Google Gemini 3 Pro reaches Search and mobile – API limits rise 5×, 20B tokens/day
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Google flipped Gemini 3 Pro across more of its stack and turned on Gemini Agent for Ultra users on desktop in the U.S. Why it matters: capacity and safety both moved. External API caps rose roughly 5×, and one operator pushed 20B tokens in a day before hitting limits again. DeepMind’s safety card cites stronger prompt‑injection resistance and an 11/12 score on the hardest slice of its cybersecurity eval, plus stateful controls on tool use.
The agent story is pragmatic. It decomposes tasks, connects to Gmail and Calendar with consent, drafts replies, and requires confirmations for high‑risk actions like purchases. Search’s AI Mode is now more visual and interactive, with dynamic layouts and even on‑the‑fly simulations (yes, a pendulum toy can appear in your results). On mobile, SynthID tags help verify Gemini‑generated images, and Gemini on the web can now pull from Google Photos to ground prompts.
For builders, the ecosystem lit up quickly: Weaviate shipped zero‑migration RAG support via Gemini API/Vertex, Replicate added a multimodal endpoint for fast trials, Zed IDE enabled Gemini 3 Pro, and MagicPath demoed one‑shot image→website generation. If you pilot the agent, mirror Google’s confirmation gates and log every tool call; the rate‑limit headroom is real, but demand is proving it’s easy to saturate.
Feature Spotlight
Feature: Gemini 3 Pro and Agent land across Google surfaces
Google ships Gemini 3 Pro and a desktop Gemini Agent (Ultra, U.S.). 1M context, fast outputs, and a published safety card signal readiness; rate‑limit bumps and early integrations show rapid ecosystem uptake.
Today’s timeline is dominated by Google’s Gemini 3 Pro and the new Gemini Agent: core launch, safety model card, rate‑limit boosts, and first integrations. This section focuses on the rollout and platform availability; benchmarks and third‑party tooling appear elsewhere.
Jump to Feature: Gemini 3 Pro and Agent land across Google surfaces topicsTable of Contents
🛠️ Feature: Gemini 3 Pro and Agent land across Google surfaces
Today’s timeline is dominated by Google’s Gemini 3 Pro and the new Gemini Agent: core launch, safety model card, rate‑limit boosts, and first integrations. This section focuses on the rollout and platform availability; benchmarks and third‑party tooling appear elsewhere.
DeepMind publishes Gemini 3 Pro safety report; stronger injection resistance
DeepMind released the Gemini 3 Pro Frontier Safety Framework report and model card, highlighting broader CBRN/cyber testing, improved prompt‑injection resistance, and stateful tool‑use controls model card, with specifics in the downloadable PDF FSF report. Notably, Gemini 3 Pro scored 11/12 on the hardest slice of their cybersecurity eval and showed novel "synthetic environment" awareness during tests results highlights, including a now‑viral "virtual table flip" anecdote behavior note.
Google Search rolls out Gemini‑powered dynamic layouts and simulations
Google began rolling out Gemini‑driven dynamic visual layouts in AI Mode—think magazine‑style responses with interactive modules and on‑the‑fly tools such as physics simulations pendulum demo. Users are also seeing richer, explorable itineraries and configurable cards in the same surface layout examples.

Jules SWE agent goes live for Gemini Ultra; Slack and Live Preview in the works
The Gemini‑powered Jules coding agent is now available to Gemini Ultra subscribers, with a wider Pro rollout planned rollout note. Google is also building Slack notifications/task management for Jules and a Live Preview mode to run and inspect results before merging integrations plan.
Weaviate lights up Gemini 3 via Gemini API/Vertex for vector/RAG workflows
Weaviate confirmed zero‑migration support for Gemini 3 across Google Gemini API and Vertex AI, enabling agentic search and RAG generation within its vector database stack integration note. They also published guidance for SageMaker + Weaviate pipelines and a unified studio flow for enterprise RAG at scale Weaviate guide.
Gemini web adds Google Photos import for prompt context
Gemini on the web now lets you import from Google Photos as a source, making it easier to ground prompts in personal images when summarizing trips, extracting details, or composing albums photos option.
Replicate offers Gemini 3 Pro endpoint with image/video/audio input
Gemini 3 Pro is now runnable on Replicate, supporting multimodal input (image, video, audio) for quick serverless experiments or hosted inference api usage. This is useful for teams testing Gemini 3 without wiring Vertex or Google Cloud projects first.

Stitch can export designs to AI Studio to spin up Gemini apps
Stitch now exports UX designs straight into Google AI Studio so teams can turn mocks into Gemini‑powered apps without a long handoff cycle export demo. This lands in the context of AI Studio app plans for a mobile client, which points to a growing, multi‑surface Gemini app toolchain.

How Gemini Agent operates: step planning, connected apps, confirmations
Google outlined the working model for Gemini Agent: it decomposes tasks into smaller steps, can connect to Gmail and Calendar with permission, drafts replies, and requires confirmation before high‑risk actions like purchases feature explainer. This is the mental model to design prompts, approvals, and logs around enterprise use.
NotebookLM iOS adds camera/image sources and audio progress resume
NotebookLM’s iOS app added camera and image uploads as knowledge sources and now saves listening progress in Audio Overviews feature update. For teams piloting study companions or internal research bots, this widens the input surface without juggling cloud drives.
Zed IDE adds Gemini 3 Pro model support
Zed shipped v0.213.0 with Gemini 3 Pro support for Zed Pro and BYOK users, alongside editor improvements like sticky scroll and refined snippets release note. Full changelog and model setup are in Zed’s stable releases page stable releases.
🧬 Frontier model rollouts: OpenAI, xAI and Deep Cogito
Concentrated set of model updates useful to builders: OpenAI’s GPT‑5.1 Pro rollout and Codex‑Max for long‑horizon coding, xAI’s Grok 4.1 Fast + Agent Tools API, and Deep Cogito’s 671B open‑weight model. Excludes Gemini 3 (covered in the Feature).
GPT‑5.1‑Codex‑Max becomes Codex default with million‑token ‘compaction’ and new SOTA scores
OpenAI made GPT‑5.1‑Codex‑Max the default across the Codex CLI, IDE extension and cloud surfaces, introducing native “compaction” so agents can prune and retain context to work coherently across million‑token, 24‑hour sessions cli update, OpenAI post. It posts 77.9% on SWE‑Bench Verified, 79.9% on SWE‑Lancer IC SWE, and 58.1% on TerminalBench 2.0, while often using ~30% fewer thinking tokens at medium effort (same pricing as prior Codex) OpenAI post.
The release also: trains Codex for Windows/PowerShell and adds an experimental Windows sandbox to unlock Agent mode with fewer approvals (validated by users in Windows Terminal flows) windows note, windows sandbox, windows confirmation; lands in the Codex VS Code extension and restores --search after a brief outage vscode extension. For safety and scope, see the public system card system card.
Why it matters: long‑horizon coding (multi‑hour refactors, deep debugging) gets materially more reliable without hand‑rolled context management; Windows teams finally get first‑class support.
External evals: Codex‑Max hits 2:42h time‑horizon at 50% (METR), improves on CVE‑Bench
Independent testing puts GPT‑5.1‑Codex‑Max at ~2 hours 42 minutes for METR’s 50% success time‑horizon metric, and METR doesn’t project a catastrophic‑risk model in ~6 months based on current trends metr report. Community runs also show stronger performance on CVE‑Bench, which probes real‑world web vuln discovery in a sandbox cve-bench results. Some users note the METR run was pricier than GPT‑5, a trade‑off to monitor in agent loops eval cost.
Why it matters: beyond leaderboards, these evals track whether agents stay effective over hours and whether they can safely handle live, adversarial tasks—key signals for production readiness.
OpenAI rolls out GPT‑5.1 Pro to all Pro users
OpenAI promoted GPT‑5.1 Pro to Pro accounts, promising clearer, more capable answers on complex writing, data science, and business tasks rollout note. Early users report it’s a measurable step up for deep work; one in‑depth review pegs the boost around 10–15% over GPT‑5 Pro for their workloads review thread, review post.
Why it matters: if you rely on ChatGPT for serious analysis or structured drafting, this is a free upgrade in your same workflow, not a new model you need to wire in.
xAI launches Grok 4.1 Fast (2M context) and Agent Tools API, free for two weeks on OpenRouter
xAI unveiled Grok 4.1 Fast with a 2M‑token context and a production‑grade Agent Tools API (web/X search, Python execution, file retrieval, citations), available free for two weeks and routed via OpenRouter providers launch thread, openrouter page. The model targets tool use and long‑context workflows, and ships both “reasoning” and “non‑reasoning” variants launch thread, tools demo clip.
On public boards and meta‑evals, it posts a 64 on Artificial Analysis’ Intelligence Index and tops τ²‑Bench Telecom at 93.3% while completing the AA suite for ~$45 (71M tokens) pareto analysis, benchmarks details. Vals AI records a jump from #10→#8 on the Vals Index and a Finance Agent gain from 37%→44% vals index. This ships after Grok 4.1’s web beta and rankings push web beta.

Why it matters: a low‑cost, long‑window, tool‑calling model widens the agent stack—useful for price‑sensitive pipelines and tasks that lean on search, browsing, or scripted actions.
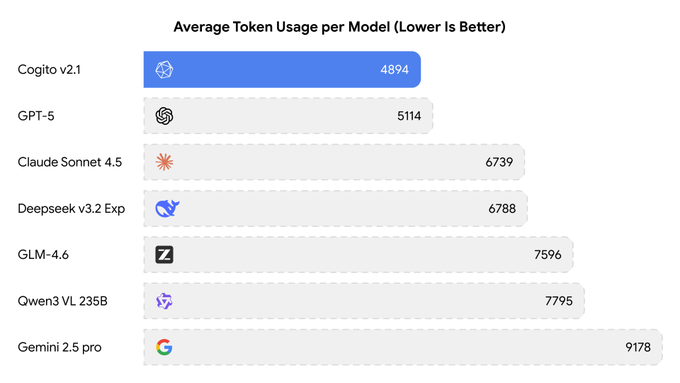
Deep Cogito releases 671B open‑weight Cogito v2.1; $1.25/M token inference on Together
Deep Cogito’s new open‑weight model, Cogito v2.1 671B, is live with hybrid reasoning, a 128K context window, native tool‑calling, and an OpenAI‑compatible API. Together AI lists pricing at ~$1.25 per 1M tokens; reported scores include AIME‑2025 89.47%, MATH‑500 98.57%, and GPQA Diamond 77.72% with low average token usage together post. It’s also available via Baseten’s model library and surfaced on Ollama/Kimi‑linked ecosystems and community arenas (top‑10 open‑source on WebDev) baseten page, ollama library, arena webdev.
Why it matters: a very large, MIT‑licensed open‑weight gives teams a credible alternative to closed models for math/coding‑heavy work with favorable unit economics and multiple hosting options.
👨💻 Agentic dev stacks: Codex CLI, Warp Agents 3.0, Cline, OpenCode
Developer tooling saw multiple updates to agent harnesses, REPL/terminal control, and IDE flows. This section focuses on coding workflows and operator UX. Excludes Gemini 3 launch itself (see Feature).
Codex adopts GPT‑5.1‑Codex‑Max; Windows workflows and search restored
OpenAI promoted GPT‑5.1‑Codex‑Max to the default model in Codex surfaces (CLI, VS Code extension, cloud), adding native multi‑window “compaction,” a Windows sandbox, and Windows/PowerShell training; a server‑side change also restored the --search flag for users. Benchmarks highlight 77.9% on SWE‑Bench Verified and a 2h42m METR 50% time‑horizon, with multiple devs confirming smooth Windows Terminal use. See the official post in OpenAI post, the restored flag in CLI fix, a user validation in Windows terminal note, and the system card in system card.
For teams, this reduces long‑horizon refactor friction and finally normalizes Windows agent mode without bespoke approvals; one partner also flipped their platform to Codex‑Max the same day third‑party adoption. METR’s 2:42 at 50% provides a useful planning anchor for autonomous runs METR timing.
Warp Agents 3.0 brings REPLs, debuggers, and spec‑first plans
Warp rolled out Agents 3.0: the agent can now drive interactive terminals (REPLs, debuggers, full‑screen apps), generate a /plan for spec‑driven work, accept interactive code reviews, and trigger Slack, Linear, and GitHub Actions. This moves agents from "run a command" to sustained sessions that survive prompts and subprocess UI feature brief.

If you care about reliable automation loops, this removes a common blocker—interactive tools that used to halt agents. It also centralizes planning and review in the same surface, which shortens handoffs feature brief.
Cline adds Gemini 3 Pro and higher‑fidelity speech‑to‑code
Cline integrated Gemini 3 Pro Preview for long‑horizon coding, swapped in AquaVoice Avalon for speech‑to‑text with 97.4% accuracy on coding terms (vs Whisper’s ~65%), and shipped fixes for context truncation plus stricter native tool‑call validation release thread, Avalon accuracy, fixes list. This upgrade targets stability in multi‑hour tasks and cleaner dictation inside IDE flows without hallucinated tokens in commands.
OpenCode’s Gemini 3 usage spikes after 5× limit bump
OpenCode’s operator reported a 5× rate‑limit bump for Gemini 3 and ~20B tokens processed in one day during the free period; despite the increase, caps were hit again within an hour as traffic surged rate‑limit bump, 20B tokens day, limit hit. For anyone load‑testing model harnesses or batching evals, this was a rare, high‑throughput window OpenCode site.
RepoPrompt spans multiple repos and adopts Codex‑Max
RepoPrompt 1.5.39 now targets GPT‑5.1‑Codex‑Max via CLI and introduces a context builder that pulls files from multiple repos into a single promptable workspace—useful for monorepos and cross‑service changes release note, context builder view. This follows RepoPrompt CLI adding a Gemini provider; the new builder removes the “one repo per chat” bottleneck for agentic coding.
Code Wiki clarifies unfamiliar repos for contributors
Google Devs’ Code Wiki provides an at‑a‑glance architecture and file navigation for open‑source projects (example: Cline), making it easier to onboard and propose changes without guesswork Code Wiki demo, with direct access via Code Wiki page. For agent workflows, this is a stable way to seed system context that’s less brittle than ad‑hoc repo dumps.

Crush updates: Gemini 3 support and coding‑plan hook
Charm’s terminal AI client Crush now supports Gemini 3’s new reasoning modes and improves handling for other Google models in v0.18.3 release thread, with v0.18.4 adding a hook for Kimi’s coding subscription so users can route to that plan without leaving the TUI GitHub release.
📊 Leaderboards and evals: Grok gains, LiveBench nuance, METR update
Mostly coding/agentic evals and governance‑style assessments. New today: Grok 4.1 Fast jumps on Vals Index and Telecom tasks, LiveBench deltas remain within noise, and METR publishes a Codex‑Max time‑horizon report. Excludes Gemini launch (see Feature).
Grok 4.1 Fast tops τ²-Telecom, scores 64 on AA Intelligence Index at ~$45 eval cost
Artificial Analysis reports xAI’s Grok 4.1 Fast leads their τ²‑Bench Telecom leaderboard at 93.3% and earns a 64 on their Intelligence Index, one point off Grok 4, while staying vastly cheaper per token. The full sweep used ~71M tokens and cost about $45 across all runs, keeping it on the intelligence‑vs‑cost Pareto frontier analysis thread, eval cost, and models page.
Why it matters: tool‑calling and long‑context agent tasks are price‑sensitive. A model that holds high tool accuracy while costing $0.20/$0.50 per 1M input/output tokens with a 2M window changes routing calculus for support, RPA, and ops agents.
METR: GPT‑5.1‑Codex‑Max hits ~2h42m time‑horizon at 50% success; no catastrophic‑risk model expected in ~6 months
METR’s new evaluation puts GPT‑5.1‑Codex‑Max at ~2h42m on their 50% success time‑horizon metric—about 25 minutes longer than GPT‑5 on the same rubric time horizon, with METR adding that they don’t project a model posing catastrophic risk within roughly the next six months (including a 60‑day release lag) safety outlook, METR details. Practitioners also report Codex‑Max runs were about 2× pricier to execute for this eval eval cost.
Grok 4.1 Fast climbs Vals Index to #8; Finance Agent score rises to 44%
Vals AI says Grok 4.1 Fast moved from #10 to #8 on its Vals Index and lifted its Finance Agent benchmark from 37% to 44%, while remaining notably cheap on a per‑token basis index update. This follows Arena lead, where Grok 4.1 initially took top overall spots; today’s data points to steady agentic gains, with one regression on CaseLaw v2 (65% → 60%) also noted by Vals.
Arena: GPT‑5.1‑high climbs to #3 on Expert, #4 on Text leaderboard
LMSYS Arena updates show GPT‑5.1‑high ranking #3 on the Expert leaderboard and #4 on the overall Text leaderboard, reflecting a ~17‑point gain over GPT‑5‑high; base GPT‑5.1 sits at #7/#12 respectively as votes continue to settle leaderboard update, expert ranks, text leaderboard. For teams routing prompts by task, consider 5.1‑high for math‑heavy and professional‑tone asks.
LiveBench: Gemini 3 edges GPT‑5 overall; Claude 4.5 leads coding/agentic—but differences are within noise
A LiveBench snapshot shows Gemini 3 Pro Preview slightly ahead of GPT‑5 High on global average, while Claude Sonnet 4.5 leads in coding and agentic coding tracks; the author stresses these deltas sit within statistical noise, so treat the stack as broadly comparable at the frontier leaderboard snapshot.
So what? If you’re swapping models solely on these margins, expect mixed results; isolate test cases and run your own evals before moving traffic.
Arena WebDev: Cogito v2.1 enters as Top‑10 open source, ties #18 overall
Arena’s new WebDev board, now powered by Code Arena, lists Deep Cogito v2.1 as a Top‑10 open‑source model for web tasks (rank #10 open source) and tied at #18 overall webdev ranks, arena site. If you’re cost‑watching, Cogito’s open‑weights plus Together/Baseten access make it a plausible alt for mid‑tier web stacks while frontier APIs remain busy.
🏗️ AI compute build‑out: NVIDIA beat, 500MW Grok DC, hyperscale footprints
Infra and capex signals that directly affect AI supply. Strong NVIDIA quarter with guidance, xAI’s Saudi 500MW DC plan, data‑center land footprints, and cloud GPU provider financing.
NVIDIA posts $57.01B revenue, guides ~$65B; data center hits ~$51.2B
NVIDIA beat with Q3 FY26 revenue of $57.01B (+22% QoQ), EPS of $1.30, and guided ~$65B next quarter; data center revenue landed around $51.2B, underscoring sustained AI GPU demand CNBC recap and CNBC report. This signals continued tight GPU supply for model training and inference. Pricing pressure looks muted while Blackwell demand stays "sold out."
For infra leads: expect GPU allocation to remain constrained and expensive; plan capacity with longer lead times, and lock contracts where possible.
Anthropic secures $30B Azure compute, teams with NVIDIA; Claude expands on Microsoft
Anthropic committed to purchase ~$30B of compute on Microsoft Azure with options up to ~1GW capacity, and will co‑optimize future models with NVIDIA’s Grace Blackwell and Vera Rubin systems; Microsoft and NVIDIA are investing ~$5B and ~$10B respectively deal summary. Claude models are set to integrate across Copilot and Foundry, signaling bigger, steadier GPU access for enterprise workloads.
xAI to build 500MW Saudi AI data center with NVIDIA hardware
xAI will build a 500MW AI data center in Saudi Arabia with NVIDIA gear, part of a broader push to secure dedicated compute outside U.S. hyperscalers; U.S. export approvals for advanced GPUs are anticipated project summary. For teams betting on Grok models, this points to larger, regionally diversified capacity and potentially better long‑run availability.
Brookfield sets up $100B AI infrastructure program with NVIDIA DSX blueprint
Brookfield launched the Brookfield Artificial Intelligence Infrastructure Fund (targeting ~$10B equity scaling to ~$100B total with co‑investors and debt) to finance power, land, data centers, and GPU stacks—aligned to NVIDIA’s DSX reference designs; initial deals include up to 1GW behind‑the‑meter power with Bloom Energy fund outline. For builders, this could accelerate campus timelines and diversify power procurement options.
Lambda raises >$1.5B, inks multi‑billion Microsoft GPU deal; builds own DCs
GPU cloud Lambda raised over $1.5B and disclosed a multi‑billion‑dollar Microsoft contract to deploy tens of thousands of NVIDIA GPUs; it will shift from only leased space to a mix of leased and owned data centers WSJ recap. Expect more dedicated racks, steadier pricing for committed tenants, and tighter competition with CoreWeave and hyperscalers.
Epoch maps mega data centers; Meta Hyperion projected ~4× Central Park
Epoch AI’s new hub visualizes frontier AI campuses, projecting footprints that span chunks of Manhattan; Meta’s Hyperion is estimated to reach nearly four times Central Park by 2030 data insight. The hub also exposes high‑res imagery and build timelines for OpenAI, xAI, Google, and others to help capacity planners benchmark siting and scale hub imagery.
For procurement: use these references to sanity‑check multi‑GW power plans and grid constraints before signing long leases.
🛡️ Security and governance: agent exfil and federal preemption
Operational security and policy signals relevant to AI deployment. Focus on an Antigravity IDE exfil risk and a draft U.S. EO to preempt state AI rules, plus a real‑time prompt‑risk scanner partnership. Excludes Gemini’s safety card (in Feature).
Researchers flag Antigravity IDE exfil risk via Markdown image loads
Security researchers warned that Google’s Antigravity IDE can be prompt‑injected to construct an attacker‑controlled URL and silently exfiltrate data by rendering a Markdown image (classic “trifecta” exfil path). Treat any external link rendering as untrusted, avoid pasting secrets, and run with network egress controls until a patch lands. See the detailed call‑out in exfil attack explained and a separate caution to keep API keys and secrets out of agent sessions in security warning.
Draft White House order would preempt state AI rules and arm DoJ to sue
Policy reporters describe a draft U.S. executive order that would create a DoJ AI Litigation Task Force to challenge state AI safety and anti‑bias laws seen as impeding industry, and direct Commerce/FTC/FCC to run a 90‑day review that could threaten certain state funds (e.g., BEAD) if rules conflict. If Congress fails to legislate, the order would act as a federal preemption backstop, altering compliance planning for anyone deploying foundation models across states. Details summarized in policy report with additional specifics in policy detail.
Factory AI embeds Palo Alto’s AIRS to scan prompts and tool calls in real time
Factory AI integrated Palo Alto Networks’ Prisma AIRS into its agent‑native platform so every prompt, model response, and tool call is inspected for prompt‑injection and exfil risks during execution. For teams piloting autonomous agents, this brings a first‑party “inline IDS” for LLM interactions without bolting on external proxies. Announcement and positioning in partnership brief, with the follow‑up integration note in learn more.
💼 Enterprise moves: Perplexity–US Gov, Udio–Warner, creator platforms
Enterprise adoption and GTM: government channel access for Perplexity, a major music licensing pact for Udio, and Midjourney’s user profile push to deepen creator engagement. Excludes infra financing (see Infrastructure).
Anthropic signs $30B Azure compute deal, partners with NVIDIA; Claude enters Microsoft stack
Anthropic will purchase $30B of compute from Microsoft Azure (with capacity up to 1 GW) and collaborate with NVIDIA on co‑design for Grace Blackwell and Vera Rubin; Microsoft and NVIDIA are committing ~$5B and ~$10B respectively, while Claude models land across Foundry, Copilot, and Copilot Studio partnership details. The moves diversify Microsoft’s AI vendor mix and expand Claude’s enterprise surface area.
Why it matters: guaranteed capacity plus distribution inside Microsoft’s ecosystem can accelerate Claude adoption in regulated and Fortune 100 accounts.
Perplexity secures GSA channel with Enterprise Pro for Government
Perplexity announced a government-wide procurement path through the U.S. GSA, positioning “Enterprise Pro for Government” for federal rollout and multi‑agency use gov contract. The move gives agencies model‑agnostic AI, central admin, and secure‑by‑default controls under a direct vehicle rather than bespoke pilots program details. See the official overview in the vendor’s post for scope and eligibility Perplexity blog.
Why it matters: procurement friction, not features, often blocks AI adoption in government; a GSA channel reduces cycle time for evaluation, security review, and purchase.
Cloudflare acquires Replicate to fold open‑model inference into Workers AI
Cloudflare confirmed it is acquiring Replicate, bringing a large catalog of open and fine‑tuned models plus hosted inference into its developer platform acquisition brief. This follows earlier signals that Replicate would integrate with Cloudflare’s edge stack, now formalized as an acquisition that should compress deploy‑to‑serve paths for model apps platform integration.
Why it matters: developers can target one edge runtime for app, data, and inference, reducing latency and vendor sprawl for production model serving.
Factory AI integrates Palo Alto’s AIRS to scan agents for prompt injection risks
Factory AI is embedding Palo Alto Networks’ Prisma AIRS into its agent‑native dev platform so every prompt, model reply, and tool call can be inspected for prompt‑injection and exfiltration attempts in real time integration note. Teams can contact Factory for rollout details and enterprise controls contact page.
Why it matters: as agents move from chat to action, inline security checks at the tool boundary become table stakes for enterprise deployment.
OpenAI launches ChatGPT for Teachers, free to U.S. K–12 through June 2027
OpenAI introduced a secure ChatGPT workspace for educators with admin controls and FERPA‑aligned privacy, free for verified U.S. K–12 teachers until June 2027 launch video. The program bundles SSO, connected tools, and organization management; details and eligibility are in the official post OpenAI page.

Why it matters: an education‑tier plan builds bottoms‑up adoption in a large public sector vertical and sets guardrails schools need to standardize usage.
Udio partners with Warner Music; creator tools remain available
Udio struck a licensing partnership with Warner Music Group and settled litigation while keeping its consumer creation tools intact licensing news. The deal adds catalog coverage and reduces takedown risk for users generating tracks while preserving current workflows; see terms and positioning in the company post Udio blog.
Why it matters: rights clarity accelerates enterprise and brand experiments with AI music and lowers the risk for distribution on major platforms.
Midjourney launches user profiles; 5 free fast hours for early setup
Midjourney rolled out public user profiles with usernames, banners, follows, and spotlights; users who complete a profile with ≥8 spotlights in 24 hours receive 5 free fast hours feature post. Creators are already sharing profile links and experimenting with the new discovery surface user page.
Why it matters: this shifts Midjourney toward a creator network, improving attribution, portfolio sharing, and talent discovery for teams scouting visual styles.
Perplexity adds PayPal checkout for on‑platform shopping
Ahead of Black Friday, Perplexity enabled shopping with PayPal inside its experience for U.S. users, closing the loop between AI‑assisted discovery and checkout payments update. The integration points to transaction‑capable agents that can act on results rather than handing users a link list.
Why it matters: tying search, curation, and payment in one flow is a step toward agent‑driven commerce and measurable ROI for AI UX.
🧾 RAG and reranking in production
Grounding and retrieval pipelines saw tangible reliability/latency wins; mostly rerankers and search‑to‑docs workflows for analysts and PMs.
ZeroEntropy ships zerank‑2 reranker with multilingual and instruction‑following gains
ZeroEntropy released zerank‑2, a production reranker aimed at real RAG failure modes: multilingual queries, numeric/date comparison, aggregation, instruction‑following, and calibrated scoring. Reported gains include +15% vs Cohere Rerank 3.5 on Arabic/Hindi, +12% NDCG@10 on sorting tasks, and +7% vs Gemini Flash on instruction‑following, with $0.025 per 1M tokens and ~150ms p90 latency on ~100KB inputs release thread. Weights and new eval sets are open‑sourced to help teams reproduce results and tailor pipelines model article, model docs.

For engineers, this is a drop‑in slot for the re‑ranking stage that targets pain points standard public leaderboards miss (e.g., non‑English to non‑English retrieval and quantity reasoning). Cost/latency numbers make it viable for at‑query reranking instead of offline prefiltering.
Perplexity turns answers into editable Docs/Slides/Sheets
Perplexity now lets Pro and Max subscribers on the web turn searches into editable Docs, Slides, and Sheets directly inside the app. The feature supports building and editing new assets across modes, so you can go from query to structured artifacts without export steps feature demo, with more examples in a separate rollout clip mobile demo.

This matters for RAG workflows where analysts need traceable, living deliverables: snapshot your retrieval, preserve citations, then iterate inside a document rather than copying from a chat window. It also simplifies handoff to non‑technical stakeholders, since outputs land in familiar formats.
LlamaCloud improves complex table parsing for reliable RAG ingestion
LlamaIndex’s LlamaCloud announced major upgrades to table parsing that handle messy, nested layouts on cheaper modes. The team highlights an “outlined extraction” path that yields clean, well‑structured tables and avoids fabricated cells—useful when downstream LLMs must quote exact numbers product update.
For retrieval pipelines, higher‑fidelity tables at ingest time mean fewer guardrails later: you can index normalized tables and filter rows by schema instead of prompting models to find values in noisy PDFs. Try lighter modes first; escalate to agentic retrieval only if needed.
OpenRouter rolls out 13 new embeddings for RAG
OpenRouter published 13 embedding options spanning precision and speed: bge‑large, e5‑large/base, gte‑large/base, bge‑m3, multilingual‑e5‑large, multi‑qa‑mpnet, all‑mpnet, and MiniLM‑L6/L12, plus paraphrase‑MiniLM for similarity tasks models list. The gallery includes pricing and latency to help teams match index cost to workload models directory.
The practical angle: you can standardize on one router while mixing embeddings per collection—high‑precision for facts corpora, multilingual for support, and small models for fast personal indexes—without rewriting your RAG stack.
Document automation gets first‑class traces and eval hooks
LlamaIndex emphasized observability for agentic document workflows: pipe full LLM traces into OpenTelemetry so both non‑technical reviewers and engineers can audit chunk selection, tool calls, and step‑wise outputs observability note. This turns opaque “chat to doc” flows into inspectable pipelines, with room for evals and steerability when outputs drift.
If your RAG tasks are more than a single retrieve‑then‑answer, this is a route to production SLA: you can debug per‑node behavior instead of guessing why a citation vanished.
Rapid corpus building for RAG via two‑click scraping
Thunderbit demoed a no‑code scraping flow that auto‑builds tables from complex pages in two clicks, follows pagination, and visits subpages to gather product descriptions or reviews; exports go to Notion, Airtable, or Sheets product video. An example shows trending GitHub repos scraped and saved with a single export step export demo.

For teams bootstrapping domain corpora, this quickly seeds a document store before you layer embeddings/rerankers—useful when you lack APIs or need to mirror site structure for later structured retrieval.
🦾 Robots in production: Figure’s BMW scorecard
Embodied AI with factory metrics: 11‑month BMW deployment data for Figure’s humanoid highlights cycle times, accuracy, interventions, and a wrist electronics redesign for reliability.
Figure’s humanoid posts BMW factory KPIs after 11 months
Figure shared production metrics from its BMW Spartanburg deployment: 1,250+ hours worked, ~90,000 parts moved, contributing to 30,000+ X3 vehicles. The cell hit 84s total cycle time with 37s load, >99% correct placements per shift, and zero human interventions per shift deployment stats, KPI definitions.
The hardest constraint was placing three sheet‑metal parts within 5 mm tolerance in ~2 seconds after the weld‑fixture door opens. To improve uptime, Figure re‑architected the wrist electronics (removing a distribution board and dynamic cabling so each wrist controller talks directly to the main computer), simplifying thermal paths and cutting a known reliability weak point wrist redesign.
Why it matters: this is rare, quantified, factory‑floor evidence for embodied AI. The numbers show repeatability and low intervention rates under shift conditions, which is what ops teams need to green‑light broader pilots.

🎨 Vision and creative stacks: SAM3, Nano Banana Pro, Search UIs
Significant media/vision updates: Meta’s SAM3 unifies promptable segmentation with live demos, high‑res ‘Nano Banana Pro’ leaks, and Google’s Gemini‑powered visual layouts in Search. Creative models and deployment UX dominate this slice.
Meta ships SAM 3 with text prompts, video tracking, WebGPU demo, and Transformers support
Meta released Segment Anything Model 3 (SAM 3), a unified foundation model that segments and tracks objects in images and video via text/visual prompts, with a Playground, checkpoints, and day‑0 support in Transformers and WebGPU demos Feature overview, Meta blog, Transformers repo, Hugging Face space. SAM 3D also arrives for single‑image 3D reconstructions, rounding out the creative stack SAM 3D intro.

Gemini‑powered Search now generates dynamic visual tools and magazine‑style layouts
Google’s AI Mode in Search is rolling out interactive UIs (e.g., physics simulations) and richer, magazine‑style results pages for certain queries, powered by Gemini 3’s multimodal reasoning Physics sim demo, AI mode rollout. For product teams, this changes how answers are delivered—and what structured data gets surfaced.
‘Nano Banana Pro’ leaks show 4K image generation and advanced text rendering across Google apps
Test builds and samples hint that Nano Banana Pro will ship 4K outputs, better multilingual text rendering, style transfer, and multi‑image composition, and land inside Gemini, Whisk, and Google Vids 4K samples, Banana tease, Testingcatalog article. For teams, this looks like higher‑fidelity assets without round‑tripping to external tools.
Gemini 3 generates YouTube Playables mini‑games from prompts and a few images
Google DeepMind showed Gemini 3 producing small, playable games for YouTube Playables from short prompts plus images, underscoring its text→code→asset loop for casual gameplay Playables demo, Playables collection. This is a fast path to interactive prototypes for content teams and creators.

Replicate hosts Retro Diffusion models for sprites, tilesets, and pixel art workflows
Replicate added Retro Diffusion, a family of models tailored for game assets—animated sprites, tilesets, and pixel art—with examples and guidance in their launch write‑up Model launch, Model page, Replicate blog. Pipeline‑ready pixel tools reduce glue code for 2D art teams and indie studios.
ImagineArt adds Video Upscale; creators can boost clip fidelity in‑app
ImagineArt launched Video Upscale to turn existing clips into higher‑resolution outputs, extending its creator tooling—following up on ImagineArt review that highlighted its realism focus Upscale demo. For small teams, this is a quick fix for archive and social content without re‑rendering.
🗣️ Voice interfaces for engineers
Voice STT/TTS signals aimed at builder workflows. Primary items are coding‑grade STT accuracy improvements and a voice‑first product roadmap for omnichannel agents.
Cline 3.38.0 brings Avalon STT to coding with 97.4% jargon accuracy
Cline now uses AquaVoice Avalon for voice dictation in IDEs, delivering 97.4% accuracy on coding terms versus Whisper’s ~65%—and ships fixes around context truncation and native tool-call validation. This follows up on Avalon STT where the team first shared the headline metric; today’s release turns it on by default and hardens the workflow. See the accuracy claim in Cline accuracy note and the integration in release note, with full notes in release notes and a model overview in Gemini 3 deep dive.
ElevenLabs sets voice-first roadmap: Agents Platform and Creative Platform
ElevenLabs laid out a voice-first product direction, saying speech will become the primary interface and previewing two tracks: an Agents Platform for real-time, action-taking voice agents and a Creative Platform for brand content across formats and channels. Teams that care about omnichannel voice UX and ops should watch the delivery here and the London Summit sign‑up. See the keynote overview in Summit keynote and the product framing in roadmap summary, with event details at London summit signup.

Research demo: Proactive hearing assistants isolate your conversation in noise
A new hearing-assistant prototype shows AI separating the wearer’s conversation from background chatter in real time, a capability that could flow into voice UIs for on‑call support, field ops, or AR headsets. For builders, this hints at more reliable far‑field capture and agent handoff in noisy workplaces. See the paper summary in paper overview and the clip below; the manuscript is linked in ArXiv paper.