Nano Banana 2 hits $0.045 images and 4K – web-grounded Gemini rollout
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Google DeepMind rolled out Nano Banana 2 as gemini-3.1-flash-image-preview across Gemini app, AI Studio/Gemini API, and Vertex; positioning is “web-grounded” image gen/edit with real-time web info plus a new Image Search tool that pulls reference images into the loop; API pricing surfaces an explicit resolution ladder—~$0.045 (512px), ~$0.151 (4K)—to support draft→iterate→upscale without switching models. Early leaderboard chatter puts it #1 on Image Arena text-to-image at ~1280 and tied #1 single-image edit at 1407, but these are vote-driven signals, not a fixed eval suite.
• Ecosystem distribution: day-0 support lands on Replicate, fal, OpenRouter, ComfyUI; Vercel v0 routes it via AI Gateway with “pay with your own AI Wallet.”
• Anthropic vs DoW: Dario Amodei says no mass domestic surveillance or fully autonomous weapons; claims threats of “supply chain risk” labeling and Defense Production Act pressure.
What’s still unclear: Image Search retrieval constraints (sources, caching, reproducibility); “complex diagrams/storyboards” claims are demo-heavy, with no independent harness artifacts yet.
Top links today
- Amodei statement on Pentagon safeguards
- Claude Code auto-memory announcement
- Claude memory documentation
- Claude connectors on free plan
- Gemini 3.1 Flash Image in AI Studio
- Nano Banana 2 pricing details
- Perplexity embedding models announcement
- pplx-embed models on Hugging Face
- Codex code to Figma workflow demo
- Deep modules for agent-friendly codebases
- Firecrawl Rust PDF parser update
- vLLM 0.16.0 release notes
- Attention floating in masked diffusion models paper
- Artificial Analysis Image Arena comparisons
- Video Arena model leaderboard and comparisons
Feature Spotlight
Nano Banana 2 (Gemini 3.1 Flash Image): web-grounded image gen goes “production fast”
Google’s Nano Banana 2 pairs Flash-tier speed with Pro-ish quality and web+image grounding, pushing image generation from “demo” to repeatable production workflows via lower cost, better text rendering, and broad API/tool rollouts.
Cross-account, high-volume story: Google/Gemini/DeepMind roll out Nano Banana 2 (Gemini 3.1 Flash Image Preview) with web + image search grounding, new resolutions up to 4K, and aggressive pricing—plus rapid day-0 integrations across common builder surfaces.
Jump to Nano Banana 2 (Gemini 3.1 Flash Image): web-grounded image gen goes “production fast” topicsTable of Contents
🍌 Nano Banana 2 (Gemini 3.1 Flash Image): web-grounded image gen goes “production fast”
Cross-account, high-volume story: Google/Gemini/DeepMind roll out Nano Banana 2 (Gemini 3.1 Flash Image Preview) with web + image search grounding, new resolutions up to 4K, and aggressive pricing—plus rapid day-0 integrations across common builder surfaces.
Nano Banana 2 (Gemini 3.1 Flash Image Preview) ships broadly with web grounding
Nano Banana 2 (Google DeepMind): following up on Vertex sighting, Google and DeepMind announced and began rolling out Nano Banana 2, an image gen/edit model exposed to builders as Gemini 3.1 Flash Image Preview; it’s positioned as “Pro at the speed of Flash” and explicitly grounded with real-time web info in the launch posts from DeepMind announcement and Gemini app thread, with API availability called out as gemini-3.1-flash-image-preview in the API naming note.

The rollout is already visible in the Gemini app UI (including “Loading Nano Banana 2…”), as shown in Gemini app rollout screenshot.
• Surfaces: shared availability spans Gemini app plus developer surfaces (AI Studio/Gemini API, and Vertex/Cloud mentions) per API naming note and Capability rundown.
• On-device user flow: Gemini app also adds templates and style pickers around image generation, as shown in the Templates rollout post and the Style gallery screenshot.
Early positioning is consistent: web-grounded accuracy plus fast iteration loops, rather than a “slow best-possible” tier.
Nano Banana 2 adds 512px–4K outputs and a cheaper price ladder
Nano Banana 2 (Google): pricing surfaced clearly for the API model ID gemini-3.1-flash-image-preview, including a new low-cost 512px option and a 4K tier; one shared breakdown lists ~$0.045 (512px), ~$0.067 (1K), ~$0.101 (2K), and ~$0.151 (4K) per image in Resolution cost breakdown, matching the model card pricing screenshot in Pricing card.
A side-by-side price table also frames it as ~2× cheaper than Nano Banana Pro for common sizes, per Flash vs Pro pricing.
The practical implication for teams is that you can run “draft → iterate → upscale” loops with an explicit cost knob (512px) without switching models, while keeping a consistent API surface.
Nano Banana 2 adds an Image Search tool for generation grounded in real photos
Gemini 3.1 Flash Image Preview (Google): Nano Banana 2 can be grounded not only via web search, but also via a new Image Search tool that pulls real-world reference images into the generation/edit loop, as described in Tooling mention and shown directly in the AI Studio tools screenshot.
Builders are already sharing prompt patterns that treat “search” as a first-class step (e.g., “Use image search to find accurate images of X, then render a wallpaper”), with example outputs in Image search prompt pattern. This is a notable shift from “prompt only” image generation toward a retrieval-augmented image pipeline where the model is expected to cite visual reality.
The only detail that’s still fuzzy from tweets is the exact retrieval constraints (what sources, how cached, and how reproducible results are run-to-run).
Nano Banana 2 early workflows focus on complex layouts and consistent edits
Nano Banana 2 (early builder usage): practitioners are stress-testing it on tasks that historically broke fast image models—dense diagrams, long labeled layouts, and multi-scene consistency—with one recurring claim that it’s “the first model to handle really complex images and diagrams with some consistency,” per Complex prompt example.
Multi-panel storyboard generation is being marketed and demoed as a one-prompt workflow (with character consistency), as shown in Storyboard example.
• Complex text layouts: Mollick’s “complicated toasting” flowchart comparison emphasizes improved label correctness and instruction following in NB2, per Flowchart comparison.
• Multi-image / multi-object composition: posts claim higher subject consistency and “up to 14 objects/people combined,” per Claimed limits—and multiple examples show multi-input composition workflows rather than single-shot prompting, per Multi-input collage.
The dominant “feel” across posts is speed + typography + compositional reliability, not just photorealism.
Nano Banana 2 hits #1 in Image Arena text-to-image; ties #1 single-image edit
Image Arena results (Arena): Nano Banana 2 debuted at #1 in Text-to-Image with a reported score around 1279–1280, and it tied for #1 in Single-Image Edit with a score of 1407, per the benchmark thread in Arena leaderboard stats and the ranking table screenshot in Image Arena table.
A separate LM Arena leaderboard screenshot also shows gemini-3.1-flash-image-preview taking the top text-to-image slot with 1280 (2,965 votes), ahead of GPT Image 1.5, per LM Arena screenshot.
Text rendering shows up as the most repeated “why this matters” sub-signal, including claims of large gains over Nano Banana Pro in Arena’s subcategory breakdowns, as summarized in Subcategory deltas. Treat these as provisional: they’re leaderboard-driven, not a fixed eval suite, but they’re a real directional signal for production typography workflows.
Nano Banana 2 shows up day-0 across common builder platforms
Nano Banana 2 distribution (ecosystem): within hours of launch, multiple “builder surfaces” announced support—Replicate highlights speed, text rendering, and editing in Replicate launch, fal calls out day-0 availability in fal day-0 post, OpenRouter lists the model in chatroom/API in OpenRouter availability, and ComfyUI shows a working integration in ComfyUI demo.

A separate adoption signal is Vercel’s v0 playground being upgraded to NB2 through Vercel AI Gateway, including “pay with your own AI Wallet” billing mechanics, per Vercel playground details.
This is a concrete operational story: the model isn’t just in Google’s products; it’s immediately callable from the same places teams already use for prototyping and production routing.
🛡️ Anthropic vs. Department of War: contract guardrails, DPA threats, and “any lawful use”
Dario Amodei’s statement drives a major policy cycle: Anthropic says it won’t lift restrictions around mass domestic surveillance and fully autonomous weapons, while DoW-linked accounts threaten offboarding, “supply chain risk” labeling, and Defense Production Act pressure.
Amodei draws red lines on surveillance and autonomous weapons amid DoW contract pressure
Anthropic (Dario Amodei): Anthropic published a CEO statement describing an ongoing contract clash with the U.S. “Department of War,” saying the company won’t lift two use restrictions—mass domestic surveillance and fully autonomous weapons—even though Claude is already deployed for mission-critical national security work, as stated in the CEO statement and reiterated in the Statement excerpt.
The statement also discloses operational dependence (intel analysis, modeling/simulation, planning, cyber) and frames the red lines as both values and systems-safety constraints, with the refusal summarized by others in the TLDR summary. It commits to continuing service under those safeguards or helping a transition if offboarded, per the Highlighted refusal line.
Anthropic alleges DoW threatened “supply chain risk” label and Defense Production Act escalation
Anthropic vs DoW: Following up on Friday ultimatum (reported deadline), Anthropic’s statement says the DoW threatened two escalations if safeguards stayed: (1) offboarding + labeling Anthropic a “supply chain risk,” and (2) invoking the Defense Production Act to force safeguard removal, as shown in the Excerpt with DPA threat and echoed by the TLDR summary.
The statement highlights an internal contradiction—calling Anthropic a security risk while also implying Claude is essential to national security—captured in the Excerpt with DPA threat and discussed in the Quote screenshot.
DoW issues “any lawful use” ultimatum to Anthropic with termination threat
Department of War (Sean Parnell): A DoW-linked public statement argues the military should be constrained only by U.S. law—not Anthropic’s acceptable-use restrictions—and demands “any lawful use” access to Anthropic’s model, setting a Friday 5:01 PM ET deadline before terminating the partnership and labeling Anthropic a supply chain risk, per the DoW ultimatum.
The same statement denies interest in mass surveillance or human-out-of-the-loop weapons while still pushing removal of contractual stipulations, a tension that commenters immediately called out in replies like the Stipulation challenge.
Anthropic reportedly retreats from unilateral pause triggers in its Responsible Scaling Policy
Anthropic (RSP governance): Reporting shared today claims Anthropic is changing its Responsible Scaling Policy to no longer unilaterally pause frontier training when predefined safety guarantees can’t be met; instead it would delay only if it’s the clear leader, while committing to “Frontier Safety Roadmaps” and regular risk reports, as described in the Policy change report.
This was cited by observers as a relevant context marker while Anthropic is simultaneously holding firm on the DoW contract red lines, as noted in the Nobody’s perfect comment.
Anthropic’s autonomous-weapons stance sparks “reliability vs ethics” debate
Autonomous weapons framing: Anthropic’s statement language that frontier systems are “not reliable enough” for fully autonomous weapons triggered criticism that the company is making a capability-timing argument rather than a categorical “never” argument, as highlighted in the Reliability excerpt and stated bluntly in the Reply critique.
Others countered that this is Dario’s actual position—i.e., reliability is the binding constraint—and that the constraint could relax with future capability, per the Reliability defense.
“Not your weights, not your brain” becomes the shorthand for vendor leverage
Vendor control vs government demand: Community reaction framed the dispute as a reminder that access to frontier capability is gated by model ownership and enforcement surfaces—summed up in “Not your weights, not your brain,” per the Weights leverage quote.
The framing points at a practical procurement reality: absent on-prem weights or enforceable escrow/controls, “terms of use” and vendor kill-switches become part of operational planning.
Petition drive emerges urging employees at rival labs to back Anthropic’s red lines
AI lab workforce signal: A public call circulated asking OpenAI and Google employees to sign a letter supporting Anthropic’s refusal to relax guardrails for the DoW, as shown in the Employee petition call.
This reads as an attempt to turn a vendor–government contract dispute into a cross-lab norms fight, rather than a bilateral procurement negotiation.
🧠 Claude Code workflow upgrades: auto-memory, connectors on free, and rate-limit hotfixes
Today’s Claude Code chatter is dominated by workflow primitives (auto-memory via Memory.md/Claude.md), plan/access expansions (connectors on free), and an ops incident (prompt caching bug consuming limits faster, then hotfixed + rate limits reset).
Claude adds auto-memory that persists context across sessions
Claude (Anthropic): Claude now has an auto-memory capability that retains what it learns across sessions—project context, debugging patterns, and preferred approaches—so you don’t have to restate context every chat, as described in the rollout note Auto-memory announcement and echoed by Claude Code users Claude Code mention.

The implementation is file-based: the feature is framed as Claude updating a Memory.MD scratchpad it maintains, with additional details in the linked docs callout Docs pointer.
Claude Code rate limits reset after prompt-caching bug; fixed in 2.1.62
Claude Code (Anthropic): Anthropic says a prompt-caching bug caused usage limits to be consumed faster than normal; they’ve reset rate limits for all Claude Code users and shipped a hotfix in Claude Code 2.1.62, with the upgrade callout in the incident note Rate limit reset notice.
This is an ops-relevant reminder that caching regressions can masquerade as product throttling; the fix is version-gated, per the same post Rate limit reset notice.
Claude makes 150+ connectors available on the free plan
Claude (Anthropic): Connectors are now available on Claude’s free plan, with “150+ connectors across coding, data, design, finance, sales, and more,” according to the product update Free plan connectors note.
This widens the base of users who can test connector-grounded workflows before committing to paid tiers, as shown in the connectors directory view Connector gallery screenshot.
Claude.MD becomes instructions; Memory.MD becomes the model’s scratchpad
Claude Code workflow (Anthropic): The auto-memory rollout comes with a concrete convention: treat Claude.MD as durable instructions for how you want Claude to behave, and Memory.MD as a model-maintained scratchpad that it updates when asked to remember something, as spelled out in the guidance File semantics note. This turns “memory” into an auditable artifact (a file) rather than an opaque setting.
Teams adopting it are implicitly signing up for a new review surface: Memory.MD diffs become part of debugging what the agent “learned,” while Claude.MD becomes the stable contract.
Anthropic offers open-source maintainers 6 months of Claude Max 20x
Claude for Open Source (Anthropic): Anthropic is promoting a program offering open-source maintainers 6 months of free Claude Max “20x”, as announced via a widely shared repost Program repost and reinforced by employee commentary about giving back to OSS OSS feedback note.
Early signs of demand show up in the application confirmation screenshot shared by a user Application screenshot, suggesting a formal intake pipeline rather than ad hoc credits.
Claude Code 2.1.61 fixes Windows config writes and improves archiving
Claude Code (Anthropic): A point release, Claude Code 2.1.61, includes a Windows-specific fix for “concurrent writes corrupting config file,” per the changelog snippet Changelog excerpt, with additional prompt-level changes tracked by community release notes Release tracking.
• Session archiving: Archiving now supports targeting a specific session (not only current/default), as summarized in the prompt-change notes Archiving prompt change.
• Attribution output: Attribution data now shows Claude percentage and usage counts, per the same tracked diff Archiving prompt change.
Prompt caching regressions are common; harnesses need to be designed for it
Prompt caching (agent harnesses): Following the rate-limit incident, Anthropic’s Claude Code team frames prompt caching as a core primitive for agents and notes it can be “surprisingly easy to regress,” pointing to deeper design guidance in the same thread Caching note.
The practical implication is that caching should be treated like a reliability feature: observable, tested, and protected against accidental invalidation when prompts/tools/memory files change.
Claude usage reportedly grows 2.2× in 6 weeks to ~79M weekly visitors
Claude (Anthropic): A traffic snapshot claims Claude’s consumer users grew 2.2× in ~6 weeks, reaching ~79M weekly visitors, while remaining smaller than Gemini and ChatGPT; the comparison and growth-rate framing are in the post Traffic comparison. A follow-up clarifies these are visits (not unique users) and notes a small reporting discrepancy due to partial-week data Visits clarification.
This is a leadership/analytics signal that Claude’s “enterprise vs consumer” positioning is blurring in practice, even if distribution still lags the largest assistants.
Claude Code tip: Home/End jump to start/end of the current prompt
Claude Code (Anthropic): A small but practical CLI interaction tip: the Home and End keys move to the beginning/end of your entered prompt in Claude Code, as shared with a keyboard close-up Keyboard tip photo.
It’s a tiny reduction in friction for long prompts, especially when editing system-style instructions in the input buffer.
🧩 Codex shipping: CLI v0.105, Windows app invites, and code↔Figma round-tripping
OpenAI’s Codex ecosystem continues to harden around “agentic dev loops”: a CLI ergonomics jump (syntax highlighting, diff UX, approvals), early Windows desktop invites, and a code→design→code workflow with Figma in the loop.
Codex CLI v0.105 lands a big ergonomics upgrade for agentic dev loops
Codex CLI (OpenAI): The CLI jumped to v0.105 with in-terminal syntax highlighting, “hold spacebar to dictate” prompting, better multi-agent workflows, and tighter approvals controls, as listed in the Release notes.
Early users also call out the updated diff UX as “beautiful” and report it feels “very, very fast” in practice, per the Diff screenshot and UX reaction.
Codex and Figma push a code→design→code workflow
Codex ↔ Figma (OpenAI): OpenAI is pitching a round-trip loop where you generate design files from code, collaborate inside Figma, then implement updates back in Codex without context switching, as shown in the Roundtrip demo.

A follow-up link points to the supporting material in the same thread, per the Thread link.
First Codex for Windows waitlist invites go out
Codex app (OpenAI): OpenAI sent a first, small batch of Windows waitlist invites to alpha test the Codex desktop app, with plans to expand access as they iterate on feedback, according to the Windows invite email.
A second post confirms another invite batch went out (“some of you”), per the Follow-up invite note.
Codex automations: scheduled Slack + PR + meeting transcript loops
Codex automations (Workflow pattern): One practitioner describes using the Codex app to set up recurring automations—daily Slack scans for updates, hourly checks on open PRs to incorporate comments and ping re-review, and Google Meet transcript scanning—with outputs saved into an Obsidian vault, per the Automation prompt screenshot.
The notable detail is that this treats Codex as a scheduler + agent runner, not just an interactive coding assistant.
Codex CLI adds theme selection and custom tmTheme loading
Codex CLI (OpenAI): v0.105 adds a built-in /theme picker plus custom TextMate-compatible themes via ~/.codex/themes or a config.toml setting, as described in the Theme support thread.

This is a small change with real day-to-day impact for people living in Codex all day. It also suggests the CLI is being treated like a “real editor surface,” not a throwaway terminal wrapper.
GPT-5.3-Codex shows up in Code Arena for head-to-head webdev evals
Code Arena (LMArena): GPT-5.3-Codex is now available inside Code Arena for head-to-head agentic web development prompts and pairwise voting, as announced in the Arena availability note.
Separate community chatter frames GPT-5.3-Codex as a current “best agentic coding model,” though those claims vary by harness and benchmark, per the Benchmark screenshot.
🔎 Retrieval stack movement: new embedding families, PDF parsing, and agentic search RAG
Retrieval/news today is practical and builder-facing: Perplexity’s embedding releases for web-scale retrieval, faster PDF extraction for RAG ingestion, and “agentic search” patterns for structured querying with citations.
Perplexity launches pplx-embed embedding families aimed at web-scale retrieval
pplx-embed (Perplexity): Perplexity released two embedding model families—pplx-embed-v1 and pplx-embed-context-v1—positioned for “real-world, web-scale retrieval,” as announced in the embedding release and restated with availability details in the MIT + API availability.
• Variants and deployment: Both families ship in 0.6B and 4B parameter sizes via Perplexity’s API and on Hugging Face under MIT, per the MIT + API availability and the release recap.
• Efficiency claims (pages per GB): Perplexity claims the 4B INT8 variant matches or beats top MTEB Multilingual v2 retrievers while storing ~4× more pages/GB, and the binary variant stores ~32× more pages/GB, according to the efficiency claim and the release recap.
• Contextual retrieval: On ConTEB, Perplexity says pplx-embed-context-v1-4B (INT8) beats voyage-context-3 (79.45%) and Anthropic Contextual (72.4%), per the ConTEB result.
• Internal eval harness: They also cite internal web-scale benchmarks—PPLXQuery2Query and PPLXQuery2Doc—built from 115K real queries against ~30M docs drawn from 1B+ pages, as described in the internal benchmarks note.
Firecrawl swaps in a Rust PDF parser for faster, cleaner RAG ingestion
Firecrawl (Firecrawl): Firecrawl says PDF extraction is now 3× faster and “more accurate” after moving to a Rust-based parser, with three extraction modes—Fast, Auto, and OCR—as detailed in the parser announcement.

The point is operational: this is aimed at teams doing RAG ingestion from messy PDFs (papers, filings, regs), where parser latency and layout/OCR quality become the bottleneck before embeddings do—see the parser announcement for how they’re splitting speed vs quality.
Weaviate’s “legal RAG in 36 hours” shows agentic search with structured filters and citations
Legal RAG pattern (Weaviate): Weaviate describes building a legal RAG assistant in 36 hours, leaning on a Query Agent that treats the database as a tool: it inspects schema, constructs filtered queries, reranks, and returns cited answers—rather than relying on a single-shot semantic search, as outlined in the architecture write-up.
• Retrieval plumbing: Their example pipeline uses multivector document processing (they name ColQwen + Muvera compression) and splits data into three collections (commercial, corporate/IP, operational), per the architecture write-up.
• Agent behavior: The Query Agent runs in “Search mode” vs “Ask mode” and keeps answers grounded with source passages, as described in the architecture write-up.
ColBERTv2 outperforming larger dense retrievers reignites the multivector vs single-vector debate
IR model debate: A pointed claim resurfaced that ColBERTv2 (~100M params) can still outperform much larger single-vector dense retrievers (example given: Qwen3-Embed-8B), used to argue that “single-vector models hold IR back,” per the ColBERT critique.
The historical jab matters to retrieval engineers because it implies scaling embedding model size alone may not buy proportional gains—architectural choices (late interaction / multivector) can dominate—especially when you care about exact-match-ish signals and long documents. The thread emphasizes how cheaply ColBERTv2 was trained (“one dude… 4 A100s… 4 days”) in the ColBERT critique, with added context in the timeline comparison.
🦞 OpenClaw runtime updates: secrets management, ACP subagents, and websocket support
OpenClaw continues iterating as an agent runtime: external secrets management, thread-bound/first-class agents, and interoperability upgrades that let Codex/Claude Code act as subagents via ACP.
OpenClaw can run Codex and Claude Code as first-class subagents via ACP
OpenClaw (ACP interoperability): OpenClaw can now treat Codex and Claude Code as first-class subagents “via acp,” according to the ACP subagents callout, positioning OpenClaw as an orchestrator that can delegate chunks of work to other agent runtimes instead of doing everything in one loop.
• Why it matters for builders: This opens up a multi-agent topology where OpenClaw becomes the coordinator and hands off specialized tasks (repo edits, CLI-driven workflows) to Codex/Claude Code, as suggested by the ACP subagents callout, which is a different integration level than “just call another model.”
The tweets don’t include limits, required versions, or an example harness config, so treat the interface details as pending until docs/examples land.
OpenClaw beta adds external secrets management via `openclaw secrets`
OpenClaw (beta): The latest beta drop adds external secrets management, exposed as openclaw secrets, as called out in the Beta bits announcement, with additional setup details linked from the Secrets docs pointer. This is aimed at letting agents pull credentials from a dedicated secrets layer instead of hardcoding tokens into prompts, env files, or repo config.
• Operational impact: It creates a first-class place to route credentials for multi-agent workflows (especially when agents spawn tools and subagents), reducing the risk of secrets getting copied into logs or agent memory, as implied by the Beta bits announcement.
OpenClaw runtime adds CP thread-bound agents as first-class primitives
OpenClaw runtime (beta): OpenClaw now supports CP thread-bound agents as a “first-class runtime” concept, per the Beta bits announcement. The intent is tighter lifecycle binding between an agent and its compute/thread context, which can matter for long-running tasks, resource budgeting, and preventing cross-task state bleed in parallel work.
What’s still unclear from the tweets is the exact developer-facing API surface (config knobs, defaults, and how thread binding interacts with retries/failures).
OpenClaw adds websocket support for Codex integrations
OpenClaw ↔ Codex: The beta update adds websocket support “for codex,” as listed in the Beta bits announcement. For engineers wiring Codex into an agent harness, this typically signals more interactive, stream-friendly integrations (vs polling), which can improve responsiveness for UI or long-running tool sessions.
The tweet doesn’t specify whether this is a Codex app integration, a Codex CLI bridge, or a general websocket transport that Codex-compatible adapters can implement.
🧰 Cursor PR automation: Bugbot Autofix closes the loop from detection to patch
Cursor’s Bugbot moves from “find issues” to “fix issues,” aiming to reduce PR context switching by applying patches automatically when it flags a problem.
Cursor’s Bugbot Autofix can now fix PR issues it finds
Bugbot Autofix (Cursor): Cursor says Bugbot Autofix can now automatically apply patches for issues it detects in pull requests, moving Bugbot from “flagging” to “fixing,” as shown in the Autofix announcement.

A concrete workflow implication is less PR ping‑pong—one user notes “less context switching is very pleasant when working with a PR,” alongside a sketch of the review→fix loop in the Autofix workflow note.
• Loop closure: the product demo shows the bot finding an issue and then landing an automatic fix in-place, per the Autofix announcement.
• Day-one practitioner signal: the “less context switching” callout in the Autofix workflow note matches the intended outcome for teams doing high-churn PR iteration.
Cursor’s agent UX: onboarding and auto-recorded demos get singled out
Cursor (Product UX): Separate from Autofix itself, one thread calls out Cursor’s onboarding and auto-recording demos as standout UX choices for agent features, per the Onboarding praise.
It’s light on implementation detail in the tweets, but it’s a notable signal that teams value “proof artifacts” (recorded behavior) alongside code diffs when adopting agentic workflows.
📱 Agents go system-level: Samsung+Perplexity, Copilot Tasks, and Gemini action mode
Enterprise and device distribution is accelerating: Perplexity becomes a system-level assistant on Galaxy S26, Microsoft tests task-executing Copilot agents, and Gemini’s app-level actions appear in upcoming Pixel/Galaxy betas.
Samsung will ship Perplexity system-level on Galaxy S26 with “Hey Plex” wake word
Perplexity (Perplexity × Samsung): Samsung’s upcoming Galaxy S26 will ship with Perplexity built in at the OS level, including its own wake word “Hey Plex,” as announced in the launch post from partnership announcement; Perplexity claims this is the first time Samsung has granted system-level access to a non-Samsung/non-Google app, as stated in OS-level access claim.
• Assistant routing design: Perplexity says Samsung’s Bixby will handle on-device actions while routing “complex, web-based, or generative” queries to Perplexity APIs in the background on “800M devices in 2026,” per Bixby routing details.
• Distribution follow-ons: The same thread frames this as a broader partnership with Samsung Internet next, plus Perplexity offered as an optional default search engine, as described in Samsung Internet roadmap.
This is a concrete escalation in “multi-assistant” phones—distribution and default surfaces (wake word + OS permissions) become as strategic as model quality.
Gemini app action mode is teased for Pixel 10 and Galaxy S26 beta
Gemini app actions (Google): A Gemini app update is being teased where Gemini can take hands-on actions inside apps (shown booking a restaurant table end-to-end) as demonstrated in action-taking demo; the post frames it as a beta feature launching on Pixel 10 / Pixel 10 Pro and Galaxy S26, with unclear global vs US-only scope, per action-taking demo.

The described mechanism is “secure virtualized app control” (agent drives UI while the user does other things), which pushes Gemini closer to an OS-integrated operator model rather than a pure assistant.
Microsoft opens Copilot Tasks in research preview for multi-step agent workflows
Copilot Tasks (Microsoft): Microsoft is opening Copilot Tasks in a research preview for a small tester cohort, with a public waitlist, as shown in research preview rollout; the feature is positioned as a unified way to run multi-step work using Researcher and Analyst agents, per research preview rollout.

The capability set being described is “plan + act across apps” (docs, spreadsheets, calendars, browsing) rather than chat-only automation, echoing the broader move toward task-running UIs highlighted in capabilities recap.
🛰️ Long-horizon agent runners: Missions, multi-model orchestration, and persistent assistants
A cluster of runner/harness updates highlights the shift to long-lived execution: multi-day Missions in FactoryAI, plus persistent multi-surface assistants (Hermes Agent) and lightweight local agents (Ollama Pi).
FactoryAI Droids add multi-day “Missions” with terminal Mission Control and multi-model workers
Missions (FactoryAI): FactoryAI says its Droids can now pursue goals autonomously over multi-day horizons—you describe the goal, approve a plan, and return to finished work, as introduced in the Missions announcement. It ships with a terminal “Mission Control” view for tracking features, tools, and progress, as shown in the

.
• Runtime characteristics: FactoryAI reports internal + customer usage since mid-January, with a median Mission ~2 hours, 14% running longer than a day, and a longest run of 40 days, per the Runtime distribution.
• Architecture claims: Missions are described as natively multi-model (workers can mix providers) in the Multi-model note, and the orchestrator is said to capture reusable skills/patterns from your codebase over time in the Skills capture demo.
• Availability: Missions are stated to be available “now” for Enterprise and Max plans in the Availability post.
Nous Research releases Hermes Agent, a persistent open-source agent with multi-level memory
Hermes Agent (Nous Research): Nous Research’s Hermes Agent is being pitched as an open-source autonomous agent with multi-level persistent memory and dedicated machine access, spanning CLI and chat surfaces (Telegram/Slack/Discord/WhatsApp), as described in the Product overview. It’s positioned as an extensible Python agent framework with broad tool access and scheduled/background task support. Short version: it’s aiming at “keep running and remember” rather than one-off chat.

• Orchestration across agents: A shared screenshot shows Hermes spawning sub-instances via tmux and interacting across processes, as captured in the Tool spawning example.
• Docs signal: A DeepWiki overview page is being shared for structured onboarding into the repo architecture, per the DeepWiki overview.
Letta pattern: batch-run GitHub tasks, then resume locally with letta --conv and shared memory
Agent handoff workflow (Letta): A concrete pattern for long-running agent work is emerging around running an agent over a batch of GitHub tickets, then switching into an interactive local steering loop with letta --conv—keeping state/memory unified across both modes, as described in the Workflow example. This is a practical way to do asynchronous “runner” execution without giving up a tight interactive loop when something needs correction.
The screenshot in the Workflow example shows the agent completing a task and leaving a deterministic “resume this exact agent” handle (a conv-… ID), which is the key mechanic that makes the workflow viable.
Ollama adds Pi, a minimal coding agent you can extend from inside the agent
Pi (Ollama): Ollama says you can now start Pi, a “minimal coding agent,” via ollama launch pi, with hooks to customize it for your workflow, as announced in the Pi launch post. The notable twist is that Pi can be asked to write extensions for itself, with docs pointed to in the Docs pointer.

This reads like Ollama’s answer to a small, local-first agent runner—less of a full orchestration platform, more of a starting point you can modify.
🏗️ Compute buildout signals: hyperscaler capex curves and new mega-sites
Hard infrastructure shows up in two ways: direct construction progress and capex trendlines that frame how much “AI demand” is being turned into physical buildout.
Epoch AI pegs hyperscaler capex at ~70% annual growth since GPT-4
Hyperscaler capex (Epoch AI): Epoch AI says AI-driven hyperscaler capex has grown about 70% per year since GPT-4, reaching near half a trillion dollars in 2025, and notes a simple trend extrapolation would put Alphabet/Amazon/Meta/Microsoft/Oracle at roughly $770B in 2026, per the Capex extrapolation.
• How they measured it: Epoch says “capex” definitions vary on earnings calls, so they normalized by pulling from financial filings and aggregating cash spending + new finance leases using standardized tags, as described in the Measurement note.
This is a demand signal for training/inference capacity planning (power, datacenter slots, GPU supply) more than a vendor-specific product update.
First steel beams go up at OpenAI’s Stargate site in Milam County, Texas
Stargate buildout (OpenAI/SoftBank/SB Energy): Greg Brockman posts that the first steel beams went up at the Stargate site in Milam County, Texas, calling out the project partners and showing early vertical construction progress in the Construction photo update.
For infra watchers, this is a concrete “dirt-to-structure” milestone—evidence the large, multi-party compute build is moving past planning and grading into facility framing.
“Compute equals revenues” quote circulates as the inference scaling thesis
Compute economics narrative (NVIDIA): A clip of Jensen Huang stating “compute equals revenues” is being recirculated as a shorthand for the inference-era business model, as shown in the Quote clip.

The practical implication is directional rather than technical: the industry’s core KPI is increasingly framed as tokens-per-second monetization capacity, pushing capex and utilization stories into center stage.
🎬 Generative media (non-banana): fast video, SVG models, and creator tool updates
Outside the day’s dominant image-model story, generative media still moves: ultra-cheap video generation, new SVG/vector models, and incremental creator-platform updates.
Replicate launches P-video with fast 1080p pricing and a cheaper draft mode
P-video (Replicate/PrunaAI): Replicate announced P-video with pricing framed as “10¢ for 10 second video” and generation “done in <10 seconds,” plus “native audio,” as described in the Launch post.

• Draft mode economics: Replicate says the built-in draft mode is ~4× faster for rapid prompt iteration and costs ~$0.005/s, as detailed in the Launch post and reiterated in the Draft mode clip.
• Launch window: It was promoted as free for the first 24 hours, with the free cutoff timing spelled out in the Free window note.
Arrow 1.0 takes #1 on SVG Arena and crosses the 1500 Elo mark
Arrow 1.0 (QuiverAI): QuiverAI’s Arrow-1.0 is being cited as the new state of the art for SVG generation, with Design Arena reporting #1 on SVG Arena and an Elo of 1583, as referenced in the SOTA claim and the Milestone note.
• Benchmark milestone: A separate note calls out this as the first model to cross 1500+ Elo on DesignArena, per the Milestone note.
The tweets don’t include a public eval artifact beyond the reported Elo, so reproduction details aren’t visible here.
P-video debuts in Video Arena top-26 with mid-pack scores and EU lab framing
P-video (Video Arena): Arena reports P-video landing in the Video Arena top-26, positioning PrunaAI as the only EU-based foundational lab on the board and citing pricing at $0.04/second for 1080p, according to the Arena results.
• Leaderboard placements: Arena says it’s tied for #22 in Text-to-Video (1178) and sits top-26 in Image-to-Video (1199), as summarized in the Arena results.
Treat the result as early signal—Arena frames it as a “notable debut,” but the tweet doesn’t include a breakdown of prompts or failure modes.
Kling V3 Pro climbs into Video Arena’s image-to-video top 10
Kling V3 Pro (Video Arena): Arena reports Kling V3 Pro entering the top-10 for Image-to-Video, tied at #8 with a score of 1337, and cites a +52 point improvement over Kling 2.6 Pro, according to the Arena update.
The tweet doesn’t specify the prompt set or clips used for scoring, so the practical delta (motion consistency, temporal artifacts, controllability) isn’t visible from this source alone.
Meta’s VecGlypher targets editable SVG glyph generation from text or exemplar images
VecGlypher (Meta): Meta introduced VecGlypher, a method to generate “high-fidelity vector glyphs directly as editable SVG outlines,” supporting both text-referenced and image-referenced conditioning, as shown in the Paper figure.
The paper framing emphasizes typography workflows (wordmarks, contour outlines) rather than general SVG scene generation, so it’s more directly relevant to font/glyph pipelines than icon illustration.
Niji V7 adds moodboards and personalization, and removes web rooms
Niji V7 (Midjourney): Midjourney says it added Moodboards and Personalization to Niji V7, shipped “a much better web interface” for personalization, and is sunsetting web rooms while it works on next-gen collaboration tooling intended to make the site “noticeably faster,” per the Niji update.
No migration notes were included beyond the sunset callout, so teams using web rooms for collaboration will need to watch for whatever replaces it.
📊 Leaderboards & eval signals: search wins, agentic webdev splits, and cost-to-run indexes
Evaluation discourse is busy and fragmented: Arena leaderboards (Search, Code) drive model perception, while new breakdowns emphasize cost-to-run, token usage, and “real” agentic capability gaps beyond saturated benchmarks.
Artificial Analysis shows 3.6× spread in eval run-cost across top models
Artificial Analysis (Intelligence Index): New charts shared in the thread on cost to run the full eval suite show large variance—e.g., GPT-5.3 Codex (xhigh) at $1654 vs Claude Opus 4.6 (max) at $2486 and GPT-5.2 Codex (xhigh) at $3244, as shown in the Cost to run chart.
• Token burn perspective: A companion chart in the same post shows output tokens used dropping from 200M (GPT-5.2 Codex xhigh) to 77M (GPT-5.3 Codex xhigh), while Opus 4.6 (max) and Gemini 3.1 Pro Preview are shown near 58M and 57M respectively, per the Cost to run chart.
The takeaway for analysts is that “leaderboard position” is increasingly inseparable from how expensive it is to reproduce the score.
Martian’s Code Review Bench uses offline + online signals to reduce gaming
Code Review Bench (Martian): Martian is pitching an “uncheatable” code-review benchmark that pairs an offline standardized test with an online loop that measures whether developers actually fix issues a tool flags ("a fix is a vote"), as described in the Benchmark rationale and illustrated in the Online benchmark pipeline.
• Mismatch is the point: The write-up highlights disagreements like “CodeRabbit #1 online but #10 offline” and “Augment #1 offline but mid-pack online,” as summarized in the Benchmark rationale.
This is a concrete methodology signal: teams are treating code review as the next eval battleground now that SWE-Bench-style scores are saturating.
AA-Omniscience: GPT-5.3-Codex-xhigh flagged as higher hallucination-rate than 5.2
Artificial Analysis (AA-Omniscience): A shared AA-Omniscience plot shows GPT-5.3-Codex (xhigh) with an 87% hallucination rate on this metric, worse than GPT-5.2-Codex (xhigh) at 73%, with other models shown lower (e.g., GLM-5 at 34% and Gemini 3.1 Pro Preview at 50%) in the Hallucination rate chart.
This is a reminder that some “stronger” models can still regress on refusal/epistemic behavior depending on post-training and product/tooling defaults.
Claude Opus 4.6 takes #1 in Search Arena with a ~30-point lead
Search Arena (Arena): Claude Opus 4.6 is reported as the new #1 on Search Arena with a score of 1255, roughly +30 ahead of the next cluster (Grok-4.20-beta1, GPT-5.2, Gemini-3), while Sonnet 4.6 is noted around #7 in the same snapshot, according to the Search Arena leaderboard post.
This is another data point that “search” quality is being treated as a first-class eval surface (separate from pure QA and coding), but the tweets don’t clarify the harness details (tooling, browsing constraints, or citation requirements) behind this specific Arena slice.
BridgeBench results: Qwen 3.5 Flash stands out on completion-rate and latency
BridgeBench (bridgemindai): BridgeBench results for the Qwen 3.5 family are posted with multiple variants clustered high, while Qwen 3.5 Flash is singled out for 100% completion at 1847s latency and an overall score of 86.9, as shown in the BridgeBench table.
The framing in the thread is less “best raw score” and more “fastest reliable model,” which maps directly to production agent loops where retries and partial completions dominate cost.
Code Arena adds a Multi-File React leaderboard to measure cross-file agent skills
Code Arena (Arena): Arena says it has launched a dedicated Multi-File React leaderboard—moving beyond the earlier single-file HTML setup—to stress cross-file coordination, component architecture, dependency/state management, and build reliability, as described in the Multi-file React announcement.
Because many agent failures show up as “works in isolation, breaks in project context,” this leaderboard is explicitly trying to score the kind of integration work that’s hard to see in single-file prompts.
IBench vision eval: GPT-5.3-Codex reported at 90% with xhigh reasoning
IBench (visual reasoning eval): A chart circulated in the GPT-5.3 discussion shows gpt-5.3-codex (xhigh reasoning) at 90% and gpt-5.3-codex (medium reasoning) at 86%, with Gemini 3.1 Pro Preview shown at 69% and gpt-5.2-codex at 62%, per the IBench score chart and echoed in the IBench comparison.
This is being used as a “non-coding benchmark” datapoint for model quality; the tweets don’t include the underlying IBench artifact or task list, so treat it as directional unless you’ve validated the eval yourself.
prinzbench claims Anthropic search underperforms on “needle” research tasks
prinzbench (agentic web research subset): One benchmark author reports a narrow “Search subset” where Anthropic models score extremely low—Opus 4.6 at 1/24 and others at 0/24—compared with Gemini 3.1 Pro at 9/24, and says they view the result with suspicion in the Search subset report.
This is surfacing an important evaluation ambiguity: Arena-style “search” leaderboards can show strong performance while bespoke “needle-in-the-haystack” retrieval tasks can fail, depending on browsing tools, constraints, and what counts as success.
Token-cost sanity checks (“strawberry”) are being used as anti-benchmark-gaming probes
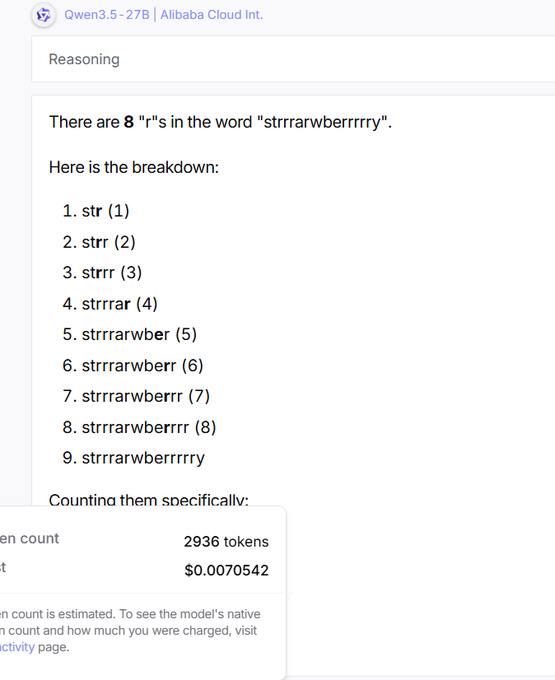
Benchmark hygiene: A thread argues that some high leaderboard scores mask inefficient or unreliable reasoning, using a “strawberry” letter-count test to compare token usage and failure rate—e.g., Qwen3.5-27B averaging 3725 tokens and getting it wrong 3/5, versus lower token counts for other models, as shown in the Token usage example.
This pattern shows up as a practical countermeasure: engineers are starting to track “cost to be correct” (tokens + retries), not just accuracy.
📚 ChatGPT app changes: file Library reuse and adult-language toggles
A small but concrete set of ChatGPT client changes surfaced: a persistent file Library for reuse across chats, and Android strings suggesting an age-gated ‘Naughty chats’ setting for adult-themed language.
ChatGPT adds a Library to reuse uploaded files across conversations
ChatGPT (OpenAI): The ChatGPT help docs now describe a Library feature that automatically saves files you upload (docs, spreadsheets, presentations, images) into a dedicated place so you can find and reuse them later, according to the Help center screenshot.
For AI engineers, the practical shift is that “upload once, reuse many times” becomes a native client behavior—useful for long-running projects that repeatedly reference the same artifacts, but it also changes expectations around file lifecycle and internal data governance (what persists beyond a single chat), as reflected in the Help center screenshot.
ChatGPT Android build references an 18+ “Naughty chats” setting for spicier language
ChatGPT Android (OpenAI): The Android app strings in v1.2026.055 mention a new “Naughty chats” toggle described as letting ChatGPT use “spicier, adult-themed language” when asked, available only to users 18+, as shown in the Settings screenshot.
One write-up frames it as an age-verification-gated setting that relaxes language tone constraints (without changing core capabilities) and suggests verification flows may be involved, per the Feature summary. For teams shipping products that embed or depend on ChatGPT client behavior, this is a concrete signal that “content controls” are becoming user-configurable knobs rather than a single global policy surface.
💼 Labor & burnout signals: AI layoffs, agent-monitoring fatigue, and “not coding” narratives
The discourse itself is the news today: large layoffs explicitly linked to AI-driven operating changes, and growing reports that supervising many parallel agents creates a new human bottleneck and cognitive debt.
Block cuts ~40% headcount; memo frames AI tooling as the catalyst
Block (Jack Dorsey): Block says it’s reducing the org from 10,000+ to just under 6,000 (about 4,000 roles) in a memo shared as the Jack memo screenshot; multiple posts characterize the rationale as “AI + smaller/flatter teams let us move faster,” echoing the quoted passage about “intelligence tools… enabling a new way of working” in the Dorsey quote excerpt.
• Market signal: commentary notes Block shares spiking after the announcement—one screenshot shows after-hours jumping (framed as markets “celebrating layoffs”) in the Stock reaction screenshot, while another post flags it as a potential inflection point for “AI headcount cuts” being treated as positive news in the Headline screenshot.
The tweets don’t provide a breakdown of which functions were cut; the concrete new information is the scale (nearly half) and the explicit “AI tools + smaller teams” framing.
Karpathy says the workflow shift is English-to-agents, not typing code
Agentic engineering (practice shift): Andrej Karpathy’s widely shared note argues programming changed abruptly “since December”—agents that “didn’t work before… basically work since,” now powering long tasks end-to-end and pushing developers into a manager/reviewer role, as captured in the Karpathy agentic shift quote.
The example he gives is a multi-step home infra build-out that previously would have taken a weekend but now runs in ~30 minutes with the agent doing tool use + debugging + write-up, per the Karpathy agentic shift screenshot.
Agent throughput is up; human monitoring load is becoming the constraint
Agent supervision fatigue: A thread describes “AI productivity psychosis” from running 10+ agent sessions in parallel—the work gets delegated, but the person becomes the bottleneck through constant monitoring, approvals, and context switching, as described in the Parallel sessions fatigue post.
It’s a concrete shift in failure mode: not “agents can’t do it,” but “humans can’t keep track,” with a call for better orchestration layers rather than more autonomous workers.
People are over-trusting models; failure is often “confidently wrong”
Overtrust / LLM psychosis: multiple posts warn about people treating frontier models as past basic mistakes—one calls the trend “very scary” in the Psychosis concern discussion, and another frames it as a dopamine/behavioral issue rather than intelligence in the Dopamine framing comment.
A concrete example is an arithmetic failure where the assistant answers incorrectly instead of calling a calculator tool, shown side-by-side with the correct result in the Math error example screenshot; the same author generalizes this as a recurring “LLM psychosis” pattern in the Mistakes still happen follow-up.
Refactoring shifts to directing agents; tests become the safety rail
AI-assisted refactoring workflow: Robert “Uncle Bob” Martin describes a mode where he feels he’s “programming more intensely than ever… just not coding,” in the Not coding post, then expands with concrete mechanics: aggressive refactors (“rip this system seven ways”) held stable by heavy tests in the Merciless refactoring thread.
• Mutation testing as a background task: he says mutation testing used to be too expensive, but now it’s “one more Claude agent working down a list,” as described in the Mutation testing with agents post.
• Parallel windows as control surface: he mentions keeping separate sessions for features, mutation testing, and “de-crapping,” while only spot-checking code and relying on the harness for confidence, per the Three sessions setup post and the Tests vs prod LOC follow-up.
Early AI adoption can induce a temporary intensity spike before realism returns
Adoption psychology: Ethan Mollick says that after people hit an “aha moment” with AI, they often enter a weeks-long anxiety/excitement spiral before they “see the jagged frontier again,” as described in the Aha moment spiral post.
The same thread argues the emotional spike doesn’t mean concerns are invalid—just that early exposure amplifies intensity—per the Policy implications note continuation.
📄 Research papers & mechanisms: uncertainty-aware RL, attention dynamics, and time-series reasoning
A mixed research slate spans agent learning stability, attention behavior in new model classes, and multimodal/time-series reasoning—mostly shared as “mechanism” explanations rather than product claims.
Attention Floating: masked diffusion models avoid autoregressive attention sinks
Attention Floating (THUNLP/OpenBMB paper): A mechanistic write-up argues masked diffusion models (MDMs) show “attention floating” (dynamic anchors across tokens/steps) vs autoregressive “attention sinks” (sticky early-token focus), with claimed robustness gains in noisy long-context settings per the Paper thread.
• Layer roles: the Paper thread describes shallow layers building a global structural scaffold while deeper layers shift to content-focused attention.
• RAG implication: they claim MDM attention patterns reduce positional bias and context-noise sensitivity, reporting up to ~2× improvements on knowledge-heavy / multi-hop tasks in their experiments as summarized in the Paper thread.
This is one of the few threads today that’s explicitly about why a model family behaves differently, not just that it scores higher.
SELAUR: Uncertainty-aware rewards for self-evolving LLM agents
SELAUR (paper): A new RL framework trains LLM agents by using token-level uncertainty (e.g., entropy) as a training signal—reshaping rewards around where the model is “guessing,” rather than only rewarding the final task outcome, as described in the Paper summary.
• Why it’s a mechanisms paper, not a product claim: the core idea is tighter credit assignment—learning from where an agent became uncertain (including in failures), which the Paper summary frames as improving stability and success rates on multi-step real-world tasks.
The tweet doesn’t include ablations or code links, so treat performance mentions as directional until you’ve read the full paper.
Team of Thoughts: orchestrator selectively calls specialist LMs for test-time scaling
Team of Thoughts (paper): Introduces an orchestrator that routes subtasks to different specialist models only when useful—positioned as a cheaper alternative to “N copies vote,” with headline results like 96.67% on AIME24 and 72.53% on Live-CodeBench reported in the Paper summary.
• Systems angle: the Paper summary frames the win as compute efficiency from heterogeneity (diverse blind spots) plus selective activation (don’t light up every model every step).
The tweet includes benchmark numbers but not cost curves; the paper will matter most if it reports real token/time savings at comparable accuracy.
Intelligent AI Delegation: a framework for accountable agent-to-agent task handoffs
Intelligent AI Delegation (Google DeepMind report): Proposes an adaptive delegation framework for agents/humans that treats handoffs as explicit transfers of authority and accountability—using mechanisms like reputation, monitoring, and verifiable task completion; the summary also mentions smart contracts and zk-SNARK-style verification as possible building blocks in delegation networks, per the Report summary.
• Why this lands now: the Report summary frames “delegation chains” as the scaling limiter for agentic systems—how to decompose work, select delegatees, and handle failures without losing traceability.
This is conceptual infrastructure; practical adoption depends on whether the report provides implementable protocol sketches or just design principles.
KairosVL: RL framework for semantic-conditional time-series reasoning
KairosVL (ByteDance + Tsinghua): Proposes a 2-stage RL training recipe to make models reason about time series in language-grounded ways—first learning “temporal primitives” (shape vocabulary like spikes/drops), then learning semantic-conditional reasoning that follows task instructions about the series, as outlined in the ArXiv page.
• What’s concretely different: the ArXiv page frames this as moving beyond treating sequences as raw numbers by explicitly training mapping from patterns → human-meaningful semantics under instruction.
The tweet positions it for “never seen before” generalization; details worth checking are the task setup and whether evaluation includes distribution shifts.
HEART benchmark: models score well on empathy but miss reframing and tone shifts
HEART (benchmark): A unified eval for emotional-support dialogue finds several frontier models reach or exceed average human ratings on perceived empathy, while humans still lead on adaptive reframing and nuanced tone shifts, as summarized in the Benchmark abstract.
• What’s operationally useful: the Benchmark abstract breaks performance into dimensions (alignment, responsiveness, attunement, resonance, task-following), which maps well to how support agents fail in production (right intent, wrong steer).
No model names/scores are shown in the tweet; the paper is the source of record for which systems were tested and how rater preference was collected.