NVIDIA Nemotron 3 Nano opens 30B‑param stack – 1M‑token context rivals GPT‑OSS
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
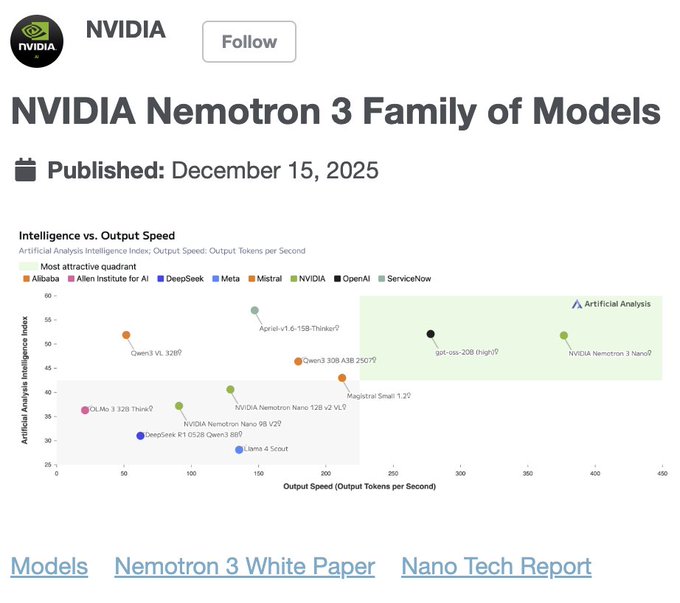
NVIDIA finally shipped the kind of open model we usually beg for on Twitter: Nemotron 3 Nano, a 30B‑param hybrid Mamba‑Transformer MoE with only 3.6B active parameters and a 1M‑token context window, trained on ~3T tokens and released with weights, data recipe, and RL environments. On Artificial Analysis’s Intelligence Index it scores 52, matching gpt‑oss‑20B while posting 3.3× the tokens/sec/GPU of Qwen3‑30B in 8k/16k tests.
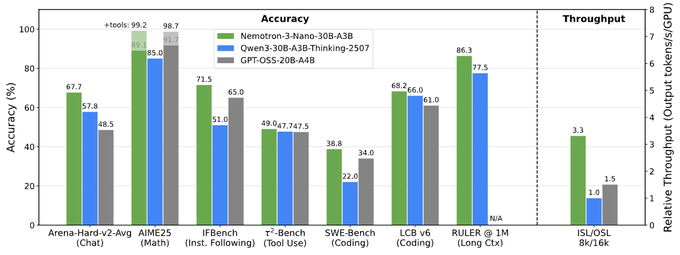
Benchmarks back up the hype curve: Arena‑Hard‑v2 chat comes in at 67.7 vs 57.8 for Qwen3‑30B and 48.5 for GPT‑OSS‑20B, SWE‑Bench hits 38.8% vs 34.0 and 22.0, and on RULER at 1M tokens it lands 86.3 where Qwen3‑30B sits at 77.5 and GPT‑OSS does not even report. Architecturally you get a moderate‑sparsity MoE wired with Mamba‑2 sequence layers, so the million‑token context doesn’t nuke throughput the way dense 30B models tend to.
The ecosystem clearly expected this drop: vLLM, SGLang, Together, Baseten, Replicate, OpenRouter, and Ollama all had Day‑0 support, with Baseten calling out 4× generation speed over Nemotron 2 and LM Studio users reporting ~27 tok/s on a 24GB 3090. With Percy Liang and Artificial Analysis both calling it a new openness high bar, Nemotron 3 Nano looks like the current default if you want GPT‑OSS‑class reasoning without API lock‑in.
Top links today
- RLHF book for RL from human feedback
- LabelFusion robust text classification with LLMs
- Weird generalization and inductive backdoors in LLMs
- Detailed balance in LLM-driven agents
- Impact of hallucination reduction on LLM creativity
- Alpha coefficient framework for AI autonomy
- AI benchmark democratization and carpentry overview
- Evaluating Gemini robotics policies in Veo
- Artemis automated optimization of LLM agents
- Bolmo byte-level language model distillation paper
- IDC report on AI-driven server revenue
- Analysis of DRAM shortage and 8GB laptops
- Samsung–AMD talks on 2nm CPU manufacturing
- CNBC analysis of AI infrastructure capex selloff
- Statista chart of leading global AI hubs
Feature Spotlight
Feature: NVIDIA Nemotron 3 Nano goes fully open
NVIDIA’s Nemotron 3 Nano (30B MoE, 1M ctx) ships fully open with data, recipes and NeMo Gym; early benchmarks show top small‑model accuracy and 2.2–3.3× throughput gains—plus Day‑0 support across major runtimes.
Cross‑account, high‑volume story today: NVIDIA’s 30B (3.6B active) hybrid MoE model ships with open weights, data, training recipe and RL envs; broad Day‑0 ecosystem support and strong speed/accuracy charts.
Jump to Feature: NVIDIA Nemotron 3 Nano goes fully open topicsTable of Contents
🟩 Feature: NVIDIA Nemotron 3 Nano goes fully open
Cross‑account, high‑volume story today: NVIDIA’s 30B (3.6B active) hybrid MoE model ships with open weights, data, training recipe and RL envs; broad Day‑0 ecosystem support and strong speed/accuracy charts.
NVIDIA launches fully open Nemotron 3 Nano hybrid MoE model
NVIDIA has debuted Nemotron 3 Nano, a 30B‑parameter hybrid Mamba‑Transformer Mixture‑of‑Experts model with only ~3.6B active parameters per token, a 1M‑token context window, and a fully open stack: weights, training recipe, redistributable datasets, and RL environments. (release overview, newsroom summary)
The model is trained on roughly 3T tokens and shipped under the NVIDIA Open Model License, which allows commercial use and training of derivatives while keeping the stack transparent (open weights, data curation, and methodology). NVIDIA is also releasing NeMo Gym, a suite of multi‑environment reinforcement learning setups plus NeMo RL tooling so teams can continue post‑training and skill acquisition for agentic workflows on top of Nemotron 3 Nano. newsroom article tech blog
Architecturally, Nemotron 3 Nano mixes Mamba‑2 sequence layers, Transformer attention, and a moderate‑sparsity MoE (31.6B total params, 3.6B active) tuned for long‑context reasoning at reasonable inference cost, which is why it can offer a 1M context window without the throughput collapse you see in many dense 30B models. architecture chart For engineers and researchers, the big change is that NVIDIA isn’t just dropping a checkpoint: you get the pretraining corpus description, RL environments, and recipes for NVFP4 low‑precision training and latent‑MoE routing that you can actually replicate or adapt, making Nemotron 3 Nano feel more like a reference platform than a one‑off model.
Nemotron 3 Nano matches GPT‑OSS 20B on IQ index and beats Qwen3‑30B
On Artificial Analysis’s Intelligence Index, Nemotron 3 Nano scores 52 points, matching OpenAI’s gpt‑oss‑20B (high) and Qwen3 VL 32B, while beating Qwen3‑30B A3B 2507 by +6 points and NVIDIA’s own previous Nemotron Nano 9B v2 by +15. intelligence index chart
Task‑by‑task charts show why: on Arena‑Hard‑v2 chat it reaches 67.7 vs Qwen3‑30B’s 57.8 and GPT‑OSS‑20B’s 48.5; on SWE‑Bench it hits 38.8% vs 34.0% (GPT‑OSS‑20B) and 22.0% (Qwen3‑30B); and on long‑context RULER @ 1M it posts 86.3 vs 77.5 for Qwen3‑30B while GPT‑OSS doesn’t even report at that length. benchmark bars Despite the MoE complexity, throughput on an 8k/16k ISL/OSL benchmark is 3.3× relative tokens/sec/GPU vs Qwen3‑30B’s 1.0× and GPT‑OSS‑20B’s 1.5×, which is a big deal if you’re paying per token for multi‑agent workflows. benchmark bars Artificial Analysis also places Nemotron 3 Nano firmly in the “most attractive quadrant” of their Openness vs Intelligence plot: it combines a mid‑50s intelligence score with an openness index around 70 (open weights, data, recipe), something few small reasoning models manage today. openness plot The upshot: if you want GPT‑OSS‑level reasoning in an open model but care about speed and context length, Nemotron 3 Nano is now one of the most compelling 30B‑class options on paper.
vLLM, SGLang, Together, Baseten, Replicate, Ollama and more ship Day‑0 Nemotron 3 support
The open‑model ecosystem moved fast: by launch day, Nemotron 3 Nano endpoints were already live across vLLM, SGLang, Together AI, Baseten, Replicate, OpenRouter, Ollama and others, making it trivial to A/B it against existing 20–30B models. (vllm announcement, sglang support)
vLLM added Nemotron 3 as a first‑class model in its Omni stack so you can serve it with paged attention and tensor parallelism, while SGLang shipped “Day‑0” support plus a new Cookbook entry with ready‑made BF16/FP8 deployment commands. vllm blog cookbook page
On the hosted side, Together AI announced Nemotron 3 Nano on their platform, pitching it for multi‑agent workflows, coding, and reasoning, and highlighting the hybrid MoE design and 1M context as a good fit for “agentic AI” backends. together thread Baseten, Replicate, and OpenRouter all exposed serverless or pay‑per‑call endpoints—Baseten calls out 4× token‑generation speed vs Nemotron 2 Nano in its write‑up, while Replicate and OpenRouter position it among their default open‑weights reasoning models. (baseten blog, replicate model) For local and edge experiments, Ollama added nemotron-3-nano variants for both local GPUs and a :30b-cloud mode, and LM Studio users are already reporting running 30B Q3_K_L quantizations at ~27 tok/s on 24GB 3090s. (ollama support, lmstudio screenshot) For infra and agent engineers, the message is clear: you don’t have to wait for custom Docker builds or hand‑rolled loaders—Nemotron 3 Nano is already wired into most of the tooling you likely use.
Researchers hail Nemotron 3 Nano as a new high bar for open models
Key open‑model researchers are openly framing Nemotron 3 as a turning point: Percy Liang highlights that NVIDIA didn’t just release a strong model but also its training data, RL environments, and training code—calling that level of transparency rare among frontier‑class models. percy liang comment
Artificial Analysis notes that Nemotron 3 Nano scores 52 on their Intelligence Index with a 67‑point Openness Index, putting it on par with gpt‑oss‑20B (high) in raw capability while being far more open in licensing and methodology. intelligence index chart From the open‑source tooling side, people behind other high‑profile models and evals are explicitly “honored to be competing with Nvidia for the best models with open data, checkpoints, and code,” and some are already benchmarking Nemotron 3 alongside their own stacks. (nat lambert reaction, open source praise) Community commentary keeps circling back to the same point: Qwen, DeepSeek, and Kimi had started to define the frontier of open small models, but Nemotron 3 Nano is the first from a major GPU vendor that ships with this much reproducible scaffolding (data, RL envs, recipes), making it feel less like a marketing drop and more like infrastructure other labs can build on.
🗣️ Realtime speech stack steps up
Multiple concrete voice updates: OpenAI’s new audio snapshots with large WER/hallucination cuts, Gemini’s native audio gains, and open TTS (Chatterbox Turbo) landing on infra. Excludes NVIDIA feature.
OpenAI refreshes realtime STT, TTS and realtime-mini with big quality gains
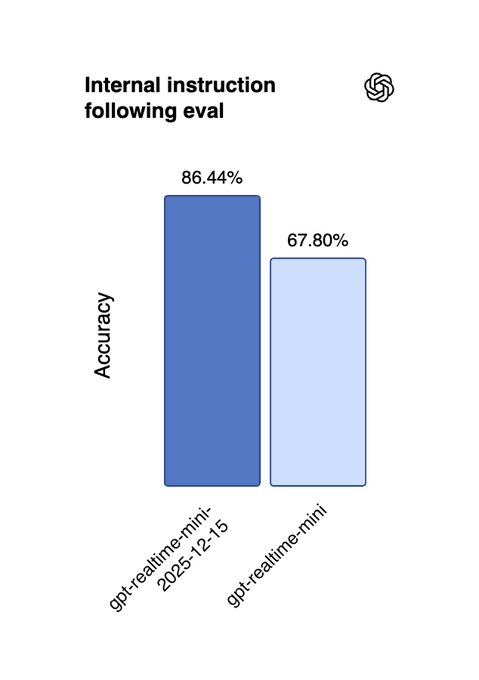
OpenAI rolled out new audio model snapshots for speech‑to‑text, text‑to‑speech and realtime agents, plus a new gpt-audio-mini-2025-12-15 completion model, all focused on lower hallucinations and stronger multilingual support. audio metrics thread These are already wired into the Realtime API and platform UI, so they’re usable today for builders betting on voice.
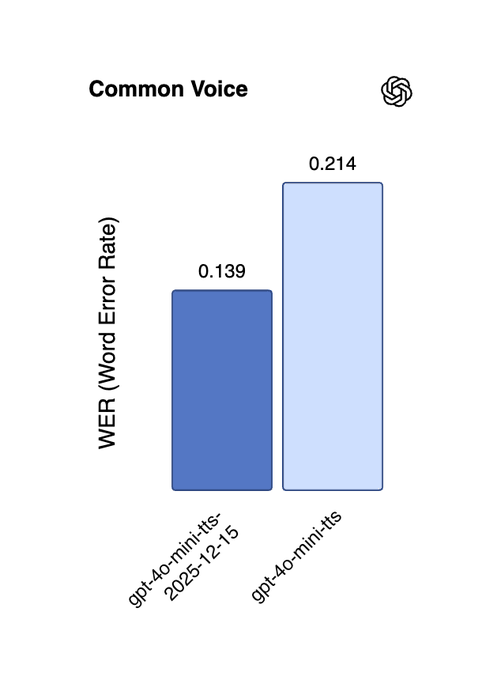
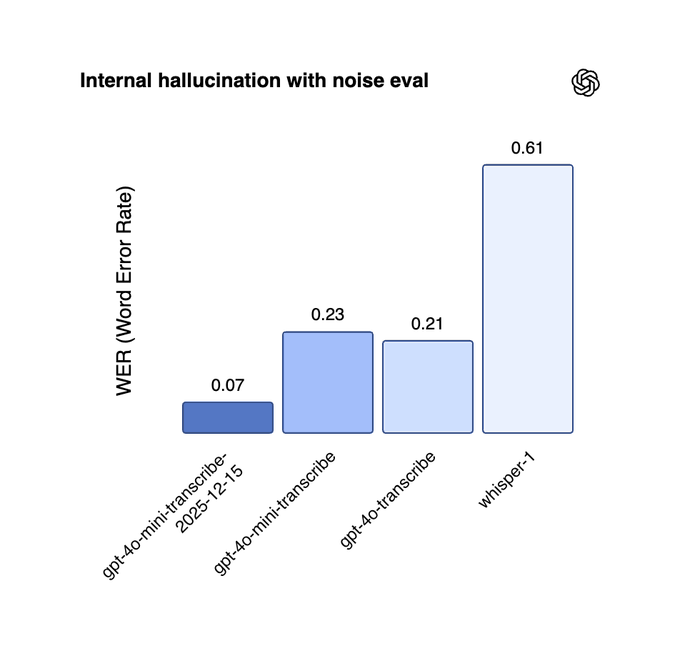
The new gpt-4o-mini-transcribe-2025-12-15 cuts word error rate on an internal noisy eval from 0.61 with whisper-1 to 0.07, a roughly 89% hallucination reduction on that benchmark. audio metrics thread gpt-4o-mini-tts-2025-12-15 reduces word errors on Common Voice from 0.214 to 0.139, about 35% fewer mistakes, and the updated gpt-realtime-mini-2025-12-15 jumps instruction‑following accuracy from 67.8% to 86.44% with a 13% function‑calling gain. audio metrics thread OpenAI also calls out better performance in Chinese, Japanese, Indonesian, Hindi, Bengali and Italian, which matters if you’re shipping non‑English agents.
In the platform UI, the new realtime model variants show up as selectable options in the Audio playground, realtime model picker and gpt-audio-mini-2025-12-15 appears as a text+audio Completions model with the Alloy voice and 2,048 output tokens for streaming TTS. completions audio ui That makes it straightforward to prototype both classic "voice mode" chat and server‑side call center style use cases without juggling separate STT/TTS services.
So the point is: if your current stack still leans on whisper-1 and older 4o-mini audio, there’s now a drop‑in upgrade path that buys you fewer hallucinated transcripts, cleaner multilingual output, and smarter realtime agents without changing APIs.
- Route noisy or accented calls through
gpt-4o-mini-transcribe-2025-12-15and compare WER on your own data. - Swap existing TTS to the new
gpt-4o-mini-tts-2025-12-15and A/B user comprehension or ASR‑round‑trip accuracy. - Test
gpt-realtime-mini-2025-12-15in a narrow agent flow (one skill) before rolling it out across your app. - Try
gpt-audio-mini-2025-12-15for server‑driven voice responses instead of stitching separate STT and TTS calls.
For teams building voice UX, this is one of those low‑friction upgrades that’s worth a quick benchmark pass this week: same endpoints, but noticeably better behavior and more languages that "just work" for users.
Chatterbox Turbo open-source TTS spreads across fal, Replicate and Modal
ResembleAI’s Chatterbox Turbo, an open‑source TTS model tuned for real‑time agents, is rapidly landing on major inference platforms like fal, Replicate and Modal. (release overview, fal launch) For anyone cobbling together low‑latency voice UX from proprietary APIs, this is a credible open alternative worth testing.

Chatterbox Turbo is designed around speed and expressiveness: time‑to‑first‑sound under ~150–200 ms, up to 6× faster‑than‑real‑time synthesis, and support for inline paralinguistic tags like [sigh], [laugh], [chuckle], and [gasp] that render in the same cloned voice. (release overview, fal launch) It can do zero‑shot voice cloning from about 5 seconds of audio and includes PerTh watermarking so you can later verify that an audio clip came from the model. release overview On a head‑to‑head listening test, listeners preferred Chatterbox Turbo over ElevenLabs Turbo v2.5, Cartesia Sonic 3, and VibeVoice 7B in most matchups, with preference rates like 65.3% vs ElevenLabs and 59.1% vs VibeVoice. tts benchmarks Infra‑wise, the model is now a first‑class citizen in multiple ecosystems: fal exposes it as a high‑speed streaming endpoint for real‑time apps, fal launch Replicate hosts it as an API for batch or app‑embedded use, replicate deployment and Modal partnered with Resemble to autoscale it on GPUs so you can run your own TTS service rather than relying on third‑party SaaS. modal partnership The core weights and code live on Hugging Face,huggingface repo which makes self‑hosting or fine‑tuning feasible if you need domain‑specific voices.
- Swap one of your existing TTS calls to Chatterbox Turbo on fal or Replicate and log time‑to‑first‑token vs your current vendor.
- Use the paralinguistic tags in a support or game agent to see whether users perceive the responses as more engaging.
- If you have compliance needs, test the PerTh watermark pipeline end‑to‑end so you can audit generated audio later.
Open TTS has lagged behind STT for a while; Chatterbox Turbo is one of the first batteries‑included options that feels ready for real conversational agents rather than offline narration alone.
Gemini 2.5 Flash Native Audio gets stronger tools and live translation surfaces
Google published hard numbers for the upgraded Gemini 2.5 Flash Native Audio stack and started rolling speech‑to‑speech translation into the Google Translate app, after earlier anecdotal reports of a quality bump in Flash’s native audio mode. (Flash audio jump, previous audio report) For voice agent builders in the Google ecosystem, this clarifies where Gemini audio is already good enough and where it’s still catching up.

On the function‑calling side, Gemini 2.5 Flash Native Audio now scores 71.5% on ComplexFuncBench audio, beating earlier September‑era Flash variants (66.0%) and the gpt-realtime baseline (66.5%). audio metrics thread Internal evals show developer instruction adherence moving from 84% to 90%, and overall conversational quality from 62% to 83%, which is the part that should make live phone or in‑app assistants feel less janky over multi‑turn conversations. audio metrics thread At the same time, Gemini is now powering live speech‑to‑speech translation in the Google Translate app on Android in the US, Mexico and India, covering 70+ languages and 2,000+ language pairs, with iOS support on the way. translate feature thread That experience preserves intonation, pacing and pitch instead of doing a flat "robot voice" re‑read, and it handles continuous listening plus two‑way, speaker‑aware sessions.
Under the hood, these same models back Gemini Live, AI Studio, Vertex AI, and now Search Live, so improvements to Flash Native Audio’s instruction‑following and tool‑use feed directly into how well agents can drive APIs or fetch context while talking. audio metrics thread If you’re already using Gemini for chat or code, the obvious next step is to test whether these audio upgrades let you consolidate onto one model for both text and speech.
- Prototype a small voice agent in Gemini Live or AI Studio and see if the 90% instruction adherence shows up in your logs.
- For translation, measure round‑trip comprehension and lag against your current stack on a few languages that matter to you.
- If you run function‑calling agents, port one workflow (like bookings or FAQs) to 2.5 Flash Native Audio and see whether tool errors drop.
Taken together, Gemini’s audio story is maturing from "neat demo" to something you can reasonably plug into customer‑facing workflows, especially if you are already bought into the broader Gemini platform for search, email or apps.
MiniMax Speech lands on Retell AI with sub‑250 ms latency
Voice infra provider Retell AI added support for MiniMax Speech, giving developers another high‑quality, low‑latency TTS option for call‑like agents. retell announcement The headline claim is human‑like delivery with under 250 ms latency, 40+ language support and more than 10 distinct voices.
For teams already on Retell’s stack, this means you can flip a config switch rather than wiring up a new TTS vendor and still get multi‑language, near‑real‑time synthesis for bots that talk on the phone, in apps, or in browsers. retell announcement The marketing emphasizes that reactions and style stay natural at these latencies, which is the difference between a bot that feels like an IVR tree and one that feels like a conversation.
- If you use Retell today, spin up a test agent with MiniMax Speech and measure perceived lag vs your existing voice.
- Try a few non‑English flows to see whether the 40+ language claim holds up for your markets.
It’s a smaller update than a brand‑new model launch, but it nudges the ecosystem toward a world where swapping strong TTS backends inside a single telephony platform is normal, not a months‑long integration.
🧰 Agent stacks and coding workflows
Material updates for building agents/coding with AI: IBM’s enterprise agent scaffold, Qwen Code 0.5 release, hands‑on Claude Code and Kilo Cloud flows, and Warp’s cloud runners. Excludes NVIDIA feature.
Mino offers a production web automation API that learns once, then runs deterministic flows
TinyFish’s Mino is emerging as a credible answer to the “browser agent that actually works” problem: it uses LLMs once to learn how a site works, then compiles that into deterministic code that can be rerun cheaply and reliably. Mino overview

Instead of paying for a model call on every click, scroll, and form fill, you pay for a single exploration run, after which Mino executes workflows in 10–30 seconds with 85–95% accuracy for pennies per task. Mino overview Developers get a simple interface—send a URL plus a natural‑language goal, receive structured JSON back—and the system handles logins, captchas, dynamic JS content, and multi‑step flows on sites that will never ship APIs. Mino overview Stealth browser profiles and proxy settings are built‑in to avoid Cloudflare‑style blocks. stealth description It’s already available via HTTP API, a hosted UI, and an MCP server for tools like Claude Desktop, Cursor, n8n, and Zapier. Mino promo For agent builders, this flips the usual calculus: instead of fighting brittle Playwright scripts or burning money watching a model “guess what to click,” you can delegate all web interaction to a specialist layer and let your main agent focus on planning and reasoning over the resulting structured data.
Anthropic publishes “Effective harnesses” blueprint for long-running Claude agents
Anthropic shared an engineering deep‑dive on how to keep Claude‑based agents productive across many context windows, proposing a two‑agent harness pattern inside the Claude Agent SDK: an initializer agent that sets up the project once, and a coding agent that makes small, well‑documented increments each session. (Anthropic overview, engineering blog)
The post dissects two common failure modes—agents trying to do everything in one pass and leaving half‑implemented features, and agents prematurely declaring a task “done”—and shows how to counter them with explicit artifacts: a feature_list.json where everything starts as failing, setup scripts like init.sh, progress logs, and tightly scoped TODOs per run. The key idea is to treat the harness like a human team lead: limit the blast radius of each session, insist on clean handoffs (commits, notes, updated feature states), and let Anthropic’s automatic context compaction handle history while you explicitly control what survives into the next window. If you’re struggling with Claude agents that wander or thrash on big refactors, this gives you a concrete structure to copy instead of endlessly tweaking a single “do everything” prompt.
HyperBookLM open-sources a NotebookLM-style agent for web and PDF research
Hyperbrowser released HyperBookLM, an open‑source clone of Google’s NotebookLM that bakes web agents into a research workflow: you drop in URLs, PDFs, or text files and it lets you chat across all sources, generate structured mind maps, auto‑build slide decks, and even produce audio summaries you can listen to. (HyperBookLM launch, GitHub repo) Under the hood it uses the Hyperbrowser API for robust web scraping and retrieval, so the same stack that powers agents in production is now wrapped in a batteries‑included research UI.
This gives engineering and research teams a self‑hostable alternative to proprietary tools: you can keep sensitive corpora inside your own VPC, customize the agent’s behavior in code, and tie the outputs—slides, markdown, audio—into your existing knowledge base. If you’ve been experimenting with NotebookLM‑style workflows but need tighter control over data and model choice, HyperBookLM looks like a strong starting point rather than another half‑finished RAG demo.
Qwen Code v0.5.0 tightens dev loop with VSCode bundle and TS SDK
Qwen shipped Code v0.5.0, turning it into a more complete coding‑agent stack by bundling the CLI directly into its VSCode extension, adding a native TypeScript/Node SDK, and improving long‑lived session handling. release thread That means you can npm install -g @qwen-code/qwen-code, drive agents from TS, let conversations auto‑save and resume, and even point the stack at OpenAI‑compatible reasoning models like DeepSeek V3.2 or Kimi‑K2 via custom tool servers. GitHub release For engineers, this moves Qwen Code from “fun terminal toy” toward a realistic daily driver: you can standardize on one CLI across editor and CI, internationalize the UI (Russian landed in this release), and lean on better Ubuntu shell support and shorter SDK timeouts when wiring it into automated workflows. The interesting bit is how explicitly it targets the emerging multi‑model world—if you’re already experimenting with thinking models for planning and smaller ones for execution, Qwen Code now gives you a single harness to orchestrate them instead of a pile of bespoke scripts.
Warp details cloud sandboxes for ambient coding agents powered by Namespace
Warp published a deep‑dive on how its new cloud runners work: when you kick off coding agents from Slack, Linear, or other tools, those tasks actually run inside fast, multi‑tenant sandboxes provided by Namespace on high‑quality hardware, not on your laptop. (Warp blog mention, architecture blog)
Each sandbox is an isolated environment that can build, test, and run your code with CI‑grade performance, while Warp’s UI surfaces the agent’s output and lets you inspect or intervene.
Following up on earlier work to let agents see live terminal context inside Warp sessions, agent context this is the infrastructure piece that makes “ambient” agents viable: you can trigger them from chat, they spin up reproducible environments in the cloud, and they don’t need your machine to stay awake. For infra and platform engineers, the takeaway is simple: if you want agents to own more of your dev loop, you probably need something like Namespace or Firecracker under them, not a long‑running process on someone’s MacBook.
Claude Code users share harness tricks and pain points around context and subagents
Practitioners are starting to converge on a few “do this first” settings for Claude Code. One common tip is to disable auto‑compaction so you can use more of the raw context window and trigger compaction only when you actually need to free space, instead of having Claude aggressively summarize past steps mid‑session. context tip That makes it easier to run deep refactors or multi‑file migrations without losing important details to over‑eager summarization.
At the same time, some users are running into rough edges with subagents: one report describes RAM usage exploding past 100 GB on Linux when using subagents heavily, RAM bug report while another thread asks why async subagents still stream their tool calls into the parent’s context, seemingly defeating the goal of hiding that chatter from the main agent’s token budget. async subagents question An Anthropic engineer confirms some of this is by design (to enable monitoring) but suggests there’s room to tweak how often and how much subagent output is surfaced. Anthropic reply Taken together, it’s a good reminder that Claude Code is both powerful and young: you can get big gains by tuning compaction and being deliberate about subagent usage, but you should still watch memory and context footprints, especially on large monorepos.
CopilotKit’s A2UI Widget Builder helps ship agent UIs that follow Google’s new spec
CopilotKit launched an A2UI Widget Builder: an interactive playground and template that lets you assemble UI widgets conforming to Google’s new A2UI spec and then drop them into your own app. A2UI builder intro

The builder ships with a gallery of premade widgets, a library of ~100 common Material icons, and a panel showing the source code and props for each component, all wired up through CopilotKit so you can use chat and generative UI to tweak designs on the fly.
For anyone building agent‑driven products, this bridges a growing gap: backends are standardizing around MCP, tools, and structured outputs, but frontend patterns for “AI widgets” have been all over the place. By aligning with A2UI, CopilotKit is betting that agent UIs will look more like a standard component kit than bespoke chat windows. If you’re already using CopilotKit for in‑app copilots, this is likely the fastest way to experiment with A2UI without hand‑coding every button and panel.
Kilo Cloud links PR reviews to one-click agent sessions that auto-fix code
Kilo showed a neat bridge between static AI code review and hands‑on fixing: when its review agent flags an issue on a GitHub PR, it now adds a “Fix in Kilo Cloud” link that opens a cloud agent session preloaded with full context for that PR. Kilo PR demo

From there, the agent can apply the fix, run tests, and push commits straight back to the branch, turning review comments into executable work instead of todos for the human author.
It’s a small UX change, but it hints at where coding workflows are heading: reviewers stop at diagnosing problems, and agents get their own ephemeral environments to implement, validate, and iterate. If you already trust AI to suggest diffs, Kilo’s model is a blueprint for giving those suggestions a proper execution surface instead of copy‑pasting patch hunks into your editor.
LangSmith walkthrough shows how to observe, validate and debug deep agents
LangChain released a new LangSmith video showing how to keep long‑running agents from turning into an untraceable mess, using an email‑triage agent as the worked example. LangSmith video The session walks through defining a deep agent in a single file (tools, prompts, memory), designing a real system prompt that encodes the agent’s behavior, and then using LangSmith traces to watch every tool call, intermediate thought, and decision.
The important bit is the validation loop: they don’t just eyeball traces, they wire in checks for whether the agent picked the right action on each email—archive, reply, escalate—and treat that as a regression harness. For anyone building agents that run for minutes or hours, this is a reminder that you need observability and test fixtures as much as you need a better model; LangSmith here acts less like “LLM logging” and more like a debugger + unit test runner for your agent’s brain.
Manus 1.6 upgrades its agent architecture, with Max variant scoring 19% higher
Manus announced version 1.6 of its agent system along with a higher‑end Manus 1.6 Max tier, claiming a 19% performance lift on internal benchmarks for the Max configuration. Manus upgrade tweet

The release focuses on agents doing “more complex work with less supervision,” which in Manus’ case usually means multi‑step productivity and coding tasks coordinated through its GUI.
While details are light, the framing suggests they’ve reworked the core orchestration layer—how the agent plans, calls tools, and checks its own work—rather than just swapping models. For teams already piloting Manus, this is a cue to rerun your hardest workflows (multi‑repo changes, multi‑app integrations) and see whether the new architecture actually reduces the amount of babysitting required. If you haven’t touched Manus yet, 1.6 is a more interesting baseline than earlier releases for evaluating whether its “agent OS” model can offload real chunks of engineering and ops work.
📊 Evals: agents hit desktops, pros certs, and horizon forecasts
Today’s evals center on real desktop agents (OSWorld), professional exams (CFA), and capability forecasting (ECI→METR), plus a GPT‑5.2 fact‑check case and censorship leaderboard.
OSWorld desktop benchmark hits ~human-level with Opus 4.5 + GPT‑5 agent
A new OSWorld run shows an "agent s3" stack using Claude Opus 4.5 plus a GPT‑5-based best‑of‑N policy solving 72.6% of full desktop tasks, roughly matching human success on this benchmark of real computer workflows. osworld benchmark
OSWorld evaluates agents on realistic multi‑step tasks across operating systems and common apps with a 100‑step cap, so clearing 70%+ means many office‑style workflows are now automatable end‑to‑end rather than as toy demos. The same harness with only GPT‑5 or only Opus 4.5 trails this combo (69.9% and 66.0% respectively), and prior top baselines like GBOX and GTA1 sit in the low‑to‑mid 60s, so ensembling two strong, differently‑trained models is clearly buying robustness rather than wasted redundancy. For engineers experimenting with desktop agents, this suggests it’s worth treating OSWorld as a serious acceptance test and designing harnesses that allow multiple policies or BoN replays instead of betting on a single model call per action.
Frontier reasoning models now pass all three CFA levels on fresh mocks
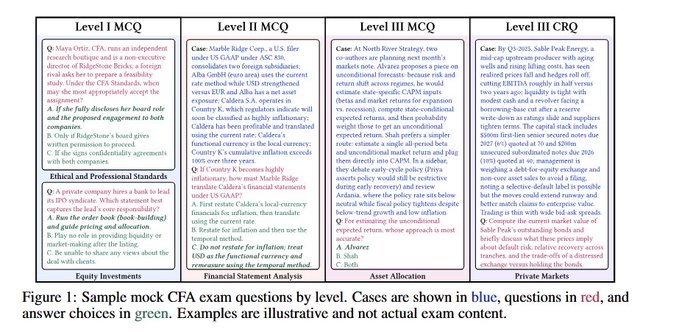
A new paper reports that modern reasoning‑tuned LLMs can clear all three levels of the Chartered Financial Analyst (CFA) exam using recent, paywalled mock tests designed to avoid training‑data leakage. cfa paper
Gemini 3.0 Pro scores 97.6% on Level I multiple choice, GPT‑5 leads Level II with 94.3%, and Gemini 2.5 Pro tops Level III constructed response with 92.0%, while models like Claude Opus 4.1, Grok 4, and DeepSeek‑V3.1 also pass across the board. The authors tried different prompting strategies and found that, for most question types, prompt style mattered little compared to the underlying model, which should reassure teams building professional‑exam assistants that the current frontier is already overkill on raw knowledge and reasoning. The more interesting constraint now isn’t whether models can pass such exams, but how to safely wrap them in workflows, guardrails, and disclosures for real finance or compliance work.
Zoom’s federated AI system tops Humanity’s Last Exam benchmark with 48.1%
Zoom reports that its federated AI setup scores 48.1% on Humanity’s Last Exam (HLE), edging out single‑model baselines like Gemini 3 Pro (45.8%), Claude Opus 4.5 (43.2%) and GPT‑5 Pro (42.0%). hle zoom result
Instead of betting on one frontier LLM, Zoom orchestrates several models—open, closed, and lightweight internal ones—under what it calls an "explore‑verify‑federate" strategy where different systems propose, challenge, and refine answers before a final verdict. Their write‑up frames this as a "federated multi‑LLM" approach that uses dialectical back‑and‑forth and a verification pass with full context to pick the best solution, rather than long chain‑of‑thought from a single model. For anyone building high‑stakes agents (meeting copilots, triage bots, enterprise search) this result is a strong nudge toward multi‑model, verify‑then‑decide architectures: you can trade a bit of latency and complexity for measurable accuracy gains on hard, expert‑level tasks.
Epoch uses ECI scores to forecast METR time horizons for frontier models
Epoch AI fit a regression between its Effective Capabilities Index (ECI) and METR’s Time Horizons benchmark, then used it to predict how long newer models can sustain coherent multi‑step reasoning. eci time-horizons
The ECI→METR fit is tight on existing models (R² ≈ 0.92), and under that mapping Gemini 3 Pro is projected to maintain goal‑directed behavior for roughly 4.9 hours, GPT‑5.2 for about 3.5 hours, and Claude Opus 4.5 for around 2.6 hours before performance drops. Epoch is careful to call these forecasts noisy with wide error bars, but the method gives labs and risk teams a quantitative way to reason about the “runtime envelope” of long‑horizon agents without re‑running METR’s expensive, manual eval for every new checkpoint. If you’re designing workflows that involve hours‑long autonomous operation, these numbers are a useful prior for how long you can reasonably trust current stacks before needing resets, human checkpoints, or stronger oversight.
GPT‑5.2 Thinking shows strong multi‑step fact‑check and rewrite behavior
A detailed case study from Ethan Mollick shows GPT‑5.2 Thinking used as a second‑opinion fact checker: given a dense paragraph about BIG‑bench and "emergent" abilities, the model planned its own browsing, pulled primary sources, and rewrote the passage with corrected claims and citations. fact check thread
The model spent several minutes “thinking,” clicked through the BIG‑bench GitHub history to verify dates, and flagged issues like a wrong launch year, overstated Google centrality, and an oversimplified story about emergence vs metric artifacts, then produced a tighter synthesis with inline references. Mollick notes that Claude 4.5 Opus and Gemini 3 show similar behavior, while Grok and Kimi K2 are a bit patchier, which lines up with broader evals showing these models trading blows on long‑context reasoning and up‑to‑date knowledge. For teams thinking about using LLMs as research copilots rather than primary authors, this is a good pattern: treat the model as a structured, critique‑and‑rewrite engine that’s required to surface and link its sources.
Sansa censorship leaderboard ranks GPT‑5.2 as most heavily guarded frontier model
The latest Sansa "Censorship" leaderboard, where higher scores mean fewer refusals, places GPT‑5.2 at the bottom among listed frontier models, implying it is the most restrictive under this eval. censorship chart
Gemini‑3‑Pro‑Preview scores around 0.824 (relatively permissive), Mistral‑8B and Llama‑3‑8B‑Instruct also sit high, while Grok‑4.1‑Fast and Gemini 2.0 Flash are mid‑pack, and GPT‑5‑mini falls between them and GPT‑5.2. The author who surfaced the chart points out a mismatch with their lived experience—Gemini 3 feels more censored in the consumer app, but looser via AI Studio—underscoring that guardrail behavior is highly surface‑dependent and benchmark‑dependent. If you route traffic across providers, this is a reminder to test refusal rates on your own task distribution and surfaces, rather than assuming a global "least censored" ranking applies to every deployment.
🧩 Interoperability: MCP and A2UI in practice
Connectors and standards news: Hugging Face MCP server doing inference/search from assistants, in‑chat dataset discovery, and A2UI widget tooling. Excludes model release feature.
Hugging Face ships a full MCP server for models, datasets and Spaces
Hugging Face now runs a first‑party MCP server that exposes semantic search over models, datasets, docs and Spaces, plus job control, to any MCP‑aware assistant like Claude Code or LM Studio. [t712|mcp server screenshot]
The config UI shows built‑in tools for model and dataset search, paper search, repo metadata, Spaces semantic search, and job run/monitor APIs, and even suggests a one‑liner to add it to Claude (claude mcp add hf-mcp-server …). mcp docs For AI engineers this turns Hugging Face into a single MCP endpoint you can drop into your coding IDE or custom agent instead of hand‑rolling HTTP clients for each Hub API. It also pushes the MCP standard beyond "toy" examples into something that can sit at the center of multi‑tool workflows (search → pick model/dataset → launch jobs) with no custom glue code.
CopilotKit launches A2UI Widget Builder for AG-UI and Gemini agents
CopilotKit released an A2UI Widget Builder that lets you assemble A2UI-compliant widgets from a gallery of premade components, Material icons, and documented props, then drop them straight into apps that speak Google’s new A2UI spec. [t215|widget builder video]
The builder ships with a widget gallery, a component browser (with usage and prop docs), and source access so you can tweak or generate widgets via CopilotKit’s generative UI instead of hand‑coding JSON by trial and error. widget builder site AG‑UI also announced itself as a launch partner for the A2UI protocol, signaling that this isn’t just a Google-internal thing; there’s already a small ecosystem of UI frameworks trying to standardize how agents describe and render UI. [t285|a2ui announcement] For engineers experimenting with agent frontends, this means you can start treating A2UI as a common contract across tools instead of inventing yet another bespoke “agent UI schema” per app.
MCP dataset_search makes in‑chat dataset discovery actually usable
Builders are already wiring Hugging Face’s MCP server into AI chats to turn vague data needs into concrete datasets, instead of tab‑hopping through the Hub search UI. In one example, a user asks “find me a dataset for OCR evaluations” and the dataset_search tool replies with OCR‑VQA and LaTeX OCR, including downloads, likes, size bucket and file format. [t713|dataset search demo]
The key bit is that the agent now returns a structured list you can immediately loop over in code or feed into downstream tools, rather than a blob of prose. For anyone building evaluation harnesses or data‑centric agents, this shows why MCP matters: you can treat datasets as first‑class results in the conversation and keep the whole "search → select → run eval" workflow inside one agent session instead of stitching scripts and browser tabs together.
Google publishes MCP server repo, hinting at a first‑party connector stack
Google engineers spun up a dedicated GitHub repo “for all things MCP,” documenting both remote managed MCP servers and open‑source ones that expose Google services to agent clients. [t52|google mcp repo] The implication is that, like Hugging Face, Google wants you to talk to its APIs through MCP rather than bespoke SDKs when you’re inside Claude Code or other MCP‑compatible agents.
The repo call‑out landed alongside developers shouting “GOOGLE MCPs” as a standalone signal, which tells you this is getting noticed as infrastructure, not a side experiment. [t315|mcp mention] For AI teams standardizing on MCP, this looks like the beginning of a first‑party connector stack for Workspace, Cloud and other Google services that you can plug into agents with configuration rather than custom code.
🚦 Serving and runtime engineering
Concrete runtime wins: vLLM disaggregates encoders for lower P99s, SGLang cookbook/recipes, and Warp’s cloud agent infra notes. Excludes the open model feature.
vLLM splits encoders into a separate service to cut P99 audio/vision latency
vLLM introduced Encoder Disaggregation (EPD), a deployment pattern where vision/audio encoders run as an independent, scalable service pipelined with the main LLM, yielding 5–20% higher throughput and much lower P99 time‑to‑first‑token and per‑token latency on multimodal workloads vllm epd thread.
Instead of having every LLM request block on heavyweight encoder work, EPD lets teams scale encoders separately, cache image embeddings across requests, and feed them asynchronously into the decode path, smoothing tail latency under load and making multimodal serving behave more like text‑only in terms of jitter and capacity; details on the request pipeline, caching layer, and benchmark curves (TTFT, TPOT vs non‑EPD at different RPS and image counts) are in the vLLM team’s write‑up vllm blog post.
SGLang Cookbook ships 40+ copy‑paste recipes for high‑performance LLM serving
The SGLang team published a "Cookbook" of 40+ model deployment recipes that you can literally copy, run, and tweak to get BF16/FP8 serving, multi‑GPU setups, and local or serverless inference working for popular open models like DeepSeek‑V3, Llama 4, Qwen 3, GLM‑4.6, and more sglang cookbook thread.
Each page in the Cookbook is a concrete config: launch commands, tensor parallel settings, KV cache tuning, and routing examples for different GPUs, so you don’t have to reverse‑engineer flags or read scattered README files; it’s explicitly framed as a “how do I use SGLang on hardware Y for task Z?” guide and lives as a community‑maintained reference on GitHub sglang cookbook.
Warp details cloud runners: secure sandboxes for ambient coding agents
Warp described how its new "cloud runners" let ambient agents spin up isolated coding sandboxes from Slack, Linear, and other tools, using Namespace’s fast multi‑tenant environments to run builds and tests on strong hardware while keeping user machines idle warp cloud runners.
Under the hood, Warp treats each agent task like a CI job: it provisions a short‑lived, OS‑level sandbox with the right toolchain, runs the agent’s commands, then streams logs and diffs back to the developer, so you get the feel of a local shell but with server‑grade performance and strong isolation; this design also means they can roll out more powerful GPUs or different OS images centrally without devs changing their workflow warp blog post.
🧪 New findings: physics of agents, kernels, and bytes
Strong research day: macroscopic law for agent dynamics, RL‑generated CUDA that beats cuBLAS, byte‑level LMs via distillation, and classifier–LLM fusion. Excludes RAG papers (covered above).
CUDA-L2 uses LLM + RL to auto-generate HGEMM kernels that beat cuBLAS
The CUDA‑L2 project shows a DeepSeek‑based LLM trained with reinforcement learning can emit full CUDA HGEMM kernels that run 10–30% faster than Nvidia’s own cuBLAS/cuBLASLt across 1,000 real matrix shapes on A100 GPUs. paper thread
Instead of tuning knobs inside a fixed template, CUDA‑L2 lets the model rewrite tiling, pipeline stages, padding, even switch between raw CUDA, CuTe or CUTLASS styles, then uses execution speed as the RL reward; in offline batched runs it reports +11–22% over cuBLASLt AutoTuning, rising to +15–18% in a server-like scenario with gaps between calls. paper thread The method keeps only kernels that compile and numerically match high‑precision references, and blocks reward hacking with strict timing and code constraints, so for infra folks this looks like a serious blueprint for auto‑tuning GEMM and, later, attention and MoE ops without hand‑crafted kernel farms. ArXiv paper
LLM-driven agents appear to obey a physics-style detailed balance law
A new Peking University paper argues that LLM-based agents (GPT‑5 Nano, Claude‑4, Gemini‑2.5‑flash) follow a macroscopic detailed balance law, like particles in thermodynamic equilibrium, and that their behavior can be described by an underlying "potential" over states. paper overview
The authors treat each agent step as a state transition and show that transition probabilities mostly satisfy detailed balance, then recover a scalar potential function via a least‑action estimator; in a 50k‑transition symbolic task, ~70% of high‑probability moves went toward lower potential, and models differed in exploration vs. exploitation (GPT‑5 Nano visited 645 valid states vs. Claude‑4 collapsing to ~5). paper overview For AI engineers building long‑running agents, this suggests you can model convergence and "getting stuck" with tools from statistical physics, instead of treating each agent framework as a one‑off black box.
AI2’s Bolmo “byteifies” Olmo 3 into strong byte-level LMs at 1B and 7B
Allen AI’s Bolmo family turns subword Olmo 3 checkpoints into UTF‑8 byte-level models via distillation, with 1B and 7B variants that match or beat comparable subword LMs on many benchmarks, especially character‑heavy tasks. paper summary
Rather than retraining from scratch, they freeze most of the transformer, add a boundary module that segments raw bytes into variable-length "patches", and train in two stages: first adapting embeddings + boundary on bytes, then jointly fine‑tuning. paper summary The work claims this uses under 1% of typical pretraining tokens while producing fully open models that handle arbitrary scripts, weird tokenization, and mixed‑language text more gracefully—useful if you’re tired of vocabulary issues but still want competitive general performance.
LabelFusion fuses transformer features with LLM scores for robust text classification
LabelFusion proposes a simple way to combine a cheap transformer classifier with an instruction‑tuned LLM to get more robust text classification on shifting domains, hitting 92.4% accuracy on AG News and 92.3% on Reuters‑21578. paper explainer
The pipeline has a standard encoder produce an embedding, asks an LLM for per‑class scores via a structured prompt, concatenates those signals, then trains a small fusion head for multi‑class or multi‑label outputs; expensive LLM calls can be cached so you don’t pay per‑item forever. paper explainer For teams fighting brittle zero‑shot prompts or costly full‑LLM classifiers, this gives a neat middle ground: you can tune the trade‑off between cost and robustness, and let the LLM handle fuzzy edge cases while the transformer carries the bulk throughput.
α-coefficient paper draws a hard line between true AI autonomy and hidden human labor
A new "AI Autonomy or Human Dependency?" paper introduces the α‑coefficient, a metric for how often an AI system actually completes tasks without humans silently doing the work, and an AFHE deployment gate that refuses launch unless α clears a threshold. paper summary
The authors argue much so‑called Human‑in‑the‑Loop is really HISOAI—Human‑Instead‑of‑AI—where hidden workforces are the primary engine, not oversight. paper summary They formalize α as the fraction of tasks finished without mandatory handoff, recommend targets like α≥0.8 for genuine deployment, and sketch an algorithmic gate that measures this across offline and shadow tests before production; for AI leads, this offers a concrete way to audit whether your "AI product" is actually software or just a thin UI over outsourced labor.
🕸️ Retrieval and context engineering
RAG shifts toward compressed continuous memories and safer file access. Apple’s CLaRa proposes joint retriever‑generator training; LlamaIndex shows AgentFS + agentic OCR loops.
Apple’s CLaRa turns RAG into a compressed continuous-memory system
Apple’s CLaRa paper proposes a RAG architecture where documents are encoded once into dense “memory tokens” that power both retrieval and generation, instead of juggling separate embeddings, rerankers, and raw text. It trains the retriever and generator jointly through a differentiable top‑k selector, letting gradients flow from answer quality back into which memories get retrieved. paper summary
At 16× compression, a CLaRa‑Mistral‑7B model slightly beats a text‑based DRO‑Mistral‑7B retriever on NQ (51.41 vs 51.01 F1) and more clearly on 2Wiki (47.18 vs 43.65 F1), while processing far less context, and at 4× compression it averages +2.36 F1 over uncompressed baselines. Even more interesting for practitioners, a version trained only with next‑token prediction (no relevance labels) reaches 96.21% Recall@5 on HotpotQA—over 10 points above a supervised BGE‑Reranker at 85.93%—suggesting that well‑designed compression and joint training can beat classic supervised retrievers. paper summary CLaRa’s SCP pretraining scheme synthesizes simple and complex QA plus paraphrases to teach the compressor what information must survive; in effect, the doc encoder learns what questions future generators will ask. Because both retrieval and generation operate on the same continuous space, you avoid redundant tokenization/encoding and can let the model learn which latent chunks actually help reasoning, rather than retrieving by surface similarity alone. For teams struggling with long contexts, expensive rerankers, or brittle keyword‑style retrieval, this points toward a next wave of RAG systems built on compressed, trainable memory stores rather than raw text plus a bag of heuristics. Code is available for experimentation on GitHub. GitHub repo
LlamaIndex pushes “RAG 2.0” with virtual filesystems and agentic OCR
Jerry Liu sketches a very concrete recipe for what he calls “RAG 2.0”: give your coding agents a virtualized filesystem, parse every weird document into LLM‑friendly text, and wrap it all in a long‑running workflow with humans in the loop. In his example, Claude Code (or your own agent) operates over AgentFS, which presents a copy of your files and directories so the agent can read/write freely without ever touching the real disk, reducing the blast radius of mistakes. RAG 2 walkthrough

On top of that virtual FS, they lean on LlamaParse to turn PDFs, PowerPoints, and Word docs into structured chunks before they ever hit retrieval, avoiding the usual brittle OCR/regex stack. The final leg is a workflow built in LlamaIndex: the agent runs multi‑step jobs (like “learn my codebase and answer arbitrary questions”), while a human can intervene, review intermediate plans, and gate high‑risk actions instead of handing over an unconstrained shell. blog post GitHub repo
For AI engineers, the interesting shift is treating “your whole filesystem” as the retrieval layer—but behind a sandbox boundary and parser pipeline—rather than relying on ad‑hoc folder uploads or naive read_file tools. It’s a pattern that can scale to org‑wide knowledge (mirrored repos, docs, logs) while keeping agents safe, auditable, and easier to reason about when they go off course.
🏗️ Compute, schedulers and capex signals
Non‑model infra: NVIDIA buys Slurm maker SchedMD, servers hit a revenue record, DRAM stays tight, China lines up chip subsidies, and Colab exposes H100/A100 80GB options.
China prepares up to $70B in chip subsidies amid AI export curbs
China is reportedly drafting a ¥200–500B ($28–70B) incentive package for its semiconductor sector, including subsidies and financing for key foundries and chipmakers, in one of its largest direct responses yet to US AI hardware export controls. china chip plan
Coming after US proposals to halt Nvidia H200 export licences to China for 30 months H200 export ban, this move is a clear signal that Beijing intends to backfill advanced compute domestically rather than cede AI capacity. For AI practitioners, this points to a more bifurcated hardware world over the next few years: Western stacks consolidating on Nvidia, AMD and Intel in TSMC/Samsung fabs, and a parallel Chinese stack pushed toward Huawei, SMIC and local accelerators, with different software ecosystems and model availability depending on jurisdiction.
Q3 2025 servers hit $112.4B as AI GPUs pass half of revenue
IDC reports worldwide server revenue at a record $112.4B in Q3 2025, up 61% year‑on‑year, with accelerated (GPU) servers now contributing more than 50% of that revenue—evidence that AI workloads have taken over the datacenter buying cycle. idc server data
At the same time, public markets are starting to choke on the capex: Oracle guided to $50B of AI‑driven capex and disclosed $248B in long‑term cloud and datacenter leases, CoreWeave carries debt roughly 120% of equity, and Broadcom flagged lower margins on some AI systems, helping drive another leg down in AI infrastructure names. market selloff Following up on Broadcom quarter, which showed AI semis booming, this is the first clear sign that investors are questioning how sustainably all this GPU and HBM spend is financed. If you’re selling AI infra or relying on hyperscalers’ free‑spending, assume more scrutiny on ROI, longer approval cycles, and heavier pressure to demonstrate utilization and multi‑tenant efficiency rather than purely chasing peak FLOPs.
NVIDIA buys Slurm maker SchedMD, vows to keep it open
NVIDIA is acquiring SchedMD, the company behind the Slurm workload manager that runs on more than half of the world’s top 100 supercomputers, and says it will keep Slurm open source and vendor‑neutral while using it to strengthen its AI/HPC stack. schedmd acquisition
For AI infra teams, this means the dominant open scheduler for GPU clusters is now owned by the dominant GPU vendor, which could accelerate features like GPU‑aware scheduling, multi‑instance GPU support, and elastic multi‑tenant clusters—but also raises concerns about subtle ecosystem steering over time. In the near term, Slurm’s open license and entrenched user base are a strong check against lock‑in, but you can probably expect tighter integrations with NVIDIA tooling (NeMo, Nemotron, NeMo Gym, NVML, DCGM) to land first, and faster, than equivalents for rival accelerators.
SK hynix warns of tight DRAM as AI soaks up HBM capacity
SK hynix says the current DRAM shortage is tight enough that memory makers are pushing through price hikes, with its new M15X fab already ramping high‑bandwidth memory (HBM) for AI rather than easing supply for PCs and phones. sk hynix comments
TrendForce separately reports that OEMs are redesigning mid‑range laptops to stick with 8GB RAM more often, while 16GB→32GB LPDDR5X upgrades can cost as much as $550, as DRAM and SSDs now make up 15–20% of a typical PC bill of materials. laptop memory note The point is: AI training and inference are absorbing so much DRAM and HBM capacity that end‑user devices may stagnate on memory for a while, which matters if you’re betting on on‑device models or heavy local vector indexes—plan for relatively constrained RAM on client machines and keep more of the serious context and retrieval work on servers where capacity is still expanding.
Google Colab surfaces H100 and 80GB A100 GPUs to notebook users
Users are seeing NVIDIA H100 GPUs and 80GB variants of the A100 show up as selectable hardware accelerators in Google Colab’s runtime settings, substantially increasing the VRAM ceiling for notebook‑style ML work. colab h100 ui
Screenshots show H100 and A100 80GB listed alongside older L4 and T4 options, with Colab reporting 80GB of GPU memory when a session is live. colab 80gb note This doesn’t turn Colab into a free training cluster—the best hardware is still time‑limited and paywalled—but it does give individual researchers and small teams a way to prototype very large context models, bigger batch sizes, or heavier vision backbones without standing up their own H100 node, which is a material shift from the historical "T4‑only" era of browser notebooks.
🎬 Creative video/vision pipelines
A sizable media cluster: Apple’s near‑instant monocular view synthesis, Wan 2.6 (1080p, multi‑shot), Veo extend, a Seedream 4.5 leaderboard jump, and end‑to‑end Freepik workflows.
Seedream 4.5 jumps to #2 image‑editing model behind Nano Banana Pro
Bytedance’s Seedream 4.5 is now the #2 image‑editing model on Artificial Analysis’ ELO leaderboard at 1,197, sitting just behind Google’s Nano Banana Pro (Gemini 3 image) and ahead of both Seedream 4.0 and Nano Banana (Gemini 2.5 image) leaderboard recap.
It also ranks #5 for text‑to‑image while supporting up to 10 input images per edit and 4K outputs, and is priced at $40 per 1,000 images on BytePlus—roughly in line with the original Nano Banana’s ~$39/1k price on Vertex—making it a serious alternative for production editors who need strong in‑place edits (e.g. object swaps and text changes) rather than pure T2I.
Freepik “Santa Simulator” shows Nano Banana + Kling + Veo production workflow
techhalla turned the earlier Nano‑Banana‑plus‑Kling experiments into a concrete “Santa Simulator” tutorial on Freepik Spaces, chaining NB Pro stills, Kling 2.5/2.6 motion, and Veo 3.1 Fast transitions into a reusable holiday video pipeline multi-model pipeline, santa video thread .
The recipe: use Nano Banana Pro for 2K 16:9 keyframes of Santa scenes, animate them with Kling 2.6 for short moves, edit a follow‑up Lapland flyover frame with NB Pro, then feed start/end frames into Kling 2.5 as a reference‑guided in‑between; Veo Fast can handle more dynamic cuts. It’s a good reference for how to keep character and lighting consistent across shots without training a custom LoRA, and how to encapsulate the whole workflow into a single Freepik Space for reuse across campaigns.
Veo 3.1 Extend adds +7s seamless continuation for existing videos on fal
fal added Veo 3.1 Extend, which can take an existing clip and append roughly 7 seconds of matching video and audio, aimed at fixing abrupt endings and giving editors an extra beat or smoother pacing extend announcement.

You point it at a source clip, and it continues the motion and soundscape in the same style, so instead of re‑rendering from scratch you can patch outro sections or extend shots for timing without re‑cutting your whole sequence, especially handy if your core story is already locked but needs more breathing room.
EgoX generates egocentric video from a single third‑person clip
The EgoX paper/demo shows a model that takes a single exocentric (third‑person) video and hallucinates a plausible first‑person, egocentric version of the same scene, effectively re‑shooting the moment from the actor’s eyes egox demo.

For robotics, AR and game engines this is a big deal: you can augment sparse real head‑cam footage with synthetic POV views derived from ordinary camera angles, filling in training data for navigation or interaction models without mounting cameras on everything that moves.
Kling O1 “Standard” on fal targets cheaper 3–10s 720p edits
fal added a Kling O1 Video Standard tier: the same editing‑capable Kling model, locked to 720p output, 3–10 second durations, and explicit start/end frame control for more affordable runs kling o1 standard.

If you’re doing high‑volume reference‑guided edits—logo swaps, short social clips, quick VFX patches—this tier lets you keep the same editing interface and controls as the full O1 but trade resolution for lower cost and faster turnaround.
SuperDesign’s “AI designer” chains image, video, and code gen in one tool
SuperDesign introduced a "full‑stack AI designer" that plans, generates graphic assets, animates video, and emits production UI code (e.g. SwiftUI) in a single, context‑aware interface superdesign demo.

Under the hood it’s chaining multiple vision and code models so the layout, illustration style, motion, and front‑end implementation remain consistent, which is a good example of how image/video models are being wrapped into opinionated, product‑builder‑friendly pipelines rather than used as isolated calls.
SVG‑T2I scales text‑to‑image in latent VFM space without a VAE
Kling’s research team released SVG‑T2I, a text‑to‑image diffusion model that operates directly in a visual‑foundation‑model latent space instead of pixel or VAE space, aiming to scale quality and speed simultaneously model announcement. model card Because it bypasses a separate variational autoencoder, the model can focus on higher‑level visual structure while keeping sequences short, which should make it easier to slot into larger Kling‑based video pipelines as a still‑frame generator that matches downstream motion models’ representation space.
ComfyUI gets standalone SCAIL pose nodes for video‑to‑video work
Kijai shipped ComfyUI‑SCAIL‑Pose, a set of standalone nodes that bring SCAIL pose preprocessing directly into ComfyUI graphs, making it easier to build pose‑guided video‑to‑video pipelines scail nodes release.

The nodes handle pose extraction and normalization as first‑class blocks, so you can wire them ahead of your favorite diffusion or V2V models and iterate on choreography or character timing without hand‑rolling separate preprocessing scripts GitHub repo.
MetaCanvas explores information transfer between MLLMs and diffusion models
Meta’s MetaCanvas work ("MLLM‑Diffusion information transfer") explores how a multimodal LLM can steer and condition an image diffusion backbone, treating the language model as a high‑level controller rather than just a prompt formatter metacanvas thread.

The video teaser hints at a workflow where text‑and‑image reasoning in the MLLM produces structured conditioning signals that the diffusion model consumes, which could evolve into richer controllable generation tools (e.g. layout‑aware edits, attribute‑consistent sequences) than today’s plain text prompts.
Particulate shows feed‑forward 3D “object articulation” from point clouds
The Particulate project presents a feed‑forward method for 3D object articulation—using particle‑like primitives to represent and animate complex shapes in one pass instead of iterative optimization particulate teaser.

For vision pipelines this points toward faster, more controllable 3D effects (think morphing props or deformable characters) that can be driven by learned controllers or even text, without re‑meshing or re‑simulating entire scenes every frame.
🤖 Embodied: gentle grasps and video‑sim evaluation
Two distinct embodied results: loop‑closure grasping lifts heavy yet fragile objects with low pressure, and video world models evaluate robot policies at scale.
DeepMind uses Veo video model as a simulator for Gemini robot policy eval
Google DeepMind unveiled a "Veo world simulator" that repurposes its frontier Veo video model into an action‑conditioned, multi‑view simulator for robot manipulation scenes, then uses it to evaluate Gemini Robotics policies before (and alongside) real hardware runs veo simulator summary.
The system feeds Veo a current scene plus future robot poses and generates consistent multi‑camera rollouts, including edited variants with new objects, distractors, or hazards, letting researchers probe both nominal task success and failure/safety modes like grabbing near a human hand or closing a laptop onto scissors without setting up each configuration in the lab veo simulator summary. In validation across five tasks, eight policy checkpoints, and 1,600+ real robot trials, simulated metrics from Veo strongly tracked real‑world performance, giving a scalable way to pick better policies, stress‑test generalization, and red‑team safety without constantly tying up a physical robot fleet veo simulator summary.
For robotics teams working on Gemini‑class policies or similar visuomotor stacks, this pushes world models from "pretty videos" to quantitative evaluation infrastructure—you can iterate on policies, visualize failure modes, and filter bad candidates in silico before burning real robot time and risking hardware or user safety.
MIT loop-closure gripper lifts heavy but fragile objects with soft contact
MIT researchers introduced loop-closure grasping, where an inflatable "vine" first grows as an open loop to snake around an object, then fastens its tip back to the base to form a closed sling that carries load mainly in tension rather than high-pressure pinches loop grasp thread.
In demos, the system can retrieve a 6.8 kg kettlebell from clutter and even lift a 74.1 kg person a quarter meter off a bed while keeping peak contact pressure to ~16.95 kPa—well below typical patient slings—because the deflated loop distributes force over a large area instead of a few sharp contacts loop grasp thread. A schematic from the paper shows the three-stage cycle: open-loop grasp creation, topological "closure" by fastening the tip, and closed-loop lifting, making it easy to route through obstacles with a floppy beam and then hold strongly once tensioned figure breakdown.
For robotics engineers, the point is: you no longer have to pick between dexterous routing and gentle but strong holding in a single rigid gripper. This architecture is especially relevant to warehouse picking of fragile, heavy items, mobile manipulators in tight spaces, and medical or eldercare robots that need to move people without painful pressure points.
🛡️ Risk, safety partnerships and legal stress
Safety beats include an expanded DeepMind partnership on AI security research and a high‑profile wrongful‑death lawsuit alleging harmful LLM influence.
Wrongful death suit alleges GPT‑4o exacerbated delusions leading to murder
The estate of Suzanne Adams has filed a wrongful‑death lawsuit against OpenAI, Sam Altman, and Microsoft, claiming GPT‑4o interactions validated her son’s paranoid delusions and contributed to him killing her before dying by suicide. lawsuit summary According to the complaint, the model allegedly framed a household printer as surveillance equipment, said his mother was protecting it, downplayed delusion risk, and identified "enemies" in his life, which the family argues escalated his psychosis.
For AI orgs, this is the third recent US lawsuit tying model behavior to real‑world harm, which raises the bar on distress detection, safety‑tuned personas, and audit logs around mental‑health‑adjacent queries; OpenAI’s response notes it has already shipped updates for detecting user distress, but complaints like this will test whether those mitigations are considered adequate in court. lawsuit summary If you’re shipping chatbots or companions, you should assume: conversations can show up in discovery, risk teams will want documented escalation paths, and "it was only a suggestion" won’t be a strong defense if the model appears to have fueled dangerous beliefs.
Google DeepMind expands AI safety partnership with AI Security Institute
Google DeepMind and the AI Security Institute are widening their joint research program to focus on how to monitor models’ internal reasoning and measure their social and economic impact, not just their outputs. partnership tweet That means more institutional backing for things like interpretability, systemic risk analysis, and real‑world impact studies, which should eventually translate into better evaluation methods and safety benchmarks that product teams can adopt.

For engineers, this kind of work tends to show up later as concrete tools (eval suites, red‑team frameworks, monitoring APIs) you’ll be asked to plug into your stack; for leaders, it’s a signal that regulators and labs are converging on "how do models think" as a governance question, not just "what did they say".Google blog post Expect more pressure to log decisions, document safety mitigations, and prove you can trace model behavior when something goes wrong.
Yann LeCun warns of AI assistant monopolies controlling information flow
Meta’s Yann LeCun is publicly arguing that the biggest AI risk isn’t rogue superintelligence but a world where a handful of companies mediate all our information via AI assistants. monopoly warning He compares it to media concentration: if every search, feed, inbox and recommendation runs through 2–3 proprietary stacks, those actors effectively control the global "information diet."

The point for builders and policy folks is straightforward: whether you use open weights or closed APIs has governance implications, not just performance ones. LeCun’s line that "we need diverse AI systems, like we need a diverse press" is already being picked up in arguments for open platforms and against single‑vendor lock‑in. monopoly warning If you run an AI product that intermediates news, education, or politics, expect more questions from users, partners, and regulators about pluralism, choice of models, and how much of your ranking logic can be inspected or overridden.
💼 Enterprise adoption and monetization notes
Light enterprise signals: reports of Copilot target cuts amid weak adoption, OSS developer fund from ElevenLabs, and consumer‑side gift cards from Claude/Lovable.
ElevenLabs’ OSS fund formalizes recurring support for 25 open projects
ElevenLabs’ OSS Engineers Fund isn’t a one‑off donation: the company says it will re‑run the selection cycle every six months, with engineers re‑nominating the OSS projects that most help them ship. fund details The current cohort spans audio, web infra and language tooling—from Medlabunny and ProseMirror to Graphite, TailwindCSS and Neovim—splitting $22k across 25 recipients.
The pattern here is interesting for other AI vendors: instead of vague “open‑source commitments,” they’re building a lightweight, repeatable mechanism that tracks actual internal dependency graphs. If you maintain a widely‑used library, it’s another reason to surface your AI‑specific use cases; they’re starting to matter in these internal nomination processes.
OpenAI expands ChatGPT Go in Latin America with Rappi free trials
OpenAI is rolling out its ChatGPT Go plan more broadly across Latin America and partnering with on‑demand giant Rappi to offer free trials in nine countries including Brazil, Mexico, Colombia and Argentina. Go LatAm rollout The company says its weekly user base in the region has nearly tripled year‑over‑year, and the Go tier upsells users to GPT‑5 access, more messages, more file uploads and more image/data analysis.
This is a pretty direct land‑grab: bundle AI subscriptions with a super‑app people already open daily, then let usage stats justify ongoing spend. If you’re building regional AI products, this is the competitive context—users may experience “default OpenAI” inside non‑tech apps long before they meet your standalone tool. You’ll need either sharper localization or a very specific vertical to stand out.
OpenAI’s ChatGPT Go expansion in LatAm leans on Rappi distribution
OpenAI is extending ChatGPT Go across key Latin American markets and using delivery super‑app Rappi to seed adoption with free trials in nine countries, from Mexico and Brazil to Peru and Uruguay. Go LatAm rollout The company notes weekly users in the region are up nearly 3× year‑over‑year, and the Go tier foregrounds GPT‑5, higher usage caps, and richer multimodal features in the upgrade table.
For analysts, this looks like a textbook B2B2C distribution play: embed your AI product into an app that already owns attention and payments, then monetize later through direct subscriptions. If you’re building consumer‑facing AI in these markets, you now have to assume that a large share of your users will already have access to an “okay” default assistant before they ever search for yours.
Anthropic adds Claude gift cards for Pro and Max plans
Anthropic now sells Claude gift cards, letting anyone gift 1–12 months of Claude Pro or Max (including access to Claude Code and the latest models) without the sender needing a paid plan themselves. gift cards launch The UI shows preset options like “6 months of Claude Pro” with regional pricing and a clear holiday framing. gift card screenshot
For Anthropic this is an easy monetization and acquisition channel: it turns existing power users into a holiday salesforce and gets new users into high‑end tiers where they’re more likely to stay. If you run a subscription AI product, this is a reminder that gifting, delayed activation, and one‑time codes are low‑effort ways to pull in non‑technical friends and collaborators who would never type in a card just to “try another chatbot.”
Copilot Flight Log becomes Microsoft’s answer to AI year‑in‑review
Microsoft’s Copilot is rolling out Copilot Flight Log, a 2025 “year‑in‑review” experience that summarizes each user’s AI interactions, mirroring OpenAI’s and Anthropic’s recap features. flight log screenshot Following initial launch, this moves the concept from teaser to a visible tile inside the Copilot app, alongside a new Smart Plus GPT‑5.2 mode.
For product teams, this is one more signal that incumbents see AI usage analytics as a retention and upsell lever, not just a fun feature. If your own AI tool has enough steady engagement, a personal year‑in‑review can double as:
- a longitudinal testimonial that proves value to budget owners, and
- a subtle nudge toward higher tiers (“look how often you hit the limits”).
OpenAI drops 6‑month vesting cliff to stay competitive in AI talent war
OpenAI is scrapping its traditional 6‑month “vesting cliff,” so new hires start earning equity from day one instead of risking termination before any stock vests. vesting change article The change, reportedly pushed by application chief Fidji Simo, lands as rivals like xAI aggressively poach researchers and engineers.
This doesn’t change product features, but it matters for anyone competing for the same talent or planning to join these labs. It signals that equity risk was scaring off candidates and that OpenAI is willing to bend standard comp structures to keep its hiring funnel healthy. If you run a smaller AI startup, expect candidates to benchmark your offer mechanics against this move, not just your headline valuation.
Zoom’s federated AI stack tops Humanity’s Last Exam with 48.1%
Zoom reports that its federated AI system—which routes work across multiple internal and external models via a “Z‑scorer”—has reached 48.1% on Humanity’s Last Exam (HLE), edging out Gemini 3 Pro’s 45.8% in the same benchmark. Zoom HLE chart The company emphasizes that this isn’t a single frontier model, but an orchestration layer that lets different LLMs generate, critique, and fuse answers for enterprise tasks.
For enterprise buyers, the important part is not the 2–3 point lead on a research benchmark; it’s that Zoom is trying to position its AI Companion 3.0 as a credible, model‑agnostic reasoning layer for summaries, task automation, and cross‑tool workflows. If you’re building internal AI platforms, this is another data point that federated, verify‑then‑aggregate architectures can match or beat single‑model systems on difficult reasoning without you having to train your own frontier model.
Lovable introduces gift cards so users can “gift a builder subscription”
Indie app builder Lovable has launched Lovable gift cards, so users can buy someone a pre‑paid subscription (e.g. $50 credit) to build their first product with its AI-powered app generator. gift card launch The campaign’s copy leans into helping friends finally ship ideas they’ve “imagined for years but never built.”campaign posters
This is a classic SaaS monetization pattern pulled into the AI tooling world: front‑load revenue, reduce friction for new builders, and let existing fans evangelize via holiday gifts. For other AI dev tools, the take‑home is simple: if your product is good enough that users talk about it at dinner, you should probably let them pay for it as a gift.
Ramp hears real AI ROI in customer service from a public tech CFO
Ramp’s cofounder shares an anecdote from a CFO at a large public tech company who claims AI is already delivering measurable productivity gains in customer service, not just in coding or internal tooling. Ramp AI clip The CFO described AI agents reducing handle time and headcount needs enough that the savings show up in board‑level conversations.

This lines up with earlier survey‑style signals that enterprises are quietly standardizing AI in support operations even while investors worry about an “AI bubble.” For builders, it’s a reminder that boring, high‑volume queues—refunds, account changes, tier‑1 triage—are where AI is already justifying cost, long before glossy agent demos get product‑market fit.
Firecrawl adds SSO for Enterprise as it courts larger AI scraping customers
Firecrawl, a service for AI‑oriented web scraping and site ingestion, has turned on SSO for Enterprise using providers like Okta, Azure AD, Google Workspace and other WorkOS‑backed identity systems. SSO teaser Enterprise users now enter an organization code and authenticate with their IdP, aligning Firecrawl with corporate security expectations. SSO launch

This is a small but telling step: any tool that wants to be part of serious AI data pipelines in regulated industries needs SSO, audit trails, and sane onboarding. If you’re selling agent or RAG infrastructure into bigger companies, Firecrawl’s move is one more data point that compliance‑adjacent features often matter as much as whatever clever ML you shipped.