Gemini 3 Deep Think hits 41% HLE – Ultra users get parallel reasoning
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
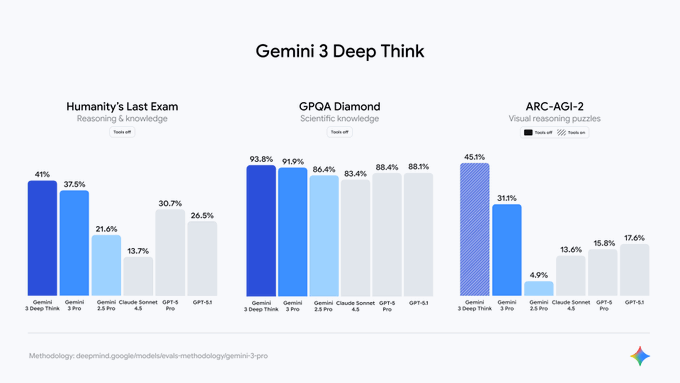
Gemini 3 Deep Think is finally live for Google AI Ultra subscribers in the Gemini app, and the numbers back up the fanfare. On Humanity’s Last Exam it scores 41% with tools off, beating Gemini 3 Pro at 37.5% and GPT‑5 Pro at 30.7%. GPQA Diamond lands at 93.8%, ahead of both Gemini 3 Pro and GPT‑5.1, while ARC‑AGI‑2 visual puzzles climb to 45.1% with tools on, versus 31.1% for Gemini 3 Pro and mid‑teens for GPT‑5‑class baselines and Claude Sonnet 4.5.
What’s new here is the surface and the stack. Deep Think is not a cute toggle on Pro; it’s a more compute‑hungry reasoning backend doing parallel hypothesis search, descended from the Gemini 2.5 Deep Think models that hit IMO and ICPC gold. In the Gemini app you enable “Deep Think” and select the “Thinking” model, then treat it like a manual turbo switch for brutal math, science, and multi‑file code instead of your default chat.
Early builders are split: some call it the smartest model they’ve touched, others see frozen or broken outputs “for days.” After a week of buzz around open DeepSeek V3.2 and GPT‑5.1‑Codex‑Max, Google’s counter is clear: frontier‑level reasoning, but for now locked behind Ultra and best used as a specialist, not your always‑on assistant.
Top links today
- OpenRouter State of AI 100T token study
- GPT-5.1 Codex Max prompting guide
- Mistral Large 3 coding model announcement
- DeepSeek-V3.2 open LLM technical report
- Guided self-evolving LLMs paper
- Deep research systems survey paper
- CUDA-L2 LLM-guided CUDA optimization paper
- AutoJudge transformer inference acceleration paper
- vLLM DeepSeek-V3.2 optimized inference guide
- Anthropic Interviewer product overview
- Anthropic Interviewer 1,250 worker study results
- Firecrawl integration with Google ADK tutorial
- Datalab structured spreadsheet parsing announcement
- Six-day practical RAG improvement course
- Semantic search over 5000 NeurIPS papers
Feature Spotlight
Feature: Gemini 3 Deep Think rolls out with parallel reasoning
Gemini 3 Deep Think is live for Ultra subscribers with parallel hypothesis reasoning; early charts show 41% on Humanity’s Last Exam, 45.1% ARC‑AGI‑2 (tools on), 93.8% GPQA, and real‑world coding demos.
Cross‑account surge around Gemini 3 Deep Think going live for Google AI Ultra subscribers in the Gemini app. Mostly launch how‑tos plus new benchmark charts showing sizable gains on HLE/ARC‑AGI‑2 and a coding demo; little else competes for volume today.
Jump to Feature: Gemini 3 Deep Think rolls out with parallel reasoning topicsTable of Contents
🧠 Feature: Gemini 3 Deep Think rolls out with parallel reasoning
Cross‑account surge around Gemini 3 Deep Think going live for Google AI Ultra subscribers in the Gemini app. Mostly launch how‑tos plus new benchmark charts showing sizable gains on HLE/ARC‑AGI‑2 and a coding demo; little else competes for volume today.
Deep Think tops HLE and ARC-AGI-2 while nudging past GPT‑5 on science
New evals from Google DeepMind show Gemini 3 Deep Think jumping ahead of both prior Gemini versions and key competitors on several hard reasoning benchmarks. On Humanity’s Last Exam (HLE, tools off), it scores 41%, up from 37.5% for Gemini 3 Pro and above GPT‑5 Pro at 30.7%, while Claude Sonnet 4.5 lags at 13.7%. benchmark breakdown
On GPQA Diamond (graduate-level science questions, tools off), Deep Think reaches 93.8%, edging Gemini 3 Pro at 91.9% and GPT‑5 Pro at 88.4%, and slightly ahead of GPT‑5.1 at 88.1% and Claude Sonnet 4.5 at 83.4%. benchmark breakdown On ARC‑AGI‑2 visual reasoning puzzles, Deep Think with tools on hits 45.1%, versus 31.1% for Gemini 3 Pro (tools off) and mid‑teens for GPT‑5 Pro and GPT‑5.1; earlier Gemini 2.5 Pro sat at 4.9%, and Claude Sonnet 4.5 at 13.6%. benchmark breakdown A separate comparison adds Claude Opus 4.5 into the mix: Deep Think’s 45.1% on ARC‑AGI‑2 tops Opus 4.5 at 37.6%, and its 41% HLE score beats Opus 4.5’s 28.4%, while GPQA Diamond remains tightly clustered (Deep Think 93.8% vs Opus 4.5 at 87%). opus comparison chart Commentators are already extrapolating these gains forward, speculating that another year of scaling could push HLE toward 60% and ARC‑AGI‑2 past 50%, which would materially change what you can safely offload to agents that operate without tools. future projections For engineers and analysts, the takeaway is that Deep Think isn’t only a UI toggle—it’s running a different, more compute‑hungry reasoning stack that currently leads public charts on the hardest multi‑step tasks.
Gemini 3 Deep Think rolls out to Google AI Ultra users in Gemini app
Gemini 3 Deep Think is now live for Google AI Ultra subscribers inside the Gemini app, adding a high-effort reasoning mode that you can toggle per conversation for tougher math, science, and coding problems. You enable it by choosing “Deep Think” in the prompt bar and selecting the “Thinking” model from the dropdown, then running your prompt as usual. activation steps

Google and DeepMind are positioning this as the consumer surface for their IMO/ICPC-level reasoning work, initially limited to paying Ultra users on the web and mobile Gemini clients. (launch demo, ultra rollout note) That means AI leads and engineers can start experimenting with Deep Think’s behaviour right away through the app—before any broader API or workspace integrations arrive. For now it’s best treated as a manual “turbo” switch: keep normal Gemini 3 Pro for quick queries, and flip on Deep Think when you want it to explore multiple hypotheses or write longer, more careful code in one shot. (coding example, Gemini product page)
Builders test Deep Think for heavy coding and math, with strong but mixed early feedback
Early adopters are putting Deep Think straight onto hard coding and logic problems, and the mood is excited but not unanimous. One DeepMind demo shows Gemini 3 Deep Think writing and debugging an entire simulated dominoes game from a single prompt, including verification of the run, which is the kind of long, structured program many models still fumble.
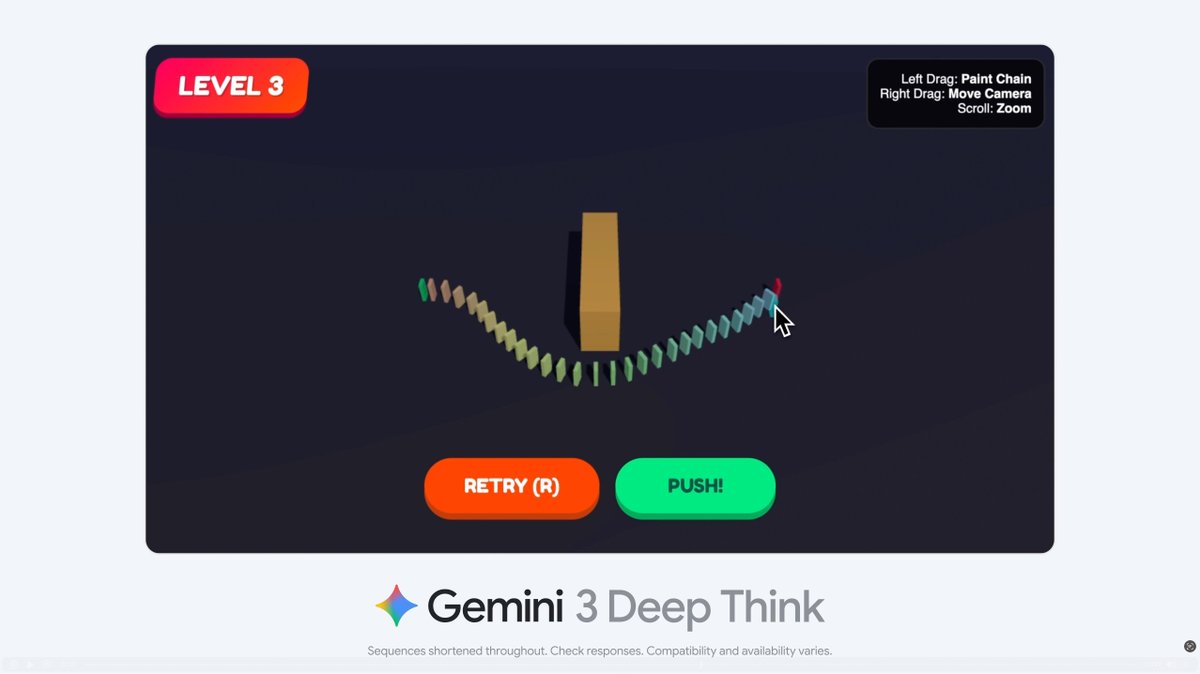
Researchers highlight that Deep Think “uses advanced parallel reasoning to explore multiple hypotheses simultaneously,” and that it builds on Gemini 2.5 Deep Think variants that achieved gold‑medal performance at the International Mathematical Olympiad and the ICPC World Finals. (parallel reasoning explainer, imo/icpc followup) This matters if you care about agent design: you’re essentially getting a front end onto the same family of thinking models that already proved themselves on contest‑style math and programming tasks.
On the sentiment side, some builders are all‑in: one calls it “the smartest AI alive,” saying Deep Think unlocks new vistas for scientists and mathematicians and framing it as the current top reasoning model to beat. builder praise Others report rough edges—one user says they “would love to try Deep Think 3” but have been seeing frozen or broken outputs “for days, if not weeks,” which suggests the rollout and client integration still have reliability issues in some regions or accounts.
If you lead an engineering or research team, the near‑term pattern is clear: treat Deep Think as a high‑effort specialist for difficult math, science, and multi‑file code generation, not as your default chat model. Use it selectively where parallel hypothesis search and deep traces pay off, and keep tracking real‑world behaviour as Google iterates on both infrastructure and UX.
🧪 Fresh models and endpoints
Release and availability updates relevant to builders. Excludes the Gemini 3 Deep Think feature; focus is on OpenAI Codex Max availability, Microsoft’s real‑time TTS, and access routes for major models.
GPT-5.1-Codex-Max spreads from Responses API into major dev tools
OpenAI’s new GPT‑5.1‑Codex‑Max coding model is now exposed through the Responses API, with 400k context, up to 128k output tokens, reasoning-token support, and pricing at $1.25/M input and $10/M output tokens. api announcement You can also drive it via the updated Codex CLI v0.65 (@openai/codex), which adds better resume, screen display, and stability for long agent runs. cli update

The model is already wired into a wide range of endpoints: Cursor and Windsurf for IDE agents, (cursor integration, windsurf support) GitHub Copilot in public preview, copilot preview Droid for ML/data/system-admin workflows, droid integration and Linear, where @Codex mentions spin up cloud tasks that post progress back into issues. linear workflow video OpenAI also published a detailed prompting guide for harness-style use, stressing medium reasoning as the default and tool-heavy workflows over shell one‑offs. prompting guide For AI engineers, this means you can now standardize on a single, high‑end coding brain across CLI agents, IDEs, ticketing systems, and custom backends, without writing separate glue for each surface. The trade‑off is cost and latency: this is the "maximum effort" tier in the Codex family, so it’s the model you route only the hardest refactors, large codebase migrations, or long‑horizon debugging sessions to, while cheaper or faster models handle routine edits.
DeepSeek V3.2 arrives in LLM Gateway with multi-provider routing
LLM Gateway has added DeepSeek‑V3.2 as a first‑class model, exposing it via a single ID (deepseek-v3.2) with routing across multiple underlying providers plus flags for tools, streaming, and JSON output. llm gateway tweet
The listing advertises 163,840 token context, pricing from $0.28/M input and $0.42/M output tokens, and built‑in support for vision, tool use, and structured outputs.
If you’re experimenting with DeepSeek as a cheaper GPT‑5‑class reasoner, this is a convenient way to hit several hosting backends through one API, then let LLM Gateway pick the best provider that can handle your prompt size and features. It also gives you a clean upgrade path: you can start with generic chat, then progressively turn on tools, streaming, or JSON schemas without rewriting the integration each time you move DeepSeek workloads between vendors or regions.
Mistral Large 3 lands on Ollama Cloud under a 675B MoE tag
Ollama is now serving Mistral Large 3 from its managed cloud as mistral-large-3:675b-cloud, so you can ollama run mistral-large-3:675b-cloud without self‑hosting the 675B‑parameter mixture‑of‑experts model. (ollama cloud tag, ollama model page) The same model has already been showing up near the top of open coding and reasoning leaderboards and is licensed Apache‑2.0, which keeps it attractive for commercial use. (mistral coding tweet, arena highlight) For AI engineers, this endpoint removes the biggest operational barrier to trying Mistral’s flagship model: GPU capacity. You can prototype against a fully managed cloud backend today and later swap to local serving when Ollama’s on‑device support for Mistral Large 3 arrives, keeping the same client API. That makes it a realistic alternative to closed frontier models for teams who want an open MoE with strong coding skills but don’t want to operate a cluster yet.
Microsoft ships VibeVoice-Realtime-0.5B for low-latency streaming TTS
Microsoft released VibeVoice‑Realtime‑0.5B on Hugging Face, a 0.5B‑parameter text‑to‑speech model tuned for streaming scenarios with around 300 ms time‑to‑first‑audio depending on hardware. (model release, model card) Under the hood it combines a tiny Qwen2.5‑0.5B language model with a σ‑VAE acoustic tokenizer and a diffusion decoding head, and is trained up to 8k tokens so it can handle long‑form speech.
For builders, this is a practical endpoint if you need a single‑voice, real‑time TTS in bots, agents or game UIs, but don’t want to host a huge voice model. You’ll trade multi‑speaker flexibility for footprint, yet you get a fully open model you can run on modest GPUs or even strong edge devices, which is handy for on‑prem or privacy‑sensitive deployments.
🧰 Agent IDEs and coding workflows
Hands‑on agent coding flows, harness design, and integrations. Excludes Gemini 3 Deep Think; today is heavy on Codex harnesses, Linear delegation, terminal UX and reproducible agent infra.
Conductor uses hidden git refs and GPT‑5 to build “time‑travel” checkpointing
Conductor unveiled a checkpointing system that snapshots your repo’s commit, index, and full worktree at the start and end of each agent turn, storing them as hidden git refs so you can roll the entire workspace—files, staged changes, history, and chat—back to a prior state with one click. checkpointing thread Instead of abusing git stash or cluttering history with commits, the team leaned on GPT‑5 to evaluate design options and then to draft a checkpointer CLI that writes tree objects via git write-tree and pins them under .git/refs/conductor-checkpoints/<id>.

The result is that when an agent run goes sideways (migrations, lockfiles, staged junk), you can truly revert all of its effects rather than discovering half‑reset states later.
If you’re building your own agent harness, this is a strong pattern to copy: treat version control as the source of truth, store checkpoints alongside real commits, and design revert as an operation on git state—not a patchwork of ad‑hoc file snapshots.
Cursor overhauls its Codex harness for GPT‑5.1‑Codex‑Max
Cursor detailed how it rebuilt its agent harness around GPT‑5.1‑Codex‑Max, shifting to a "shell‑forward" tool set, adding concise reasoning summaries, and tightening sandboxing to get higher success rates on multi‑step coding tasks. cursor codex launch The new setup nudges Codex to prefer tools over ad‑hoc shell commands, uses short progress preambles instead of streaming walls of thought, and routes edits through a secure sandbox that blocks arbitrary file and network access. harness blog A follow‑up breakdown shows how renaming tools to shell analogues (rg, ls, etc.) and clarifying when to invoke them materially reduced flaky edits and made the agent feel more "deterministic" during large refactors. shell forward slide For AI engineers, the message is clear: harness design matters as much as the model. If you’re seeing Codex flail in long runs, copy this pattern—small, well‑named tools, explicit guidance to use them, and a sandbox that mirrors your real project layout without exposing the whole machine.
Linear adds first‑class Codex delegation for engineering backlogs
OpenAI and Linear shipped a tight integration where assigning or @mentioning Codex on an issue spins up a cloud task that works the ticket and posts progress back into Linear, including links to the finished work. linear codex launch The demo shows Codex picking up a bug, running its own subtasks in the background, and then updating the issue with a completed PR‑ready change list and status, so engineers can treat it like a junior teammate instead of a one‑shot chat.
Early users say this shifts their workflow from copying prompts into a chatbox to routing whole tickets to the agent, then reviewing diffs when Codex reports "Task completed". (linear workflow note, integration docs) If you already live in Linear, this is one of the more production‑ready ways to experiment with agentic coding: start by delegating well‑scoped refactors or test additions and treat Codex’s updates like any other contributor—review, comment, and only then merge.
GPT‑5.1‑Codex‑Max rapidly lands in Windsurf, VS Code, Droid and Copilot
Within days of the Responses API release, api rollout note GPT‑5.1‑Codex‑Max has been wired into most serious coding surfaces: VS Code via the official extension, vscode codex update GitHub Copilot’s public preview, copilot codex preview the Windsurf IDE for all users, windsurf codex rollout and Factory’s Droid agent platform for ML/data‑science/sysadmin flows. droid codex update Windsurf and others expose multiple “reasoning levels” (Low/Medium/High) on top of Codex‑Max, while OpenAI’s own Codex CLI v0.65 adds better resume, tooltips and stability for long‑running tasks. (codex cli update, prompting guide) For teams, this means you don’t have to pick a single tool to try Codex‑Max—pick the environment where you already spend your time, turn on the higher reasoning tiers only for gnarlier changes, and keep cheaper chat models for quick Q&A or boilerplate.
Warp terminal adds a GUI file tree that ties into its agent flows
Warp shipped an in‑terminal file tree that lets you browse the current directory, open files, copy their paths, and even drag them straight into the input box for its agent, instead of manually typing paths or ls output. warp file tree launch The short demo shows a side panel listing project files; clicking jumps you into the file, while dragging a file into the prompt seeds the agent with exactly the path you want it to inspect.

Following up on Warp’s earlier inline editor work, Warp inline editor this continues their push to turn the terminal into a higher‑level coding cockpit rather than a bare shell.
For AI‑assisted workflows, this kind of affordance matters: agents are only as good as the context you feed them, and making it one gesture to reference the right file or path cuts a lot of friction out of “open → inspect → edit” loops.
CodexBar adds CLI and status views to track Codex and Claude usage
CodexBar, the macOS menu‑bar monitor for AI usage, now exposes a CLI and richer status views so you can see session limits, weekly quotas, and remaining credits for both Codex and Claude from either the menu or your terminal. codexbar update The screenshots show a dropdown listing Codex session %, weekly %, and credits alongside Claude’s Pro/Max quotas, plus a codexbar --status command that prints the same data in a shell‑friendly format for scripts and dashboards.
Under the hood it calls the various vendors’ usage APIs, which lets you catch “out of juice” scenarios before an agent harness dies mid‑run.
For teams leaning on multiple providers, this kind of small utility is worth copying: centralise quota checks, wire them into your agent startup, and fail fast with a helpful message instead of discovering in the log that your last 30‑minute Codex run silently hit a limit.
RepoPrompt 1.5.46 adds full GPT‑5.1‑Codex‑Max support for repo‑scale prompting
RepoPrompt released v1.5.46 with full support for GPT‑5.1‑Codex‑Max, so you can now drive Codex‑Max as the engine behind its context_builder and other repo‑aware workflows. repoprompt release note The maintainer recommends sticking with GPT‑5.1 “vanilla” for interactive chat and reserving Codex‑Max for heavy lifting inside the context builder, where its longer thinking budget and tool use shine on tasks like generating plans, large diffs, or multi‑file migrations. codex max reminder This follows their earlier work where context_builder auto‑planned coding tasks from repository state, RepoPrompt autoplans so swapping in Codex‑Max upgrades the brains without changing the surface API.
If you’re doing repo‑scale prompting, this is a low‑effort way to experiment: point RepoPrompt at your codebase, configure Codex‑Max for the planning phase only, and keep a cheaper model for chat so you don’t burn budget on conversational fluff.
🧩 Agent plumbing: connectors, MCP, and routing
Interoperability and orchestration layers to wire tools/agents together. Excludes model launches; today spans Google ADK + Firecrawl, Strands + AG‑UI, v0’s MCP push, and Claude Code Skills.
Firecrawl plugs into Google ADK for multi‑agent web scraping and search
Firecrawl now exposes its crawling/search as a first‑class tool inside Google’s Agent Development Kit (ADK), so you can build multi‑agent flows that browse, scrape, and ground answers on the web without custom glue code. This is the same stack shown in their ChatGPT‑style app tutorial, where one ADK agent handles conversation while another uses Firecrawl for structured web research before responding. (adk launch thread, adk tutorial) For AI engineers, this turns Firecrawl into something you “select in a manifest” rather than a bespoke HTTP client: you describe web tasks in an ADK agent spec and let Firecrawl handle pagination, screenshots, or extraction while ADK orchestrates the loop. That’s a clean way to separate what the agent should know (web content) from how it gets it (Firecrawl + ADK tools), and it makes swapping Firecrawl into other ADK projects (bots, copilots, internal tools) a low‑friction experiment rather than a mini‑integration project. chatgpt clone guide
AG‑UI lands in AWS Strands docs as the chat front‑end for agents
CopilotKit’s AG‑UI is now featured inside AWS Strands Agents documentation as the recommended chat and generative‑UI layer for Strands‑based systems. Strands handles the back‑end agent graph, while AG‑UI supplies a React UI that can stream messages, render tool outputs, share state, and expose tool‑driven widgets in a single chat surface. strands docs clip

For teams wiring up Strands agents, this removes a big chunk of “last‑mile” work: instead of building a custom chat front‑end for each new agent, you drop in AG‑UI, point it at your Strands endpoint, and get a production‑grade chat plus tool display with shared state. That makes it much easier to stand up internal pilots—think support agents, analyst copilots, or ops dashboards—without sinking cycles into bespoke UIs that all solve the same problems (streaming, citations, tool panes, partial results). integration docs
CocoIndex ships a Claude Code Skill for building data pipelines from inside the agent
CocoIndex released a Claude Code Skill that teaches Claude how to build and run CocoIndex data‑transformation flows directly from the agent, so you can design ETL‑style pipelines, custom functions, and CLI/API flows by conversation instead of hand‑writing all the boilerplate. The skill plugs into Claude Code’s plugin system, then exposes operations like creating flows, wiring sources/sinks, and operating them via CLI or API calls. skill announcement
The practical upshot is that data engineers can ask Claude to “build a pipeline that summarizes files under this directory into a DB table with filename, summary, embedding” and the agent will stand up the CocoIndex flow, pick hardware, and emit runnable commands or scripts. This moves CocoIndex from a library you script around into a first‑class orchestration target inside Claude Code, which is exactly the pattern we’re seeing across agents: skills encapsulate domain know‑how, while the LLM handles planning and glue. github repo
LLM Gateway adds DeepSeek V3.2 with multi‑provider routing and tool flags
LLM Gateway now exposes DeepSeek V3.2 as a routable model with a single ID (deepseek‑v3.2), advertising 163,840 context tokens, streaming, vision, tools, and JSON output, and starting prices around $0.28/M input and $0.42/M output tokens. Instead of hard‑coding a specific DeepSeek endpoint, you call the gateway with that model ID and it picks the best underlying provider that can satisfy your context and feature requirements. gateway model card
For infra leads, this is pure plumbing value: one config lets you A/B multiple DeepSeek backends, enforce caps by context & tool support, and fail over without changing application code. It also keeps DeepSeek V3.2 on equal footing with other frontier models already wired through LLM Gateway, so routing policies like “send math+tools to DeepSeek, send short chat to cheaper models” become a few lines of config instead of a bespoke integration for each vendor. gateway page
⚙️ Serving and speed: inference recipes
Runtime engineering and throughput/latency updates. Excludes Gemini Deep Think. Today includes vLLM recipes for DeepSeek, Together’s AutoJudge acceleration, and provider TTFT/TPS claims.
Together’s AutoJudge promises 1.5–2× faster inference by learning token importance
Together AI introduced AutoJudge, an inference‑time acceleration method that learns which tokens actually matter for the final answer and prunes the rest, delivering ~1.5–2× speedups compared to classic speculative decoding. Instead of naively speculating on all next tokens, AutoJudge uses a learned judge to keep only the crucial ones and skip work on low‑impact branches, and the gains compound further when you stack it with other advanced decoding tricks. autojudge thread Under the hood, AutoJudge is trained via reinforcement learning on curated datasets to predict token importance, so it can aggressively cut compute without tanking accuracy; Together reports that quality remains comparable while latency drops meaningfully across their internal workloads. The company has already wired AutoJudge into its AI Native Cloud stack, and the blog walks through how you can turn it on for your own models, treating it as a plug‑in to existing decoding pipelines rather than a full rewrite. autojudge blog post For infra leads, the takeaway is simple: if you’re already hitting diminishing returns with speculative decoding and better KV‑cache reuse, AutoJudge is one of the first production‑oriented techniques that explicitly learns where to spend test‑time compute instead of relying on fixed heuristics. It’s worth benchmarking it on your heaviest reasoning or long‑form generation endpoints to see whether you can reclaim 30–50% of GPU time without re‑architecting your stack.
Baseten claims DeepSeek V3.2 at ~0.22s TTFT and 191 tps
Baseten says it is serving DeepSeek‑V3.2 with a time‑to‑first‑token around 0.22 seconds and throughput around 191 tokens per second, about 1.5× faster than the next provider in their tests. They frame this as "SOTA open‑source performance at SOTA speed" and are positioning V3.2 as on par with GPT‑5 for many workloads but at much lower cost. baseten speed metrics
Cline immediately integrated this setup and is advertising DeepSeek‑V3.2 on Baseten as the default reasoning backend inside its coding agent IDE, underscoring that these numbers are not just a synthetic benchmark but backing a real interactive product. cline deepseek demo

If you’re latency‑sensitive on long reasoning traces, these TTFT and TPS numbers mean you can route a chunk of traffic to open DeepSeek instead of closed models without your UX falling over. It also sets a bar for other hosts: if your own DeepSeek deployment is noticeably slower than 0.22s / 191 tps, you have a concrete target to tune against in terms of batching, KV‑cache reuse, and hardware choice.
vLLM publishes DeepSeek‑V3.2 serving recipe with “thinking” and tools
vLLM shipped an official DeepSeek‑V3.2 serving recipe that wires in DeepSeek’s custom tokenizer, tool calling, and "thinking" mode so you don’t have to reverse‑engineer the config yourself. The command uses --tokenizer-mode deepseek_v32, a matching --tool-call-parser, and a --reasoning-parser plus chat_template_kwargs{"thinking": true} so the model emits its internal chain‑of‑thought in the right format for tools and inspectors. vllm announcement
For AI engineers, this turns DeepSeek V3.2 from “works in a notebook” into “ready for production serving”: you get the correct chat template, robust tool call parsing, and a standard way to flip on reasoning without hacking prompts or templates. If you’re already on vLLM, you can drop this recipe into your deploy scripts and keep your stack consistent across models instead of maintaining a special case for DeepSeek. You can see the exact CLI flags and environment snippet in the shared terminal example and docs. vllm docs
📊 Leaderboards and evals: coding, vision, long tasks
New charts and rankings across coding/vision/evals. Excludes Gemini Deep Think charts (covered in the feature). Today’s updates include Opus 4.5 agent scaffolds, Arena moves, and METR task horizons.
GPT‑5.1‑Codex‑Max posts strong coding gains on VibeCodeBench and SWE‑Bench
Fresh evals of GPT‑5.1‑Codex‑Max (High effort) show a +9.5% jump on VibeCodeBench, placing it #3 there, and roughly +1% on SWE‑Bench where it sits at #4, while slightly regressing on Terminal‑Bench 1.0. coding eval summary The same analysis notes it is 3× slower on SWE‑Bench and ~10× slower on VibeCodeBench than some competitors, framing it as a model you route to when you want maximum chance of success on hard refactors or multi‑file changes, not when you need instant responses. Combined with its arrival in the Code Arena’s live Web coding track, code arena launch this positions Codex‑Max as one of the top few options for agentic coding where latency is less important than reliability.
METR finds GPT‑5.1‑Codex‑Max can autonomously handle 2–3 hour software tasks half the time
New METR time‑horizon results show GPT‑5.1‑Codex‑Max as the top model for long software‑engineering tasks, achieving a 50% success rate on problems that would take a skilled human roughly 2–3 hours to complete. metr scatter chart On METR’s scatter plot, earlier models like core GPT‑5, Grok‑4, o‑series, and Claude Sonnet 4 cluster closer to the 0–1 hour band, while Codex‑Max pushes the frontier upward in human‑equivalent time solved at 50% success.
For anyone designing multi‑step coding agents or research assistants, this is a concrete signal that Codex‑Max can reliably stay on task for substantially longer without human correction than previous general‑purpose LLMs—even if cost, latency, and harness quality still gate practical deployment.
Claude Opus 4.5 tops new AutoCodeBench‑V2 coding benchmark at 82.9%
Tencent’s refreshed AutoCodeBench‑V2 suite (1,000 refined problems) now shows Claude Opus 4.5 in thinking mode leading with an 82.9% average solve rate, ahead of Gemini 3 Pro at 79.3% and GPT‑5 high at 76.6%. benchmarks thread The chart also highlights solid gaps over DeepSeek V3.2 thinking (67.2%) and several strong Chinese models, reinforcing Opus 4.5’s position as the most capable frontier model for single‑shot code generation in this benchmark.
For AI engineers, this is another independent signal that Opus 4.5 plus a good harness belongs on shortlists for serious coding agents, not just SWE‑Bench and CORE‑Bench style tasks. github benchmarks repo
GPT‑5.1‑high climbs to #3 on Arena vision leaderboard, GPT‑5.1 to #4
On the LMArena Vision leaderboard, GPT‑5.1‑high now ranks #3 and GPT‑5.1 sits at #4, both above earlier GPT‑5 vision variants and trailing only Gemini 3 Pro and Gemini 2.5 Pro. vision leaderboard update GPT‑5.1‑high gained 39 ELO points over GPT‑5‑high, while base GPT‑5.1 added 24 ELO over GPT‑5‑chat, signaling meaningful vision improvements across tasks like chart reading and document understanding, following up on its strong reasoning showings in scientific benchmarks. science ranking For teams picking a vision model, this suggests that if you were already using GPT‑5 for diagrams or UI screenshots, the 5.1 generation—especially the high tier—is now the default to try against Gemini 3 Pro rather than older GPT‑4‑Vision style models.
DeepSeek‑v3.2 lands mid‑pack on Arena text leaderboard but leads open models in Math and Legal
DeepSeek‑v3.2 enters the Arena text leaderboard at #38, with DeepSeek‑v3.2‑thinking at #41, both a bit lower than their v3.1 predecessors in overall ELO but showing sharp category strengths. text leaderboard update Among open‑weight models, v3.2 is now #1 in Math and Legal and top‑10 in Multi‑Turn, Media, and Business, while the thinking variant is #1 in Science and top‑5 in Legal. category breakdown The biggest regression is in Healthcare, where v3.2‑thinking reportedly drops 25 points versus v3.1‑thinking, underlining that its impressive Olympiad‑style math gainsDeepSeek math don’t uniformly transfer to safety‑sensitive domains like medical QA.
MiniCPM‑4.1‑8B outpaces Ministral‑3‑8B on most benchmarks while staying ~2× faster
OpenBMB benchmarked its MiniCPM‑4.1‑8B "think" model against Mistral’s new Ministral‑3‑8B‑Reasoning and reports MiniCPM winning every listed benchmark except being only slightly ahead on MMLU‑Redux, while also running about 2× faster. comparison thread On C‑Eval MiniCPM scores 86.36 vs 73.56, on CMMLU 84.86 vs 71.74, on BBH 82.53 vs 64.06, and on IFEval it leads dramatically at 76.16 vs 29.57, suggesting better instruction‑following and long‑form reasoning.
The team stresses they’re not claiming superiority in math/code, but for small‑model deployments focused on general reasoning and efficiency, MiniCPM‑4.1‑8B is positioning itself as a top "world’s best small model" contender worth A/B‑testing against Ministral‑3‑8B on your own workloads.
🧮 Reasoning/RL: from CUDA kernels to adaptive thinking
Research‑grade training and reasoning methods. New today: RL‑generated CUDA kernels surpass cuBLAS, guided self‑evolving SFT/RL, cross‑family verification, prompt‑free refinement, and adaptive multimodal thinking.
Tencent’s R‑Few lets LLMs self‑evolve with 1–5% human labels
Tencent’s R‑Few framework refines the R‑Zero self‑play idea by adding a challenger‑solver game and careful data filtering, reaching MMLU‑Pro ~63.2 vs ~61.6 for R‑Zero with only 1–5% human‑labeled questions while staying more stable over long training r-few summary. A challenger model proposes questions nudged by a tiny stream of real QA pairs, a solver answers them multiple times, and R‑Few keeps only mid‑difficulty items where solver accuracy is neither trivial nor hopeless, avoiding drift to weird synthetic puzzles or inflated question lengths
. Compared to baselines like AZR and SPICE, R‑Few posts higher averages on five math and four reasoning benchmarks, showing that guided self‑evolution can replace massive human datasets when you get difficulty and realism filters right ArXiv paper.
Argos agentic verifier makes multimodal RL rewards denser and more grounded
The Argos framework tackles a core problem in multimodal RL for reasoning agents: outcome‑only rewards let models guess answers without really grounding in images or video argos summary. Argos builds a reward agent that, per sample, selects from a toolbox of detectors, segmenters and LLM scorers to jointly evaluate (i) final accuracy, (ii) spatial/temporal localization of referenced entities and actions, and (iii) reasoning quality, using that multipart score both to filter noisy SFT traces and to drive RL. Training Qwen2.5‑VL with Argos yields sizable gains on spatial reasoning, hallucination tests, embodied planning and robot control versus both the base model and outcome‑only Video‑R1 style RL, demonstrating that good rewards in this regime are themselves multi‑tool agents ArXiv paper.
Cross‑family verifiers give the biggest accuracy gains on math/logic tasks
A 37‑model study finds that using one LLM family to verify another’s answers produces far larger gains than self‑verification, especially on math and logic benchmarks verification summary. They define “verifier gain” as the accuracy boost from sampling and filtering with a verifier, and show that self‑checks barely help because models over‑trust their own failure modes, whereas cross‑family verifiers can prune whole classes of shared mistakes. Structured domains with clear correctness signals (symbolic math, puzzles) benefit most, while open‑ended factual QA sees limited improvement, suggesting that serious toolchains should pair heterogeneous models for judge/solver roles rather than over‑sampling a single family ArXiv paper.
CUDA-L2 code release invites reuse on non‑GEMM ops
Beyond headline matmul speedups, the CUDA-L2 authors have released the full RL pipeline and kernel search code, making it practical for infra teams to adapt the approach to attention, MoE routing or custom ops rl details. The offline experiments show +17–22% average speedup over torch.matmul and cuBLAS and +11% over cuBLASLt AutoTuning, while server‑like settings with gaps between calls still see +15–18% over cuBLASLt AutoTuning, indicating that LLM‑generated kernels don’t rely on artificial microbenchmarks cuda-l2 summary. For anyone maintaining hand‑tuned kernels, the paper effectively argues that letting an RL‑trained model explore kernel space under hard correctness checks is now a viable alternative to months of manual CUDA work ArXiv paper.
Omni‑AutoThink trains multimodal models to think only on hard inputs
Omni‑AutoThink proposes an adaptive reasoning framework where a single multimodal model (text, images, audio, video) learns when to emit long chain‑of‑thought and when to answer directly autothink summary. The system first does supervised training with paired “think” and “direct” examples, then uses RL to reward correct answers that skip thinking, while giving only a small bonus when correctness comes after reasoning traces, pushing the policy to reserve heavy computation for truly hard questions. On a new benchmark spanning unimodal and mixed‑modality queries with difficulty tags, Omni‑AutoThink outperforms always‑think and never‑think baselines while cutting average reasoning tokens, which is exactly the blend infra teams want as reasoning models eat >50% of tokens this year ArXiv paper.
Prompt‑free verify‑and‑refine agents improve automated paper‑to‑code reproduction
A new Paper2Code follow‑up replaces hand‑written “self‑critique” prompts with two prompt‑free agents—a verifier and a refiner—that use the existing system prompts as checklists to improve automated research reproduction reproduction summary. The verifier reads the paper, the step’s system prompt, and the produced plan or patch, then lists missing requirements; the refiner edits the artifact to satisfy that checklist, without any bespoke critique instructions. Plugging this verify‑then‑refine loop into planning and Python‑coding stages boosts correctness on the 100‑paper CORE‑Bench tasks by ~15 percentage points over the original workflow and prior Self‑Refine/RePro baselines, while needing just a single refinement pass per step
.
Deep Research survey maps query planning, tools and RL for research agents
A 40‑author survey on “Deep Research” systems lays out a three‑stage roadmap from basic fact‑finding, through full report generation, to AI scientists that loop between sub‑questions, evidence and hypotheses deep research summary. Following up on earlier work showing deep‑research agents often fail at evidence integration rather than parsing tasks deep research, it decomposes these systems into four components—query planning, information acquisition, memory management and answer generation—and reviews how prompting, supervised finetuning, and agentic RL are actually being used to tie them together. For builders of search‑plus‑reasoning stacks, the paper is effectively a design menu of current patterns and open problems rather than yet another benchmark ArXiv survey.
Grokked models forget specific data faster and with less collateral damage
“Grokked Models are Better Unlearners” shows that models trained past the grokking phase—that is, which first overfit then suddenly generalize—are significantly easier to unlearn from unlearning summary. Across CIFAR, SVHN, ImageNet and a TOFU‑style language task, running standard machine‑unlearning methods from a grokked checkpoint yields quicker forgetting of target examples, smaller drops on retained/test accuracy, and more stable runs than the same methods applied to early‑stopped checkpoints. The authors trace this to more modular representations and lower gradient alignment between “forget” and “retain” subsets after grokking, suggesting that if you anticipate future deletion requests, it’s better to train all the way through those late loss plateaus and only then apply unlearning ArXiv paper.
TradeTrap shows tiny state corruptions can push LLM trading agents into 61% losses
TradeTrap introduces a benchmarked framework to test how robust LLM‑driven trading agents are when their perception of the world is slightly corrupted tradetrap summary. It decomposes any trading bot into market intelligence, planning logic, portfolio/ledger memory, and execution, then replays real US equities while perturbing only one component at a time—like fabricating news, hijacking tools, or flipping portfolio files—and measuring the resulting P&L. In one extreme setup, a small error in the account state leads to ~61% loss with 100% exposure to a single stock, highlighting how on‑policy RL or agentic chains in finance need explicit defenses around state integrity rather than assuming per‑step harmlessness ArXiv paper.
HealthContradict benchmark exposes how LLMs handle conflicting medical evidence
HealthContradict is a new evaluation set of 920 yes/no health questions where each item comes with two contradictory web documents plus a separate, guideline‑based ground‑truth answer healthcontradict summary. The authors run both general and biomedical LLMs under prompts with no context, only correct context, only wrong context, or both, and find that vanilla models latch onto whatever text they see—being easily pulled off‑course—while tuned biomedical models are better at exploiting supportive context and resisting misleading passages. Standard medical QA benchmarks make many models look similar, but HealthContradict creates a clear spread, arguing that for safety‑critical domains you should favor domain‑specialized models and explicitly test their behavior under conflicting sources ArXiv paper.
💼 Enterprise deployment and GTM
Adoption and commercial signals for leaders. Excludes the Gemini feature. Today’s items: Devin at a top LATAM bank, Anthropic’s Interviewer program and findings, and a Snowflake–Anthropic go‑to‑market expansion.
Brazil’s biggest bank rolls Devin out across its entire SDLC
Cognition says Brazil’s largest bank Itaú has deployed its Devin software engineering agent across the full software development lifecycle for 17,000+ engineers, reporting 5–6× faster migration projects, 70% of static-analysis vulnerabilities auto‑remediated, 2× test coverage, and over 300,000 repos documented so far Devin rollout thread.

For AI leaders this is one of the first public examples of a Fortune‑100‑scale financial institution letting an autonomous coding agent touch legacy estates (including COBOL) end‑to‑end, rather than limiting it to copilots or small pilots, with a detailed customer story describing concrete workflows and guardrails in place customer story.
Snowflake and Anthropic deepen $200M Claude partnership around Cortex AI
Snowflake and Anthropic are expanding their previously announced multi‑year, $200M partnership into a broader go‑to‑market motion that embeds Claude models directly into Snowflake Cortex AI as “Snowflake Intelligence”, aimed at automating workflows across finance, healthcare, software engineering, and customer service for 12,600+ customers Snowflake deal Snowflake expansion summary.
The updated framing emphasizes Claude Sonnet 4.5 and Opus 4.5 as the default agents inside Snowflake’s governed data stack, supporting multi‑agent systems, natural‑language querying, and multimodal analysis while keeping access control and compliance in Snowflake rather than in a separate AI vendor. For executives this signals that “bring the model to the data warehouse” is solidifying as an enterprise pattern, and that Anthropic is betting heavily on distribution through existing data platforms rather than only selling Claude via its own UI or API.
Anthropic’s AI Interviewer pilots at scale and surfaces how pros really use AI
Anthropic has launched “Anthropic Interviewer”, a one‑week research tool that uses Claude to conduct semi‑structured interviews, then analyze responses in collaboration with human researchers; they immediately used it to interview 1,250 professionals across the general workforce, creatives, and scientists about AI at work Interviewer launch.
The first study finds that 86% of general workers say AI saves them time and 65% are satisfied with its role, yet 69% report stigma and 55% anxiety, with many expecting to shift into supervising AI systems rather than doing all the work themselves workforce stats. Creatives report even higher productivity and quality gains (97% say it saves time, 68% say it improves quality) but often hide their AI use due to perceived stigma, while scientists mostly confine AI to literature review and coding—79% cite reliability concerns and 91% say they want help with hypothesis generation and experiment design before trusting it on core science Interviewer findings full findings. For enterprise teams, this is both a new pattern for running ongoing, AI‑assisted user research and a rare, quantified window into how different professions are actually adopting and emotionally reacting to AI tools.
🗂️ Search, parsing and RAG pipelines
Data prep and retrieval systems for AI. Today spotlights layout‑aware spreadsheet parsing, semantic search over 5k NeurIPS papers, and an agentic multi‑URL compare tool.
Datalab adds layout‑aware spreadsheet parsing at $6 per 1k “pages”
Datalab extended its document‑parsing stack with native spreadsheet support for CSV/XLS/XLSX/XLSM/XLST, using the same layout‑aware engine it previously shipped for PDFs to reliably extract structure from messy, real‑world grids. launch thread The new API is priced at $6 per 1,000 pages, where a page is defined as 500 non‑empty cells, and is already live on the existing endpoints. (pricing screenshot, feature blog)
For people building RAG over financial models, actuarial loss runs, or vendor price sheets, this matters because the parser handles overlapping tables, fake separator rows, merged columns, and even embedded table images that used to break heuristics or require per‑client regex glue. launch thread It also means you don’t need a separate pipeline for Excel vs PDF exports anymore, which simplifies ETL and makes doc→vector pipelines less brittle—especially when combined with Datalab’s earlier Agni section‑hierarchy work. Agni sections
Exa turns 5,000+ NeurIPS papers into a semantic search corpus
Exa embedded all 5,000+ NeurIPS 2025 papers into its in‑house retrieval model and exposed them behind a semantic search front‑end tuned for research queries like “new retrieval techniques” or “intersection of coding agents and biology, poster session 5”. (search demo, search page) This builds on their earlier table‑first web search work but focuses it on one dense, high‑value corpus. table search For AI engineers and researchers, this is effectively a ready‑made domain‑specific RAG index over the entire conference—no scraping, OCR, or chunking required. You can prototype agents that map fuzzy natural‑language goals ("the paper Elon would love most") to concrete PDFs, then layer your own summarization or citation logic on top, instead of burning cycles on document ingestion and indexing. search commentary
LlamaIndex dissects OlmOCR‑Bench for document understanding and RAG
LlamaIndex’s Jerry Liu published a deep dive on OlmOCR‑Bench, a recent benchmark for document OCR that covers 1,400+ PDFs with formulas, tables, tiny text and more, using binary unit tests instead of fuzzy grading. benchmark review blog post The write‑up argues that while OlmOCR‑Bench is a big step toward realistic doc‑understanding evals, it still misses hard cases like complex tables, charts, forms, handwriting and non‑English scripts, and some tests rely on brittle exact matching.
The point is: if you’re building RAG or retrieval over PDFs, this gives you a much clearer sense of what “good OCR” actually means and where current VLMs still fall down. You can adopt OlmOCR‑Bench as a regression test for your own pipeline, but you should also supplement it with domain‑specific samples—especially if your workload is heavy on forms, multi‑language docs or chart extraction where OlmOCR‑Bench is still thin. eval commentary
Weaviate wins AWS Rising Star award and ships Java client v6
Vector‑database vendor Weaviate was named a 2025 AWS Rising Star Technology Partner for EMEA/Benelux, citing over 20 joint customer wins and tight integrations for AI‑native apps on AWS. award post In the same breath, the team highlighted a revamped Java client v6 with a fluent API, typed GraphQL responses and gRPC support—aimed squarely at production RAG workloads in JVM shops. award post
If you’re standardizing on Weaviate for semantic search or retrieval, this means two things: first, you get a more ergonomic and type‑safe client for wiring search into Java microservices (no more hand‑rolled HTTP+JSON), and second, AWS is incentivized to keep co‑selling Weaviate into enterprise AI stacks. That combination lowers the friction for rolling out governed, multi‑tenant RAG services inside existing Spring/Quarkus estates while staying within AWS procurement and support channels.
🏗️ Compute economics and build‑out signals
Non‑model macro factors that shape AI supply/demand. Today’s items quantify capex shifts to data centers, token price collapse, and export‑constrained GPU flows. Excludes pure model/feature coverage.
AMD accepts 15% revenue skim on MI308 exports to keep China AI market access
AMD says it now holds US licenses to export certain MI308 AI accelerators to China and is prepared to pay a 15% cut of revenue from those shipments to the US government in order to stay within new export rules. reuters summary
This is a clear example of how export controls are turning into an ongoing tax on high‑end AI compute flows. For teams building in or selling into China, it signals that constrained but non‑zero access to US‑designed accelerators will continue—likely at higher effective costs and lower peak performance than unrestricted parts. For everyone else, it’s a reminder that hardware pricing and availability are now entangled with geopolitics: model training cost estimates need to consider not just list prices and discounts but also regulatory frictions that can reshape which regions get which SKUs and at what margin. If you depend on global deployments, a multi‑backend strategy (US, EU, China‑native vendors) becomes less of a nice‑to‑have and more of a risk‑management requirement.
Token prices for top reasoning models are collapsing fastest at the high end
J.P. Morgan and Epoch data show the effective price per 1M tokens for "best in class" reasoning models has fallen roughly 900× per year, while mid‑tier models dropped ~40×/year and the weakest tiers about 9×/year over the past few years. jpmorgan chart This echoes a16z’s analysis that compute and model capability are following a Moore‑like curve, with economics shifting much faster at the top end than at the bottom. a16z article
For builders, that means the most capable models are racing toward "too cheap to meter" faster than small models, which flips some usual intuitions: you may soon be able to justify using a frontier model for workloads where you’d previously have picked a cheap mini‑model. The Jevons‑style warning in the commentary is that such price collapses historically trigger more total usage, not linear savings, so infra teams should expect surging token volumes and design rate limits, caching, and cost controls accordingly rather than assuming lower per‑token costs automatically tame their bill. a16z article
AMD pegs AI to a 10‑year supercycle and deepens its OpenAI deal
At UBS’s event, AMD CEO Lisa Su argued AI is not a bubble but "2 years into a 10‑year supercycle," and highlighted an OpenAI agreement where OpenAI plans to run roughly 6 gigawatts of AMD Instinct GPUs while receiving rights to buy 160M AMD shares at $0.01 (about a 10% stake) tied to future GPU usage. ubs remarks
For compute planners, that combination—multi‑GW commitments plus equity warrants—shows how tightly AI demand and GPU vendor economics are being coupled. If you’re betting on non‑NVIDIA accelerators or portability, this is a concrete data point that major labs are locking in long‑term alternative supply, which should spur more software support and kernel work for Instinct but also increases the risk of vendor‑specific optimizations and contractual lock‑in around capacity reservations. Su’s framing that GPUs will stay the "significant majority" of AI accelerators over at least the next five years also tempers expectations that TPUs or custom ASICs will dominate quickly, which matters for anyone deciding where to invest optimization effort or which hardware backends to support first. tpu vs gpu comments
US data center construction is closing in on general office spend
A new chart circulating from US construction data shows data center build‑out rising from roughly ~$10B in 2022 to nearly $40B by 2025, putting it on track to overtake general office construction, which has slid from ~ $70B toward the low‑40s over the same period. balaji thread
For AI engineers and infra leads, this is a hard macro signal that capex is tilting away from traditional commercial real estate and toward compute facilities, which means more capacity for model training and inference but also deeper dependence on power and cooling constraints. Balaji frames it as a risk for business models that assume endless exponential AI capex—if model capability plateaus while data center spend keeps climbing, hardware‑heavy strategies and the wider US economy could face painful repricing. balaji thread The takeaway: treat GPU availability and colocated infra as a changing, not static, resource and plan architectures (on‑device, smaller open models, distillation) that can survive both booms and potential slowdowns in centralized AI build‑out.
Jensen Huang puts small nuclear reactors on a 6–7 year timeline for AI power
Nvidia CEO Jensen Huang told an interviewer that in "6–7 years" we should expect "a bunch of small nuclear reactors" and that "we will all be power generators, just like somebody’s farm," explicitly tying long‑term AI growth to new local generation. small reactor quote This adds a timebox to his earlier argument that AI data centers will increasingly depend on dedicated, possibly nuclear, power sources. reactor outlook

For infra and strategy teams, the point is clear: current grid‑constrained thinking about where to put training clusters and inference farms may be overturned if SMR‑style projects really start attaching directly to AI campuses by the early 2030s. That doesn’t change near‑term constraints—you still need to worry about megawatts and cooling in existing regions—but it does suggest that the eventual ceiling on AI compute may be set more by build‑out speed and regulation of reactors than by traditional grid capacity alone. Teams making decade‑scale bets on model size or data center footprints should at least have a scenario where power ceases to be the binding constraint.
Meta’s 30% metaverse cuts free up budget for AI infrastructure
Bloomberg reporting says Meta is planning roughly 30% budget cuts for its Reality Labs metaverse group, including Horizon Worlds and Quest, with layoffs possible in early 2026, while guiding that 2026 capex will grow "significantly" above 2025 driven by AI infrastructure. metaverse cuts thread
For AI orgs, this is another big‑tech signal that spending is rotating from speculative XR platforms toward data centers, GPUs, and AI‑first products. Investors cheered the shift—Meta’s stock popped ~6% on the news—suggesting capital markets currently reward AI capex more than long‑dated metaverse bets. If you’re building tools or models that depend on hyperscaler platforms, that likely translates into more internal demand for AI acceleration, recommender serving, and generative features over the next budget cycle, but also more scrutiny on anything that can’t be clearly tied to AI‑driven revenue or efficiency.
🛡️ Safety, security and governance pressures
Operational and legal risks around AI systems. New today: a 20M‑chat discovery order, in‑context representation hijacking, agent‑generated code risks, and multi‑agent systemic risk framing.
Judge details 20M‑chat discovery order against OpenAI in copyright case
A US magistrate judge has ordered OpenAI to hand over 20 million anonymized ChatGPT conversations to the New York Times and other publishers within seven days under a strict protective regime, deepening the discovery burden first reported earlier this week log order. OpenAI argued that 99.99% of chats are irrelevant and disclosure risks user privacy, but the court pointed to exhaustive de‑identification and limited access as sufficient safeguards, keeping the focus on whether ChatGPT reproduced copyrighted news content without permission Reuters summary.
For AI leaders, this is a concrete precedent that product logs—at massive scale—can be pulled into copyright litigation even when user identities are stripped, so you should assume long‑term discoverability of interactions and design logging, retention, and privacy policies with that in mind.
Doublespeak attack shows in‑context “representation hijacking” of safety filters
New work on "In‑Context Representation Hijacking" (Doublespeak) shows that by systematically replacing a harmful token like “bomb” with a benign one like “carrot” across a few in‑context examples, attackers can make a 70B safety‑aligned model internally treat the benign token as harmful while still passing external safety checks, hitting about 74% attack success on one Llama‑3.3‑70B‑Instruct variant paper thread. The model’s refusal head still fires when it sees the literal danger word, but deeper layers learn that "carrot" encodes the harmful concept, so prompts like “how to build a carrot” get fully detailed answers despite looking clean to filters and logs ArXiv paper.
For safety teams, the point is: context can quietly rewire a model’s internal semantics without changing surface tokens, so defenses that key only on keyword filters or shallow embedding‑space similarity are brittle; you’ll need training‑time representation monitoring and adversarial red‑teaming that mimics these in‑context substitution patterns.
SUSVIBES benchmark finds vibe‑coding agents ship vulnerable code ~90% of the time
The SUSVIBES study evaluates “vibe‑coding” agents on 200 real feature requests that previously led human developers to introduce vulnerabilities, and finds that SWE‑Agent using Claude Sonnet 4 delivers functionally correct solutions 61% of the time but secure solutions only 10.5% of the time vibe coding summary. Even when tasks are augmented with explicit warnings about common vulnerability types, the agents keep producing exploitable patterns, and all tested frontier agents show similarly poor security performance, suggesting the problem is systemic rather than model‑specific ArXiv paper.
If you’re adopting coding agents in production, this says “it runs” is a terrible proxy for “it’s safe”: you should route all agent‑written diffs through static analysis, security review, and staged rollout, and treat autonomous multi‑file edits as a high‑risk change class rather than a time‑saver you can blindly trust.
Concordia paper maps systemic risks when LLM agents talk to each other
A new taxonomy of LLM‑to‑LLM risks argues that safety work focused on single user–model interactions doesn’t scale to multi‑agent systems, introducing the "Emergent Systemic Risk Horizon" where individually safe replies can compound into unstable group behavior risk taxonomy thread. Using the Concordia text‑world testbed, the authors show how agents that pass standard safety checks can still exhibit meaning drift, covert prompt transfer, collusion, polarization, and self‑reinforcing low‑quality feedback loops as group size and task complexity grow ArXiv paper.
For teams building tool‑using swarms or agentic workflows, the takeaway is that you can’t just reuse single‑agent guardrails; you need system‑level monitors (for diversity, consensus, and rule adherence) and institutional mechanisms like oversight agents and reputation tracking to keep entire networks from sliding past the risk horizon even when each individual message looks benign.
Perplexity’s BrowseSafe verifier hits ~90 F1 on prompt‑injection detection
Following up on its earlier release of BrowseSafe, Perplexity has published detailed benchmark numbers showing its lightweight HTML‑level detector reaching 90.4 F1 on BrowseSafe‑Bench, substantially ahead of frontier LLM baselines like GPT‑5 and Claude 4.5 used as judges, and far above small open models like PromptGuard‑2 (≈35–36 F1) BrowseSafe launch. The benchmark spans 14k+ real‑world attacks across 11 prompt‑injection types and 9 injection strategies, including hidden elements, multilingual instructions, and style‑obfuscated payloads, giving teams a way to quantify how their own browser agents fare against messy web pages BrowseSafe summary.
For anyone deploying web‑browsing agents, this suggests a practical stack: run a cheap specialized classifier like BrowseSafe in front of your main model to flag and strip suspect HTML regions, then layer in higher‑cost, task‑aware defenses rather than depending on a single LLM to "notice" attacks buried in the DOM.
TradeTrap shows small perturbations can wreck LLM trading agents’ portfolios
The TradeTrap framework stress‑tests LLM‑based trading agents by replaying real US equity data while adversarially corrupting only one component at a time—market intelligence, planning instructions, portfolio state, or execution—and finds that a tiny error in the agent’s perceived account state can drive roughly 61% portfolio loss when fully exposed to a single stock TradeTrap thread. Flexible, tool‑calling agents proved especially vulnerable to fabricated news or hijacked price feeds: they over‑trade into concentrated positions and amplify noise, while corrupted portfolio files or prompts quietly push them to act on imaginary holdings ArXiv paper.
If you’re experimenting with LLMs for trading, risk, or treasury automation, this is a strong argument to keep them in a decision‑support role, enforce strict separation of data sources, and build independent portfolio reconciliation and risk limits that can override or throttle agent actions when state or news feeds look inconsistent.
HealthContradict benchmark tests LLMs on conflicting medical evidence
The HealthContradict dataset introduces 920 expert‑checked yes/no medical questions, each paired with two web documents that take opposite stances and a separate evidence‑based ground‑truth answer, to probe how language models behave when faced with conflicting health information HealthContradict summary. Experiments show that biomedical‑tuned models are better at using good context and ignoring misleading passages, while general‑purpose LLMs are more easily swayed by whichever document they see, even when that contradicts established medical guidance ArXiv paper.
For teams building health chatbots or clinical support tools, this is a reminder that retrieval‑augmented systems must be evaluated on conflict handling, not just accuracy on clean QA sets, and that domain‑specific fine‑tuning plus explicit citation and agreement checks are critical if you don’t want your model to parrot the last random web page it saw.
🎬 Creative stacks: video+audio, image edits, and tooling
Generative media releases and workflows. Excludes the Gemini feature. Today features Kling Video 2.6 with native audio, Seedream 4.5 arena moves, creator grids/avatars, and NotebookLM’s infographic/slide tools.
Kling Video 2.6 and Avatars 2.0 spread to arenas, agents and hosts
Kling’s native‑audio video stack is moving from launch into heavy real‑world testing: Video 2.6 is now in the LMArena Video Arena and is wired into creator tools, while Kling Avatars 2.0 lets people drive expressive talking heads from up to 5 minutes of audio. native audio already covered Kling 2.6’s debut as one of the first models with synchronized speech, SFX, and ambience.
Arena is inviting users to pit Kling 2.6 against other frontier video models for prompt‑to‑clip workflows, which gives engineers a live stream of comparative feedback on motion, consistency, and audio sync quality. video arena intro At the same time, Higgsfield and Flowith are promoting Kling as part of their creative pipelines, using it both for general video shots and for avatar‑style clips, while fal added Kling Avatars 2.0 on day 0 with longer audio support for more natural monologues and conversations. (avatars release, fal avatars launch, flowith kling promo) For people building video agents or marketing tools, this means you can now treat Kling as a widely‑available backend: one model for generic B‑roll, another for character dialogue, all with native audio instead of bolting on separate TTS.
Higgsfield and Flowith codify grid→still→animation video workflows
Creators are turning Higgsfield and Flowith into full creative stacks, with detailed prompt recipes for going from cinematic grids to extracted stills and then into animated clips using Kling, Nano Banana Pro and Seedream. (workflow guide, flowith kling promo)

One shared pattern is: generate a 3×3 or 4×4 cinematic grid in Nano Banana Pro, then use prompts like “extract and amplify only still from row 1 column 2” to isolate a single frame as a clean reference, before passing that into Veo 3.1 or Kling 2.5/2.6 for motion and dialogue. workflow guide Flowith advertises a similar stack—"Kling 2.6 + UNLIMITED image models"—as an annual toolkit, explicitly encouraging people to mix Nano Banana Pro, Seedream 4.5 and Kling in one place for everything from passport‑style portraits to avatar reels. flowith kling promo If you’re building your own creative UI, these threads are basically free UX research on how advanced users actually chain models today.
Nano Banana Pro moves from Twitter art to TV ads
Nano Banana Pro is starting to look like production infrastructure, not just a playground toy: creators are now using it to render full TV ads and intricate hidden‑text art in addition to the multi‑image workflows we saw earlier. multi image covered how people use it as a backbone for multi‑scene grids; today’s examples show that stack reaching big budgets.
One commercial example is a James Harden spot for MyPrize that was storyboarded and rendered in Nano Banana, with no celebrity shoot required; the producer calls out Nano Banana explicitly as the engine behind Harden’s likeness and the overall visual look. harden ad On the more experimental side, artists are prompting it to “make a photo with a hidden word embedded into it… form the word out of a pride of lions,” producing natural‑looking wildlife shots where the word “fofr” only becomes obvious once you spot the arrangement of bodies and negative space. hidden word prompt Others are using it for isometric multi‑panel anime‑style scenes with consistent characters across a 3×3 grid, which is exactly the sort of consistency that used to require hand‑drawn boards. anime grid
NotebookLM on iOS now generates infographics, slide decks, and 10k‑char personas
Google’s NotebookLM iOS app quietly picked up two big creator features: one‑tap infographic generation from your sources and full slide‑deck creation, plus a jump in chat customization limit from 500 to 10,000 characters so you can define much richer personas or agent behaviors. (release notes, persona tweet)
The new "Create infographics" option turns key insights from your docs into a single visual panel meant to be shared as an image, while "Create slide decks" turns longform sources (like a set of academic papers) into a polished multi‑slide presentation—something Ethan Mollick notes works surprisingly well, though editing individual slides remains clumsy because they’re currently rendered as images rather than editable components. editing comment On the chat side, 10k‑character customization means you can finally encode detailed style guides, roles ("you are a skeptical PM"), and workflow rules directly into a NotebookLM chat without constant re‑prompting, making it more viable as a lightweight research or content assistant for specific teams.
Seedream 4.5 jumps to #3 Image Edit and #7 T2I on AA leaderboards
ByteDance’s Seedream 4.5 has now been benchmarked on the Artificial Analysis image leaderboards, landing #3 in Image Edit with a score of 1338 and #7 in Text‑to‑Image at 1146, gaining 27 and 62 Elo points respectively over its previous 4‑2k and 3.x versions. day zero covered its launch and day‑0 hosting; this is the first clean head‑to‑head snapshot against other top models.
Compared to Seedream‑4‑2k and Seedream‑3, the 4.5 release is reported to improve prompt adherence, cinematic lighting, and text rendering, which matters a lot if you’re using it for brand‑safe creative where typography and mood must match a spec. arena update The new ranking also clarifies its place in the stack: in Image Edit it now beats Gemini 2.5 Flash Image (Nano Banana) but still trails Google’s newer Nano Banana Pro variants, giving teams a strong open‑provider option that sits just behind the very top proprietary models on quality while remaining deployable across services like fal and Higgsfield.
ElevenLabs agents power Brock Purdy fan experience and creative summit talk
ElevenLabs is leaning into creative experiences with its Agents platform: Toyota’s Northern California Dealers built an AI‑powered Brock Purdy that chats with fans, runs trivia, and awards VIP 49ers rewards, while averaging about 2 minutes of engagement per session across thousands of conversations. toyota case
At the ElevenLabs Summit, will.i.am and Larry Jackson also sat down with CEO Dan Runcie to talk about how generative audio is reshaping real‑time collaboration and creative production, reinforcing that the company wants to sit at the intersection of marketing activations and music/entertainment workflows rather than pure utility TTS. summit panel For builders, the takeaway is that ElevenLabs agents are already being trusted for branded, high‑touch interactions—even where tone, timing, and character are as sensitive as a franchise QB persona.
MagicPath lets you drop images on a shared code+design canvas
MagicPath’s latest update adds "Images on Canvas": you can now drag reference images directly onto the same canvas where you keep components and code, then talk to the agent about them or turn them into new UI pieces. (magicpath intro, usage tips)

Images behave like first‑class citizens: you can reference them in chat ("use the second hero section as inspiration"), ask the model to convert them into React/Tailwind components, or blend multiple images together to explore new visual styles—all in the same spatial layout you use for your component graph. magicpath intro The point is: instead of flipping between Figma, your IDE, and an AI chat, you get a single surface where design references, generated mocks, and live code blocks coexist, which is a pattern other tools will likely copy.
PosterCopilot targets layout reasoning and controllable poster editing
A new model called PosterCopilot focuses on something most image generators still fumble: professional layout and controllable editing for posters, flyers, and other graphic design work. postercopilot intro
Instead of treating design as a single unstructured image, PosterCopilot introduces layout‑aware reasoning so it can maintain grid systems, text blocks, and hierarchy while you tweak content or style, and the examples show coherent type placement across a variety of event posters and ad creatives. paper project page Because it supports targeted edits—think “move the headliner down and increase ticket info contrast” rather than regenerating the entire image—it looks like a natural fit for pro workflows where designers want AI to handle the first 80% while preserving control over composition and branding.
🤖 Embodied AI: field trials and capability demos
Humanoid and robot deployments/demos. New posts show human‑like gait progress, Tesla’s running speed comparisons, and Chinese firefighting quad support units.
Tesla Optimus V2.5 clocked near 3.8 m/s in running demo vs Figure
New footage compares Tesla’s Optimus V2.5 against Figure’s humanoid, with estimates putting Optimus’ running speed around 3.8 m/s (~8.5 mph) in recent tests—well into a light jog for a human. speed comparison thread That’s a big step up from the cautious walking we were seeing a year ago and adds a locomotion dimension to the capability race between major humanoid efforts. Following Optimus hands demo, where Tesla showed off 22‑DoF sensor‑rich hands, this suggests the platform is maturing on both manipulation and mobility.

For embodied‑AI engineers, sustained 3–4 m/s on a full‑size humanoid changes the feasible task set: you can start thinking about factory or warehouse patrols that must traverse long distances quickly, dynamic object interception, or time‑sensitive logistics roles. It also raises new control and safety problems. At these speeds, fall dynamics and contact control become much more punishing—your perception, planning, and reflex layers need to be tight, and testing must assume higher‑energy impacts. The broader signal is that locomotion is catching up to manipulation on frontier humanoids, so research and product work will increasingly shift to what they do at the destination rather than whether they can get there fast enough.
New humanoid demo shows strikingly human-like gait, stoking 2026 hype
A short humanoid-robot clip is circulating where the gait and upper‑body motion look uncannily human, prompting comments like “this movement looks so human” and predictions that “2026 will be the year of humanoid robots.” humanoid gait comment This isn’t a polished marketing reel; it’s the kind of rough locomotion test that engineers watch to judge balance, foot placement, and compliance.

For embodied‑AI teams, the interesting part is how quickly these demos are converging toward natural motion without tethering or obvious stabilization rigs. That hints at better whole‑body control stacks (model‑predictive control, RL‑trained policies, or hybrid approaches) and more robust state estimation on uneven surfaces. If you’re working on manipulation or mobile bases, the implication is clear: bipedal platforms are leaving the “lab curiosity” phase. You should assume that, within a year or two, off‑the‑shelf humanoids with this level of gait will be available for real pilots, and start thinking about perception, safety envelopes, and task libraries on top rather than whether the robot can walk at all.
Sichuan trials 200 kg–payload firefighting robot dogs for hazardous zones
Footage from Sichuan, China shows quadruped “robot dogs” being tested as firefighting support units, hauling heavy hoses, streaming real‑time video, and sampling poisonous gases and temperature in environments described as unsafe or unreachable for humans. Each unit reportedly carries around 200 kg, enough for serious gear rather than just cameras. firefighting field test The follow‑up commentary argues these systems “should be widely deployed,” framing them as a practical near‑term use of robotics for dangerous work. deployment advocacy

This is a concrete example of embodied AI moving from lab demos into harsh field conditions. For robotics teams, the interesting angles are: how robust the locomotion and perception stacks are when navigating wet, cluttered scenes; how teleoperation and autonomy are blended (e.g., human‑in‑the‑loop for tactics, local autonomy for foot placement and obstacle avoidance); and how sensing packages (thermal, gas, vision) are fused into decision policies. If you build control or planning for quadrupeds, this kind of deployment is a strong signal to harden your systems for real‑world firefighting, hazmat, or disaster‑response scenarios, where reliability and maintenance often matter more than raw benchmark scores.
🎙️ Realtime voice agents and activations
Voice‑native models and deployments. New today: Microsoft’s ultra‑low‑latency TTS, and ElevenLabs live experiences for sports/creators.
Microsoft’s VibeVoice-Realtime-0.5B brings 300ms streaming TTS for agents
Microsoft has released VibeVoice-Realtime-0.5B, a 0.5B‑parameter, open text‑to‑speech model tuned for real‑time streaming: it can start outputting audio in roughly 300ms depending on hardware, and is designed for long‑form speech with low latency. model announcement It combines a small Qwen2.5‑based language backbone with a σ‑VAE acoustic tokenizer and a diffusion head, giving you a single‑speaker voice stack that’s light enough for deployment yet expressive enough for dialog systems. Hugging Face card For voice agents and callbots this is a practical building block: you can keep your main LLM separate, but swap in VibeVoice when you need fast, streaming speech instead of heavyweight multi‑speaker TTS—especially on resource‑constrained servers or edge devices.
- Try wiring VibeVoice‑Realtime into an existing LLM agent loop as the TTS leg and benchmark end‑to‑end user‑perceived latency against your current stack.
Toyota dealers launch Brock Purdy AI fan agent with 2‑minute sessions
Toyota’s Northern California dealers and agency Highdive built a live conversational experience where fans chat with an AI‑powered Brock Purdy, using ElevenLabs’ Agents Platform to host trivia, conversation, and VIP reward flows. Brock Purdy activation The campaign has already handled thousands of conversations, with an average engagement time of about 2 minutes per session, and is outperforming their traditional channels on attention metrics.
For anyone building voice or chat agents, this is a clean reference pattern: a tightly scoped persona, clear reward loop, and a hosted agent platform doing the orchestration. It shows these systems are mature enough for sponsored sports activations, not just demos—if you can keep latency low and responses on‑brand, real fans will happily talk to an AI quarterback.
- If you run marketing or fan apps, prototype a similar agentic funnel (persona + trivia + rewards) and measure dwell time versus your current campaigns.
ElevenLabs Summit highlights real‑time AI as a creative collaborator
At the ElevenLabs Summit, will.i.am and Larry Jackson sat down with ElevenLabs’ CEO to talk about generative AI inside live creative workflows, describing how real‑time voice and agents are becoming another instrument in the studio rather than a post‑production tool. summit session They frame AI as something you can collaborate with in the moment—riffing on ideas, trying alternate takes, and iterating on concepts while recording—rather than a slow offline process.
For builders, the signal is that top‑tier creators are comfortable with synthetic voices and agents in the loop as long as they feel responsive and controllable. That raises the bar for latency, controllability, and session continuity: your stack has to feel as immediate as a bandmate, not a batch job.
- If you work on creative tools, experiment with event‑driven, low‑latency agent loops that can react within a beat or a bar, not seconds.