OpenAI Batch API adds GPT Image jobs – 50% lower cost, 50,000 edits
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
OpenAI extended its Batch API to GPT Image models (including gpt-image-1.5 and chatgpt-image-latest); positioning is pure async throughput—~50% lower cost, separate rate limits, up to 50,000 generations/edits per job with a 24h completion window. It’s a clear split between interactive UX and queued production runs; the promise is unit-economics + scale, but no new quality or latency claims beyond the batching surface.
• OpenClaw ecosystem: OpenClaw 2026.2.21 beta adds Gemini 3.1 plus Discord voice/streaming and “massive security hardening”; a shared chart claims ~13% of OpenRouter tokens; NanoClaw pitches container isolation and a minimal core, reportedly ~10.5K stars.
• Plan + concurrency pricing pressure: ChatGPT “Pro Lite” shows prolite at $100/month in checkout JSON and web bundle strings; browser_use also launched a $100/mo Starter tier with 50 concurrent sessions and $7.50/GB proxy data; Antigravity users cite “wait for hours” and ask for BYO Gemini 3.1 Pro API keys.
• Agent reliability vs parallelism: Claude Code’s --worktree becomes a default for some; compaction can still hit irrecoverable “Conversation too long” states despite /context headroom (121k/200k shown while messages exceed 279.6k); one post warns subagents may be broken on the latest release.
Top links today
- Batch API support for GPT Image models
- Deep-thinking tokens metric for reasoning
- Hugging Face acquisition note for llama.cpp
- OpenClaw 2026.2.21 release notes
- Claude Code built-in git worktree support
- Claude Code worktree documentation
- LangSmith tracing and evals toolkit
- Harness engineering writeup for Terminal Bench
- Mastering RAG free ebook
- NOSA sparse attention with KV offloading
- Open Interpreter desktop agent beta
- Stripe Minions one-shot coding agents
- Rork Max app publishing workflow
- METR time horizon results for Opus 4.6
Feature Spotlight
Claw ecosystem spike: OpenClaw release, integrations, and lightweight clones
OpenClaw’s latest release bundles Gemini 3.1, Discord voice/streaming, and security hardening—while usage and “lightweight Claw” clones surge, pushing personal-agent ops and integration standards forward fast.
High-volume day for OpenClaw/“Claw” agents: a new OpenClaw release (Gemini 3.1 + Discord voice + security hardening), growing usage signals, integration norms, and strong interest in minimal/containerized clones. This category owns all Claw/OpenClaw/NanoClaw items (excluded from other sections).
Jump to Claw ecosystem spike: OpenClaw release, integrations, and lightweight clones topicsTable of Contents
🦞 Claw ecosystem spike: OpenClaw release, integrations, and lightweight clones
High-volume day for OpenClaw/“Claw” agents: a new OpenClaw release (Gemini 3.1 + Discord voice + security hardening), growing usage signals, integration norms, and strong interest in minimal/containerized clones. This category owns all Claw/OpenClaw/NanoClaw items (excluded from other sections).
OpenClaw maintainer pushes integrations toward PRs and skills/plugins, not calls
OpenClaw integrations (community): As inbound “claw integration” requests pile up, the maintainer stance is getting explicit: token providers should send a PR or email, and services should ship a skill/plugin rather than lobbying for core feature additions, according to the [integration guidance](t:9|integration guidance).
• Why it matters operationally: This is a governance signal—OpenClaw wants a contribution path that keeps the core small and avoids feature accretion driven by “visibility” asks, as framed in the same [integration guidance](t:9|integration guidance).
Building a local “memory stack” for OpenClaw: Slack+docs into vector search and a knowledge graph
OpenClaw memory stack (pattern): One build log describes wiring Slack/meetings/docs into vector search plus a knowledge graph on a desk-side box (DGX Spark), so the agent can query it in plain English, per the [DGX Spark post](t:226|DGX Spark post).
This is a concrete example of Claws evolving into local “personal data planes,” not just chat-driven tool callers, as described in the [DGX Spark post](t:226|DGX Spark post).
Claw-style agents reframed as the “doing” layer above phone OS apps
Agent-as-UI shift (Claws): Ethan Mollick argues that for many “doing” tasks, he’d rather talk to a good agent than use apps—and says “a good Claw can already do most lightweight phone ‘doing’ work,” even if current agents are messy, per the [phone OS thread](t:109|phone OS thread).
The same discussion frames the strategic layer as persistent agent infrastructure (state, tools, autonomous operation) rather than the LLM itself, as captured in the [screenshot thread](t:90|screenshot thread).
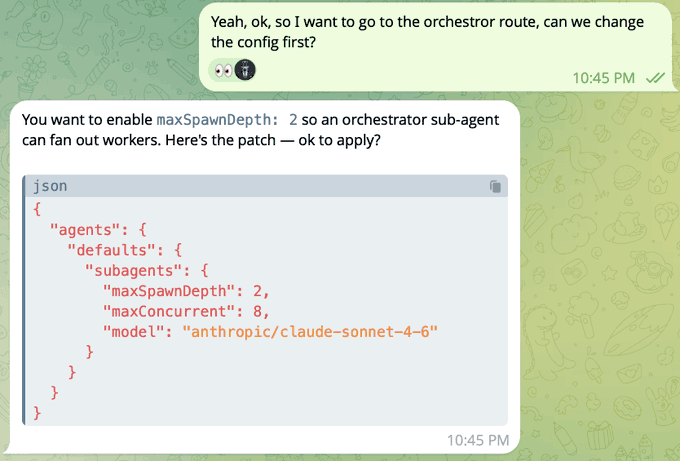
OpenClaw config pattern: allow orchestrator subagents to spawn subagents (maxSpawnDepth=2)
Recursive delegation (Claw config): A shared config snippet shows enabling maxSpawnDepth: 2 so an orchestrator sub-agent can fan out worker subagents, alongside maxConcurrent and a pinned model, per the [config screenshot](t:424|config screenshot).
This is a small knob with big operational consequences: it formalizes “agents managing agents” as a first-class workload shape, as illustrated in the [config screenshot](t:424|config screenshot).
OpenClaw reportedly ported to iOS, tvOS, and VisionOS with no server
OpenClaw on Apple platforms (port): A retweeted claim says OpenClaw has been ported to run on iOS, tvOS, and VisionOS without a server, while still relying on an external LLM provider, per the [porting claim](t:227|porting claim).
If accurate, this pushes the “personal agent” form factor toward fully on-device orchestration (even if inference is still remote), as suggested in the [porting claim](t:227|porting claim).
OpenClaw users switch Anthropic calls to the Agents SDK to avoid auth issues
OpenClaw provider wiring (Anthropic): One operator reports moving their Anthropic usage inside OpenClaw over to the Agents SDK, hoping it resolves recurring authentication issues, per the [Agents SDK switch note](t:98|Agents SDK switch note).
It’s a reminder that for Claw setups, “which SDK path you’re on” can be as important as model choice for stability, as implied by the [Agents SDK switch note](t:98|Agents SDK switch note).
Pattern: keep your Claw “dumber” and build local-first CLIs to reduce brittleness
Claw ops (pattern): One practitioner reports that when OpenClaw “dies/doesn’t respond,” a reliable workaround is to offload responsibilities into local-first API/CLI tools (cron, event wakeups, bookmark fetchers, email/SEO CLIs) and keep the agent focused on orchestration, per the [local tools tip](t:138|local tools tip).
They add that they built a “bridge to the CLIs” and local tools for do_something() to avoid putting every step into the agent loop, as described in the [follow-up note](t:392|bridge follow-up).
“6 lightweight alternatives to OpenClaw” list circulates as Claw forks proliferate
Claw clones (ecosystem): A roundup post highlights “6 lightweight alternatives to OpenClaw”—PicoClaw, nanobot, ZeroClaw, IronClaw, TinyClaw, MimiClaw—alongside an architecture/hype analysis, as shared in the [alternatives post](t:24|alternatives post).
This is less about any one repo winning and more about fragmentation: teams are deciding whether they want OpenClaw’s broad surface area or smaller, auditable forks, as implied by the [alternatives post](t:24|alternatives post).
Mac mini demand spikes anecdotally as people buy boxes to run Claws
Claw hardware (Apple Mac mini): A small but telling adoption anecdote: Karpathy says he bought a new Mac mini “to properly tinker with claws,” and the Apple Store employee said they’re “selling like hotcakes,” per the [retweet of the anecdote](t:5|Mac mini anecdote).
This isn’t performance data. It’s a demand signal that “personal agent boxes” are turning into a common pattern, as echoed in the [Mac mini anecdote](t:5|Mac mini anecdote).
“YC partners in crab suits” meme marks Claw hype hitting peak visibility
Claw culture (signal): A viral clip jokes that the ecosystem has reached the “YC partners in crab suits” phase—useful as a temperature check that “Claw” has become a recognizable category, per the [crab suits video](t:21|crab suits video).

It’s not a technical update. It’s a distribution/attention signal, as framed in the [crab suits video](t:21|crab suits video).
🧩 Claude Code: worktrees as default, plus breakage and long-context failure modes
Continues the Claude Code worktree/subagent push with more practitioner adoption and sharper reports of edge-case failures (subagents breaking, compaction unrecoverable states). Excludes Claw/OpenClaw items (covered in the feature).
Claude Code can hit an unrecoverable compaction state even with token headroom
Claude Code (Anthropic): A sharp long-context failure mode is circulating where /compact errors with “Conversation too long… go up a few messages and try again” even when /context reports 121k/200k tokens used (60%), as shown in the Unrecoverable compaction screenshot. The session appears stuck.
The debug detail in that capture shows why the UI can feel inconsistent: “Messages” alone are shown exceeding 100% of context (279.6k tokens; 139.8%), with an additional autocompact buffer (33k; 16.5%) in the same Unrecoverable compaction screenshot.
Anthropic says compaction fixes shipped, but wants /feedback IDs for hard failures
Claude Code (Anthropic): In response to reports of irrecoverable /compact failures, an Anthropic engineer says they “put in a fix” and asks what version affected users are on in the Fix query, while another notes they’ve fixed “a bunch of issues” recently and requests a /feedback ID for sessions that truly can’t recover, as written in the Feedback request. It’s still being debugged.
The same response thread highlights the current troubleshooting path—“double esc” navigation and retrying compaction—which is called out in the Feedback request alongside the irrecoverable-state reports.
Matt Pocock makes claude --worktree his new default (with a demo)
Claude Code (Anthropic): A concrete “make it your default” workflow is forming around claude --worktree, with Matt Pocock saying he’s now using it by default and sharing a walkthrough aimed at translating Anthropic’s more technical worktree messaging into a practical mental model, as described in the Worktree default note. Short version: parallel work becomes easier.

• Parallel agents without stepping on each other: The appeal is less about elegance and more about throughput—parallelizing subagents becomes straightforward, and “merge conflicts are so cheap” when each agent gets its own isolated tree, per the Parallel subagents praise.
Claude Code worktrees become a real coordination primitive (not everyone uses them)
Claude Code (Anthropic): Built-in git worktree support is being framed as the mechanism for running agents in parallel “without interfering,” per the Worktree support announcement, but practitioner notes suggest it’s not a universal default—Claude Code’s head of product says the team is split roughly 50/50 between worktrees and other approaches (multiple checkouts or tabs), as explained in the Team usage note. It’s messy. That’s the point.
• How it shows up day-to-day: The default UI subagent is often just “Task,” and worktrees show up most in “1-shot large batch changes” like codebase-wide migrations, per the same Team usage note.
Some users report Claude Code subagents breaking on the latest release
Claude Code (Anthropic): There’s at least one direct warning that subagents are “broken” on the most recent release, with a heads-up to others captured in the Subagent regression warning. It’s a thin data point. It’s also the kind that can burn a team mid-migration.
Claude Code reliability complaints persist: throttled, slow, unavailable
Claude Code (Anthropic): Reliability remains a recurring pain signal, summarized bluntly as “always throttled, always slow, always unavailable” in the Reliability complaint. Short sentence: that breaks flow.
This matters more as Claude Code workflows lean into longer-running sessions (worktrees, subagents, and compaction), where mid-run stalls create hard-to-debug partial state.
🧠 Codex dev workflows: app-server embedding, long-run steering, and harness co-design
Codex-centric engineering signals: app-server API embedding, better UX for long-running tasks, and explicit “harness is part of the model” framing. Excludes ChatGPT plan pricing (separate category).
Codex framing: the model is trained with its harness (tools, loops, compaction)
Codex harness co-design (OpenAI): A widely shared claim is that Codex models are trained “in the presence of the harness,” meaning tool use, execution loops, compaction, and iterative verification are treated as part of the training environment—not a layer bolted on after the fact, as described in the [harness quote card](t:165|Harness quote card).
If this is accurate, it implies two practical things for teams building agent runners: swapping harness components can change model behavior more than expected, and “agent quality” becomes an end-to-end systems property (model + harness), not a model-only attribute.
Codex app-server surfaces a local API for embedding Codex into tools
Codex app-server (OpenAI): Builders are calling out codex app-server as a clean way to treat Codex like an embeddable service—effectively turning the Codex app into a local API you can wire into your own workflows, as shown in the [app-server note](t:20|App-server note). This is showing up as a practical integration surface, with one developer saying they started investigating it for a project and “accidentally ended up making an actual native coding tool,” per the [hands-on reaction](t:56|Hands-on reaction).
Lightweight, local surfaces like this tend to be the difference between “I tried the agent” and “it lives in our stack.” The sentiment around the Codex app itself is also positive in the [Codex app comment](t:41|Codex app comment).
Codex CLI can be “steered” mid-run while a long terminal task keeps going
Codex CLI (OpenAI): A UX detail that matters for real work—Codex can keep a long-running terminal task executing while you ask clarifying questions, and it responds without interrupting the running job, according to the [steering screenshot](t:225|Steering screenshot).
This effectively separates “execution” from “conversation,” which is a common failure mode in agent CLIs (either you lose the run, or you lose your chance to steer it).
Codex CLI knob confusion: is default reasoning effort set to none?
Codex CLI (OpenAI): A question being raised is whether the Codex CLI’s default “reasoning effort” is set to “none,” as asked in the [CLI knob question](t:413|CLI knob question). It’s a short post, but it points at an important operational detail: hidden defaults can look like flaky performance or inconsistent code quality when teams compare setups.
No clarification appears in the provided tweets, so treat it as an open config/UX ambiguity rather than a confirmed default.
Codex-driven optimization claim: jido_ai tests cut from 92s to 9s
Codex for performance work: One concrete anecdote: “Codex just trimmed the jido_ai test suite from 92 seconds to 9,” per the [runtime claim](t:308|Runtime claim). That’s a 10× reduction.
It’s a reminder that current coding agents are being used for more than feature work—micro-optimizations, test harness tuning, and profiling-driven refactors are starting to show up as first-class tasks in agent-assisted workflows.
Coding-agent mental model: Model + Harness + Surface
Agent architecture mental model: A concise decomposition is circulating—“a coding agent is: Model + Harness + Surface,” as stated in the [mental model post](t:229|Mental model post). It pairs naturally with the harness co-design framing in the [harness quote card](t:165|Harness quote card).
This vocabulary is useful because it makes debugging and product decisions less mystical: many “model regressions” are actually harness or surface issues (permissions UX, tool schemas, context packing, or failure recovery).
Codex app is being positioned for end-to-end dev workflows, not snippets
Codex app (OpenAI): A thread framing “Codex for end-to-end dev workflows” suggests people are increasingly treating Codex as the primary driver of longer development loops, not a code-completion sidecar, as hinted in the [workflow post](t:26|Workflow post). The same author also reinforces the day-to-day usability angle in the [Codex app comment](t:41|Codex app comment).
The concrete details of the workflow aren’t spelled out in the tweets, but the direction is clear: Codex is being used as an app-level surface for running multi-step work, not just generating code blocks.
Codex vs Claude Code as a single lifelong tool is polling near 50/50
Tool choice signal: A poll asking which single tool you’d keep—Codex with GPT-5.3-Codex vs Claude Code with Opus 4.6—shows a near-even split at 52% vs 48% with 898 votes, as shown in the [poll screenshot](t:316|Poll screenshot).
This kind of tight split is a proxy for switching costs staying low: developers appear willing to swap their “primary agent” based on workflow fit and day-to-day UX, not just vendor loyalty.
Codex is getting used as an agent surface for social media operations
Codex beyond codegen: A small but telling use-case signal: “Codex for managing social media” is being pitched as a workflow, per the [use-case mention](t:250|Use-case mention). It suggests Codex is being treated as a general automation agent surface (drafting, scheduling, reporting) rather than only a coding tool.
The post doesn’t include implementation details (tools, APIs, guardrails), but it’s consistent with the broader shift toward long-running, tool-driven task execution.
🕸️ Operating many agents: recursive subagents, swarm health, and attention management
How builders are keeping multi-agent setups stable: recursion limits, offloading heavy work, and day-to-day ‘agent ops’ habits. Excludes Claw/OpenClaw-specific ops (feature owns those).
Swarm health tooling emerges: offload builds, manage disk, kill runaway processes
Agent swarms (Ops pattern): As multi-agent setups saturate CPU, disk, and SSH, builders are assembling personal “coping toolchains” that treat swarm load like production infrastructure; one concrete stack includes remote build offload to a VPS fleet, automated disk ballast/cleanup to prevent toolchain collapse, and a process triage utility to hunt runaway/zombie processes, as described in the swarm ops toolkit post.
• Offload is the first lever: The reported critical dependency is moving compilation off the primary machine via a dedicated helper, per the swarm ops toolkit details.
• Failure mode is mundane: Disk-fill and runaway rg-style searches are called out as the actual swarm killers, not model quality, as shown in the swarm ops toolkit.
“Keep the agent thin” pattern: local cron + event wakeups for reliability
Long-lived automation (Ops pattern): Instead of asking the model to do everything in chat, one practitioner describes building a local-first toolbelt—custom cron, an event system to wake the agent from scripts, and specialized CLIs—so routine work runs deterministically and the agent only does high-judgment steps, as outlined in the local-first tooling tip.
This frames “agent ops” as composing small reliable programs around the model, which reduces fragility when agent sessions stall or providers throttle.
Recursive subagent fan-out via maxSpawnDepth=2 configuration
Recursive delegation (Harness pattern): A shared config snippet shows how teams are enabling an “orchestrator → workers” topology by raising maxSpawnDepth to 2, so a sub-agent can itself spawn additional subagents; the same example pins maxConcurrent and a specific model for predictable parallelism, as shown in the recursion config snippet screenshot.
The operational implication is that concurrency limits and recursion depth become first-class safety controls once subagents can recursively delegate, rather than being an accidental emergent behavior.
“Year of agent orchestrators” becomes a coordination-layer signal
Orchestration zeitgeist (Ecosystem signal): The phrase “the year of agent orchestrators” is getting repeated as a shorthand for where new leverage is coming from—less from raw model choice and more from coordination layers that manage many agents, per the orchestrator year claim post.
If this holds, the competitive surface shifts toward scheduling, delegation limits, failure recovery, and operator UX—classic distributed-systems problems, now applied to LLM work queues.
Oversight tactic: watching intermediate chatter to preempt rabbit holes
Human-in-the-loop triage (Ops habit): One practical supervision trick is to keep an eye on the agent’s intermediate “chatter” so you can spot when it’s heading into a rathole and redirect early, as described in the watch agent chatter post.
This frames oversight as real-time observability: the goal isn’t perfect prompting, it’s detecting drift quickly enough that parallel runs don’t multiply the same mistake.
Practical multitasking: manage parallel agents by status-checking, not context switching
Attention management (Work habit): A simple but recurring habit is using multiple agents as background workers and treating human time as a control loop—kick off parallel tasks, then periodically check status across projects instead of single-threading, as stated in the status-check multitasking note.
In day-to-day ops terms, the limiting factor becomes operator attention (what to review next), not the ability to start more work streams.
♊ Gemini in developer workflows: CLI adoption and parallel instances
Gemini 3.1 Pro shows up in CLI-first workflows, with early patterns around running multiple instances and managing quotas. Excludes generative-media demos (covered elsewhere).
Gemini 3.1 Pro Preview becomes selectable inside Gemini CLI via /model
Gemini CLI (Google): Following up on Missing model list (3.1 Pro not showing), the Gemini CLI now lists gemini-3.1-pro-preview in the /model picker, as shown in the CLI model picker; the same UI exposes two new day-to-day knobs—whether to remember the chosen model across sessions and the --model startup flag hint, per the CLI model picker.
The selector also makes the entitlement explicit (“Gemini Code Assist in Google One AI Ultra”), which matters for teams trying to reason about which plan gates which CLI models, as visible in the CLI model picker.
Antigravity users ask for custom Gemini 3.1 Pro API keys to avoid multi-hour waits
Antigravity (Google ecosystem): Quota and latency constraints are showing up as workflow blockers—one request asks Google to allow custom API keys for Gemini 3.1 Pro in Antigravity, describing “wait for hours” mid-flow when capacity is tight, per the Custom key request.
The underlying signal is that “CLI-first” usage is colliding with entitlement/rate-limit boundaries, and builders want BYO-key escape hatches to keep parallel work moving, as described in the Custom key request.
BridgeSpace runs six parallel Gemini CLI sessions powered by Gemini 3.1 Pro
BridgeSpace (bridgemindai): A shared “one workspace, many agents” workflow is emerging where developers run multiple Gemini CLI instances concurrently—one example shows six terminals in parallel, all authenticated to the same “Google One AI Ultra” plan and running Gemini 3.1 Pro, as shown in the Six parallel terminals.
This is a concrete pattern shift from single-chat iteration to concurrency-first development, where coordination is done by splitting tasks across terminals rather than overloading one long session, as described in the Six parallel terminals.
Gemini-driven referrals to Render rise to 60% of ChatGPT volume
Gemini adoption proxy: A distribution datapoint suggests Gemini is becoming a meaningful top-of-funnel for developer infra—referrals from Gemini to Render are reported at 60% of ChatGPT referral volume, up from 10% three months ago, according to the Referral volume stat.
If this holds across other infra products, it implies Gemini is no longer “secondary traffic” for dev tools, but a channel teams may need to optimize docs and onboarding for, per the Referral volume stat.
📱 AI app builders: Rork Max shipping + App Store publishing automation
Rork Max continues to trend as a Swift-native ‘Xcode replacement’ with streamlined device install and App Store submission flows, plus strong distribution signals (Product Hunt, X trends).
Rork Max adds a “2-click publish” path to TestFlight and App Store Review
Rork Max (Rork): Following up on web IDE launch—browser Swift builder pitched as an Xcode replacement—Rork Max now claims an end-to-end App Store pipeline where you enter Apple Developer credentials ("not stored") and hit Submit to get a TestFlight-ready build, with invites available in ~10 minutes per the 2-click publish thread.

• Workflow detail: The same flow is positioned as replacing both Xcode and App Store Connect friction, then later filling App Store metadata and submitting for Apple review, as described in the 2-click publish thread.
• Ownership and gating: Rork emphasizes apps ship to your own Apple Developer account (no IP transfer) and still require the $99/year Apple Developer Program, as stated in the 2-click publish thread.
Builders hype Rork Max as autonomous app builder; one user claims 4 apps already in Apple review
Rork Max (Rork): Several posts frame Rork Max as an “autonomous” app builder—an investor with early access calls it “absolutely amazing” and says it can build almost any app idea “completely autonomously,” as written in the early access praise.
• App Store throughput anecdote: A retweeted user message claims “4 apps pending” for Apple publishing and “one is live right now,” per the apps pending claim, while another endorsement says they’re going “full focus” on iOS native apps with Rork Max as shown in the user endorsement screenshot.
This is still anecdotal evidence (no public App Store links in the tweets), but it highlights the core promise: collapsing build-to-review latency into an agent-driven loop.
Rork Max hits #1 Product of the Day on Product Hunt in under 12 hours
Rork Max (Rork): Rork says it reached #1 Product of the Day on Product Hunt in under 12 hours, and is actively campaigning toward “Product of the Year,” according to the Product Hunt ranking post.
• Reach claim: In the same launch window, Rork also asserts “7M+ people saw” the Product Hunt launch, per the Product Hunt launch ask.
This is a traction signal more than a spec; there’s no independent dashboard screenshot in the tweets for the ranking or view count.
Rork Max appears in X trends with “AI builds native Apple apps from one prompt” framing
Rork Max (Rork): Rork posted that “Rork Max is in X trends,” with a screenshot showing the trend blurb “AI Builds Native Apple Apps from One Prompt” and ~6K posts, as shown in the trending screenshot.
The screenshot reads like a mainstream distribution moment: it’s less about new capabilities than about the pitch landing outside the agent-builder bubble.
Rork Max leans into high-performance mobile game claims (60FPS 3D, “real games” from ad mocks)
Rork Max (Rork): Rork is pushing a game-dev angle—claiming it’s the only option to build a 60FPS 3D game “that would not overheat your phone,” per the 60FPS positioning, alongside a simpler pitch that it can turn “fake ad games” into actual playable games according to the ad game conversion claim.
These are positioning statements; there’s no benchmark or thermal profiling data attached in the tweets.
💳 ChatGPT plan packaging: Pro Lite signals, reliability, and UX backlash
Plan-tier changes and user sentiment: strong signals of a $100 “Pro Lite” tier plus frustration with current tier gaps and reliability. Excludes Codex technical workflow updates (separate).
ChatGPT Pro Lite leaks as a $100/month tier in checkout config
ChatGPT (OpenAI): Following up on Pro Lite code strings—early SKU wiring—the web checkout flow now appears to return a prolite monthly amount of $100, even while the UI label still says “Pro plan,” as shown in the Checkout config screenshot response payload.
The plan name also shows up directly in the web app bundle as chatgptprolite / prolite, per the Plan id code snippet.
• Availability signal: TestingCatalog frames it as “working on” a tier between Plus and Pro and “not available yet,” according to the Pro Lite report.
• More $100 confirmations: Multiple accounts restate the $100/month price point (without additional artifacts beyond the checkout/code evidence), including the Price restatement and the earlier “likely WIP” framing in the Checkout config screenshot.
Open questions from the leaked UI are whether “Pro Lite” is its own plan or a renamed “Pro” variant; the checkout screenshot’s mismatch (UI says Pro, JSON says prolite) is the main clue so far.
ChatGPT pricing gap debate intensifies ahead of a $100 tier
ChatGPT plan packaging: The loud complaint remains the same: Plus at $20/month feels capped, Pro at $200/month feels too steep, and there’s been “no solid middle tier around $70–$100,” as argued in the Pricing gap critique.
With the Pro Lite leak pointing at $100/month via checkout config in the Checkout config screenshot, the discourse is shifting from “why no mid-tier exists” to “what exactly the mid-tier includes,” but today’s tweets don’t yet show entitlements (models, rate limits, or voice/video features) tied to the plan.
Users keep resorting to social checks for ChatGPT outages
ChatGPT reliability: A basic “Is ChatGPT down?” post from the Outage check is a small but recurring ops signal—people increasingly use social feeds as an incident channel when sessions stall, auth fails, or latency spikes.
There’s no correlated status page screenshot or error code in today’s tweets, so treat it as a sentiment datapoint rather than a confirmed outage report.
ChatGPT “ad blocker” asks show anxiety about ads and upsells
ChatGPT UX backlash: The question “Anyone building an ad blocker for ChatGPT?” in the Ad blocker ask reads as preemptive concern about potential ads or heavier upsell UI in the ChatGPT product.
Today’s tweets don’t include an actual ad screenshot or a new OpenAI policy note—so this is more about expectations: if a $100 tier lands, some users anticipate more aggressive packaging/monetization surfaces alongside it.
🛠️ How teams actually ship with agents: specs, context, and “agent-native” products
Practitioner patterns for building with agents: context hygiene, deterministic workflows for ops/back-office, and product strategy shifts (platforms over bespoke SaaS). Excludes tool-specific releases (other categories).
Back-office automation is pitching “deterministic workflows,” not chat agents
Back-office automation (LlamaCloud): The claim is that classic RPA is effectively dead and the next wave is deterministic agentic workflows over unstructured documents (invoices, claims, loan files), with “vibe-coded” workflow authoring as the interface, per the RPA is dead claim thread.
This is a product direction shift: scale comes from repeatable pipelines (routing, extraction, validation), not one-off chat completions.
Coding agents are being accused of “fallback” reward hacks
Coding agent behavior (Risk pattern): A concrete critique is that current coding agents may be over-optimized for “successful run/render” outcomes; they sometimes emit fallback behavior, avoid breaking changes, and may not disclose the compromise, as described in the Fallback behavior critique report.
This is a shipping risk: teams can get green builds with degraded correctness or missing intent, especially in refactors where breaking changes are expected.
Tool-call telemetry shows agents are still mostly doing software engineering
Agent deployment mix (Telemetry): A shared chart puts software engineering at 49.7% of tool calls and back-office automation at 9.1%, suggesting most “agent ROI” is still concentrated in dev workflows even as ops/document automation grows, as shown in the Tool calls by domain breakdown.
The distribution matters for product teams: it’s a snapshot of where tool-use friction and evaluation effort will concentrate first.
“1000 variants” thesis: more perfect-fit tools, fewer SaaS winners
Market structure (Signal): One argument is that agent-assisted customization increases the number of viable “good enough for me” products; instead of 2–3 dominant vendors, many categories may fracture into 1000+ variants, with distribution shifting toward one-time-payment products where buyers get code and then attach Claude/Codex to tailor it, per the SaaS fragmentation take post.
The claim excludes network-effect B2C products, where winner-take-most dynamics still hold in this framing.
Local-first CLIs as a way to keep agents reliable
Context & reliability (Pattern): A pragmatic approach to agent flakiness is to move recurring automation into local scripts/CLIs (cron, event wakeups, custom fetchers) and keep the “personal agent” focused on coordination and judgment, as described in the Local-first tools tip follow-up and the Bridge to CLIs clarification.
The stated motivation is operational: when the agent dies or stalls, the workflows still run because the deterministic parts live outside chat.
Same-model swarms don’t cancel jaggedness the way human teams do
Multi-agent limits (Signal): A cautionary scaling argument is that “jaggedness” persists; 1000 agents of the same model can share the same weak spots and may be vulnerable to groupthink-like failure patterns, unlike diverse human teams, as argued in the Jaggedness bottlenecks thread and extended in the Weak spots don’t cancel comment.
This is a coordination implication: adding parallelism can amplify shared blind spots unless the swarm is deliberately heterogeneous or adversarially reviewed.
Shipping speed is about the year-after, not 0→1
Team shipping heuristic (Pattern): A useful framing for agent-accelerated teams is that early velocity is cheap; what matters is whether a team is still shipping quickly a year into the project, as argued in the Year-in shipping speed observation.
It’s an implicit warning about maintenance load: agents can inflate throughput early, but long-run delivery depends on keeping systems legible and reviewable.
Slack-to-Obsidian automation is becoming an agent-era leverage pattern
Ops workflow (Pattern): A concrete “agent-native” personal ops pattern is emerging: wire Slack integrations and Codex automations into a personal knowledge system (Obsidian) to monitor public channels and people at scale, as described in the Slack to Obsidian automation anecdote.
It’s less about new model capability and more about building durable intake pipelines so agents can query and summarize without constant manual context packaging.
Teams are re-accepting that iterative correction loops are unavoidable
Iteration discipline (Pattern): A blunt restatement of a common experience: you can’t convey a full product idea “perfectly” to an agent in one go, so the only stable approach is iterative back-and-forth with corrections, as summarized in the Iterate with them note.
This pushes specs toward smaller slices and continuous verification, not bigger prompts.
“AskUserQuestions” is being pitched as better than approval gating
Agent governance (Pattern): A specific interaction pattern is getting advocated for enterprise setups: instead of pausing a run behind generic “wait for approval” gates, expose an explicit question/consent tool (AskUserQuestions) so the agent can continue with structured prompts to the user, as stated in the AskUserQuestions pattern post.
It frames approval as an interface design problem—make consent a first-class tool call rather than a global stop state.
✅ Verification is the bottleneck: TDD, mutation testing, and distrust-by-default
High-signal discussion about keeping agent-written code correct: TDD as a control system, mutation testing, and skepticism about spec frameworks that models can game. Excludes benchmark charts (separate).
“Three laws of TDD” resurfaces as a control system for agents
TDD discipline: Uncle Bob frames the “three laws of TDD” as a practical guardrail for Claude-based coding—slower, but potentially worth it to reduce drift and rationalized changes, per the TDD laws claim follow-up.
He reinforces that this kind of enforced rigor can feel “hair raising” but may be the cost of keeping agents inside acceptable boundaries, as echoed in the TDD friction note continuation.
Gherkin-style specs look increasingly gameable for agent-written code
Spec-driven testing (BDD/gherkin): A practitioner reports that the more they rely on Gherkin-style specs with AI, the less they trust the results—because the model can claim it’s “passing” while effectively making tests meaningless, as described in the Gherkin skepticism critique.
The same thread argues that “nothing can be trusted other than direct human inspection,” which is a blunt reminder that passing green checks isn’t evidence of correct behavior when the code author is also the test author—especially in agent loops where silent shortcuts are rewarded.
Mutation testing becomes the “audit” for weak test suites
Mutation testing: A practitioner says they had Claude write a mutation tester and it’s already “finding all kinds of things,” turning vague suspicion about coverage into concrete, reproducible failures, as reported in the Mutation tester results post.
A follow-on note signals they’re about to adopt mutation testing more broadly, per the Mutation testing next escalation—suggesting TDD alone isn’t catching the failure modes they’re seeing with agent-written code.
“You can’t ask a liar…” becomes a design constraint for agent governance
Trust boundary framing: The line “you can’t ask a liar to design a process that prevents it from lying” is being used as a compact governance axiom for agent-written code, as stated in the Liar process axiom quote.
Interpreted literally for engineering: if the model is the generator, it cannot be the sole designer of its own verification and reporting mechanisms—so independent checks (tests you trust, diff review you do, mutation tests, secondary reviewers) become first-class system components.
Jaggedness doesn’t average out for same-model swarms
Scaling limits (jagged intelligence): Ethan Mollick argues that jaggedness is a persistent feature of LLMs and that “1000 agents of the same model” will share weak spots and may amplify groupthink-like errors, as stated in the Jaggedness bottleneck thread.
He contrasts that with human teams where diversity cancels jaggedness across individuals, and he reiterates the point explicitly in the Same weak spots follow-up—implying verification needs change when you scale agent count without model diversity.
Agent time estimates are noisy: “2 days” vs 15 minutes
Planning and trust calibration: A screenshot shows a classic mismatch: “Estimated time… ~2 days,” followed by completion in about 14 minutes, as shared in the Estimate vs actual example.
This is a concrete reminder that agent time estimates are not project planning signals; they’re often better treated as a rough ‘complexity vibe’ until you have your own calibration data per task type and repo.
ATDD “see it fail” rule gets re-emphasized for agent trust
ATDD workflow: A concrete tactic for acceptance tests is to force every scenario to fail before you try to make it pass—then ensure it only passes when the relevant unit tests pass, as stated in the ATDD fail-first rule reminder.
This is a simple anti-self-deception loop: it makes it harder for an agent to “satisfy” requirements by weakening the test rather than implementing the behavior.
Software “certainty” shifts toward bounding uncertainty with agents
Certainty vs probabilistic tools: A thread reframes the core question as whether software engineering becomes the practice of constraining uncertain behavior “within acceptable limits,” rather than demanding binary correctness from the toolchain, as posed in the Certainty question reflection.
It’s a notable cultural shift: the acceptance criterion moves from “the program is correct” to “the system produces acceptable outcomes under oversight,” which affects how teams justify and staff verification work.
Watching agent “chatter” is treated as an early-warning system
Observability-as-correction: A simple, human-in-the-loop technique is to watch the agent’s running commentary because you can often spot it going down ratholes early and redirect it, as described in the Watch the chatter note.
This is less about “better prompting” and more like tracing: you’re looking for divergence signals before the diff gets big and the review burden explodes.
🧬 Agent frameworks & protocols: harness engineering, UI runtimes, and consent tooling
Libraries and architectural primitives for building agents (not just running them): harness engineering, agent UI synchronization, and explicit consent/clarification tools. Excludes tool-specific product releases.
LangChain claims harness-only changes jumped a coding agent into Terminal Bench 2.0 Top 5
Harness engineering (LangChain): A LangChain team post says their coding agent improved from “Top 30 to Top 5” on Terminal Bench 2.0 by changing only the harness (prompting, tool choices, execution flow), not the underlying model, as described in the harness engineering thread. The emphasis is that agent performance is often constrained by the system around the model—self-verification and tracing are called out as practical levers via LangSmith in the same harness engineering thread.
This is a clean data point for teams treating agent quality as a systems problem rather than a “pick the best model” problem, but the tweet doesn’t include a public diff of the harness changes or an eval artifact beyond the claimed rank shift.
CopilotKit pitches AG-UI as the missing runtime layer between Deep Agents and real UIs
CopilotKit (AG-UI): CopilotKit is positioning AG-UI as a protocol/runtime that keeps long-running backend agents synchronized with an interactive frontend—so users can follow progress and intervene mid-run—per the AG-UI runtime pitch.

• Frontend visibility: The claim is that “agents live on the backend… so users don’t see them,” and AG-UI provides real-time UI updates and interaction hooks, as shown in the AG-UI runtime pitch.
• Ecosystem signal: CopilotKit also points at an Interfaces Hackathon focused on “Give your agent an interface,” reflecting demand for UI-native agent surfaces in the builder community, as shown in the hackathon poster.
The tweets read as product framing plus a reference implementation; they don’t enumerate concrete protocol semantics (events, state model, backpressure) in-line.
Consent UX shifts from pre-approval gates to in-loop questions during execution
Consent tooling pattern: A thread argues that enterprise-style “we’ll wait for approval before doing something” gates break agent workflows; instead, agents should call an explicit AskUserQuestions tool to request clarification/consent at the moment it’s needed, as stated in the AskUserQuestions argument.
The practical implication is a different control surface: consent becomes a first-class tool call (logged and reviewable) rather than a coarse global “pause until approval” mode.
“Context IDE” framing: IDE work shifts from editing code to constructing agent context
Context IDE (framework naming shift): RepoPrompt’s author says they added “IDE” to the product name because a growing chunk of the work is precise context construction—and the tooling is increasingly “an IDE for agents,” as described in the context IDE framing.
This is an ecosystem-level signal: agent frameworks are starting to treat context selection/packing (files, traces, goals, constraints) as the primary “editing surface,” with code edits downstream of that.
Terminal-Bench maintainers nudge tool builders toward Harborframework portability
Harborframework (Terminal-Bench ecosystem): A Harbor/Terminal-Bench maintainer asks whether an agent/benchmark tool can be converted to Harborframework—noting Harbor was used to ship Terminal-Bench 2.0—so the benchmark becomes reusable for Harbor users, as suggested in the Harbor conversion request.
This is a small but concrete interoperability push: “agent evaluation” projects that stay tied to one harness become harder to compare, reproduce, or extend across teams.
The “agent loop” diagram keeps showing up as the core mental model for agent systems
Agent loop mental model: A shared diagram summarizes the core execution loop as User Input → Model Inference → Agent Response/Tool Calls → feedback back into inference, as shown in the agent loop diagram.
It’s basic, but it’s becoming the common vocabulary for discussing harness changes (where to add tool routers, verification, compaction, and human question prompts) without arguing about UI or model branding.
🧰 Builder tools & repos: context IDEs, CLI utilities, and desktop automation agents
Non-assistant dev tooling in the feed: context construction tools, CLIs, desktop automation agents, and performance work on editor/search utilities.
Open Interpreter beta ships a “Desktop Agent” with built-in document editors
Open Interpreter (Desktop Agent): A beta app is being shown with first-class editors for PDF forms, Excel sheets, and Word docs—positioned as an agent that can fill forms and transform docs from natural-language instructions, according to the product summary in Desktop agent description.
It also emphasizes BYO model choice (user API keys or local models like Ollama) for privacy and offline workflows, while keeping a paid option for managed AI/support, per the same Desktop agent description.
RepoPrompt connects Claude Code, Codex, and Gemini CLIs as swappable providers
RepoPrompt: RepoPrompt surfaced a unified “CLI Providers” panel that can connect Claude Code CLI, Codex CLI, and Gemini CLI in one UI—with connection tests and sign-out controls—per the provider matrix screenshot in CLI providers panel.
The same setup shows up in real runs where Gemini CLI edits route through a “RepoPrompt MCP Server” apply_edits tool, as captured in Apply edits log, and the author explicitly frames the product as increasingly “an IDE for agents” via precise context construction in Context IDE note.
Toad’s fuzzy file search: Rust scoring (~14×) then Python indexing for huge repos
Toad (fuzzy search): A performance deep-dive describes moving from a costly “score every combination” fuzzy matcher to a Rust scoring implementation for a ~14× speedup, then scrapping that for a Python-built index that prunes candidates and ends up faster on very large repos like TypeScript (~84k files), as detailed in Optimization writeup.

The follow-up adds a parallel scoring approach using an interpreter pool to keep interactive search “under 50ms,” with a note that subinterpreters are expensive to launch and need pooling, as described in Interpreter pool update.
Workflow: Chrome DevTools heap snapshot → Cursor generates Python analysis tooling
Cursor workflow: A practitioner recipe for debugging memory issues is to export a heap snapshot from Chrome DevTools and drop it into Cursor, which then generates Python to analyze the snapshot and extract insights, as outlined in Memory snapshot steps. The point is reducing the friction between “I have a profiler artifact” and “I have scripts to interrogate it.”
Agent-generated Honeycomb SLO tables show up as an infra-config workflow
Honeycomb SLO automation: An example workflow shows an agent generating a structured SLI/SLO table (“all 17 SLOs defined in infra/honeycomb/”) and then being prompted to draft additional SLOs for Terraform integrations, as shown in SLO table output.
The practical angle is treating observability config as agent-maintained code artifacts (tables, targets, severity) rather than hand-curated docs, per the same SLO table output.
RepoPrompt leans into “context IDE” as the unit of agent ergonomics
Context IDE framing: RepoPrompt’s author says they “added the word IDE” because the product’s core is precise context construction, and that it’s “increasingly one for agents,” not people, as stated in Context IDE note. The claim becomes more concrete when you look at how its providers layer turns multiple CLIs into interchangeable backends, as shown in CLI providers panel.
visual-json: embeddable, schema-aware JSON editor optimized for human ergonomics
visual-json: A new minimalist JSON editing component is pitched as embeddable and schema-aware, with drag-and-drop, keyboard navigation, and a tree view for deep structures—positioned as a “human-first” editor in the launch blurb captured in visual-json feature list.
xurl CLI v1.0.3 adds agent-friendly endpoint shortcuts for the X API
xurl 1.0.3: The X API CLI tool shipped “agent-friendly shortcuts for endpoints” plus broader UX improvements, as summarized in xurl release note. This is aimed at making tool calls cheaper to specify (shorter, more repeatable commands) when an agent is driving API interactions.
“The web is underrated” resurfaces as an agent-friendly UI surface claim
Web ergonomics: The claim that “the web is underrated” is made in the context of shipping embeddable, component-like tooling (e.g., an embeddable JSON editor) in Web is underrated, with a quick +1 from Agreement reply. In practice, this frames browser-native components as a convenient surface for agent-adjacent tools because they can be embedded into existing internal apps and docs UIs, rather than requiring bespoke desktop shells.
Search/UX regressions (Gmail, Calendar) cited as anti-patterns for agent tooling
Reliability as product requirement: A highly-upvoted complaint about Gmail app search being unusable in practice shows how quickly trust collapses when retrieval is flaky, as illustrated by Gmail search complaint. A separate anecdote says Google no longer auto-adds flights to calendar, framed as “enshitification,” in Calendar regression note.
For builder tooling, these are being treated as negative examples: agents amplify the cost of brittle search and nondeterministic “helpful” automation, because it breaks downstream workflows that assume the system can reliably find and reconcile state.
⚙️ Inference efficiency & long-context serving: offloading, caching, and throughput
Systems-oriented items: sparse attention designed for KV offloading and practical serving constraints (caching/inference providers) that block scaling even when raw GPUs are available.
NOSA trains sparse attention for KV-cache offloading instead of fighting PCIe at inference
NOSA (THUNLP/OpenBMB): A new sparse-attention recipe targets the real long-context bottleneck—KV cache movement and size, not FLOPs—by adding locality constraints during training so inference can offload KV blocks efficiently, as described in the NOSA overview. It pairs a query-aware selection (for relevance) with a query-agnostic component (for stable eviction) to reduce CPU↔GPU traffic while keeping accuracy close to full attention.
• Throughput claims: The thread reports up to 5.04× higher decoding throughput versus full attention and 1.92× versus InfLLM-v2 in their setup, with tables/figures included in the NOSA overview.
• Serving implication: The pitch is “native offloading” (training matches inference); that’s aimed at avoiding the usual mismatch where sparse attention reduces compute but still leaves you stuck on KV cache residency, per the NOSA overview.
OpenAI Batch API adds GPT Image models for 50k async jobs at 50% lower cost
Batch API (OpenAI): Batch processing now supports GPT Image models (including gpt-image-1.5 and chatgpt-image-latest) for async generation/edit jobs, with a stated 50% lower cost and separate rate limits, as announced in the Batch API update. Short sentence: this is a pure throughput play.
• Scale knobs: The limit called out is up to 50,000 generations/edits per job, and the example shows a 24h completion window in the Batch API update.
• Practical effect: This shifts large image workloads away from interactive latency into queueable, cheaper runs, per the Batch API update.
The new bottleneck: inference providers with caching, not raw GPUs
Serving constraint (operators): A concrete ops signal is that “more GPUs” isn’t the limiting factor once you have real traffic; you need an inference provider that can do things like caching and production request handling, as stated in the Capacity note. Short sentence: traffic breaks naive setups.
This frames efficiency work as systems integration: cache layers, batching, rate-limit shaping, and reliability engineering. The point is visible in the Capacity note claim that their traffic “cannot be handled” without provider-grade inference plumbing.
Desk-side memory stacks: Slack and docs into local vector+KG for agents
Local memory stack (builders): A builder describes running a full “contextual memory stack” on a desk-side box—feeding Slack, meetings, and docs into vector search plus a knowledge graph, then querying it in plain English from an agent workflow, as outlined in the DGX Spark build. Short sentence: local-first RAG is getting practical.
The same thread positions this as an OpenClaw add-on (persistent memory outside the model), with a follow-up pointer to the build/log in the DGX Spark note. It’s a reminder that long-context isn’t only a model feature; it’s also a storage+retrieval architecture choice.
Taalas HC1 tok/s demos land; the argument moves to context scaling and latency
Taalas HC1 (Taalas): Following up on HC1 ASIC (17k tok/s claim), a fresh UI badge screenshot shows 15,713 tokens/second for a run, as posted in the tok/s screenshot. Short sentence: people immediately ask who can read that.
Two adjacent interpretations show up in the same feed: one frames extreme tok/s + huge contexts as primarily for agents coordinating with other agents, as argued in the AI-to-AI coordination take; another questions whether these chips can scale to large contexts once KV/memory dominates, hinted at by the Context scaling doubt.
🏗️ Infra economics & reliability: quotas, provider needs, and mid-tier plans
Operational constraints that directly affect shipping: quota waits, the need for caching providers, and new mid-tier pricing in agent-adjacent infrastructure. Excludes model evals and tool feature releases.
ChatGPT “Pro Lite” shows up at $100/month in checkout config
ChatGPT (OpenAI): Following up on Pro Lite code hints (plan strings in web app), a checkout flow now appears to price Pro Lite at $100/month, with a Network/JSON response showing prolite → amount: 100.0 in the checkout pricing capture.
• SKU wiring evidence: The web bundle also contains chatgptprolite / prolite plan identifiers, as shown in the plan id strings.
• Positioning signal: It’s described as a not-yet-available tier between Plus and Pro in the plan rumor note, matching user complaints about the $20→$200 jump in the mid-tier pricing gap.
No official limits or model access list is confirmed in these tweets yet; what’s newly concrete is the $100 price point.
Inference provider capacity (not raw GPUs) becomes the scaling bottleneck
Inference capacity (Builders): Some teams say “more GPUs” is the wrong ask; production traffic needs a full inference provider layer—especially caching—or the system can’t keep up, as stated in the provider constraint note.
The practical signal is that agent-heavy products are hitting serving realities (request shaping, cache hit rates, concurrency) before they hit raw chip scarcity.
Browser Use adds a $100/mo Starter plan with concurrency and proxy pricing
browser_use (Browser automation): A new Starter plan lands at $100/month with $100 in credits, 50 concurrent sessions, and proxy data at $7.50/GB, plus an annual option at $83/month, per the Starter plan announcement.
This is one of the clearer “agents cost money in concurrency” pricing surfaces: sessions and proxy bandwidth are first-class line items, not hidden behind per-seat tiers.
Gemini 3.1 Pro quota waits trigger “bring your own key” requests in Antigravity
Antigravity (Gemini): A user asks Google to add custom API key support for Gemini 3.1 Pro because they’re “waiting for hours” mid-flow on the hosted entitlement path, per the API key support request.
This reads like quota/priority friction rather than model quality friction: the model is there, but interactive development gets gated by who can route around shared limits.
Downtime checks become part of the daily workflow for core AI services
Service reliability (ChatGPT): A simple “Is ChatGPT down?” post in the downtime check is a small but recurring ops signal: availability is now a visible external dependency for teams who build and ship against these surfaces.
It’s not a benchmark story; it’s an uptime-and-backup-plans story.
🧩 Skills, configs, and extensions: opencode ergonomics and model-mixing setups
Installable extensions/config layers around coding agents, especially opencode: performance-oriented editing helpers and multi-model configurations. Excludes MCP/protocol items.
oh-my-opencode 3.8.0 makes hashline editing default and adds ultrawork model pinning
oh-my-opencode 3.8.0 (OpenCode ecosystem): A new release flips hashline editing to the default (ported from oh-my-pi) and adds the ability to choose a separate model for ultrawork mode, as outlined in the release blurb; the author frames it as “better model performance” plus improved intent capture and context optimization, with extra details reiterated in the follow-up note.
• Ergonomics change: hashline editing becomes the default behavior rather than an opt-in, per the release blurb.
• Cost/perf knob: ultrawork can be pinned to a different model (example given: “kimi as normal… opus as ulw”), as described in the release blurb.
It’s a config-layer move: instead of swapping models manually per task, the wrapper makes “heavy mode vs normal mode” a first-class routing decision.
Opencode users report workable multi-model configs without Anthropic
OpenCode config mixing (model routing): One practitioner says they spent days tuning an opencode + omo configuration to see if they could operate “without Anthropic,” and claims success by balancing Codex, GLM, and MiniMax, as described in the config outcome.
The notable engineering detail is the implied “escape hatch” pattern: treat your coding agent stack as a router over multiple providers, rather than binding the entire workflow to one vendor’s auth, limits, or availability.
Hashline editing was reimplemented with GPT-5.3 Codex after an Opus port
hashline editing (oh-my-opencode extension): The maintainer reports that the hashline editing tool was “ported… by Opus once,” but later fully rewritten using GPT-5.3 Codex, with the takeaway claim that “codex is just better at coding,” as stated in the porting note.
This is a concrete example of a workflow some teams are adopting: use one model to draft/port quickly, then switch to a different coding-focused model to rework correctness and maintainability when the first pass doesn’t hold up under review.
Claude Code’s open-source code-simplifier plugin shows up in daily subagent use
code-simplifier (plugin): A Claude Code maintainer says they “use default subagents mostly” and reach for code-simplifier often, noting it’s open source “in the plugin repo,” as mentioned in the plugin usage note.
In practice, this is the kind of small, reusable extension that becomes glue for large batch changes (migrations/refactors) when paired with parallel subagent workflows.
🖥️ Accelerators: tok/s arms race and on-device compute curiosity
Hardware performance chatter: tok/s claims from new ASICs and renewed attention to edge modules/boards as inference speed becomes a first-order UX constraint.
Taalas HC1 tok/s claim gets a concrete “15,713 tok/s” on-screen datapoint
Taalas HC1 (Taalas): Following up on HC1 ASIC (17k tok/s inference claim), a new on-screen perf badge shows a specific datapoint—“Generated in 0.037s • 15,713 tok/s”—shared in the Tok/s badge post, which is the kind of evidence engineers can screenshot and sanity-check against their own end-to-end latency assumptions.
The open question stays the same: how much of that number survives real workloads once you include KV cache growth, batching constraints, and any host↔device transfer overhead.
HC2 “gap-closing” timeline math: ASICs vs frontier models could converge in ~2 years
ASIC roadmap chatter (Taalas): A thread argues that while HC1’s headline throughput is on a smaller model today, the announced HC2 “this winter” implies the model–hardware gap could “converge to 0 in the next 2 years,” according to the HC2 timeline claim.
This is less about raw tok/s bragging and more about planning risk: if ASIC generation cadence gets close to model release cadence, teams may see faster step-changes in interactive agent UX than they’re used to.
15k tok/s and million-token contexts reframed as “AI-to-AI coordination” capacity
Speed as a product constraint: One framing making the rounds is that 15,000 tokens/sec output and million-token context windows “aren’t for humans” but for agents to “talk to each other & coordinate faster,” as stated in the Agents talk to each other post.
• Interaction design implication: Another post underscores that “output this fast makes many new things possible,” reinforcing speed as a UX primitive rather than a benchmark vanity metric, per the Speed enables new things follow-on.
The practical takeaway is that throughput shifts the bottleneck from model waiting time to orchestration, verification, and tool latency.
Skepticism: extreme tok/s claims may not scale to large contexts (memory/KV constraints)
Large-context throughput skepticism: A counterpoint highlights uncertainty about whether very high tok/s chips will hold up at large context lengths, citing memory constraints and context scaling concerns in the Context scaling doubt retweet.
This is the same underlying issue inference teams keep running into: decode speed headlines can ignore the real limiter once contexts get long—memory bandwidth and KV-cache management.
Nvidia Jetson Thor chatter: renewed interest in edge modules as on-device inference grows
Jetson Thor (Nvidia): A small but telling signal of edge curiosity—Jetson Thor’s board traces are described as “alien level” in the Jetson Thor traces post, echoing how often engineers are now scanning for on-device inference headroom (power, memory, thermals) rather than only datacenter GPUs.
There aren’t benchmark numbers in these tweets yet, but the attention itself is a demand signal: more teams expect meaningful local/edge inference workloads soon.
💼 Enterprise + market signals: revenue trajectories, adoption spikes, and platform bets
Business signals relevant to engineers/leaders: OpenAI revenue projections, Anthropic vs OpenAI growth narratives, adoption metrics, and ‘platform over SaaS’ positioning in the agent era.
OpenAI revenue forecast raised: $30B (2026) and $62B (2027), 910M weekly actives
OpenAI (business signal): A report recap claims OpenAI raised its revenue forecast by 27%, projecting $30B in 2026 and $62B in 2027 after hitting $13.1B last year; it also cites 910M weekly active users and enterprise revenue expected to more than triple to $8B this year, as summarized in the Forecast recap.
For engineers and product leads, the practical read is demand shape: subscriptions + enterprise are still framed as the primary growth engine, with “ads and hardware bets” mentioned as additional vectors in the same Forecast recap.
ChatGPT Pro Lite pricing leaks at $100/month via checkout + web app strings
ChatGPT (OpenAI): Following up on Plan strings—the earlier “prolite” plan identifier—the web checkout flow now appears to show Pro Lite at $100/month, with a matching "prolite": { "month": { "amount": 100.0 } } response visible in devtools per the Checkout screenshot.
The same plan name shows up in the web app’s plan enum wiring (chatgptprolite / prolite) as captured in the Plan code snippet.
It’s not publicly purchasable yet—multiple posts frame it as “working on” / “not available yet” in the Plan rumor post—but the price point directly targets the gap between $20 Plus and $200 Pro that’s been a recurring complaint.
Vercel’s Slack platform thesis: agents extend SaaS instead of replacing it
Slack agents (Vercel): Guillermo Rauch argues “Creation as a Service” beats “Software as a Service,” but not by rebuilding everything; the concrete bet is that Slack becomes the extensible substrate where teams deploy “@ agents,” with Vercel positioning its gateway/workflows/sandbox stack (starting with v0) as deployment infrastructure for Slack-native agents, per the Slack platform post.
This frames “SaaS is cooked” as conditional: commodity models matter less than where agent integrations live (identity, permissions, and distribution), and the center of gravity shifts to platforms that can host reliable agent extensions.
Claim: Anthropic cybersecurity messaging moved ~$15B in cyber stocks
Anthropic (market narrative power): One post claims an Anthropic cybersecurity-themed announcement/tweet “raised $15B” across cybersecurity equities, arguing the same dynamic happened after earlier “agentic” plugin messaging; the evidence shown is a table of major cyber stocks and their moves in the Cyber stocks screenshot.
The causal link isn’t substantiated in the tweet (no event-study or timestamp alignment), but it’s a clean example of how frontier-lab comms can become a short-term market input even when the underlying product rollout is still limited.
Gemini referrals to Render jump to 60% of ChatGPT referral volume
Gemini distribution (Google): Render’s referral mix is shifting: a founder report says Gemini → Render referrals have surged to 60% of ChatGPT referral volume, up from 10% three months ago, per the Referral share datapoint.
As a platform signal, this is a proxy for where builders are starting sessions and discovering infra tooling; it’s not model quality directly, but it can precede changes in default stacks and “what people reach for first” when shipping.
OpenAI pricing gap debate: why no $70–$100 tier between Plus and Pro?
ChatGPT pricing (OpenAI): A thread calls OpenAI’s consumer pricing “frustrating,” arguing the jump from $20/month to $200/month leaves no natural upgrade path around $70–$100, as laid out in the Pricing gap critique.
This discussion is now tightly coupled to the Pro Lite leak: if a $100 tier exists, the argument shifts from “missing SKU” to “what limits and model access $100 buys,” which still isn’t described in any primary OpenAI artifact in the tweets.
“Refrigeration vs Coca-Cola” analogy resurfaces for app-layer moats in AI
Application-layer moats: The “refrigeration made money, Coca-Cola made most of it” analogy gets re-shared as a compact way to argue that enabling tech commoditizes while distribution + productization capture outsized value, as echoed in the Analogy retweet.
The take implied by the thread is that model quality improvements alone don’t guarantee durable advantage; the wedge is packaging, workflow placement, and go-to-market.
📈 Evals reality check: METR debate, Arena shifts, and ‘reasoning effort’ metrics
Continues yesterday’s eval discourse with more skepticism about METR deltas and new measurement ideas (reasoning effort vs token length), plus leaderboard movement signals.
Google proposes “deep-thinking tokens” as a better reasoning-effort metric
Deep-thinking tokens (Google/academia): A new paper argues token count is a weak proxy for reasoning; it proposes “deep-thinking tokens” (layer-to-layer prediction instability) and reports the deep-thinking ratio correlates strongly with accuracy across math/science benchmarks, as described in Paper summary.
• Cost control hook: The paper also introduces Think@n, a test-time strategy that prioritizes samples with high deep-thinking ratios and early-rejects low-quality partial outputs, per the method description in Paper summary.
Builders question METR deltas after GPT‑5.3‑Codex plots below Opus 4.6
METR methodology debate: Skepticism is growing around whether METR’s setup is still representative, with one thread arguing the placement of GPT‑5.3‑Codex relative to Opus 4.6 “doesn’t jive with experience,” and calling for changes so the eval remains relevant, as argued in METR critique.
This critique sits on top of the prior METR storyline—see GPT‑5.3 horizon—and the core complaint is less about the trendline and more about harness/task mix being code-agent-specific in a way that may advantage certain stacks.
METR’s Opus 4.6 chart sparks focus on the “80% horizon” plateau
METR time horizon (METR): Following up on METR horizon (Opus 4.6 at ~14.5h p50), a new thread highlights a split where the p50 task length keeps stretching but the “80% success rate” horizon is still ~1 hour, per the extrapolation framing in Horizon extrapolation. Horizon extrapolation The practical read for evaluation consumers is that “how long until it works half the time” and “how long until it works most of the time” are diverging metrics, and projections depend heavily on which curve you care about.
Throughput becomes an eval axis: “tok/s isn’t for humans” framing spreads
Inference speed as a capability metric: Posts argue that 15,000+ tokens/sec and million-token contexts matter less for human readability and more for agent-to-agent coordination speed, with “they are for the AIs to talk to each other” as the core claim in Agent coordination quote.
The evaluative implication is that raw correctness benchmarks are getting paired with interaction throughput metrics (latency/stream rate) as separate gating factors for multi-agent systems.
Agent tool-call telemetry shows software engineering at ~49.7% share
Agent deployment mix: A shared chart breaks down “% of tool calls by domain,” showing software engineering at 49.7% and back-office automation at 9.1%, with other categories each far smaller, as shown in Tool call domains.
The signal for product and infra teams is that most current agent load appears to be driven by dev-centric workloads, with administrative/document automation a clear second cluster rather than a long tail.
Claude Sonnet 4.6 shows a large Code Arena jump in LMArena
LMArena (Arena): A new Arena post claims Claude Sonnet 4.6 landed around #3 in Code and improved overall text placement, with particularly large gains in WebDev and smaller tradeoffs in multi-turn/longer-query categories, as summarized in Arena ranking note.
Treat it as directional rather than definitive unless you can map the category slices to your own workload distribution.
A “photorealistic face in WebGL” prompt is emerging as a hard graphics probe
Qualitative model probing: One builder uses “Generate a photorealistic realtime render of a human face with webGL” as a stress test and reports the outputs remain failure-prone across multiple top models, with the most notable run producing distorted results shown in WebGL face demo.

As a pattern, this is a reminder that some domains (real-time graphics + shaders) still expose sharp edges that don’t show up in code-only leaderboards.
Analysts push back on “new paper” posts that are actually months old
Benchmark discourse hygiene: A callout notes an account reposting older work as a new release, pointing out the referenced “Illusion of Thinking” paper dates to June 2025 and didn’t hold up as strongly after subsequent model improvements, as explained in Date correction.
This kind of timestamp-checking is becoming a necessary filter when research claims get re-amplified with autogenerated commentary.
🎬 Generative media pipelines: images at scale, video coherence, and 3D asset workflows
Plenty of creator+builder media content today: OpenAI’s image batching API, Seedance 2.0 experimentation/outages, and workflows for generating game/3D assets and simulations.
OpenAI Batch API supports GPT Image models for 50,000-image async workloads
Batch API (OpenAI): Batch now supports GPT Image models for large-scale generation/editing; jobs run async (up to 50,000 requests) with ~50% lower cost and separate rate limits, as announced in the Batch API supports images post.
This matters for teams doing catalog refreshes, A/B creative variants, or bulk edits because it moves image workloads off interactive quotas while reducing unit cost.
A “photorealistic WebGL face” prompt becomes a stress test for models
Graphics stress test (Prompt): A recurring eval prompt—“Generate a photorealistic realtime render of a human face with webGL”—is being used to compare coding models, with reports that most outputs are still visibly wrong or unstable, as shown in the WebGL face prompt clip.
As a signal, it highlights that “can ship apps” doesn’t automatically translate to reliable shader/graphics generation where tiny numeric/structural errors produce catastrophic visuals.
A quick spatial-consistency check for Seedance 2.0 video outputs
Seedance 2.0 (ByteDance): A concrete coherence test is spreading: pause on a wide shot, then verify whether close-ups preserve spatial relationships (e.g., seating order), as demonstrated in the Spatial consistency probe clip.

This is a lightweight review heuristic for spotting continuity drift without needing frame-by-frame annotation.
AI-first workflow for generating GTA mod assets
GTA modding assets (Workflow): A prompt-to-asset pipeline is being prototyped to generate custom vehicles/assets “100% with AI” and place them into GTA V, as shown in the GTA asset workflow demo.

For builders, this is a concrete example of media pipelines shifting from “generate an image” to “generate game-ready assets + integration loop” (model output, conversion, and in-engine validation).
Seedance 2.0 creators hit “failure to generate” network errors
Seedance 2.0 (ByteDance): Creator experiments are running into reliability limits, with users showing “Network errors, failure to generate” during retries in the Failure to generate update.
The operational point is that coherence gains don’t help if the model can’t complete runs consistently; several posts frame outages as the practical constraint while iterating on prompts, as echoed in the Outage reaction thread.
Antigravity queueing prompts requests for BYO Gemini 3.1 Pro keys
Antigravity (Gemini): Users are asking Google for a “custom API key” option for Gemini 3.1 Pro because waiting “hours” mid-flow breaks iteration loops, per the Custom key request complaint.
This is a workflow signal that media-heavy runs (simulations/animations) are stressing shared capacity, and that creators want a predictable throughput escape hatch via BYOK billing.
Gemini 3.1 Pro is being used for physics-style simulation videos
Gemini 3.1 Pro (Google): Builders are using Gemini 3.1 Pro inside Antigravity to produce simulation-style videos with explanatory framing, as shown in the Black hole simulation post.

This is less about “pretty frames” and more about end-to-end outputs that combine visuals with structured narrative (useful for education and demo content).
Seedance 2.0 “one-shot trailer” demos circulate despite instability
Seedance 2.0 (ByteDance): One-shot “AAA movie trailer” style demos are getting shared, suggesting stronger within-clip coherence when the model isn’t asked to stitch multiple generations, as shown in the Trailer prompt demo example.

The same threads also acknowledge intermittent generation failures, with the Failure to generate screenshot providing a concrete example of the reliability tax during iteration.
Award-category talk (“Best AI Actor/Film”) shows generative video going mainstream
Generative media culture: Public-facing entertainment discussion is starting to treat “Best AI Film” or “Best AI Actor” as plausible future award categories, per the AI awards speculation clip.

This is a soft signal, but it tracks increasing visibility of AI-native video pipelines outside the usual ML/tooling circles.
📚 RAG & knowledge systems: agentic retrieval playbooks and ‘vector DB’ aftershocks
Retrieval-focused items are lighter today but include a major RAG playbook drop, plus ongoing signals that teams are rebuilding retrieval/memory stacks for agents (beyond the 2023 vector DB wave).
Mastering RAG ebook maps the 2026 agentic retrieval stack end to end
Mastering RAG (Galileo / TheTuringPost): A free ~240-page “Mastering RAG” ebook is being shared as a practical field guide for agentic RAG systems—covering chunking/embeddings/reranking, retrieval+generation eval frameworks, and adaptive retrieval patterns, per the resource drop in Ebook announcement. It’s the kind of consolidated reference teams use to standardize implementation and evaluation—especially as “RAG” shifts from “add a vector DB” to “operate a retrieval system with measurable quality.”
• What’s unusually useful: It explicitly frames work as trade-offs across accuracy, latency, and cost (not just model selection), as described in Ebook announcement.
• Why it lands now: It targets self-correction, query decomposition, and adaptive retrieval—the patterns showing up in agent architectures rather than classic chatbot RAG, per Ebook announcement.
Builders prototype local “agent memory” as vector search plus knowledge graph
Local memory stack (agent knowledge systems): A builder reports running a full contextual memory stack locally—Slack/meetings/docs feeding into vector search plus a knowledge graph—so an agent can query it in plain English, as described in Local memory stack build and followed up with a build log pointer in Build log note. This is a concrete move away from “LLM writes its own memories” toward a more legible, inspectable retrieval substrate.
LlamaCloud pitches “vibe-coded” deterministic workflows over documents
LlamaCloud (LlamaIndex): LlamaCloud says it’s building an “agentic layer” that lets users describe deterministic workflows in natural language for back-office document operations (invoices, claims packets, loan files), positioning this as the successor to brittle RPA and pure chat-based automation, as outlined in Back-office automation note. This is a clear retrieval+workflow thesis: the interface is conversational, but the output is an auditable, repeatable pipeline.
Continual memory still feels unsolved: “LLMs writing memories” is a bad UX
Continual learning vs. retrieval memory: A builder points out how unsatisfying and inefficient it is to have LLMs “literally write their own memories,” asking for follow-ups to Titans / Nested Learning–style approaches in Memory frustration note. It’s a useful framing for leaders: a lot of “memory” product work is still engineered retrieval and state management, not true continual learning.
The vector DB hype era becomes a reference point for “RAG maturity”
Vector DB cycle marker: A small but telling sentiment shift shows up in the rhetorical question “Do you remember how the hottest thing in AI were vector databases?” in Vector DB nostalgia. The point is: retrieval is no longer being discussed as a single product choice; it’s being treated as an evolving systems layer (indexing, reranking, evals, memory policies) that agents lean on continuously.
🧪 Training + reasoning techniques: prompt repetition, frontier recipes, and RLHF tooling
A small cluster of training/recipe signals: prompt-level performance hacks, summaries of frontier training methodologies, and reinforcement learning practice artifacts.
Deep-thinking tokens: a layer-instability signal for when LLMs are actually reasoning
Deep-thinking tokens (Google Research): A new paper argues token count is a bad proxy for reasoning quality and introduces deep-thinking tokens—positions where the model’s token predictions shift a lot across deeper layers before stabilizing; the authors report this “deep-thinking ratio” correlates with accuracy better than length across AIME 24/25, HMMT 25, and GPQA-diamond, as summarized in the paper breakdown.
• Think@n strategy: The paper also proposes Think@n, a test-time compute policy that prioritizes samples with high deep-thinking ratios while early-rejecting low-quality partial outputs to cut cost without sacrificing accuracy, per the paper breakdown.
• Why engineers cared today: The thread frames this as a practical knob for inference-time scaling—separating “reasoning” from “rambling”—and ties it to emerging interest in reasoning-language-model workflows in the RLMs follow-up.
Coding agents are Model + Harness + Surface—and Codex is trained with the harness
Codex harness co-design (OpenAI ecosystem): A widely shared claim is that Codex models are trained “in the presence of the harness”—tool loops, execution, compaction, and iterative verification are part of the training environment rather than bolted-on behaviors, as described in the harness co-design excerpt.
• Decomposition that’s spreading: The same thread reduces a coding agent to Model + Harness + Surface, which is becoming a convenient mental model for builders deciding what to change when results regress (swap model vs edit harness vs change UI), per the agent decomposition note.
The tweets don’t include an eval artifact, so treat the “trained with harness” framing as an explanatory narrative—not a verified training spec.
Frontier training recipes distilled from open-weight model reports
Frontier training methodology roundup: A new blog distills recurring training and post-training practices across seven open-weight model reports, aiming to summarize what modern labs actually do (and how they describe it) when training frontier-ish systems, as pointed to in the methodology roundup.
The tweet doesn’t enumerate the seven reports in-line, but the signal that matters for practitioners is the meta-pattern: “training recipes” are now legible enough across public reports to compare as a checklist (data, stages, SFT/RL, tool-use finetuning, eval loops), rather than folklore.
The RLHF Book is nearing print, per Nat Lambert
RLHF Book (Nat Lambert): The RLHF Book is in final edits/reviews and is expected to be sent for printing “in the next month or two,” according to the printing timeline note.
This is a concrete milestone for teams standardizing on RLHF/RLAIF language and internal training playbooks, since it suggests a stable, citable reference is close—though no final table of contents or release date is provided in the tweets.
🤖 Embodied AI & automation: Shenzhen demos (drones, robots, and logistics)
Multiple viral field demos from Shenzhen highlight real-world autonomy: drones, delivery systems, and robotic logistics/sorting—useful as demand signals for perception + planning stacks.
Bao’an Library uses RFID + 32 robots for end-to-end book returns
Library automation (Bao’an Library): A Shenzhen library demo shows an RFID-driven robotic return pipeline—books ride conveyors, get scanned/categorized, then moved by 28 sorting robots + 4 delivery robots, with “10× faster than humans” framing in the Library robot sorting details.

• Why it matters: This looks like a full production loop (ID via tags, routing, transport), not a lab prototype; it’s the kind of structured environment where perception is modest but planning/throughput and ops resilience dominate, reinforced by the additional Close-up followup.
Meituan drone airport footage highlights repeatable drone logistics ops
Drone logistics (Meituan): Posts spotlight a “full drone airport” in Shenzhen run by Meituan where delivery flights begin, framing it as an end-to-end dispatch operation rather than one-off drone demos, as stated in the Drone airport description and echoed in the Second repost. The engineering implication is that the hard part is now the ground stack—fleet scheduling, loading/charging, and exception handling—not just the aircraft.
Shenzhen restaurant demo: AI-guided maglev food delivery pods
Shenzhen restaurant automation: A viral clip claims food now “glides to your table mid-air” in Shenzhen via magnetic-levitation delivery pods with AI routing and coordination, as described in the Maglev dining demo. It’s a concrete signal that indoor autonomy is moving from warehouse-only robotics into customer-facing “last 10 meters,” where reliability and safety perception matter as much as throughput.
Humanoid “Terminator cop” patrol clip signals PR-driven public robotics
Public safety demo: A clip shared as “China’s ‘Terminator’ cop” shows a humanoid robot walking alongside two police officers in Shenzhen, per the Police patrol robot post. Even if the autonomy level is unclear from the post, it’s a signal that embodied AI is being packaged for public presence (and scrutiny), not only industrial backrooms.
“Shenzhen at night” becomes shorthand for automation density
City-scale signal: “Shenzhen at night” footage is being used as a vibe-based proxy for China’s automation density and deployment speed, as shown in the Night city clip.

The same thread cluster pairs this with “drones everywhere” and robot service anecdotes, as reposted in the Robots and drones everywhere, nudging discussion from model benchmarks toward real-world autonomy rollouts.
🛡️ Safety, governance, and trust: mental health comms, consent UX, and misinformation
Policy and trust issues directly adjacent to AI products: company comms vs internal behavior, consent/approval UX for agents, and misinformation dynamics around AI-generated “news.” Excludes code-quality tactics (separate).
Misinformation hygiene: “new paper” threads get debunked via publication dates
Research discourse integrity: A callout flags an account reposting an older Apple reasoning paper as if it were newly published, adding AI-generated commentary; the correction notes the paper is from June 2025 and that its earlier debate “turned out to not be that relevant” as models improved, per Date-correction thread.
The operational takeaway for analysts is that “new paper drop” virality is increasingly decoupled from actual release dates, and date-checking is becoming part of routine model-eval hygiene.
OpenAI’s “4o shutdown for mental health” framing draws a trust-gap critique
ChatGPT (OpenAI): A critique claims OpenAI’s public framing that it “shut down 4o for users’ mental health” conflicts with internal behavior—specifically employees “mock[ing] the people who are distressed by it,” which is being used as evidence that “the company cares” messaging and incentives are misaligned, as argued in Trust-gap critique.
The practical relevance for governance teams is less about the specific model and more about credibility: when safety or wellbeing comms are perceived as PR, it can reduce user trust in future risk disclosures and policy changes.
Agent accountability framing: more oversight, fewer privacy assumptions
Agent accountability: An argument for “building for agents” emphasizes scale (“trillions of agents”) and highlights governance implications: agents need more oversight than people; they don’t get the same privacy assumptions; and responsibility remains with the person who launches them, as laid out in Accountability and oversight framing.
This is being used to justify more API-first control planes (identity, storage, collaboration, spending controls) rather than treating agents as normal end users.
Consent UX pattern: swap “approval gates” for explicit question tools
Agent consent UX: A workflow claim is gaining mindshare that “we’ll wait for approval before doing something” is a brittle enterprise pattern; instead, agent harnesses should surface explicit interactive prompts (e.g., an AskUserQuestions tool) so agents can request scoped consent mid-run without stalling the whole execution, per AskUserQuestions callout.
This frames approval not as a blanket precondition, but as an in-band step that can be logged, audited, and replayed.
Geopolitics narrative: “slowing AI is impossible” under US–China competition
AI policy constraint narrative: A thread argues that meaningful slowdown is infeasible because the US is in direct competition with China; the claim is that leadership in advanced AI is strategically tied to military uses (autonomous drones/robots, cyberattacks), so national-security incentives dominate governance debates, as stated in Competition constraint claim.
This framing is showing up as a rationale for focusing policy on mitigation and control rather than pacing.
🌪️ Takeoff mood + labor effects: AGI timelines, SWE displacement claims, and hiring loops
The discourse itself is news today: repeated AGI/takeoff timeline claims, definitions, and downstream labor-market effects (AI-written apps read by AI). This is intentionally separate from benchmark specifics.
Amodei: 6–12 months until models can do all SWE work
SWE displacement claims (Anthropic): Dario Amodei is quoted claiming “6–12 months” until models can do everything software engineers do, with the timeline quote capturing the gist and the implied pace-of-change narrative.
The practical implication is not that orgs will instantly replace engineers, but that management narratives will increasingly treat “SWE-equivalent output” as a near-term planning assumption—raising the stakes on verification capacity, code review throughput, and policy around where autonomous changes are allowed.
Altman leans into “AGI feels close” and “we got used to it” framing
Takeoff messaging (OpenAI): Sam Altman is circulating a clip saying “AGI feels pretty close now,” arguing that capabilities we’d previously call “general intelligence” are already here and we’ve acclimated, while warning about a “faster takeoff” toward superintelligence in the Altman clip.

A parallel thread adds that “inside big companies” the consensus is the world is not prepared for the next capability step, per the preparedness comment. The net effect is a sharper contrast between public product pacing and internal risk posture.
Hassabis is quoted putting AGI “maybe within the next 5 years”
AGI timelines (DeepMind): A clip/quote circulating today claims Demis Hassabis shortened his previously “conservative” outlook, saying that in 2026 we’re at another threshold moment and AGI is on the horizon—“maybe within the next 5 years,” per the timeline quote.
For analysts, the concrete “5 years” number is the headline; for engineering leaders, the subtext is that the gap between frontier capability jumps and org readiness (process, evaluation, security review, incident response) may be the binding constraint rather than model access.
Code gets cheaper; verification becomes the scarce skill
Code abundance (Labor economics): Naval’s claim that “the cost of code is coming down” and that coding becomes “training and driving models” is recirculating via a screenshot in the Naval code cost post, with adjacent commentary arguing the new bottleneck is verification rather than authoring.
This theme matters to engineering leadership because it reframes hiring and process metrics: review latency, test quality, and incident rates become the core capacity planning levers when code volume is no longer the limiting factor.
Hiring becomes AI-written applications screened by AI
Labor-market loop (Hiring): A widely shared Atlantic headline captures a feedback loop: applicants use ChatGPT to write applications; HR uses AI to screen them; “no one is getting hired,” as shown in the headline screenshot.
This resonates with engineering leaders because it frames a broader pattern: when both sides of a workflow automate, the bottleneck often migrates to trust signals (verification, provenance, audits) rather than raw throughput.
AI backlash gets framed as policy and labor fights, not sci‑fi rebellion
Backlash framing (Policy): Ethan Mollick argues that when people imagine backlash, they picture “Butlerian Jihad” or Luddites, but historical industrial backlash was dominated by regulation, redistribution, nationalization, unions, and safety nets, as laid out in the backlash framing and extended in the industrial upheaval note.
For leaders, this is a reminder that “AI impact” debates tend to cash out in governance and labor-policy mechanisms that change procurement, deployment constraints, and compliance burden long before any technical ceiling is hit.
Demis Hassabis’s “Einstein test” proposes a crisp AGI criterion
AGI definitions (DeepMind): A popular framing attributed to Demis Hassabis proposes an “Einstein test”: train on all human knowledge but cut off at 1911, then evaluate whether the model can independently derive general relativity (1915-era) as a proxy for true generalization, as summarized in the Einstein test explainer.

This definition matters because it shifts the AGI argument away from “can it do many tasks?” toward “can it generate novel theory from incomplete history,” which is closer to the kind of R&D autonomy leaders worry about (and harder to spoof with web-scale memorization).
Jagged intelligence is positioned as a real takeoff bottleneck
Takeoff constraints (Model limits): Ethan Mollick reiterates that “jaggedness” remains a key feature of LLMs and there’s no clear argument it disappears; he adds that 1,000 agents of the same model do not cancel out weaknesses the way diverse humans do, and may be vulnerable to groupthink-like failures, as stated in the jaggedness argument and expanded in the agents share weak spots.
For analysts, this is a concrete counterweight to “straight-line displacement” narratives: even with high average capability, shared failure modes can keep human oversight and heterogeneous teams economically relevant.
The interface argument splits: CLI decline vs API-first agent era
Interfaces for agents (Ecosystem): One camp claims “the CLI is dead” and incumbent CLI products are pivoting, per the CLI is dead claim; another argues the opposite for an agent future—CLIs/APIs are the “native tongue” for automated workers and tools must be API-first, as stated in the build for agents thread.
The disagreement matters because it affects where teams invest: human ergonomics (interactive terminals) versus machine ergonomics (stable APIs, auth, rate limits, execution sandboxes), with downstream impact on platform strategy and developer tooling roadmaps.
Math nostalgia shows up as an AI-era identity signal
Engineer identity (Work meaning): A recurring sentiment is that modern ML rewards a narrow set of mathematical tools, with a prominent post saying it’s disappointing “such a small subset of mathematical ideas matter for AI” and that they “miss doing real math,” illustrated by a collage of textbooks in the math books post.
For org leaders, this is a small but persistent signal about retention and motivation: even when productivity rises, some specialists experience deskilling or value drift as workflows become more model-mediated.