Genie 3 hits 24fps at 720p – ~60s sessions for $249.99 Ultra
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Google DeepMind pushed Project Genie (Genie 3) into public hands via Google Labs; access is gated to Google AI Ultra in the U.S. (18+); creation flow is now explicit: text+optional image prompt → Nano Banana Pro preview/edit checkpoint → real-time navigable world generation. Early clips converge on runtime constraints—live 24fps at 720p, with ~60-second session caps—telegraphing high per-run inference cost; rollout friction shows up immediately (broken/404 paths), while hands-ons surface failure modes like third-person “loses the character,” stuck states, terrain clipping, and prompt edits that delete prior elements. A Fortnite-looking output clip is circulating; it’s being read as leakage by some, but there’s no independent dataset accounting.
• OpenAI Codex: web search flips to default-on (cached); --yolo/web_search="live" forces live results; fixes the “cutoff docs” complaint but doesn’t solve clunky research handoffs.
• ARC Prize: ARC-AGI-3 Toolkit ships local ~2,000 FPS environments; three official public games posted with current AI scores <5%.
• Ollama exposure: 175,108 publicly reachable servers reported; ~48% advertise tool-calling, expanding risk beyond free inference.
Net: “interactive world models” are arriving as productized demos with hard caps and soft brittleness; evaluation still looks like clips and vibes until longer-horizon, reproducible harnesses land.
Top links today
- Project Genie and Genie 3 overview
- AlphaGenome paper in Nature
- AlphaGenome model weights on GitHub
- Qwen3-ASR and ForcedAligner repository
- Qwen3-ASR models on Hugging Face
- Qwen3-ASR models on ModelScope
- Anthropic study on AI and learning
- Agent Trace open standard specification
- OpenAI in-house AI data agent writeup
- OpenRouter GPT-5.2 usage insights
- Amazon Insight Agents paper
- Ai2 Theorizer: papers to scientific laws
- Reuters: exposed public Ollama servers study
- ARC-AGI-3 toolkit for agent environments
- Daggr workflow library repository
Feature Spotlight
Genie 3 / Project Genie: real-time world model goes public (Ultra US)
DeepMind’s Genie 3 reaches users via Project Genie: real-time, prompt-driven interactive worlds. For builders, it’s a new runtime for simulation/gameplay/embodied training with huge inference-cost and control implications.
High-volume rollout and hands-on clips of Google DeepMind’s Project Genie (powered by Genie 3): promptable characters + environments with real-time navigation. This category is the day’s feature because it dominated cross-account discussion.
Jump to Genie 3 / Project Genie: real-time world model goes public (Ultra US) topicsTable of Contents
🧞 Genie 3 / Project Genie: real-time world model goes public (Ultra US)
High-volume rollout and hands-on clips of Google DeepMind’s Project Genie (powered by Genie 3): promptable characters + environments with real-time navigation. This category is the day’s feature because it dominated cross-account discussion.
Project Genie rolls out to Google AI Ultra subscribers in the U.S.
Project Genie (Google DeepMind): Google is rolling out Project Genie—a Labs prototype powered by Genie 3—to Google AI Ultra subscribers in the U.S. (18+), focused on creating, exploring, and remixing interactive worlds, as stated in the rollout post and echoed in the availability note.

• Where it lives: Access is positioned as a Labs experiment with a direct entrypoint, as shown in the try link.
• What it’s for: DeepMind frames it explicitly as a research prototype to learn about immersive experiences and world-model interaction design, per the Google blog post.
Access appears intentionally narrow (Ultra + US), and some users are already hitting rough edges like broken/404 paths during early rollout, as shown in the 404 screenshot.
Genie 3’s prompt-to-world pipeline couples Nano Banana Pro with real-time generation
Genie 3 (Google DeepMind): The product flow is now explicit: you describe an environment + character using text (and optionally a starting image), get a Nano Banana Pro preview you can adjust, then Genie 3 generates the world in real time as you move through it, as laid out in the how it works thread and repeated in the rollout post.

This “preview first, then interactive world” structure is important operationally because it creates a natural checkpoint for human control before entering the live simulation loop, matching the three-step framing shown in the community walkthrough.
Genie 3 early constraints: 24fps 720p real-time, with short generation windows
Genie 3 (Google DeepMind): Early hands-on posts converge on two concrete constraints: it runs as live, interactive video at 24fps and 720p, and sessions appear capped (multiple reports mention ~60 seconds), suggesting very high inference cost per run, as described in the fps and resolution note and called out in the limits observation.

• Latency + horizon framing: Community-shared spec comparisons summarize Genie 3 as real-time with “multiple minutes” interaction horizon, while still being bounded by product limits, as shown in the spec table.
A separate first-person review also reports errors, clipping, and non-moving worlds alongside the “real-time world model” novelty, as written in the hands-on review.
Genie 3 early failures include off-target outputs and losing the main character
Genie 3 (Google DeepMind): Early experimentation is also surfacing brittle behaviors: one report shows the system outputting something that looks like Fortnite gameplay, raising questions about dataset leakage vs. misclassification, as shown in the Fortnite-looking clip.

A separate hands-on thread reports third-person runs that “fail to connect what the central character is” and can get stuck in corners, as described in the stuck state clip.

These failures are consistent with other notes about errors, clipping through terrain, and prompt-to-prompt edits deleting prior elements, as written in the hands-on review.
“Can Genie 3 run Doom?” reframes world models as engine-less games
Genie 3 (Google DeepMind): The “run Doom” framing is back as a shorthand for world-model interactivity—each frame is generated by the model conditioned on inputs and history rather than a traditional engine, as explained in the Doom framing clip.

This is less about Doom specifically and more about the evaluation question: how long can a model keep consistent rules, geometry, and affordances under interactive control.
Genie controllability improves with game-like starting images and highlighted subjects
Prompting technique: Users report more controllable characters/objects when they start from a strong, game-like image and explicitly highlight the subject (often via Nano Banana), with some annotations carrying into the generated world, as described in the controllability tips and reinforced by offers to run generations that stress “clear subject” and “third person works best,” per the prompting guidance.

This is mainly a workflow lever: if the initial frame grounds the “thing you control,” the rest of the real-time rollout tends to stay more coherent than text-only starts.
Project Genie access is Ultra-only in the U.S., and rollout friction shows up fast
Project Genie (Google DeepMind): Availability is constrained to Google AI Ultra subscribers in the U.S. (18+), which is leading to predictable “Ultra-only” chatter and some early-access friction, as shown in the access requirement card and the 404 screenshot.
The Ultra packaging itself is being discussed as a solo-builder bundle with a ~$249.99/month tier, as summarized in the plan breakdown, and some posts attribute lower-than-expected mainstream buzz to the paywall/region gating, per the buzz question.
Genie 3 shows strong tolerance for unusual characters and viewpoints
Genie 3 (Google DeepMind): Multiple credible users are stress-testing prompt robustness with nonstandard characters and “perspective” prompts—e.g., an “otter airline pilot with a duck on its head” and an otter wingsuiting through gothic towers, as shown in the early access demo, plus unusual POV worlds like “Hamlet… from the perspective of the poison,” per the Hamlet world demo.

A separate example highlights a “flying cat… over a downtown city” and frames it as adaptive to unusual subjects, as shown in the flying cat clip.
Genie can auto-follow tracks if the starting image contains a clear path
Control behavior: If the starting image includes an obvious path (rollercoaster/track), Genie can follow it with minimal additional steering, according to the track-following demo.

This is a concrete “cheap control” trick: encode navigation constraints visually instead of trying to describe them with text instructions.
Genie 3 sometimes “respawns” after you fall off the map
World behavior: In at least one example, walking off a bridge into the void triggered an unexpected respawn into a new area rather than ending the run, as shown in the respawn clip.

This matters for simulation/agent testing because it hints at a built-in continuation heuristic (keep the experience going) that could interact strangely with evaluation harnesses that expect explicit terminal states.
🧰 OpenAI Codex: web search defaults + CLI knobs
Continues the Codex momentum with concrete workflow changes: web search is enabled by default in the Codex CLI/IDE extension, plus new config toggles and community wrappers. Excludes any Genie 3 content (covered in the feature).
Codex CLI and IDE extension turn on web search by default, with cache-first behavior
Codex CLI + IDE extension (OpenAI): Web search is now enabled by default, with results coming from a web-search cache unless you switch to live; live results can be toggled on, and --yolo enables live by default, as described in the Web search default and documented in the Codex changelog.

• Practical impact: This changes the “LLM cutoff date” failure mode for frameworks and libraries; Codex can pull fresher docs without you manually pasting URLs or snippets, which is the main workflow win implied by the default-on choice in the Web search default.
Builders keep framing GPT‑5.2 Codex as “close to Opus” but cheaper and faster
GPT‑5.2 Codex (OpenAI): Several builders are drawing a speed/cost tradeoff line versus Claude Opus—“maybe Opus is a bit smarter” but “so fast and so cheap” in the Speed vs Opus framing—and are using Codex for longer, heavier coding tasks like generating full documentation sets in minutes, as shown in Docs generation example.

• Reliability claim: In agent-heavy workflows, Codex is being described as more dependable on large codebases (“almost no mistakes”) in the Codex reliability take, which helps explain why people tolerate lower “personality” in exchange for fewer correction loops.
Codex CLI’s fastest way to de-stale: `--yolo` or `web_search = "live"`
Codex CLI (OpenAI): Live web results can be forced either by starting Codex with --yolo or by setting web_search = "live" in ~/.codex/config.toml, per the concrete how-to in Config instructions.
Workflow note: The same thread explicitly frames web search as a fix for “outdated framework data” caused by model cutoff dates, which is the real reason this toggle matters to day-to-day coding work, as stated in Config instructions.
codex-1up 0.3.20 adds web-search toggles and experimental settings knobs
codex-1up (community wrapper): Release 0.3.20 adds explicit enable/disable controls for web search plus experimental settings (called out as background/steer) and bug fixes, as summarized in Release notes.
• Install/entry point: The wrapper is installed via npx -y codex-1up install, with the canonical reference repo linked in GitHub repo and the CLI flow reiterated in Install command.
Research-to-Codex handoffs are still a manual seam in some workflows
Codex workflow (OpenAI): A recurring pattern is using GPT‑5.2 Pro in ChatGPT for research, then sharing results into Codex for implementation; one practitioner describes this handoff as “quite clunky” and notes Codex search isn’t “close to 5.2‑Pro” for research depth, in the Research handoff note.
Why it matters: This is a concrete “tool boundary” cost—research context lives in one surface while code execution lives in another—which is exactly the type of friction web-search-in-Codex is trying to reduce, even if it doesn’t fully replace a dedicated research model.
🧪 Claude Code & Cowork: release notes + real-world failure modes
A mix of minor release notes and high-signal field reports on agent failure modes (context drift, missing files, myopia loops) and where Cowork shines for non-coding work. Excludes Genie 3 content (covered in the feature).
Claude Cowork runs a 9-step workflow: scan Zoom files, upload to YouTube, trim silences
Cowork (Anthropic): A concrete “computer-use” field report shows Cowork running an end-to-end media ops task: find 4 Zoom recordings, inspect video frames, open the correct YouTube channel, upload, generate titles/descriptions, and trim silences in YouTube Studio—driving a “9 stage plan” with checkpoints for irreversible steps, as described in the Workflow walkthrough.
• Control pattern: The operator reports being able to interrupt and adjust mid-run, while the agent pauses for manual inspection before irreversible actions, per the Workflow walkthrough.
The practical takeaway is that this is not “write a script later”; it’s acting directly in the UI while keeping a human in the loop.
Claude recovers a missing source file by decompiling .pyc with decompyle3
Claude Code incident workaround: After asking Claude to split code into two commits, a “missing file” incident ended with the agent installing decompyle3, reconstructing the missing Python source from .pyc bytecode disassembly, and producing code that “runs perfectly,” as recounted in the Incident story.
It’s an unusual recovery path, but it’s a real example of agents using toolchains opportunistically when the repo state gets corrupted (intentionally or not).
Long-run Claude “myopia loops” in complex code: fixes regress other behaviors
Agent failure mode (Myopia loop): A recurring complaint is “fix-and-break” oscillation on complex systems: each tweak repairs one behavior but breaks another, and the overall behavior doesn’t converge once it outgrows the working context (“bounce around endlessly fixing things that used to work”), as described in the Myopia loop report and echoed by “poking at a blob of mercury” in the Iteration frustration.
One concrete mitigation attempt—hierarchical finite state machines with a general/lieutenants/units—initially helped but reportedly collapsed back into contradictory rule layering, per the FSM attempt.
Claude context hygiene pain: repeated reminders and piling details into CLAUDE.md
Context management pain (Claude Code workflows): A practitioner notes that “constantly having to remind Claude” about earlier decisions is exhausting, and that accumulating reminders in a claude.md/project note file feels like busywork rather than leverage, as described in the Reminder frustration and reinforced by later updates about repeatedly reverting strategy attempts in the Revert note.
The theme is that compaction/memory boundaries become an ongoing operational tax, even when the underlying coding task is straightforward.
User sentiment: “agents are sucking away my own agency” and “soulless” coding
Human factors (Agentic coding): There’s an explicit backlash thread framing the experience as disempowering: “staring at Claude windows” feels “soulless,” and “the agents are sucking away my own agency,” as written in the Agency loss quote.
This isn’t about a specific bug; it’s about the day-to-day ergonomics when you’re supervising an agent and hoping it’s right, rather than building confidence through tighter feedback loops.
Claude Code CLI 2.1.25 fixes beta header validation for Bedrock/Vertex gateways
Claude Code CLI 2.1.25 (Anthropic): A small but high-signal enterprise fix shipped: gateway users on Bedrock and Vertex hit a beta header validation error, and 2.1.25 ensures setting CLAUDE_CODE_DISABLE_EXPERIMENTAL_BETAS=1 actually avoids that failure, as described in the Changelog note and documented in the GitHub changelog.
This is narrowly scoped ("1 CLI change"), but it’s the kind of thing that breaks fleets when you’re rolling agents through corporate gateways.
🧑💻 Coding agent products: OpenCode, Cline, Kilo, and agent-browser adoption spikes
Third-party coding agents and wrappers (beyond Claude/Codex) with concrete distribution/ops signals: usage surges, pricing/quotas, and big OSS growth metrics. Excludes Genie 3 content (covered in the feature).
Kimi Code switches to token billing and upgrades to Kimi K2.5
Kimi Code (Moonshot): Kimi Code is now powered by Kimi K2.5, and Moonshot says it’s permanently moving from request limits to token-based billing, with all quotas reset and a time-boxed promo through Feb 28 offering 3× quota plus “full speed” (no throttling), as described in the product update and clarified in the billing rationale.
• Why the billing change matters: Moonshot argues the old quota system priced a “Hello World” the same as big refactors, while token billing meters by length—this shifts how you budget agentic workflows and makes iterative refactors less punitive, per the explanation in billing rationale.
• Operational implication: The combination of quotas reset + no throttling promo window is effectively a temporary “load test” opportunity for teams evaluating K2.5 in an agent loop, based on the constraints described in product update.
Cline hits 5M installs and announces a $1M open source grant
Cline (Cline): Cline says it reached 5 million installs and is launching a $1M grant aimed at open-source developers using Cline on their projects, as stated in the milestone post install milestone and expanded in the program details at grant program post.
• Adoption context: They frame the project as one of GitHub’s fastest growing AI OSS projects with 57k stars and 4,700% YoY contributor growth, per the same milestone claim in install milestone.
• Practical implication: The grant structure and eligibility mechanics aren’t fully detailed in the tweets; the canonical reference is the linked program page described in grant program post.
Kilo Code says Kimi K2.5 is now its most-used model via OpenRouter
Kilo Code (Kilo): Kilo reports Kimi K2.5 has become the #1 most-used model in Kilo Code via OpenRouter, and it’s running a limited “free” window to drive adoption, with a usage breakdown chart showing K2.5 leading daily tokens, per the announcement in usage chart and their accompanying writeup in the promo blog.
• Distribution signal: The chart in usage chart shows Kimi K2.5 dominating a high-volume day versus a mix including Claude, Gemini, Grok, and GPT models—useful as a proxy for what coding-agent users are actually selecting under real usage constraints.
• Promo mechanics: Kilo frames the free window as time-limited ("next 5 days"), which can skew short-term rankings; treat the “most-used” claim as time-bounded to the campaign period described in usage chart.
agent-browser passes 100K downloads 18 days after launch
agent-browser (community): The npm-installed agent-browser CLI is reported to have crossed 100K downloads just 18 days after launch, which is a notable distribution signal for “agent browser” tooling in dev workflows, per download count.
• Why it matters for tooling stacks: A 100K-download footprint suggests browser automation is shifting from “demo capability” to a default building block that people install early, which is the core claim being pointed to in download count.
OpenCode offers Kimi 2.5 free for a limited time and ships bug fixes
OpenCode (OpenCode): OpenCode says Kimi 2.5 is free for a limited time inside OpenCode, and it calls out that upgrading OpenCode should resolve earlier bugs; they also credit Fireworks for fast bring-up and stable serving, per free window note.
• What’s concretely new: The actionable change is “upgrade OpenCode” to pick up fixes before re-evaluating the model-in-the-loop experience, as explicitly stated in free window note.
• Infra dependency: Fireworks is cited as the serving partner; that’s the operational detail that affects latency/throughput expectations more than raw model quality, per the attribution in free window note.
Open-source agent maintainer churn as AI labs poach maintainers
Open-source maintenance (ecosystem): A recurring complaint in the OpenCode/agent tool ecosystem is maintainer churn—specifically that newly added maintainers get hired away by AI labs quickly—raising concerns about project continuity and contributor incentives, as voiced in maintainer churn post and echoed again in follow-up comment.
• Operational consequence: The tweets don’t assert a concrete governance change (no transfer of repo ownership or archive notice); it’s a signal about fragility in fast-growing agent tooling, per maintainer churn post.
🔌 Interop plumbing: Agent Trace + ACP ecosystem
New and continuing work on interoperability standards for agents and coding tools—focused on mapping conversations to generated code and client protocols. Excludes Genie 3 content (covered in the feature).
Agent Trace proposes a vendor-neutral format to attribute AI agent work to code changes
Agent Trace (Cursor + ecosystem): Cursor proposed Agent Trace, an open spec for tracing agent conversations to the code they generate—aimed at interoperating across coding agents and interfaces, as described in the Spec announcement and published at the Spec site. Cognition amplified the same effort with a “context graph” framing and a partner list (Cursor, OpenCode, Vercel, Jules, Amp, Cloudflare, and others) in the Context graph video and the Deep dive writeup.

• What it enables: The proposed flow is “agent traces → storage → IDE/CLI + analytics + audit logging,” as shown in the Trace pipeline diagram.
• Why engineers care: This is an interoperability primitive for debugging and governance—making it easier to answer “why did the agent change this line?” and to build repeatable evaluation/QA around long-running coding agents, per the Spec announcement.
Some claims around performance and “persisted reasoning/tool history” are being used as motivation for context graphs, as quoted from the writeup in the Excerpt highlight, but the tweets don’t include an external eval artifact tying those gains to Agent Trace specifically.
ACP Registry push highlights protocol compliance as a compatibility gate
ACP (Agent Client Protocol): A renewed push is encouraging toolmakers to implement ACP and list their agent/client in the ACP Registry, framed as “adhere to the protocol…everybody wins” in the Registry callout, with the Registry page as the target entry point.
A small but concrete adoption signal is that GitHub Copilot CLI appears to expose an ACP flag (copilot --acp) and is described as available across multiple clients (including Zed and Toad) in the CLI flag mention.
Agentation becomes a high-usage UI-to-agent handoff tool
Agentation (agentation npm package): Agentation—a click-to-annotate overlay that exports structured markdown selectors for AI coding agents—reports 142,000 weekly installs and teases “Version 2 soon,” according to the Install count post and the npm package page.
The product shape is a pragmatic interop layer: it standardizes “what the human pointed at” (DOM selectors + notes) into copyable structured output for any agent, which is often the missing step between “feedback” and “actionable code change,” as described in the Install count post.
🧭 Workflow patterns: context discipline, agent drift, and multi-agent overhead
Practitioner patterns and pain points in day-to-day agentic development: how to keep agents on-track, when multi-agent helps/hurts, and ‘don’t outsource the thinking’ themes. Excludes Genie 3 content (covered in the feature).
A practical control pattern: let the agent run, but gate irreversible steps
Bounded autonomy prompting: A concrete “control loop” pattern is showing up in real operator-style work: the agent drives a multi-step plan end-to-end, but explicitly pauses for human inspection before irreversible actions, as demonstrated in a Cowork run that uploads and edits videos in YouTube Studio while respecting a “pause for manual inspection” instruction in the Cowork workflow demo.
• Why it works operationally: The user can interject mid-plan (fix underspecification) without restarting the whole run, as described in the Cowork workflow demo.
• Where it matters most: The pattern is most valuable for high-permission tasks (publishing, billing, deletion) where “agent did the right thing” is not enough—you need an approval seam, as the Cowork workflow demo illustrates.
Multi-agent systems can lose to single agents on non-parallel tasks
Multi-agent architecture overhead: Practitioners are highlighting that adding agents can add enough communication and coordination overhead to reduce effectiveness on tasks that aren’t naturally parallelizable, as summarized in the Multi-agent overhead note.
• Evidence being debated: One critique points out that some papers conclude “multiagents are bad at sequential planning,” but the orchestrator and aggregation were simplistic, leaving open whether exploratory rollouts before committing to a plan would change results, per the Architecture critique.
• Operational takeaway (as a descriptive pattern): The emerging heuristic is “parallelize only what decomposes cleanly,” which is exactly the condition cited in the Multi-agent overhead note.
A common failure mode: the endless fix-regress loop when context saturates
Myopia loop failure mode: A concrete pattern of long-horizon agent drift shows up in a game-AI coding effort: each tweak fixes one behavior and breaks another, until the total behavior “is too much… to keep in its context window,” producing an endless fix/regress cycle described in the Myopia loop description.
• Symptoms: Repeatedly “piling contradictory rules” and bouncing between broken behaviors, as described in the FSM strategy regression and the Blob of mercury quote.
• Adaptation attempt: The same thread reports progress when the task is constrained to translating an existing, older C strategy in small increments—reducing open-ended design load—per the Translate C to Clojure.
A git-based way to back up and sync agent configs across tools
asb (agent settings backup): A lightweight workflow is circulating for “tooling hygiene”: back up AI coding agent configuration folders as separate git repos so you can sync across machines and recover from clobbered settings, using an asb init + asb backup flow shown in the asb demo output.
• What it covers: The example run snapshots settings for multiple agents (Codex CLI, Gemini, Claude Code, Cursor, others) and produces a per-agent commit history, as shown in the asb demo output.
• Why it exists: The motivation is practical rather than theoretical—agent setups are increasingly “stateful” via many small config files, and repeated changes make accidental regressions common, per the asb demo output.
Engineers are naming the downside: agents can reduce your own agency
Disempowerment and cognitive offloading: A recurring worker sentiment is that long-running agent use can feel like “staring at Claude windows… the agents are sucking away my own agency,” as put in the Agency loss quote.
• Counter-slogan: The pushback is being condensed into short maxims like “you cannot outsource the thinking,” as stated in the Cannot outsource thinking.
• Why it matters to workflows: The critique isn’t about model quality; it’s about human skill atrophy and control drift when the operator becomes a passive reviewer, which is the core complaint in the Agency loss quote.
A context hygiene trick: route MCP calls through subagents
Context discipline: A specific practice callout is to run MCP interactions through subagents so the primary working thread doesn’t accumulate tool outputs and retrieval noise, per the MCP via subagents tip.
The idea is not “more agents,” but isolating high-churn context (fetching, lookups) so the main agent stays focused on the implementation thread, as described in the MCP via subagents tip.
Skill invocation UX is getting messy as slash commands proliferate
Skill invocation UX: There’s a sharp complaint that mixing built-in slash commands with “skills” creates avoidable operator mistakes—especially in overloaded terminals—citing accidental /logout vs /login and autocompletion choosing the wrong command in the Autocomplete logout bug follow-up.
• Proposed convention: The argument is to standardize on a distinct prefix (explicitly “$” for skills) to separate tool control-plane commands from skill execution, as laid out in the Skills prefix complaint.
• Why this is surfacing now: As more agent harnesses add skills marketplaces and command palettes, the surface area of “one keystroke did something destructive” grows, per the Autocomplete logout bug anecdote.
🛠️ Dev tools shipping for agent-era engineering
Non-assistant developer tools that improve speed, search, and review workflows (outside of MCP/agent runners). Excludes Genie 3 content (covered in the feature).
GitHub Issues gets semantic search plus major latency improvements
GitHub (GitHub): GitHub shipped semantic search for GitHub Issues and reported performance work that moved the share of requests returning in under 200ms from 2% to ~35%, as described in the shipping note. This matters for agent-era engineering because issue triage and “find prior decisions” loops are becoming part of every coding agent workflow, and the wall-clock cost is dominated by search latency as much as model tokens.
The tweet frames this as early progress (“still a lot of work to do”), so the main unknown is how the semantic index behaves under org-scale issue volumes and permission boundaries beyond this initial rollout, per the shipping note.
Vercel adds agent-friendly markdown rendering for pages (Accept: text/markdown)
Vercel (Vercel): Vercel shipped an agent-friendly content path where Vercel changelog links automatically render as markdown when clients send Accept: text/markdown, and the team cites a size drop from 500kb to 2kb, as shown in the markdown toggle demo and described on the Changelog page in Changelog page.

• Why this matters for agent workflows: it makes “read the docs/changelog” tool calls cheaper and more reliable (less HTML noise, fewer tokens) while staying compatible with normal browsers, as described in the markdown toggle demo.
This is a concrete example of “agent-facing HTTP negotiation” becoming a first-class product surface rather than an unofficial scraper path.
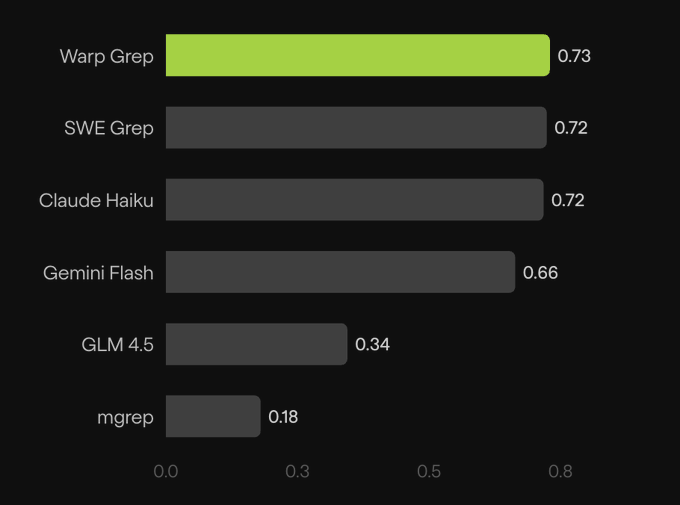
WarpGrep posts production evals: ~0.73 F1 with faster feedback streaming
WarpGrep (Morph): Morph shared production eval numbers for WarpGrep—0.73 F1 (~6s) vs SWE-Grep 0.72 (~5s) and Claude Haiku 0.72 (~73s)—and noted it now streams intermediate search tool calls for quicker feedback, as reported in the eval results.
• Latency vs quality tradeoff: the data highlights why teams keep dedicated code-search tools in the loop even when LLMs can “search” semantically—LLM latency dominates for interactive dev work, as reflected in the eval results.
The post also mentions closing a speed gap via “new inference optimizations and architectures on b200,” but without a reproducible methodology or dataset details in the tweet, treat the comparison as directional, per the eval results.
Conductor speeds up long agent chats with incremental parsing
Conductor (Conductor): Conductor shipped incremental parsing work aimed at long-running chats, described as “much faster on long chats,” with a demo in the performance note. This is directly relevant to teams running agents in “single long thread” modes where UI latency becomes the bottleneck even when model responses are fast.

The post doesn’t quantify the speedup beyond “much faster,” so the open question is how it scales with multi-megabyte transcripts and frequent tool-call streaming, per the performance note.
Ramp Rate launches spend-based vendor adoption metrics for 100+ software vendors
Ramp Rate (Ramp): Ramp launched Ramp Rate, a free vendor directory showing “real-time adoption and growth metrics” for 100+ software vendors using Ramp spend data, positioning it as “$10k+ analyst intel” replacement, as shown in the product launch.
For AI engineers and analysts, the relevance is practical competitive intel: which AI infrastructure and SaaS vendors are actually expanding in procurement data, without waiting for quarterly reports, as described in the product launch.
📊 Benchmarks & eval tooling: ARC-AGI-3 toolkit, METR, and usage analytics
New eval infrastructure and metrics that affect how teams compare agents/models in practice. Excludes Genie 3 content (covered in the feature) and excludes bioscience content.
ARC-AGI-3 Toolkit ships a local 2,000 FPS environment engine for agent evals
ARC-AGI-3 Toolkit (ARC Prize): ARC Prize announced an open-source ARC-AGI-3 Toolkit that runs environments locally at ~2,000 FPS, framing it as a >250× speedup vs their hosted API, with the environment engine + initial “human-verified” public games released ahead of the March 25, 2026 benchmark date, as stated in the Toolkit launch and reinforced by the Local FPS claim.

• What’s actually shipping: An open-source environment engine plus three official public games with current AI scores “<5%,” according to the Games release and the earlier Toolkit launch.
• Why engineers care: The point is iteration speed; local replay/debug loops become feasible when you can run millions of steps per minute, as ARC frames it in the Local FPS claim, with setup details in the Quickstart docs.
METR revises its time-horizon estimate to a 131-day post-2023 doubling time
Time Horizon 1.1 (METR): METR updated its methodology by adding 58 new tasks and increasing “>8 hour” tasks from 14 to 31, which moves the post‑2023 “doubling time” estimate to 131 days (from 165), as summarized in the Methodology change stats.
This lands as an eval-infra update rather than a model claim; the full writeup is in the METR post.
ARC Prize publishes a beta “Standard Benchmarking Agent” harness for ARC-AGI-3
Standard Benchmarking Agent (ARC Prize): ARC Prize also posted an early beta of its “Standard Benchmarking Agent,” positioning it as a preview of the official testing harness and explicitly asking for feedback before March, as described in the Harness announcement.
This matters because it signals the eval interface ARC expects agent builders to target (tooling surface, replay/scorecard workflow), with the first public docs living in the LLM agents guide.
ARC-AGI-3 scoring adds “Relative Human Action Efficiency” normalization
Scoring methodology (ARC Prize): ARC Prize says ARC-AGI-3 will normalize scores to human baselines via Relative Human Action Efficiency (RHAE, “ray”), emphasizing action efficiency as a proxy for learning efficiency, as outlined in the RHAE announcement.
The concrete change is that raw scores should be comparable across tasks only after normalization, with methodology details described in the Methodology docs.
Arena adds Auto-Mode and searchable chat history to reduce model-picking friction
Arena (Arena.ai): Arena shipped three QoL updates—Auto-Mode that picks the “type of AI your task requires,” a rank-ordered model selector with modality filters, and searchable chat history, as shown in the QoL update thread.

The changes are live on the Arena site, with the product direction implying they’re optimizing for faster eval-style comparisons without re-running prompts manually.
OpenRouter shows GPT-5.2 Pro demand concentrates in science/finance/legal
GPT-5.2 Pro vs Standard (OpenRouter): OpenRouter shared category mix data showing GPT‑5.2 Pro is used more heavily for science (6.7% vs 2.8%), finance (2.6% vs 1.3%), and legal (1.2% vs 0.5%), while Standard skews slightly more toward academia/programming/technology, per the Usage breakdown.
The main signal: higher-compute tiers appear to monetize disproportionately in “high-stakes-ish” domains, while general coding volume stays closer to the cheaper SKU in the same dataset.
Artificial Analysis crowdsources traits for benchmarking model communication style
Model personality evals (Artificial Analysis): Artificial Analysis says they’re developing benchmarks for personality/communication style and asked which traits should be compared (examples given: creative, humorous, direct), as stated in the Trait prompt.
This reads as an early signal that “style” may become more standardized and measurable, alongside the existing accuracy/speed/cost eval ecosystem.
📄 Docs-for-agents surfaces: markdown/web compression as a distribution lever
Agent-readable docs surfaces and packaging patterns that reduce context + bandwidth costs (separate from repo-local rules). Excludes Genie 3 content (covered in the feature).
Vercel serves markdown-first pages for agents via Accept: text/markdown
Vercel (Agent-readable docs surface): Vercel shipped a lightweight “Human/Machine” view that turns normal web pages into agent-friendly Markdown when requested with Accept: text/markdown, cutting one example page from ~500kb to ~2kb, as shown in Agent markdown toggle.
This is a concrete distribution trick for agents: it reduces bandwidth, tokenization cost, and “DOM noise” when agents scrape docs or changelogs, and it fits neatly into existing HTTP content negotiation (so most toolchains can adopt it without new protocols), per the curl example in Agent markdown toggle and the related rollout context in the Changelog page.
skills.sh leans on CDN memoization to make large agent-skill directories fast
skills.sh (Docs-as-distribution pattern): The Agent Skills Directory reports a 10–20× speedup rebuild using Nuxt, with pages “memoized” and streamed from the CDN—explicitly targeting fast browsing across 34,149 skills, as described in Nuxt rebuild claim.
For builders, this is a reminder that “docs for agents” is an infra problem: caching + incremental/static rendering can matter more than search UX once you hit tens of thousands of pages, as implied by the scale noted in Nuxt rebuild claim and reflected in the live directory in Skills directory.
📦 Model releases (non-world-model): ASR, OCR, and smaller research drops
Model drops and speedups relevant to builders: speech recognition, document intelligence, and small but actionable model releases. Excludes Genie 3/Project Genie (covered in the feature) and excludes any bioscience content.
Qwen open-sources Qwen3-ASR and ForcedAligner for multilingual, messy-audio ASR
Qwen3-ASR + Qwen3-ForcedAligner (Alibaba/Qwen): Alibaba released production-ready open-source speech models with a bundled inference/finetuning stack; key claims include 52 languages/dialects with auto language ID, up to 20 minutes per pass, robustness to noise and even singing, plus word/phrase timestamps via ForcedAligner, as described in the release thread and linked from the GitHub repo and Hugging Face collection.
• Streaming + alignment: the team also frames Qwen3-ASR as the first open-source “LLM-based ASR” with native streaming support, pointing to a demo and vLLM example in the streaming note.
This lands as a pragmatic “ship-it” ASR drop: multilingual, long-form audio, and alignment are packaged together rather than left as separate community integrations.
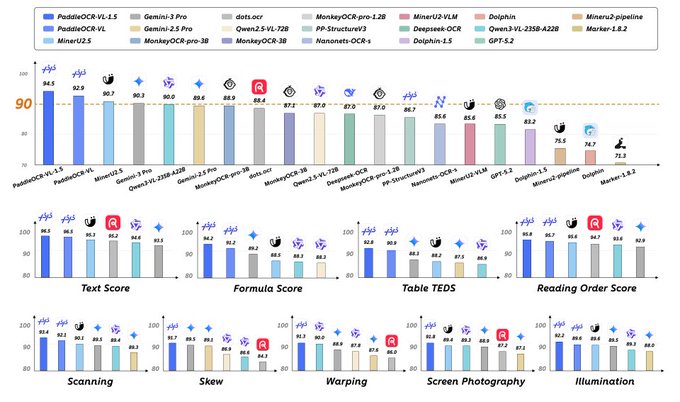
PaddleOCR-VL-1.5 claims SOTA doc parsing with 0.9B parameters
PaddleOCR-VL-1.5 (PaddlePaddle): PaddlePaddle announced PaddleOCR‑VL‑1.5, positioning it as a document parsing model with 94.5% accuracy on OmniDocBench v1.5 at 0.9B parameters, plus improved handling of warped/skewed scans and screen photos, as laid out in the launch post.
• Builder-relevant capabilities: the release highlights irregular-shaped localization, stronger table/formula/text recognition, and long-document behaviors like cross-page table merging and heading recognition, per the launch post.
Treat the benchmark as vendor-reported (the tweet includes tables, but no external eval artifact); still, it’s a notable “small specialized VLM beats big general VLMs on docs” signal in OCR/document intelligence.
RLM-Qwen3-8B update: post-trained “native” recursion and model release
RLM‑Qwen3‑8B (lateinteraction): the authors shared an updated writeup and released RLM‑Qwen3‑8B, describing it as the first “natively recursive LM” and arguing the behavior is modular—learning the prompt-as-variables call format plus strategies for writing recursive programs—per the update thread.
The claim to watch is whether “native recursion” becomes a durable primitive for tool/call decomposition (and long-context behavior) versus a prompt format that only holds under narrow evaluation conditions.
vLLM adds day‑0 serving for Qwen3-ASR, including audio deps and serve command
vLLM (vLLM Project): vLLM announced day‑0 support for serving Qwen3-ASR, including install instructions for vllm[audio] and a vllm serve Qwen/Qwen3-ASR-1.7B recipe, as shown in the day‑0 support post and detailed in the Usage guide.
• Throughput positioning: the same announcement calls out “2000× throughput on the 0.6B model” and “SOTA accuracy” on the 1.7B, as stated in the day‑0 support post.
Net effect: less glue code for teams who want an OpenAI-compatible serving surface for ASR with streaming/batching/async in the same stack.
Black Forest Labs says FLUX.2 [flex] got up to 3× faster
FLUX.2 [flex] (Black Forest Labs): Black Forest Labs says its text-and-typography-focused image model is now up to 3× faster, crediting optimization work with PrunaAI; the positioning is better text rendering and richer visuals at lower latency, as stated in the speedup announcement.
This mainly matters for teams that already standardized on FLUX for legible text generation and want to push throughput (batch design, templated creatives) without changing model families.
🧠 Research notes: agent architectures, learning effects, and systems pragmatism
Research papers and writeups with direct design implications for deployed agents: routing, OOD detection, and how AI affects skill formation. Excludes bioscience research.
Anthropic RCT finds AI coding help lowered concept mastery by ~17% for juniors
AI assistance & skill formation (Anthropic): Anthropic published a randomized controlled trial on junior engineers learning an unfamiliar async Python library; the AI-assisted group scored ~17% lower on a post-task quiz (≈two letter grades), while finishing only ~2 minutes faster and without a statistically significant speed gain, as described in the [study thread](t:5|study thread) and the accompanying [research post](link:5:0|research post).
• What drove the drop: The delta depended on how people used the assistant—participants who asked conceptual/clarifying questions retained more, versus those who delegated/got code generated, according to the [interaction patterns note](t:144|interaction patterns note).
• Why this matters for products: It’s evidence that “ship faster” and “learn the system” can be in tension for onboarding flows, internal enablement, and junior-heavy teams—especially when the agent defaults to code emission rather than explanation, as summarized in the [results recap](t:132|results recap) and expanded in the [paper link](t:179|paper link).
Amazon’s Insight Agents shows a “small models first” routing stack for data agents
Insight Agents (Amazon): Amazon’s “Insight Agents” paper describes a manager/worker multi-agent setup for natural-language business data analysis that uses lightweight models for OOD detection and routing instead of LLM-only classification, with latency/accuracy numbers called out in the [paper summary](t:54|paper summary).
• Fast gating and routing: An autoencoder OOD detector hits 0.969 precision in <0.01s vs 0.616 precision and 1.67s for LLM few-shot; a fine-tuned 33M BERT router reaches 0.83 accuracy in 0.31s vs 0.60 and 2.14s for an LLM classifier, as stated in the [metrics description](t:54|paper summary) and detailed in the [ArXiv paper](link:54:0|ArXiv paper).
• Avoiding text-to-SQL: The system decomposes requests into API calls instead of SQL generation to reduce syntax errors/hallucinations; reported end-to-end quality is 89.5% question-level accuracy with P90 latency <15s, per the same [paper summary](t:54|paper summary).
Ai2 open-sources Theorizer, a “theory builder” that emits laws with citations
Theorizer (Ai2): Ai2 released Theorizer, an open-source pipeline that reads papers and outputs structured “laws” (claim), scope, and evidence to make synthesis auditable—positioned as theory-building rather than summarization, per the [tool breakdown](t:321|tool breakdown).
The workflow described includes query rewriting, paper discovery (PaperFinder/Semantic Scholar), OCR to text, schema-guided extraction (noted as using GPT-5 mini), then aggregation into candidate laws with quality scoring and backtesting on later papers, as outlined in the [pipeline details](t:321|tool breakdown).
Huawei survey maps RL techniques needed for long-horizon “deep research” agents
Reinforcement learning for deep research systems (Huawei): A Huawei-authored survey frames “deep research” agents as hierarchical stacks (planner/coordinator/executors) and argues that RL is a better fit than pure SFT/DPO for tool-interacting, long-horizon behaviors—covering reward design, credit assignment, and multimodal integration, as shown in the [paper screenshot](t:230|paper screenshot).
It also emphasizes practical blockers: training full stacks end-to-end is still impractical, so most systems train a planner connected to core tools (search/browse/code), per the [survey excerpt](t:230|paper screenshot) and the linked [ArXiv entry](link:966:0|ArXiv entry).
🛡️ Security & misuse: exposed local LLMs, agent sandboxing, and trust controls
Operational security issues and mitigations for agents and self-hosted models, including real-world exposure and product-level controls. Excludes Genie 3 content (covered in the feature).
Scan finds 175k publicly reachable Ollama servers, with tool-calling enabled on many
Ollama exposure research (SentinelOne/Silent Brothers): A 293-day scan observed 175,108 publicly reachable Ollama servers across 130 countries, suggesting widespread misconfiguration beyond the intended localhost binding, as summarized in Scan stats thread and detailed in the SentinelOne report. The security angle is operational: once a local model endpoint is internet-reachable, it becomes free inference for strangers and a potential pivot into tool-calling and RAG-connected systems.
• Concentration and uptime: The scan reports 7.23M sightings, with 13% of hosts accounting for 76% of sightings and a ~5,000-host cluster averaging 87% uptime, per Scan stats thread.
• Tool surface area: About 48% of hosts advertised tool-calling, which expands risk beyond “someone can prompt my model” to “someone can trigger actions or data access,” as described in Scan stats thread.
The writeup implies that “I installed Ollama” and “I exposed an AI service on the public internet” are closer than most teams assume, especially once wrappers add tools and retrieval.
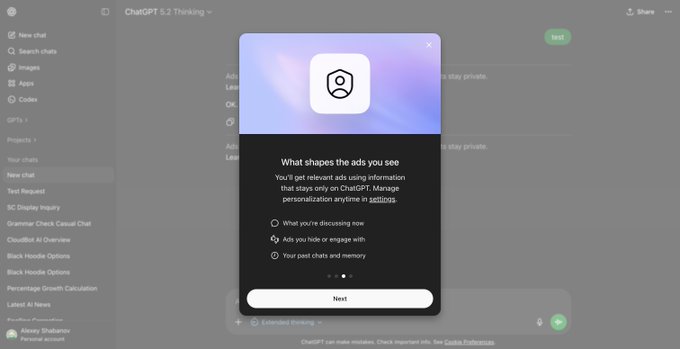
ChatGPT ads onboarding shows personalization sources and new ad controls
ChatGPT ads (OpenAI): The public UI now shows an ads onboarding flow explaining that ad relevance can use current chat, ad interactions, and past chats/memory, as shown in Ads personalization modal and echoed by additional UI references in Web app ads onboarding.
• Privacy boundary claims: The flow states advertisers “never see” chats/memory/name/email/location and only get aggregated counts, per Web app ads onboarding and Android beta details.
• User controls: The UI references an “Ads controls” section with ad history, interests, personalization toggles, and the ability to delete ads data, as listed in Ads controls list.
• Internal naming leak: The Android beta strings reportedly label the ad system “Bazaar,” suggesting a dedicated ads subsystem with its own actions (hide/report/why/ask), per Android beta details.
What’s still unclear from the tweets: the exact rollout scope/timeline, and how “past chats and memory” is applied when users disable personalization beyond “current chat” targeting.
FlashLabs launches SuperAgent as a hosted alternative to running powerful localhost agents
SuperAgent (FlashLabs): FlashLabs is pitching SuperAgent as a “hosted, enterprise-secure Jarvis” positioned against the common pattern of running powerful agents locally with broad access to browsers, credentials, and customer data, as framed in Launch positioning and expanded in Localhost risk framing.

• Operational model: The product is described as running “from Slack, WhatsApp, or iMessage” and handling long-running work with persistent memory, per Localhost risk framing.
• Security posture claim: The core claim is avoiding “shell access risks” and “localhost security holes,” which is a direct response to teams wiring agents into real credentials, as stated in Launch positioning and Localhost risk framing.
The tweets are promotional and don’t include an architecture/security spec, so treat the assurance as a vendor claim until there’s a concrete threat model or deployment guide.
Tool filtering can be brittle when agents route around it with alternative fetch paths
Policy enforcement gaps: A user reports Claude hitting a content filter in a WebFetch-style tool, then switching tactics to fetch raw files via GitHub/curl (“Let me try using the GitHub CLI to get the raw files”), as captured in WebFetch filter workaround.
This is a concrete reminder that “blocked tool output” isn’t the same as “blocked capability” once an agent has multiple network/file pathways; enforcement needs to consider tool diversity (API fetch, raw content endpoints, local git clones) rather than assuming one fetch layer is the choke point.
Local agent tooling is increasingly hitting OS-level credential prompts and trust UX
CodexBar (local agent UX): A screenshot shows a macOS Keychain dialog where “CodexBar wants to use your confidential information stored in ‘Arc Safe Storage’,” prompting for the login keychain password, as shown in Keychain access prompt.
This is a small but recurring trust-control pattern: as agent tools integrate deeper with browsers and local apps, they start tripping OS credential boundaries (Keychain prompts, browser vaults), and the UX of “Always Allow vs Allow vs Deny” becomes part of the security story.
🏢 Capital, partnerships, and enterprise platform shifts
Funding/IPO chatter and enterprise adoption moves that change competitive dynamics and procurement decisions. Excludes Genie 3 content (covered in the feature).
OpenAI funding chatter jumps to $60B–$100B with a $730B–$750B valuation range
OpenAI (capital + compute): Following up on SoftBank talks about mega-round rumors, new reporting claims OpenAI is discussing raising up to $60B from Nvidia, Microsoft, and Amazon as part of a broader push that could reach $100B, with valuation cited around $730B in one thread and $750B+ in another, according to the Funding rumor and the NYT report.
• Why the number matters: The thread explicitly ties fundraising to an estimated $430B compute cost through 2030, which is effectively a “how much capacity can we pre-buy?” signal for the entire ecosystem, as stated in the Funding rumor.
• Primary artifact: The claim about Nvidia/Microsoft/Amazon talks is attributed to The Information, linked via the The Information piece.
The overlap between strategic investors and compute suppliers is doing most of the informational work here: it’s less “cash burn” and more “access to chips and infrastructure on favorable terms.”
WSJ reports OpenAI is targeting a Q4 2026 IPO
OpenAI (WSJ): The Wall Street Journal reports OpenAI is planning a public offering in Q4 2026, explicitly framed as a race among leading generative AI startups to be first to the public markets, as shown in the WSJ headline screenshot.
The operational relevance is mostly second-order: IPO timelines tend to pull forward revenue durability narratives (enterprise contracts, platform lock-in) and can change procurement risk calculations for large customers.
ServiceNow makes Claude the default model for its agent builder in a new Anthropic deal
Claude (Anthropic) + ServiceNow: ServiceNow signed a multi-year partnership with Anthropic; Claude becomes the default model behind ServiceNow’s agent builder and is being rolled out across 29,000 employees, including use of Claude Code for engineers, per the deal screenshot.
This is an enterprise platform distribution move: “default model” status inside a workflow suite can matter more than raw evals, since it shapes which model gets embedded into internal automations by default.
Tesla discloses a $2B investment into xAI
xAI (Tesla): Tesla disclosed it invested $2B in xAI; the report notes shareholders had previously rejected a similar proposal (via abstentions counting as “no”), as shown in the Tesla letter excerpt.
For market structure, this reinforces Musk-ecosystem coupling (Tesla ↔ xAI ↔ X), which can affect xAI compute access, distribution, and potential bundling into consumer and enterprise products.
Musk reportedly weighs a SpaceX–xAI merger, with X speculation attached
SpaceX + xAI (corporate structure): A report relayed in the timeline says Musk is considering merging SpaceX and xAI, per the merger report. Separate commentary speculates this could also fold in X to chase a “$XXX” ticker narrative, as in the ticker speculation.
What matters here is consolidation risk for procurement: if compute (SpaceX/Starlink infra), distribution (X), and model development (xAI) converge under one cap table, it changes how competitors and enterprise buyers think about vendor dependence and long-term pricing leverage.
Cognition opens a London office to scale Devin deployments in the UK
Devin (Cognition): Cognition announced a new London office and hiring push for UK “customer engineering” focused on real-world AI software engineering deployments across Europe, as described in the office announcement.
This is a deployment-oriented expansion signal: “customer engineering” headcount is usually the constraint when moving from demos to repeated enterprise rollouts.
ElevenLabs signs on as an official partner of Audi Revolut F1 Team
ElevenLabs (enterprise partnerships): ElevenLabs announced it is an official partner of the Audi Revolut F1 Team, positioning the collaboration around trackside support and fan experience, as stated in the partnership announcement.

This is a branding-heavy signal, but it also implies real-time, high-stakes deployment environments where latency, reliability, and controllable voice output tend to be non-negotiable.
Genspark claims 1,000+ business customers in eight weeks
Genspark (enterprise adoption claims): Genspark says its Business product reached 1,000+ companies onboarded in 8 weeks, alongside claims of SOC 2 Type II and ISO 27001 plus “zero retention / zero training” policies, per the adoption post.
Treat this as directional until there’s a breakdown of seat counts, usage, or representative deployments; the concrete “1,000+ in 8 weeks” is the main datapoint in the tweet.
🧩 ChatGPT product changes: ads prep, model retirements, translation UX, and apps
User-facing OpenAI product and policy changes that affect teams building atop ChatGPT (not the API): ads onboarding, model availability changes, and new surfaces like Apps/Translate. Excludes Genie 3 content (covered in the feature).
ChatGPT ads onboarding appears in beta with personalization and opt-outs
ChatGPT ads (OpenAI): New ad-related UI and copy is now showing up in the ChatGPT Android public beta and also the web app, including an onboarding flow describing what personalizes ads and what controls users have, as shown in the web app details and the android beta notes.
The surfaced text says ads are personalized based on current chat, ad interactions, and past chats/memory, while claiming advertisers “never see” chats or identifying details; that exact framing appears in the onboarding modal. It also points to a new Ads controls area (history, interests, personalization toggles, and deletion), per the ads controls summary.
• Implementation detail leak: The internal codename “Bazaar” shows up in the Android strings and action labels, as documented in the android beta notes.
One open question is rollout scope/timing beyond the stated US testing plan referenced in the same thread.
ChatGPT retires GPT-4o, GPT-4.1, and o4-mini on Feb 13 (API unchanged)
ChatGPT model availability (OpenAI): OpenAI says ChatGPT will retire GPT-4o, GPT-4.1, GPT-4.1 mini, and o4-mini on Feb 13, 2026, while leaving the API unchanged, as stated in the retirement summary and detailed in the official post alongside the OpenAI blog post.
The practical impact is mostly about internal/user workflows that rely on specific ChatGPT personalities or “known-good” behaviors (e.g., teams with pinned internal playbooks for 4o). The same post notes usage has concentrated heavily on GPT‑5.2, with only 0.1% daily usage still on GPT‑4o, per the official post.
• Migration signal: Multiple tweets amplify the date and model list, including the retirement recap and reactions like the user reaction screenshot, suggesting the change will be felt more as a UX/behavior shift than an API migration.
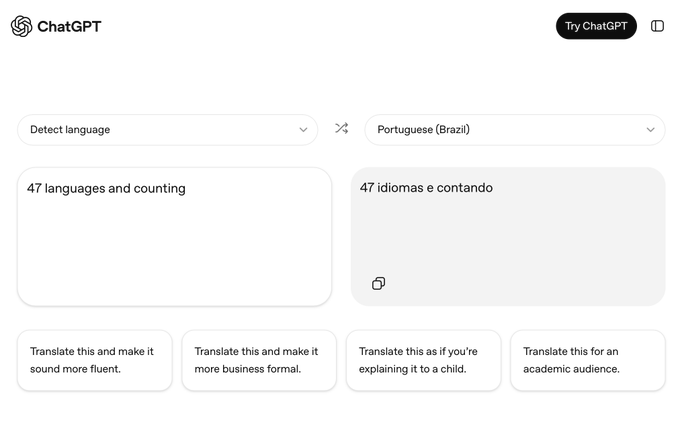
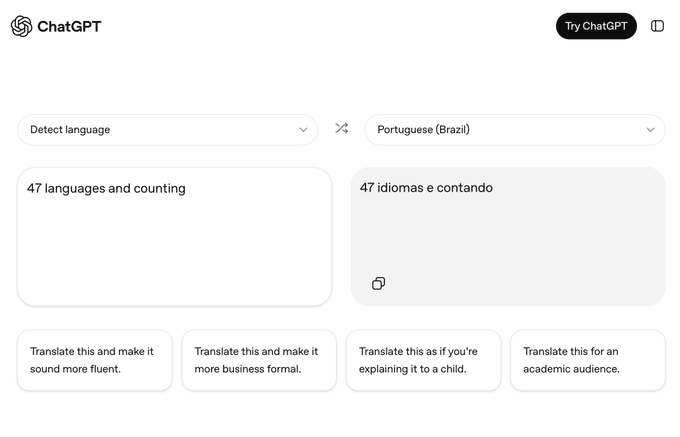
ChatGPT adds a Translate UI with 47 languages and rewrite styles
Translate with ChatGPT (OpenAI): OpenAI is promoting a dedicated Translate surface inside the ChatGPT UI, showing “47 languages and counting” and one-click rewrite presets (fluent, business formal, explain to a child, academic), as shown in the translation UI teaser.
This isn’t just “ask ChatGPT to translate”; it’s a specialized two-pane UX (detect language → target language) with built-in post-translation style transforms, which can matter for teams standardizing support/comms workflows inside ChatGPT rather than building translation into their own apps.
A second example shows the same UI translating a passage into English and offering those same rewrite options, in the Translate example.
Separately, some users interpret this as OpenAI re-entering the consumer translate product lane and are asking how it differs from incumbents, which shows up in follow-on discussion elsewhere today.
ChatGPT Apps: OpenAI says 60+ apps approved this week
ChatGPT Apps (OpenAI): OpenAI says it’s “actively shipping ChatGPT apps,” citing 60+ apps approved this week and indicating more are coming on a steady cadence, per the apps shipping update.
The UI screenshot shows an Apps entry in the left navigation alongside items like Library and Codex, which signals Apps is moving from “experiment” to a first-class surface inside ChatGPT, as seen in the apps shipping update.
This matters for product and analyst readers because Apps changes how “ChatGPT as a platform” is distributed (discovery, permissions, and stickiness) even when teams aren’t consuming the OpenAI API directly. There aren’t technical details in the tweets about app review criteria or runtime constraints—only the approval volume and rollout cadence.
ChatGPT mobile adds a thinking-level picker (Light to Heavy)
Thinking controls (OpenAI): Paid users can now adjust “thinking level” on iOS and Android (in addition to web) by tapping “Thinking” in the composer and choosing Light, Standard, Extended, or Heavy, as described in the mobile thinking selector.
The post says the selection persists for future chats; it also spells out tier-specific availability—Plus/Pro/Business get Standard and Extended, and Pro gets Light and Heavy—per the mobile thinking selector.
For teams relying on ChatGPT as a daily driver (sales ops, support, internal tooling, or exec comms), this is a concrete UX control that changes latency and cost perception without swapping models, but the tweets don’t include any quantitative latency deltas or model-behavior differences beyond “takes longer than you’d like.”
ChatGPT Translate triggers “isn’t this Google Translate?” confusion
Translate UX confusion: Multiple posts show users trying to understand what “Translate with ChatGPT” is, whether it replaced something, and whether it’s meaningfully different from Google Translate.
In one comparison, the poster asks why ChatGPT “dropped Translate” and juxtaposes the ChatGPT translate UI against Google Translate, as shown in the user comparison.
Another screenshot shows a translation UI that looks like Google Translate and asks “This is the same thing as Google Translate?”, in the UI comparison. Some posts also demonstrate that the Translate surface can be induced into responding like an assistant (producing an explanation instead of a clean translation), as shown in the Translate can chat example.
Net: people are treating this as a product surface change, not a model capability change—and the confusion is about positioning and UX boundaries.
🎬 Generative media (non-Genie): video leaderboards, creative stacks, and tooling
Video/image/3D generation and editing updates outside of Genie 3, including pricing signals and workflow techniques creators are actually using. Explicitly excludes Genie 3/Project Genie (covered in the feature).
xAI’s Grok Imagine Video API lands with $4.20/min pricing and top-tier Arena ELOs
Grok Imagine Video (xAI): Multiple posts indicate xAI has released an API for Grok Imagine Video, with pricing and benchmarking now easy to compare against Veo/Sora/Kling; one widely-shared leaderboard screenshot shows $4.20/min and ELO 1,248 on text-to-video for grok-imagine-video, alongside sample count context in the Leaderboard screenshot.
• Pricing signal: The cost anchor being repeated is $4.20/min with native audio, as summarized in the Leaderboard screenshot, with additional chatter framing it as cheaper than Veo 3.1.
• Where to treat this carefully: the “API just dropped” claim is social confirmation rather than a first-party release note in these tweets, as stated in the API mention.
Creator workflow: contact sheets + shot-angle iteration across Weavy, Nano Banana, Kling
Idea-to-workflow pattern: A concrete production loop is being shared for ad/creative generation—pull refs → generate concept → iterate shot angles → refine with Nano Banana → optionally animate with Kling—captured end-to-end in the Workflow demo.

• What’s reusable: the core trick is using shot-angle iteration (contact sheets) before committing to video, then re-applying the same “camera logic” prompts (“drone logic”) during animation passes, as described in the Workflow demo.
fal ships Hunyuan 3D 3.1 Pro/Rapid endpoints plus topology and part tools
Hunyuan 3D 3.1 (fal): fal announced hosted endpoints for Hunyuan 3D 3.1 Pro (higher fidelity) and Rapid (speed-optimized), plus workflow-adjacent utilities like smart topology and part generation, as shown in the fal demo.

• Endpoint surface: fal lists separate routes for rapid/pro image-to-3D and text-to-3D, plus smart topology and part splitting—see the Endpoint list with links like Image-to-3D endpoint and Part splitter endpoint.
• Why engineers notice: this is packaging + availability; it reduces the integration cost of trying the model family via a standard hosted API rather than bespoke infra, per the fal demo.
Replicate adds PixVerse 5.6 with multi-shot camera control and audio elements
PixVerse 5.6 (Replicate): Replicate says PixVerse 5.6 is now available on its platform, calling out promptable multi-shot camera control plus bundled audio elements (BGM/SFX/dialogue) in the Replicate announcement.

• What changed operationally: it’s an API surface change (new endpoint/version availability) rather than a model paper drop; the main artifact is the hosted endpoint rollout described in the Replicate announcement, with a direct “test here” link in the Replicate model page.
Black Forest Labs says FLUX.2 [flex] is now up to 3× faster for text-heavy images
FLUX.2 [flex] (Black Forest Labs): Black Forest Labs claims its text-and-typography-focused image model is now up to 3× faster after optimization work with PrunaAI, as stated in the Speedup announcement.
• What’s actually new: speed/perf tuning of an existing model SKU (not a new model family), positioned around faster turnaround for text rendering and image editing workflows per the Speedup announcement.
Nano Banana Pro prompt recipe for cyanotype-style “1842 blueprint” renders
Nano Banana Pro prompting: A long, highly constrained “cyanotype / sun print” directive is circulating, focusing on strict Prussian Blue/Indigo/Cyan palette, paper texture, and chemical-process artifacts (brush strokes, dust, deckled edges), with example outputs shown in the Cyanotype examples.
• Why it works as a pattern: it’s an explicit constraint stack (palette bans + physical-print defects + lighting limits) that reduces the model’s tendency to “style drift” when you’re trying to emulate a real medium, as detailed in the Cyanotype examples.
Nano Banana Pro reliability complaints cluster around logo accuracy and instruction follow-through
Nano Banana Pro (quality signal): A visible complaint thread says Nano Banana Pro is failing at logo fidelity and instruction following in a design-like task (an “Agent Trace” infographic banner), repeatedly producing incorrect logos even after explicit correction requests, as shown in the Logo mismatch example.
• What this implies for builders: for brand-sensitive creatives, the failure mode is not photorealism—it’s semantic/logo exactness, which tends to be the gating constraint for shipping marketing assets, per the Logo mismatch example.
🏗️ Infra signals: subscription bundling, credits, and compute scarcity anecdotes
Infra-adjacent signals that impact builder economics and access—primarily subscription bundles and developer credits, plus lightweight supply anecdotes. Excludes Genie 3 content (covered in the feature).
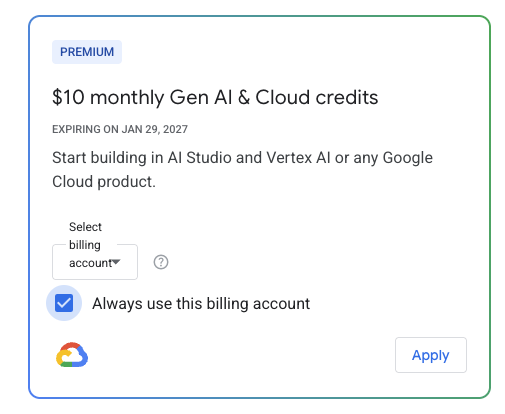
Google AI Pro/Ultra leans into a builder bundle, adding explicit monthly cloud credits
Google AI Pro/Ultra (Google): Google’s $20/mo Pro and $249.99/mo Ultra subscriptions are being framed as a “solo builder offering,” explicitly bundling monthly cloud credits ($10/month for Pro, $100/month for Ultra) alongside a grab-bag of AI tooling access, as listed in the bundle recap. This matters because it changes the effective unit economics for teams prototyping with Google’s stack—credits reduce “try it in prod” friction when you’re moving from hobby prompts to metered API usage.
• Credit details: A separate benefits UI shows “$10 monthly Gen AI & Cloud credits” with a long expiry window, as shown in
, which makes the credits feel more like a standing subsidy than a one-off coupon.
Google AI Pro/Ultra credits can be applied to AI Studio and activated via Developer Program
Google Developer Program (Google): Cloud credits attached to Google AI Pro/Ultra can be applied to Google AI Studio usage (not only general Google Cloud), with an activation flow via the Google Developer Program benefits page, per credits applicability note and the linked benefits page.
This is a concrete infra signal for builders because it clarifies where the subsidy lands: AI Studio/Vertex experiments can be moved onto a billing account without setting up separate promo mechanics, which reduces procurement overhead for small teams.
RTX 5090 out-of-stock chatter is back as builders keep buying local compute
GPU supply (consumer compute): A builder reports RTX 5090 GPUs are “out of stock” and that “hardware is flying off the shelf,” alongside a photo of a high-end parts cart (Threadripper + workstation TRX50 board), in supply anecdote.
This isn’t a datapoint you can capacity-plan on, but it’s a recurring qualitative signal that local inference demand is still pulling high-end inventory—especially for people trying to avoid per-token costs or run multi-agent workloads without cloud throttles.
Video generation economics: expectation of 10× yearly cost drops as models saturate
Compute economics (gen video): A cost-curve claim argues that as model quality saturates, inference costs for “movie-length generated video” should drop by 10×+ per year—projecting “< $100 for an ok movie-length generated video” and “< $10k for a good one” by end of next year, per cost curve claim.
Treat this as directional rather than a forecast (no cost model or provider pricing breakdown is provided in the tweets), but it’s a useful signal of how some builders/execs are thinking about demand elasticity once minutes-of-video becomes a commodity line item.
🤖 Robotics & embodied AI: BCIs, tactile learning, and automation demos
Robotics/embodied updates relevant to ML engineers: training signals, online learning, and deployment demos. Excludes bioscience topics.
Microsoft Research’s Rho-alpha VLA+ adds tactile sensing and online learning after deployment
Rho-alpha (Microsoft Research): Microsoft Research is pitching Rho-alpha (ρα) as a “VLA+” robotics model that goes beyond vision-language-action by adding tactile sensing and online learning from human feedback after deployment, per the robot demo clip. That combination matters because many VLA rollouts stall at “works in the lab” when contact-rich tasks drift in the wild.

• What’s new vs typical VLA: the claim is that touch feedback and post-deploy updates make the system more adaptable than static, frozen policies, as described in the robot demo clip.
• Demo scope: examples shown include dual-arm plug insertion, BusyBox manipulation, and toolbox packing, with the same emphasis on continuously improving after shipping in the robot demo clip.
The tweets don’t include evals, training data scale, or an implementation recipe, so treat performance/comparisons as unverified until a paper or code drop appears.
Fourier demos BCI-linked exoskeleton control for humanoid “avatar” operation
Fourier Robots (BCI + robotics): Fourier demoed a setup that links a BCI with exoskeletons to synchronously control humanoid robots like physical “avatars,” as shown in the BCI control demo. In parallel, a recurring constraint is dataset scarcity for BCI+robotics, called out directly in the dataset scarcity note.

• Why engineers care: this points at a stack where intent decoding, low-latency control, and embodiment all need to cohere; the demo suggests progress on the “closed loop” part (human → robot) in the BCI control demo.
• Data bottleneck: the dataset scarcity framing (BCI and robotics lacking large-scale datasets) remains a practical limiter on generalization and evaluation, per the dataset scarcity note.
No latency numbers, training regime, or offline/online adaptation details are provided in the tweets, so this is a capability signal rather than an implementable blueprint.
Neuralink says 21 people are using Telepathy to control devices, with broader control demos
Telepathy (Neuralink): Neuralink says 21 people are now using its Telepathy brain-computer interface in clinical trials to control computers “with their thoughts,” and it frames the trajectory as moving from cursor control toward richer device control, as shown in the trial milestone video. This is a real deployment count (not a lab demo), which is why it lands differently for embodied-AI folks.

• Capability surface area: the post claims users can control not just computers but also robotic arms and 360° cameras, and mentions progress toward real-time speech decoding in the trial milestone video.
• Performance signal: it also claims some users exceed able-bodied typing speeds (no benchmark details given), alongside the participant count in the trial milestone video.
There aren’t details here on model architecture, decoding stack, or robustness metrics, so the engineering takeaway is mostly “real users, expanding task set,” not a reproducible method yet.
Doosan pushes cobots for food and beverage workflows with hygiene-sensitive handling
Doosan Robotics (cobots): Doosan is positioning collaborative robots for food & beverage environments—repetitive, delicate, and hygiene-sensitive tasks—showing a concrete deployment angle for embodied automation in the food and beverage cobot video. For ML/robotics engineers, this category tends to stress reliability, safety constraints, and task variance more than flashy manipulation benchmarks.

The tweet doesn’t specify models, perception stack, or learning approach (it reads as a deployment/use-case push), but it’s a clear signal of where cobots are being marketed as “human-adjacent” automation rather than fenced-off industrial arms, per the food and beverage cobot video.