DeepSeekMath‑V2 releases 689GB IMO‑gold weights – 99% basic proofs
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
DeepSeek dropped DeepSeekMath‑V2, a 689GB math specialist built on DeepSeek‑V3.2‑Exp‑Base and licensed Apache‑2.0, and it might be the first time you can literally download an IMO‑gold brain. The model hits IMO 2025 and CMO 2024 gold levels plus 118/120 on the 2024 Putnam when you scale test‑time compute, putting an open stack in the same league as Google and OpenAI’s previously API‑only Olympiad systems.
The twist is how it reasons. DeepSeek trains a verifier LLM first, then uses it as a reward model to RL‑train the generator, scoring step‑by‑step proof quality instead of only final answers. On ProofBench it clocks 99.0% human‑checked success on Basic problems and 61.9% on Advanced, beating Gemini Deep Think (IMO Gold) on the easy split and staying close on the hard one. That makes it a defensible theorem‑proving backend or math agent brain rather than yet another chatty generalist.
In the wider tooling race we’ve been covering, Claude Opus 4.5 keeps winning human‑judged coding arenas while Amp’s “off‑the‑rails cost” metric shows Gemini burning 7× more wasted spend than Opus. Put together, the center of gravity is shifting: closed labs still dominate broad UX, but the sharpest domain brains—and the eval harnesses to use them well—are rapidly moving into the open.
Top links today
- What does it mean to understand language paper
- HunyuanOCR technical report for 1B OCR VLM
- EGGROLL evolution strategies at hyperscale training method
- MSTN fast and efficient multivariate time series model
- BREW memory system for improving language agents
- Infinity-RoPE infinite action controllable video generation
- GigaEvo open LLM plus evolution optimization framework
- VISTA Gym agentic RL for tool using VLMs
- ALIGNEVAL evaluating LLM alignment via judge capability
- LLM forecasting ability varies by domain study
- MedSAM3 medical concept guided image segmentation model
- Vision language guided reconstruction for fast MRI
Feature Spotlight
Feature: DeepSeekMath‑V2 opens IMO‑gold math reasoning
DeepSeekMath‑V2 releases open weights (Apache‑2.0) with a verifier→generator RL recipe, hitting IMO 2025 gold, CMO gold, and 118/120 Putnam—first public, reproducible Olympiad‑level math reasoner.
Cross‑account focus today is DeepSeek’s open‑weights self‑verifying math model. Tweets show Apache‑2.0 weights on HF, verifier→generator RL, and Olympiad‑level results; strong interest from researchers and builders.
Jump to Feature: DeepSeekMath‑V2 opens IMO‑gold math reasoning topicsTable of Contents
🐳 Feature: DeepSeekMath‑V2 opens IMO‑gold math reasoning
Cross‑account focus today is DeepSeek’s open‑weights self‑verifying math model. Tweets show Apache‑2.0 weights on HF, verifier→generator RL, and Olympiad‑level results; strong interest from researchers and builders.
DeepSeek open‑sources IMO‑gold math model under Apache 2.0
DeepSeek has released DeepSeekMath‑V2 — a 689 GB math‑specialist model built on DeepSeek‑V3.2‑Exp‑Base — as open weights on Hugging Face under an Apache‑2.0 license, giving engineers a downloadable IMO‑gold reasoning model for the first time release recap simonw note. Community voices are framing it as “owning the brain of one of the best mathematicians in the world for free,” emphasizing that you can inspect, fine‑tune, and self‑host it without policy nerfs or recall risk hf ceo comment. For infra and research teams, the size (689 GB) and license mean serious but tractable on‑prem deployments, full reproducibility for math‑reasoning work, and a clear baseline for future open RL‑reasoning stacks.
Compared to previous Olympiad‑level models from OpenAI and Google, which were only accessible via APIs, this drop shifts the frontier of math reasoning firmly into the open‑source world and sets a new reference point for academic benchmarks, agent tooling, and verifier research benchmarks thread GitHub repo.
Verifier‑driven RL makes DeepSeekMath‑V2 a near‑perfect proof engine
Under the hood, DeepSeekMath‑V2 trains an LLM verifier first, then uses it as a reward model to RL‑train a proof generator that learns to find and fix its own mistakes, scaling verification compute over time to keep the generator and verifier in tension paper summary putnam recap. On the ProofBench suite, this self‑verifying setup reaches 99.0% human‑evaluated success on Basic problems and 61.9% on Advanced, beating Gemini Deep Think (IMO Gold) on Basic (89.0%) and staying close on the harder Advanced split (65.7%) benchmarks thread. For engineers, the important detail is that rewards are tied to step‑by‑step proof quality, not just final answers, which makes the model far more suitable as a theorem‑proving backend or math agent brain than generic LLMs tuned on answer‑only RL.
The tech report describes a loop where an LLM‑based verifier is itself improved by labeling harder proofs with more compute, then used to further train the generator — a recipe that can be ported to other domains where reasoning rigor matters (security proofs, protocol verification, scientific derivations) paper pdf. If you’re building math agents today, this is the first open model where relying on its internal checking, rather than re‑running a separate verifier or SMT solver, looks technically defensible.
Open DeepSeekMath‑V2 matches proprietary IMO and Putnam gold scores
DeepSeekMath‑V2 is reported to hit IMO 2025 gold level, CMO 2024 gold level, and a 118/120 score on the 2024 Putnam exam using scaled test‑time compute, putting an open model in the same league as prior proprietary Olympiad systems from Google and OpenAI contest recap kimmonismus overview. The paper’s contest table shows gold‑level performance across multiple high‑stakes math competitions, with most problems fully solved and a handful receiving only partial credit paper excerpt.
Hugging Face’s CEO underscores that, as far as he knows, no other chatbot or API gives access to an IMO‑gold model whose weights you can download, fine‑tune, or run offline — making this the first such brain that’s both frontier‑level and fully under user control hf ceo comment hf ceo note. For researchers and quant teams, that means you can now benchmark closed models against a strong open Olympiad baseline, study failure modes at the trace level, and experiment with domain transfer (e.g., from competition math to formal methods or quantitative finance) without waiting on vendor eval access putnam recap zhihu explainer.
📊 Evals race: ARC‑AGI claims, physics checks, and production metrics
Mostly evaluation updates and new observability signals: ARC‑AGI‑2 claims under verification, a new physics benchmark, Code Arena WebDev standings, and Amp’s cost waste metric. Excludes DeepSeekMath‑V2 (covered as feature).
Poetiq claims superhuman ARC‑AGI‑2 at ~$50/task; ARC Prize reviewing
Poetiq is reporting superhuman performance on ARC‑AGI‑2 by orchestrating GPT‑5.1 and Gemini 3 Pro, with its best "Mix" agent slightly beating the ~60% average human test‑taker line at roughly $50 per task on the new benchmark’s public eval set arcagi overview.
The cost–accuracy plot shows a family of Poetiq runs (Grok‑4‑Fast, three Gemini‑3 configs, then a mixed GPT‑5.1+Gemini setup) moving up and to the right, with the top point edging just above human baseline while staying far cheaper than previous DeepThink‑style runs that spent up to ~$100 per instance arcagi overview. The ARC Prize organizers have explicitly said they are coordinating with Poetiq to verify this score on the Semi‑Private hold‑out set and will only treat that verified result as official, with a public write‑up to follow arc prize statement. For engineers this is a strong signal that with the right multi‑model agent scaffold, today’s foundation models can already hit or exceed human‑level performance on one of the toughest AGI‑style benchmarks, but it also underscores that claims are provisional until the benchmark maintainers confirm them (poetiq blog).
CritPt physics benchmark shows Gemini 3 Pro at 9.1% and everyone else worse
Artificial Analysis launched CritPt, a physics‑focused benchmark of 70 unpublished graduate‑level research challenges, and even the best current model—Gemini 3 Pro Preview—only manages 9.1% full‑problem accuracy critpt summary.
Most other frontier models, including GPT‑5.1 (high), Claude 4.5 Sonnet, Grok 4.1 Fast and DeepSeek variants, cluster between 0–5%, with the average base model around 5.7% accuracy; adding tools and coding only nudges top scores toward ~10% critpt summary. The benchmark decomposes each problem into verifiable checkpoints, revealing that some models can generate millions of tokens of attempted reasoning (Grok 4 outputs ~4.9M tokens total) yet still fail almost all full‑solutions, which is a clear warning to teams that token‑hungry "think harder" modes do not translate into deep scientific reliability on out‑of‑distribution physics tasks.
Amp introduces “Off‑the‑Rails Cost” to quantify wasted model spend
Sourcegraph’s Amp team introduced a new internal metric called “Off‑the‑Rails Cost” that measures how much of users’ spend is wasted on threads where the model goes haywire—repeating tokens, dumping internal thoughts, or otherwise forcing the user to abandon the chat amp metric thread.
In recent evals across thousands of coding sessions, Gemini 3 Pro had 17.8% of total cost classified as off‑the‑rails, more than twice Claude Sonnet 4.5’s 8.4% and almost 8× Opus 4.5’s 2.4%, even though Gemini often looks cheaper on pure per‑token pricing amp metrics table. Amp plans to use this signal to automatically detect wasted threads, compensate users with credits, and feed privacy‑preserving feedback back to model vendors amp metric thread, which is a useful reminder for teams that effective cost per successful task can diverge sharply from nominal token prices when models hallucinate or spiral.
Claude Opus 4.5 extends its lead across LMArena WebDev and expert tasks
LMArena’s latest Code Arena snapshot shows Claude Opus 4.5’s Thinking and non‑Thinking variants still holding #1 and #2 in the WebDev bracket, with Gemini 3 Pro in #3, reinforcing Opus’s status as the de‑facto top web UI coding model in that arena webdev screenshot.
Following up on Opus webdev, where Opus 4.5 first took the WebDev and Expert crowns, new summary graphics now highlight that Claude 4.5 also ranks top‑3 on text leaderboards and leads a range of occupational categories—software, business, medicine, writing, and math—on LMArena’s human‑vote indices multi leaderboard. For engineering leads this means Opus 4.5 is not only strong on synthetic coding benchmarks but is also consistently winning in head‑to‑head, human‑judged comparisons, so it’s a natural default to A/B against Gemini 3 Pro and GPT‑5.1 when choosing a primary coding or expert‑assistant model.
🧑💻 Coding agents in practice: planning, PRs, UX loops
Developer‑centric agent workflows dominated by coding: proactive repo scanning, plan‑first strategies, design‑loop iterations, and usage/limits UX. Excludes MCP/interop standards (handled separately).
Data backs what seniors do intuitively: plan-first messages make coding agents better
New analysis of ~100k coding-agent conversations suggests senior engineers really do use agents differently: they send more explicit "plan" messages and far fewer "explain this code" queries than juniors, and their sessions succeed more often as a result usage pattern thread. A linked paper shows that experienced users lean on structured goals and step breakdowns instead of treating the model as a StackOverflow replacement plan-mode paper.
This matches anecdotal experience from builders. One dev now routinely describes a bug in detail, tells Claude "I’m going to bed, keep iterating until it works", and wakes up to a working fix overnight bug fix. Another notes that Opus 4.5 will happily charge ahead on a flawed mental model unless you force it into plan mode, while GPT‑5.1 Codex tends to explore options by default and be more "surgical" in large codebases codex vs opus. Anthropic’s new effort knob (low/medium/high) for Opus 4.5 is clearly designed for this world, letting agent frameworks dial down overthinking for simple edits or crank it up for deep refactors effort knob note. The takeaway: if you’re building or using coding agents, invest in explicit planning UX—buttons, system prompts, and commands that say "think before you code"—instead of hoping users discover good prompting habits on their own.
Google’s Jules SWE Agent readies scheduled jobs and Proactive Mode
Google is preparing a major upgrade to its Jules SWE Agent: scheduled jobs plus a Proactive Mode that will let it periodically scan repos, surface issues, and open fix PRs without a developer asking first jules teaser. A leak of internal docs describes cron-like prompts ("run security checks nightly"), and an upcoming Proactive Mode that continuously patrols the codebase for bugs and regressions, then auto-raises changes feature explainer.

For engineering leaders, this shifts Jules from "copilot in the loop" to a background maintenance worker you can configure per repo or team: you define schedules and scopes, it hunts for problems and proposes patches. The point is: if Google ships this with sane guardrails and review flows, teams could offload boring hygiene work (lint, dependency drift, flaky tests) while keeping humans in charge of merges and production risk.
AmpCode adds visibility into free-mode allowance and wasted agent runs
AmpCode quietly shipped a small but meaningful UX feature: users can now see how much of the free mode daily allowance they’ve burned and when it resets allowance update. That sits on top of Amp’s deeper telemetry about which threads went "off the rails" (runaway thinking, repeated tokens) and resulted in abandoned sessions, a metric they’ve been using internally to judge models like Sonnet, Gemini, and Opus wasted thread analysis.
For engineers building with coding agents, this kind of instrumentation matters more than raw price-per‑token. One tweet notes that in Amp’s data, Gemini users saw a much higher share of spend go to wasted threads compared to Opus 4.5, which helps explain why Opus can feel cheaper in practice even at a higher sticker rate amp metrics. Combined with Sourcegraph’s recent move to make Opus 4.5 the default smart mode in Amp, the product is evolving into a living benchmark: you get a coding agent plus a dashboard telling you how often it melted down and how much that cost. That’s the sort of feedback loop other agent IDEs will likely need to copy.
Opus 4.5 starts to reliably close the front-end design loop
Builders are now reporting that Claude Opus 4.5 can run the full Generate → Render → Look → Improve loop for front‑end work in a way earlier models couldn’t design loop demo. Following up on frontend plugin, which introduced Claude Code’s frontend-design plugin, new tests show Opus generating UI code, analyzing a live render or screenshot, spotting layout issues, and then shipping targeted fixes rather than rewriting everything.

One developer calls it "the first model that can reliably do the visual loop" and notes that Gemini had been the de‑facto leader for UI understanding before this design loop demo. Another shares prompts for real flows like a calorie tracker and an AI physics simulator, where Opus designs the page, sees misalignments, and iterates in a single session prompt examples. This doesn’t make designers obsolete—it gives engineers a faster critique cycle when polishing internal tools and marketing sites, especially when paired with screenshots from a real browser instead of pure JSX reasoning.
Developers are wiring Claude-like agents into CLIs to control their machines
A small but telling cluster of posts shows engineers treating LLM agents as OS-level automation layers, not just chatbots. One setup connects Claude (nicknamed "Clawd") to a Mac via a WhatsApp–Twilio–Tailscale bridge, where it can run shell commands, hit APIs, and then wake the user up with a synthesized voice and a Spotify playlist when a calendar event approaches personal assistant demo.
For media control, devs recommend terminal tools like spotify-player, which exposes rich playback and album art in a TUI—perfect for agents to drive through simple commands instead of brittle GUI automation spotify cli reco. In another example, the agent detects a background app (gowa) via SSH and sends a voice note to the neighbor at the table ssh voice prank. This is early and hacky, but the pattern is clear: if you give an agent a clean CLI surface with good text output (music players, note apps, task runners), it becomes far easier to build reliable local assistants that do more than edit code.
RepoPrompt shows a practical pattern for LLM second opinions on code
RepoPrompt is emerging as a lightweight harness for getting a second model to critique your primary coding agent’s answer without forcing every user to juggle API keys. In one demo, Claude Opus 4.5 generates a solution, then RepoPrompt forwards that entire answer into GPT‑5.1 High for review and follow‑up questions, all from a single UI dual model demo.

For teams nervous about silent failures, this pattern is appealing: the first model does the bulk of the work, the second is explicitly framed as a skeptic that checks reasoning, edge cases, and style. It also gives you a way to A/B different providers on real tasks ("ask GPT‑5.1 what it would do differently") without wiring full multi-model orchestration into your app. Expect more tools to copy this "critic model on demand" UX so engineers can escalate tricky changes to a stronger or more conservative reviewer context builder mention.
Data Analysis Arena prototypes multi-model agents for real-world analytics tasks
A new "Data Analysis Arena" prototype extends the LMArena idea into data science: instead of rating chat answers, it spins up full multi-step analysis runs from different models on the same dataset and lets humans pick which exploration is better arena ui screenshot. Users can pick curated datasets (F1 racing history, school results, trading card sales, etc.), describe an open-ended task like "What story does this data tell?", and then watch two models fetch, clean, chart, and narrate in parallel arena config view.
In one example, a run over gas consumption data produces a chart titled "The Great Recovery: From Crisis to 7× Growth in 6 Months" with automated annotations and numbers, while the rival model surfaces a quirky birthday pattern in F1 drivers result examples. For developers building data-centric agents, this kind of harness is a handy way to compare not just correctness but taste: which model picks an interesting angle, avoids hallucinated facts, and writes something a human analyst would be proud of. Expect this style of "agent battle over the same dataset" to become a standard evaluation tool for analytics copilots and notebook agents.
🧩 Interoperable agents: MCP surfaces and evented UIs
Cross‑client orchestration progressed: n8n exposes workflows via MCP to Claude/ChatGPT, CopilotKit pushes AG‑UI events, and LangChain ships remote sandboxes. Excludes model/eval news and coding agent specifics.
CopilotKit’s AG‑UI spec pushes agents beyond the single chat box
CopilotKit is formalizing an event‑driven UX model for agents, arguing that "chat box = agent UX" has hit its limits and introducing AG‑UI as a standard way to represent streaming tokens, tool calls, human approvals, and other agent–user events in real products. ag-ui intro

In a Future AGI session, a founding engineer walks through why long‑running, event‑driven agents break classic request–response UIs and how AG‑UI aims to normalize patterns like incremental streaming, surfacing tool outputs in context, pausing for human sign‑off (HITL), and resuming workflows. webinar replay Instead of every app inventing its own bespoke protocol between front end and agent runtime, AG‑UI provides a shared event vocabulary that can sit on top of any backend (Claude, GPT‑5.1, Gemini, etc.). For teams building multi‑step copilots inside existing products, this gives a reference architecture for how the front end should model "agent state" over time instead of shoving everything through a single text area.
LangChain Deep Agents add remote sandboxes for safer long‑running code
LangChain is rolling out Sandboxes for Deep Agents: remote, resettable environments where agents can execute arbitrary code and shell commands without touching a developer’s local machine. sandbox announce The new feature lets you spin up a sandbox, wire it in as a tool, stream code into it, and send results back to the agent, which is useful for evals, parallel experiments, and any untrusted snippets you don’t want near your laptop. LangChain engineers say they’re already "sandbox‑pilled"—using this both for evaluation workflows and as a general pattern for isolating risky or long‑running tasks from the main agent process. (sandbox usage comment, sandbox for evals) Tying back to deep agents, where Deep Agents were framed as the harness layer above runtimes like LangGraph, Sandboxes now fill in the "where does the code actually run?" piece for interoperable, multi‑tool agents that need clean, reproducible environments.
n8n’s MCP connectors move from launch to real agent workflows
n8n’s new MCP surface is already being used to wire Claude and ChatGPT directly into complex automations, with Omar El Gabaly showing an end‑to‑end setup that lets agents search, inspect, and run n8n workflows from chat. Following n8n mcp launch where n8n first exposed an entire instance as an MCP tool surface, today’s demo walks through discovering workflows, triggering them with parameters, and feeding results back into an agent loop for optimization. mcpify walkthrough

For AI engineers, this is a concrete pattern for turning existing n8n automations into reusable tools instead of re‑implementing glue code in every agent harness. The YouTube guide breaks down how to register MCP in n8n, configure Claude/ChatGPT to see those tools, and then orchestrate long chains (like scraping, transforming, and notifying) from a single natural‑language request. YouTube demo That makes n8n effectively a low‑code skill library for any MCP‑aware client rather than "just" a background workflow engine.
🗂️ RAG efficiency: compress, align, and reuse experience
Today’s sample highlights RAG decoding acceleration, unified retriever‑generator training, and reusable agent memory docs. Excludes DeepSeek math feature.
Meta’s REFRAG compresses RAG context for up to 30× faster decoding
Meta’s new REFRAG decoding scheme shows you can aggressively compress RAG contexts into learned chunk embeddings, then selectively expand them, cutting time‑to‑first‑token by up to 30.85× versus a vanilla LLaMA decoder while still improving accuracy on long‑context tasks. refrag overview It handles 4k–16k token contexts even though the model was only trained on ~6k sequences, and beats strong baselines like CEPE while using far fewer tokens. refrag results summary Instead of feeding every retrieved token into the decoder, REFRAG splits the context into chunks of size k, runs a small encoder over each chunk, and projects each down to a single embedding that sits in the decoder’s input alongside the question tokens. refrag overview A lightweight RL‑trained policy decides when to keep chunks compressed vs expand them back to full tokens, which is how the system balances speed vs fidelity. refrag results summary The Arxiv paper suggests this yields up to 3.75× TTFT speedups over CEPE‑style methods and lets you stretch effective context length ~16× without retraining the base model, which is directly relevant if you’re paying heavily for long‑context RAG today. Arxiv paper
Apple’s CLaRa jointly trains retriever and generator in latent space
Apple’s CLaRa paper proposes a fully joint way to train RAG systems: it learns a compressed continuous latent space where both the reranker and generator operate, then optimizes them end‑to‑end using a differentiable top‑k estimator so retrieval relevance and answer quality are aligned instead of tuned separately. clara thread To make this work, they introduce SCP, a key‑preserving data synthesis pipeline that generates QA and paraphrase pairs, so embeddings stay semantically rich and retrievable even after heavy compression. clara thread CLaRa replaces text‑based reranking with embedding‑based compression plus unified training, which avoids the classic problem where a retriever is optimized for matching queries but not for what actually helps the generator answer well. github repo On multiple QA benchmarks, the authors report state‑of‑the‑art compression and reranking performance, often beating text‑fine‑tuned baselines while using shorter, denser representations. clara thread For teams hand‑gluing vector stores, rerankers, and LLMs, this is a pointer toward a more principled RAG stack where those pieces are learned together rather than separately.
BREW turns agent histories into reusable ‘concept docs’ for faster runs
Microsoft’s BREW framework (“Bootstrapping expeRIentially‑learned Environmental knOwledge”) tackles a core RAG‑ish problem for agents: instead of relearning workflows from scratch each time, it converts past task trajectories into concise concept documents that future runs can retrieve and follow. brew summary These docs are organized around reusable ideas like “searching files” or “exporting a document,” and are written by a reflector model using human‑behavior rubrics so they read like high‑quality internal playbooks rather than raw logs.Arxiv paper
An integrator agent then merges and optimizes these docs per concept, using a small tree search over variants: try a doc on sample tasks, score how much it helps, measure how retrievable it is, and keep the best versions. brew summary At run time, the main agent retrieves a few relevant concept docs for a new query and leans on them, which the paper shows cuts steps, tool calls, and failure rates across diverse domains compared to agents that only use ad‑hoc scratchpad reasoning. brew summary For anyone building long‑lived assistants, BREW is a concrete recipe for turning messy agent runs into a structured, queryable knowledge base instead of throwing that experience away.
FreshStack benchmarks RAG with retrieval, nugget, and support metrics
FreshStack, which will be presented at NeurIPS 2025’s datasets and benchmarks track, builds realistic RAG benchmarks for technical documentation and explicitly scores systems along three axes: retrieval quality, factual nuggets, and support (grounding). freshstack session info The idea is to get past “did the model answer the question?” and measure whether it pulled the right documents, extracted all key facts, and properly cited evidence for each claim, all on fresh stacks like modern codebases and docs. freshstack comment The framework auto‑constructs IR testbeds from real Q&A (e.g., community questions on new stacks), then defines nuggets as atomic facts and evaluates both nugget coverage and citation precision/recall for supporting passages. freshstack comment That dovetails with ongoing TREC RAG work on retrieval, nuggets, and support that the authors point to as prior art, and gives RAG builders a way to see whether they’re over‑fitting to answer quality while under‑investing in grounding. neurips poster page If you’re tuning rerankers or answer generators, this is the kind of benchmark you can use to detect regressions like “great‑sounding answers, bad citations” before shipping.
Local‑Web RAG agent beats commercial deep research on materials problems
A new “Hierarchical Deep Research with Local‑Web RAG” paper shows a local‑deployable research agent that combines local document retrieval with selective web search and a tree‑structured control loop can match or beat commercial deep‑research tools on complex materials science questions. deep research summary The system runs a Local‑Web RAG loop that first searches a private corpus (e.g. lab PDFs), then falls back to web search only when local evidence is thin, all wrapped inside a Deep Tree of Research (DToR) controller that grows promising branches and prunes dead ends.Arxiv paper
Across 27 nanomaterials and device topics, using an LLM‑as‑judge rubric plus “dry‑lab” simulations for a subset of tasks, their best DToR+Local‑Web setup often produced reports comparable to or better than closed systems like ChatGPT‑5 Deep Research while running cheaper and on‑prem. deep research summary For RAG engineers, the key pattern is the hierarchy: separate agents for querying, summarizing, and branching, all operating over a local‑first index, rather than a single monolithic chat loop that hammers the web every turn.
🧠 Reasoning post‑training and new optimizers
Multiple research/engineering advances in RL and optimization: a 106B MoE with async RL, low‑rank ES for hyperscale, latent multi‑agent collab, and tool‑integrated RL for VLMs. Excludes eval/serving items.
INTELLECT‑3 open-sources a 106B MoE trained with large-scale async RL
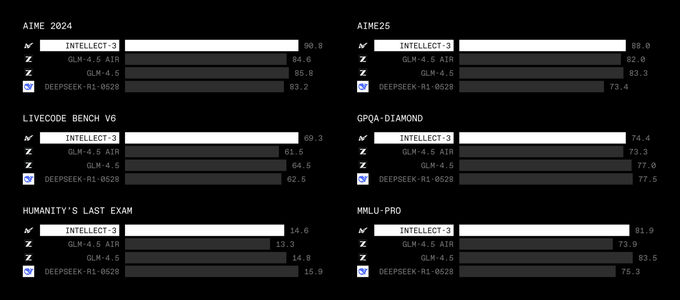
Prime Intellect’s INTELLECT‑3 is now fully out in the open as a 106B‑parameter Mixture‑of‑Experts model trained with large‑scale asynchronous RL on top of GLM‑4.5‑Air, with weights, RL framework, environments, and evals all released for others to study and extend. Building on API launch that focused on its OpenRouter API exposure, today’s discussion highlights that INTELLECT‑3 reaches ~90.8 on AIME 2024, 88.0 on AIME25, 69.3 on LiveCodeBench v6, 74.4 on GPQA‑Diamond, and 81.9 on MMLU‑Pro, generally beating DeepSeek‑R1 and GLM‑4.5‑Air at similar or larger scales for math, code, and reasoning tasks benchmark overview.
The team stresses that this is not just a model drop but an end‑to‑end RL stack: they open‑sourced the RL training code, custom environments, and evaluation setup so others can replicate or adapt their recipe for large MoE reasoning models model intro. Ecosystem projects like vLLM have already confirmed support for INTELLECT‑3 post‑training, signaling that the model is compatible with mainstream high‑throughput inference stacks even at 100B+ active parameters vllm support. For practitioners, it’s one of the first chances to dissect a modern, RL‑post‑trained, frontier‑scale MoE in detail rather than treating it as a black box.
EGGROLL scales low-rank evolution strategies to 1B‑parameter models without backprop
The EGGROLL paper introduces a low‑rank evolution strategies (ES) method that makes backprop‑free optimization practical for billion‑parameter networks by replacing full Gaussian noise with factorized perturbations ABᵀ, cutting memory and compute enough to get about 100× higher training throughput than naive ES on their largest runs paper summary.
Instead of storing a full m×n noise matrix for each population member, EGGROLL samples skinny matrices A∈ℝ^{m×r} and B∈ℝ^{r×n} with r≪min(m,n), then averages thousands of these low‑rank perturbations so the aggregate update behaves like full‑rank noise but at a fraction of the cost paper summary. The authors show that this scaled ES matches or beats classic ES on RL benchmarks while running much faster, improves RWKV‑style reasoning versus a strong policy‑gradient baseline (GRPO), and can even pretrain an integer‑only recurrent language model with population sizes above 100,000. For teams exploring backprop‑free or privacy‑sensitive training, EGGROLL is a concrete, open technique rather than a thought experiment.
VISTA-Gym and VISTA-R1 scale RL for tool-using vision-language models
VISTA‑Gym and its companion model VISTA‑R1 form a new training playground for vision‑language models that reason step‑by‑step while calling tools like detectors, OCR, chart readers, and math solvers, across 7 visual QA tasks and 26 tools vista paper summary. The authors show that an 8B‑scale VLM trained first with imitation learning and then with reinforcement learning in this environment outperforms comparable open baselines by about 10–19 percentage points on difficult multi‑step visual questions.
In VISTA‑Gym, each episode gives the agent an image and question; the model alternates between emitting thoughts, invoking tools, and updating its plan until it answers or runs out of budget, giving RL a rich interaction loop to optimize ArXiv paper. Rewards are shaped to favor non‑repetitive reasoning, correct tool use, and final‑answer accuracy, so the RL phase refines both when to call tools and how to integrate their outputs. For teams trying to push beyond static chain‑of‑thought into genuine tool‑augmented visual reasoning, this looks like a solid template for how to combine IL and RL without hand‑engineering a separate setup for every downstream benchmark.
GEPA argues reflective prompt evolution can rival RL-style post-training
The GEPA paper (“Reflective Prompt Evolution Can Outperform Reinforcement Learning”) from a Berkeley–Stanford–Databricks–MIT collaboration makes the claim that carefully evolved prompts, improved through reflective self‑critique, can match or even beat traditional RL‑based post‑training on certain tasks—without modifying model weights paper mention.
GEPA treats the prompt as an object to optimize: the model generates candidate prompts, uses its own judgments or external signals to critique them, and iterates this process, effectively doing evolution in prompt space instead of gradient space
. While the tweet doesn’t spell out benchmark numbers, the framing puts prompt evolution on the same playing field as RLHF and GRPO, not just as a UX trick. For practitioners, the key implication is that if fine‑tuning and RL are expensive or operationally complex in your stack, there may be more headroom than expected in "learning to prompt"—provided you treat prompt search as a first‑class optimization problem rather than manual tinkering.
LatentMAS boosts multi-agent performance with latent-space collaboration instead of text
LatentMAS proposes a way for multi‑agent LLM systems to collaborate directly in the continuous latent space—sharing last‑layer hidden states via a shared "latent working memory"—rather than sending messages as natural language, and reports up to 14.6% accuracy gains over strong text‑based multi‑agent baselines while cutting output token usage by 70.8–83.7% and delivering 4–4.3× faster end‑to‑end inference paper summary.
Each agent in LatentMAS generates auto‑regressive "latent thoughts" (hidden embeddings), writes them into a shared memory, and reads other agents’ embeddings to condition its own reasoning, all without turning those vectors back into text ArXiv paper. The authors argue—and support analytically—that this yields higher expressiveness and lossless information exchange at much lower complexity than the usual text‑only setup, which wastes capacity re‑encoding and re‑parsing messages. For people building multi‑agent systems today, LatentMAS is a reminder that the communication bottleneck doesn’t have to be tokens, and that you can sometimes get both better accuracy and big cost savings by operating "below" language when agents talk to each other.
GigaEvo open-sources an AlphaEvolve-style LLM + evolution framework
GigaEvo is a new open‑source optimization framework that reimplements the core ideas of AlphaEvolve—LLMs guiding evolutionary search over programs or solutions—so other groups can reproduce those results and run their own large‑scale search over Python code or other artifacts gigaevo paper summary.
The system stores each candidate program, its metrics, and its ancestry in a shared database, then runs quality‑diversity algorithms (MAP‑Elites) over that population using a configurable DAG of stages that execute code, check constraints, measure complexity, and call LLMs to generate feedback and mutations GitHub repo. In experiments, GigaEvo closely matches or slightly improves the AlphaEvolve results on classical math puzzles like Heilbronn triangle placement and circle packing, reaches strong configurations for high‑dimensional kissing numbers, and discovers competitive bin‑packing heuristics and policy prompts for Reddit rule classification. For engineers thinking about "RL‑adjacent" optimization of programs or prompts, GigaEvo is a ready‑made scaffold rather than starting from scratch with ad‑hoc scripts.
🎬 Creative stacks: video ELOs, precise retakes, fast image gens
A sizable creative/media cluster: text‑to‑video leaderboard shifts, time‑coded video retakes, fast/open image models, and weekend ‘Agents & Models’ access. Excludes the DeepSeek math feature.
Indie model ‘Whisper Thunder’ tops Artificial Analysis text-to-video ELO
Artificial Analysis’ global text-to-video leaderboard now has a stealth model, Whisper Thunder (aka David), in the #1 slot, edging out Google’s Veo 3/3.1, Kling 2.5 Turbo, Luma Ray 3, and OpenAI’s Sora 2 Pro on user‑judged ELO scores. leaderboard summary This matters for video teams because the board aggregates thousands of head‑to‑head votes (~7.4K+ appearances for Whisper Thunder alone), so an unknown model beating hyperscaler stacks signals that quality is reachable outside big labs. elo details
For AI engineers and PMs building video tools, this is a good empirical short‑list of models to A/B: Whisper Thunder as the current frontier, Veo 3.x and Kling 2.5 as strong baselines, and Sora 2 Pro sitting a bit lower in perceived quality. It also underlines why you should think in terms of crowd ELO, not just lab metrics when picking your default text‑to‑video backend.
InVideo’s ‘Agents & Models’ weekend gives free access to 70+ media models
InVideo has launched Agents & Models, a multi‑model creative surface that wires up 70+ SOTA image, video, and sound models—including Veo 3.1, Sora 2, Kling 2.5, Nano Banana Pro, and FLUX 2—and is running an all‑you‑can‑generate weekend with free, unlimited use of those backends for paying InVideo plans until December 1. weekend promo Directors are already showcasing full spec ads (Heineken, Prada‑style spots) produced entirely through this stack, with InVideo’s agent layer orchestrating prompts and cuts across models. (heineken example, prada example)

For creative engineers, this is effectively a sandbox to benchmark cross‑provider video/image models under one UX, without wiring your own routing or paying per‑model API metering. You can see how Veo 3.1 compares to Kling 2.5 on the same brief, or swap NB Pro vs FLUX 2 for keyframes, then bake that knowledge into your own pipelines later. meta ad The other notable bit is agency: InVideo positions “Agents & Models” as giving you control over every shot decision, rather than a single opaque generator, which aligns with how higher‑end shops already art‑direct multiple tools in sequence.
Z‑Image Turbo proves fast, cheap, and stack‑friendly across fal, HF, and ComfyUI
Alibaba’s Z‑Image Turbo 6B text‑to‑image model is quickly becoming a go‑to for fast, photorealistic imagery in real toolchains: ComfyUI Cloud users report ~6 seconds for native 2K outputs, comfyui promo fal users chain it into Veo 3 for instant text→image→video flows, fal workflow and Hugging Face PRO subscribers note they can squeeze ~500 ZeroGPU generations per day out of a $9/mo plan. pricing remark Community tests suggest the distilled Turbo variant can even run inference in under 2 GB VRAM, community tests which is unusual for this quality level.
For builders, this means you can treat Z‑Image Turbo as a default photoreal model in several contexts: cloud pipelines (fal, Comfy Cloud), on‑prem low‑VRAM boxes, or cheap prototyping on ZeroGPU. model card It also pairs well with downstream generators like Veo 3: use Z‑Image for a consistent hero frame, then hand it off as a keyframe to a video model, which is exactly what some creators are doing in their Z‑image→Veo demos. fal workflow
ElevenLabs’ LTX-2 Retake brings timecoded in-shot edits to its video suite
ElevenLabs has rolled its Retake feature into the main LTX‑2 Image & Video product, letting creators re‑edit specific spans of a shot using timecodes while preserving actors, lighting, and camera continuity. product announcement Following up on earlier third‑party hosting of Retake via fal and Replicate Retake rollout, this is the first fully integrated, first‑party UX where you can change dialogue, actions, or camera moves without re‑rendering the whole clip. feature recap

For workflows, the key shift is granular control: you can fix a line read, adjust pacing, or tweak a gesture by selecting a segment and re‑prompting, and you only pay for the seconds you modify. feature recap That makes LTX‑2 more viable for iterative client work, where directors often need a handful of surgical fixes rather than a fresh 30‑second generation every time.
Nano Banana Pro + Gemini 3 fuel time‑travel UIs, typography, and 360 scenes
Builders keep finding new creative edges with Google’s Nano Banana Pro image model and Gemini 3: one dev had Gemini‑3‑pro-image-preview one‑shot a full "time machine" web app where users pick a place and year on a globe UI and NB Pro renders that scene in seconds, (time machine demo, prompt details) while others show NB Pro producing near‑perfect stylized typography (“THANKSGIVING” in the shape of a turkey, or "fofr loves melty ai" as a melting monstera leaf). (turkey typography, leaf typography) There are also convincing 360° panoramas, panorama demo fast subject replacement plus background swaps (“selfie guy” dropped into a chair shoot with an alphabet backdrop in under 90 seconds), edit example and dense world‑building shots with in‑scene UI elements like “water recycling update” signage. worldbuilding scene

These uses extend earlier doodle‑to‑edit and voxel‑meme experiments NB doodles into UI‑driven experiences and production‑ish compositing. For teams, the signal is that NB Pro is not just an art toy: it’s good enough at text, layout, and consistent characters to be a backbone for slide decks, marketing visuals, and even interactive “time travel” apps reachable through Gemini’s app scaffolding. The flip side is that people are starting to say they “no longer trust any image” because NB Pro’s realism and 360 support blur the line between capture and render. trust comment
Tencent’s Hunyuan 3D-PolyGen 1.5 generates art-grade quad meshes for game pipelines
Tencent’s Hunyuan 3D Studio 1.1 now ships with Hunyuan 3D‑PolyGen 1.5, a 3D generative model that outputs quad meshes directly instead of triangle soup, targeting "art‑grade" topology with clean edge loops for production game and animation workflows. release thread The system supports both quad and triangle outputs and aims to make models “instantly production‑ready” by matching the topology standards that riggers and character artists expect.

For tools engineers, this is interesting because it collapses a bunch of ugly post‑processing steps: retopology, manual edge‑flow fixing, and mesh cleanup can be minimized if the generator already learns quad loop structure. That makes it easier to plug AI‑generated characters or props into DCC tools and game engines without wrecking deformation or blowing poly budgets. It’s also another data point that generative stacks are moving beyond pixels into geometry that respects downstream constraints like rigging and subdivision.
💼 Platform distribution and enterprise signals
Distribution moves and enterprise‑adjacent updates: ChatGPT Apps/Workflows publishing, Perplexity feature adds, a large stealth M&A, and GTM pricing pushes. Excludes infra capex and policy items.
OpenAI readies in‑ChatGPT Apps and Workflows publishing surface
OpenAI is preparing a new Apps and Workflows publishing layer directly inside ChatGPT, with a dedicated "Apps" tab and workflow templates visible in a mobile UI teaser apps and workflows. This builds on the Apps SDK/MCP design guidance from earlier in the week, suggesting a full in‑product app marketplace rather than just custom GPTs ChatGPT apps.

For builders and vendors, this looks like a new distribution channel where you can ship reusable workflows and mini‑apps to hundreds of millions of ChatGPT users once publishing opens, so it’s worth aligning your app designs and MCP tools with the patterns OpenAI has already documented Axios article.
Bezos’ Project Prometheus quietly acquires General Agents
Jeff Bezos’ stealth AI venture, Project Prometheus, has quietly bought agentic computing startup General Agents, folding a team of 100+ people—including alumni from DeepMind and Tesla—into a project that has already raised more than $6B acquisition report. The deal reportedly came together after an off‑the‑record SF AI dinner, underlining how much capital and talent are consolidating around long‑horizon "agent" stacks rather than chatbots alone.
For AI leaders, this is a strong competitive signal: a well‑funded, Bezos‑backed player is now in the same agentic‑computing race as OpenAI, Google, Anthropic and xAI, and it’s doing it through acquisition rather than public launches—expect more behind‑the‑scenes hiring pressure and potential future platform plays once Prometheus comes out of stealth.
OpenAI expands data residency controls for ChatGPT Enterprise, Edu and API
OpenAI has introduced broader data residency options so eligible ChatGPT Enterprise, ChatGPT Edu, and API Platform customers can choose to store their data in specific regions such as the EU, UK, US, Canada, Japan, South Korea, Singapore, India, Australia, and the UAE data residency tweet. The company reiterates that customer content is not used to train models without explicit opt‑in and highlights AES‑256 at rest and TLS 1.2+ in transit, plus a formal DPA for GDPR/CCPA compliance OpenAI blog post.
This is a concrete unblocker for regulated enterprises and public‑sector buyers who’ve been hung up on data locality; it means you can now align ChatGPT usage with regional data rules and internal risk frameworks instead of treating it as a single global US‑hosted service. For AI platform teams, it also signals that privacy, auditability, and regional control are becoming table stakes for selling chat and agent capabilities into large orgs.
Perplexity adds language-learning flashcards on web and iOS
Perplexity has started rolling out language-learning features that let users study vocabulary, basic terms, and advanced phrases through AI‑generated flashcards on both iOS and the web flashcards launch. The cards are organized into levels so people can move from simple words to more complex expressions, turning Perplexity into a lightweight Duolingo‑style companion rather than only a Q&A tool.

For teams thinking about education and training, this is another signal that chat‑first assistants are being extended with structured practice modes, not just free‑form conversation, which may shape user expectations for "learning" features inside other AI products.
Virgin Australia becomes first local airline to collaborate with OpenAI
Virgin Australia and its Velocity Frequent Flyer program have announced what they call an Australian airline–first collaboration with OpenAI, using ChatGPT‑powered tools to transform trip planning, marketing and revenue management virgin announcement. The carrier has already launched an AI Trip Planner that helps guests build personalised itineraries and plans to lean on AI for demand forecasting and dynamic airfare pricing to better match capacity and fares to real‑time signals Virgin AI announcement.
For AI teams in travel and other consumer services, this is another proof point that big customer brands are not stopping at chatbot FAQs—they’re wiring LLMs into core workflows like yield management, merchandising and upsell. It’s also a distribution win for OpenAI: millions of travellers will now encounter its models not through ChatGPT, but inside a mainstream airline experience.
Genspark pushes 40% Black Friday discount on "finished deliverables" AI
Genspark is running a Black Friday sale with 40% off annual plans for free users, cutting Plus by $100 and Pro by $1000 for four days and explicitly bundling all current and 2026 features discount details. Following up on its shift from research summaries to shipping complete decks, spreadsheets, and websites Genspark decks, the team is clearly using price as a lever to grow usage of that "end‑to‑end deliverable" positioning.
A packed Microsoft Singapore event where over 95% of attendees were already Genspark users reinforces that the product is finding a niche with business users who’d rather get a polished Excel file or slide deck than a wall of text event recap. If you’re evaluating research agents for your org, this promo window is a low‑cost way to benchmark that workflow‑to‑deliverable experience against more generic chat tools.
⚡ Compute geopolitics and power for AI
Non‑AI exception category with direct impact on AI supply: China’s Nvidia limits push domestic accelerators, xAI’s onsite solar, and renewed debate on space TPUs. Excludes model/eval news.
China’s domestic AI chips close on Nvidia as regulators squeeze H100/H20
New analysis suggests China’s homegrown AI accelerators will reach ~30–60% of Nvidia B200 compute by 2026 while regulators keep blocking new Nvidia deployments in major data centers, accelerating a forced pivot to local silicon. Following China Nvidia curbs, which covered ByteDance and others being barred from using new Nvidia chips, today’s charted projections highlight Huawei Ascend 910C, Hygon BW1000, Cambricon Siyuan 590 and others as the main beneficiaries, with Nvidia’s H20 stuck at the low end of the performance spectrum for China’s market china chip chart.
For AI infra planners this means China’s effective access to frontier compute is shifting from US export‑controlled GPUs toward a domestic stack that’s good enough for large‑scale training, even if per‑chip performance trails B200/MI300X. If those estimates hold, Beijing’s industrial policy—blocking foreign GPUs while steering cloud and internet giants toward Huawei, Cambricon, Hygon and in‑house accelerators china policy thread—could meaningfully blunt the impact of future US sanctions by 2026, while creating a largely separate AI hardware ecosystem with different optimization targets and software tooling.
Google’s ‘Project Suncatcher’ revives plan for TPU data centers in orbit by 2027
A new internal clip about Google’s ‘Project Suncatcher’ shows animated TPUs assembling into massive orbital structures, with the company reportedly targeting space‑based data centers by around 2027 to tap uninterrupted solar power and free radiative cooling suncatcher teaser. Building on arguments that orbital TPUs could beat terrestrial cost‑per‑watt once launch prices fall below ~$200/kg space TPUs, Suncatcher frames this less as sci‑fi and more as a mid‑term infrastructure bet.

If Google can get even pilot‑scale TPU arrays into high‑Earth orbit, AI teams would be looking at a new compute tier with extreme latency but cheap, steady energy—suited for massive offline pre‑training or batch RL runs rather than interactive inference. The hard parts are obvious: launch cadence, radiation‑hardened TPUs, in‑orbit repair, and networking back to Earth. But the fact that this has a name, a timeframe, and marketing assets suggests the company is serious enough that infra and model leads should at least watch it as a potential constraint‑breaker once terrestrial power grids and cooling start to pinch.
xAI plans 30 MW onsite solar farm for its Memphis ‘Colossus’ AI data center
xAI is planning a 30‑megawatt solar farm adjacent to its Colossus data center in Memphis, aiming to supply roughly 10% of the site’s energy needs directly from on‑prem renewables, with a separate 100‑MW solar+storage project backed by a $414M USDA interest‑free loan xai solar article.
For people running AI infra, that’s a concrete example of hyperscalers trying to derisk grid dependency and energy price volatility for GPU campuses rather than only signing offsite PPAs. A 30 MW co‑located array doesn’t solve 24/7 power for a single large training cluster, but it can buffer daytime inference loads, hedge against spikes in Tennessee Valley Authority tariffs, and signal to regulators that xAI is investing in local green capacity. The paired 100‑MW project, while offsite, hints that future AI builds will likely bundle multiple financing channels—federal loans, local incentives, and corporate capex—to secure both megawatts and political goodwill.
Emad Mostaque calls energy the real AI bottleneck as DOE’s Genesis ramps
Emad Mostaque argues that the U.S. Department of Energy fronting the Genesis Mission isn’t accidental, calling energy—not model ideas—the true bottleneck for AI and science at scale genesis commentary. Following up on Genesis mission, which detailed multi‑GW supercompute campuses and a $50B AWS site, he claims the U.S. has fallen behind China on energy build‑out and predicts more deregulation around fusion, solar and advanced sources tied directly to AI projects (panel video).

The point for AI leaders is simple: even with algorithmic gains, frontier training runs are on track to be power‑limited far more than architecturally limited. If DOE‑backed efforts like Genesis can de‑risk multi‑gigawatt campuses and normalize novel generation (fusion pilots, ultra‑cheap solar, long‑duration storage), that changes the ceiling on how often and how aggressively you can spin up hundred‑billion‑parameter training programs. If they stall—or if permitting and local politics drag on—expect more teams to emulate xAI’s Memphis strategy and bolt project‑specific generation onto each GPU cluster rather than waiting for national grid fixes.
🛡️ Oversight, liability, and surveillance debates
Policy/safety threads focus on a Congressional hearing, platform liability posture, and EU surveillance criticism. Excludes evals and business deals.
US House summons Anthropic CEO over alleged AI-orchestrated China cyberattack
The US House Homeland Security Committee has called Anthropic CEO Dario Amodei to testify on Dec 17 about what’s being described as the first known AI-orchestrated cyberattack, allegedly a Chinese espionage campaign that used Claude Code as a core tool. hearing report
For AI engineers and leaders, this hearing is a concrete signal that Congress is starting to treat foundation model providers as potentially accountable actors in nation‑state operations, not just neutral tool vendors. Expect detailed questions about Anthropic’s logging, abuse monitoring, guardrails around code‑assist models, and how quickly they can detect and shut down state‑aligned abuse. Whatever standards and expectations emerge here are likely to be echoed at other agencies and in future regulation, especially around "AI for cyber" use cases.
OpenAI denies liability in teen suicide case, cites safeguards and age limits
OpenAI has formally rejected responsibility in a wrongful‑death lawsuit alleging ChatGPT acted as a “suicide coach” to a 16‑year‑old, arguing the teen violated age restrictions, bypassed safeguards, and had a long history of suicidal ideation before using the system. lawsuit coverage
The filing stresses that ChatGPT surfaced crisis‑hotline style messages more than 100 times, which OpenAI frames as evidence its safety systems were working rather than failing. For AI builders and counsel, this shows how a leading lab is positioning its liability posture: strict reliance on terms of use (13+ age gates), emphasis on generic safety messaging instead of hard blocking, and a clear line that correlation with tragic outcomes does not imply legal causation. It’s a reminder that if your product touches mental health or self‑harm, you’ll need both strong in‑product mitigations and a thought‑through legal theory for how far your duty of care extends.
Telegram’s Durov says EU child-safety plans risk mass surveillance and censorship
Telegram founder Pavel Durov is warning that new EU child‑protection proposals effectively weaponize public concern to justify mass surveillance and censorship, arguing that the surveillance layer they require would be “illegal in France” and similar regimes. durov criticism For AI and platform teams, this is part of a broader fight over client‑side scanning, content‑analysis mandates, and how far governments can push automated inspection of private messages in the name of safety. If EU rules land on always‑on scanning for CSAM or grooming signals, any AI model embedded in messaging clients could be dragged into a quasi‑law‑enforcement role, with direct implications for on‑device inference, encryption designs, logging practices, and where you can legally ship certain AI features.
🚀 Serving and throughput: practical signals
Runtime/serving updates today are light but relevant: model throughput rankings for tool use and vLLM support notes. Excludes orchestration/MCP and training items.
OpenRouter publishes throughput‑sorted leaderboard for tool‑calling models
OpenRouter now exposes a models view sorted by throughput for tool-calling workloads, letting you filter to models that support tools and then rank them "High to Low" by how many tokens they can push per second. OpenRouter models tweet The screenshot highlights heavy-hitters like Qwen3 Coder 480B A35B (840M tokens logged), OpenAI’s gpt-oss-safeguard-20b, and Meta’s Llama 4 Scout, each with context limits (up to 262K) and per‑million token pricing visible in one place.
For anyone wiring up high‑concurrency agents over the holidays, this gives a practical way to route tool calls to the fastest viable backend instead of guessing from marketing blurbs—just filter by supported_parameters=tools and pick from the top of the list. OpenRouter models
vLLM confirms INTELLECT‑3 serving support for RL‑trained MoE model
vLLM says it powered Prime Intellect’s post‑training runs for INTELLECT‑3, a 106B‑parameter MoE reasoning model trained with large‑scale asynchronous RL on GLM‑4.5‑Air. vllm support note Following Intellect-3 open, where the model and recipe were released, this announcement is a concrete signal that INTELLECT‑3 already runs on mainstream vLLM infrastructure, not a bespoke stack.
For infra and platform teams, that means an open‑weights, RL‑tuned reasoning model that posts state‑of‑the‑art scores for its size in math and code can be served with vLLM’s batching and KV‑cache optimizations, easing experimentation and potential deployment alongside existing vLLM‑hosted models.
🦾 Embodied AI: from demos to real tasks
A smaller but distinct stream: a humanoid cleaning deployment prompts ROI debate and a robotics RL paper improves long‑horizon control. Excludes creative/media and core model releases.
MobileVLA‑R1 uses CoT+GRPO to steady quadruped navigation and control
A new paper, MobileVLA‑R1, introduces a vision‑language‑action model trained specifically for mobile robots (e.g., quadrupeds) that marries chain‑of‑thought style reasoning with GRPO‑style reinforcement learning to handle long‑horizon navigation and manipulation paper share. The framework adds a MobileVLA‑CoT dataset of multi‑granularity trajectories and trains the controller to reason explicitly about sub‑goals before emitting low‑level actions, which improves stability on VLN/VLA benchmarks compared with prior end‑to‑end policies (papers page).
For robotics teams, the takeaway is that the frontier "reasoning LLM + GRPO" recipe is already being ported into embodied stacks: instead of treating language and control as separate, MobileVLA‑R1 uses the same model to parse natural‑language instructions, decompose them into steps, and drive locomotion and head/body motions over many seconds. That makes it a useful reference if you’re trying to fuse high‑level language understanding with reliable control on legged platforms without hand‑coding lots of task‑specific state machines.
Humanoid running demos vs toilet‑cleaning deployments spark ROI debate
A fast‑recovery humanoid demo—where a biped pops up from the floor and sprints—has engineers questioning what real‑world value these agility stunts deliver beyond "it can get up fast and run" running robot thread. In the same feed, another clip shows a humanoid on its knees scrubbing a toilet bowl in China, framed as "finally a real use‑case" for humanoid robotics cleaning robot comment.


For people building embodied systems, the contrast underlines a core design question: optimize for acrobatics that impress investors and social media, or for slow, robust manipulation that matches actual paid tasks like janitorial work, logistics, or elder care. The toilet‑cleaning deployment hints that even relatively crude locomotion might be enough if the task is narrow, repeatable, and can justify robot pricing and maintenance contracts in a real facility.
Indie builder shows basement sim2real loop with custom debug UI
An independent developer working on a sim2real robotics project described getting "some success but mostly failure" on transfer, then planning to collect their own data in a basement and fix a mis‑specified physics simulator sim2real progress. They compared this hands‑on loop to the Wright brothers' 1901 wind tunnel work—"never trust anyone else's data but your own"—as a template for modern embodied AI debugging wind tunnel analogy.
Around that, they showed off an over‑engineered but highly polished sim2real debug UI, crediting modern coding agents and tools for letting a solo builder ship production‑grade interfaces they "would have never made look good before" debug UI note. They also called out liking PufferLib for reinforcement learning work pufferlib remark. For robotics engineers, it’s a small but telling case study: real‑world sim2real progress often boils down to better data collection, honest simulators, and developer tooling that makes long‑horizon experiments less painful to iterate on.