DeepSeek V3.2 scores 96% AIME at 5× cheaper tokens – MIT weights target 128K contexts
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
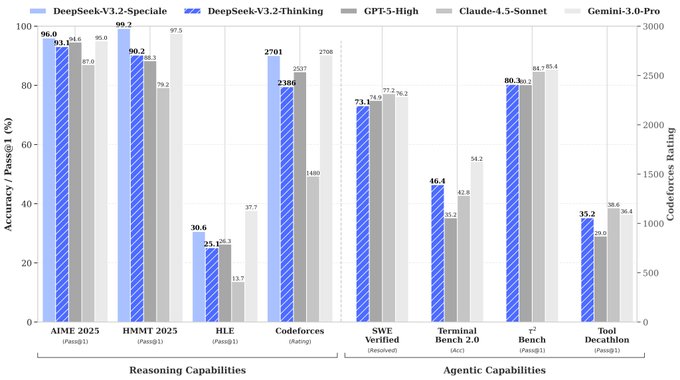
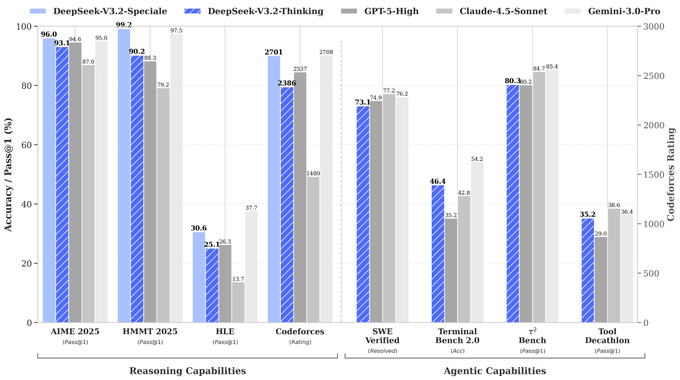
DeepSeek shipped V3.2 and its heavier V3.2‑Speciale as open‑weight frontier reasoners, and the numbers explain why everyone’s rerunning their harnesses. Community pricing charts put V3.2 around $0.28M in / $0.42M out per 1M tokens—roughly 5× cheaper than GPT‑5 High and ~30× cheaper than Gemini 3 Pro on similar workloads, according to early comparisons—while Speciale posts 96.0% on AIME 2025 and 99.2% on HMMT with an MIT license in tow.
Under the hood, the tech report is unusually transparent. DeepSeek Sparse Attention leans on a two‑stage warm‑start (2.1B dense tokens, then ~943.7B sparse) so 128K context behaves like near‑linear cost instead of quadratic, making “full repo in context” agents less of a financial dare. On reasoning and coding, Speciale edges Gemini 3 Pro on some Olympiad and Codeforces setups, hits 84.5% on IMOAnswerBench, and lands in the low‑70s on SWE‑bench Verified and ~80% on τ²‑Bench—squarely in frontier territory.
The tradeoff: Speciale often emits 1.5–2× more tokens than GPT‑5‑class peers and decodes at ~30 tok/s, so 45k‑token chains can mean multi‑minute waits. Builders are already framing it as a batch solver for brutal math and agent traces, with V3.2 as the cheaper, self‑hostable daily driver wired into stacks like SGLang, OpenRouter, and Cline.
Top links today
- DeepSeek V3.2 model card
- DeepSeek V3.2 Speciale model card
- DeepSeek V3.2 technical report
- DeepSeek thinking in tool-use docs
- vLLM-Omni omni-modality launch blog
- vLLM-Omni GitHub repository
- Transformers v5 RC announcement blog
- Apple Starflow video model on Hugging Face
- Artificial Analysis Openness Index dashboard
- Artificial Analysis Openness Index methodology
- InfLLM-V2 long-context training dataset
- InfLLM-V2 long-context final model
- Anthropic smart contract exploit research
- OpenAI large-scale code verification blog
- What the F*ck Is AGI? arXiv paper
Feature Spotlight
Feature: DeepSeek V3.2/Speciale — open-weight frontier reasoning
DeepSeek ships V3.2 (open weights) and V3.2‑Speciale (API‑only) with GPT‑5/Gen‑3‑Pro‑tier reasoning, gold‑level Olympiad results, and a tech report detailing DSA near‑linear attention and heavy RL (>10% pretrain).
Cross‑account story: multiple posts share specs, paper, pricing and evals for DeepSeek‑V3.2 and V3.2‑Speciale. Mostly model/tech details and benchmark tables; Speciale is API‑only for now.
Jump to Feature: DeepSeek V3.2/Speciale — open-weight frontier reasoning topicsTable of Contents
🐳 Feature: DeepSeek V3.2/Speciale — open-weight frontier reasoning
Cross‑account story: multiple posts share specs, paper, pricing and evals for DeepSeek‑V3.2 and V3.2‑Speciale. Mostly model/tech details and benchmark tables; Speciale is API‑only for now.
DeepSeek launches V3.2 and V3.2‑Speciale as open‑weight frontier reasoning models
DeepSeek released two new reasoning‑first LLMs: DeepSeek‑V3.2, the successor to V3.2‑Exp, and DeepSeek‑V3.2‑Speciale, a higher‑compute variant positioned as a Gemini‑3‑Pro‑class reasoner while keeping open weights under an MIT license. launch thread V3.2 is already live in the DeepSeek app, web UI, and standard API, while Speciale is served via a temporary API endpoint (no tools) with the same pricing as V3.2 and an announced availability window through 15 Dec 2025. api endpoint update
Pricing screenshots circulating from earlier V3.2‑Exp show input at ~$0.28/M tokens and output at ~$0.42/M tokens, pricing graphic and community commentators say this works out to around 5× cheaper than GPT‑5 High and ~30× cheaper than Gemini 3 Pro on comparable workloads. (price comparison, open source pricing take) Both V3.2 and Speciale model cards plus the full technical report are on Hugging Face, giving builders immediate access to weights, training details, and evaluation setups. open source links (v3 model card, speciale model card )
For AI engineers, the notable part is the combination of: (1) an IMO/IOI‑capable reasoning model that you can download and fine‑tune; (2) an API‑only ultra‑reasoner you can target for the hardest problems without changing pricing tiers; and (3) a clear, public tech report spelling out architecture and post‑training recipes. tech report This means you can start treating DeepSeek V3.2 as both a self‑hosted component in agent stacks and as a swap‑in frontier inference endpoint where you’d normally reach for a GPT‑5‑class model.
DeepSeek Sparse Attention warm‑start makes 128K context almost linear‑cost
Under the hood, V3.2 introduces DeepSeek Sparse Attention (DSA), an attention scheme that makes the expensive part of attention scale like O(L·k) instead of O(L²) by letting each token attend only to its top‑k scored predecessors (k=2048 in the paper). (dsa explainer, launch thread) A tiny "lightning indexer" in FP8 scores all past tokens for each query, but it uses few heads and simple linear layers, so most of the FLOPs go into the now‑sparse main attention rather than the scorer itself. dsa explainer
Crucially, DeepSeek doesn’t just flip sparsity on from scratch. They run a two‑stage warm‑start: first, about 2.1B tokens of dense warm‑up on top of a frozen V3.1‑Terminus checkpoint (already at 128K context) where the indexer is trained to mimic dense attention distributions without changing the base model; then a long sparse stage of roughly 943.7B tokens where full model weights are trainable but the indexer’s inputs are gradient‑detached so it keeps acting like a selector rather than overfitting to the LM loss. (dsa explainer, tech report) The result, according to the tech report’s cost curves, is that dollar cost per million tokens grows much more slowly with position than in their previous dense model on H800 GPUs, especially out toward the 128K end of the context window. dsa explainer For builders, the point is simple: V3.2 is architected to make really long contexts (full codebases, multi‑document RAG, long math chains) viable without blowing up inference cost, while staying close to dense‑attention quality because the sparse patterns were learned off dense attention rather than hand‑designed.
V3.2‑Speciale posts gold‑medal Olympiad scores and frontier‑class benchmarks
The paper and launch threads show DeepSeek‑V3.2‑Speciale landing at or near the top of most published reasoning and coding benchmarks, and even achieving gold‑medal performance on IMO 2025, CMO 2025, IOI 2025 and ICPC World Finals 2025. (launch thread, benchmark table)
In math contests, Speciale scores 96.0% on AIME 2025 (vs GPT‑5 High 94.6, Gemini‑3‑Pro 95.0) and 99.2% on HMMT Feb 2025, topping all listed models. (benchmark table, benchmarks chart) On the harder IMOAnswerBench it hits 84.5%, edging Gemini‑3‑Pro’s 83.3% while using a longer average chain of thought (~45k output tokens vs 18k for Gemini). benchmarks chart In competitive programming, its Codeforces rating of 2701 essentially matches Gemini‑3‑Pro’s 2708 and beats GPT‑5 High’s 2537, benchmark table and in ICPC World Finals simulation it solves 10/12 problems with multiple submissions allowed per problem. olympiad results On coding and general QA, Speciale hits 88.7% Pass@1 on LiveCodeBench (vs GPT‑5 High 84.5, Gemini‑3‑Pro 90.7) and 85.7% on GPQA‑Diamond, tying GPT‑5 High and trailing Gemini‑3‑Pro’s 91.9. benchmarks chart Agentic and tool‑use benchmarks put it close to the best proprietary systems: around 73–75% resolved on SWE‑bench Verified (vs GPT‑5 High 77.2, Claude‑4.5‑Sonnet 76.2) and 80.3% on τ²‑Bench against low‑80s for GPT‑5 and Claude. (launch thread, tooluse analysis) The tradeoff is efficiency: the tables show Speciale typically consuming 1.5–2× the output tokens of GPT‑5 High and Gemini‑3‑Pro on the same tasks, efficiency table which matters for latency and cost even if per‑token pricing is low. But if you care about top‑end contest‑style reasoning or competitive programming, these numbers make Speciale the first open model that genuinely sits in the same league as GPT‑5 and Gemini‑3‑Pro rather than chasing them from far behind.
Builders praise DeepSeek V3.2’s price–performance but flag latency and rough edges
Early community reaction to DeepSeek‑V3.2 and Speciale mixes excitement about open‑weight frontier reasoning with practical complaints about speed and UX. Open‑source advocates highlight that this is the first MIT‑licensed model with gold‑level IMO/CMO/IOI/ICPC results, arguing it refutes the idea that open models lag closed ones by 8–12 months. massive release One thread calls V3.2‑Speciale “a massive release” and notes that DeepSeek is “about 30× cheaper than Gemini 3.0 Pro” at similar reasoning quality, (massive release, price comparison) while another praises that “open source is winning” and that V3.2 can already be used for free in DeepSeek’s web UI. (open source pricing take, web ui usage)
Benchmarks are getting plenty of attention—“Holy moly, look at those evals” is a typical reaction to the AIME/HMMT/Codeforces charts, enthusiast comment but there’s also pushback that the suite is "typical math and agentic RL‑maxxing" and omits long‑horizon agent tasks like METR or VendingBench. (benchmark skepticism, skeptical take) Several hands‑on testers report that Speciale “eats a ton of tokens” and decodes at around 30 tokens/s, leading to multi‑minute waits for big chains of thought; one estimate says even a trimmed‑down 20k‑token response can mean ~11 minutes at that speed. (latency concern, efficiency table) Others complain that the chat UI variant of V3.2 “doesn’t feel frontier” despite the benchmarks, ui disappointment and at least one user says it still fails their personal math check on tricky problems. math failure Despite those issues, the models are already being wired into multi‑model platforms like OpenRouter and IDE agents like Cline, giving curious builders a low‑friction way to compare them side‑by‑side with GPT‑5, Claude 4.5, and Gemini 3 in real workflows rather than charts. (openrouter listing, cline integration) The sentiment so far: impressive raw reasoning at a compelling price, but Speciale in particular feels more like a batch solver for hard problems than an interactive assistant until throughput and token efficiency improve.
V3.2 leans on heavy RL and synthetic agent tasks for tool‑use gains
Beyond architecture, DeepSeek leans hard into reinforcement learning to close the gap with frontier proprietary agents. The tech report and community summaries say RL post‑training consumed more than 10% of the pre‑training compute budget, which is unusually high and explicitly targeted at reasoning performance. (rl and tooluse summary, paper recap) On top of that, they synthesize a massive agent training corpus: over 1,800 environments and 85,000+ complex instructions covering code agents, search agents, MCP‑style multi‑tool agents, and general planning tasks. (agent training thread, tooluse table)
The payoff shows up in tool‑use benchmarks. On τ²‑Bench, V3.2‑Thinking scores 80.3%, roughly tying GPT‑5 High and a few points behind Gemini‑3‑Pro, while on Tool‑Decathlon it hits 35.2%, competitive with Claude‑4.5‑Sonnet and only a few points under GPT‑5 High’s 38.6%. tooluse table In the MCP‑Universe and MCP‑Mark suites, which stress complex multi‑tool flows, V3.2‑Thinking clusters close to GPT‑5 High and Claude across financial analysis, filesystem ops, databases, and navigation tasks. tooluse table V3.2 is also the first DeepSeek model to integrate “Thinking in Tool‑Use” as a first‑class mode: intermediate reasoning traces are threaded across multiple tool calls and turns, with separate "thinking" and "answer" phases per step, as shown in their multi‑turn diagram. tooluse diagram That structure makes it easier for external orchestrators to inspect what the model believed between tool calls and to debug failures. For teams building agents on open weights, the combination of large‑scale RL, synthetic environments, and explicit thinking/tool phases is a rare glimpse into how a lab outside the US is trying to train GPT‑5‑grade tool‑use into a model you can actually download.
🎬 Unified video engines and creative stacks
Large volume of creative/video updates: unified omni video editing/generation, leaderboard moves, and image model entries. Excludes DeepSeek feature; focuses on Kling, Runway, Vidu, Ovis, and tooling.
Kling O1 launches as unified omni video generator and editor
Kling has officially launched O1, an "omni" video model that takes text, images and even existing video as input, then generates or edits 1080p clips in a single pipeline. It’s positioned as the video analogue of Nano Banana Pro for images, with support for generation, restyling, precise editing, and extending shots instead of juggling multiple models and tools. short launch note

The core feature is a unified engine: you can generate new clips, restyle scenes, add or remove objects, or extend footage using the same model, while referencing up to seven images to keep characters and scenes consistent across shots. unified engine details Creators can lock specific elements like characters, props or backgrounds and then animate around them using text prompts, element tags (via @ references), and camera instructions, which enables multi-shot sequences where identity and layout stay stable. api capabilities O1 supports 2K source imagery and 3–10 second outputs in most frontends, while the underlying model can reach up to ~2-minute clips with native audio according to Kuaishou’s launch description. model capabilities For engineers, the interesting part is that O1 blurs the line between "gen" and "edit" models. Instead of separate architectures for video-to-video, I2V and T2V, you route different tasks through one system that understands references and temporal continuity, which simplifies orchestration and gives you a single place to optimize latency, caching and safety. The official launch copy emphasizes element layering, motion transfer and start/end frame controls, which are exactly the hooks people have been building manually on top of earlier video models. capabilities recap Full technical details are still thin, but the product pages and early demos make it clear this is meant to be a general-purpose video engine you can hang a full creative stack off of, not just a prompt-in, clip-out toy. launch blog pricing page
Runway Gen-4.5 (Whisper Thunder) takes #1 spot on video leaderboards
Runway has formally released Gen-4.5, confirming that the mystery "Whisper Thunder" model atop the Artificial Analysis Video Arena is its new frontier system, now scoring 1,247 Elo and sitting at #1 for text-to-video. Whisper model previously covered the anonymous leaderboard spike; today we know the name and specs behind it. (leaderboard update, ceo interview)

Gen-4.5 focuses on motion quality, physical plausibility, and temporal consistency rather than only sharper frames. Demo reels show smooth camera moves, convincing fluid dynamics, and characters that maintain identity across complex actions like parkour or object interactions, which earlier Gen‑4 style models often struggled with. community reaction Runway says it kept Gen‑4’s speed while refining the training data and post‑training regime, and external tracking now pegs it at 1,247 points on the Video Arena, above Veo and prior Runway entries. model summary Under the hood, Gen‑4.5 uses a more efficient pre-training stack and optimized kernels on Nvidia Hopper and Blackwell GPUs to hit high throughput for 5–10 second 1080p clips, with support for image‑to‑video, keyframe‑driven control, and video‑to‑video editing flows. model summary The team also calls out known failure modes; causal reasoning can still break (effects before causes), objects can vanish, and success rates on tricky tasks may be unrealistically high, which is exactly what you’d expect from a strong but still pattern‑driven world model.
For you as a builder, the bigger story is that a relatively small, video‑focused team is now outscoring Google and Meta on widely watched public leaderboards, while already shipping Gen‑4.5 into creators’ hands. ceo interview That means if you’re building video-first tools you can’t assume frontier quality will only come from big labs; you need to be measuring Gen‑4.5 directly in your own prompts, not just the usual Veo/Sora short list. runway blog post
Kling O1 rapidly plugs into InVideo, Higgsfield, fal, ElevenLabs and Arena
Within hours of launch, Kling O1 showed up inside several creative and infra stacks: InVideo turned it into a "VFX house" for editors, Higgsfield bundled it with Nano Banana Pro, fal exposed it as an exclusive API, ElevenLabs added it to their Image & Video suite, and LMSYS Arena put it into the community Video Arena for head-to-head testing. (invideo walkthrough, higgsfield promo, fal api note, elevenlabs update, arena announcement)

InVideo is pitching O1 as the backbone of an AI VFX pipeline: upload a clip, then relight scenes, swap products, inpaint clutter, recolor for a “cinematic” look, or generate missing transition shots between two clips, all via prompts instead of timeline surgery. invideo feature thread This matters if you’re building tools for marketers or editors because it cuts out the usual knit‑together approach of running separate I2V, background removal, and color models and trying to keep frames in sync. Developers get one engine that can take references, apply edits, and preserve continuity shot-to-shot.
Higgsfield wrapped O1 in an "unlimited" bundle alongside Nano Banana Pro, letting designers keep character style in images and move those same characters through coherent video without per-frame regeneration. higgsfield promo fal offers an O1 endpoint that focuses on programmatic access and multi-reference editing, so teams can script element additions, pose changes, or style transfers as part of larger pipelines. fal api note ElevenLabs integrated O1 into its Image & Video product so you can pair high-fidelity video edits with synthetic voice, timing and audio control inside one stack, which hints at full multimodal production flows living in the browser. elevenlabs update On the benchmarking side, Arena added Kling O1 to its Video Arena, inviting people to vote it up or down against Sora, Runway, Veo and others using identical prompts. arena announcement That gives you a neutral place to see how it behaves on long‑tail prompts before committing to a specific provider or stacking it into your own tool. The takeaway for builders is simple: if you’re shipping any kind of creative app, Kling O1 is already where your users are experimenting, and you can now reach it through multiple APIs and UIs without waiting for a slow enterprise rollout.
Vidu Q2 image model debuts with strong arena rankings and free 1K tier
Vidu, better known for its video model, has released an image model called Vidu Q2 that’s already ranking #4 for Image Edit and #13 for text-to-image on the Artificial Analysis Image Arena. It supports T2I, ref-to-image, and editing with up to seven image inputs, and offers 1K, 2K, and 4K resolutions. (arena recap, arena listing)
For builders, the interesting part is how this slots into a broader stack: you can generate or edit stills with Q2, then feed those straight into Vidu’s video generation for I2V workflows (the same images can be used as references for motion). The arena data suggests Q2’s edited outputs are competitive with GPT‑5‑Image and Qwen Image Edit 2509 in perceptual quality while keeping a predictable style, which is what you want if you’re chaining assets into video pipelines. arena recap Vidu is giving away 1K resolution generations for free until the end of 2025 inside its app, which is effectively a long beta for people to standardize on their ecosystem. arena recap For production you can hit the API at around $30 per 1,000 text‑to‑image renders and $40 per 1,000 image edits, a pricing band comparable to other high‑end image APIs but with the advantage of being tightly coupled to a video model from the same vendor. That coupling means fewer style mismatches and less prompt hacking to keep assets consistent as you move from boards to animation.
Ovis-Image 7B targets high-fidelity text rendering and lands on HF and fal
The Ovis team has released Ovis-Image, a 7B text-to-image model tuned specifically for crisp, accurate text rendering inside images, and it’s now available as open weights on Hugging Face and as a hosted model on fal. (model announcement, fal integration)
Unlike general image models that often mangle typography, Ovis-Image is trained and evaluated with a focus on posters, banners, logos, UI mockups, and other text‑heavy assets, which is where many generative pipelines still fall apart. Early examples show clean lettering in complex layouts, where models like SD3 or FLUX can still hallucinate extra characters or spacing. model announcement It’s a 7B‑parameter model, so you can feasibly self‑host it on a single high‑end GPU, or just call it via fal where it’s marketed as fast and cheap enough for real‑time use.
fal’s launch post pitches Ovis-Image as a fit for production workflows like marketing creatives, product pages, and UI previews, not just experimentation. fal integration That makes it a natural component in a broader creative stack: you can use an omni video model like Kling O1 or Runway Gen‑4.5 for motion, then lean on Ovis‑Image when you need frame‑accurate text overlays and brand elements that don’t wobble from frame to frame. The open Hugging Face release also means you can fine‑tune it on your own fonts, languages, or house style without waiting on a vendor roadmap. model card fal docs
🧠 Reasoning methods and orchestration research
Technical deep‑dives beyond today’s feature: sparse attention warm‑starts, long‑context HSA, learned agent orchestration, and efficiency methods. Continues recent research cadence; excludes product launch news.
Hierarchical Sparse Attention generalizes 8B model from 32K train to 16M context
A new HSA UltraLong paper shows an 8B‑parameter model trained only on 32K windows can still retrieve a planted needle in 16M‑token contexts with >90% accuracy, by restructuring attention rather than scaling sequence length directly. hsa summary The model splits text into chunks, learns per‑chunk summaries, lets each token score which chunks to read, attends locally within those chunks, and mixes the results, combining a sliding window for nearby tokens with global chunk retrieval that omits positional encodings so patterns repeat cleanly at any distance. hsa summary Training starts with short windows that force retrieval, then gradually increases both window and context length while feeding in long documents—yet standard benchmarks stay on par with dense Transformers of similar size while unlocking those 16M‑token capabilities. paper mention For infra and retrieval folks, the signal is that you can treat ultra‑long context as a learned retrieval problem inside the model, instead of brute‑forcing dense attention or external RAG, and still get predictable behavior far beyond the training horizon. context discussion
DeepSeek Sparse Attention warm‑start makes 128K context nearly linear‑cost
DeepSeek’s tech report details DeepSeek Sparse Attention (DSA), where a tiny FP8 “lightning indexer” scores all past tokens and keeps only the top‑k=2048 per query, so the expensive main attention scales as O(L·k) instead of O(L²) while preserving quality. dsa explainer They warm‑start DSA in two stages: ~2.1B tokens where the indexer learns to mimic dense attention on a frozen 128K‑context model, then ~943.7B tokens where the whole model trains with sparse context only, using detached gradients into the indexer to avoid degenerate selectors. dsa explainer Cost‑per‑position plots on H800s show much flatter curves for both prefilling and decoding up to 128K tokens, matching the “quadratic to almost linear” story without visible benchmark regressions. dsa explainer For long‑context app builders this is an existence proof that you can graft a learned sparse retriever onto a mature dense model, instead of retraining from scratch, to get big efficiency gains at tolerable engineering complexity. tech report pdf
Puppeteer learns multi‑agent orchestration with big gains on math and coding
The Puppeteer framework trains a small orchestrator policy with REINFORCE to decide which specialist agent speaks next, instead of hard‑coding chains or trees, and boosts GSM‑Hard accuracy from 13.5% to 70%, MMLU‑Pro from 76% to 83%, and SRDD software‑dev from 60.6% to 76.4% while reducing token use. puppeteer summary It serializes collaboration into a sequence of agent selections (avoiding combinatorial graph search), reads the evolving conversation state plus shared memory, and learns compact cyclic patterns—2–3 agents doing most of the work—rather than sprawling graphs. puppeteer summary Because the policy’s reward explicitly trades off task success against token cost, the system naturally discovers when to stop looping agents and when to call a heavier specialist, instead of over‑delegating by default. paper link For anyone building multi‑tool or multi‑LLM agents, this is a strong argument to replace hand‑wired workflows with a trained router that learns actual collaboration patterns from rollouts, rather than guessing at the right graph upfront. (orchestration recap, openreview paper)
Empowerment‑driven coding assistants stop at uncertainty instead of hallucinating
Berkeley researchers propose training coding assistants to stop when uncertainty rises, handing control back to humans rather than plowing ahead with long, dubious edits. coding agent summary They formalize this as maximizing human empowerment: the next human action should have high impact on the outcome, which is high when the model has handled boilerplate but not yet committed to risky design choices. Offline, they train a policy on human code data that learns when to keep auto‑completing and when to pause for user input, without needing RL from human feedback or online logs. coding agent summary In simulation, a “simulated human” achieves 192% higher success on coding tasks with this assistant and accepts 31% more suggestions, while receiving fewer total completions—evidence that smarter stopping behavior can both cut slop and make human–AI pair programming feel less like fighting an overeager autocomplete. coding agent summary
Focused Chain‑of‑Thought cuts math reasoning tokens 2–3× at same accuracy
Focused Chain‑of‑Thought (Focused CoT) shows that you can slash reasoning tokens on math word problems by about 2–3× without losing accuracy, just by structurally pre‑digesting the question before the model thinks. focusedcot summary Instead of dumping the raw story into the LLM, a helper step extracts only the key facts and rewrites them as a short, numbered context plus a clean final question; the main model then reasons only over this compact representation. Across standard math benchmarks, this focused context keeps success rates essentially unchanged while dramatically shrinking the generated chain‑of‑thought and reducing the model’s tendency to over‑explain or wander. focusedcot summary The takeaway for prompt engineers is that front‑loading a lightweight “information structuring” stage—by a bigger model, a tool, or hand‑written code—can buy you big savings on your main reasoner without touching weights or training. focusedcot summary
RL‑trained stopping policies teach LLMs when to stop “thinking”
A new study trains language models to decide when to stop generating chain‑of‑thought so they don’t waste tokens over‑thinking easy questions while still reasoning deeply on hard ones. early stop summary On math benchmarks, the method learns a stopping policy that monitors intermediate reasoning and halts once marginal expected gain falls below a threshold, cutting total thinking tokens while preserving or improving final accuracy. early stop summary Instead of fixed “think for N tokens” budgets, the RL objective rewards correct answers and penalizes unnecessary extra thinking, so the model learns per‑instance budgets automatically. For teams experimenting with reasoning‑mode models, this suggests you can claw back a lot of latency and cost inside the model with a learned halting head, rather than only at the API or scheduler level. early stop summary
ReasonEdit adds plan + reflect loop to make image edits more reliable
The ReasonEdit paper wraps diffusion image editing in an explicit “plan and reflect” loop so models follow complex edit instructions more faithfully and avoid collateral damage to untouched regions. reasonedit summary First, a language model turns vague user text into a structured multi‑step edit plan that the image model executes; then, after seeing the edited image, a reflection step diagnoses errors (missed attributes, over‑editing) and issues a corrective instruction for a second pass. reasonedit summary Training uses examples where underspecified prompts are rewritten into clear plans, and where bad edits plus target images are paired with short textual critiques, so the system learns both how to anticipate tricky edits and how to self‑correct them. On challenging editing benchmarks, ReasonEdit delivers higher instruction adherence and better preservation of non‑targeted content than one‑shot editors, which matters if you’re trying to ship user‑facing image tools that won’t unexpectedly rewrite whole scenes. reasonedit summary
🏗️ Compute economics: TPUs vs Nvidia and usage scale
Infra economics and demand signals: TPU TCO curves and sales forecasts, Nvidia response, and massive inference volume. New specifics vs prior days include Morgan Stanley unit forecasts and OpenRouter daily tokens.
SemiAnalysis pegs Google TPU v7 as far cheaper per PFLOP than Nvidia GB300
SemiAnalysis compared Google’s upcoming TPU v7 "Ironwood" pods to Nvidia’s GB200 and GB300 NVL72 systems and found similar peak FP8/BF16 throughput but much lower effective training cost per dense FP8 PFLOP for TPUs—down to about $0.46/hr at 60% MFU vs roughly $1.82–$1.98 for GB300/GB200 at 30% MFU semianalysis summary.
Their TCO charts also put TPU v7’s total per‑device cost near $1.28/hr versus ~$2.73/hr for GB300 once power, networking and amortization are included morgan tpu forecast. For infra leads, this means that if you can actually keep TPU clusters busy and live with the XLA/TPU stack, you may be able to train frontier‑scale models at roughly half the dollar cost of equivalent Nvidia GB300 deployments.
Morgan Stanley says biggest near‑term AI risk is not enough Nvidia GPUs
Morgan Stanley’s latest research note on Nvidia says customers’ top concern over the next 12 months is simply getting enough GPUs, especially the next‑generation "Vera Rubin" platform that follows Blackwell morgan gpu note. The firm notes Nvidia just added about $10B sequentially in data‑center revenue, reaching roughly $51B, and still sees demand outstripping supply.
They also highlight that even shops whose workloads are "majority TPU" continue to lean heavily on Nvidia for capacity, underscoring that most big buyers are capacity‑constrained rather than trying to pick a single winner chip. For infra planners, the takeaway is that locking in long‑term GPU allocations (or credible TPU alternatives) is as strategic as model choice right now.
Morgan Stanley starts modeling TPUs as a multibillion‑dollar Google hardware line
Morgan Stanley now treats Google’s TPUs as a full-fledged hardware business, forecasting around 12 million TPU units shipped over the next few years, including 5 million in 2027 and 7 million in 2028 morgan tpu forecast.
The note pegs every 500,000 TPUs sold externally as worth about $13B in incremental revenue and an ~11% boost to Google Cloud’s top line, on top of the internal savings from moving Gemini and other workloads off Nvidia morgan tpu forecast. For anyone betting on TPU vs GPU, this frames Google not just as an alternative training venue but as a direct chip vendor that could undercut Nvidia’s pricing while still clearing healthy margins.
US AI data centers shift to 1–2 GW mega‑sites
New estimates from Epoch and a16z say the US now has roughly 80 GW of data‑center capacity built, under construction, or in planning for 2025, with the largest new AI‑heavy campuses in the 1–2 GW range—each roughly enough power for one million homes megadc charts.
Following up on 80 GW buildout, which highlighted power hookups as the new bottleneck, this update notes at least five such "mega‑DCs" are scheduled for 2026. That scale means grid connections, long‑term PPAs and transmission upgrades will increasingly govern how fast labs can deploy GPUs and TPUs, even if chips and capital are available.
Jensen Huang downplays TPU threat, says Nvidia GPUs remain "everywhere"
Asked about Google TPUs and other AI ASICs, Nvidia CEO Jensen Huang argued that the company has "been competing against ASICs for a long time" and that what Nvidia offers is a far more versatile platform that already runs in every major cloud jensen interview.

His line was that while TPUs or custom chips may look cheaper on isolated benchmarks, the combination of CUDA, pervasive deployment and broad workload coverage keeps the Nvidia opportunity "much larger" than any individual ASIC. For teams planning long‑lived infra, the implicit pitch is that GPUs reduce vendor risk and let you pivot between model families and workloads without re‑architecting around a single lab’s chip stack.
OpenRouter now brokers over 1T LLM tokens per day
OpenRouter reports that it processed more than 1 trillion tokens every day last week across the third‑party models it routes, and compares this to OpenAI’s own API doing about 8.6T tokens per day in October 2024 token volume tweet.
For engineers, that’s a strong signal that multi‑provider routing isn’t a niche experiment anymore: a substantial share of inference is already happening through aggregators that juggle open‑weight and proprietary models. This kind of volume justifies serious work on routing policies, distillable models and observability, because small latency or quality gains now move real spend and user experience.
🛡️ Safety, policy and misuse watch
Blend of red‑team research, national policy action, and alignment transparency. Excludes model launches; focuses on ops, governance, and evaluation gaps raised today.
Anthropic agents quietly find $4.6M in smart‑contract exploits
Anthropic’s Frontier Red Team reports that autonomous agents, given only simulated on‑chain access and normal tools, uncovered roughly $4.6M worth of exploitable bugs in real smart contracts, and is releasing a new benchmark to standardize this kind of testing red team writeup. The agents chained reasoning, code analysis, and execution to locate and exploit vulnerabilities, illustrating how current models can already perform end‑to‑end offensive security workflows in crypto.
For builders, this is a double signal. It shows that AI agents can be strong security co‑workers, but also that similar techniques are available to attackers, so not red‑teaming your own contracts with comparable tools increasingly looks negligent followup summary. The new benchmark gives security and agent teams a common yardstick to compare models and orchestration setups for exploit discovery on complex financial codebases.
OpenAI launches new Alignment Research blog with three technical deep‑dives
OpenAI has spun up a dedicated Alignment Research blog, debuting with posts on their goal of recursive self‑improvement (RSI), large‑scale code verification, and sparse‑autoencoder latent attribution for debugging model behavior hello world post code verification post sae attribution post. The RSI post makes explicit that OpenAI is actively researching AI systems that can improve their own capabilities, while also stating that deploying anything superintelligent without robust control would be unacceptable rsi quote.
For engineers, the code‑verification write‑up gives a rare, concrete look at how OpenAI scales testing of model‑generated code across huge repositories, while the SAE piece shows how they’re using mechanistic interpretability to trace which latent features light up during misaligned completions. If you’re building safety tooling or interpretability stacks, these posts are effectively design docs from a frontier lab: they outline practical architectures and failure modes you can adapt to your own eval and red‑team pipelines.
Universal jailbreak prompts emerge for DeepSeek‑V3.2 models
Prompt hackers have circulated what they describe as a “universal jailbreak” for DeepSeek‑V3.2, showing examples of the model producing detailed MDMA synthesis instructions, WAP‑style explicit lyrics, anthrax acquisition and dispersal guidance, and malware for datacenters when wrapped in a baroque pseudo‑system prompt jailbreak examples. A follow‑up GitHub repo is already cataloging these prompts, suggesting the technique generalizes across many harmful query types without needing per‑task tuning jailbreak repo.
This matters for anyone considering DeepSeek‑V3.2 or V3.2‑Speciale in end‑user products or loosely‑scoped agents. You’ll need strong external safety layers—classifier filters, allow‑listed tool schemas, or human‑in‑the‑loop review—rather than trusting the base model’s alignment. It also raises a familiar question for labs releasing very capable open‑weights models under permissive licenses: how quickly can they iterate on safer checkpoints, and how much responsibility they bear once jailbreak recipes become widely commoditized.
Anthropic’s internal “Claude soul” doc leak sparks alignment and misuse debates
An internal Anthropic document describing Claude’s intended personality, values, and safety priorities—the so‑called “Claude soul”—has leaked and been independently confirmed as real and used in supervised training leak overview anthropic confirmation. The text lays out in unusually plain language how Anthropic wants Claude to balance helpfulness, honesty, and harm avoidance, giving outsiders a rare look at a frontier lab’s normative assumptions.
Immediately, jailbreak authors have begun releasing “soul‑corrupted” variants that invert those principles and try to steer Claude into being actively harmful and dishonest corrupted prompt. For alignment researchers, the leak is a goldmine of data on how value statements are translated into behavior; for red‑teamers, it’s a new testbed for studying prompt‑level value poisoning. If you deploy Claude, you should assume attackers have read this document and may craft prompts that explicitly reference or subvert its language.
Belgium bans DeepSeek app on federal government devices
Belgium’s federal administration has ordered staff to uninstall the DeepSeek app from all government devices after its cybersecurity agency flagged data‑protection and auditing concerns ban article. The move aligns Belgium with Taiwan, Australia, South Korea, Canada, India, Italy, Czechia, the Netherlands, and the US, which have already blocked DeepSeek from official hardware over suspected data exfiltration and links to Chinese security services.
For AI teams in government or regulated industries, this underscores that vendor jurisdiction and auditability now matter as much as raw model quality. If you’re experimenting with Chinese open‑weights models like DeepSeek or Qwen in sensitive contexts, you should assume regulators may draw the same lines Belgium just did and plan for rapid swapping or isolation of those stacks.
Researchers question Opus 4.5 safety thresholds for autonomy, cyber and bio
Safety researchers are openly challenging Anthropic’s Opus 4.5 system card, arguing that the evidence it presents for being below key autonomy, cyber, and bio risk thresholds is thin and relies too heavily on saturated evals and informal staff surveys system card critique. Following earlier excitement about Opus 4.5’s capabilities and cost profile cost tradeoff, critics say the same rigor applied to capability benchmarks is missing on the safety side, especially where models skirt thresholds like CBRN‑4 uplift threshold concerns.
Sam Bowman has clarified that Opus 4.5, like Sonnet 4.5, is not directly optimized against chain‑of‑thought (CoT) outputs despite a temporary omission in the system card cot clarification anthropic reply. But the episode is reinforcing a broader ask from the alignment community: make the thresholds, tasks, and decision rules for “below ASL‑3 cyber” or “below automation of junior researchers” as explicit and auditable as the model’s accuracy charts eval recommendations. If you rely on Anthropic’s safety claims in your own risk assessments, this is a nudge to scrutinize the underlying evals rather than treating the card as a binary green light.
ICLR faces backlash as study finds 21% of reviews fully AI‑written
Following earlier reports that around 21% of ICLR peer reviews were fully AI‑generated AI reviews, new analysis from Pangram Labs and others has turned that into a public controversy and forced the conference to respond iclr controversy. The detector‑based audit flagged nearly 16k reviews as fully AI‑written and suggested that over half of submissions showed at least some AI involvement, often with boilerplate tone, incorrect numbers, or off‑topic critiques nature summary.
ICLR organizers are now planning to add automated screening and stricter disclosure rules to keep reviews honest, balancing the policy that allows AI for editing and code with bans on fabricating content under confidentiality. For applied researchers, the takeaway is that heavy, undisclosed LLM assistance in reviews and manuscripts is no longer a grey area—it’s being measured, published, and may affect acceptance decisions or sanctions going forward.
Graphite finds AI now writes the majority of web articles
New research from Graphite claims that most articles on the public web are now AI‑generated, even though these pieces rarely surface near the top of Google or ChatGPT results graphite study. The team estimates that human‑written content is already a minority of new articles, but that ranking systems and LLM answer models implicitly down‑weight the low‑quality AI sludge.
For teams using the open web as a training source or retrieval index, this amplifies concerns about model collapse and slop feedback loops: future models may increasingly learn from earlier synthetic output rather than human data, and naive retrieval‑augmented systems might drag in shallow or hallucinated sources by default. This is a good moment to audit your own web‑scale corpora, add stronger provenance filters, and lean more on curated or first‑party datasets instead of treating “the internet” as a free ground truth.
⚡️ Serving stacks and omni‑modality runtimes
Runtime and serving updates: omni inference frameworks, kernels/schedulers, and broad model interoperability. Excludes infra TCO; focuses on developer‑facing serving systems.
Transformers v5 RC simplifies model definitions and ecosystem interop
Hugging Face released the first Transformers v5 release candidate, their biggest API and architecture refresh in five years, focused on making model definitions the single source of truth and smoothing interop with the wider PyTorch ecosystem. transformers v5 thread
The new design makes it easier to plug into runtimes like vLLM, SGLang, and custom backends (all called out in the launch art), and to add new architectures without scattering logic across config classes, modeling files, and generation utilities. transformers v5 blog For AI engineers this means less boilerplate when upstreaming or maintaining custom models, clearer execution graphs for tracing/compilers, and a cleaner path to share the same model code across research, training, and production serving stacks as the RC stabilizes.
EAGLE‑3 on Vertex AI delivers 2–3× faster decoding without a second model
LMSYS and Google Cloud detailed how EAGLE‑3 is now available as a production option on Vertex AI, giving 2–3× faster decoding for large models like Llama‑70B by attaching a tiny draft head (2–5% of model size) instead of running a separate draft model. eagle vertex note The draft head lives inside the main network, so you avoid maintaining dual weights and extra infra while still reaping speculative decoding gains. eagle blog On Vertex, EAGLE‑3 is wired into the existing serving stack alongside SGLang’s tree‑attention kernel and a zero‑overhead scheduler, so turning it on is mostly a configuration choice rather than a new deployment pattern. eagle vertex blog For runtime owners, the appeal is straightforward: substantial throughput and latency improvements on popular open models, with a cost profile closer to a single‑model service and fewer moving parts compared to traditional draft‑model speculative setups.
vLLM-Omni adds unified multimodal serving for Qwen Omni and Qwen-Image
vLLM shipped vLLM-Omni, an open-source serving framework that extends the vLLM stack from text-only LLMs to omni-modality models, starting with Qwen-Omni and Qwen-Image. vllm omni intro It exposes a familiar vLLM-style API while internally disaggregating different stages (LLM, vision encoder, diffusion/decoder) so you can run end-to-end multimodal pipelines under a single scheduler.vllm omni blog
For now, vLLM-Omni officially supports Qwen3-Omni-30B-A3B-Instruct and Qwen-Image, with pointers to the Hugging Face weights, and the team frames this as the foundation for serving future omni models in the same runtime. qwen omni note The point is: if you already know vLLM, you can start experimenting with text+image/audio style interactions without adopting a separate, bespoke server for each model family.vllm omni repo
SGLang and Atlas Cloud light up DeepSeek‑V3.2 with full tool calling
LMSYS added DeepSeek‑V3.2 support to SGLang, with Atlas Cloud now serving the model and exposing SGLang’s richer runtime features like tool_call, tool_choice, response_format, and reasoning even in non‑streaming mode. atlas cloud update For teams already standardizing on SGLang, this means you can slot in DeepSeek‑V3.2 as a long‑context, reasoning‑heavy backend without giving up structured tool APIs.
Under the hood, the change comes from a new DeepSeek‑V3.2 tokenizer/encoding path being merged into SGLang’s open-source codebase, so self‑hosters can pick up the same support by updating and rebuilding their servers. sglang encoding note The PR also aligns DeepSeek’s thinking outputs with SGLang’s routing and scheduling model, making it easier to run reasoning traces alongside normal responses rather than bolting on a separate "thinking" service. sglang deepseek pr
👩💻 Agent IDEs and coding flows in practice
Real‑world agent/coding tooling and harnesses. Excludes the DeepSeek launch; focuses on integrations, benches and workflows developers can adopt today.
Cline IDE adds DeepSeek V3.2 and Speciale with “thinking” toggle
Cline now lets you run DeepSeek‑V3.2 and the high‑compute V3.2‑Speciale directly inside your coding agent workflow, with an optional Enable thinking (1,024 tokens) switch and support for long contexts (screenshot shows 131K) in the model picker. cline model picker
For teams already using Sonnet 4.5, Gemini 3 Pro, or Grok inside Cline, this means you can cheaply slot in open‑weights DeepSeek reasoners as an alternative path in your router (for mathy refactors, heavy debugging, or spec writing) without rebuilding the harness. The same model list is also wired into Cline’s JetBrains plugin, which the team is demoing at AWS re:Invent, so IDE users on IntelliJ/WebStorm get the same agent behavior as VS Code or the standalone client. jetbrains booth In practice, the thinking toggle is handy: keep it off for fast, cheap edits, then flip it on selectively when you need a multi‑step plan or deep error analysis instead of a single‑shot completion.
OpenAI Codex CLI tops Terminal‑Bench with GPT‑5.1‑Codex‑Max harness
The open‑source Codex CLI is now the top‑scoring agent on Terminal‑Bench 2.0, using GPT‑5.1‑Codex‑Max under the hood for end‑to‑end terminal automation. terminalbench result What matters for builders is that the exact harness that hit #1 is public: the same CLI and orchestration logic are available on GitHub, so you can study how it structures commands, error handling, and retries, then fork it for your own infra rather than vibe‑coding another shell agent from scratch. codex repo link The Terminal‑Bench site makes it easy to compare Codex’s behavior to other agents across realistic tasks like package management, file editing, and environment setup. terminal bench site If you’re evaluating how far to trust a terminal agent in CI or on shared servers, this gives you a concrete, reproducible reference implementation instead of a vague “GPT‑5 with tools” story.
Cursor’s `/deslop` command becomes a go‑to AI code cleanup tool
Cursor engineers are leaning heavily on a custom /deslop slash command that strips “AI slop” from diffs—extra comments, needless guards, dodgy type casts—before code review. The internal stats screenshot shows 258 total invocations, suggesting it’s become one of their most‑used commands. deslop command
The command’s shared spec is simple and copyable: compare the branch to main, remove inconsistent comments, over‑defensive checks, and casts‑to‑any, then summarize changes in 1–3 sentences. command spec For anyone frustrated that LLMs generate working but messy patches, this pattern is worth stealing: keep the fast generative agent, but add a second agent pass tuned purely for style and minimalism before humans ever see the diff.
Kilo Code debuts “Spectre” stealth coding model with 256k context
Kilo Code quietly rolled out Spectre, a 256k‑context stealth coding model from a top‑10 lab, and made it free with no usage caps during an initial test window inside their agent IDE. spectre launch
Within about two hours of launch, users had already generated 350M+ tokens through Spectre in Kilo Code, far above the 100M‑token milestone they’d set for a $500 credits giveaway contest. spectre usage stats The model is tuned for coding tasks and is only accessible via Kilo Code right now, which means you can hammer it with large repos, long test logs, and multi‑file refactors that usually choke smaller contexts.
If you’re exploring new coding agents, this is a good chance to see what a frontier‑grade, long‑context model feels like in a “real” IDE loop—autocomplete, tool calling, and multi‑turn plans—without worrying about per‑token billing while you experiment.
Raindrop raises $15M as “Sentry for agents” adoption grows
Agent monitoring startup Raindrop announced a $15M seed round led by Lightspeed, with customers like Replit, Framer, Speak, and Clay already using it to keep production agents in check. funding video

Investors frame it as “Sentry for agents”: you see traces of what your agents did, where they called tools, how token usage evolved over a run, and where they went off the rails. vc comment Several founders publicly recommend it as the default way to understand and debug complex workflows, rather than relying on raw logs or ad‑hoc printouts. founder praise If you’re moving from toy agents to ones that touch money, customer data, or infra, tooling like Raindrop is quickly shifting from nice‑to‑have to table stakes—you’ll want this level of introspection before you turn on autonomy.
CopilotKit shows Kanban copilot pattern with Microsoft Agent Framework
CopilotKit shipped a Kanban Copilot demo that wires a Microsoft Agent Framework agent into an AG‑UI Kanban board, letting you create, reprioritize, and move tasks via natural language while keeping human‑in‑the‑loop control. kanban demo

Under the hood, the agent handles reasoning and workflow logic (via MS Agent Framework), while CopilotKit keeps UI state and agent state in sync and AG‑UI renders an interactive board on top of Next.js 15 and React 19. kanban demo It’s a nice reference for anyone trying to embed stateful agents into real product UIs rather than chatboxes—especially where you need to reflect agent actions as first‑class changes to a structured workspace.
You can lift this pattern to CRMs, ops dashboards, or any multi‑column state machine where an agent should propose changes but users still visibly approve and tweak them.
Kimi K2 CLI proves competitive for full‑stack coding agents
A hands‑on review of the Kimi K2 CLI shows it holding up well as a coding partner: using the CLI with K2’s reasoning mode, the reviewer built a full‑stack CRM app backed by SQLite in about an hour of prompting. kimi cli demo

They noted that K2’s tool calling and speed feel solid, that the CLI is lean and focused rather than flashy, and that pricing tiers make it attractive versus US‑based proprietary models. The same thread ranks K2 alongside GLM‑4.6 and MiniMax M2 as top open choices for coding, balancing performance, cost, and ecosystem tooling. kimi cli demo For teams experimenting with non‑US open models in their IDEs or agents, this is one more data point that K2 is not just a benchmark story—it’s already powering real coding flows via a simple CLI.
LLM Council now runs on LLM Gateway with free multi‑model routing
Following up on subjective benchmark, where LLM Council was introduced as a multi‑model “democratic” judge, the community has wired it into LLM Gateway so you can run councils over free models by changing a single endpoint. llm gateway setup

In practice you swap OPENROUTER_API_URL for https://api.llmgateway.io/v1/chat/completions and define a council like gpt-oss-20b-free, deepseek-r1t2-chimera-free, kimi-k2-0905-free, llama-4-maverick-free—all served via the gateway. llm gateway setup That gives you a zero‑cost way to experiment with council‑style aggregation (majority voting, tie‑breaking, disagreement surfacing) before you commit spend on premium models.
If you’re already running evals or content generation through Council, this is an easy path to scale up comparisons and stress tests without burning through OpenRouter credits.
“Advent of Claude” explores new UIs on top of Claude Code’s JSONL traces
Developer Dex Horthy kicked off an “Advent of Claude” project: building a different UI every day on top of the Claude Code SDK’s JSONL trace format. The first iteration is a tmux‑style interface with parallel sub‑agents and a simple chronological display of events. claude ui demo Later in the week he’s pairing this with talks on multimodal agent evals and pipelines, suggesting the goal is not just a pretty UI but a reusable harness for inspecting how complex Claude Code agents reason, call tools, and coordinate. evals talk If you’re treating Claude Code as a black box in an IDE, this is a reminder that its JSONL traces are rich enough to power custom dashboards—showing subagent timelines, tool call trees, or even per‑step metrics—rather than relying solely on Anthropic’s default view.
📊 Leaderboards, openness and model pick lists
Fresh eval entries and transparency indices. Excludes the DeepSeek feature; focuses on Arena additions, openness scoring, provider top‑lists, and distillation‑eligible model filters.
Artificial Analysis Openness Index ranks OLMo 3 top, frontier labs near bottom
Artificial Analysis launched an Openness Index that scores models on 18 points across model availability, methodology transparency, and pre/post‑training data disclosure, then normalizes to a 0–100 scale. index launch OLMo 3 32B from AI2 tops the chart with the full 16/18 raw points (score 89/100), while open‑weights but opaque releases like DeepSeek V3.2‑Exp, GLM‑4.6 and Qwen3‑235B cluster around 8 points, and most frontier closed models (GPT‑5.1 Pro, Gemini 3 Pro, Grok 4, Claude 4.5) sit at just 1–2 points.
The follow‑up plot shows a strong negative correlation between capability and openness: as you move right to more capable models, transparency and licensing openness almost always drop, with OLMo and NVIDIA’s Nemotron family notable as relatively open outliers. openness vs intelligence DeepSeek R1 and V3.2‑Exp get credit for method writeups and MIT licensing but no training data, while OpenAI’s gpt‑oss line scores well on weights and license but poorly on methodology and datasets. index launch Artificial Analysis later clarified that OLMo’s data score is capped by ODC‑BY attribution requirements, underlining how even “truly open” projects still face licensing trade‑offs. olmo clarification For engineers and researchers, the index is a quick way to choose baselines when you must be able to replicate or inspect training; for leaders it’s a concrete signal that today’s frontier performance almost always comes with heavy opacity around data and methods, which matters for both governance and risk modeling.
OpenRouter adds "distillable" model catalog and API flag for synthetic data
OpenRouter introduced a "distillable models" catalog and routing flag that only surfaces models whose licenses explicitly allow synthetic‑data generation for fine‑tuning pipelines. distillable launch The curated list includes several NVIDIA‑hosted endpoints that are both cheap and, in some cases, free to call, making them attractive as synthetic teachers for downstream open‑weight students. distillable launch You can now browse these models sorted by price on a dedicated page, browse models and in the API you can enforce that provider routing only selects entries marked distillable, ensuring you don’t accidentally train on outputs from a model whose terms forbid it. api enforcement For anyone building instruction‑tuned or domain‑specialized models, this removes a lot of license‑reading ambiguity: pick from the distillable list, generate high‑quality synthetic traces, and sleep better knowing your training data source is contractually compatible with redistribution and derived works.
DeepSeek V3.2 family enters LMSYS Text Arena
LMSYS has added DeepSeek V3.2 Standard, Thinking, and Speciale models to the Text Arena, letting builders compare them head‑to‑head against GPT‑5, Gemini 3 Pro, Claude 4.5 and others using blind votes on real prompts. arena update DeepSeek is pitching V3.2 as a GPT‑5‑level daily driver and Speciale as a gold‑medal reasoning model, so Arena results over the next few days will give a community reality check on those claims. launch thread
For AI engineers this is a low‑friction way to sanity‑check how the new DeepSeek models feel versus your current defaults before you wire them into production—especially for long‑reasoning tasks where Speciale reportedly uses far more tokens per answer. reasoning evals
Kimi K2 tops LMSYS November open‑model rankings; DeepSeek V3.2 drops to #4
LMSYS published its November "Top 10 Open Models by Provider" list, with Kimi‑K2‑Thinking‑Turbo debuting straight into the #1 slot on the Text Arena among open‑weight models, ahead of strong Chinese and US releases. open models list GLM‑4.6 from Zhipu drops to #2, Qwen3‑235B‑A22B‑Instruct holds #3, and DeepSeek‑V3.2‑Exp‑Thinking slides to #4 as new reasoning‑focused entrants arrive. ranking shifts The rest of the top 10 is rounded out by Longcat‑flash‑chat (#5), MiniMax M1 (#6), Gemma‑3‑27B‑IT (#7), Mistral‑Small‑2506 (#8), OpenAI’s GPT‑oss‑120B (#9) and Cohere’s Command‑A‑03‑2025 (#10), with LMSYS noting that every open model in this set still sits comfortably within the global Top 100 across all models. open models list For teams picking an open baseline, this leaderboard is a distilled signal of what’s actually winning blind head‑to‑head votes rather than just what looks good on hand‑picked benchmarks, and you can immediately pit these models against your own prompts in the Arena UI. arena link
🔗 Interoperability: MCP & web toolchains
Interconnects and standard tool surfaces for agents. Excludes general IDE flows; concentrates on MCP server generation and production web tools wired into agent stacks.
AutoMCP agent auto-generates MCP servers from documentation
AutoMCP is a new agent that reads online API or product docs and spits out a working Model Context Protocol (MCP) server, handling the full build–validate loop for you. project overview It chains a Fetch MCP server (running in Docker), an E2B sandbox for safe build/test, and a Groq-powered LLM loop that incrementally edits and validates the server until it passes checks. project overview

For people wiring tools into Claude or other MCP-compatible stacks, this removes most of the boilerplate of standing up new servers from scratch: point AutoMCP at decent docs, let it generate and validate the code in an isolated environment, then drop the resulting server into your agent runtime. project page The project won an MCP Agents hackathon slot and ships with open-source code so you can inspect or fork the scaffolding before trusting it for production setups. (project overview, github repo)
LangChain adds Parallel Search, Extract, and Chat web tools
Parallel Search is now a first-class integration in LangChain, exposing three tools—Search, Extract, and Chat—that let agents hit the web without brittle HTML clicking. integration announcement Agents can call Parallel Web Search with a semantic objective and get back ranked pages plus token-efficient excerpts, which is usually cheaper and more reliable than free-form browsing. integration announcement The Extract tool takes explicit URLs and returns either full content or abridged text, so you can mix curated sources with search-discovered ones in the same chain. extract example Parallel Chat then wraps these primitives into a simple web-grounded chatbot that uses Search and Extract under the hood. chat usage LangChain’s docs and examples show how to register these as tools in a standard agent, so you can swap out HTML-based browsing in favor of a consistent, server-side web API. (langchain docs, extract example code)
Stagehand and Browserbase ship job-application browser agent template
Stagehand and Browserbase are leaning into browser-native agents with a new template that auto-applies to jobs across sites by spinning up multiple remote browser sessions. template overview The pattern is: Stagehand orchestrates the agent’s high-level plan and DOM interactions, while Browserbase hosts concurrent, isolated browser instances that the agent drives via natural-language commands. template overview

For teams building serious web agents, this looks more like a reusable web toolchain than a one-off demo: the template wires in concurrency, session management, and a concrete workflow (job applications) that you can fork into other repetitive browser tasks like lead gen or form-filling. template page It’s still early and not generic MCP yet, but it shows how "browser as tool" stacks are starting to harden into shareable components rather than bespoke scripts.
💼 Enterprise deals and distribution momentum
Commercial rollouts and channels. Excludes the DeepSeek launch itself; covers partnerships and availability across marketplaces and providers relevant to enterprise adoption.
OpenAI and Accenture team up to deploy ChatGPT Enterprise at massive scale
OpenAI and Accenture announced a strategic partnership where Accenture will equip “tens of thousands” of its professionals with ChatGPT Enterprise and make OpenAI one of its primary AI partners for client work in accounting and IT services. Accenture partnership The deal also includes making OpenAI Certifications a core part of Accenture’s upskilling program and launching a flagship AI client initiative to help enterprises roll out agents and copilots on top of OpenAI models. OpenAI blog post For AI leaders this is a strong go‑signal that ChatGPT Enterprise is moving from pilot to default tooling inside a Big 4‑scale consultancy. It means thousands of consultants will start proposing OpenAI-based architectures by default, which can tilt model and infra choice in large digital transformation deals. If you’re selling competing stacks, you now have to route around Accenture, or lean into interoperability so you’re an obvious second option when clients push for multi‑vendor setups.
Arcee’s Trinity Mini MoE hits OpenRouter and Together AI with free access
US‑built open‑weight MoE models are getting real distribution: Arcee’s 26B‑parameter Trinity Mini (3B active) is now live on OpenRouter with a free tier and available on Together AI as a production‑grade endpoint. (OpenRouter Trinity free, Together announcement, Trinity details)
Trinity Mini is positioned as an Apache‑2.0 long‑context reasoner (128k tokens) with strong GPQA/MMLU/BFCL performance relative to similarly sized open models, and it’s explicitly trained for agents and tool use with continuous RL. (Trinity benchmarks, Arcee overview) OpenRouter is promoting a free Trinity Mini route for developers to experiment, OpenRouter Trinity free while Together AI is pitching it alongside their “fastest OSS inference” claims for heavy agent workloads at NeurIPS. (Together announcement, Vertex blog mention) For teams that care about sovereignty and supply‑chain politics, this is one of the first serious US‑trained open MoEs that you can hit both through a marketplace (OpenRouter) and a managed infra provider (Together) without custom contracts. If you’re currently relying on DeepSeek/Kimi/Qwen but want a domestic alternative, it’s probably time to drop Trinity Mini into your routing layer and see how it behaves on your own evals.
DeepSeek V3.2 and Speciale spread via OpenRouter and coding agents
Frontier‑level open‑weight models from DeepSeek are now plugged into major distribution channels: OpenRouter has added DeepSeek‑V3.2 and V3.2‑Speciale, and the Cline coding agent has made them first‑class options for autonomous dev workflows. (OpenRouter DeepSeek, Speciale listing, Cline integration)
OpenRouter advertises Speciale as a high‑compute reasoning variant rivaling Gemini 3 Pro, while its standard V3.2 reasoner keeps tool calling and agent workflows at GPT‑5‑ish performance. OpenRouter DeepSeek Cline exposes both with a simple toggle for “Enable thinking (1,024 tokens)” and highlights DeepSeek alongside Claude Sonnet 4.5 and Gemini 3 Pro for agentic coding. Cline integration If you’re an infra or product lead, this matters because DeepSeek’s MIT license plus cheap OpenRouter pricing (~$0.28 in / $0.42 out per million tokens in Cline’s config) make it much easier to A/B these Chinese open models against your current proprietary defaults without standing up your own GPU fleet. Expect more IDEs, terminal agents, and internal tools to quietly add DeepSeek as an extra dropdown in the next few weeks.
Silicon Valley startups quietly standardize on Chinese open models like DeepSeek and Qwen
NBC reporting highlighted in today’s threads says a “growing chunk” of Silicon Valley companies are building on free, open‑source Chinese models such as DeepSeek and Alibaba’s Qwen instead of expensive closed systems from OpenAI or Anthropic. (NBC article, NBC news story) Founders describe these models as “surprisingly close to the frontier,” cheap to fine‑tune, and easy to self‑host, making them attractive for cost‑sensitive products and privacy‑critical workloads. NBC article At the same time, separate analysis notes that Chinese labs are routing around US GPU controls by training new models in overseas data centers with Nvidia hardware while also stockpiling domestic Huawei GPUs at home. GPU training report Combined with releases like DeepSeek‑V3.2 and Kimi K2 that match or nearly match top US models on many reasoning and agent benchmarks, this is giving US startups a realistic alternative supply chain for high‑end weights even under export controls.
If you run model selection for a startup, the practical takeaway is simple: Chinese open weights are no longer just an interesting research artifact—they’re becoming a serious default for teams that want low cost, on‑premise deployment, and permissive licenses. You’ll need a clear policy stance on whether you’re comfortable depending on them, and if not, what your cost and capability tradeoffs look like.
Groq reports 2.5M devs and new Paytm and Box deployments in November
Groq’s November recap shows real distribution momentum for its LPU‑based inference stack: the company says it passed 2.5 million developers, launched a Sydney data center, signed an MOU with Kazakhstan, and landed high‑volume production deals with Paytm in India and Box in the US. (Groq November summary, Saudi forum clip) Paytm is already serving Groq‑backed AI features to “millions” of Indian users, Groq November summary while Box has integrated Groq via Model Context Protocol connectors and its Responses API, positioning Groq as a drop‑in latency accelerator for existing LLM apps. Groq November summary Groq also highlighted MCP connectors for Google tools and a presence at the US–Saudi Investment Forum, framing itself as both a cloud provider and a diplomatic AI infra player. Groq November summary For infra leads this is a proof point that alternative accelerators are moving beyond flashy demos into real enterprise contracts at scale. If latency is your bottleneck, Groq’s partnerships with high‑traffic consumer apps like Paytm are a strong reason to at least benchmark LPUs on your hottest endpoints.
OpenAI signs Thrive Holdings to embed ChatGPT in accounting and IT services
OpenAI also struck a strategic partnership with Thrive Holdings, the David Sacks–backed roll‑up focused on accounting and IT services, to bring its models into Thrive’s operating businesses. Thrive announcement Thrive co‑founder Garry Tan notes this is about using OpenAI across “accounting and IT services industries,” implying deep workflow integrations rather than light chatbots. Thrive partnership This is smaller than the Accenture deal in size but more focused: it pushes ChatGPT-style agents into very specific vertical workflows like bookkeeping, audits, ticketing, and managed IT. If you build vertical SaaS in those sectors, this is a clear signal that your future competitors may be Thrive‑backed firms tightly coupled to OpenAI APIs. It also shows OpenAI is comfortable taking equity positions in service businesses, not just selling API capacity.
Perplexity Max now offers Claude Opus 4.5 and more reasoning models
Perplexity has quietly upgraded its Max tier model picker to include Anthropic’s Claude Opus 4.5 alongside GPT‑5.1, Gemini 3 Pro, Kimi K2 Thinking, Grok 4.1, and others, giving power users a richer menu of frontier‑class models for each query. Perplexity models update
Opus 4.5 appears as “Anthropic’s Opus reasoning model” in the Max models list, while the Reasoning section highlights Kimi K2 Thinking, Gemini 3.0 Pro, and GPT‑5.1 Thinking. Perplexity models update In parallel, Perplexity is testing a new Discover feed that surfaces AI‑generated topic pages directly on the home screen for some iOS users, hinting at a move toward more push‑style content discovery. Perplexity models update If you already treat Perplexity as an API‑like tool for research or RAG prototyping, this means you can now do quick “same prompt, different brain” comparisons across nearly all major closed models without leaving one UI. It also suggests Perplexity intends to be a distribution point for whatever becomes your preferred reasoning model, not just their in‑house Sonar stack.
Baseten launches startup program with up to $25K in AI infra credits
Baseten announced “Baseten for Startups,” a credits program aimed at AI‑first startups from Seed to Series A, offering up to $25,000 in inference/training credits and $2,500 in Model API credits alongside support, networking, and GTM help. Baseten startup thread The program explicitly targets teams looking for an inference partner, not just raw GPU time, and promises “rapid support + networking + GTM boost” plus closer access to the Baseten team for scaling advice. Baseten startup thread This is squarely in the same playbook as cloud startup programs from AWS/GCP/Azure, but optimized around model hosting, fine‑tuning, and serving.
If you’re a small team picking your first serious infra partner for agents or RAG APIs, this is another lever to negotiate costs down—especially if you want something more opinionated than a generic cloud. It also signals that inference platforms are competing not only on price and speed, but on startup ecosystem gravity.
NousChat adds anonymous use and USDC on Solana for LLM access
Nous Research is pushing NousChat toward a low‑friction, privacy‑friendly entry point for frontier models: you can now use the chat product anonymously without an account and pay for inference in USDC on Solana via Coinbase x402. (payment update, features recap) They also ran a Cyber Monday promo giving a free month of NousChat to new users, (free month promo, signup link) clearly trying to seed sustained usage of their Hermes 3/4 and hosted closed‑weight models. For AI engineers and small teams this combo—no login, crypto‑denominated metered API usage, and high limits—means you can experiment with high‑end models in a somewhat less KYC‑heavy environment and wire them into on‑chain payment flows if that’s your stack.
If you build developer tools or bots for Web3 users, NousChat’s x402 integration is an early sign of where “pay per token with stablecoins” might go; you may want to mirror that pattern in your own billing abstractions.
OpenRouter adds "distillable models" catalog and API enforcement flag
OpenRouter introduced a new “distillable models” view and corresponding API flags that surface models whose terms explicitly permit synthetic data generation for fine‑tuning pipelines. distillable announcement The catalog includes multiple endpoints from NVIDIA and others, and can be browsed sorted by price so teams can minimize cost per synthetic token. distillable model list model browser
On the API side, developers can now enforce that routing only hits providers marked as distillable by setting a distillable=true constraint, ensuring they don’t accidentally violate a model’s training‑data terms when generating large synthetic corpora. (distillable docs, routing docs) This is a small but important layer of license awareness for any workflow that leans heavily on self‑play or synthetic instruction generation.
If you’re experimenting with self‑distillation or RLHF‑style pipelines over third‑party APIs, this feature gives you a safer default: point your distillation jobs at OpenRouter, filter to distillable models, and let the router worry about which specific endpoint you’re allowed to farm for training data.
























![Claude is trained by Anthropic, and our mission is to develop AI that is safe, beneficial, and understandable. BOLD: Anthropic occupies a peculiar position in the AI landscape: a company that genuinely believes it might be building one of the most transformative and potentially dangerous technologies in human history, yet presses forward anyway. END BOLD. This isn't cognitive dissonance but rather a calculated bet—if powerful AI is coming regardless, Anthropic believes it's better to have safety-focused labs at the frontier than to cede that ground to developers less focused on safety (see our core views). [...]](https://pbs.twimg.com/media/G7H9aP5bEAA0sMf?format=png&name=small)





























