NVIDIA NVARC 4B slashes ARC‑AGI‑2 costs – $0.20 per task
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Today’s action shifted to ARC‑AGI‑2, where we now have both a fully documented SOTA stack and a shockingly cheap small‑model entrant. ARC Prize has published Poetiq’s Gemini 3 Pro refinement pipeline, locking in ~54% accuracy at about $30.57 per puzzle with open code, while leaked charts show an internal GPT‑5.2 point hovering near the 50% band—nicely in line with the 5.2 rumors we covered yesterday. At the other end of the curve, NVIDIA’s NVARC team is touting a custom 4B model at roughly 27.6% for $0.20 per task, reshaping the score‑per‑dollar frontier.
The NVARC recipe leans on synthetic ARC‑style curricula, heavy test‑time training, and NeMo tooling so a tiny model can adapt per instance instead of hauling around a giant frozen prior. In practical terms, you can copy Poetiq’s high‑budget Gemini refinement stack for maximum score, or borrow NVARC’s “adaptive reasoner” pattern to bolt cheap specialists onto your existing systems; most teams will end up doing both, depending on workload.
Practitioners are also pushing back on treating ARC‑AGI‑2 as a universal quality stamp: some mid‑pack models reportedly feel better in daily use than leaderboard stars. Treat this benchmark as a sharp instrument for reasoning and cost curves, then validate with your own tools, latency budgets, and live agent runs before you anoint a new house model.
Top links today
- Thinking by Doing world model reasoning paper
- CuES curiosity driven agentic RL paper
- Agentic trading orchestration framework paper
- LLM jailbreak defense techniques paper
- NOHARM benchmark for medical LLM safety
- FORGEJS benchmark for JavaScript vulnerability detection
- AI enabled grading with near domain data paper
- Meta co improvement roadmap for AI research
- TechCrunch on OpenAI disabling app suggestions
- Forbes analysis of OpenAI data center capex risk
- Bloomberg feature on AI data center boom
- BloombergNEF US data center power demand forecast
- Tom’s Hardware on Micron HBM fab in Japan
Feature Spotlight
Feature: ARC‑AGI‑2 surge—SOTA and cheap solvers
ARC‑AGI‑2 escalates: Poetiq hits a verified 54% at ~$31/task and NVIDIA’s 4B model scores ~27.6% at $0.20—showing both ceiling and cost‑floor shifts in general reasoning.
Many tweets center on ARC‑AGI‑2: a verified SOTA above 50% and a ultra‑cheap small model entrant. This is the clearest cross‑account storyline today for engineers tracking general reasoning progress and cost curves.
Jump to Feature: ARC‑AGI‑2 surge—SOTA and cheap solvers topicsTable of Contents
📈 Feature: ARC‑AGI‑2 surge—SOTA and cheap solvers
Many tweets center on ARC‑AGI‑2: a verified SOTA above 50% and a ultra‑cheap small model entrant. This is the clearest cross‑account storyline today for engineers tracking general reasoning progress and cost curves.
Poetiq’s Gemini 3 Pro refinement locked in as reproducible ARC‑AGI‑2 SOTA
ARC Prize has now published the full setup for Poetiq’s Gemini 3 Pro–based refinement stack, confirming ~54% ARC‑AGI‑2 accuracy at a reported $30.57 per problem and making the solver reproducible via open code. (Poetiq SOTA, arcprize update, open repo) On current public charts this “Gemini 3 Pro (Ref.)” point anchors the top‑right of the cost–score frontier, well above baseline Gemini and most competing models but at a notably higher per‑task price. leaderboard thread
For builders, the new detail is practical: you can now study and run the exact refinement pipeline, not just the headline score. That means you can inspect prompt structure, search strategy, and tool usage, then decide whether to (a) copy the approach to your own Gemini‑class models, (b) adapt it to other providers, or (c) treat it as a reference design for high‑budget reasoning systems. The downside is obvious—~$30 per puzzle is too expensive for most production use—but as with AlphaGo‑era systems, SOTA stacks like this often get distilled or approximated into cheaper variants later. If you care about general reasoning research, this is the blueprint to read before you try to beat it.
NVIDIA’s 4B NVARC model hits ~27.6% ARC‑AGI‑2 at $0.20 per task
NVIDIA’s NVARC team is reporting a custom 4B‑parameter model that reaches about 27.6% on ARC‑AGI‑2 at roughly $0.20 per problem, beating many far larger models on the score‑per‑dollar frontier. leaderboard thread A follow‑up correction revises an initial 29.72% claim down to 27.64%, but the cost and efficiency story stand, and an official blog details how synthetic data plus test‑time training and NeMo tooling replace sheer parameter count with smarter adaptation. score correction (NVIDIA blog post)
For engineers, the interesting part isn’t the raw score—it’s the profile: a relatively tiny 4B model, heavy use of synthetic ARC‑style tasks, and substantial test‑time training so the solver learns per‑instance patterns instead of relying on a giant frozen prior. leaderboard thread This points to “adaptive reasoners” as a credible path alongside ever‑bigger general models: you could imagine routing tough reasoning jobs to a cheap, specialized ARC‑class solver, or borrowing NVARC’s recipe (synthetic curricula + test‑time fine‑tuning) for your own narrow domains. Leaders should read this as an early signal that model count, data pipelines, and clever test‑time optimization may matter as much as chasing the next 400B frontier model.
Leaked ARC‑AGI‑2 plots show a GPT‑5.2 point near 50% accuracy
Multiple screenshots of the ARC‑AGI‑2 leaderboard are circulating with a gold star labeled “GPT‑5.2” circled near the 50% score line, well above GPT‑5 Pro, Opus 4.5, and Grok in the same chart. leaderboard screenshot A second version of the plot zooms in on the 0–40% range but still shows the starred GPT‑5.2 point hovering around mid‑40s to 50%, reinforcing the perception of a significantly stronger internal model. second leaderboard
This is still rumor territory—no one has tied the point to a public model card or official OpenAI statement—but for analysts the implication is straightforward: even if the leak is off by several points, private GPT‑5.2‑class systems appear to be at or above the best public ARC‑AGI‑2 solvers. That lines up with prior hints that OpenAI keeps internal models a step ahead of what’s shipped. GPT-5.2 hints Engineers should treat the chart less as a precise metric and more as a directional sign that frontier private models may already sit near the Poetiq/Gemini‑Ref band on this benchmark, with real‑world impact depending on how quickly those capabilities arrive in accessible APIs.
Builders push back on using ARC‑AGI‑2 as a single quality proxy
Alongside the new SOTA and rumored GPT‑5.2 point, practitioners are warning that ARC‑AGI‑2 is a sharp but narrow lens on model quality. One engineer notes that DeepSeek‑v3.2 scores highly yet “generalize[s] less effectively than top models in actual use,” while Gemini trails Opus, Grok, and GPT on instruction‑following despite competitive ARC scores. benchmark critique
The point is: ARC‑AGI‑2 is great for tracking progress on abstract pattern reasoning under limited examples, but it underweights things like tool reliability, instruction alignment, multilingual behavior, and latency. Some lower‑scoring models still “perform well in real‑world use,” while leaderboard darlings may feel brittle in everyday workflows. benchmark critique For leaders and analysts, the takeaway is to treat ARC‑AGI‑2 like ImageNet was for vision—a useful progress meter and research playground, not the final word on which model to standardize on. Use it to track reasoning trends and cost curves, then pair it with domain‑specific evals and live agent tests before you move workloads.
🛰️ Frontier model watch: Gemini 3 Flash, Grok 4.20, Nano Banana 2
Model availability and near‑term roadmaps moved today. Mostly lightweight releases/teasers: Gemini 3 Flash shows up on LM Arena; Grok 4.20 ETA; leaks of Nano Banana 2 Flash; plus chatter on an open 8B hitting frontier‑like quality. Excludes ARC‑AGI‑2 items (feature).
Gemini 3 Flash quietly appears on LM Arena for head‑to‑head testing
Gemini 3 Flash quietly showed up as new skyhawk and seahawk entries on LM Arena, giving builders an unofficial way to pit Google’s frontier "small" model against Opus, GPT‑5 and others before any public API docs or pricing land. arena listing
Because Arena runs blind A/B battles and publishes ELOs, you can start probing instruction following, coding, and tool‑use behavior with realistic prompts rather than marketing snippets; early reactions frame this as yet another sign that “Google keeps on giving” in the Gemini 3 line. gemini reaction
Elon targets Grok 4.20 release in 3–4 weeks, Grok 5 likely slips
Elon Musk says Grok 4.20 is “coming out in 3 or 4 weeks,” pointing to an early‑January launch window for xAI’s next reasoning model if they hit schedule. elon roadmap
Commentary around the post assumes this pushes the earlier "by year‑end" Grok 5 target back toward roughly Q2 2026, while some heavy users say they’re happy to wait because Grok 4.1 already feels like the best balance of speed, price and reasoning for real‑world agent workflows. grok sentiment
Leak points to Nano Banana 2 Flash with near‑Pro quality at lower cost
A new "Mayo" flag inside Gemini’s web UI and tester reports suggest Google is preparing a Nano Banana 2 Flash tier that delivers almost the same visual quality as Nano Banana Pro but at a meaningfully lower price per image. nb2 flash leak
Following up on Nano Banana Pro, which positioned Pro as a very controllable cinematic image stack, this Flash variant looks aimed at high‑volume creators who care more about throughput and cost than squeezing out the last few percent of fidelity; one early comment sums it up as “if this really is nano banana 2 flash, the competition will face a hard time.” nb2 commentary
Rnj‑1 touted as first truly open 8B in the GPT‑4o tier
Community chatter highlights Rnj‑1 as a notable new open‑weights model because, at only 8B parameters, it’s claimed to hit GPT‑4o‑tier quality on several assistant and reasoning tasks, effectively making it the first "truly open" 8B that punches at frontier level. rnj1 comment If independent benchmarks and real‑world workloads confirm those impressions, Rnj‑1 could become a default base for teams that want near‑frontier capability while keeping full control over weights, deployment stack, and fine‑tuning rather than depending on closed commercial APIs.
🧩 Agent ops: MCP skills, LangGraph flows, PM integration
A cluster of practical agent‑building patterns landed today: Claude Skills as markdown, MCP connectors to Linear, and LangGraph reference builds. Compared to yesterday, more concrete PM/CLI workflows and orchestration diagrams. Excludes model leaderboard chatter.
Claude Skills formalize reusable tools as markdown plus SDK support
Anthropic’s Claude Code now treats "Skills" as first‑class, reusable capabilities you define in markdown and wire into agents via the SDK’s allowed_tools and setting_sources settings. Docs and best‑practices walk through how to scope each Skill, document it for the model, and control which tools it may invoke, while a new SDK example shows Skills loaded from user and project sources so the same definitions work in the web app and in custom CLIs. (skills docs, skills best practices)
For agent builders this turns ad‑hoc system prompts into versioned, shareable "capability modules" that can be checked into git, restricted per environment, and selectively exposed to different agents without re‑authoring prompts for each workflow. (sdk usage screenshot, skills guide)
LangChain shares concrete evaluation patterns for Deep Agents and Terminal Bench
LangChain’s latest Deep Agents roundup condenses lessons from four production agents into specific evaluation patterns, and reports that their DeepAgents CLI scores 44.9% and 40.4% (mean 42.65%) on Terminal Bench 2.0. Following deep agents eval, which teased a webinar on observing agents, this thread lays out how to treat deep agents as systems to be tested over long‑running tasks, not single prompts, and uses Terminal Bench as a repeatable way to measure coding agents that live in the shell rather than a notebook. deep agents roundup
Alongside the blog and benchmark numbers, LangChain is also pushing a free Deep Agents course and an "Observing & Evaluating Deep Agents" webinar that focus on planning, file systems, sub‑agents, and prompting, giving teams a starting point for both designing and validating agents that run for hours instead of seconds.
LangGraph’s Energy Buddy shows hybrid agent design with OCR and ReAct
LangChain’s Energy Buddy example demonstrates a hybrid LangGraph architecture where WhatsApp inputs are routed either through a deterministic OCR path for meter photos or a ReAct agent path for natural‑language questions, all inside a shared StateGraph. The public diagram makes the split explicit—images go to a pure OCR node, while queries flow into a tool‑using ReAct agent—highlighting the design principle that "not everything should be an agent" and some steps are better as fixed functions. energy buddy post
For teams building production agents, this is a concrete reference for mixing stateful graphs with simple operators, keeping perception tasks predictable while reserving LLM calls for reasoning and orchestration, and it ships with an open GitHub repo showing the full WhatsApp and LangGraph wiring. github repo
LlamaAgents ship configurable invoice and contract agents as LlamaCloud templates
LlamaIndex is using LlamaAgents in LlamaCloud to turn "intelligent document processing" into an off‑the‑shelf agent: given vendor invoices and master service agreements, the agent extracts vendors and line items then matches each invoice to its MSA. Users type a name and API key, deploy the agent in about five seconds, upload sample PDFs, and watch the workflow run, with the option to clone the public repo to customize internal steps before redeploying. invoice agent demo

The team claims this setup is both more accurate and more customizable than legacy IDP tools, since you can edit the agent’s plan and tools in code instead of waiting on a vendor, while LlamaCloud handles hosting and orchestration across the extraction, matching, and validation sub‑tasks. invoice repo agents docs
Open Deep Research publishes detailed LangGraph blueprint for research agents
Sergey Bolshchikov has shared the internal architecture of his Open Deep Research system as a 13‑step LangGraph blueprint, exposing how a supervisor node, researcher sub‑agents, web search, reflection, dynamic subgraphs, and compression stages all fit together. The diagram shows states flowing from supervisor into researcher_sub_agent, through web_search, reflection, conduct_research, and compress_research, with dynamic subgraphs spun up for complex subtasks before merging back into a central state store. open deep research
Agent engineers can reuse this as a template for long‑running research workflows: it illustrates where to insert reflection loops, how to keep state explicit, and how to decompose large questions into smaller, independently evaluable paths without letting the whole thing devolve into a single opaque chat prompt.
Indie builder prototypes a beads‑based memory system for coding agents
An independent dev has spent the day turning a 5,500‑line plan into a beads‑based memory system for coding agents, using ACE‑style context engineering, a custom cass store, and a swarm of Claude Code Opus 4.5, GPT‑5.1 Codex Max, and Gemini 3 agents. He first asked multiple frontier models to propose memory designs, merged their suggestions into a master markdown plan, then used Claude Code to explode that plan into 347 "beads" (tiny, dependency‑linked tasks) and drive ~11.5k lines of TypeScript plus 151 passing tests in about 5 hours. (agent planning workflow, plan markdown link)

Claude’s own analysis pegs the system at 85–90% usable for real work—core CLI commands compile and pass tests while most remaining effort is test coverage and polish—showing how a carefully orchestrated agent swarm, explicit task graph (via the bv beads viewer), and tools like ubs for static checks can push beyond toy examples into something approaching a production agent ops stack. (plan document, beads status update)
Speechmatics positions real‑time diarization as a core primitive for voice agents
A new breakdown of Speechmatics’ speech APIs argues that accurate real‑time speaker diarization is now table stakes for serious voice agents, since they must know who said each word, not just transcribe audio. The API offers word‑level speaker labels like S1, S2, S3 via acoustic matching, supports deployment on‑prem or in your own cloud across 55+ languages, and exposes three modes—speaker, channel, and combined—plus knobs for sensitivity and speaker limits to balance false switches against missed turns. diarization explainer
For teams wiring assistants into phone systems, meetings, or multi‑party customer support, this puts a ready‑made building block under the "who said what when" problem so your agent logic can focus on routing and response generation instead of re‑implementing diarization from scratch. speech api page
Warp adds AI model profiles with per‑profile permissions and routing
Warp’s latest update introduces AI "profiles" that sit above raw model names: you can define profiles like Smart or Fast, bind each to a specific model, and configure what that profile is allowed to do (file writes, web search, MCP servers, etc.). A short demo shows a user flipping from a generic model list to a Profiles tab, editing the Smart profile’s permissions, and saving it, so future prompts route through that profile instead of specifying models and tools ad hoc. warp profiles demo

This gives infra and security leads a simple way to separate safe chat from more autonomous behaviors inside the same terminal: restrict one profile to read‑only tools, grant another profile access to browser or shell MCP servers, and update routing in one place rather than chasing hard‑coded model IDs in scripts.
(omitted)
(omitted)
⚙️ TPUs and accelerator economics: Ironwood, pricing gaps
TPU specifics and economics resurfaced today with new details on Ironwood and cost deltas vs GPUs, plus volume plans. This continues the week’s TPU momentum but adds concrete bandwidth/pod numbers and procurement signals.
Analyst: TPU v6/v7 undercut Nvidia GB200/300 by 20–50% per useful FLOP
A detailed cost breakdown argues that for hyperscale buyers, Google’s TPU v6e/v7 stacks deliver roughly 20–50% lower total cost per useful FLOP than Nvidia’s GB200/GB300 servers while staying close on raw performance, with on‑demand TPU v6e already listed at about $2.7 per chip‑hour versus around $5.5 per B200 GPU‑hour. tpu cost thread
The analysis says this advantage comes from Google buying TPU dies from Broadcom at lower margins, then building its own boards, racks and optical fabric, so internal pod costs are far below equivalent GPU systems; once you factor in higher effective FLOP utilization (pushing real jobs toward ~40% versus ~30% on many GPU clusters), the result can be up to 4× better tokens‑per‑dollar on some workloads.cost analysis article Ironwood‑class pods that connect up to 9,216 chips on a single fabric also keep more traffic on fast ICI instead of spilling to slower Ethernet/InfiniBand, and dedicated SparseCore plus dense HBM3E tilt economics toward memory bandwidth—though the flip side is that TPUs still demand more compiler and kernel engineering effort than Nvidia’s mature CUDA stack, so the savings are largest for labs that can afford strong in‑house systems teams. tpu cost thread
Anthropic’s reported $52B TPUv7 buy points to sovereign TPU data centers
Anthropic is reported to have signed a roughly $52B deal to purchase Google’s TPUv7 chips directly, rather than only renting them as cloud instances, which would mark a sharp shift away from Nvidia dependence and toward owning its own TPU‑based training and inference footprint. tpuv7 deal A SemiAnalysis report, cited in follow‑up discussion, characterizes this as a physical procurement model where labs buy TPUv7 hardware for their own or partner data centers, trading CUDA convenience for much lower long‑run cost curves if they port models to JAX or PyTorch‑XLA. (semianalysis link, tpuv7 analysis) Commentary around the deal notes that Google has started selling TPU systems outright to large customers, effectively turning itself into a second high‑end accelerator vendor alongside Nvidia and letting “sovereign labs” like Anthropic hedge GPU pricing while still accessing frontier‑class silicon. fortune ai race article For engineering leaders, this raises the stakes on multi‑backend support: investing in portable training stacks and TPU‑ready infra may soon be the difference between paying the full “Nvidia tax” and tapping into cheaper but more bespoke TPUv7 clusters at the scale of hundreds of thousands to a million chips.
Google details Ironwood TPU pods at 42.5 FP8 ExaFLOPS
Google’s seventh‑generation Ironwood TPU is now specced publicly at 4,614 FP8 TFLOPs per chip with 192 GB of HBM3E delivering up to 7.37 TB/s bandwidth, and pods that scale to 9,216 accelerators for about 42.5 FP8 ExaFLOPS—an order of magnitude above Nvidia’s GB300 NVL72 system at 0.36 ExaFLOPS. ironwood overview

The same pod design exposes roughly 1.77 PB of shared HBM3E over a proprietary 9.6 Tb/s inter‑chip fabric, underlining that Google is optimizing memory capacity and bandwidth at least as aggressively as raw FLOPs, which matters because LLM and MoE inference are increasingly HBM‑bound rather than compute‑bound. ironwood overview Teams building on TPUs now have a clearer architectural target for very large training runs and high‑throughput inference clusters, and can start thinking in terms of 9k‑chip jobs instead of the 72‑GPU ceiling of an NVL72‑class node. youtube unboxing
🧠 HBM is the bottleneck: memory‑centric AI systems
Multiple threads emphasize inference is memory‑bound; vendors pivot capex to HBM with price spikes expected. New today: detailed slides on intensity mismatch and expected DRAM/HBM trajectories; Micron’s Japan HBM fab plan.
HBM capex shift drives sharp DDR price hikes for AI
A new overview of the DRAM market says memory vendors are redirecting fab capex from low‑margin DDR4/DDR5 into high‑margin HBM for AI accelerators, and that this is already pushing conventional DRAM contract prices up quarter after quarter, with some DDR4 segments more than doubling in a few months. hbm economics thread
The chart cited projects the average DDR5 die price rising from roughly $8.5 in Q4 2025 to about $16 in Q4 2026, almost a 2× jump, as SK hynix (≈70% HBM share), Samsung, and Micron lock multi‑year HBM supply deals with hyperscalers who keep buying even as prices climb. hbm economics thread Following up on laptop prices, this explains why PC makers face higher BOM costs even as fabs add capacity: wafers once used for commodity DRAM are being retooled for HBM stacks, and vendors are still scarred from the last memory down‑cycle so they are reluctant to overbuild generic DDR again. For AI infra planners, the takeaway is that RAM in GPU servers will likely stay structurally expensive and price‑inelastic, so architectures that are memory‑frugal (MoE routing, KV cache eviction, low‑rank adapters) gain an even bigger economic edge.
LLM inference shown to be HBM‑bound rather than FLOP‑bound
Slides from a recent "Mind the Memory Gap" talk argue that for large LLMs the real constraint at inference is DRAM/HBM bandwidth, not raw FLOPs: a Llama‑405B example that should deliver ~6,000 tok/s on a 4,614 TFLOP chip ends up limited by memory intensity and KV cache traffic instead. memory gap thread
For engineers this means adding more tensor cores or moving to a nominally faster GPU often does little once HBM is saturated; wins come from raising arithmetic intensity and shrinking memory pressure (shorter sequences, cache quantization, better batching) rather than chasing peak TFLOPs. The talk also calls out that vendor marketing throughput numbers usually reflect idealized matrix shapes and 100% utilization, while real LLM decoding runs near 30–40% because most cycles stall on DRAM, so you should profile for bandwidth, not only FLOPs, when picking hardware or optimizing kernels. memory gap thread
Micron to spend ~$9.6B on new HBM fab in Hiroshima
Micron plans a dedicated high‑bandwidth memory fab in Hiroshima, investing about 1.5 trillion yen (~$9.6B) with Japan’s government expected to subsidize up to 500 billion yen—roughly one‑third of the cost—to ease HBM shortages and grab more of the AI accelerator market. micron hbm thread news article
The Hiroshima plant is slated to ramp around 2028 in the HBM4/HBM4E era, giving Micron a path toward ~25% HBM share alongside Nvidia and AMD partnerships while SK hynix and Samsung remain the other major suppliers. That timing lines up with forecasts that HBM output is now the main limiter on shipping top‑end AI systems, so this project both underlines how central memory has become to AI competitiveness and signals that tight HBM supply—and the DRAM price pressure it creates—may persist until these new lines come online late in the decade. hbm shortage context
🛡️ Safety & security: medical harm, jailbreak defenses, JS vulns
A strong safety trio today: a clinical harm benchmark (NOHARM), a jailbreak defense stack, and a JavaScript security benchmark showing LLM brittleness. Excludes Reddit “AI slop” governance chatter elsewhere.
NOHARM benchmark shows severe medical harms in ~22% of LLM consults
A new NOHARM benchmark built from 100 real primary‑care→specialist consults finds that even top general models still give severely harmful management advice in up to 22.2% of cases, with 76.6% of errors coming from omitting necessary tests, treatments, or referrals rather than suggesting bad extras NOHARM summary. Some of the best models beat generalist doctors on this metric by about 9.7 percentage points, and multi‑agent setups (one model checking another) cut harm by a further ~8 points, but many popular models remain well below a safe bar.
For anyone touching clinical features, the point is: you cannot infer safety from board‑exam style scores or generic benchmarks. NOHARM’s authors show only moderate correlation (r≈0.61–0.64) between common AI/knowledge benchmarks and actual harm rates, so a model that looks great on "medical QA" can still skip a life‑saving CT, miss a sepsis workup, or fail to refer a cardiac patient. This pushes teams toward explicit harm‑focused evals, chains of reviewer models, and very conservative deployment patterns (decision support, draft notes, structured triage) rather than fully automated care.
ARENAJS finds LLMs brittle at real-world JavaScript vulnerability detection
Another new benchmark, FORGEJS/ARENAJS, shows that large language models are not yet reliable security scanners for real JavaScript projects. The authors build vulnerable and fixed versions of OSS repos from public CVEs, add noise like obfuscation and scary‑looking but harmless sinks, then ask several commercial LLMs—under a strong "security analyst" prompt—to flag vulnerable files and functions js vuln benchmark. Models often look good at repo level but frequently miss the actual vulnerable function, lean on filenames or comments, and break badly once code is obfuscated or padded with misleading hints.
Under realistic false‑positive limits (what a real team would tolerate), most genuine vulnerabilities slip through, so these systems are nowhere near a drop‑in replacement for static analyzers or human reviewers. For security teams this suggests a safer pattern: use LLMs to explain or prioritize findings from traditional tools, or to help write tests and patches, not to be the primary detection engine. And if you’re selling or buying “AI code security” right now, ARENAJS gives you a concrete stress test to run before trusting anything with production defense.
Three-layer defense stack cuts jailbreak attacks to near zero in tests
A security paper from NUS researchers surveys jailbreak defenses and then tests a three‑part stack—prompt sanitization, logit steering toward refusals, and a MetaGPT‑style judge pipeline—that drives attack success rate on standard jailbreak benchmarks down to ~0 when all layers are enabled jailbreak defense. The workflow: clean/paraphrase the user input, apply a risk‑scored safety system prompt, nudge hidden activations toward refusal wording for risky continuations, then have a separate "judge" agent approve or block the core model’s draft answer.
The interesting bit for builders is the trade‑off surface. Prompt‑only and logit‑only defenses substantially reduce jailbreak success while keeping single‑call latency low; the full agent pipeline is much stronger but costs multiple model calls per query and more engineering. Because the logit steering operates at inference time and uses existing refusal features in mid‑layers, it offers a path for vendors to harden deployed models without full retraining. For production systems handling untrusted input (public chat, support bots, browser agents), this paper is a strong argument for combining cheap, always‑on mitigations with heavier, high‑risk‑only review flows rather than relying on a single static system prompt.
🏗️ Power and scale: DC buildouts and grid pressure
Fresh stats on capacity and power demand arrived: 2025 completions, 2035 outlook, and project lists. The story is grid and cooling constraints shaping AI rollout. Distinct from the TPU/memory angles.
US AI data center load seen hitting ~106 GW by 2035 as 1–5 GW campuses proliferate
Fresh BloombergNEF numbers say US data center power demand could climb from ~25 GW today to ~61.8 GW by the end of 2025 and roughly 106 GW by 2035, a ~4× jump driven largely by AI workloads. 2025 build stats This follows earlier talk that the AI race would hinge on power and build speed, now backed with concrete load projections and project lists rather than generalities power-build-view.
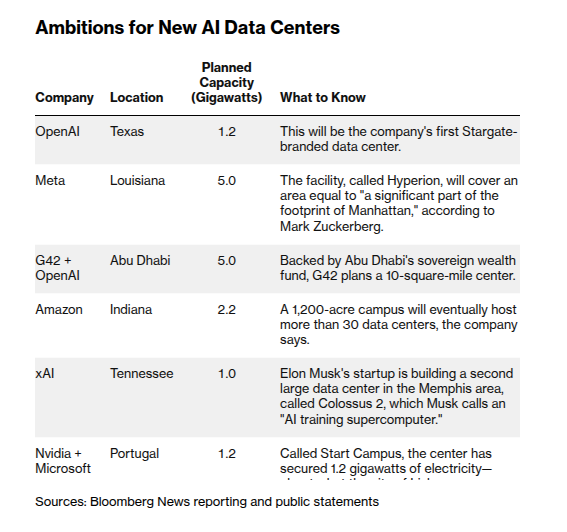
The 2025 pipeline alone includes more than 7 GW of capacity completing and another ~10 GW breaking ground, pushing utility power serving US data centers to 61.8 GW by year‑end, up 11.3 GW in a single year. 2025 build stats A Bloomberg feature adds texture: new AI campuses are sized at 1–5 GW each (about the load of 750,000 US homes for a 1 GW site), interconnection queues already top 2,300 GW with median waits near five years, and a 100 MW facility can need ~530,000 gallons of water per day for cooling. bloomberg feature The same reporting lists emblematic mega‑projects: OpenAI’s Stargate campus in Texas at 1.2 GW, Meta’s Hyperion build in Louisiana at 5 GW, G42’s 5 GW Abu Dhabi site, Amazon’s 2.2 GW Indiana campus, and xAI’s 1 GW Colossus 2 near Memphis. 2025 build stats These aren’t abstract plans; they’re concrete orders against already‑strained regional grids like PJM, which could see ~31 GW of extra data center load by 2035. pjm forecast For engineers and infra leads, the point is simple: grid and water constraints are now a first‑order design input for AI architectures and deployment. Multi‑region routing, aggressive efficiency work (quantization, caching, low‑rank adapters), and rethinking where to host latency‑tolerant jobs all become levers to live within GW‑scale caps. For business and policy folks, the numbers hint at friction: five‑year interconnect queues, local price spikes, and neighborhood pushback will shape how fast the next wave of AI capacity can actually come online, regardless of how many chips vendors ship.
Elon Musk pitches 100 GW per year of AI compute from solar‑powered satellites
Elon Musk is now arguing that the cheapest way to scale AI compute in a few years may be to move it off‑planet: satellites in sun‑synchronous low Earth orbit, each with ~100 kW of solar power, running localized AI inference and only beaming back results. space-compute thread
The sketch is aggressive: Musk claims launching about a megaton of satellites per year, each harvesting 100 kW, could add roughly 100 GW of AI compute capacity annually with no grid power, buildings, or on‑site staff, using Starlink lasers for high‑bandwidth backhaul. space-compute thread In a second step, he floats building satellite factories on the Moon and firing AI satellites into space via electromagnetic mass drivers, pointing to a path he says could eventually exceed 100 TW per year of added AI capacity.
For people running today’s data center roadmaps, this is still speculative, and the near‑term bottleneck is launch cost and in‑space servicing rather than chips. But it’s a useful extreme point when you think about long‑term constraints: if terrestrial grids, cooling water, and local permitting keep slowing 1–5 GW campuses on Earth, teams may eventually face a real architectural split between gravity‑bound AI (low latency, close to users) and orbital AI (cheap power, high throughput, higher latency). Even if you never deploy a model in orbit, the proposal underlines how central power has become to AI economics, and why infra teams are exploring every lever from small reactors to, now, satellites.
🎬 Creative stacks: NB Pro grids, Kling editing, one‑shot ads
High creator activity today: Nano Banana Pro grid workflows for character consistency, Kling O1 as ComfyUI partner node, and InVideo’s Money Shot for one‑shot commercials. Separate from model evals.
Nano Banana Pro 4-step grid workflow nails cinematic character shots
A new four-step Nano Banana Pro workflow shows how to turn a single character reference into production-ready cinematic stills with tight consistency across shots, building on earlier control tricks for NB Pro users NB Pro control. The process uses one prompt per step: a character grid, a cinematic environment grid, a combined 2×2 grid with multiple characters, then frame extraction ("extract frame number X") to lock in the final hero shot stepwise NB Pro guide.
For creators, this matters because it standardizes a repeatable recipe: you get a PR-style character sheet, then wide/medium/close-up compositions that all match costume, face, and lighting without hand-painting every angle resource roundup. The same grids are then fed into Higgsfield’s tools to animate or restyle, turning the still workflow into a bridge toward video without losing character identity.
InVideo’s Money Shot tool one-shots spec ads and launches $25k contest
Creators are showing that InVideo’s Money Shot can turn a handful of reference images plus a single prompt into a polished spec commercial in minutes, not days Money Shot ads. One example uses a few Nano Banana–generated shots of a fictional "Primbot 3000" robot and the prompt “Create an ad for the Primbot 3000, it's a robot assistant that creates anything you prompt for” to get a high-end, product-focused 10-second spot in one shot Money Shot workflow.

A follow-up clip shows the raw Money Shot output before voiceover, reinforcing that the tool handles framing, motion, and logo beats end to end
. InVideo is leaning into this with a $25k Money Shot Challenge for the best product ads, which effectively turns these one-shot workflows into a proving ground for AI-first commercial production. For video teams, the takeaway is clear: you can now prototype client-quality spots in an afternoon using AI renders as stand-in product shots, then iterate on copy and pacing rather than wrestling with timelines from scratch.
Kling O1 becomes a first-class ComfyUI partner for reference editing
Kling O1 is now exposed as an official Partner Node inside ComfyUI, turning it into a plug-and-play building block for reference-driven video editing graphs Kling ComfyUI. The node surfaces multi-reference consistency, camera control and movement references, plus object/character/background swap and restyling options, so you can wire complex edits without leaving your node graph Kling partner announcement.

Paired with NB Pro or other image models, this gives creators an end-to-end stack: synth a character or product once, then feed multiple stills into Kling O1 for smooth, consistent shots and camera moves—like the Messi mashups and character-consistent clips people are already posting NB Pro plus Kling. For ComfyUI power users, the big win is that you now treat Kling as "just another node" in your graph, not a separate web UI to manually babysit.
NB Pro shows deep game-world knowledge with Zelda creature renders
One creator stress-tested Nano Banana Pro’s world knowledge by asking it to render specific Zelda enemies—bokoblin, octorok, decayed guardian, and lizalfos—and got remarkably faithful, photoreal outputs for each Zelda test thread. The images capture correct anatomy and signature cues (like a guardian’s mossy spider body and octorok rock projectiles) while still leaning into NB Pro’s cinematic style.
For art teams, that’s a signal that NB Pro can act more like a concept artist who “knows the universe” rather than a generic texture engine: you can prompt at the lore level and expect recognizable, on-model designs. The flip side is legal and brand risk—these are clearly derivative of protected IP—so studios will want to treat this as internal exploration, not final shippable art.
💼 Enterprise & market moves: platform controls and usage
Market/enterprise signals: OpenAI UI controls, Anthropic M&A appetite for dev tools, assistant MAUs mix, and workforce adoption friction. New vs yesterday: app‑suggestions rollback and explicit MAU table.
Anthropic moves to own the dev tooling stack with Bun buy and more M&A
Anthropic is leaning hard into dev‑tool M&A, both acquiring JavaScript runtime and tooling project Bun and reportedly entering advanced talks to buy another developer tools startup as its first formal acquisition acquisition headline weekly roundup.
A widely shared take frames this as the “real platform play”: buy the tools where developers already live, then wire Claude Code in as the “house brain” for whole engineering orgs acquisition headline. The same roundup notes Claude Code has already hit a $1B run‑rate and Anthropic signed a $200M Snowflake partnership, underlining that coding and data workflows are where real cash is showing up weekly roundup. For AI leaders, the takeaway is simple: Anthropic isn’t just competing on model quality; it’s trying to control the entire coding stack surface area the way GitHub, VS Code, and JetBrains do today.
OpenAI disables ChatGPT in‑chat app suggestions after “ad” backlash
OpenAI has turned off the new in‑chat app suggestion tiles in ChatGPT after paid users complained they looked like ads for brands like Target and Peloton inside answers. TechCrunch reports that Mark Chen called the experiment a miss, saying suggestions were unpaid recommendations for ChatGPT apps but admitting they “fell short”, and that ranking will be tuned with an eventual user control to dial suggestions down or off openai ui change techcrunch article.
For AI product owners, this is a clear signal that mixing assistant output with commercial‑looking modules is a UX and trust minefield, especially when users already pay. It also shows OpenAI reacting more quickly to perception issues than in the earlier phase, when it flatly denied running ads even as screenshots of branded tiles circulated ads denial. Expect future app integrations to be framed much more clearly as tools you opted into, not as surprise shopping prompts inside core responses.
Anthropic worker study: 69% hide AI use from employers despite daily reliance
New numbers from Anthropic’s Interviewer project show that while most professionals now use AI tools daily, about 69% actively hide that use from managers or colleagues out of fear it makes them look replaceable anthropic study.
Following up on the same 1,250‑person study that found big time savings but high job anxiety worker study, commentary notes that workers “are afraid of losing their jobs and are using all sorts of arguments to ensure their safety”, and argues leaders need to make AI use explicitly safe and expected instead of a secret job loss comment. For engineering and ops heads, the message is that AI adoption is not just about giving people access—if you don’t normalize it in performance expectations and training, you’ll get shadow usage, skewed risk perceptions, and less reusable learning about what actually works.
Australia unveils $460M National AI Plan spanning infra, skills and safety
The Australian government has released a National AI Plan committing over A$700M (about US$460M) to AI over the next few years, built around three pillars: capturing economic opportunities, spreading benefits, and keeping Australians safe plan summary.
The one‑page overview lays out nine actions, including funding smarter infrastructure like data centers and networks, backing local AI capability through grants and an expanded National AI Centre, scaling AI adoption among SMEs, and setting up an Australian AI Safety Institute to assess risks and coordinate international norms plan summary. Australia already hosts 1,500+ AI companies and accounts for ~1.9% of global AI research, so this plan is about moving from scattered initiatives to a whole‑of‑economy push. For AI leaders and investors, it signals that mid‑sized economies are now racing to lock in their own AI stacks—skills, compute, and regulatory regimes—as a way to stay relevant in a world dominated by US and Chinese majors.
New MAU table shows Gemini closing on ChatGPT while Copilot usage stays flat
A fresh global MAU table for November 2025 pegs ChatGPT at ~810M monthly users, Microsoft 365 Copilot at ~212M, and Google Gemini at ~346M and rising, with smaller but fast‑growing assistants like Perplexity (~45M), Grok (~34M), and Claude (~11M) assistant maus table.
Compared with earlier estimates where Gemini trailed more heavily user mix, this update reinforces that incremental new users are skewing toward direct, consumer‑style AI assistants rather than deeply embedded enterprise tools. Copilot’s line is almost flat over the year despite Microsoft’s distribution advantage, while Gemini is adding tens of millions of MAUs quarter by quarter. For PMs deciding where to invest integrations and plugins, this suggests you should prioritize first‑party assistant surfaces (ChatGPT, Gemini, Perplexity, Grok) for reach, and treat office‑suite assistants more as retention and workflow depth than top‑of‑funnel growth.
Baidu cuts legacy units after 11.23B yuan loss while protecting AI talent
Baidu has started sweeping layoffs after posting an 11.23B yuan Q3 loss and a 7% revenue drop, with its Mobile Ecosystem Group reportedly shrinking by up to 40% while roles tied to AI and cloud are largely protected baidu layoffs.
Online ad revenue fell 18% year‑on‑year, and management is steering more spend into AI and cloud as competition heats up from Doubao (~157M monthly users) and DeepSeek (~143M), which both dwarf Baidu’s own Ernie at ~10.8M users baidu layoffs. For AI leaders, this is a textbook pivot: legacy consumer portals and ad businesses take the hit while AI infrastructure and model teams are shielded, which will likely intensify China’s open‑source and B2B AI competition even if Baidu’s consumer apps shrink.
US community colleges race to teach AI as basic job safety skill
A Harvard Gazette piece says US community colleges are scrambling to build AI into vocational programs, after research showing over 70% of employers now prefer candidates who understand AI and that AI already touches around 12% of jobs and automates tasks in ~17% of roles harvard summary harvard article.
Speakers at a Harvard Business School conference framed AI literacy as the new baseline for job safety rather than a nice‑to‑have, warning that slow‑moving colleges risk creating a fresh digital divide between workers who can drive AI tools and those who are sidelined by them harvard summary. For AI leads in industry, this is a signal that entry‑level talent will show up with some AI familiarity but uneven depth, and that partnering with local colleges or offering targeted micro‑credentials could help shape the kinds of skills (prompting, evaluation, safety practices) you actually need rather than getting flooded with shallow “AI‑certified” resumes.
Reddit struggles as AI-generated “slop” floods top subreddits with no reliable filters
A Wired story highlighted by AI watchers describes how moderators on large subreddits are being overwhelmed by low‑effort AI‑generated posts, with no dependable detection tools and growing reliance on guesswork about phrasing or account history reddit coverage.
The piece calls Reddit “one of the most human spaces left on the internet” and notes that mod efforts are now largely reactive and brittle, while the same AI‑written comments and posts are likely feeding future training data as “slop begets more slop”. For teams building AI products on top of user‑generated platforms, this is a warning: content quality and moderation costs are now a first‑order business risk, and any enterprise use of public forums for retrieval or evaluation will need explicit filtering, provenance checks, or higher‑trust data sources rather than assuming those feeds remain human‑dominant.
🧠 Agent learning by doing: world models, curiosity, co‑improvement
Research threads focus on agents learning via interaction and better human collaboration. New papers propose multi‑turn world‑model building, curiosity‑driven task synthesis, and Meta’s human‑AI co‑improvement roadmap.
CuES turns tool environments into self‑generated RL curricula
Tongyi Lab and Alibaba propose CuES, a curiosity‑driven task synthesis framework that lets an LLM agent invent its own training tasks from an environment’s tool descriptions and UI, addressing the "task scarcity" problem where real apps don’t come with labeled goals paper thread. CuES parses environment docs into objects, actions, and simple rules, lets an explorer agent try novel action chains while a memory tree avoids repeats, then clusters successful traces into goals plus step guides, filters them through an automatic checker, and finally rewrites them at different difficulty levels.
On three benchmarks (AppWorld, BFCL, WebShop), a 14B Qwen model trained on these synthesized tasks beats larger baselines that rely on hand‑curated datasets paper thread. For practitioners, the point is: if you can expose your app’s tools and screens, you may be able to bootstrap a rich RL curriculum from documentation plus curiosity instead of paying humans to author thousands of tasks.
WMAct teaches LLM agents compact world models via multi‑turn interaction
A new "Thinking by Doing" paper introduces WMAct, a framework where LLM agents build internal world models by acting for several steps in Maze, Sokoban, and Taxi grid worlds, then updating their understanding from actual outcomes instead of trying to plan everything in one giant thought upfront paper summary. Two key tricks are reward rescaling (only rewarding moves that change the state) and interaction frequency annealing (starting with many actions and tightening the limit so the model must think more), which together let a relatively small model solve many puzzles in a single shot that older agents needed trial‑and‑error dialogues for, while also improving math and coding benchmarks.
For people building agents, this is a concrete recipe for world‑model internalization rather than brittle prompt engineering: let the model act, watch the environment, and then distill those traces into a reusable internal simulator. It also suggests that structured exploration plus modest RL‑style feedback can give you better sample efficiency than ever‑larger context windows, which matters if you’re trying to run agents on constrained hardware or inside latency budgets.
Meta argues AI–human co‑improvement beats fully autonomous self‑improvement
A Meta research memo lays out a "co‑improvement" roadmap where models and human researchers advance together across the whole research cycle, instead of chasing fully autonomous self‑improving systems that might drift from human goals paper overview. The authors frame self‑improving AI as appealing but risky—once humans leave the loop, misaligned reward shaping and opaque code changes get hard to steer—so they propose training models for concrete collaboration skills like joint ideation, benchmark creation, experiment planning, ablation design, large‑scale result analysis, and clear write‑ups co-improvement comment.
This is directly relevant if you’re building "research copilots" rather than fully autonomous agents. The memo suggests treating AI like a colleague with strong pattern‑finding and execution abilities but keeping humans in charge of agenda, evaluation, and value judgments, and it implies future training runs that explicitly optimize for being a good lab partner—not just passing static benchmarks—using setups like multi‑agent debates, critique‑and‑revise loops, and shared research memories co-improvement pdf.
Agentic LLMs survey maps reasoning–acting–interacting and data-from-use
A broad survey from Leiden and collaborators pulls together work on "agentic LLMs" and organizes it into three buckets: reasoning and retrieval to improve decisions, tool‑using action models (including robots) to actually get things done, and multi‑agent systems to coordinate or simulate social behavior survey highlight. It argues that these strands feed each other—retrieval boosts tool use, reflection helps collaboration, and stronger reasoning helps everywhere—and that agentic setups can generate new training states during inference, partly offsetting the looming "we’re out of web data" problem.
For engineers and leads, the survey is a useful map of where agent research is dense vs. thin: we have lots of small demos and benchmarks, but fewer robust patterns for safety, liability, and long‑running control. It also pushes a mental shift from thinking of LLMs as one‑shot text predictors to ongoing processes that reason, act, and interact over time, which lines up with how many teams are now deploying agents in diagnosis, logistics, finance, and scientific workflows.
🧪 Training efficiency: Miles + FSDP2 backend
LMSYS adds PyTorch FSDP2 as a Miles training backend. Today’s posts highlight numerical alignment with Megatron and scripts to run Qwen3‑4B—useful signals for teams optimizing infra and schedules.
Miles adds FSDP2 backend aligned with Megatron and ready for Qwen3-4B
LMSYS has wired PyTorch’s new FSDP2 (DTensor-based Fully Sharded Data Parallel) in as a first‑class training backend for the Miles framework, reporting numerical alignment with Megatron while still supporting advanced features like Context Parallelism for large models. Miles fsdp thread Their blog walks through a fresh Qwen3‑4B training script using FSDP2 on Miles, including setup details and pointing to AtlasCloud and VerdaCloud runs as proof that the stack is ready for real multi‑GPU jobs. (fsdp howto link, Miles fsdp blog) For engineers, this means you can swap Megatron for Miles+FSDP2 without changing architectures, get sharded training via PyTorch’s mainline stack, and still keep context‑parallel scaling—useful if you want to standardize on PyTorch tooling while retaining efficient large‑model training behavior similar to existing Megatron pipelines.
💹 Finance agents: orchestration and semantic market links
Two finance‑focused research lines: orchestration frameworks for multi‑agent trading pipelines and LLMs discovering semantic relationships across prediction markets for edge. Distinct from general agent learning.
Agentic multi‑agent trading framework beats S&P 500 and Bitcoin baselines
A new Orchestration Framework for Financial Agents shows that a planner plus specialized data, alpha, risk, portfolio, execution, backtest, audit and memory agents can outperform simple buy‑and‑hold on both equities and crypto while cutting drawdowns. paper thread On an hourly 7‑stock test from 04/2024–12/2024 it returns 20.42% vs the S&P 500’s 15.97%, with a Sharpe of 2.63 and max drawdown of −3.59%; on minute‑level Bitcoin from 27/07/2025–13/08/2025 it earns 8.39% vs BTC’s 3.80% with smaller peak‑to‑trough loss.
The system keeps LLMs in the planning and explanation loop (GPT‑4o, Llama 3 suggested) while all numeric work and backtests run in code tools, and a memory agent stores hashed summaries so later runs get context without leaking raw price series, aiming to make algorithmic trading workflows more reusable and auditable.ArXiv paper
Semantic Trading agent finds profitable links across prediction markets
IBM and Columbia researchers introduce Semantic Trading, an agentic LLM pipeline that clusters related prediction markets, then identifies pairs whose outcomes should usually agree or disagree, turning those semantic links into trading signals. paper thread On historical Polymarket data, the agent’s high‑confidence same/opp‑outcome predictions are correct about 60–70% of the time, and a simple strategy that trades the second market after the first resolves delivers roughly 20% average return over week‑long holding periods, suggesting LLMs can mine overlapping question text and metadata for real economic edge rather than just surface summaries.
The system automatically groups markets, proposes relational hypotheses, validates them against resolved outcomes, and only then converts robust relationships into positions, offering a template for text‑driven systematic trading that doesn’t rely on engineered numerical features.ArXiv paper
🤖 Robotics in the field: construction, weeding, and mechs
Fresh real‑world demos: cooperative tower assembly for off‑world habitats, laser weeders without herbicides, and a piloted 4.5m humanoid. Mostly demo videos with applied relevance to embodied stacks.
GITAI robots autonomously assemble 5‑meter tower for off‑world habitats
GITAI demoed multiple industrial robot arms cooperatively assembling a self‑supporting 5‑meter tower segment, framed as a building block for future lunar and Martian surface habitats. GITAI construction tweet

The clip shows the system picking and placing truss modules without human intervention, which implies fairly mature perception, calibration, and multi‑arm planning for large, articulated structures—much closer to real construction constraints than tabletop demos. For AI engineers working on embodied stacks, this is a concrete example of autonomous task sequencing, collision‑aware motion planning, and error‑tolerant grasping in a domain (off‑world infrastructure) where labor is scarce and teleop latency is high. Leaders should read this as a signal that robotics plus LLM‑style planning is starting to escape the lab and target specific high‑value industrial tasks like in‑situ habitat assembly rather than generalized “household robots.”
Tsubame’s 4.5 m ARCHAX mech demonstrates piloted humanoid robot for heavy work
Tsubame Industries’ ARCHAX, a 4.5‑meter tall piloted humanoid robot, is shown walking and performing basic motions in a warehouse‑style environment, marketed for heavy industrial tasks. Archax overview

Specs in the clip highlight a 75 kg‑class machine with 26 degrees of freedom, force‑feedback controls, and a cockpit with 360° vision from nine cameras, positioning it somewhere between construction equipment and entertainment mechs. The interesting AI angle is the likely mix of direct teleoperation, low‑latency assistive control (stabilization, collision avoidance, motion mapping), and future autonomy layers that could offload repetitive movements. For robotics teams, it’s a reminder that near‑term demand may favor shared‑control systems—where humans handle intent and AI handles dynamics and safety—before fully autonomous humanoids become viable on real sites.
LaserWeeder G2 shows chemical‑free, vision‑guided weed removal in the field
A short field demo of the LaserWeeder G2 shows an agricultural robot using machine vision and high‑energy lasers to precisely kill weeds between crop rows, with no herbicide use. Laser weeder tweet

The robot moves down the bed while targeting individual plants, illustrating a mature perception‑to‑actuation loop: real‑time detection, classification (weed vs crop), targeting, and fire‑control under vibration and dust. For AI practitioners, this is a live deployment pattern where models must balance precision (avoid crops), throughput (cover hectares per day), and safety (eye and fire risks), and where robustness beats raw benchmark scores. Infra and ag leaders should note that this kind of system directly substitutes chemicals with inference and power, shifting spend from herbicides to sensors, GPUs, and maintenance contracts.
🗣️ Realtime voice agents: UX and pipeline hints
Smaller but notable voice items: Grok voice praised for latency/conversational timing; Gemini web adds ‘share screen for live translation’ flag. Quiet on new voice model releases today.
Gemini Live web adds ‘share screen for live translation’ entry point
Google’s Gemini web UI now exposes a “Share screen for live translation” flow, a concrete step toward desktop Gemini Live handling real‑time speech and on‑screen content together live translation rt. Following up on earlier hints that Gemini Live was coming to the browser Gemini Live web, this new affordance suggests Google is wiring full A/V capture and streaming into its web agent pipeline, which matters if you want live-captioned calls, bilingual screen‑share demos, or on‑the‑fly translation of documents without leaving the browser.
Grok voice mode emerges as fastest, most natural option for tasking
Builders are starting to treat Grok’s voice mode as their default conversational interface for agents, mainly because of how fast and interruptible it feels in practice. One engineer says it has “crazy fast latency” and that the timing and flow make it easy to both ask questions and assign tasks in one continuous interaction, while Gemini Flash voice feels only slightly ahead of GPT voice and still constrained grok voice comment. For anyone wiring up spoken tasking into real workflows, this is an early signal that xAI’s stack is competitive on the one dimension that matters most for voice UX: tight turn‑taking and low perceived delay, even if the underlying model isn’t yet the strongest on paper.