Claude Opus 4.5 scores 70 AA index at $1.5k – powers 30‑minute coding runs
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Following Monday’s launch, Opus 4.5 now has real scoreboard gravity, not just a shiny price cut. Artificial Analysis pegs Opus 4.5 (Thinking) at 70 on its Intelligence Index, tied with GPT‑5.1 (high) and trailing only Gemini 3 Pro at 73, while burning 48M output tokens and roughly $1.5k to clear 10 benchmarks versus Opus 4.1’s ~$3.1k. With list pricing already slashed to $5/$25 per 1M input/output tokens, it now sits on the Pareto edge of “brains per token,” even if absolute dollars still run higher than Gemini 3 Pro or GPT‑5.1 for long reasoning chains.
On the harder “AGI‑flavored” tests, Opus 4.5 closes most of the gap with Gemini 3: 43.2% on Humanity’s Last Exam with search against Gemini 3’s 45.8%, and a class‑leading 80.0% / 37.6% on ARC‑AGI‑1/2 among released models. Builders are backing that up with usage: Claude Code and Devin both report 20–30 minute autonomous coding sessions that stay coherent, with some teams routing GPT‑5.1 Pro for planning and handing actual edits to Opus 4.5.
Ecosystem behavior is catching up too: Kilo is hosting a joint deep‑dive on Opus 4.5 workflows, while Epoch’s Capabilities Index quietly shows GPT‑5.1 flat with GPT‑5, making Opus’s token‑efficient rise on alternative leaderboards the more interesting frontier move this week.
Top links today
Feature Spotlight
Feature: Opus 4.5’s post‑launch reality — evals, cost, and fast adoption
Opus 4.5 cements itself post‑launch: AA Index #2 (70) with 48M tokens and ~$1.5k eval cost, rapid integrations (Perplexity, Devin), strong HLE results, and builders reporting 20–30 min autonomous coding runs.
Cross‑account focus today shifts from the release to what Opus 4.5 is doing in the wild: independent index placement/cost profiles, coding agent uptake, and early practitioner sentiment. This section owns all Opus 4.5 follow‑ups.
Jump to Feature: Opus 4.5’s post‑launch reality — evals, cost, and fast adoption topicsTable of Contents
🚀 Feature: Opus 4.5’s post‑launch reality — evals, cost, and fast adoption
Cross‑account focus today shifts from the release to what Opus 4.5 is doing in the wild: independent index placement/cost profiles, coding agent uptake, and early practitioner sentiment. This section owns all Opus 4.5 follow‑ups.
Opus 4.5 ranks #2 on AA Intelligence Index with strong token efficiency
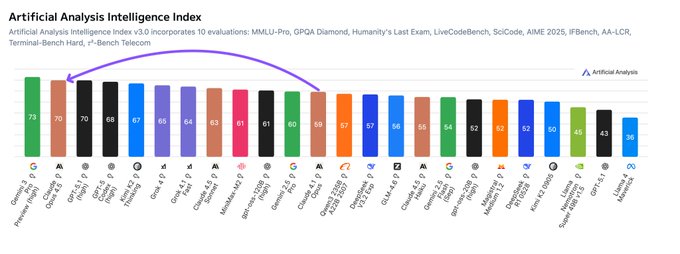
Artificial Analysis now places Claude Opus 4.5 (Thinking) at 70 on its Intelligence Index, tied with GPT‑5.1 (high) and behind only Gemini 3 Pro at 73, while using 48M output tokens and costing about $1.5k to run the full 10‑benchmark suite vs Opus 4.1’s ~$3.1k and 30M tokens. aa index summary
Opus 4.5 also scores 2nd on the new AA‑Omniscience Index with a score of 10, 43% accuracy, and a 58% hallucination rate, sitting between Gemini 3 Pro Preview and earlier Claude/GPT‑5.1 models on knowledge vs fabrication. aa index summary It achieves Anthropic’s best results yet across all 10 component evals (MMLU‑Pro, GPQA Diamond, LiveCodeBench, Terminal‑Bench Hard, etc.), including the top Terminal‑Bench Hard score at 44% and a tie with Gemini 3 Pro on MMLU‑Pro at 90%. aa index summary On the cost and scaling side, Anthropic has cut list pricing to $5/$25 per 1M input/output tokens for Opus 4.5, down from $15/$75 for Opus 4.1 and closer to Sonnet 4.5’s $3/$15, while still using far fewer reasoning tokens than peers like Gemini 3 Pro (92M), GPT‑5.1 (81M), and Grok 4 (120M) for the same AA suite. (aa index summary, tokens and cost chart) For engineers, this means Opus 4.5 sits on the Pareto frontier of “intelligence vs output tokens”, but is still one of the more expensive frontier options in absolute dollars, especially compared to Gemini 3 Pro and GPT‑5.1 when running long, reasoning‑heavy workflows.
Builders report 20–30 minute autonomous coding runs with Opus 4.5
Early users are starting to treat Opus 4.5 as a serious autonomous coder, with multiple reports of 20–30 minute, largely hands‑off sessions that produce clean, idiomatic code for non‑trivial tasks. adam wolff quote
Adam Wolff describes the new Claude Code model powered by Opus 4.5 as “a glimpse of the future we’re hurtling towards,” saying that sessions often run for 20–30 minutes on their own and still yield code he wouldn’t bother to inspect, arguing that soon we’ll check AI output as rarely as we check compiler output. adam wolff quote In parallel, Cognition reiterates that Opus 4.5 is now part of Devin’s model harness and claims “significant improvements to our hardest evals while staying sharp through 30+ minute coding sessions,” building on their earlier integration announcement. (devin harness update, Devin harness) Around these anecdotes, community patterns are forming: one engineer calls the “perfect agentic coding stack” a combo where GPT‑5.1 Pro/Codex Max handles planning and Opus 4.5 handles actual implementation, highlighting its strength in grounded code editing and refactors rather than meta‑reasoning alone. stack suggestion Together these signals suggest Opus 4.5 is becoming the workhorse model inside long‑running coding agents and IDE flows, even when planners or routers lean on other frontier models.
Opus 4.5 closes on Gemini 3 in Humanity’s Last Exam and ARC‑AGI
New numbers on the hardest “AGI‑style” reasoning tests show Opus 4.5 significantly narrowing the gap with Gemini 3 while pulling ahead of GPT‑5 baselines, sharpening the picture that started in earlier benchmark drops. hle bars On Humanity’s Last Exam without search, Opus 4.5 reaches 30.8% accuracy vs GPT‑5 at 24.8%, GPT‑5 Pro at 30.7%, and Gemini 3 at 37.5%; with search, Opus climbs to 43.2% vs GPT‑5 Pro at 42.0% and Gemini 3 at 45.8%, a big jump over Opus 4.1 (22.7%→43.2% with search) and Sonnet 4.5. hle bars
These are the kinds of long‑tail, multi‑step science and reasoning questions people associate with early “research assistant” capabilities.
Separately, the ARC‑AGI semi‑private leaderboard now shows Claude Opus 4.5 (Thinking, 64K) scoring 80.00% on ARC‑AGI‑1 and 37.64% on ARC‑AGI‑2, the best results among released models, with only Gemini 3 Deep Think (Preview) in a similar range at higher per‑task cost. arc agi update
For teams tracking AGI‑flavored benchmarks, this paints Opus 4.5 as a top‑tier reasoning model that trades a few points of raw score for better token efficiency than many of its closest competitors.
Kilo and Anthropic schedule deep‑dive on Opus 4.5 workflows
Kilo announced a live session where its DevRel team and Marius from Anthropic’s Applied AI group will walk through Claude Opus 4.5’s performance, prompting strategies, and workflow impact for developers using Kilo’s coding tools. kilo session The event is pitched as a way to break down how to route tasks into Opus 4.5, tune prompts for its reasoning vs speed trade‑offs, and understand where it outperforms previous Claude models inside real engineering pipelines, rather than just on benchmark charts. kilo session For AI engineers and team leads, this kind of joint education session is a sign that Opus 4.5 is now important enough in day‑to‑day stacks that ecosystem tools are investing in formal guidance, not just toggles in a model picker.
📊 Leaderboards tighten: ECI parity and creative writing reshuffle
Today is rich with non‑Opus eval signals. Excludes Opus 4.5 specifics (covered in the feature) and instead tracks GPT‑5.1 parity, creative writing standings, and ARC‑AGI preview plots.
Epoch Index shows GPT‑5.1 matching GPT‑5 at 151
Epoch AI’s latest Capabilities Index update scores GPT‑5.1 (high) at 151, essentially identical to GPT‑5 (high), and notes that 5.1 mainly spends more tokens on hard items without measurable accuracy gains. eci comparison
For engineers and evaluators, this says GPT‑5.1 doesn’t represent a new capabilities frontier over GPT‑5 on this composite benchmark; it’s more of a behavioral/feature refresh than a raw IQ jump, so there’s little reason to re‑route eval-heavy workloads based on ECI score alone, though the higher token usage on difficult problems may matter for latency and cost-sensitive deployments.
ARC‑AGI‑1 leaderboard shows Gemini 3 Deep Think near 80% at high cost
Updated ARC‑AGI‑1 plots from the ARC Prize team now show Gemini 3 Deep Think (Preview) clustered near the 80% score line but at the far right of a log‑scaled cost‑per‑task axis, signaling strong abstract reasoning performance that currently comes with a steep inference bill. arc agi scores
Complementary ARC‑AGI‑2 numbers discussed elsewhere put the same Gemini Deep Think preview at 47%, well ahead of other released models like Gemini 3 Pro (31%), Grok 4 (18%), Claude Sonnet 4.5 (15%), and GPT‑5 (12%), underlining that state‑of‑the‑art systematic generalization remains expensive and still far from saturation even at the top of the leaderboard. arc agi context
GPT‑5 Pro leads Creative Writing Benchmark with 8.47 mean score
A new Creative Writing Benchmark ranking 400 human‑judged stories (600–800 words) puts GPT‑5 Pro on top with a mean score of 8.47/10, barely ahead of GPT‑5.1 (medium reasoning) at 8.44 and GPT‑5 (medium) at 8.43, while Gemini 3 Pro Preview sits 5th at 8.22 and Claude Opus 4.5 variants land in the top ten around 8.17–8.22. writing benchmark
The spread between the leading closed models is small—roughly 0.3 points across the top 5—which suggests that for long‑form narrative and stylistic work, model choice will hinge more on price, safety, and tool ecosystem than on headline "creativity" scores; the chart also reinforces the broader pattern that Ethan highlights, where looking back 6–8 months shows a clear upward drift in multi‑task benchmarks even if each incremental release feels modest. capability trend
🧰 Computer‑use and browsing agents grow up
Hands‑on agent stacks for real computer use and automated browsing. Excludes Opus 4.5 integration stories (feature) and focuses on platforms you can wire up today.
Hugging Face ships a Qwen3‑VL computer‑use agent with E2B sandbox
Hugging Face quietly rolled out a browser/computer‑use agent that wires Qwen3‑VL models into an E2B sandbox, so the model can actually click, type, and navigate while exposing every tool call and reasoning step in a simple web UI agent demo.

The app lets you pick different Qwen3‑VL variants, then watch the agent plan, execute OS or browser actions, and iterate, which makes it a practical way to debug real computer‑use flows instead of guessing from plain chat transcripts agent demo. Because it runs in a managed sandbox and already handles the browser plumbing, you can plug this into higher‑level agent stacks today to prototype automated web tasks (onboarding flows, dashboard checks, simple backoffice chores) without standing up your own Playwright/Selenium infra agent page.
Hyperbrowser introduces cloud browser substrate for autonomous agents
Hyperbrowser is positioning itself as "browser infrastructure for AI agents": a hosted cloud‑browser layer that agents can drive via APIs instead of humans clicking in a normal UI platform overview. It exposes primitives like /scrape, /crawl, and /extract plus automated browsing control, so you can script multi‑step sequences (search, paginate, click, parse) from your agent stack without running or scaling your own headless Chrome fleet.
For AI engineers building research, lead‑gen, or KYC agents that must reliably browse arbitrary sites, this shifts the hard part from browser orchestration to prompt and tool design, and makes “use the web like a person” a single, abstractable tool rather than a bespoke mini‑platform per product.
📄 Document AI and OCR stacks: compact models, day‑0 serving
Multiple document AI drops: a compact SOTA OCR model, immediate vLLM serving, and a practical two‑stage layout→recognition pipeline. Mostly OCR/document parsing; little generic RAG today.
Tencent open-sources 1B HunyuanOCR with vLLM day-0 serving
Tencent released HunyuanOCR, a compact ~1B-parameter end-to-end OCR model that hits a SOTA score of 860 on OCRBench for sub‑3B models and 94.1 on OmniDocBench, while handling text spotting, complex documents, subtitles, and 14‑language photo translation in a single pass HunyuanOCR launch. The vLLM team shipped a day‑0 usage guide showing how to serve it behind an OpenAI‑compatible API, including recommended low temperature settings and disabling prefix caching for better OCR behavior vLLM support HunyuanOCR guide.
For engineers, the stack matters more than any single benchmark: you get a small model that can parse real‑world documents (tables, formulas to HTML/LaTeX, full‑page markdown, video subtitles) and can be dropped into existing OpenAI client code via vLLM with a few config tweaks HunyuanOCR launch. The combination of high scores for a 1B model plus turnkey serving makes this attractive for latency‑ or cost‑sensitive workloads like on‑prem document ingestion, browser‑side assist tools, or as a specialized OCR stage in larger RAG systems instead of calling a frontier multimodal model for every page.
PaddleOCR-VL pushes two‑stage layout + 0.9B VL recognizer for documents
PaddlePaddle highlighted PaddleOCR‑VL, a document AI stack that cleanly separates layout understanding from recognition: an RT‑DETR‑based PP‑DocLayoutV2 first detects blocks (text, tables, formulas, charts) and predicts human‑like reading order, then a 0.9B visual‑language model with NaViT‑style dynamic resolution plus ERNIE 4.5‑0.3B decodes each region PaddleOCR-VL overview.
The point is: instead of one huge end‑to‑end model hallucinating layout, this two‑stage design stabilizes multi‑column and mixed layouts, boosts throughput by parallelizing element‑level recognition, and makes it easier to bolt on new element types like code blocks or diagrams. For builders working on large‑scale PDF → markdown/JSON → RAG pipelines, this gives a concrete architecture pattern—detect/crop/recognize/reassemble—that’s already wrapped in a public demo and API, rather than a research‑only prototype PaddleOCR-VL overview.
🏗️ AI infra and national initiatives: deadlines and demand
Compute and public‑sector platform signals dominate: a DOE‑run AI initiative with tight deadlines plus hyperscaler/chip demand notes. Excludes model launches.
Nvidia faces roughly $500B in AI chip and networking demand
Nvidia CEO Jensen Huang reportedly told investors the company is staring at around $500 billion in demand for AI chips and networking, underscoring a multi‑year backlog for core AI infrastructure capacity nvidia demand quote. For anyone planning large training or inference fleets, that number reinforces that GPU and high‑speed interconnect scarcity will stay a planning constraint, not a short‑term blip.
For engineers and infra leads, the point is: assume persistent queueing for top‑tier accelerators and design around it with better utilization, routing, and model efficiency rather than waiting for supply to magically catch up. For analysts, the figure helps explain why hyperscalers keep ramping capex and why alternative accelerators, sparsity tricks, and serving efficiency work all have real commercial room, even if model‑level benchmarks grab more headlines.
AWS footprint hits 900+ facilities across 50+ countries amid AI capex surge
Commentary today highlights that Amazon is pouring record capital into AI‑focused data centers, with AWS now operating 900+ facilities across more than 50 countries aws capex note. That scale makes clear why AWS remains a default choice for many AI workloads and why new regional GPU clusters keep appearing even as capacity feels tight.
For AI teams, this footprint matters because it shapes where low‑latency or data‑sovereign deployments are realistic, and how quickly new regions might get meaningful GPU pools. For leaders tracking competition, it’s another reminder that AI infra is consolidating around a few players that can afford both the capex and the regulatory work needed to run hundreds of sites globally.
Anthropic teams up with Microsoft and Nvidia for Claude hosting and GPUs
A circulated clip frames Satya Nadella as playing “4D chess” as Anthropic partners with Microsoft and Nvidia, with Microsoft set to host Claude models while Nvidia supplies the underlying GPU stack anthropic partnership note. This effectively turns Claude into a first‑class citizen on another hyperscaler’s infrastructure, alongside Anthropic’s existing distribution via AWS and others.
For AI engineers, this likely means more native surfaces to reach Opus and the wider Claude family from Azure‑centric stacks, plus another major GPU pipeline behind those endpoints. For strategists, the three‑way tie‑up highlights how model labs, cloud platforms, and chip vendors are locking into cross‑aligned alliances, which will influence pricing, regional availability, and which models feel “default” inside different enterprise ecosystems.
💼 Monetization and distribution signals
Business updates beyond the feature: ad‑funded inference traction, traffic spikes, community promos, and an early pre‑seed. Excludes Opus 4.5 integrations (see feature).
AmpCode’s ad-funded free tier rumored at $5–$10M ARR
AmpCode’s ad-supported “free with ads” coding agent is already rumored to be generating on the order of $5–$10M in annual recurring revenue, using ads to subsidize inference while reserving a paid “smartest agent” tier for harder work. The launch slide frames the split clearly: a free Rush mode backed by cheaper models like Haiku, Grok Code Fast 1, Kimi K2 and Qwen3 for quick tasks, and a paid mode for complex bugs with no incentive to nerf results AmpCode slide.
A follow‑up internal proposal from the founders suggests going even further, turning "Amp Free" into a daily dollar allowance that can be spent on any mode (including the expensive smart tier) before falling back to paid credits, with ads shown whenever the allowance is active Amp free idea. The point is: AmpCode is the first mainstream coding agent leaning hard into an ad-funded model for inference, and if the ARR rumors are accurate it proves that “YouTube economics” for code assistants is viable much sooner than most teams expected.
Grok 4.1 spike hits nearly 10M daily visits on release
Grok 4.1’s public release drove a sharp traffic spike, with Similarweb data showing daily visits to grok.com approaching 10M around the November 18 launch, well above the 6–8.5M band it had been oscillating in previously Grok visits chart. That’s a big jump in attention for xAI’s assistant, and it happened in a week already crowded with GPT‑5.1, Gemini 3, and Opus 4.5 launches.
For AI engineers and product leads, this is a signal that Grok is becoming a distribution channel you can’t entirely ignore, especially if xAI follows through on Elon Musk’s hints about Grok 5 having live video input and human‑level reflex constraints for games Grok 5 constraints. It also shows that new model drops can still move user behavior meaningfully, even in a saturated assistant market.
Riverline.ai raises $825k pre-seed to simplify AI data flows
Riverline.ai closed an $825k pre‑seed round led by South Park Commons, with follow‑on investment from DeVC Global and Gradient Ventures among others riverline funding. The team is building an “AI data plumbing” layer, aiming to help companies wire data and models together without re‑implementing pipelines from scratch.
This is a small but telling funding event: investors are still writing early checks for infrastructure that makes it easier to operationalize LLMs, not just for yet another chat UI. If Riverline can abstract away messy ETL and routing, it could sit in the same stack tier as tools like LangChain or Airbyte, but with a stronger focus on production dataflow rather than agent logic.
KwaiKAT uses referral promo to sell higher API limits
KwaiKAT launched a “Coder Friend‑zy” campaign that trades referrals for temporary throughput boosts on its KAT‑Coder‑Pro V1 model: invite three new users who make at least one successful API call and you unlock RPM 100 and TPM 400M for one day, stackable up to 30 days KwaiKAT promo. It’s still a free model, but the promotion effectively turns usage limits into a growth lever.
The design is clever for AI infra teams to watch: instead of discount codes, Kwai is selling priority access—more requests per minute and more tokens per minute—as the main incentive. That reinforces a trend where capacity (RPM/TPM, queue priority) becomes the primary currency in growth loops for API‑first AI products, especially those courting heavy experimenters and small teams who are price‑sensitive but hungry for bursts of speed.
📑 New research: abstention, benchmark QA, and review dynamics
A compact set of fresh papers with practical angles: better abstention, automatic benchmark item QA, and empirical insights into ICLR rebuttals. Also theory on explicit agent structures and an MM reasoning recipe.
Aspect-Based Causal Abstention teaches LLMs when to say “I don’t know”
A new paper from RMIT proposes Aspect-Based Causal Abstention (ABCA), a method that gets LLMs to inspect their own knowledge from several perspectives before answering and to abstain when internal evidence conflicts or is too weak. Instead of only looking at final answers or self-check prompts, ABCA asks the model to generate multiple reasoning chains across aspects like historical, legal, or recent context, then uses those to decide between a concrete answer and two abstention types (conflict vs ignorance), reducing confident wrong answers while preserving overall accuracy. abca summary For engineers building production assistants, the key point is that abstention is decided before answer generation, based on structured internal disagreement rather than shaky post-hoc heuristics. That makes it easier to wire ABCA-style prompts into toolchains that must choose between calling a model, escalating to a human, or asking for more data, especially on mixed factual/tricky questions where hallucinations are most costly. abca summary
“Agentifying Agentic AI” argues LLM agents need explicit beliefs, goals, and plans
The "Agentifying Agentic AI" paper argues that current practice—bolting tools onto a single LLM and hoping its next-token predictions line up with good behavior—is not enough for real-world agents. agent theory summary Because LLMs reason over documents, not grounded world states, they can treat impossible or harmful actions as fine, and they can choose different actions for the same request depending on small prompt shifts.
The authors advocate reusing ideas from classic Autonomous Agents and Multi-Agent Systems: give agents explicit, inspectable beliefs, goals, and plans, plus typed messages, norms, roles, and shared plans so multiple agents coordinate rather than just talking. agent theory summary For people building serious workflow or organizational agents, this points toward hybrids where LLMs generate or update structured mental state, but the decision logic and coordination live in explicit, auditable machinery that can be checked, constrained, and explained.
“Fantastic Bugs” flags broken benchmark questions using only model response patterns
Stanford’s "Fantastic Bugs and Where to Find Them in AI Benchmarks" shows you can automatically spot bad benchmark items just from how different models get them right or wrong, no manual inspection required. benchmark bug summary The method treats a benchmark like an exam taken by many models, assumes one dominant underlying skill, and then uses test-theory style statistics to flag questions whose score patterns don’t line up with overall ability.
Experts reviewing the flagged items found that up to 84% truly had issues—ambiguous wording, wrong answer keys, or grading bugs—so this is more than theory. benchmark bug summary For anyone running leaderboards or relying on composite scores, the paper is a strong nudge to add an automatic QA pass like this before publishing results, and to routinely re-check legacy benchmarks where even a small fraction of flawed items can distort model rankings and research conclusions.
DeepSeek Sparse Attention beats Native Sparse Attention on long-context tasks
A Zhihu deep-dive compares DeepSeek Sparse Attention (DSA) to Native Sparse Attention (NSA) and finds DSA reliably performs better on long-context retrieval tasks thanks to two design choices: supervising its indexer with true attention scores, and using token-level rather than block-level sparsity. dsa article That means the part of the model selecting key–value pairs is trained on the actual objective—"pick the important tokens"—instead of being nudged only by language-model loss.
The piece also walks through how DSA’s training is made memory-feasible by fusing the index-scoring and top‑k selection into a single TileLang kernel with a 2K buffer and bitonic-sort merge, avoiding O(n²) storage that would kill FlashAttention’s savings. dsa article For infra and model engineers experimenting with long-context sparsity, this gives both a conceptual template—distill attention scores and stay token-level—and a practical recipe for implementing the heavy bits without hand-written CUDA.
DiRL shows diffusion LMs can match 32B autoregressive models with smart RL
Fudan’s DiRL framework tackles a missing piece for diffusion language models: how to actually do supervised fine-tuning and RL-style post-training when there are no token-level logits. dirl article DiRL combines a tailored SFT stage with DiPO, a diffusion-native RL method that optimizes at the generation-step level, filters zero-advantage samples, and stays aligned with the diffusion training objective.
On benchmarks, an 8B diffusion LM trained with DiRL reaches about 83% on MATH500, 93% on GSM8K, and 20%+ on AIME 2024/2025, putting it in the range of or ahead of 32B autoregressive baselines. dirl article For teams tracking non-autoregressive alternatives, this is an early but concrete signal that diffusion LMs aren’t just a curiosity—they can be post-trained and RL-optimized into strong reasoning models if you’re willing to adopt a bespoke RL recipe rather than reuse PPO/GRPO off the shelf.
ICLR review data shows rebuttals rescue about 20% of accepted papers
A large-scale analysis of ICLR 2024–2025 review logs finds that author rebuttals mostly matter for borderline papers, and that roughly 20% of ultimately accepted submissions likely crossed the accept line because reviewer scores rose after rebuttal. iclr study summary Most reviews never change scores at all, and when they do, the movement is usually upward rather than downward.
The study also shows reviewers’ scores converge after they see each other’s reports—disagreements shrink—while LLM-based tagging of review text links low scores to unclear writing, weak experiments, and shaky methods, and high scores to novel ideas and solid methodology. iclr study summary For researchers, the message is pragmatic: rebuttals help most when your initial scores are middling, other reviewers are already somewhat positive, and you respond with concrete new evidence or clarifications instead of vague defenses.
⚖️ Policy and legal: branding dispute and state‑rule pause
Governance/legal items relevant to AI operations. Excludes safety system cards and model behavior (covered yesterday); today centers on a trademark TRO and regulatory posture signals.
Court bars OpenAI from using “Cameo” name in Sora features
A federal judge in the Northern District of California granted Baron App (Cameo) a temporary restraining order blocking OpenAI from using the “Cameo” mark for any Sora video‑generation feature or related marketing in U.S. commerce until December 22, 2025 tro document. The order explicitly covers variants like “Cameos”, “CameoVideo” and “Kameo”, and sets a December 19 hearing on a preliminary injunction, signaling that courts will move quickly when AI labs name new features after well‑known consumer services.
For AI leaders, this is a concrete reminder that playful or descriptive feature names can cross into trademark territory long before a product reaches scale, and that branding reviews need to be part of launch checklists alongside privacy and safety. Teams shipping Sora‑style tools or packaged “apps” on top of models should assume that established platforms will aggressively defend their marks if an AI feature risks user confusion over affiliation or endorsement.
White House pauses AI order that would weaken state‑level AI rules
Reporting today says the White House has backed off and paused a draft AI executive order that would have undercut or preempt many state‑level AI regulations, leaving those state rules fully in force for now state order pause. That means companies still have to design AI governance around a patchwork of state laws—rather than a single federal baseline—even as legislators in places like California and Colorado keep tightening requirements.
For AI policy and compliance teams, the point is: do not bet on near‑term federal preemption to simplify your obligations. You still need clear inventories of which AI systems operate in which jurisdictions, how they touch consumers or workers, and which transparency, risk‑assessment, or audit duties apply under each state regime, because the hoped‑for harmonization just got pushed further out.
Fei‑Fei Li disputes Hinton’s 10–20% AI extinction risk estimate
Fei‑Fei Li has publicly disagreed with Geoffrey Hinton’s claim that there is a 10–20% chance advanced AI leads to human extinction, saying she does not share that level of existential risk estimate risk debate. This isn’t a formal policy move, but it highlights how divided top researchers remain on framing AI danger to governments and the public.
For people working on AI policy or corporate governance, this divergence matters because it shapes which narratives get traction: arguments for aggressive, precautionary regulation lean on higher x‑risk probabilities, while more moderate voices like Li’s can be used to justify focusing on nearer‑term harms (jobs, bias, security) over speculative catastrophe. Expect regulators and industry lobbyists to selectively cite these differing expert views to support very different rulemaking agendas.
🎬 Creative pipelines: NB Pro + Kling loops and prompts
A sizable share of posts cover creative workflows. Focus on practical ImagineArt recipes, model pairings, and community prompts; no new model releases today.
ImagineArt workflow chains NB Pro and Kling 2.1 into seamless video loops
A detailed community tutorial shows how to build an ImagineArt Workflow that uses Nano Banana Pro for stills and Kling 2.1 Pro for start/end‑framed clips to create perfectly looping "alien in my head" transitions in minutes. The guide walks through adding an Upload node, a long instruction prompt, a 16:9 NB Pro image node, then splitting the before/after frames into separate images and finally wiring two Kling 2.1 Pro video nodes whose first/last frames are explicitly bound to those stills, so the opening and closing shots match for a clean loop workflow overview image node setup.
Screenshots and alt‑text include the full prompts for extracting left/right halves of the composite "BEFORE/AFTER" image and for the two transformation clips, plus a diagram clarifying that the initial still feeds the top clip’s first frame and bottom clip’s last frame, while the final still does the inverse to close the loop split frame prompts loop wiring.
For engineers and motion designers, this effectively codifies a reusable pattern: NB Pro handles semantic transformation and composition, while Kling 2.1 Pro provides high‑quality motion with frame anchoring, turning complex VFX‑style transitions into a shareable node graph rather than bespoke timeline work video nodes demo.
Creators praise ImagineArt 1.5 for highly realistic renders
User feedback is starting to match the earlier hype around ImagineArt 1.5’s realism, with one creator calling it “an insane model, sooo realistic” after trying the latest version user praise. Following up on image preview, which framed 1.5 as a photoreal contender, this kind of unsolicited reaction suggests it’s now good enough to stand in for portrait and lifestyle shoots in practical pipelines, especially when paired with structured workflows like the NB Pro + Kling recipes circulating today.
Nano Banana Pro nails voxel re-creations of classic memes
New samples show Nano Banana Pro rendering multiple classic memes—Wojak mask, Doge on a couch, the buff‑vs‑skinny "Chad" scene, and the Distracted Boyfriend photo—as coherent 3D voxel/8‑bit sculptures, all in one small gallery nb pro showcase.
The outputs keep pose, composition, and recognizability while switching to a chunky block aesthetic, reinforcing earlier observations about NB Pro’s strong layout and style control across very different prompts prompt grids. For teams prototyping indie games, toy brands, or collectible packs, this is a concrete signal that NB Pro can handle consistent stylized asset sets, not only single hero shots.
Viral "cursed plastic surgery" prompt becomes a reusable style recipe
A meme thread of celebrities given grotesquely overdone cosmetic surgery—swollen lips, taped‑back skin, identical hotel‑lobby lighting—highlights how a single long prompt can lock an image model into a very specific, repeatable aesthetic across dozens of subjects thread opener.
Follow‑up posts show the same look applied to Taylor Swift, Messi, Kamala Harris, Pedro Pascal, LeBron James, Shakira and others, and the author ends by sharing the full text prompt as a public recipe that “works on ANY CHARACTER,” turning this from a one‑off joke into a portable style preset anyone can plug into their own model or UI prompt link prompt page. For people building consumer image apps, it’s a good reminder: users will happily standardize on long, ugly prompts if they reliably produce a distinctive “filter” others recognize.
🤖 Humanoids: agility clips and fine manipulation
Light but notable embodied AI items: an agile biped demo and a Germany‑based full‑size humanoid with small‑part handling. No product SKUs or pricing.
Agile One humanoid debuts with tiny-screw picking and touchscreen skills
Germany’s Agile Robotics has unveiled Agile One, a full‑size humanoid able to pick tiny screws, tap touchscreens, and “feel” its way around using real‑world‑trained AI, signaling that fine manipulation is catching up to the agility demos from labs like MagicLab Z’s biped. Agile One teaser

For engineers and robotics leads, this points to humanoids moving from pure balance and locomotion benchmarks toward factory‑relevant dexterity and haptic‑style perception, where high‑precision part handling and safe interaction with off‑the‑shelf devices (e.g., industrial touch UIs) become realistic design targets rather than purely scripted showpieces.