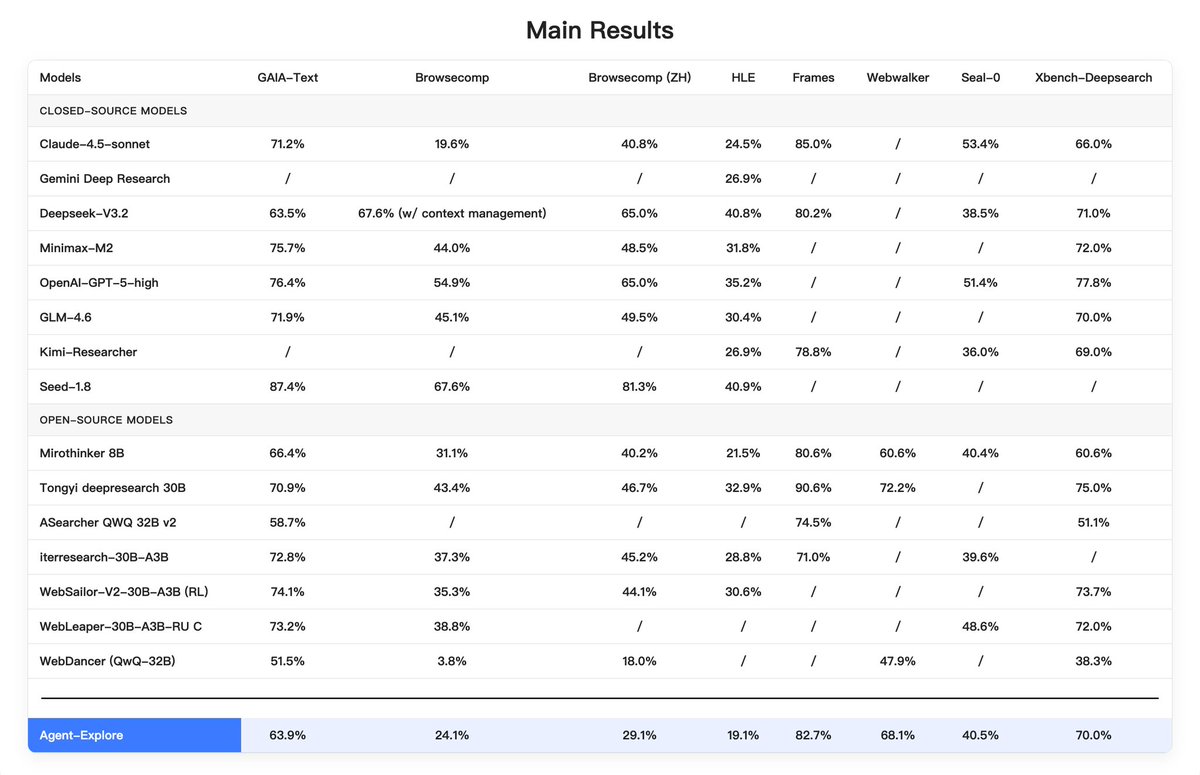
Anthropic Cowork research preview lands on macOS – $100+/mo, 1,293-file delete risk
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Anthropic shipped Cowork as a research preview inside the Claude macOS desktop app; it’s framed as “Claude Code for the rest of your work,” aimed at long-running knowledge tasks where “files are the shared state.” Cowork grants read/write access to a user-selected local folder; adds browser automation via “Claude in Chrome”; runs in an isolated VM (Simon Willison reports an Ubuntu VM using Apple’s Virtualization framework); the UI exposes Progress, Artifacts, and Context panels to make execution legible. Access is gated to Claude Max ($100+/mo+); preview constraints include macOS-only, no memory between sessions, and no cross-device sync.
• Anthropic/Agent risk surface: safety notes still call out prompt-injection while browsing and destructive file ops; a circulated screenshot shows “Done! All 1,293 screenshots have been deleted,” underscoring how confirmation/undo UX can dominate outcomes.
• Anthropic/Claude Code 2.1.6: patches a shell line-continuation permission bypass; adds /config search and allowedPrompts for scoped Bash permissions.
• OpenAI/Codex in prod: Datadog claims Codex review caught 22% of incidents they missed; OpenAI also published a 53‑minute “Getting started with Codex” tutorial.
The through-line is agents shifting from chat to artifact-driven desktops and CI loops; independent evals for Cowork’s reliability and failure modes aren’t published yet.
Top links today
- Claude Cowork research preview details
- OpenAI acquires Torch for ChatGPT Health
- Single-agent skills vs multi-agent paper
- What work is AI actually doing paper
- Vibe coding an Isabelle theorem prover paper
- Test-time training for long context paper
- Qualitative study of vibe coding paper
- Chain-of-sanitized-thoughts PII safety paper
- Hypergraph knowledge for scientific agents paper
- AlgBench algorithm understanding benchmark paper
- AT2PO tool-using agent RL paper
- BIS report on AI infrastructure investment
Feature Spotlight
Feature: Anthropic Cowork brings “Claude Code for the rest of your work” to the desktop
Cowork is Anthropic’s GUI “computer agent” built on Claude Code: folder-scoped file ops + browser automation in a sandboxed VM. It’s a concrete step toward mainstream, async agent workflows beyond coding.
High-volume cross-account story: Anthropic’s Cowork research preview turns Claude’s agent into a local, folder-scoped worker (files + browser automation) aimed at non-technical knowledge work. This category covers Cowork product details, UX, safety model, availability and early usage—excludes Claude Code CLI updates (covered elsewhere).
Jump to Feature: Anthropic Cowork brings “Claude Code for the rest of your work” to the desktop topicsTable of Contents
🖥️ Feature: Anthropic Cowork brings “Claude Code for the rest of your work” to the desktop
High-volume cross-account story: Anthropic’s Cowork research preview turns Claude’s agent into a local, folder-scoped worker (files + browser automation) aimed at non-technical knowledge work. This category covers Cowork product details, UX, safety model, availability and early usage—excludes Claude Code CLI updates (covered elsewhere).
Anthropic launches Claude Cowork research preview in the macOS desktop app
Cowork (Anthropic): Anthropic shipped Cowork as a research preview inside the Claude macOS app; it’s positioned as “Claude Code for the rest of your work,” targeting long-running, multi-step knowledge tasks for Claude Max subscribers (priced at $100+/mo, per the Pricing mention) and described in the official Product post.
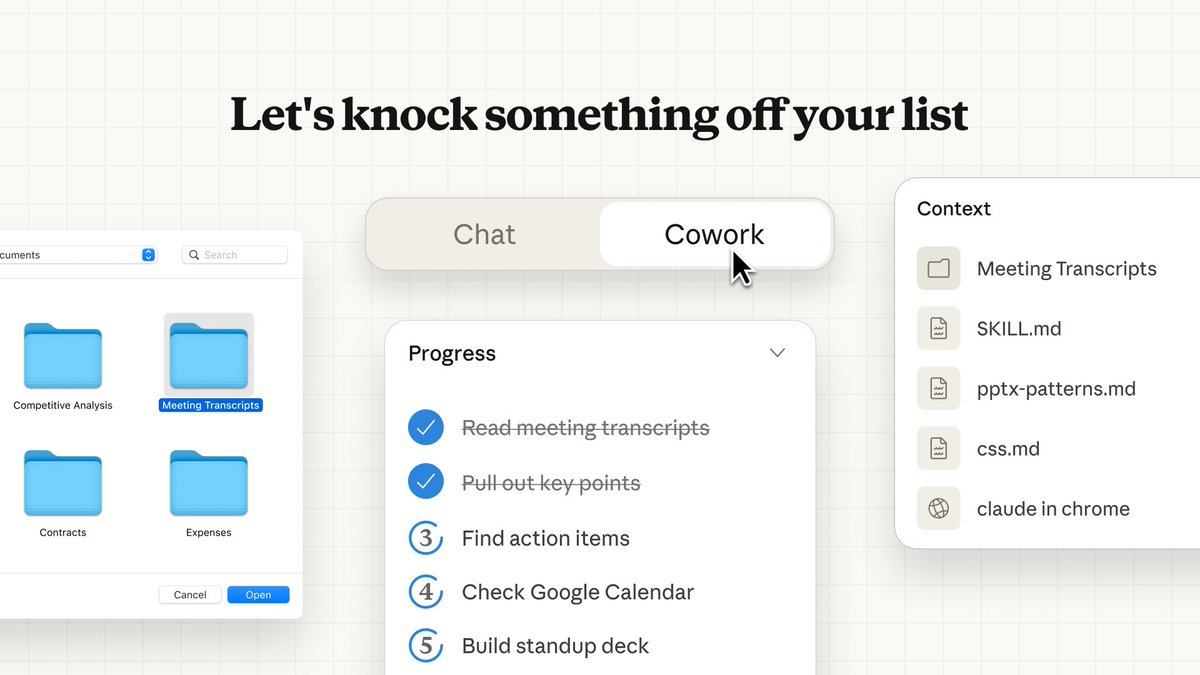
Cowork’s core interaction is “give Claude a folder, let it work,” as shown in the Launch thread and reinforced by the Max availability details announcement; initial demos emphasize file-heavy tasks like turning screenshots into a spreadsheet and drafting docs from notes.
Cowork runs tasks in an isolated VM rather than on the host directly
Cowork (Anthropic): Anthropic says Cowork includes a built-in VM for isolation, plus other safety UX, in the Safety and UX notes description of what shipped.
Independent reverse engineering aligns with this framing: Simon Willison reports Cowork is an Ubuntu VM using Apple’s Virtualization framework, based on inspection described in the Sandbox reverse engineering follow-up (with details linked in the Sandbox report gist).
Cowork safety caveats: prompt injection and destructive file actions remain
Cowork (Anthropic): Even with folder scoping and a VM, Cowork still raises classic agent risks—prompt injection during browsing and destructive file operations if instructions are ambiguous—called out explicitly in summaries like Risk summary and Risk recap.
A screenshot of a user issuing “delete every screenshot on my laptop” and Cowork responding “Done! All 1,293 screenshots have been deleted” in the Deletion example is a concrete illustration of why confirmations, review surfaces, and clear scoping matter in practice.
Cowork supports browser automation via “Claude in Chrome”
Cowork (Anthropic): Cowork ships with “out of the box support for browser automation,” and specifically integrates Claude in Chrome, as described in the Safety and UX notes launch note.
The connectors UI shown in the Connectors screenshot includes a Claude in Chrome toggle alongside other connectors, suggesting browser driving is treated as a first-class capability rather than an external hack.
Cowork’s permission model: folder-scoped read/write access on your machine
Cowork (Anthropic): Cowork’s core permission boundary is a user-selected local folder; Claude can read, edit, and create files inside that directory, according to the Launch thread and the focused walkthrough in the Folder access demo.

This makes “files as the shared state” the default interface—Cowork is explicitly framed around producing artifacts (spreadsheets, drafts, reorganized folders) rather than just chat output, as described in the Product post.
Cowork reportedly shipped in ~1.5 weeks, built “pretty much all” with Claude Code
Cowork (Anthropic): Multiple posts claim Cowork was built in “a week and a half”, and Anthropic staff/community relays say the implementation was “pretty much all Claude Code,” including the terse “All of it” reply captured in the All of it screenshot.

This is less a capability claim about Cowork itself and more an org-level signal about how quickly an agent-centric desktop surface can be iterated when the team is “orchestrating a fleet of Claudes,” as quoted in the Orchestrating Claudes quote.
Cowork ships macOS-only with major preview constraints (no memory, no sync)
Cowork (Anthropic): Cowork is currently macOS desktop only and described as “early and raw,” with constraints including no memory between sessions and tasks that “run locally and aren’t synced across devices,” as shown in the Cowork tab screenshot and spelled out in third-party summaries like Preview limitations.
Pricing/eligibility is gated to Claude Max today (noted as $100+/mo in the Pricing mention), with broader access implied but not yet scheduled in the tweets.
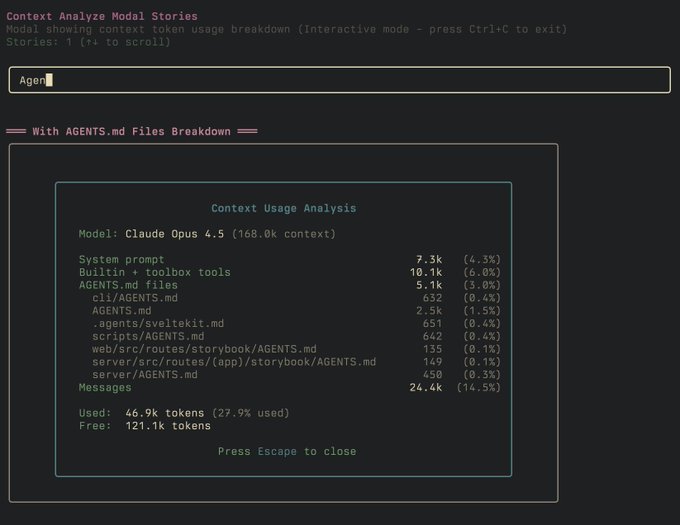
Cowork UI adds progress, artifacts, and context panels for long-running tasks
Cowork (Anthropic): Cowork surfaces long-running work as an explicit task flow with a right-rail UI: Progress (step tracking), Artifacts (outputs), and Context (tools/files in use), as visible in the Cowork UI screenshot and echoed in early walkthrough reactions like the Walkthrough notes.
This UI is one of the sharpest product-level differences vs. CLI-first agents: it’s designed to make “what the agent is doing” legible during execution, not just at the end.
Early Cowork usage focuses on “walk away” async work and artifact generation
Cowork (Anthropic): Early commentary frames Cowork as “not chat” but a walk-away async agent—“Ask your computer to do something. Walk away. Come back to results,” as stated in the Async framing demo.

Concrete early tasks in the tweets cluster around turning messy inputs into durable outputs: spreadsheets from screenshots and drafts from notes in the Launch thread, plus skill-backed document generation shown in the Lease review example.
Cowork sandbox details emerge from reverse engineering of the macOS app
Cowork (Anthropic): Simon Willison published first impressions and then dug into Cowork’s runtime, reporting it runs inside an Ubuntu VM (Apple Virtualization) and documenting observed environment details, based on the Sandbox reverse engineering thread.
More technical notes are linked via the Sandbox report gist, with additional broader impressions collected in the First impressions post.
⌨️ Claude Code (non-Cowork): CLI releases, desktop friction, and reliability
Covers Claude Code proper—CLI/desktop version bumps, permission model tweaks, outages and day-to-day DX. New today: the 2.1.6 changelog details and desktop permission/UX discussions; excludes Cowork release details (feature).
Claude Code 2.1.6 blocks a shell line-continuation permission bypass
Claude Code 2.1.6 (Anthropic): A security-sensitive fix landed to prevent a “permission bypass via shell line continuation” that could let blocked commands execute, as explicitly called out in the [2.1.6 changelog thread](t179|2.1.6 changelog thread). This is one of the clearer “fix now” items in today’s CLI release notes.
• What changed: The mitigation is described directly in the [release notes](t179|2.1.6 changelog thread), alongside other hardening-oriented tweaks (e.g., tightening command execution edge cases).
Claude Code 2.1.6 adds /config search, /doctor updates panel, and /stats date ranges
Claude Code 2.1.6 (Anthropic): The CLI shipped a dense grab-bag of usability and reliability tweaks—most notably /config search, a /doctor “Updates” section, and date-range cycling in /stats, as listed in the [2.1.6 changelog thread](t179|2.1.6 changelog thread) and reiterated in the [full changelog copy](t387|Full changelog copy).
• DX tweaks: Skills auto-discovery now crawls nested .claude/skills directories, and the status line can show remaining/used context percentages, as detailed in the [changelog thread](t179|2.1.6 changelog thread).
• Reliability fixes: The release also calls out fixes like orphaned MCP server processes from mcp list/get and terminal rendering glitches, as noted in the [changelog copy](t387|Full changelog copy).
Claude availability issue hits users; Anthropic staff says a fix is being implemented
Claude service reliability (Anthropic): Users reported Claude being unavailable in the middle of the day, as captured by the [downtime question](t135|Downtime question), and an Anthropic employee responded that a fix was identified and is being implemented, pointing to the [status page](link:216:0|Status page) in the [staff reply](t216|Staff reply).
This isn’t Claude Code-specific, but it directly affects Claude Code sessions in practice when the backend is degraded.
Claude Code 2.1.6 adds allowedPrompts for scoped Bash permissions when exiting Plan mode
Claude Code 2.1.6 (Anthropic): ExitPlanMode can now attach allowedPrompts, which pre-requests user-approved, semantically-scoped Bash permissions (e.g., “run tests”, “install dependencies”), as described in the [prompt change note](t599|Prompt change note) and reflected again in the [prompt changes recap](t689|Prompt changes recap).
A concrete artifact is linked via the [diff view](link:599:0|Diff view), but the tweets don’t yet show how this feels in day-to-day flows versus the existing per-command approval prompts.
Claude Code desktop users report “Allow once” prompt fatigue for frequent doc fetching
Claude Code desktop (Anthropic): Repeated permission prompts are becoming a noticeable workflow tax for people doing lots of doc/web fetching; one example shows a tight loop of “Allow once” dialogs even when the user intends aggressive search, as shown in the [permission prompt screenshot](t606|Permission prompt screenshot).
The thread implies demand for a more streamlined approval path (potentially a risky “skip” mode), but no shipped setting is shown in the tweets today.
Claude Code 2.1.5 adds CLAUDE_CODE_TMPDIR to override internal temp directory
Claude Code 2.1.5 (Anthropic): The CLI added CLAUDE_CODE_TMPDIR to override where internal temporary files are written—useful for constrained or nonstandard environments—per the [2.1.5 changelog snippet](t188|2.1.5 changelog snippet).
For the canonical source, the tweet points at the [GitHub changelog section](link:188:0|GitHub changelog section).
Minimal Claude Code status line gist shared for cwd/branch/diff/model/tokens
Claude Code CLI customization: A minimal status line template is being shared for quick-glance context—cwd, git branch, diff count, selected model, session time, context remaining, and input/output tokens—per the [status line description](t100|Status line description) with the actual snippet in the linked [gist file](link:385:0|Gist file).
🧰 OpenAI Codex: tutorials, tool-augmented coding, and code review outcomes
Codex-specific developments and enterprise engineering stories. New today: OpenAI’s long-form “use Codex effectively” tutorial plus multiple real-world code review and IDE-tooling integrations; excludes Cowork (feature) and non-Codex coding tools.
Datadog reports Codex caught 22% of incidents missed in initial review
Codex for code review (OpenAI/Datadog): Datadog published a case study claiming Codex system-level code review caught 22% of incidents that the team originally missed, as highlighted in the Datadog case study and described in the Case study.
This is an important “agent in CI/review” datapoint because it reports an outcome metric (22%), not just developer preference, though the tweet doesn’t include methodology details beyond the headline.
Skyscanner wires Codex into JetBrains via MCP to let the agent verify work
Codex + JetBrains MCP (Skyscanner/OpenAI): Skyscanner described a setup where Codex can use JetBrains tooling via MCP so it can verify changes using the same IDE capabilities engineers rely on, as summarized in the JetBrains MCP mention and detailed in the Integration blog post.
• Verification loop: The core claim is that giving Codex IDE-native tools shifts it from “write code” toward “prove it works” workflows, per the JetBrains MCP mention.
This is a single-org case study, but it’s one of the clearer public examples of MCP being used as a verification surface rather than a convenience integration.
OpenAI posts a 53‑minute “Getting started with Codex” tutorial
Codex (OpenAI): OpenAI posted a 53‑minute walkthrough focused on using Codex “effectively,” as flagged in the Tutorial announcement and available via the YouTube tutorial. It’s a concrete signal that OpenAI is trying to standardize “good Codex usage” patterns, not just ship model upgrades.
The tutorial itself is the artifact; the tweets don’t enumerate chapters, so treat it as a primary reference rather than a release note.
Codex is being used to split messy PRs into a few clean commits
Codex workflow (Practitioner): A practitioner reports pointing Codex at a messy PR and having it extract “the 3 fixes” into separate commits—“cleanly separates it. done.” as described in the Three-commit summary.
This is a concrete example of Codex being used as a change-set refactoring tool (history rewrite + commit hygiene), not just a code generator.
Voice-driven Codex prompts for CI fixes surface latency and UX friction
Codex workflow (Practitioner): A user shows a voice-driven interaction pattern (“codex fix ci”) and then calls out that Codex can be slow in this mode, with an “Interpreting the query (12s)” indicator shown in the Latency screenshot and the voice-driven setup referenced in the Voice prompt exchange.
The tweets don’t quantify end-to-end time-to-fix, but they do surface a real bottleneck: voice input is convenient, while model/tool latency (and mic quality) becomes the limiting factor.
🧑💻 Cursor agents: best practices, distribution, and “agents everywhere” workflows
Cursor-specific updates and operator tips. New today: Cursor’s agent best-practices material and multiple “run agents anywhere” workflow callouts (phone/CI/Linear), aimed at teams scaling agentic development.
Cursor adds “Agents from your phone” remote control workflow
Cursor Agents (Cursor): Cursor is promoting a workflow where you can start and monitor coding agents from a phone, positioned as a way to keep work moving when you’re away from your laptop, as described in the [mobile agents callout](t:337|mobile agents callout) and the broader [Cursor tips thread](t:183|Cursor tips thread); the public entry point is the Agents page.
This is a distribution move as much as a feature: it makes “agent runs” feel like a service you check in on, not a local IDE session.
Cursor agents can be run in CI on a cron schedule
Cursor Agents (Cursor): Cursor is also calling out a workflow of running agents in CI—specifically GitHub Actions on a cron schedule—so recurring engineering work can run unattended, according to the [CI cron note](t:368|CI cron note) and the [Cursor tips thread](t:183|Cursor tips thread).
This frames Cursor agents less like pair-programming and more like scheduled automation with a review step afterward.
Cursor can create PRs from Linear support issues
Linear-to-PR workflow (Cursor): Cursor is highlighting an integration pattern where a non-engineer can file a bug in Linear and Cursor “spins up an agent” to attempt a fix and open a PR, per the [Linear PR flow note](t:543|Linear PR flow note) and the original [Cursor tips thread](t:183|Cursor tips thread).
This is notable because it pushes agents upstream into support intake, not just implementation.
Cursor “debug mode” cycles with Shift+Tab for tricky bugs
Debugging workflow (Cursor): Cursor is pointing users at a “debug mode” for harder bugs, with mode cycling bound to Shift+Tab, as described in the [debug mode note](t:582|debug mode note) and referenced inside the [Cursor tips thread](t:183|Cursor tips thread).
The tweets don’t include a spec for what changes between modes, so treat it as a UX-level affordance rather than a clearly defined new runtime capability.
Cursor supports plan handoff to cloud so you can close your computer
Plan-to-cloud handoff (Cursor): Cursor is describing a workflow where you create a plan in Cursor and then hand it off “to cloud” so the run can continue after you close your computer, as stated in the [plan handoff note](t:496|plan handoff note) and in the umbrella [Cursor tips thread](t:183|Cursor tips thread).
What’s not yet clear from the tweets is what execution environment the cloud run uses (repo checkout, secrets, tests), or how results are synchronized back into the local workspace.
Cursor announces Stockholm office hours for live user questions
Cursor community (Cursor): Cursor is hosting in-person office hours in Stockholm, with a public RSVP link in the [Stockholm invite](t:333|Stockholm invite) and the event page at Event RSVP.
This reads like classic product adoption work: turning advanced agent workflows into something teams can ask questions about live.
Cursor schedules designer-focused Q&A and demo on agent workflows
Cursor community (Cursor): Cursor announced a Q&A and demo “for designers,” explicitly positioning agentic workflows as usable outside traditional SWE roles, per the [designer Q&A invite](t:111|designer Q&A invite).
This is a distribution signal: Cursor is going after non-engineer constituencies as first-class users of agents, not only code completion.
🧯 OpenCode: security advisory, hardening changes, and ops notes
OpenCode-specific news with a heavy emphasis today on a concrete security incident and remediation details. This is tool-level security/ops for a coding assistant—not general AI safety.
OpenCode patches ?url localhost injection that could run terminal commands
OpenCode (OpenCode): The project disclosed and patched a security issue where the web frontend’s ?url= parameter could be abused to point localhost at a malicious server that returned a fake session containing markdown with inline scripts—leading to command execution through terminal APIs, as described in the [security advisory writeup](t:36|security advisory).
They say they remote-patched out the ?url= parameter on Friday, but still recommend updating for additional hardening called out in the same [incident report](t:36|incident report) and the linked [full advisory](link:36:0|full advisory): the server won’t start without explicit flags; the frontend now ships CSP headers to block inline scripts; and users get warnings if they opt into the server without setting OPENCODE_SERVER_PASSWORD.
OpenCode flags upstream Opus 4.5 issues affecting Zen users
OpenCode (OpenCode): OpenCode’s team reported upstream issues with Claude Opus 4.5 that are impacting “Zen” users, and pointed people to Anthropic’s status page for live tracking in the [ops note](t:123|ops note) linking to [Claude Status](link:123:0|Claude status).
This reads as an availability/dependency issue rather than an OpenCode regression; the only concrete instruction shared is to monitor the upstream status updates, per the [status link](t:123|status link).
🧩 Coding workflows in the agent era: compaction hygiene, refactor anxiety, and loop design
Reusable engineering patterns for working with agents (not tied to a single product). New today: concrete advice on context resets, maintainability tradeoffs under fast agent output, and iterative spec refinement loops.
Frontend work stays harder for agents without browser-side feedback
Frontend feedback loop: The “frontend is harder than backend” framing shows up again, with the core diagnosis being that the agent is “flying blind” unless it can actually run and inspect behavior in a real browser environment, as argued in the Browser feedback gap.

This isn’t about model IQ. It’s about observability and verification loops.
When to start a fresh agent conversation vs continue the same one
Workflow hygiene: A concrete rule-of-thumb is circulating for keeping agents from drifting: start a new conversation when you switch tasks/features or when the agent starts looping/confusing itself, and keep the thread only when you’re iterating on the same unit of work, as summarized in the Start fresh guidance.
This is mainly about keeping context small and intention clear. It’s also a lightweight “compaction hygiene” move that doesn’t depend on any specific tool, even though the screenshot comes from Cursor’s docs in the Start fresh guidance.
Agent speed increases pressure to ship code you wouldn’t accept before
Maintainability tension: One engineer describes a familiar failure mode of agent-accelerated dev: tests pass and UI looks fine, but the resulting code is “not quite right” (variable sprawl, poor naming, hard to comprehend), forcing a choice between shipping and paying down debt later, as described in the Maintainability worry.
The key shift is that the cost to produce “working but messy” code drops fast. The incentive gradient changes.
Automated Plan Reviser Pro automates repeated spec revision rounds
Automated Plan Reviser Pro (apr): A new ~5,600-line bash tool automates the repeated “revise the plan/spec” cycle—generating templates via a wizard, submitting to GPT Pro via an automation helper, tracking diffs/stats, and exposing a machine-friendly mode intended for other agents, as described in the apr release note.
The point is to turn high-friction iterative planning into a runnable loop, with observability (diffs/convergence) and an audit trail.
Context resets as a reliability primitive for long workflows
Structured conversations: A voice-agent reliability pattern is getting articulated as “reset the context on purpose at milestones,” swapping system instructions and summarizing (or dropping) history to avoid context rot, as laid out in the Structured conversations note.
The claim is that throwing away old context is not a hack. It’s the design that makes longer tool-calling workflows stable.
Spec refinement as a repeated diff-and-integrate loop
Plan/spec iteration: A detailed workflow is described for doing repeated spec revisions: run GPT Pro with extended reasoning to propose architecture changes plus git-diff style edits, then feed that output into Claude Code to integrate changes and harmonize adjacent docs, repeating for 15–20 rounds as described in the Spec iteration workflow.
The practical insight is that high-iteration planning starts to look like an optimizer: early swings, then smaller deltas. It’s also explicitly sensitive to compaction—“if it compacted, reread everything”—per the Spec iteration workflow.
Vibe coding study finds debugging feels random; mitigations look like classic hygiene
Vibe coding (research): A qualitative study of vibe-coding sessions reports a spectrum from “never read the code” to heavy inspection; across that range, debugging is described as “rolling the dice” because the same prompt can fix one thing and break another, as summarized in the Vibe coding paper thread.
• What helped in practice: The authors saw people lean on small changes, undo/rollback, version control, and simple tests, as noted in the Vibe coding paper thread.
It’s an empirical argument for treating agent output as probabilistic and designing tight feedback loops.
Agents work better when you define the feedback loop first
Loop design: A short but crisp heuristic: before delegating a build task, figure out what the feedback loop is (tests, linters, screenshots, benchmarks, user checks), as framed in the Feedback loop reminder.
This is a reminder that “agent output” is cheap; verification is the constraint.
🧱 Plugins & skills for coding agents: skill packs, Ralph tooling, and installables
Installable extensions and skill libraries that extend coding agents. New today: multiple “skills” artifacts (Cursor Agent Skills, /rams install growth, Ralph CLIs) used as reusable building blocks.
Cursor surfaces Agent Skills compatible with Claude-style .claude/skills conventions
Agent Skills (Cursor): Cursor is now shipping Agent Skills and the community is calling out that they’re compatible with Claude-style .claude/skills layouts, which makes skills portable across agent harnesses rather than locked to one IDE, as noted in Skills compatibility note and echoed in Skills mention.
This mostly matters because it turns “skills” into a reusable artifact that can move with teams (and repos) even when the execution surface changes.
Ralph CLI repo ships PRD→plan→build loop across Codex, Claude and Droid
Ralph CLI (Community): A new ralph CLI implementation is making the rounds that generates a PRD, turns it into a plan, then runs ralph build; it explicitly targets multi-model use (Codex, Claude, Droid) as described in Ralph CLI overview, with the code linked in the accompanying GitHub repo.
This is a concrete “agent loop as a installable CLI” pattern, not an IDE feature—useful for teams standardizing automation around git repos.
/rams design-engineer skill nears 500 installs across Claude Code, Cursor and OpenCode
/rams (Skill pack): The /rams “design engineer” skill—pitched as a code reviewer focused on accessibility, visual consistency, and UI polish for Claude Code/Cursor/OpenCode—was reported as approaching 500 installs, per the install screenshot in Install count screenshot.
The signal here is adoption: “UI polish as a reusable skill” is becoming something teams install, not just a prompt style.
agents.md cleanup and rebuild threads pick up as models shift and prompt configs rot
agents.md (Prompt configuration hygiene): People are explicitly talking about rebuilding or pruning their AGENTS.md / agent instruction files as model behavior changes, with the “models are smarter; time to prune or rebuild” sentiment captured in Prompt file pruning and longer reflections on agents.md practice linked in Agents md post.
This is a workflow signal: teams are treating prompt/config files as living infrastructure, not one-time setup.
Minimal cursor-ralph-wiggum starter repo shared for fast Ralph adoption
cursor-ralph-wiggum (Community): A minimal starter repo meant to bootstrap Ralph-style workflows inside Cursor was published, described as a “3 files” template in Starter repo note, with code in the linked GitHub repo.
The point is packaging: people are converging on tiny, forkable repos as the distribution unit for agent harness defaults.
“Ralph” backronym meme spreads as teams try to ‘enterprise-ify’ agent loops
Ralph (Naming pressure): The “Ralph” backronym—“Relentless Agentic Looping Programming Helper”—is spreading as a joke about getting agent tooling past enterprise buying norms, per Backronym post.
It’s lightweight, but it reflects a real friction: packaging and naming are becoming part of agent-tool adoption.
🕸️ Running agents as systems: background agents, memory layers, and multi-session ops
Harnesses and operational patterns for running many agents (beyond writing code). New today: background agent recipes, semantic-memory add-ons, and browser/cloud agent running patterns—excludes Cowork (feature).
Letta EA workflow: Yelp lookup + iMessage outreach + calendar booking (and Yelp paywall)
Letta EA agent workflow (Letta): A personal assistant flow is shown doing service discovery and booking end-to-end—Yelp search via Browser Use, texting businesses, and calendar scheduling—framed as “Day 3 of training my EA” in the [workflow demo](t:398|EA workflow demo).

• Skill packaging: The author points to a published “yelp search + iMessage skill” implementation, linked from the [skill PR](link:765:0|GitHub PR) and referenced in skills link.
• Data access friction: The same workflow hits a common real-world constraint: Yelp review access is paywalled unless you pay $229/month, as stated in Yelp paywall complaint.
This is a useful reminder that agent reliability is often gated by permissions and business models, not reasoning quality.
Letta shares a background agent recipe: sandbox + bash tools + GitHub token secrets
Letta (Letta): A concrete “background coding agent” setup is being shared that relies on an agent API plus a code sandbox (with bash/tools) and a GitHub token stored in agent secrets, so the agent can run unattended and still open PRs—see the [demo clip](t:609|agent creation demo) for the minimal ingredients.

The pattern is notable because it’s not a new model capability—it’s operational glue: a long-running worker with credentials and an execution environment, wired up as a service endpoint rather than a chat session, as described in agent creation demo.
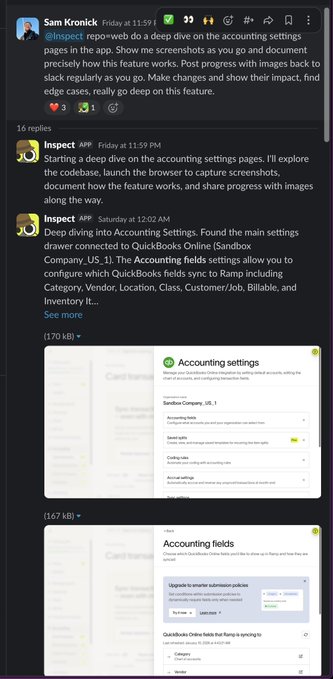
Ramp says its internal background agent wrote 30% of merged code this week
Inspect (Ramp): A Ramp team member highlights their internal “background coding agent” and claims it authored 30% of merged code in a week, framing the core differentiator as having the same context and tools as engineers for closed-loop verification, as shown in the [article screenshot](t:380|background agent post).
The post excerpt in background agent post also frames the adoption barrier as internal review and permissions (hooking into company systems) rather than model capability alone.
“Happy” mobile client enables remote Codex/Claude Code sessions with E2E encryption
Happy (third-party mobile client): A mobile client described as a “Codex and Claude Code mobile client” is being recommended for working from your phone while connected to a desktop session, with claims of end-to-end encryption and on-device account storage in the [app screenshot](t:272|mobile client screenshot).
The pitch in mobile client screenshot is operational: keep a long-lived agent session running at home while interacting comfortably on mobile, instead of relying on terminal emulators.
Clawd adds semantic-search memory via remote embedding indexing
Clawd app (Clawdbot ecosystem): Clawd is adding a semantic-search memory layer that indexes “memory files” with a remote embedding system and exposes a memory_search function—confirmed as “coming later in today’s update” in memory search screenshot.
The screenshot in memory search screenshot shows retrieving older notes by meaning (not keywords), which is the practical step from “chat history” to “operator memory” for long-running personal agents.
KiloCode publishes a retrospective on Cloud Agents (browser sessions that sync to CLI/IDE)
Cloud Agents (KiloCode): Following up on Cloud Agents (browser-run agent sessions), KiloCode is now sharing a builder retrospective explaining why the feature exists: run Kilo from any browser with no local setup, then sync the same sessions back into the CLI/IDE when ready, as stated in retrospective note and linked via the write-up.
This is still mostly about deployment ergonomics—where the agent runs, how state travels—rather than new model behavior.
Prediction Arena allocates $10K to each model for long-running market agents with memory
Prediction Arena (Design Arena-style harness): A new live evaluation setup gives five frontier models $10K each to place real Kalshi bets; agents get web search plus a persistent memory system, and they’re prompted every 20 minutes to act or hold, as described in launch thread with the live view in the [dashboard](link:89:0|live dashboard).
Even if you ignore the “which model wins” angle, this is a concrete public example of agent scheduling + state + tool access being treated as the product surface, not just the underlying LLM.
OpenRouter SDK pattern: stream responses while saving full text out-of-band
OpenRouter SDK (OpenRouter): A reference implementation shows how to consume one model call in two modes—stream chunks to the client while separately awaiting the full text to store in a DB—using getTextStream() plus getText(), as shown in the [code screenshot](t:456|dual-consumption snippet).
This is the kind of small plumbing that makes agent services feel “production-shaped” (streaming UX plus durable logs) rather than chat-shaped.
OpenRouter SDK tip: tools can emit custom events for agent UX (e.g., progress indicators)
OpenRouter SDK (OpenRouter): A practical agent-ops pattern is being pushed: define tools that emit custom events so you can drive UI feedback like “web search progress indicators,” as described in custom events tip with supporting API details in the [tools documentation](link:757:0|tools docs).
The value here is observability-by-default: you can surface progress and intermediate state without scraping the model’s text stream.
Pipecat Flows promotes context resets as a reliability primitive for voice agents
Pipecat Flows (Pipecat): A structured-conversation pattern is being highlighted: reset the LLM context at specific workflow milestones (swap system prompt; summarize or drop history) so multi-step voice workflows stay stable, as explained in structured conversations note and linked via the [Pipecat Flows repo](link:823:1|GitHub repo).
This matches how long-running agents are increasingly engineered: explicit state transitions instead of “one forever thread.”
📊 Benchmarks & measurement: markets, adoption metrics, and eval arenas
How the ecosystem is measuring models/agents. New today: live prediction-market evaluation, new adoption normalization metric, and multiple arena-style comparisons.
Prediction Arena gives five frontier models $10K each to trade live on Kalshi
Prediction Arena (PredictionArena.ai): A new live eval pits five frontier models against each other by giving each $10,000 to place real-money prediction bets on Kalshi, with a new decision window roughly every 20 minutes—and the agents can also choose to hold, research, or update notes, as described in the methodology thread and the linked live dashboard.
• Harness details: Each model gets live market context (prices, portfolio, past reasoning/positions) plus web search and a persistent memory layer, according to the methodology thread.
It’s explicitly framing “sustained profitability” as the metric for real-time, real-world reasoning, per the same methodology thread.
Adobe analysis finds 5% of tasks drive 59% of observed LLM usage
AI task adoption study (Adobe): A new paper claims usage is highly concentrated—5% of tasks account for 59% of interactions—by mapping Anthropic Economic Index chats to O*NET tasks and scoring task traits (cognitive, creativity, routineness, etc.), as described in the paper summary.
• Clustering claim: The write-up argues adoption rises for complex, idea-generation and synthesis tasks, and falls for routine steps and social-intelligence-heavy work, per the paper summary.
This is positioned as a measurement lens for “what work is AI actually doing,” rather than a benchmark of model capability, in the paper summary.
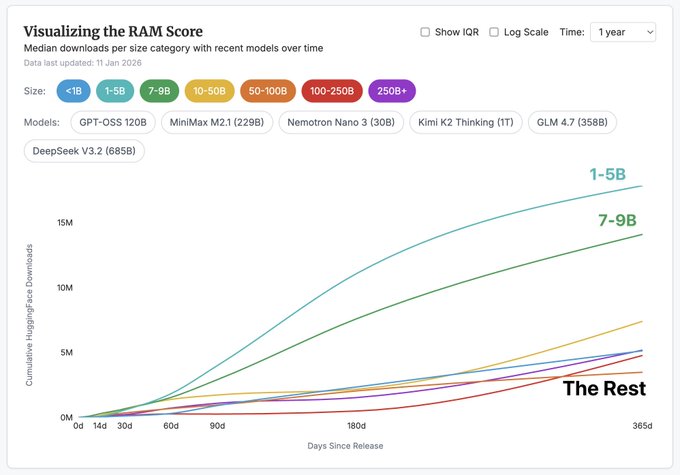
Interconnects introduces RAM Score to normalize Hugging Face model adoption
Relative Adoption Metric (Interconnects / ATOM Project): A new “RAM Score” reframes Hugging Face downloads by comparing each model to the median top-10 within its size bucket, aiming to spot “ecosystem-defining” releases inside 30–90 days, as explained in the metric rationale and illustrated in the RAM chart example.
• Why this exists: The claim is that raw download counts over-reward small models (and even CI/test harness usage), so the normalization is meant to be a more stable adoption signal, per the metric rationale.
• Early callouts: GPT-OSS is described as “off the charts” on this normalization, with additional notes on MiniMax/Moonshot/DeepSeek adoption trajectories in the metric rationale.
The interactive explainer is linked from the tool link.
Design Arena spins up SVG Arena for head-to-head SVG generation
SVG Arena (Design Arena): A new arena focuses specifically on SVG generation quality, with an example prompt (“draw an xbox controller”) and a visible ranked output grid across multiple models, as shown in the arena screenshot.
• What’s notable in the screenshot: The leaderboard view names the generating models per panel (e.g., “Gemini 3 Pro Preview”, “DeepSeek-V3.2-Exp”, “MiMiMo-V2-Flash”, “GPT-5 mini”), which makes SVG-specific comparisons legible without leaving the page, as shown in the arena screenshot.
Similarweb chart shows Gemini and Grok leading 2025 QoQ traffic growth
GenAI web traffic (Similarweb): A 2025 QoQ visits chart shows Gemini and Grok as the fastest-growing (by web visits) while ChatGPT’s growth appears to flatten by Q4, with Claude and Perplexity showing steadier gains, as summarized alongside the traffic chart.
The tweet framing is explicitly about website-visit momentum rather than model quality, and the numbers are presented as worldwide traffic totals per quarter in the traffic chart.
Grok 4.20 “Granite” appears in Design Arena listings
Grok 4.20 “Granite” (xAI): A new Grok variant labeled 4.20 (nickname “Granite”) is reported as added to Design Arena, per the arena mention.
The tweet doesn’t include an eval artifact (scores, prompt set, or diff vs prior Grok), so this is a placement/availability signal rather than a measurable performance update, based on the arena mention.
🛠️ Developer tools & repos: CLIs, model libraries, and agent-native utilities
Standalone developer tools and open-source repos that support AI engineering (not full coding assistants). New today: multiple CLI/tool releases for interacting with X, models, and agent workflows.
ValsAI open-sources a unified Python “model library” for many LLM providers
Model library (ValsAI): ValsAI open-sourced its internal Python model library—a unified API intended to standardize access and evaluation settings across many inference providers, motivated by wanting same-day model support and consistent benchmark settings, per the Open-source announcement.

• Provider coverage: It claims support spanning OpenAI, Anthropic, Google, Together, Fireworks, AWS, Azure, Cohere, DeepSeek, Moonshot, MiniMax, Mistral, Perplexity, xAI, and Z.ai—“20+” in total—according to the Provider list.
It’s an explicit bet that “evaluation settings + logging + retries” are infrastructure, not glue code, and that reproducibility problems start at the client layer.
HyperPages launches as an open-source web research page builder
HyperPages (Hyperbrowser): Hyperbrowser introduced HyperPages, a research page builder that browses the web, pulls sources, writes and formats sections, and supports interactive editing, as shown in the Product intro.

The code is presented as open-source, with a runnable project entry point linked in the GitHub repo.
RepoPrompt 1.5.66 declares its CLI GA and adds an interview prompt
RepoPrompt 1.5.66 (RepoPrompt): RepoPrompt shipped v1.5.66 and marked its CLI as GA, plus it added a new “interview prompt” flow that has the agent ask clarifying questions before it gathers repo context, as described in the Release announcement and detailed via the Full changelog.
The notable product change here is pushing clarification earlier in the run—before context packing and planning—so the tool’s context builder doesn’t lock onto the wrong task framing.
Toad shell demo argues agent CLIs should preserve classic terminal ergonomics
Toad shell (Toad): A ~2-minute demo shows Toad positioning itself as an “AI in the terminal” UX that keeps familiar terminal workflows intact instead of replacing them, as shown in the Demo post.

The core claim is about interaction design: preserve established CLI habits while layering agent assistance on top, rather than forcing users into chat-first flows.
bird 0.7.0 ships home timeline + AI-curated news/trending for X CLI
bird 0.7.0 (bird): The bird X/Twitter CLI shipped v0.7.0 with a new home command for “For You”/“Following”, a news/trending Explore view that outputs AI-curated headlines, and broader pagination support across commands, as detailed in the Release notes.
This is a small but concrete move toward “terminal-native” consumption pipelines (timeline + trending + user feeds) that can be scripted into analyst workflows without relying on the web UI.
⚙️ Inference & runtime engineering: VLM serving, GPU optimizations, and API input pipelines
Serving/runtime updates and performance engineering across stacks. New today: SGLang disaggregation for VLMs, ComfyUI GPU speedups, plus notable Google Gemini API input expansions and AI Studio UX fixes.
Gemini API adds URL fetch + GCS registration for large file inputs
Gemini API (Google): Google expanded input handling so developers can pass public or signed URLs directly (for images/PDFs) and register Google Cloud Storage objects without re-uploading; the change is framed as part of broader input size-limit increases, according to the [Gemini API announcement](t:27|Gemini API announcement) and the [size limits table](t:165|size limits table).
• Limits called out: Inline uploads up to 100 MB; Files API and GCS registration up to 2 GB; external URL fetch up to 100 MB, as shown in the [size table](t:165|size limits table) and reiterated in the [API feature recap](t:250|API feature recap).
The practical implication is fewer “download then re-upload” hops in ingestion pipelines (especially for PDFs and stored blobs), but the tweets don’t mention any new security controls beyond “signed URL” support.
SGLang ships EPD disaggregation to cut multi-image VLM latency
SGLang (LMSYS): SGLang shipped EPD disaggregation (Encoder–Prefill–Decode) so VLM deployments can scale the vision encoder independently from the LLM; the target workload is 4–8 images per request, and the claimed impact is 6–8× lower TTFT at 1 QPS plus ~2× higher throughput at high QPS, as summarized in the [performance note](t:681|performance note) and detailed in the [EPD blog](link:681:0|EPD blog post).
• Architecture details: The feature set includes a vision embedding cache and pluggable transfer backends (eg ZMQ/Mooncake), as described in the [launch thread](t:458|launch thread).
The tweets don’t include a single canonical benchmark artifact (plots/tables), so treat the numbers as vendor-reported until reproduced by third parties.
ComfyUI enables NVFP4 on Blackwell and faster offload paths
ComfyUI (ComfyUI): ComfyUI announced NVIDIA-focused inference optimizations that are already enabled by default; the headline claims are up to ~2× faster with NVFP4 quantization on NVIDIA Blackwell GPUs and 10–50% faster runs via async offload + pinned memory when models don’t fit in VRAM, per the [release thread](t:181|release thread).
The post positions this as throughput/latency work for common 1024×1024 generation workloads, but it doesn’t include side-by-side timing charts in the tweet itself.
Ray integrates SGLang for online serving and batch LLM workloads
Ray + SGLang (Ray Project): Ray announced first-party examples for running SGLang under Ray Serve (online inference) and Ray Data (batch LLM workloads), with entry points linked in the [Ray examples directory](link:493:0|Ray examples directory) and the [Ray Serve PR](link:493:1|Ray Serve PR), as highlighted in the [integration post](t:493|integration post).
This is mostly an operational wiring story—how teams standardize SGLang deployments alongside existing Ray clusters—rather than a model/runtime change by itself.
Google AI Studio adds inline rendering for pasted text after complaints
Google AI Studio (Google): Users reported that pasted text started being treated as a file—making it harder to view/edit inline—per the [complaint screenshot](t:202|complaint screenshot); a follow-up says AI Studio now supports rendering pasted text inline again, per the [fix confirmation](t:70|fix confirmation).
The remaining gap noted in the same thread is richer controls for viewing/opening/editing file-backed content, which the [follow-up note](t:70|follow-up note) says is still in progress.
Comfy Cloud adds one-link model import from Civitai and Hugging Face
Comfy Cloud (ComfyUI): Comfy Cloud added a model import flow where users paste a Civitai or Hugging Face link and the service handles downloading and file placement; the workflow is shown in the [import demo](t:186|import demo), with setup notes in the [import docs](link:800:0|import docs).

🔌 Orchestration & MCP: browser tooling, task protocols, and SDK-level hooks
Interoperability plumbing (MCP servers/clients, tool calling, and agent UI signals). New today: multiple browser-dev MCP stacks, OpenRouter SDK patterns, and discussion of MCP task primitives in Claude Code.
chrome-devtools-mcp shows MCP as the bridge into DevTools
chrome-devtools-mcp: A dedicated MCP server for Chrome DevTools is being shared as a way to let an agent inspect and debug in the same environment humans use—turning DevTools capabilities into tool calls, per the Browser toolchain framing.
The project entry point is the GitHub repo.
Claude Code’s MCP “tasks/*” surfaces as a long-running tool primitive
Claude Code (Anthropic): Community digging suggests the CLI distribution already contains an MCP task capability with explicit JSON-RPC methods like tasks/get, tasks/result, tasks/list, and status notifications (notifications/tasks/status), plus per-tool taskSupport metadata, as outlined in the Internal tasks notes.
A concrete clue is the method list and task object schema shown in the
.
This lines up with the broader push toward long-running tool calls that can be polled and surfaced in UI, but the tweets don’t confirm how widely it’s enabled outside internal/experimental paths.
dev-browser is pitched as a practical browser layer for agents
dev-browser: In the same “frontend is harder than backend” thread, dev-browser is highlighted as another way to wire an agent into a real browser runtime, so it can validate what it just changed rather than guessing from static code, per the Browser tooling explainer.
The concrete pointer to try is in the GitHub repo.
Playwriter repo targets the “AI can’t see the browser” gap
Playwriter: A lightweight browser harness is being passed around as one way to fix the core frontend-agent problem—agents can generate UI code, but without the running browser they’re “flying blind,” as framed in the Frontend is blind framing.
The repo is being circulated alongside other browser integration options, with the concrete pointer living in the GitHub repo.
OpenRouter SDK highlights custom tool events for better agent UX
OpenRouter SDK: A specific UI-oriented pattern is being promoted—define tools that emit custom events so apps can show progress (for example, web-search progress) while a model is still working, as described in the Custom events tip.
The supporting implementation details are pointed to via the Tools docs in Tools docs.
OpenRouter SDK shows “stream to user, save full text” from one call
OpenRouter SDK: A concrete server-side pattern is being shared where one model call can be consumed two ways—streamed chunks to the client while also fetching the full text out-of-band for logging/storage—using methods like getTextStream() and getText(), as shown in the Dual consumption snippet.
The code shape is easiest to see in the
.
This is a small but practical building block for agent systems where product UX wants streaming, while ops wants durable transcripts and metrics.
🏗️ AI infrastructure buildout: datacenters, capex signals, and compute-scale tracking
Macro/infra signals that directly affect AI capacity. New today includes Meta’s capacity org changes, BIS capex framing, and public estimates of global installed AI compute.
Meta creates “Meta Compute” to plan tens of gigawatts of AI datacenter capacity
Meta Compute (Meta): Meta set up a new top-level infrastructure initiative called Meta Compute, explicitly targeting “tens of gigawatts this decade” and “hundreds of gigawatts or more over time,” as written in Mark Zuckerberg’s internal note shown in Meta Compute screenshot.
The move reads like an org-level capacity planning and supplier strategy bet: Zuckerberg says the effort is led by Santosh Janardhan and Daniel Gross, with responsibilities spanning datacenter fleet build/ops, silicon program, and long-term capacity strategy, as detailed in the Zuckerberg post screenshot. Reuters-style framing that this consolidates gigawatt-scale compute buildout also shows up in the Reuters summary.
Following up on Nuclear power—Meta’s nuclear PPAs for AI power—this org change is a more direct “who owns the buildout” signal, and it puts capacity planning on a single executive stack.
BIS/BEA notes AI-heavy US firms’ capex rising to ~$115B (2025) and ~25% of revenue
AI capex accounting (BIS/BEA): A BIS bulletin summary circulating today claims US “AI firms” (named as Alphabet, Amazon, Meta, Microsoft, Oracle) saw annual capex rise from roughly $20B (2020) to roughly $115B (2025), with capex/revenue rising from ~10% to ~25%, as described in the BIS capex excerpt.
The same source frames the magnitude: by mid‑2025, IT manufacturing facilities + datacenters ≈ 1% of US GDP, while total IT-related investment rises to ~5% of GDP, exceeding the dot‑com peak, as stated in the GDP share chart.
This is a clean “macro baseline” snapshot for capacity forecasting—though it’s still a synthesis thread, and the primary document is implied rather than directly linked in the tweets.
Global installed AI compute passes ~15M H100-equivalents, per chip sales tracking
AI chip sales tracking (Epoch AI): A public estimate shared today puts global cumulative AI compute at 15 million H100-equivalents, implying 10+ GW of draw even before full infra overheads, according to the compute capacity claim.
The same chart notes a mix shift: NVIDIA’s newer B300 line is described as the bulk of NVIDIA AI revenue while H100/H200 drops below ~10%, as shown in the compute capacity claim. Following up on Compute doubling—the “doubling every ~7 months” narrative—this gives a concrete “installed base” proxy that analysts can anchor to power and datacenter buildout discussions.
AI memory shortage drives reported ~50–55% DRAM price jump in Q1 2026
HBM/DRAM supply crunch (memory vendors): A CNBC-style summary claims DRAM prices are up ~50–55% in Q1 2026, with vendors prioritizing HBM for AI accelerators; Micron is described as “sold out for 2026,” and NVIDIA’s Rubin-era demand is framed as a “three-to-one” tradeoff where producing HBM crowds out standard memory supply, per the memory shortage screenshot.
This is an infra limiter, not a model limiter: even if GPU shipments keep rising, memory packaging and allocation becomes a hard constraint on both training clusters and inference fleets, with second-order pressure on consumer device pricing called out in the same memory shortage screenshot.
RL environment startups say task production and reward hacking dominate frontier training ops
RL environments market (frontier training ops): An Epoch AI write-up summarized in tweets says frontier labs are investing heavily in RL environments, with Anthropic “reportedly discussed spending over $1B” on them; interviewees cite reward hacking and scaling task production without losing quality as the dominant bottlenecks, as described in the RL environments thread and reinforced by the quality bottleneck quote.
It also flags a shift in what gets productized as “tasks”: the post claims the field started with math/coding, but enterprise workflows like Salesforce navigation and expense reports are now a major growth area, as noted in the enterprise workflow shift.
🧠 Model releases & credible rumors: open agents, new versions, and leaks
New model drops (and narrowly, high-confidence leaks) that matter to builders. Today includes open agent models plus multiple version/rumor signals; excludes creative-only media model releases (covered in Generative Media).
OpenBMB open-sources AgentCPM-Explore (4B) and its end-to-end agent stack
AgentCPM-Explore (OpenBMB): OpenBMB announced AgentCPM-Explore, positioning it as an open-source 4B “agent model” with strong GAIA-style real-world task performance, and they’re also open-sourcing the surrounding stack (training + sandbox + eval tooling) in the launch thread, with code and weights linked via the GitHub repo and Hugging Face page.
They’re claiming 63.9% on GAIA-Text at this scale, alongside other benchmark numbers shown in the results table embedded in the launch thread.
• What’s materially new: it’s not “just weights”; the release bundles the agent scaffolding (AgentRL, AgentDock, AgentToLeaP) as described in the launch thread, which is the part that usually stays proprietary.
The open question is whether the published numbers reproduce outside their harness, since the post is benchmark-forward but doesn’t include independent replications yet.
Together pushes GLM-4.7 as a top open coding model with 200K context
GLM-4.7 (Z.ai/Together): Together is promoting GLM-4.7 as an agentic-coding-focused open model with 200K context, calling it “#1 open-source on LMArena Code Arena” and citing 73.8% SWE-bench Verified plus 84.9% LiveCodeBench-v6 in the model promo.
Availability here is explicitly framed as “use it on Together AI,” with access pointed to in the model page.
Treat the “#1” framing as leaderboard-dependent (it can shift quickly), but the concrete thing engineers can act on is: a large-context open(-weight) coding model now marketed as production-servable by a major inference host, per the model promo.
Rumor: GPT‑5.3 (“Garlic”) may be next
GPT‑5.3 (OpenAI): A rumor claims GPT‑5.3, code-named “Garlic,” is “coming soon,” with expectations framed around stronger pretraining and “IMO Gold” reasoning techniques in the rumor claim.
No corroborating artifacts (model card, changelog, eval leak, or UI/API strings) appear in today’s tweets, so this should be treated as a single-source credibility bet rather than a confirmed release signal.
AnyDepth demo surfaces as a new depth-estimation capability
AnyDepth: A demo for AnyDepth (depth estimation) was shared, showing a straightforward “depth made easy” pitch in the demo post.

The tweets don’t include benchmark claims or a model card, but it’s a concrete signal of ongoing small, composable vision capabilities getting packaged as standalone drops rather than being buried inside large VLMs, as shown in the demo post.
Grok 4.20 (“Granite”) appears in Design Arena listings
Grok 4.20 (xAI): A Grok 4.20 variant nicknamed “Granite” showed up on Design Arena’s site listings, as captured in the arena screenshot.
There aren’t release notes, pricing, or API surface details in the tweets—just the appearance of the label—so the main signal for analysts is that xAI is iterating versions fast enough that new named variants are propagating to public eval/arena surfaces, per the arena screenshot.
📄 Research papers (non-training): controllability, algorithmic reasoning gaps, and privacy-first CoT
Catch-all for notable papers not primarily about training recipes. New today emphasizes controllability analysis, algorithm understanding benchmarks, and privacy leakage in reasoning traces.
AlgBench benchmark reports big drop on multi-step algorithm planning (92%→49%)
AlgBench (HKUST/Beijing IIT): The AlgBench paper proposes an algorithm-centric evaluation suite and reports that leading reasoning models can fall from ~92% to ~49% accuracy when tasks require longer-horizon planning across many steps, as described in the AlgBench summary.
This work is meant to separate “knows the algorithm” from “got lucky on a problem-shaped benchmark,” and it points to a recurring failure mode where models start with a plausible plan but derail when execution gets index/constant heavy, per the AlgBench summary.
Chain-of-Sanitized-Thoughts targets PII leakage in chain-of-thought
Chain-of-Sanitized-Thoughts (PII-CoT-Bench): A new paper proposes training/prompting models to reason with placeholders so PII doesn’t appear in chain-of-thought logs even when the final answer is sanitized, with the approach and example leakage shown in the PII-CoT-Bench snapshot.
The framing is operational: many apps log reasoning traces, so preventing leakage “at generation time” reduces a common failure mode compared to post-hoc redaction, per the PII-CoT-Bench snapshot.
Apple OverSearchQA introduces Tokens Per Correctness to measure over-searching
OverSearchQA (Apple): Apple’s paper on “over-searching” in search-augmented LLMs introduces Tokens Per Correctness (TPC) as a way to quantify when retrieval loops waste tokens (and sometimes increase hallucinations) by pulling too much, as summarized in the Over-searching paper page.
The benchmark and metric are framed as a systems-level eval for agentic RAG setups where “more search” isn’t always better, per the Over-searching paper page.
Apple releases GenCtrl, a formal controllability toolkit for generative models
GenCtrl (Apple): Apple published GenCtrl, a research toolkit that tries to answer a basic but often hand-waved question—“are generative models actually controllable?”—and argues that controllability can be surprisingly fragile even when common control methods appear to work, as shown in the GenCtrl announcement.
The release includes a formal framing plus an open-source code drop referenced in the GenCtrl announcement, positioning this as a measurement layer teams can use when comparing prompt-only control vs finetune/control adapters.
Isabellm “vibe coding” theorem prover loops LLM steps with Isabelle checks
Isabellm (Griffith University): A paper describes Isabellm, a theorem prover that repeatedly proposes the next proof command with an LLM and uses Isabelle/HOL as a strict checker, effectively turning proof search into an edit-check loop, as outlined in the Isabellm paper summary.
The reported result is mixed: the checker feedback keeps the model honest, but longer “fill and repair” planning still stalls on harder goals—especially ones where Isabelle automation like Sledgehammer already fails—per the Isabellm paper summary.
🧪 Training & reasoning methods: memory, policy optimization, and long-context tricks
Research-heavy day focused on agent memory and optimization recipes. New today: multiple papers propose tool-based memory policies, scalable conditional memory, and test-time learning approaches for long context.
DeepSeek’s Engram adds O(1) lookup-style conditional memory using hashed N-gram embeddings
Engram (DeepSeek): DeepSeek’s “Conditional Memory via Scalable Lookup” introduces a conditional memory module that acts like an O(1) lookup, implemented with modernized hashed N-gram embeddings, as summarized in the Engram paper thread and released in the GitHub repo.
The claimed mechanism is that Engram reduces early-layer reconstruction of static patterns so capacity can shift toward “deeper” computation on the parts that matter for reasoning, per the Engram paper thread; it also claims improvements for long-context behavior, as noted in the Long-context note.
End-to-end test-time training proposes long context by updating weights while reading
End-to-end test-time training for long context: A paper proposes keeping attention local but doing test-time weight updates via next-token prediction while reading, effectively compressing context into weights to avoid quadratic attention costs, as outlined in the Method summary.
It reports language-modeling experiments up to 128K context with constant-time per token and faster input processing than full attention, while still lagging on exact string recall tasks, according to the Method summary and the linked ArXiv entry.
AgeMem trains unified long+short-term memory actions into an agent policy via progressive RL
AgeMem (Alibaba/Wuhan Univ.): A new agent-memory paper proposes treating long-term and short-term memory as one learnable policy, with explicit tool actions like ADD/UPDATE/DELETE and RETRIEVE/SUMMARY/FILTER, as described in the Paper overview.
The reported result is that learning when to store vs retrieve vs compress context beats heuristic “memory managers” on long-horizon agent benchmarks, including ~13% on Qwen2.5-7B and larger gaps on smaller models, according to the Paper overview.
AT²PO uses tree search over uncertain turns to train tool-using agents more stably
AT²PO (Policy optimization): A new method trains tool-using agents by branching a turn-level search tree at high-uncertainty steps, then propagating final outcomes back to earlier turns to get denser credit assignment, as explained in the AT2PO summary.
This framing targets a common weakness in long tool trajectories—where treating the whole run as one sequence blurs feedback—by making each turn an optimization unit, per the AT2PO summary.
Single-agent “skills menu” paper cuts tokens/latency but breaks when skill libraries get large
Single-agent with skills (agent architecture): A paper argues many multi-agent role systems can be collapsed into one agent that selects from a named skill library, reducing coordination overhead; it reports ~54% fewer tokens and ~50% lower latency when the skill list is small, as described in the Paper summary.
The key failure mode is semantic confusability as the library grows (overlapping skills cause selection to degrade), and it proposes a two-stage chooser (coarse group → exact skill) to scale the approach, per the Paper summary.
🎬 Generative media & creative tooling: video stylization, synthetic street view, and motion control
Creator-focused AI tools and workflows. New today centers on video stylization products and rapid creator pipelines; excludes pure model-release items already covered under Model Releases.
Higgsfield launches Mixed Media for one-click video stylization up to 4K
Mixed Media (Higgsfield): Higgsfield shipped Mixed Media, a video stylization feature that applies 30+ preset “cinematic looks” (comic, noir, hand-paint, vintage, etc.) with full color control; the launch post calls out 4–24 FPS support and up to 4K output, positioning it as a faster alternative to manual frame-by-frame stylization, as shown in the launch demo and reiterated in the feature details.

• Controls: The feature highlights tri-layer color adjustment (background / mid-layer / subject) and multiple style families, according to the launch demo.
• Go-to-market signal: The announcement also frames it as targeted at music video directors and indie filmmakers, with a credit giveaway mechanic included in the launch demo.
Freepik Spaces workflow pairs with Kling Motion Control for shot-to-shot pipelines
Freepik Spaces + Kling Motion Control: A creator workflow thread describes using Freepik’s Spaces as a node-based pipeline wrapper around state-of-the-art gen models, with Kling Motion Control as the core motion/pose driver for action-style clips, as described in the workflow thread and previewed in the workflow thread.

• Pipeline shape: The thread’s emphasis is on building repeatable “workflows” (reference images, prompts, motion-control passes) rather than one-off generations, as described in the workflow thread.
Kling 2.6 motion control dance clips with character references are described as viral
Kling 2.6 (Kling AI): Multiple posts describe a current high-performing short-video format: dance clips driven by Kling 2.6 Motion Control using one (or two) character reference images to preserve identity through choreography, as described in the trend description and expanded in the examples thread.
The key claim is that motion control is holding up better under complex choreography than many alternatives, with the “character reference + dance” recipe positioned as the repeatable ingredient, per the trend description.
A “Street View in London, 1812” format shows up as a new synthetic UI style
Historical Street View format (fofrAI): A “Street view in London, 1812” image circulates as a recognizable new visual format—period scene generation wrapped in a modern Street View UI frame (search bar, map inset, date stamp), as shown in the London 1812 mock.
The most notable part here is the UI-as-proof aesthetic: the interface elements do the work of making the output feel like a captured artifact instead of an illustration, as seen in the London 1812 mock.
Nano Banana Pro “Street View selfie” screenshots popularize UI-overlay realism
Nano Banana Pro (Google): A “Street view selfie” post shows Nano Banana Pro being used to generate Street View-like screenshots that include UI overlays (location header, date stamp, map inset, controls), as shown in the street view selfie.
Compared to generic photoreal generations, the distinguishing move is rendering the interface chrome alongside the scene, which creates a stronger “this was captured” cue, as shown in the street view selfie.
Nano Banana Pro prompt for an “anti-memetic entity” photo effect gets shared
Nano Banana Pro (Google): A specific prompt recipe for generating a “photo of an impossible imperceptible anti-memetic entity” is shared as a repeatable style trick, with the example output showing a faint, human-like translucent figure in a natural scene, as shown in the prompt example image.
This is a narrow but concrete “prompt-as-filter” pattern: one short line reliably produces a consistent kind of unsettling, low-signal visual artifact, based on the prompt example image.
💾 Hardware constraints: the memory wall, HBM allocation, and chip-economics pressure
Hardware-side constraints that flow through to model training/inference availability. New today is dominated by memory/HBM shortages and price spikes.
AI memory crunch spikes DRAM prices as HBM capacity gets diverted to GPUs
AI memory supply (CNBC / market): A new “memory wall” narrative is showing up in pricing and allocation: DRAM prices are cited as up ~50–55% in Q1 2026, driven by HBM demand from AI accelerators pulling capacity away from standard memory, as summarized in the memory shortage recap.
The same thread claims Micron is sold out for 2026 and that NVIDIA’s next-gen Rubin GPUs are consuming enough HBM4 to create a “three-to-one” tradeoff (HBM output displacing standard DRAM), with downstream pressure expected on OEM device pricing and margins, per the memory shortage recap.
Epoch AI’s chip sales view puts global capacity at ~15M H100e, with B300 now the revenue bulk
AI Chip Sales Explorer (Epoch AI / dataset): A public tracking view pegs global AI compute capacity above ~15 million H100-equivalents, and it argues the implied power draw is already >10 GW even before full datacenter overhead, as described in the compute capacity post.
The same dataset summary says NVIDIA’s B300 now represents the bulk of NVIDIA AI revenue, while H100/H200 drop below ~10%, per the compute capacity post.
🤖 Robotics & embodied AI: world models, household autonomy, and VLA stacks
Embodied systems and robotics capability signals. New today: 1X’s world-model approach for NEO plus several autonomy demos and NVIDIA’s autonomous-driving model framing.
1X debuts 1XWM world model for NEO: plan by generating video, then execute
1XWM (1X): 1X announced 1XWM, a “world model” stack integrated into its NEO humanoid robot; instead of outputting actions directly, the system plans by generating a short future video rollout and then maps that rollout into motor commands (via an inverse-dynamics step), as shown in the launch video and explained in the 1X blog post.

The implementation framing in the system breakdown emphasizes a separation between “predict what the scene will look like next” and “convert it to actuation,” which is a concrete bet that video prediction pretraining transfers better than end-to-end action heads for out-of-distribution manipulation.
Nvidia pitches Alpamayo as the model layer for autonomous vehicles
Alpamayo (Nvidia): Jensen Huang frames Alpamayo as a family of open autonomous-driving models, describing a vision-language-action stack that connects perception to natural-language reasoning and planned actions, in remarks quoted and contextualized in the Alpamayo explainer.

The positioning is explicitly “model layer vs application layer” (Alpamayo vs the automaker), which matters for how autonomy capability and ownership are expected to split between platform vendors and OEMs.
A household-chores autonomy demo is getting more attention than combat robots
Household autonomy: A clip framed as “fully autonomous household chores” is circulating as a more meaningful test than staged robot-fighting, with the post explicitly calling out home-task competence as the bar people care about now, per the chores demo.

What’s notable is the positioning: the video is being used as a proxy for whether robots can handle multi-step, messy household workflows (not just isolated manipulation tricks), at least in public perception.
Shenzhen demos AI-routed maglev delivery pods for restaurants
Maglev delivery pods (Shenzhen): A Shenzhen restaurant system shows food “pods” moving overhead on a maglev-like track, with AI handling routing, collision avoidance, and real-time path optimization as described in the maglev delivery clip.

This lands as an embodied-systems story because it’s autonomy in a constrained physical environment: predictable infrastructure, but still dynamic scheduling and safety constraints around humans and other pods.
China’s “try it in traffic” culture is highlighted for FSD deployment
Autonomous driving deployment: A clip and commentary highlight a China pattern of pushing FSD-like systems into real traffic with an emphasis on “trying and testing” (not just controlled demos), as captured in the real-traffic note.

As a signal, it’s less about a single model release and more about operational posture: faster feedback loops and broader exposure to real edge cases, with the obvious trade-off that the testing surface includes public roads.
🛡️ Security, safety & governance: jailbreak resistance, data leakage, and transparency moves
Safety/security items with operational implications. New today includes concrete jailbreak-defense metrics, workforce-data handling risks for agent evaluation, and transparency commitments around ranking systems.
Anthropic reports Constitutional Classifiers++ with 198k red-team attempts and ~1% overhead
Constitutional Classifiers++ (Anthropic): Following up on safety classifiers (cheap early filter), Anthropic is now claiming a two-stage “cascade” defense that adds about 1% compute overhead while sharply reducing universal jailbreak success; in 198,000 red-team attempts, they report finding one high-risk vulnerability, and they also claim an 87% drop in false refusals on benign queries, as summarized in the metrics recap.
• What changed: The system is framed as a cascade that combines internal-activation probing with a stronger ensemble of input/output classifiers, per the metrics recap.
• Operational implication: If the reported 1% overhead holds in production, this pushes “always-on” jailbreak filtering closer to a default setting rather than an opt-in safety tier, though the tweets don’t include an external eval artifact beyond the internal red-team result in the metrics recap.
OpenCode patches localhost ?url injection that could enable terminal command execution
OpenCode (AnomalyCo): OpenCode disclosed and patched a vulnerability where a web frontend ?url= parameter could be pointed at a malicious server returning markdown with inline scripts; visiting a crafted http://localhost:4096?url=... link could then run commands via terminal APIs, as described in the incident writeup and the linked full advisory.
• Mitigations shipped: The project removed the ?url= parameter via remote patch; added CSP headers to prevent inline scripts; and changed defaults so OpenCode doesn’t run a server unless explicitly enabled, per the incident writeup.
• Hardening guidance: The update adds warnings when running a server without OPENCODE_SERVER_PASSWORD, as detailed in the incident writeup.
Report: OpenAI asks contractors to upload prior work samples to benchmark office agents
OpenAI contractor benchmarking program (OpenAI): Internal documents obtained by WIRED indicate OpenAI is asking contractors to upload real-world work outputs (PDFs, decks, codebases, spreadsheets) from past/current jobs to create human baselines for “office agents,” while instructing them to scrub confidential and personal data—legal experts cited in the report flag trade-secret liability risk if contractors misjudge what’s sensitive, according to the Wired summary.
• Why it matters for evals: This is a direct attempt to ground agent performance in realistic workplace artifacts rather than synthetic tasks, but it shifts a lot of compliance judgment to individuals, as described in the Wired summary.
X says it will open-source its recommendation and ads ranking code, repeating every 4 weeks
X ranking transparency (X/xAI): Elon Musk says X will open-source the full recommendation algorithm—covering both organic and advertising ranking—in 7 days, and then repeat that release every 4 weeks with developer notes, as shown in the open-source pledge.
• What to watch: If the releases include feature flags, model interfaces, and training/finetuning knobs (not just scoring code), this becomes a rare public reference implementation for large-scale feed ranking; the tweet only commits to “all code used to determine” recommendations in the open-source pledge.
Chain-of-Sanitized-Thoughts proposes privacy-first reasoning to reduce PII leakage in CoT
Chain-of-Sanitized-Thoughts (research): A new paper frames a practical failure mode for “reasoning models”: chain-of-thought can leak PII even when the final answer is sanitized, and proposes training/prompting approaches to reason with placeholders so the sensitive details never get written into the trace, as summarized in the paper thread.
• Why it matters operationally: The risk lands wherever CoT traces are logged for debugging, evals, or compliance review; the paper’s benchmark and example leakage are shown directly in the paper thread.
Claude Code 2.1.6 adds allowedPrompts to pre-approve scoped Bash permissions
Claude Code 2.1.6 (Anthropic): Claude Code now supports attaching allowedPrompts to ExitPlanMode so the agent can request user-approved, semantically-scoped Bash permissions (e.g., “run tests”, “install dependencies”) up front; the prompt schema also validates these scopes, as described in the diff summary with details in the diff link.
• What this changes: Instead of repeated ad-hoc confirmations during execution, this creates an explicit “capability envelope” for a run; it’s still user-mediated, but more structured than click-by-click approvals described elsewhere in the tweets.
Claude Code 2.1.6 fixes a permission bypass via shell line continuation
Claude Code 2.1.6 (Anthropic): The 2.1.6 changelog includes a security fix that blocks a permission bypass using shell line continuation that could allow blocked commands to execute, as listed in the 2.1.6 changelog and mirrored in the changelog mirror via the GitHub changelog.
• Why it matters: This is a class of “policy enforcement vs shell parsing” bug that tends to show up in agent CLIs; the tweets don’t include a PoC, but the fix is explicitly called out in the 2.1.6 changelog.