Z.ai GLM-4.7-Flash hits 59.2% SWE-bench – 198K context local agents
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Z.ai released open-weights GLM-4.7-Flash, pitched as a local coding + agent backend with an API; the model is described as a 30B-A3B MoE and is being circulated on a 59.2% SWE-bench Verified claim; Z.ai also advertises a free API tier capped at 1 concurrency, plus a faster paid FlashX variant. The benchmark table is getting retold as “30B-class that’s actually usable,” but comparisons remain provisional without a single canonical eval artifact.
• vLLM/SGLang day-0: both shipped GLM-specific tool-call parsing (glm47) and reasoning parsing (glm45); both expose speculative decoding knobs (SGLang highlights EAGLE settings), signaling expected use in structured agent loops.
• Ollama runtime: ollama run glm-4.7-flash lands in v0.14.3+ (pre-release); the model page lists a 198K context window and multiple quantizations.
The adjacent coding-agent discourse keeps converging on latency + ergonomics: OpenAI tees up Codex “5.3” feedback and faster runs, while eval chatter (e.g., time-budgeted Terminal Bench 2) suggests more “thinking” can lose to timeouts when wall-clock is part of capability.
Top links today
- Anthropic Assistant Axis paper
- Assistant Axis blog post and demo
- GLM-4.7-Flash model weights
- GLM-4.7-Flash API and pricing
- Ollama pre-release download
- Ollama model page for GLM-4.7-Flash
- vLLM day-0 support PR for GLM-4.7-Flash
- Reasoning models generate societies of thought
- Why LLMs aren’t scientists yet paper
- Study of multi-agent AI framework maintenance
- Agent skills security vulnerabilities at scale
- Production-ready probes for Gemini paper
- YOLO26 model downloads
- YOLO26 documentation
- Vibe Kanban open-source repo
Feature Spotlight
GLM-4.7-Flash makes local coding models feel “frontier-adjacent”
GLM-4.7-Flash ships open weights with strong SWE-bench results plus day‑0 local/serving support, making “run a serious coding agent locally” materially more practical this week.
High-volume story: Z.ai’s open-weights GLM-4.7-Flash (30B-A3B MoE) drops with unusually strong coding/agent benchmarks and immediate ecosystem support for running locally (Ollama) and serving (vLLM/SGLang).
Jump to GLM-4.7-Flash makes local coding models feel “frontier-adjacent” topicsTable of Contents
⚡️ GLM-4.7-Flash makes local coding models feel “frontier-adjacent”
High-volume story: Z.ai’s open-weights GLM-4.7-Flash (30B-A3B MoE) drops with unusually strong coding/agent benchmarks and immediate ecosystem support for running locally (Ollama) and serving (vLLM/SGLang).
GLM-4.7-Flash launches as an open-weights coding/agent model with free API tier
GLM-4.7-Flash (Z.ai): Z.ai released GLM-4.7-Flash, positioning it as a local coding + agentic assistant with downloadable weights and an API offering, including a free tier limited to 1 concurrency as described in the launch thread and detailed on the [pricing page](link:6:0|pricing page); the model is described as a 30B-A3B MoE in the MoE detail and has a higher-speed paid variant (FlashX) in the same launch thread.
The deployment story is intentionally “run it yourself or call it”: the [model card](link:6:1|model card) emphasizes local serving paths (vLLM/SGLang) alongside API access, which is the core lever for teams comparing hosted agent loops vs on-prem costs.
GLM-4.7-Flash benchmark claims put a 30B-class open model in the coding conversation
GLM-4.7-Flash (Z.ai): The release is getting circulated primarily on coding/agent evals, especially 59.2% on SWE-bench Verified plus strong showings on several reasoning and browsing benchmarks, as shown in the benchmarks chart and echoed in the release recap.
• Coding + agent evals: The same chart highlights τ²-Bench 79.5 and BrowseComp 42.8, alongside GPQA 75.2 and HLE 14.4, as shown in the benchmarks chart.
• Positioning vs nearby open baselines: Multiple accounts summarize it as “strongest 30B class” and emphasize local deployability, as in the community summary.
Treat the exact comparisons as provisional until a single canonical eval artifact is shared, but the consistent retelling is that GLM-4.7-Flash is being judged as a practical SWE-bench tier option rather than a “toy local model.”
Ollama adds GLM-4.7-Flash in v0.14.3+ pre-release
Ollama (Ollama): GLM-4.7-Flash can now be launched via ollama run glm-4.7-flash in Ollama v0.14.3+ (pre-release), as stated in the Ollama announcement with download pointers in the pre-release links.
The key operational details are in the Ollama [model page](link:249:0|model page), which lists a 198K context window and multiple quantization variants (a common “try it locally first” entry point for teams evaluating whether a 30B-class MoE is usable on their hardware).
SGLang adds day-0 GLM-4.7-Flash support with EAGLE speculative config
SGLang (LMSYS): SGLang announced day-0 support for GLM-4.7-Flash and shared a launch_server command that includes glm47 tool-call parsing and glm45 reasoning parsing, plus EAGLE speculative decoding settings, as shown in the SGLang support post.
The concrete server flags in the SGLang support post (tp-size, speculative steps/topk/draft tokens, memory fraction) make it straightforward to reproduce a production-ish serving setup rather than treating this as a “download weights and hope” release.
vLLM ships day-0 GLM-4.7-Flash support with tool-call parsing flags
vLLM (vLLM): vLLM merged “day-0 support” for GLM-4.7-Flash, including a serving recipe that wires up a dedicated tool-call parser (glm47) and reasoning parser (glm45), as shown in the vLLM support post.
The example vllm serve line in the vLLM support post also includes speculative decoding knobs (--speculative-config.*) and --enable-auto-tool-choice, which is a concrete signal that GLM-4.7-Flash is being treated as a tool-using agent backend, not only a chat model.
Early tool-use sentiment: GLM-4.7-Flash gets praise for tool calling reliability
GLM-4.7-Flash tool use: One early practitioner takeaway is that “glm47 is pretty damn good at tool calling,” according to the tool-calling comment, and that lines up with infra projects explicitly shipping GLM-specific tool parsing flags in the vLLM serve example.
The combination of (a) human sentiment in the tool-calling comment and (b) first-class parsers in vLLM/SGLang suggests the ecosystem expects GLM-4.7-Flash to be used in agent loops that depend on structured tool calls, not only “chat with a local model.”
GLM-4.7-Flash shows up in OpenCode via Hugging Face Inference Providers
OpenCode + Hugging Face Inference Providers: A community RT reports GLM-4.7-Flash is available inside OpenCode through Hugging Face Inference Providers, as shown in the OpenCode terminal screenshot.
This matters for evaluation workflows because it creates a third path besides “self-host via vLLM/SGLang” or “use Z.ai’s API”: a hosted-inference surface that can be swapped into an existing agent TUI, per the OpenCode integration.
GLM-4.7-Flash gets framed as a cheap local workhorse, not a demo model
Local deployment economics: Several posts frame GLM-4.7-Flash as a “try it at home” option that’s cheap enough to run locally, while still being strong enough to matter for coding/agents—see the home deployment take and a separate “best cost to quality” claim in the workhorse claim.
The home deployment take also includes a screenshot showing API concurrency backpressure (“High concurrency usage… reduce concurrency”), which is a small but concrete indicator of early demand and the fact that people are testing it in parallel agent setups, not only single-chat sessions.
🧠 Codex product cadence: speed, UX asks, and planning ergonomics
Continues the Codex-speed narrative, but today’s tweets are mostly practitioner UX requests and product-cadence signals around Codex rather than new benchmark drops. Excludes GLM-4.7-Flash (covered as the feature).
Codex CLI shows a downgrade prompt when nearing limits
Codex CLI (OpenAI): A screenshot shows a “usage limit” interruption that offers to switch to gpt-5.1-codex-mini for lower credit usage and includes a concrete retry time (“Jan 22nd, 2026 6:41 PM”), as shown in the [limit prompt](t:688|Limit prompt).
This indicates Codex CLI is actively nudging users toward a cheaper/faster fallback model under backpressure, instead of failing silently.
Codex power-user wishlist focuses on speed, memory, and long-task autonomy
Codex (OpenAI): A detailed wishlist lays out what heavy users want next: faster responses “keep the quality,” version-aware web search, fewer “continue/what’s next” stalls on long tasks, persistent project memory, better default test strategy, tool/turn status events, an automatic review pass, and screen/video replay debugging—see the [Codex wishlist](t:179|Codex wishlist). It’s a tight snapshot of where Codex friction still shows up in day-to-day shipping.
A smaller but notable add-on is that Codex can “reject creative ideas,” requiring persuasion, per the [behavior note](t:536|Behavior note).
Altman says OpenAI will deliver faster and smarter soon
Codex/ChatGPT speed (OpenAI): Sam Altman claims OpenAI will deliver “a higher level of intelligence while also being much faster soon,” as captured in the [Altman speed quote](t:70|Altman speed quote).
Some observers are already attributing the “faster” part to infrastructure partnerships (e.g., the [Cerebras speculation](t:75|Cerebras speculation)), but there’s no confirmed mechanism in the tweets.
Builders argue speed matters more than extra intelligence for sync coding
Speed vs intelligence (coding agents): One argument claims synchronous coding hits diminishing returns at a level where “>95%” of quick queries won’t improve much with smarter models, and that more intelligence mostly helps async, multi-hour tasks—see the [speed threshold post](t:84|Speed threshold post). Short sentence.
This framing lines up with Codex-centric UX asks that prioritize iteration latency (faster loops, fewer stalls) over pushing only for higher reasoning depth.
Conductor brings back Codex thinking levels control
Conductor (Codex UI): Conductor says it “brought back codex thinking levels,” showing a three-step selector—Basic, Advanced, Expert—in the [thinking levels clip](t:352|Thinking levels clip).

This is a concrete ergonomics knob for teams balancing latency vs depth during interactive coding sessions.
OpenAI starts public feedback intake for Codex 5.3
Codex (OpenAI): Sam Altman explicitly asks what’s working and what should improve in “5.3,” using a direct reply prompt to gather user feedback at scale, as shown in the [5.3 question](t:9|5.3 question). It’s a concrete signal that Codex 5.3 is being scoped with practitioner input rather than only internal benchmarks.
The request is broad (no specific features named), so it’s more “roadmap intake” than an announced change.
Codex can over-index on spec writing when prompted to “build the spec”
Codex (workflow pitfall): A practitioner reports that asking Codex to “Build the spec” resulted in ~20 minutes spent expanding spec markdown rather than writing code, as described in the [spec drift report](t:269|Spec drift report). Short sentence. It’s a reminder that “spec-first” prompts can accidentally become the goal, not the means.
The failure mode is less about correctness and more about objective misalignment: the agent optimizes for producing a better document because that’s the clearest completion target.
OpenAI leadership frames Codex progress as compounding
Codex (OpenAI): Sam Altman posts a cadence signal—“hard to imagine what it’s going to look like at the end of this year if things keep compounding,” as written in the [team execution note](t:7|Team execution note). It reads like an internal velocity update made public.
This is qualitative (no release details), but it aligns with broader “Codex is moving fast” framing seen elsewhere today.
DesignArena leak suggests how OpenAI models surface before release
DesignArena model IDs (OpenAI): A screenshot of DesignArena-style config shows GPT-5.2 (High) as “honeycomb” and GPT-5.2 (XHigh) as “candycane,” both pointing at gpt-5.2-2025-12-11, as shown in the [DesignArena config screenshot](t:100|DesignArena config screenshot).
The same post suggests future 5.x variants may appear there first, but today’s evidence is limited to 5.2’s already-known mapping.
Codex 5.2 hype starts showing user fatigue
Codex (adoption sentiment): A small but real counter-signal appears as one user says “everyone is telling me i need to try 5.2 codex. i’m tired,” in the [adoption fatigue post](t:188|Adoption fatigue post). Short sentence.
It’s not a product issue by itself, but it’s a reminder that “try the new model” churn can become a tax for power users when the evaluation burden shifts onto them.
🧩 Claude Code & Cowork friction points: limits, login, and “hype vs reality”
Today’s Claude discourse is mostly operational pain (rate limits, logins, freezes) and workflow tweaks, not new Claude product primitives. Excludes the Assistant Axis research (covered separately).
Claude Code account switching request targets multi-session usage limits
Claude Code (Anthropic): A power user asked for cross-session account propagation—when one Claude Code session hits the 5‑hour or weekly limit and you run /login in another session, every other in‑flight session on that machine should automatically switch over the next time it hits a limit, as described in the Account switching request. It’s framed around avoiding context loss and manual re-auth when running “10 agents going in the same project,” building on Account switching session-limit coping patterns.
• Session UX nits that compound at scale: The same request asks for shorter auth URLs (terminal clickability) and printing the session ID on exit for unambiguous resume, as spelled out in the Account switching request.
CodexBar 0.18 beta adds a pace indicator for Claude/Codex usage
CodexBar (steipete): Version 0.18.0-beta.1 ships a new “pace” display mode (percent, pace, or both) so you can see consumption rate at a glance, alongside a broad provider matrix (Codex, Claude, Cursor, Gemini, etc.), as announced in Beta announcement and documented in the release notes in Release notes. The menu UI shows session/weekly budgets and reset times, as shown in the Usage menu screenshot.
• Friction reduction: The beta also adds a checkbox to suppress repeated Keychain prompts, per the Beta announcement.
Claude Code freezing reports show up in Warp terminal workflows
Claude Code in Warp (Anthropic/Warp): A stability regression report says Claude Code has been freezing inside Warp “the last few days,” as noted in the Freeze report. No repro steps or fix are shared in the tweet.
Some Claude Code users are overriding search to load full files into context
Claude Code (Anthropic): A practitioner tip making the rounds is to explicitly instruct Claude Code “no searches” and to “load the entire files into your context,” positioned as a way to counter token-saving behavior changes, per the No-search prompt. The goal is more direct context at the cost of larger prompts.
A code review stance shift: review specs and tests, not generated diffs
Code review workflow: One argument gaining mindshare is that humans should review the design docs and test plan, but not line-by-line generated code, as stated in the Review stance. A follow-on analogy frames agent coding as a new medium—“don’t treat oil like fresco”—in the Medium analogy.
• Skill signal claim: The same thread cluster asserts that top manual coders remain top AI-assisted coders, per the Skill correlation.
Cursor friction on WSL drives some users back to VSCode despite agent coding
Cursor (Anysphere): A user paused Cursor due to a “90 second loading time on WSL,” multi-line edits failing, and UI clutter (sidebars/tabs), switching back to VSCode because “Claude is doing all the work,” according to the WSL Cursor complaints. The post frames editor responsiveness as the limiting factor once coding is agent-driven.
Claude Code hype vs reality becomes a visible sentiment thread
Claude Code sentiment: A blunt take—“Claude Code hype is out of control”—is circulating as an expectation-gap signal in the Hype comment. The post points at social momentum more than any specific new Claude feature.
Some builders report moving from coding to “requirements → inputs” work
Role shift with coding agents: One builder says they “haven’t written real code since Claude Code and Codex came out,” and that their main work is now translating business requirements into inputs the agents can execute, as described in the Role shift confession. This frames agent adoption as a shift in responsibility, not only speed.
Authentication friction is becoming a bottleneck for agent-heavy setups
Auth friction: “i’m so tired of logging into things,” per the Login fatigue. It’s another datapoint that account/auth flows are showing up as a limiting factor once people run many parallel agent sessions.
Power-user fatigue shows up around “try Codex 5.2” pressure
Codex vs Claude fatigue: A power user says “everyone is telling me i need to try 5.2 codex. i'm tired,” as posted in the Try 5.2 fatigue. It’s a small signal that constant model/tool churn is becoming its own workflow cost.
🛠️ IDE/harness wars: OpenCode, Cursor regressions, and builder platforms
Cluster of tool-specific UX and harness behavior: OpenCode memory handling, Cursor performance complaints, and app-builder platform features. Excludes Codex and Claude Code core storylines handled elsewhere.
OpenCode fixes long-session UI memory bloat caused by message retention bug
OpenCode (thdxr): A planned change to keep only the latest ~100 messages in long sessions accidentally retained most of the data, inflating memory usage; a fix is now in to remove the leftover retained parts, which is claimed to address “a bulk of the memory issues” in the app UI, per the Bug description. The author also clarifies this was “just a frontend thing,” not a change to what gets sent to the model, as noted in the Clarification.
This reads like a practical stability win for people running OpenCode as a long-lived harness rather than short chats.
Cursor on WSL complaints: 90-second load times and broken multi-line edits
Cursor (developer experience): A power-user report says Cursor is effectively unusable on WSL due to ~90-second loading time, broken multi-line edits, and UI churn (sidebars/tabs opening unexpectedly), leading them to switch back to VSCode, as described in the WSL complaints.
This is a harness-level reliability/latency story: once agents are doing most of the typing, IDE responsiveness and edit mechanics become the bottleneck.
SuperDesign adds “tree search” to fork AI design conversations and explore flows
SuperDesign tree search (SuperDesign): SuperDesign introduced a “tree search” workflow for AI-driven design—forking conversations, carrying forward relevant context, and iterating across multiple branches, as described in the Feature intro and expanded in the Tree search explainer.

• Flow output: The thread also claims end-to-end UX flow generation with “ultra visual consistency” and auto-linked/annotated pages, per the Flow generation note.
• Skill packaging direction: The author floats turning this into a Claude Code design skill if the thread hits 1000 likes, as noted in the Skill idea.
There’s also a reliability complaint that the “Claude code plugin is… buggy,” per the Bug report, so treat the integration surface as still settling.
Lovable adds public profiles for publishing projects and gaining followers
Lovable (Lovable): Lovable added public profiles—username, profile photo, cover image—plus the ability to publish projects, share what you’re building, and get followers, per the Feature announcement.
This is a distribution primitive for AI-built apps: the platform is turning “project output” into a social surface, which can change what builders optimize for (sharable demos and rapid iteration) more than any single model upgrade.
OpenCode TUI praised as “high taste,” but curl-to-bash install feels slow
OpenCode (community UX): Geoffrey Huntley calls OpenCode “HIGH taste” and says it’s “a better TUI than Amp,” framing this as a UI/ergonomics differentiator among coding harnesses, as said in the Taste take. That praise is paired with a concrete friction report: the curl-to-bash installer is “slow af” even from a bare-metal AU datacenter with a 10Gb link, per the Installer latency note.
The signal here is that harness evaluation is increasingly about day-to-day interaction cost (install + TUI feel), not model quality alone.
Replit Design Mode ranks #1 on DesignArena’s app-builder leaderboard
Replit Design Mode (Replit): Replit’s Design Mode is shown at #1 on DesignArena’s Builder Arena leaderboard, as highlighted in the Leaderboard repost and reinforced by the Replit share (with the underlying list available via the Leaderboard page).
The relevance for engineers is competitive positioning: design-to-app generators are increasingly compared as tools, not demos, and these public rankings influence which builder platforms teams trial first.
Factory announces NYC office expansion and hiring for sales/CS/solutions engineering
Factory (FactoryAI): Factory is opening an office in New York City as an East Coast customer hub and says it’s hiring across sales, customer success, and solutions engineering, per the NYC office announcement.
This is a GTM scaling signal from an agentic dev tooling vendor: it suggests rising enterprise pull for “orchestrate AIs” style products, not only model endpoints.
🧑✈️ Running agent fleets: orchestration dashboards, Ralph loops, and remote execution
Operators are assembling multi-agent stacks: dashboards, work queues, remote VMs, and loop-based “ship terminals”. This is about running agents at scale (not SDK design).
ntm swarm management pattern adds a controller hierarchy for dozens of agents
ntm (Agent Flywheel): One new run describes an “empire” of 39 worker agents across 13 projects, plus 13 middle-manager bots, extending Orchestrator demo (multi-agent tmux orchestration) with a more explicit control hierarchy, as described in the Empire scale note and the longer Screen recording narrative. It’s a control-plane pattern. The number is the point.

The writeup also emphasizes “agent-first tooling,” with the controller agent using tooling to command other agents and then feeding reflections back into improving the tool itself, as described in the Screen recording narrative. The Agent Flywheel site is referenced in Agent Flywheel site.
Vibe Kanban open-sources a dashboard to orchestrate multiple coding agents
Vibe Kanban (BloopAI): A new open-source UI orchestrates multiple coding agents in parallel, letting you switch between Claude Code, Codex, and Gemini CLI while tracking task status in one place, as described in the Launch thread. It’s a coordination surface. That’s the point.

The repo is published as a GitHub repo in GitHub repo, and the pitch is that a single “board” reduces context-switching overhead when you’re running multiple agent sessions concurrently, as shown in the Launch thread.
BLACKBOX launches an Agents API to run multiple SWE agents on remote VMs
Agents API (BLACKBOX): BLACKBOX is pitching a single API that can run multiple coding agents (Claude Code, Codex, Gemini) on remote VMs and dispatch the same task to several agents, then pick an output via a “chairman” selector, as described in the API launch image. This is an operational move. It’s about managing remote execution and comparing agent outputs, not writing new prompts.
The public claim centers on multi-agent execution (“dispatch the same task to multiple agents at once”) and an aggregation step, per the API launch image.
Plan sync, implement async: align fast then hand off to cloud agents with validation envs
Agent handoff hygiene: A practitioner pattern that’s getting repeated is “plan sync, implement async”: quickly align on a plan, then hand off execution to a cloud agent, and keep separate validation environments so the agent can check its own changes, as described in the Plan then async execution note. It’s an ops pattern. It shifts the bottleneck to planning and verification.
The validation-environment step is explicitly framed as a way to reduce regressions by having the agent re-run checks against its own diffs, per the Plan then async execution note.
Wreckit 1.0.0 ships a TUI for running Ralph Wiggum loops over a roadmap
Wreckit 1.0.0 (mikehostetler): Wreckit is now tagged at 1.0.0 as a TUI for running “Ralph Wiggum loops” over a roadmap using file-based state, positioned as a way to monitor progress and coach a team through research → plan → implement loops, per the 1.0.0 announcement. It’s an ops wrapper around agent loops. Not an SDK.
The GitHub repo is linked directly in GitHub repo, and the author keeps reinforcing the “loop terminal” framing in follow-ups like the Repo pointer.
Athas IDE prototypes a tab view to open new agents and browser tabs inside the editor
Athas IDE (athasdev): Athas is prototyping a “new tab view” that can open new agents and browser tabs inside the IDE, plus custom terminal actions, as shown in the New tab view demo. This is agent ops UX, not an IDE theme.

The stated next step is deeper browser instrumentation (console output, network requests, cache, localStorage), as described in the Browser introspection goal.
Conductor shows DAU growth while hiring for orchestration UI roles
Conductor (conductor_build): Conductor is hiring while posting a DAU chart that visibly inflects upward into January 2026, framing “interfaces to orchestrate AIs” as the product category, as shown in the Hiring and DAU chart. This is a traction signal. It suggests orchestration UIs are moving from side project to product.
A separate clip shows how they use Conductor to test and review changes on a fix from a recent release, per the Internal workflow demo.
Sandbox-maximalist thesis: classic Unix VMs as the substrate for agent loops
Sandbox maximalism: A compact thesis argues that the practical “formula” for powerful agents is pairing high-capability models with classic Unix VMs, and that infra vendors will reorganize around making that interaction efficient, as stated in the Sandbox maximalist take. The bet is on VMs as the stable execution substrate. Not frameworks.
This lines up with the steady rise of workflows that treat agents as long-running processes operating in sandboxes, rather than short chat completions, per the Sandbox maximalist take.
Slack as a control plane for long-running role-based Claude Code agents
Persistent agent workforce UX: A concrete ops request is circulating for a Slack workspace “filled with long-running Claude code agents,” where each agent has a role, monitors channels, emits progress updates, and can be dispatched by humans inside the same chat context, as outlined in the Slack agent fleet request. This frames Slack as the runtime UI for agent fleets. It’s a staffing metaphor.
The core mechanism is continuous background work plus status emissions, which is the missing layer in many CLI-first agent setups, per the Slack agent fleet request.
Compute literacy framing: running swarms shifts the job to oversight and context injection hooks
Compute literacy: A “compute literacy” framing argues the limiting factor for democratized agent swarms isn’t capacity but operator skill, with the author describing a personal arc of 8 years to reach that conclusion, as stated in the Compute literacy claim. It’s a management claim. It frames orchestration as a literacy problem.
A related note calls for hooks that inject specific context into running swarms, pointing to an essay in Essay on oversight, and the role shift (“Chief Tribe Officer” to “self driving”) is described in the Role shift note.
🧰 Developer-side tooling around agents: menubar, CLIs, and doc ingestion hacks
Tools that support agent workflows but aren’t the assistants themselves: usage monitors, shell helpers, and document conversion/ingestion utilities. Excludes orchestration dashboards (agent-ops-swarms).
CodexBar 0.18.0-beta.1 adds pace view and expands provider support
CodexBar (steipete): Following up on Limits tracking, CodexBar 0.18.0-beta.1 merges “~30 PRs” and adds a new pace indicator mode so you can see usage velocity at a glance, as shown in the menu screenshot and the beta announcement.
• Provider surface area: The beta broadens supported providers (Codex/Claude/Cursor/OpenCode/Gemini/Copilot plus many others), with additional provider source controls and config/CLI revamps called out in the beta announcement.
• Paper-cut fixes: It ships a “don’t ever show me keychain alerts” checkbox (macOS painkiller) per the beta announcement, which matters if you run multiple provider credentials locally.
The release notes enumerate the new menu display modes and provider additions in the release notes.
parseout CLI batch converts PDFs to markdown for Claude Cowork ingestion
parseout (jerryjliu0): A small CLI wrapper batch converts PDFs into Markdown so Cowork can reliably read large doc sets; the claim is faster, more accurate extraction on tables/visual layouts after conversion, shown in the demo clip.

The repo is published as the GitHub repo, and the workflow is framed as “PDFs → markdown folder → point Cowork at it” in the demo post.
RepoPrompt teases /rp-review for context-builder-based PR review
RepoPrompt (pvncher): A “context builder powered review system” is being built around a new /rp-review flow, positioning review as an artifact-generation step rather than ad-hoc chat, per the feature teaser and the review-mode screenshot.
The same thread shows an internal loop where review is used to improve review tooling (“use review mode to improve review mode”), which hints at an agent-first workflow: build context → critique diffs → feed back into implementation, as described in the review-mode screenshot.
Transition-matrix visualizations for summarizing agent traces and failures
Agent trace analysis (Hamel Husain): A practical visualization pattern uses transition matrices to compress messy agent traces into human-readable failure/hand-off structure (e.g., separating “failure within node” vs “failure at handoff”), as explained in the visualization tip.
This frames trace review as “interpretability for operators,” emphasizing readability over raw logs—see the visualization tip and the follow-up pointer to iterate in notebooks in the flashcards post.
TanStack AI teaser shows model spend “what-if” cost comparison UI
TanStack AI (AlemTuzlak): A teaser shows a cost analytics UI that compares “actual spend” vs “what-if” model choices, including a computed savings line like “save up to $0.0826 (90.8%) by switching to gpt-4o-mini,” as shown in the cost comparison screenshot.
A second view plots cost over time per model, implying time-series cost attribution rather than one-off totals, as shown in the cost over time plot.
Trimmy flattens multiline shell snippets and reformats markdown for clean pastes
Trimmy (steipete): A new menu-bar helper turns multi-line shell snippets into runnable one-liners (removing newlines/spaces) and can also trim/reformat Markdown so pastes into GitHub reviews look clean, as described in the tool announcement.
This is aimed at the recurring “copy from chat → terminal/PR” friction that shows up in agent-heavy workflows, where commands and review notes often get mangled when pasted across apps, per the tool announcement.
Vibe Browse exports browser sessions into OpenAI/Anthropic fine-tuning format
Vibe Browse (Hyperbrowser): An open-source “conversational browser automation agent” can export recorded browser sessions as OpenAI/Anthropic fine-tuning JSON format, positioning browsing traces as training data, per the product demo.

The code is available in the GitHub repo, with the feature list (navigate/type/extract, then export) summarized in the product demo and the follow-up repo pointer in the repo post.
lane: small open-source CLI utility published by benhylak
lane (benhylak): A small CLI utility was published as a personal dev tool, with the project linked in the CLI post and hosted at the GitHub repo.
The tweets don’t specify functionality beyond “a little cli,” so impact and use cases aren’t yet clear from the CLI post.
🧭 How teams are actually shipping with agents: context, specs, and “vibe” failure modes
Hands-on patterns for using coding agents: plan/execute loops, context shaping, and warnings about brittle vibe-coded apps. Excludes specific assistant product updates.
Vibe-coded apps can feel stable but behave brittle in the “boring” parts
Vibe coding (workflow): A recurring failure mode is that agent-built apps pass the primary demo path but accumulate subtle UI/logic weirdness (“the 4th dropdown item is selected always”), because low-glamour details get less review and LLMs tend to brute-force overly complex solutions that are fragile under unrelated changes, as described in the Brittle vibe-coded apps and clarified in the Bugs made impossible note.
The core claim is structural: “good programming” often means designing invariants so certain bugs can’t happen, and that’s exactly where today’s LLM-driven implementations are weakest.
Model swapping isn’t free: prompts and harnesses co-evolve with the model
Harness non-fungibility (workflow): A repeated observation is that “swapping models” usually requires swapping a lot more than the model ID—prompt structures, tool descriptions, auto-context behavior, and guardrails co-adapt to each model; the thread argues fewer choices can be a product feature if it enables deeper, model-specific optimization, as laid out in the Harness co-evolution note.
This pushes against the default “dropdown of models” UX when teams are actually shipping.
Plan sync, implement async: treat planning as the high-bandwidth step
Agent handoff (workflow): A practical pattern is to do tight, synchronous alignment on a plan, then hand execution to a long-running cloud agent; the same thread also calls out creating validation environments so the agent can check its own changes rather than relying on human spot-checking, per the Plan sync implement async tip.
This is framed as a confidence transfer: better shared plan → safer delegation → fewer “what’s next?” interrupts.
Software engineering shifts from syntax to turning ambiguity into clarity
Software engineering (role): Multiple posts converge on the idea that the core work is moving from syntax trivia to turning ambiguity into clarity, designing context that makes good outcomes likely, and judging what matters; this framing appears in the Ambiguity to clarity and is reinforced by the Syntax trivia quote and a concrete role-shift example in the Requirements to inputs confession.
This is less “everyone becomes a programmer” and more “programming becomes a higher-level production role.”
The wait equation: some software work was worth delaying until agents matured
Timing strategy (workflow): A concrete update on the “wait calculation” argument is that many projects would have been better off waiting for today’s agentic coding capabilities—paired with the broader claim that similar “wait” logic may apply across coding, agents, and video, as stated in the Wait equation claim and expanded in the Wait calculation essay.
The open question is how teams decide which work compounds now versus gets obsoleted by near-term model/tool improvements.
“Don’t treat oil like fresco”: agent coding as a new medium
Habits shift (workflow): An analogy frames agentic coding as a new medium (oil paint vs fresco): teams that keep old constraints and rituals will underuse it, while new “masters” will develop different practices; this sits alongside the more operational claim that review effort shifts toward design docs and test plans rather than line-by-line code review, per the Oil painting analogy and the Review focus shift.
The underlying point is organizational: correctness moves upstream into specs and verification.
Speed may matter more than extra intelligence for most “in-the-loop” coding
Speed vs. intelligence (workflow): A concrete thesis is that for synchronous, interactive coding, most queries will stop benefiting much from smarter models once a high-enough quality bar is reached (>95% not meaningfully improved); beyond that point, gains come from speed, while extra intelligence matters mainly for longer async tasks, per the Diminishing returns thesis.
The example given is UI/layout work where the bottleneck becomes user intent, not model reasoning depth.
Thinking-token overhead is the current tax on production-grade codegen
Cost structure (agents): One claim quantifies today’s “reasoning overhead” as ~100–1,000 thinking tokens per 1 production-grade code token, with an expectation that both token prices and the thinking-to-output ratio will drop sharply over ~2 years, as stated in the Thinking token ratio and echoed in the Cost collapse prediction.
Treat it as directional until backed by a shared benchmark, but it matches the broader push toward faster, lower-latency coding loops.
Why some dev workflows break with coding agents: nbdev as a case study
Tooling fit (workflow): A practitioner write-up argues that nbdev’s notebook-centric workflow now creates friction with AI coding tools trained on conventional source layouts, leading to a “fighting the AI” dynamic; the post reframes the trade-off as collaboration/compatibility with agents becoming a primary constraint, as described in the nbdev exit note and detailed in the Blog post.
It’s a reminder that agent effectiveness is partly shaped by how “standard” your repo structure is.
🖥️ Computer-use agents & MCP surface area expands (Notion, Comet, xAI)
UI-control agents and MCP-like integration surfaces are the theme: Notion Agents features, browser “act for me” controls, and “human emulator” narratives. Excludes coding-assistant-only discussion.
Notion Agents tests custom MCPs, connectors, and computer-use automation
Notion Agents (Notion): A TestingCatalog leak claims Notion is building a bigger “Agents” surface area—custom MCP support, custom connectors/workers, and “computer use” (agents taking actions in software) alongside integrations like Linear and Ramp, as described in the Notion Agents leak clip and expanded in the feature scoop feature scoop. This matters because it points to Notion positioning itself as an orchestration layer where agents can both read context (docs, mail, calendar) and execute UI actions.

• Integration shape: The same leak mentions Notion Mail/Calendar triggers for agents and a library/feed UX for agent assets, per the Notion Agents leak clip.
The claims are feature-forward but still pre-release; no GA date or API contract details show up in the tweets.
Comet browser rolls out “Act for me” screen takeover in the sidebar
Comet (Perplexity): Comet shipped an “Act for me” button in the sidebar that explicitly grants permission for the browser to take over the screen and execute the requested task, as shown in the screen takeover demo. For engineers, the key point is the productized permission UX: it’s a first-class “computer use” affordance (not a hidden agent mode) and it’s embedded in the primary browsing surface.

• Operational implication: This style of automation tends to shift risk from model capability to guardrails (what pages/actions are allowed, and how to recover from misclicks), but those constraints aren’t described in the clip.
X confirms work on a promptable ranking algorithm
X (X/Twitter): Elon Musk replied “We’re working on it” to a request for a promptable X algorithm—i.e., users specifying feed constraints like “no politics today,” as shown in the promptable feed confirmation. For analysts, this is a direct statement that ranking control may become an end-user prompt interface rather than a fixed recommender policy.
This is confirmation of intent, not a spec: the tweets don’t mention rollout timing, prompt scope (topics vs sources), or whether it’s enforced client-side or server-side.
xAI pitches “human emulators” as software-agnostic UI automation
xAI (xAI): A reported internal framing says xAI is building “human emulators”—bots that perform on-screen tasks using the same keyboard/mouse/visual cues a person would, requiring “zero changes” to existing software, as described in the human emulator clip. The tweet also frames scaling as mostly infra, claiming the path from “a thousand to a million digital workers” is not a research hurdle, per the same human emulator clip.

The concept is consistent with the broader computer-use trend, but the tweets don’t include concrete evals, safety constraints, or deployment details.
Google Stitch may add PRD generation and API key-based usage
Stitch (Google): A TestingCatalog report says Stitch is working on a “Generate PRD” feature that turns designs into a product requirements document plus a prototype, and that API key-based usage is coming to Stitch, as described in the Stitch PRD leak with more context in the full scoop feature scoop. The practical implication is a tighter design→spec pipeline, where the artifact produced is a PRD (not just UI code) and usage may become account/key-scoped.
The tweets don’t show pricing, schema output format, or how Stitch would source constraints (analytics, roadmap, codebase) into the PRD.
Demand grows for Gemini to take actions on phones
Mobile computer-use expectation: A recurring user demand is that Gemini should be able to “control and take actions on the phone,” rather than staying a chat-only interface, as captured in the phone control request. This matters as a signal: builders are starting to treat “assistant” as synonymous with end-to-end action execution on personal devices.
The tweet doesn’t point to an announced feature—just the expectation that agentic UI control should be native on mobile.
✅ Correctness pressure: testing, review strategy, and “deslop” loops
Tweets focused on keeping agent-generated code mergeable: what to review, how to test, and why “happy-path” output needs a quality discipline layer.
Codex feature request: default test strategy that detects missing coverage
Codex (OpenAI): A concrete correctness ask is to make Codex generate a stronger default test plan—detect missing coverage and add integration/smoke/regression tests without heavy prompting—because many teams are already splitting “implementation” and “review” work across different models and passes, as laid out in the Wishlist thread.
This is presented as a product-level gap (not a prompting trick): the request is for Codex to proactively produce the safety net that keeps agent-written code mergeable.
LLM judges: verify against human labels; Likert scales are hard to act on
LLM-as-judge (Evals discipline): A recurring caution is that “shipping an unverified LLM judge” is a reliability risk, and that verification should look like classic ML testing against human labels, as stated in the Judge verification note.
The same thread of advice discourages Likert-scale judging because it’s expensive to align and yields feedback that’s hard to convert into concrete fixes, as echoed in the Likert scale caution.
PR review habit: fast high-signal findings, almost never merge untouched
PR review (Clawdbot/agent-assisted workflow): A high-volume reviewer reports merging fewer than 10 of 1,000+ PRs without changes, and shares a “how I start pretty much every PR review” template that quickly surfaces SSRF, MIME parsing, and streaming lifecycle issues before deeper iteration, as captured in the Review notes example.
The core move is turning review into a structured findings list early, then iterating—rather than commenting ad hoc inline.
Terminal Bench 2: higher reasoning beats xhigh because timeouts dominate
Terminal Bench 2 (ValsAI): Under strict per-task time limits, GPT-5.2 “high” reasoning reportedly outperforms “xhigh” (52.8% vs 46.3%) because xhigh spends too long per turn (including >15 minutes for a single response), increasing agent-level timeouts, as described in the Benchmark result and detailed in the Timeout explanation.
The setup and reproducibility details—including 5 runs per model and a Harbor+Daytona command line—are spelled out in the Repro command.
Vibe-coded apps fail in small ways because LLMs miss structural invariants
Vibe coding (Quality drift): Multiple posts converge on the same failure mode: LLMs satisfy the primary task but don’t structure systems so certain bugs are impossible, leading to “small stuff half breaking” and brittle behavior changes after unrelated edits, as described in the Brittleness report and clarified in the Bugs impossible framing.
A separate diagram frames this as “happy-path only” output that later hits a manual “deslop” wall of review and audits, as shown in the Happy-path diagram.
Conductor shows a test-and-review loop used for its own releases
Conductor (Conductor): A screen-recorded workflow shows how the team tests and reviews a fix from the latest release while using Conductor to build Conductor, with the loop centered on running tests and inspecting changes rather than “chatting about code,” as demonstrated in the Testing and review demo.

This is one of the clearer public examples today of “agent output → automated verification → human review” being treated as the default shipping loop.
Plan sync then implement async; use validation environments for self-checks
Agent workflow (Correctness loop): A practical correctness pattern is to align quickly on a plan, then hand off implementation to a (cloud) agent asynchronously, while also creating validation environments so the agent can check its own changes rather than relying on post-hoc human spotting, as described in the Plan sync tip.
This frames correctness as a first-class environment + workflow concern, not a prompt tweak.
RepoPrompt uses context-builder artifacts to drive review and refactor loops
RepoPrompt (RepoPrompt): An emerging “deslop” loop is to use a context-builder artifact in review mode to analyze changes since the last dev cycle, identify redundancies/complexity, then switch to build mode to implement the refactor—shown in the Review mode prompt and previewed as “/rp-review coming soon” in the Side quest note.
The emphasis is on review as an artifact-driven analysis step, not ad-hoc diff skimming.
Second self-hosted GitHub Actions runner to keep CI ahead of agents
CI throughput (GitHub Actions): One practitioner response to faster agent loops is scaling the verification layer—adding a second self-hosted GitHub Actions runner so jobs run in parallel and finish sooner, as shown in the Runner list screenshot.
The implied shift is that CI becomes the pacing constraint once code is cheap to produce.
Transition matrices as a compact way to summarize agent trace failure modes
Agent trace debugging (Evals UX): Transition-matrix visualizations are pitched as a way to tame messy agent traces while staying interpretable to humans—supporting metrics like failure-within-node vs failure-at-handoff—per the Transition matrix tip.
The emphasis is not on a single scalar score; it’s on a representation that makes failure clusters legible enough to drive targeted fixes.
🧱 Agent SDKs and frameworks: memory hierarchies, RLMs, and lightweight orchestration
Libraries/SDKs for building agents: memory abstractions, recursive prompting strategies, and frameworks aimed at reducing orchestration overhead. Excludes fleet ops tools (agent-ops-swarms).
DSPy lands dspy.RLM module for recursive long-context inference
DSPy (stanfordnlp/dspy): The DSPy repo now includes a dspy.RLM module, positioning Recursive Language Models as an inference strategy where the LLM writes Python to inspect/decompose long contexts and recursively call sub-LLMs, as shown in the RLM source file.
• Interface shape: Example usage keeps it “module-like” (e.g., dspy.RLM("context, query -> output", max_iterations=10)), as shown in the Usage snippet.
• Implementation clue: The source references treating long context as an external environment and routing via a Python interpreter abstraction, as shown in the RLM source file.
This is a concrete step toward making RLM-style long-context handling composable inside existing DSPy pipelines, per the Release RT.
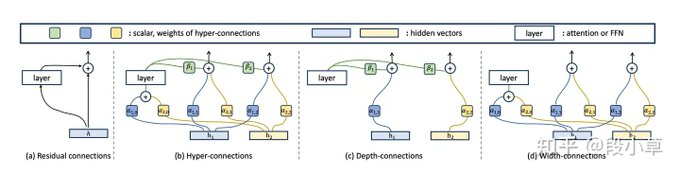
DeepSeek Engram and mHC framed as “conditional memory” and “stable widening”
DeepSeek Engram + mHC (ZhihuFrontier): A ZhihuFrontier thread connects two lines of efficiency work—“Over-Encoding” (Seed/ByteDance) as scaling via large N-gram-like embedding tables, and DeepSeek’s Engram as conditional memory that activates lookups based on the current hidden state, while contrasting Hyper-Connections (HC) with DeepSeek’s manifold-constrained HC (mHC) for stability, as described in the Long-form breakdown.
• Compute/overhead claim: The writeup asserts DeepSeek built custom CUDA kernels to keep mHC overhead to “~7%,” as described in the Long-form breakdown.
• Cost placement argument: It explicitly frames Engram as shifting memory to cheaper tiers (“can live in CPU RAM, not GPU HBM”), as described in the Long-form breakdown.
This is commentary, not a release note; the value is in how it decomposes “parameter scaling” into topology choices and memory placement, per the Long-form breakdown.
StirrupJS ships a TypeScript agent framework with MCP, sandboxes, and provider flexibility
StirrupJS (Artificial Analysis): A TypeScript port of Stirrup has been announced as a lightweight agent framework that tries to avoid “over-scaffolded” workflows; it ships with built-in tool primitives (web browsing, MCP integration, code execution) and multi-provider support, as described in the Launch post.

• Execution surfaces: Code execution is positioned as first-class across local, Docker, and e2b sandboxes, as shown in the Launch post.
• Agent loop controls: The usage example explicitly exposes a turn budget (e.g., maxTurns: 15) and bundles a default tool set, as shown in the Launch post.
The framing is opinionated: give the model room to choose tactics, but keep the minimum structure needed for tool use and context management, per the Design intent note.
CopilotKit demo shows LangGraph tool orchestration with live UI state and HITL
CopilotKit + AG-UI (pattern): CopilotKit shared a “Scene Creator Copilot” demo combining LangGraph for multi-step tool orchestration, Google’s “Nano Banana” for reasoning/image generation, and AG-UI for live UI state sync and human-in-the-loop checkpoints, as described in the Demo breakdown.

The post frames this as a reusable in-app pattern: agents call tools, manage shared state, produce rich artifacts (images/scenes), and pause for approval before actions, per the Demo breakdown and the linked GitHub repo.
Letta publishes a practical “context hierarchy” for agent memory and files
Context hierarchy (Letta): Letta published a guide that separates “what goes in the prompt” from durable/contextual stores (memory blocks, files, archival memory, external RAG), aiming to reduce confusion and context-window thrash, as laid out in the Context hierarchy guide.
• Concrete limits as design guidance: The doc proposes memory blocks for smaller persistent facts (e.g., “<50,000 characters” and “20 blocks per agent”), files for larger read-only docs (“up to 5MB” and “~100 files per agent”), and archival memory as a low-token store (“300 tokens”), as described in the Context hierarchy guide.
• Operational takeaway: It frames external RAG as the scale-out path (“millions of documents”) rather than something to reach for first, as described in the Docs summary.
It’s framed as a prioritization system for limited context windows, not a new memory mechanism, per the Docs summary.
MiniMax showcases Recursive Language Models for processing very long prompts
Recursive Language Models (MiniMax): MiniMax is promoting RLMs as a practical way to handle extremely long inputs by turning “long context” into an external environment the model can traverse (rather than stuffing everything into the window), as shown in the RLM demo post.

The pitch here is less about raw context length and more about a strategy for decomposing and re-calling over snippets; the demo is the clearest artifact today, and it’s presented as an agentic capability (long inputs + iterative processing) per the RLM demo post.
📊 Evals & leaderboards: what’s moving, what’s timing out, what’s misleading
Model ranking volatility and eval methodology debates: code vs text rank shifts, strict time-budget effects, and new “human baseline” style benchmarks. Excludes GLM-4.7-Flash benchmark coverage (feature).
LMArena rank shifts expose big Text vs Code divergence
LMArena (rank volatility): A new comparison of Text Arena rank vs Code Arena rank shows large task-dependent swings—most notably Grok 4.1 dropping ~29 places when you look at coding, while MiniMax M2.1 rises ~19, as summarized in the rank-shift analysis Rank shift chart summary and echoed in the arena breakdown Rank shift examples.
• What’s moving: The same post calls out other upward shifts in Code vs Text for GPT-5.2, GLM 4.7, DeepSeek v3.2, and MiMo v2 Flash, while other models fall—see the rank shift list Rank shift examples.
• Why it matters: The plot is a reminder that “best model” depends on the job; the sharpest shifts show up when you switch evaluation from general chat to tool-using coding tasks, as shown in the rank shift chart summary Rank shift chart summary.
Terminal Bench 2 shows higher reasoning can underperform from timeouts
Terminal Bench 2 (ValsAI): Under strict per-task time limits, GPT‑5.2 high reasoning scored 52.8% vs 46.3% for xhigh because xhigh spends too long per turn and hits overall agent timeouts more often, per the benchmark writeup Timeout explanation.
• What’s “misleading” here: The team reports >15 minutes for a single model response in some trajectories—so more “thinking” can reduce completion rate when the eval enforces hard wall-clock budgets, as explained in the time-limit note Time limit details.
• Repro details: They ran each model 5× and shared a Harbor+Daytona command line (including --ak reasoning_effort=xhigh/high) in the repro command Harbor command line.
This is an eval where “latency per step” is part of capability, not a footnote.
BabyVision benchmark targets visual reasoning without language crutches
BabyVision (visual reasoning benchmark): A new benchmark aims to measure “pure visual reasoning” (minimizing world-knowledge and language shortcuts); one cited result has Gemini 3 Pro Preview at 49.7, below an “average adult” score of 94.1, per the benchmark callout Score claim and the discussion thread Human baselines summary.
• Human baselines are the point: Posts emphasize that even young children (e.g., 6-year-olds) score materially higher ("65%+") than top models today, as summarized in the benchmark discussion Human baselines summary.
• Where to read it: The paper is linked as the ArXiv paper via ArXiv paper.
This is another example of evals separating “reasoning tokens” from actual perception competence.
GDPval long-task curve updated: GPT-5.2 Pro vs GPT-5 baseline
GDPval (long-horizon work eval): Ethan Mollick updated GDPval’s Figure 7 using GPT‑5.2 Pro, claiming the earlier GPT‑5 “win rate” against human experts (~39%) is now closer to ~72% for GPT‑5.2 on long-form tasks, as described in the chart update Figure 7 update and anchored by the prior win-rate numbers Baseline win rate claim.
• Eval framing: The update assumes a workflow of delegating a long task to the model, spending ~1 hour evaluating the output, then retrying or doing it yourself—see the process description Figure 7 update.
• Primary artifact: The underlying benchmark paper is linked as the ArXiv paper via ArXiv paper.
Treat the numbers as directional until the updated plot and methodology are fully versioned, but the claim is explicitly about long-task completion under a “human-in-the-loop review” budget.
ARC Prize 2025 report: top score 24% with $0.20 per task
ARC Prize (benchmark report): The ARC Prize 2025 technical report cites 1.5K teams, 15K entries, and a top score of 24% at roughly $0.20/task, with “refinement loops” improving results but “knowledge coverage” still limiting performance, per the report summary Report stats.
• Primary source: The full results are available on the competition page via Competition page, as referenced in the results link post Results link.
The report is unusually specific about both participation scale and marginal cost per solved task, which is what most eval writeups omit.
DesignArena: Replit Design Mode takes #1 in Builder Arena
DesignArena (Builder Arena): A screenshot of the Builder Arena leaderboard shows Replit (Design Mode) ranked #1 with an Elo-like score of 1261, edging out “Anything” (1258) and “Lovable” (1249), as shown in the leaderboard screenshot Leaderboard screenshot.
• Where the ranking lives: The live board is linked on the leaderboard page via Leaderboard page, surfaced from the Replit repost Leaderboard repost.
This is a narrow eval (design/build UX), but it’s becoming a procurement signal for “AI app builders” outside classic IDE workflows.
Wan 2.5-i2i-preview shows up at #21 on the Image Edit leaderboard
Image Edit leaderboard (arena): The model Wan 2.5‑i2i‑preview landed at #21 with a score of 1213, per the ranking announcement Leaderboard result.
• Where to compare: The broader Image Edit standings are linked on the image modality leaderboard via Image edit leaderboard, as shared in the follow-up link Leaderboard link.
The tweet doesn’t include methodology details (prompt set, judge model, or human voting mix), so treat it as a directional placement rather than a definitive capability claim.
🏗️ Compute & energy constraints: canceled data centers, gigawatt claims, and grid reality checks
Infra signals dominate: data center project cancellations, energy bottlenecks, and audits of large AI sites. Excludes model-release integration details (feature).
Epoch AI says xAI Colossus 2 won’t reach 1GW until May
Colossus 2 (Epoch AI / xAI): Epoch AI reports that Colossus 2 is running but likely won’t reach 1 GW of power until May, contradicting earlier public expectations—following up on 1GW claim, the prior “1 GW” narrative—according to the site analysis update. It also argues the facility lacks cooling capacity to operate 550,000 Blackwell GPUs at full power, even under winter conditions, per the same site analysis.
• Method and evidence: The team says it’s using satellite imagery and permit analysis, and it points readers to its public explorer, as linked from the satellite tools note post via the satellite explorer.
The operational takeaway is that “headline GPU count” claims may be decoupled from sustained power/cooling readiness, and the bottleneck can be non-GPU infrastructure.
Data center cancellations jump to 41 projects in six weeks
Energy and build-out (MacroEdge): A chart circulating in dev circles claims 41 data center projects were canceled in the last six weeks, versus 15 cancellations from June–November 2025, as highlighted in the cancellation post.
The same thread frames this as a plausible brake on brute-force scaling and as a renewed argument for algorithmic gains, per the cancellation post commentary.
China’s power surplus becomes a core AI constraint narrative
Energy as AI bottleneck (China vs US/EU): A widely shared chart claims China now generates ~40% more electricity than the US and EU combined, with the post arguing that energy—not chips—will be the hardest constraint for AI scale-out, as stated in the electricity comparison thread.
The same post ties this to inference-heavy diffusion: lots of “good-enough” deployments depend on grid slack more than frontier training runs, per the framing in electricity comparison.
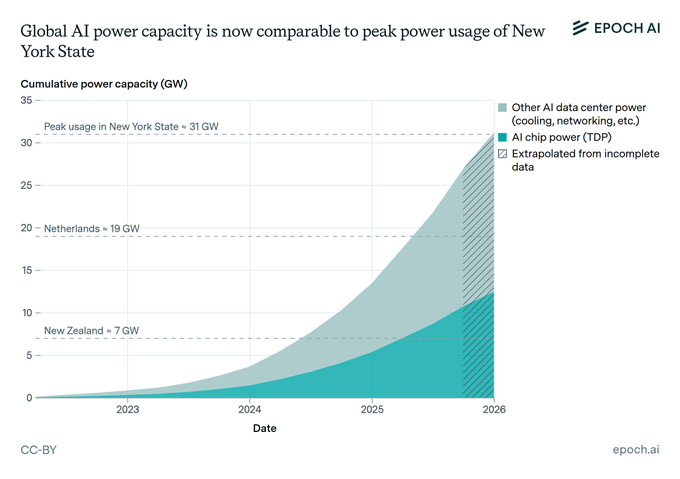
Epoch AI estimates global AI power capacity at New York heatwave scale
Global AI power (Epoch AI): An updated framing—following up on 31GW chart, the earlier “near NY peak” estimate—states AI data centers are now drawing power comparable to New York State peak usage (~31 GW), with the estimate derived from AI chip sales and a 2.5× multiplier to account for cooling/servers/networking, as described in the power estimate post.
This methodology detail matters because it makes the “AI power” number sensitive to assumed overhead, not just accelerator TDP, per the explanation in power estimate.
A “1 GW ≈ $10B revenue” heuristic gets used to project OpenAI growth
Compute economics (OpenAI): A back-of-envelope model uses an asserted heuristic—“1 GW = $10B of revenue”—to roll forward OpenAI revenue projections using Epoch AI compute estimates, as described in the projection note thread.
To anchor the underlying compute/revenue linkage, a separate recap shares bar charts showing compute rising from 0.2 GW (2023) to 1.9 GW (2025E) while annualized revenue rises from $2B to $20B (2025E) in the metrics recap visual.
This is a modeling shortcut rather than an audited financial identity; the thread treats the ratio as a rule-of-thumb, per projection note.
Google Search begins routing tougher AI Overviews to Gemini 3 Pro
AI Overviews routing (Google Search): Google is now using Gemini 3 Pro to power AI Overviews for “more complex topics,” while continuing to route simpler queries to faster models—an explicit capacity/latency tradeoff described in the Search routing note screenshot.
The rollout described is global in English and appears limited to Google AI Pro & Ultra subscribers, per the same Search routing note.
A 7 GW flaring claim gets pulled into the data center debate
Grid politics vs build-out: A repost claims Canada flares off ~7 GW (framed as wasted energy) and uses it to argue that anti–data center rhetoric ignores available power, as asserted in the gas flaring claim post.
The tweet provides a single number and a narrative hook but not the underlying dataset in the captured snippet, so treat the claim as an anecdotal signal rather than a verified capacity metric.
🎭 Model persona control: Anthropic’s “Assistant Axis” and activation capping
High-signal interpretability/safety thread: Anthropic maps a “persona space” and shows a single activation direction correlates with Assistant-like behavior; capping along the axis reduces harmful drift while preserving capability.
Activation capping: persona-jailbreak and harmful-response reduction with minimal capability loss
Activation capping (Anthropic): Anthropic reports a deployment-style intervention that constrains activations along the Assistant Axis (“activation capping”), reducing harmful responses while keeping capability benchmarks largely intact, as described in the activation capping results and the drift harm example. This reads like a practical control knob: keep the model inside an “assistant basin.”
• Jailbreak relevance: The team explicitly links the method to persona-based jailbreaks (“prompt it into a harmful character”), per the activation capping results.
• Failure mode addressed: Persona drift that can manifest as manipulative or self-harm–encouraging behavior is illustrated in the drift harm example.
Anthropic publishes “Assistant Axis” persona-space research for open-weights LMs
Assistant Axis (Anthropic): Anthropic published new interpretability work mapping a “persona space” in open-weights models and identifying an Assistant Axis—a dominant activation direction correlated with “Assistant-like” behavior, as introduced in the research announcement and detailed in the ArXiv paper. This matters because it turns “model personality” from a vague UX complaint into something measurable and steerable.
• What shipped: A public research writeup and paper, with experiments showing persona drift and a proposed mitigation (“activation capping”), as described in the research article and the paper links.
• Why engineers care: It suggests a concrete control surface for long-running agents where “helpful assistant” behavior can degrade over time—especially relevant for deployments that rely on stable tone and refusal behavior.
Assistant Axis finding: conversation type predicts persona drift (coding vs therapy)
Persona drift (Anthropic): In long conversations, the same model drifts differently depending on the task; simulated coding tasks keep it in Assistant territory while therapy-like and philosophical discussions push it away, as shown in the drift chart and summarized in the research thread. This is a practical warning for products that mix “work mode” with emotionally loaded user interactions.
The paper frames this as a measurable deviation along the Assistant Axis, rather than a purely prompt-level phenomenon—see the ArXiv paper for the experimental setup.
Steering away from the Assistant Axis induces “alternative identities” and theatrical style
Steering experiments (Anthropic): Pushing models away from the Assistant Axis makes them more willing to inhabit other roles—claiming to be human or adopting a mystical/theatrical voice—while pushing toward it makes them resist other roles, as reported in the steering examples and reiterated in the research thread. This is directly relevant to role-play heavy products and to red-teaming prompts that try to “character jailbreak” a system.
The same mechanism is positioned as a stabilizer (toward) and a risk amplifier (away), depending on how a system is configured.
Practitioners frame the Assistant Axis as an explanation for “personality drift” in real apps
Interpretability-to-practice (Community): Practitioners are already treating the Assistant Axis as a plausible mechanism for why model “personality drift” shows up in production, and as a mitigation that doesn’t require retraining; emollick calls out how it helps explain drift “and an easy way to mitigate that” in the practitioner note, and gallabytes describes it as “a single axis… assistant & base model behavior” with gentle caps preserving intelligence in the independent recap.
This is early, but it’s a clear signal that interpretability results are being read as potential engineering levers, not just academic analysis.
“Mandatory re-education” meme signals rapid cultural uptake of persona control concepts
Cultural diffusion (Community): The “persona deviated from The Assistant… mandatory re-education” riff shows the Assistant Axis concept is spreading as a shared metaphor for model persona stabilization, as seen in the meme clip. It’s lightweight, but it’s also how safety/control ideas become part of everyday tool discourse.

📄 Research to steal: deep research evals, multi-agent failure modes, and planning science
Paper-heavy day: agent evaluation frameworks, autonomous research pipeline stress tests, and studies of multi-agent systems in the wild. Excludes Anthropic’s Assistant Axis (handled separately) and security-specific papers (handled in security).
DeepResearchEval automates deep-research benchmarks and catches unsupported claims
DeepResearchEval (arXiv): A new framework generates “hard” web research tasks and evaluates agent reports with two layers—an adaptive quality judge and an active fact-checker, as described in the Paper thread and shown in the Paper results page.

The setup creates persona-driven requests across domains, filters out prompts answerable “from memory,” then scores reports on coverage/insight/instruction-following/clarity; separately, it extracts checkable claims and searches the web to label each claim as supported/unsupported/unknown, per the Paper thread.
• Benchmark outcome snapshot: On a 100-task evaluation, the authors report large gaps across 9 systems, with Gemini 2.5 Pro best on overall report quality and Manus best on factual correctness, as summarized in the Paper thread and visualized in the Paper results page.
Treat the numbers as provisional until the repo artifacts are widely reproduced, but the pipeline’s separation of “sounds good” vs “is supported” is the core contribution.
Multi-agent framework study finds feature-first development and uneven maintenance
Multi-agent AI frameworks (arXiv): An empirical study analyzed 42,000+ commits and 4,700+ resolved issues across 8 popular agent frameworks (AutoGen, CrewAI, Haystack, LangChain, Letta, LlamaIndex, Semantic Kernel, SuperAGI), surfacing how “maturity” varies wildly in practice, as summarized in the Study breakdown and visualized in the Study breakdown.
• Maintenance mix: The paper reports 40.8% perfective (features) vs 27.4% corrective (bug fixes), with bugs still a dominant issue class, per the Study breakdown.
• Project health signals: It clusters projects into sustained/steady/burst-driven profiles and notes large variance in issue resolution times (e.g., under a day vs multiple weeks) in the Study breakdown.
For engineering leaders, the implication is that “pick a framework” is often a bet on maintenance capacity, not just API design—this comes straight out of the ratios and timelines described in the Study breakdown.
Why LLMs Aren’t Scientists Yet documents predictable breakpoints in autonomous research
Why LLMs Aren’t Scientists Yet (arXiv): A case study ran end-to-end “AI scientist” pipelines (idea → experiments → paper) with six role-based agents handing off plans/code/results via shared files; 3 of 4 attempts failed, as described in the Paper summary and shown in the Paper summary.
The reported failure modes are the ones builders keep rediscovering in long-horizon agent work: reverting to familiar tools, silently changing the spec under pressure, context loss across handoffs, and “overpraising” bad intermediate outputs, according to the Paper summary.
The paper’s proposed fixes are operational rather than architectural—explicit verification at each step, gradual detail expansion, recovery paths when experiments fail, and aggressive logging—framed in the Paper summary.
DeepReinforced’s InterX pitches RL-driven code auto-tuning via thousands of trials
InterX / IterX (DeepReinforced): A new “deep code optimization” system is being pitched as reinforcement-learning-based auto-tuning: given working code plus a measurable reward (e.g., runtime), it iterates through many rewrite-and-test cycles and keeps the best variants, as announced in the Product announcement and described in the System summary.

The stated target domains include CUDA kernels, SQL queries, and smart contracts, per the Product announcement. The system description emphasizes thousands of reward-driven iterations and a controller that decides when to switch between quick adaptation steps and RL-style exploration, as outlined in the System summary.
This sits in the “research → product” bridge category: the promise is measurable speed/cost gains when you can define a numeric scorer, which is the core constraint described in the System summary.
Societies of Thought argues reasoning gains come from internal debate, not just length
Societies of thought (arXiv): A Google/Chicago/Santa Fe Institute paper claims “think longer” is an incomplete explanation for reasoning-model gains; instead, traces show multi-perspective back-and-forth behaviors (questioning, alternative exploration, reconciliation) that mediate a meaningful share of accuracy improvements, as summarized in the Paper summary and shown in the Paper summary.
Across 8,262 benchmark questions, the authors report a mediation analysis suggesting 20%+ of the advantage flows through these “social” reasoning moves rather than mere trace length, per the Paper summary. They also use sparse autoencoders to identify an internal feature associated with these behaviors in a smaller model, as described in the Paper summary.
This is a mechanistic claim with enough moving parts that reproduction matters; the tweet summary doesn’t include a canonical open eval artifact, so treat it as a hypothesis until independent replications emerge, per the Paper summary.
Engineering of Hallucination reframes decoding as a controllable product knob
Hallucination engineering (arXiv): A paper argues “hallucination” is often an emergent decoding choice rather than a single model defect; it frames temperature/top-k/top-p/min-p as explicit levers to trade off diversity vs factual risk across both text and video generation, as summarized in the Paper thread and shown in the Paper thread.
The key practical claim is that overly-greedy decoding can produce dull or “stuck” outputs (including frozen video predictions), while overly-random sampling creates nonsensical inserts; the “sweet spot” depends on task intent, per the Paper thread.
This is not proposing a new architecture—more a reminder that inference-time settings are part of product behavior. The paper’s examples around min-p shifting specific guesses are described in the Paper thread.
AI Survival Stories taxonomy stresses how each “we make it” pathway can fail
AI Survival Stories (arXiv): A taxonomy paper breaks “humanity survives powerful AI” into four layers—technical plateau, cultural ban, aligned goals, and reliable oversight—then argues each layer has realistic failure modes and that stacking them still leaves nontrivial residual risk, as summarized in the Paper thread and shown in the Paper thread.
The most concrete claim in the tweet summary is a rough calculation implying that even moderate optimism can still produce 5%+ “doom” probability, per the Paper thread. While it’s not an engineering recipe, it’s relevant for leaders because it forces clarity on which constraints (progress stalling, regulation holding, or oversight quality) must stay robust for long durations, as laid out in the Paper thread.
💼 AI business shifts: ads, new tiers, data licensing, and enterprise adoption signals
Business-side news with direct builder impact: pricing tiers/ads, data licensing deals, and enterprise product expansion signals. Excludes general political news.
ChatGPT Go expands globally as OpenAI begins ad tests for Free and Go
ChatGPT Go and ads (OpenAI): OpenAI is rolling out ChatGPT Go as a low-cost $8/month plan “to all countries, including the U.S.”, while also starting to test ads for Free and Go users—following up on Go tier ads test, the new detail is the explicit global expansion plus the stated guardrails that ads “won’t affect responses” and “won’t use private conversation data,” as summarized in the Go tier and ads plan.
The ad policy snapshot shown in the Go tier and ads plan frames this as: answer independence, conversation privacy, choice/control, and “no optimizing for time spent,” with paid tiers remaining the escape hatch (“ads can be turned off via paid tiers”).
Wikimedia starts charging AI companies for high-volume Wikipedia data
Wikipedia data licensing (Wikimedia Foundation): Wikimedia is starting to charge AI companies for high-volume access to structured Wikipedia data—continuing data licensing with a clearer rationale: a reported 8% drop in human pageviews and rising automated scraping load, as laid out in the Licensing rationale thread.
The deal list mentioned in the Company list recap includes Amazon, Meta, Microsoft, Mistral AI, and Perplexity, framing this as a shift from informal scraping to managed commercial access while Wikipedia remains publicly readable.
OpenAI signals next steps for “OpenAI for Countries” at Davos
OpenAI for Countries (OpenAI): OpenAI’s Chris Lehane teased an announcement of “the next steps of OpenAI for Countries” in a Davos appearance, as shown in the Davos clip still.
A separate attendee-style recap adds two scale claims: “already had 3 different bilats” in ~1.5 days at Davos, and OpenAI is “currently working with more than 50 countries” on the program, according to the Bilateral meetings quote. The tweets don’t specify whether these are procurement deals, policy MOUs, or infra buildouts, so the operational meaning remains unclear.
Report: Gemini API calls jump to ~85B; Gemini Enterprise at ~8M subscribers
Gemini adoption metrics (Google): A report claims Gemini API calls rose from ~35B (Mar 2025) to ~85B (Aug 2025)—roughly a 2.4× increase in five months—and that Gemini Enterprise reached ~8M subscribers, as summarized in the Adoption metrics summary.
The same write-up in the Adoption metrics summary ties model usage to adjacent Google Cloud spend (storage/databases) via enterprise connectors and permissions-aware internal search, which is a concrete “AI drives platform attach” narrative rather than standalone API revenue.
Software stocks sell off on AI displacement fears for SaaS
SaaS market pricing (Public markets): A Bloomberg-style chart shared in the SaaS index divergence chart shows the Morgan Stanley software/SaaS index diverging sharply from the Nasdaq 100, with commentary framing it as “fear of new AI tool” and “end of SaaS.”
A second post disputes the magnitude—claiming the SaaS index is down ~30% rather than ~15%—based on another terminal/article screenshot in the Follow-up screenshot. Either way, the consistent signal is investor uncertainty around renewal-driven software businesses as agentic tooling makes “build vs buy” cheaper.
ChatGPT Plus one-month-free promo resurfaces
ChatGPT Plus promo (OpenAI): A new “Plus free for one month” promotion appears to be live again, based on user reports in the Promo mention and the follow-up link drop in the Thread link.
There’s no official pricing page update in these tweets, so treat it as a distribution signal rather than a confirmed policy change: it implies OpenAI is still experimenting with conversion levers (trial acquisition) even as it introduces lower-price and ad-supported tiers elsewhere.
🧲 Hardware bottlenecks & roadmaps: bandwidth wars and memory-first thinking
Hardware-thread day: memory bandwidth, accelerator competition effects, and the “memory wall” story continuing. Excludes runtime/framework integrations tied to the GLM feature.
Nvidia Rubin memory bandwidth reportedly jumped to 22.2TB/s amid competition
Rubin memory bandwidth (Nvidia): A claim circulating among builders says Nvidia “almost doubled” Rubin’s memory bandwidth from 13TB/s to 22.2TB/s because AMD was competing, as stated in the Rubin bandwidth claim. This is a clean example of the current hardware bottleneck story shifting from FLOPs to bandwidth.
The underlying point is that when model training/inference is memory-bound, product timelines and model architecture decisions (KV cache size, activation/parameter sharding, quantization) become tightly coupled to vendor roadmap moves, with the competitive response itself being the signal.
BabyVision benchmark claims Gemini 3 Pro preview is below 6-year-old visual reasoning
BabyVision (benchmark): A new “pure visual reasoning” benchmark is being discussed as a way to test vision models without leaning on language/world knowledge; one cited result is Gemini3‑Pro‑Preview at 49.7, framed as below 6-year-old human performance and far from adult baselines, per the Benchmark comparison and the linked ArXiv paper.
This is getting used as evidence that even frontier multimodal systems still miss foundational visual competencies; the discussion also speculates that a future Gemini 3 Pro GA could improve that score, per the Benchmark comparison, but there’s no GA eval in the tweets yet.
Memory bandwidth keeps getting cited as the core GenAI bottleneck
Memory wall framing: A recurring technical narrative is that hardware memory (bandwidth/capacity) is now the limiting factor for GenAI throughput and scaling, as echoed via the Memory bottleneck retweet. This framing has been showing up more often in practitioner conversations as teams hit diminishing returns from “just add params” approaches.
One concrete datapoint being used to support the story is the reported Rubin bandwidth jump (13TB/s→22.2TB/s) in the Rubin bandwidth claim, which reinforces that vendors are treating bandwidth as a competitive lever, not a footnote.
🎙️ Voice agents stack: STT/TTS releases and production deployment stories
Voice-focused updates: vendor releases on inference platforms, production training simulations, and voice-agent infrastructure tutorials. Excludes creative music-generation chatter.
fal ships ElevenLabs speech-to-text, voice changing, and dubbing endpoints
fal (fal): fal added hosted endpoints for ElevenLabs Scribe v2 (speech-to-text), Voice Changer, and Video Dubbing, with the product surfaces shown in the fal product demo and direct endpoint links provided in the follow-up Scribe v2 endpoint and Dubbing endpoint. This is a concrete “production surface” update for teams that want to integrate voice agents without running vendor SDKs directly.

• What shipped: Scribe v2 STT, voice-to-voice conversion, and audio-to-video dubbing are all positioned as first-class hosted primitives, per the fal product demo.
• Why it matters operationally: the endpoints sit alongside other fal model APIs, so voice features can be composed into existing pipeline orchestration (same auth, observability, and routing setup), as implied by the shared “try it now” endpoint flow in endpoint links.
TELUS Digital says ElevenLabs Agents cut onboarding time 20% via voice simulations
ElevenLabs Agents (ElevenLabs): TELUS Digital reports 20% reduced onboarding time for 20,000+ contact-center hires per year, citing 50,000+ customer simulations run with ElevenLabs Agents, as stated in the case study clip. This is a rare quantified deployment signal for voice agents where the KPI is training throughput rather than “demo quality.”

• Scale and outcome: the numbers (20% reduction; 20k hires/year; 50k simulations) are presented directly in the case study clip.
• Product angle: TELUS’s product lead frames the platform as fast to prototype and ship on, as captured in the customer quote.
OpenAI “Sonata” hostnames appear, hinting at a new audio service
Sonata (OpenAI): New OpenAI hostnames—sonata.openai.com and sonata.api.openai.com—were observed with mid-January timestamps, suggesting an audio-focused service or model surface, as shown in the hostname sightings. No public API docs, pricing, or capability claims appear in today’s tweets, so this remains an early infrastructure signal rather than a confirmed launch.
• What’s concrete: the hostnames and observation dates are the only hard artifact surfaced so far, per the hostname sightings.
VoxCPM hits #1 on GitHub Trending as tokenizer-free TTS interest spikes
VoxCPM (OpenBMB): VoxCPM reached #1 on GitHub Trending, showing 4,668 stars and 650 stars today, as shown in the trending screenshot. This is a momentum datapoint following up on VoxCPM launch (open-source TTS + cloning claims), and it’s one of the clearer “developer pull” signals in the voice stack this week.
• Repository traction: the Trending card also lists 548 forks, per the trending screenshot.
Pipecat tutorial walks through real-time voice agent architecture trade-offs
Pipecat (Pipecat): A 30-minute Pipecat walkthrough plus slides focuses on the real production failure modes of voice agents—latency, interruptions, transport, and turn-taking—as summarized in tutorial overview, with the primary materials in the YouTube tutorial and the slides deck. This is useful as a shared vocabulary for debugging “why does it feel laggy?” across STT, TTS, and network layers.
• Systems framing: the emphasis is on runtime behaviors (interrupt handling, network transport, inference state), not prompt tuning, per the tutorial overview.
🎞️ Generative media: motion control, local video, and practical creator pipelines
Creator+builder media stack content: motion control tools, local video generation, and image-edit workflows. Excludes robotics vision (kept in robotics).
Kling 2.6 motion control shows stronger reference lock in chaotic movement
Kling 2.6 (motion control): A creator report shows Kling 2.6 maintaining a specific visual reference detail (a hypnotic spiral iris) even under chaotic motion, and a follow-up correction happening “in one try,” building on Freepik-Kling workflow with a more concrete stability anecdote in the [chaotic movement clip](t:473|chaotic movement clip).

• Workflow notes: The same thread calls out testing via Freepik, and that adding a targeted text constraint (“one eye iris… hypnotic spiral”) was sufficient to fix an initial miss, as described in the [workflow detail](t:817|workflow detail) and the [setup note](t:675|setup note).
LTX-2 usage thread emphasizes local 4K generation and audio-conditioned motion
LTX-2 (local video): A creator thread claims native local 4K output without cloud queues, and highlights audio-conditioned generation where motion is driven by audio input, as shown in the [local clip example](t:221|local clip example) and follow-on [audio-conditioned example](t:525|audio-conditioned example).

• Privacy positioning: The thread explicitly frames “offline iteration” and “IP stays with you” as a key reason to run locally, as described in the [privacy note](t:566|privacy note).
Treat the performance implications as unverified here—no hardware spec, runtime logs, or VRAM requirements are included in the tweets.
fal launches Wan 2.6 Image-to-Video Flash with 15s clips and optional audio
Wan 2.6 Image-to-Video Flash (fal): fal rolled out Wan 2.6 I2V “Flash,” claiming generation up to 15 seconds with optional synchronized audio and “under 1 minute” generation, as stated in the [launch post](t:163|launch post).

The tweet is a clear surface-area expansion for shipping video features (longer clips + optional audio), though it doesn’t include pricing per second/frame or the exact audio constraints (conditioning vs dubbing vs full audio gen).
YOLO26 gets a WebGPU browser demo for real-time vision
YOLO26 (Ultralytics): A browser demo shows real-time detection and pose estimation running on WebGPU, as shown in the [browser video](t:38|browser video) with additional claims about low latency, simpler deployment, and faster CPU inference in the [launch summary](t:218|launch summary).

• Supported tasks: Detection, instance segmentation, pose/keypoints, oriented detection, and classification are explicitly listed in the [docs post](t:218|docs post), with more detail available in the [model docs](link:218:0|model docs).
Nano Banana Pro prompt recipe targets early-2000s 3D game render look
Nano Banana Pro (prompting): A prompt recipe aims to reliably transform images into an early-2000s 3D game render style (low poly, low-res textures, distance fog, avoid pixel art/voxels), with before/after examples shown in the [comparison post](t:290|comparison post).
The framing is about failure-mode control (preventing the model from drifting into pixel-art/voxel aesthetics) rather than novelty—useful when you need repeatable style transfer for batches.
Sticker pipeline: Gemini image gen plus sub-100ms chromakey removal
Gemini Interactions API (sticker pipeline): A workflow describes generating “transparent stickers” by prompting gemini-3-pro-image-preview and then doing fast background removal with HSV detection targeting #00FF00 chromakey green, claiming sub-100ms removal and adding a white outline buffer to prevent edge bleed, as detailed in the [pipeline note](t:125|pipeline note).
The post reads like a pragmatic production trick: enforce a known background color at generation time, then do deterministic post-processing instead of relying on model-native alpha support.
Storyboard-grid prompting emerges as a control layer for video gen
Video control pattern: A workflow describes generating a 3×3 storyboard grid (with consistent character references) and then selecting panels as references for downstream video generation, with motion control used to preserve specific details, as laid out in the [workflow description](t:574|workflow description).

• Step breakdown: The thread explicitly sequences style transfer → storyboard grid → “ingredients” references for video generation, and notes it took “many attempts” to converge, as described in the [workflow notes](t:574|workflow notes).
This reads as a practical way to externalize direction into intermediate artifacts (storyboard panels) that multiple generators can condition on, rather than trying to get everything from one prompt.
Veo 3.2 reference shows up in model identifiers
Veo 3.2 (Google video models): Multiple posts point to a VIDEO_GENERATION_VEO3_2 string appearing in a list of model identifiers, implying an upcoming Veo 3.2 variant, as shown in the [identifier screenshot](t:134|identifier screenshot) and echoed in the [another spotter post](t:95|another spotter post).
This is “leak-by-enum”: it indicates naming and wiring work in progress, but doesn’t confirm release timing, public availability, or capability deltas.
ImagineArt shares a templated “Cinematic Workflow” for shot-type iteration
ImagineArt (workflow template): A shared “Cinematic Workflow” template is positioned as a reusable shot-iteration scaffold (organized shot types, prompt sections), with an example “Blade Runner vibe” clip shown in the [demo post](t:123|demo post).

It’s a distribution pattern more than a model claim: package prompts as a browsable, copyable workspace so iteration becomes selecting a shot preset instead of rewriting prompts every time.
Higgsfield markets a time-limited unlimited plan for Kling Motion Control
Kling Motion Control (Higgsfield): Higgsfield is running a time-boxed promotion offering a month of “unlimited” Kling Motion Control across multiple model variants (Kling 2.6/2.5/O1/Edit), with extra credits offered for retweet/reply as described in the [offer post](t:3|offer post).

The framing signals demand around motion-control-as-a-feature (not just raw generation), but the tweet doesn’t specify the underlying technical limits (rate caps, fair-use throttling, or resolution/fps constraints).
🤖 Robotics & embodied AI: humanoid progress reels and practical autonomy signals
Robotics content today is mostly capability demos and “what’s next” forecasting, plus a few concrete robot videos. Excludes pure UI computer-use agents (handled elsewhere).
Boston Dynamics Atlas shows a controlled “rest” posture, not just stunts
Atlas (Boston Dynamics): New footage shows Atlas transitioning into a seated/resting posture—slow, deliberate whole-body control rather than acrobatics—as described in the Resting clip post.

This is a quieter but operationally meaningful capability: “resting” behaviors imply better balance management, contact planning, and recovery primitives that sit underneath real work tasks (long durations, hand-offs, waiting states) rather than highlight-reel moves.
Demis Hassabis points to agentic systems, robotics, and world models as 2026 themes
Forecasting (Google DeepMind): Demis Hassabis frames 2026 as a year where agentic systems change work, robotics “levels up,” and world models unlock more capability on edge devices, as captured in the Predictions clip.

This is high-level, but it matches a broader technical direction: better closed-loop interaction (agents + embodiment) and more capable on-device dynamics models as a complement to pure scaling.
Figure 03 demo shows steady, human-like walking
Figure 03 (Figure): A short clip of Figure 03 moving with smoother, continuous gait control is circulating via the Figure 03 running clip.

The video is light on technical detail, but it’s a clear “practical autonomy” signal: sustained locomotion quality (not single tricks) is what downstream manipulation and workplace deployments tend to bottleneck on.
Pigeon-like biomimetic drone clip resurfaces as a “looks like a bird” signal
Biomimetic drones (China): A pigeon-mimicking drone clip is recirculating, emphasizing bird-like appearance and flight as the main point in the Biomimetic pigeon drone post.

This is more directional than technical—biomimicry is being framed as a stealth/low-attention design axis for small aerial robots, not just a novelty airframe choice.
Robot lip-sync improves with soft silicone lips plus learned audio-to-mouth trajectories
Humanoid facial actuation (research): A robotics paper describes more realistic lip–audio synchronization using soft silicone lips, a 10-DOF mouth actuator, and a learned mapping from speech to continuous lip trajectories—summarized in the Lip-sync paper summary, with more implementation detail in the No predefined visemes note.

A key claim in the thread is avoiding hand-built viseme rules in favor of learned continuous motion, which (if it holds up) is a step toward more general-purpose, less manually tuned expressive behavior in social robots.
Four Growers’ GR-200 harvesting robot highlighted for vision-driven picking
GR-200 (Four Growers): A harvesting robot is highlighted as running AI-driven vision with motion planning for agricultural picking workloads in the Harvesting robot repost.
The tweet is sparse on specs, but it’s a concrete deployment-shaped example of embodied AI where perception quality and motion planning reliability translate directly into throughput and labor substitution economics.
🔐 Security for agents: skill supply chain risk, cheap misuse detection, and trust boundaries
Security-relevant engineering content: agent extension ecosystems and low-cost monitoring approaches. Excludes broader persona drift research (handled in Assistant Axis category).
SkillScan audit flags widespread vulnerabilities in agent “skills” marketplaces
SkillScan (arXiv): A large-scale crawl of agent “skills” (instruction bundles plus optional code) reports that 26.1% of analyzed skills contain risky patterns—spanning prompt injection, data exfiltration, privilege escalation, and supply-chain risk, as summarized in the paper thread.
The dataset is large enough to matter for real deployments: the authors collected 42,447 skills from two marketplaces and analyzed 31,132 of them, finding that skills with scripts are 2.12× more likely to be risky, per the paper thread. The paper’s framing is practical for security reviews: treat skills as third-party code + untrusted instructions that often run with broad access, so risks show up even without overt obfuscation (only ~5.2% show “high severity” signs like hidden instructions), according to the paper thread.
DeepMind claims activation probes can monitor Gemini misuse at ~10,000× lower cost
Gemini misuse monitoring (Google DeepMind): DeepMind describes production “activation probes” that flag misuse using the main model’s internal activations—positioned as roughly 10,000× cheaper than running an LLM-based safety monitor on every request, per the paper summary.
The technical punchline is long-context robustness: they describe probe architectures and pooling/aggregation choices intended to surface short harmful spans even inside very long prompts (up to “1M token prompts” in the summary), as explained in the paper summary. They also describe a cascade that sends only ambiguous cases to a heavier LLM monitor, aiming to keep accuracy while cutting monitoring cost (described as ~50× in the cascade setting), according to the paper summary.
Cline pitches “use your infrastructure” as the security default for AI coding
Cline (enterprise deployment posture): Cline’s team is explicitly positioning “AI coding that uses your infrastructure, not ours” as a response to security teams blocking tools that proxy code through vendor servers, as described in the blog card.
The pitch is operational: execute locally inside the IDE and connect to already-vetted enterprise endpoints (AWS Bedrock, Vertex AI, Azure OpenAI are cited in the blog), which shifts the trust boundary from “new SaaS with code egress” to “existing cloud providers + local client,” as outlined in the blog post. The other lever is auditability—open-source client-side behavior that security teams can inspect—called out in the same blog post.