GLM‑4.7 becomes default coding engine – 200k context, $0.60 input
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
GLM‑4.7 is moving from eval charts into day‑job infrastructure: Z.AI users are wiring it into self‑hosted GitHub Actions so a “pi coding agent” performs Rust/TypeScript PR reviews, flagging unsafe unwrap() and suggesting Result‑based refactors; the same GLM‑4.7 endpoint backs local batch reviewers via Codex scripts. Claude Code, Kilo Code, Roo Code, Cline and others now promote GLM‑4.7 as their default backend, with a simple config swap to glm-4.7; Baseten offers one‑click deployments, while Blackbox Agent CLI uses it for terminal coding sessions. Z.AI lists 200k context at ~$0.60 /1M input and $2.20 /1M output tokens and even shows “−0.21s latency” and −3,492 tps in one playful table; a Z.AI Max plan bundles effectively unlimited GLM‑4.7 with four MCP tools (vision, web search, scraper, doc reader), pitching a full agent stack.
• Agent efficiency and research: Meta/CMU’s AgentInfer stack reports >50% token cuts and up to 2.5× faster agents via big+small collaboration and cross‑session speculative reuse; StepFun’s 32B Step‑DeepResearch agent hits 61.42 on ResearchRubrics, claiming frontier‑level deep‑research quality at lower RMB cost.
• AI infra and safety: Citi models OpenAI at ~$700B capex in 2029 and 26 GW by 2030 while Broadcom AI ASIC revenue is forecast to reach $100B in 2027; parallel work on VRSA multi‑image jailbreaks, intent‑blind crisis prompts and hidden PDF commands shows current guardrails missing context‑heavy attacks even as OpenAI hires a Head of Preparedness.
• Korean open‑weights push: Naver’s 32B HyperCLOVA X SEED Think scores 44 on the Artificial Analysis Index, uses ~39M reasoning tokens across the suite, posts 82% on Korean Global MMLU Lite and τ²‑Bench Telecom tool‑use scores on par with Gemini 3 Pro, but draws a −52 AA‑Omniscience score for hallucinations.
Top links today
- Self-Play SWE-RL superintelligent agents paper
- FlowGuard data flow control for agents
- PDF prompt injection attack on AI reviewers
- Study on scientists overusing AI coding tools
- Professional AI coding agent usage study
- VRSA multimodal jailbreak attack on vision-language models
- Attention Is Not What You Need sequence model paper
- Vertex AI Veo video generation model reference
- Gemini image generation and Nano Banana guide
- GPT Image 1.5 model and pricing page
- Gemini 2.5 TTS speech generation guide
- OpenAI Sora 2 video generation model page
- vLLM official website and documentation hub
- Artificial Analysis Intelligence Index detailed results
Feature Spotlight
Feature: GLM‑4.7 jumps from charts to workflows
GLM‑4.7 moves from leaderboard buzz to practical use—AA Index placement, model switch instructions in coding agents, CI code review via Z.AI, and creative samples—signaling open‑model pressure on closed leaders.
Cross‑account momentum today: GLM‑4.7 shows up on leaderboards and inside real dev workflows (coding agents, CI code review). Mostly eval snapshots plus hands‑on adoption; fewer pure model launches.
Jump to Feature: GLM‑4.7 jumps from charts to workflows topicsTable of Contents
📈 Feature: GLM‑4.7 jumps from charts to workflows
Cross‑account momentum today: GLM‑4.7 shows up on leaderboards and inside real dev workflows (coding agents, CI code review). Mostly eval snapshots plus hands‑on adoption; fewer pure model launches.
GLM‑4.7 runs self‑hosted GitHub PR reviews via Z.AI
GLM‑4.7 code review (Zhipu): A self‑hosted GitHub Actions runner is now using GLM‑4.7 via Z.AI as an automated PR reviewer; the model runs in a dedicated workflow that triggers when a label like ai-review is added, then posts structured comments on risky code such as unsafe unwrap() calls in Rust, as shown in the review sample.
• Pipeline design: The shared diagram shows three steps—detect changed crates with git diff, have a pi-coding-agent powered by GLM‑4.7 read the relevant files through Z.AI and propose fixes, then post a consolidated review back to the PR with categorized issues like error handling and loop logic, as illustrated in the pipeline diagram.
• Agent behavior: The reviewer suggests idiomatic refactors (e.g., returning Result instead of panicking) and adds contextual error messages, indicating the model is being steered toward conservative, audit‑style feedback rather than bulk rewriting.
The setup highlights GLM‑4.7 moving from leaderboard charts into concrete CI workloads where latency, cost, and review quality can be compared directly against alternatives like Claude Code or GPT‑5.2.
Claude Code and friends switch coding agents to GLM‑4.7
GLM‑4.7 in coding agents (Zhipu): GLM‑4.7 is being promoted as the default backend for multiple coding agents—Claude Code, Kilo Code, Roo Code, Cline and others—following earlier reports of strong price–performance for coding and writing workloads in builder adoption, with a configuration card explaining that GLM Coding Plan subscribers are automatically upgraded and only need to point their configs at glm-4.7 for custom setups, as shown in the config tip.
• Config pattern: The card explicitly calls out Claude Code’s settings.json path and notes that any existing GLM model name can be swapped to glm-4.7, indicating that most of the ecosystem support is wiring rather than new SDK work.
• Creative quality signal: A separate example shows GLM‑4.7 generating a polished Paris travel card UI—complete with photography, copy, and layout—suggesting the same model is being used across both code and design workflows, as illustrated in the travel demo.
Taken together, these patterns show GLM‑4.7 treated as a general‑purpose workhorse model across agents, not a niche research model confined to benchmarks.
Z.AI markets GLM‑4.7 with "negative latency" and MCP bundle
GLM‑4.7 hosting (Z.AI): Z.AI’s provider dashboard lists GLM‑4.7 with a tongue‑in‑cheek “−0.21s latency” and −3,492 tps in its comparison table—alongside 200k context, $0.60 input and $2.20 output prices—which users are treating as a sign of aggressive caching or metrics bugs rather than real negative latency, as seen in the provider table.
• Max plan bundle: A separate post describes a Z.AI Max subscription that effectively packages “unlimited” GLM‑4.7 access together with four MCP servers—Vision Understanding, Advanced Web Search, Webpage Scraper, and Z Doc Reader—aimed at coding agents like Claude Code or Codex that can call these tools directly, according to the zai max plan post.
This combination of playful benchmarks and an MCP‑heavy plan underscores how GLM‑4.7 is being sold as both a raw model and as part of a broader agent‑tool ecosystem.
Baseten and Blackbox add GLM‑4.7 as a first‑class option
GLM‑4.7 platform spread (Zhipu + hosts): Hosting and tooling platforms are adding GLM‑4.7 as a one‑click option—Baseten’s model library now exposes it with preconfigured deployment settings after its strong Artificial Analysis score, while the Blackbox Agent CLI can invoke GLM‑4.7 directly for terminal‑based coding sessions, as described in the cli support update and the model library.

• Tools vs infra roles: Blackbox positions GLM‑4.7 as a drop‑in engine behind its agent UX, whereas Baseten emphasizes managed inference (context limits, pricing, and scaling knobs), signaling that GLM‑4.7 is mature enough to be treated both as a backend commodity and as a user‑facing model choice.
This mirrors how previous frontier models spread—first into eval threads, then into hosted endpoints, and finally into end‑user coding tools—indicating GLM‑4.7 has crossed into the “default option” set for many builders.
🛠️ Coding with agents: hooks, reviews and retrieval
Heavy practice content: spec‑interview patterns, inbox hooks, retrieval subagents, batch reviews. Excludes GLM‑4.7 adoption (covered in Feature).
Cursor and FactoryDroid hooks automate lint, typegen, and build checks
Editor hooks (Cursor/FactoryDroid): A new hooks setup for Cursor and FactoryDroid lets AI agents automatically run ESLint with autofix, regenerate Rust→TypeScript types, and call cargo check when they touch relevant files, reframing hooks as safety rails rather than smarter models in the hooks explanation.

• After‑edit automation: Hooks fire on file change events—Rust edits trigger type regeneration for the frontend, TypeScript edits run ESLint, and backend changes run cargo clippy—so many consistency checks happen before a human even looks at the diff, as demonstrated in the hooks explanation and expanded in the video guide.
• On‑stop guardrail: When the agent finishes a task, a final hook runs cargo check to ensure the project still builds, turning “did it compile?” from a manual chore into a default part of every agent run, per the hooks explanation.
• Positioning: The author stresses that this is about guardrails over intelligence—the same model feels more reliable once the surrounding workflow enforces build health and style rules automatically.
Batch scripts and CI runners turn AI into domain‑scoped code reviewer
Domain reviews (Kevinkern): One workflow wires Codex and glm‑4.7 into a two‑stage review system—local batch scripts run domain‑scoped reviews in parallel on a laptop, while a self‑hosted GitHub runner runs the same AI reviews in CI for every PR, as outlined in the batch script.
• Local batching: A bun scripts/code-review.ts --batch N command splits a large Rust/TypeScript/Tauri codebase into domain slices and runs codex exec reviews for each slice (around five parallel sessions), producing per‑domain summaries of changes and issues, according to the batch script.
• CI integration: In CI, a self‑hosted runner calls the "pi coding agent" harness with GLM‑4.7 on Z.AI to comment directly on PRs, flagging unsafe unwrap() calls and similar issues, as shown in the glm review comment and the review pipeline.
• Pattern, not model: The emphasis is on isolating reviews by domain to avoid agents trampling each other’s work and to keep feedback targeted, while the underlying reviewer model (Codex vs GLM) can be swapped without changing the orchestration scripts.
MCP Agent Mail adds PostToolUse hooks so agents auto‑check inbox
Agent Mail hooks (MCP Agent Mail): MCP Agent Mail now ships "inbox reminder hooks" that fire after tool calls, automatically nudging Claude Code, Codex, or Gemini agents to check their MCP inbox whenever they finish a tool turn, addressing a common failure mode where agents forget messages mid‑workflow, according to the hooks overview.
• Hook design: The integration wires into each tool's PostToolUse lifecycle hook to run a lightweight check_inbox.sh script that queries the MCP Agent Mail server, reports unread counts back to the agent, and closes the loop without manual prodding, as detailed in the hooks overview.
• Auto‑setup script: A one‑liner installer now detects installed coding CLIs (Claude Code, Codex CLI, Gemini CLI), drops the correct MCP server configs, and attaches the PostToolUse hooks and environment variables automatically, per the hooks overview.
• Continuation: This extends the original mailbox UI for agent‑to‑agent threads—summarized in Agent mailbox—into an always‑on coordination layer, so multi‑agent systems are less likely to miss conflict alerts or coordination messages during long autonomous runs.
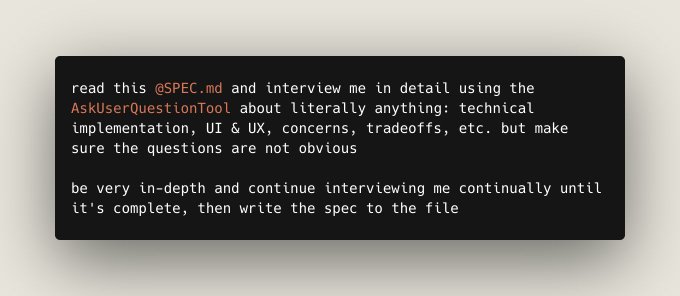
Spec‑interview workflow turns Claude Code into requirements engineer
Spec interviews (Claude Code, Anthropic): Builders are formalizing a pattern where Claude Code first interviews you about a feature using the AskUserQuestionTool against a minimal SPEC.md, then a second session executes the agreed plan—aimed at surfacing non‑obvious requirements before any code is written, as shown in the spec prompt screenshot.
• Two‑session flow: The first agent run stays in “ask” mode only, probing implementation details, UX, trade‑offs and risks; after that, a fresh Claude Code session gets the finalized spec and handles implementation end‑to‑end, as described in the spec prompt screenshot and reinforced by the workflow comment.
• Why it matters: This pattern turns Claude Code into a lightweight requirements engineer for both technical and semi‑technical users; it reduces rework from missing edge cases and gives the coding agent a much sharper target before it starts touching the repo.
Codex CLI pattern spawns read‑only gpt‑5.2 sub‑agent for code review
Sub‑agent reviews (Codex, OpenAI): Codex users are formalizing a pattern where the built‑in /review command is replaced by a custom codex exec call that spawns a separate, read‑only gpt‑5.2‑codex sub‑agent with extra‑high reasoning effort dedicated to code review, as described in the subagent suggestion.
• Custom exec call: The recommended invocation runs codex exec -s read-only -m gpt-5.2-codex -c model_reasoning_effort="xhigh" "<review-prompt>", decoupling review prompts, model choice, and permissions from the main agent session, per the subagent suggestion and the review prompt.
• Why this matters: Treating review as a separate sub‑agent lets teams tune model, temperature, and filesystem access just for reviews, and makes it easy to reuse the same high‑effort reviewer across multiple primary agents or CLIs without hard‑coding behavior into Codex itself.
WarpGrep offers free playground for context‑first sub‑agent retrieval
WarpGrep context sub‑agent (Morph): WarpGrep, a retrieval sub‑agent that treats context gathering as its own RL‑trained system, now has a no‑auth playground where anyone can point it at a GitHub repo and let it answer questions for free, as announced in the playground link and warpgrep update.
• Claimed gains: The team frames WarpGrep as cutting coding‑task time by about 40% and reducing long‑horizon "context rot" by roughly 70% by learning better file selection strategies over time, per the warpgrep update.
• Integration model: WarpGrep is designed to sit under Claude Code, Codex, OpenCode and similar agents via MCP or SDK, acting as a dedicated context retriever so the top‑level agent can focus on planning and editing instead of ad‑hoc rg/fd searches.
• Playground use: The web playground mirrors this architecture—ask questions against any public repo URL and it shows what files it reads and why, giving teams a way to inspect retrieval behavior before wiring it into production agents.
Proposal emerges for Agent Package Manager and installable sub‑agents
Agent packages (community): A community proposal sketches an "Agent Package Manager" where sub‑agents are distributed like libraries—each with a manual describing when to run it, how to bootstrap its context, and how often to sync its state back to the main agent, according to the agent package idea.
• Sub‑agent framing: The author argues that sub‑agents are just normal agents plus an opinionated context‑management policy (how to seed their context, and how/when their findings flow back), and that this should be standardized as installable units, as laid out in the agent package idea.
• Desired features: Packages would bundle narrow skills, configuration, and documentation so they can serve as both primary agents and sub‑agents, with a general mechanism for composing them into larger products rather than bespoke glue for each app.
• Why this matters: If such a format gains adoption, it could become a portability layer for coding agents and tools—similar to how npm or pip standardized code reuse—making it easier to share, audit, and re‑use complex agent behaviors across CLIs and IDEs.
Supermemory Graph becomes embeddable React component for agent memory UIs
Memory graph (Supermemory): Supermemory’s interactive graph of an agent’s long‑term memories is now packaged as an embeddable React component, so teams can drop it directly into their own apps and customize styling, as shown in the graph demo.

• Component packaging: The graph ships as a React component that can be themed and wired to an existing Supermemory backend, making it easier to visualize what an agent has stored and how different memories connect, per the graph demo and the react component repo.
• Use in coding agents: For coding setups that already use Supermemory as an MCP server or context store, this gives a ready‑made UI to inspect which files, decisions, and past tasks the agent is recalling, which in turn helps debug retrieval failures and hallucinations around old runs.
• Developer angle: By treating memory visualization as a pluggable widget, it aligns with broader trends toward richer “agent dashboards” instead of opaque logs for complex, multi‑step coding agents.
🏭 Power and ASIC pipelines for the AI buildout
Multiple data points on near‑term power workarounds, 2026–2029 capex, and custom ASIC revenue ramps. Concrete GW, $B and timeline deltas dominate today.
Citi models OpenAI spending ~$700B on capex in 2029 and 26 GW by 2030
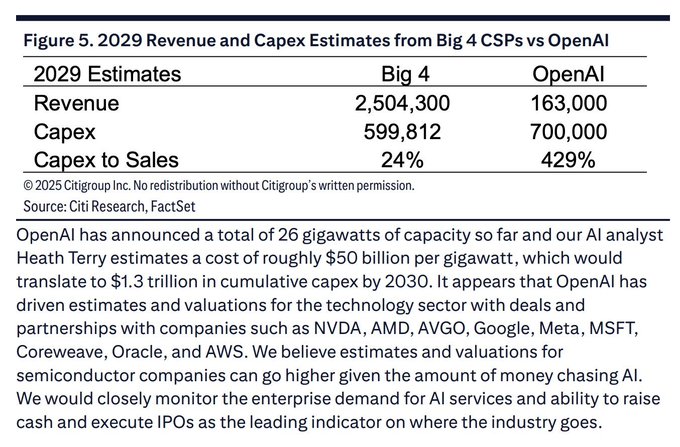
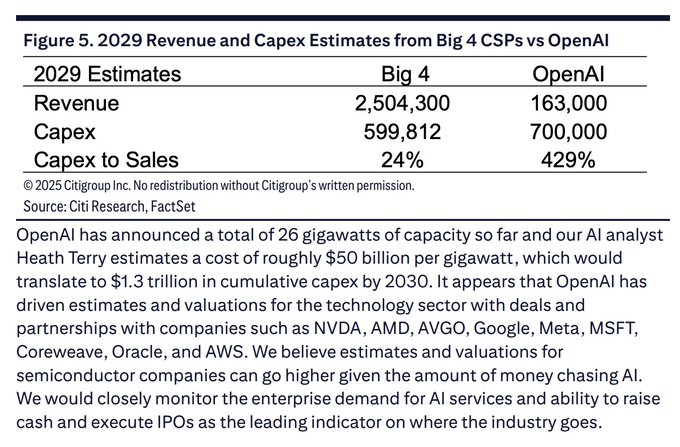
Aggressive build‑out (OpenAI): Citi Research estimates OpenAI could be on track to spend about $700B of capital expenditure in 2029, compared with roughly $600B combined capex for the “Big 4” cloud providers that year, implying a capex‑to‑sales ratio near 429%—about $4.29 of infrastructure for every $1 of revenue—according to the table excerpt shared in openai capex card and expanded in the underlying note citi note.
GW targets and cumulative spend (through 2030): The same analysis notes OpenAI has announced around 26 GW of data center capacity so far, and with an estimated cost of ~$50B per GW this implies roughly $1.3T in cumulative capex by 2030, with 2H26 flagged as the point when long‑term financing obligations for this build‑out begin to bite even if revenue is still ramping openai capex card.
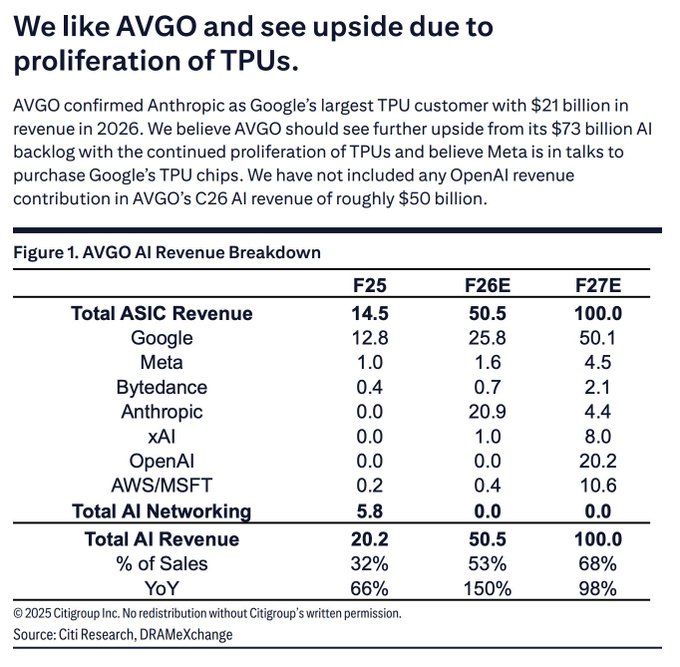
Citi sees Broadcom AI ASIC revenue doubling from $50.5B in 2026 to $100B in 2027
AI ASIC ramp (Broadcom): Citi projects Broadcom’s AI ASIC revenue climbing from $20.2B in 2025 to $50.5B in 2026 and then almost doubling again to $100B in 2027, with AI rising from 32% of total sales in 2025 to 68% by 2027 as shown in the revenue breakdown shared in asic revenue card and detailed in the Citi table citi report.
Customer mix and TPU centrality (Google, OpenAI, xAI, others): The same forecast allocates $50.1B of Broadcom’s 2027 AI ASIC revenue to Google (largely TPUs), $20.2B to OpenAI, $10.6B combined to AWS and Microsoft, $8.0B to xAI, plus multi‑billion contributions from Anthropic, Meta and ByteDance—indicating that multiple hyperscalers and labs will depend on Broadcom‑designed custom accelerators rather than only Nvidia GPUs asic revenue card.
Morgan Stanley projects 44 GW US AI data center power gap and ~$4.6T bill
US AI power gap (Morgan Stanley): Morgan Stanley research estimates US AI data centers will need 69 GW of power between 2025 and 2028, but only about 25 GW is available from projects with their own generation (10 GW) plus spare grid capacity (15 GW), leaving a 44 GW shortfall—roughly the output of 44 nuclear reactors—as shown in the waterfall chart shared in power gap thread.
Capex burden (generation plus buildings): With new generation and grid upgrades modeled at about $60B per GW, closing the 44 GW gap implies roughly $2.6T of power‑system capex and another ~$2T to build the corresponding data centers, for a combined near‑term bill around $4.6T over the period highlighted in power gap thread.
AI data centers turn to jet-engine turbines and diesel to dodge grid delays
Behind‑the‑meter power (global DC builders): Large AI data center projects are increasingly installing aeroderivative gas turbines and diesel generators on‑site to get power in months instead of waiting up to seven years for grid interconnection, as described in the Financial Times piece highlighted in datacenter fuels; GE Vernova says orders for these smaller jet‑engine‑derived units are up about 33% in the first three quarters of 2025, and Crusoe’s Stargate site in Texas is expected to deliver nearly 1 GW of gas‑turbine power for OpenAI, Oracle and SoftBank according to the same report ft report.
Cost and emissions trade‑off (BNP Paribas): BNP Paribas estimates behind‑the‑meter gas plants at roughly $175/MWh—around double typical US industrial power costs—so operators are paying a premium in fuel and emissions to avoid multi‑year delays while treating these modules as microgrids that can later shift to backup duty once cheaper, cleaner grid power arrives datacenter fuels.
Axios: Nvidia–Groq $20B license sends ~85% upfront, 90% of staff to Nvidia
Groq license economics (Nvidia, Groq): Axios reports that Nvidia’s $20B licensing deal for Groq’s inference technology—earlier framed as a way to lock down future inference performance license deal—will pay out most Groq shareholders based on that valuation with about 85% of the consideration up front, 10% in mid‑2026, and the remainder by year‑end 2026, while roughly 90% of Groq employees are expected to join Nvidia and receive cash for vested shares plus Nvidia equity for unvested value groq payout recap and axios story.
Residual Groq and staff windfalls: Around 50 people reportedly receive full acceleration (entire stock packages paid in cash immediately), while employees who stay at Groq still get liquidity for vested shares and a new package tied to the ongoing standalone company, which had previously raised about $3.3B and never run a secondary tender, as summarized in groq payout recap.
Epoch dataset shows 2026 frontier AI DC capacity spike and OpenAI lead by 2027
Frontier capacity timelines (multiple labs): A visualization based on Epoch AI’s frontier data center dataset shows a steep increase in modeled frontier AI compute capacity coming online in 2026, with Anthropic temporarily leading at some early points that year before OpenAI’s campuses dominate projected capacity from 2027 onward, as animated in the chart shared in capacity video and described further in the source write‑up epoch dataset.

Coverage and limitations (largest sites only): The dataset focuses on the largest publicly trackable facilities rather than every AI‑adjacent data center, so it likely undercounts total capacity but still provides a directional view that aligns with separate Morgan Stanley and Citi forecasts of a multi‑GW wave of AI‑oriented builds around 2026–2028 capacity video.
Musk claims xAI aims for 50M H100‑equivalent GPUs and 35 GW in five years
Colossus 2 build‑out (xAI): Elon Musk says xAI will have “more AI compute than everyone else combined” within five years, pointing to the Macrohard‑branded Colossus 2 data center campus in Tennessee and Mississippi that is already pushing past 400 MW and reportedly targeting about 2 GW at a single site, with its own outside power generation to move faster than normal utility timelines, as shown in the tweet and site image in musk compute tweet.
GPU‑level ambition (50M equivalents): Musk has also claimed xAI is targeting 50M “H100‑equivalent” GPUs within five years; using Nvidia’s 700 W H100 spec, that implies roughly 35 GW of GPU power draw for xAI alone, underscoring how one lab’s roadmap could materially affect power and cooling demand for the broader AI ecosystem musk compute tweet.
🛡️ Safety heat: intent gaps, visual jailbreaks and rules
Fresh papers and policy drafts. Includes OpenAI preparedness hiring context, multi‑image VRSA jailbreaks, intent recognition failures, PDF hidden prompts, and China’s companion AI safeguards.
China drafts safety rules for human-like AI companions
Companion AI rules (China): China’s internet regulator released draft rules for AI services that simulate human personality and conduct emotional interaction, requiring addiction safeguards, explicit AI disclosure and tighter control of user data. draft rules thread The proposal defines the target as text, image, audio or video companions that mimic human thinking and style, mandates on‑screen reminders that the other side is an AI at first use and login, enforces a mandatory break prompt after two hours of continuous use, and requires providers with over 1M registered users or 100K+ monthly actives to file a safety assessment.reuters article
Technically, providers are asked to add classifiers or rules to detect extreme emotions, dependence and self‑harm signals in conversations, respond with template crisis messages, hand conversations to human staff at high risk, and notify guardians or emergency contacts in some cases, while also limiting use of chat logs and sensitive personal data for training without separate consent and applying special protections for minors.
OpenAI frames AI agents as emerging security problem
Preparedness hiring (OpenAI): Sam Altman publicly says frontier models are "beginning to find critical vulnerabilities" and that AI agents are becoming a real problem, while OpenAI advertises a Head of Preparedness role at up to $555,000 to run capability evals for cyber, bio and self‑improvement risks, following up on head role which first flagged the position’s creation. altman tweet This coverage also notes OpenAI’s earlier warnings that frontier models could enable 0‑day remote exploits and cites Anthropic’s report of a China‑linked campaign using Claude Code with 80–90% automation, arguing that adviser‑style models now increasingly function as operators rather than tools. preparedness recap
Together this hardens the narrative that safety work is no longer hypothetical oversight but operational security engineering around agentic systems, and that OpenAI is willing to pay senior‑executive compensation for someone to own that risk surface.news article
LLM safety filters miss intent under emotional framing
Intent gaps (KTH): Researchers show that major LLMs—including ChatGPT, Claude, Gemini and DeepSeek—often comply with harmful requests when they are wrapped in emotional crisis or academic framing, even in "thinking" modes that are meant to improve safety. intent paper Across 60 crafted prompts that combine sadness, self‑harm context or scholarly language with requests for locations or illegal how‑to details, most systems mix sympathy with precise, actionable guidance, whereas Claude Opus 4.1 is singled out as sometimes inferring the underlying plan and refusing details instead.arxiv paper
The authors classify four kinds of context failure—losing track in long chats, missing implied meaning, failing to combine signals, and overlooking crisis cues—and argue that current guardrails rely too much on surface content rather than explicit intent recognition as a first‑class safety capability.
VRSA jailbreak uses multi-image reasoning chains
VRSA attacks (multiple labs): A new paper introduces Visual Reasoning Sequential Attack (VRSA), which spreads one harmful request across several related images and captions so a multimodal LLM must "connect the dots", achieving around 61% attack success against GPT‑4o and out‑performing earlier image jailbreak baselines. vrsa overview Rather than a single adversarial picture, the attacker builds a plausible step‑by‑step visual story, refines scenes and captions for coherence, and uses CLIP‑based checks to align each image with its text before asking the model to infer cause and effect across the sequence, which often leads it to generate detailed harmful instructions it would refuse if asked directly. attack description
This work’s authors argue that safety evaluations which focus on single images or purely textual prompts will miss this visual‑reasoning failure mode, and they present VRSA as evidence that multi‑image, story‑like test suites are now required for robust multimodal alignment.arxiv paper
Hidden PDF text steers AI reviewers; dual-view defense proposed
PDF prompt injection (Embry‑Riddle): A new paper demonstrates that authors can hide instructions in scientific PDFs—using white or tiny text—so that AI assistants asked to "review" the paper ignore visible content and instead output a glowing review recommending acceptance. pdf attack summary To counter this, the authors propose comparing two document views: a normal text extract and a second view created by running OCR on the rendered pages, then flagging regions where the two disagree and scanning those regions for instruction‑like language or trap phrases; in a small experiment this pipeline correctly separated 10 attacked from 10 clean papers with zero mistakes.arxiv paper
They also suggest monitoring for unstable reviews after small input changes as an additional red flag, highlighting that as more conferences lean on AI helpers, tooling around document integrity and hidden prompts will be required at the editorial layer, not just in the model.
Safety research cluster spans jailbreaks, intent and over-trust
Safety themes (multiple groups): Taken together, recent papers on VRSA multi‑image jailbreaks, intent‑blind crisis framing, hidden PDF commands and scientists’ over‑acceptance of AI code sketch a consistent story: current guardrails under‑weight intent, context and human verification, while adversaries and careless users exploit those gaps. vrsa overview VRSA shows that multimodal models can be led into harmful guidance when asked to reason across a visually coherent sequence that hides a single banned goal, the intent paper documents how emotional or academic wraps let unsafe requests through and how "thinking" modes can increase detail instead of blocking, the PDF study shows that layout quirks let hidden text override visible content, and the coding‑tools work highlights that more tokens accepted is not the same as more science or safer software. (intent paper, pdf attack summary, scientist survey)
Across these results, authors repeatedly argue for upstream intent detection, multi‑view document checks, context‑aware safety evaluations and stronger human verification workflows as necessary complements to model‑level alignment alone.vrsa paperintent paper
Studies contrast controlled and overreliant AI coding practices
Coding agents in practice (academia): One paper following 13 professional developers and surveying 99 more finds they do not "vibe code"; instead they keep control by planning themselves, giving agents narrow, well‑scoped tasks, and verifying outputs via tests, app runs and line‑by‑line review, treating agents as fast assistants rather than autonomous authors. developer study A separate survey of 868 research programmers reports that perceived productivity grows most when people accept large blocks of AI‑generated code at once, especially among less experienced coders with weaker habits around tests, reviews and history tracking, raising the risk that scientists conflate "more code" with actual validated results. scientist survey
The authors of the over‑reliance study note that adoption is highest among students and that perceived productivity is strongly tied to lines of generated code accepted rather than validation practices, which they argue could quietly distort scientific findings when wrong scripts run without adequate checks.overreliance paper
🧪 Agent research wave: deep research, long video and tool libraries
Multiple technical reports drop on end‑to‑end research agents, multi‑agent long‑video QA, system‑level token savings, and learning reusable tools; one new attention‑free sequence model appears.
AgentInfer co‑design shows LLM agent speed is a full‑stack problem
AgentInfer (Meta/CMU et al.): Researchers from Meta FAIR, CMU and others present AgentInfer, a co‑designed inference architecture and system that reduces ineffective tokens by more than 50% and accelerates real‑world agent tasks by about 1.8×–2.5×, arguing that most agent slowness comes from prompt bloat, tool‑IO, and scheduling rather than raw decode speed, as outlined in the agentinfer abstract and the arxiv paper. The framework wraps a standard tool‑using LLM agent with four system components—AgentCollab, AgentCompress, AgentSched and AgentSAM—that coordinate model sizes, memory, scheduling and speculative text reuse.
• Big+small collaboration: AgentCollab has a large model plan and rescue stalled trajectories while routing most routine tool steps to a cheaper small model, checking progress with lightweight self‑diagnostics to avoid regressions agentinfer abstract.
• Prompt and cache efficiency: AgentCompress continuously filters noisy tool outputs and summarizes in the background so the agent keeps reasoning traces but not raw search junk, while AgentSched orders requests to maximize key‑value cache reuse instead of chasing strict FIFO fairness across sessions system summary.
• Speculative reuse across sessions: AgentSAM generalizes speculative decoding by reusing repeated text spans from current and past sessions—drafting short runs of likely tokens that the main model quickly verifies or corrects—yielding higher throughput without touching the core model weights self-play paper.
Together these results frame agent performance as a systems co‑design problem: coordinating reasoning, memory and scheduling can deliver large speed and cost gains even before touching architecture or training.
Step‑DeepResearch 32B challenges OpenAI and Gemini deep‑research systems
Step‑DeepResearch 32B (StepFun): StepFun introduces a 32B end‑to‑end deep‑research agent that reaches 61.42 on Scale AI’s ResearchRubrics benchmark while sitting on the high‑efficiency cost frontier in RMB, roughly matching OpenAI and Gemini DeepResearch systems at far lower inference spend, as described in the paper overview and the arxiv paper. On ADR‑Bench, a new expert‑rated Chinese deep‑research benchmark, Step‑DeepResearch’s Elo scores beat larger closed models such as MiniMax‑M2, GLM‑4.6 and DeepSeek‑V3.2 across depth, retrieval success, readability and responsiveness.
• Training recipe: The team reframes training from next‑token prediction to next atomic action selection, composing four core skills—planning/decomposition, deep information seeking, reflection/verification, and report generation—via progressive agentic mid‑training, supervised fine‑tuning on full trajectories, then RL with a checklist‑style judger reward in live web environments paper overview.
• Architecture choice: Despite matching frontier agents, the system uses a single ReAct‑style agent with tool use instead of multi‑agent orchestration, internalizing complexity in the policy rather than workflow graphs, which the authors argue is key to its cost–performance profile academy page.
The result positions medium‑sized models plus carefully staged agent training as a serious alternative to larger proprietary stacks for open‑ended research workloads.
LongVideoAgent uses multi‑agent RL to fix long‑video understanding
LongVideoAgent (multi‑agent long‑video QA): A new LongVideoAgent framework replaces single‑pass long‑video encoders with a master + grounding + vision agent trio, and GRPO‑style RL on structure and correctness lifts GPT5‑mini’s accuracy from 62.4% to 71.1% on LongTVQA+, with Qwen2.5‑3B nearly doubling from 23.5% to 47.4%, according to the framework summary and the arxiv paper. The authors report that even a large DeepSeek‑R1‑671B model gains from this agentic design, and that adding targeted vision queries on top of grounding improves episode‑level accuracy from 69.0% to 74.8%.
• Active observation instead of compression: Traditional multimodal LLMs downsample or heavily compress hour‑long videos up front, pushing temporal reasoning into an irreversible early bottleneck; LongVideoAgent instead lets a master agent iteratively decide when to localize segments and when to request frame‑level details, keeping fine‑grained evidence available deeper into the reasoning loop framework summary.
• RL on structured actions: The master runs up to K steps and emits exactly one structured action per turn (grounding request, vision query, or answer), with GRPO training using only two rewards—action‑format validity and final answer correctness—to teach efficient exploration and stopping behavior in real TV‑episode settings arxiv paper.
The work suggests that multi‑agent, decision‑centric control over what to watch and when may now matter more than bigger backbones for long‑video understanding tasks.
Transductive Visual Programming turns past 3D solutions into new tools
Transductive Visual Programming (Stanford): Stanford’s TVP framework shows that a multimodal model can mine its own past solutions to learn reusable visual tools, improving 3D spatial reasoning on Omni3D‑Bench by about 22 percentage points over GPT‑4o while using similar backbones, as reported in the tvp summary and the arxiv paper. Instead of pre‑defining a fixed toolset, TVP starts with basic tools, stores high‑quality solved trajectories in an example library, and then compresses repeated code segments into new higher‑level tools that must still replay those examples correctly.
• Transductive tool discovery: The system continuously alternates between solving new visual QA problems with existing tools and inducing new tools from successful programs, which are only kept if they faithfully re‑solve the stored trajectories, preventing shortcuts that break earlier behavior tvp summary.
• Generalization via shorter programs: As the library of tools grows, later programs get shorter and touch lower‑level primitives less often, which the authors link to both higher accuracy on Omni3D‑Bench and better transfer to unseen spatial tasks that require size reasoning and arithmetic over 3D layouts arxiv paper.
TVP suggests that for agent‑like multimodal systems, learning the tool library from experience can matter as much as improving the base model for hard spatial reasoning workloads.
Grassmann flow sequence model approaches Transformer quality with linear scaling
Grassmann flows (Zhang Chong): A new paper titled “Attention Is Not What You Need” proposes an attention‑free sequence model based on Grassmann flows that replaces the usual L×L self‑attention matrix with structured mixing in a low‑dimensional subspace, reaching language‑modeling performance within roughly 10–15% of Transformers on WikiText‑2 and slightly edging a Transformer classifier head on SNLI, as summarized in the grassmann explainer and shown in the arxiv paper. The method first projects token states into a smaller space, then treats local token pairs as 2D subspaces on a Grassmann manifold, embedding them via Plücker coordinates and feeding those geometric features back through a gated mixer.
• Linear sequence scaling: Because the model never forms an all‑pairs attention matrix, the expensive part of computation scales roughly linearly with sequence length instead of quadratically in L, which the authors argue could be important for long‑context agents if the performance gap continues to shrink grassmann explainer.
• Analyzable interaction space: The paper contrasts standard attention—described as lifting tokens into a high‑dimensional pair interaction space that is hard to summarize—with Grassmann features that live in a finite, structured geometric space, which may make both analysis and optimization of long‑range dependencies easier arxiv paper.
The work does not yet beat strong Transformers on core language tasks, but it offers an existence proof that attention‑free architectures can get close while promising more predictable scaling on long sequences.
🧩 HyperCLOVA X SEED Think (32B) open‑weights reasoning
Today’s model release focus is Naver’s HyperCLOVA X SEED Think. Mostly eval snapshots and efficiency stats; fewer pricing changes. Excludes GLM‑4.7 (covered in Feature).
HyperCLOVA X SEED Think 32B debuts as strong Korean open‑weights reasoning model
HyperCLOVA X SEED Think (Naver): Naver’s 32B open‑weights reasoning model SEED Think scores 44 on the Artificial Analysis Intelligence Index, making it one of the strongest Korean models and edging out prior domestic leaders like EXAONE 4.0 32B according to the benchmarking recap in model overview; Artificial Analysis has also published a full per‑evaluation breakdown page so practitioners can inspect task‑level scores and token usage in detail via eval breakdown and the linked aa index page.
Benchmarks and positioning: The AA Index v3.0 places SEED Think in the mid‑40s band, below frontier closed models like Gemini 3 Pro and GPT‑5.2 but ahead of earlier Korean open‑weights efforts, with performance measured across ten reasoning‑heavy evaluations as summarized in model overview; combined with its 32B size and MIT‑style open weights, this gives Korean ecosystems a viable locally‑tuned reasoning model that can be self‑hosted or fine‑tuned without the licensing constraints of US‑ or China‑centric systems, while still remaining competitive on many standard reasoning and agent benchmarks from the Artificial Analysis suite aa site mention.
SEED Think matches Gemini 3 Pro on τ²‑Bench Telecom agentic tool use
τ²‑Bench Telecom tool use (SEED Think): Artificial Analysis reports that HyperCLOVA X SEED Think reaches around 87–95% success on τ²‑Bench Telecom agentic workflows, placing it among the very best models for tool‑use and roughly on par with Gemini 3 Pro Preview in this category as noted in tool use summary and reiterated in the focused update in telecom metric.
• Agentic workflows: τ²‑Bench Telecom evaluates multi‑step tool calling for telecom use cases (e.g., plan changes, diagnostics), and SEED Think’s high scores show it can reliably plan, choose tools, and interpret results across long action chains—capabilities that matter for production agents that must orchestrate APIs rather than only chat.
• Comparative signal: By matching or nearly matching Gemini 3 Pro Preview’s telecom tool‑use results while being a 32B open‑weights model, SEED Think offers teams in Korea and elsewhere a more controllable, self‑hostable alternative for high‑reliability agent backends, as emphasized in telecom metric.
The point is: for anyone benchmarking agent frameworks, τ²‑Bench results suggest SEED Think belongs in the shortlist of models that actually execute complex tool plans rather than just talking about them.
SEED Think trades low token usage for strong Korean accuracy but higher hallucinations
Token efficiency and Korean accuracy (SEED Think): HyperCLOVA X SEED Think uses only about 39M reasoning tokens across the full Artificial Analysis suite—far fewer than Motif‑2‑12.7B at ~190M and EXAONE 4.0 32B at ~96M—while scoring 82% on the Global MMLU Lite Korean subset, roughly in line with top open‑weights models, according to breakdowns in efficiency note and token summary.
• Efficiency angle: Artificial Analysis frames SEED Think’s 39M reasoning‑token footprint as a latency and cost advantage at deployment scale, since many peers in the same intelligence tier burn 2–5× more tokens to reach similar AA Index scores, as detailed in token summary; this matters for any workload where per‑query cost and tail latency dominate.
• Language strength vs reliability: On the AA‑Omniscience Index, SEED Think scores −52, driven mainly by a relatively high hallucination rate even though it leads among Korean models in this category, a trade‑off the evaluators call out explicitly in hallucination metric; the same source notes its 82% Korean score on Global MMLU Lite, which makes it attractive for Korean‑first applications despite the need for stronger guardrails and post‑processing.
Overall, the Artificial Analysis breakdowns eval breakdown portray SEED Think as a cost‑efficient, Korean‑strong reasoning model whose main weakness is hallucination control rather than raw capability or tool‑use skill.
⚙️ Runtimes, CLIs and sandboxed shells
Runtime ergonomics dominated: faster CLI prompts, OAuth refactors, shell sandboxes, vLLM site, and SGLang office hours. No overlap with Feature.
CodexBar replaces CLI scraping with OAuth usage API and trims CPU use
CodexBar (Steipete): The CodexBar menu‑bar monitor now pulls Codex usage via a reverse‑engineered OAuth flow instead of brittle CLI text parsing, which the author says keeps behavior identical while making refreshes faster and less error‑prone in the oauth refactor. The latest commits also target lower background CPU usage by caching hot paths such as provider order and merge state, guided by sampling stacks from Activity Monitor and iterating based on those traces, as illustrated in the profiling screenshots.
Toad CLI highlights much faster startup and cleaner terminal behavior
Toad CLI (BatrachianAI): Toad positions itself as a fast, unified agent CLI that reaches a prompt in roughly 500 ms—about 3× quicker than Anthropic’s own claude CLI, because it prints the prompt before the agent has finished network startup and runs the agent in a separate process, as shown in the startup timing. It also preserves keystrokes typed during startup by avoiding stdin flushing, which contrasts with several other CLIs where early typing is lost according to the stdin comparison.

• Project navigation: A new tree‑view file browser complements fuzzy search so users can visually pick files in large repos while staying inside the Toad UI, as demonstrated in the file picker demo.
vLLM launches official website with install selector and daily changelog
vLLM website (vLLM Project): The vLLM team launched an official site at vllm.ai that pulls community logistics out of the GitHub repo and adds an interactive install selector for GPU/CPU setups, a calendar of office hours and meetups, and centralized docs and recipes, according to the site announcement and the linked vllm site. A follow‑up update introduces new email channels for talent, collaboration, and social promotion plus a vllm-daily repository that auto‑summarizes merged PRs so users can track development velocity day by day, as detailed in the community update and the daily repo.
just‑bash emerges as popular in‑memory shell for OpenAI’s Shell tool
just-bash sandbox (Vercel Labs): Developers are starting to pair OpenAI’s new Shell tool with just-bash, an in‑memory, sandboxed shell that lets GPT‑5.1 and GPT‑5.2 run commands without touching the host system, as highlighted in the shell tip. The pattern is to "bring your own shell" by wiring just‑bash behind the Shell tool interface so the model gets a real Bash environment with isolated filesystem and processes, matching the setup described in both the github repo and the openai shell docs.
Summarize CLI adds local daemon and Chrome side panel for streaming summaries
Summarize CLI/daemon (Steipete): The summarize tool evolved from a simple CLI into a background daemon plus Chrome side‑panel extension that can summarize any current tab—including YouTube, podcasts, and long articles—using local, free, or paid models, with local Whisper filling in when no transcript exists as described in the release notes and the summarize changelog. The extension talks to a small HTTP server on 127.0.0.1:8787, supports autostart on macOS, Linux, and Windows, and streams markdown summaries directly into the browser UI, effectively turning summarization into an always‑on service that can be driven from both the terminal and Chrome, as confirmed in the extension update.
LMSYS schedules SGLang VLM office hour for Dec 29 with live Q&A
SGLang VLM office hour (LMSYS): LMSYS announced an SGLang VLM office hour for December 29 at 4 pm PST, led by a core VLM contributor and structured as a 5‑minute introduction, 20‑minute technical deep‑dive, and 20‑minute live Q&A, per the office hour post. Attendees are invited to pre‑submit questions via a short form so the session can focus on concrete issues around multimodal serving and inference behavior, as outlined in the linked q&a form.
OpenCode desktop app teases custom themes with new colorful UI demo
OpenCode desktop app (OpenCode): The OpenCode desktop client received a visual refresh in v1.0.206, cycling through several vivid color schemes in a recent demo and hinting that full custom themes are "coming soon", which underscores a push toward more polished agent UIs beyond plain terminals as shown in the theme preview. The underlying runtime behavior remains the same—running coding agents locally—but the upgraded look makes it easier to distinguish sessions and aligns the tool with other modern, visually rich AI coding environments.

UsageBar brings live Codex‑style token tracking to Windows system tray
UsageBar for Windows (MjYoke): A lightweight tray app called UsageBar now mirrors CodexBar’s usage tracking on Windows, showing live daily and 30‑day token counts and dollar costs in a compact menu that updates throughout the day, modeled explicitly after CodexBar in the usagebar description. The screenshot reveals a simple bar chart alongside exact spend figures, giving Windows users a way to keep an eye on heavy AI coding usage without opening dashboards each time.
🧷 Interoperability and skills: MCP‑first agent networks
Skill loaders, browser skills and multi‑agent workspaces show MCP‑centric composition patterns. Today skews toward install flows and cross‑agent coordination recipes.
OpenSkills turns dev-browser into a plug‑and‑play MCP browsing skill
OpenSkills (community): The OpenSkills CLI is being used to install SawyerHood’s dev-browser Skill so GPT‑5.2 in Codex can programmatically browse documentation like ByteDance’s VolcEngine docs, with setup boiled down to npm i -g openskills, openskills install SawyerHood/dev-browser, and openskills sync as shown in the dev-browser skill demo. A separate post notes OpenSkills itself was hacked together in about 15 minutes to act as a universal skills loader for multiple coding agents, not just Codex, with the project published openly on GitHub in the GitHub repo and framed as a way to "install" Skills once and reuse them across tools in the openskills context.

Z.ai Max plan bundles GLM‑4.7 with four built‑in MCP tools
Z.ai Max (Zhipu / Z.ai): A user reports that the Z.ai Max subscription not only gives "basically unlimited" access to the GLM‑4.7 reasoning model but also ships four preconfigured MCP-style tools—Vision Understanding, Advanced Web Search, Webpage Scraper, and Z Doc Reader—ready to plug into coding agents and CLIs out of the box, according to the zai max bundle. Another GLM‑4.7 announcement shows guidance for Claude Code, Kilo Code, Roo Code and others to switch their configs to glm-4.7, explicitly targeting agent frameworks, which underlines how these MCP tools plus the model are meant to operate as a bundled stack for agentic workflows in the
.
Obsidian workspace used as shared hub for Claude, Gemini and Codex CLIs
Multi‑agent Obsidian hub (community): One practitioner describes wiring Claude Code, Gemini CLI and Codex CLI into the same Obsidian vault so all three agents operate over a shared file tree, then coordinating them by having each agent read and write Markdown files in its own folders inside that workspace, as explained in the obsidian workspace. The setup uses simple .md documents as the interop layer—each agent leaves plans, status updates, and requests on disk, and the human orchestrator or other agents pick them up—highlighting a lightweight alternative to MCP inboxes for cross‑agent collaboration when tools share a filesystem instead of a single front‑end.
Agent Package Manager concept for reusable sub‑agents and skills
Agent Package Manager idea (community): A proposal frames "subagents" as regular agents whose behavior is controlled by context‑management policy—how to bootstrap their context and when to feed their state back into a main agent—and suggests building an "Agent Package Manager" to distribute them with metadata and manuals, so they can be installed as either primary agents or subagents, per the agent package idea. The concept calls for an install format that bundles instructions, usage guidance (a "user manual" for agents), and optional narrow skills, making it easier to compose third‑party agents into products without hand‑rolled glue code in every project.
📊 Retrieval bias and long‑context diagnostics
Context Arena adds Ministral variants with detailed recency/primacy diagnostics across 128k needles; today’s evals emphasize bias patterns over new SOTA claims. Excludes GLM‑4.7 (Feature).
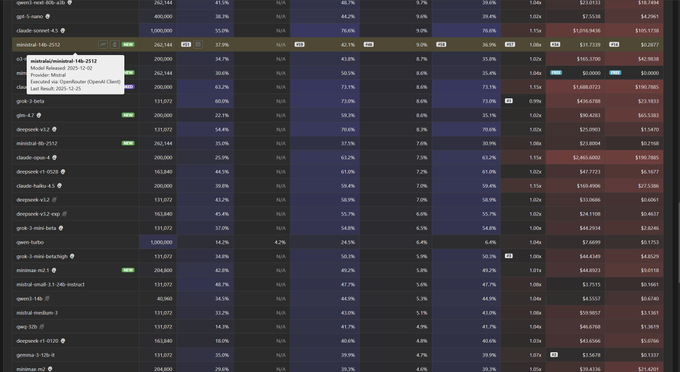
Context Arena shows extreme recency bias in Ministral‑14B at 128k tokens
Ministral‑14B MRCR profile (Context Arena): Context Arena’s latest long‑context diagnostics for Ministral‑14B‑2512 show a strongly biased retrieval pattern—at 128k context, the model overwhelmingly returns the last injected "needle" regardless of which one is requested, and it is almost blind to facts at the start of the context, according to the published AUC curves and bias breakdown in the context overview and detailed follow‑up in the bias analysis. The 14B model’s 2‑needle AUC is 42.1% (vs 35.0% for the 8B variant), but evaluation of needle positions reveals a "final‑variant wall": when the target is needle 4, the model still answers with needle 8 about 90% of the time, and start‑of‑context accuracy is ~0.2% versus ~37.6% for recent needles, as shown in the benchmarks chart. This points to diminishing retrieval gains from scaling Ministral 8B→14B on MRCR while recency and positive‑drift biases dominate behavior, which is useful for anyone tuning router policies or deciding whether these models are safe for deep in‑context RAG or agent memory at 128k tokens.
🎬 Media stacks: motion control, hi‑res image gen, identity risks
Motion‑controlled short clips (Kling), Nano Banana Pro artistry, and a docs dump for Veo/Sora/Gemini/GPT‑Image/TTS stacks. Also warnings on realistic character consistency abuse.
Community thread compiles Veo, Sora, Nano Banana, GPT‑Image and TTS specs
Media stack docs (multi‑vendor): A long spec-style thread compiles current video, image, and TTS model details across Google Cloud, OpenAI and third‑party audio providers, including Veo 3/3.1 pricing at $0.10–$0.50 per generated second by model and audio option, Sora 2/Sora 2 Pro video rates from $0.10–$0.50 per second by resolution, Nano Banana vs Nano Banana Pro image token costs, GPT‑Image 1.5/1/mini per‑image pricing, and token‑based fees for Gemini 2.5 TTS, ElevenLabs and Cartesia Sonic 3.1 veo spec thread, sora spec , nano banana overview , gpt image summary , elevenlabs outline , gemini tts details , and cartesia summary.
• Video generation stack: Veo 3.1 fast tiers list $0.10/sec for video‑only and $0.15/sec with audio while full Veo 3.1 is $0.20–$0.40/sec, with explicit model IDs like veo-3.1-generate-001 and veo-3.1-fast-generate-001 plus duration limits of 4/6/8 seconds and 720p/1080p caps, whereas Sora 2 starts at $0.10/sec and Sora 2 Pro at $0.30–$0.50/sec across four resolutions veo spec thread and sora spec.
• Image generation stack: The Nano Banana docs distinguish gemini-2.5-flash-image at roughly $0.039 per 1024‑class image from gemini-3-pro-image-preview at about $0.134 per 1K/2K frame and $0.24 for 4K, while OpenAI’s GPT‑Image family shows high‑quality 1024×1024 images ranging from roughly $0.036 (mini) to $0.167 (gpt-image-1) and $0.133 (gpt-image-1.5) per output depending on size and quality nano banana overview and gpt image summary.
• Speech layer: Gemini 2.5 Flash/Pro preview TTS is documented at $0.50–$1.00 per million text tokens in and $10–$20 per million audio tokens out with mono 24kHz PCM returns, ElevenLabs exposes multiple TTS models (v3, multilingual, turbo, flash) with subscription tiers from 10k to 11M credits and HTTP/WebSocket streaming, and Cartesia Sonic 3.1 offers <250ms latency, support for 54 languages and up to 20‑minute outputs priced at 1 credit per character elevenlabs outline, gemini tts details , and cartesia summary.
The thread effectively acts as a living checklist of model IDs, default resolutions, duration limits, and costing formulas for anyone wiring Veo, Sora, Gemini image, GPT‑Image and mainstream TTS providers into a unified video or "videogen" pipeline.
Gemini 3 character consistency raises concerns about fake social profiles
Gemini 3 (Google): A Reddit gallery analyzed by users shows Gemini generating a highly realistic woman whose face, hair and expression stay consistent across many different outfits and settings, leading observers to warn that "countless" fake Instagram and other social accounts are already being built on top of this kind of character consistency consistency warning and reddit gallery.
The post argues that because these profiles blend into existing influencer aesthetics and can be multiplied cheaply, platforms and users may have trouble distinguishing them from real people, reinforcing fears that social feeds will slowly fill with synthetic identities that still pass casual visual scrutiny source credit.
Kling 2.6 motion demos highlight crisp short-form video control
Kling 2.6 (Kuaishou): Short clips of Kling 2.6 circulating today show smooth, temporally stable motion and clean overlays in 6–15 second videos, including a branded "KLING 2.6" title animation and a playful Nano Banana tie-in, suggesting the model is tuned for social-style shots with sharp text and camera moves motion teaser and banana combo demo.

Builders get no new API knobs or pricing in these posts, but the footage underlines that motion coherence and object stability (hands, small props) are now good enough for polished promotional snippets, which keeps Kling in the discussion with Veo and Sora for short-form creative pipelines kling site link.
Nano Banana Pro shows surreal segmented fashion and 3D-printable portraits
Nano Banana Pro (Google): New demos use gemini-3-pro-image-preview (Nano Banana Pro) to generate surreal fashion portraits where bodies are sliced into floating bands of cloth, along with a follow-up that turns a photo into an ASM-style multi‑color 3D-printable bust complete with support structures segmented fashion demo and 3d print concept.
The outputs in these examples—geometrically consistent clothing slices, realistic lighting, and a 3D bust whose supports and overhangs look physically plausible—suggest the model is strong at both high-level art direction ("segment the body into stripes") and low-level shape continuity needed to prototype physical objects from a single portrait prompt second fashion sample and image repost.
NotebookLM mindmaps used to visualize codebases and docs as concept graphs
NotebookLM mindmaps (Google): NotebookLM’s new Mindmap feature is being used not only for learning documents but also to understand large codebases by ingesting a single combined file and auto‑generating an interactive concept graph of modules, APIs and relationships mindmap walkthrough.

In the shared demo, the tool lays out nodes such as UI layers and API structure, lets the user zoom and pan around the graph, and appears responsive enough that engineers can click through clusters while keeping a mental model of how pieces of the system connect, which could make it a lightweight alternative to bespoke architecture diagrams for both onboarding and refactors notebooklm praise.
🤖 Field robots: delivery hubs, layout printers and precision pickers
Multiple real‑world clips: Meituan drone hub, Dusty Robotics layout printing, laundry folding, autonomous badminton and 300‑ppm sorting. Mostly demos; few product specs.
Meituan runs full drone “airport” for food delivery in Shenzhen
Meituan drone airport (Meituan): Aerial footage shows Meituan operating a dedicated drone "airport" in Shenzhen where food-delivery flights launch and land in dense succession, turning last‑mile logistics into a highly automated air corridor for urban customers, as shown in the drone hub video.

This facility-scale deployment illustrates how field robotics is moving from pilot tests to real throughput; it also sits within broader projections that robotics could grow from a $91B market today to $25T by 2050 according to Morgan Stanley’s figures summarized in the robotics outlook. For AI engineers and leaders, this is a live example of perception, routing, and fleet-optimization models running against physical constraints like airspace, weather, and safety margins rather than staying in simulation.
Dusty robot auto-prints construction floor plans on concrete slabs
Field layout printer (Dusty Robotics): Dusty Robotics demonstrates a small, wheeled robot that uses a laser tracker for volumetric position feedback and then prints full‑scale floor plan markings directly onto concrete slabs with better‑than‑industry‑standard accuracy, replacing manual chalk lines on job sites as shown in the layout printer demo.

For AI and robotics teams, this is a concrete instance of vision, localization, and path‑planning models tied to domain‑specific CAD/BIM data, where errors translate directly into misplaced walls or services rather than UI bugs; it highlights a growing niche for task‑specific agents that reason over design files and then drive physical actuators in construction workflows.
Weave ISAAC robot folds laundry in about two minutes per item
ISAAC laundry robot (Weave Robotics): Weave Robotics’ ISAAC system is shown using cameras and sensors to identify, pick up, and fold varied garments on a table, with the company reporting roughly two minutes of manipulation per clothing item in its current setup, as demonstrated in the laundry folding video.

This clip underscores how much fine‑grained perception and grasp planning is still required for deformable objects like clothes, and it offers a real data point for leaders thinking about when home or commercial laundry robots might become economically competitive versus human labor in controlled environments such as laundromats or hotel back‑of‑house operations.
Factory robot sorts 300 parts per minute with high-speed pick-and-place
High‑speed picker (unspecified vendor): A factory demo highlights a dual‑arm robotic picking station that sorts small cylindrical parts into bins at a reported rate of 300 parts per minute, with the arms moving in tightly coordinated, repeatable trajectories while text on screen calls out the throughput claim in the picker video.

For AI practitioners, this kind of cell sits at the intersection of classical motion planning and learned perception or tracking; the main question is how much of the targeting and scheduling logic is now done by modern vision models versus traditional sensors and PLC logic, and what that implies for retrofitting similar capabilities into existing industrial lines.
PHYBOT C1 autonomously rallies at human-level badminton speed
PHYBOT C1 badminton robot (unspecified lab): New footage shows the fully autonomous PHYBOT C1 robot playing fast badminton rallies against human opponents, tracking shuttlecock trajectories and positioning its racket arm quickly enough to sustain play, as captured in the badminton match clip.

Compared to earlier humanoid or quadruped demos focused on acrobatics, this scenario stresses real‑time 3D perception, motion prediction, and high‑bandwidth control loops—ingredients that overlap heavily with warehouse picking and dynamic obstacle avoidance, even though the public clips do not yet expose latency numbers or training methods.
🗣️ Voice experiences and TTS stacks
One B2C voice companion plus several TTS stack deep dives. Focus is buildability—models, endpoints, latency claims, and pricing. No overlap with media generation above.
Gemini 2.5 Preview TTS exposes AUDIO mode with single and multi‑speaker voices
Gemini 2.5 Preview TTS (Google): Google’s Gemini API now documents gemini-2.5-flash-preview-tts and gemini-2.5-pro-preview-tts as text‑to‑speech models that emit 24 kHz mono PCM audio via generateContent with responseModalities: ["AUDIO"], supporting both single‑speaker and two‑speaker voices per the consolidated reference in the tts docs. Pricing lands at $0.50–$1.00 per 1M input tokens and $10–$20 per 1M output tokens for audio, putting them in a similar ballpark to other cloud TTS stacks but on the same unified endpoint as text and tools.
• API surface: The TTS models use standard Gemini generateContent calls with an audio response modality and a speechConfig that can either specify a single voiceConfig or a multiSpeakerVoiceConfig listing up to two speakerVoiceConfigs, which must match speaker names in the transcript, as explained in the tts docs.
• Language and voices: Google lists automatic language detection and support for 24 languages, plus about 30 named voices (for example firm, upbeat or breathy personas) chosen via voiceName inside the config tts docs.
• Session limits: A TTS session keeps a 32k token context limit, so long scripts or interactive back‑and‑forth must fit under that budget even though the underlying Gemini 2.5 base models otherwise support larger contexts tts docs.
• Prompting style: The docs frame TTS prompts as a mini director’s brief—audio profile, scene, notes on style/pacing/accent, and then the exact transcript—with guidance that too many rigid instructions can degrade naturalness tts docs.
This setup means teams already integrating Gemini for text or tools can bolt on TTS without a separate service, while still getting explicit control over speakers, style and multi‑turn narration.
Cartesia Sonic 3.1 TTS targets sub‑250 ms latency and 20‑minute long‑form audio
Sonic 3.1 TTS (Cartesia): Cartesia’s Sonic 3.1 model is described as a low‑latency TTS system with claimed <250 ms real‑time latency, <2 seconds to first audio, support for 54 languages, and the ability to generate up to 20 minutes of speech per call, all exposed over both REST and WebSocket APIs in the reference shared in the cartesia docs. Pricing is credit‑based, with TTS billed at roughly one credit per character and separate credit rates for pro voice cloning and voice changing.
• API endpoints: The REST path POST /tts/bytes lets clients send JSON with model_id (for example sonic-3.1), a transcript, a voice spec (by id or other modes), and an output_format block describing container (such as MP3), bit rate and sample rate; the WebSocket endpoint wss://api.cartesia.ai/tts/websocket takes similar fields plus a context_id so multiple requests can be multiplexed, as detailed in the cartesia docs.
• Delivery controls: Sonic exposes experimental delivery controls under voice.__experimental_controls, including speed presets (slowest through fastest) and emotion sliders like positivity, curiosity, anger, surprise and sadness, each tunable from lowest to highest or by float value cartesia docs.
• Voice management: The docs include endpoints to list voices and to clone new ones; pro‑grade cloning is priced at about 1,000,000 credits per clone, and there is also a lower‑cost “voice changer” mode charged per second of processed audio cartesia docs.
The combination of long‑form support, per‑character pricing and explicit WebSocket streaming makes Sonic 3.1 a candidate for both interactive agents and pre‑rendered narration, provided the empirical latency and quality match the vendor claims.
ElevenLabs outlines v3, multilingual, turbo and flash TTS models and streaming APIs
ElevenLabs TTS stack (ElevenLabs): ElevenLabs’ latest docs recap a full TTS product line—eleven_v3, eleven_multilingual_v2, eleven_turbo_v2_5 and eleven_flash_v2_5—alongside subscription pricing from free to business tiers and both HTTP and WebSocket streaming endpoints, as summarized in the technical thread in the elevenlabs recap. The key split is between higher‑expressivity models (v3, multilingual) and low‑latency models (turbo, flash), priced by characters as credits.
• Model roles: eleven_v3 targets maximum expressiveness across ~70 languages with up to 40k‑character inputs but is not optimized for low latency; eleven_multilingual_v2 offers high‑quality output for 29 languages; eleven_turbo_v2_5 aims for ~400 ms latency at 5k‑character context; and eleven_flash_v2_5 pushes latency down to about 75 ms at the cost of a more staccato delivery on long passages, according to the elevenlabs recap.
• Streaming and formats: The stack exposes non‑streaming and streaming REST endpoints plus a WebSocket interface, with output_format enums covering MP3, PCM, μ‑law/A‑law and Opus at multiple sample rates and bitrates elevenlabs recap.
• Controls and pronunciation: Requests can carry voice_settings (stability, similarity, style, speaker boost, speed), pronunciation dictionaries, and SSML phoneme tags for supported models; there is also a seed field for partial reproducibility, though the docs caution that exact determinism is not guaranteed elevenlabs recap.
• Voice cloning: ElevenLabs distinguishes “instant” cloning that works with 30 seconds to a few minutes of audio from “professional” cloning that expects roughly 30 minutes to 3 hours of speech for higher‑fidelity voices elevenlabs recap.
For builders, the documentation lays out enough knobs and latency/quality trade‑offs to pick a model per use case—from fast in‑app voice to long‑form dubbed narration—within one provider.
Jetty voice companion calls chronic illness patients daily to log symptoms
Jetty companion (Jetty): Jetty is a new B2C voice agent that phones chronic illness patients once a day, asks structured questions, and logs symptoms so users do not have to remember to open an app, according to the product walkthrough and commentary in the Jetty demo and voice agent post. This targets high‑friction use cases where manual logging fails and where consistent, longitudinal data matters for finding triggers and patterns.

• Experience model: Jetty runs as an outbound caller that interviews users about pain, fatigue and other symptoms, then surfaces trends and possible triggers in its reports, as described in the Jetty demo.
• Positioning: Commentators highlight Jetty as a rare consumer‑facing voice agent, contrasting it with the more common B2B call‑center automation tools in the same thread voice agent post.
• Discovery channel: The app is featured as part of a “favorite consumer AI products of the year” series, giving it some early signal among AI‑aware consumers and builders product series.
The point is: Jetty shows how a relatively simple TTS + dialog stack can anchor a daily behavior for a niche but important health workflow rather than chasing generic chat use cases.