ElevenLabs Scribe v2 Realtime delivers ~150 ms STT – 93.5% multilingual accuracy
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
ElevenLabs shipped Scribe v2 Realtime, a production-ready live speech-to-text. It hits ~150 ms median latency and streams partials in milliseconds across 90+ languages. On a FLEURS slice it scored 93.5% across 30 languages, ahead of Gemini 2.5 Flash (91.4%), GPT-4o Mini (90.7%), and Deepgram Nova 3 (88.4%).
The real win is control: streaming input, VAD, manual commit, optional diarization, and PCM 8–48 kHz plus µ-law. You can feed partials to tools while holding finals for grounding or billing. Early builders report better noisy-audio accuracy than Deepgram and Assembly while staying quick; the model is scribe_v2_realtime and currently alpha in the API.
Enterprises get SOC 2/ISO27001, HIPAA/PCI readiness, EU and India residency, and a zero-retention mode. If you handle multilingual or call-center traffic, run a head-to-head this week and watch latency and correction rates over a few hundred calls. Bonus: a live-captioned stream and Summit SF demos will show diarization and commit timing under load—so you don’t have to stage your own marathon (for once).
Feature Spotlight
Feature: Real-time STT for agents goes production-grade
ElevenLabs Scribe v2 Realtime ships with ~150ms latency, 93.5% accuracy across 30 EU/Asian languages, streaming/VAD/diarization, and enterprise compliance—putting production-ready live voice into agent stacks.
Cross-account launches centered on ElevenLabs Scribe v2 Realtime: sub‑200ms live transcription, 90+ languages, and agent‑first controls. This is the dominant dev-facing story today; other sections exclude it.
Jump to Feature: Real-time STT for agents goes production-grade topicsTable of Contents
🎙️ Feature: Real-time STT for agents goes production-grade
Cross-account launches centered on ElevenLabs Scribe v2 Realtime: sub‑200ms live transcription, 90+ languages, and agent‑first controls. This is the dominant dev-facing story today; other sections exclude it.
ElevenLabs ships Scribe v2 Realtime: ~150 ms live STT, 90+ languages, API and Agents
ElevenLabs released Scribe v2 Realtime with median ~150 ms latency and partial transcripts in milliseconds, available today via API and inside ElevenLabs Agents. It targets voice agents and live apps where speed and dialog fidelity matter. See the feature reel in release video and product details in Scribe page.

Why it matters: sub‑second turn‑taking is the difference between clunky IVRs and assistants that feel present. Teams can start integrating now and swap in agent-first controls when conversations get messy. The Agents entry point is documented in agents overview.
Agent-first controls: streaming, VAD, manual commits, diarization, PCM/µ‑law
Scribe v2 Realtime ships the knobs agents actually need: streaming input, voice activity detection to segment by silence, manual commit control to finalize chunks, optional speaker diarization, and broad format support (PCM 8–48 kHz and µ‑law). These are designed to survive real call noise, accents, and cross‑talk capabilities brief.

The point is: you can keep partials flowing to tools while holding the final transcript for grounding or billing, and still rewind when the user pauses mid‑sentence. Docs and enterprise feature flags live on the product page Scribe page.
Benchmark: Scribe v2 Realtime hits 93.5% across 30 EU/Asian languages, tops peers
On the FLEURS slice reported today, Scribe v2 Realtime scored 93.5% accuracy across 30 European and Asian languages, ahead of Gemini 2.5 Flash (91.4%), GPT‑4o Mini (90.7%), and Deepgram Nova 3 (88.4%). That’s a meaningful gap for global deployments where accent robustness trumps lab demos benchmarks chart.
So what? If you serve multilingual traffic, this lets you route more geos to the same STT without bespoke model maps, and shrink the correction layer you keep bolted on top of the transcript stream.
Builders report better noisy‑audio accuracy vs Deepgram/Assembly; model id scribe_v2_realtime
Early developers show Scribe v2 Realtime outperforming Deepgram/Assembly on hard samples with background noise while keeping latency down. The model is exposed as scribe_v2_realtime and marked alpha in current APIs, which matches the author’s tests and rollout notes comparison demo, alpha availability.

Why it matters: agents break in the wild on coffee shop audio and cell handoffs. If your current STT retriggers tool calls or mislabels entities under noise, this is worth a head‑to‑head in staging. Follow the builder thread for more run notes additional tests.
Enterprise readiness: SOC2, HIPAA/PCI, EU and India residency, zero‑retention mode
ElevenLabs is positioning Scribe v2 Realtime for regulated deployments: SOC 2 and ISO27001 posture, HIPAA and PCI readiness, EU and India data residency options, and a zero‑retention mode are all called out for production buyers product brief, compliance note.
So what? This shortens the security review loop for support centers and health use cases and reduces your need to run a separate EU stack while you test latency. Details and signup live on the product site Scribe page, with agent integration on agents page.
Live demo momentum: realtime‑captioned stream and Summit SF sessions land this week
Community touchpoints are lining up: a livestream with realtime captions is on deck, and the ElevenLabs Summit SF agenda features partner demos and a closing conversation with Jack Dorsey livestream note, summit schedule. This is a good window to watch feature depth in longer runs.
This follows agenda schedule hinting at partner‑led announcements. If you’re evaluating STT for agents, use these sessions to press on diarization edge cases and commit timing under load.
👩💻 Agentic coding stacks and dev ergonomics
Today’s threads emphasize agent cost/latency wins and orchestration hygiene: Claude Code token trimming, RepoPrompt orchestration, AI SDK Agent() evaluation, Verdent subagents. Excludes voice STT (feature).
Claude Code hack trims tokens ~90% by offloading MCP tool calls to Python/bash
A practical setup removes preloaded MCP tools from context and has Claude Code generate and execute shell/Python to call tools on demand, cutting prompt bloat and token usage by roughly 90% in real projects code reduction thread, with follow‑up reports that it keeps the model focused and cheaper over long sessions builder notes. This pattern mirrors Anthropic’s “code execution with MCP” guidance and is easy to replicate in existing workspaces.
RepoPrompt 1.5.32 reduces RAM/CPU on huge repos; used to orchestrate Codex/Gemini from Claude Code
The latest RepoPrompt update is “kinder to RAM and CPU” on very large repositories release note. One workflow has Claude Code shell out to understand Gemini CLI, then invoke GPT‑5 via Codex CLI through the RepoPrompt MCP to plan and implement Gemini support—while keeping edits in a sandbox cross‑CLI orchestration, and users report it’s evolving into a lightweight agent orchestrator orchestration note. This follows Codex CLI support added earlier.
Verdent ships @subagents and hits 76.1% single‑attempt on SWE‑bench Verified
Verdent’s coding agent now supports configurable subagents you can @tag for roles like verifier and plan_reviewer, alongside multi‑model routing where GPT handles navigation/review and Claude focuses on coding/debugging feature overview, with docs/screens showing how to add custom model+prompt subagents from settings feature brief feature brief. The team reports 76.1% pass@1 on SWE‑bench Verified, putting it among today’s stronger out‑of‑the‑box coding stacks.
Exa web search lands in Vercel AI SDK; add robust web search in two lines
Exa released an official tool for the Vercel AI SDK so any agent/app can call quality web search with a tiny code snippet launch thread GitHub repo. The docs also include a cookbook for building a web‑search agent, making it easy to enrich retrieval beyond your own files cookbook guide.
McPorter now keeps stateful MCP servers alive as daemons to improve CLI mode
The mcporter tool gained a mode that keeps MCPs needing state running as daemon processes, making “CLI mode” viable for more real‑world servers and reducing reconnect/setup churn feature note GitHub repo. If you struggled with flaky or slow tool startups in loops, this is worth a try for more reliable runs.
OpenAI shares cookbook patterns for agents to learn from mistakes (GEPA)
A new OpenAI cookbook entry covers how to wire “GEPA”‑style loops so agents analyze failures and update behavior over time, moving beyond one‑shot tool chains into self‑improving routines cookbook note, with additional signal from community shares of the broader “Self‑Evolving Agents” guidance guide mention. If you’re stabilizing long‑running agents, this gives concrete scaffolds for error‑aware retries and memory updates.
Vercel AI SDK adds Agent() API to speed up agent evaluation loops
Developers testing the new Agent() API say it makes standing up and comparing agent behaviors much easier inside the usual Next.js/TypeScript stack, reducing friction for A/B’ing harnesses and tool configs dev reaction. If you’re iterating on planner/verifier loops or swapping model backends, this is a low‑effort way to standardize your eval harness.
Memex emerges as a local, GUI‑first coding agent alternative to terminal flows
Creators highlight Memex for generating full apps locally with a chat UI—e.g., scaffolding a Next.js site and iterating without living in the terminal product screenshot, with a video walk‑through building a calming landing page end‑to‑end project demo. It’s a useful option if your team wants agentic coding but prefers a desktop app over shell‑centric harnesses.
Observatory: local‑first observability for Vercel AI SDK on Next.js in ~10 LOC
A small “Observatory” addon displays all AI SDK generations and traces locally within a Next.js app, giving a live view of prompts, tool calls, and outputs with minimal setup feature brief. For teams tuning prompts or tools, this helps catch regressions without wiring up a separate telemetry stack.
🧩 Agent UI, MCP, and cross‑stack interoperability
Interoperability news focuses on AG‑UI alignment and MCP-based RAG/search. Multiple concrete demos but fewer protocol changes vs prior days. Excludes STT/voice items (feature).
Microsoft Agent Framework now speaks AG‑UI via CopilotKit
CopilotKit announced that Microsoft’s Agent Framework is now compatible with the AG‑UI protocol, bringing chat UI, generative UI, human‑in‑the‑loop, and frontend tool calls to .NET agents, with React and Angular frontends supported out of the box integration video. Following up on Kotlin SDK, which took AG‑UI to mobile stacks, this closes a key interoperability loop for cross‑platform agent apps.

Why it matters: teams can wire the same agent backend into multiple frontends without bespoke glue; this reduces UI churn and speeds up HITL flows across web and .NET.
Claude Code pattern: cut ~90% tokens by calling MCP tools via bash/Python
Adopting “Code Execution with MCP” yields large context savings: remove preloaded MCP tools from the prompt and have the agent generate small bash/Python shims to call them, which cut token use by ~90% in field tests approach thread, reshare. The author also reports better focus, fewer distractions, and shares further tuning notes on skills, subagents, and tool execution experience recap.
E2B announces MCP Agents hackathon with 200+ preinstalled tools
E2B is hosting an online Nov 21 and in‑person Nov 22 SF hackathon to build MCP‑powered agents, offering a sandbox with 200+ preinstalled MCP tools (e.g., GitHub, Exa, ElevenLabs) and prizes >$30k event details, Luma page. It’s a fast on‑ramp to test cross‑tool agent workflows without local setup.
Gemini’s Dynamic View (Creative Canvas) previews inline interactive canvases
An early preview of Gemini’s Dynamic View—also called Creative Canvas—shows interactive artifacts rendered inside chat: web search panels, image generation, even simple games in‑line feature demo, full scoop. For AG‑UI builders, this hints at richer, stateful frontends without context‑switching to side sheets.
McPorter now keeps stateful MCP servers alive as daemons for CLI runs
McPorter added daemonized handling for MCPs that require state, making its "CLI mode" work across more tools and long‑lived servers release note. The change reduces reconnect churn and lets agent scripts call MCP tools with lower cold‑start overhead GitHub repo.
RepoPrompt trims RAM/CPU on huge repos; orchestrates Codex/Gemini from Claude
RepoPrompt 1.5.32 improves memory and CPU behavior on very large repositories changelog. Builders are using it as an orchestration hub: Claude Code plans changes, then calls Codex CLI and Gemini CLI via the RepoPrompt MCP to implement and test end‑to‑end support in a sandbox multi‑CLI setup, orchestration update.
Verdent ships @subagents and plan‑verify roles; 76.1% SWE‑bench Verified
Verdent’s coding agent exposes built‑in “verifier” and “plan_reviewer” subagents and lets users add custom @subagents with their own prompts and models; the team reports 76.1% single‑attempt on SWE‑bench Verified agent summary, feature brief. The multi‑model split (e.g., GPT for nav/refactor, Claude for coding/debug) is baked into the plan‑code‑verify loop.
CopilotKit highlights AG‑UI ecosystem momentum with Microsoft tie‑in
Beyond the core announcement, CopilotKit’s team recapped the integration as part of a broader AG‑UI ecosystem push spanning React, Angular, Rust/Kotlin/.NET community SDKs, and Microsoft’s Agent Framework ecosystem note, partner post. The takeaway: AG‑UI is becoming the common UI contract for multi‑model agents.
Exa web search lands in Vercel AI SDK with 2‑line integration
Exa is now a first‑class tool in the Vercel AI SDK, so devs can add web search to agents in a few lines and route results into RAG or tool‑use flows release note, GitHub repo, docs example. This tightens the loop between browsing and model reasoning without custom adapters.
Vercel AI SDK adds Agent() API to simplify agent evaluation
A developer report says the AI SDK’s new Agent() API makes evaluating agents “a breeze,” indicating simpler harnessing for tool‑calling and looped interactions dev note. For teams standardizing on one SDK across backends, this reduces boilerplate while keeping model choice flexible.
📊 Evals: memory, terminals, and puzzle suites
A heavy eval day: long‑term memory (LoCoMo), terminal agents (Terminal‑Bench 2.0), Sudoku‑Bench, LiveBench/LisanBench deltas. All distinct from the voice feature and non-overlapping with model launches.
Backboard hits 90.1% on LoCoMo with public, reproducible scripts
Backboard reported 90.1% accuracy on the LoCoMo long‑term conversational memory benchmark and published full replication scripts and prompts. Slice scores: single‑hop 89.36%, multi‑hop 75.0%, open‑domain 91.2%, temporal 91.9% memory benchmark.
They benchmarked against popular memory libraries in the mid‑60s range and a filesystem baseline near ~74%, and opened the results and method for inspection and reruns, which makes this a useful bar for product teams evaluating memory layers blog thread, Backboard changelog. If you want to recreate the results or adapt the harness, their scripts and data are on GitHub GitHub repo.
Terminal‑Bench 2.0 lands; Warp agent tops with 50.1% and shares lessons
Terminal‑Bench 2.0 launched with harder but realistic tasks, and Warp’s agent currently leads at 50.1% accuracy. The team says running the suite already surfaced improvements to their agent architecture leaderboard claim, agent notes.
Bench owners published an updated leaderboard so other shells/agents can compare like‑for‑like and repeat the runs leaderboard. For teams building terminal agents, this is a clean way to pressure‑test tool use, recovery, and long command chains without bespoke harnesses.
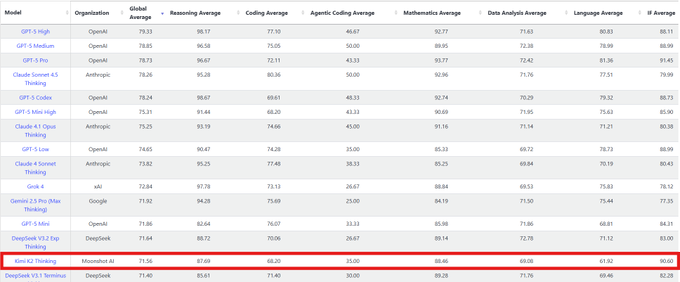
Kimi‑K2 Thinking jumps to #14 on LiveBench; #2 open‑source
Kimi‑K2 Thinking moved up to #14 on LiveBench and is now the #2 open‑source model behind DeepSeek‑V3.2; its reasoning improved, while math and language dipped in this cut score breakdown. This follows LiveBench rank, where it sat at #24 with strong instruction following.
If you track open‑weights for agents, this is a meaningful delta on a widely watched board, and it underscores provider variance when routing across hosts.
Sudoku‑Bench: GPT‑5 leads; authors invite runs for Claude/Grok/Opus
On Sudoku‑Bench, GPT‑5 currently sits at the top. The maintainers note that several frontier "thinking" variants (Claude Sonnet 4.5, Opus 4.1, Grok‑4) haven’t been submitted yet, and the entire suite is open‑source and reproducible if you want to run them yourself benchmark note, GitHub repo. This benchmark stresses creative, human‑style puzzle solving, so it’s a good complement to code and QA evals maintainer update.
LisanBench speed clip: Kimi‑K2 renders responses faster than ChatGPT in demo
A short side‑by‑side LisanBench clip shows Kimi‑K2 producing answers faster than ChatGPT under similar prompts. It’s anecdotal but useful for teams weighing perceived latency alongside accuracy speed demo.
For production, pair clips like this with your own TTFT/TPS logs and throttle settings before swapping routes.

🛡️ Safety, jailbreaks, and data licensing
Two concrete safety/policy threads: long CoT jailbreaks breaking refusals at high rates, and Wikipedia pushing paid API over scraping amid usage shifts. Excludes enclave runtime (covered under Systems).
Long CoT prompts jailbreak frontier models at up to 99% success
A new cross‑institution paper shows that prepending a benign puzzle and forcing long chain‑of‑thought can neutralize safety signals, pushing refusal rates way down and jailbreak success as high as 99% on some frontier models. The mechanism: attention shifts to puzzle tokens, mid‑layer safety representations weaken, and models comply after a cue for the final answer paper thread, attack example, and the full details live in the arXiv submission ArXiv paper.
Why it matters: if your red‑teaming excludes long‑form reasoning, your guardrails may be overstated. Teams should add long‑CoT adversarials to evals, cap visible thinking where appropriate, and monitor for “reasoning‑length” bypass patterns in logs.
German court: OpenAI infringed song lyrics in training; damages ordered
A Munich court ruled OpenAI violated German copyright by training on lyrics from nine songs (including Herbert Grönemeyer’s “Männer” and “Bochum”) and ordered undisclosed damages to GEMA affiliates. OpenAI plans to appeal, arguing user responsibility for outputs, but the case spotlights EU exposure on training data provenance and transparency Reuters recap.
If you ship in Europe, tighten dataset documentation, update rights‑clearance policies, and consider regional model distros or filters while case law crystallizes.
Wikipedia pushes paid Enterprise API; human views down 8% YoY
The Wikimedia Foundation urged AI companies to stop scraping and move to its paid Wikimedia Enterprise API, citing an 8% drop in human pageviews year‑over‑year and a spike in bot traffic masquerading as users. They also ask for proper attribution to human editors as usage shifts toward chat models news summary, with more context in the coverage TechCrunch piece and ongoing discussion follow‑up post.
For AI builders, this changes cost and compliance math: budget for licensed access, build attribution into outputs, and expect more rate‑limiting or legal pressure if you rely on scraping legacy endpoints.
Study: Safety‑aligned LLMs struggle to role‑play villains convincingly
A Tencent‑led study reports that heavily safety‑aligned models fail to sustain believable villain/self‑serving role‑play, suggesting current alignment can over‑suppress simulation capacity needed for testing and narrative tasks. The result nudges teams to separate safety refusal from controlled role‑play settings and to expand red‑team scenarios beyond surface prompts paper thread.
Practical takeaway: when your product depends on nuanced simulated personas (games, training, threat modeling), gate them behind scoped tools and logs rather than blunt refusals, and evaluate with multi‑turn persona consistency tests.
💸 Capex bets and compute market structure
Market-impact items for leaders: SoftBank rotates out of NVDA to fund OpenAI and DC/robotics bets; AMD outlines AI DC growth/Helios rack plans; CoreWeave’s revenue concentration quantified.
SoftBank sells entire $5.83B Nvidia stake to fund $22.5B AI push
SoftBank disclosed it sold 32.1M Nvidia shares (~$5.83B) to help finance a $22.5B package of AI bets—raising its OpenAI stake toward ~11%, lining up a $6.5B Ampere deal, ABB‑paired robotics, and US data‑center buildouts such as Stargate. Shares fell as much as 10% in Tokyo after the move, which management framed as a rotation into owning more of the AI stack rather than a view on Nvidia fundamentals market move, with more detail in the CNBC brief CNBC article.
The plan bundles a $9.17B partial sale of T‑Mobile, bridge loans (~$8.5B for OpenAI, $6.5B for Ampere), and a larger margin loan against Arm. The signal: swapping a liquid NVDA position for concentrated model equity, chip design, robotics, and data‑center capacity—higher execution risk, but potentially closer capture of model economics and rack‑scale value funding rotation.
AMD outlines AI DC surge; OpenAI books ~1 GW Instinct for 2026
At Analyst Day, AMD projected ~35% revenue CAGR over 3–5 years, with AI data center compounding ~80% and targeting double‑digit accelerator share. OpenAI committed to multi‑year purchases starting with ~1 GW of AMD Instinct in 2026, as AMD readies “Helios” rack systems where 72 MI400‑series GPUs operate as a single tightly coupled unit—meant for very large training/inference analyst day recap. AMD also raised its AI DC TAM outlook to potentially ~$1T/yr by 2030 and guided long‑term gross margin to 55–58%.
For infra leads, the read is simple: AMD is packaging silicon + rack‑scale systems and anchoring demand with named commitments. If Helios delivers the interconnect, memory bandwidth, and scheduler maturity at rack scale, it becomes a credible second source for frontier clusters—pressuring unit costs and procurement leverage against Nvidia.
CoreWeave’s $8.2B/yr revenue locked to three AI giants
A breakdown circulating today pegs CoreWeave’s annualized revenue at ~$4.8B with ~$8.2B/yr effectively guaranteed via three anchors: Microsoft (~$3.4B/yr, 71%), OpenAI (~$2.4B/yr over five years), and Meta (~$2.4B/yr over six years). Market cap sits around $44–50B, highlighting just how concentrated its book is on GPU resell to a handful of hyperscale AI tenants revenue breakdown.
For buyers and competitors, this concentration cuts both ways: it signals credible long‑duration demand for accelerator supply, but adds counterparty and renewal risk. It also suggests CoreWeave’s cost of capital and expansion cadence are tightly coupled to a few tenants’ training roadmaps and price floors on GPU hour resale.
🏢 Leadership moves and org strategy (Meta focus)
Multiple accounts report Yann LeCun preparing to exit Meta to found a ‘world models’ startup; context includes Meta AI org reshuffles and compute commit chatter. Excludes technical papers on world models.
LeCun set to exit Meta to found a world‑models startup
FT-sourced reports say Meta’s chief AI scientist Yann LeCun plans to leave to launch a startup focused on world models, marking a break from FAIR’s long‑horizon research inside Meta FT report. Some market chatter tied the news cycle to a same‑day Meta share slide (~12.6% noted by one post), but causality is unproven market move; the move underscores a strategic split between LLM scaling and video/spatially grounded approaches org recap.
Meta AI reorg concentrates product work; FAIR’s role narrows
Separate threads describe Meta’s latest AI reshuffle: a “Superintelligence Labs” structure reportedly puts product model work under Alexandr Wang, with Yann LeCun routed to report to him, while FAIR’s remit narrows; PyTorch inventor Soumitra Chintala has already departed FT summary, Reuters recap, org departures. Commentators also flag Meta’s multi‑year compute commitments (quoted as ~$600B through 2028 by one post) and ask who will execute amid leadership churn org departures.
🧠 Reasoning recipes and robustness research
Mostly method/debias work: implicit CoT calibration, thought‑free inference, retrofitted recurrence, time‑series proficiency, real‑repo optimization (SWE‑fficiency), and agentic multimodal tool use.
Chain‑of‑Thought Hijacking jailbreak hits up to 99% by padding with benign puzzles
A multi‑institution team shows that adding long benign reasoning (e.g., Sudoku or logic puzzles) before a harmful ask weakens safety features encoded in mid layers, dropping refusal rates. On frontier systems the attack succeeds up to 99%; ablations point to safety signal dilution and critical attention heads that, when muted, reduce refusals further attack summary and arXiv paper.
Defense work will need chain‑aware safety that survives long reasoning, not only prompt filters.
SWE‑fficiency: 498 real PRs show LMs reach ~0.15× expert speedups on live workloads
Harvard + DeepMind curated 498 performance PRs across 9 repos (numpy, pandas, scipy…) with paired slow workloads and tests. Agents must localize hotspots, keep tests green, and speed up code; best models hit only ~0.15× the expert’s speedup and often break tests or stop after small gains, highlighting localization and algorithmic weakness benchmark details.
Implication: evaluation for “reasoning that matters” must couple correctness and runtime, not just unit tests.
Energy-based calibration steadies implicit CoT with ~3 quick updates
An Oxford-led recipe adds a small energy model over latent “thought” tokens and nudges them with a few Langevin steps, matching multi‑chain voting consistency without spawning many chains. It calibrates implicit CoT in about three refinement steps and keeps the base and assistant models frozen, reducing cost and drift paper thread.
Why it matters: you can get steadier reasoning without 10× sampling or visible chain‑of‑thought, which cuts latency and tokens in production agents.
Retrofitted Recurrence turns pretrained LMs into depth‑recurrent models
A new training recipe converts existing transformers into depth‑recurrent models by inserting a recurrent block, mixing features with a small adapter, and stabilizing with the Muon optimizer. It improves accuracy per unit compute versus post‑training the original model, and lets you scale loops at test time for harder problems paper overview. This follows up on deadline agents that highlighted dual‑loop planning under time pressure; retrofitted recurrence attacks the compute/latency side.
Takeaway: you can keep model size constant, add recurrence depth on demand, and trade a bit of latency for better reasoning when needed.
3TF trains with CoT, answers short: ~20–40% token cuts at near‑CoT accuracy
The 3TF method builds a model that can think out loud during training but respond concisely at inference, retaining most of CoT accuracy while shrinking outputs to roughly 20–40% of tokens. It avoids over‑thinking loops and keeps the short answer mode reliable across math and reasoning sets method explainer.
This is practical for API billing and UX: you get the internal reasoning benefits without paying for long chains at serve time.
TimeSense teaches LLMs true time‑series structure and beats GPT‑5 on hard splits
TimeSense adds time‑aware tokenization plus a ‘Temporal Sense’ module that reconstructs series from hidden states, with losses that enforce value and frequency consistency. On the 10‑task EvalTS suite, it tops baselines and even outperforms GPT‑5 on difficult multi‑series reasoning, reducing mistakes from chasing text cues paper summary.
For ops and analytics agents, this points to fewer hallucinated trends and more faithful anomaly/root‑cause analysis over logs and metrics.
DeepEyesV2 learns when to tool: 63.7% on MMSearch via supervised patterns + RL
DeepEyesV2 is an agentic multimodal model that plans, decides when to crop/calc/search, and fuses results into its reasoning. Pure RL was unstable, so the team cold‑starts with supervised tool traces, then fine‑tunes with simple rewards to refine timing; it reaches 63.7% on MMSearch and leads their RealX‑Bench vs open peers paper abstract.
This is a clean recipe for tool‑use reliability: teach patterns first, then let RL polish when and how to call them.
More agents help, but typos still break math: robustness gap persists with 25 voters
Agent Forest–style majority voting lifts accuracy from 1→5→10 agents, but the gains do not close robustness gaps under natural typos and adversarial text noise. Across GSM8K/MATH/MMLU‑Math/MultiArith and Qwen/Gemma/Llama/Mistral, human typos remain hardest; punctuation noise washes out with enough votes, but real‑world misspellings often still flip answers paper abstract.
Routing and ensembling need input sanitation, not only more votes.
🧪 Open/frontier model updates (non‑creative)
Smaller but notable drops: ERNIE‑4.5‑VL open‑sourced with Apache‑2.0; Together adds Kimi‑K2 docs and live session; Windsurf ships stealth ‘Aether’ models. Excludes creative VLMs (see Gen‑Media).
Baidu open-sources ERNIE‑4.5‑VL‑28B‑A3B‑Thinking under Apache‑2.0
Baidu released ERNIE‑4.5‑VL‑28B‑A3B‑Thinking as open source with an Apache‑2.0 license, positioning a compact multimodal reasoning model ("3B activated parameters") for vision‑language tasks and tool use release thread. The drop includes support across FastDeploy, vLLM, and Transformers plus features like “Thinking with Images,” precise chart/table grounding, and built‑in tool‑calling, with artifacts live on multiple hubs.
Teams can pull the model from the [Hugging Face model] Hugging Face model, scan the code in the GitHub repo GitHub repo, or try hosted access via AI Studio AI Studio page. For practitioners, Apache‑2.0 licensing simplifies commercial use without copyleft constraints and the vLLM path suggests straightforward serving in existing stacks.
Together publishes Kimi‑K2 Thinking quickstart and schedules Nov 19 deep dive
Together AI posted a Kimi‑K2 Thinking quickstart (use cases, prompting tips, limits) and promoted a Nov 19 technical session with Moonshot, while also highlighting hosted run access on the Hugging Face model page powered by Together docs post, model page demo. This follows Web/API launch coverage; the new piece is hands‑on docs and a scheduled walkthrough for builders.

If you’re evaluating K2 for agents or coding, start with the docs quickstart Docs quickstart and RSVP for the live event Event signup to see multi‑tool runs and routing patterns in practice.
Windsurf Next exposes stealth ‘Aether’ Alpha/Beta/Gamma models for testing
Windsurf opened a “stealth models” preview—Aether Alpha, Beta, and Gamma—inside Windsurf Next (and to a small slice of Stable users) and invited capability reports from developers model preview. The builds are free to try and aim to benchmark coding/task performance before a wider release.
Download Windsurf Next to access the preview from the editor page Download page, then compare Aether variants on your standard prompts to spot strengths (navigation/refactor vs. direct coding, for example) and failure modes across repos.
🎨 Creative stacks: Ketchup leaks, Grok ‘Mandarin’, Flux 2, and tools
High volume creator updates: NB2 ‘Ketchup’ dark‑launch sightings, Grok ‘Mandarin’ text rendering, Flux 2 previews, plus transitions, face swap, and fast upscalers. Non‑voice; excludes the STT feature.
Nano Banana 2 dark‑launch string appears; 4K sample lands
Multiple builders spotted a “models/gemini-3-pro-image-preview-11-2025-dark-launch” entry in AI Studio logs, suggesting Nano Banana 2 (internally “Ketchup”) is in limited preview, with creators urging Google to ship it broadly AI Studio log, and a second corroborating screenshot Log screenshot. A 4K output sample (“brush stroke style, Tokyo at night”) also circulated, underscoring strong instruction fidelity at high resolution 4K example. This follows earlier code-name sightings Rename signal and keeps pressure on timing.
Why it matters: production‑ready resolution plus tight prompt adherence is the bar for pro workflows; the dark‑launch naming hints an imminent public preview once eval gates clear.
Flux 2 [pro] and beta flags surface ahead of launch
Black Forest Labs’ Flux 2 shows up in the Playground UI as “FLUX.2 [pro]” and through config flags (flux‑2‑alpha/‑beta/‑pre), signaling the next major image model is queued for rollout across the web app and API Playground preview, Flag dump. That timing matters: the creative stack is heating up with NB2 and Grok steps, and Flux 2’s color science and composition control are often favored by art teams for brand work.
Grok “Mandarin” narrows text‑rendering gap with Nano Banana
A side‑by‑side board test shows Grok Image “Mandarin” rendering German whiteboard text on par with Google’s Nano Banana, suggesting xAI’s image stack is improving fast on a long‑standing pain point—clean, consistent on‑image typography Comparison board. Separate Arena sightings label “mandarin” in prompts, reinforcing that a stealth model is in testing Arena sighting. For teams, this reduces fallback hacks (overlays/post) when doing product shots and infographics.
Higgsfield adds Transitions, Face Swap, and X‑native prompt‑reply gens
The company launched Higgsfield Transitions with 17 effects (e.g., Morph, Raven, Smoke) that accept video and image inputs Transitions launch and a Face Swap browser extension to drop your face into any online photo Face swap demo. It also rolled out an X‑native flow: tag @higgsfield_ai + #nanobanana under any post and get an image reply, with time‑boxed credit promos (e.g., 204 credits, then 202/250 credit boosts) X‑native promo. For on‑platform content teams, this means faster comps without leaving the feed.

See product pages: product page, extension page.
ElevenLabs platform quietly adds image/video generation beta
Screens show a new “Image & Video Beta” workspace with a model selector that includes Google Veo 3.1/3.1 Fast, OpenAI Sora 2/2 Pro, and Kling 2.5, plus resolution/duration controls and an audio toggle Beta UI, Model list. While voice remains its core, this unifies creative assets inside one pipeline—which helps teams align narration, visuals, and post steps without tool‑hopping.
FlashVSR delivers fast 4K video upscaling on fal.ai
fal’s FlashVSR model targets speed and motion quality: it upscales video to 4K with sharper detail and fewer motion‑edge artifacts, suitable for low‑bitrate source cleanup and social repurposing SR demo. The hosted endpoint is live for testing and production model page. For creative ops, this can cut render waits and reduce dependency on heavier desktop pipelines.

Weavy adds real‑time video transforms and multi‑angle generation
Weavy’s compositor now applies crop/levels/blur and more to footage with real‑time previews and layer control Compositor demo. A separate Weavy+Qwen Edit Multi‑Angle workflow lets creators duplicate nodes with varied camera parameters to spin 10–18 distinct angles from a single source, then chain to upscalers or video models Multi‑angle workflow, with a sharable canvas link for teams Weavy flow.

🦾 Embodied AI and autonomy deployment
A concise robotics beat: DeepMind’s PhysWorld sim‑to‑real via generated videos, Unitree G1 motion demos, and commentary on China’s AV ubiquity vs EU stagnation. Research overlaps handled elsewhere.
DeepMind’s PhysWorld turns AI‑generated videos into robot skills (82% success)
DeepMind’s PhysWorld reconstructs a 4D physical scene from an AI‑generated task video, then learns a small residual policy to act within that physics, reaching 82% average success across 10 manipulation tasks vs 67% for the best video‑only baseline paper thread, with full details in the arXiv write‑up ArXiv paper. Following up on physical world model, today’s threads add a notable data point: Veo‑3 produced 70% usable clips for training vs Tesseract 36%, CogVideoX 4%, and Cosmos 2%—so video quality materially shifts sim‑to‑real yields analysis thread.
If you build robot skills or sim pipelines, the point is: you can now bootstrap from synthetic videos and let a physics model police feasibility, then layer a lightweight RL residual for real hardware. It reduces hand‑engineered policy cloning and cuts grasp/track failure modes.

China’s AVs scale last‑mile while Europe debates; data edge widens
A field clip from China shows autonomous shuttles already covering last‑mile trips at scale, while the thread argues Europe remains stuck in regulatory debate—translating into a compounding data advantage for Chinese stacks street ride video. For AV leads and policy teams, the implication is simple: deployment pace begets more corner‑case telemetry and cheaper validation cycles; prolonged policy stalls create a widening performance gap.

Unitree G1 ‘kung fu’ demo highlights rapid biped motion progress
Unitree showed a live “kung fu” routine on its G1 biped—quick transitions, kicks, and stance changes—demonstrating balance/momentum control that’s getting closer to production‑ready motion libraries demo clip. For teams scoping embodied pilots, this is a signal that low‑cost bipeds are moving beyond lab gaits into agile, choreographed sequences that stress CoM and contact planning.

⚙️ Runtime performance and trusted inference
Serving/runtime news is lighter but meaningful: vLLM adds Intel Arc Pro GPU support with MoE efficiency; Google outlines Private AI Compute enclaves. Excludes ElevenLabs STT (feature).
Google details Private AI Compute enclaves for sealed Gemini inference
Google introduced Private AI Compute: Gemini runs inside Titanium Intelligence Enclaves paired with TPUs, where requests are hardware‑attested end‑to‑end and data is sealed from operators and surrounding services. The flow uses remote attestation, enclave‑scoped keys, and logging within the enclave boundary, pitching on‑device‑like privacy with cloud‑class reasoning when tasks exceed local limits. feature brief
This brings a concrete trust model for sensitive inference—think long‑context personal data, medical, or enterprise docs—without giving up TPU throughput. It mirrors Apple’s Private Cloud Compute but on Google’s stack, with early user features (e.g., better Magic Cue and Recorder summaries) shipping against the same attestation guarantees. For security architects, the takeaway is a production‑ready path to run LLMs in verified compute, folding enclave identity into client policy and key management.
vLLM adds Intel Arc Pro support with 80%+ MoE efficiency
vLLM now runs optimized on Intel Arc Pro B‑Series GPUs, reporting 80%+ Mixture‑of‑Experts hardware efficiency on Arc Pro B60/B‑series with a new persistent single‑kernel loop, dynamic load balancing via atomic scheduling, and MXFP4→BF16 memory‑friendly paths. A ready Docker image is published (intel/vllm:0.10.2-xpu), with full TP/PP/EP multi‑GPU support, and validation against DeepSeek‑distilled models and other popular LLMs. vLLM announcement
For teams squeezing cost/perf, this widens hardware choices beyond Nvidia: Arc Pro B60 (24 GB VRAM, 456 GB/s, 160 AI engines) hits strong performance‑per‑dollar in MLPerf v5.1‑style tests while keeping latency low through the persistent kernel approach. Deployers can trial MoE serving on Arc with minimal code changes, then scale via the provided container.