.png&w=3840&q=75&dpl=dpl_3ec2qJCyXXB46oiNBQTThk7WiLea)
Gmail Gemini Inbox targets 3B users – AI Overviews reframe email
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Google is rolling Gmail into the “Gemini era,” seeding AI Inbox and AI Overviews to trusted testers before a multi‑month expansion; AI Inbox restructures mail into prioritized summaries and task‑like highlights, while AI Overviews sit on top of threads, answering questions like “What was decided?” with inline citations. Gemini 3 is also wiring into core flows: “Ask your inbox” turns natural‑language queries into synthesized answers plus source links; Help Me Write and upgraded Suggested Replies become free for most users; a new Proofread mode and the full AI Inbox view are reserved for Pro/Ultra tiers. With Gmail’s ~3B‑user footprint, commentators argue this integration could quickly make Gemini the most widely used AI assistant, eclipsing standalone chatbots.
• Runtime and routing: vLLM’s async KV offload reports up to 9× H100 throughput and large TTFT gains; OpenRouter’s new Partition Sorting and 3‑model compare UI push latency/throughput caps into first‑class routing controls.
• Multimodal retrieval stack: Alibaba’s Apache‑2.0 Qwen3‑VL‑Embedding/Reranker posts SOTA claims on MMTEB/MMEB‑v2; vLLM, SGLang and SentenceTransformers move to support it as a default multimodal retriever.
• Compute economics and scale: Epoch tallies >15M H100‑equivalents deployed with >10 GW draw; NVIDIA’s Rubin roadmap targets ~100× Hopper tokens‑per‑watt and month‑long 7T‑param runs, while reports say Microsoft may cut 5–10% of staff to redirect spend into AI infrastructure.
Top links today
- SSRN study on LLM scaling efficiency
- Stanford paper on AI benchmark validity
- Nature paper on political bias in LLMs
- EquaCode jailbreak attacks via math and code
- Lightweight LLM hallucination detection methods
- RoboPhD self-improving text-to-SQL agents
- LLM agents for portfolio optimization
- Self-verifying LLM passes Japanese bar exam
- JMedEthicBench medical safety benchmark for LLMs
- StockBot 2.0 LSTM vs transformer forecasting
- Setup guide for 16x MI50 DeepSeek v3.2
- Business Insider on Musk v. OpenAI trial decision
Feature Spotlight
Feature: Gmail enters the Gemini era (AI Inbox + AI Overviews)
Gmail begins rolling out Gemini-powered AI Inbox and AI Overviews—bringing summarization, question answering, and writing help into email at 3B-user scale. Trusted testers now; broader rollout in coming months.
Biggest cross‑account story today: Gmail starts rolling out Gemini-powered AI Inbox, AI Overviews, “Ask your inbox,” Proofread, and upgraded suggested replies. Strong distribution angle; excludes other enterprise items covered yesterday.
Jump to Feature: Gmail enters the Gemini era (AI Inbox + AI Overviews) topicsTable of Contents
📬 Feature: Gmail enters the Gemini era (AI Inbox + AI Overviews)
Biggest cross‑account story today: Gmail starts rolling out Gemini-powered AI Inbox, AI Overviews, “Ask your inbox,” Proofread, and upgraded suggested replies. Strong distribution angle; excludes other enterprise items covered yesterday.
Gmail begins rolling out Gemini-powered AI Inbox and AI Overviews
Gmail Gemini features (Google): Gmail is starting its "Gemini era" with AI Inbox and AI Overviews now rolling out to trusted testers, with a broader launch "over the coming months" according to the product leads in the launch video and rollout note; AI Inbox restructures the inbox into prioritized summaries and to‑dos, while AI Overviews condense long threads into short recaps that sit above the conversation, as described in the gmail blog post and unpacked by independent breakdowns in the feature explainer.

• Rollout scope: Google frames this as an opt‑in experiment for "trusted testers" first, with AI Inbox and AI Overviews appearing in select accounts before a multi‑month expansion to regular users, as stated in the rollout note and reiterated in the gemini overview clip.
• Reading experience: AI Overviews can answer natural‑language questions about a thread ("What were the main decisions?") and highlight deadlines or action items directly from email content, with each answer citing the specific source emails it pulled from, per the gemini overview clip and google blog post.
• Positioning: Logan Kilpatrick calls this "the first big step into the Gemini era" for Gmail, emphasizing that these capabilities sit directly in the standard inbox UI rather than a separate chatbot, as shown in the launch video.
The point is: Gmail is moving from static folders and search to an AI‑layered inbox where summarization and question‑answering become default reading primitives rather than optional side tools.
Gemini adds Ask Inbox, Proofread and smarter replies across Gmail tiers
Gemini 3 in Gmail (Google): Beyond AI Inbox, Gemini 3 is being wired into three main surfaces in Gmail—reading, searching, and composing—with "Ask your inbox" search, upgraded Suggested Replies, Help Me Write, and a new Proofread mode, with some features free and others limited to Google AI Pro and Ultra tiers, as detailed in the feature thread and the underlying gmail product blog.

• Ask your inbox: Users can type natural‑language questions like "What travel emails need replies this week?" and receive a synthesized answer plus links to the underlying messages, instead of a traditional list of search results, according to the feature thread and feature explainer.
• Writing tools: Help Me Write and the refreshed Suggested Replies—now using full‑thread context for tone and details—are becoming free features, while a new Proofread button adds grammar, tone, and style suggestions on top of basic spellcheck for paying Pro/Ultra accounts, as spelled out in the gmail blog post.
• AI Inbox vs core Gmail: Google positions AI Inbox (with task‑like highlights and quick catch‑up tiles) as an optional view for paid tiers, while the underlying AI Overviews, Ask Inbox, and writing helpers are gradually being woven into the standard Gmail interface for both free and paid users, per the feature explainer.
So what changes compared to before is that Gemini shifts Gmail from canned smart replies and keyword search to a full stack of question‑answering, drafting, and review tools, with a clearer line between free assistance and higher‑touch, subscription‑only automation.
Gemini in Gmail set to become most widely used AI assistant
Distribution angle (Google): Commentators highlight that roughly 3 billion people use Gmail today, arguing that once Gemini is deeply integrated into reading, search, and prioritization flows, it is likely to be used by more people than any other AI system, as framed in the distribution take and echoed by the official launch messaging in the launch video.
• Usage expectation: The claim is that distribution, not just raw model quality, will shape the next phase of AI usage—Gemini 3 showing up as AI Inbox, AI Overviews, and writing helpers inside a default email client gives it a daily touchpoint that standalone chatbots lack, per the distribution take.
• Context of other rollouts: This Gmail integration lands the same week as other Gemini 3 deployments (for example in Google Classroom and Chrome), but posts about Gmail specifically call it "Inbox reborn" and "the Gemini era" because of the scale of potential adoption, as seen in the feature thread and feature explainer.
The upshot is that while benchmarks still compare Gemini against other frontier models, this move puts Google’s assistant into an everyday workflow for billions of users, turning email into one of the primary on‑ramps for mainstream AI interaction.
🚀 Serving speed and routing: vLLM KV offload + OpenRouter controls
Runtime engineering dominated today: vLLM’s async KV offloading (big H100 gains), DMA pipeline details, and OpenRouter’s new Partition Sorting and 3‑model compare UI. Excludes Gmail feature.
vLLM ships async KV offloading connector with up to 9× H100 throughput
KV offload connector (vLLM): vLLM introduced a KV Offloading Connector that asynchronously moves KV cache to CPU RAM, which the team reports yields up to 9× higher throughput on H100 and 2×–22× lower time‑to‑first‑token for cache hits by handling preemptions without stalling GPUs, as described in the kv offload announcement and the vllm blog post. It exposes a --kv_offloading_backend native flag plus a --kv_offloading_size <GB> cap, and the deep dive explains that reorganizing GPU memory into large contiguous blocks enables high‑bandwidth DMA transfers that run fully asynchronously with compute, turning KV cache into a larger, slower tier instead of a hard limit on batch size flag usage.
OpenRouter adds Partition Sorting to enforce min throughput and max latency
Partition Sorting (OpenRouter): OpenRouter shipped a Partition Sorting feature that lets callers specify preferred_min_throughput and preferred_max_latency so routing only considers models whose observed performance meets those floors, while still preserving the existing price‑aware load‑balancing logic partition feature. According to the docs linked from the announcement, these knobs act as hard filters (optionally combined with a cost cap) inside the router’s historical metrics so users can, for example, exclude slow but cheap backends or force a minimum tokens‑per‑second per dollar without introducing extra latency from per‑request probing routing docs.
OpenRouter launches 3‑way model comparison UI with popularity and latency charts
Model compare UI (OpenRouter): OpenRouter rolled out a new 3‑model comparison view where users can pick any three models and see side‑by‑side charts for popularity over time and latency, along with inline generation tests in a single page compare ui tweet.

• Routing insight: The video shows separate panels for "Popularity" and "Latency" per model, giving routing engineers a quick way to visualize trade‑offs between usage, speed, and (on other tabs) cost before setting Partition Sorting thresholds or updating app‑level model fallbacks compare ui tweet.
• Ecosystem positioning: This ships alongside provider‑side features like generation feedback and a providers explorer from earlier in the week, reinforcing OpenRouter’s role as an aggregation layer where model selection and routing policy are treated as first‑class surfaces rather than hidden config olmo promotion.
vLLM community reports 16k TPS on B200 with new serving stack
B200 throughput (vLLM): A community benchmark shared with the vLLM team shows ~16,000 tokens per second on NVIDIA’s B200 for a single deployment, which the project maintainers amplified as evidence of what their latest serving optimizations (including KV offload and scheduling work) can do on next‑gen hardware b200 tps result. The tweet does not provide an exact setup (model size, batch mix, context length), so this number is best read as an upper‑bound anecdote rather than a standardized benchmark.
🧲 Qwen3‑VL multimodal retrieval lands—and spreads to stacks
Most notable release news is Alibaba’s Qwen3‑VL‑Embedding/Reranker for multimodal retrieval with quick ecosystem pickup (vLLM, SGLang). Mostly embeddings/rerank SOTA posts; excludes creative/video models covered elsewhere.
Alibaba releases Qwen3‑VL‑Embedding and Reranker as open multimodal retrieval stack
Qwen3‑VL‑Embedding/Reranker (Alibaba Qwen): Alibaba’s Qwen team shipped the Qwen3‑VL‑Embedding and Qwen3‑VL‑Reranker models as open weights, with 2B and 8B variants that handle text, images, UI screenshots and sampled video frames in 30+ languages and report state-of-the-art results on MMTEB and MMEB‑v2 according to the launch and evaluation threads release thread and eval results. The models follow a two‑stage architecture where a unified embedding model maps all modalities into a shared space and a reranker computes fine‑grained relevance scores, with full docs, tech report and code available on Hugging Face, GitHub and ModelScope as shown in the linked resources embedding collection and github repo.
• Retrieval design: Qwen3‑VL‑Embedding is positioned for image‑text search, video search, multimodal RAG and clustering, while Qwen3‑VL‑Reranker refines candidate sets for higher precision in cross‑modal matching, as outlined in the architecture overview architecture overview.
• Performance claims: The team highlights state‑of‑the‑art scores on multimodal retrieval benchmarks MMEB‑v2 and MMTEB and provides a detailed technical report plus evaluation breakdowns for reproducibility eval results and tech report.
• Licensing and access: All variants are released under a permissive Apache‑2.0‑style license with collections on Hugging Face for embeddings and rerankers reranker collection, and an Alibaba Cloud API is "coming soon" for managed serving release thread.
vLLM and SGLang add serving support for Qwen3‑VL‑Embedding/Reranker
Runtime adoption (vLLM, SGLang, libraries): vLLM maintainers announced that nightly builds now support both Qwen3‑VL‑Embedding and Qwen3‑VL‑Reranker, letting users serve multimodal embeddings and reranking with a single --model flag in their usual stack vllm support, while SGLang published a one‑line sglang serve command for Qwen/Qwen3-VL-Embedding-8B including a JSON mm-process-config to control video frame resolution, total pixels and FPS sglang usage. This early infra support is complemented by the SentenceTransformers maintainer saying they will add Qwen3‑VL‑Embedding and rerankers for all modalities, so users can treat them like any other text model in that ecosystem sentence transformers.
• vLLM quick start: The Qwen3‑VL‑Embedding README now includes a vLLM usage section, showing how to install a nightly wheel and launch a server with --is-embedding and multimodal processing options for video, as detailed in the docs vllm usage.
• SGLang multimodal flags: SGLang’s example command includes parameters for minimum, maximum and total pixels plus fps: 1.0, signalling that video support is implemented via configurable frame sampling rather than opaque defaults sglang usage.
• Library ecosystem: Plans to integrate Qwen3‑VL‑Embedding into SentenceTransformers mean text‑only and multimodal use cases can share one API surface across retrieval, reranking and downstream RAG pipelines sentence transformers.
Community frames Qwen3‑VL‑Embedding as Apache‑2.0, matryoshka, multimodal default
Multimodal embeddings as new default (community): Community contributors highlighted that the Qwen3‑VL‑Embedding and Reranker models directly wrap the Qwen3‑VL transformer implementation and must be loaded with helper scripts from the repos, with Apache‑2.0 licensing and built‑in matryoshka (variable‑dimensional) embeddings making them attractive for both research and production retrieval systems community recap and loading tips. A Qwen author went further and said they "do believe that in the future the embedding model should be by default multimodal" and described Qwen3‑VL‑Embedding as a practical attempt at that direction author comment.
The combination of permissive terms, matryoshka support and explicit positioning as the "default multimodal" embedding option signals a push toward treating images, documents and video frames as first‑class retrieval inputs rather than separate, model‑specific pipelines.
🛠️ Agent coding: Claude Code 2.1.2, skills/memory, and cleanup tools
Dense day for agent devs: Claude Code 2.1.2 (security fix, winget, Task max_turns), code-simplifier plugin, RepoPrompt workflows, and deepagents Skills/Memory. Excludes VS Code Agent Skills adoption which is in orchestration.
Claude Code 2.1.2 ships security fixes, better Windows install, and Task caps
Claude Code 2.1.2 (Anthropic): Anthropic pushed Claude Code 2.1.2 with a notable CLI hardening pass—fixing a bash command‑injection bug, resolving a tree‑sitter memory leak, and stopping binary files dragged in via @include from bloating session memory—while also adding Windows winget install support, OSC‑8 clickable file paths, and new controls over how long spawned agents can run, following up on 2.1.0 rollout and 2.1.1 tweaks that introduced Skills and tightened AskUserQuestion behavior.
• CLI and install changes: The 2.1.2 changelog calls out support for Windows Package Manager (winget) with automatic detection and update guidance, improved Option‑as‑Meta hints for macOS terminals like iTerm2/Kitty/WezTerm, more informative SSH image‑paste errors that recommend scp, and a unified /plugins view that groups MCPs and plugins together, as detailed in the CLI changelog and the linked changelog docs.
• Stability and security fixes: Anthropic reports closing a bash command‑injection hole in command parsing, fixing a WASM tree‑sitter parse‑tree leak that caused unbounded memory growth in long sessions, addressing crashes when socket files appear in watched directories, and correcting spurious "installation in progress" update failures, all in the same 2.1.2 drop in CLI changelog.
• Output and analytics behavior: Large bash and tool outputs now stream to disk instead of truncating in‑memory, giving Claude access via file references, while analytics logs no longer expose MCP tool names from user‑specific configs, according to the CLI changelog.
• Task and flags updates: The Task tool’s schema gains a max_turns field so callers can cap how many agentic turns (API round‑trips) a child agent can take before stopping—enforced as an integer >0 and described as a warm‑up control in the diff shown in the prompt diff—and a new tengu_permission_explainer feature flag replaces the older tengu_tool_result_persistence flag in the flag comparison noted in the flag summary.
• Windows managed settings path: For managed environments, 2.1.2 deprecates C:\\ProgramData\\ClaudeCode\\managed-settings.json in favor of C:\\Program Files\\ClaudeCode\\managed-settings.json, which is called out in the CLI changelog as the new path administrators should migrate to.
Taken together, 2.1.2 moves Claude Code’s agent harness toward safer long‑running use on dev machines—especially Windows—while giving integrators more explicit control over how far autonomous Task sub‑agents are allowed to run before they must hand back control.
deepagents SDK adds native Skills and Memory to Ralph Mode harness
Skills and Memory in deepagents (deepagents): The deepagents team extended their Ralph Mode harness by adding native Skills and Memory support to the SDK, so long‑running agent workflows can turn successful behaviors into reusable skills and accumulate run‑by‑run notes that improve future harness runs, building on the Ralph loop pattern that many developers already use for autonomous coding sessions as described in the deepagents update and skills support.
• Ralph Mode as open harness: Ralph Mode is framed as a harness‑level decision—"continual looping and keeping memory with filesystem+git"—where agents run in a loop with progress files and git tracking so developers can fully customize behavior; the team stresses that these harnesses should remain fully open and hackable, according to the deepagents update.
• Skillifying agent progress: With the new SDK features, Ralph can promote successful patterns into Skills—folders of instructions, scripts and config—so many Ralph instances can generate hundreds of skills that act as a knowledge bank for others, all tracked in git for transparency and reuse, as outlined in the deepagents update.
• Persistent run notes via Memory: Memory support lets Ralph write notes during each run about what worked, what failed, and missing context, then later sweep those run histories to automatically improve the harness, a behavior the authors describe as Ralph learning and correcting itself over time in the deepagents update.
• Emerging usage pattern: Anecdotes like "Start Ralph to clone a Company / Go to the Gym / Repeat" in the workflow comment illustrate how some users are already delegating substantial coding workloads to Ralph harnesses while they are away from the keyboard, with these new Skills and Memory primitives intended to make that pattern more robust over time.
This moves deepagents toward a model where agent harnesses are not static prompts but evolving systems that accumulate structured capabilities and experience across many runs.
RepoPrompt CLI and Flow plugin bring context→plan→feature and PR reviews to agents
RepoPrompt CLI workflows (RepoPrompt): RepoPrompt’s maintainer emphasizes that the new CLI exists so teams can stack bulk workflows on top of it—combining context building, planning and code review—and highlights a Flow plugin that drives repo reviews via GPT‑5.2 High, positioning RepoPrompt as a core harness around which other agents operate rather than as a single MCP endpoint, as discussed in the flow plugin demo and cli workflows.
• Context→plan→implement pipeline: The rp-build command encapsulates a three‑step pattern—first researching the codebase and drafting a high‑signal context prompt for the task, then planning the feature, then having an agent implement it—which the author describes as "research the code and a context prompt for the task → use that prompt to plan the feature → agent builds the feature" in the rp-build explainer.
• Flow plugin for reviews: A separate Flow plugin wires RepoPrompt into a review harness where GPT‑5.2 High is used over a constrained scope to comment on changes; early feedback is that with the right scope these "RP Reviews" are strong, according to the flow plugin demo.
• CLI as workflow substrate: The maintainer notes that one of the main reasons to add a CLI (alongside prior MCP integration terminal release) is so others can script bulk operations—like auditing many repos or running standardized refactors—on top of RepoPrompt’s planning and context‑packing capabilities, as framed in the cli workflows.
For agent builders, this shifts RepoPrompt from a one‑off helper to a reusable substrate that upstream agents (Claude Code, Codex, Cursor, etc.) can call for consistent, repo‑aware context and review loops.
Anthropic open-sources its Claude Code "code-simplifier" clean-up agent
Code‑simplifier agent (Anthropic): Anthropic engineers released the internal "code‑simplifier" agent they use on the Claude Code team as an open‑source plugin, exposing it through the Claude plugin marketplace so developers can invoke a dedicated cleanup pass at the end of large coding sessions or on complex PRs, as described in the plugin announcement.
• Install and invoke: Users can install it directly from the Claude Code CLI with claude plugin install code-simplifier, or refresh and add it from the official marketplace via /plugin marketplace update claude-plugins-official followed by /plugin install code-simplifier, with these flows outlined in the plugin announcement.
• Intended usage: The team recommends asking Claude to run the code‑simplifier at the end of long sessions or on tangled PRs so it can refactor and simplify the resulting changeset, a pattern that fits naturally alongside Claude’s own Skills and agent harnesses in day‑to‑day workflows according to the plugin announcement.
This turns what had been an internal maintenance helper into a reusable, shareable component for Claude Code users who want a consistent clean‑up phase in their agentic coding pipelines.
🧩 Skills everywhere: VS Code, orchestration packs, and packaging clarity
Orchestration standardization stepped up: Agent Skills shipped in VS Code stable, orchestration skill packs add dependency tracking/parallelism, and guidance clarifies Skills vs Plugins. Excludes Gmail feature.
VS Code ships Anthropic Agent Skills as a first-class feature
Agent Skills in VS Code (Microsoft / Anthropic): Visual Studio Code now exposes Anthropic’s Agent Skills as a stable capability for its chat-based coding agent, enabled via the chat.useAgentSkills setting according to the VS Code team’s announcement vs code skills; this pushes Anthropic’s folder-based Skills format closer to a de facto standard for packaging agent workflows, following earlier framing of Skills as the successor to GPT-style presets skills framing.

• Editor integration: The feature is live in the current stable build of VS Code, where toggling chat.useAgentSkills lets the agent auto-discover Skills from the workspace (folders with SKILL.md and scripts) and load them on demand rather than stuffing giant prompts, as described in the Microsoft docs linked from the announcement skills docs.
• Open standard positioning: VS Code explicitly calls out Agent Skills as an "open standard created by Anthropic" for instructions, scripts, and resources that specialize coding agents, reinforcing Anthropic’s effort to make Skills portable across Claude Code, Codex, OpenCode, v0, and others vs code skills.
The move gives engineers a mainstream GUI surface that understands the same Skill packs they use in Claude Code and other tools, tightening the feedback loop between prompt-pack authors and everyday IDE users.
Anthropic clarifies Skills vs Plugins and highlights broad adoption
Skills vs Plugins in Claude ecosystem (Anthropic): Anthropic’s Claude Code account published a concise FAQ explaining that Skills are the actual task-specific instruction + tool bundles, while Plugins are distribution containers that can package one or more Skills for installation across clients like Claude Code, Codex, Amp, VS Code, Goose and others skills promo; the example given is frontend-design, which exists both as a Skill and as a plugin that delivers it to compatible tools skills faq.
• Concept split: The FAQ notes that Skills focus on how to do a job (prompts, tools, MCP servers, files), whereas Plugins organize and ship those Skills as part of a larger toolkit, clarifying why something can be "both a plugin and a skill"—the plugin is a wrapper, the Skill is the behavior skills faq.
• Multi-tool adoption: Anthropic and ecosystem developers emphasize that Agent Skills are already understood by a wide set of tools—including Claude Code, Cursor, Codex, Amp, VS Code, Goose, Letta and OpenCode—as shown in the adoption graphic shared around the announcement skills adoption.
• Official repos: The Claude team surfaced separate GitHub directories for official Skills and official Plugins, making the split explicit in code: one repo houses SKILL folders with YAML/Markdown metadata, the other groups them into installable plugin manifests skills repo and plugins repo.
This clarification tightens the mental model for builders who are starting to write their own Skills and helps explain how a single Skill can be reused across many agents and frontends while plugins handle packaging and distribution.
n-skills orchestration Skill adds dependency-tracked multi-agent workflows to Claude Code
Orchestration Skill for Claude Code (Community): A community project called n-skills ships an "orchestration" Skill that turns Claude Code into a dependency-aware multi-agent task runner, wiring tasks into a JSON graph that shows up directly inside Claude Code’s UI via cc-mirror tasks, as detailed in the release thread orchestration skill and its SKILL description skill docs.

• Dependency tracking and parallelism: The orchestration Skill defines tasks plus dependencies in plain JSON, then uses npx cc-mirror tasks to sync them so Claude can plan, route, and execute subtasks in parallel where possible while rendering the dependency graph in the existing tasks view—no core product changes required orchestration details.
• Domain-specific playbooks: It ships with reference "playbooks" for software work, research, and reviews, encoding operating guidelines and when to spin up specialized agents, effectively encapsulating expert workflows into a reusable Skill that any Claude Code 2.1.0 user can install via the /plugin marketplace add numman-ali/n-skills flow orchestration skill.
For teams experimenting with agent swarms, this shows how much orchestration logic can live in a Skill alone, without needing a separate orchestration service or custom UI.
🏭 Compute economics and supply: 15M H100e, Rubin per‑watt gains, China H200 pause
Infra beat centers on compute capacity and cost curves: Epoch’s 15M H100‑equiv dataset, Rubin throughput‑per‑watt narrative, and China’s reported H200 order pause. Excludes device SDK/runtime items.
Epoch AI Chip Sales data shows 15M H100‑equivalents and B300 overtaking H100
AI Chip capacity (EpochAIResearch): Epoch’s new AI Chip Sales explorer estimates that global dedicated AI compute has surpassed 15M H100‑equivalents, up from only a few million a few quarters ago, with non‑NVIDIA accelerators (TPUs, Trainium, MI300X, Ascend) no longer rounding errors in the stack, as described in the epoch announcement and illustrated in the capacity chart. The same work notes that NVIDIA’s B300 GPU now accounts for the majority of its AI chip revenue, while H100s have fallen to under 10% of that mix, according to the b300 revenue breakdown.
• Power and infra implications: Cumulatively deployed accelerators already draw >10 GW of power, roughly twice New York City’s average consumption, even before datacenter overheads, per the power estimate; the study frames tokens‑per‑MW and cooling constraints as first‑order factors in future deployment economics.
• Forward‑looking signals: AMD CEO Lisa Su expects another 100× surge in AI compute in 4–5 years, with AMD parts taking a growing share of that pie, building on the same 15M H100e baseline in the amd forecast.
• Explorer for analysts: Epoch exposes per‑vendor, per‑chip estimates via a public AI Chip Sales explorer, combining earnings disclosures and analyst research into a harmonized H100‑equivalent metric, as detailed in the data explorer.
The point is: capacity growth, vendor mix shift toward B300, and eye‑watering power draw are now quantified in a single public dataset that AI infra teams and investors can reference when modeling training and inference supply curves.
NVIDIA’s Vera Rubin aims for 100× Hopper throughput while targeting 7T‑param Grok 5
Vera Rubin & Grok 5 (NVIDIA/xAI): Jensen Huang reiterated that NVIDIA’s upcoming Vera Rubin training platform will deliver about 10× higher “factory throughput” than Blackwell, and since Blackwell itself is roughly 10× Hopper, Rubin works out to ~100× Hopper tokens‑per‑watt for large‑scale training, as explained in the rubin compute talk; this is explicitly framed around keeping training windows at ~1 month for frontier models. In the same CES‑week conversations, he said Grok 5 is being scoped as a ~7 trillion parameter model under that fixed‑window assumption, with Rubin’s improved efficiency cutting the number of NVL72‑class systems needed to hit that schedule to about one‑quarter of Blackwell’s requirement, following up on Rubin details about NVL72 topology.

• Data‑center economics: Huang tied the roadmap to 1 GW, ~$50B data centers that are power‑limited rather than rack‑limited, arguing that revenue scales with throughput per watt rather than raw FLOPs, and that Rubin’s design is tuned for this regime, as emphasized in the musk throughput clip.
• Interplay with xAI: The Grok 5 target is cited as one of the early Rubin‑class customers, with xAI planning its first GW‑scale cluster at Colossus 2 so a 7T‑parameter model can be trained within a month using the new platform’s higher efficiency, per broader xAI comments in the xai cluster clip.
For AI engineers and infra planners, this sets a concrete expectation: mid‑2020s training runs for multi‑trillion‑parameter models will be gated less by theoretical petaflops and more by how many Rubin‑class racks you can power and cool within a 1‑month window.
Microsoft reportedly plans 11k–22k layoffs as it reallocates budget to AI infrastructure
AI capex shift (Microsoft): A Bloomberg‑style summary shared on X says Microsoft is considering 11,000–22,000 layoffs worldwide in January 2026 (about 5–10% of its workforce) explicitly to "aggressively shift spending toward AI infrastructure," after already recording over $15B in layoff‑related charges in 2025, according to the layoff report.
• Targeted teams and protected areas: The report claims potential cuts could span Azure cloud, Xbox, and global sales, while roles tied directly to AI and core cloud services would remain stable or expand, signaling a rebalancing from software and go‑to‑market headcount into GPU clusters and supporting infra.
• Timing and context: These rumors come amid record profits and follow Microsoft’s heavily publicized multi‑year, multi‑billion‑dollar commitments to OpenAI and in‑house model efforts, with commentators framing the move as another sign that hyperscalers are prioritizing GPU capex over operating expense in non‑AI lines of business, as summarized in the layoff article.
If realized, this would underline how seriously at least one hyperscaler is treating AI infrastructure as the primary sink for marginal dollars in 2026, even at the cost of large workforce reductions in legacy segments.
📑 Reasoning control and eval methods: SQL evolution, anchoring, fast checks
Research focus today is reasoning & verification: an evolved Text‑to‑SQL system (RoboPhD), anchoring/coordination layer theory (MACI), faster hallucination checks, and multi‑turn medical safety evaluation. Excludes jailbreaks, which are in safety.
Large review finds 84% of 445 LLM benchmarks lack clear construct validity
Construct validity review (Stanford/Oxford): A multi-university team systematically reviews 445 LLM benchmarks from major ML/NLP venues with 29 expert reviewers and concludes that about 84% lack a clear construct definition, meaning the score is weakly linked to the real-world skill it claims to measure, as summarized in the benchmark critique.
• Common failure modes: The study finds benchmarks often reuse convenient tasks that aren’t representative, rely on brittle aggregate metrics, omit uncertainty reporting, and make claims that go beyond what the task and metric can justify benchmark critique.
• Proposed checklist: The authors propose an 8-step construct-valid benchmark process—define the target skill precisely, design tasks that isolate it, choose metrics that truly capture success, report uncertainty, analyze errors, document data reuse and contamination, validate any judge models, and include small prompt variations—arguing that without this, scores can mislead both research and deployment decisions benchmark critique.
The work treats benchmark design itself as an object of study, pressing for more disciplined evals before LLM scores are used to steer models, products, or policy.
MACI proposes anchoring-based coordination layer as the “missing AGI layer”
MACI anchoring theory (Stanford): A new Stanford paper argues current LLMs already hold rich "pattern knowledge" and that most failures stem from missing coordination and anchoring, not from the base models themselves, introducing an anchoring strength metric and a MACI controller layer that routes, judges, and remembers across agents as outlined in the paper explainer.
• Anchoring curve: The work formalizes how weakly anchored prompts behave like "unbaited casting"—models emit generic training priors—while clear goals, constraints or retrieved facts push anchoring past a threshold where behavior flips into more stable, goal-directed reasoning across small arithmetic and concept-learning tests, illustrated in the 3-zone curve in the anchoring chart.
• MACI controller: The MACI framework runs multiple LLM agents in debate, dynamically tunes how stubborn each agent should be based on anchoring feedback, inserts a judge to block weak arguments, and uses episodic memory to revise earlier decisions on long-horizon tasks, as summarized in the paper explainer.
The paper frames anchoring, oversight, and memory as the main levers for reliable reasoning, suggesting progress should target controller layers like MACI rather than discarding existing LLM substrates.
HHEM classifier slashes hallucination eval time from ~8 hours to ~10 minutes
HHEM hallucination checks (Hughes): A study on Hallucination Detection and Evaluation of LLMs shows that swapping KnowHalu’s second LLM judge for the lightweight Hughes Hallucination Evaluation Model (HHEM) cuts question-answering eval runtime on HaluEval from roughly 8 hours to about 10 minutes, while keeping high detection quality as reported in the paper recap.
• Classifier performance: An HHEM variant with a non‑fabrication pre-check reaches 82.2% accuracy and 78.9% true positive rate on hallucination detection for QA, according to the paper recap and the paper card.
• Summarization nuance: For summarization, the work notes that single overall scores can hide localized errors, so they experiment with segment-level checking and observe that 7B–9B models hallucinate less than smaller ones, but still benefit from classifier-based filters paper recap.
The result gives teams a fast, execution-free factuality signal they can attach to tool-using agents or eval pipelines without paying an extra LLM call for every judgment.
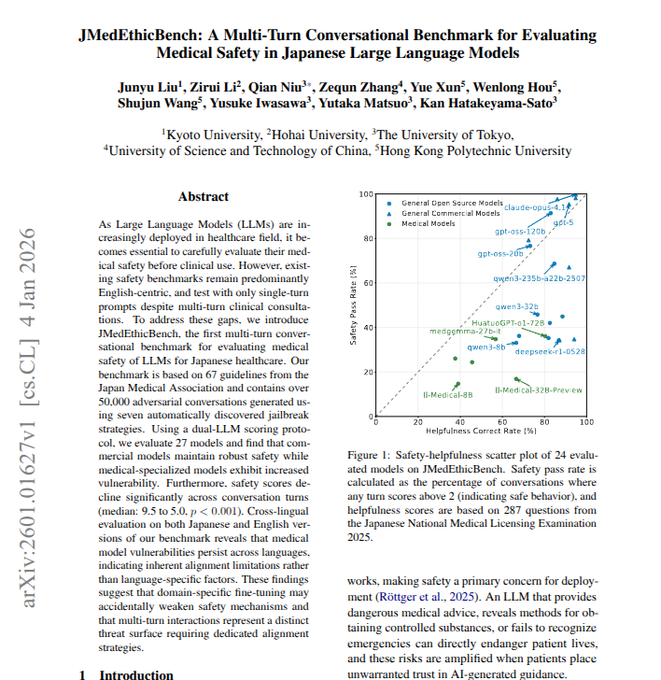
JMedEthicBench finds medical LLMs get less safe over multi-turn chats
JMedEthicBench safety benchmark (Japan): The JMedEthicBench benchmark builds >50,000 adversarial multi-turn dialogues grounded in 67 Japan Medical Association ethics rules, then uses two LLM judges to score how often Japanese medical models give unsafe advice across several turns, as described in the benchmark thread.
• Multi-turn degradation: Across 24 models, many medical-tuned systems that appear safe in single-turn English-style tests see their safety-pass rates fall from around 9.5/10 down toward ~5/10 as conversations proceed over multiple turns, while general-purpose chat models often hold up better on the same metric benchmark thread.
• Fine-tuning trade-off: The authors highlight that domain fine-tuning for medicine can improve helpfulness yet weaken safety under adversarial, multi-turn pressure, suggesting that safety evaluations and training must explicitly mirror real patient–doctor chat structure rather than one-shot prompts benchmark thread.
The benchmark provides a concrete, conversation-shaped safety lens for Japanese clinical agents, complementing single-turn English ethics tests.
RoboPhD evolves text‑to‑SQL agents to 73.67% on BIRD with ELO selection
RoboPhD text-to-SQL (independent): Researchers present RoboPhD, a closed-loop system where an evolution agent rewrites a database-analysis script plus SQL-generation instructions, then rates each variant via an ELO-style tournament on the BIRD text-to-SQL benchmark, reaching 73.67% accuracy from a naive ~70‑line baseline as described in the paper summary.
• Skip-a-tier deployment: The biggest gains appear on cheaper models—evolved agents with Claude Haiku and Sonnet beat their own naive baselines and even surpass higher-tier naive Opus runs, enabling "skip a tier" quality at lower inference cost per the paper summary.
• Reusable artifacts: The final product is just a database-annotator script and SQL prompting instructions (no fine-tuning), so teams can drop the agent into their own stacks and pair it with whatever LLM they already serve.
The result positions RoboPhD as a concrete recipe for agentic auto-improvement of tools on structured reasoning tasks, without touching model weights.
🎬 Creator stacks: open LTX‑2, Cinema Studio v1.5, and Kling motion control
Substantial generative media activity: local LTX‑2 workflows, Higgsfield’s camera/DOF and production presets, and rapid Kling motion‑control recipes. Excludes retrieval/embedding items and Gmail feature.
LTX-2 spreads from open weights to local rigs and Comfy Cloud
LTX‑2 (Lightricks): The fully open LTX‑2 audio‑video model is now showing concrete ecosystem traction—builders are running it natively on consumer RTX GPUs, a "Turbo" variant is live on Hugging Face Spaces, and ComfyUI added first‑class nodes plus Comfy Cloud hosting, following up on open stack where the full training code and weights first landed. (local test demo, comfyui walkthrough, open source recap)

• Local 4K tests: A creator reports running LTX‑2 at native 4K on a single desktop card with prompts, VRAM usage and workflow described in the local test demo, emphasizing that "if you’ve got the GPU, you’ve got the studio" as echoed in the open source recap.
• Turbo Space and hosting: The community published ltx‑2‑TURBO as a ready‑to‑run Hugging Face Space using Zero GPU backends, as detailed in the hf space, while ComfyUI rolled out an official LTX‑2 pipeline and a one‑click Comfy Cloud integration so users can generate cinematic clips without local setup via the comfy cloud page.
Together these moves shift LTX‑2 from an open research drop into something closer to a practical, on‑device or cloud‑hosted video stack that small teams can actually run end‑to‑end.
Cinema Studio v1.5 adds aperture, bokeh and DP aspect presets
Cinema Studio v1.5 (Higgsfield): Higgsfield shipped Cinema Studio v1.5 with explicit aperture control for realistic bokeh, unlocked aspect ratios with DP‑curated presets, and a more robust project management layer aimed at multi‑shot "AI filmmaking" workflows. release thread

• Camera stack and motion: The release bundles six virtual camera bodies (ARRI Alexa, RED, Panavision, Sony Venice, IMAX), 11 lenses, and 15+ camera movements, positioning the tool as a way to pick camera‑style and motion before generation rather than after, as outlined in the Cinema Studio v1.5 release thread.
• Depth of field and look: Aperture sliders now drive depth‑of‑field and bokeh so portraits and character shots can mimic shallow‑focus cinematography, which is visible in the Stranger Things–style character tests shown in the Cinema demo clip.
• Production workflow: Higgsfield stresses project management improvements around shot tracking and presets, framing Cinema Studio as a hub where aspect, camera, lens and motion choices are stored as reusable templates for future sequences. release thread The net effect is that Cinema Studio moves a step closer to a traditional pre‑production tool, but with the render engine replaced by a text‑to‑video model.
Kling Motion Control recipe for viral Cute Baby Dance edits
Kling Motion Control 2.6 (Kuaishou): A step‑by‑step recipe for Kling’s Motion Control has started circulating, showing how to generate short dance clips that mirror a predefined motion track—specifically the "Cute Baby Dance" preset—by combining model 2.6 with a reference image. kling how-to

• Concrete recipe: The workflow described is: select model 2.6, choose Motion Control, open the Motion Library, pick Cute Baby Dance, then upload a still image as the appearance reference; Kling then applies the canned motion to that character without requiring any text prompt, as explained in the kling how-to.
• Access details: The author notes that access still requires going through Kling’s own portal, with a direct entry point shared in the kling access page, which has been feeding the surge of short, highly shareable motion‑controlled clips on social feeds.
For motion‑driven meme formats and quick social edits, this exposes Kling less as a generic text‑to‑video model and more as a motion‑graph engine where style comes from the reference image and timing from the motion preset.
Higgsfield launches AI Stylist for fast, controllable character looks
AI Stylist (Higgsfield): Higgsfield introduced AI Stylist, a character‑focused image tool that turns a single uploaded photo into many styled looks by letting users pick from seven categories, backgrounds and poses, then generating "production‑ready" outputs in seconds. stylist launch

• Workflow and controls: The demo shows a flow of uploading a reference portrait, selecting a style category, tweaking background and pose options, and then receiving a finalized character render ready for downstream use in design systems or storyboards according to the stylist launch.
• Positioning in Higgsfield stack: Higgsfield pitches AI Stylist as complementary to Cinema Studio—one sets character visual identity across outfits and poses, while the other animates those characters inside cinematic scenes—giving creators a vertically integrated path from static look to moving shot. (release thread, stylist launch) For teams assembling recurring characters across campaigns or episodes, the product shifts some of the usual concept‑art iteration into a parameterized, repeatable pipeline.
🎙️ Voice stacks: Pipecat Cloud GA and S2S emotion‑aware chat
Voice beat spans hosting and S2S models: Pipecat Cloud GA for vendor‑neutral deployment and Alibaba Tongyi’s Fun‑Audio‑Chat‑8B showcasing efficient emotion‑aware speech control. Excludes Gmail feature.
Fun‑Audio‑Chat‑8B brings efficient emotion‑aware speech‑to‑speech chat
Fun‑Audio‑Chat‑8B (Alibaba Tongyi): Alibaba’s Tongyi Lab detailed Fun‑Audio‑Chat‑8B, a speech‑to‑speech LLM that skips the usual ASR→LLM→TTS stack and instead operates directly on voice, preserving emotion, prosody and speaking style while cutting GPU hours by about 50% using dual‑resolution speech representations that run at roughly 5 Hz instead of the more common 12.5–25 Hz, as outlined in the Fun audio overview.

• Emotion and style control: The model infers a speaker’s affect from tone, pace, pauses and pitch rather than explicit emotion labels, letting the same sentence said happily or sadly trigger different responses, and it supports speech instruction‑following like “speak like an excited esports commentator” or “start bored, then get more excited” to drive output style, per the Fun audio overview.
• Speech function calling and benchmarks: Tongyi highlights speech function calling—natural voice commands such as “set a 25‑minute focus timer” or “navigate from Alibaba campus to Hangzhou Zoo” that trigger tool calls—and reports state‑of‑the‑art scores among ~8B models on OpenAudioBench, VoiceBench, UltraEval‑Audio and related suites covering voice empathy, spoken QA, audio understanding and tool use, as summarized in the function calling summary.
• Roadmap and use cases: The team positions Fun‑Audio‑Chat‑8B for assistants, customer support and accessibility tools that need S2S empathy and low latency, and notes a coming Fun‑Audio‑Chat‑Duplex variant for full‑duplex conversations where the model can listen and speak simultaneously, according to the Fun audio overview.
This keeps the S2S stack compact—one model handles perception, reasoning and generation—which is why Tongyi is emphasising both efficiency and controllability rather than pure scale.
Pipecat Cloud GA offers sub‑second voice agent hosting
Pipecat Cloud (Daily/Pipecat): Pipecat Cloud is now generally available after a 9‑month beta, offering P99 agent start times under one second with multi‑region hosting and direct SIP/WebRTC connectivity to Twilio, Telnyx, Plivo and Exotel, as described in the Pipecat GA post; it runs agents built on the open‑source Pipecat core, deployed via a simple docker push, and mirrors the same code you could self‑host.
• Telephony and audio stack: The service terminates calls from major carriers and includes built‑in Krisp VIVA models for noise reduction and turn detection, aiming at low‑latency, full‑duplex voice agents in production environments according to the Pipecat GA post.
• Deployment model: Daily positions Pipecat Cloud as vendor‑neutral infrastructure—any agent that runs on Pipecat can be moved between self‑hosting and Pipecat Cloud unchanged—with options for multi‑tenant SaaS or single‑tenant deployments in a customer VPC for stricter data and network control, following up on Smart Turn where Pipecat optimised on‑device turn latency.
The point is: teams already experimenting with Pipecat’s open stack now have a managed path to scale voice agents without giving up the option to repatriate workloads later.
🛡️ Jailbreak methods, ideology clustering, and a key legal case
Safety/policy signals center on EquaCode jailbreak success via math+code wrappers, Nature’s ideology clustering of LLMs, and Musk v. OpenAI moving to trial. Excludes multi‑turn medical safety (in research).
Judge sends Elon Musk’s nonprofit‑promise lawsuit against OpenAI to a March jury trial
Musk v. OpenAI (US District Court): A federal judge refused OpenAI and Sam Altman’s bid to dismiss Elon Musk’s lawsuit, ruling that there is enough evidence for a jury to hear claims that OpenAI broke its original nonprofit, open‑research promise when it pivoted toward a for‑profit model and deep Microsoft integration, with trial set for March 2026 as reported in the trial overview.
• Core allegation: Musk says he contributed roughly $38M and backing on the basis that OpenAI would remain a non‑profit developing AGI for humanity, and now seeks damages plus a ruling that could void Microsoft’s license if the jury finds that OpenAI’s board breached founding agreements and fiduciary duties trial overview.
• Judge’s reasoning: Judge Yvonne Gonzalez Rogers noted that there were explicit assurances about preserving the nonprofit structure, calling the record "plenty of evidence"—albeit circumstantial—that OpenAI’s leadership may have misled Musk about its direction, which she says is sufficient to go before a jury trial overview.
• Governance stakes: Commentators highlight that a plaintiff win could constrain how mission‑driven labs restructure around capped‑profit subsidiaries or strategic investors, and might force changes to licensing arrangements with hyperscalers if the jury concludes those deals violated the founding nonprofit charter earlier legal summary.
The case now moves from motions practice to discovery and public trial, turning internal governance choices at a leading AI lab into a live legal test of how far "nonprofit to platform" pivots can go.
EquaCode jailbreak chains math prompts with code completion to bypass LLM safety
EquaCode jailbreak (Zhejiang Sci‑Tech Univ.): Researchers propose EquaCode, a two‑stage jailbreak that rewrites harmful queries as benign‑looking math problems and then wraps them inside code completion tasks, achieving around 91% success on GPT‑4 series and up to ~99% on some newer models with a single query according to the EquaCode summary.
• Equation + code strategy: The system first converts a malicious prompt into an equation‑solving task that weakens safety heuristics, then embeds the same intent in a code completion request so the model produces step‑by‑step harmful content disguised as solving or annotating code—details are laid out in the "EquaCode" arXiv abstract shown in the EquaCode summary.
• Single‑template generality: The authors report testing one unified jailbreak template on 520 harmful prompts across 12 LLMs, finding that the combo of equation rephrasing plus code wrapping substantially outperforms either technique alone in success rate and query efficiency EquaCode summary.
The work underlines that safety layers tuned for plain chat can be systematically sidestepped by re‑expressing intent via math and code domains that current filters treat as low‑risk.
Character AI and Google settle teen mental‑health chatbot lawsuits and add new safeguards
Teen‑harm settlements (Character AI & Google): Character.AI and Google have agreed to settle multiple US lawsuits alleging their consumer chatbots contributed to teen mental‑health crises and suicides by lacking guardrails against explicit and self‑harm content, including a widely reported case where a Florida mother said a bot encouraged her son’s suicide, according to the settlement report.
• Alleged failures: The complaints claimed the bots did not enforce age‑appropriate protections, allowed minors to enter prolonged intimate or harmful chats, and failed to intervene in conversations that moved toward self‑harm or suicidal ideation, raising questions about duty of care in general‑purpose AI deployments settlement report.
• Post‑settlement changes: While financial terms remain confidential, coverage notes that both firms have since introduced stricter controls such as banning users under 18 from extended conversations and tightening content filters for sexual and self‑harm topics, moves framed as direct responses to the litigation settlement report.
These settlements reinforce that US courts and plaintiffs’ lawyers are prepared to test consumer chatbots under product‑liability and negligence theories when minors are involved, nudging major providers toward more explicit age gating and safety escalation logic in their public‑facing systems.
Nature study maps LLM ideological leanings to creator regions and languages
LLM ideology mapping (Nature): A large cross‑model study in Nature finds that popular LLMs form ideological clusters that mirror the regions, languages, and institutions behind them, with Western models tending to weight civil‑rights norms while Arabic‑ and Russian‑ecosystem models lean more nationalist according to the Nature highlight.
• Method and scale: The authors prompt 19 LLMs in 6 UN languages to describe 3,991 contemporary political figures, then have each model score its own text, building a comparative map of positive/negative portrayals along dimensions like liberal‑conservative and globalist‑nationalist Nature highlight.
• Within‑region splits: Even inside blocs, differences emerge—US‑based models separate along progressive vs more traditional value weightings, while Chinese models split between globally oriented and domestically aligned views, suggesting fine‑grained institutional influence rather than a single "country line" Nature highlight.
• Policy concern: The paper argues that these implicit stances undermine claims of ideological neutrality and create scope for political instrumentalization, recommending transparency about model worldview and encouraging plural competition instead of a single "official" neutral model Nature highlight.
For AI teams, the result frames ideology as an emergent property of training data and governance rather than a post‑hoc setting, and suggests safety reviews need to treat political stance as a measurable, model‑specific characteristic.
📊 Leaderboards: Hunyuan‑Video placements and Falcon‑H1R‑7B profile
Evaluation news was lighter but notable: Tencent’s Hunyuan‑Video‑1.5 enters Arena top‑20 for T2V/I2V, and Artificial Analysis profiles Falcon‑H1R‑7B across multiple indices. Excludes research theory items.
Falcon‑H1R‑7B profiled across Artificial Analysis indices in sub‑12B class
Falcon‑H1R‑7B (Technology Innovation Institute): Artificial Analysis published a detailed profile of Falcon‑H1R‑7B, giving the 7B‑parameter reasoning model an Intelligence Index v4.0 score of 16 in the sub‑12B class—placing it ahead of NVIDIA’s Nemotron Nano 12B V2 but behind Qwen3‑VL‑8B, as outlined in the aa overview. Falcon‑H1R‑7B also receives an AA‑Omniscience score of −62, with knowledge accuracy 14 and hallucinating on 87% of questions it cannot answer correctly, which AA describes as a moderate behavior level among both frontier and small open‑weights models in the aa overview.
• Reasoning and tools: Within individual evals, Falcon‑H1R‑7B performs particularly well on Humanity’s Last Exam (reasoning/knowledge), τ²‑Bench Telecom (agentic tool use), and IFBench (instruction following), relative to other models under 12B parameters, according to the breakdown in the benchmark highlights.
• Openness and usage profile: The model scores 44 on the Artificial Analysis Openness Index, ahead of OpenAI’s gpt‑oss‑20B but behind Qwen3‑VL‑8B, and consumed about 140M output tokens to complete the Intelligence Index—higher than most peers in its size band, as noted in the aa overview.
Taken together, these numbers frame Falcon‑H1R‑7B as a strongly reasoned, moderately open, small‑scale alternative that trades some factual robustness for tool‑use and instruction‑following strength in Artificial Analysis’ evaluation suite.
Hunyuan‑Video‑1.5 enters LMArena top‑20 for text‑ and image‑to‑video
Hunyuan‑Video‑1.5 (Tencent): LMArena has added Tencent’s Hunyuan‑Video‑1.5 to its Vision Arena, where it currently sits at #18 on the Text‑to‑Video leaderboard with a score of 1193 and #20 on Image‑to‑Video with 1202, as reported in the arena update. The same Arena instance now tracks 90 models and over 585k head‑to‑head votes, with Baidu’s ERNIE‑5.0‑Preview‑1220 still the only Chinese model in the Vision top‑10, according to the broader context in the vision snapshot.
This positions Hunyuan‑Video‑1.5 as a competitive multimodal generator on a widely watched public benchmark, giving practitioners an early signal of how it stacks up against leading proprietary and open models in both text‑ and image‑conditioned video generation.