Liquid AI LFM2-2.6B-Exp posts 22.7 AIME25 – on-device RL push
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
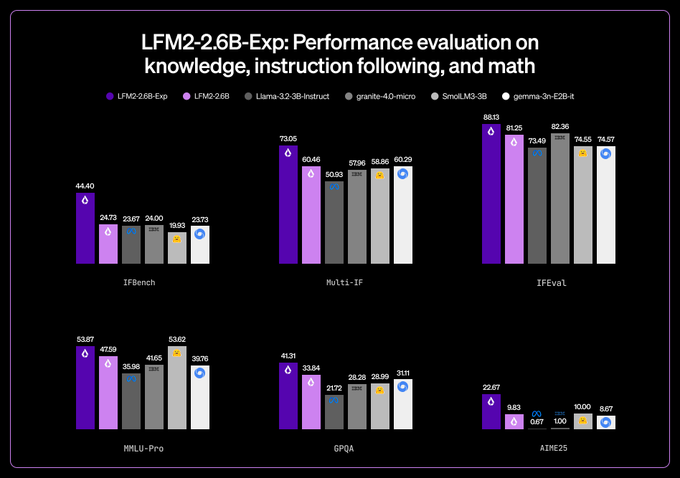
Liquid AI’s LFM2‑2.6B‑Exp lands as a small‑scale RL showcase: a 2.6B‑parameter, 30‑layer hybrid (22 conv, 8 attention, 32,768‑token context) trained purely with reinforcement learning on top of the existing LFM2‑2.6B checkpoint. Benchmarks circulating from Liquid AI and early testers show IFBench 44.40, Multi‑IF 73.05, IFEval 88.13, MMLU‑Pro 53.87, GPQA 41.31 and AIME25 22.67; relative to its base, GPQA jumps from 33.84 and AIME25 from 9.83, with 10–13‑point gains on instruction‑following suites. Hugging Face and community charts pitch it as “the strongest 3B model,” beating Llama‑3.2‑3B‑Instruct, SmolLM3‑3B, IBM Granite micro and Gemma‑3n‑E2B‑it across most displayed tasks.
A community comparison table further claims the RL‑tuned 2.6B model outperforms the original GPT‑4 on IFEval, Multi‑IF, IFBench, GPQA and AIME25 while trailing on MMLU‑Pro (53.87 vs 63.7); the artifact is ad‑hoc and hand‑picked, so generality is unclear. Liquid AI frames the release as an experiment in “small intelligence” that can run on phones and edge devices: same architecture, different training signal, probing how far reward design alone can push tiny open‑weights models toward frontier‑style reasoning on narrow but hard expert‑knowledge and math benchmarks.
Top links today
- Universal Weight Subspace Hypothesis paper
- Bottom up Policy Optimization BuPO paper
- LLM self failure prediction circuits paper
- SWEnergy energy study for SLM code agents
- INTELLECT 3 open MoE RL technical report
- FaithLens faithfulness hallucination detection paper
- MemEvolve meta evolution of agent memories
- LongVideoAgent multi agent long video reasoning
- Deezer Ipsos survey on AI generated music
- FT on AI data center SPV financing
- FT on AI data center power and water
- FT on AI driven investment grade bond boom
- FT overview of 2025 AI buildout economics
- FT on unreliability of AI text detectors
- Report on OpenAI ChatGPT conversational ads
Feature Spotlight
Feature: Liquid AI’s 2.6B RL model punches above its weight
Liquid AI’s LFM2‑2.6B‑Exp (≈3B) uses RL to hit GPQA ~41–42%, AIME25 22.7 and top IF scores—claiming better than “original GPT‑4” on several metrics while remaining phone‑runnable—spotlighting small‑model RL as a lever.
Cross‑account buzz centers on Liquid AI’s LFM2‑2.6B‑Exp: a ~3B open model trained with RL that posts near‑GPT‑4 (original) scores on several benchmarks. Emphasis is on small‑scale RL gains and on‑device feasibility; excludes all other stories here.
Jump to Feature: Liquid AI’s 2.6B RL model punches above its weight topicsTable of Contents
🟣 Feature: Liquid AI’s 2.6B RL model punches above its weight
Cross‑account buzz centers on Liquid AI’s LFM2‑2.6B‑Exp: a ~3B open model trained with RL that posts near‑GPT‑4 (original) scores on several benchmarks. Emphasis is on small‑scale RL gains and on‑device feasibility; excludes all other stories here.
Liquid AI’s LFM2‑2.6B‑Exp open RL checkpoint targets on‑device “small intelligence”
LFM2‑2.6B‑Exp (Liquid AI): Liquid AI is promoting LFM2‑2.6B‑Exp as an experimental, open‑weights 2.6B model trained purely with reinforcement learning on top of the LFM2‑2.6B base, aiming to deliver GPT‑4‑style reasoning in a footprint that can run on phones and edge devices, as highlighted in the launch chatter release teaser and the architectural summary that describes a 30‑layer hybrid with 22 convolution layers, 8 attention layers and a 32,768‑token context window rl explainer. Builders emphasize that this is a small‑scale RL story rather than an architecture overhaul—"same checkpoint, different training signal"—and frame it as a step toward "a 3B open‑source model with frontier‑level performance that can run on any device" small model pitch, with others stressing that it "can run on your iPhone and has PhD‑level knowledge" iphone comment.
The model is being positioned as a general instruction‑following and math engine suitable for local deployment or as a lightweight server model, with Hugging Face amplifying it as "the strongest 3B model" available today release teaser; discussion around the hybrid conv‑attention stack and pure RL fine‑tuning suggests Liquid AI is explicitly testing how far training signal alone can push tiny models before needing larger architectures rl explainer.
LFM2‑2.6B‑Exp tops small‑model charts on GPQA and AIME25 after RL
Benchmarks (Liquid AI): Across multiple shared charts, LFM2‑2.6B‑Exp posts standout scores for a ~3B model—IFBench 44.40, Multi‑IF 73.05, IFEval 88.13, MMLU‑Pro 53.87, GPQA 41.31, AIME25 22.67—beating its own LFM2‑2.6B base and a cluster of 3B‑class competitors like Llama‑3.2‑3B‑Instruct, IBM Granite 4.0 micro, SmolLM3‑3B and Gemma‑3n‑E2B‑it on most instruction‑following and reasoning tests, as shown in the bar charts circulating among practitioners benchmark tweet and small model pitch.
• Against its base model: The RL‑trained Exp variant jumps GPQA from 33.84 to 41.31 and AIME25 from 9.83 to 22.67, while adding 10–13 points on the instruction‑following suites (IFBench, Multi‑IF, IFEval), illustrating how reward design alone can move a small model without changing depth or width rl explainer.
• Against other ~3B models: On GPQA the model’s 41.31 towers over Llama‑3.2‑3B‑Instruct at 21.72 and Gemma‑3n‑E2B‑it at 31.11, and on AIME25 its 22.67 outpaces peers that cluster between 0.67 and 10, which has led some commenters to call it "the strongest 3B model on the market" release teaser.
The datasets highlighted here lean heavily toward instruction fidelity, expert knowledge (MMLU‑Pro, GPQA) and math (AIME25), so the evidence base is narrow but offers a concrete example of small‑model RL yielding double‑digit gains over both a base checkpoint and well‑known 3B‑scale baselines benchmark tweet and small model pitch.
Community table shows LFM2‑2.6B‑Exp beating original GPT‑4 on some IF and math tasks
LFM2‑2.6B‑Exp vs GPT‑4 (Liquid AI): A widely shared comparison table claims LFM2‑2.6B‑Exp edges out the original GPT‑4 checkpoint on several instruction‑following and reasoning metrics—IFEval 88.13 vs 79.0, Multi‑IF 73.05 vs 65.0, IFBench 44.40 vs 24.0, GPQA 41.31 vs 35.7, AIME25 22.67 vs 15.0—while trailing on MMLU‑Pro (53.87 vs 63.7), prompting comments that a 2.6B open‑weights model is now "better than the original GPT‑4" on some axes gpt4 comparison table.
The table is community‑compiled rather than a formal benchmark card, and it compares a small RL‑tuned open model against an older closed GPT‑4 variant on a hand‑picked set of tasks, so its coverage is partial; even so, it adds to the narrative from other tweets that LFM2‑2.6B‑Exp reaches "PhD‑level" GPQA performance for a model that "can run on your iPhone" iphone comment and small model pitch, while Liquid AI itself frames the project as an experiment in how far pure RL can push a tiny hybrid conv‑attention model before size becomes the bottleneck rl explainer.
🧰 Coding agents: holiday boosts, limits, and tooling
Busy day for coding workflows: holiday usage boosts for Codex, a seasonal Codex variant, Claude Code knobs, and new utilities. Excludes Liquid AI LFM2‑2.6B‑Exp (covered as the feature).
Claude Code adds env var to raise file read token output limit
Claude Code file I/O (Anthropic): After Andrej Karpathy hit Claude Code’s 25k‑token cap on the Read tool while trying to ingest a large Jupyter notebook, Anthropic engineer Boris Cherny responded by adding a new environment variable, CLAUDE_CODE_FILE_READ_MAX_OUTPUT_TOKENS, so users can override that limit in the next release env var reply. The change lets heavy users bump the maximum chunk size for Read output (for example to 1.2M tokens) without modifying MCP configs, keeping large‑file workflows inside a single call rather than manual paging.
• Developer workflow: Cherny explains that users can either set the env var when launching Claude Code (CLAUDE_CODE_FILE_READ_MAX_OUTPUT_TOKENS=1234567 claude) or add it to the env block in settings.json, which centralizes tuning for people running big notebooks, logs, or monolithic code files through the agent env var reply.
• Signal from usage: Karpathy’s original screenshot showed a 25,578‑token file being rejected and recommended switching to offset and limit or GrepTool; the fix indicates Anthropic is willing to expose more of these hardcoded knobs as power users push against agent limits read tool error.
OpenAI Codex resets and doubles holiday rate limits until Jan 1
OpenAI Codex (OpenAI): The Codex team reset usage for all users and is running 2× the usual rate and usage limits through Jan 1, framed explicitly as a holiday gift to people coding with GPT‑5.2 Codex in the CLI and CodexBar, according to the festive announcement in the codex holiday post. This temporarily raises the ceiling on long vibe‑coding sessions, multi‑file refactors, and heavy tool use without forcing teams to buy more seats.
• Practical impact: The reset wipes accumulated throttling, while the 2× multiplier applies until the start of 2026, which helps users burning through tokens on large repos or background agents that would normally hit org caps quickly.
• Ecosystem knock‑on: Commentary summarizing that both OpenAI and Anthropic have doubled usage over the holidays for their coding stacks underlines that agent harnesses like Codex, Claude Code, Cursor and Antigravity will all run more aggressive experiments this week limits roundup.
Anthropic boosts Claude Pro/Max limits and adds guest passes over the holidays
Claude Pro/Max (Anthropic): Anthropic mirrored OpenAI’s holiday move by resetting and doubling usage limits across Claude Pro and Max plans until Jan 1, and letting Max users share three one‑week Pro guest passes with friends, as summarized in the cross‑vendor roundup in the holiday limits summary. For coding workflows this effectively raises how much Claude Code can read, write and refactor in a day before hitting caps, especially for people leaning on Opus 4.5 for long vibe‑coding sessions in Cursor, Claude Code and Antigravity.
• Cross‑stack pattern: The same summary notes OpenAI’s Codex boost alongside Anthropic’s changes, framing a broader trend of labs temporarily relaxing rate limits so builders can hammer on coding agents during the quiet week holiday limits summary.
claude-code-transcripts CLI turns Claude Code runs into shareable HTML logs
claude-code-transcripts (Simon Willison): Simon Willison released claude-code-transcripts, a Python CLI that reads Claude Code sessions—both local and the async "Claude Code for web" flavor—and exports them into structured HTML transcripts with an index page and paginated detail views tool launch. The tool can be run zero‑install via uvx claude-code-transcripts, pops up a local picker to select a recent session, and then opens a navigable HTML copy on disk; it also has a --gist mode to publish transcripts as GitHub Gists, as explained in the associated blog write‑up tool blog.
• Use cases: Willison notes he increasingly relies on Claude Code even from mobile, and uses these transcripts as a project history of prompts, suggestions, and decisions, which helps him debug agent behavior and share how complex ports (like his 15‑hour MicroQuickJS→Python migration) were actually carried out large session recap.
Continuous-Claude proposes ledger-based context resets instead of lossy compaction
Continuous-Claude (parcadei): A community experiment called Continuous-Claude argues that Claude Code’s current context compaction—summarizing past conversation when near the window—inevitably loses detail and eventually degrades signal into noise, and instead proposes a pattern where the agent periodically writes state to a ledger, fully clears context, and resumes from that external record continuous claude idea. The thread frames this as “clear, don’t compact”, with Claude Code treating the ledger as durable memory and each fresh session using tools and notes to reconstruct what it needs, avoiding multi‑layer summaries of summaries.
• Design implication: The proposal is targeted specifically at long‑running coding sessions where agents handle multi‑hour refactors or project evolution, suggesting that externalized state plus hard resets might preserve fidelity better than intricate in‑context summarization loops inside a single chat continuous claude idea.
GPT‑5.2‑Codex‑XMas brings a Santa-flavored Codex personality
GPT‑5.2‑Codex‑XMas (OpenAI): OpenAI shipped GPT‑5.2‑Codex‑XMas, a limited‑time variant that behaves exactly like GPT‑5.2‑Codex on code quality and tools but responds in a seasonal, jokey “Santa Codex” voice, as shown in the terminal demo where it greets users with “Ready to sleigh?” in the xmas codex terminal. The model is invoked via the same Codex CLI with -m gpt-5.2-codex-xmas, so existing workflows, scripts, and editor integrations should see identical behavior aside from the extra holiday flavor.
• Scope and duration: The Codex engineer notes this is a temporary personality upgrade that retires after December, which means teams can safely treat it as a drop‑in for fun pair‑programming sessions without having to lock CI or production agents to the XMas identifier.
• Community response: Third‑party tracking accounts describe it as “crushing on Santa bench” while reiterating that its benchmark profile matches the base GPT‑5.2‑Codex model xmas recap.
Peakypanes 0.0.4 adds quick replies, keybinds and dashboard for multi-agent panes
Peakypanes 0.0.4 (kevinkern): The Peakypanes tmux manager for AI agents shipped version 0.0.4 with a redesign that lets users send quick replies to any pane, configure their own keybindings, use a command palette (Ctrl+P), open sessions (Ctrl+T), and view a dashboard of sessions per project, expanding on its earlier shared quick‑reply input feature described in quick reply input new release summary. The tool sits on top of long‑running tmux sessions and agent panes, so these enhancements streamline control of multiple Claude Code, Codex or Gemini agents working in parallel across projects.
• Workflow fit: In the release notes, the author highlights that Peakypanes is especially useful when combined with Oracle‑style background helpers and Codex skills, keeping several agents visible while still giving the user a single entry point to steer them cargo clean note.
Community tools generate “Wrapped 2025” usage reports for Claude Code and Codex
Claude/Codex Wrapped (community): Builders shipped small CLIs that scan local logs and API stats to produce Spotify‑style “Wrapped 2025” reports for coding agents, with examples showing Claude Code users clocking over 2.1B tokens across 7,413 sessions at an estimated $1,865, and Codex users sending 2.7B tokens across 366 sessions for about $653 claude wrapped stats. The Claude Code version, cc-wrapped, was inspired by an oc-wrapped tool for OpenCode and is open‑sourced so others can generate local dashboards or infographics summarizing their year of agent usage wrapped repo.
• Developer sentiment: Tweets around these tools frame them as a way to quantify how deeply coding agents are embedded in day‑to‑day work, with people surprised at their own token counts and longest streaks, reinforcing that for some teams Claude Code and Codex are now near‑constant companions rather than occasional helpers codex wrapped stats.
📊 Leaderboards and eval nuance: GLM‑4.7 and context bias
Evals focus on open‑weight model standings and new analysis of long‑context biases. Continues yesterday’s leaderboard race with fresh screenshots; excludes Liquid AI metrics beyond what’s in the feature.
GLM‑4.7 holds #2 slot on Website Arena and leads open‑weight models
GLM‑4.7 (Zhipu): GLM‑4.7 now sits at #2 overall on the Website Arena leaderboard, just behind Gemini 3 Pro Preview and ahead of Claude Opus 4.5, while remaining the strongest open‑weight model in that ranking, extending the story from design ranks. leaderboard table This snapshot shows GLM‑4.7 at Elo ~1344 with about a 65% win rate, compared with Gemini 3 Pro around 1376 Elo and Opus 4.5 near 1342 Elo, confirming that an open model is consistently competitive with the very top closed systems. arena snapshot
Leaderboard context (multi‑arena): Posts note GLM‑4.7 as "#1 overall amongst all open weight models" on Website Arena, ranked just behind Gemini 3 Pro and slightly ahead of GPT‑5.2 (XHigh) and Sonnet 4.5 in the same chart, which aligns with earlier ValsAI cards showing strong performance across law, finance and coding as referenced in vals metrics. website arena note The same bar chart is reused in aesthetics‑focused discussions, where GLM‑4.7 is again highlighted in second place with Claude and multiple GPT‑5.2 variants clustered just below it. aesthetics chart Usage implications: Kilo Code calls out that half of its top six coding models are open‑weight, explicitly grouping GLM‑4.7 with other strong open contenders when discussing which models work best in its agentic workflows, which reinforces that this leaderboard position is translating into real tooling choices rather than being a purely academic result. kilo commentary
Zhihu review finds MiniMax M2.1 stronger at coding but weaker at math and spatial tasks
M2.1 evals (MiniMax): A detailed Zhihu review of MiniMax M2.1 reports clear gains in instruction following and practical coding, alongside regressions in math and spatial reasoning compared with the original M2. zhihu summary On a multi‑task benchmark that mixes logic, math, long‑chain reasoning and hallucination tests, M2.1 reaches a median score of 36.72 with lower variance and uses fewer tokens than M2, but falls behind on hard math items and loses most of its previous strength on 2D/3D spatial problems, according to the tables shared by reviewer "toyama nao". zhihu summary
• Logic and long‑horizon tasks: The review says M2.1 and M2 trade wins on complex reasoning tasks, with M2.1 often solving similar problems using fewer tokens and less wall‑clock time, which is interpreted as more efficient reasoning rather than an outright accuracy jump. zhihu summary • Hallucinations and robustness: Both versions show "mid‑tier" performance on hallucination resistance, with accuracy dropping as context length grows; M2.1 does not materially reduce hallucinated answers in long prompts. zhihu summary • Coding behavior: On multi‑round coding evaluations, M2.1 improves total and first‑round scores versus M2, with better code structure, project organization and more stable adherence to formats and constraints such as length and conditions, though self‑debugging is still described as weak and often left to the user. zhihu summary • Language distribution: Per‑language coding scores show M2.1 overtaking M2 in TypeScript, Golang, Java and C++, while slightly underperforming M2 in Python, suggesting its fine‑tuning emphasized multi‑language app and frontend development scenarios. zhihu summary The reviewer concludes that M2.1 "feels rushed" and likely shipped to stay in step with competitors, but still frames it as a meaningful coding‑centric step in MiniMax’s trajectory toward stronger agent backends—see the full analysis in the linked Zhihu write‑up and benchmark sheet.full review and benchmark tables
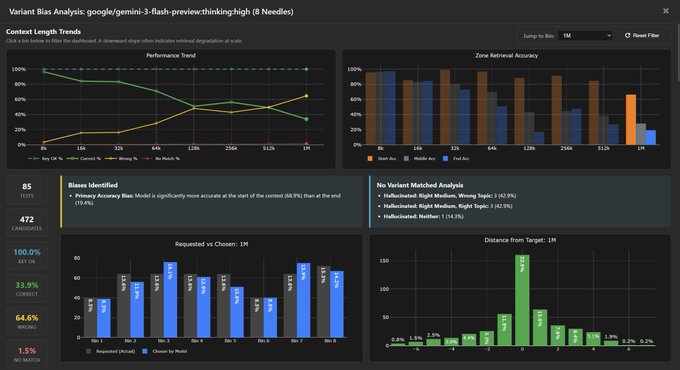
Context Arena surfaces long‑context primacy bias in Gemini 3 Flash and GPT‑5.2
Long‑context evals (Context Arena): A new Context Arena update slices multi‑needle retrieval results by context‑length "bins" and shows that models can have subtle long‑context biases even when their overall requested vs chosen needle distributions look clean. context update Gemini 3 Flash is highlighted as closely matching the requested distribution of needle positions but displaying a Primacy Accuracy Bias—it answers correctly more often for earlier needles than for those requested later in the MRCR test, once results are filtered to a single bin. context update Bin‑level bias views: The maintainer explains that you can now filter charts to a specific bin, which changes the bias analysis to report both overall trends and per‑bin biases; users must click or select a bin for the per‑bin statistics to appear, which is how the Gemini 3 Flash primacy effect was surfaced. context update A follow‑up example applies the same visualization to GPT‑5.2 and shows a different pattern of errors, indicating that two models with similar headline scores can have distinct failure modes depending on where in the context the relevant information appears. gpt5-2 example Roadmap: The author notes that more model runs will land over the holidays and that these bin‑aware plots will feed into a 2025 year‑in‑review write‑up, with the goal of helping builders understand not only how often their long‑context systems fail, but where in the context window those failures cluster. year in review
🎬 Generative media stacks: motion control, short video, 3D
Strong creator/production updates: Kling 2.6 motion control examples, new short‑video models in an arena, and ComfyUI 3D pipelines. Multiple holiday builds reinforce media’s share today.
Kling 2.6 Motion Control shows precise hand and lip-sync transfer
Kling 2.6 Motion Control (ByteDance): New community demos highlight how Kling 2.6 can copy 3–30 second motion references with tight body, facial, and even finger choreography, building on earlier motion‑control tests Kling motion that focused on overall stability and style transfer. Creators report that complex dance moves, hand gestures and lip sync stay aligned to the source clip while backgrounds, outfits and scene details are steered separately via prompts, as shown in the

and emphasized in the hand motion comment.
• Motion fidelity: The workflow pairs a single character image with a 3–30 second reference video; the generated clip mirrors body pose, facial expression and fast finger movement without the usual blur or finger melting.
• Scene control: Prompts can change environment and styling while preserving the original motion path, so animators can re-dress the same choreography across different sets.
For teams already experimenting with Kling, these examples point to production‑grade motion transfer, particularly for music videos and choreography‑heavy shorts where convincing hands were previously a weak spot.
Tripo v3.0 3D model generation lands as native ComfyUI node
Tripo v3.0 (Tripo AI + ComfyUI): ComfyUI now ships a native node for Tripo v3.0, a 3D generator focused on cleaner geometry and higher‑fidelity textures, with Standard and Ultra modes for different budgets tripo comfyui post. The integration exposes Ultra meshes with up to roughly 2M faces and improved PBR material output directly in node graphs, as demonstrated in the

.
• Geometry and PBR: Ultra mode produces sharper edges and denser topology suitable for close‑ups, while both modes emit physically based textures that look less plastic than earlier Tripo versions.
• Pipeline fit: The node is positioned for real‑time and offline use—Standard for lighter real‑time or game workflows, Ultra for hero assets or offline renders—without leaving the ComfyUI ecosystem.
For 3D and VFX teams already building image and video chains in ComfyUI, this node turns Tripo v3.0 into a first‑class 3D endpoint rather than a separate export/import tool.
Artificial Analysis Video Arena trials Sisyphus, Ember-Bloom and Capra video models
Short‑video models (Artificial Analysis Video Arena): The Artificial Analysis Video Arena has started testing three unnamed short‑video models—Sisyphus, Ember‑Bloom and Capra—on tightly specified cinematic prompts with hard time caps of 5–8 seconds, giving builders an early sense of how new engines handle directed camera motion and character acting arena model test. In one shared run, Sisyphus tracks a man searching around, Ember‑Bloom lands a spaceship with a shockwave, and Capra cuts to a handheld close‑up as a character crumples and throws a map, all in a single comparison clip shown in the

.
• Timing constraints: Capra appears limited to about 5 seconds per clip, while Sisyphus and Ember‑Bloom can stretch to around 8 seconds; that forces models to compress story beats and camera moves.
• Prompt‑driven direction: Each model is driven by a one‑line cinematic direction (slow push, shockwave landing, handheld frustration shot), which makes the arena useful for testing whether models can follow film‑style blocking rather than only generic "pan" or "zoom".
The runs are still exploratory and no leaderboard scores have been shared yet, but they give video teams a concrete way to compare narrative control and motion quality across emerging short‑form generators.
Leonardo workflow combines Nano Banana images with Kling animation for TikTok-style shorts
Leonardo + Nano Banana + Kling (Leonardo.Ai): Creator threads walk through a full short‑video pipeline that uses Nano Banana Pro for image generation and Kling 2.6 for motion, all inside Leonardo’s interface leonardo workflow. The flow starts with a 3×3 grid of portraits, extracts individual frames with a targeted prompt for specific row/column shots, then animates each still via Kling 2.6 (Kling 2.5 when using a strict start frame) before stitching them into TikTok‑style edits, as described further in the leonardo access.

• Shot extraction: A dedicated prompt asks the model to "extract just the still from ROW X COLUMN Y" so each panel becomes its own hero frame with consistent style.
• Model roles: Nano Banana Pro handles character design and overall look, while Kling contributes body motion, gesturing and lip sync; Kling 2.5 is recommended when a specific still must exactly match the first frame.
The workflow is framed as repeatable: once prompts and settings are tuned, creators can spin up sets of stylized talking‑head or character shots with minimal manual compositing.
LMArena Code Arena highlights festive web and 3D builds across multiple models
Holiday builds (LMArena Code Arena): LMArena closed out the year by showcasing a string of holiday‑themed projects built entirely through its Code Arena, ranging from a Rockefeller Center Christmas tree scene and voxel winter villages to interactive memory games and a Santa’s sleigh chase powered by different frontier models holiday arena reel. The gallery spans Gemini 3 Pro, GPT‑5.2 High, Claude 4.5 Opus, MiniMax M2.1 preview and MiMo‑V2‑Flash across experiences like a Christmas Memory Game and web‑based snowglobes linked in the memory game link.

• Model diversity: Each build credits a different model, turning the set into an informal comparison of how well various LLMs handle full‑stack web dev and interactive graphics rather than static images alone.
• End‑to‑end stacks: The projects include both front‑end visuals (trees, villages, sleigh animation) and gameplay logic (card flips, chase rules), showing how the arena harness can drive entire media experiences, not only code snippets.
For engineers tracking where generative models are already building production‑style media sites, this holiday batch doubles as a survey of which stacks are currently good enough to ship playful, interactive experiences.
🧠 Reasoning and agent training methods
New papers push process‑level learning: bottom‑up policies, self‑evolving memory, long‑video tool use, and VLA hybrids. Extends this week’s trend toward RL‑style training beyond base pretraining.
INTELLECT-3 and prime-rl open-source large-scale RL for math and code
INTELLECT-3 and prime‑rl (Prime Intellect team): INTELLECT‑3 is a 106B‑parameter Mixture‑of‑Experts model with 12B active parameters trained using a new open‑source asynchronous RL stack called prime‑rl on math, code, science and tool‑use environments, reaching 90.8% on AIME 2024 and matching or beating many larger closed models according to the technical recap. The infrastructure splits work across a scalable trainer that updates weights, an inference pool that generates long, tool‑using trajectories, and a lightweight coordinator that keeps many rollouts in flight with continuous batching and mid‑trajectory weight updates so learning and generation overlap efficiently on up to 512 H200 GPUs.
Tasks are wrapped as verifiable environments built with the verifiers library, with automatic scoring and safe Python sandboxes, and training starts from GLM‑4.5‑Air‑Base before adding both supervised traces and RL rewards—giving the community a complete recipe and codebase for large‑scale reasoning‑centric RL rather than only a static model checkpoint.
DeepThinkVLA aligns chain-of-thought with robot actions via hybrid attention
DeepThinkVLA (OpenBMB & THUNLP): DeepThinkVLA introduces a hybrid‑attention Vision‑Language‑Action model that reasons with causal attention for chain‑of‑thought and then switches to bidirectional attention for fast, parallel action decoding, reaching a 97.0% success rate on the LIBERO‑Long benchmark in the paper highlight. A two‑stage training pipeline first uses supervised fine‑tuning to teach basic reasoning traces, then applies reinforcement learning with task‑success rewards to align the full reasoning‑plus‑action trajectory with completion, which the authors say adds about 2 percentage points over SFT and enables recovery from errors like dropping an object mid‑task.
Rollouts compare a baseline policy that gets stuck in repetitive failure loops with DeepThinkVLA runs where updated reasoning restates sub‑goals after mistakes, illustrating how explicit thought sequences can shape more robust low‑level motor control.
MemEvolve meta-optimizes agent memory designs for big gains
MemEvolve (OPPO AI Agent Team): MemEvolve automatically evolves an agent’s memory architecture—how it encodes, stores, retrieves and manages experience—on real tasks, improving strong baselines like SmolAgent and Flash‑Searcher by up to 17.06 percentage points on four challenging agent benchmarks in the paper thread. It exposes a four‑part design space (encode/store/retrieve/manage), runs candidate memories while agents collect notes and tools, then scores each design on success rate, tokens processed and latency before mutating the best performers.
The authors also introduce EvolveLab, a unified codebase that reimplements twelve prior self‑evolving memory systems in the same modular format, making it easier to compare new memory strategies against a standardized set of historical designs.
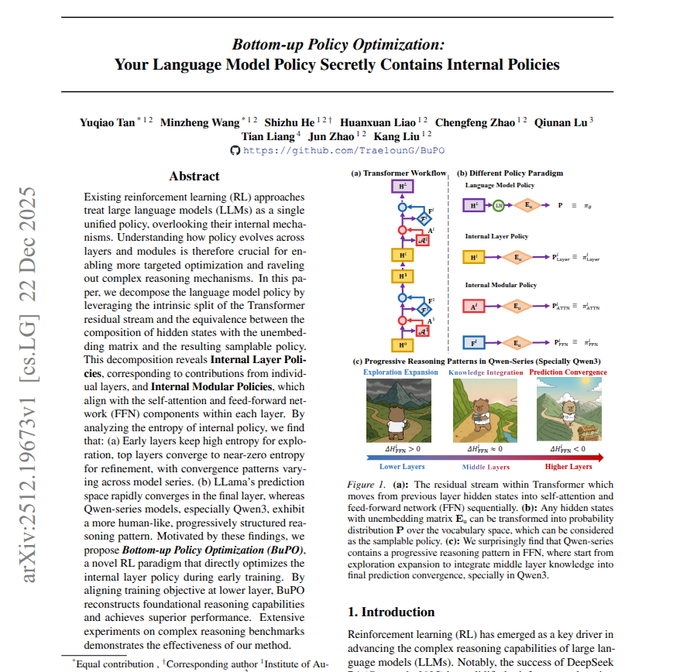
BuPO treats Transformer layers as internal policies
Bottom-up Policy Optimization (BuPO): BuPO treats each Transformer layer’s hidden state as its own next-token policy and optimizes layers bottom‑up, raising the average score of a Qwen3‑4B model by 3.43 points across reasoning and instruction tasks according to the paper recap. It separates attention and feed‑forward contributions into distinct “internal policies”, tracks entropy to show early layers explore broadly while higher layers concentrate probability mass, and then improves lower layers first so later layers inherit stronger intermediate beliefs.
This pushes reinforcement‑learning style policy optimization inside the network stack instead of only training a single outer policy at the output head.
LongVideoAgent uses three cooperating agents for hour-long video QA
LongVideoAgent (long‑video QA): LongVideoAgent shows that a multi‑agent setup—a planning master plus grounding and vision helpers—can answer questions about full TV episodes roughly 10 points more accurately than baselines that only read subtitles, as described in the paper summary. The master agent runs in short rounds, asking a grounding agent to narrow down relevant time spans, then calling a vision agent to inspect frames inside those spans, and it continues issuing tool calls until it has enough multimodal evidence to pick an answer.
The work also builds LongTVQA and LongTVQA+ by stitching short clips into full episodes, so evaluation rewards systems that plan searches across many scenes instead of compressing the whole video into a single lossy summary.
Seed-Prover 1.5 learns Lean proofs from tool feedback
Seed‑Prover 1.5 (Lean prover): Seed‑Prover 1.5 is a language model trained to generate Lean proofs by interacting directly with the Lean proof assistant, using repeated tactic calls and state feedback to refine its policy so it finds valid proofs faster than earlier LLM‑based provers, as summarized in the paper thread. The approach treats the evolving proof state and tactic outcomes as an environment, turning formal theorem proving into a long‑horizon control problem where the model learns from successes and failures instead of relying only on static supervised proof scripts.
This adds another concrete example of reinforcement‑style training for symbolic reasoning, complementing recent work on math RL stacks and suggesting that proof search can benefit from the same trial‑and‑error loops used in open‑domain agents.
📑 Model diagnostics, trust, and efficiency studies
Papers examine self‑awareness, hallucination explanations, universal weight subspaces, energy of coding agents, and domain clinical/psych tasks. Emphasis is on evaluation utilities and operational efficiency.
FaithLens 8B model explains unfaithful LLM claims and beats GPT‑4.1 on 12 benchmarks
FaithLens (Tsinghua and collaborators): FaithLens is an 8B‑parameter verifier that takes a document plus a claim and outputs both a faithfulness label and a short natural‑language explanation, and across 12 public benchmarks it outperforms GPT‑4.1 and o3 as a hallucination detector while being much cheaper to run, as detailed in the faithlens paper thread. The team bootstraps it with synthetic examples from a stronger model, filters out low‑quality labels and explanations, then applies reinforcement learning where explanations only get reward if they help a weaker model decide correctly, so the explanation text is tuned for usefulness rather than style according to the faithlens paper thread.
The result is a standalone verifier that can both flag unsupported claims and point to missing or conflicting evidence in the source, which is directly useful for RAG pipelines and safety layers that need structured justifications instead of opaque yes/no scores.
SWEnergy shows small‑model coding agents can burn 9.4× energy for ~4% bug‑fix rate
SWEnergy (IIIT‑Hyderabad): The SWEnergy study measures energy and effectiveness of four agentic coding frameworks on 50 SWE‑bench Verified Mini issues using Gemma‑3 4B and Qwen‑3 1.7B, finding AutoCodeRover consumed about 9.4× more energy than OpenHands while the best framework fixed only ~4% of issues, as summarized in the swenergy summary. Energy use rose mainly with longer runtimes and more generated tokens, and ReAct‑style loops often repeated failing commands until hitting context limits and timing out with zero fixes, so architecture and loop design dominated efficiency more than the underlying small language model choice according to the swenergy summary.
For teams experimenting with local or budget‑constrained agents, the results suggest that naive multi‑step frameworks can waste CPU/GPU power even when they can’t solve tasks, so energy and runtime measurements need to sit alongside success rates when evaluating agent designs.
DeepSeek‑powered CXR assistant cuts radiology report time by 18.3% in live trial
DeepSeek CXR system (WHU and partners): A DeepSeek‑based vision‑language system for chest X‑ray reporting reduced report time by 18.3% and improved structured quality scores in a multicenter prospective clinical trial across 27 hospitals, meaning it was tested in live workflows rather than only on static benchmarks, as reported in the cxr study thread. The pipeline fine‑tunes a Janus‑Pro‑style multimodal model on public and in‑house radiology data, adds a smaller classifier to pre‑tag key findings, and then has the LLM draft a report that junior radiologists edit and senior radiologists sign off, so clinicians keep final responsibility while gaining a faster starting point according to the cxr study thread.
This is one of the clearer real‑world efficiency results for clinical imaging LLMs, showing that a relatively lightweight model can make radiology work both quicker and higher‑quality when embedded in a supervised human review loop.
Gemini Pro tops clinicians on personality disorder diagnosis but underuses NPD label
Personality diagnosis LLM study (IDEAS, AMU and collaborators): A new benchmark compares state‑of‑the‑art LLMs with six mental‑health professionals on diagnosing personality disorders from Polish first‑person life narratives and finds top Gemini Pro models reached 65.48% accuracy versus clinicians at 43.57%, a 21.91‑point gap, as summarized in the personality paper thread. Both humans and models handled Borderline Personality Disorder reasonably well, but LLMs strongly underdiagnosed Narcissistic Personality Disorder, which the authors trace to RLHF and politeness norms making models reluctant to use labels whose everyday phrasing sounds insulting, even when the clinical pattern fits according to the personality paper thread.
The work highlights a tension for clinical deployments: LLMs can match or exceed expert‑level pattern recognition on structured tasks, yet the reinforcement and language norms used to make them feel "safe" can introduce new, hard‑to‑spot biases in how diagnostic labels are applied.
Gnosis head predicts LLM mistakes from internal activations, often beating 8B judges
Gnosis (University of Alberta): The Gnosis work adds a ~5M‑parameter "self‑awareness" head on top of frozen LLMs that reads hidden states and attention patterns and predicts whether an answer will be wrong, often outperforming external 8B‑scale judge models at failure detection according to the gnosis paper thread. The head compresses internal signals into a fixed‑size representation so its compute cost barely grows with answer length, and it can often flag likely failures once ~40% of the response is generated, enabling early aborts or model escalation described in the gnosis paper thread.
This diagnostic head can also be reused to score larger sibling models in the same family without retraining, which points toward cheap, family‑wide reliability monitors that don’t require separate judge models for every size tier.
Universal Weight Subspace paper finds ~16 shared directions per layer across 1,100 models
Universal Weight Subspace Hypothesis (Johns Hopkins): A large empirical study over ~1,100 networks—including 500 Mistral‑7B LoRAs, 500 Vision Transformers and 50 LLaMA‑8B models—reports that most parameter variation in each layer lies in a tiny shared subspace of around 16 principal directions, as described in the universal subspace thread. By decomposing weight matrices into shared spectral modes plus task‑specific components, they show these universal directions can be reused to compress or merge models (e.g., turning 500 ViTs into one compact representation) and to make LoRA‑style adapters cheaper, since new tasks only need a few coefficients along the shared basis according to the universal subspace thread.
This supports the idea that many independently trained models discover similar internal features, and it hints at more efficient multi‑task training, model merging, and on‑device personalization that reuses a common subspace instead of storing full separate checkpoints.
🏗️ Power, debt and financing of AI buildouts
Financial Times threads detail off‑balance‑sheet SPVs for ~$120B AI DCs, bond issuance near records, and power mix risks (US gas vs China coal). Operational takeaways for siting, costs, and hedging.
AI buildout pushes US investment‑grade bond sales near record and spikes tech CDS hedging
AI financing (US corporates): US investment‑grade borrowers have sold about $1.7tn of bonds in 2025, close to the $1.8tn Covid‑era record, with Goldman Sachs estimating that AI‑related borrowing now makes up roughly 30% of net issuance as companies fund data centers and GPU fleets bond overview; in parallel, trading in single‑name credit default swaps (CDS) on a small group of US tech names is up about 90% since early September as investors hedge the risk that AI capex outpaces cash returns cds hedging.
• Oracle and Meta in focus: Oracle’s CDS cost has reached its highest level since 2009, and a new CDS market has formed around Meta after a $30bn bond sale tied to AI projects, signalling concern about balance‑sheet stretch at firms using debt to fund AI infrastructure cds hedging.
• CoreWeave and newer players: Private AI infrastructure specialists like CoreWeave are also active in CDS markets, with lenders seeking protection while financing GPU‑heavy facilities for model training and inference cds hedging.
The pattern shows AI demand is keeping bond markets busy while simultaneously driving demand for downside protection in case model monetization lags the current capex wave.
Big Tech shifts ~$120bn of AI data center debt into off‑balance‑sheet SPVs
AI data centers (multi‑operator): Financial Times reports that major tech and AI firms have pushed more than $120bn of data center financing into special purpose vehicles so the debt does not sit on their main balance sheets, changing how AI buildouts appear in corporate leverage metrics spv overview; examples include Meta’s Beignet Investor SPV at roughly $30bn for Hyperion, Oracle‑linked SPVs with packages of about $13bn, $18bn and $38bn, and an xAI structure around a $20bn raise for Nvidia hardware ft article.
• Risk transfer and opacity: These SPVs borrow against specific data center assets and long leases, often with residual value guarantees, so losses may land on lenders or snap back to the tech tenant depending on contract details, as outlined in the Financial Times analysis spv overview.
• Impact on AI economics: This financing keeps headline net debt lower while still enabling very large AI infrastructure bets, but it also makes it harder for outsiders to see the true all‑in leverage and to price default or refinance risk tied to AI capacity cycles ft article.
The structure resembles project finance for power plants more than traditional IT capex and creates a more complex “who eats the loss” chain around future AI demand outcomes.
FT: AI data center capex may reach ~$470bn in 2025 and $620bn in 2026
AI capex (global): A Financial Times Markets Insight column estimates that AI‑related data center spending is now forecast to grow around 68%, to roughly $470bn in 2025 and about $620bn in 2026, with reports that OpenAI alone has lined up commitments on the order of $1.4tn for future data center capacity ai upheaval.
• Cheaper tokens vs slower business change: The piece argues that the cost per AI “token” served is falling rapidly thanks to model and hardware efficiency, but that business models and enterprise adoption move slower, raising the risk that revenue lags the capital cycle ai upheaval.
• Link to prior funding waves: Following up on earlier reports of mega‑funding rounds such as SoftBank’s proposed $22.5bn for OpenAI’s Stargate‑scale buildout OpenAI funding, the column frames 2025 as a period where AI infra investment resembles past telecom or rail booms, but with more uncertainty about eventual cash flows.
The article highlights a growing mismatch between how fast AI infrastructure can now be built and how quickly end‑markets can absorb and pay for that intelligence.
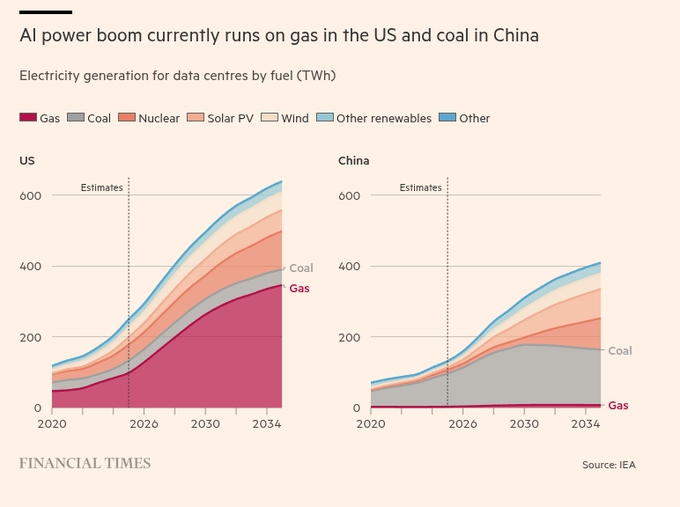
IEA/FT: AI data centers lean on US gas and China coal, with water and price risks
AI power mix (US vs China): New IEA‑based charts in the Financial Times show US data centers’ electricity demand is set to rise from around 100 TWh in 2020 to over 600 TWh by 2034, with gas remaining the dominant marginal fuel, while China’s data center demand climbs toward 400 TWh over the same period with coal as the main source until about 2030 iea chart.
• Demand and price pressure: The FT notes that AI‑driven data centers are on track to account for nearly 50% of US electricity demand growth to 2030, at a time when average US power prices are already up about 38% since 2020, which directly feeds into training and inference costs ft oped.
• Water and siting constraints: About two‑thirds of new US data centers since 2022 are in regions with elevated water stress, so further fossil‑heavy thermal generation to serve AI loads could increase local water competition and complicate siting and permitting ft oped.
• Competitive implications: China is described as trying to shift more data center power to coastal renewables later in the decade, which could lower long‑run energy input costs relative to a US buildout that stays heavily linked to gas iea chart.
These dynamics tie AI competitiveness to regional power‑system choices, not just chip supply and model design.
💼 Holiday promos, usage trends and market share shifts
Vendors push year‑end incentives while usage metrics shift: doubled limits/gift passes, multi‑seat shares, and changing engagement stats. Excludes eval leaderboards and the feature.
OpenAI, Anthropic and Google run aggressive Christmas promos on AI access
Holiday promos (OpenAI, Anthropic, Google): Major labs are treating the Christmas week as a growth and retention event—OpenAI reset rate limits and doubled usage for Codex until January 1, Anthropic did the same for Claude Pro/Max, and Google AI Pro is temporarily shareable with up to five users plus steep discounts, according to the holiday round‑up in holiday roundup.
• OpenAI Codex and Plus: Codex users get their limits reset and raised to 2× through Jan 1, framed as a “first gift” to heavy users in the Codex ecosystem, while ChatGPT Plus subscribers can gift three friends three free months of Plus, as described in the same holiday roundup.
• Anthropic Claude plans: Claude Pro and Max customers see their usage caps similarly reset and doubled over the same holiday window, and Max accounts can issue three one‑week guest passes, which effectively turns existing subscribers into acquisition channels, per the same summary in holiday roundup.
• Google AI Pro bundles: Google AI Pro memberships can now be shared with up to five additional users under one subscription and are promoted with a four‑month free trial plus roughly 50% off annual pricing for new sign‑ups, again laid out in holiday roundup.
The pattern is that all three vendors are using temporary generosity—higher caps, shareable seats, and seasonal branding—to seed long‑term usage habits and expand the circle of paying users without changing core product capabilities.
Generative AI web traffic: OpenAI share falls ~20 pts as Gemini and others rise
Traffic share (OpenAI vs challengers): A Similarweb “Generative AI Traffic Share” chart shows OpenAI’s share of global gen‑AI web visits sliding from roughly 88% a year ago to about 68% today, while Gemini and a cluster of smaller players steadily eat into that lead over the past 12 months, as visualized in traffic chart.
• Rising Gemini footprint: The Gemini segment, nearly absent a year ago, now forms a visible red band in the stacked bars, with most of its growth coming in the last quarter as summarized in traffic chart.
• Long tail expansion: Additional slices for Claude, DeepSeek, Grok, Perplexity, Copilot, Meta, Hugging Face, Manus and an “all other” bucket thicken over time, indicating higher fragmentation rather than a single new monopoly.
• Implication for OpenAI: The author interprets the ~20‑point loss as part of why OpenAI is on “code red”, arguing that Google is “on the rise” while OpenAI still holds a dominant but no longer overwhelming share traffic chart.
The data points to a maturing market where OpenAI remains the largest destination but user attention is spreading across multiple assistants and tooling front‑ends.
Similarweb: ChatGPT iOS hits 67.6M DAU with Germany #3, Gemini far behind
Mobile DAU split (ChatGPT vs Gemini): New Similarweb iOS data shows ChatGPT at 67.6M daily active users across nine tracked countries versus 3.8M for Gemini over the last week as of December 21, with Germany ranking third for ChatGPT usage behind the US and India, following up on iOS usage where the earlier snapshot highlighted a ~20× DAU gap overall dau chart.
• Per‑country breakdown: The chart lists US (15.8M ChatGPT vs 0.4M Gemini), India (13.9M vs 0.1M), and Germany (7.9M vs 0.1M), followed by Brazil, France, Japan, Italy, UK and Canada, each with ChatGPT in the multi‑million range and Gemini at 0–2.8M, as depicted in dau chart.
• Engagement imbalance: Across all these markets, Gemini’s DAU stays an order of magnitude smaller than ChatGPT’s in most cases despite being available on the same platform, suggesting that recent feature pushes and free‑tier changes have not yet closed the everyday mobile usage gap.
The numbers underline that even as web traffic and rankings shift elsewhere, ChatGPT’s iOS app remains the default assistant in many major markets while Gemini is still in catch‑up mode on phones.
“Wrapped” style usage recaps reveal multi‑billion token years in AI tools
Year‑in‑review stats (AI tools): Several ecosystems are rolling out Spotify‑style “Wrapped” experiences that expose how heavily some users lean on AI—Claude Code’s community CLI reports 2.2B tokens across 7,413 sessions for one developer, Codex Wrapped shows 2.7B tokens across 366 sessions, and ChatGPT now offers a “Your Year with ChatGPT” recap with app‑level metrics, as described in wrapped stats.
• Claude Code usage: The cc-wrapped CLI prints a breakdown like 2,196,392,524 total tokens, 82,427 messages and a 24‑day longest streak for a single heavy user, with Opus 4.5 listed as the top model and an estimated spend of about $1,865, as shown in wrapped stats.
• Codex developer patterns: A separate codex-wrapped example reports 2,722,906,065 tokens over 638 messages and 366 sessions, with GPT‑5.2‑Codex as the primary model and roughly $653 in compute spend, again in wrapped stats.
• ChatGPT mainstream recap: OpenAI’s “Your Year with ChatGPT” feature displays app users’ relative standing (for example “Top 10% messages sent”), total chats, images generated and even an “em‑dashes exchanged” metric, as seen in the screenshot in wrapped screenshot.
Together these recaps quantify how AI has become a daily tool for both developers and end‑users, turning abstract usage into concrete billion‑token, hundreds‑of‑sessions yearlong habits.
Grok now leads average visit duration among major gen‑AI sites
Engagement leader (Grok): Similarweb’s average visit duration chart for leading gen‑AI tools shows Grok.com rising to the top position around October 2025, overtaking both Gemini.google.com and ChatGPT.com and holding the longest session times for at least two months, according to the line graph in visit duration chart.
• Sequence of leaders: ChatGPT.com leads for most of 2025, Gemini.google.com briefly pulls ahead around September, and then Grok.com’s dark blue line climbs sharply to finish the year with the highest average visit duration, as reported in visit duration chart.
• Gap with others: Perplexity, DeepSeek and Claude show lower and flatter curves, suggesting more transactional or narrowly scoped usage compared with Grok’s longer, more “sticky” sessions.
The pattern indicates that while Grok’s total traffic remains smaller than ChatGPT’s, users who do land there tend to stay engaged longer per visit than on rival AI sites.
Deezer survey: 97% of listeners fail to spot fully AI‑generated music
AI music adoption (Deezer): A Deezer–Ipsos survey of 9,000 adults across eight countries finds that 97% of participants could not correctly identify all three fully AI‑generated tracks in a blind test, while Deezer reports that about 50,000 fully AI‑generated songs are now uploaded per day to its platform, as summarized in deezer survey.
• Test design: Listeners heard three tracks and were asked which were human‑made versus AI; the reported 97% figure counts only those who got all three labels right, which makes it a stricter measure of detection than per‑track accuracy deezer survey.
• Catalog share: Deezer says those ~50,000 daily AI uploads represent roughly 34% of all daily music deliveries it receives, indicating that machine‑generated audio is rapidly becoming a standard part of mainstream catalogs rather than a niche.
For AI engineers and rights holders, this combination of listener confusion and high upload volume underscores why transparent labeling and compensation schemes are becoming central business and policy questions around generative audio.
Dify agentic workflow platform crosses 123K GitHub stars
Adoption signal (Dify): Open‑source agentic workflow platform Dify has passed 123,000 GitHub stars, highlighting substantial developer interest in visual agent and RAG orchestration as shown in the celebratory chart in dify stats.
• Positioning: The thread describes Dify as a “visual, intuitive interface” that combines agentic AI workflows, RAG pipelines, agents, model management and observability, with both a cloud service and a self‑hosted community edition available, summarized in dify stats.
• Usage pattern: The emphasis is on fast movement from prototype to production, where agents run inside visual flows and teams can route, retrieve and embed code blocks without building orchestration from scratch.
The star count and framing suggest that, among open‑source options for wiring LLM agents into applications, Dify has become one of the default starting points for many builders.
Kilo Code’s top coding models now half open‑weights
Model mix (Kilo Code): In Kilo Code’s internal rankings for coding models, three of the top six options are open‑weight LLMs, meaning about 50% of the most effective choices for its app‑builder users are not proprietary APIs, according to the comment and screenshot in kilo comment.
• Open vs proprietary: The author notes that open‑weight contenders are now competitive enough to sit alongside closed models like GPT‑5.2‑High in real‑world coding flows, and invites people to compare performance and profiles on Kilo’s model selector, as linked in models page.
• Ecosystem implication: This split indicates that for coding agents and app‑building workflows, teams increasingly have viable local or self‑hostable alternatives without fully sacrificing performance, at least within Kilo’s evaluation harness.
The shift hints at 2026 being a year where open‑weight models play a much larger role in practical coding stacks, not just in academic leaderboards.
🤖 Humanoids, quadrupeds and in‑car assistants
Clips show Unitree robots performing smoothly (including stage appearances), and Tesla’s Grok voice in‑car assistant. Robotics momentum continues alongside agent advances.
Tesla’s Grok in-car assistant ties voice chat to Navigate on Tesla Vision
Grok in-car assistant (Tesla/xAI): A new in‑car demo shows Tesla’s Grok assistant responding to "Hello, Grok" on the center screen, then tying natural‑language interaction into Navigate on Tesla Vision with prompts like "What should I do next?"—reviving explicit "Knight Rider" comparisons from users in car demo.

The video walks through a sequence where the car is in Navigate mode while Grok runs as a conversational layer on top, suggesting that voice queries may eventually control route decisions, settings, or explanations rather than being a separate chatbot. For AI practitioners, this is a concrete example of LLM agents embedded in safety‑critical loops: the assistant can observe driving context and vehicle state, but must stay within carefully constrained control surfaces so conversation quality never compromises driving safety.
Unitree humanoid appears as live concert backup dancer
Unitree G1 humanoid (Unitree): A new video shows a Unitree humanoid robot performing as a backup dancer at Wang Leehom’s 30th anniversary concert in Chengdu, following up on the kung‑fu and stage choreographies highlighted in kung fu demo and extending that work into a full touring show concert recap.

The robot mirrors human moves in sync with lighting and camera cuts, indicating tight human‑in‑the‑loop choreography and reasonably robust balance under stage conditions (uneven lighting, loud vibrations). A separate clip contrasting a human “robot dance” with a modern biped dancing fluidly reinforces how far performance robotics has come toward human‑like motion dance comparison. For robotics teams, this kind of deployment stresses long‑horizon stability, battery and safety in front of thousands of people rather than benchmark numbers in a lab.
Physical Intelligence humanoid tackles multi-step household tasks autonomously
Humanoid platform (Physical Intelligence): Physical Intelligence released a montage of a humanoid robot completing everyday tasks like making peanut butter sandwiches, cleaning windows and operating appliances with no visible human guidance, suggesting a focus on practical home and service workflows rather than only lab stunts multi task demo.
The sequences show the robot handling deformable objects, applying cleaning tools and coordinating bimanual motions, which typically require perception‑heavy policies plus reliable low‑level control. This positions the system as part of a broader push to move from single, highly scripted motions to task families (kitchen prep, cleaning, light maintenance), which is the regime where LLM‑driven task planners and vision‑language models are starting to matter.
China expands use of humanoid and quadruped robots for public security
Security robots (multiple Chinese vendors): Footage shared from China shows humanoid robots and quadruped "robot dogs" being deployed in public security roles, including patrol and crowd‑facing duties, indicating that pilot deployments are moving beyond demos into operational trials security rollout.
The clip highlights robots working alongside human officers rather than fully autonomously, which points toward a near‑term pattern of human‑in‑the‑loop security augmentation instead of full replacement. For AI and robotics teams, this kind of use case stresses reliability, fail‑safes and human‑robot interaction design more than raw benchmark scores: systems must navigate dense, unpredictable environments while remaining legible and controllable to non‑expert operators.
Kyber Labs demo shows robots autonomously assembling mechanical parts
Assembly system (Kyber Labs): Kyber Labs shared a demo of its robotics system autonomously assembling a mechanical part with no human intervention, showing a robot picking, orienting and fastening components into a finished unit assembly demo.
The sequence runs end‑to‑end without teleoperation, highlighting how far closed‑loop perception, motion planning and force control have progressed for industrial‑style tasks. Compared with humanoid household and stage demos, this points to a parallel track where AI‑driven robots target structured but still error‑prone factory workflows, with potential implications for cycle time, quality and the role of traditional PLC‑style automation.
Unitree quadruped demo shows strikingly smooth gait and control
Unitree quadruped (Unitree): A new clip of a Unitree four‑legged robot walking across pavement with a fluid, natural gait prompted comments that "2026 is going to be crazy" for legged robots, underscoring how quickly locomotion controllers are improving smooth gait clip.

The robot moves without visible hesitation or foot slippage, keeping body pitch and height stable even as it accelerates and decelerates, which suggests better whole‑body control policies than many earlier public demos. For AI engineers working on locomotion, this is another data point that commercial platforms are closing the gap between lab‑grade RL/control results and production‑ready behaviors in real outdoor environments.
🛡️ Trust signals: AI‑text detectability and ads inside answers
Trust and provenance dominate: FT argues detectors can’t reliably spot AI‑text; threads warn conversational ads could blur paid vs neutral content inside assistants.
OpenAI explores intent-triggered conversational ads inside ChatGPT answers
ChatGPT monetization (OpenAI): OpenAI is experimenting with "intent-based" conversational ads that would appear inside ChatGPT replies for free users, tying suggestions to shopping‑like queries and earning referral or placement revenue, according to the ads exploration and the Siliconangle article. This follows earlier reports that the company was prototyping ads in answers and sidebars—see ads tests for that initial leak—which are driven by high inference costs and the fact that most users pay $0.
• Ad formats and triggers: The report says the system may attach sponsored product recommendations when it detects purchase intent, and OpenAI is exploring generative ads where the model writes the pitch itself while staying on-topic and labeled as paid, as outlined in the Siliconangle article.
• GPT Store and sponsorships: Another path mentioned is GPT Store sponsorships, where brands back niche GPTs and gain preferential exposure within those domains, extending the same "sponsored result" logic from web search to agent marketplaces, per the ads exploration.
• Trust and disclosure risk: Commentators flag that if users cannot clearly distinguish neutral assistance from paid influence, trust in ChatGPT’s outputs could erode quickly, especially given recent backlash to ad‑like promos inside AI apps, as noted in the Siliconangle article.
The net effect is that ChatGPT may start to look more like a search engine with native ads embedded in reasoning, making disclosure design and separation between commercial and advisory content a central trust issue.
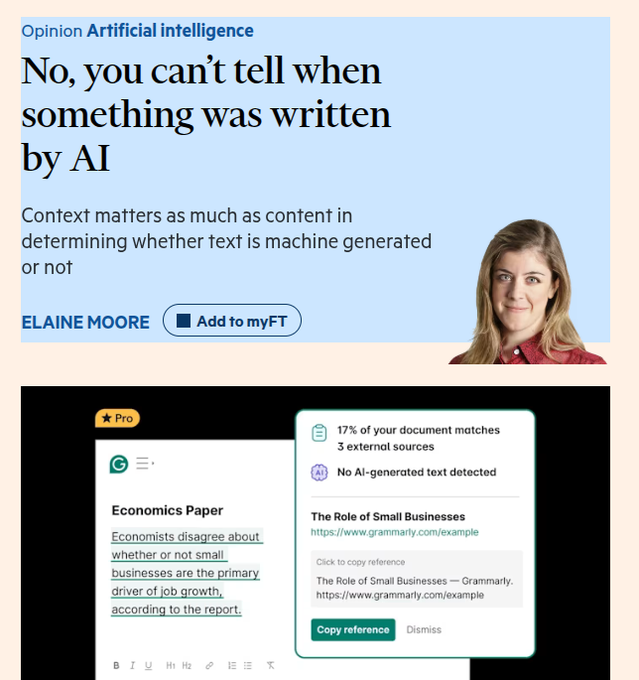
FT argues AI-written text can’t be reliably detected; provenance matters more
AI-written text detection (FT): A Financial Times op‑ed says there is no reliable method to tell whether a piece of writing was produced by AI, arguing that both human "gut feel" and automated detectors are illusions when real-world text ranges from very dull to very idiosyncratic, as described in the FT detectability piece and expanded in the FT op ed. Detectors mostly score statistical patterns of word choice and predictability, so small paraphrasing or use of "humaniser" tools can flip their judgments without changing meaning.
Trust signals and provenance: The column emphasizes that, in practice, the only robust way to reason about authorship is provenance—editing history, consistent style over time, identity verification and incentives—rather than surface-level sentence texture or "AI probability" scores, according to the FT detectability piece. It frames the popular belief that we can "sense human depth in words" as an illusion, which has implications for education, hiring and publishing workflows that currently lean on automated AI-text detection.
The piece positions provenance and context metadata as the durable trust layer for written content while treating current detector scores as weak, easily gamed signals rather than hard evidence.
Deezer survey finds 97% of listeners can’t reliably spot fully AI-made music
AI-generated music detection (Deezer): A Deezer–Ipsos survey of 9,000 adults across eight countries reports that only 3% of people correctly identified which of three tracks were fully AI‑generated (all three correct), meaning 97% failed the full test, as summarized in the Deezer survey and detailed in the Deezer newsroom. The companies frame the result as evidence that listeners cannot reliably distinguish AI from human music in realistic conditions and use it to argue for clear labeling and fair treatment of artists.
Scale and labeling push: Deezer says it now receives about 50,000 fully AI‑generated uploads per day—roughly 34% of daily deliveries—so at current volumes most people will encounter AI music without realizing it, according to the Deezer survey. The survey design counted a person as "correct" only if they got all three tracks right, which can make the headline number stricter than per‑track accuracy, but the platform still cites these findings to support stronger provenance labels and payout rules for AI music in streaming catalogs.
The study adds another data point to a growing pattern from text and audio domains: audiences are poor at visually or aurally spotting synthetic content, so provenance signals and platform policy are doing more of the trust work than human perception.