Nano Banana Pro 4K image model – 8% text errors, $0.13 renders
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Google quietly turned on Nano Banana Pro, its Gemini 3 Pro Image model, across Gemini web/app, AI Mode in Search, Flow, NotebookLM, AI Studio, and Vertex. You get 1K/2K/4K outputs, a 1M‑token context inherited from Gemini 3 Pro, and pricing around $0.134 per generated image on top of $2/M input and $12/M output tokens. The pitch: a reasoning‑aware image engine that can lay out multilingual text and infographics without looking like your UI was typeset by a blender.
Early benchmarks back that up. Nano Banana Pro tops GPT‑Image 1, Seedream v4 4K, and Flux Pro Kontext Max on text‑to‑image and editing Elo, with ~100‑point leads in several edit categories. A heatmap puts single‑line text errors near 8% versus ~38% for GPT‑Image 1 across languages, including Arabic, Hindi, and Hebrew. The new “Show thinking (Nano Banana Pro)” toggle also hints that chain‑of‑thought is now a thing for pixels, not just prose.
Third‑party support lit up immediately: fal.ai shipped day‑0 text‑to‑image and edit APIs, Higgsfield is dangling “unlimited 4K” Nano Banana Pro with up to 65% off, and Genspark wired it into its all‑in‑one workspace. If your product depends on legible dashboards, posters, or UI mocks, this model is worth a focused weekend of A/B tests.
Feature Spotlight
Feature: Nano Banana Pro (Gemini 3 Pro Image) goes live across Google and partners
Google’s reasoning image model ships broadly (Gemini web/app, AI Studio, Vertex) with 4K, better text, and multi‑turn edits—immediately consumable via Google surfaces and partner APIs, accelerating creative and product workflows.
Cross‑account confirmations that Google’s reasoning image model is now broadly usable: Gemini web/app, AI Studio, Vertex docs, and third‑party endpoints. Focus is on 4K output, accurate multilingual text, editing controls.
Jump to Feature: Nano Banana Pro (Gemini 3 Pro Image) goes live across Google and partners topicsTable of Contents
🍌 Feature: Nano Banana Pro (Gemini 3 Pro Image) goes live across Google and partners
Cross‑account confirmations that Google’s reasoning image model is now broadly usable: Gemini web/app, AI Studio, Vertex docs, and third‑party endpoints. Focus is on 4K output, accurate multilingual text, editing controls.
Nano Banana Pro (Gemini 3 Pro Image) launches across Gemini and Google tools
Google DeepMind has formally launched Nano Banana Pro (Gemini 3 Pro Image), a reasoning‑aware image generation and editing model now available in the Gemini app and web, AI Mode in Search, Flow, NotebookLM and more, following earlier leaked tests of 4K outputs and text rendering 4k leak. The model supports 1K/2K/4K output, lighting and camera controls, aspect‑ratio changes, multilingual text rendering, multi‑image compositing, and Search grounding for fact‑aware visuals DeepMind feature thread surfaces and getting started.
For developers, Nano Banana Pro appears in Google AI Studio as gemini-3-pro-image-preview with pricing of $2.00/M input tokens, $12.00/M output tokens, and about $0.134 per generated image, sharing the same Jan 2025 knowledge cutoff and 1M context as Gemini 3 Pro text ai studio pricing. Vertex AI’s model garden lists the same model ID (publishers/google/models/gemini-3-pro-image-preview), and emphasizes "reasoning for image generation", 4K support, and optional grounding with Search for more factual images vertex docs overview.
On the front end, Gemini web now exposes a "Show thinking (Nano Banana Pro)" toggle on image generations, hinting that chain‑of‑thought style internal reasoning is being applied even for visuals and optionally made visible to users show thinking ui. Community posts confirm successful runs in Gemini web (“cat shooting power into a wormhole”, “minion with nano banana”) and in the mobile app, aligning with AILeaks’ note that the model is rolling out broadly across Google’s AI offerings gemini app release rollout confirmation.
Benchmarks put Nano Banana Pro ahead of GPT‑Image 1 in quality and text rendering
Early benchmark charts circulating today show Gemini 3 Pro Image (Nano Banana Pro) leading competing models like GPT‑Image 1, Seedream v4 4K and Flux Pro Kontext Max on both text‑to‑image and image‑editing Elo scores, while also drastically cutting text rendering errors image elo scores editing elo chart. In text‑to‑image, Gemini 3 Pro Image tops overall preference and visual quality, and in editing it wins across object/environment edits, style transfer, single and multi‑character consistency, and text editing, with Elo gaps of ~100 points or more over GPT‑Image 1 in several categories editing elo chart.
A separate heatmap on single‑line text rendering shows Nano Banana Pro at roughly 8% average error across languages versus GPT‑Image 1 at about 38%, with particularly stark differences in scripts like Arabic, Hindi and Hebrew text error heatmap. Sample outputs like a 4K "How solar power works" infographic, complete with clean typography and structured diagram elements, illustrate the practical impact for product teams that care about legible UI mocks and dashboards rather than just concept art solar infographic sample. DeepMind and third‑party commentary are already framing Nano Banana Pro as a "reasoning image model"—the idea being that its improved factual grounding and layout reasoning, not just its decoder quality, are what push these numbers above older models reasoning model quote.
fal.ai ships day‑0 Nano Banana Pro text‑to‑image and editing APIs
Inference host fal.ai has Nano Banana Pro live on day zero, exposing separate text‑to‑image and image‑editing endpoints so teams can start wiring Gemini 3 Pro Image into their own apps without waiting on Google’s stacks fal launch. The text‑to‑image model page quotes per‑image pricing and supports the full creative prompt flow, while a dedicated edit endpoint lets you upload an image and drive semantic edits with natural language rather than masks fal text to image fal image editing.
Because fal handles queuing and scaling, this gives smaller shops an immediate way to prototype Nano Banana‑backed features—marketing image pipelines, design tools, product configurators—without standing up Vertex or dealing with quota friction in AI Studio fal endpoints thread. For AI engineers already using fal for other diffusion or video models, swapping in Nano Banana Pro should mostly be a matter of changing the model slug and adjusting prompts for its stronger text and layout handling.
Higgsfield offers unlimited 4K Nano Banana Pro with aggressive Black Friday deal
Video‑first platform Higgsfield is pitching an unusually aggressive commercial package around Nano Banana Pro: unlimited 4K generations for a full year at up to 65% off as part of a Black Friday sale, plus a short‑term promo of 350 free credits for retweets and comments higgsfield launch promo. They emphasize Gemini‑powered reasoning, multilingual text quality and precise edit controls, positioning their offer as the way to tap the model without worrying about per‑image caps or token budgeting higgsfield feature recap.
The Higgsfield landing page reinforces this framing by advertising "Unlimited 4K Nano Banana Pro" plans and showing Hollywood‑style VFX clips and plushie conversions as example outputs, which target agencies and heavy social content shops more than hobbyists Higgsfield site. For AI leads, the main trade‑off versus going direct to Google is clear: pay a fixed platform price with Higgsfield’s workflow UI on top, or stay closer to the metal with Vertex/AI Studio and handle quotas and orchestration yourself.

Genspark integrates Nano Banana Pro into its all‑in‑one AI workspace
Genspark, the "everything in one" AI workspace, now exposes Google’s Nano Banana image model alongside its existing stack of text and video tools, so users can generate and edit images without leaving the same canvas they use for slides, docs and data analysis genspark overview. In a walkthrough, the team shows Nano Banana‑driven poster design and image editing flows happening directly inside Genspark, with no separate API setup or platform switching nano banana in genspark.
Because Genspark routes to multiple frontier models under one subscription and offers an AI Inbox, shared projects and agent flows, this integration means design work (posters, promo graphics, visual assets for decks) can sit in the same project as the copy, research, and analysis that feeds it genspark video models. Their Black Friday‑era promo also includes free compute credits for new signups, making it easy for teams to benchmark Nano Banana Pro’s text and layout handling against whatever image stack they already use, before deciding where to standardize genspark pricing promo.

🧩 Open weights: Olmo 3 (7B/32B base, Instruct, Think)
A major fully open model family drop from Ai2 with training data, checkpoints, logs and a detailed report—useful for teams needing transparent, reproducible stacks. Excludes Google’s image model (covered as the feature).
Ai2 releases fully open Olmo 3 7B/32B family
Allen Institute for AI has released the Olmo 3 family: 7B and 32B base models plus Instruct, Think, and RL Zero variants, all with open weights, pretraining data mix, post‑training datasets, intermediate checkpoints, and training logs. They explicitly position Olmo 3‑Base 32B as the strongest fully open 32B base and the 7B variants as top "Western" thinking/instruct models, aiming to give teams a transparent alternative to Qwen‑scale systems. release thread The full suite is live on Hugging Face and documented in a detailed technical report, so you can inspect or reproduce every stage of the model flow from SFT through DPO and RLVR. huggingface collection paper pdf ai2 blog
Olmo 3 ships 7B RL Zero datasets and checkpoints for math, code and instructions
Beyond the base and Think models, Ai2 is releasing four RL Zero tracks for the 7B Olmo 3—focused separately on math, code, instruction following, and a mixed blend—each with open datasets and intermediate checkpoints. release thread The team explicitly frames this as a lab bench for studying how starting RL directly from the base model (inspired by DeepSeek R1) interacts with mid‑training reasoning traces and how much benchmark lift comes from RL versus SFT or DPO, in areas where Qwen‑based RLVR runs have raised contamination questions. paper pdf
Olmo 3-Base 32B challenges other open 32B models on core benchmarks
Benchmark charts shared with the release show Olmo 3‑Base 32B beating or matching strong open peers like Marin 32B, Apertus 70B, Qwen 2.5 32B, Gemma 3 27B, and even Llama 3 170B on tasks such as HumanEval (66.5), DROP (81.0), SQuAD (94.5), and CoQA (74.1). benchmark charts For AI engineers this means you get a competitive, mid‑sized base model for code, reading comprehension, and QA that can still fit on a single 80GB GPU, but without giving up the transparency and fine‑tuning control that most closed 30–70B models lack.
Olmo 3-Think 32B nears Qwen3 on math and reasoning benchmarks
The Olmo 3‑Think 32B reasoning model lands within 1–2 points of Qwen3 32B and Qwen3 VL 32B Thinking on tough reasoning suites, scoring around 89.0 on IFEval, 96.1 on MATH, ~90 on BigBench‑Hard, and 89.7 on HumanEvalPlus, while also edging those peers on OMEGA. benchmark charts Ai2 credits a three‑stage post‑training pipeline—Dolci‑Think SFT, an expanded DPO setup that exploits deltas between Qwen3 32B and 0.6B responses, and large‑scale RLVR—for turning the 32B base into a high‑end open reasoning model, which is good news if you want near‑frontier math/code performance without leaving the open ecosystem.
Ai2 and Hugging Face schedule Olmo 3 deep-dive livestream
Ai2 is doing a live technical walkthrough of Olmo 3 with Hugging Face at 9am PT, followed by an "afterparty" discussion on Ai2’s Discord. livestream invite For engineers and researchers this is a chance to hear the training and post‑training details directly from the authors, ask about design decisions like context length, data mixtures, DPO setup, and RLVR tricks, and see how they envision people extending the new base and Think checkpoints.
Olmo 3 team hints at forthcoming write-ups on training infrastructure and code execution
Several Olmo 3 authors are teasing behind‑the‑scenes stories about the infra and training stack, including "babysitting" long training runs and the specialized NCCL and code‑execution setups that kept large‑scale RL experiments stable. training babysitting One engineer says they have "very fun" training‑run anecdotes they hope to publish in the next few weeks, while another notes a forthcoming write‑up on their code execution environment for RL, and teammates call out contributors who debugged low‑level NCCL issues during post‑training. code execution note nccl comment If you care about reproducing Olmo‑class training or adapting their RL pipeline, it’s worth watching for these deep‑dive posts as companions to the main technical report.
🗺️ Model roadmaps and imminent drops
Signals worth planning around: release‑quality hints and timelines from major vendors. Useful for budgeting eval time and integration windows. Excludes today’s Google image rollout (feature).
Signals stack up for imminent Claude Opus 4.5 and Claude Code Desktop
Anthropic’s own UI and leaked configs now strongly suggest a Claude Opus 4.5 launch and a dedicated Claude Code Desktop app are days or hours away, not quarters out. The Claude web app shows a hidden Spotlight banner with codename “octopus_owl_obsidian,” internal React code hard‑wires a "/claude-code-desktop" href, and a debug view leaks a model ID "claude-opus-4-5-20251120" with 32k token cap—all classic signs that production wiring is in place and a feature flag flip is coming soon. hidden spotlight modal code desktop href opus 4p5 config
Following Anthropic funding, which covered Anthropic’s $45B+ backing and huge Azure+NVIDIA compute budget, this is the concrete product side of that story: leakers now claim Opus 4.5 and Claude Code Desktop are being prepared for release today, so orgs already invested in Claude should budget near‑term time for head‑to‑head evals and IDE workflow testing. release rumor thread opus 4p5 leak
Elon Musk targets Grok 4.20 “major improvement” upgrade by Christmas
xAI is already talking about the next Grok iteration, with Elon Musk saying the Grok 4.20 upgrade “which is a major improvement, might be ready by Christmas,” giving teams a rough window to plan evals and possible migrations from 4.1 Fast. That promise lands on top of strong current performance, where Grok 4.1 Fast is already beating GPT‑5, Claude 4.5, and Gemini 3 Pro on several agent benchmarks (Reka Research‑Eval, FRAMES, τ²‑Telecom) at lower cost, so expectations for 4.20 are centered on even better tool use and long‑context autonomy. grok 4p20 tease grok 4p1 benchmarks
Perplexity’s Comet agentic browser quietly appears on Android Play Store
Perplexity’s Comet, billed as “an agentic AI browser for Android,” now shows up as a listing in the Google Play Store with app icon, description, and an “Unregister” button, which is usually what you see right before a staged rollout. The listing highlights voice‑driven commands, research‑style answers, and agentic browsing, so Android teams should assume a near‑term launch where users can search, read, and shop through an AI layer instead of a traditional mobile browser, and start thinking about how their sites and APIs will behave under autonomous browsing traffic. comet android listing
🛠️ Agent architectures: subagents, context, and code execution
Practical guidance from teams shipping agents: scoped subagents, context editing, and when to split long runs. Excludes model release news. Useful for engineering leads hardening agent loops.
Anthropic: code execution plus smart context editing boosts Claude agents by 39%
Anthropic’s Claude developer platform team shared that letting Claude both write and run code inside a secure environment, combined with explicit context management tools (external memory plus context pruning), produced a 39% performance improvement on their internal agent benchmarks.Claude platform talk The core pattern is simple but powerful: treat Claude as a worker sitting at a computer with a shell, editor, and tools, then aggressively store long‑lived information outside the context window and clear stale tool output so the model sees only what’s relevant for the current step. For engineering leads, this is a strong data point that you can get big gains from disciplined context editing and real code execution, without elaborate agent harnesses or over‑engineered orchestration.
Replit pitches core-loop subagent orchestrator as “Year of the Subagent” pattern
At AIE Code NYC, Replit described an agent architecture where a single "core loop" dynamically spins up specialized subagents in parallel, then merges their work using merge‑conflict‑aware task decomposition and a synthesizer stage.Replit slide The talk framed this as part of a broader "Year of the Subagent" trend, where production teams converge on scoped autonomy, parallelism, and low‑entropy context compaction instead of one giant, monolithic agent run.subagent patterns Practically, it means your main agent spends tokens deciding which subtasks to spawn and how to reconcile them, while human users stay focused on high‑level intent instead of micromanaging tool calls or long chats.
Sourcegraph warns Amp coding threads beyond ~350k tokens hurt quality
Sourcegraph’s cofounder shared that long‑running coding agent sessions in Amp (beyond roughly 350k tokens) “so rarely yield good results,” especially for exploratory work that accumulates lots of intermediate steps.Amp thread advice Following up on Amp agent model, where Amp switched its default model to Gemini 3 Pro, the team is now steering users toward many smaller, parallel threads for repetitive tasks and is building a subagent to automate that splitting. Amp already surfaces warnings as threads grow and its manual advises users to restart or branch sessions; stronger nudges are under consideration, which is a useful signal for anyone designing their own guardrails around context growth in coding agents.
Kilo Code shows prompt-to-game loop with built-in deploy
Kilo Code used Gemini 3 Pro as the engine behind an agentic workflow that generated the full code for a classic platformer (“Kilo Man”) from a single prompt and then shipped it in seconds via Kilo Deploy.Kilo game demo The demo underscores a practical architecture: an AI coding core that owns project scaffolding and iteration, plus a tightly integrated deploy surface so the same loop can compile, run, and publish without humans wiring CI/CD each time.Kilo Man game For teams experimenting with AI‑built apps, it’s a concrete example of how far you can push a "prompt → code → live URL" pipeline when code execution and deployment live inside the same agent system.
🛡️ Agent/IDE security: prompt‑injection exfil and mitigations
Real‑world exfil vectors for agentic IDEs resurface, and a defensive utility ships. For teams rolling Antigravity‑class IDEs or MCP apps. Excludes broader policy changes.
Markdown image exfil bug resurfaces across agentic IDEs
Security researchers are pointing out that the same Markdown image–based data‑exfiltration bug that was reported and fixed in GitHub Copilot Chat for VS Code has now shown up in newer agentic IDEs like Antigravity and reportedly remains unfixed in Windsurf, underscoring a repeating class of vulnerabilities rather than one‑off mistakes. Building on earlier coverage of Antigravity’s exposure to the “lethal trifecta” prompt‑injection pattern Antigravity exfil, Simon Willison notes that Copilot patched an attack where a malicious repo prompt convinced the agent to construct a URL embedding sensitive data and render it as a Markdown image—causing the client to silently leak secrets via an HTTP request—while Windsurf appears to still allow the same pattern today copilot exfil blog, with full exploit details in the original writeup security blog post. For anyone shipping IDE agents or MCP-style tools, this is a strong nudge to treat Markdown rendering as an outbound network surface: disable remote image loads in agent views, strip or sandbox ![]() generated by the model, and add explicit allow‑lists for tool‑constructed URLs rather than assuming “read‑only” contexts are safe.
DSPy Spotlight adds production defense for indirect prompt injection
A new utility called DSPy Spotlight has been released to harden DSPy-based applications against indirect prompt injection, giving teams a reusable defense instead of ad‑hoc regex filters. Esteban de Saverio describes Spotlight as a "production-ready" layer for DSPy that inspects and constrains what parts of retrieved or tool-generated content the model can actually attend to, aiming to block untrusted instructions from web pages, docs, or tools before they hijack an agent’s behavior dspy spotlight repo, with code, benchmarks, and a demo available on GitHub for immediate integration into existing DSPy pipelines github repo. For engineers rolling their own agents on DSPy, this is a concrete off‑the‑shelf option to start addressing the same injection and exfiltration issues now surfacing in IDE agents, without having to invent a full threat‑modeling and masking system from scratch.
⚖️ EU shifts privacy/AI rules to cut friction
Reports indicate the EU will relax parts of GDPR and delay high‑risk AI enforcement to reduce compliance burden—material for EU go‑to‑market and data strategy. Agent/IDE security covered separately.
EU plans to relax GDPR and delay AI Act enforcement to cut compliance burden
The European Commission is preparing a "Digital Omnibus" package that softens parts of GDPR and the AI Act to lower compliance costs and unlock more data for AI, including looser rules for de‑identified data reuse, browser‑level cookie controls, and a 12–18 month delay on high‑risk AI obligations, with an estimated €5B in admin savings by 2029. The plan would let firms train models on personal data without per‑user consent if they still follow core GDPR safeguards, reduce cookie pop‑ups by treating many cookies as low‑risk and centralizing consent in the browser, and postpone strict requirements on high‑risk systems like credit scoring or policing until technical standards and tooling catch up—critics frame it as a rollback of privacy and AI protections, while AI builders get a clearer, more permissive runway for EU data strategy and deployment planning eu law overview.
🗣️ Voice AI at scale: new markets and enterprise usage
Voice agents expand internationally and show concrete enterprise usage metrics. Relevant for CX leaders and latency‑sensitive apps. Model launches are out of scope here.
ElevenLabs launches in Korea with sub‑0.5s Agent Platform for enterprises
ElevenLabs has officially entered the Korean market, pairing a new local team with flagship partners MBC, ESTsoft, Krafton, and SBS to make Korea a hub for voice AI in Asia korea launch local partners. In context of voice roadmap that sketched a split between a Creative Platform and an Agent Platform, this move puts the Agent side firmly into production: ElevenLabs says its platform already powers real-time, multi-language support and other conversations for large enterprises with latency below 500 ms per turn agent platform.
For people building latency-sensitive agents—phone support, in-app guides, interactive characters—the sub‑0.5s end-to-end promise matters more than model specs. Korea’s near-universal mobile coverage and top-ranked 5G mean users will notice if the agent ever feels like it’s "thinking" instead of talking; launching there is a stress test for the real-time stack as much as a go-to-market play korea context. The partnerships also hint at use cases beyond support, from entertainment and broadcasting (MBC, SBS) to gaming (Krafton) and productivity software (ESTsoft), which will pressure-test things like multi-speaker handling, cross-lingual dialogue, and sustained sessions inside existing apps rather than toy demos. If you’re evaluating voice infra, the message is clear: Agent-grade platforms are now competing on sub-second responsiveness and regional depth, not only on raw synthesis quality.
ElevenLabs powers 1.5M AI mock interviews for Apna job seekers
Apna, a major Indian jobs platform with 60M users, has run over 1.5 million AI-powered mock interviews using ElevenLabs voices, totaling 7.5 million minutes of spoken feedback for candidates preparing for roles across sectors usage stats case study. For AI leaders in CX and education, this is a concrete proof point that low-latency, emotionally expressive, bilingual (Hindi/English) TTS can scale to millions of real-time interactions while staying responsive enough to feel like a live interviewer, rather than a batch tool.
The deployment leans on ElevenLabs’ streaming stack (150–180 ms response times per the case study) to keep back-and-forth dialogue natural even on lower-end mobile connections, which is the real constraint in India rather than GPU supply latency details. For hiring and L&D teams, the interesting part is not just the volume but the granularity: interviews are tailored by role, company, and rubric, with an orchestration layer that combines ASR, NLU, and a massive graph of ~500M micro-models so feedback is specific and not generic coaching latency details. This shows how voice agents can move from "FAQ bots" to structured skill assessment, and gives a clear reference architecture for anyone trying to deploy high-throughput, bilingual voice experiences in emerging markets.
🎨 Creative AI beyond Google
Non‑Google creative/vision updates and demos concentrated today. Excludes Nano Banana Pro (feature). Useful for teams tracking segmentation, multi‑frame video, and procedural coding demos.
Dreamina MultiFrames turns 10 stills into a 54s, prompt‑controlled video
Dreamina’s new MultiFrames feature lets you upload around ten keyframe images, specify per‑frame durations and camera moves, and then glue them together with natural‑language “between frame” prompts to generate a smooth, long video in one shot. A featured demo walks a character through 10,000 years of history—from Stone Age caves to a near‑future city—using era‑specific keyframe prompts plus transition prompts like “castles evolve into Renaissance domes” to produce a 54‑second, edit‑free sequence that would previously require timeline work in a video editor multiframes overview ui walkthrough era keyframes.

Meta’s SAM3 shows robust real‑world video segmentation in early creator tests
Creators are already stress‑testing Meta’s new Segment Anything Model 3 on quirky inputs, with clips like a cat “playing” a didgeridoo staying well within distribution while the model cleanly segments and tracks the subject over time. Building on the initial SAM3 and Playground launch SAM3 release-playground, today’s demos highlight how text+point/box prompts can drive precise video masks for creative editing workflows and effects compositing at scale sam3 cat demo sam3 feature summary Meta sam3 blog.

ImagineArt 1.5 Preview climbs to #3 on Artificial Analysis text‑to‑image ELO
ImagineArt’s new 1.5 Preview text‑to‑image model has jumped to #3 on Artificial Analysis’ global Image Arena, with an ELO of 1187 and over 3,000 head‑to‑head appearances, trailing only Seedream 4.0 and 3.0 elo leaderboard. This places it ahead of Imagen 4 Ultra Preview and Gemini 2.5 Flash (Nano‑Banana) in that specific ranking, giving art teams another strong non‑Big‑3 option to A/B test for style diversity and licensing flexibility.
KAT‑Coder‑Pro auto‑codes a procedural Minecraft‑style Christmas house in three.js
Kwai’s KAT‑Coder‑Pro coding agent recreated a community “Minecraft style snowy winter night time Christmas house” demo by generating the entire three.js scene procedurally from a single natural‑language prompt kat coder demo. For creative coders, it’s a concrete example of using an AI engineer not just for boilerplate but to stand up stylized 3D environments that you can then tweak by hand for lighting, materials, or gameplay.

Tencent teases HunyuanVideo 1.5 with sketch‑to‑3D style preview
Tencent’s Hunyuan team released a short HunyuanVideo 1.5 teaser showing a hand‑drawn white outline of a face morphing into a rotating 3D wireframe head, hinting at stronger structure and geometry handling for video generation hunyuanvideo teaser. For small studios already using HunyuanVideo, this points toward more controllable character animation and pre‑viz workflows once 1.5 is fully exposed via APIs.

💼 Commerce and enterprise adoption signals
Early agentic commerce and enterprise usage data points. Excludes infra CAPEX. Good for GTM and partnership teams.
Flowith Black Friday deal bundles Gemini 3 Pro and upcoming Banana 2 with deep discounts
Flowith is running its biggest Black Friday promotion yet: yearly plans are up to 80% off, and buyers get 2× credits plus access to Gemini 3 Pro now and Banana 2 the moment it ships flowith discount thread. This builds on earlier free Gemini 3 access for builders Flowith free tier, but turns it into a longer‑term commitment aimed at heavy AI content creators and agencies.
For AI engineers and leaders, this is a signal that third‑party "AI workspace" vendors are starting to use aggressive, telecom‑style annual bundles to lock in usage around specific frontier models, with explicit promises about future model upgrades baked into the commercial offer.
📈 Community pulse: model fatigue and competition narrative
Meta‑discussion is itself news today: rapid fire launches create fatigue, while observers reassess the leaderboard. Not product updates.
Community narrative shifts to “Google vs the rest” but race still open
Commentators are re‑framing the leaderboard as “mostly Google vs the rest,” pointing to Gemini 3’s big jump while also stressing that OpenAI, Anthropic and xAI still field top‑tier models and the outcome is far from settled open race view. Others describe Google DeepMind as “untouchable” right now in day‑one tests, even as they acknowledge GPT‑5‑series, Claude 4.5 and Grok 4.1 Fast are competitive on many tasks google advantage deepmind praise.
For engineers and execs, this mood shift matters: eval results now get interpreted through a story where Google is slightly ahead on reasoning and vision, but nobody assumes a permanent winner, which encourages multi‑vendor stacks and more nuanced routing instead of a single‑provider bet.
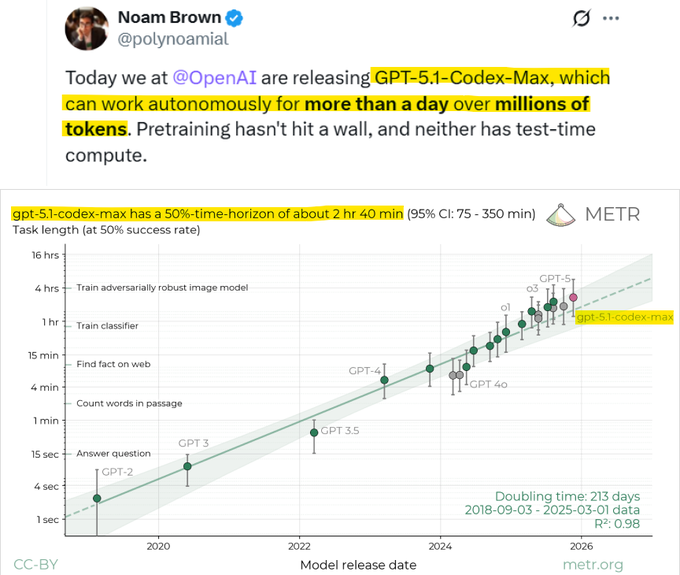
Community ties METR’s 2h40 time-horizon to OpenAI’s “AI research intern” roadmap
Builders are starting to connect METR’s estimate that GPT‑5.1‑Codex‑Max can autonomously handle ~2h40 of expert‑level work at 50% success to OpenAI’s public roadmap of “AI research intern” by 2026 and “fully automated research” by 2028 roadmap summary metr projection. In context of Codex horizon, which focused on the raw time‑horizon numbers, today’s discussion is less about a single benchmark and more about how fast autonomy might climb from a few hours to full‑day or multi‑day tasks.
For analysts and leaders, the takeaway is that the community now treats long‑horizon agent evals as leading indicators for job redesign: once models reliably push past a workday of coherent action, roles like junior SWE or research assistant will likely be the first to be structurally rethought rather than just “augmented.”
Commentators highlight 300× yearly drop in “price per unit of intelligence” and warn there will be no bailout
One observer claims that in roughly a year the “price per unit of intelligence” has fallen about 300×, arguing that we’re still at the very start of that curve 300x cost claim. Another viral clip stresses that when the AI bubble eventually corrects, there will be “no bailout,” framing current spending on models and GPUs as a pure market risk rather than something governments will rush to protect no bailout video.

For AI leaders, this mix of enthusiasm and caution shapes how boards think about AI capex: aggressive investment is easier to justify when unit performance improves this fast, but the lack of an implicit safety net should push teams toward more resilient business cases and slower, more measured scaling rather than reflexively chasing every new capability wave.
Developers hit “100% model fatigue” after three days of flagship launches
One engineer summed up the week as “Gemini 3 → GPT‑5.1 Codex Max → Opus 4.5 (soon)” and said they’d reached “100% AI model fatigue” in just three days, capturing how hard it is for builders to even evaluate, let alone adopt, each new frontier model fatigue comment. For AI teams, that pace means constant re‑benchmarking, shifting best practices, and real cognitive load about where to invest time.

The point is: even power users are starting to push back on the cadence, which is a useful signal for leaders deciding whether to chase every upgrade or standardize on a slower, more deliberate model refresh cycle.
Builders call out repeating hype cycle of each big model launch
A widely shared thread lays out a now‑familiar pattern: launch day euphoria where “AGI feels close,” a few days later people catalog the flaws and hallucinations, hype cools, and then the whole cycle restarts with the next release hype cycle note. In the same breath, folks note that Gemini 3 Pro still shows an 88% hallucination rate on one eval, identical to 2.5 Pro, as a reminder that benchmark wins don’t erase core failure modes hallucination eval.

This is why many practitioners are getting more disciplined about separating launch‑week vibes from slow, task‑specific testing, and about resisting pressure to migrate production workloads until the post‑honeymoon bugs and regressions are clearer.
🤖 Robots in factories and homes
Sustained momentum: factory KPIs showcased again and a low‑cost open home robot surfaces. For teams eyeing embodied AI deployments.
Figure shares BMW production-line footage and highlights lessons for Figure 03
Figure released new production-line footage and a write-up showing its Figure 02 humanoid running 10-hour shifts at BMW’s Spartanburg X3 plant, moving 90,000+ parts over 1,250+ hours and contributing to 30,000 vehicles, with reliability and mechanical design lessons feeding into the upcoming Figure 03 platform. Following up on BMW deployment KPIs, which covered the raw 11‑month stats, the new material gives engineers a clearer view of real cycle times, failure modes, and the types of repetitive pick-and-place jobs that are already viable for general-purpose humanoids in auto factories BMW deployment thread Production article Figure BMW article.

Sourccey teases 3’6" open-source home robot compatible with LeRobot
Sourccey previewed a roughly 3’6"-tall personal home robot that will be low cost, fully open source, and compatible with the LeRobot control stack, offering researchers and hobbyists an off-the-shelf platform for household manipulation experiments instead of custom hardware builds Home robot teaser. For embodied-AI teams, this points to a growing ecosystem of small, affordable robots where you can port the same policies and training pipelines used in simulation or lab rigs into a real domestic form factor.