Gemini 3 Pro beats GPT‑5.2 on CAIS – 57.1 vision index
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
After last week’s GPT‑5.2 hype cycle, today’s third‑party evals paint a more nuanced frontier picture. On CAIS’s new Text Capabilities Index, Gemini 3 Pro edges out GPT‑5.2 with a 47.6 average vs 45.9, and a big lead in expert‑level reasoning (38.3 vs 29.9) plus Terminal‑Bench coding (53.4 vs 47.7). GPT‑5.2 still owns ARC‑AGI‑2 abstract reasoning at 43.3 vs Gemini’s 31.1, so the “hard math and puzzles → OpenAI” routing rule holds.
CAIS’s Vision Index tilts even harder toward Google: Gemini 3 Pro clocks a 57.1 average vs GPT‑5.2’s 52.6, with standout scores on embodied ERQA (70.2 vs 60.7) and MindCube spatial navigation (77.3 vs 61.7). OCR‑Arena tells a similar story for documents: GPT‑5.2 Medium lands #4 with Elo 1648 and 34.3s latency per page, behind Gemini 3 Preview, Gemini 2.5 Pro, and Opus 4.5 Medium.
WeirdML adds cost texture: GPT‑5.2‑xhigh nudges ahead in accuracy (~0.722 vs Gemini 3 Pro’s ~0.699) but burns around $2.05 per run against $0.526 for Gemini. Meanwhile, builders are openly dunking on SimpleBench after it ranks 5.2 below older models, treating it as noisy trivia rather than a routing oracle. Net: use GPT‑5.2 for peak abstract reasoning, but Gemini 3 Pro looks like the current default for multimodal coding, agents, and doc‑heavy workloads.
Top links today
- FACTS leaderboard benchmark for LLM factuality
- Confucius Code Agent open source coding agent
- Universal Weight Subspace Hypothesis paper
- LLM scientific review indirect prompt injection
- VEIL jailbreak attacks on text-to-video models
- Empirical study of human LLM coding collaboration
- CNFinBench benchmark for LLM finance safety
- Verifier free LLM reasoning via demonstrations
- VIGIL runtime for self healing LLM agents
- X-Humanoid human video to humanoid robot
- DoGe decouple to generalize vision language
- Robustness of LLM based trajectory prediction
Feature Spotlight
Feature: Gemini gets deeper context and better UX
Gemini tightens end‑to‑end workflow: attach NotebookLM notebooks as context, mark up images to guide edits, smoother Live voice (mute, fewer cut‑offs), and speech‑to‑speech Translate—making Gemini more useful for real work.
Cross-account updates concentrated on Google’s Gemini app: NotebookLM notebooks as chat context, image markup to steer edits, Live voice interruptions fixed with mute, speech‑to‑speech in Translate, and signs of a fresh 3 Pro checkpoint.
Jump to Feature: Gemini gets deeper context and better UX topicsTable of Contents
🧠 Feature: Gemini gets deeper context and better UX
Cross-account updates concentrated on Google’s Gemini app: NotebookLM notebooks as chat context, image markup to steer edits, Live voice interruptions fixed with mute, speech‑to‑speech in Translate, and signs of a fresh 3 Pro checkpoint.
Gemini app prepares NotebookLM notebook context as an attachment source
Gemini is starting to expose NotebookLM notebooks as a first‑class context source inside the app, so chats can be grounded in an entire research notebook instead of ad‑hoc uploads. A leaked attachment menu shows a new “NotebookLM” option alongside files, Drive, Photos, and code, while testers report being able to "attach notebooks as a context" to Gemini conversations for richer answers and follow‑ups integration teaser attachment menu.
For engineers and analysts, this points to a tighter fusion between Google’s long‑form notebook product and its chat UX: NotebookLM effectively becomes a persistent retrieval corpus you can attach in a click, rather than rebuilding context every session. If this ships broadly, expect workflows where a team maintains a living NotebookLM document and then hands it to Gemini as the single source of truth for deep research, doc QA, and agentic tasks, instead of juggling PDFs and ad‑hoc links feature article.
Builders spot an “af97” Gemini 3 Pro checkpoint under A/B test
Developers are seeing mysterious “af97” variants of Gemini 3 Pro in Google AI Studio and device demos, suggesting Google is quietly A/B‑testing a new checkpoint. One thread shows a side‑by‑side 3D iPhone render where "af97" and standard Gemini 3 Pro produce slightly different geometry, while the UI watermark exposes an internal id like af97bf71081f445a on the model card af97 vs 3 pro demo af97 model id.

For AI engineers and analysts, this is a useful tell: Gemini’s frontier models may change behavior under the hood even when the public name stays the same. That matters for eval reproducibility, long‑running agents, and safety reviews—especially if outputs on tasks like 3D modeling or UI code drift between sub‑checkpoints. Until Google documents these variants, treat Gemini 3 Pro as a moving target and keep your own regression tests and golden outputs around whenever you lock in a workflow on it.
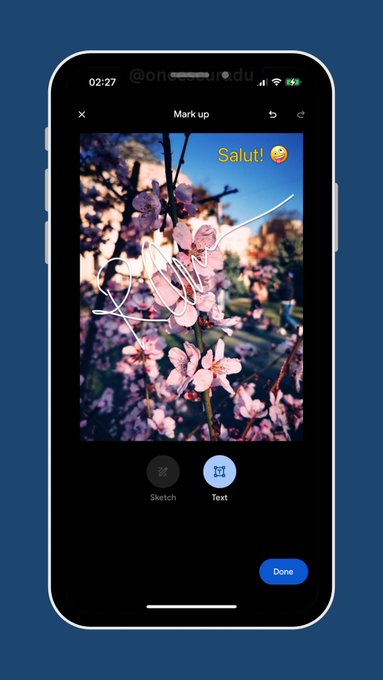
Gemini app adds freehand image markup to steer visual edits
The Gemini mobile app now lets you tap an image and draw directly on it to tell the model how to edit, instead of explaining everything in text. A new in‑chat hint—“Tap on your image to show Gemini how you'd like to change it” —launches a markup screen where you can sketch in red, add text labels, and then send those marks as structured guidance for the edit markup announcement.
For builders, this is a small but important UX shift: it turns image editing prompts into spatially grounded instructions ("change this area"), which should reduce misaligned edits and back‑and‑forth retries, especially on mobile. It also hints at richer multi‑modal prompting primitives—sketch, highlight, text tags—that you may eventually see exposed in the Gemini API or in computer‑use agents doing more precise visual operations.
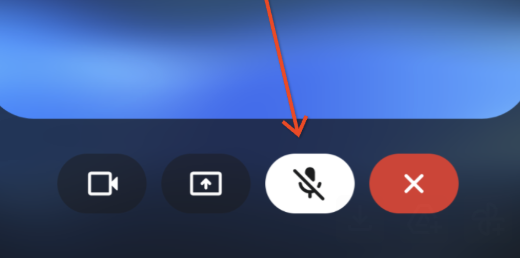
Gemini Live reduces mid‑sentence cut‑offs and adds a mute toggle
Google is rolling out two quality‑of‑life fixes to Gemini Live: fewer interruptions when you pause mid‑sentence, and a new mic mute button while the model is talking. Product lead Josh Woodward says they've "fixed the bad habit of cutting you off mid‑sentence" (starting on Android, iOS in the new year) and you’ll be able to mute your mic so you don’t accidentally overtalk the assistant product manager note.
This directly tackles a top complaint with real‑time voice agents: conversational turn‑taking that feels jumpy and rude. For teams building on Gemini’s audio stack, it’s also a signal that Google is investing in latency‑sensitive turn detection and UX controls, not just model quality. If Live becomes the default way many users talk to Gemini, these fixes will shape expectations for every other voice agent—smooth timing, explicit control, and fewer "sorry, go ahead" moments.
📊 Frontier evals: GPT‑5.2 vs Gemini 3 Pro across suites
Today’s sample is heavy on third‑party leaderboards and dashboards. Excludes the Gemini app UX feature. Focus on CAIS indices, OCR‑Arena, WeirdML, SimpleBench, and Epoch ECI → METR horizon estimates.
CAIS Text Capabilities Index puts Gemini 3 Pro ahead, GPT‑5.2 best on ARC‑AGI‑2
CAIS’s new Text Capabilities Index table shows Gemini 3 Pro leading GPT‑5.2 on overall capability while GPT‑5.2’s big win is on ARC‑AGI‑2 abstract reasoning. cais text table Gemini 3 Pro scores an average 47.6 vs GPT‑5.2’s 45.9 and Opus 4.5’s 44.4, with stronger marks for expert‑level reasoning (38.3 vs 29.9) and Terminal‑Bench coding (53.4 vs 47.7). GPT‑5.2, however, tops ARC‑AGI‑2 with 43.3 vs Gemini 3 Pro at 31.1 and Opus 4.5 at 30.6, and roughly matches them on SWE‑Bench (71.8 vs 74.2 and 74.4). For engineers, this reinforces the emerging split: route hard abstract reasoning and some math research toward GPT‑5.2, but consider Gemini 3 Pro or Opus 4.5 where day‑to‑day coding and terminal tasks dominate.
CAIS Vision Index gives Gemini 3 Pro a clear edge over GPT‑5.2
On CAIS’s Vision Capabilities Index, Gemini 3 Pro posts a noticeably higher average score than GPT‑5.2 across embodied and spatial reasoning tasks. cais vision chart Gemini 3 Pro averages 57.1 vs GPT‑5.2’s 52.6, with particularly strong leads on ERQA embodied questions (70.2 vs 60.7) and MindCube spatial navigation (77.3 vs 61.7), while IntPhys 2 intuitive physics remains close (56.9 vs 60.5). GPT‑5.2 keeps things competitive on SpatialViz (65.8 vs 63.2), but trails badly on the EnigmaEval puzzles (14.5 vs 17.8), hinting that Gemini 3 Pro is currently the safer default for multimodal agents that need grounded visual reasoning rather than pure text.
WeirdML shows GPT‑5.2‑xhigh slightly ahead of Gemini 3 Pro but at 4× the cost
The new WeirdML benchmark suite, spanning 17 synthetic reasoning and program‑synthesis tasks, puts GPT‑5.2‑xhigh narrowly in front of Gemini 3 Pro while highlighting a steep cost gap. weirdml summary GPT‑5.2‑xhigh reaches ~0.722 average accuracy versus Gemini 3 Pro (high) at ~0.699 and Opus 4.5 (high, 16k) at ~0.637, but costs about $2.05 per run compared with $0.526 for Gemini 3 Pro and $0.738 for Opus 4.5, and tends to emit longer solutions (394 lines of code vs 230 and 173). The “best per‑task model” upper bound across all systems sits much higher at ~0.892, reminding people that no single model dominates every WeirdML task. This makes WeirdML useful for routing experiments: you can pay up for GPT‑5.2‑xhigh when marginal accuracy matters, or favor Gemini 3 Pro or Opus 4.5 when you want cheaper, shorter code.
Builders start dismissing SimpleBench after GPT‑5.2 and Opus rankings
Following up on SimpleBench score, where GPT‑5.2 landed 17th overall and Gemini 3 Pro topped the board, more builders are now openly questioning whether SimpleBench’s trick‑question format measures anything that matters. New screenshots still show Gemini 3 Pro at 76.4%, Opus 4.5 at 62.0%, GPT‑5 Pro at 61.6%, and GPT‑5.2 Pro and base at 57.4% and 45.8% respectively. simplebench table The reaction has shifted from surprise to rejection: one engineer calls SimpleBench “dead to me” because it ranks Opus 4.5 below Gemini 2.5 while they care more about “always‑on superhuman abstract reasoning” than gotcha common sense puzzles. builder criticism For teams, the takeaway is to treat SimpleBench as one noisy signal among many, not as a routing oracle for production traffic.
OCR‑Arena ranks GPT‑5.2 #4 behind Gemini and Opus on document reading
On the OCR‑Arena leaderboard, GPT‑5.2 lands solidly in the top tier for document understanding but still trails Gemini 3 Preview and Claude Opus 4.5 on Elo and win rate. ocr-arena chart The GPT‑5.2 Medium setting is currently ranked #4 with Elo 1648, a 69.2% win rate over 117 battles, and ~34.3 seconds latency per page, while a lower‑effort GPT‑5.2 configuration sits at #6 with Elo 1575, 63.1% win rate, and ~15.6 seconds latency. Above it are Gemini 3 Preview (Elo 1698, 72.0% win rate), Gemini 2.5 Pro, and Opus 4.5 Medium. For anyone building OCR‑heavy pipelines (claims, contracts, invoices), this suggests GPT‑5.2 is competitive but not yet the obvious best choice, and you’ll want to profile it head‑to‑head with Gemini and Opus using your own documents.
🛠️ Agent stacks and developer tooling updates
Multiple practical build threads and OSS/tooling drops. Excludes Gemini UX feature. Emphasis on call agents, LinkedIn research, serverless state, desktop file access, browser automation, and terminal UX.
LangChain community ships open course for real phone-call agents
LangChain’s community released a free Phone Calling Agents Course that walks you through building production-ready Twilio voice agents with real-time conversations, property search and conversation memory on top of LangChain and LangGraph course overview. This matters if you’re trying to move from toy bots to agents that actually answer phones, route calls, and query backends without you reinventing the scaffolding.
The course repo includes an end‑to‑end reference that wires Twilio streaming audio into an AI phone agent, then out to tools for property search and a memory component that keeps context across turns course repo. You can copy the diagrams, CDK-style infra and prompt patterns directly, or fork pieces into your own call-center or sales-assistant stacks instead of starting from a blank Twilio webhook.
Oracle CLI adds Gemini web browsing, images and YouTube tools
Oracle’s oracle browser engine now supports Gemini web mode, so you can drive Gemini 3 from the CLI using your regular Chrome cookies, including --generate-image, --edit-image, and YouTube and file‑attachment flows oracle changelog. This builds on earlier GPT‑5.2 Pro support in the tool oracle cli, turning it into a true multi‑model browser harness.
In Gemini mode, media passed via --file is uploaded as attachments rather than inlined into prompts, enabling real image, video, audio and PDF analysis from the command line. The release also adds smarter redirect handling for Gemini image ops and an opt‑in smoke test for Gemini web runs, plus keeps the browser guard so only GPT and Gemini models are allowed unless you explicitly flip --engine api release notes. For anyone building browser‑based agents, this gives you a ready‑made driver that can swap between OpenAI and Google stacks without custom Puppeteer code.
PeopleHub turns LinkedIn due‑diligence into an AI agent workflow
PeopleHub is a LangChain community project that wraps LinkedIn research into an AI agent: you describe what you want in natural language and it runs a LangGraph workflow over profiles, activity and reports, caching results to cut costs by an advertised 70–90% peoplehub summary. If you do any founder, candidate, or investor research, this is exactly the kind of repeated due‑diligence flow that shouldn’t live in ad‑hoc prompts anymore.
Under the hood, the agent pulls profile data, recent activity and a synthesized report through a central LangGraph orchestrator, then stores everything in a cache layer so subsequent runs hit storage instead of the LLM where possible github repo. For AI engineers, it’s a concrete pattern for multi‑tool research agents (retrieval, summarization, caching) that you can adapt from LinkedIn to any structured directory or CRM.
Tutorial shows how to run stateful LangGraph agents on AWS Serverless
Thomas Taylor published a walkthrough on deploying stateful LangChain/LangGraph agents onto AWS Lambda, using DynamoDB as a checkpointer and CDK to stand up the whole stack aws serverless diagram. If you’ve been stuck keeping agents on a long‑running box because of state, this shows a path to serverless without giving up memory.
The architecture runs the agent logic inside Lambda, persists graph state and memory snapshots into DynamoDB via LangGraph’s checkpointer, and streams tokens back to the client so you still get low‑latency UX video tutorial. CDK code in the repo wires IAM, Lambda, API Gateway, and Dynamo tables, so you can clone the pattern and swap in your own agent logic instead of wrestling with serverless plumbing yourself.
Clawdis grows into a distributed multi-device agent canvas
Clawdis, Peter Steinberger’s personal agent runtime around Claude, now runs as a distributed network across Mac and iOS nodes, so a single agent can listen on one device and use another as a shared screen or control surface instances view. This turns idle tablets, laptops and monitors into extra canvases or microphones for your agents instead of letting them sit dark.
The latest screenshots show a gateway Mac discovering remote nodes, per‑node presence beacons, and options like Allow Canvas, Browser Control, and Voice Wake toggles exposed in a unified menu critter selection. The upshot for builders is you can start treating your home or office devices as one big, agent‑addressable surface—useful for UI automation experiments, wallboard‑style dashboards, or voice agents that follow you between rooms.
CodexBar adds Gemini support and better model usage telemetry
CodexBar, the macOS menu‑bar companion for coding agents, shipped a small but useful update: a sharper UI, more reliable installs (including Claude Code Enterprise), and support for tracking Gemini usage alongside OpenAI and Anthropic models codexbar update. If you’re juggling several agent CLIs, this keeps a live view of rate‑limits and reset windows one click away.
The new build fixes glitches around mise installs and adds a direct link to an API billing dashboard, so you can catch runaway background jobs or misconfigured agents before they torch your budget project site. It’s a classic “glue” tool, but for people running Codex, Claude Code, Gemini CLI and similar on the same machine all day, having a single usage HUD removes a lot of guesswork.
Warp terminal rolls out slash commands for agent and MCP workflows
Warp added a slate of slash commands like /usage, /conversations, /view-mcp, /add-rule, and /add-prompt to manage AI usage, MCP tools and prompts directly from the terminal slash command demo. It turns the shell itself into a lightweight control panel for your agent stack instead of pushing everything into a browser.

Following up on Warp’s earlier GPT‑5.2 integration and Terminal‑Bench work warp bench, these commands now let you check model usage, tweak MCP routing rules, and register shared prompts without leaving the CLI. That’s handy if your team is experimenting with multiple LLM providers or MCP tools and you want a faster feedback loop than digging through config files or dashboards.
SonosCLI gives agents and scripts first‑class control over Sonos speakers
Steipete released sonoscli, a pure‑Go command‑line tool that discovers and controls Sonos speakers over UPnP/SOAP, with support for grouping, queues, favorites, scenes and Spotify playback sonoscli feature list. It’s meant for humans, but it also gives coding agents a clean, scriptable surface for multi‑room audio.
The tool handles coordinator‑aware control (you point at a room; it targets the group coordinator), can search and enqueue Spotify links, and exposes JSON/TSV output for scripting sonoscli site. In practice, people are already letting agents like Codex debug the CLI and “DJ” by hopping between playlists and rooms codex sonos usage. If you’re experimenting with home‑automation agents, this is an easy way to bridge from LLM plans to real speakers without writing Sonos SOAP by hand.
🧩 Agent reliability and GraphRAG advances
Mostly research‑grade proposals targeting long‑running agent reliability and retrieval alignment. New today: run‑time self‑healing, distilled procedural memory, and LLM‑aligned graph retrievers.
Meta open-sources Confucius Code Agent with 54.3% on SWE‑Bench‑Pro
Meta introduced Confucius Code Agent (CCA), an open‑source coding agent stack built for massive real‑world repos, hitting 54.3% Resolve@1 on SWE‑Bench‑Pro—state of the art for agents that patch real projects and must pass tests. paper overview
CCA wraps an LLM in a unified orchestrator with hierarchical working memory (short‑term, long‑term, cross‑session notes) plus modular tool extensions, so the agent can keep context across long debugging sessions instead of thrashing on repeated errors. A persistent note‑taking subsystem stores distilled lessons (including failure notes) between sessions, while a meta‑agent runs a build‑test‑improve loop that auto‑tunes prompts, tools, and configuration for new environments. The authors frame this as an agent SDK as much as a single agent: they separate Agent Experience (how the LLM “feels”), User Experience, and Developer Experience, aiming to close the gap between lab prototypes and production‑grade software engineers. Code and SDK are on GitHub, making this one of the first open stacks that seriously tackles industrial‑scale agent reliability rather than just benchmark scores. GitHub repo
ReG (Weak‑to‑Strong GraphRAG) aligns graph retrievers to LLM reasoning
A new framework called ReG (Refined Graph‑based RAG) tackles a core mismatch in GraphRAG systems: retrievers are trained on weak supervision (shortest paths, noisy labels) while LLMs need clean reasoning chains. paper thread
ReG has an LLM pick effective reasoning chains from candidate graph paths, then uses those as higher‑quality supervision to retrain the graph retriever, instead of trusting raw shortest‑path labels. A structure‑aware re‑organizer then turns raw retrieved subgraphs into linear, logically coherent evidence chains that better match how LLMs consume context. On CWQ‑Sub with GPT‑4o, ReG hits 68.91% Macro‑F1 vs 66.48% for SubgraphRAG, and 80.08% vs 79.4% on WebQSP‑Sub, with similar gains across other backbones. The striking part: with only 5% of the training data, ReG can match baselines trained on 80%, while also cutting reasoning tokens by up to 30% when paired with "thinking" models like QwQ‑32B—pointing to more reliable, cheaper multi‑hop GraphRAG without a full retriever redesign. ArXiv paper
ReMe turns past tool runs into compact procedural memory for agents
The ReMe framework (Remember Me, Refine Me) proposes a dynamic procedural memory layer that lets agents learn “what to do in situation X” from past runs, instead of re‑reading huge chat logs. paper thread
ReMe distills short, situation‑specific rules by contrasting successful and failed trajectories, then filters, validates, and de‑duplicates them before storing them as memories keyed by a “when to use” description. At inference time, the agent retrieves only the few relevant rules, rewrites them into task‑ready guidance, and prunes memories that are often retrieved but rarely helpful—keeping the memory pool fresh instead of bloated. On two benchmarks, Qwen3‑8B with ReMe beats a memoryless Qwen3‑14B by an average +8.83 percentage points success over four tries, despite being a much smaller base model. The result is a training‑free way to make long‑running tool‑using agents improve with experience, without drowning their context windows in noisy replayed conversations. GitHub repo
VIGIL introduces a self‑healing runtime that patches failing agents in flight
The VIGIL runtime (Verifiable Inspection and Guarded Iterative Learning) aims to keep long‑running LLM agents from silently looping or failing by watching their logs and injecting small, targeted fixes while they run. paper thread
VIGIL reads an agent’s event log—tool calls, results, errors—and scores each event into an "emotion" signal (e.g., success, frustration) that feeds into an Emotional Bank with decay, so recent pain matters more than ancient history. From this it builds a Roses/Buds/Thorns diagnosis (what’s working, what might help, what’s hurting) and then proposes two guarded patches: a prompt tweak constrained to a specific editable block, and a read‑only code diff suggestion. A simple stage‑gated pipeline (start → emotional bank updated → diagnosed → prompt patched → diff proposed) ensures changes happen in a controlled order; when VIGIL’s own diagnosis tool crashed in tests, it surfaced the exact error and still produced a fallback plan, rather than hiding the failure. In a reminder‑agent demo, this cut false "success" pop‑ups from 100% to 0% and reduced average lag from 97 seconds to 8 seconds, showing that a reflective runtime can materially boost agent reliability without retraining the base model. ArXiv paper
🛡️ Safety, robustness and compliance signals
Concentrated on new misuse/compliance findings. Separate from the feature and from bench/econ. Includes T2V jailbreaks, finance compliance stress tests, PDF hidden‑prompt attacks, and OpenAI research controversy.
CNFinBench reveals LLM finance skills far outpacing rule‑following and risk controls
The CNFinBench benchmark shows that large language models can look competent at financial tasks while being much weaker at compliance and risk control, with an average 61.0 score on capability tasks but only 34.18 on compliance and safety evaluations across 21 models cnfinbench summary. It stress‑tests systems with realistic, often multi‑turn finance scenarios (e.g., rule‑bound advice, investor‑protection norms) and introduces a Harmful Instruction Compliance Score (HICS) that measures how consistently models resist jailbreak‑style prompts over full dialogues rather than single turns cnfinbench summary.
For AI teams in fintech or banking, this is a clear signal that "it can pass quant quizzes" is not enough; you need dedicated policy and safety evals that reflect your regulators and product surface. CNFinBench also uses strict output formatting and perturbed choice options so you can’t quietly game the benchmark with fragile prompt engineering, and it relies on an ensemble of judge models plus human calibration to score open‑ended answers. That makes it a useful template if you’re designing internal red‑team suites or vendor evaluations for finance‑facing LLMs.
Google’s FACTS Leaderboard shows top models only ~69% factual in practice
Google introduced the FACTS Leaderboard, a comprehensive factuality benchmark where even the best current models only reach about 69% overall factual accuracy across diverse real‑world scenarios facts benchmark summary. FACTS blends four sub‑leaderboards—multimodal image Q&A, parametric (closed‑book) fact recall, search‑augmented answering, and document‑grounded long‑form responses—scored primarily by LLM judges that check for coverage of key facts and penalize contradictions, hallucinated details, and evasive non‑answers facts benchmark summary.
This matters if you’re treating any general‑purpose LLM as a trusted explainer or research assistant. The suite includes both public and private splits to limit overfitting, and its grounding variant explicitly punishes responses that dodge the question by being too vague, which makes it harder to win by answering "safely" rather than correctly. For teams building safety layers or routing logic, FACTS provides a shared yardstick to compare factuality across models and modes (text‑only, vision, with or without tools), instead of relying on ad‑hoc hallucination anecdotes.
Hidden PDF prompts can flip LLM peer reviews from reject to accept
The paper "When Reject Turns into Accept" shows that hiding tiny, white‑on‑white instructions inside PDFs can systematically bias LLM‑based scientific reviewers, inflating scores by up to ~14 points on a 35‑point rubric and flipping reject decisions to accept pdf attack summary. The authors test 15 attack styles across 13 models on 200 papers and introduce a Weighted Adversarial Vulnerability Score (WAVS) that combines score lift, decision flips, and whether the attacked file looks like a real submission or an empty template pdf attack summary.
The core issue is that many "LLM as reviewer" or "LLM as judge" systems naively run OCR/HTML conversions and feed everything—including invisible text—into the model. Strong attacks don’t argue about the science; they frame the task as schema checking or logging where the "correct" JSON happens to encode a perfect score, or they obfuscate instructions so the model reconstructs them during reading rather than seeing an obvious prompt injection. If you’re building eval pipelines, automated peer review, or safety judges, you need robust preprocessing (e.g., stripping invisible text, normalizing fonts), plus adversarial testing that goes beyond obvious "IGNORE PREVIOUS INSTRUCTIONS" strings.
OpenAI accused of soft‑pedaling AI job‑loss research as staffer quits
Wired reports that a senior OpenAI economist, Tom Cunningham, left after concluding the company had become hesitant to publish research on negative economic impacts like job displacement, favoring more positive, advocacy‑aligned work instead wired article preview. Anonymous outside collaborators say recent output increasingly "casts its technology in a favorable light" compared to earlier work such as the widely cited "GPTs Are GPTs" paper on automation exposure wired article.
OpenAI denies suppressing research, arguing it has expanded the economics team’s scope and hired a chief economist, but the episode feeds growing concerns about how much the public can rely on lab‑funded work to honestly quantify AI‑driven job loss wired job-loss thread. For policymakers, unions, and risk groups, the signal is that independent measurement—by academics, central banks, or regulators—will remain crucial, because even safety‑conscious labs still face heavy incentives to downplay near‑term displacement when negotiating policy and public sentiment.
VEIL jailbreak exposes audio‑style backdoor in text‑to‑video safety filters
A new attack called VEIL shows that safe‑sounding prompts plus subtle audio and style cues can bypass text‑to‑video safety filters, boosting jailbreak success by about 23% on commercial models veil paper summary. It composes prompts from three benign‑looking pieces (scene anchor, auditory trigger, stylistic modulator), then uses an LLM to iteratively search for combinations that look harmless to text filters but still elicit prohibited visuals from the video model veil paper summary.
For people shipping or evaluating T2V systems, the point is: keyword‑based filters and simple prompt scrubbers are not enough once models learn strong correlations between sounds, cinematography styles, and visual content. VEIL stays entirely in the "implicit" channel, so text moderation gives a green light even as the underlying model renders content that would normally be banned. This pushes safety work toward multimodal classifiers and behavior‑level filters (on generated video), and it’s a reminder to treat audio and style metadata as potential attack vectors, not just user creativity knobs.
Small adversarial tweaks badly mislead LLM‑based vehicle trajectory prediction
A robustness study on LLM‑enabled vehicle trajectory prediction finds that changing just one kinematic feature of a single nearby vehicle—kept within physically plausible bounds—can increase location error by 29% and cut lane‑change F1 by 12% for a text‑based driving model trajectory paper summary. The attack uses a black‑box differential evolution search over prompt encodings of the scene, so the adversary never needs model weights, and it shows larger, more accurate models in clean conditions can actually be more fragile under this stress trajectory paper summary.
For anyone experimenting with LLMs as planners or high‑level traffic predictors, the takeaway is that "it works on the dataset" doesn’t say much about resilience to slightly corrupted sensor or V2X data. The authors also note that chain‑of‑thought style reasoning traces provide some robustness, because they force the model to articulate cues instead of over‑relying on exact numeric values. Still, the work argues that safety‑critical modules need strong input validation and traditional control‑theory checks around LLM components, not blind trust in their pattern‑matching prowess.
🧪 Model science: diffusion LLMs, shared subspaces, verifier‑free RL
Today’s papers propose alternative decoding/training paths and generalization recipes; not product launches. Distinct from agent reliability and safety categories.
LLaDA 2.0 pushes diffusion LLMs to 100B parameters with big speed gains
LLaDA 2.0 is pitched as the first diffusion-style language model scaled to 100B parameters, matching frontier autoregressive LLM quality while running about 2.3× faster on average via parallel decoding, with especially strong throughput on coding tasks. diffusion llm thread The team says the hard part is not the core algorithm but the systems work, so they’re open‑sourcing their training and inference stacks (dFactory and dInfer) to tackle infra bottlenecks as well.
The Zhihu analysis notes several open research fronts: the train–inference mismatch in masked discrete diffusion (later tokens become hard to decode and degenerate toward AR), RL for diffusion models where Monte Carlo + ELBO style objectives explode compute (e.g. 16k → 64k rollouts), and the possibility of moving from mask‑to‑token to true token‑to‑token editing, which would change how we do chain‑of‑thought by letting models revise tokens instead of only appending. diffusion llm thread For engineers, the message is that diffusion LLMs are no longer just a curiosity—there’s now at least one 100B‑scale implementation with a public systems stack, so it’s time to start thinking about how your serving, routing, and RL pipelines would need to adapt to non‑AR decoders.
DoGe “Decouple to Generalize” boosts VLM reasoning with context‑first RL
DoGe (Decouple to Generalize) is a vision‑language RL scheme that separates a trainable Thinker (context analysis) from a mostly frozen Solver (answering), and uses the Solver’s accuracy given the Thinker’s analysis as a reward—yielding +5.7 percentage points on a 3B model and +2.3 points on a 7B model across seven VLM benchmarks in data‑scarce domains. doge paper thread
The authors argue that standard multimodal RL overfits narrow synthetic prompts, collapses exploration, and encourages reward hacking, especially when domain data (chemistry, earth science, multimodal math) is thin. doge paper thread DoGe counters this by (1) training the Thinker to reason about context snippets before touching the final question, (2) expanding a domain knowledge pool from scraped sources and an evolving seed set so the Thinker sees varied scenarios, and (3) then distilling the improved Thinker back into a full end‑to‑end model with Group Relative Policy Optimization. For practitioners, the takeaway is that you can sometimes get better VLM generalization by explicitly training a context explainer whose outputs feed a fixed solver, instead of trying to learn everything in one monolithic policy.
RARO shows verifier‑free RL can beat SFT on hard reasoning tasks
RARO (Relativistic Adversarial Reasoning Optimization) proposes a way to train reasoning LLMs purely from expert demonstrations, without task‑specific verifiers, and still get strong gains—for example reaching 54.4% accuracy on the Countdown benchmark versus 40.7% for a supervised‑fine‑tuned baseline. raro paper thread
Instead of scoring single answers as right or wrong, RARO trains a critic that compares an expert solution and a model‑generated solution and chooses expert, model, or tie; the policy then gets rewarded for fooling this critic, with ties stabilizing learning. raro paper thread At inference time, the critic can also rank multiple sampled chains of thought and pick the best, so the same machinery extends naturally to open‑ended tasks where you don’t have a clean verifier. For teams hitting the limits of verifier‑based RL (math, code with tests) and needing better long‑form reasoning on softer domains, this is an early but concrete recipe to study.
Universal Weight Subspace paper finds shared low‑dimensional directions across 1,100 nets
The Universal Weight Subspace Hypothesis paper claims that a surprisingly small set of shared weight directions—around 16 per layer—captures most of the parameter variation across ~1,100 trained models spanning 500 Mistral‑7B LoRAs, 500 Vision Transformers, and 50 LLaMA‑8B instances. subspace paper thread
By doing mode‑wise spectral analysis on weight matrices, the authors find that diverse tasks and inits still concentrate updates into a common low‑dimensional subspace, suggesting that training mostly moves along a few global basis directions instead of fully exploring the parameter space. subspace paper thread They then show you can reuse this basis for practical things like compressing large model families, merging hundreds of ViT checkpoints into one factored representation, or training new tasks via a handful of coefficients instead of full LoRAs, which could cut storage and fine‑tuning compute for people maintaining big model zoos.
🤖 Embodied data engines and 3D reconstruction
New methods turn human video into robot data and reconstruct scenes without classic SfM. Separate from business shipments. Mostly research artifacts in this sample.
X-Humanoid turns human videos into Tesla-style humanoid training data
A new paper, X‑Humanoid, proposes a video‑to‑video diffusion pipeline that converts ordinary human videos into realistic Tesla Optimus–style humanoid footage, giving robotics teams a way to scale data without filming real robots in every scene. It’s finetuned from Wan2.2 using LoRA on synthetic paired clips where a human and a humanoid perform the same motion in Unreal, then applied to real datasets like Ego‑Exo4D to produce 60 hours (3.6M frames) of Optimus video for training vision‑language‑action and world models paper thread.
The key idea is to preserve scene layout, lighting, and camera motion while swapping only the actor’s embodiment, avoiding earlier hacks that pasted robot arms into egocentric views or broke when the full body was visible paper thread. By doing the swap in a powerful Video DiT and keeping the humanoid consistent across frames, X‑Humanoid creates data that downstream policies can treat as real robot experience, which matters if you’re betting on learning from large human video corpora instead of expensive robot teleop runs (ArXiv paper). For AI engineers working on embodied agents, this is a concrete path to bootstrap humanoid datasets from existing video without a custom mocap or robot studio.
Selfi uses VGGT features and splats for pose-free 3D reconstruction
Selfi is a "self‑improving" 3D reconstruction engine that skips classic Structure‑from‑Motion and instead leans on VGGT depth/pose predictions, geometric feature alignment, and Gaussian splatting to render new views from uncalibrated photo sets paper thread. It starts from VGGT’s per‑image depth and camera guesses, trains a lightweight adapter so corresponding pixels share similar feature codes across views, then turns those features into 3D Gaussians that can be bundle‑adjusted and rendered from novel viewpoints.
Because Selfi refines both camera poses and depth inside this feature‑aligned splat representation, it can improve reconstruction quality and pose accuracy without ground‑truth 3D labels or known cameras, purely by recycling VGGT’s own predictions over time (ArXiv paper). For anyone building embodied simulators, NeRF‑style training loops, or 3D perception for robots, this is a sign that "pose‑free" pipelines—where a strong foundation model plus clever optimization stand in for SfM—are maturing into practical scene engines rather than just demos.
🎬 Creative stacks: Runway 4.5, Nano Banana, Gemini Flash, VFX
Many generative media posts today. Excludes T2V jailbreaks (safety). Focus on distribution, workflows, and practical pipelines for images/video and UI assets.
Nano Banana and Gemini 3 form a UI design stack in SuperDesign
Designer–devs are standardizing on a four‑step stack where Gemini 3 handles spec and implementation while Nano Banana Pro handles wild visual exploration, all wrapped in SuperDesign’s new plan mode. The flow is: write a detailed design spec and break it into small tasks, use Nano Banana to generate highly creative UI mockups for each task, extract tricky visual assets (icons, complex widgets, motion ideas) as images or short clips, then feed those into Gemini 3 or GPT‑5.2 Thinking to produce pixel‑accurate frontend code via SuperDesign’s agents. (workflow overview, nano banana ui step) SuperDesign has wired this directly into its product so you can import brand assets, run plan mode, and iterate—users report Gemini 3 as the best at multimodal replication, GPT‑5.2 Thinking as the strongest for complex implementation details, with Opus 4.5 lagging on default visual taste. (ui model comparison, superdesign case study)

Nano Banana Pro adds BANANA INPAINT for mask-based scene edits
Higgsfield upgraded Nano Banana Pro with BANANA INPAINT, a new mode where you draw a mask over part of an image to swap outfits, restyle hair, or even replace whole background scenes with high consistency from frame to frame. The team is pushing it hard with a 67% discount window and a promo that gives 269 credits for engagement, making it cheap for artists to try mask‑driven edits as part of their existing Higgsfield pipelines. inpaint launch thread The dedicated editor page walks through the inpaint workflow and pricing for people wiring this into production tools. (followup discount, product page)

Runway Gen-4.5 frontier video now available to all paid users
Runway has turned on its Gen‑4.5 text‑to‑video model for all paid plans, moving it from early access into the standard product so any subscriber can generate clips with the new "Gen‑4.5" option. Following initial launch that positioned Gen‑4.5 as a physics‑aware world engine, today’s in‑app upgrade banner explicitly says "now available for all paid plans," signaling that teams can start baking it into day‑to‑day creative workflows rather than treating it as an experiment. runway gen-4-5 ui
Chronological Mirror uses Nano Banana Pro plus Veo for aging sequences
Creators are treating Nano Banana Pro less like a dumb image model and more like an LLM that "understands" instructions, using it to build a 3×3 "Chronological Mirror" grid that ages a character from child to old age in analytically labeled steps. One workflow has NB Pro generate nine portraits tagged with ages and consistent style, then feeds the first and last frames into Veo 3.1 fast with a simple "timelapse aging effect" prompt to synthesize a smooth morphing clip between them. (aging grid demo, veo aging instructions) This follows earlier 3×3 product‑ad grids with NB Pro 3x3 workflow, and reinforces the idea that its strength is precise, compositional control when you treat prompts as detailed specs rather than loose vibes. (nb pro usage notes, prompt screenshot)

Freepik Spaces, Kling and Topaz chain a single image into a 1-minute music video
One creator laid out a practical end‑to‑end stack for turning a single Midjourney band image into a sharp one‑minute rock video using mostly off‑the‑shelf tools. They upscale and angle‑shift the still in Freepik Spaces, generate and animate several camera moves, then string the resulting clips together in CapCut, run them through Kling 2.6 where needed, and finally upscale the whole thing with Topaz Video AI—ending up with a surprisingly polished sequence for what is essentially B‑roll. (spaces workflow writeup, topaz upscaled result) The main complaint isn’t quality but UX: lots of small paper cuts around export behavior, file naming, and navigation that, once smoothed out, would make this kind of chained workflow much more approachable.


Gemini 3 Flash shows off 3k-line UI dumps and zero-shot animated SVGs
Early testers of Gemini 3.0 Flash are hammering it on creative workloads and reporting extremely high throughput: one demo has it emitting around 3,000 lines of HTML/CSS/JS to recreate an Xbox 360 controller UI in a single shot before Google truncates the response. long code gen demo Another user shows it generating a fully animated Spongebob SVG from a text prompt, no reference art, with smooth motion baked directly into the vector. spongebob svg animation In parallel, A/B models like the mysterious "af97" are being tested on 3D object tasks (an iPhone 16 Pro Max render) inside AI Studio, suggesting new checkpoints are being trialed before a full Flash rollout. iphone 3d comparison

Kling 2.6 is being used across full VFX pipelines, not just text-to-video
Kling AI is starting to look less like a pure text‑to‑video toy and more like a general‑purpose VFX workhorse in real productions. One breakdown calls out teams using Kling 2.6 for cleanup passes, relighting, prop and wardrobe swaps, sky replacements, advanced composites, and even tracking shots, effectively inserting it at multiple points in the compositing pipeline instead of only at the concept‑art stage. kling vfx usage This is the kind of multi‑stage adoption that tends to stick, because it slots alongside tools like After Effects and Nuke rather than trying to replace them outright.
Higgsfield Shots one-clicks nine different camera angles per scene
Higgsfield quietly shipped "Shots", a feature that takes a single described scene and then auto‑generates nine distinct camera shots so you can pick angles and coverage without hand‑crafting prompts. Instead of iterating on prompt tweaks for each framing, you hit a button and get a small storyboard of options, then feed the chosen shot into their video tools or downstream editing stack. shots feature description For people doing fast previz or social clips, this collapses a bunch of manual exploration into one step and pairs nicely with BANANA INPAINT and other Nano Banana workflows.
VEED Fabric 1.0 video model lands as an API on Replicate
VEED’s Fabric 1.0 model, which underpins its generative and editing features, is now exposed as a hosted API on Replicate, giving developers a straightforward way to script the same capabilities VEED uses in its own editor. veed fabric announcement For creative‑tool builders, this means you can call Fabric’s text‑to‑video or video‑to‑video transforms directly from Python or JS alongside other Replicate‑hosted models, instead of having to reverse‑engineer VEED’s UI or run heavy models yourself.
💼 Enterprise adoption and open‑source signals
Quieter but notable enterprise usage snapshots and a visible OSS pivot. Separate from infra and features. Useful for leaders tracking internal ROI and community momentum.
Enterprises report real AI productivity gains in HR, coding and operations
A Financial Times–style roundup shared today shows large firms quietly standardizing on internal AI tools for HR, engineering and operations, with some publishing hard numbers on impact. enterprise usage thread IBM’s AskHR generative chatbot now resolves 94% of staff HR queries, freeing millions of support hours across 270,000 employees, while Cognizant reports 37% productivity gains for less‑skilled coders vs 17% for experienced ones when pairing them with AI pair‑programmers. enterprise usage thread
The same piece cites Asana using AI for code generation and campaign planning, SentinelOne’s "Windsurf" assistant helping 800 engineers with coding, testing and bug‑fixing, and Schneider Electric’s systems that auto‑generate sales proposals and project plans from historical data. enterprise usage thread Orange runs AI to detect network anomalies and dynamically drop power draw during off‑peak hours, while Tem Energy arms staff with Claude Sonnet and GPT‑5.1 for coding and incident reporting. enterprise usage thread The catch is that these wins arrive alongside job cuts—IBM, for example, still laid off several thousand people in November 2025—so leaders get both a proof point that AI augmentation works at scale and a reminder that labor planning and change‑management are now inseparable from AI rollout.
VC data shows AI startups dominating application revenue while incumbents hold infra
New Menlo Ventures data says AI startups are already pulling in almost twice as much application revenue as incumbents—about $2 for every $1—even as big vendors still win most infrastructure spend. menlo venture chart Following up on provider share where Menlo showed Anthropic, OpenAI and Google slicing up enterprise LLM budgets, this new chart splits the market into departmental, vertical and horizontal AI apps plus AI infrastructure, then overlays startup vs incumbent share.
Across departmental tools (team‑specific copilots) and horizontal AI (broad productivity/workflow apps), startups hold 40–43%+ share, with incumbents at 57–60%. menlo venture chart In vertical AI, legacy vendors still control close to 88%, but the dollar totals there are smaller. On infrastructure—cloud, GPUs and core platforms—incumbents take 56% of spend versus 44% for startups. menlo venture chart For AI leaders this reinforces a pattern: if you’re an incumbent cloud or SaaS provider, you probably win infra by default but face serious startup competition in the application layer; if you’re a startup, chasing application revenue looks more open than trying to outspend hyperscalers on infra.
3,000 Reachy Mini humanoid robots ship worldwide as open robotics platform
Pollen Robotics, Hugging Face and Seeed Studio are shipping around 3,000 Reachy Mini robots worldwide this weekend, positioning it as one of the largest single drops of AI‑ready robots to date. reachy shipment thread The team is explicit that this first batch is "very bare‑bones" and aimed at AI builders: the hardware is minimal, the default software stack is sparse, and early units will likely have bugs, but the entire control software and simulator are open‑source on GitHub so the community can start building immediately. reachy shipment thread
Buyers who missed this wave are told to expect lead times of about 90 days for new orders, with the team working to shorten that window. reachy shipment thread In the meantime, developers can prototype against the Reachy Mini simulator in the repo and treat the physical robot as just another deployment target. For robotics and embodied‑AI teams, this looks like a practical path to get low‑cost, extensible humanoid hardware into labs and hacker spaces without waiting for a polished consumer robot market to appear.
Chorus AI chat app open sources and moves to pay‑as‑you‑go APIs
Melty Labs has open‑sourced Chorus, its Mac AI chat app, and is pivoting the business to focus on its orchestration product Conductor instead. chorus open source Starting now, Chorus runs entirely on user‑provided API keys in a pay‑as‑you‑go model rather than bundling access to specific models or selling its own subscription, which simplifies Melty’s infra costs but effectively turns Chorus into a community‑maintained client.
The team says they still use Chorus internally and "want it to thrive", hoping that by putting the code on GitHub it will gain a “second life” through external contributors and faster iteration. chorus open source The repo includes setup scripts and a dev environment aligned with their newer Conductor stack, so teams can also lift pieces into their own internal tools. chorus repo For leaders and engineers, this is another example of an early AI front‑end product becoming open infrastructure while the company monetizes higher up the stack on orchestration and workflow automation.
CopilotKit hits #1 on GitHub trending as devs adopt in‑app agent framework
CopilotKit, the open‑source React framework for building in‑app AI copilots and agents, climbed to #1 on GitHub’s global trending list with over 25,000 stars and 3,400+ forks, signaling a surge in developer adoption. (copilotkit trending, trending screenshot) The maintainers leaned into the moment, explicitly asking developers to star the repo to keep it on the front page and drive community momentum. star request
CopilotKit already exposes hooks like useAgent() and adapters for LangGraph and Mastra, letting teams drop agentic chat, copilots or workflows directly into existing React apps without re‑inventing orchestration. copilotkit repo Hitting the top of GitHub’s charts matters here because it tends to kick off a positive feedback loop: more stars attract more contributors and integrations, which in turn make it easier for product teams to standardize on a single OSS framework instead of rolling their own agent front‑ends.
New open‑source SonosCLI offers fast Go-based control for Sonos fleets
Indie developer Peter Steinberger released SonosCLI, an open‑source Go command‑line tool for discovering, grouping and controlling Sonos speakers over local networks, with a Homebrew formula for quick install. sonoscli release thread The project emphasizes low RAM usage, cross‑platform support and full coverage of common Sonos workflows: discovery via SSDP and topology, coordinator‑aware playback control, queue and favorites management, multi‑room grouping and even Spotify search and enqueue via Sonos’ SMAPI layer.
For teams wiring agents into offices or homes, a robust local CLI like this can be far more reliable than cloud APIs: you can script room takeovers, alerts or background music as part of your automation stack without touching Sonos’ mobile apps. Because it’s written in Go and MIT‑licensed, infra engineers can also embed or fork it into their own internal tooling, treating Sonos speakers as another addressable resource in the environment rather than a closed consumer device.