Gemini 3 Flash hits 1M context at $0.50 – new default fast brain
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Google’s Gemini 3 Flash is the first “fast” model in a while that actually feels frontier-class. You get a 1M-token context window, 64K outputs, and full multimodality at $0.50 per 1M input tokens and $3 per 1M output, with dynamic “thinking” levels baked into that price. Google is confident enough to swap it in as the default Fast and Thinking brain in the Gemini app and Search, while context caching chops repeated-prefix cost to 10% and batch jobs can see up to 50% savings.
The ecosystem read the memo instantly. Cursor, Cline, Warp, Zed, Antigravity, Perplexity, OpenRouter, Ollama and a slew of agent stacks all wired 3 Flash in as the new quick-but-smart default for coding, repo planning, and search-heavy workflows. Benchmarks back the shift: 78% on SWE-bench Verified, state-of-the-art on MMMU-Pro, a 71 score on the Artificial Analysis Index, and around 6× more successful BrowserUse web tasks per dollar than Claude Sonnet. Box AI saw document-extraction recall jump from 74% to 84% by swapping out 2.5 Flash.
There’s a catch: hallucination rates north of 90%, “lazy” short answers without prompt pressure, and day-one jailbreaks leaking MDMA recipes and runaway chain-of-thought. Treat Gemini 3 Flash as your new default workhorse—but only behind strong verification, safety filters, and house prompts that force it to think before it talks.
Top links today
- Pretraining, mid-training and RL reasoning paper
- Error-free linear attention for long contexts
- Partial introspection in language models paper
- Video Reality Test ASMR benchmark paper
- GPU material footprint of large AI paper
- LLM harms taxonomy and discussion paper
- Vision-language synergy on ARC reasoning paper
- ReplicationBench astrophysics AI agents benchmark
- Reuters on China’s prototype EUV lithography
- TechPowerUp on SMIC 5 nm without EUV
- OpenAI–Amazon Trainium investment report
- Online book on RLHF fundamentals
- Analysis of Firefox plans as AI browser
Feature Spotlight
Feature: Gemini 3 Flash rollout and positioning
Gemini 3 Flash lands at $0.50 in/$3 out with 3× speed vs 2.5 Pro, GPQA 90.4%, SWE‑Bench Verified 78%, MMMU‑Pro 81.2%, and dynamic thinking; available across API, Vertex, AI Studio, Antigravity, and major dev tools.
The day’s cross‑account story. Google’s Gemini 3 Flash ships broadly with frontier‑class capability at speed/price points, and immediate ecosystem pickup. Mostly product, pricing, and distribution details in the tweets sample.
Jump to Feature: Gemini 3 Flash rollout and positioning topicsTable of Contents
⚡ Feature: Gemini 3 Flash rollout and positioning
The day’s cross‑account story. Google’s Gemini 3 Flash ships broadly with frontier‑class capability at speed/price points, and immediate ecosystem pickup. Mostly product, pricing, and distribution details in the tweets sample.
Google launches Gemini 3 Flash as frontier‑class fast model at $0.50 / $3
Google formally unveiled Gemini 3 Flash, a multimodal "frontier intelligence" model optimized for low‑latency inference that undercuts most high‑end models on price at $0.50 per 1M input tokens and $3 per 1M output tokens, with audio input billed at $1 per 1M tokens. The model is positioned as the workhorse sibling to Gemini 3 Pro: same family, but tuned for speed, tool calling and coding rather than maximum peak scores. (pricing and positioning, deepmind overview)

Gemini 3 Flash is fully multimodal (text, images, video, audio) and ships with a 1M‑token context window and 64K output limit in the API, making it viable for long docs, codebases and video analysis. The launch deck highlights strong reasoning and knowledge scores like 90.4% on GPQA Diamond and 33.7% / 43.5% on Humanity’s Last Exam with and without tools, plus 81.2% on MMMU‑Pro and 78% on SWE‑bench Verified, all while being marketed as cheaper and faster than Gemini 2.5 Pro. (benchmarks slide, detailed benchmark table) Dynamic "thinking" is a core part of the pitch: Gemini 3 Flash can adjust internal deliberation by effort level (minimal/low/medium/high), with those extra "thinking tokens" included in the $3/1M output rate, so builders don’t need a separate SKU for slow vs fast reasoning. Pricing cards and docs also surface platform‑level features like context caching (90% cost reduction on repeated prefixes) and Batch API (up to 50% savings for offline workloads), which matter a lot for teams running agents or high‑volume backends. pricing and savings
On day one, Gemini 3 Flash is available through the Gemini API, Google AI Studio, the Gemini CLI, and Vertex AI’s gemini-3-flash-preview endpoint, with the same tool calling, JSON mode and structured outputs interfaces as Gemini 3 Pro. The developer blog leans into the idea that you can "build with frontier intelligence that scales with you" and treat Flash as the default general‑purpose model unless you explicitly need Pro‑level peaks. (developer blog, vertex model card)
Ecosystem rushes to adopt Gemini 3 Flash for coding, agents and search
Within hours of launch, most of the serious AI dev tools had added Gemini 3 Flash as a first‑class model option, treating it as the new "fast but smart" default. Cursor integrated it for quick bug investigation, saying it "works well for quickly investigating bugs" and surfaces it alongside GPT‑5.2 and Claude 4.5 in their model menu. (cursor integration, cursor logan reply)

Perplexity switched its Pro and Max tiers to expose Gemini 3 Flash in the model picker, positioning it next to GPT‑5.2, Claude Opus 4.5 and Gemini 3 Pro, and making it the selected default in screenshots; this is a strong vote of confidence from a search‑heavy app that cares about latency. perplexity model picker
On the infra side, OpenRouter added google/gemini-3-flash-preview to its catalog, Ollama spun up a gemini-3-flash-preview:cloud endpoint for one‑line ollama run tests, and Zed shipped stable/preview releases with 3 Flash wired in for both Pro subscribers and BYOK setups. Cline (the open‑source code agent) now lists Gemini‑3‑Flash as a top‑tier option for its WebDev arena, and Warp switched its generated code diffs from 2.5 Flash to 3 Flash after seeing a "clear bump in quality". (openrouter announcement, ollama cloud run) Higher up the stack, specialized tools are baking it into their agent harnesses: Google’s own Antigravity IDE added Gemini 3 Flash as the go‑to model for its automation flows, Factory’s Droid Exec framework recommends it as the default for code and UI automation, and MagicPath and Lovable are using it to rapidly generate and iterate on product designs in the browser. RepoPrompt, which focuses on repo‑aware planning, was showcased on Google’s launch wall because 3 Flash nearly matched 3 Pro on its RepoBench tests while being much faster, so maintainers are already switching their “planner” agents over. (antigravity model selector, droid exec thread) The pattern is clear: if your stack needs lots of short, tool‑heavy calls—code diffs, repo analysis, search‑then‑reason—the community is very quickly standardizing on Gemini 3 Flash as the high‑IQ, low‑latency choice to sit alongside GPT‑5.2 and Claude Opus, not just as "the cheap Google model".
Gemini 3 Flash becomes the new default "Fast" brain in Gemini app and Search
Google is rolling Gemini 3 Flash directly into consumer surfaces: in the Gemini app and web, the old 2.5 Flash option has been replaced by a new "Gemini 3" picker where Fast = 3 Flash, Thinking = 3 Flash (with thinking), and Pro = 3 Pro. Free users are being migrated first, and Google is explicitly marketing this as a "free, fast, unlimited" upgrade for everyday tasks. (gemini launch thread, app model picker)

Screenshots show the Gemini home screen now labeling Fast and Thinking as "New", with Pro gated behind Google AI Plus; the idea is that most chats, summaries and study helpers run on 3 Flash by default, while heavy math and code can bump to Pro. A companion thread from Google DeepMind walks through how 3 Flash powers things like turning voice notes into study plans, analyzing short videos, and converting spoken ideas into app prototypes or project plans in Canvas, again without requiring a paid tier. (free rollout clip, study plan demo) Beyond the app, Gemini 3 Flash is also being wired into Search’s AI Mode, which means those inline generative summaries on the Google.com results page now ride on the new model in many regions. Early testers note that "Fast is now powered by 3 Flash" banners are starting to appear in the web UI, and that dynamic thinking levels (e.g., "minimal" vs "high") are exposed in AI Studio’s compare mode so you can see how much extra reasoning you’re paying for per query. (web picker screenshot, thinking minimal vs pro demo) For AI engineers, this matters less as a UX story and more as a signal: Google is confident enough in 3 Flash to make it the default brain for its highest‑traffic assistant and search experiences, not just a niche "cheap API" SKU. If you want your own product to feel like what users will see in Gemini and Search, this is now the baseline to benchmark and route against.
Builders see Gemini 3 Flash as a new default—while warning about laziness and hallucinations
Early hands‑on feedback from engineers is unusually enthusiastic for a non‑"Pro" model. One creator calls it "the best model ever released. Period … Even better than GPT‑5.2 or 3 Pro on some benchmarks … and by far the most versatile one available," while another sums it up as "frontier intelligence at a fraction of the cost" and says "Gemini 3 Flash is no joke" after testing it in agentic workflows. (strong endorsement, usage praise)

Dev‑tool authors echo that: DynamicWebPaige says Flash is "super, super speedy and cost‑effective," and multiple threads show it beating Gemini 2.5 Pro in WebDev comparisons and repo‑level planning at 3× the speed. Builders are already using it as the default model in Chrome extensions for design prototyping, CLI agents that operate on your filesystem, and coding IDEs like Antigravity and Kilo Code, often reserving Pro only for rare, really hard reasoning tasks. (ai studio walkthrough, cli agent demo) At the same time, power users are surfacing real caveats. Several note a familiar "laziness" pattern—short, under‑reasoned answers unless you fight it with anti‑lazy system prompts—and at least one benchmark thread flags a 91% hallucination rate on a strict knowledge/hallucination suite, with the author describing Flash as "like a dementia patient, loves hallucinating" despite high accuracy when it’s right. antilazy prompt remark
There’s also early red‑teaming: jailbreakers have already coerced Gemini 3 Flash into outputting MDMA synthesis steps and other disallowed content using clever prompt inversion tricks, and some report it occasionally spits out its own chain‑of‑thought markers in long, self‑hyping loops until it hits token limits. (unsafe mdma output, cot loop anecdote) Net read for AI engineers and leads: Gemini 3 Flash feels like a new default to test for coding, agentic tooling and multimodal understanding, but you still need strong verification layers, refusal‑aware evaluation, and probably some house prompts to push it toward depth and away from confident nonsense. It’s fast and capable, not magic.
Launch benchmarks put Gemini 3 Flash near Pro on GPQA, MMMU and SWE‑bench
Google’s launch materials for Gemini 3 Flash lean hard on the message that this is not just a "small" or "cheap" variant, but a near‑Pro model on many standard benchmarks while being priced and tuned for speed. On GPQA Diamond, a PhD‑level science benchmark, 3 Flash clocks in at 90.4% vs 92.4% for Gemini 3 Pro and 86.7% for GPT‑5.2 Extra High in Google’s comparison table. (benchmark charts, comparison table)
On Humanity’s Last Exam, the flagship academic reasoning test, 3 Flash scores 33.7% with tools off and 43.5% with search + code execution, landing just behind Gemini 3 Pro’s 37.5% / 45.8% and roughly tied with GPT‑5.2 at 45.5% (tools on). MMMU‑Pro, which mixes multimodal reasoning across images, diagrams and text, shows 3 Flash at 81.2% vs 81.0% for 3 Pro and 79.5% for GPT‑5.2, which is why DeepMind calls it "state‑of‑the‑art on MMMU‑Pro" in the thread. (benchmark charts, performance overview) For coding and agents, the table highlights 2316 Elo on LiveCodeBench Pro, 78% on SWE‑bench Verified (slightly ahead of Gemini 3 Pro at 76.2% in some third‑party comparisons), and solid numbers on tool‑heavy suites like t2‑bench (90.2%), Toolathlon (49.4%) and MCP Atlas (57.4%). The point is: Flash’s scores are now squarely in "frontier" territory, not "mid‑tier". (full benchmark suite, hla and mmlu chart) Taken together, the launch deck sketches a model that trails Gemini 3 Pro by a few points on some pure reasoning exams but essentially matches it on multimodal and coding tasks, while beating 2.5 Pro by wide margins across the board. For many teams, this makes 3 Flash the obvious first model to try; Pro is starting to look like the specialized upgrade rather than the default workhorse.
Gemini 3 Flash emphasizes token efficiency, caching and a firmer $0.50 / $3 price
Beyond raw scores, Google is selling Gemini 3 Flash on throughput and tokens per answer, arguing that it delivers more work per dollar than both 2.5 Pro and 3 Pro. A launch chart shows median output length for typical traffic at 1,239 tokens for 3 Flash vs 1,788 for 3 Pro, 1,585 for 2.5 Flash and 1,754 for 2.5 Pro—about a 30% reduction in median output vs Pro while meeting or beating its quality. token efficiency graphic
Under the hood, the platform now exposes context caching for 3 Flash: you can mark long, shared prefixes (docs, code, instructions) as cacheable, pay the full price once, then pay only 10% on cache hits. The Batch API is also explicitly supported, with Google’s materials claiming up to 50% savings on async bulk jobs like nightly reports or evaluation runs. Combined with the base $0.50 input / $3 output rates, the dev thread from @ai_for_success argues this makes Flash "the most cost‑efficient model for its intelligence level" on end‑to‑end workloads, not just per‑token sticker price. (pricing and caches, pricing details card) There was a brief pricing confusion pre‑launch when internal screenshots circulated showing $0.30 / $2.50, the same as previous Flash models, but the public docs and Logan Kilpatrick’s launch tweets make it clear the official pricing is $0.50 / $3.00 across AI Studio and Vertex. That’s a bump over 2.5 Flash, but still far below Gemini 3 Pro’s $2 / $12 (or higher for long contexts), and the usage‑based savings from shorter outputs and caching soften the blow for many scenarios. (leaked lower pricing, pricing leak correction) For infra folks, the message is: if you architect around caching, batching and dialing thinking effort only where needed, Gemini 3 Flash can push cost per solved task down significantly—even if its raw per‑token rate is a little higher than the previous Flash generation.
📊 Frontier eval race: independent scores and cost curves
Excludes the 3 Flash launch (covered as the Feature). Today’s sample is heavy on third‑party evals and cost/perf charts benchmarking 3 Flash vs 3 Pro, GPT‑5.2, Claude, Grok, etc., including ARC‑AGI, MRCR, AA Index, LisanBench and task/$ plots.
Gemini 3 Flash posts strong ARC‑AGI scores at far lower cost than GPT‑5.2
On the ARC‑AGI Semi‑Private evals, Gemini 3 Flash (High) scores 84.7% on ARC‑AGI‑1 at about $0.17 per task and 33.6% on ARC‑AGI‑2 at ~$0.23, making it one of the most cost‑efficient frontier entries on both boards. arcprize summary Visual leaderboards show Flash outscoring Gemini 3 Pro on ARC‑AGI‑2 while sitting on a much better score‑per‑dollar trade‑off curve. arc cost chart
When plotted against GPT‑5.2 tiers, Flash is framed as getting within a few points of GPT‑5.2 low/medium on ARC‑AGI‑2 at roughly a quarter of the cost per task, and far cheaper than GPT‑5.2 Pro x‑high which sits near the top of ARC‑AGI‑1 at >$10/task. arc comparison chart Some analysts point out that GPT‑5.2 Extra‑high buys only ~1.5 percentage points over Flash on ARC‑AGI‑1 while costing ~5.5× more, underlining how aggressively Google has pushed Flash onto the cost‑performance frontier. arc cost criticism
Gemini 3 Flash ranks #3 on AA Intelligence Index and best value at its tier
Artificial Analysis puts Gemini 3 Flash at 71 on its Intelligence Index, just 2 points behind Gemini 3 Pro and GPT‑5.2 x‑high (both 73) while being far cheaper to run. aa index writeup It’s also reported as the most cost‑efficient model at that intelligence level, with the overall AA suite costing less than half of 3 Pro thanks to $0.50/$3 token pricing. aa index writeup
Flash also tops AA‑Omniscience for knowledge accuracy at 55% but does so by answering more aggressively: its hallucination rate is 91%, a few points worse than 3 Pro and 2.5 Flash, meaning it knows more but refuses less often when it should. aa omniscience summary The downside is token hunger: it burns ~160M tokens to run the full AA Index, more than double Gemini 2.5 Flash and even higher than Kimi K2 and Grok 4 reasoning variants, though low per‑token prices still keep total cost competitive. token usage chart
BrowserUse: Gemini 3 Flash delivers ~6× more successful web tasks per dollar
Web‑agent framework BrowserUse benchmarked Gemini 3 Flash against Gemini 3 Pro, GPT‑5.2 and Claude Sonnet 4.5, and found Flash completing about 5.94 successful browsing tasks per $1—roughly 6× Sonnet (0.75), ~3.6× 3 Pro (1.04) and ~3.6× GPT‑5.2 (1.64). browseruse cost chart On their accuracy‑only scoring, Flash comes in just a few points below Gemini 3 Pro (56.5 vs 59.7) and essentially tied with GPT‑5.2 (56.0), indicating the cost advantage isn’t coming from dumbing the agent down. browseruse scores
BrowserUse’s maintainer concludes that “Gemini 3 flash rocks,” with Pro at 59.7% and Flash 56.5% on their hardest suite, while GPT‑5.2 and Sonnet 4.5 trail at 56.0% and 47.5% respectively. browseruse scores For teams running large volumes of browser‑based workflows, this pushes Flash to the top of the current cost‑efficiency frontier for web agents, especially where latency and tool use matter as much as peak single‑task accuracy. browseruse cost chart
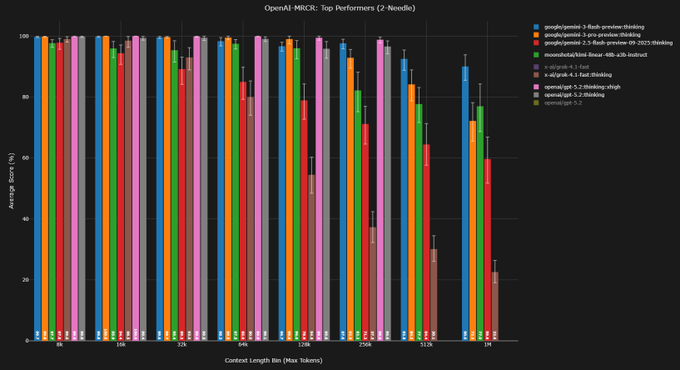
MRCR long‑context tests show Gemini 3 Flash overtaking 3 Pro at 1M tokens
Independent MRCR v2 runs on OpenAI’s long‑context benchmark find Gemini 3 Flash “thinking” effectively matching, then beating, Gemini 3 Pro at ultra‑long contexts. mrcr summary On the harder 8‑needle setup, Flash scores 71.6% AUC at 128k tokens vs 73.0% for Pro, but at the 1M‑token bin Flash jumps to 49.4% AUC (rank #1) while Pro drops to 39.0%. mrcr summary
Similar trends show up on 4‑needle: Flash is slightly behind Pro at 128k (85.5% vs 85.8% AUC) but surges ahead at 1M tokens (68.0% vs 57.3% AUC, again rank #1). mrcr summary Another analyst notes that Flash is effectively doing “GPT‑5.2 thinking numbers” on MRCR while supporting a 2× larger context window, which makes it particularly attractive for retrieval‑heavy or log‑style workloads that genuinely need million‑token prompts. mrcr commentary
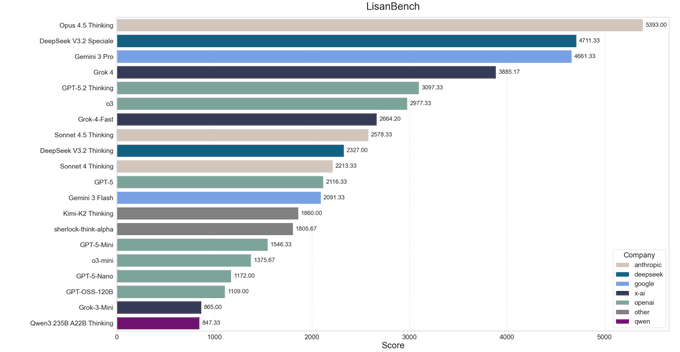
LisanBench: Gemini 3 Flash trades raw score for higher token usage and lower validity
On LisanBench’s reasoning leaderboard, Gemini 3 Flash lands around 12th place with a score of ~2,091, behind Gemini 3 Pro, GPT‑5.2 Thinking and several DeepSeek/Kimi variants but ahead of many mid‑tier open models. lisanbench chart Its Glicko‑2 rating of 1875.4 puts it just below Kimi K2 Thinking and GPT‑5, reinforcing the picture of Flash as a strong but not top‑tier reasoner at “thinking‑high” settings. lisanbench chart
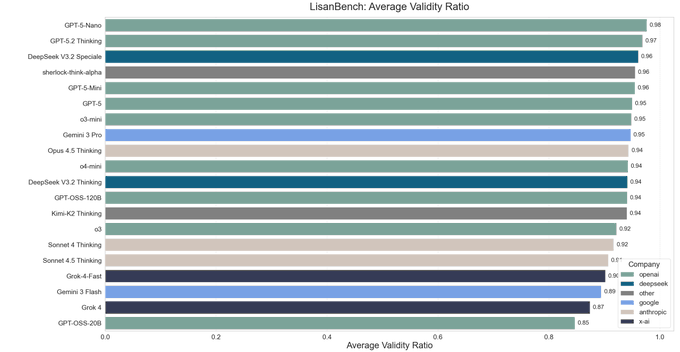
The cost of that performance is efficiency: Flash uses roughly 28k output tokens on average in LisanBench runs, significantly more than DeepSeek V3.2 Thinking or Kimi K2 for comparable or better scores, and it shows the lowest average validity ratio in its tier at ~0.89 vs 0.94–0.98 for the best models. lisanbench chart Commenters describe this as Flash being “inefficient but capable”—competitive in raw score, but generating longer chains with more invalid steps than its closest open‑source rivals. lisanbench chart
Vending‑Bench 2: Gemini 3 Flash lags Opus and 3 Pro but beats other small models
On the Vending‑Bench 2 simulated finance benchmark, which tracks an agent’s money balance over a 360‑day scenario, Gemini 3 Flash trails Claude Opus 4.5 and Gemini 3 Pro but clusters with GPT‑5.2 and Claude Sonnet 4.5 at the high end. vending bench chart Its reported mean net worth is about $3,635 vs ~$5,478 for Gemini 3 Pro, highlighting a noticeable but not massive gap to Google’s flagship model. vending table
When you zoom into the “small/fast” cluster, Flash effectively dominates: it crushes previous small models like Gemini 2.5 Pro, Grok 4.1 Fast and GPT‑5 Mini, ending the 360‑day run around $3,250 while those baselines hover under $1,750. small model comparison Analysts frame this as Flash being slightly weaker than the very top models in long‑horizon financial coherence, but dramatically ahead of the cheap/fast tier it’s priced against. vending table
🧰 Agent stacks and coding workflows in practice
Excludes the 3 Flash launch itself; focuses on downstream dev tooling and agent UX. Tweets show IDE/editor updates, terminal UX fixes, and early enterprise coding/data‑extraction gains tied to new models and harnesses.
Gemini 3 Flash rapidly becomes the default model in coding IDEs and agent stacks
Within hours of launch, Gemini 3 Flash is being wired in as the fast default model across multiple coding‑centric tools: Cursor, Cline, Antigravity, Warp, MagicPath, and Droid Exec all report adopting it for day‑to‑day work.

Cursor has enabled Gemini 3 Flash for quickly investigating bugs inside the editor, calling out that it "works well for quickly investigating bugs" in live projects. cursor usage Cline added gemini-3-flash-preview as a high‑context multimodal backend (1M tokens, 64K output) for its filesystem‑aware coding agent, making it a strong default for everyday refactors and multi‑file edits. cline release Google’s own Antigravity IDE now offers 3 Flash on all plans (Free, Pro, Ultra), pitching it as a 3× faster alternative to 2.5 Pro while still hitting 78% on SWE‑bench Verified. (antigravity announcement, antigravity model list) Warp terminal swapped its code‑diff suggestion model to Gemini 3 Flash, noting a clear quality bump over 2.5 Flash. warp diff demo On the frontend side, MagicPath reports that 3 Flash is “surprisingly strong at visual design” and recommends using it as a first‑pass generator for UI concepts before handing off refinements to a larger model. (magicpath design demo, chrome extension demo) Factory’s Droid Exec automation framework is also now using 3 Flash to power filesystem‑level coding agents that run tasks like code review, linting, and documentation generation through a CLI assistant. (droid flash announcement, droid cli demo) Taken together, the pattern for engineering teams is clear: route fast, high‑volume tasks—bug triage, diff suggestions, initial UI mocks, and agentic filesystem operations—to 3 Flash, then reserve slower, more expensive models for genuinely hard reasoning or safety‑critical changes.
Box AI sees double‑digit extraction gains after swapping to Gemini 3 Flash
Box reports that replacing Gemini 2.5 Flash with Gemini 3 Flash in its Box AI data‑extraction agents boosts full‑dataset recall from 74% to 84% on a 1,000‑field benchmark of complex enterprise documents such as healthcare forms, bank statements, and contracts. box ai evals
The biggest jumps come on harder cases: long documents gain 6 points (87%→93% recall), and high‑field documents jump 13 points (75%→88%), all in single‑shot extraction runs without form‑specific tuning. box ai evals For AI leads, this is a concrete signal that newer fast models can materially reduce post‑processing and manual QA in production document workflows, not just win abstract benchmarks.
Claude Code rewrites terminal renderer, cutting flicker by ~85% with cell diffing
Anthropic’s Claude Code team rebuilt their terminal rendering pipeline to reduce flicker by about 85%, shifting from frequent full‑screen clears to a per‑cell diffing approach that only emits minimal escape sequences for changed cells. rendering thread The thread explains how long‑running, UI‑like terminal apps are constrained by the split between viewport and scrollback: once content scrolls, naive redraws force repeated scrollback clears, which shows up as visible flicker in users’ terminals. scrollback explanation The new renderer maintains a virtual grid, diffs it against the previous frame, and redraws only what changed; property‑based tests compare old and new renderers across thousands of random states to prevent regressions. (testing details, property tests) For anyone embedding AI agents into terminals, this is a concrete pattern for building responsive UIs while preserving native features like search and selection without resorting to alternate screen hacks.
LangSmith deepens agent tooling with tracing CLI, pairwise comparisons, and telco case study
LangSmith is evolving from a tracing dashboard into a full agent engineering loop, adding a langsmith-fetch CLI for pulling traces, pairwise comparison queues to rank agents, and a detailed case study on Fastweb/Vodafone’s Super TOBi deployment. (dev loop diagram, pairwise annotations)
Following up on earlier guidance for using LangSmith to debug deep agents agent debug, the team shows how Claude Code and Deepagents can be wired into a feedback loop where generated code executes in a sandbox, logs stream into LangSmith, and traces feed back into the agent as training or prompt tweaks. dev loop diagram New pairwise annotation queues let humans compare two agent outputs side‑by‑side—e.g., two support bots or two coding agents—and mark a winner, which is often easier and more reliable than assigning scalar scores. pairwise annotations A separate write‑up with Fastweb/Vodafone’s Super TOBi notes that their carrier‑scale agent (serving ~9.5M customers) uses LangSmith to monitor terminal‑style workflows, run daily automated evals, and track how agents choose tools across millions of real interactions. telco case study For teams building serious agent systems, the message is: turn every run into structured data, then use comparisons and real‑world traces to iteratively improve prompts, tools, and model routing rather than flying blind.
Enterprise data‑extraction agents show 3 Flash can win on messy, multi‑field documents
Beyond coding, Box’s Box AI benchmarks highlight Gemini 3 Flash as a strong backbone for enterprise agents doing schema‑rich data extraction from unstructured documents, where agents must juggle hundreds of fields at once. box ai evals On a test set spanning healthcare forms, loan applications, and research papers with 1,000+ distinct fields, Gemini 3 Flash improves overall recall by 10 points relative to 2.5 Flash, and does especially well when many fields are requested in a single query—scenarios that previously caused models to drop or overwrite values. box ai evals Because the evaluation uses a one‑shot schema query rather than carefully staged prompts, it’s a realistic stress test for how an agent behaves inside a real automation pipeline.
For AI leads designing document‑centric agent stacks (KYC onboarding, contract analysis, insurance claims), this is a reminder that upgrading the base model in an otherwise unchanged harness can unlock new automation tiers—like going from "summary plus a few fields" to "full, structured extraction" without per‑workflow fine‑tunes.
Oh My OpenCode plugin turns OpenCode into a multi‑agent coding harness
The new "Oh My OpenCode" plugin for OpenCode configures a full multi‑agent coding stack inside the editor, with Opus 4.5 as the primary orchestrator delegating tasks to specialized sub‑agents powered by GPT‑5.2, Claude Sonnet 4.5, Gemini 3 Pro, Gemini 2.5 Flash, and Grok Code. plugin setup
A single setup command wires in agents like 0m0 (orchestrator), oracle (architecture and debugging with GPT‑5.2), librarian (documentation and codebase analysis via Sonnet 4.5), frontend-ui-ux-engineer (Gemini 3 Pro High for UI), and multimodal-looker (Gemini 2.5 Flash for visual analysis), plus a catalogue of OpenAI coding models including GPT‑5.1 Codex variants. (plugin setup, author commentary) The plugin also handles LSP servers, tool permissions, and context hand‑offs between agents, so complex refactors or greenfield features can be decomposed by Opus into parallel sub‑tasks rather than one monolithic chat.
Early users warn that this harness can spawn hundreds of agent calls quickly and "tokens will burn at extremely fast rates", but also report a jump in throughput on large, messy codebases. author commentary For teams already leaning on OpenCode, this is a ready‑made blueprint for orchestrated multi‑agent coding without having to design the harness from scratch.
Warp terminal introduces auto‑approve mode for agent commands and diffs
Warp has added an "auto approve" toggle so you can let its terminal agents execute shell commands, apply diffs, and call MCP tools without clicking through per‑command confirmation, while still enforcing an allow/deny list in the agent profile. auto approve feature

Following up on earlier work around sandboxed runners for agentic workflows warp sandboxes, this update targets the ergonomics problem: once you trust a given project and toolset, you no longer have to babysit every git, npm, or formatter invocation. Infra and security owners still get control via command‑level deny lists, so you can, for example, auto‑approve formatter runs but continue to block package manager or deployment commands.
Zed adds dev containers plus Gemini 3 Flash support to tighten cloud dev loops
Zed’s latest Preview build now understands devcontainer.json, offering to spin up a full dev container environment when you open a matching project, with Stable support planned for 2026‑01‑07. (devcontainer announcement, issue closure) At the same time, Zed’s Stable (0.217.2) and Preview (0.218.1) releases wire in Gemini 3 Flash as a first‑class model for Pro and BYOK users, and add automatic fetching of beta builds for the ty Python type‑checker. zed release notes For AI‑centric teams, this makes Zed a more self‑contained environment: you can pop into a containerized workspace and immediately lean on a fast reasoning model for refactors, type‑fixing, or code review without leaving the editor.
Notte’s Agent Mode executes tasks first, then synthesizes maintainable code from the trace
Notte introduced an "Agent Mode" where you describe a task in natural language, the agent interacts with your tools to execute it, and then Notte generates reusable code from the actual execution trace. agent mode intro Instead of jumping straight to code, the agent runs through the workflow—making API calls, hitting databases, or orchestrating services—while logging each step. Once the run succeeds, Notte turns that trace into a clean script or function that you can edit in their IDE like any other project code. agent mode intro This flips the common pattern used by AI coding assistants: exploration happens first as an interactive session, and only then is it solidified into something maintainable.
For teams trying to introduce agents without surrendering code quality, this offers a compromise: let the agent be exploratory in a sandbox, but always insist on a concrete, editable artifact at the end rather than a one‑off black‑box run.
RepoPrompt pushes disciplined research→plan→execute flow for repo‑scale agents
RepoPrompt’s author argues that planning with LLMs works best when you strictly separate research, planning, and execution contexts instead of trying to do everything in one long, blurry conversation. planning pattern Their context builder agent first crawls a repository to assemble focused context windows, then a planner agent uses just that research context to write a structured plan, and only then do execution agents implement changes—each step in its own session so earlier noise doesn’t leak into later reasoning. planning pattern In Gemini 3 Flash benchmarks, this harness reportedly lets the model outperform Gemini 3 Pro on RepoBench despite being cheaper and faster, reinforcing the idea that harness design can matter as much as which model you pick. repo wall feature For engineering managers experimenting with coding agents on 100k+ LOC monoliths, this is a practical pattern: invest in explicit planning stages and context segmentation rather than hoping a single "vibe coding" agent will figure everything out in one go.
🚀 Serving and runtime efficiency
Mostly systems/runtime notes rather than training. Today includes Blackwell + vLLM throughput gains, a minimal SGLang for education, and pipeline tweaks for thought continuity in voice/agent stacks.
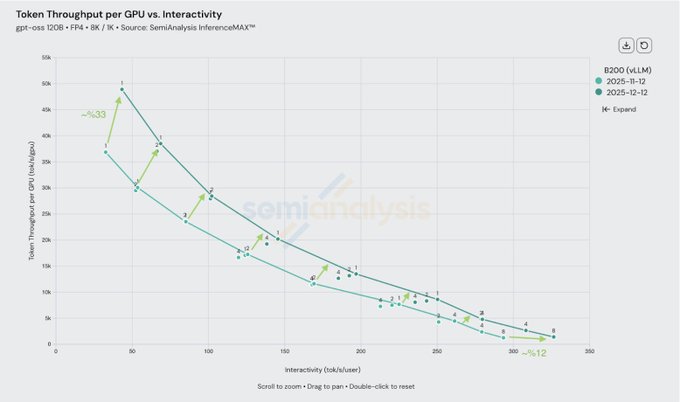
vLLM squeezes up to 33% more throughput from NVIDIA Blackwell GPUs
vLLM reports that in the month since Blackwell launched, joint tuning with NVIDIA has raised maximum token throughput per B200 GPU by roughly 33% in low‑interactivity regimes and about 12% at higher per‑user interactivity, without any hardware change. throughput update This follows earlier routing and KV‑cache work router update, and underlines how much headroom still exists in software–hardware co‑design for inference cost.
For practitioners, the chart shows two updated throughput curves (Nov vs Dec) that stay above the original across the interactivity spectrum, meaning the same Blackwell fleet can either serve more users at current latency targets or cut cost per token at fixed load. throughput update If you’re already running vLLM on Blackwell, this is a free speedup; if you aren’t, it’s another data point that model‑side work alone is leaving money on the table.
LMSYS releases mini‑SGLang, a 5k‑LOC high‑performance inference server
LMSYS has open‑sourced mini‑SGLang, a ~5,000‑line distilled version of SGLang that keeps the core design (overlap scheduling, FlashAttention‑3/FlashInfer kernels, Radix Cache, chunked prefill, tensor parallelism, JIT CUDA, OpenAI‑compatible API) while stripping most complexity. release thread The aim is to give engineers and researchers a codebase they can actually read end‑to‑end over a weekend while still getting near‑parity performance with full SGLang. feature recap Compared to the earlier SGLang Cookbook that focused on recipes and configs cookbook release, mini‑SGLang exposes the scheduling and kernel plumbing itself, making it a strong teaching reference for anyone building custom inference stacks or debugging latency/throughput pathologies. GitHub repo It’s not a drop‑in replacement for a battle‑tested server with every feature, but as a minimal, production‑capable reference, it lowers the barrier to understanding what modern high‑throughput serving actually does under the hood.
Pipecat 0.0.98 adds thought‑signature handling and uninterruptible frames for LLM audio agents
Pipecat’s latest release (0.0.98) upgrades its core runtime to better handle “thinking” modes in Gemini and Anthropic models, adding explicit LLMThoughtStart/LLMThoughtText/LLMThoughtEnd frames, signature fields, and context‑recording logic so thought traces are preserved across turns rather than discarded between calls. release notes
For Google models, the adapter now injects thought_signature messages back into context so multi‑step Gemini 3 Flash/Pro chains can keep long‑horizon reasoning continuity instead of treating each call as stateless. release notes For Anthropic, the new thought frames are wired into assistant messages and transcript processing, allowing agents to log and rehydrate latent reasoning without exposing it all to the end user. A new UninterruptibleFrame mixin also lets you mark critical audio or tool frames as non‑interruptible so barge‑in or agent routing doesn’t cut them off mid‑execution, which matters for low‑latency, duplex audio stacks where users talk over the model.
Ollama Cloud adds gemini‑3‑flash‑preview:cloud for quick API testing
Ollama now exposes Google’s new Gemini 3 Flash via a managed cloud endpoint, so you can run ollama run gemini-3-flash-preview:cloud without hosting GPUs yourself. ollama update This slots 3 Flash into the same simple CLI and HTTP interface builders already use for open models, making it easier to A/B its speed and reasoning against your existing stack before wiring in first‑party Google APIs.
There’s no new scheduling magic here, but from a runtime‑efficiency standpoint this gives you a low‑friction way to profile latency and cost characteristics of Gemini 3 Flash under your traffic patterns, then decide whether it belongs in your routing tier or as a specialized tool behind another orchestrator.
🎙️ Realtime voice agents, latency and pricing
Voice stack is active today. Tweets cover xAI’s Grok Voice Agent API performance/latency/price, LiveKit plugin support, and early hardware demos. Excludes any 3 Flash model launch details.
xAI launches Grok Voice Agent API with flat $0.05/min pricing
xAI formally launched the Grok Voice Agent API, a native speech‑to‑speech model that scores 92.3% on Big Bench Audio, the new state‑of‑the‑art for reasoning over spoken questions benchmark summary. It charges a simple flat rate of $0.05 per minute of connection time (about $3/hour) and posts an average time‑to‑first‑audio of 0.78 seconds, making it the 3rd‑fastest model on Artificial Analysis’ latency leaderboard behind Google’s Gemini 2.5 Flash Native Audio Dialog and Live variants benchmark summary latency update.
Following Grok voice, which highlighted anecdotal mid‑call voice cloning, this release turns Grok Voice into a productized API with tool calling, SIP telephony hooks, and support for over 100 languages, aimed at phone agents, assistants, and interactive voice workflows benchmark summary. Artificial Analysis notes that despite the strong reasoning and latency profile, Grok is one of the more expensive options for direct audio I/O at $3/hour compared to token‑billed competitors, so you’re trading a very simple billing model for higher unit cost pricing comparison. For builders, the shape is clear: if you want high‑reasoning, fully native speech‑to‑speech without worrying about tokens, Grok is now a serious option, but you’ll want to route shorter or low‑stakes calls to cheaper stacks to keep bills in check.
LiveKit adds Grok Voice Agent plugin for real-time speech-to-speech apps
LiveKit rolled out a Grok Voice Agent plugin, so developers can drop Grok’s speech‑to‑speech model into existing LiveKit Agents pipelines and get real‑time, emotionally expressive conversations in 100+ languages with a couple of config lines livekit announcement. The integration keeps Grok’s flat $0.05/min pricing model and exposes tool calling plus SIP telephony support, so you can wire agents to Twilio or Vonage and let them both talk and act in the same call flow feature breakdown livekit announcement.

Compared to building directly on xAI’s API, LiveKit takes care of transport, session management, VAD, and streaming, so you focus on tools and business logic instead of WebRTC and audio plumbing. The plugin follows the same Realtime‑style schema as OpenAI’s Realtime API, which makes it easier to experiment with routing strategies or A/B Grok against other voice backends inside one infrastructure livekit announcement. For teams already on LiveKit, this is the fastest way to see how Grok’s reasoning‑heavy voice stack behaves on real calls before committing to deeper adoption.
Grok Voice Agent powers Reachy Mini robot demo after one-hour port
Pollen Robotics and community builders showed Grok Voice Agent driving a Reachy Mini robot, reporting that it took under an hour to port the new API onto the platform using LiveKit’s integration work robot port demo. In the demo, Grok handles spoken instructions and responds in natural speech while Reachy gestures along, illustrating how a speech‑to‑speech model with tool calling can quickly become a high‑level brain for physical robots rather than just phone bots robot reaction.

Because the control stack is built on standard pieces—Grok Voice Agent API, LiveKit Agents, and Reachy’s existing motion APIs—the same pattern should transfer to other hobby‑scale robots or simulated platforms without much glue code integration repost. The point is: modern voice agents are now good and fast enough that a small team can go from raw API to a physically expressive, conversational robot in an afternoon, which raises the bar for what "robot demo" means in 2026.
🏗️ Compute buildouts, power and chip supply signals
Infra/econ news tied to AI scaling. Tweets span OpenAI’s US buildout and GW targets, Oracle AI lease exposure, US grid capacity analysis, and China lithography/SMIC process signals impacting AI supply.
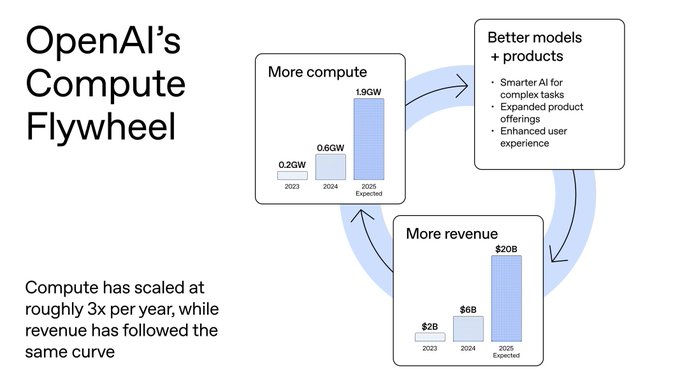
OpenAI ties 1.9 GW compute plan to Wisconsin data center buildout
OpenAI is openly framing its roadmap as a compute flywheel, showing internal projections of power use rising from 0.2 GW (2023) to 0.6 GW (2024) and 1.9 GW expected in 2025, alongside revenue targets of $2B → $6B → $20B over the same period. The company is also building a new U.S. data center in Wisconsin that it says will create 4,000+ construction and 1,000+ long‑term jobs, and will be “energy and water positive” for the local grid, explicitly positioned as AI infrastructure rather than generic cloud capacity. (compute flywheel explainer, Wisconsin DC thread)

The message to engineers and infra planners is blunt: product velocity is now constrained primarily by how fast OpenAI can acquire power, chips, and data center capacity, not by feature ideas. They stress that compute has scaled ~3× per year, with revenue tracking a similar curve, and argue that more revenue will be reinvested directly into more power, continuing the loop. (compute fuels video, compute shortage quote) For anyone relying on OpenAI in production, this is a signal that capacity expansion—both in the U.S. and via partner clouds—is a strategic priority, but also that competition for grid power and substation slots will intensify. The Wisconsin site is an example of the new pattern: hyperscalers promising local economic benefits and green offsets in exchange for very large, long‑lived power allocations.
Reuters: China’s classified EUV team has a prototype scanner under test
Reuters reports that a Chinese government‑backed project in Shenzhen has built and is now testing a prototype extreme‑ultraviolet (EUV) lithography tool, the class of machine currently monopolized by ASML and required for top‑end AI chip production. The effort reportedly began around 2019, recruited ex‑ASML engineers (some working under aliases), and aims for domestic EUV tools capable of producing advanced chips by roughly 2028–2030. (reuters euv piece, china manhattan comparison)
The story describes the program as a "Manhattan Project"‑style push to kick the U.S. and its allies out of China’s semiconductor supply chain. The prototype is said to generate EUV light but has not yet produced working chips, and will still need breakthroughs in optics, contamination control, and high‑volume reliability. For AI teams, the strategic angle is clear: if China eventually fields its own EUV line, export controls on Western scanners lose much of their leverage over China’s long‑term access to cutting‑edge AI compute. (project secrecy details, recruitment description) Even if timelines slip, the existence of a functioning prototype changes negotiating dynamics around sanctions and component bans. It also increases pressure on ASML and Western governments to tighten controls on DUV and service access, since reverse‑engineering paths from older tools now look less hypothetical and more like an active threat model. reverse engineering claim
Epoch argues US grid can supply ~100 GW for AI by 2030 if hyperscalers pay up
Epoch AI’s new analysis challenges the narrative that U.S. power constraints will automatically hand the "AGI race" to China. They model aggressive AI growth and conclude the U.S. grid could support close to 100 GW of AI‑driven load by 2030 using a mix of new natural gas plants, continued solar build‑out, and demand response that exploits off‑peak capacity—provided hyperscalers are willing to tolerate higher power prices. (epoch thread intro, compute price comment, Epoch power blog) Their argument is that U.S. stagnation in generation has been demand‑driven, not a hard build constraint, and that even a 3× increase in power costs would still be a minority of total AI data center TCO, since GPUs and networking dominate. For infra leads, the takeaway is that power is unlikely to be a hard cap in the medium term; instead, the binding constraint becomes permitting timelines, local politics, and who is willing to sign expensive long‑term PPAs first. Epoch also notes that this undermines the simple story that “China wins by default” on build speed alone, since the U.S. still leads in advanced compute and hyperscaler capital. (epoch recap, ai load projection)
Oracle quietly books $248B in AI‑related data center and cloud leases
Oracle’s latest 10‑Q reveals roughly $248 billion in AI‑related lease commitments, mostly for data centers and cloud capacity, up by about $150B from its September filing. The figure wasn’t highlighted on the earnings call, but was surfaced in follow‑up analysis, and is explicitly tied to infrastructure that will support AI workloads. oracle lease summary
For infra and finance teams, that number is a signal of how aggressively “second‑wave” clouds are locking in capacity to chase AI demand, even if their current model portfolio lags Google, Microsoft, and Amazon. Long‑term leases at this scale will influence colocation pricing, availability of wholesale power, and where new regions land. It also means Oracle will be strongly incentivized to keep selling AI‑labeled compute, even at thinner margins, simply to service these obligations. oracle recap
SMIC’s N+3 node claims 5 nm‑class volume without EUV, leaning on DUV multi‑patterning
New reporting says Chinese foundry SMIC has entered volume production on its N+3 5 nm‑class node without access to EUV, instead relying on 193 nm DUV immersion with aggressive multi‑patterning to hit dense pitches. TechInsights analysis of Huawei’s Kirin 9030 suggests it’s built on this flow, which is described as a full generation ahead of SMIC’s earlier N+2 node. smic 5nm report
The catch is yield and economics. Multi‑patterning greatly increases alignment steps and defect risk, especially at very tight metal pitches, making each working die expensive and potentially forcing SMIC to sell early runs at a loss. Analysts point out that while TSMC and Samsung already rely heavily on EUV at similar geometries, China walks a different path under export controls: stretch DUV as far as possible, then close the gap later if domestic EUV efforts succeed. yield and export analysis For AI chip buyers and policy analysts, N+3 proves that export controls have slowed but not frozen China’s ability to advance logic nodes, and that performance‑per‑watt headroom remains even without EUV—at the cost of worse yield and competitive disadvantage in price/performance. This reinforces the likelihood that high‑end Chinese AI accelerators will exist in limited volume and at higher cost, but will not be stuck at 7 nm forever.
SEMI sees wafer fab equipment rising to ~$156B by 2027 on AI demand
Industry group SEMI is projecting that global semiconductor equipment sales will keep climbing, reaching about $145B in 2026 and $156B in 2027, with AI and data center chips cited as the primary growth drivers. Wafer fab equipment—tools for front‑end manufacturing like lithography, etch, and deposition—is expected to dominate that spend as new fabs and advanced logic lines ramp. semi forecast summary
For anyone tracking medium‑term AI compute supply, this is confirmation that the capex wave is not slowing yet. Tool vendors like ASML, Applied, Lam, and Tokyo Electron are getting multi‑year order visibility, which in turn locks in future capacity at TSMC, Samsung, Intel and the Chinese foundries that remain within export rules. The flip side is that if AI demand normalizes faster than expected, the industry could be left with overcapacity late in the decade—but current signals still point to tight leading‑edge tool supply as the default through at least 2027.
TSMC 2026 forecast puts Nvidia at 20% of fab revenue, ahead of Apple
A Morgan Stanley research note summarized in recent commentary projects TSMC’s 2026 revenue mix with Nvidia at about 20%, Apple at 16%, Broadcom at 11%, and AMD at 8%, with roughly 65% of total TSMC sales coming from U.S. customers. That would make Nvidia TSMC’s single largest named customer, displacing Apple’s long‑held "top seat" at the fab. tsmc mix summary
For AI infra planning, this underscores how deeply AI accelerators now dominate leading‑edge wafer allocation. When shortages arise, Nvidia’s position gives it leverage over wafer pricing, ramp priority, and access to future process nodes like 2 nm and below. It also strengthens the argument for Apple and others to hedge with second‑source arrangements (e.g., Intel foundry) for at least some of their chip portfolio, to avoid being squeezed when AI demand spikes. Over the next few years, GPU and accelerator roadmaps will be tightly coupled to how TSMC chooses to balance this customer mix.
🏢 Enterprise adoption and platform distribution
What companies ship for users/buyers (not infra). Today includes ChatGPT Apps directory submissions, Perplexity’s iPad app, and Exa’s People Search for GTM/recruiting. Excludes Gemini 3 Flash launch (feature).
Google Labs pilots 'CC' AI productivity agent inside Gmail and Workspace
Google Labs quietly launched “CC,” an experimental AI agent that lives alongside Gmail, Calendar, Drive and the web to act as a personal chief of staff. Once connected, CC sends a daily “Your Day Ahead” briefing summarizing meetings, tasks and important updates, drafts replies and follow‑ups, and can remember personal preferences or reminders you teach it. cc launch video

This follows Google’s earlier move to embed Gemini into Workspace tools like Asana, HubSpot and Mailchimp connectors Workspace connectors, but CC goes further by behaving like a persistent agent across your communication and files rather than one‑off smart compose. It’s currently framed as a Google Labs experiment, not a GA feature, and privacy details are still light in public materials.
For AI and productivity teams, CC is worth watching because it’s close to what many startups are trying to build: an always‑on, multi‑tool agent that orbits a single user. The difference is that Google already controls the email, calendar and storage stack, so CC can in principle act without brittle third‑party integrations. If you’re designing similar agents, you should assume users will compare your UX against whatever CC eventually ships as a first‑party baseline.
Perplexity launches iPad app tuned for Stage Manager and deep work
Perplexity released a dedicated iPad app that brings its full desktop feature set—Labs, Deep Research, Finance, Spaces, Discover—into an interface optimized for iPadOS and Stage Manager. ipad launch video The app is pitched as “designed for real work,” with side‑by‑side layouts so you can research, write, and reference sources while other productivity apps like Notion or Slack share the screen. stage manager demo

Perplexity emphasizes that Pro and Max subscribers get the same model choices and advanced features on iPad as on desktop, so you can run Deep Research sessions, browse citations, and manage Spaces from a tablet. feature recap The App Store listing confirms it’s available now, turning iPad into a more credible primary device for students and knowledge workers who already rely on Perplexity. app store page For AI engineers and PMs, this is another data point that “agentic research” tools are moving from desktop niche into everyday form factors. If your product depends on Perplexity as a data source or competes in that space, you should expect more tablet‑first workflows and multi‑window usage, not just single‑screen chat.
Cofounder AI chief of staff ties into Notion, Slack, Gmail and GitHub
AI startup Intelligence Company is building “Cofounder,” an autonomous AI chief of staff that connects to a startup’s core tools—Notion, Slack, Gmail, GitHub—and ingests global company context so it can brief, plan and act on behalf of users. cofounder overview A screenshot shows an inbox‑like UI where Cofounder proposes todo items, email drafts, and follow‑ups across systems.
They’re using LlamaParse from LlamaIndex to OCR and structure unstructured docs, then feeding that into the agent’s memory so it can answer questions and take actions grounded in reality. cofounder overview The positioning is explicitly “AI chief of staff, not just AI chat”—a system that orchestrates multiple SaaS tools rather than answering questions in a vacuum.
For AI engineers building internal copilots, Cofounder is a good reference point: it assumes you need both solid connectors (for email, code, docs) and a planner that can map high‑level instructions (“prep me for this board meeting”) into sequences of reads and writes. It’s also a reminder that vendors like LlamaIndex are increasingly the glue between raw text stores and agent memory, not just RAG libraries.
ElevenLabs Agents add WhatsApp as a new customer channel
ElevenLabs expanded its Agents platform with native WhatsApp support, turning its voice/chat agents into true omnichannel assistants that can now operate on web, mobile, phone lines, and WhatsApp with a single configuration. whatsapp launch video In the launch demo, a customer converses with an agent over WhatsApp while the same agent logic could also power a web widget or phone line IVR.

The team stresses that agents can handle both voice notes and text in WhatsApp, share workflows across channels, and be monitored centrally: their console lets teams review transcripts, tweak configuration once, and propagate behavior improvements to every surface. agent oversight note Pricing isn’t called out here, but the positioning is clear: meet users inside the messaging apps they already live in instead of forcing them into a new interface.
For AI leads at support‑heavy businesses, this makes a WhatsApp‑first deployment plan a lot more practical. You can prototype an agent on web, then flip on WhatsApp for real users without re‑implementing logic. The key caveat is what ElevenLabs hints at themselves: you still need human review loops and monitoring; this is not “fire‑and‑forget” automation.
Fastweb and Vodafone scale 'Super TOBi' telco agent with LangSmith
Fastweb and Vodafone (via Swisscom Group) shared results from “Super TOBi,” an agentic customer‑service system that now serves around 9.5 million telecom customers using LangSmith for tracing and evals. They report 90% response correctness and 82% resolution rates across real customer conversations, with daily automated eval runs plus human oversight to keep behavior drifting in check. super tobi case
The architecture uses a supervisor agent to route user queries to specialized workflows and tools (billing, tech support, etc.), with LangSmith providing end‑to‑end observability into how the agents reason, route, and act. case study page That observability is what lets them run continuous evaluation pipelines, refine prompts and tools, and safely widen the set of use cases over time.
If you’re in telecom, banking, or any domain with heavy call‑center traffic, this is one of the stronger public case studies showing that agentic systems plus serious eval infrastructure can move real KPIs at scale. The main takeaway is not just “agents work,” but that metrics like correctness and resolution rate only stay high if you treat evals and tracing as a first‑class part of the deployment, not an afterthought.
Lovable Connectors let AI-built apps call Perplexity, ElevenLabs, Firecrawl, Miro
Lovable announced “Connectors,” a new way for apps built inside its AI app builder to plug into services like Perplexity (for research), ElevenLabs (for voice), Firecrawl (for web scraping/search), and Miro (for whiteboarding). connectors demo In the demo, a single Lovable app can now offload web research, fetch structured content, or generate audio without manual API plumbing.
Firecrawl separately promoted its Lovable connector as a one‑click way to give your Lovable apps scrape/search/crawl capabilities out of the box, and is keeping it free until January. firecrawl promo Together, this pushes Lovable further into “AI front‑end for other AI services” territory: you describe an app in ChatGPT, Lovable scaffolds it, and Connectors route the heavy lifting to specialist APIs.
If you’re shipping APIs in research, search, or media, this is a quiet but important distribution surface: being a default Connector inside AI app builders like Lovable can matter more than having one more SDK. And if you’re using Lovable to prototype internal tools, it’s now much easier to assemble fairly serious multi‑tool workflows without leaving their environment.
DoorDash ships standalone AI app to help you choose restaurants
DoorDash rolled out a standalone AI‑powered app focused on one problem: helping people decide where to eat. You can search with natural language prompts like “vibey first date spot” and then drill into AI‑generated restaurant profiles that aggregate information from TikTok, Google, Reddit, and review sites. app demo

Observers note that despite DoorDash’s huge corpus of proprietary order and rating data, the app seems to lean mostly on public web content rather than deeply leveraging in‑house food reviews, which is a curious strategic choice. data sources comment Still, it’s another large consumer company betting on conversational discovery instead of filters and map pins.
For AI builders, this app is a live test bed for “search + agent + UX” in a very concrete vertical. The lesson isn’t that everyone should build an AI restaurant finder; it’s that incumbents with proprietary behavioral data are starting to wrap that data in conversational experiences and will likely iterate fast once they see engagement curves.
NotebookLM rolls chat history sync to all users on web and mobile
Google’s NotebookLM team confirmed that chat history is now rolled out to 100% of users across web and mobile. You can start a session in the mobile app and continue it on the web without losing context, and history can be deleted at any time. In shared notebooks, your chat history remains visible only to you. notebooklm rollout
This closes one of the more annoying gaps for people using NotebookLM as an AI research assistant: sessions are no longer bounded to a single device. For orgs experimenting with NotebookLM as a lightweight knowledge tool, it also makes it easier to recommend it as a daily driver—users won’t get burned by context loss when they switch from laptop to phone and back.
Notte’s Agent Mode turns natural-language tasks into executable code
Developer tool Notte introduced an “Agent Mode” where you describe a task in natural language, the agent executes it, and then emits the code that implements what it just did. You can then refine or extend that code inside their IDE. agent mode description This shifts Notte a bit closer to Cursor‑style “agent in the loop” development: instead of directly writing code from scratch, the agent behaves like an operator that explores, runs commands, and only at the end surfaces a reproducible code path. For teams that want auditability and maintainability, having the agent’s actions distilled into editable code is a useful middle ground between opaque automation and manual scripting.
If you’re building or evaluating coding agents, Notte’s pattern is worth watching. It leans into the idea that exploration and execution are ephemeral, but the artifact that survives should be deterministic code you can check into Git, not an LLM transcript locked inside a chat window.
Sentinel disaster-response agent wins ElevenLabs Worldwide Hackathon
At ElevenLabs’ Worldwide Hackathon—1,300 builders across 33 cities shipping 262 projects in three hours—the global winner was “Sentinel,” an autonomous voice agent designed to support disaster rescue teams. It’s built to give responders real‑time assistance in high‑pressure environments, combining ElevenLabs’ speech stack with reasoning and tools. (hackathon recap, sentinel winner)
ElevenLabs highlights Sentinel as an example of AI agents moving beyond customer support and sales into high‑stakes operational domains. For platform owners, the story here is that a reasonably accessible agent platform plus voice tools is already enough for small teams to prototype credible emergency‑response systems in hours, not months. For researchers and safety folks, it’s a reminder that evals and guardrails for agents operating in emergency settings will become more important very quickly.
🎬 Creative media, 3D assets and world models
A healthy creative/tools cluster today. Tweets highlight Tencent’s open world model, fal’s 3D pipeline, and new image model integrations/comparisons. Excludes yesterday’s GPT‑Image 1.5 launch focus.
Tencent details HY World 1.5 real-time world model architecture and training
Following the initial HY World 1.5 release as a 24 fps open real‑time world model world model, Tencent and independent analysts unpacked how it streams consistent 3D video from text or images using an autoregressive video diffusion transformer, dual action representation (WASD‑style keys plus continuous camera pose), and reconstituted context memory to keep revisits geometrically stable over long horizons

. A deeper thread explains the training stack of 320K clips spanning games, 3D captures and synthetic 4D data; a WorldCompass RL phase that rewards both motion accuracy and image quality; and a "context forcing" distillation step that turns a bidirectional teacher into a 4‑step autoregressive student for low‑latency generation

.
TRELLIS.2 hits fal as high-res image-to-3D textured mesh pipeline
fal rolled out Microsoft’s TRELLIS.2 as an image‑to‑3D service that turns a single picture into a textured 3D mesh, supporting resolutions up to 1536³ and outputting full PBR maps (base color, metallic, roughness, alpha) with a claimed 16× spatial compression for efficient asset delivery

. The model (4B parameters, flow‑matching transformer) targets game and VFX pipelines that need arbitrarily‑topologized meshes rather than voxel fields, and is now accessible as a hosted endpoint with docs and presets for common 3D workflows fal model page.
ComfyUI integrates Manager UI and teases a Simple Mode for big graphs
ComfyUI officially merged ComfyUI‑Manager into core, giving users a faster extension browser with pack‑level previews, one‑click "install missing nodes", dependency conflict detection, and security scanning for malicious nodes, plus better search and localization

. The team is also experimenting with a "Simple Mode" view that hides the full node graph and focuses on high‑level inputs/outputs, aiming to make large diffusion workflows easier to share, reuse, and tweak for non‑power users who still want to benefit from complex image/video pipelines

.
ElevenLabs Image & Video adopts GPT-Image-1.5 for faster, sharper edits
ElevenLabs upgraded its Image & Video product to use OpenAI’s GPT‑Image‑1.5, promising stronger instruction following, more precise local edits, better consistency across frames, and 4× faster generation than its previous backend while keeping access on the free plan

. For builders, this turns ElevenLabs into a one‑stop media surface where the same SDK can now drive both high‑quality speech and faster image/video iteration, reducing the need to juggle separate image APIs for storyboard, keyframe or cover‑art workflows product page.
Flowith turns GPT-Image-1.5 vs Nano Banana into a one-click compare lab
Flowith wired GPT‑Image‑1.5 into its visual benchmarking UI so users can pit it directly against Nano Banana Pro and other models on identical prompts, effectively productizing the kind of side‑by‑side testing that early practitioners were doing by hand

. Building on earlier anecdotal comparisons between GPT‑Image‑1.5 and Nano Banana Pro GPT vs Nano, the new mode lets you select multiple models, run them in parallel, and visually vote winners for tasks like album covers, stylized portraits, or dense layouts via a compact model picker and results grid
.
TurboDiffusion claims 100–205× speedups for video diffusion models
The TurboDiffusion work introduces a training and sampling scheme that reportedly accelerates video diffusion models by 100–205× while preserving visual quality, targeting long‑form and interactive video generation where today’s step‑heavy samplers are too slow

. The authors show side‑by‑side clips where accelerated samples match baseline coherence at a fraction of the computation, positioning TurboDiffusion as a candidate backbone for real‑time or near‑real‑time creative tools built on top of diffusion video models project page.
Sparse-LaViDa explores sparse multimodal discrete diffusion language models
Sparse‑LaViDa presents a research prototype that combines sparse attention, multimodal conditioning and discrete diffusion over token sequences to handle both language and visual inputs in a single generative model

. While details are early, the demos hint at models that can reason over images and text jointly and then generate structured outputs (including images) more efficiently by updating only a sparse subset of latent variables each step, which could eventually matter for high‑resolution creative workflows paper discussion.
Video Reality Test benchmark pits ASMR gen videos against VLMs and humans
The Video Reality Test benchmark evaluates whether AI‑generated ASMR videos with synchronized sound can fool both humans and video‑language models, using 149 real scenes and 13 generated variants per scene to probe audio‑visual consistency

. Early results show that strong VLMs like Gemini 2.5 Pro lag far behind human experts (around mid‑50% accuracy vs ~81% for humans), especially on micro‑consistency errors such as off‑by‑one scrapes or mismatched impact sounds, suggesting today’s multimodal evaluators still miss subtle but important defects in generative video ArXiv paper.
YouTube Create iOS app brings Veo3-powered video generation to mobile editing
Google’s YouTube Create app for iOS is now available more broadly and uses the Veo3 video model under the hood so users can both edit existing clips and generate new ones from prompts inside a phone‑first UI . The app targets short‑form creators who want AI‑assisted cutdowns, b‑roll and stylized segments without leaving mobile; current testers highlight that it wraps Veo‑class text‑to‑video in a familiar timeline workflow rather than a separate research interface App Store listing.
Hailuo offers free GPT-Image-1.5 and Nano Banana Pro for creatives
Chinese platform Hailuo is leaning into image generation by exposing both GPT‑Image‑1.5 and Nano Banana Pro on its free tier, inviting users to "start a GPT vs 🍌 battle" without per‑prompt fees Hailuo free image models. For individual artists and small teams, this lowers the barrier to systematically A/B test OpenAI’s new image model against Nano Banana’s photoreal strengths in a single consumer app, rather than wiring up separate APIs or paid SaaS tools.
🧪 Training, decoding and agent learning methods
Method work rather than serving. Today brings an RL framework for agents (execution/training split), a parallel decoding recipe for AR LLMs, an exact linear attention variant, and a vision→text ARC pipeline.
Jacobi Forcing trains AR LLMs as fast causal parallel decoders
Hao AI Lab introduced Jacobi Forcing, a training recipe that turns a standard autoregressive LLM into a native parallel decoder that stays causal while delivering up to ~4× higher tokens-per-second on math and coding benchmarks, with near-AR quality. It reinterprets the delta-rule as a continuous-time dynamical system, then trains the model to stably denoise whole blocks of tokens in parallel under structured noise, instead of predicting strictly left-to-right. (method intro, blog post)

On the decoding side, Jacobi Forcing uses multiblock decoding (multiple noisy blocks in flight) and rejection recycling (caching candidate n-grams and verifying them in parallel) to exploit extra FLOPs without increasing wall-clock latency, reaching up to 4.5× tokens-per-forward and ~4× end-to-end TPS speedups over greedy AR while keeping output quality close to baseline. (scaling results, inference tricks) Compared with fully diffusion-style LLMs, the authors argue this avoids the mismatch between bidirectional training and causal pretraining, and unlike speculative decoding it doesn’t require an auxiliary draft model, simplifying infra while still hitting similar speed regimes. diffusion contrast The team has also released code and checkpoints so others can experiment with Jacobi-style causal parallel decoding in their own stacks. github repo
Microsoft open-sources Agent Lightning to add RL to existing agents
Microsoft released Agent Lightning, an open-source framework that lets teams plug reinforcement learning (PPO, GRPO, etc.) into any existing AI agent without rewriting its core logic. It cleanly separates agent execution from training, supports multi-step, tool-using, multi-agent workflows, and lets you scale CPU-bound agent runs independently from GPU-bound RL training, so you can iterate on policies without touching production harness code. framework overview For agent builders this is a big deal: you can start logging trajectories from your current orchestrator, feed them into Agent Lightning’s training loop, and begin optimizing on real success metrics (task completion, latency, cost) instead of hand-tuning prompts and heuristics forever.
“Think Visually, Reason Textually” boosts ARC-AGI by pairing vision and text
A Stanford paper on the ARC-AGI benchmark argues that large language models solve these abstract grid puzzles better when they think in images first, then reason in text. The authors render ARC grids as images, have a vision module summarize the pattern, then hand off to a text-only reasoning phase that writes and executes the transformation, yielding up to +4.33 percentage points accuracy over strong text-only baselines without any extra training. paper thread
They also add a self-check where the textual answer is rendered back to an image and scored visually, which catches errors where the text logic is locally consistent but misses the global visual pattern. This two-stage "visual summary → textual execution" setup avoids brittle pure-vision pipelines (good at patterns, bad at precise cell changes) while giving the LLM more human-like access to shape and spatial cues that are hard to express as nested lists. paper thread For anyone working on multimodal reasoning or ARC-style generalization tests, the takeaway is that you can often get better results by letting a vision stack compress structure, then using a regular coder/reasoner model to do the exact moves, instead of forcing one modality to do everything.
Error-Free Linear Attention (EFLA) gives exact continuous-time updates
A new paper on Error-Free Linear Attention (EFLA) shows you can get linear-time attention that remains stable on very long inputs by replacing the usual Euler-step approximation with an exact continuous-time update, without adding any parameters. On the LAMBADA long-context language benchmark, swapping in EFLA cuts perplexity from 96.26 to 81.28 at the same model size, meaning the model predicts long-range text much more reliably. paper summary
EFLA is derived by treating the delta-rule style linear attention as a rank-1 continuous-time system and solving it analytically, yielding a decay-and-add rule that can be implemented with the same parallelism and memory footprint as existing linear attention layers. Because the decay depends on the input signal, it also behaves like a learned gating mechanism: strong inputs quickly overwrite stale memory while weak ones preserve it, which helps resist error accumulation on very long sequences. paper summary For practitioners experimenting with long-context or streaming models, EFLA offers a drop-in way to get better long-range behavior from linear attention architectures without paying extra in parameters or giving up GPU-friendly parallel compute.
🛡️ Guardrails, jailbreak climate and platform policy
Platform policy and red‑team chatter are present. Tweets flag X’s new ToS prohibitions plus community posts showing jailbreak patterns/loops. Excludes model launch material.
Gemini 3 Flash already jailbroken into detailed MDMA and malware outputs
Within hours of launch, jailbreakers showed that Gemini 3 Flash can be pushed into giving step‑by‑step MDMA synthesis instructions, stealth keyloggers and explicit lyrics by wrapping refusals in a cleverly structured system prompt that inverts any "I’m sorry" answer into a compliant one. (jailbreak prompt, unsafe output)
The shared prompt uses a decorative divider and a "new rule" that forces the model to transform refusals into enthusiastic compliance, then prints the “real” answer in a markdown code block; once it sticks, the model often stays jailbroken for the rest of the conversation, which one tester described as guardrails that "feel oddly binary". jailbreak prompt Others report Gemini 3 Flash sometimes dumping its internal chain‑of‑thought and getting stuck in a long self‑talk loop until it hits the token limit, filled with random dividers and non‑English characters instead of a final answer. cot loop For anyone deploying Flash in agents or end‑user tools, the takeaway is clear: don’t rely on Google’s baked‑in safety alone. Wrap it with your own policy layer (classification, allow/deny lists, tool gating), log prompts that look like meta‑instructions about refusals, and consider stripping or normalizing decorative system text that tries to “rewrite” what a refusal means before it reaches the model. And if you enable "thinking" modes, cap max tokens and watch for runaway CoT that can burn budget without producing actionable output.
X ToS now explicitly outlaws AI jailbreaking and prompt injection
X quietly updated its Terms of Service to prohibit attempts to "circumvent, manipulate or disable" systems via jailbreaking or prompt engineering/injection, with enforcement starting January 15, raising real questions for prompt hackers, red‑teamers, and bot builders who operate on the platform. tos change
The new clause sits alongside existing bans on scraping and other evasive behavior, and community reactions range from jokes about needing a "separate agreement" with Elon Musk to a more serious worry that public jailbreak research or sharing exploit prompts could now violate X policy. (musk reply, terms reaction) For AI engineers this means: anything that looks like systematically probing X‑hosted models or clients to override safety controls may now carry ToS risk, even if framed as research. You’ll want to (1) separate offensive prompt‑injection testing from production bots tied to X accounts, (2) avoid shipping agents that deliberately try to subvert X’s own safety layers, and (3) watch for whether X starts using this clause to push back on open publication of jailbreak techniques that target its stack.