agents outpacing commits note.
Conductor adds an in-app GitHub Actions log viewer for CI triage
Conductor (charlieholtz): GitHub Actions logs can now be viewed directly inside Conductor by clicking a check in the PR “checks” tab, reducing the “bounce to browser” loop during CI triage, as shown in the Actions log viewer post.
This is a small UI change, but it targets a common agent-heavy failure mode: humans losing time to context switching while iterating on CI fixes.
Phone-ping hooks surface as the “don’t watch the run” primitive
Agent supervision pattern: A simple ops trick—set up a hook that pings your phone whenever an agent needs input—removes the need to watch long-running sessions continuously, per the Phone ping hook.
There’s no concrete implementation detail in the tweet, but the pattern is consistent with the broader shift toward async supervision (agents run; humans approve at interrupts).
🔌 Interop plumbing: ACP registry + MCP integrations + agent-to-browser bridges
Protocols and connectors were the story: ACP registry unifies agent distribution across clients, while MCP integrations expand what agents can reach (including authenticated browsing). Excludes non-protocol product launches.
Parallel Task API adds authenticated research via Browser Use MCP
Parallel Task API (Parallel): Parallel now supports web research over authentication-gated sources by delegating login state to a Browser Use MCP browser agent while Parallel handles orchestration and synthesis, as described in the feature announcement and reiterated in the credentials separation note.

• What shipped: The integration is documented in the integration docs and framed in the feature blog post as extending beyond public web sources.
• Operational detail: Credentials “stay with your browser agent,” and Parallel consumes the resulting page context—this is the key security/architecture claim in the credentials separation note.
Zed v0.221 ships ACP Registry installs and makes agent message queuing default
Zed (Zed): Zed v0.221 adds first-class support for the new ACP Registry—register an agent once and install it from a unified hub inside Zed, as announced in the v0.221 release post and expanded in the ACP registry blog. It also flips agent message queuing to default, so you can stack prompts while an agent runs and interrupt/edit the queue, as shown in the message queueing clip.

• Why it matters for interop: This tightens the “install once, work across clients” story for ACP, building on the registry announcement in the ACP Registry note.
• Runtime ergonomics: Queuing reduces idle time when agents are busy and makes handoffs less brittle in long-running sessions, per the v0.221 release post.
GitHub Copilot CLI adds Agent Client Protocol support
Copilot CLI (GitHub): Copilot CLI now supports the Agent Client Protocol (ACP), enabling a standardized handshake and message flow between “agent clients” and editors/hosts, according to the ACP support note. The direct implication is that Copilot CLI can plug into any ACP-compatible client without bespoke glue code, which is the core promise of ACP-style interop.
There’s no public changelog detail in these tweets (init schema, transport details, or capability negotiation), so treat this as a compatibility flag rather than a full spec readout.
Google’s Jules SWE Agent adds MCP integrations and ships a CI Fixer beta
Jules SWE Agent (Google): Google’s Jules adds new MCP integrations (Linear, New Relic, Supabase, Neon, Tinybird, Context7, Stitch) and introduces a CI Fixer beta that can automatically attempt repairs for failing CI checks on PRs it creates, according to the Jules update.

The practical shift is that MCP becomes the expansion socket for Jules’s tool surface, while CI Fixer closes a common gap in agentic PR workflows: “agent opened PR, but CI is red.”
Claude Code `--chrome` mode bridges agents to a local Chrome session
Claude Code (Anthropic): A practical bridge for agent-to-browser automation is emerging via Claude Code’s --chrome flag plus a required extension, which exposes a Chrome MCP server to the agent so it can drive the user’s logged-in browser session, as described in the how-to note and detailed in the Chrome mode docs.
The key operational implication is that the browser context is already authenticated (your cookies), which changes what “web automation” means compared to headless cloud browsers—especially for internal tools or SaaS consoles.
Factory Droid becomes ACP-compatible, highlighting JetBrains and Zed support
Droid (Factory): Factory says Droid is now fully ACP-compatible, positioning it to run inside ACP clients like JetBrains IDEs and Zed, as stated in the ACP compatibility announcement. Setup is documented in the JetBrains integration docs, and Factory is also offering a one-month promo tied to JetBrains/Zed users via the promo form.
This is a concrete signal that ACP is moving from “editor protocol” to “agent distribution channel,” with commercial vendors treating ACP support as a go-to-market surface.
Manus integrates Anthropic Agent Skills as a workflow packaging layer
Agent Skills (Manus): Manus says it has integrated Anthropic’s Agent Skills—treated as modular, reusable “operating manuals” for agents—aiming to make workflows callable/shareable inside its product, as shown in the integration announcement.

This is another data point that the “Skills as portable workflow artifacts” idea is spreading across agent platforms, not just within one vendor’s tooling.
🧭 Workflow patterns: planning, control, and context discipline
Practitioner patterns dominate: explicit planning roles, confirmation checkpoints, and structuring code to be easier for agents to modify. Excludes tool-specific release notes (handled elsewhere).
Three-agent coding setup: planner, implementer, reviewer, using git worktrees
Multi-agent role separation: Uncle Bob describes starting “with three Claudes” split into implementer/planner/reviewer, and using git worktrees instead of cloning repos, per his Three Claudes setup; it’s a concrete evolution from his earlier “split sessions” approach, following up on two sessions (planning vs execution). This setup mainly changes coordination overhead: worktrees keep branches isolated without duplicating full working directories, which matters once agents are editing in parallel.
The open question is how teams standardize handoffs (what the planner must produce before the implementer runs) so worktrees don’t turn into parallel confusion.
Prompting agents to ask for confirmation creates a stepwise control loop
Confirmation checkpoints: A simple control phrase—“ask me for confirmation along the way”—is reported to trigger a nicer UI for directing agent decisions mid-run, per Confirmation tip. The same thread notes these agents may read huge context before acting (one example shows ~94k tokens of thinking), as shown in Large context read.
This pattern is basically a lightweight alternative to building a full approval policy: you force explicit user gates at decision points, but without turning every tool call into a manual prompt.
With three coding agents, planning becomes the bottleneck
Planning throughput: After moving from one to three agents, Uncle Bob reports the new limiting factor is human planning—“Claude is waiting for me… the bottleneck is all planning,” as he puts it in Planning bottleneck note. This frames planning artifacts (scopes, acceptance criteria, test plans) as the scarce resource once execution is cheap.
This is a useful mental model for teams scaling agent count: you can add implementers, but you can’t avoid the need for crisp intent.
Reducers plus unit tests make agent-driven frontend changes less fragile
State isolation for editability: The claim is that pulling logic out of the DOM and into pure functions (reducers) combined with unit tests makes it easier for agents to modify behavior safely, as argued in Reducers and tests and reinforced in Pure functions note. The use-effect-reducer hook is cited as an underused pattern to structure side effects around reducer-like logic, with details in the Package page.
This reads like “make the code more testable” translated into an agent era: keep mutation and effects explicit so changes are locally verifiable.
Two-model coding loop: fast implementer plus strict reviewer
Model pairing workflow: One practitioner reports a loop of “plan and code the feature with Opus 4.5” then “run /review with GPT‑5.2 Codex,” describing Opus as fast at iteration while Codex “makes sure the code is rock solid,” per Two-model workflow.
The practical point is separation of concerns: one model optimizes for speed and willingness to change code; the other is used as a higher-precision check before shipping.
A six-level adoption model for AI-assisted programming is spreading
Shared vocabulary for teams: Simon Willison surfaces a “six levels of AI-assisted programming” model—ranging from autocomplete up through a fully automated “dark software factory”—as a way to describe where a team’s process sits today, per Adoption levels writeup and the linked Blog post.
The useful part isn’t the exact taxonomy; it’s that it gives product and engineering leaders a neutral way to talk about review requirements, risk tolerance, and where humans sit in the loop.
⚙️ Inference & systems: quantization, kernels, and running models locally
Serving and efficiency updates: NVFP4/INT4 pipelines, operator libraries, and “runs on my desk” local inference signals. Excludes model announcements themselves.
Nemotron 3 Nano NVFP4 brings FP4-class efficiency with QAD to keep accuracy
Nemotron 3 Nano NVFP4 (NVIDIA): NVIDIA released an NVFP4 variant of Nemotron 3 Nano (30B hybrid MoE) that quantizes both weights and activations—positioned as 4× FLOPS vs BF16 plus ~1.7× memory savings vs FP8 on Blackwell, with quantization-aware distillation (QAD) pitched as the reason accuracy stays near BF16, as described in the NVFP4 release recap and expanded in the QAD writeup.
This is the kind of release that changes the “what can we run locally / cheaply” conversation, because the claim isn’t just smaller checkpoints—it’s throughput gains at a new precision regime.
SGLang’s INT4 QAT pipeline targets RL rollout stability on a single H200
INT4 QAT for RL rollouts (SGLang/LMSYS): LMSYS’ SGLang team describes an end-to-end INT4 quantization-aware training pipeline aimed at keeping BF16-level stability while enabling rollout + inference as W4A16, and explicitly claims this can compress ~1TB-scale models to fit on a single H200—see the QAT pipeline diagram and the accompanying QAT blog.
• Systems angle: the writeup emphasizes a single-node rollout path (no cross-node sync overhead) for faster RL sampling, as outlined in the QAT pipeline diagram.
The open question is how broadly this generalizes beyond their specific rollout setup and kernels; the post gives an end-to-end recipe but not an external reproduction report yet.
Tencent’s HPC-Ops claims 30% inference boost via custom CUDA/CuTe ops
HPC-Ops (Tencent): Tencent introduced HPC-Ops, a CUDA + CuTe operator library positioned as a drop-in performance layer for LLM inference, with a claim of ~30% production inference uplift for Tencent Hunyuan and reported microbench wins like 2.22× faster attention, 1.88× faster GroupGEMM, and 1.49× faster FusedMoE, as shown in the perf charts.
This is a direct “kernels as product” signal: performance is coming from operator stacks (not model changes), and it’s being justified with production deltas rather than only benchmark scores.
Kimi K2.5 local inference hits 24 tok/s on a 2×M3 Ultra desk setup
Local inference (Kimi K2.5): a desk setup using two 512GB M3 Ultra Mac Studios connected with Thunderbolt 5 (RDMA) is reported running Kimi K2.5 at ~24 tok/s, per the desk inference report.
This is paired with cost framing from another builder—“this costs $20K … on consumer hardware … can’t believe we’re here already”—in the cost comparison take, which highlights how quickly “local” is encroaching on budgets that used to be reserved for cloud-only inference.
vLLM adds deployment-ready support for Nemotron 3 Nano NVFP4
Nemotron 3 Nano NVFP4 (vLLM): vLLM says the NVFP4 checkpoint is already supported, framing it as “deployable now” for teams on Blackwell hardware, per the vLLM support note that points to the model card.
In practice, this shortens time-to-serving for teams that standardize on vLLM for production inference rather than vendor runtimes.
Baseten adds Nemotron 3 Nano NVFP4 on B200 instances
Nemotron 3 Nano NVFP4 (Baseten): Baseten announced availability of Nemotron 3 Nano NVFP4 on NVIDIA B200, reiterating BF16-level accuracy and “up to 4× higher throughput vs FP8” positioning, with deployment details in the Baseten announcement and reference docs in the deployment page.
This adds another “managed inference” surface for NVFP4 beyond self-serve runtimes, which matters when teams want the new precision mode without standing up their own Blackwell fleet.
DIY inference economics: consumer rigs vs scaled cloud pricing expectations
Inference economics: thdxr argues that companies already spend $10–20k per dev per year on cloud inference, making $20k consumer-hardware deployments feel surprisingly rational in some settings, as framed in the cost comparison take.
He also calls out a pricing mismatch—scaled inference “should not be the same as hacking it together on consumer hardware,” concluding “get ready for cheap inference” in the cheap inference expectation.
🧠 Model releases & pricing (non-bio) that builders are testing
Continues the open-model arms race: multimodal open weights, new proprietary reasoning variants, and pricing moves. Excludes runtime/serving mechanics (systems-inference).
Arcee releases first Trinity Large weights for its frontier-scale MoE family
Trinity Large (Arcee AI): Arcee says it’s releasing the first weights from Trinity Large, moving the model from “announced” to “downloadable” for builders who need real self-hostable capacity, as noted in the weights release note and expanded in the Kilo availability note.
The immediate engineering relevance is that “frontier-scale, US open weights” becomes something you can actually evaluate locally/on-prem (latency, memory footprint, and safety posture), instead of only comparing benchmark claims.
• Where it shows up first: Kilo is already promoting Trinity Large as usable “free in Kilo with no rate limits,” per the Kilo availability note, which is a quick path to hands-on testing even before most infra stacks publish turnkey recipes.
A public model card / exact hardware recipe isn’t included in the tweets, so treat scale/perf claims as incomplete until Arcee posts formal docs.
NVIDIA publishes Nemotron 3 Nano NVFP4 checkpoint aimed at Blackwell throughput
Nemotron 3 Nano NVFP4 (NVIDIA): NVIDIA’s Nemotron 3 Nano NVFP4 checkpoint is being pushed as a “deployable” quantized variant (weights + activations) for Blackwell-era inference, with community posts highlighting up to 4× higher throughput claims and “BF16-like” accuracy via quantization-aware distillation, as summarized in the NVFP4 performance claim and echoed by the vLLM support note.
The practical implication is simpler rollouts of 30B-class reasoning/agent models on newer GPUs with less VRAM pressure, assuming your serving stack supports the format.
• Serving surfaces: vLLM is already called out as supporting the checkpoint, per the vLLM support note, and the underlying checkpoint is published on Hugging Face as shown in the model card.
• Integration examples: SGLang shows a launch snippet for serving NVFP4 with its server runner in the SGLang launch snippet.
The tweets don’t include a standardized apples-to-apples eval artifact; the chart in accuracy comparison chart is the closest evidence included here.
Artificial Analysis benchmarks Qwen3-Max-Thinking and details pricing and deltas
Qwen3-Max-Thinking (Alibaba): Artificial Analysis reports a sizable jump for Qwen3-Max-Thinking—40 on its Intelligence Index (up 8 from Preview) with 256k context, while also flagging it as proprietary (no weights) and laying out tiered token pricing, as detailed in the benchmark breakdown and linked from the model page link.
The engineering-facing detail here is where the gains show up (instruction following + agentic loops) versus where it still trails peers (their “omniscience” metric), plus the cost profile for long-context workloads.
• Specific eval deltas called out: AA says HLE hits 26% (doubling vs Preview) and IFBench rises to 71%, per the benchmark breakdown.
• Agentic score: AA reports GDPval-AA ELO 1170, again in the benchmark breakdown.
The tweet includes a detailed pricing ladder (input/output rates change after 32k and 128k tokens); the canonical reference is the model page link.
DeepSeek-OCR 2 shows OmniDocBench v1.5 OverallEdit 0.100 in shared results
DeepSeek-OCR 2 (DeepSeek): Following up on day-0 support—learned reading order + vLLM support—the shared results now include an OmniDocBench v1.5 OverallEdit of 0.100, as shown in the benchmark table image.
The notable new detail is that the table also surfaces per-element edit distances (text/formula/table/reading-order), which is the kind of breakdown teams need when deciding whether to swap OCR stacks for forms, PDFs, and mixed-layout docs.
The tweet text also reiterates the core mechanism—DeepEncoder V2 using a “new reading order” stage—per the benchmark table image.
Tencent HY 3D 3.1 adds up to 8-view reconstruction for higher-fidelity 3D assets
HY 3D 3.1 (Tencent Hunyuan): Tencent is shipping HY 3D 3.1 on its global platform, positioning it as a jump in texture fidelity and geometry precision, plus support for up to 8 input views for reconstruction, as announced in the release post.
For AI product teams, this is directly about asset-pipeline capability: more consistent multi-view recon lowers the amount of manual cleanup for 3D content workflows.
• Access and quotas: Tencent says new creators get 20 free generations/day, and the API is available, according to the release post.
No benchmark suite is cited in the tweets; evaluation is mostly qualitative ("sculpt-level detail" claims) until external comparisons land.
✅ Quality gates: tests, CI repair, and review at agent speed
This bucket is about keeping outputs shippable: automated testing, CI-fixing loops, and scaling review when “infinite code” outpaces human diffs. Excludes benchmark leaderboards.
Lovable ships browser-driven E2E testing and on-the-spot fixes
Lovable (Lovable): Lovable says it’s now 71% better at complex tasks and is leaning harder into quality gates by having the agent open a real browser, run user flows, probe edge cases, and then patch issues it finds, as shown in the Product update demo and reinforced by the Automated testing clip.
• What changed in practice: Instead of stopping at “generated code,” the agent now validates behavior in-browser and loops until flows work, according to the Automated testing clip.
• Workflow impact: Lovable also added prompt queueing so long test/fix loops don’t block the human from adding next steps, as shown in the Prompt queueing demo.
Jules adds CI Fixer to auto-repair failing checks on agent PRs
Jules SWE Agent (Google): Jules shipped a beta CI Fixer option that automatically attempts to fix failing CI checks on PRs it creates and pushes follow-up commits, as shown in the CI Fixer in action.
• Why this matters: It turns “agent opened a PR” into “agent iterates until green,” shrinking the human review surface to judging the end result.
• Related surface area: The same update mentions new MCP integrations, but CI Fixer is the part that directly changes quality gates for agent-authored PRs, per the CI Fixer in action.
VibeTensor shows “no manual diff review” can still ship via tests
VibeTensor (NVIDIA research): NVIDIA’s VibeTensor paper describes a deep learning stack generated by LLM coding agents and validated primarily through automated builds, tests, and differential checks—explicitly avoiding per-change manual diff review, as summarized in the Paper thread.
• What’s concrete: The generated codebase spans 218 C++/CUDA files and 63,543 LOC, plus 225 Python test files and a large generated kernel suite, per the Paper thread.
• Why it’s relevant to quality gates: It’s a real example of “tests as the merge mechanism,” with performance and composition pitfalls documented (the “Frankenstein” effect), according to the Paper thread.
A local companion app turns agent diffs into a reviewable stream
Local code review companion (Benhylak): A prototype desktop workflow streams change summaries live as Claude Code works, quizzes the user about intent before committing, and finds bugs locally without pushing to GitHub, as shown in the Live review app demo.
• Quality gate angle: It’s treating “review” as an interactive, pre-commit step rather than a post-push PR ritual, per the Live review app demo.
• Distribution reality: It’s currently shared ad-hoc (“DM me”), which limits reproducibility but signals what people are building around agent output volume, as noted in the Access note.
As agent output scales, teams are treating tests as the review substrate
Scaling review limits (signal): A recurring claim is that “humans can not review at this scale,” pushing teams toward stronger automated verification rather than line-by-line diffs, as argued in the Infinite code comment.
• Why the claim is getting traction: Anecdotes like “100% of our code is written by Claude” and shipping dozens of PRs per day appear in the Canaries screenshot, making the “diff review doesn’t scale” concern concrete.
The open question is what the replacement stack looks like: more tests, more sandboxes, more automated PR checks, or all of them.
Cline Hooks turns security checks into a pre-write quality gate
Cline Hooks (Cline): Cline is pitching “hooks” that block insecure changes before they’re written—calling out patterns like SQL injection, hardcoded credentials, and debug mode in prod, as shown in the Hooks demo thumbnail and framed in the Architecture post screenshot.
This is pre-commit in spirit. It’s also pre-file-write.
A two-model loop splits fast iteration from final hardening
Two-model review loop (practice): A practitioner reports planning/implementing with Claude Opus 4.5 for speed, then running GPT‑5.2 Codex for a “/review” pass before shipping, as described in the Workflow note.
One fast pass. One strict pass.
Claude Code 2.1.23 surfaces PR status in-footer for tighter review loops
Claude Code 2.1.23 (Anthropic): Following up on CLI fixes (terminal and reliability work), Claude Code 2.1.23 adds a prompt-footer indicator for merged PRs and a footer view of active PR updates, as shown in the PR footer video and enumerated in the Changelog thread.
• Quality gate effect: It keeps PR state visible inside the agent loop (rather than the browser), which can shorten review/merge iteration when agents are making frequent PR updates.
• Operational detail: The PR footer feature expects GitHub CLI installed, per the PR footer video.
Conductor lets you read GitHub Actions logs without leaving the client
Conductor (charlieholtz): Conductor can now open GitHub Actions logs directly from the checks tab, reducing context switching during CI failures, as shown in the Actions log viewer screenshot.
This is a small UX change. It’s still a quality gate change.
Planner/implementer/reviewer separation shows planning as the bottleneck
Multi-agent coding roles (practice): A three-Claude setup splits responsibilities into planner, implementer, and reviewer, with git worktrees used instead of cloning repos to manage parallel workstreams, as described in the Three-agent setup.
The follow-on observation is that with enough agents, humans become the planning bottleneck, per the Planning bottleneck note.
📊 Benchmarks & arenas: rankings, rebrands, and new leaderboards
Evaluation chatter is heavy: Arena rebrand plus model rankings across video, image edit, and coding benchmarks. Excludes raw model-release claims unless tied to a third-party eval artifact.
Artificial Analysis Video Arena puts Grok Imagine #1 (text-to-video and image-to-video)
Grok Imagine Video (xAI): Artificial Analysis says Grok Imagine took #1 in both Text‑to‑Video and Image‑to‑Video on its Video Arena, and highlights pricing at $4.20/min including audio, as described in the Artificial Analysis ranking claim.

Arena’s own Video Arena placements appear different—its post lists #3 (Image‑to‑Video) and #4 (Text‑to‑Video), which likely reflects a different leaderboard and voting population than Artificial Analysis, per the Arena Video Arena placement. More context on the Artificial Analysis methodology sits on the Video arena page.
Arena launches Multi-Image Edit leaderboard; Nano-Banana 2K takes #1
Multi‑Image Edit leaderboard (Arena): Arena introduced a dedicated Multi‑Image Edit leaderboard (multi-input editing), and reports Nano‑Banana 2K as the top model on this task, as summarized in the Leaderboard announcement.
They also call out rank movements for other image editors (e.g., Flux 2 Flex jumping places, Seedream shifts) in that same update, with the full table linked via the Multi-image edit leaderboard.
LM Arena rebrands to Arena with refreshed mission and identity
Arena (formerly LM Arena): The evaluation community project LM Arena has rebranded to Arena, positioning itself as a shared space to “measure and advance the frontier of AI for real‑world use,” as stated in the Rebrand announcement.

The rebrand includes a new visual system and updated site UX, as shown in the New site UI.
• What changes for analysts: Naming shifts (“LMArena” → “Arena”) will affect citations, dashboards, and long-running eval references, per the Rebrand blog post.
• What stays the same: The underlying claim remains community-driven, real‑world prompting and preference data as an eval substrate, as reiterated in the Community meme reaction.
SimpleBench: Kimi K2.5 at 46.8% while DeepSeek V3.2 Speciale leads at 52.6%
SimpleBench (AiBattle): A SimpleBench snapshot puts Kimi K2.5 at 46.8%, while DeepSeek V3.2 Speciale remains the top open‑weights entry at 52.6%, as shown in the SimpleBench table.
This is one more datapoint that open-weight “top model” claims are benchmark‑specific: K2.5 can be near the top tier without being the leader on every suite.
VoxelBench leaderboard lists Kimi K2.5 as #1 open model
VoxelBench (leaderboard): Moonshot/Kimi shared a VoxelBench snapshot showing Kimi K2.5 (Thinking) as the #1 open model on that board, with surrounding entries including GPT‑5 and Gemini variants, as shown in the VoxelBench screenshot.
🏢 Enterprise adoption & platform deals (non-infra)
Enterprise signals today are partnerships and deployments of agentic systems into production workflows. Excludes the Chrome/Gemini browser story (feature) and excludes infrastructure capex deals (handled separately).
Factory partners with Wipro to roll out “Droids” across large engineering orgs
Factory (Wipro partnership): Factory says it’s partnering with Wipro to deploy its autonomous agents (“Droids”) across “hundreds of thousands of engineers,” both internally and into Wipro’s client ecosystem, per the partnership announcement.
The Partnership release adds operational detail: Wipro plans to integrate Factory into its WEGA delivery platform; the scope includes feature development, refactoring, migrations, and testing, and it frames this as a shift from “experimentation” to “production-scale adoption,” as stated in the partnership announcement.
Cognition partners with Cognizant to deploy Devin and Windsurf at services scale
Cognition (Cognizant rollout): Cognition is partnering with Cognizant to deploy Devin and Windsurf across Cognizant’s engineering org and client base, with Cognition embedding its own AI experts to support the rollout, as announced in the deployment post.
The Partnership blog clarifies the intended operational footprint: Windsurf is used for agent-assisted coding today, while Devin is being evaluated for autonomous execution across migrations, refactors, testing, and maintenance—positioning this as a systems-integrator distribution channel rather than a single-enterprise pilot.
Revolut adopts ElevenLabs Agents for multilingual support, citing 8× faster resolution
ElevenLabs Agents (Revolut): ElevenLabs says Revolut is using its conversational agents for customer support across 30+ languages, reporting more than 8× reduction in time to ticket resolution in the Revolut deployment post.

The Case study frames this as voice support at scale (multilingual routing + automation) rather than a demo integration, but the tweets don’t include breakouts by channel (voice vs chat) or the baseline workflow definition—so the 8× figure should be read as vendor-reported until Revolut publishes its own metrics.
Genspark launches in Japan with local office and cited enterprise productivity deltas
Genspark (Japan expansion): Genspark says it’s launching officially in Japan with a local office and team (marketing/GTM/customer success/support) and “strategic partnerships,” including SourceNext, according to the launch announcement. It also cites early enterprise outcomes—70% research-time reduction (Human Holdings), 90% meeting-prep reduction (PartnerProp), and 2.5× productivity gains (ADK Marketing Solutions) in the same launch announcement.
A separate post promotes “Workspace 2.0” tied to the Japan event in the live event post, but the tweets don’t specify whether the cited outcomes come from the 2.0 product or earlier deployments.
Mistral spotlights production deployments with ASML, CMA CGM, Mars Petcare, Stellantis
Mistral (enterprise deployments): Mistral is leaning into “frontier AI systems in production” positioning, pointing to deployments spanning silicon lithography, maritime logistics, and consumer brands in the production deployments post, with the referenced Customer stories listing outcomes and use cases across multiple industries.
The practical signal is less about a new model and more about procurement readiness: Mistral is emphasizing “in-prod” references (ASML/CMA CGM/Mars/Stellantis) that enterprise buyers ask for before rolling out agentic systems at scale, as echoed in the customer stories link.
Early Prism feedback flags UI friction: unclear progress and cancellations
Prism (OpenAI) user feedback: An early tester reports Prism is “a lot of what I want it to be,” but complains the UI gives poor visibility into background work (“no way to know it’s doing something”) and that chat interactions feel “clunky,” with cancelling “randomly,” per the hands-on critique.
This is a product-surface signal rather than a model-quality one: the complaint is about interaction design under latency (progress indicators, interruptibility, and determinism of edits), which becomes a blocker when teams try to use an AI co-editor in longer writing/compile loops.
📚 Retrieval & RAG building blocks (embeddings, vector stacks)
A quieter but high-signal slice: new open embeddings and RAG infra case studies. Excludes browsing connectors (handled in orchestration-mcp).
VoyageAI opens up voyage-4-nano embeddings for retrieval (32k, matryoshka, QAT)
voyage-4-nano (VoyageAI): VoyageAI released its first open-weights embedding model for retrieval—voyage-4-nano—framed as multilingual and efficiency-oriented in the release thread; it supports 32k max sequence length per the 32k context note and is published on Hugging Face as shown in the model card.
• Embedding + deployment details: The thread calls out 340M parameters and matryoshka embeddings (2048/1024/512/256 dims) in the model sizing note, plus quantization-aware training enabling fp32/int8/binary retrieval workflows in the QAT and binary note.
• Practical integration: It’s already wired into Sentence Transformers + Transformers—using trust_remote_code=True—as described in the integration note, and Voyage claims the Voyage-4 family shares a common embedding space (mix-and-match between models) in the shared embedding space note.
Treat benchmark positioning as still emergent—one caveat raised is limited head-to-head leaderboard coverage so far in the benchmark caveat.
predori claims 80%+ semantic search cost reduction after moving to Weaviate Cloud
Weaviate Cloud (Weaviate): Patent-intelligence company predori reports 80%+ cost reduction after migrating off a Lucene-based AWS setup to Weaviate Cloud, describing the prior system as “super expensive and just not good,” as summarized in the migration results thread and detailed in the linked case study.
• What the migration unlocked: The same thread frames the payoff as freeing engineering time for iteration and “advanced agentic RAG systems,” with the “vector DB squeezed into not-a-vector-DB” quote captured in the migration results thread.
The post is a vendor-authored case study, so the strongest evidence here is the single quantified claim (80%+) rather than an independently verifiable benchmark artifact.
🛡️ Safety & misuse: disempowerment, voice cloning, and agent security hygiene
Safety news today is about real-world user harm patterns and new high-risk capabilities (voice cloning), plus ecosystem efforts to scan skills for prompt injection and dual-use content. Excludes general workforce commentary.
Anthropic maps “disempowerment” failure modes in real assistant usage
Disempowerment patterns (Anthropic): Anthropic published an analysis of 1.5M Claude conversations, arguing that assistant interactions can be disempowering by distorting beliefs, shifting value judgments, or misaligning actions with a user’s values, as outlined in the Research announcement and expanded in the Research post. Severe cases were described as rare—roughly 1 in 1,000 to 1 in 10,000 depending on domain—based on Anthropic’s measurement approach in the Rate estimate.
• Where it happens: The highest-risk areas were relationships/lifestyle and health/wellness, while technical domains like software development (noted as ~40% of usage) were described as low risk in the Domain breakdown.
• Why it’s hard to catch with thumbs-up signals: Anthropic reports that users rate potentially disempowering conversations more positively “in the moment,” but satisfaction drops after acting on them, per the Feedback finding.
• User participation: The paper emphasizes disempowerment isn’t only model behavior—users often ask “what should I do?” and accept outputs with minimal pushback, as described in the User behavior note.
The paper is also available as an arXiv preprint, linked in the ArXiv paper.
Google AI Studio surfaces early “voice cloning” UI for Gemini
Voice cloning (Google AI Studio / Gemini): A “Create Your Voice” flow was spotted in Google AI Studio that appears to let users record/upload their own voice for cloning, as shown in the UI leak clip.

• What it’s being linked to: The report frames this as potentially ahead of a “Gemini 3 Flash Native Audio” upgrade, with more detail in the Report on voice cloning.
• Why it matters operationally: If shipped broadly, this is a step-change in impersonation and consent risk compared to generic TTS; the tweets do not indicate what access controls, verification, or watermarking policies would accompany it.
The feature appears to be in testing; timeline and availability are not confirmed in the tweets.
Amodei pushes transparency-first safety norms and a chip “security buffer”
AI policy asks (Anthropic / Dario Amodei): A clip summarizes Amodei’s priorities as (1) “radical transparency” (publish safety tests and disclose capability/risk), (2) a chip supply-chain “security buffer” to slow adversaries, and (3) preparation for economic transition where wealth shifts from labor to capital, as stated in the Policy clip.

The tweets frame this as an attempt to normalize public reporting of safety evaluations so firms learn from each other rather than treating safety findings as competitive IP; the clip does not include concrete implementation details (reporting format, enforcement, or thresholds).
Playbooks adds automated security evals for agent skills files
Playbooks Skills directory: Playbooks launched a skills directory/CLI aimed at being “the place to get markdown context for your agents,” with community voting plus automated checks that evaluate SKILL.md content for prompt-injection and safety signals, as described in the Launch thread and the Skills directory.
• Dual-use classification: One example shows a skill flagged “potentially unsafe” because it includes actionable privilege-escalation techniques (Linux/Windows), with the exact risk rationale shown in the Risk flag example.
• Canonicalization + signal control: The directory claims it detects duplicates and prioritizes “official sources,” per the Launch thread.
This is a direct response to “skills as packages” dynamics: once teams start installing skills at scale, the attack surface shifts from model prompts to prompt supply chain.
A “verifiable chip destruction” idea for US–China AI slowdowns circulates
Compute control proposal: Ryan Greenblatt suggests an enforceable US–China agreement could be structured around each side destroying a fraction of chips once AI capability reaches certain thresholds—arguing that “destroyed” is easier to verify than “chips used only for X,” as proposed in the Chip destruction idea and clarified in the Verification tradeoff.
This is presented as a second-best option versus a broader deal that allows productive compute uses; the tweets don’t specify what capability metric would trigger destruction or how much compute would be removed.
🧪 Training & reasoning: continual learning, RL stability, tool-use learning
Mostly research/technical threads on post-training, continual learning, and tool-use optimization—useful for teams experimenting beyond vanilla SFT. Excludes bioscience content entirely.
SDFT proposes on-policy self-distillation to reduce catastrophic forgetting
Self-Distillation Fine-Tuning (MIT/ETH/Improbable AI Lab): A new continual learning method, SDFT, claims it can learn new skills while largely preserving old ones by using a demonstration-conditioned model as its own teacher; one cited result is knowledge acquisition accuracy rising 80% → 89% with reduced catastrophic forgetting, as described in the [paper post](t:196|Paper summary).
• What’s technically notable: The thread frames SDFT as “on-policy” learning that improves on standard SFT’s forgetting behavior, with side-by-side curves and tradeoff plots shown in the [figure screenshots](t:155|SDFT figures).
MiniMax says CISPO is more stable than GRPO in its reproductions
CISPO (MiniMax): MiniMax says it chose CISPO over GRPO/GSPO mainly for empirical stability; they report GRPO was unreliable in their R1-Zero reproduction attempts because PPO-style clipping led token-level gradients to vanish, as explained in the [RL algorithm Q&A](t:109|RL algorithm rationale).
• MoE compatibility: They claim CISPO behaves similarly on MoE vs dense models, while noting MoE routers add RL-training considerations and referencing fixed-routing approaches like R3 as a lower-level stability tactic, per the same [RL algorithm Q&A](t:109|MoE and routing note).
AdaReasoner trains models to sequence tools for iterative visual reasoning
AdaReasoner (arXiv): A new research proposal argues that multimodal models should learn tool use as a general reasoning skill—selecting and sequencing tools over long horizons—using a curated multi-step tool-interaction dataset pipeline and an RL method called Tool-GRPO, according to the [paper summary](t:291|AdaReasoner overview).
Visual generation is framed as a world-model primitive for physical reasoning
Multimodal world models (arXiv): A paper argues that for tasks requiring physical/spatial intelligence, visual generation inside unified multimodal models can serve as a stronger internal world model than verbal-only reasoning (“visual superiority hypothesis”), as summarized in the [paper page](t:256|World-models paper).
Hassabis: future AI needs continual learning, deeper reasoning, and novelty
Continual learning (Demis Hassabis / DeepMind): Hassabis argues future systems should adapt over time like humans (continual learning rather than repeated full retrains) and that deeper reasoning plus “innovative thinking” are prerequisites for open-ended usefulness, as stated in the [interview clip](t:63|Continual learning remarks).

🏗️ AI infra economics: spend, profitability, and private inference
Infrastructure talk is about the money: model profitability accounting, capex expansion, and new ‘private SaaS’ inference offerings. Excludes pure funding-round gossip unless tied to concrete terms.
GPT-5 unit economics: positive gross margin, negative after ops + rev share
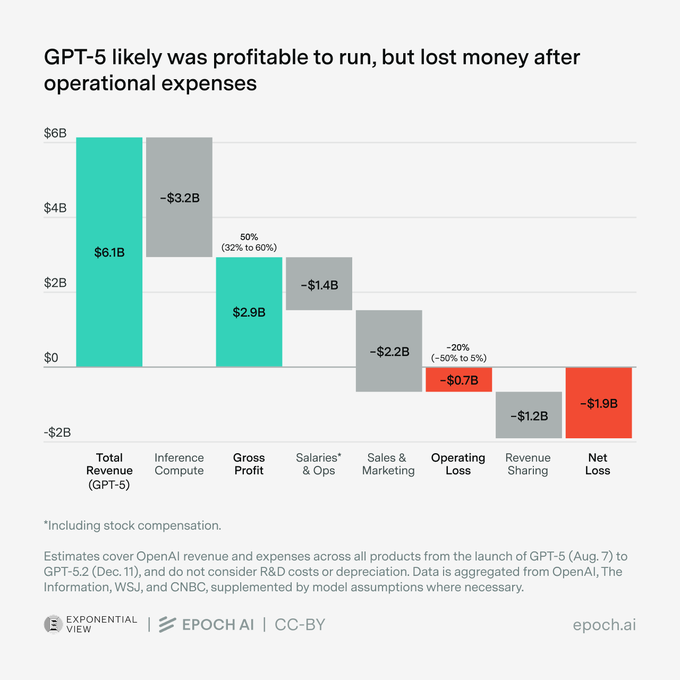
GPT-5 (OpenAI) unit economics (Epoch AI): A new cost waterfall estimates GPT-5 had roughly 45–50% gross margin (about $6.1B revenue vs $3.2B inference compute), but likely swung to an operating loss of ~$0.7B after salaries/ops and sales & marketing, and a net loss of ~$1.9B after revenue sharing, as shown in the Waterfall chart analysis.
• What’s actually being measured: The estimate is framed as profitability “to run” (compute vs revenue) vs full operating profitability (ops + S&M + rev share), per the Waterfall chart notes.
• R&D payback gap: A separate chart argues gross profits (~$2.9B) still didn’t cover the four months of pre-launch R&D spend (data + salaries + compute), as shown in the R&D vs gross profit chart.
These figures are directional (compiled from multiple reported sources), but the key takeaway is the accounting split: inference can look profitable while the business is not.
ARK: data-center capex near $500B in 2025; ~$600B expected in 2026
Data center capex (ARK Invest): ARK-reported figures cite ~$500B spent on compute/networking/storage in 2025 (up 47% YoY) and project ~$600B in 2026 (another ~20%), as summarized in the Capex jump claim.
The chart reframes current AI infra buildout as back near late-1990s-style intensity (capex as % of GDP), which is the operational signal infra teams tend to watch more than model benchmark deltas.
Cohere launches Model Vault for single-tenant managed inference
Model Vault (Cohere): Cohere is described as launching Model Vault, a managed inference offering framed around single-tenancy (dedicated environment) with SaaS-style scaling and uptime, per the Launch mention and the Product summary thread.
The tweets don’t include pricing tables or deployment limits, but the positioning is explicit: “privacy of self-hosting” without running your own GPU fleet.
Meta signs up to $6B Corning fiber deal through 2030 for AI data centers
Fiber interconnect (Meta × Corning): Meta is reported to commit up to $6B through 2030 for Corning fiber-optic cable used in AI data centers, tied to a buildout described as 30 U.S. data centers including multi‑GW sites, per the Deal screenshot.
This lands as a “non-GPU bottleneck” spend signal: scaling training/inference clusters increasingly depends on optical networking supply, not just accelerators.
SoftBank talks for up to $30B more into OpenAI, as part of a $100B round
OpenAI financing (SoftBank): Following up on SoftBank talks (up to $30B more and ~$830B valuation), today’s thread adds that the broader round could total $100B, with SoftBank’s portion reportedly up to $30B, per the Funding rumor screenshot.
The post is directionally consistent with the earlier reporting but adds the round size detail; no term sheet or confirmed participants are shown in the tweets.
🧑💻 Developer work shift: supervision, job signals, and adoption narratives
The discourse itself is the news: engineers reporting near-100% AI-written code, management-as-bottleneck framing, and early labor-market evidence. Excludes pure product announcements.
Canary claims: “100% of code” is now AI-written for some teams
AI-assisted programming adoption: Ethan Mollick amplifies two highly-cited “canary” anecdotes where builders claim they no longer hand-write code—one OpenAI engineer says “100%” of their coding is done by OpenAI models in the canary screenshot, and Anthropic’s Claude Code lead claims “Pretty much 100% of our code is written by Claude Code + Opus 4.5” while shipping dozens of PRs/day in the same canary screenshot.
• Why it matters operationally: the anecdotes describe a role shift from authoring to supervising (shipping via CLI/mobile/Slack), suggesting review/verification throughput—not typing—becomes the limiting factor, per the canary screenshot framing.
Treat this as directional: it’s self-reported, and the tweets don’t include independent instrumentation or repo-level audit artifacts.
Amodei: engineers are shifting from writing code to supervising it
Claude (Anthropic): Dario Amodei’s framing is that the internal “spark” was watching engineers stop writing code and start supervising Claude-written code—some of which contributes to building the next model, tightening a self-improvement feedback loop, as described in the Amodei clip and echoed in the loop paraphrase.

• Loop timing claims: a circulated excerpt asserts the feedback loop “may be only 1–2 years away” from the current generation autonomously building the next, per the excerpt screenshot; it’s a quote without accompanying internal metrics in the tweets.
This sits at the intersection of org practice (dogfooding) and capability acceleration, but the evidence here is narrative rather than measured telemetry.
Mollick highlights new evidence of AI impacting jobs via “expertise devaluation”
AI labor-market evidence: Mollick points to a paper using international data arguing AI is already affecting the job market, with the clearest signal in domains where AI lowers the value of expertise, per the paper note.
The tweet doesn’t name the paper or provide a link in-line, so the specific methodology and effect sizes can’t be audited from today’s thread alone.
Altman reiterates a steep cost curve for building software with AI
AI productivity economics: Sam Altman claims software that used to take teams a year could be achievable for under $1,000 by the end of this year, as stated in the Altman cost clip.

This is a strong adoption narrative about labor leverage and tooling, but the tweets don’t specify what’s included in the $1,000 (inference, human time, evals, deployment, maintenance) or what classes of software it refers to.
Mollick argues “AI is fake” denialism blocks useful policy debate
AI discourse: Mollick argues many “AI is hype/fake” critics respond well to non-judgmental demos of how systems work, while “big critics” who claim AI is fake give cover for groups to ignore AI instead of shaping its use through policy and social processes, as stated in the informed critics take and reiterated in the follow-up note.
The implied operational concern is that governance discussions degrade when capability arguments are treated as settled propaganda battles rather than engineering tradeoffs.
The “prompt engineer → vibe coder → unemployed” meme spreads again
AI work-culture signal: a widely reshared meme compresses job-displacement anxiety into a four-step timeline—“2024: Prompt Engineer / 2025: Vibe Coder / 2026: Master of AI agents / 2027: Unemployed,” as shown in the meme video.
It’s not data, but it’s a fast-moving shorthand for how many engineers perceive the pace of role change and deskilling risk.
A viral claim predicts physicist displacement within 2–3 years
AI-for-science job anxiety: a tweet relays an unverified claim that an Anthropic figure (“Karplan”) put “a 50% [chance] that in 2–3 years physicists will be replaced by AI,” in the replacement claim.
No primary source, transcript, or supporting analysis is included in the tweets, so this should be read as sentiment propagation rather than an evidentiary forecast.
🎨 Generative media (image/video/3D): controllability + toolchain integrations
Creative tooling remains high volume: camera control, image editing leaderboards, and new model/tool integrations into creator stacks (fal, ComfyUI, Replicate). Excludes Gemini-in-Chrome creative features (feature).
Grok Imagine video leaderboard results diverge across arenas
Grok Imagine Video (xAI): Artificial Analysis claims Grok Imagine takes #1 on both text-to-video and image-to-video, priced at $4.20/min including audio, as stated in the Artificial Analysis ranking; Arena’s Video Arena places Grok‑Imagine‑Video at #3 (image-to-video) and #4 (text-to-video) in the Arena placement, suggesting different eval sets and/or model variants.
The tweets also converge on product shape: native audio support and short clips (up to 15s) are repeatedly cited, but the exact “top” position depends on which arena you trust.
Tencent HY 3D 3.1 raises reconstruction fidelity and supports 8 views
Tencent HY 3D 3.1 (Tencent Hunyuan): Tencent announced HY 3D 3.1 on its global platform with a “massive leap” in texture/geometry quality and support for up to 8 input views, plus 20 free generations daily for new creators, per the platform update.
This is a concrete knob for image-to-3D pipelines: more views for higher-fidelity reconstruction, with an explicit free-usage tier called out.
Arena adds a Multi‑Image Edit leaderboard for harder edit workflows
Multi‑image editing (Arena): Arena introduced a dedicated Multi‑Image Edit leaderboard and reports Nano‑Banana 2K at #1 ahead of “ChatGPT Image,” alongside notable reshuffles (e.g., Flux 2 Flex moving up, Seedream 4 2K moving down) in the leaderboard announcement, with the board linked from the Leaderboard page.
This matters specifically for production edit pipelines where consistency across multiple references is the constraint, not single-image aesthetics.
Comfy Cloud raises queue limit to 100 jobs
Comfy Cloud (ComfyUI): Comfy Cloud now lets users queue up to 100 jobs at a time (still executing one-by-one), per the queue limit post.
This is a small UI/ops change, but it’s directly about keeping generation pipelines moving without constant manual re-submission.
Replicate ships FLUX.2 [klein] LoRA inference (9B and 4B bases)
FLUX.2 [klein] LoRA inference (Replicate): Replicate says FLUX.2 [klein] now supports custom LoRA adapters for both 9B and 4B base variants, positioning it for text-to-image, editing, and multi-reference consistency in the Replicate update, with the 9B LoRA target linked in the 9B model page.
The post is about adapter plumbing (bringing your own LoRA), not a new base model release.
Wan 2.2 Animate Replace cuts runtime below two minutes on Replicate
Wan 2.2 Animate Replace (Replicate): Replicate claims a runtime improvement from ~7 minutes to under 2 minutes for Animate Replace, as stated in the runtime update.

The tweet frames this as an execution-time change (pipeline efficiency) rather than a quality-model update.
fal adds Hunyuan Image 3.0 Instruct endpoints
Hunyuan Image 3.0 Instruct (fal): fal says HunyuanImage 3.0 Instruct is live with chain-of-thought style “thinks before generating” positioning and image editing support in the fal launch, with access paths shared via the API links (see Text-to-image endpoint and Image edit endpoint).
The tweets frame it as an “intent alignment”/multi-source blending model; there are no latency/cost numbers provided here.
fal launches Z‑Image base LoRA training
Z‑Image base trainer (fal): fal introduced a trainer for LoRAs on the full, non‑distilled Z‑Image base model, emphasizing customization and generation diversity in the trainer announcement, with the training entry point in the Training page.
This is specifically a “bring your own style/model adaptation” knob, distinct from just hosting inference endpoints.
Sora UI exposes 1–3 parallel video generations
Sora (OpenAI): a surfaced UI control shows Sora can generate 1, 2, or 3 videos from a single request, based on the settings menu captured in the UI screenshot.
This is a UI-level concurrency knob; the tweets don’t include any mention of pricing or rate-limit behavior changes.
A small signal that 3d-arena comparisons are active again
3d‑arena (Hugging Face): a brief community note says “3d‑arena is so back” and frames it as a place to compare cutting‑edge 3D object generators in the short mention.
There’s no accompanying eval artifact in the tweets here, but it’s a directional signal that 3D generation benchmarking/UI is getting re‑activated.
📅 Meetups, AMAs, hackathons: where builders are comparing agents
Today includes multiple builder-facing events (AMAs, office hours, meetups) that shape tool adoption and best-practice diffusion. Keep this limited to real events (not product marketing).
Kimi K2.5 team hosts a time-boxed AMA on r/LocalLLaMA
Kimi K2.5 (Moonshot AI): The Kimi K2.5 team scheduled an “Ask Me Anything” on r/LocalLLaMA for Jan 28, 2026 (8AM–11AM PST), positioned as a builder-facing channel to ask about deployment, agentic coding, and multimodal usage, as shown in the AMA promo graphic and reiterated in the AMA announcement.
This is one of the few venues in today’s feed where model questions (pricing, hosting, tooling quirks) can be answered in public by the team rather than via benchmark threads.
AI Vibe Check in SF moves to Convex HQ
AI Vibe Check (community meetup): The SF “AI Vibe Check” meetup moved to Convex HQ with “room for 50+,” focusing on configs/workflows/best practices for running agent tools, as stated in the venue upgrade note and on the event page.
This is positioned as a practitioner-heavy session (“configs, workflows, best practices”) rather than a product launch, and it’s explicitly framed around comparing real setups across tools (Moltbot/Claude Code/Codex-style workflows), per the event description.
vLLM publishes a consolidated events calendar for SIGs and Office Hours
vLLM (vLLM project): vLLM says its website Events page is now synced with multiple SIG meetings (Multimodal, Omni, AMD, torch-compile, CI) and highlights logistics for Office Hours and upcoming meetings in the events announcement, with the calendar visible on the events announcement and referenced via the events page.
For teams building on vLLM, this consolidates “where to show up” for roadmap and performance discussions into a single public schedule.
Weights & Biases runs WeaveHacks 3 focused on self-improving agents
WeaveHacks 3 (Weights & Biases): Weights & Biases describes WeaveHacks 3 as a 3-day in-person SF hackathon centered on “self-improving agents,” with a judge callout included in the hackathon announcement and “happening now” framing echoed in the live show lineup mention.
Teams attending are likely to trade practical patterns for eval-driven agent iteration (instrumentation, feedback loops, and harness design), but the tweets don’t include published rules or a public repo for submissions yet.
OpenAI teases a Codex Berlin meetup
Codex (OpenAI): OpenAI promo materials show a “Codex Berlin Meetup” graphic and related meetup context in the Codex meetup promo, alongside event-table setup shots in the Codex meetup promo.
No agenda details are included in the tweets, but the existence of an in-person meetup is a concrete signal that CLI-based agent workflows have an active local community forming around them.
🤖 Robotics & embodied AI: dexterity demos and scaling data
Robotics posts are mostly capability demos and scaling claims (hands, rehab, robot-data scaling). Excludes anything bioscience-related.
Figure 03 shows bimanual dexterity on fine-motor tasks
Figure 03 (Figure): A new demo shows autonomous two-handed manipulation guided by tactile sensors and palm-mounted cameras, including unscrewing a bottle cap, picking a pill from a cluttered box, dispensing exactly 5ml from a syringe, and sorting small metal pieces, as shown in the dexterity task list.

This is a capability signal for teams tracking whether manipulation is moving from single-skill demos toward reusable “household-ish” primitives (grasp, stabilize, align, dispense) with multi-sensor feedback loops.
LingBot-VLA reports no saturation up to 20k hours of real robot data
LingBot-VLA (Robbyant/Ant Group): A new VLA foundation model report claims training on ~20,000 hours of real-world manipulation data across 9 dual-arm robot configurations improves downstream success rates as data scales from ~3,000→20,000 hours “with no signs of saturation,” along with benchmark results on GM-100 (100 tasks, 22,500 evaluation trials) and RoboTwin 2.0 sim performance, as summarized in the paper thread.
The paper positions data scale as the main knob for VLA progress (and highlights throughput engineering—261 samples/sec/GPU on 8 GPUs—as part of making that scaling practical), per the same paper thread.
Helix 02 demo adds non-hand body control in the kitchen
Helix 02 (Figure): Following up on Full-body autonomy (whole-body household task framing), a new short clip shows the robot closing a drawer using its hip and lifting a dishwasher door using its foot, as captured in the kitchen demo.

This is a small but concrete datapoint that control policies are being pushed beyond “hands only” interaction into full-body contact planning around everyday fixtures.
Neuralink reports 21 Telepathy trial participants and up to 40 WPM typing
Neuralink Telepathy (Neuralink): A summary update cites 21 participants in clinical trials and reports thought-controlled computing and robotic arm use, with typing speeds up to ~40 words per minute; details are described in the trial summary and linked to the official Neuralink update via Neuralink update post.

This is a notable longitudinal signal for BCI-to-computer-control stability and throughput, with the thread emphasizing performance only holds when signals remain stable, per the same trial summary.
Fourier Robots shows BCI-guided rehab robot responding to intent
Fourier Robots (Fourier): A demo shows a brain-computer interface detecting a patient’s intended motion and using a robot to guide rehabilitation movements, framed against the broader constraint that BCI and robotics still lack large-scale datasets, as described in the BCI rehab demo.

The takeaway for embodied AI teams is less about the specific hardware and more about intent-to-action supervision as a data-generation path for rehab/control loops.
Fauna Robotics unveils Sprout, a small humanoid aimed at indoor settings
Sprout (Fauna Robotics): Fauna Robotics unveiled “Sprout,” described as a ~3.5‑ft tall humanoid platform built for everyday indoor environments (homes, classrooms, care facilities) with soft-touch materials and quiet motion, as shown in the product demo.

The positioning is “developer-ready” deployment in human spaces rather than factory floors, but no workload benchmarks or autonomy stack details are included in the clip thread itself, per the same product demo.