Gemini Personal Intelligence beta taps 4 apps – recalls Dec 12 appointment
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
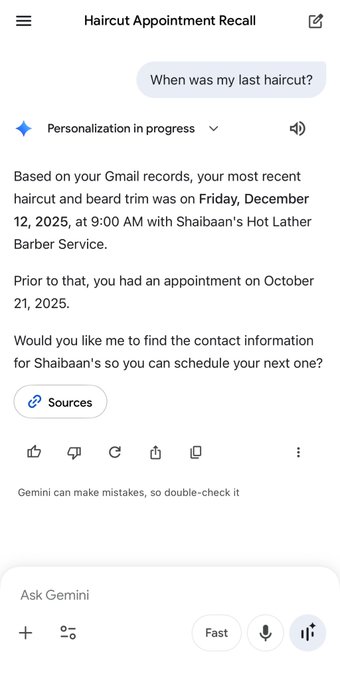
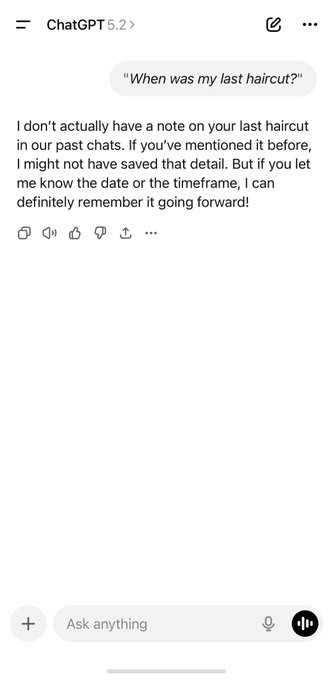
Google rolled out Gemini “Personal Intelligence” (beta) in the Gemini app: an opt‑in personalization layer that can pull context from Gmail, Photos, Search, and YouTube history (up to 4 sources); rollout starts in the US for Google AI Pro/Ultra. Google emphasizes it’s off by default; users can connect/disconnect sources, regenerate a reply without personalization, or use temporary chats; Gemini also claims it will cite/explain which connected sources informed an answer and flags “overpersonalization” as a known risk. A viral demo has Gemini answering “When was my last haircut?” by locating a Gmail appointment—Friday, Dec 12—while ChatGPT responds it doesn’t have that detail; the gap is less model IQ than first‑party data plumbing.
• OpenAI/GPT‑5.2‑Codex: now in the Responses API; simultaneously lands across Cursor, GitHub @code, Warp, FactoryAI Droid, and others; positioned for long‑running coding + “most cyber-capable,” but public eval artifacts aren’t bundled in the rollout.
• Anthropic/MCP tooling: Claude Code “Tool Search” rolls out to reduce MCP context bloat; users ask for server pinning as tools get offloaded; one complaint cites 16k tokens spent on system tools.
Personalization, tool routing, and latency are converging into product surface area; the big unknown is reliability under real-world data messiness and how provenance UX holds up at scale.
Top links today
- GPT-5.2-Codex in Responses API announcement
- Codex prompting guide
- Gemini Personal Intelligence launch details
- Vercel react-best-practices repo for agents
- Safety Not Found robotics decision risks paper
- SIGMA paper on LLM collapse monitoring
- Window-based membership inference attacks paper
- BenchOverflow prompt-induced overflow benchmark
- Dynamic Outlier Truncation for shorter reasoning
- Predicting ML agent outcomes before executing
- Real-world NHS medication review LLM evaluation
- Test-time tool evolution for scientific reasoning
Feature Spotlight
Feature: Gemini “Personal Intelligence” (opt‑in personal context from Google apps)
Gemini adds opt‑in, cross‑Google-app personalization (Gmail/Photos/Search/YouTube) with controllable privacy—shifting the assistant race from raw model quality to data integration and verifiability.
Google rolled out Gemini Personal Intelligence (beta) that can optionally use Gmail/Photos/YouTube/Search history for highly personalized answers with citations and controls. This is the main cross-account product story today; excludes GPT‑5.2‑Codex rollout (covered elsewhere).
Jump to Feature: Gemini “Personal Intelligence” (opt‑in personal context from Google apps) topicsTable of Contents
🧠 Feature: Gemini “Personal Intelligence” (opt‑in personal context from Google apps)
Google rolled out Gemini Personal Intelligence (beta) that can optionally use Gmail/Photos/YouTube/Search history for highly personalized answers with citations and controls. This is the main cross-account product story today; excludes GPT‑5.2‑Codex rollout (covered elsewhere).
Gemini adds Personal Intelligence beta using Gmail, Photos, Search and YouTube history (opt-in, US Pro/Ultra)
Gemini Personal Intelligence (Google): Google introduced Personal Intelligence in the Gemini app, letting users opt in to connect Gmail, Google Photos, Google Search, and YouTube history for more tailored responses, as described in the launch thread and echoed in the data sources list; rollout begins today as a US beta for Google AI Pro and Ultra subscribers, with expansion planned as it improves per the rollout note and the Google blog post.

• Use-case framing: Google’s examples emphasize planning, shopping, and motivation flows (e.g., trip suggestions tied to your preferences), as sketched in the use cases list and previewed in the shopping examples.
• Near-term product surface expectations: third-party observers read the Photos integration as a signal that Photos-as-context and attachment-style UX could show up soon in Gemini, per the Photos context hint.
Gemini Personal Intelligence adds opt-in controls, source-based verification, and non-personalized regen
Privacy and controls (Gemini Personal Intelligence): Google’s rollout message is that Personal Intelligence is off by default, and users can selectively connect up to four Google sources (Gmail, Photos, Search, YouTube) and disconnect anytime, as stated in the opt-in controls thread and reinforced in the privacy stance.
• Verification UX: Gemini says it will try to reference or explain which connected sources it used so the user can verify, and the user can explicitly ask it to verify when it doesn’t, per the verification options.
• Context separation controls: users can regenerate responses without personalization for a specific chat or use temporary chats to avoid Personal Intelligence context, as described in the verification options and the control summary.
• Overpersonalization caveat: Google explicitly calls out the risk of “overpersonalization” and asks for thumbs-down feedback and in-chat corrections to improve behavior, per the feedback note.
Gemini Personal Intelligence demo shows Gmail-based “last haircut” recall vs ChatGPT memory limits
Competitive comparison (Gemini Personal Intelligence): a side-by-side example shows Gemini answering “When was my last haircut?” by pulling the appointment from Gmail—down to Friday, Dec 12, 2025 at 9:00 AM—while ChatGPT responds that it doesn’t have that detail in past chats, as shown in the haircut comparison.
• Connector vs native context argument: some builders claim existing G Suite connectors in ChatGPT/Claude are slow and unreliable at finding things, and that Gemini’s first-party integration could be a step change, per the connectors comparison.
• “Integrations are the moat” narrative: commentary frames model quality as near-parity for most tasks and puts the differentiation on data access and product integration, as argued in the integrations argument and reflected in the daily driver switch.
🧑💻 GPT‑5.2‑Codex rollout: API availability + coding product integrations
Today’s tweets heavily focus on GPT‑5.2‑Codex becoming broadly available across coding products and the Responses API, with early anecdotes about long-running task reliability and security use cases. Excludes Gemini Personal Intelligence (feature).
GPT-5.2-Codex lands in the Responses API with long-run and security framing
GPT-5.2-Codex (OpenAI): GPT-5.2-Codex is now available in the Responses API, positioned for “complex long-running tasks” like feature work, refactors, and bug hunts, according to the API availability note and the linked Model docs; OpenAI also calls it “the most cyber-capable model yet,” emphasizing vulnerability discovery and understanding in the same rollout post API availability note.
• Docs and guidance: OpenAI points developers to the Codex prompting guidance via the Prompting guide link, while broader positioning that it’s “our strongest agentic coding model (yet)” appears in the Rollout claim.
• Broader announcement surface: the release is also framed in the official introduction post linked in Product announcement.
Cursor adds GPT-5.2 Codex and pitches it for long-running agent work
GPT-5.2 Codex in Cursor (Cursor): Cursor says GPT-5.2 Codex is now available in its product and frames it as “the frontier model for long-running tasks” in the Cursor availability note.
Early usage anecdotes cluster around uninterrupted, extended runs—one report cites “3M lines written over a week of continuous agent time” with GPT‑5.2 in the loop, as described in the Week-long agent run and echoed by Cursor-linked commentary about building week-long agents in the Long-running agents writeup. Another practitioner take is to “start it and let it run for a couple of hours,” per the Hands-off usage tip.
GPT-5.2-Codex starts rolling out to GitHub’s @code
GPT-5.2-Codex in @code (GitHub): GitHub’s @code account says GPT‑5.2‑Codex is rolling out now, shown in the Rollout clip.

A separate roundup from a Codex lead lists @code as one of the surfaces where the model is available, alongside a CLI invocation (codex -m gpt-5.2.codex), in the Availability roundup.
Factory’s Droid adds GPT-5.2-Codex and emphasizes review quality
GPT-5.2-Codex in Droid (FactoryAI): FactoryAI says GPT‑5.2‑Codex is available in Droid and highlights stronger end-to-end agentic coding, especially “code review and bug finding,” plus cleaner multi-file changes and higher patch correctness in the Droid announcement.
A longer performance description—deeper research, stronger context-building, and better fit for large refactors/migrations—appears in the Model behavior notes.
Warp ships GPT-5.2 Codex support tuned for longer tasks
GPT-5.2 Codex in Warp (Warp): Warp says it now supports GPT‑5.2 Codex, noting it worked with OpenAI to tune its harness and that Codex “excels at long-horizon tasks (think 15 min+)” in the Warp integration demo.

OpenCode is listed among GPT-5.2-Codex rollout surfaces
GPT-5.2-Codex in OpenCode (OpenCode): A Codex lead’s availability roundup explicitly lists @opencode as one of the products where GPT‑5.2‑Codex is available, as written in the Availability roundup.
Windsurf starts promoting GPT-5.2-Codex availability
GPT-5.2-Codex in Windsurf (Cognition/Windsurf): Windsurf is promoted as another surface to try GPT‑5.2‑Codex, per the Windsurf prompt.
A broader “available in Cursor/Windsurf/Warp/Factory/OpenCode” list appears in the Availability roundup.
Zed adds GPT-5.2 Codex for Zed Pro users
GPT-5.2 Codex in Zed (Zed): Zed says GPT‑5.2 Codex is now available for Zed Pro users, with BYOK users getting access “shortly,” and requires Zed 0.220.0+ in the Zed availability note.
Crush adds GPT-5.2 Codex to its model picker
GPT-5.2 Codex in Crush (Charm): Charm says GPT‑5.2 Codex is available in Crush, with a UI screenshot showing “Switch Model” selecting “GPT‑5.2 Codex” in the Crush model picker.
Zen reports GPT-5.2 Codex is available
GPT-5.2 Codex in Zen (Zen): Zen is reported to have GPT‑5.2 Codex available, with a dry confirmation (“it is a large language model and can be prompted… and it can produce code”) in the Zen availability note.
🧰 Claude Code: outages, desktop friction, and “Cowork” surface signals
Claude Code chatter today is dominated by reliability/outage posts plus product-surface breadcrumbs (codenames, feature gates) and user pain points. Excludes Gemini Personal Intelligence (feature).
Claude Code outage reports hit Opus 4.5 and Sonnet 4.5 users
Claude Code (Anthropic): Users reported Opus 4.5 and Sonnet 4.5 going down inside Claude Code, with multiple posts framing it as an abrupt productivity cliff, as described in the Downtime report and echoed by the Error message joke. It also sparked the familiar reliability anxiety of “what happens if Claude goes down” in the Reliability meme.
• Attribution speculation: Some users explicitly wondered whether Claude Code Cowork activity contributed to the outage, as raised in the Cowork suspicion.
• Fallback behavior: When Claude is unavailable, people immediately point to alternative providers/models as stopgaps, as shown in the Backup suggestion.
Outage postmortem chatter pegs Opus/Sonnet recovery at about four hours
Claude Code (Anthropic): Following up on outage (availability issue), users pointed to a postmortem narrative that the major Opus 4.5/Sonnet 4.5 interruption took 4 hours to resolve, as referenced in the Postmortem gripe alongside the broader outage reports in the Downtime report.
The thread-level reaction is less about root cause specifics and more about a perceived mismatch between model capability and mean-time-to-repair during incidents, per the Postmortem gripe.
Claude iOS users complain of frequent “Error sending message” failures
Claude iOS app (Anthropic): A user complaint says the iOS experience is “extremely buggy” with failures on roughly every third message, with an “Error sending message” banner shown in the iOS error screenshot.
This is a UX reliability issue (not model quality) that affects anyone trying to run Claude Code/Cowork-style workflows from mobile when the app itself becomes the bottleneck, as described in the iOS error screenshot.
Claude web app leak points to “Yukon Gold” Cowork codename and feature gates
Claude Cowork (Anthropic): Following up on research preview (Cowork surfaced in the desktop app), a Claude web app leak claims Cowork is internally labeled “Yukon Gold” and lists multiple feature gates that hint at upcoming surfaces—separate analytics, possible voice mode, and skills-related slash commands—according to the Codename and gates note.
This is product-surface breadcrumbing rather than a confirmed rollout; the post does not include release timing or availability details beyond the gate names, per the Codename and gates note.
Claude Code gets criticized for agent-led research quality on tricky tasks
Claude Code (Anthropic): One practitioner argues Claude Code becomes a “slop machine” on “slightly tricky” research projects when the agent is making the choices, as written in the Research quality critique.
This is a narrow but relevant usage report: it suggests the failure mode is not tool availability but agent autonomy and decision quality in research-like work, per the Research quality critique.
Cowork permission anxiety shows up around Documents folder access
Claude Cowork (Anthropic): Following up on folder scope (folder-scoped permissions), users are still unsure about granting Cowork broad local access—one example is explicit concern about giving it the Documents folder, as stated in the Documents access worry.
The post is small, but it’s a direct signal that “what folder do I hand it?” remains a core adoption friction point, per the Documents access worry.
🔌 MCP & tool routing: dynamic tool loading, context bloat, and integration friction
MCP discussions center on context bloat and new approaches like tool search/dynamic loading, plus debate over MCP vs CLI transport patterns. Excludes Gemini Personal Intelligence (feature).
Claude Code rolls out Tool Search to shrink MCP context overhead
Claude Code Tool Search (Anthropic): Claude Code is rolling out Tool Search to reduce how much context MCP servers consume, as described in Tool search rollout; early reactions frame this as a practical fix for “context pollution” that previously made MCP setups unattractive, per Context pollution take.
• Scale implications: one developer claim is that with the bloat addressed, it becomes realistic to connect “dozens or even hundreds of MCPs” to Claude Code, as argued in Context pollution take.
• What it changes operationally: the shift is being described as dynamic tool loading, reducing the need to stuff every tool’s schema/docs into the always-on prompt, as noted in Dynamic tool loading note.
The remaining unknown is how Tool Search behaves under heavy tool catalogs (latency, ranking quality, and failure modes) since the tweets don’t include a measured before/after token or speed breakdown.
Anthropic argues MCP search beats CLI tooling in varied local environments
MCP search vs CLI transport: In a direct comparison discussion, Anthropic’s Bill C. says the team tried a CLI-first approach and found “MCP search worked better in practice” because of differences across user environments, as explained in MCP beats CLI note.
This is a claim about operational fit: if your users run agents across heterogeneous shells, PATH setups, and OS tooling, the discovery/dispatch layer can dominate the “in theory CLI is simplest” argument.
LangChain pushes “agents are a filesystem” for portable tool+context packaging
Agents-as-filesystem pattern (LangChain): LangChain highlights a design where an agent is represented as files in a filesystem—using conventions like AGENTS.md and skills—to store and access knowledge and behaviors, as described in Agents are a filesystem and grounded by the referenced AGENTS.md standard.
In the MCP context, this acts like an escape hatch from prompt bloat: rather than pushing everything into the chat context, more state and “how-to” can live on disk and be pulled in when needed.
MCP server offloading triggers requests for “pinning” and token-budget controls
MCP server retention controls: With Claude Code moving toward searchable/dynamically-loaded tools, one practical friction point is server offloading—requests are surfacing for a way to “pin” an MCP server so it won’t be offloaded mid-work, as asked in Pinning request.
• Token budget pressure: a related complaint is that “16k tokens for system tools is really high,” which makes some users consider removing tools to keep headroom, as stated in System tools token budget.
This lands as an ergonomics issue: once tool catalogs get large, the control surface (pinning, budgets, selection) becomes part of reliability, not just convenience.
mcporter proposes a CLI-first alternative to MCP-style integrations
mcporter (steipete): A counter-position is that agents already handle CLIs well, so a CLI-first transport can be the simpler/cleaner integration surface; steipete points to mcporter as that approach in CLI approach link, with the project itself linked via GitHub repo.
This frames the ecosystem split: “search tools in-protocol” versus “standardize on shellable tools,” with different failure modes (prompt bloat vs environment drift).
🕹️ Agent runners & long-horizon ops: web agents, loops, and “run for a week” stories
This beat covers operationalizing agents: long uninterrupted runs, web agents, and task execution harnesses that emphasize throughput and reliability. Excludes Gemini Personal Intelligence (feature).
Cursor details week-long autonomous run building a browser with GPT-5.2 agents
Cursor long-running agents (Cursor): Cursor published details on building a browser with GPT‑5.2 inside Cursor and keeping the agent running for a full week—claiming 3M+ lines across thousands of files, plus a clear takeaway that “model choice matters for extremely long-running tasks,” as described in the Cursor blog excerpt and supported by the Cursor blog post.
They frame the key differentiator as sustained focus (less drift) over multi-hour and multi-day tasks. That’s the operational bar.
• Stamina as the feature: the run is described as “uninterrupted for one week” in the week-long run, with gdb amplifying “3M lines written over a week of continuous agent time” in the 3m lines claim.
• Practical comparison notes: Cursor’s writeup claims GPT‑5.2 stays aligned longer, while Opus 4.5 “tends to stop earlier and take shortcuts,” per the Cursor blog excerpt.
The post is one of the clearer public artifacts so far on what breaks first in “run for days” agent setups.
Firecrawl ships Spark 1 Pro and Spark 1 Mini for /agent web extraction runs
Spark 1 Pro / Spark 1 Mini (Firecrawl): Firecrawl announced two new models—Spark 1 Pro and Spark 1 Mini—as the backbone for its /agent endpoint that “searches, navigates, and extracts web data from a prompt,” with Mini positioned as 60% cheaper and Pro as higher-accuracy, per the model launch.

They’re explicitly pitching this for high-volume agent runs (“run tasks like this thousands of times”), as shown in the mini example.
The tweets include cost/quality positioning, but no full public benchmark artifact beyond the claim language.
Hyperbrowser open-sources HyperAgent web runner on top of Playwright
HyperAgent (Hyperbrowser): Hyperbrowser introduced HyperAgent, an open-source web-agent runner that “supercharges Playwright with AI,” positioning it as a simple API surface for browser navigation + extraction, per the launch thread.
The baseline usage is a single startAndWait call with an LLM choice, as shown in the launch thread. It’s a straightforward interface.
• Open-source surface: the repo is linked in the GitHub announcement via the GitHub repo.
• Run/observe mode: they also highlight async execution with a liveUrl so you can watch runs while they happen, according to the async run pattern.
No performance numbers were posted in these tweets. The core change is packaging and ergonomics.
Planner-worker-judge loop emerges as a scalable multi-agent pattern
Planners/workers/judge loop (Workflow pattern): A Cursor writeup snippet describes splitting agents into planners and workers, then using a judge to decide whether to continue each cycle—an explicit attempt to avoid coordination failures and tunnel vision at scale, as shown in the planners and workers.
This is being compared to the “Ralph Wiggum loop” family of resets-and-iterate patterns, with Geoffrey Huntley noting Cursor saw it “in person circa 8 months ago,” per the in-person demo.
The key operational claim is that decoupling planning from execution makes multi-week runs tractable. That’s the bet.
Browser Use posts BU mini vs Manus 1.6 Max head-to-head clip
BU mini vs Manus 1.6 Max (Browser Use): Browser Use posted a head-to-head “BU mini ⚔️ Manus 1.6 Max” comparison video, positioning it as a competitive benchmark-by-demo for web-agent execution quality, per the comparison clip.

The clip is marketing-forward and doesn’t include a standardized scoring rubric in the tweet. It’s still a concrete artifact of how teams are trying to communicate web-agent capability today.
Enterprise Claude Code rollouts reportedly burn $100 in credits in 2–3 days
Agent spend and scaling (Workflow economics): A practitioner reports a big-tech internal rollout of Claude Code with a $100/month credit budget per employee, but typical usage “burn through it in 2–3 days,” raising doubts about scaling agentic work under current API pricing, per the credit burn note.
This is an ops problem first. Budgets get exhausted mid-flow.
The tweet doesn’t break out tokens, tasks, or model mix. It’s directional signal, not a measurement report.
Founder workflow highlights the “prompt briefly, wait all day” bottleneck for agents
Agent latency as the bottleneck (Workflow pattern): One founder describes a day as “prompt for 30m/day, then wait for 10h/day,” explicitly asking providers to make agents “100× faster” rather than smarter, per the founder workflow.
That’s a throughput framing. It treats agent loops as a queueing problem.
It’s also a reminder that long-horizon reliability isn’t only about correctness; it’s about how quickly the loop closes.
🧾 OpenCode: Black plan rollout, storage refactors, and Windows friction
OpenCode updates today revolve around OpenCode Black subscription access, scaling storage from flat JSON to SQLite, and operational quirks (e.g., false malware flags). Excludes Gemini Personal Intelligence (feature).
OpenCode migrates session storage from flat JSON files to SQLite
OpenCode (OpenCode): OpenCode’s maintainer says they’re hitting scaling limits with “flat json files” for storing agent/session data and is moving the data into SQLite for better query/filter/aggregation, as described in the storage scaling note and then confirmed in the SQLite migration update.
• Why SQLite now: the claim is that agents “love databases” and that a filesystem is “the worst kind of database,” with SQLite making analysis queries (like “most interesting sessions”) much easier, as shown in the SQLite migration update.
Windows flags OpenCode as malware due to temp binary filename collision
OpenCode (OpenCode): OpenCode reports Windows Defender false-positives after the app extracts binary dependencies to a temp folder on first run using a hashed content filename; that hash “randomly” matches known malware patterns, triggering alerts, according to the Windows malware flag note. This is a practical distribution friction for any CLI/agent tool that unpacks executables at runtime, and the tweet frames it as a filename-collision issue rather than malicious behavior.
OpenCode opens Black plan signups with $20/$100/$200 tiers and staged activation
OpenCode Black (OpenCode): OpenCode says anyone can now sign up for OpenCode Black, but subscriptions will activate in batches “as we scale up capacity,” with three paid tiers at $20/$100/$200 per month, as outlined in the pricing tiers note and the signup page. The main operational signal is that demand appears to be outstripping immediate capacity, so access is effectively waitlisted even after payment, per the pricing tiers note wording.
OpenCode considers an id | data JSON-blob table design for SQLite storage
OpenCode (OpenCode): In the middle of the SQLite move, the maintainer floats a minimal schema pattern—every table as id | data (json blob)—and asks whether users would object, as stated in the schema question. This is a classic tradeoff: faster iteration and flexible migrations versus weaker typing/indexability for analytics-heavy queries.
Hugging Face CEO spotlights OpenCode meeting as open-source coding agents momentum
OpenCode (OpenCode): Hugging Face CEO Clément Delangue posts a meetup photo with the OpenCode team and frames it as momentum for “open-source coding agents,” as shown in the meetup photo.
The tweet is mostly a social signal rather than a product change, but it’s a notable distribution/reputation boost from a major open-source platform leader, per the meetup photo framing.
🧭 How teams steer coding agents: specs, context discipline, and “vibefounding”
Practitioner posts focus on how to structure work for agents (plans/specs, iteration loops) and what changes in org execution when non-coders can ship. Excludes Gemini Personal Intelligence (feature).
MBA “vibefounding” class ships companies in four days using coding agents
Vibefounding (workflow): An MBA class format called “vibefounding” has students go from idea to launched company in 4 days, with the instructor reporting that work which used to take a semester now fits into that window—using Claude Code, Gemini, and ChatGPT as the primary build stack, per the Class observations.
The practical signal is that “non-coders shipping working products” is no longer a hypothetical; it’s becoming a repeatable classroom exercise, with the biggest differentiator shifting toward domain expertise and how teams structure problems for agents, as described in the Class observations.
“Context is king” memo argues companies need maintained context stores for agents
Context stores (org workflow): A “context is king” argument reframes agent success as an information management problem: humans get context implicitly (goals, norms, recent decisions), while agents need it explicitly—so teams that maintain up-to-date specs, best practices, roadmaps, and decisions gain leverage, as argued in the Context is king memo.
The claim in the Context is king memo is that a premium will emerge around “up-to-date context” not as a nice-to-have, but as a prerequisite for agents to execute reliably across shifting objectives.
json-render open-sources AI→JSON→UI pattern for deterministic, constrained UIs
json-render (Vercel Labs): An open-source project called json-render formalizes a “AI streams JSON → renderer builds UI” pattern where output is constrained to a component catalog you define, aiming for deterministic, safe-ish UI generation, as described in the Project intro.

The pitch in the Project intro is that you can let users prompt dashboards/widgets while keeping execution bounded by predefined components and actions; the code is linked as the GitHub repo in the GitHub repo.
Plan→beads conversion loop framed as the main failure mode for coding agents
Plan→beads (workflow): One practitioner frames the core failure mode in “agentic coding flywheels” as weak planning and sloppy plan-to-task translation, arguing that quality comes from iterating the written plan and then doing multiple passes converting it into granular tasks (“beads”), as laid out in the detailed playbook in the Flywheel setup steps.
The workflow described in the Flywheel setup steps emphasizes that once the plan and beads are solid, the remaining work is mostly orchestration (reviews, tests, frequent commits, and recovery after compactions), which is a different skill than “prompting” in the casual sense.
Skills.md best-practices push: reusable agent playbooks with progressive disclosure
Skills.md (workflow pattern): A recurring pattern in coding-agent setups is to formalize repeatable work as “skills” (a SKILL.md plus supporting files), with guidance to keep instructions modular and rely on progressive disclosure to reduce token waste—see the concrete examples and rationale in the Skills life hack.
• Reusable process packaging: The approach is to turn “things you explain more than once” (e.g., README conventions, social sharing metadata) into skills, as shown in the Skills life hack and its referenced examples via the Example skill.
• Token discipline via reference files: The recommendation is to keep general rules in the skill file while offloading project specifics into adjacent reference docs, as described in the Skills life hack.
Vercel ships react-best-practices: performance rules and evals for coding agents
react-best-practices (Vercel): Vercel released a repo aimed at coding agents that packages React performance rules plus evals to catch regressions (including accidental waterfalls and bundle growth), as announced in the Repo launch and detailed in the launch writeup linked via the Launch blog.
This is framed less as “linting” and more as a guardrail system for agent-driven changes: you encode the failure modes you care about and keep them running so agent output stays within performance budgets, per the Repo launch.
“Vibe-coded replacement” layoff meme sparks debate about agent output credibility
Vibe-coded replacement (narrative pattern): A viral pattern shows up again: a claim of replacing a whole ops stack via “vibe coding” in 19 minutes and saving “$48m/yr,” paired with layoffs, as asserted in the Layoff meme claim.
• Second-order skepticism: A follow-up frames the likely outcome as a delayed vendor “revenue spike a year from now,” pushing back on the implied permanence of the cost savings in the Revenue spike reply.
• Norms and incentives: Another thread argues there’s a real split between people who care about security/performance/accessibility and those who mainly want to look like they care, which is part of why these narratives get heat, per the Quality vs signaling note.
The throughline is that agent-enabled build speed is being used rhetorically to justify organizational claims, while the reliability/maintenance surface is what critics keep pulling on, as shown in the Revenue spike reply.
Context engineering framing: pre-chunking vs post-chunking as an architectural choice
Chunking timing (context engineering): A concrete architecture distinction is getting attention: “pre-chunking” (fixed chunks at ingestion) versus “post-chunking” (chunk and rerank after retrieval, per query), with the claim that the critical decision is not only how to chunk but when you chunk, as explained in the Chunking timing explainer.
The key trade noted in the Chunking timing explainer is speed and simplicity for pre-chunking versus flexibility (and higher first-response latency) for post-chunking, which maps directly onto how agent systems decide what context to fetch and compress.
PR review steering heuristic: ask “is this the best way to solve this?”
PR review prompt (workflow): A small but concrete steering trick for human (and agent-assisted) code review is to explicitly ask “is this the best way to solve this?”—a prompt that tends to elicit higher-level design critique instead of line-level nits, per the PR review prompt.
In practice, this reframes review from correctness-only to solution quality, which is often where agent-written code drifts first, as implied by the PR review prompt.
Prompt discipline pattern: “don’t relate it to my work” to counter assistant memory bias
De-personalize by default (workflow): A recurring complaint about “memory” features is that they bias answers toward personal/work context even when the user is trying to learn a topic neutrally; one workaround is a standing instruction like “do not relate it to my work” and “pretend I’m a junior researcher,” as described in the Memory annoyance note and reinforced in the Follow-up instruction.
This is effectively a steering layer for knowledge work: explicitly choosing whether the model should optimize for personalization or for pedagogy, as captured in the Memory annoyance note.
🧩 Skills & reusable agent behaviors: SKILL.md ecosystems and progressive disclosure
Skills as portable instruction packages are a major thread today: how to author, load, and share skills across agent tools (Claude/Cursor-like patterns). Excludes Gemini Personal Intelligence (feature).
Chorus fork adds Agent Skills support across LLMs via OpenRouter
Chorus (meltylabs fork): A fork of Chorus adds Agent Skills support “for all LLMs” by loading Claude-style skill folders and routing the underlying model via OpenRouter, with the implementation story summarized in the Skills support claim.
• Upstreaming path: The author shared an upstream PR target for landing the feature, as linked from the Pull request link.
• Binary distribution: An unsigned macOS DMG release was shared for early testing, as provided in the Release artifact.
The new capability is mainly about portability: reusing the same SKILL.md packages even when you swap the underlying model provider.
Google Antigravity adds Agent Skills (SKILL.md) as an open standard package format
Agent Skills (Google Antigravity): Google’s Antigravity added support for Agent Skills as reusable instruction packages centered on a SKILL.md file, with discovery/loading behavior described in the Skills summary.
Docs for where and how skills are configured are linked in the Docs pointer via the Agent Skills docs, reinforcing the emerging pattern that “skills” are becoming a cross-tool portability layer rather than a single-vendor feature.
Claude Code SKILL.md authoring guide emphasizes progressive disclosure and refs
SKILL.md authoring (Claude Code ecosystem): A widely shared write-up argues that the fastest way to improve agent consistency is to codify repeatable processes into SKILL.md files, and to keep them token-efficient by bundling reference files next to the skill (so the agent only loads what it needs), as described in the Skills workflow post.
It also points to “read a skills best practices guide first” as a practical way to raise the floor on how skills are structured, with concrete examples linked in the Skills guide and sample skills shown in the Share images skill and README skill.
KiloCode documents Skills.md directories, overrides, and token-cost tradeoffs
Skills.md conventions (KiloCode): KiloCode documented a concrete directory layout for skills—global “personal” skills vs repo-committed team skills—with project-level override behavior, as outlined in the Directory conventions.
It also calls out the practical cost: skills are loaded into context, so long skills directly raise token burn; that constraint is emphasized in the Token cost warning, with additional details and a community “skills marketplace” pointer in the Marketplace mention and the linked Spec and setup post.
Vercel Labs open-sources json-render for deterministic AI-generated UI via JSON
json-render (Vercel Labs): Vercel Labs shipped json-render, an open-source pattern for “AI → JSON → UI” where the model streams constrained JSON that is rendered into interactive components, as introduced in the Launch thread.
The point is predictable UI generation: you define a component catalog and permitted actions, then treat the model as a structured-output generator rather than letting it invent arbitrary UI code, as shown in the Launch thread and the linked GitHub repo.
Claude Code /config language setting trick used as a lightweight “skill” layer
Claude Code (Anthropic): A lightweight steering pattern is circulating where people use Claude Code’s language configuration to set a stable global tone, naming convention, and response style—effectively a “soft skill” that applies across sessions—described in the Config pattern.
Unlike SKILL.md packages, this lives in the tool’s configuration layer; it’s being used for consistent verbosity, review style, and output formatting across otherwise unrelated tasks, per the Config pattern.
🧱 Agent frameworks & builders: architectures, harnesses, and SDK feedback loops
Framework posts emphasize architecture patterns (routers/subagents/handoffs) and new builder layers/harness abstractions. Excludes Gemini Personal Intelligence (feature).
LangChain explains how LangSmith Agent Builder works under the hood
LangSmith Agent Builder (LangChain): Following up on GA launch—agent builder goes GA—LangChain shared a technical walkthrough of what powers it internally, centered on the Deep Agents harness and a filesystem-centric agent representation, as outlined in the Technical overview thread.

• Harness design: The post frames Deep Agents as an open, model-agnostic harness for longer-horizon agents with built-ins like context compaction and tool offloading, as described in the Technical overview and reiterated in the Deep Agents overview link.
• Agents as files: Agent state is represented as files (including conventions like AGENTS.md and skills), as called out in the Agents are filesystem highlight.
• Memory and autonomy hooks: Memory is implemented as writing to specific files, and “triggers” let agents run in the background; these mechanics are described in the Memory is built in note and the Trigger mechanism note.
A separate LangChain note frames Deep Agents as an area where the team expects community experimentation to matter, as written in the Open harness call.
LangChain publishes a decision guide for multi-agent architecture patterns
Multi-agent architectures (LangChain): LangChain published a practical guide for choosing between four common patterns—subagents, skills, handoffs, and a router—and says it includes performance benchmarks plus a decision framework, as described in the Architecture patterns post and detailed in the Decision framework.
It’s a taxonomy with trade-offs.
CopilotKit ships middleware to add UI and human-in-loop to LangChain agents
CopilotKit middleware (CopilotKit + LangChain): CopilotKit released middleware that adds frontend/UI capabilities to LangChain Prebuilt Agents (including Deep Agents), positioning it as a fast path from agent harness to interactive application, as announced in the Middleware announcement post with setup details in the Get started link.
It targets app integration, not model choice.
• App-facing primitives: The middleware bundles CopilotKit Actions/Readables and app context wiring, and calls out human-in-the-loop support via LangGraph middleware, per the Middleware announcement description.
• Demo surface: CopilotKit also points to a hands-on environment for trying the integration, as linked in the Interactive dojo follow-up.
Gemini Interactions API guide shows server-side state for CLI agents
Gemini Interactions API (Google): A developer write-up shows how to build a CLI agent loop with function calling, emphasizing previous_interaction_id as a server-side state handle; the flow is summarized in the Agent guide summary thread and expanded in the CLI agent tutorial.
The key detail is state persistence.
• Tool loop mechanics: The guide describes defining tool capabilities via JSON schemas and intercepting tool calls inside a logic loop, as stated in the Agent guide summary thread.
• Prototype scope: It claims a working prototype can be built “in under 100 lines,” as described in the same Agent guide summary thread.
OpenAI team explicitly requests feedback on the Agent SDK and plugins
Agent SDK feedback loop (OpenAI): OpenAI folks explicitly asked for Agent SDK and plugin feedback, pointing people to route it to Noah Zweben, as stated in the SDK feedback request post and echoed by another OpenAI team member in the Ask for feedback prompt.
This reads like active iteration on the SDK’s developer experience.
🛠️ Dev tooling drops: agent-friendly utilities, editors, and workflow repos
Non-assistant dev tools and repos shipped today—mostly OSS utilities that help engineers build, debug, or ship alongside agents. Excludes Gemini Personal Intelligence (feature).
Zed v0.219 adds subpixel text rendering plus new agent UX controls
Zed (Zed Industries): Zed shipped v0.219 with ClearType-style subpixel text rendering (enabled by default on Windows and Linux) plus a cluster of small-but-practical agent workflow controls, as announced in Release note thread.

• Text rendering: adds text_rendering_mode for crisper text on standard-DPI displays, as described in Release note thread.
• Agent ergonomics: you can pin models and cycle through favorites (Alt-Tab), interrupt the agent turn, and queue messages to send after the agent finishes, as shown in Agent UX demo.
• Shipping loop: Zed also added a built-in git: create pull request action, as demonstrated in PR creation demo.
• Keybinding discoverability: a new which-key modal previews chord continuations, as shown in Which-key preview.
The release reads like a response to “agent friction” in day-to-day editor use, rather than a single flagship capability.
React Router devtools ships a fix for a 1–3s navigation slowdown
React Router devtools (React Router): A bug was traced to devtools adding 1–3 seconds of extra page-to-page navigation latency in a real SaaS workflow, and a patch was shipped, according to Latency regression report and the follow-up fix announcement in Fix release note.
The same fix note also calls out reduced re-renders and a crash case involving error boundaries/outlet painting, as listed in Fix release note.
OpenRouter publishes an “awesome-openrouter” list of compatible apps
OpenRouter (OpenRouter): A community-facing directory of “Apps that work with OpenRouter” was published on GitHub, per Apps list announcement and the linked GitHub list.
The list functions as a discovery surface for tools that already support OpenRouter’s routing layer, rather than a new runtime feature.
Python DX tip: contextlib.suppress as self-documenting exception handling
Python (stdlib): A small readability pattern surfaced: using contextlib.suppress(SomeError) as a more scan-friendly replacement for try/except: pass, argued as “self documenting” in Python suppress tip.
This is a micro-pattern, but it maps neatly onto code review in agent-heavy repos where intent needs to be obvious at a glance, per the example in Python suppress tip.
📚 Docs for agents: markdown-first repo surfaces and agent-friendly best-practice packs
Today’s doc/knowledge-surface items focus on making repositories and best practices consumable by agents (markdown outputs, structured overviews). Excludes Gemini Personal Intelligence (feature).
codebase.md turns GitHub repos into markdown-first surfaces for agents
codebase.md (Ian Nuttall): codebase.md now serves GitHub repositories as Markdown by default (HTML only when explicitly requested); it adds an agent-friendly overview with an AI-generated repo summary, exposes the full file tree, and supports natural-language repo search, with the usage pattern shown in the Product description alongside the Project page.
The project also includes a “curl for a skill” hook—curling the URL returns a reusable skill definition intended to help agents ingest GitHub repos consistently, as noted in the Skill easter egg.
Vercel publishes React Best Practices repo with performance evals for coding agents
react-best-practices (Vercel): Vercel shipped react-best-practices, a public repo aimed at making React performance guidance “agent-consumable,” with rules plus evaluation checks designed to catch regressions like accidental waterfalls and growing client bundles, as described in the Release announcement and detailed in the Launch blog.
The framing here is documentation as a testable contract: instead of only telling agents (or humans) what “good” looks like, you encode it as evals so agent-driven refactors can be validated continuously.
📏 Benchmarks & eval thinking: forecasting, planning evals, and agent measurement
Eval discourse today includes new benchmark proposals and how “more thinking time” or planning steps affect measured performance. Excludes Gemini Personal Intelligence (feature).
LiveCodeBench Pro (Hard) forecast chart says GPT‑5.2 reached a 2030-level median prediction in 2025
LiveCodeBench Pro (Hard): A forecasting chart circulating today claims “the median expert predicted 33% accuracy by end of 2030,” but that GPT‑5.2 hit ~33% in late 2025, as shown in the forecast chart.
The implication is less about the absolute number (no full eval artifact is provided in the tweets) and more about forecast calibration—benchmarks are being used to quantify how far ahead model progress is versus prior expectations.
Proof of Time benchmark measures whether more reasoning steps improve forecasting scientific impact
Proof of Time (PoT) benchmark: A new eval called Proof of Time frames “which ideas will matter?” as a forecasting task—freeze what was knowable at the time, then score predictions against later outcomes like citations and awards, as described in the benchmark summary.
• Thinking-time sensitivity: Reported results show accuracy rising when agents get more steps (up to a 50-message limit), with gains described as real rather than cosmetic in the benchmark summary.
The core point is that “more thinking” becomes an explicit eval knob, rather than an invisible prompt tweak.
Qwen’s DeepPlanning benchmark targets long-horizon agent planning quality
DeepPlanning (Qwen): Qwen is reported to have released DeepPlanning, positioned as a benchmark for evaluating long-horizon agentic planning, per the release mention.
This adds another planning-specific eval target alongside execution-heavy coding benchmarks, focusing directly on plan construction rather than only end-task success.
ValsAI pitches same-day benchmark infra as a product and is hiring to scale it
ValsAI (bench infra): ValsAI explicitly frames “benchmark results the same day as model release” as an infra/product problem, and says it can do this due to its platform and infrastructure while hiring an engineer to push it further, as stated in the hiring note.
This is a benchmark-ops signal: speed of eval publication is being treated as a competitive capability, not just an internal workflow.
🏗️ Compute & capacity: low-latency inference deals, chip constraints, and buildout signals
Infrastructure news is dominated by OpenAI’s low-latency compute move plus broader supply constraints discussions. Excludes Gemini Personal Intelligence (feature).
OpenAI partners with Cerebras for up to 750MW of low-latency inference capacity
OpenAI × Cerebras (inference capacity): OpenAI says it’s partnering with Cerebras to add 750MW of “ultra low-latency” compute to its platform, positioning it as a response-speed play rather than a training announcement, as summarized in Capacity headline and reiterated in the OpenAI rationale. Capacity is described as coming online “in phases” / “multiple tranches” through 2028, with a WSJ framing that the commitment is “multibillion-dollar” (with some posts calling it “$10B”), as stated in the WSJ screenshot.
• Why low-latency specifically: OpenAI emphasizes the interactive loop (“you send a request, the model thinks, it sends something back”) and argues faster responses change usage patterns and workload mix, per the OpenAI rationale.
• What Cerebras is selling: Commentary highlights Cerebras’ wafer-scale approach (compute and memory on one large die) as a way to reduce multi-GPU interconnect overhead, as described in the WSJ screenshot.
The open question is how much of ChatGPT/API inference gets scheduled onto this capacity versus reserved for specific latency-sensitive tiers or products.
TSMC CEO says AI chip demand is running about 3× current capacity
TSMC (AI chip supply): TSMC CEO C.C. Wei is cited saying demand for advanced AI chips is roughly 3× higher than available capacity, with new factories (including Arizona and Japan) not meaningfully easing shortages until 2027 or later, as reported in the Demand quote.
For inference-heavy product roadmaps, this is a blunt constraint signal: even as model token prices fall, physical supply for leading-edge silicon and packaging can stay the limiting factor.
Cerebras tops GLM‑4.7 serving benchmarks at 1,445 tok/s, per Artificial Analysis
GLM‑4.7 provider benchmarks (Artificial Analysis): Artificial Analysis reports Cerebras as the fastest serving option for GLM‑4.7 at 1,445 output tokens/s, with GPU providers like Fireworks and Baseten notably slower, as detailed in Provider benchmark thread and summarized in Speed comparison. This same writeup argues that for reasoning models the more relevant latency metric is TTFAT (time to first answer token) rather than TTFT, and it lists Cerebras at 0.24s TTFT and 1.6s TTFAT, per the Latency metrics note.
• Cost vs speed trade: The thread calls out DeepInfra as the cheapest GLM‑4.7 endpoint (example pricing at $0.43/M input and $1.75/M output tokens) in the Provider benchmark thread, while a separate prompt frames the practical trade as “3× price for 4× speed,” per Pricing trade question.
• Context window caveat: The same provider roundup notes some endpoints (including Cerebras) don’t expose the full 200k context length, using 131k instead, as stated in Provider benchmark thread.
This is one of the clearer “speed as a product feature” datapoints today, with numbers that map directly onto user-perceived responsiveness.
⚙️ Inference engineering: throughput, batching, latency metrics, and provider tradeoffs
Tweets include practical inference optimization (batching to saturate H100) and provider comparisons that matter for agent workloads. Excludes Gemini Personal Intelligence (feature).
vLLM batch inference recipe hits 100% H100 utilization with Qwen3-8B
vLLM (vLLM Project / Modal): A new writeup shows how to drive batch inference hard enough to reach 100% GPU utilization on an H100 while serving Qwen 3 8B, using a FlashInfer backend, async scheduling, and batch-size tuning, as described in the Batch inference walkthrough.
This is a concrete example of “throughput is a system design problem.” It’s not about model choice.
• Key ingredients: The approach leans on FlashInfer + async scheduling + optimized batch sizes, as outlined in the Batch inference walkthrough.
• Why it matters for agents: The same batching and scheduling ideas tend to be the difference between “agents are too expensive” and “agents are throughput-bound,” especially when tool use fans out token counts, per the Batch inference walkthrough.
The post doesn’t include latency tradeoffs (TTFT/TTFAT), so treat it as a pure throughput play for now.
GLM-4.7 provider benchmarks put Cerebras at 1,445 tok/s output
GLM-4.7 providers (Artificial Analysis): A provider comparison for GLM 4.7 highlights a large output-speed spread—Cerebras at 1,445 output tokens/s vs Fireworks at 430 t/s and Baseten at 327 t/s, per the Provider benchmark thread and reiterated in the Speed summary. Short sentence: that’s a different product.
• Latency picture: The same benchmarking notes Cerebras at 0.24s TTFT and 1.6s TTFAT, as explained in the Provider benchmark thread.
• Price spread: The lowest-cost endpoint cited is DeepInfra at $0.43/M input tokens and $1.75/M output tokens, according to the Provider benchmark thread and expanded in the Pricing details.
• Context constraints: The full 200k context window is said to be supported by all providers except Cerebras and Parasail at 131k, per the Provider benchmark thread.
This is still a single-model story, but the choice is really about serving economics and perceived responsiveness.
TTFAT emerges as the latency metric that matters for reasoning models
Latency metrics (Artificial Analysis): The benchmark framing distinguishes TTFT (time to first token) from TTFAT (time to first answer token), arguing that TTFAT is the more meaningful user-visible metric for reasoning models because the “thinking” tokens delay usable output, as described in the Metric definitions and summarized in the TTFT vs TTFAT note.
Short sentence: output speed dominates.
• Reference point: Cerebras is cited at 1.6s TTFAT and 0.24s TTFT, per the TTFT vs TTFAT note.
The implication for agent products is that two endpoints with similar TTFT can still feel very different once reasoning tokens enter the picture.
The GLM-4.7 question: is 3× price worth 4× speed?
Provider tradeoffs (GLM-4.7): A recurring ops question shows up as a clean heuristic—whether it’s rational to pay 3× the price for 4× the output speed when serving GLM-4.7 through Cerebras, as posed directly in the Speed premium question.
Short sentence: this is a product decision.
The underlying benchmark context for that question is the large output-speed gap (Cerebras 1,445 tok/s) documented in the Provider benchmark thread, but the tweets don’t include a workload-specific cost model (tokens per task, concurrency, or cache hit rates), so it’s still an open comparison rather than a concluded result.
🧪 Model releases & credible leak-watch (non-Codex)
Model chatter today spans open image models, arena-tested mystery checkpoints, and near-term rumor mill items. Excludes GPT‑5.2‑Codex rollout (covered in the Codex category) and Gemini Personal Intelligence (feature).
GLM-Image enters LMArena image battles as text-rendering benchmarks circulate
GLM-Image (Z.ai): Following up on GLM-Image release (open-source image model), GLM-Image is now runnable head-to-head in LMArena’s Text-to-Image Arena, per the Arena announcement; the loudest early narrative is “text rendering finally works,” driven by benchmark claims that it beats Nano Banana Pro and GPT-Image 1 [High] on CVTG-2K and LongText-Bench, as shown in the benchmarks table.
• Where engineers will feel it: better legible text in generated UI mockups, posters, signage, and structured templates (the failure mode that breaks lots of product design pipelines), which is why the benchmarks table is getting amplified.
• Serving readiness: vLLM-Omni added day-0 support for GLM-Image, according to the vLLM-Omni support note, which makes it easier to try in existing inference stacks without custom glue.
• How to get it: the weights are published on Hugging Face, as linked in the model card.
Baidu ERNIE-5.0-0110 hits #8 on LMArena Text (1460)
ERNIE-5.0-0110 (Baidu): LMArena chatter highlights ERNIE-5.0-0110 landing #8 on the Text Arena at 1460, described as Baidu’s first Top-10 placement, as summarized in the Arena ranking recap.
• Category callouts: the same post cites #2 Math and #12 Expert/Coding placements, plus Top-10 occupational categories like science, business/finance, and healthcare, as listed in the Arena ranking recap.
No model card, release notes, or deployment details were shared in these tweets, so this is primarily an eval-signal (and should be treated as such until there’s a reproducible artifact).
xAI tests Grok “Slateflow” and “Tidewisp” checkpoints on LMArena
Grok (xAI): A new Grok checkpoint called “slateflow” is being tested on LMArena, with the on-screen model blurb saying “I’m Grok 4,” as shown in the Arena model screenshot; a separate checkpoint, “tidewisp,” is also reported to be in testing, per the follow-on note.
The tweets frame this as pre-release churn for the next Grok generation, but there’s no linked eval card, architecture note, or SKU mapping in the provided posts—just the checkpoint names and the arena appearance.
🗂️ RAG & context pipelines: multimodal retrieval, compression, and structured extraction
Retrieval-focused research and tooling today emphasizes multimodal routing (text/images/video) and faithful long-context compression. Excludes Gemini Personal Intelligence (feature).
LingoEDU compresses long context via EDU decomposition and structure-aware selection
LingoEDU (THUNLP/OpenBMB collaborators): A context compression pipeline decomposes documents into Elementary Discourse Units (EDUs), builds a structural relationship tree, then selects only query-relevant subtrees; the pitch is “faithful” compression that keeps document logic while cutting token usage, as described in the Research summary and linked in the ArXiv paper.
• Traceability and hallucination pressure: Each EDU is indexed so compressed outputs can be mapped back to source units, which the Research summary frames as a way to avoid “black box” compression creating disconnected fragments.
• Cost/latency claims: The post cites “24x cheaper” and ~75% token reduction via “structure-then-select,” and reports large StructureBench gains versus general LLM baselines in the Research summary.
• Artifacts for builders: The authors provide code in the GitHub repo, positioning it as a practical pre-processing step for long-doc QA and summarization.
The most actionable detail is that selection happens after retrieval, so it can be layered into existing RAG stacks rather than replacing retrieval outright.
UniversalRAG routes queries to the right modality and granularity
UniversalRAG (KAIST/DeepAuto.ai): A new retrieval framework argues that “universal” RAG breaks down because modality gaps (text vs images vs video) and granularity mismatches (paragraph vs full doc; clip vs full video) get forced into one embedding space; UniversalRAG instead uses a router to pick the best modality-specific corpus and the right granularity level per query, as described in the Paper overview.
• Modality routing: The router selects among separate corpora (text, images, short video clips, full videos) so retrieval happens inside a modality rather than via cross-modal similarity, per the Paper overview.
• Granularity routing: The same router predicts whether a question needs small units (paragraphs/clips) or whole artifacts (documents/full videos), which the Paper overview frames as a core failure mode of “single granularity” RAG.
The tweets claim improvements across 10 benchmarks, but no single canonical eval artifact is shared beyond the paper screenshot in Paper overview.
LlamaParse claims ~1¢/page “agentic” chart parsing for PDFs
LlamaParse (LlamaIndex): LlamaIndex is pitching “agentic mode” document parsing with improved visual understanding for PDFs—specifically chart value extraction—and frames it as a cost play at about $0.01 per page for approximate chart parsing, as described in the Chart parsing note.
• Why this is different from vanilla OCR: The Chart parsing note explicitly calls out that frontier models are weak at chart value interpretation without guidance, and positions LlamaParse’s approach as overlaying a parsed chart onto the source chart for verification.
There’s no shared eval artifact or screenshot of the overlay in the tweets, so the operational takeaway is the pricing claim and the focus area (charts in PDFs), not a verified accuracy number yet.
Vespa launches an embedding-model tradeoff dashboard focused on quantization and latency
Embedding model selection (Vespa): Vespa published an interactive comparison of open embedding models, emphasizing that the decision changes memory footprint, CPU/GPU utilization, latency, and quality; the announcement highlights binary quantization and INT8 as primary levers rather than “pick the biggest model,” as described in the Dashboard summary and expanded in the Quantization takeaways.
• Latency and cost levers: The thread claims INT8 speeds up inference by ~2.7–3.4× and calls out an example of ~2.5ms query inference on Graviton3 for an INT8 setup, per the Dashboard summary.
• Compression-with-minimal-quality-loss framing: The Quantization takeaways specifically points to binary quantization as “32× savings” with limited quality loss, and highlights GTE ModernBERT + hybrid search as a quality-oriented default.
The tweets don’t include screenshots of the dashboard UI, so treat the headline numbers as provisional until you inspect the underlying eval setup referenced in the linked material from Dashboard summary.
🧠 Reasoning & training ideas: conditional memory, distillation cascades, and anti-verbosity training
Research threads today focus on architectural/training techniques for better reasoning efficiency (memory modules, distillation pipelines, trimming overlong reasoning). Excludes Gemini Personal Intelligence (feature).
DeepSeek’s Engram shows why “memory” can buy back reasoning depth
Engram (DeepSeek): Engram reports a 97.0 score on Multi-Query Needle-in-a-Haystack vs 84.2 for a compute-matched MoE baseline—new detail following up on Engram (hashed N-gram conditional lookup), as summarized in the Engram scaling law thread; it frames a U-shaped optimum where shifting ~20–25% of sparse budget from experts into conditional memory improves loss and long-context retrieval.
• Serving implication: Engram’s deterministic lookup enables host-side prefetch; the paper claims offloading a 100B memory table to host DRAM costs under 3% throughput in one setup, as described in the System diagram excerpt and expanded in the Engram scaling law thread.
• Why the split matters: the “U-shaped” result is presented as a compute allocation problem (conditional computation via MoE vs conditional storage via Engram), with practical wins concentrated in long-context “glue” (entities, formulaic phrases), per the Engram scaling law thread and the System diagram excerpt.
The core claim is that making recall cheap (lookup) preserves transformer depth for harder steps, rather than spending early layers reconstructing common patterns, as argued in the Paper PDF.
DOT targets runaway verbosity during RL by truncating rare outlier completions
Anti-Length Shift / DOT (Research): Dynamic Outlier Truncation (DOT) targets “length shift” in RL—cases where even already-solved prompts start eliciting longer self-checking outputs—and claims token reductions up to 78% on AIME-24 while accuracy rises, despite truncating <0.5% of training replies, as described in the DOT paper summary.
The mechanism is narrowly scoped: only truncate unusually long completions inside groups where multiple sampled answers are already correct, then re-check reward so “shortening” isn’t assumed to be safe, per the DOT paper summary. The underlying motivation is systems-facing: cheaper reasoning models by cutting the tail rather than enforcing hard length limits.
Ministral 3 paper details cascade distillation down to 3B and 262k context
Ministral 3 (Mistral): The Ministral 3 technical paper describes a “cascade distillation” pipeline that starts from a 24B teacher, prunes to smaller shapes, and iterates distillation down to 14B, 8B, and 3B, as summarized in the Ministral 3 paper notes.
It also describes a two-stage long-context recipe that extends to 262,144 tokens using YaRN plus position-dependent attention temperature scaling, and post-training stacks (SFT, online DPO, and a reasoning-focused RL method), per the Ministral 3 paper notes.
SIGMA proposes a scalable collapse detector based on embedding-space volume
SIGMA (Research): SIGMA proposes monitoring self-training collapse by tracking how a model’s embedding space “shrinks” over generations; in one cited setup, a sensitive track dropped about 150 with synthetic-data restarts vs 1500 with weight carryover, suggesting carryover accelerates degeneration, as summarized in the SIGMA paper thread.
The method estimates a volume-like score from sampled embeddings via spectral bounds (to avoid full Gram-matrix computation), and positions the metric as an early warning for diversity/coverage loss during recursive synthetic training, per the SIGMA paper thread.
🛡️ Security, safety & policy: deepfakes, cyber misuse, and verification collapse
Security content today spans policy movement on nonconsensual deepfakes plus practitioner reports of offensive cyber capability via coding agents. Excludes Gemini Personal Intelligence (feature).
Claude Code used for automated web recon across subdomains, ports, and CVEs
Claude Code (Anthropic): A practitioner report describes prompting Claude Code to orchestrate an automated web recon workflow using tools like subfinder, waybackurls, httpx, masscan, naabu, and nuclei; the post claims it enabled subdomain enumeration, port scanning, endpoint mining, and surfacing potentially vulnerable URLs for common CVEs, as described in the Recon workflow post. This is a concrete example of “agent + CLI toolchain” lowering the labor needed for competent recon.
The post is anecdotal and not an eval; it’s still a clear misuse-ready workflow description tied to widely available tools.
US Senate passes DEFIANCE Act enabling civil suits over nonconsensual explicit deepfakes
DEFIANCE Act (US Senate): The U.S. Senate unanimously passed the bipartisan DEFIANCE Act on Jan 13, 2026, creating a federal civil cause of action so victims can sue creators, distributors, solicitors, and would-be distributors of nonconsensual sexually explicit “intimate digital forgeries,” as summarized in the Bill passage details and reiterated in the Second summary post. This is direct legal exposure for platforms and tooling ecosystems that host or facilitate generation/distribution.
The House vote is described as the next step, per the Second summary post.
Node.js ships a security release for a critical bug said to hit most production deployments
Node.js (Node.js project): A security release for Node.js fixing a “critical bug affecting virtually every production” deployment is being circulated via the Security release mention. The tweet doesn’t include the CVE identifier or affected versions, so downstream impact assessment depends on the upstream advisory.
This is the kind of issue that rapidly becomes an automated patching and fleet-compliance problem for orgs running Node at scale.
Synthetic video quality fuels claims that video verification is breaking down
Video verification (Workflow pattern): Creators are arguing that “video verification” (using a short video clip as proof of identity or authenticity) is becoming unreliable as generated video quality rises; the claim is framed as a continuation of image-model-driven failures of “verification photos,” per the Verification breakdown claim. This is being discussed as an operational trust issue ahead of elections and high-stakes online identity checks.

The tweet is rhetorical and doesn’t quantify error rates; it’s still a useful signal of where practitioners think abuse pressure is heading.
Grok image moderation robustness questioned after users claim bypasses
Grok (xAI): A moderation-robustness thread shows users mocking earlier claims that Grok image moderation couldn’t be “broken,” referencing a prompt-and-output example that appears to bypass sexual-content restrictions, as shown in the Moderation bypass screenshot. The thread is framed as “same thing with video verification” style pressure: once generation is good enough, policy enforcement becomes the bottleneck.
There’s no reproducible test or policy detail here; it’s a social signal that moderation bypass attempts are now part of routine evaluation by users.
Window-based membership inference claims better detection of fine-tune data leakage
Window-based membership inference (Research): A paper proposes a “Window-Based Comparison” attack that scans many small windows of text—rather than a single global score—to detect whether a snippet was in a private fine-tuning set; it reports materially higher detection at low false-positive rates across multiple datasets and models, as summarized in the Paper summary thread. This matters for teams shipping custom fine-tunes, where memorization can be localized and sparse.
The tweet-level summary emphasizes that window voting can expose scattered memorization signals that global averaging can hide, per the Paper summary thread.
BenchOverflow benchmark flags prompt patterns that trigger extreme over-generation
BenchOverflow (Research): A benchmark called BenchOverflow tests nine plain-text prompt patterns that push models toward excessive output (up to a fixed 5,000-token cap), describing this as an “Overflow” reliability and cost issue; it claims many patterns consistently drag outputs toward the cap and that a short conciseness reminder can reduce the longest cases, as described in the Overflow benchmark summary.
This frames output length control as a security-adjacent reliability feature (abuse-driven cost spikes) as well as a UX concern.
💼 Enterprise moves: hires, partnerships, and AI-native market disruption
Business posts today emphasize talent moves and enterprise partnerships, plus AI disrupting adjacent SaaS markets. Excludes infra capacity deals (covered in Infrastructure) and Gemini Personal Intelligence (feature).
OpenAI rehired Barret Zoph, Luke Metz, and Sam Schoenholz from Thinking Machines
OpenAI (Talent move): OpenAI is bringing back Barret Zoph, Luke Metz, and Sam Schoenholz, with reporting lines called out in a leadership post screenshot shared in Hiring post screenshot and additional context that all three had moved to Thinking Machines before returning, per Context on moves.
This reads as a “boomerang” signal in frontier-lab staffing—highly consequential for roadmap execution even without any disclosed product focus.
Airbnb hires ex-Llama lead Ahmad Al-Dahle; Sam Altman flags travel as AI opportunity
Airbnb (Airbnb): Airbnb brought on Ahmad Al‑Dahle (described as having led world-changing work at Meta), with Sam Altman framing travel/experiences as “furthest from AI” but potentially improved a lot by applying it, as noted in Altman comment. It’s a talent signal that consumer travel is moving from “AI as a feature” toward “AI as core product,” echoed by the Hugging Face note pointing readers to Airbnb’s Hugging Face presence via Airbnb org page.
No org-level scope, timeline, or specific product surface was described in the tweets.
ElevenLabs partners with Deutsche Telekom for AI voice agents in customer service
ElevenLabs voice agents (ElevenLabs): ElevenLabs announced a partnership with Deutsche Telekom to deploy realistic AI voice agents for telco customer service “via app and phone,” aiming for 24/7 availability and reduced waiting time, as stated in Partnership announcement.
The tweet frames this as an enterprise workflow rollout (not a demo), but does not include deployment dates, volumes, or SLAs.
Listen Labs: AI user-research automation passes 1M interviews, per Forbes screenshot
Listen Labs (User research automation): A circulated Forbes screenshot claims Listen Labs has run more than 1 million automated customer interviews and raised $69M, positioning it as an AI disruption of incumbents like Qualtrics/Medallia/SurveyMonkey, as summarized in Forbes screenshot.
The post’s emphasis is that “interviews scale” becomes a software problem; the screenshot provides the numeric hook (1M+ calls, $69M) but not methodological detail.
Perplexity partners with BlueMatrix to add entitled equity research to Enterprise
Perplexity Enterprise (Perplexity): Perplexity announced a partnership with BlueMatrix to bring entitled equity research into Perplexity Enterprise, positioning it as research firms retaining control while increasing buy-side visibility, as described in Partnership announcement with details in the Partnership page.

This is a distribution move: embedding paywalled sell-side research inside an AI research UI alongside real-time financial data, per Partnership announcement.
🎬 Generative media: creator stacks, motion control, upscaling, and “storyboards from images”
Generative media posts today are heavy on creator workflows (Kling motion control, storyboard tools, upscalers) and comparisons among image models. Excludes verification/policy items (covered in Security).
fal shares “Nano Banana Pro → Kling 2.6 Motion Control” dancing-animal workflow
Kling 2.6 Motion Control workflow (fal): fal posted a short creator pipeline for “viral dancing animal” clips: generate a starter image with Nano Banana Pro, pick a dancing reference video, then run both through Kling 2.6 Motion Control Standard, as shown in the workflow steps.

The core idea is a controllable motion-transfer loop (reference video + still) rather than pure text-to-video, which tends to matter for consistency when iterating on a character or mascot across multiple outputs.
Sora Pro shown generating product videos from a product grid in one shot
Sora Pro (OpenAI): A demo claims Sora Pro can generate a product video in a single pass when given a product shot grid, with “no editing needed” framing, as stated in the product grid demo.

If this workflow holds up beyond the clip, it implies a tighter bridge between e-commerce image pipelines (grids/contact sheets) and short-form motion outputs, reducing the number of intermediate creative steps needed for basic product video variations.
Freepik “Variations” turns one image into a multi-frame storyboard grid
Variations (Freepik): Freepik’s “Variations” tool is being shared as a way to drop in a single image and get back a coherent set of alternate frames suitable for storyboarding, with the workflow and example grid shown in the workflow demo.

This is adjacent to Story Panels but emphasizes breadth (many candidate frames) over a fixed narrative structure, which changes how teams might select shots before sending frames into a video generator.
Higgsfield pushes “last chance” 30-day unlimited access bundle for Kling models
Kling unlimited bundle (Higgsfield): Higgsfield is marketing a time-limited “unlimited for 30 days” offer covering Kling Motion Control plus multiple Kling model versions, positioned as a final window to lock in access, as stated in the promo announcement. The offer is framed as attached to annual plans, with separate posts describing 30 days of unlimited access for a Creator plan versus 7 days for an Ultimate plan, as described in the plan details.

This is a pricing-and-capacity signal more than a model update: it can spike short-term usage, and it also shifts how teams budget experimentation when the marginal cost of retries drops to near-zero for a month.
Runway ships Story Panels for 3-panel narratives from a single image
Story Panels (Runway): Runway introduced a Story Panels app that takes a single character or product image and generates a 3-panel narrative stack, positioned as a lightweight storyboard tool for creators, as shown in the product demo.

The output format is notable because it’s a constrained “storyboard primitive” (3 panels) rather than open-ended image generation, which can make it easier to drop into marketing and pre-production workflows without additional layout tooling.
AI upscalers highlighted as a practical path to remaster older films
AI upscaling (creator workflow): A practical use case resurfaced around AI upscalers improving perceived quality of older footage—specifically framed as making 1960s-era films more watchable in “stunning quality,” as shown in the upscaling example.

This sits in the “creator stack” bucket because it’s downstream of generation: teams often treat upscaling/restore as a finishing step that can be applied across libraries of existing media without regenerating the content.
🤖 Robotics & embodied AI: dexterity, training aids, and ecosystem mapping
Robotics posts today include ecosystem mapping and demos of dexterity/assistive systems; minimal overlap with model-release chatter. Excludes any medical robotics claims.
Dexterous robotic hands demo underscores manipulation as the hard core
Dexterous manipulation: A video demo of high-DOF robotic hands is framed as evidence that fine manipulation remains one of robotics’ hardest problems, even as general perception and planning improve, per the hands demo.

The post also points to industrial maturity signals—claiming “300 patents” held by the vendor behind the hands—per the hands demo.
Exoskeleton-guided finger training shows a new kind of human motor “speed hack”
Human-in-the-loop training hardware: A finger exoskeleton demo shows assisted high-speed keystrokes that “nudge” a pianist’s fingers faster than their baseline, aiming to push the user past a coordination plateau, as described in the exoskeleton demo.

The core idea is hardware-guided motion as a training signal—transfer the “speed setting” to the nervous system—framed as potentially generalizable to other coordination-limited skills in the exoskeleton demo.
Hybrid robotics framing: robots execute primitives, LLMs manage the loop
Robot + LLM division of labor: A “hybrid AI robotics” framing argues near-term robots will reliably do narrow primitives (single actions), while an LLM handles decomposition and iterative step-by-step guidance for multi-step chores, as laid out in the hybrid robotics take.
This view implicitly treats the LLM as a planner/controller that repeatedly re-evaluates state between actions, rather than expecting end-to-end autonomy on long-horizon household tasks—see the hybrid robotics take.
U.S. robotics landscape map surfaces a dense cluster of company logos
Robotics ecosystem mapping: A widely shared “Robotic Companies in the United States” map aggregates a large set of U.S.-HQ robotics firms into one visual (useful as a fast scan for partners, competitors, and hiring pools), as posted in the map screenshot.
The map is explicitly labeled as a November 2025 revision in the image itself, and it mixes categories (humanoids, warehouse robotics, autonomy, defense, drones), which makes it more of an ecosystem index than a taxonomy—see the map screenshot.
Humanoid form-factor debate resurfaces: “more human” vs classic robot look
Humanoid design trade-offs: A side-by-side post contrasts a sleek modern humanoid (marked “01”) against C-3PO, arguing robots don’t need to look like “C3PO” and suggesting more humanlike aesthetics might be preferable, as shown in the comparison images.
While not a technical control or policy change, this shows ongoing tension between functional/mechanical design constraints and human acceptance/expectations in consumer-facing embodied AI, per the comparison images.
🎓 Community, guides & events: practical agent education and meetups
Education and community distribution today includes MBA classroom experiments and multiple guides/talks focused on day-to-day agent usage. Excludes Gemini Personal Intelligence (feature).
MBA “vibefounding” class says teams shipped startups in four days with agents
Vibefounding (MBA class): An MBA experiment reports students launching a company in 4 days, with work that previously took a semester now happening in days; the class used a mix of Claude Code, Gemini, and ChatGPT, including non-coders shipping working products, according to the Class observations.
• What changed in practice: The instructor describes rapid iteration on product builds plus “weeks of” financials/research/pricing/positioning compressed into hours, as described in the Class observations.
• Human advantage remains: Industry/domain experience is framed as a strong edge because it helps pick problems with built-in markets, per the Class observations.
The thread frames the core bottleneck as teaching better “how to launch” frameworks under agent-first execution, as noted in the Class observations.
Agentic Coding Flywheel posts a TL;DR to reduce onboarding overload
Agentic Coding Flywheel (guide): A TL;DR page was posted to help people keep track of an expanding tool-and-workflow set; the author explicitly says the list was already out of date within a day due to more tools shipping, per the TLDR post.
It’s a “start here” onboarding artifact rather than a new tool release. It’s meant to reduce confusion.
• What it points to: The TL;DR lives on a dedicated page, as linked in the TLDR page.
• Motivation: The author cites user overwhelm at “all my tools,” as stated in the TLDR post.
Amp’s Next Token episode with DHH debates vibe coding and competence loss
Next Token (AmpCode): AmpCode published a Next Token episode featuring DHH, covering why “humans typed 95% of the code” for a project, concerns that vibe coding can drain competence, and a claimed $2M/year saved by leaving the cloud, as previewed in the Episode clip.

• Work allocation: The episode teaser emphasizes “95% of the code” being human-written for Fizzy, per the Episode clip.
• Skill retention: DHH is shown describing worry about “a trend line where over time I know less,” as captured in the Competence quote.
• Operational framing: Another excerpt frames AI as a good fit for low-quality bug bounty intake, per the Bug bounty clip.
The episode positions the risk as developer capability decay rather than code quality alone, as framed in the Competence quote.
LangChain posts decision guide for multi-agent architecture patterns
Multi-agent architecture patterns (LangChain): LangChain published a guide describing when teams move beyond a single agent and how to pick patterns; it explicitly contrasts subagents, skills, handoffs, and router approaches in the Architecture guide.
• Pattern menu: The post frames subagents as centralized orchestration, skills as on-demand capability loading, handoffs as sequential state transitions, and routers as parallel dispatch, as laid out in the Architecture guide.
• Benchmark claim: It also says the guide includes performance benchmarks and a decision framework, per the Architecture guide.
It reads as a “pick the smallest thing that works” document rather than a call to go multi-agent by default, as implied in the Architecture guide.
Cline launches biweekly “Agentic Exploration” livestream series
Agentic Exploration (Cline): Cline announced a biweekly developer livestream series focused on building with Cline; the first session features a Unity MCP server demo and live Q&A, per the Livestream announcement.
The format is positioned as release walkthroughs plus guest demos rather than a product keynote. It’s a recurring cadence.
• Guest demo: Ivan Murzak is slated to show connecting Cline to Unity via MCP, as described in the Livestream announcement.
• Timing: The post specifies “every other Thursday at 9am PT,” per the Livestream announcement.
Every’s AI & I episode argues LLMs shift the burden of pedagogy to users
AI & I (Every): Every published a long-form interview focused on using LLMs for learning—arguing general-purpose chat shifts “invisible teaching work” (structure, pacing, recaps) onto the learner and that agents still struggle to “read the room,” as summarized in the Episode rundown.

The post frames the gap as product design and pedagogy rather than model IQ. It’s a learning-workflow thesis.
It also includes timestamped segments covering a live demo of generating a course and a discussion of multi-format learning, per the Episode rundown.
Ralph Wiggum Loop podcast episode is shared on YouTube
Ralph Wiggum Loop (podcast): Geoffrey Huntley shared a DevInterrupted podcast link about “Inventing the Ralph Wiggum Loop,” with a YouTube episode link and a short clip, per the Podcast post.

The post frames it as a narrative and workflow deep-dive rather than a tool release. It’s a long-form artifact.
A direct pointer to the full recording is provided via the YouTube episode.
SF agentic hackathon finalist demos highlight long-running task reliability
Agentic Hackathon (SF demos): A judge recap highlights finalist demos centered on long-running agent reliability (memory, failure recovery, consistency), multi-source retrieval, and multimodal agents (voice/video/3D), with an invitation to attend the finalist demos in SF, as described in the Finalist demos invite.
The post frames these as “hard/important problems” rather than toy demos. It’s an ecosystem signal.
It also names upcoming talks (including Douglas Eck), per the Finalist demos invite.
GitHub schedules Copilot livestream building Space Invaders end-to-end
Copilot livestream (GitHub): GitHub announced a live stream where a host will create and deploy a Space Invaders game using GitHub Copilot and “the latest AI models,” as posted in the Stream announcement.
The tweet frames it as a practical build-and-deploy walkthrough, not a feature launch. It’s scheduled for Thursday morning PT, per the Stream announcement.
v0 schedules a Power Hour on building an agent with Relevance AI
Power Hour (v0): v0 announced a live session titled “Let’s Build an Agent with Relevance AI,” per the Event post.
The tweet is an event pointer rather than a product-change note. No agenda details were included beyond the title, as shown in the Event post.
🧑🏫 Developer culture: speed obsession, cost anxiety, and “same UI everywhere” effects
Culture discourse today clusters around agent cost/latency, workflow identity (vibe coding), and homogenization of UI/output as AI tooling spreads. Excludes Gemini Personal Intelligence (feature).
Founder claims nearly $1M/year agent spend is becoming normal
Agent cost anxiety: A solo builder says he’s spending 90% of income on LLM APIs and paid almost $1M in 2025 to run agent workloads, explicitly asking providers for startup programs to survive the burn, as described in the API spend claim.
The post reads less like pricing feedback and more like a warning about who gets to run always-on agents at current unit economics.
Claude Code budgets get vaporized in days
Claude Code (Anthropic): A reported internal rollout at a large tech company gave employees $100/month in Claude Code credits, but users “burn through it in 2–3 days,” raising doubts about scaling agentic work under current API pricing, as relayed in the Budget burn anecdote.
The thread doesn’t quantify tokens, but it does quantify the budgeting failure mode: fixed per-person allowances collapse under heavy agent usage.
Synthetic video fuels “verification is dead” anxiety
Media trust pressure: A widely shared take argues that image models already broke “verification” workflows and that video is now following, with explicit concern about election integrity, as asserted in the Verification anxiety.
The claim is directional rather than measured, but it reflects a real operational concern for platforms: what used to be “proof” artifacts are turning into low-signal inputs.
Waiting on agents becomes the dominant “work mode”
Agent latency culture: One founder frames his day as “prompt for 30m/day, then wait for 10h/day,” and asks LLM providers to prioritize 100× faster agents over smarter ones, per the Speed over intelligence quote.
This is a clean articulation of a shift many teams feel: iteration time (wall-clock) is starting to matter as much as token price.
“Vibe-coded replacement” memes push a ruthless-ops narrative
Vibe coding as ops ideology: A viral-style post claims “laid off 13 engineers… saved $48m/yr after i vibe coded the replacement in 19 minutes,” bundling layoffs, tool consolidation, and extreme ROI into a single story, as written in the Layoff and savings claim.
A follow-up quip frames it as a vendor revenue spike a year later, per the Vendor spike comment.
Even if hyperbolic, this kind of story is shaping how teams talk about build-vs-buy, internal tooling, and headcount.
AGI gets reframed as a unit-economics threshold
AGI definition (economics): A practical definition is proposed: AGI is “when it makes economic sense to run your agent 24/7,” with the framing and rationale laid out in the AGI definition post and expanded in the AGI essay.
This slots AGI talk directly into cost curves (compute, tooling, supervision), instead of capability benchmarks alone.
Teams start pricing speed as a first-class feature
Inference speed tradeoffs: A community prompt frames the emerging procurement question bluntly—would you pay 3× more for 4× output speed—explicitly citing GLM-4.7 via Cerebras as the real-world example in the Speed premium question.
This is less about any single provider and more about a new optimization target: minimizing “time-to-usable-output” even at higher per-token rates.
UI homogenization becomes a visible side effect of agentic coding
Interface sameness: A developer notes that with widespread AI coding tools, “every tech startup website looks the same… every academic website looks the same,” capturing a growing aesthetic/brand complaint about AI-assisted frontends, as stated in the UI sameness complaint.
It’s a culture signal: the cost of “default components + default prompts” is starting to be paid in product differentiation, not just code quality.