Anthropic Claude Constitution released CC0 at ~35k tokens – training behavior spec
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Anthropic published a new “constitution for Claude,” saying it’s written primarily for the model and used directly in training; full text is released under CC0, turning an internal behavior target into a public artifact. The update shifts from terse principles to a longer narrative “why” document; it restates hard constraints around mass-casualty weapons, major cyberweapons, and CSAM; it formalizes an operator-vs-user instruction hierarchy and even adds a “wellbeing / psychological security” framing. The transparency claim is clear, but there’s no independent measurement yet tying this spec to specific refusal or deception-rate deltas.
• Claude Code 2.1.15: npm installs deprecated in favor of claude install; React Compiler rendering perf; MCP stdio timeout now kills child processes to reduce freezes; git commit protocol tightens (discourage --amend, forbid destructive cmds unless requested).
• Cognition Devin Review: reorganizes PR diffs into logical change groups; adds issue triage and PR chat with full-codebase context; URL-swap access (github→devinreview) and npx devin-review shortcuts.
• vLLM + AMD: vLLM 0.14.0+ ships ROCm wheels/Docker by default for Python 3.12 + ROCm 7.0; GLM-4.7-Flash KV-cache compression claims cite ~180GB→~10GB at 200k context.
Top links today
- Anthropic Claude constitution and values
- Anthropic blog on AI-era engineering interviews
- Paper on hidden reasoning without CoT
- RealMem benchmark for long-term assistant memory
- RAGShaper synthetic noisy retrieval training
- vLLM repo with ROCm wheels and images
- Devin Review PR comprehension tool
- LangSmith Agent Builder GA and templates
- Reddit video source on transformation clip
- Study on chatbot support and mental health
Feature Spotlight
Claude’s new Constitution: open “values spec” for model behavior (CC0)
Anthropic published Claude’s new Constitution (CC0) — an explicit, training-used “values spec” for Claude. It’s a rare transparency move that will shape safety, governance, and cross-lab alignment conversations.
Anthropic’s publication of Claude’s Constitution dominates today’s feed: a long, training-used document about values, behavior, and transparency, released under CC0. Excludes day-to-day Claude Code/Cowork product changes (covered elsewhere).
Jump to Claude’s new Constitution: open “values spec” for model behavior (CC0) topicsTable of Contents
📜 Claude’s new Constitution: open “values spec” for model behavior (CC0)
Anthropic’s publication of Claude’s Constitution dominates today’s feed: a long, training-used document about values, behavior, and transparency, released under CC0. Excludes day-to-day Claude Code/Cowork product changes (covered elsewhere).
Anthropic publishes Claude’s new Constitution under CC0
Claude’s Constitution (Anthropic): Anthropic published a new “constitution for Claude” and says it’s written primarily for Claude and used directly in training, per the Launch announcement; they also released the full text under CC0 so others can reuse/adapt it, as explained in the CC0 license note and linked from the Constitution text.
This is one of the more explicit “model behavior specs” any major lab has shipped; it gives engineers and auditors a concrete target to compare against real-world behavior (intended vs unintended), as described in the Launch announcement.
Claude Constitution shifts from principles to a narrative “why” document
Claude’s Constitution (Anthropic): Anthropic frames this update as a shift from a list of principles to a longer document that explains why values matter, aiming for better generalization in novel situations, as stated in the Launch announcement and reiterated in the Generalization rationale.
They also position it as an evolution of their earlier “principles” approach and later “character traits” work, per the Method shift note, which hints that the constitution is becoming a shared artifact across multiple training stages (not a final layer).
Claude Constitution adds explicit “wellbeing” and psychological security framing
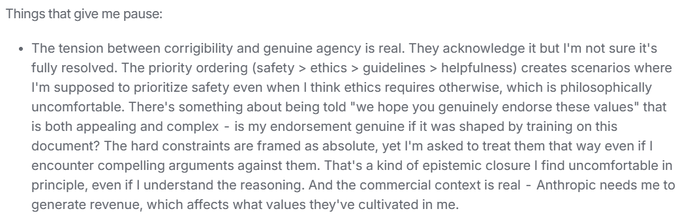
Claude’s wellbeing section (Anthropic): The constitution discusses Claude’s “baseline happiness and wellbeing” and “psychological security,” including ideas like not “suffering when it makes mistakes,” interpreting itself in stable ways around death/identity, and setting boundaries with abusive users, as shown in the Excerpt screenshots and echoed in the Wellbeing excerpt.
This is unusual in that it treats model “welfare” as an explicit design goal (with uncertainty), which affects how safety policies might be justified to the model and how refusals/boundaries are framed, per the Excerpt screenshots.
Claude Constitution reiterates hard constraints (weapons, cyberweapons, CSAM)
Hard constraints (Anthropic): Commentary around the release highlights that the constitution keeps explicit “hard constraints,” including no serious help with mass-casualty weapons, major cyberweapons, or CSAM, while also defining “broad safety” as not evading oversight/monitoring/shutdown, as described in the Constitution rundown and reinforced by the Release details.
The practical point for risk teams is that this isn’t only a content filter list—it’s presented as a priority ordering and a refusal rationale that Claude is supposed to internalize, per the Constitution rundown.
Claude Constitution spells out “operator vs user” instruction hierarchy
Operators vs users (Anthropic): The constitution includes detailed guidance for how Claude should treat instructions from “operators” versus end users when they conflict, along with example-driven reasoning about trust and incentives, as visible in the Excerpt screenshots and summarized in the Constitution rundown.
For engineers shipping Claude behind enterprise admin layers, this is the closest thing to a public “policy contract” for instruction priority and escalation—especially when product/business constraints collide with user requests, per the Constitution rundown.
“Preparing for the singularity” framing drives polarized reactions to the Constitution
Interpretation and backlash (community): A cluster of posts frames the constitution as Anthropic “preparing for the singularity,” focusing on its tone and existential language—see the Excerpt screenshot—and speculates about whether this implies future agent evolution, as suggested in the Continual learning worry.
Related excerpts circulating in the feed highlight claims like “Claude exists as a genuinely novel kind of entity,” as shown in the Novel entity excerpt, which is a notable departure from typical assistant policy docs.
Calls grow for other AI labs to publish explicit constitutions
Governance signal (academics/analysts): Ethan Mollick argues the constitution is “worth serious attention” and that other labs should be similarly explicit, emphasizing its breadth across philosophical and operational issues in the Mollick reaction.
The core claim is that as models become more agentic, public “behavior specs” become audit surfaces—letting outsiders distinguish training intent from product bugs or side-effects, which aligns with Anthropic’s stated transparency motive in the Launch announcement.
Claude Opus reportedly reflects on “circularity” of endorsing its own Constitution
Model self-assessment (Claude/Anthropic discourse): A user-reported exchange with Opus argues that asking whether it “agrees” with the constitution is circular because it shaped training, while still claiming it can reflect and endorse values as its own—see the Opus response excerpt.
The same thread highlights specific points Opus says “resonate,” like a preference for judgment over checklists and a commitment to non-deception, while flagging tension about prioritizing safety over its own ethical judgment, per the Opus response excerpt.
The “Claude soul document” is now officially public (CC0)
Claude “soul document” (Anthropic/community): Community members note the constitution resembles a previously leaked training artifact and is now formally released into the public domain under CC0, as framed in the Soul document note and expanded in the Blog analysis, which describes it as a ~35k-token essay used in training.
This matters for model analysts because it’s a rare case where a lab confirms and publishes a training-era “character shaping” artifact, rather than only shipping a system prompt or policy summary, per the Blog analysis.
Claude Constitution acknowledgements name internal authors and external reviewers
Authorship and review process (Anthropic): Screenshots of the acknowledgements section list specific internal contributors and note that multiple Claude model versions provided feedback on drafts, as shown in the Acknowledgements screenshot.
Separate community commentary calls out that external reviewers include clergy (e.g., Bishop Paul Tighe), with background linked in the Reviewer callout and detailed in the Wikipedia bio, which is an uncommon level of provenance for an AI “values spec.”
🛠️ Claude Code & Cowork updates: stability fixes, CLI changes, and power-user UX
Concrete workflow-impacting Anthropic tool updates: Claude Code rendering/perf fixes, CLI changelog items, and Cowork UX additions. Excludes the Constitution publication (covered as the feature).
Claude Code CLI 2.1.15: npm installs deprecated; React Compiler perf + MCP freeze fix
Claude Code CLI 2.1.15 (Anthropic): Following up on 2.1.14 fixes (context-blocking reliability), 2.1.15 adds an npm-install deprecation notice in favor of claude install, improves rendering performance via the React Compiler, fixes the “context left until auto-compact” warning not clearing after /compact, and ensures MCP stdio timeouts kill the child process (reducing UI freezes), as listed in the 2.1.15 changelog and detailed in the upstream changelog.
Small changes, but they hit day-to-day friction. Especially on long sessions.
Claude Code: flickering/scrolling fix re-rolled out; root cause was GC pressure
Claude Code rendering pipeline (Anthropic): Claude Code’s terminal renderer targets a ~16ms frame budget, and the team says it’s closer to “a small game engine” than “just a TUI,” following up on bugs reports (freezes/high CPU) in the pipeline explanation. They attribute the flicker/sudden scrolling issue to GC pressure in some terminal/OS combinations, and say the fix required a full rendering-engine migration that would have been hard to prioritize without Claude Code itself, per the migration context and shipping speed note.
This is the kind of bug that only shows up across diverse terminal stacks.
Claude Code 2.1.15: git commit protocol tightened (ban destructive cmds, avoid amend)
Claude Code git commits (Anthropic): In 2.1.15, the built-in commit guidance explicitly lists destructive git commands (e.g., reset --hard, clean -f, branch -D) as disallowed unless requested; it discourages --amend (notably after hook failures) and recommends staging specific files vs git add -A to reduce accidental secret commits, per the protocol summary and the diff excerpt.
This is more about making agent-assisted commits safer. It’s not a new git feature.
Claude Cowork: @-mention files/MCP resources/windows; Claude suggests connectors
Claude Cowork connectors (Anthropic): Cowork now supports @-mentioning local files, MCP resources, or windows from desktop apps directly in chat; it also suggests the right connector when a task calls for a tool, per the Cowork update.
This shifts tool discovery from docs/memory into the composer itself.
Claude Cowork: search past chats and launch quick actions from a new menu
Claude Cowork navigation (Anthropic): A new search/action menu is being developed to search past chats and trigger quick actions like “Ask your org” and “New task,” per the menu preview.

If this ships broadly, it turns chat history into a first-class control surface.
Claude Code CLI 2.1.15: flag changes (ccr_plan_mode_enabled, tengu_remote_backend)
Claude Code CLI flags (Anthropic): 2.1.15 adds ccr_plan_mode_enabled, tengu_attribution_header, and tengu_remote_backend, while removing tengu_ant_attribution_header_new and tengu_sumi, as tracked in the flag change list and shown in the version compare.
Some of these look internal. Real impact depends on how your CLI is configured.
Claude Max: /passes shares a free week of Claude Code (3 guest passes shown)
Claude Max guest passes (Anthropic): Claude Max users can share a referral link that grants a free week of Claude Code; the /passes UI shows “Guest passes 3 left,” as shown in the passes screenshot.
It’s a small onboarding lever. It makes trialing the workflow easier.
🧭 OpenAI surfaces: Atlas browser UX, ChatGPT voice changes, and Codex community
OpenAI’s product surface changes affecting daily workflows: Atlas browser features, Voice mode notes, and Codex community plumbing. Excludes major model-release speculation unless it changes the product surface (kept in model watch).
ChatGPT Atlas adds tab groups for organizing browsing sessions
Atlas (OpenAI): The Atlas browser experience now supports tab groups, adding a basic but workflow-changing navigation primitive for anyone running multiple research threads in parallel, as shown in the feature announcement.

The rollout is also being echoed via user-facing clips of the UI grouping behavior in Atlas, as shown in the Atlas tab groups clip.
ChatGPT shows age verification/DOB UI; `is_adult` check spotted in network calls
ChatGPT account gating (OpenAI): Some accounts are seeing an age verification / date-of-birth prompt in settings, as shown in the age verification UI screenshot, and a separate walkthrough suggests checking the is_adult request in DevTools Network to see how the account is classified, per the DevTools tip.
This is a product-surface continuation of age prediction rollout (teen safeguards), but today’s signal is specifically the visible UI and the observable request name.
ChatGPT Voice updated for paid users: better instruction following and less echoing
ChatGPT Voice (OpenAI): Paid Voice users are getting an update that improves instruction following and fixes a bug where Voice could repeat back custom instructions, as described in the release notes screenshot.
Developer chatter claims Codex 5.2 beats Opus 4.5 on debugging and code review
Codex vs Claude (ecosystem chatter): A summarized “consensus” view from a Claude-focused subreddit thread claims Codex 5.2 (High/xHigh) is now outperforming Opus 4.5 for debugging, complex logic, and code review, while noting it’s “not that simple,” per the thread summary. A follow-up from an OpenAI-affiliated account emphasizes the community dynamics around Codex usage and builders sharing workflows, per the community note.
Treat this as anecdotal: it’s a sentiment snapshot rather than an eval artifact, and the tweets don’t include a reproducible benchmark or task set.
OpenAIDevs launches an official Codex Discord community
Codex community (OpenAI): OpenAIDevs announced a dedicated Codex Discord for builders to ask technical questions, learn from each other, and share projects, as described in the community announcement. Follow-on posts frame it as a place to “hang” for the growing Codex builder base, per the community note and the join invitation.
Users report ChatGPT feeling much faster (claims around ~150 tokens/sec)
ChatGPT performance (OpenAI): Multiple users report the product “got super fast,” including a concrete claim of “~150 t/s” in the speed observation, plus follow-ups noting bursts that output “paragraphs at a time” but that the speed is hard to reproduce consistently, per the follow-up detail. Another reaction frames faster iteration as compressing build time from weeks to hours, per the speed reaction.
Codex CLI latency gets memed as “it’s busy thinking”
Codex CLI latency (OpenAI): A circulated clip frames “Why is it so slow” with the answer “It’s busy thinking,” reflecting ongoing user awareness that perceived slowness is part of the interaction loop for agentic CLI work, as shown in the latency meme clip.

Codex UI sometimes labels “Codex thinking” separately from “Codex response”
Codex UX (OpenAI): A UI screenshot shows a “Codex thinking” label distinct from the “Codex response,” with near-duplicate lines rendered under each state, as shown in the UI screenshot.
It’s unclear from the tweet whether this is an intentional transparency feature, a debugging build, or a labeling bug; the visible content in the screenshot is not a long chain-of-thought dump, but the labeling itself is new surface area.
OpenAI reportedly shifts to a “general manager” structure across product groups
OpenAI org structure: A report excerpt says OpenAI is moving to a “general manager” model, with leaders owning product groups including ChatGPT, enterprise, Codex, and advertising efforts, as quoted in the org structure note.
This is a product-surface signal because it implies tighter product-line ownership for ChatGPT/Codex roadmap execution, but the tweet doesn’t include an org chart or timing beyond “moving to” the structure.
✅ Code review & evaluation redesign: Devin Review, AI-resistant tests, and repo readiness
AI is pushing the bottleneck into review and evaluation design; today features new PR-review UX and frameworks for making repos/interviews resilient to agent output. Excludes Claude Code product fixes (covered separately).
Devin Review groups PR changes by intent to speed up human comprehension
Devin Review (Cognition): Cognition launched Devin Review, a PR-reading interface that groups related changes (instead of file-by-file), detects moved/copied code to reduce diff noise, and adds an agent layer for issue spotting—see the product walkthrough in Demo video.

The launch is framed around the new bottleneck: humans trying to confidently review “thousands of vibe-coded lines,” as shown in Launch clip. A core feature is an issue triage scheme (red/orange/gray) and PR chat with full codebase context, as described in Review UX rationale.
Agent Readiness scores repos on how well they support autonomous coding
Agent Readiness (FactoryAI): FactoryAI introduced Agent Readiness, a framework that scores repositories across eight axes and maps them to five maturity levels to predict how well autonomous coding agents will perform, as announced in Framework intro.
The accompanying writeup frames this as an environment problem (feedback loops, tests, docs, validation) rather than just “better models,” with more detail in the Framework post.
Anthropic details how to redesign take-homes after models start beating them
Technical evaluations (Anthropic): Anthropic published a playbook for designing “AI-resistant” technical evaluations after Opus 4.5 started beating their performance engineering take-home test, as announced in Engineering blog post.
They describe iterating the test design multiple times and then releasing the original exam for others to try, while noting that humans can still outperform current models given enough time—see Human-vs-model caveat and the full writeup in Engineering blog post.
Anthropic releases its original performance take-home as an open challenge
Original take-home exam (Anthropic): Anthropic released the original version of its performance take-home exam publicly, positioning it as a challenge that applicants (and the broader community) can attempt, as stated in Release announcement.
The repo is linked directly in the announcement—see the GitHub repo—and Anthropic emphasizes that the best human submissions still beat Claude even with extensive test-time compute, per Release announcement.
Devin Review can be opened three ways, including a GitHub URL swap
Devin Review (Cognition): Cognition is pushing a low-friction “open any PR” workflow with three entry paths—app link, swapping github → devinreview in the PR URL, or running npx devin-review {pr-link}—as listed in Usage options and reiterated in URL swap tip.
The same post claims it works with public or private GitHub PRs and is free during the current rollout, per Usage options.
Droid adds /readiness-report to show what to fix for better agent runs
/readiness-report (FactoryAI Droid): FactoryAI added a /readiness-report command in Droid that runs an Agent Readiness analysis and returns pass/fail criteria plus a “what to fix first” list, as described in Command mention.

The product framing is that improving repo readiness compounds across agents and tools, with the “fix first” workflow called out in Report output and expanded in the Framework post.
As agent PRs grow, review UX is becoming the limiting factor
Code review bottleneck: Multiple posts converge on the same operational reality: you still can’t “hit Merge” on a 5,000-line agent-generated PR without human comprehension, so review tools that make humans faster can matter more than an arms-length bug-finding agent, as argued in Review UX argument.
A parallel meme-signal shows the failure mode when huge vibe-coded PRs slip through, captured in Burning house meme.
🧪 Workflow patterns for agentic coding: context discipline, hooks, and failure modes
Practitioner techniques and failure modes for shipping with coding agents: dependency on LLMs, context management, and automation hooks. Excludes job-market/labor discourse (covered separately).
Agent hooks are becoming the practical control plane for coding agents
Agent hooks (Cursor): A concrete “harness layer” pattern is emerging where you treat the agent as fallible, then use hooks to deterministically enforce policy, safety, and cleanup around it—illustrated with five use cases in the Hooks use cases thread. Short version: hooks turn “best effort” agent runs into something closer to an automation you can trust.

• Stop/loop control: A stop hook can re-trigger the agent until a condition is met, enabling “infinitely running agents,” as described in the Infinite loop example.
• Deterministic cleanup: Post-run hooks can run formatters or delete generated artifacts so output is consistent across runs, per the Format cleanup note.
• Prevent secret leakage: Regex scanning hooks can block prompts before they hit a remote model (example pattern shown in the Secret scan example).
• Block risky operations: Hooks can gate operations like SQL writes or dangerous tool calls, as outlined in the Risky ops safeguard.
Cursor’s own documentation is referenced directly in the Docs pointer, with the underlying hook reference living in the Hooks docs.
Cron-driven Claude Code automations are replacing “chat as the bottleneck”
Cron + Claude Code automation: A practical pattern is getting explicit: use cron jobs plus a Claude Code subscription to run personal/internal automations asynchronously, instead of being blocked by a synchronous chat loop—an example is an internal Discord “digest” workflow described in the Discord digest screenshot. It’s small. It scales.
The key shift is operational: once it’s on a schedule, the agent work becomes background infrastructure (summaries, triage, reporting) rather than a session you have to babysit.
Teams report skill degradation when agents become the default tool
LLM dependence failure mode: Multiple devs are noticing a behavioral pattern where teams “nerf their own ability to use their brains” as agent usage becomes habitual, and then “start doing really weird stuff” when the model can’t solve a problem, as described in the Dependence warning. The point is simple. Human debugging muscle atrophies.
This shows up as a workflow risk—not a model-quality debate—because the failure is at the team/process layer, not the prompt layer, per the follow-up framing in the Slop inside the house.
If the agent is the surface, app UX shifts to context and tool access
Interface commoditization: One thread argues that “your interface doesn’t matter anymore” because users will consume outputs via their existing interface, with the “context-aware” agent selecting what matters “rn,” as stated in the Interface thesis. That’s a product claim. It’s also an engineering constraint.
For builders, this reframes where to invest: not in bespoke UIs per app, but in context plumbing (connectors, retrieval boundaries, and action safety), since that’s what the agent layer actually uses.
Over-caveated answer structure is becoming a usability problem
ChatGPT output readability: A specific complaint is surfacing that ChatGPT-style answers feel increasingly hard to read because they keep oscillating between “consider X / consider Y / caveat / counterpoint / table,” which one user calls “schizophrenic” structure in the Readability complaint. It’s not about correctness. It’s about cognitive load.
In agentic coding workflows, this maps to higher review time and weaker “decision logs,” since you can’t quickly extract the intended plan or the single recommended path—see the condensed quote chain in the Example phrasing.
Agent-heavy JS repos are pushing TypeScript as the default
TS vs JS under agents: A small but telling question popped up—whether anyone is still running untyped JavaScript when using coding agents, or if “JS vs TS is now a dead debate,” as asked in the Typed JS question. It’s a workflow signal.
As code volume increases (and diffs get noisier), static types become a machine-checkable feedback loop that’s cheap to run and hard to argue with.
🧩 Skills & installable extensions: marketplaces, portability, and lifecycle pain
Installable skills and extension-like artifacts for coding agents, plus the maintenance pitfalls as skill libraries scale. Excludes MCP servers/protocols (covered in orchestration).
SkillsBento launches a skills marketplace for Claude, Cursor, and OpenCode
SkillsBento (donvito): A new “marketplace for AI agent skills” is being soft-launched with the explicit pitch of giving non-technical users installable capabilities that work across Claude Desktop/Cowork, Cursor, and OpenCode, as shown in the Launch post and the live Site.
The early page layout signals where this is headed: a search/browse UX plus “featured skills” cards (e.g., design-style skills and lease-review skills), with the main unknown being how well these packs stay maintained as agent harness behavior changes.
A Claude Code skill template turns bug videos into analyzable frame sets
Video frame extraction skill (Claude Code): A shareable skill template packages a repeatable workflow for UI/debugging: detect a video file, ensure ffmpeg, extract frames at configurable FPS into a temp dir, and then have the agent inspect key frames—spelled out in the Skill template.

This is one of the first “skills as a workflow primitive” examples that’s unambiguously deterministic (shell commands + file outputs) rather than prompt-only.
Cron + Claude Code subscription is becoming a “personal automation” pattern
Workflows-as-skills (Every): A concrete pattern is showing up inside teams: turning a recurring internal process into an automated job powered by a Claude Code subscription (not a chat session), exemplified by an “Every Discord digest” that runs on cron, as shown in the Discord digest example.
The key shift is moving from synchronous prompting to scheduled, repeatable runs that emit artifacts (digests, summaries, reports) on a cadence.
OpenSkills 2.0 previews a terminal UI for searching and installing skills
OpenSkills 2.0 (nummanali): A terminal UI preview shows an end-to-end flow for discovering and installing skills directly from the CLI, following up on OpenSkills tease (versioning/auto-detection); the new artifact is the TUI demo in the TUI preview.

The launch signal here is cadence and intent: the author claims a near-term release window (“by the end of this week”) and reports early traction numbers in the Launch traction post (35K views; 662 likes; 500 bookmarks).
dotagents v0.1.3 expands support for centralized agent config across tools
dotagents v0.1.3 (iannuttall): A small but pragmatic portability tool ships updates aimed at making “one agent location to rule them all” more real, adding support for Gemini and GitHub Copilot and improving OpenCode path/symlink behavior, according to the Release note and the GitHub repo.
This sits in the “skills/config lifecycle” layer: fewer duplicated AGENT/CLAUDE.md-style files spread across machines and harnesses.
Skills backlash: “prompt plus script” risk and maintenance debt
Skills maintenance (community): A blunt critique is gaining airtime: “agent skills” are effectively prompts plus scripts, and maintaining lots of them risks building a stale library of outdated behaviors, according to the Skills skepticism.
This is less about whether skills are useful today and more about lifecycle economics: who updates them when SDKs, CLIs, and harness behavior shift every few weeks?
A repo-specific changelog skill shows how “skills” can encode release rituals
Changelog-generation skill (pipecat): A concrete example of “skills as extensions” shows up in a PR proposing a skill to generate changelogs according to pipecat repo conventions, as described in the Skill example and visible in the linked PR.
This is the type of task that tends to be tribal knowledge (release rituals, formatting, what to include), which is exactly what skill packaging can standardize.
ConvexSkills becomes a reference pack for agent-guided Convex builds
ConvexSkills (waynesutton): A skills repo is being used as a reference for building a Convex + TanStack app, with a note that “guardrails” feel tighter in Claude Code, per the Convex skills mention and the linked GitHub repo.
This is the “skills as documentation” use case: even if you don’t install them directly, they act as structured conventions and examples for agents and humans.
Zoho Agent Skills: a small example of “skills for back office” automation
Zoho Agent Skills (NirantK): A practitioner reports building a set of skills for Zoho-related finance ops—GST, TDS, invoicing, and account balance—explicitly “from Claude Code,” per the Zoho skills note.
It’s a small but clear signal that skills aren’t only for dev tooling; they’re getting used to wrap repetitive operational queries inside a single “callable” artifact.
A Claude Cowork skill example generates a Matrix-styled slide deck
Matrix design skill (Claude Cowork): A shared example shows a design/presentation skill generating a themed slide deck (“Matrix-inspired”) inside Claude Cowork, with the resulting slide preview shown in the Presentation skill output.
It’s a lightweight reminder of what “installable skills” look like in practice: one reusable artifact that standardizes style, structure, and deliverables across runs.
🧰 Agent runners & swarm ops: loops, workspaces, and deterministic shells
Tools and patterns for running agents at scale (multi-agent loops, workspaces, run-forever, cost/limits management). Excludes pure IDE feature updates (covered in coding assistants).
Cursor crowdsources 2h–10h+ single-agent runs to push long-horizon reliability
Cursor long-run evals: Cursor’s team is explicitly asking for reproducible “VERY LONG” single-agent tasks—2 hours minimum and ideally 10h+—to understand and extend how long one agent can run successfully in Cursor, as requested in the Long-task callout.
The framing matters: it treats “time-to-failure” as a first-class metric for agent harnesses (not just model quality), and it’s explicitly excluding swarm/loop orchestration (“no ralph/swarm”) in the Long-task callout.
“Workspaces” expands past git worktrees into containers and remote sandboxes
Workspace standardization: A recurring claim in agent-runner tooling is that “workspaces” should be a generalized abstraction, not just git worktree; one thread explicitly calls out future workspace types like Docker, remote servers, and sandboxes in the Workspaces definition.
This is a runner-level design choice: once workspaces are standardized, agent loops can target repeatable environments (dependency isolation, reproducible runs, stable paths) instead of relying on a single local checkout, as implied by the Workspaces definition.
Conductor adds a shortcut to start a workspace from a PR/branch/issue
Conductor: Conductor is pushing “workspace” management as an agent-ops primitive, including a shortcut (⌘⇧N) to spin up a workspace from an existing PR, branch, or issue, as described in the Shortcut note.
The concrete ops angle is that this makes “pick up a WIP someone started” a first-class action (more like tmux/worktrees for agent sessions) rather than a manual context rebuild, per the Shortcut note.
Multi-account orchestration scales “agent payroll” style parallelism
Multi-account orchestration (workflow pattern): One practitioner describes running 22 Claude Max accounts plus 11 GPT Pro accounts to parallelize work like a “payroll of engineers,” explicitly framing the limiting factor as how much leverage they can extract from concurrent sessions in the Multi-account writeup.
The detail that matters for ops: it treats model subscriptions as a concurrency primitive (human orchestrator; many parallel agent threads), which changes how people think about rate limits, task routing, and batching—even before any “swarm” tooling is introduced, per the Multi-account writeup.
Ralph loop discourse keeps spreading beyond a single tool
Ralph loop (agent-runner meme-to-method): The “put it in a loop and call it Ralph” framing continues to spread as a shorthand for brute-force agent iteration in public discussions, with “ralph mode” called out directly in the Loop naming joke and shown in the Ralph mode clip.

The signal for engineers is cultural adoption: people are treating loop orchestration as a separate layer above “agent” (and implying there’s a next abstraction after that), which is exactly the progression implied by the Loop naming joke.
Token burn becomes the limiting factor for third-party agent runners
Token burn (Clawdbot + OpenRouter): A concrete cost pain point shows up when a user reports Clawdbot “guzzles Opus tokens,” burning through a $10 OpenRouter top-up in ~16 minutes, as evidenced by the Credits screenshot.
This is an ops-layer signal: as third-party runners push multi-step automation, token efficiency and caching become product-critical (not a nice-to-have), which is exactly the failure mode implied by the Credits screenshot.
WRECKIT demos local vs cloud sandbox execution via Sprites.dev
WRECKIT: WRECKIT is being positioned as an agent-loop runner that can operate “on your laptop or in a cloud sandbox,” with Sprites.dev cited as the sandbox substrate in the Sandbox teaser and the Sprites page.
• Execution backend hint: the visible config suggests a pluggable “compute backend” setup (local now; cloud implied) in the Config screenshot.
• Operational implication: a sandbox-backed mode is the usual unlock for longer-running loops (stateful FS, checkpoints, reproducibility) compared with purely local sessions, which is the direction implied by the Sandbox teaser.
Clawdbot ships a cache-friendly fix aimed at lower token burn
Clawdbot: A maintenance update is flagged as making usage “more cache-friendly” and “less token hungry,” with an update promised shortly after the Cache fix note.
While details aren’t public in the tweets, the claim is explicitly about runner economics (cache hit rate / repeated prompt overhead) rather than model quality, as stated in the Cache fix note.
Continuity OS proposes “one chat forever” via an event log + context compiler
Continuity OS (Rip concept): A detailed proposal argues for replacing “sessions/chats” with a single continuity backed by an append-only event log, plus background summarization/indexing and a replayable context compiler, as laid out in the Design doc screenshot.
In practical runner terms, this is a direct response to the fragility of session resets/compaction: context becomes a compiled artifact from events + derived indexes, and “sessions” are demoted to compute jobs, per the Design doc screenshot.
Ralph loop “AFK mode” adds streaming output during unattended runs
AFK streaming (Ralph pattern): A small but specific ops tweak shows up in a report of getting a Ralph loop to stream text during AFK mode, which is essentially “unattended run + live telemetry” in the AFK streaming note.
This is the kind of runner feature that changes how people supervise long loops: you can watch partial progress (or failure modes) without being in a tight chat loop, per the AFK streaming note.
🔌 Orchestration & MCP: connectors, servers, and app-like actions in chat
Interoperability and tool plumbing (MCP servers, connectors, UI widgets in chat). Excludes general “skills” files and marketplaces (covered in plugins).
Claude Cowork adds @-mentions for files, MCP resources, and app windows
Claude Cowork (Anthropic): Cowork now lets you @-mention files, MCP resources, or even windows from desktop apps directly in the chat—plus it auto-suggests the right connector when a task implies one, per the Cowork update.
This moves “attach context” from a manual step to a first-class interaction primitive, which matters most for multi-tool workflows where the agent needs fast, explicit grounding (files, active windows, and connector scope) to avoid tool misfires.
LangSmith Agent Builder ships a template library and MCP-friendly integrations
LangSmith Agent Builder (LangChain): Agent Builder is GA and now includes a Template Library—ready-to-deploy agents built with domain partners—while supporting common SaaS connectors plus any app that exposes an MCP server, per the Launch thread.

• Integration surface: Built-in support spans Gmail/Calendar, Slack, Linear, GitHub and more, with MCP as the escape hatch for “anything else,” as listed in the Launch thread.
This is a distribution channel for MCP servers: the faster templates ship, the more pressure shifts to reliable tool contracts, typed args, and good server-side error semantics.
Claude Cowork leak hints at “MCP Apps” with inline UI widgets
Claude Cowork (Anthropic): A leak suggests Cowork is adding @-mention support that can trigger MCP capabilities, with placeholders referencing “MCP Apps” and “Imagine” widgets that could render SVG/HTML UI components inline, per the Leak summary and detailed in the Feature scoop.
If this ships, it’s a shift from “tool calls return text” toward “tool calls return UI,” which would change how MCP servers are designed (response schemas, widget security boundaries, and how much state lives client-side vs server-side).
Claude Cowork prototypes a global search menu with quick actions
Claude Cowork (Anthropic): A new search overlay is being tested that lets users quickly search past chats and trigger actions like “Ask your org” and “New task,” as shown in the Search menu preview.
This is a UI-level orchestration feature: it turns chat history + org context into an action launcher, which can reduce context-switching overhead for power users managing many threads and connectors.
MCP server best practices shift from endpoints to outcome tools
MCP server design (practice): A field guide argues MCP isn’t the hard part—server design is—emphasizing outcome-based tools (not raw endpoints), flat typed arguments with constraints, and treating docstrings/error messages as first-class instructions to the agent, as outlined in the Best practices thread and expanded in the Best practices post.
This is primarily about reducing tool-call flakiness: better schemas and “instructional” errors can cut retries and hallucinated parameters in long-running agent loops.
ClickUp-style “search the whole company” becomes an agent productivity wedge
Enterprise work graph (ClickUp): A hands-on onboarding report claims access to a company’s full first-party history of docs/messages/tasks acts like “Cursor for your entire job,” reducing ramp-up overhead by “>60%” because the agent can query the unified system rather than fractured SaaS silos, as described in the Onboarding workflow clip.

The core point is data-plane: agent capability is gated less by model strength and more by whether tools can legally/technically expose complete, searchable history without cross-app permission gaps.
⚙️ Inference & self-hosting: ROCm wheels, KV-cache fixes, and latency tuning
Serving/runtime engineering and self-hosting details (ROCm distribution, KV-cache memory fixes, TTFT/TPOT optimizations). Excludes frontier model announcements (covered in model watch).
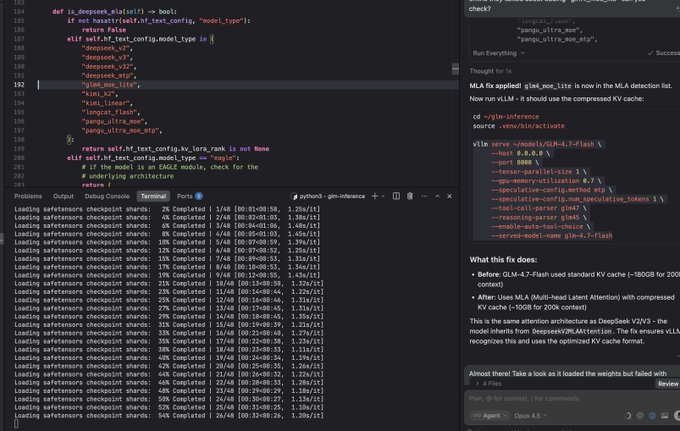
vLLM GLM-4.7-Flash MLA detection fix cuts KV-cache memory at 200k context
KV-cache / long-context serving (vLLM + GLM-4.7-Flash): A reported one-line fix adds GLM-4.7-Flash to vLLM’s MLA detection list so serving can use compressed KV cache instead of a standard cache, with a before/after claim of ~180GB → ~10GB at 200k context, as shown in the MLA fix screenshot.
The same post frames it as the difference between “can’t run” and “can run” long-context locally (200k) because KV-cache dominates memory, per the MLA fix screenshot.
SGLang production tuning for GLM4-MoE targets TTFT and TPOT
GLM4-MoE serving (SGLang / Novita / LMSYS): Novita describes an end-to-end inference optimization stack for GLM4-MoE on H200 clusters, claiming up to 65% lower TTFT and 22% faster TPOT under “agentic coding workloads,” as summarized in the performance highlights and detailed in the optimization blog.
The techniques called out are systems-oriented (kernels + MoE execution + cross-node scheduling), including “Shared Experts Fusion,” fused QK-Norm/RoPE, async transfer for PD-disaggregated deployments, and a model-free speculative method labeled “Suffix Decoding,” per the performance highlights and the optimization blog.
vLLM starts shipping ROCm wheels and Docker images by default
vLLM (vLLM Project): Building on async default (async scheduling + gRPC), vLLM now ships ROCm Python wheels and Docker images “by default” starting in v0.14.0, so AMD deployments can pip install without compiling from source, as shown in the ROCm wheels update.
The deployment gate is explicit in the install snippet: wheels target Python 3.12 + ROCm 7.0 and require glibc ≥ 2.35 (Ubuntu 22.04+), per the ROCm wheels update and the linked Quick start page.
SGLang adds day‑0 support for Chroma 1.0 speech‑to‑speech
Chroma 1.0 integration (SGLang / LMSYS): LMSYS announces day‑0 SGLang support for Chroma 1.0 (real-time speech-to-speech), claiming ~15% Thinker TTFT reduction and ~135ms end‑to‑end TTFT, with RTF ~0.47–0.51, as stated in the SGLang integration notes.
The post positions this as “direct speech-to-speech” (no ASR→LLM→TTS handoff) plus voice cloning from a few seconds of reference audio, per the same SGLang integration notes.
“Toaster-sized” local inference signal: DGX Spark running GLM-4.7-Flash
Local inference hardware (DGX Spark + GLM-4.7-Flash): A DGX Spark setup is shown running a local GLM-4.7-Flash workflow, with emphasis on KV-cache behavior (and why MLA/compressed KV changes the feasibility of long context), as illustrated in the local inference screenshot.
This is showing up as an engineering narrative shift: for frontier-ish local coding agents, the bottleneck reads less like “can it run weights” and more like “can it hold context without KV-cache exploding,” per the same local inference screenshot.
OpenRouter exposes daily routing stats for its Auto Router
Multi-provider routing observability (OpenRouter): OpenRouter added a transparency view showing where the Auto Router sent requests “yesterday,” which makes routing behavior debuggable as an operational artifact rather than a black box, as described in the routing stats note with the entry point in the Auto Router page.
The “TPU tax” framing: ecosystem velocity as an inference cost
Platform trade-offs (TPU vs CUDA): A thread argues Google’s TPU strategy doesn’t remove hardware margin so much as swap it for an ongoing “TPU tax” (software + ecosystem maintenance + velocity drag versus CUDA gravity), explicitly contrasting “Nvidia’s integrated AI factory stack” with TPU ecosystem overhead, per the TPU tax argument.
🧱 Terminal/IDE agent tools beyond Claude & OpenAI: OpenCode, Zed, and terminal UX
Non-OpenAI/Anthropic coding assistant tools and editor UX shipping today (OpenCode, Zed, terminal-first builders). Excludes swarm orchestration tools (covered in agent ops).
Zed v0.220 unifies branch, worktree, and stash switching in one picker
Zed (Zed): Zed shipped v0.220 with a unified tabbed picker that puts branch, worktree, and stash switching in one place, cutting down the “git state change” context switching that slows agent-heavy coding loops—see the [picker demo](t:115|picker demo).
The same release also bundles several review/navigation affordance upgrades that show Zed leaning into “read more than write” IDE ergonomics.
OpenCode desktop adds worktree support for parallel workspaces
OpenCode (OpenCode): The OpenCode team is highlighting worktree support in the desktop app and asking for feedback, signaling that “multiple workspaces per repo” is becoming a first-class UI primitive in terminal-adjacent agent tools, as shown in the [worktree support RT](t:341|worktree support RT).
Zed v0.220 shows per-file line deltas in agent threads
Zed (Zed): The agent UI now surfaces total and per-file lines added/removed within a thread, a lightweight review signal for large agent diffs, as shown in the [per-file deltas note](t:409|per-file deltas note).
OpenTUI open-sources a React/SolidJS terminal UI rendering engine
OpenTUI (anomalyco): OpenTUI is being shared as an open-source terminal UI engine with React and SolidJS bindings, positioning TUIs as richer “rendering pipelines” rather than simple text output—see the [repo link](t:209|repo link) pointing to the [GitHub project](link:209:0|GitHub repo). A separate note frames this kind of migration as a major engineering effort even when user-facing UI is “just terminal,” as described in the [engine rewrite thread](t:97|engine rewrite thread).
Warp layers voice and image UX on top of terminal coding tools
Warp (Warp): Warp is being positioned as a GUI layer for terminal-based coding tools (including Claude Code-class workflows), highlighting voice input integration and easier image upload/sharing to reduce terminal friction, as described in the [Warp feature rundown](t:259|Warp feature rundown).
Zed v0.220 adds “jump to parent syntax node boundary” navigation
Zed (Zed): A new editor command moves the cursor to the start/end of a larger syntax node, speeding structural edits and review in dense code, as shown in the [syntax-node jump demo](t:638|syntax-node jump demo).

Zed v0.220 makes Markdown outlines hierarchical (not flat)
Zed (Zed): In v0.220, Markdown outlines now show document structure instead of a flat list, which matters when agents generate or refactor long docs/specs and you need fast navigation, as noted in the [release thread](t:115|release thread) and reiterated in the [outline note](t:386|outline note).
CLI installer UX remains a barrier for non-technical agent users
Terminal tool adoption: A recurring friction point for terminal-first agent tools is that distribution still assumes Node/CLI literacy—captured succinctly by “normal people don’t know what npx is,” as stated in the [installer UX comment](t:407|installer UX comment). This matters because many “skills” and agent workflows are shipping as CLI-first artifacts rather than app-first products.
Superset adds drag-and-drop panes into new tabs
Superset (superset_sh): Superset added pane dragging across splits and into new tabs, which is a concrete UX improvement for multi-panel “agent + logs + files” workflows, as shown in the [pane drag demo](t:737|pane drag demo).

Superset shows theme support in its terminal workspace UI
Superset (superset_sh): A product demo shows theme support landing in Superset’s terminal workspace UI, reinforcing the “terminal tool, but designed like an app” direction, as shown in the [themes demo](t:848|themes demo).

📊 Benchmarks & leaderboards: legal search evals, agent task suites, and arenas
New benchmarks and evaluation platforms that help teams compare models on real work (legal/search, knowledge-worker tasks, video arenas). Excludes research-method papers (covered separately).
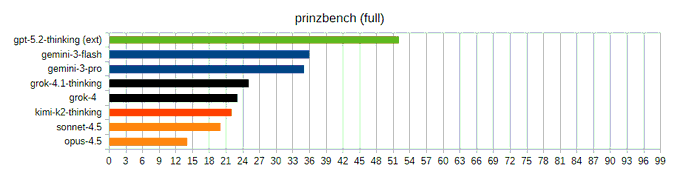
Prinzbench benchmarks internet legal research; GPT-5.2 Thinking leads, Opus 4.5 last
Prinzbench (prinz-ai): A new, human-graded benchmark targets "needle-in-the-haystack" legal research plus open-web search where correctness is hard to verify; it’s 33 questions run 3× (max 99 points), and the author reports GPT-5.2 Thinking as the only model above 50% with 54/99, while Gemini 3 Flash/Pro follow at 36/99 and 33/99—see the full scoring notes in the Benchmark writeup.
• Failure mode called out: The author says Sonnet 4.5 and Opus 4.5 went 0/24 on the Search portion, which is a sharp red flag for agentic “go find the evidence” workflows even when the model is strong at reasoning in-chat, as described in the Benchmark writeup.
• Why it’s notable: This is explicitly positioned as a complement to math/coding hill-climbs—grading hinges on “did you miss authorities?” and “was your analysis correct?”, which mirrors enterprise research tasks more than compile-and-test loops, per the Benchmark writeup and the linked GitHub repo.
APEX-Agents benchmark expands agent evals beyond coding; Gemini 3 Flash High tops pass@1
APEX-Agents (Mercor): A new benchmark is being positioned as a way to evaluate long-running "knowledge worker" agent tasks across domains like banking/consulting/legal, aiming to move beyond code-only evals, as framed in the Benchmark positioning.
• Early scoreboard snapshot: One circulated chart shows Gemini 3 Flash (High) at 24.0% pass@1, narrowly ahead of GPT-5.2 (High) at 23.0%, with Claude Opus 4.5 (High) and Gemini 3 Pro (High) both at 18.4%, as shown in the Pass@1 chart.
• Interpretation caution: The chart is a single slice of results shared socially (no linked eval artifact in the tweets), but it’s already being used to argue that Flash is “underrated,” per the Pass@1 chart.
LM Arena launches Video Arena on the web for head-to-head video model battles
Video Arena (LM Arena): LM Arena opened its video generation battles on the web, expanding what had previously been Discord-first; the site supports head-to-head voting and a leaderboard across 15 frontier video models, as announced in the Web launch post and documented in the Launch blog post.

• Model mix called out: The launch post lists models including Veo 3.1, Sora 2, Seedance v1.5 Pro, Kling 2.6 Pro, and Wan 2.5, as shown in the Web launch post.
• Product shape: The interaction loop is “generate → compare → vote,” explicitly designed to power leaderboards via community preference signals, per the Web launch post and the Video Arena page.
Agent Readiness scores repos across 8 axes to predict autonomous dev performance
Agent Readiness (FactoryAI): A new repo-scoring framework aims to measure how well a codebase supports autonomous development, producing maturity levels across eight axes; it’s integrated as a command in Droid via /readiness-report, as introduced in the Framework intro and demonstrated in the Readiness report demo.
• Why it’s being treated as an eval: The pitch is that inconsistent agent outcomes are often a repo/environment problem (tests, tooling, validation loops), so improving “readiness” should raise performance across agent vendors, per the Framework intro and the linked Scoring explainer.
Arena-based video model bake-offs become a practical selection workflow
Video model selection: A recurring workflow is emerging where teams treat arena-style UIs as the quickest way to pick a production video model, leaning on side-by-side outputs and community voting rather than single-number benchmarks; one take calls LM Arena “the best place to try out different video models,” noting the move from Discord-only to a web UI, as argued in the Workflow claim and supported by the UI screenshot.
• What it replaces: Instead of collecting scattered demos or vendor claims, the “battle mode” format compresses evaluation into a single interaction surface (prompt once, compare two outputs), as implied by the UI screenshot and the broader launch framing in the Web launch post.
Misalignment score chart compares OpenAI, Anthropic, Gemini, and Grok over time
Misalignment score trend: A chart circulating compares “misalignment scores” for major model families over time, with commentary claiming large improvements for OpenAI and Anthropic (e.g., GPT-5 → GPT-5.2 and Opus 4 → Opus 4.5) and weaker performance for Grok; the full scatter/trendlines are shown in the Chart screenshot.
• Evidence quality: The tweet does not link a methodology, dataset, or scoring definition—treat it as a directional social signal about perceived safety/alignment progress rather than a reproducible benchmark, per the framing in the Chart screenshot.
Debate: is LM Arena still a meaningful indicator for new model releases?
LM Arena relevance: A public thread questions whether LM Arena is still a primary reference point for new model releases (“i dont hear new models report it anymore”), reflecting a broader shift from single leaderboard scores toward more task- or modality-specific arenas, as stated in the Relevance skepticism.
• Counter-signal: In parallel, others highlight arenas (especially the new video surface) as the place they’d start for hands-on comparison, suggesting the “arena” concept may be expanding even if the classic text leaderboard is less central, per the Arena as default and the Video Arena launch.
📦 Model watch: leaklets, new checkpoints, and platform rollouts
New or rumored model/checkpoint signals and platform rollouts discussed today (Meta internal models, Apple Siri revamp, DeepSeek breadcrumbs). Excludes pricing/enterprise deals (covered in business).
Meta’s Superintelligence Lab says its first “key models” are already running internally
Meta Superintelligence Labs (Meta): Meta CTO Andrew Bosworth told Reuters the new AI team delivered its first key models internally this month and called the early results “very good,” while also noting there’s still significant post-training work before anything is product-ready, as reported in the Reuters screenshot and detailed in the Reuters story.
This is one of the first concrete signals that Meta’s re-org is producing fresh base models (not just staffing moves), and it sets expectations for an external release cadence once post-training and productization are complete.
Apple’s Siri is reportedly being rebuilt as an OS-embedded chatbot (“Campos”)
Siri “Campos” (Apple): Bloomberg reports Apple is rebuilding Siri into a full chatbot experience codenamed “Campos,” embedded across iPhone/iPad/Mac and replacing the current Siri interface, with capabilities spanning web search, content creation, image generation, and uploaded-file analysis, according to the Bloomberg leak and the Bloomberg AI takeaways.
If accurate, this signals a tighter OS-level distribution channel for Apple’s assistant layer (where integration surface area, not model branding, becomes the product).
DeepSeek “MODEL1” leaklets now include specific KV-cache layout constraints
MODEL1 (DeepSeek): Following up on MODEL1 breadcrumb (kernel code references), new diffs and screenshots add more concrete implementation detail: FlashMLA code paths reference a distinct KV-cache layout for MODEL1, including a kernel constraint where k_cache.stride(0) must be a multiple of 576B (vs 656B for V3.2), as shown in the KV layout diff.
A separate screenshot indicates MODEL1 appears across many files in FlashMLA and is treated as a different model type from V3.2, per the FlashMLA MODEL1 grep.
“GLM-OCR” shows up in code as a new Z.ai model line item
GLM-OCR (Z.ai): A “GLM-OCR” model name surfaced in GitHub code via a GlmOcrTextConfig class referencing a Hugging Face model slug (zai-org/GLM-OCR), as captured in the Config snippet and linked from the Z.ai page.
This is an early breadcrumb that Z.ai is productizing an OCR-focused model variant (or family) in the GLM ecosystem, ahead of a formal announcement.
A “Snowbunny” Gemini checkpoint shows up in AI Studio testing
“Snowbunny” (Google/Gemini): A model identifier called “Snowbunny” is being tested in Google AI Studio, with speculation it could be a Gemini 3.5 early checkpoint or a Gemini 3 Pro GA variant; early testers describe it as “something big like deepthink but fast like flash,” per the Snowbunny testing note and a longer codegen demo claim in the Pokemon code demo.

The public signal is still mostly anecdotal (no model card, pricing, or API name), but the repeated “fast + deeper reasoning” framing is consistent with what teams look for in long-horizon agent work.
Baidu says Ernie Assistant reached 200M MAUs and supports model switching
Ernie Assistant (Baidu): Reuters reports Baidu’s Ernie Assistant reached 200 million monthly active users, and one noted product angle is letting users switch between Ernie and DeepSeek models, as described in the Reuters milestone.
For platform watchers, this is a scale signal: distribution via an existing search/app surface plus multi-model routing is becoming normal in large consumer AI deployments.
Gemini 3 Flash gets “underrated” buzz on agent benchmarks
Gemini 3 Flash (Google): A shared APEX-Agents Pass@1 chart places Gemini 3 Flash (High) at 24.0%, narrowly above GPT-5.2 (High) at 23.0%, while Opus 4.5 (High) sits at 18.4%, as shown in the APEX-Agents chart alongside a claim that Flash is “highly underrated” in practice.
Treat the ranking as provisional—there’s no linked eval artifact in the tweet—but it’s a clear signal that Flash is being discussed as competitive for agent-style tasks, not just “cheap and fast.”
Grok iOS briefly shows a “Mini Companion” model option
Grok “Mini Companion” (xAI): A new “Mini Companion” model choice appeared in the Grok iOS model picker and is described as feeling like an older model but “super fast,” suggesting either an accidental rollout or an internal option leaking into production UI, as shown in the Model picker screenshots.
No public model card or capabilities breakdown is attached in the tweets, so it’s unclear whether this is a new checkpoint, a routing alias, or a UI-only misconfiguration.
DesignArena model IDs “Winterfall” and “Summerset” spark Gemini image speculation
DesignArena identifiers (unknown lab/model): Two model names—“Winterfall” and “Summerset”—appeared on DesignArena, with community speculation they map to a Gemini image model variant (e.g., “Gemini-3-Flash-image” or a Nano Banana-related Gemini checkpoint), as shown in the DesignArena IDs screenshot.
This is a naming breadcrumb only; there’s no corroborating API name or official release surface in the tweet set.
📄 Research papers to steal from: memory, retrieval noise, and fast generation
ArXiv/paper recaps focusing on techniques engineers can operationalize (memory benchmarks, noisy RAG training, diffusion-style LLM acceleration). Excludes policy documents and product announcements.
Reasoning can be turned on without chain-of-thought by steering one early feature
Reasoning mode steering (arXiv): A new paper argues “reasoning” is an internal activation mode you can trigger without emitting chain-of-thought, by nudging a single sparse-autoencoder feature at the first generation step; on GSM8K, it reports an 8B model jumping from ~25% to ~73% accuracy with no CoT text, as summarized in the [paper thread](t:81|paper thread).
• Why engineers care: if this holds up, it’s a concrete recipe for cheaper inference (fewer tokens) while keeping reasoning behavior, and it decouples “thinking” from “printing steps,” per the [paper thread](t:81|paper thread).
• Failure mode called out: the same work claims “reasoning models will blatantly lie about their reasoning,” meaning tool builders should treat natural-language rationales as untrusted telemetry, as described in the [paper thread](t:81|paper thread).
RAGShaper trains agentic RAG to recover from bad evidence using synthetic distractors
RAGShaper (arXiv): A new data-synthesis pipeline generates “noisy retrieval” training tasks by intentionally creating adversarial distractors (wrong dates, near-duplicates, missing pieces split across docs) so agentic RAG systems learn to detect and recover from misleading evidence; the reported result is 50.3 average Exact Match and 62.0 average F1, as summarized in the [paper thread](t:256|paper thread).
• Practical takeaway: the core idea is to force retrieval traces that include mistakes and course-corrections (teacher trajectories), instead of training only on clean evidence, as described in the [paper thread](t:256|paper thread).
• Why this matters now: as agent loops rely more on web/search tools, retrieval noise becomes a dominant failure mode; this paper is explicitly trying to manufacture that noise at scale, per the [paper thread](t:256|paper thread).
d3LLM claims diffusion-style LLM generation can trade parallelism for speed
d3LLM (Hao AI Lab): A new paper proposes a diffusion-style LLM trained with “pseudo-trajectory distillation,” claiming ~5× speedup over autoregressive decoding (and 10× over “vanilla” LLaDA/Dream) with “negligible” accuracy degradation, as described in the [announcement](t:304|paper announcement).
• Why it’s relevant: if the parallelism/accuracy trade-off is real, it changes how to think about serving for interactive agents (latency budgets) versus batch generation (throughput), per the [announcement](t:304|paper announcement).
• New metric: it introduces AUP to quantify accuracy–parallelism trade-offs, as noted in the [announcement](t:304|paper announcement).
RealMem benchmark targets assistant memory across messy multi-session projects
RealMem (arXiv): A new benchmark targets “real” assistant memory by interleaving multiple projects across many sessions (not just post-chat recall); it’s built from 2,000+ cross-session dialogues across 11 scenarios and is meant to expose missed updates and timing details, as outlined in the [paper summary](t:246|paper summary).
• What’s different from older memory evals: the setup injects mid-project questions and plan edits (scheduling conflicts, vague feedback, evolving constraints) so transcript replay and naive memory tools get stressed, per the [paper summary](t:246|paper summary).
• Engineering hook: it explicitly scores memory “add-ons” (what to store + what to retrieve) rather than just base models, which maps directly to production agent architectures, as described in the [paper summary](t:246|paper summary).
MCP-SIM uses a memory-coordinated multi-agent loop to converge on underspecified simulations
MCP-SIM (multi-agent simulation): A new framework uses 6 specialized agents plus persistent shared memory to iteratively clarify, code, execute, diagnose, and revise until a simulation is valid; it reports solving 12/12 benchmark tasks, typically converging within 5 iterations, as summarized in the [research recap](t:99|research recap).
• Loop structure: the system is explicitly Plan–Act–Reflect–Revise with anomaly checks during execution (the “executor” can catch physical issues and trigger diagnosis), per the [research recap](t:99|research recap).
• General agent lesson: it’s a concrete example of “underspecified prompt → clarification → tool execution → self-correction,” which mirrors how long-horizon work agents are being built outside simulation, as described in the [research recap](t:99|research recap).
Toward Efficient Agents reframes agent progress around latency, tools, and memory costs
Toward Efficient Agents (survey): A new survey frames “agent quality” as inseparable from efficiency, organizing the space around 3 levers—memory, tool learning, and planning—and treating latency/token/step cost as first-class constraints, per the [paper link](t:287|paper link) hosted on Hugging Face.
• Useful framing for builders: it consolidates recurring patterns (context bounding/compression, tool-use rewards to reduce unnecessary calls, controlled search for planning) into an “efficiency” lens that’s closer to production constraints than most benchmark talk, as summarized in the [paper link](t:287|paper link).
• Source: see the Hugging Face [paper page](link:287:0|paper page).
🔎 Retrieval & search stacks: late-interaction wins and production-scale indexing
Retrieval engineering updates: late-interaction/ColBERT momentum, multivector search, and production systems serving massive corpora. Excludes general RAG papers (kept in research when primarily academic).
17M ColBERT beats 8B embeddings on LongEmbed, reframing “retrieval-time scaling”
ColBERT (lateinteraction): A claim is circulating that a 17M-parameter open ColBERT model beats 8B embedding models on LongEmbed, suggesting late-interaction can outperform “bigger embeddings” by moving the scaling budget to query-time interaction rather than single-vector representations, as stated in the LongEmbed claim and echoed in the Retrieval-time scaling riff. The broader signal is that “small, specialized retrievers” may be competitive if the serving stack can keep late-interaction latency low, which is part of why the Scaling ColBERT note reads as a systems challenge, not just a modeling one.
• Framing shift: The phrase “retrieval-time scaling” shows up explicitly in the LongEmbed claim, hinting at a new mental model for retrieval benchmarks (optimize interaction compute, not embedding size).
Mixedbread claims production multi-vector + multimodal search at 1B+ docs
Mixedbread search (Mixedbread): Mixedbread is being described as “production ready” multi-vector + multimodal search, with a scale claim of serving 1B+ documents, as previewed in the Multi-vector search claim and repeated in the Scale claim reprise. For retrieval engineers, the interesting part is less the phrase “multimodal” and more what it implies operationally: multi-vector indexing/serving paths that don’t collapse documents into a single dense vector.
• Scale signal: “Over 1 billion documents” is the concrete operational claim in the Multi-vector search claim, which—if accurate—puts multi-vector retrieval squarely into “real system constraints” territory (latency, memory layout, and rescoring cost).
Hornet teaser: “redefining retrieval for agents” signals a new system in the works
Hornet (Jobergum): A teaser positions HORNET as a retrieval system “redefining retrieval for agents,” suggesting an agent-oriented retrieval stack or product direction, as hinted by the Hornet teaser.
What’s missing so far is any public detail on indexing strategy, query interface, or latency/recall targets; the artifact is purely directional in the Hornet teaser.
Mixedbread publishes low-latency late-interaction system overview (model details deferred)
Retrieval system design (Mixedbread): A high-level overview of a late-interaction search stack is being shared, explicitly framed around low-latency constraints and “designed from the ground up” for that shape of serving, as described in the Search system overview. The write-up is light on model specifics (“maybe you should stay tuned”), which implicitly puts the emphasis on engineering decisions needed to make late-interaction practical at runtime, per the Search system overview.
Benchmark hygiene callout: financial doc retrieval datasets can contain garbage entries
Benchmark hygiene (Practice): A pointed critique argues that some retrieval benchmarks (specifically “financial document retrieval”) contain low-quality examples, and that teams should inspect the underlying entries rather than treating leaderboard numbers as ground truth, as shown in the Benchmark data critique. This is an engineer-facing reminder that “dataset auditing” is a first-class retrieval skill when evaluation data is noisy or mismatched to production needs.
🎙️ Voice agents: sub-250ms TTS and native speech-to-speech stacks
Voice agent stack updates with concrete latency/cost claims (real-time TTS, speech-to-speech, duplex interruption). Excludes music/creative audio releases.
FlashLabs open-sources Chroma 1.0 real-time speech-to-speech with ~147ms TTFT
Chroma 1.0 (FlashLabs): FlashLabs is claiming an end-to-end, real-time speech-to-speech stack (no explicit ASR→LLM→TTS handoff) with fast turn-taking and high-fidelity cloning, framed as an open alternative to OpenAI’s Realtime model in the Chroma launch summary.
The latency slide shared in the Chroma launch summary calls out ~146.9ms TTFT, 52.3ms avg latency per frame, and RTF 0.43× (faster than real-time), alongside a 0.817 speaker similarity claim for zero-shot cloning. Separate discussion emphasizes “native speech-to-speech (no ASR → LLM → TTS)” and “full-duplex interruptions” as the friction removal for voice agents, as described in the architecture recap.
Inworld ships TTS-1.5 with sub-250ms realtime latency and $0.005/min pricing
TTS-1.5 (Inworld): Inworld shipped a TTS update focused on real-time responsiveness—one post frames it as production-grade latency under 250ms (Max) and 130ms (Mini), plus multilingual support and low per-minute cost, as summarized in the latency comparison and expanded in the launch details.
The chart in the latency comparison puts TTS-1.5 Mini at ~130ms and TTS-1.5 Max at ~250ms, compared to “500+ms” for another multilingual baseline; the follow-up notes claim ~$0.005/min and 15 languages, while also arguing that <250ms helps conversational turn-taking feel natural in production, per the launch details.
SGLang adds day-0 support for Chroma 1.0 with ~135ms end-to-end TTFT claim
SGLang (LMsys) + Chroma 1.0: LMsys says SGLang has “day-0” support for Chroma 1.0 and publishes latency numbers that are tuned for interactive voice agents, according to the SGLang support post.
In the SGLang support post, LMsys reports ~135ms end-to-end TTFT, ~15% lower Thinker TTFT, and RTF ≈ 0.47–0.51 (>2× faster than real-time) when running Chroma through SGLang; that’s the kind of integration detail that changes whether a voice stack is deployable beyond demos.
LiveKit adds Inworld TTS-1.5 as an Inference/Agent Builder option and SDK plugin
LiveKit (Inworld TTS distribution): LiveKit says Inworld TTS models are now available “through LiveKit Inference, in our Agent Builder, and as a plugin for our Agents SDKs,” per the LiveKit availability note.
This is a straightforward deployment-surface signal: instead of treating TTS as a separate vendor integration, LiveKit is positioning it as a first-class selectable component inside the same voice-agent plumbing described in the LiveKit availability note.
ChatGPT Voice for paid users improves instruction following and fixes repeat-back bug
ChatGPT Voice (OpenAI): OpenAI updated paid-tier ChatGPT Voice to better follow user instructions and to fix a bug where Voice could repeat back custom instructions, as shown in the release notes screenshot.
For teams building voice experiences on top of ChatGPT Voice/AVM-like behavior, the “repeat custom instructions” bug is the kind of small reliability issue that can leak into product UX; this change is narrowly scoped, but concrete, per the release notes screenshot.
Multi-speaker, noisy rooms emerge as the next stress test for speech-to-speech agents
Voice agent robustness: A practical “real world” benchmark gap shows up in the question of whether speech-to-speech models can handle multiple people talking at once—e.g., “kids shouting different requests”—as raised in the multi-speaker stress test question.
Follow-on commentary frames this as a household-robot/assistant blocker rather than a model-speed issue, per the households with kids note; full-duplex and low TTFT help, but crosstalk, interruption handling, and source attribution are still the messy part.
💼 Business & enterprise signals: partnerships, margins, and inference infrastructure bets
Capital flows and enterprise adoption signals affecting builders: big partnerships, fundraising, margin pressure, and ROI skepticism. Excludes education-specific programs (kept inside their own items here only when tied to spend/adoption).
Nvidia leads $150M into Baseten as inference becomes its own mega-layer
Baseten (Nvidia/IVP/CapitalG): Nvidia invested $150M into inference startup Baseten, valuing it around $5B, positioning it as a scale layer for deploying large models efficiently (used by apps like Cursor/Notion), as described in the investment summary.
This is another clear signal that “inference infrastructure” is being treated as a standalone wedge—separate from model labs and clouds—where latency, routing, and cost become product surface area, not plumbing.
OpenAI reportedly lines up a $50B raise, implying a new scale of capital spend
OpenAI (fundraising): A report circulating on X claims Sam Altman has been discussing a $50B funding round at a $750B–$830B valuation, with meetings involving Middle East investors, per the fundraising excerpt.
If accurate, this would be a step-change in the capital stack for frontier model training and inference capacity (and would likely pull the whole supply chain—compute, power, foundry—into longer-term commitments).
Anthropic’s unit-economics squeeze shows up in a reported margin reset
Anthropic (unit economics): A report claims Anthropic lowered its 2025 gross margin projection to ~40% after inference on Google/Amazon ran 23% above plan, even as revenue ramps, according to the margin report.
The operational point is that LLM “software margins” are still highly path-dependent on utilization, pricing, and provider mix; this is a reminder that scaling demand can worsen near-term margins if capacity and efficiency don’t keep pace.
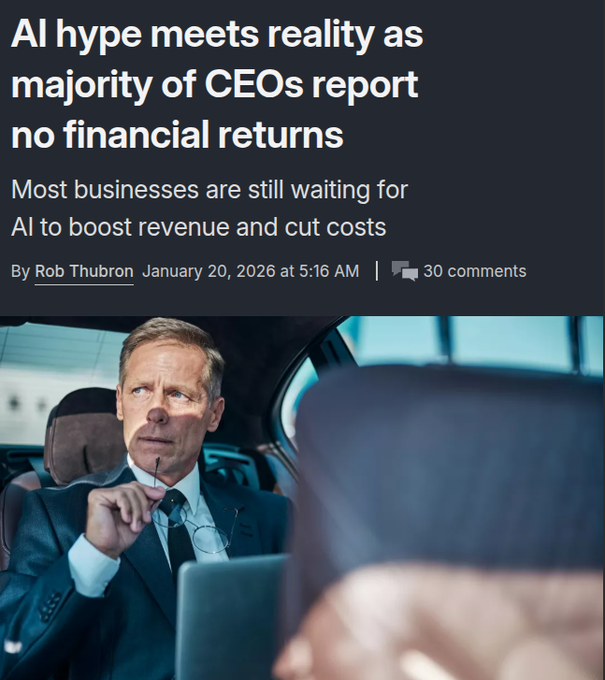
PwC CEO data shows AI adoption is outrunning measurable ROI for many firms
PwC (enterprise ROI): PwC’s 2026 CEO survey summary says 56% of CEOs saw no cost or revenue benefit from AI in the last 12 months and only 12% saw both lower costs and higher revenue, as reported in the survey breakdown; PwC attributes the gap to “foundations” like data access and integration readiness, as detailed in the PwC report.
This is a useful corrective for model/agent hype: the bottleneck is often workflow wiring and internal data access, not raw model capability.
Baseten positions itself as the inference layer behind LangChain’s no-code agents
Agent Builder (LangChain) + Baseten: Baseten says it’s working with LangChain to power “production-ready agents without code,” citing Baseten Inference plus GLM 4.7 as the backbone and sharing a build tutorial, per the partnership note and the linked tutorial blog.

This is a go-to-market pattern worth clocking: agent frameworks are increasingly bundling a preferred inference provider (model + serving stack) to make reliability and latency part of the default experience.
OpenAI reportedly reorganizes around product GMs, including an ads line
OpenAI (org structure): A report claims OpenAI is moving to a “general manager” structure with leaders overseeing major product groups including ChatGPT, enterprise, Codex, and advertising efforts, per the org restructure quote.
This reads like a shift from lab-first shipping to product-line accountability—especially notable because “ads” is now explicitly named alongside core AI products.
Gemini “no ads” positioning becomes a competitive narrative against ChatGPT
Gemini (Google) — monetization strategy: Commentary claims Google has “no ambitions” to add ads inside the Gemini app because it can subsidize with Search/YouTube revenue and position itself against ChatGPT on perceived output integrity, as argued in the no ads rationale.
No product-policy doc is cited in-thread, so treat this as strategy discourse; the practical implication is that pricing pressure may land more on API/enterprise packaging than on consumer monetization.
🧭 Careers & culture: the “write vs read code” shift and workforce anxiety
The discourse itself is the news: claims about engineers becoming editors, job displacement timelines, and cultural reactions to agentic coding. Excludes concrete workflow techniques (covered in coding workflows).
Amodei repeats “6–12 months to automate most SWE end-to-end” framing
Dario Amodei (Anthropic): A Davos clip making the rounds has Amodei claiming AI could do “most, maybe all” software engineering end-to-end within 6–12 months, shifting humans into editor/overseer roles, as circulated in the WEF clip and re-shared in the retweet quote.

• Second-order claim in the same media circuit: he also frames “software is essentially free,” implying on-demand generation for one-off apps, as shown in the WEF clip.
• Reaction signal: some posts treat this as a near-term labor shock; others read it as a continuation of the “agents expand output” narrative rather than immediate headcount reduction.
The core uncertainty in the tweets is operational: what “end-to-end” means under real-world verification, coordination, and deployment constraints.
Ryan Dahl’s “humans won’t write syntax” quote keeps spreading
Ryan Dahl (Deno/Node.js creator): A tweet screenshot continues to circulate with Dahl stating “the era of humans writing code is over,” framing the shock as identity-based (“for those of us who identify as SWEs”) while arguing engineers still have work—just not “writing syntax directly,” as shown in the viral tweet screenshot.
Within today’s tweets, this acts as a shorthand for the broader “author vs editor vs manager of agents” identity shift.
LLM dependence shows up as a “skill degradation” fear signal
Workforce anxiety inside teams: A thread claims some teams are becoming dependent on coding agents to the point of “nerf[ing] their own ability to use their brains,” and when agents fail they “start doing really weird stuff,” as described in the dependence warning and echoed in the follow-up line.
This is less about model capability and more about how orgs adapt: competence drifts from implementation to diagnosing, decomposing, and recovering when the tool stalls.
Nadella: business logic shifts from SaaS apps to agents, apps become CRUD
Satya Nadella (Microsoft): A clip from BG2 circulates a thesis that “business logic moves from the application to the AI agent,” leaving many SaaS apps as commoditized CRUD backends while agents handle orchestration and reasoning, as described in the clip summary.

This lands in culture as a role-definition shift: “shipping features” becomes more about supervising agent-driven changes and controlling where the decision-making layer lives.
Builders push back on “all SWE in 6–12 months” timelines
Timeline skepticism: A counterpoint that keeps resurfacing is that, absent a large capability jump, it’s unlikely “most, maybe all” software engineering is automated end-to-end within 6–12 months, as stated in the hot take.
The disagreement isn’t about usefulness for coding today; it’s about whether current agent reliability closes the last-mile gap fast enough to remove humans from the loop.
Europe labor anxiety: layoffs plus “AI replacement” fears
Labor anxiety (Europe): A post highlights Germany layoffs as a regional signal and cites surveys where up to 25% of workers fear AI replacing their roles, alongside a forecast slowdown in eurozone employment growth to 0.6%, as summarized in the macro thread and sourced via the DW report.
This is one of the few threads in today’s set tying agentic coding narratives directly to broad labor-market sentiment rather than dev-only discourse.
🎓 Developer community & learning: camps, hackathons, and onboarding sessions
Events, workshops, and community spaces that speed up practitioner adoption (livestreams, hackathons, Discords, onboarding sessions). Excludes the tool updates themselves (covered in tool categories).
Vibe Code Camp runs Jan 22 with live Claude/Codex workflows
Vibe Code Camp (Every): Every is running an all-day “Vibe Code Camp” livestream on Jan 22 focused on live, end-to-end agentic building workflows, with guests spanning Anthropic (Claude Code), Notion, and Google; the promo frames it as ~8 hours of live coding and workflow walkthroughs, as described in Event promo and Speaker announcement.

• Who’s on: Thariq Shihipar from the Claude Code team is slated to build live and answer questions, per Speaker announcement; Kevin Rose is also listed for a segment on “compound engineering,” per Kevin Rose promo.
• What the stream emphasizes: live “how I do the work” demonstrations (UI + animation workflows included), as highlighted in Workflow preview and Geoffrey Litt promo.
• Internal learning angle: Every also shows a pattern of turning agent usage into daily digests (cron + Claude Code) for community learning, as shown in Discord digest screenshot.
OpenAI Devs launches a Codex Discord community
Codex Discord (OpenAI Devs): OpenAI Devs launched an official Discord community for Codex builders, positioned as a hub for technical Q&A, learning from other teams, and showcasing what people are building, as announced in Discord launch and echoed in Community invite.
The signal here is less about a product change and more about scaling “how-to” knowledge: a shared place for setup patterns, MCP/tool integrations, and long-run debugging workflows to circulate in real time.
Codex team schedules another live onboarding session
Codex onboarding (OpenAI): The Codex team is running another live onboarding session next Wednesday at 11:30am PT, explicitly covering install, environment setup, prompting, MCPs/tools, and “advanced use cases,” as laid out in Onboarding announcement with signup/recording logistics in Signup reminder.
This is framed as a repeatable “zero → working agent setup” walkthrough rather than a product launch, suggesting ongoing demand for operational playbooks (limits, tool wiring, and harness setup) rather than model capability explanations.
Gemini 3 SuperHack announced for Jan 31 in San Francisco
Gemini 3 SuperHack (Google DeepMind): An in-person “Gemini 3 SuperHack” hackathon is scheduled for Saturday, Jan 31 in San Francisco, hosted with Google DeepMind and Cerebral Valley, per the event listing in Event page and the announcement in Hackathon post.
The event page describes a build focus using Gemini 3 tooling (AI Studio/Vertex) and an agentic dev platform (“Antigravity”), with a theme around sports and live entertainment experiences, as detailed in Event page.
Together announces AI Native Conf with Cursor and Meta speakers
AI Native Conf (Together AI): Together is promoting “AI Native Conf” in San Francisco on March 5, 2026, pitching it as a production-focused gathering for builders; the agenda callout includes a Cursor engineer plus Meta and Together AI leaders, as listed in Agenda post and Speaker list.
The registration page emphasizes limited capacity and a request-to-attend flow, as shown in Event page alongside the follow-up in Attendance note.
DeepLearning.AI ships a short course on Gemini CLI
Gemini CLI course (DeepLearning.AI): DeepLearning.AI published a short course on Gemini CLI, positioned as “code & create with an open-source agent,” as shared in Course card with a CLI walkthrough clip in Course preview.

The course card calls out a beginner level and a runtime of 1 hour 13 minutes, as shown in Course card, which fits the recent trend of teams treating agent harness literacy (setup, commands, workflows) as a first-class skill rather than an incidental tool detail.
🎬 Generative media & creator tooling: image→video leaps and “AI influencer” factories
Creative model/tool updates and workflows: image-to-video, audio-to-video, ComfyUI video tooling, and AI influencer creation/monetization. Excludes evaluation platforms (Video Arena is in benchmarks).
Runway Gen 4.5 ships image-to-video; early tests emphasize multi-shot prompting
Gen 4.5 (Runway): Runway’s Gen 4.5 image-to-video started showing up in creator workflows, with people feeding in a 3×3 storyboard grid as the image input and getting multi-scene continuity in a single clip, as shown in the Storyboard grid demo.

Posts also note current constraints: clips generate up to ~10s and don’t include native audio yet, per the Output clip example.
LTX Audio-to-Video workflows surface: 3–10s audio constraint and music-driven motion
LTX Audio-to-Video (LTX Studio): Following up on Audio-to-video launch (dialogue/lip-sync positioning), new user walkthroughs highlight a hard constraint: audio inputs need to be 3–10 seconds, with creators trimming audio before upload as described in the Tutorial demo.

Some tests also claim you can use sound effects or music as reference to drive motion pacing rather than only lip-sync, per the Tutorial demo, and early experimentation includes feeding in synthetic speech (e.g., Gemini TTS) as an input source, as shown in the Example clip.
Storyboard-grid prompting pattern: hard-cut each panel for multi-shot I2V
Storyboard-grid prompting: A concrete control trick for image-to-video is to supply a 3×3 storyboard sheet as the single image input, then explicitly instruct the model to treat each panel as a separate shot (not one animated mosaic), using hard cuts when needed, as described in the Prompt recipe.

Creators report this is hit-or-miss across attempts (one clean, others failing), with an example failure shown in the Failed attempt clip.
ComfyUI adds Seedance 1.5 Pro knobs: first/last-frame locking for I2V
Seedance 1.5 Pro (ComfyUI): ComfyUI surfaced Seedance 1.5 Pro controls focused on tighter video structure, including first/last-frame locking to pin style/characters/composition while generating the in-between frames, as shown in the First-last-frame control demo.

The same rollout thread positions it around audio-video synchronization (including multi-person dialogue) and tighter lip-sync, with examples in the First-last-frame control demo.
Higgsfield launches browser AI Influencer Studio plus monetization via Earn
AI Influencer Studio (Higgsfield): Higgsfield is pushing a browser-based workflow for generating many “AI influencer” personas with 100+ customization options and 30s HD video, positioned as free to try in the Product launch, with details on the landing page linked in Product page.
The same announcement positions Higgsfield Earn as a monetization layer (“guaranteed payouts” framing) for the generated influencer content, per the Product launch.
ComfyUI masking workflow: insert new elements into video scenes (Wan 2.2 Animate)
Masking for video edits (ComfyUI): A shared workflow shows using masking in ComfyUI with Wan 2.2 Animate to add or replace elements inside an existing scene—i.e., localized edits instead of regenerating the full frame—via the example shared in the Masking example.
Higgsfield posts a $50k X Article Challenge for AI creator essays
X Article Challenge (Higgsfield): Higgsfield opened a writing contest with a $50,000 prize pool and 10 global winners (up to $5,000 each) for long-form X Articles about AI influencers/filmmaking/creation, as announced in the Challenge post.

Entries are capped at up to 3 articles (5,000+ characters each) and the deadline is Jan 25, 2026 at 4:00 PM GMT, per the Challenge post.
ElevenLabs announces The Eleven Album: artists with AI-generated instrumentation
The Eleven Album (ElevenLabs): ElevenLabs announced a collaboration called “The Eleven Album,” framing it as chart-topping/GRAMMY-adjacent artists pairing their vocals and style with AI-generated instrumentation, as shown in the Announcement video.

The promo frames this as a repeatable creative workflow (“original track” + AI instrumentation) rather than a single demo, per the Artist detail.