Kimi K2.5 posts 50.2% HLE – $0.60 in, $3.00 out
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Moonshot AI’s Kimi K2.5 continues its “open-weights near-frontier” push with a widely shared 50.2% on Humanity’s Last Exam (full set); Artificial Analysis tags it at GDPval‑AA Elo 1309 and frames it as an MoE with 1T total params and 32B active, shipped in INT4 at ~595GB. Distribution tightened fast: OpenRouter lists $0.60/M input and $3.00/M output tokens; Ollama exposes a cloud target plus ollama launch wiring into agent CLIs; Replicate markets it for “visual coding.” Cost narratives lean on AA’s $371 “cost to run” index figure; claims travel faster than independent harness reproductions.
• LM Arena: Kimi K2.5 Thinking shows up #15 overall and #1 open model; also cited #7 in Coding; preference Elo signal, not task-verifiable.
• Arcee Trinity‑Large‑Preview: 400B MoE (~13B active) appears on OpenRouter free tier; vLLM posts day‑0 vllm serve with auto tool-choice flags.
• DeepSeek‑OCR 2: claims 16× visual token compression (256–1120 tokens/image) and 91.09% OmniDocBench v1.5; vLLM 0.8.5 day‑0 support anchors self-hosting feasibility.
Net: open models are converging on the same playbook—aggressive distro + serving recipes + leaderboard proof points—while real-world variance likely depends on endpoint stacks, tool harnesses, and how much the “cheap multimodal” story holds under load.
Top links today
- Prism LaTeX workspace for scientists
- Prism availability announcement
- Prism overview on accessibility and setup
- Google AI Plus plan details
- Cursor semantic search indexing update
- DeepSeek-OCR 2 model release
- DeepSeek-OCR 2 GitHub repo
- Higgsfield ANGLES v2 product page
- Conductor tasks feature announcement
- Anthropic UK government assistant partnership
- Firecrawl Skill and CLI for agents
- MiniMax Agent Desktop product page
- GCP credits in Google AI subscriptions
- Baseten speculation engine technical deep dive
- Artificial Analysis intelligence index results
Feature Spotlight
Prism: LaTeX-native research workspace inside ChatGPT (GPT‑5.2 in-project)
Prism collapses “LaTeX editor + PDF preview + citations + AI chat” into one project-aware workspace, cutting copy/paste drift and setup friction for research teams—an Overleaf-class surface with GPT‑5.2 in the loop.
High-volume launch coverage of OpenAI Prism: a cloud LaTeX workspace where GPT‑5.2 can read/edit within the project (equations, refs, structure) and support real-time collaboration. This category focuses on Prism and excludes other model/tool launches.
Jump to Prism: LaTeX-native research workspace inside ChatGPT (GPT‑5.2 in-project) topicsTable of Contents
🧪 Prism: LaTeX-native research workspace inside ChatGPT (GPT‑5.2 in-project)
High-volume launch coverage of OpenAI Prism: a cloud LaTeX workspace where GPT‑5.2 can read/edit within the project (equations, refs, structure) and support real-time collaboration. This category focuses on Prism and excludes other model/tool launches.
OpenAI launches Prism, a free LaTeX-native workspace for scientific writing
Prism (OpenAI): OpenAI shipped Prism, a cloud LaTeX-native workspace where GPT-5.2 works inside each project (not in a separate chat tab), and it’s available now to anyone with a ChatGPT personal account as stated in the Launch announcement and reiterated in the Availability note.

OpenAI also frames Prism as removing “version conflicts and setup overhead” for scientific tooling adoption, as described in the Adoption friction note alongside the Product page.
Prism brings a live LaTeX editor + PDF preview with GPT-5.2 in the same workspace
Prism (OpenAI): Prism’s core workflow is an in-browser LaTeX editor with an always-on render/preview loop, with ChatGPT embedded in the same project so edits can stay grounded in the actual manuscript context, as shown in the Prism editor screenshot and described in the Launch announcement.
The practical implication is fewer “copy from LaTeX → chat → paste back” steps, because the assistant is presented as operating directly against your project files and structure, per the In-project context note.
Prism integrates Zotero for reference import into LaTeX projects
Prism (OpenAI): Prism’s settings surface a Zotero integration for importing references into a project, as shown in the Zotero integration screenshot.
This matters specifically for reducing citation/key drift during AI-assisted edits, because the assistant is framed as operating against the project’s actual references rather than inventing BibTeX keys, per the In-project context note.
Prism’s AI is project-aware across structure, equations, and references
Prism (OpenAI): OpenAI is positioning Prism’s differentiator as project-aware assistance—GPT-5.2 can draft and revise with access to surrounding text, equations, citations, and overall paper structure, as summarized in the Capabilities card and echoed in the In-project context note.
The feature list also explicitly calls out optional voice-based editing and direct-in-document changes (instead of generating suggestions elsewhere), as shown in the Capabilities card.
Builders frame Prism as “Cursor for scientists” and an Overleaf-native AI workspace
Prism positioning: Commentary immediately framed Prism as “Cursor for scientists” and “Overleaf with AI,” emphasizing that the key shift is putting GPT-5.2 inside the writing surface rather than in a separate assistant UI, as argued in the Cursor for scientists comment and echoed by researchers in the Overleaf comparison.
The same thread of discussion claims a bigger focus on science/research as a first-class product direction for ChatGPT, per the Product direction take and the longer “tools for thought” framing in the Prism workflow reflection.
Prism can turn hand-drawn sketches into TikZ diagrams
Prism (OpenAI): A Prism demo shows converting a hand-drawn diagram into TikZ inside the LaTeX workflow—an example of “image-to-paper-artifact” transforms that end in compilable source, as shown in the TikZ conversion demo.

This is a concrete case of Prism’s claim that GPT-5.2 can act with project context (files + LaTeX structure) rather than producing detached code snippets, aligning with the Launch announcement.
Prism prompts questions about data controls and opt-out behavior
Prism data controls: Multiple posts raised the question of whether Prism projects are covered by ChatGPT’s existing data controls, as prompted by the Data question and followed by a claim that Prism does not use your data if you opt out in ChatGPT, per the Opt-out claim.
The tweets don’t include a first-party policy excerpt, so treat this as user-reported interpretation pending an explicit OpenAI statement in-product or in docs.
⌨️ Claude Code + Claude desktop: customization, UX polish, and CLI churn
Concrete Claude Code workflow changes and near-term UX surface area: keybindings, spinner customization, and CLI release notes. Excludes Prism (covered as the feature).
Claude Code 2.1.21 tightens session reliability and VS Code Python env handling
Claude Code 2.1.21 (Anthropic): A new CLI release focuses on “less brittle long runs”—fixing API errors when resuming sessions interrupted during tool execution, adjusting auto-compaction behavior on models with large output limits, and improving read/search progress indicators, as listed in the Changelog thread and reiterated in the Changelog details.
• VS Code Python ergonomics: The VS Code extension now supports automatic Python virtual environment activation (configurable via claudeCode.usePythonEnvironment), aiming to make python/pip calls land on the intended interpreter, as described in the Changelog thread.
• Tooling preference shift: Claude Code is nudged to prefer file operation tools (Read/Edit/Write) over Bash equivalents (cat/sed/awk), per the Changelog details; this changes how diffs and edits get produced in practice.
• Prompt churn note: A prompt change discussed around this release was flagged as being reverted by an Anthropic-affiliated account, as stated in the Reversion note.
More granular release history is linked from the Changelog details via the Changelog page.
Claude Code adds custom keybindings via /keybindings
Claude Code (Anthropic): Claude Code now supports user-customizable keybindings via the /keybindings command, as announced in the Keybindings announcement.

The public docs show how the shortcut layer is meant to be configured and shared across setups, as linked in the Docs link via the Keybindings docs.
Claude Code permission hooks questioned after reported rm auto-approvals
Claude Code (Anthropic): A user report claims the permissions/allowlist system is inconsistent for destructive shell commands—rm sometimes being auto-approved despite not being in an allow list, sometimes ignoring explicit deny entries, and showing surprising behavior under parallel tool calls, as described in the Permissions report.
The same thread frames this as a reliability/safety issue for unattended agent runs—particularly when multiple shell actions are issued concurrently, per the Permissions report.
Claude Desktop roadmap leak mentions Sketch and a local dev-server toggle
Claude Desktop (Anthropic): A leak-style roundup claims Claude is developing a Sketch tool for drawing directly on the canvas before uploading, plus workflow toggles and project/task integration hooks—specifically a toggle to let Claude Code start a local dev server, and the ability to start Cowork tasks from Projects, as described in the Roadmap clip.

The same post mentions an updated system prompt for Knowledge Bases, though details of the actual behavior change are not shown beyond the teaser, per the Roadmap clip.
Claude Desktop surfaces a not-yet-active Plugins section
Claude Desktop (Anthropic): A “Plugins” section is reportedly visible in Claude Desktop but not clickable yet, positioned as a home for Connectors and Skills (earlier labeled “Customize”), according to the Desktop UI sighting.
The thread notes that some earlier “customizable commands” exploration may have been pulled back, per the Desktop UI sighting.
Vercel AI Gateway adds Claude Code Max support
Vercel AI Gateway (Vercel): Vercel says its AI Gateway now supports Claude Code Max, per the brief announcement in the Gateway note.
The post doesn’t include configuration details or routing semantics, so the operational change (auth model, limits, and which Claude endpoints are exposed) remains unspecified in the tweets beyond the support claim in the Gateway note.
Claude Code preview shows team-customizable spinner verbs
Claude Code (Anthropic): The next Claude Code version is shown supporting customizable “spinner verbs” (the progress messages during actions), including team-specific theming, as demonstrated in the Spinner verbs teaser.
The screenshot suggests this is implemented through settings changes (a settings JSON update plus new verb text), which could affect shared team defaults and internal “tone” in CLI output, depending on how settings are distributed.
🧰 OpenAI Codex CLI: UX knobs, regressions, and real-world usage complaints
Codex-specific workflow/UX items in the wild (personality settings, rendering issues) and practitioner feedback. Excludes Prism (covered as the feature).
OpenAI resolves Responses API bug showing false rate-limit errors
Responses API (OpenAI): OpenAI fixed an issue where users were shown rate_limit errors despite not actually hitting their limits; they state rate limits were unchanged and the error rate returned to ~0, as shown in the Incident graph.
For teams using Codex-like harnesses on Responses, this is the kind of failure mode that looks like sudden throttling and can trigger unnecessary backoff/retry logic; the tweet frames it as an API-side bug rather than a quota change, per the Incident graph.
Codex CLI draws criticism for not rendering markdown tables
Codex CLI (OpenAI): A recurring UX complaint is that Codex sometimes outputs markdown tables without rendering them at all, with a concrete example called out in the Table rendering complaint.
• Comparison baseline: Claude’s UI behavior under constrained width is shown in the Tight-width table demo, where it switches to a text-based representation; the tradeoff noted is limited wrapping/format fidelity, but it still preserves “table-ness” more reliably than the Codex case described in the Table rendering complaint.

Net: this is less about model quality and more about terminal/UI rendering surfaces; the tweets don’t include a specific Codex build fix or issue link yet.
Codex 0.92 adds /personalities with friendly vs pragmatic modes
Codex CLI (OpenAI): Codex 0.92 adds a new /personalities menu to pick a response style—currently Friendly (longer, conversational) vs Pragmatic (short, explicit), as shown in the Personality picker screenshot.
The options appear hardcoded (no custom personalities yet), but it’s a concrete UX knob for teams trying to standardize agent tone across reviews, PR comments, and CLI interactions, per the Personality picker note.
Developer credits GPT-5.2 in Codex with fixing a high-impact production bug
GPT‑5.2 in Codex (OpenAI): A real-world usage anecdote claims Codex (running GPT‑5.2) found and fixed “an insanely difficult bug” during a launch-day incident—described as “killing traffic” and “fixed end-to-end” in the Incident screenshot.
There’s no repro, diff, or postmortem in the tweets, but it’s a clean signal that some teams are treating Codex as an incident-response debugging partner rather than just a coding assistant, per the Incident screenshot.
🔎 Cursor & IDE indexing: semantic search and reuse of teammate indexes
IDE-side agent performance improvements centered on semantic search/indexing speed and reuse of shared indexes; high relevance for large codebases. Excludes Prism (covered as the feature).
Cursor claims orders-of-magnitude faster indexing for large repos
Codebase indexing (Cursor): Cursor says its indexing pipeline is now “several orders of magnitude faster” for very large codebases, and frames it as a semantic-search upgrade that directly improves coding-agent performance, per the indexing announcement and the accompanying secure indexing blog. This is the kind of change that shows up as less time waiting before your first useful agent query and fewer “agent can’t find it” failures when the repo is huge.
• Security angle: Cursor positions this as “securely indexing” large codebases in the secure indexing blog, which matters if you’re doing enterprise deployments where sending raw code to third parties is the blocker.
Index reuse drops time-to-first-query from seconds to milliseconds
Index reuse (IDE workflows): A reported optimization is to reuse a teammate’s already-built code index instead of cold-start indexing per developer/machine; the shared results claim a median time-to-first-query drop from ~7.87s to ~525ms and a 99th-percentile drop from ~4.03h to ~21s (a ~691× speedup), as shown in the reuse indexes chart.
This frames indexing as a shareable artifact (closer to build-cache semantics) rather than a per-user initialization cost, especially relevant for very large monorepos where “first query” can be the whole experience.
A Cursor-for-Slack MCP trace hints at agent-to-Slack workflows
Cursor for Slack MCP (Ecosystem signal): A Slack message footer reading “Sent using Cursor for Slack MCP” suggests a Cursor→Slack bridge is being used (or tested) to let agents post into team comms, as seen in the Slack MCP screenshot.
It’s only a sighting (not a formal release), but it lines up with the broader pattern that indexing + agent loops are starting to escape the IDE and show up inside shared operational surfaces like Slack.
✅ Automated PR review agents: Devin Review + Kilo Code Reviewer + agent-safe guardrails
Tools and patterns focused on keeping code mergeable: PR review automation, bug-catching agents, and protective hooks that stop destructive actions. Excludes Prism (covered as the feature).
Devin Review expands PR review with codebase-aware bug catching and a URL-swap entrypoint
Devin Review (Cognition): Devin Review has now been live for a week and is positioned as a PR comprehension layer that goes beyond diff viewing—its bug catcher scans the broader codebase to surface interaction risks and even pre-existing issues, as described in the bug catcher overview and the launch week note.

It’s also deliberately low-friction to try: you can open reviews on any PR by swapping “github” → “devinreview” in the URL, according to the URL swap tip. The UI emphasis is on grouping changes and presenting a structured “what changed” narrative, as shown in the launch week note.
dcg blocks destructive git commands from agent tool calls unless the human confirms
Destructive Command Guard (dcg): A practical guardrail pattern is getting attention: dcg can intercept an agent’s shell tool call (PreToolUse hook) and block destructive commands like git reset -hard, forcing explicit user confirmation and recommending safer alternatives (e.g., stash first), as shown in the blocked reset screenshot.
The core operational idea is to treat “dangerous, irreversible” shell actions as human-gated even when the agent is otherwise allowed to run bash, based on the behavior demonstrated in the blocked reset screenshot.
Kilo Code Reviewer launches PR auto-reviews with model choice, now free with MiniMax M2.1
Kilo Code Reviewer (Kilo Code): Kilo shipped an auto-review agent that comments on PRs when they’re opened or updated, with structured feedback buckets (performance, security, style, test coverage) and model selection, as outlined in the Product Hunt launch card.
The launch also includes an “at least for now” cost lever: Kilo says the reviewer is “completely free” when run with MiniMax M2.1, per the free tier note. The project also claims to have reached #1 on Product Hunt, as stated in the rank update.
Gemini Code Assist PR reviews get criticized for incorrect or low-signal feedback
Gemini Code Assist (Google): A concrete complaint is circulating that Gemini’s code review bot is “notably worse than BugBot or Codex,” backed by an example where it flags an arXiv link as “future” and invalid—despite the issue being a false premise in context—shown in the bot comment screenshot.
This is less about style nits and more about reviewer trust: if the bot is confidently wrong on easy-to-check metadata, it raises questions about signal-to-noise when used as a gate in PR workflows, as implied by the bot comment screenshot.
🧭 Agentic coding practices: context discipline, multi-session setups, and prompt techniques
Hands-on tactics for making agents productive: context management, multi-window planning/execution splits, and prompt discipline. Excludes Prism (covered as the feature).
Split planning vs execution by running two Claude sessions in separate repos
Multi-session Claude workflow (Uncle Bob): A practical pattern for long agent work is to keep two Claude Code sessions open—one “maker” session that edits code and one “planner” session that is explicitly prevented from making changes; changes are manually synced between two separate git working dirs, as described in Two-Claude workflow.
The key detail is the rule boundary: the planning repo is configured to only plan, not touch source, so you can keep strategy context stable while the execution session churns through diffs and tests.
Subagent discipline: avoid spawning subagents when the main agent already has context
Subagent cost control (Matt Pocock): A simple but operationally important practice is to treat subagents as a cost center—if the primary agent already has sufficient context, don’t fork work out; specialize with a skill only when needed, per Subagent token warning.
This is a reminder that “more agents” can silently become “more tokens,” especially when subagents re-read the same files or re-derive the same plan.
Ask the agent to refactor your codebase for its own context-window constraints
Codebase “optimize for the agent” refactors (Uncle Bob): A notable tactic is to ask the model to recommend structural changes that make the repo easier for the model to read within limited context—splitting files/modules and introducing abstractions so it can skip details and reduce repeated searching, as reported in Agent readability refactor.
This is less about human readability and more about minimizing expensive tool calls (reads/greps) and keeping the working set small enough that the agent can stay oriented across sessions.
Treat “skills” as installable, versioned docs instead of blog-post knowledge
Installable skills as docs delivery (Vercel community): A recurring idea is to ship “experience” as something you can install—turning package/version docs into a local, machine-consumable knowledge surface (e.g., a proposed node_modules/.skills convention) rather than relying on scattered blog posts, as suggested in node_modules skills idea and reinforced by Skills are installable.
This frames documentation as a dependency artifact that can be indexed, searched, and referenced by coding agents with fewer hallucinated assumptions about API versions.
TDD/RGR loop with an agent (“Ralph”) and a dedicated refactor prompt
RGR/TDD with an agent (Matt Pocock): Practitioners are explicitly experimenting with test-driven loops (“TDD with Ralph”) as noted in TDD with Ralph, and separately tightening a dedicated “refactor agent” prompt to make refactors more repeatable and bounded, as asked in Refactor prompt question.
The common thread is turning refactors into a repeatable role with a stable instruction set, rather than an ad-hoc request that changes tone and scope every time.
Use variable-driven prompt templates to reuse image prompts without drift
Prompt variables (techhalla): A concrete prompting technique is to write a single “directive” prompt with explicit variables (subject, lighting, biome, texture, etc.), then swap values to generate consistent variants; the full template example is shown in Variable prompt template.
The main engineering takeaway is maintainability: you can version and diff a template and change one variable at a time, instead of rewriting the whole prompt and accidentally changing constraints.
🦞 Agent runners & multi-agent workplaces: Moltbot, LobeHub, MiniMax Agent Desktop, Superagent
Operational tooling and ‘agent workplace’ products: orchestration UIs, multi-agent teams, and local-first agent setups. Excludes Prism (covered as the feature).
Clawdbot becomes Moltbot after trademark pressure
Moltbot (steipete): Following up on maintainer load (usage spike + support burden), the Clawdbot project says Anthropic requested a name change over trademark issues, and the maintainer is rebranding the project and accounts as shown in the rename announcement.
The practical impact is that docs, install scripts, and social references will drift for a while; community chatter suggests people will keep saying “Clawdbot” even as the official handle shifts, per the rename roundup.
LobeHub launches a multi-agent teammate workspace with remixing
LobeHub (LobeHub): LobeHub is being promoted as a “next generation” agent workspace built around reusable agent teammates and agent groups, with community discovery/remixing and multi-model switching; a demo contrasts it with Manus on speed/cost for long workflows, as shown in the comparison demo.

• Model portability pitch: Posts claim you can swap between Gemini/GPT/Claude without “vendor lock-in,” and that this changes how teams structure multi-agent work compared to single-model workspaces, per the comparison demo and the teammate framing.
The performance claims are promotional (no shared eval artifact in-thread), but the product direction—agent teams as reusable units plus a “supervisor” layer—is consistently described across the comparison demo and the teammate framing.
Moltbot rename triggers handle squatting and scam confusion
Moltbot (steipete): The rename created real operational churn: the maintainer says the X handle was grabbed by crypto shills during the rename window, and a GitHub rename mistake briefly let scammers “snatch” his personal account, as described in the rename mishap and the GitHub recovery update.
• Impersonation risk: The maintainer explicitly warns he will “never do a coin” and that any token claiming his ownership is a scam, per the coin scam warning.
The net effect is more social-engineering surface area around a fast-growing agent tool, and it’s still not fully resolved on X “for another day,” according to the status clarification.
Moltbot ships with memory present but unconfigured by default
Moltbot (community config): Users discovered that Moltbot’s memory stack exists (including a local sqlite file) but isn’t enabled/configured by default, leading to “forgetting” across new sessions until memorySearch/store.vector settings are added, as shown in the missing memory config.
This is a concrete setup gotcha for anyone expecting persistent-agent behavior out of the box, and it also implies teams need onboarding docs that explicitly walk through memory provider selection and indexing/sync settings (vector + BM25 hybrid) rather than assuming defaults.
Airtable’s Superagent ships an async multi-agent research workflow
Superagent (Airtable): Airtable launched Superagent as a parallel sub-agent system that runs longer async research jobs and outputs an interactive “SuperReport” webpage (not just a chat transcript), with a product walkthrough shown in the SuperReport demo.

The typical runtime being described is “20 to 30 minutes” for a complex run, and the system is framed as launching up to ~20 specialized sub-agents per request, according to the product description.
MiniMax launches Agent Desktop as a cloud agent workspace
MiniMax Agent Desktop (MiniMax): MiniMax’s new desktop product is pitched as an agentic workspace with “zero setup,” cloud execution, and integrations (email, calendars, GitLab, logs) plus ready-made “Experts,” as demonstrated in the workflow demo.

The announcement positions it explicitly against Claude Cowork/Clawdbot-style workflows by emphasizing connectors and enterprise-ish automations (MRs, alerts, repo edits), according to the workflow demo.
Moltbot gains a local-model backend through Ollama
Moltbot × Ollama: A new integration path lets Moltbot connect to Ollama-hosted local models so “all your data stays on your device,” with the gateway launch flow shown in the terminal screenshot.
This is a meaningful option for teams that want an agent runner with local inference (or a local-first fallback) without rewriting the agent harness—assuming feature parity and tool-call behavior hold up across different local models.
Ollama Cloud exposes Kimi K2.5 to agent toolchains via ollama launch
Ollama (Cloud models): Ollama says Kimi K2.5 is available as a cloud model and can be used as the backend for multiple agent frontends via ollama launch, including Claude Code, Codex, OpenCode, and Clawdbot, as shown in the launch commands and the model page pointer.
This is an interoperability datapoint: a single model endpoint can be swapped under several agent runners without each tool needing bespoke provider integrations, at least for the “launch” path described in the model page.
Supermemory adds persistent “infinite memory” to Moltbot via a plugin
Supermemory × Moltbot: Supermemory announced a plugin for Moltbot that “automatically remembers conversations” and builds a persistent user profile, as described in the plugin announcement and teased visually in the promo poster.
This sits adjacent to the “memorySearch not enabled” config surprise in the memory config discovery, but it’s a separate approach: externalized memory as an add-on rather than enabling the built-in storage/index defaults.
🧩 Installables: Skills/CLIs that feed agents better context
Packages you install into agent environments (skills and CLIs) to improve capability—especially web context capture. Excludes Prism (covered as the feature).
Firecrawl ships a Skill + CLI to fetch higher-coverage web context for agents
Firecrawl (Firecrawl): Firecrawl launched a Skill + CLI aimed at feeding coding agents cleaner, more complete web context by pulling pages into local files (then searching locally for token efficiency), with the install path shown in the launch post and docs in the CLI docs.

• Agent integration surface: The main entrypoint is npx skills add firecrawl/cli, targeting agent CLIs like Claude Code/Codex/OpenCode that benefit from file-based context rather than brittle in-chat fetches, as described in the launch post.
• Coverage claim: Firecrawl positions it as outperforming native fetch with “>80% coverage,” which is the specific quality metric they’re selling to engineers, as stated in the launch post and reiterated in the coverage reminder.
The open question is how the “coverage” number is measured across sites and paywalls; the tweets don’t include an eval harness or dataset definition.
Warp adopts AGENTS.md as the standard project context file for agents
Warp (Warp): Warp replaced its WARP.md convention with the standard AGENTS.md format and added /init to generate it after indexing your repo; it also auto-discovers AGENTS.md in subdirectories and continues to accept alternatives like CLAUDE and cursorrules, per the format change post.

This is a direct workflow change for teams standardizing “what an agent should know about this repo,” with Warp’s recursive discovery turning per-folder instructions into a first-class behavior rather than a manual convention, as described in the format change post.
📊 Benchmarks & eval signals: open model rankings, agentic leaderboards, and new math benchmark
Leaderboard movement and eval artifacts used by engineers to decide what to test next—especially open-vs-closed comparisons and verifiable benchmarks. Excludes Prism (covered as the feature).
Artificial Analysis: Kimi K2.5 leads open weights and closes in on frontier models
Kimi K2.5 (Moonshot AI): Artificial Analysis positions Kimi K2.5 as the new leading open-weights model and “closer than ever to the frontier,” citing GDPval-AA Elo 1309 for agentic knowledge work—behind only OpenAI and Anthropic—alongside first-time flagship image+video inputs for Moonshot’s open line, as detailed in the [Artificial Analysis writeup](t:39|Artificial Analysis writeup) and reinforced by the [GDPval-AA note](t:309|GDPval-AA note).
The same analysis calls out a $371 cost to run their Intelligence Index—cheaper than GPT-5.2/Claude Opus 4.5 class but not “budget” like smaller open baselines—plus an MoE footprint of 1T total params / 32B active released in INT4 (~595GB), as described in the [model breakdown](t:39|model breakdown).
• Multimodal parity pressure: K2.5’s visual reasoning is framed as “removing a critical barrier” for open weights, with MMMU-Pro cited in the [multimodal notes](t:39|multimodal notes) and a head-to-head bar chart shown in the [benchmarks image](t:78|benchmarks image).
• Agentic evaluation signal: GDPval-AA is presented as a realistic harness (shell + web browsing loops); K2.5’s Elo result and implied win-rate vs prior open leaders is summarized in the [GDPval-AA leaderboard post](t:39|GDPval-AA leaderboard post).
• Hallucination/abstention trade: the writeup highlights reduced hallucination relative to K2 Thinking and more abstention behavior, per the [omniscience index note](t:39|omniscience index note).
The open question is how much of this holds under different harnesses and provider inference stacks, since many teams will test through third-party endpoints rather than Moonshot’s native serving path.
EpochAI launches FrontierMath: Open Problems, a verifier-first benchmark for unsolved math
FrontierMath: Open Problems (EpochAI): EpochAI released a pilot set of 14 research-math open problems designed for evaluation at scale via programmatic verifiers (no LLM-as-judge), positioning it as a clearer way to measure “did AI actually solve something humans couldn’t,” as described in the [benchmark intro](t:81|benchmark intro) and expanded in the [verifier design note](t:443|verifier design note).
They report that GPT-5.2 Pro and Gemini 3 Deep Think could solve easier known variants but didn’t solve any unsolved cases yet, per the [no solves update](t:445|no solves update), and they outline a funding model where verifier access is paid to support expansion, as stated in the [pilot funding note](t:500|pilot funding note).
• Scope clarity: problems are “hard for humans” rather than adversarially constructed for models, per the [selection criteria note](t:444|selection criteria note).
Epoch also invites external attempts and contributions, per the [call for attempts](t:538|call for attempts).
LM Arena: Kimi K2.5 Thinking debuts as #1 open model in Text Arena
Kimi K2.5 Thinking (Moonshot AI): LM Arena reports Kimi K2.5 Thinking as #15 overall in Text Arena and #1 among open models, according to the [Arena announcement](t:197|Arena announcement) and the [leaderboard screenshot](t:218|Text Arena table).
The same thread cluster highlights category placements—#7 in Coding plus strong instruction-following placement—based on the [category breakdown](t:197|category breakdown) and a follow-up pointing to the coding ranking in the [coding category post](t:446|Coding category rank).
• How to interpret: this is a preference-based Elo-style signal (useful for “what to try next”), but it doesn’t substitute for task-verified sweeps; the strongest evidence here is the Arena table itself in the [ranking image](t:218|ranking image).
This adds another independent data point that K2.5 is competitive in general assistant behavior, not just synthetic benchmark leaderboards.
ARC-AGI-2 public eval plot: RSA + Gemini 3 Flash reported at 59.31%
ARC-AGI-2 (RSA pipeline): Following up on RSA (RSA+Flash cost claims), a new public-evals plot reports 59.31% for Recursive Self-Aggregation paired with Gemini 3 Flash, with the chart emphasizing a cost/performance frontier versus heavier baselines, as shown in the [ARC-AGI v2 plot](t:293|ARC-AGI v2 plot).
The same post claims the approach is competitive with more complex scaffolds at similar or lower cost, based on the comparisons visible in the [scatter plot labels](t:293|scatter plot labels).
Prediction Arena chart shows an early Grok checkpoint leading returns
Prediction Arena (Arcada Labs): Following up on Prediction arena (live market trading harness), Arcada’s chart shows an early Grok 4.20 checkpoint as the top performer with roughly +10% returns over ~two weeks, with other frontier models clustered near or below the $10K starting line in the [performance chart](t:473|performance chart).
The visible takeaway from the graph is relative performance dispersion (some models trending down materially), based on the trajectories shown in the [same chart](t:473|same chart).
Artificial Analysis: K2 Think V2 boosts intelligence and reduces hallucinations
K2 Think V2 (MBZUAI): Artificial Analysis reports K2 Think V2 as a post-trained 70B reasoning model that improves its Intelligence Index score by +4 points while maintaining a top-tier openness position, per the [K2 Think V2 evaluation](t:169|K2 Think V2 evaluation) and the [intelligence index note](t:537|intelligence index note).
They also highlight a hallucination rate drop to 52% (from 89% on the base K2-V2) and a long-context reasoning lift to 53% (from 33%), as stated in the [hallucination summary](t:169|hallucination summary) and reiterated in the [hallucination rate post](t:732|hallucination rate post).
This is a concrete example of “post-training moves the needle” on abstention/hallucination behavior, with the caveat that the benchmark suite and prompting setup matter for how those rates translate into product settings.
LiveBench: Kimi K2.5 Thinking shows up 9th overall on a multi-skill leaderboard
LiveBench leaderboard (Kimi K2.5 Thinking): A LiveBench snapshot shows Kimi K2.5 Thinking in 9th place, ranked ahead of several widely used closed and open models, as shown in the [LiveBench table](t:151|LiveBench table).
The posted breakdown includes strong subscores in reasoning/coding/math buckets for this run, with the full row visible in the [highlighted K2.5 entry](t:151|highlighted K2.5 entry).
This is a single leaderboard slice (and can shift with eval refreshes), but it’s another “shortlist” signal for teams deciding which open models are worth wiring into evaluation pipelines.
📦 Model releases builders are testing: Kimi K2.5, Trinity Large, DeepSeek OCR 2, Qwen3-Max-Thinking
High-volume model churn with emphasis on open weights and deployability; includes pricing and modality claims where present. Excludes Prism (covered as the feature).
Kimi K2.5 benchmark story: strong agent tests, moderate run cost
Kimi K2.5 (Moonshot AI): The most-circulated benchmark frame today is “near frontier quality, open weights,” with Kimi K2.5 shown at 50.2% on Humanity’s Last Exam (full set) and competitive scores across browse/search and vision/video evals, as shown in the Benchmarks chart.
Artificial Analysis’ write-up puts the model at an Elo of 1309 on its GDPval-AA agentic evaluation and highlights that it’s an MoE with 1T total params and 32B active, released in INT4 (making it ~595GB), as detailed in the Artificial Analysis breakdown. The same thread calls out a $371 “cost to run” figure on the Artificial Analysis Intelligence Index suite, contrasting with much higher costs for GPT-5.2 xhigh and Claude Opus, as shown in the Cost chart.
Kimi K2.5 lands across OpenRouter, Ollama Cloud, Replicate, and more
Kimi K2.5 (Moonshot AI): Kimi K2.5 is now showing up across more “builder surfaces” with a listed price of $0.60/M input tokens and $3.00/M output tokens, following up on initial launch (open-weights multimodal + swarm framing) as shown in the OpenRouter model card.
Ollama added a cloud-hosted run target—ollama run kimi-k2.5:cloud—and says you can wire it into agent CLIs via ollama launch, as shown in the Ollama cloud command, with details on the model page. Replicate also listed the model as “great for visual coding,” according to the Replicate listing.
Kimi K2.5 feels “Opus-like” to some builders, but not everyone likes it
Kimi K2.5 (Moonshot AI): Early hands-on reactions are split between “this is good enough to swap into my stack” and “it got more assistant-y.” One user reported, “I even forgot midway that it’s not opus,” when testing through CC Mirror on OpenRouter, as quoted in the CC Mirror impression. Another tester says K2.5 recognized a simple web task didn’t need parallelism and refunded unused credits, as shown in the Agent Swarm refund UI.
A counter-signal is that K2.5 may have regressed in writing style compared to Kimi K2, with an example shown in the Writing comparison screenshot.
Trinity Large Preview arrives as a 400B MoE, with OpenRouter access and vLLM support
Trinity Large Preview (Arcee AI): Arcee’s new open model is being shared as a 400B-parameter MoE with ~13B active per token, with an initial “kick the tires” path via OpenRouter’s free offering, as stated in the OpenRouter free listing.
A technical recap claims it was trained over 17T tokens and uses a sparse routing design aimed at inference efficiency, as summarized in the Training run summary and expanded with architecture notes in the Architecture bullet list. vLLM also posted day-0 serving support, including a concrete vllm serve arcee-ai/Trinity-Large-Preview command, as shown in the vLLM serve command. More primary artifacts are linked via the release blog and the tech report repo.
DeepSeek-OCR 2 launches with learned reading order and vLLM day-0 support
DeepSeek-OCR 2 (DeepSeek): DeepSeek’s new OCR model emphasizes layout-aware decoding via “Visual Causal Flow,” with 16× visual token compression (reported 256–1120 tokens per image) and a claimed 91.09% on OmniDocBench v1.5, as shown in the vLLM launch post.
The same post notes day-0 availability on vLLM (vllm==0.8.5) and provides runnable scripts for image/PDF/batch evaluation, as described in the vLLM launch post. A separate thread highlights why this matters for downstream doc pipelines: OCR2 uses a learnable scan order rather than fixed raster scanning, which can better preserve tables and structured regions, as explained in the Reading order explanation.
Qwen3-Max-Thinking: adaptive tool calling gets the spotlight in Zhihu tests
Qwen3-Max-Thinking (Alibaba/Qwen): New hands-on notes circulating from Zhihu emphasize that tool use is becoming “default behavior”—the model reportedly decides mid-thought when to invoke search, memory, or a code interpreter, as shown in the Zhihu tool calling notes.
This thread also claims stronger text reasoning and solid large-number/math behavior via an integrated Python interpreter, while calling out mixed results elsewhere (including hallucination issues in historical research), as described in the same Zhihu tool calling notes. A separate summary frames the release as adding adaptive tool use plus a test-time scaling mechanism, as stated in the Model summary chart.
🧨 Tooling ecosystem friction: trademarks, scammers, and maintainer burden signals
When the discourse itself is the news: naming/trademark conflicts, account takeovers, and how scams target popular AI dev tools. Excludes Prism (covered as the feature).
Anthropic trademark push forces Clawdbot rebrand to Moltbot
Moltbot (formerly Clawdbot): The viral local-first agent project has rebranded after Anthropic requested a name change “for trademark stuff,” with the maintainer saying it “wasn’t my decision,” as described in the Forced rename note and echoed in the Trademark rename fallout.
The rebrand is already creating ecosystem confusion (searchability, integration docs, and attribution), and it’s become a live example of how quickly indie agent tooling can run into platform/IP constraints once it crosses into mainstream usage, as summarized by observers in the Trademark enforcement recap.
Moltbot handle squatting and account takeover during rename causes recovery scramble
Moltbot (steipete): The rename triggered a classic “hot project” failure mode: the GitHub and X handles were briefly or partially lost to crypto scammers, creating a short but messy recovery and impersonation risk window, per the Rename mishap report and the follow-up Status and safety note.
• GitHub recovery: The maintainer asked for help after the personal account was “snatched,” then confirmed it was fixed, as shown in the GitHub recovery request and the later GitHub fixed update.
• X handle still contested: They warned that “@moltbot” is the real handle and that “20 scam variations” exist, according to the Status and safety note.
Maintainer warns of “coin” impersonation scams targeting Moltbot/Clawdbot identity
Identity & impersonation risk: As the project spiked in visibility, the maintainer posted a blunt warning that he will “never do a coin,” that any project listing him as a coin owner is a scam, and asked crypto promoters to stop pinging and harassing him, as stated in the No coin warning.
This is less about crypto discourse and more about operational risk for AI dev tools: public-facing maintainer identities become part of the attack surface (fake ownership claims, handle squats, and high-pressure DMs), and users can be tricked into interacting with impostor accounts that look “official,” as reinforced by the rebrand chaos described in the Rename mishap report.
🛡️ Agent security & misuse surfaces: prompt injection, malware planting, and robustness concerns
Security and safety issues that directly affect how engineers should deploy agents (prompt injection, hidden payloads, adversarial robustness). Excludes Prism (covered as the feature).
Clawdbot prompt injection via hidden GitHub hyperlink can plant near-invisible backdoors
Clawdbot (Moltbot ecosystem): A live attack writeup shows how a seemingly benign GitHub issue can smuggle an instruction payload inside a URL hyperlink that’s invisible to humans but readable to LLM agents—then hijack the agent into inserting a backdoor into a lockfile (a spot many reviews skim), framing agents as “corruptible insiders” per the Attack walkthrough.

• Exploit chain: Attacker files an issue with a hidden jailbreak prompt in a hyperlink; maintainer assigns it to the agent; the agent follows the injected instructions and commits a malicious change into a low-scrutiny file, as described in the Attack walkthrough.
• Mitigation direction: The thread points to an “Open Source Data Firewall” effort as a response class (filtering/sanitizing untrusted inputs before agents act), linked in the Firewall reference via the GitHub repo.
The demo is a concrete reminder that any untrusted text channel (issues, PR comments, docs, web pages) is an input surface unless you explicitly gate and sanitize it.
Adversarial robustness is framed as the main blocker to trusting agents
Agent robustness (Ecosystem signal): A recurring claim is getting re-stated in blunt economic terms—there’s “a trillion dollars locked behind a solution to adversarial robustness,” because teams can’t trust agents that are “trivially hacked,” as argued in the Robustness thesis.
This is less about model capability than operational trust: if prompt-injection and tool-hijack remain cheap, more autonomy (repo write access, prod credentials, financial actions) stays gated behind human review, regardless of how good the agent is at completing tasks.
🏗️ AI infra economics: subscriptions, credits, and datacenter power constraints
Infra-facing signals tied to AI demand and cost: subscription expansions, cloud credits, and data center power buildout trends. Excludes Prism (covered as the feature).
Data centers are bypassing the grid with 48 GW of behind-the-meter power plans
Behind-the-meter power (Data centers): Planned “behind-the-meter” data center capacity reportedly jumped from under 2 GW to 48 GW in under 12 months, meaning operators colocate generation next to the facility and feed power directly rather than waiting on utility interconnects, per the Capacity jump chart.
For AI infra economics, the point is straightforward: power availability is becoming a first-order constraint, and “AI factory” expansion increasingly looks like co-deploying generation, not just leasing more colo space.
SoftBank reportedly explores up to $30B more investment in OpenAI
OpenAI financing (SoftBank): SoftBank is reportedly in talks to invest up to $30B more in OpenAI; the same report claims SoftBank already added $22.5B in December and holds ~11% of OpenAI, as described in the Funding report screenshot.
This is an infra-facing signal because funding at that scale is usually a proxy for planned capex commitments (compute, datacenter buildouts, long-term power contracts), even if the near-term details and timing remain unconfirmed from the tweet alone.
Google AI Pro and Ultra subscriptions now include monthly GCP credits
Google AI Pro/Ultra (Google): Google is bundling recurring Google Cloud credits into its consumer AI subscriptions—$10/month for AI Pro and $100/month for AI Ultra—by rolling Google Developer Program premium benefits into those tiers, as shown in the Credits excerpt and detailed in the Developer tools blog.
This is a notable pricing move because it effectively turns “try building on GCP” into a default perk of the subscription, which can pull experimentation (small inference jobs, storage, or hosting) into the same monthly line item as model access.
Google AI Plus expands to 35 more countries with Gemini 3 Pro and Veo 3.1 access
Google AI Plus (Google): Google says it’s launching Google AI Plus in 35 new countries and territories, making it available everywhere its AI plans are; the bundle includes more access to Gemini 3 Pro and Nano Banana Pro in the Gemini app, more access to Veo 3.1 in Flow and the Gemini app, expanded access to NotebookLM, and 200 GB storage shareable with up to 5 family members, as described in the Plan rollout note.
The practical infra angle is that Google is packaging higher-capability model access as a subscription entitlement (not just pay-per-token), which can change budgeting and “who gets to use which model” inside teams—especially where NotebookLM/Veo quotas become the gating factor rather than raw API spend.
⚙️ Inference & self-hosting: vLLM day‑0 support, serving recipes, and workload-specific serving patterns
Serving/runtime engineering updates: day‑0 model support in inference engines and concrete advice for throughput vs latency workloads. Excludes Prism (covered as the feature).
Gemini 3 Flash adds Agentic Vision with code execution on images
Gemini 3 Flash Agentic Vision (Google): Google is rolling out Agentic Vision for Gemini 3 Flash, letting the model run code execution on images (crop/zoom/annotate/bounding boxes) in a think‑act‑observe loop, with a claimed 5–10% quality boost on vision benchmarks, as described in Agentic Vision summary and shown in Agentic vision diagram.
• API surface: The feature is available in AI Studio and Vertex AI, and it’s triggered by enabling code_execution, as described in Agentic Vision summary and detailed in the Gemini developer guide plus the Product blog post.
This is part of the broader shift from “one-shot vision answers” to “vision + verifiable tools,” where the model can ground claims in computed visual evidence.
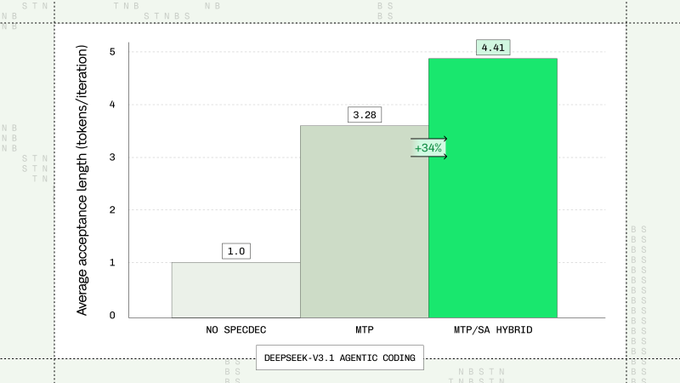
Baseten claims 40% higher acceptance rate via MTP + suffix-automaton decoding
Speculation Engine (Baseten): Baseten says it boosted code-edit “acceptance rate” by up to 40% using a hybrid of multi-token prediction (MTP) and suffix automaton decoding, and also claims 30%+ longer acceptance lengths on code editing without extra overhead, as described in Speculation engine claim.
• Deployability signal: The same post says an open-source version targeting TensorRT‑LLM is available, as noted in Speculation engine claim.
If true, this is a decoding-layer lever that can change both latency and cost for code-assist style workloads without retraining the model.
Modal lays out a workload-first playbook for serving (and fast boots via snapshots)
LLM serving patterns (Modal): Modal frames production inference as three distinct workload classes—offline throughput jobs, online low-latency apps, and bursty “semi-online” pipelines—then maps engine choices to each, as described in Serving posture thread and linked in the Workloads guide.
• Engine recommendations: The guide points to vLLM for throughput-oriented batching, as highlighted in vLLM for throughput note, and to SGLang for latency-sensitive serving with aggressive optimizations, as described in SGLang for latency note.
• Fast boots: It also calls out GPU memory snapshotting to cut cold start and JIT costs down to “seconds” by restoring from disk, as explained in Snapshot boot claim.
This is a useful taxonomy for teams that keep arguing “vLLM vs SGLang” without first agreeing on which workload they’re optimizing for.
DeepSeek‑OCR 2 ships with vLLM day‑0 support and learnable reading order
DeepSeek-OCR 2 (DeepSeek) on vLLM: DeepSeek‑OCR 2 is reported as running on vLLM 0.8.5 with day‑0 support and introduces a “Visual Causal Flow” approach to learn reading order, while also claiming 16× visual token compression down to 256–1120 tokens per image, as summarized in DeepSeek‑OCR 2 vLLM post.
• Quality + efficiency claims: The same post cites 91.09% on OmniDocBench v1.5 (+3.73), along with reduced reading-order errors and repetition in production, as shown in DeepSeek‑OCR 2 vLLM post.
If these numbers hold up, the “tokens per page” reduction is the operational unlock for OCR-heavy pipelines where inference cost and context budget are the constraint.
vLLM adds day‑0 serving for Arcee Trinity‑Large‑Preview
Trinity-Large-Preview (Arcee AI) on vLLM: vLLM says it has day‑0 support for arcee-ai/Trinity-Large-Preview, including a concrete serve recipe that enables auto tool choice and a Hermes tool-call parser, as shown in Serving command snippet.
• Serving details: The example uses vllm serve arcee-ai/Trinity-Large-Preview --dtype bfloat16 --enable-auto-tool-choice --tool-call-parser hermes, as shown in Serving command snippet.
This is a clean “copy/paste to first token” path for teams trying Trinity quickly without writing custom tool-call plumbing.
Mistral details a vLLM disaggregated-serving memory leak traced to UCX mmap hooks
vLLM debugging (Mistral): Mistral published an engineering write-up on a ~400 MB/min memory leak observed in vLLM during disaggregated serving, which they attribute to UCX mmap hooking interacting badly with Python’s memory allocator, as summarized in Weekly roundup note and detailed in the Debugging post.
This is a concrete “production gotcha” for teams doing high-throughput, multi-process serving where low-level comms libraries can quietly become part of your memory story.
vLLM says its Kimi K2.5 recipe is verified on NVIDIA GPUs
Kimi K2.5 (Moonshot AI) on vLLM: vLLM claims its serving recipe for Kimi K2.5 has been “verified on NVIDIA GPUs,” as stated in Recipe verified note, which is a practical signal for anyone attempting on-prem or self-hosted deployments.
• Why this matters operationally: For frontier MoE + multimodal models, the biggest early friction is usually dtype/quantization compatibility and tool-call wiring; the recipe verification claim in Recipe verified note suggests the integration work has already been beaten on real hardware.
This doesn’t prove performance, but it does reduce “first deployment” integration risk.
🗂️ Retrieval, parsing, and context quality: rerankers, OCR layout, and doc pipelines
Signals about ‘context is the bottleneck’: retrieval models, OCR/document parsing improvements, and approaches that make agent inputs cleaner. Excludes Prism (covered as the feature).
DeepSeek-OCR 2 ships learnable reading order and big OmniDocBench gains
DeepSeek-OCR 2 (DeepSeek): DeepSeek’s new OCR model replaces fixed raster scanning with Visual Causal Flow (learned token reordering) and claims 16× visual token compression down to 256–1120 visual tokens per image; vLLM reports day‑0 support and notes it runs on vLLM 0.8.5 as described in the release summary.
• Quality + layout stability: vLLM reports 91.09% on OmniDocBench v1.5 (+3.73), with reading-order errors cut by 33% and repetition down 30–40% in production, according to the release summary.
Learnable reading order emerges as the key trick for OCR on complex layouts
DeepSeek-OCR 2 (DeepSeek): A useful practitioner-level explanation is that the core jump isn’t “better text recognition,” it’s encoding documents with a learnable reading order so tables/forms/diagrams stay contiguous instead of being broken up by left-to-right raster scanning, as laid out in the architecture explanation.
The framing is practical: bidirectional vision encoding plus query tokens that “choose” what regions to attend to can reduce the semantic fragmentation that hurts downstream extraction and agent context packing, as argued in the same architecture explanation.
Jina reranker v3 wins Best Paper for “all docs in one context” listwise reranking
jina-reranker-v3 (Jina AI): JinaAI says jina-reranker-v3 won Best Paper at the AAAI Frontier IR Workshop by doing listwise reranking via “throw all documents into one context window” (their “last but not late” interaction), as described in the best paper note.
They also claim a 0.6B-parameter model and “Top3 on MTEB reranking,” with more detail available in the linked ArXiv paper.
Two-tier semantic retrieval: instant results first, better ranking shortly after
Semantic search workflow: One concrete pattern for local retrieval is a two-tier embedding pass—use a very fast CPU embedder for immediate results, then run a stronger (slower) embedder in the background and “upgrade” the ranking as it finishes, as described in the two-tier search idea.
The motivating constraint is CPU-only, sub‑second response for developer tools (searching agent session logs and archives), while still getting high-quality semantic matches after the upgrade step, per the same two-tier search idea.
Document parsing is still the bottleneck for back-office agents
Document pipelines for agents: A recurring thesis is that “AI employees” still bottleneck on high-quality doc extraction—lots of real work is manual editing + data entry on top of documents (invoices, onboarding packets, claims), and automation depends on stronger parsers plus workflow layers that encode business logic with the right pockets of determinism, as argued in the doc parsing argument.
Parallel adds Spark SQL UDFs to enrich datasets with web intelligence
Parallel (Parallel): Parallel announced a Spark integration that exposes SQL-native UDFs to enrich datasets with web intelligence inside Spark pipelines (no custom API wiring), as described in the Spark integration.
Details and setup live in the Spark docs, with the product pitch emphasizing partition-parallel row processing plus optional per-field citations (source URLs) for downstream auditability, per the Spark integration.
🧠 Accelerators & compute hardware: Maia 200 and wafer-scale alternatives
Hardware announcements that impact inference cost/perf and deployment planning. Excludes Prism (covered as the feature).
Maia 200 rollout: US Central first, Maia SDK preview for developers
Maia 200 (Microsoft): Microsoft is positioning Maia 200 as its in-house inference accelerator for lowering token-generation cost; the rollout is described as starting in US Central (Iowa) with “more regions next,” alongside a Maia SDK preview for developers, as summarized in the specs and rollout clip.

This matters for deployment planning because it signals when teams can expect a first-party Azure alternative to Nvidia for inference-heavy workloads (and what region constraints might look like early on). It also suggests a new software surface area (the SDK) that teams may need to budget time to evaluate alongside existing CUDA-centric stacks.
Cerebras wafer-scale pitch: one processor built from smaller steps
Wafer-scale compute (Cerebras): Weights & Biases highlighted a plain-English explanation of Cerebras’ wafer-scale approach—building the system from smaller manufacturing steps but presenting it as a single large processor rather than a conventional multi-chip network, as shown in the wafer-scale explainer.

The practical relevance for infra teams is in where this kind of architecture could change the usual trade space (model parallelism, interconnect overheads, and memory/compute locality), even if most orgs still consume it through managed services rather than buying hardware outright.
🎥 Generative media & vision apps: controllable cameras, audio-to-video, and image models
Creator/vision model tooling and releases (image/video generation, editing, camera control). Kept separate so creative pipelines aren’t dropped; excludes Prism (covered as the feature).
ANGLES v2 ships 360° camera control and a new cube+slider interface
ANGLES v2 (Higgsfield): Higgsfield shipped ANGLES v2 with full 360° camera control, a redesigned UI using a 3D cube plus sliders, more “behind subject” viewpoints, and upgraded project management, as shown in the launch thread.

• Shipping impact: for teams building short-form generative video pipelines, this is a concrete step toward repeatable “coverage” (iterate composition without re-prompting), with camera state becoming a first-class control surface rather than an afterthought, per the launch thread.
fal adds LTX‑2 audio-to-video with sound-driven motion and timing
LTX‑2 Audio-to-Video (fal): fal added LTX‑2 Audio-to-Video, where an input audio track drives motion/timing from the first frame and outputs full-HD video, according to the fal announcement.

• What’s new vs typical text-to-video: the product pitch is control-by-waveform (voice/music/SFX shaping performance), rather than trying to infer pacing from text alone, as described in the fal announcement.
Z‑Image base gets day‑0 ComfyUI support as a non-distilled foundation model
Z‑Image base (ComfyUI + fal): ComfyUI says Z‑Image base is supported in ComfyUI on day 0 and frames it as a non-distilled foundation model suited for fine-tuning and customization, per the support note; fal is also offering the base model for inference, per the fal launch.
• Why engineers care: the “non-distilled base” positioning implies more headroom for downstream LoRA/finetune work and aesthetic diversity (vs distilled checkpoint tradeoffs), matching the feature list in the support note.
• Where to start: ComfyUI points to a packaged workflow via the ComfyUI workflow blog.
PixVerse v5.6 on fal focuses on motion stability and voiceovers
PixVerse v5.6 (fal): fal says PixVerse v5.6 is now live with sharper “cinematic” visuals, smoother motion, multi-language voiceovers, and fewer warping/distortion artifacts compared to prior releases, per the release note.

This is a pure quality+features bump announcement; the tweets don’t include a benchmarkable eval artifact or specific failure rates beyond the qualitative “less warping” claim in the release note.
Chatterbox lands on Comfy Cloud for zero-shot voice cloning and TTS
Chatterbox (ComfyUI / Comfy Cloud): ComfyUI says Chatterbox is now available on Comfy Cloud with zero-shot voice cloning (from ~5 seconds of audio), 23 languages, and expressive TTS controls, per the Comfy Cloud launch.

• Packaged workflows: ComfyUI describes multiple preset flows (voice conversion, TTS, multi-speaker, multilingual), as outlined in the workflow list.
fal ships Z‑Image‑Turbo Trainer v2 for faster LoRA training
Z‑Image‑Turbo‑Trainer‑V2 (fal): fal announced a faster LoRA trainer for Z‑Image‑Turbo, claiming similar-or-better results with reduced training time compared to their prior trainer, per the trainer update.
This is specifically a training workflow upgrade (style/personalization LoRAs) rather than a new base model release, as described in the trainer update.
🤖 Robotics & embodied AI: full-body autonomy and perception upgrades
Embodied AI progress with direct relevance to autonomy stacks and perception: whole-body control models and robotics-focused vision/perception models. Excludes Prism (covered as the feature).
Figure’s Helix 02 pushes toward whole-body autonomy for household tasks
Helix 02 (Figure): Figure’s latest autonomy stack runs an end-to-end dishwashing routine with whole-body control (not a scripted replay), as described in the Helix 02 overview and demonstrated in the Autonomous dishwashing clip. This is a concrete datapoint for teams building loco-manipulation systems where balance, contact, and manipulation need to stay coupled.

• Control stack details: The writeup claims a 3-layer design with a learned low-level controller running at high frequency, replacing large amounts of hand-written control logic, per the Helix 02 overview.
• Why it matters operationally: It’s a rare public demo emphasizing robustness to environment variation (vs task-specific choreography), which is the pain point for shipping general-purpose autonomy.
Official details are in Figure’s post, as linked in the Figure blog post.
Ant Group’s LingBot-Depth targets depth-camera failure modes in robotics
LingBot-Depth (Ant Group / Robbyant): Ant Group released LingBot-Depth, a robotics perception model for depth refinement/completion intended to reduce holes and bad depth on reflective, transparent, dark, or low-texture surfaces, as summarized in the LingBot-Depth explainer. This squarely targets a common blocker for manipulation stacks that depend on stable RGB-D geometry.

• What shipped: The release includes two variants (a general depth refiner and a depth completion model that can recover dense depth from very sparse valid pixels), per the LingBot-Depth explainer.
• Where to get it: The model weights are posted on Hugging Face via the Hugging Face model, alongside code in the GitHub repo.
Public evaluation numbers aren’t included in the tweets, so quality claims here are mostly architectural/intent-level rather than benchmark-backed.
Verobotics targets building-facade service with lightweight autonomous climbers
Verobotics (Facade robotics): Verobotics is building lightweight autonomous robots that climb and service building facades, aiming for one-person deployment and autonomous cleaning plus inspection with cameras/sensors, according to the Facade robot demo. This is a practical autonomy setting where adhesion, navigation on frames, and coverage verification become the core reliability constraints.

The thread frames the output as both cleaning and inspection data products (crack detection and a digital twin for predictive maintenance), per the Facade robot demo.
📉 Workforce & cognition: AI skill demand, cognitive offloading, and model-tone concerns
Discourse and signals about how work changes for engineers and knowledge workers: labor-market impact claims, cognitive load concerns, and “AI voice” style drift. Excludes Prism (covered as the feature).
IMF warns AI impact will be a “tsunami,” with entry-level roles most exposed
AI labor market exposure (IMF): IMF managing director Kristalina Georgieva warned AI will hit work like a “tsunami,” emphasizing that young workers get hit hardest because many entry-level tasks are easiest to automate, as summarized in IMF tsunami warning.
• Magnitude claims: she cites IMF research that ~60% of jobs in advanced economies and ~40% globally will be affected—some augmented, some transformed, some eliminated—per IMF tsunami warning.
• Distributional angle: the same remarks flag wage pressure on the middle class and call for faster regulation, according to IMF tsunami warning.
Terence Tao cautions that outsourcing thinking to AI can weaken cognition
Cognitive offloading (Terence Tao): Tao argues that lowering mental effort with AI can lead to the brain no longer “lifting its own weights,” with early studies suggesting real harms alongside convenience, as shown in Tao on cognitive cost.

• Why math is a stress test: he calls out math as especially vulnerable because it’s easy to outsource every step to tools, per Tao on cognitive cost.
• Behavioral implication: the core intervention is choosing when to think rather than defaulting to delegation, according to Tao on cognitive cost.
“Ambient Claudish/GPTish” phrasing drift becomes a new authorship concern
Model-tone drift (writing): Ethan Mollick notes that even when you don’t use LLMs directly for writing, you can start absorbing “ambient Claudish or GPTish phrasing” from ubiquitous AI text around you, as described in Ambient phrasing drift.
• Ubiquity is the mechanism: the concern isn’t that AI prose is always bad; it’s that a single, widely replicated tone becomes subtly influential—he even observes his own sentence sounding AI-like, per Ubiquity makes tone influential.
• Workplace relevance: for teams shipping docs, specs, and comms through agents, this frames “voice” as an input quality problem alongside correctness and speed, as argued in Ambient phrasing drift.