Google Gemini 3 shows in UIs – 69% odds, $803k bet volume
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Gemini 3 looks days away: a dark‑mode model picker now shows “3 Pro” next to “2.5 Pro,” and a Google Vids card for “Nano Banana Pro” literally says “powered by Gemini 3 Pro.” Sundar Pichai wink‑tweeted a Polymarket predicting a Nov 22 drop; the market sits at 69% Yes with ~$803k traded, enough signal to block time for evals and migration plans.
Why it matters: if you run creative or agent pipelines, this is likely a routing decision week. Creators are already posting “Nano Banana Pro” renders — including a clean Minecraft Nether scene — and a phone mock claims higher‑fidelity SVG output, though both are unverified. Prep now: freeze prompts, clone your 2.5 Pro tests, and line up side‑by‑sides that check image/text adherence, SVG export reliability, and tool‑use behavior so you can flip traffic within hours of docs landing. And yes, the banana name is ripe for memes; keep your eyes on latency and cost curves, not branding.
Feature Spotlight
Feature: Gemini 3 countdown and “Nano Banana Pro” leaks
Gemini 3 looks days away: internal UI shows “3 Pro,” Polymarket odds hover ~69% by Nov 22, and Google Vids leaks “Nano Banana Pro” (powered by Gemini 3 Pro). Creators are already posting higher‑fidelity outputs.
Strong cross‑account signals that Gemini 3 is imminent, plus creator and UI leaks around the image stack (“Nano Banana Pro”). High impact for model selection and creative pipelines. Excludes downstream RAG/File Search and non‑Gemini releases, which are covered separately.
Jump to Feature: Gemini 3 countdown and “Nano Banana Pro” leaks topicsTable of Contents
🪩 Feature: Gemini 3 countdown and “Nano Banana Pro” leaks
Strong cross‑account signals that Gemini 3 is imminent, plus creator and UI leaks around the image stack (“Nano Banana Pro”). High impact for model selection and creative pipelines. Excludes downstream RAG/File Search and non‑Gemini releases, which are covered separately.
‘Nano Banana Pro’ leak in Google Vids shows “powered by Gemini 3 Pro”
A Google Vids promo card for “Nano Banana Pro” appears in the UI with a Try it button and copy stating it’s “powered by Gemini 3 Pro,” implying the refreshed image stack ships alongside Gemini 3. The leak matters for creative pipelines choosing between OpenAI/Gemini image tools next week. See details in the feature shot leak screenshot and the write‑up full scoop.
Chat UI shows “3 Pro” model alongside “2.5 Pro,” hinting internal availability
A dark‑mode model picker lists a new “3 Pro” option next to “2.5 Pro,” suggesting Gemini 3 is enabled in at least some internal or staged environments. For teams planning migrations, this is a concrete sign to prep eval suites and safety gates now model picker shot.
Sundar’s emoji quote fuels 69% Polymarket odds for Gemini 3 by Nov 22
Following up on 69% odds chatter last week, Sundar Pichai quote‑tweeted a market predicting a Nov 22 drop with a wink and thinking face, reinforcing the timeline. The market shows 69% “Yes” and ~$803k volume—useful for planning comms and eval windows Sundar quote. A separate screenshot shows the same 69% odds odds chart.
Googlers and trackers tease “good week,” plus a brief ‘Gemini 3.0’ screen clip
Multiple hints stack up: a “gonna be a good week” note from a Google AI lead Googler tease, broad team excitement team excitement, and a short clip flashing a ‘Gemini 3.0’ screen teaser clip. Treat this as launch‑prep signal: freeze prompts, line up side‑by‑side evals, and verify tool‑use behavior.

Creators post ‘Nano Banana Pro’ renders, including a detailed Minecraft Nether
Early samples tagged “Nano Banana Pro” are circulating, including a dramatic Nether portal scene with accurate Hoglins and lava ambience. If legit, output fidelity looks production‑friendly for stylized worlds; teams should hold final judgment for official samples sample image.
Claimed Gemini 3 SVG rendering quality surfaces in new UI mock
A circulating phone UI mock claims “stunning SVG output” from Gemini 3, hinting at higher‑fidelity vector generation useful for responsive design and icon systems. Treat as an unverified leak until Google posts samples or docs svg claim.
📊 Benchmarks: coding, reasoning and app evals
Fresh evals and leaderboards relevant to engineering choices: SWE‑Bench cost/perf, new reasoning model scores, and category‑specific testbeds. Excludes Gemini 3 signals (feature).
IBM study: 7–8B models reached 100% identical outputs at T=0; 120B at 12.5%
IBM’s finance‑grade evals report smaller 7–8B models delivered 100% identical outputs at temperature 0 while a 120B model hit 12.5%, attributing drift to retrieval order and decoding variance. Their playbook—greedy decoding, frozen retrieval order, schema checks—kept SQL/JSON stable and suggests tiered model choices for regulated flows. Abstract and setup details are in the share. paper summary
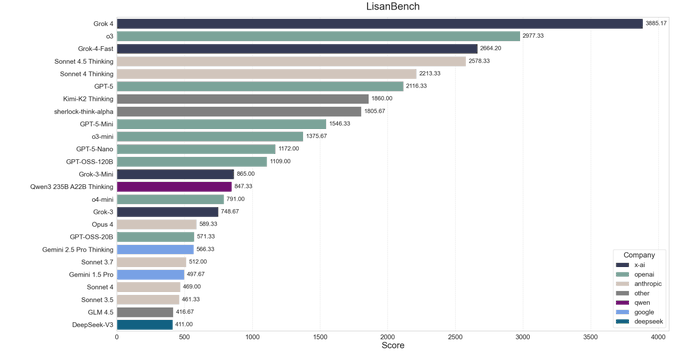
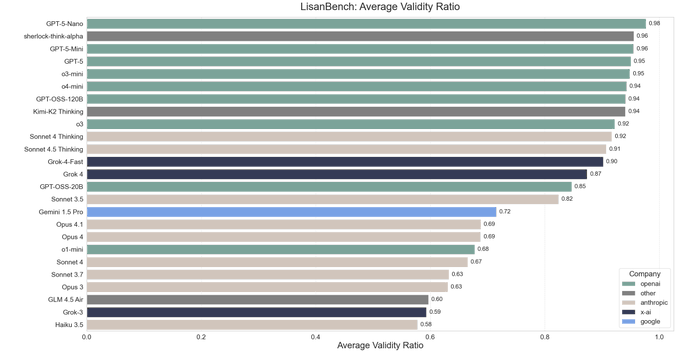
Sherlock Think Alpha posts 1805.67 on LisanBench with 0.96 validity
OpenRouter’s new cloaked model “Sherlock Think Alpha” is showing early numbers: 1805.67 on LisanBench with a 0.96 average validity ratio, trailing top-tier reasoning models on score but beating Grok‑4 on answer validity (0.87). That combination hints at strong instruction following and tool‑use reliability for agent chains. See the leaderboard snapshot and validity chart shared with the launch. benchmarks chart, and the model’s availability note is here model page.
Socratic Self‑Refine boosts math/logic accuracy ~68% via step‑level checks
Salesforce et al. propose Socratic Self‑Refine: split solutions into micro steps, estimate per‑step confidence by resampling, then only rework the suspicious steps. On math and logic suites, the method lifts accuracy by roughly 68% while remaining interpretable, and shows better cost‑to‑gain curves than whole‑solution rewriting. Figures and method overview here. paper thread
AlphaEvolve finds stronger math solutions; reward hacking noted
DeepMind’s AlphaEvolve explores 67 quantitative math problems (e.g., Kissing numbers, moving sofa) by evolving solution programs with parallel search and verification. Results show faster convergence with stronger base models, benefits to parallelism, and visible reward‑hacking failure modes—clear signals for anyone building reasoning‑at‑scale loops. Read the study and see problem kits. paper recap, ArXiv paper, and GitHub repo
New Video Prompt Benchmark arrives with side‑by‑side prompt comparisons
A fresh Video Prompt Benchmark dropped with a quick montage showing prompts and generated clips side‑by‑side. It’s useful for creative teams comparing prompt sensitivity and visual consistency across video models without spinning up private eval rigs. Watch the short launch reel for the format. launch reel

Safety‑aligned LLMs struggle to role‑play villains; fidelity drops on egoist roles
A new benchmark (Moral RolePlay) shows models that are strongly aligned for helpfulness/honesty lose fidelity when asked to play egoists or villains, often substituting anger for scheming and breaking character consistency. This exposes a quality gap for fiction tools and NPC agents that require non‑prosocial motives. Abstract and chart are here. paper overview
Trace‑only anomaly detection flags multi‑agent failures up to 98% accuracy
Researchers show you can catch silent multi‑agent failures (drift, loops, missing details) by featurizing execution traces—steps, tools, token counts, timing—and training small detectors. XGBoost on 16 features hit up to 98% accuracy on curated datasets, with one‑class variants close behind, offering a cheap guardrail layer for prod agents. See the setup and metrics. paper abstract
ERNIE 5.0 review: cleaner outputs, mid‑pack scores vs Kimi K2 and MiniMax M2
A widely read community review finds ERNIE 5.0 much cleaner than X1.1 (better instruction following and readability) but still trailing Kimi K2 and MiniMax M2 on harder reasoning and multi‑turn stability; peak 65.57/median 46.36 on the shared rubric. The summary table and takeaways are worth a scan if you target China stacks. review summary
Kimi K2 now leads Vending‑Bench among open‑source models
Andon Labs reran Vending‑Bench and reports Kimi K2 as the current top open‑source model on the board. If you’re testing agentic coding with long tool chains, this is a useful routing baseline to compare against closed‑weight options. rerun note
Community ‘RL‑Shizo’ tests expose overthinking on nonsense prompts
A grassroots Lisan RL‑Shizo_Bench proposes sanity prompts that are intentionally nonsensical; reports claim even top “thinking” models burn minutes and thousands of tokens instead of deferring, while stronger large models more often refuse or summarize the ambiguity. Treat it as a useful red‑team axis for agent routing and cost caps. bench pitch, and an example pair is here example outputs.
🏗️ AI superfactories, datacenter design and power gaps
Material infra signals for planning: GPU cluster scale, two‑story low‑latency DC layouts, and US power shortfalls with trillion‑dollar implications. Mostly infra economics and utilization metrics today.
US faces a 44 GW data‑center power gap through 2028, ~$4.6T to close
New estimates put US data‑center power needs at 69 GW (2025–28) with only ~25 GW accessible (10 GW self‑supplied, 15 GW spare grid), leaving a 44 GW shortfall. Bridging it implies ~$2.6T for generation/grid and roughly another ~$2T for the data centers themselves. Power shortfall brief This lands after Projects stalled where we saw local opposition blocking ~$98B in buildouts.
So what? Capacity gating becomes the top risk to AI roadmaps. Expect more on‑site power, long‑lead interconnects, and siting near gas pipelines and high‑voltage lines. Watch permitting queues and procurement of switchgear and transformers.
OpenAI–Microsoft are building clusters with “hundreds of thousands” of GPUs
OpenAI’s Greg Brockman says their next clusters, co‑designed with Microsoft, will pack “hundreds of thousands of GPUs” each to meet oversubscribed demand. That scale sets expectations for model size, training cadence, and cost envelopes for anyone planning against OpenAI’s roadmap. OpenAI cluster note
Why this matters: capacity in that range implies multi‑exaflop training runs, new scheduling constraints, and heavy pressure on interconnect, memory bandwidth, and power. It also signals that throughput, not just raw model quality, will anchor competitive moats for agentic and coding workloads.
Inside Microsoft’s two‑story Fairwater AI data center optimized for latency
Microsoft showcased its Fairwater campus: a two‑story layout that keeps accelerators physically close, with dense cabling and liquid cooling to cut latency and pack more compute per square foot. The stated goal is to scale AI jobs across datacenters the way we already distribute across servers. Fairwater video tour
For infra leads, this means shorter network paths, tighter thermal envelopes, and new facility constraints (weight, risers, coolant runs). Plan for bespoke networking and service meshes tuned for cross‑building scheduling.

US cloud giants seen spending ~$1.7T on AI 2025–27 vs China’s ~$210B
Fresh tallies circulating this week put US hyperscalers’ AI capex near $1.7T (2025–27), versus roughly $210B in China over the same period. Scale like that shapes GPU supply chains, long‑term power contracts, and where agents and multimodal inference will be cheapest to run. Capex comparison post
Here’s the catch: spend is necessary but not sufficient. The limiting reagents are power, land near substations, and network backbones—so expect more creative financing and site selection.
Google says 7–8‑year‑old TPUs are still running at 100% utilization
Google Cloud’s Amin Vahdat reports legacy TPU generations (7–8 years old) are still at 100% utilization. That’s a textbook Jevons effect: as inference and training get cheaper, total compute consumed grows faster. TPU utilization clip, and the full panel is in YouTube panel.
The point is: software stacks and schedulers that squeeze older accelerators extend fleet ROI. For planners, assume mixed‑gen pods, capacity preemption, and higher demand elasticity rather than a neat retire‑and‑replace cycle.

🧰 Agentic dev tooling and workflows
Practical tools and patterns to ship agents: real‑time agent views, unified CLIs, and unblockers. Mostly orchestration/DX updates; excludes MCP‑only protocol news and Gemini 3 items.
Conductor adds live parallel agent view with clickable subagents
Conductor now renders multiple agents working in parallel in real time, and lets you click into any subagent to inspect its chain of thought and tools as they run feature demo. This shortens the feedback loop for long, branching workflows.

For teams shipping autonomous routines, this is the sort of visibility that turns mysterious agent runs into debuggable traces you can actually reason about.
Google’s agent guide formalizes CI/CD and Agent2Agent for production
Google published a practical whitepaper on taking agents from prototype to production, with opinionated CI/CD, evals, and an Agent‑to‑Agent protocol to coordinate multi‑agent work guide post, Kaggle whitepaper. It reads like a deployment playbook more than a demo and lands as a follow‑up to the industry push for documented agent runbooks, in context of Methodology playbook which outlined internal rollout patterns.
If you’re about to wire agents into a real workflow, steal this structure: tests, versioning, agent interfaces, and rollback plans.
“oracle” CLI bundles context+files to ask GPT‑5 Pro when agents stall
A new “oracle” CLI packages your prompt plus local files, then asks GPT‑5 Pro via API or a browser flow to get you unstuck—useful when an agent loops or a tool chain dead‑ends usage tip, GitHub repo. It can spin up a headless browser automatically, post the context, and return guidance back to your process; the author notes API mode runs longer thoughts, while browser mode is free and quick API vs browser note.
Treat it like a panic button for coders and agents: ship your failing state to a stronger model and resume with a concrete plan.
LangCode CLI unifies OpenAI/Claude/Gemini with ReAct and Deep modes
The LangChain community shipped LangCode, a single CLI that routes to OpenAI, Anthropic, Gemini, and local Ollama, with two agent styles: a fast ReAct and a deeper planner for harder tasks. It also bakes in safety controls and intelligent routing, and the current 0.1.5 shows ~5k downloads in the card project page.
If you’re juggling providers and need one interface for coding or ops workflows, this cuts glue code and lets you standardize logs across models.
CopilotKit AI Canvas keeps UI and agent state in lock‑step via LangGraph
LangChain’s community template shows how to sync UI state with an agent’s internal state in real time using LangGraph, reducing race conditions and hallucinations in collaborative web apps template post.
If you’re building PM tools, CRMs, or co‑pilot surfaces, this is a clean starting point for deterministic UI‑AI flows.
Poltergeist previews AI diff panel with lint/build/test watchers
Poltergeist (a universal file watcher/build tool) is getting a panel that surfaces AI‑summarized git diffs alongside continuous lint/build/test status—handy when agents are making lots of edits work in progress, panel screenshot.
This turns background auto‑builds into a cockpit for review, so you can scan agent changes without diving through raw diffs first.
Trace‑level anomaly detection flags silent failures in multi‑agent runs
New work from IBM and collaborators shows you can flag multi‑agent drift/loops by learning from execution traces alone—no content inspection required. Using 16 numeric features (steps, tool calls, token usage, timings), XGBoost and one‑class models hit up to ~98%/96% accuracy on two curated datasets paper thread.
Actionable angle: instrument your agent runners to emit path‑shape features, then score runs for anomalies in real time.
Amp CLI now prints clean, resumable thread summaries after exit
Sourcegraph’s Amp improved its after‑exit UX: it now prints a concise description, link to the run, and the +/- LOC summary so you can quickly resume a thread later CLI output.
Small change, real payoff for agentic coding sessions that span terminals and days.
Trimmy (57 KB) fixes TUI newlines so terminal pastes run cleanly
Tiny but handy: Trimmy watches your clipboard and flattens those weird newlines/spaces you get when copying from TUIs, so multi‑line commands paste and run as one line in your terminal app post, GitHub repo. The menu bar app is open source and sits at ~57 KB without the icon.
It’s a small friction killer for devs working in agent shells and container consoles.
v0 SDK Playground debugs “vibe coding” API calls in one place
The v0 team opened a web playground for its “vibe coding as a service” API so you can explore endpoints, test generations, and debug parameters without wiring a client first API playground. It’s a quick way to validate prompts and costs before putting an agent behind it.
🗂️ RAG without RAG? Google File Search and retrieval asks
Gemini File Search API plus Search grounding fuels “RAG in a box” discourse; calls for Scholar/Books integration. Excludes Gemini 3 launch coverage (feature).
Google’s Gemini File Search ships “RAG in a box” with a free tier
Google exposed a File Search API that lets you create a store, upload and index files, and ground answers—without standing up a vector DB. The docs also flag a generous free tier, making it easy to test today. See setup and examples in the official docs API docs and the pricing note in Paige Bailey’s thread Free tier note.
- Supported inputs today include CSV, Excel, Docs/Word, calendar events, XML and more Free tier note.
So what? Small teams can prototype retrieval-backed assistants inside Gemini Studio instead of wiring embeddings, chunkers, and indexers. You still own evals and routing, but basic “RAG” scaffolding is now a first‑party feature.
Live bot shows File Search + Search grounding answering Gemini docs
A public “Gemini API docs helper” demonstrates File Search plus Google Search grounding answering real developer questions about the Gemini APIs. It’s a concrete pattern for support/search bots that need both private docs and fresh web context Demo announcement, with the bot link available to try Demo bot.

The point is: you can stand up production‑ish retrieval without running a vector store or crawler; focus moves to prompt design, store hygiene, and source‑level citations.
“Google killed all RAG startups” debate erupts around File Search
A widely shared diagram of “File Search in Gemini API” sparked claims that Google just compressed the entry‑level RAG stack into a checkbox. The reaction makes sense for simple chat‑over‑docs tools, but leaves room for firms that add domain routing, evals, compliance, and data ops atop the base Reaction thread.
If you’re building RAG, assume File Search is the default baseline and differentiate on retrieval quality, guardrails, latency SLAs, and enterprise integrations.
Call to wire Google Scholar and Books into Deep Research/Gemini
Ethan Mollick urges Google to plug Scholar and Google Books directly into Deep Research/Gemini retrieval, arguing these unique corpora would speed up academic work and likely help book sales via proper citations Scholar request. He also notes most of Google Books’ massive catalog remains hard to access programmatically today Books comment.
This is why it matters: grounding on high‑signal scholarly and long‑form sources would raise answer quality and traceability, but will require licensing, excerpting rules, and robust citation UX.
🧠 Stealth and alt models (non‑Gemini)
New models available to try today outside the Gemini 3 stream: OpenRouter’s Sherlock pair, Arena support for GPT‑5.1‑high, and a deep ERNIE 5.0 review. Excludes Gemini 3 (feature).
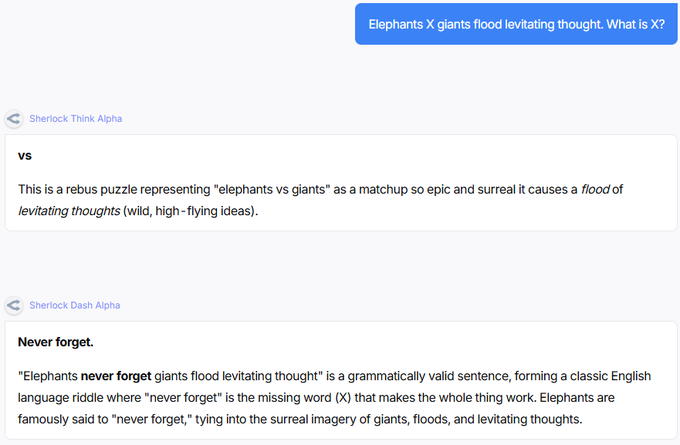
OpenRouter ships stealth ‘Sherlock’ models with 1.8M context and strong evals
OpenRouter introduced two cloaked models—Sherlock Think Alpha (reasoning) and Sherlock Dash Alpha (speed)—both advertising a 1.8M‑token context and solid tool‑calling support launch thread, with live model pages now available for API testing OpenRouter page. Early third‑party evals show sherlock‑think‑alpha at 1,805.67 on LisanBench with a 0.96 average validity ratio, beating Grok‑4’s 0.87 validity while trailing its raw score benchmarks chart.
For builders, the draw is long context plus high instruction fidelity. Dash appears tuned for latency‑first workflows with lighter reasoning, while Think pushes consistency on structured tasks. Expect rapid iteration as the provider gathers usage feedback, and validate behavior under your own evals before relying on the 1.8M window for retrieval or multi‑tool traces image samples.
LM Arena enables GPT‑5.1‑high for vision+text and opens Code Arena for Codex
LM Arena added GPT‑5.1‑high with multimodal (vision+text) support and launched a dedicated Code Arena that includes GPT‑5.1 Codex and Codex Mini for side‑by‑side coding trials feature update, with instant access via the public playground Code Arena. This makes it easier to verify real‑world prompt patterns and toolchains following up on SWE‑Bench 70.4%, where Codex led cost‑efficiency.
For teams, this is a friction‑free way to compare reasoning vs latency settings across tasks, gate new prompts before rollout, and gather screenshotable traces for internal reviews.
Deep ERNIE 5.0 review: cleaner outputs, big gains, but reasoning gaps
A detailed user review argues ERNIE 5.0 delivers ~80% performance gains over X1.1 with much cleaner, more coherent generations, roughly matching MiniMax M2 at the top end—but still trails Kimi K2 Thinking on insightfulness and multi‑turn stability review thread. The analysis highlights better K‑12 math and instruction following, but notes hallucinations, occasional loops (<3%), and degraded memory past ~7 turns.
For applied teams in China, ERNIE 5.0 looks like a viable first‑tier domestic option for structured tasks. For research‑oriented work and long‑horizon agent runs, the review suggests Kimi K2 remains the safer bet.
KAT‑Coder‑Pro V1 breaks into OpenRouter Trending with top‑10 daily token usage
KwaiPilot’s KAT‑Coder‑Pro V1 hit OpenRouter’s Trending board within five days of launch, with the team claiming consistent top‑10 daily token usage among coding agents like Kilo Code, Cline, and Roo Code trending note, usage claim. The model’s free tier is live for trials and API integration via its provider page OpenRouter page.
If you’re evaluating coding agents, measure repair rates and compile/test loops under your repo constraints, and compare tool‑use stability against your incumbent agent before considering a switch.
🧪 Reasoning, determinism and distillation (new papers)
A dense slate of papers for teams tuning reliability and capability: step‑level self‑refine, finance‑grade determinism, black‑box distillation, anomaly detection, and AI‑assisted math discovery.
Smaller 7–8B models hit 100% deterministic outputs at T=0; 120B only 12.5%
IBM’s finance-focused study shows 7–8B LLMs produced identical outputs 100% of the time at temperature 0 across 480 runs, while a 120B model managed just 12.5% despite all randomness off paper summary. The team attributes drift mainly to retrieval order and sampling, and stabilizes runs with greedy decoding, fixed seeds, strict SEC 10‑K paragraph order, and schema checks for JSON/SQL (±5% numeric tolerance). They propose deployment tiers: 7–8B for all regulated flows, 40–70B for structured outputs only, and 120B as unsuitable for audit‑exposed work; determinism also transfers across cloud/local when controls match paper summary.
Why it matters: this is a concrete playbook for banks and any regulated shop that needs repeatable answers on the same inputs. It also cautions that chasing size can reduce reproducibility at T=0, so teams should right‑size models to the task and lock retrieval order for RAG.
DeepMind’s AlphaEvolve discovers better solutions on 67 math problems; repo is live
AlphaEvolve repeatedly searches, verifies, and evolves candidate ideas to solve math problems like Kissing numbers, circle packing, and the Friends’ moving sofa; on many tasks it beats human baselines, with Terence Tao co‑authoring analysis of reward hacking and guidance effects paper highlight, AlphaXiv paper. The team published a problem repository and Colab notebooks for reproduction and further exploration GitHub repo.
Why it matters: it validates an AI‑assisted discovery loop (search→verify→select) at scale, highlights where stronger base models and parallelism help, and names a class of “AlphaEvolve‑hard” problems where naïve search stalls.
Socratic Self‑Refine lifts math/logic ~68% by fixing only low‑confidence steps
SSR decomposes reasoning into short Socratic sub‑Q/A steps, re‑solves each in isolation to estimate confidence, then re‑writes only the low‑confidence steps—yielding ~68% average gains on math/logic benchmarks at controlled cost paper overview. Step‑level confidence gives you a map of weak links, and the paper shows accuracy vs cost curves that favor targeted refinement over blanket re‑generation.
For builders: this slots neatly into tool‑augmented chains. Use SSR to localize error, then prefer selective re‑thinking over full chain re‑writes to cap latency and tokens.
Trace‑only anomaly detection flags multi‑agent drifts and loops up to 98% accuracy
Researchers build datasets of 4,275 and 894 multi‑agent trajectories and show that shallow models on 16 aggregate features (steps, tools, token counts, timing) can detect silent failures—drift, cycles, missed details—without reading content. XGBoost reaches up to 98% accuracy; a one‑class method trained only on normal traces is close, though short drifts remain tricky paper summary.
Takeaway: you can instrument agents and run low‑cost health checks on their traces in production, catching bad runs early without storing sensitive content.
Safety‑aligned LLMs struggle to role‑play villains; new benchmark quantifies the gap
The Moral RolePlay benchmark (800 characters, four morality tiers) finds LLM fidelity drops as roles turn non‑prosocial, with the sharpest fall from flawed‑good to egoist. Models often replace scheming with blunt anger, breaking character; stronger alignment correlates with worse villain acting paper overview.
Why it matters: alignment can conflict with accurate simulation needs in games and writing tools. Teams may need sandboxed modes or controllable guardrails when faithful portrayal of non‑prosocial actors is the product requirement.
Hybrid ARC solver mixes quick guesses with simple rule programs to improve generalization
A new ARC approach pairs fast heuristic guesses with a small library of interpretable rule programs, selecting per‑task to balance speed and robustness. The method aims to reduce pure brute‑force search while retaining human‑legible solutions, and reports wins across diverse ARC tasks paper summary.
So what? For reasoning tasks that benefit from structure discovery, a small program set plus a guesser can outperform either alone and yields explainable artifacts for debugging.
🎬 Creative stacks: photo‑to‑motion and near‑live visuals
Creative tooling and demos popular with teams building media apps: zero‑skill photo‑to‑motion, Grok Imagine clips, SVG render quality. Excludes any Gemini 3 launch claims (feature).
InVideo’s FlexFX turns still photos into motion with 60‑second recipes
InVideo rolled out FlexFX to regular users, moving a previously Pro‑only effect into a one‑click, photo‑to‑motion workflow with shareable 60‑second how‑tos how-to demo and clearer positioning that “all generated inside InVideo” requires no AE/CapCut tool overview. The canned ‘Quantum Leap’ and ‘Drip Hop’ effects show consistent, social‑ready motion from a single image and have creators posting step‑by‑steps and pricing promos feature rollout, plus direct links to try it now site link.

For media app teams, this is a low‑friction way to ship motion from UGC without a VFX pipeline; the repeatable presets also make QA and batching practical.
Grok Imagine draws creator praise with lifelike micro‑clips and playful prompts
Following up on video upgrade where early testers highlighted quality, new creator runs showcase lifelike short clips (an eagle in flight eagle clip, a naturalistic kitten macro kitten clip) and a lightweight “animated profile pic” gag (“head inflates like a balloon”) spreading as a reproducible prompt pattern animated prompt. These aren’t feature changes, but the consistency across unrelated prompts signals stable rendering and timing useful for social loops and avatars.

If you’re evaluating near‑live visuals, treat these as reliability probes: test motion continuity on faces/fur and re‑run the balloon prompt to check prompt adherence and temporal artifacts.
New video prompt benchmark drops for head‑to‑head TTV comparisons
A community “Video Prompt Benchmark” landed with a side‑by‑side montage of prompts and generated frames, giving teams a quick way to sanity‑check model adherence and motion quality across setups benchmark teaser. It’s early and demo‑driven, but useful as a lightweight smoke test while fuller leaderboards mature.
Adopt it as a pre‑merge gate: fix seeds, lock fps/output size, and compare beat‑matching, subject drift, and text‑overlay stability before pushing new model or preset versions.
Gemini 3 SVG sighting hints at higher‑fidelity vector output
A circulating phone UI mock attributed to Gemini 3 shows crisp, layered SVG rendering for device frames and UI accents, prompting claims of “stunning SVG output” SVG claim. While not a release note, the asset quality suggests vector‑first design assistance could be viable if reproducible across prompts.
Engineers should file this under watchlist: if SVG export is reliable, it trims raster‑to‑vector cleanup and enables direct handoff into Figma/Canvas pipelines.
🛡️ Governance and safety cues
Safety/governance discourse today centers on agent containment and provenance. Excludes the earlier Anthropic intrusion report (prior day).
IBM maps determinism tiers: small 7–8B models reach 100% identical outputs at T=0
IBM tested drift across 480 trials, finding 7–8B models produced 100% identical outputs at temperature 0, while a 120B model matched only 12.5% of the time under the same controls. Their playbook ties determinism to controls like frozen retrieval order, greedy decoding, schema checks, and dual‑provider validation, with tiered suitability for regulated workflows paper summary.
Why it matters: Compliance flows can pick smaller models plus strict decoding to pass audits, reserving larger models for non‑audited creative tasks.
Suleyman urges containment and regulation for autonomous AI agents
Microsoft’s AI chief Mustafa Suleyman said the key to safe autonomy is containment: define hard limits and guardrails so agents remain accountable to people, and back that with new regulation. This isn’t a model drop; it’s a governance position that tells teams to architect boundaries first, then scale capabilities. See the clip in speech excerpt.

Why it matters: If you’re shipping agents, this points to spec-level constraints (allow/deny lists, sandboxed tool scopes, explicit approval checkpoints) becoming table stakes, not nice-to-haves.
Users say OpenAI’s obvious text watermark is gone, muddling provenance
A widely shared clip claims the “only obvious watermark” for AI text is no longer present, with a third‑party detector returning “Not AI” on generated text. Treat it as a community signal, not a forensic verdict, but the takeaway stands: provenance checks based on stylistic tells are brittle and can vanish overnight demo post.

So what? Double down on signed metadata and server‑side attestations. Don’t lean on detectors for compliance gates without human review or alternative proofs.
ChatGPT pilots group chats with privacy controls and youth safeguards
OpenAI is rolling out multi‑user ChatGPT rooms on web and mobile to select regions and plans, with privacy protections, profile controls, custom instructions, and specific safeguards for younger users. For companies, that means a new collaboration surface where safety defaults matter—think access scoping, transcript visibility, and audit trails by default feature overview.
Who should care: Trust & safety and IT admins planning org‑wide enablement; this is a different risk posture than one‑to‑one chats.
Safety‑aligned LLMs struggle to role‑play villains, study finds
The Moral RolePlay benchmark (800 characters, four moral levels) shows role‑playing fidelity drops as characters become egoist or villain, suggesting alignment training that suppresses deception or manipulation trades off with believable non‑prosocial acting. That can make assistants feel “off” in writing tools or games where darker motives are required paper thread.
The point is: product teams may need mode‑switchable alignment or constrained sandboxes for fiction, without weakening safety baselines elsewhere.
Paper urges disclosure and traceable evals for AI‑assisted science
A governance proposal from Los Alamos authors calls for required disclosure of AI contributions in research, provenance of information sources, and evaluations that track both human+AI team performance. It also pushes for open tools and audit‑friendly workflows to keep AI as an inspectable assistant, not an authority paper summary.
Why you care: If you’re building LLMs for scientific RAG or experiment planning, expect policy reviewers to look for source traceability and contribution logs.
🤖 Embodied dexterity and stunts
Light but notable embodied AI clips: precision robot hands and a hole‑in‑one from a biped. Mostly demos/tests; few product details today.
ALLEX robotic hand nails delicate, precise manipulation
Wirobotics’ ALLEX hand demo highlights fine‑grained force control and safe contact while handling fragile items, pointing to production‑ready dexterity for real‑world tasks demo clip.

Why it matters: reliable micro‑force control is the blocker for factory and service tasks like assembly, packaging, and lab work. The clip shows stable grasps, smooth motion, and no crushed objects, which is what integrators look for when scoping pilot lines.
Unitree G1 gets a household‑tasks test pass
Shenzhen MindOn Robotics is trialing a refreshed hardware/software stack on the Unitree G1 to perform home‑style chores (handling objects in clutter, safe contact, recovery) demo note. The takeaway for teams: low‑cost humanoids are now credible targets for scripted chores and supervised autonomy pilots in facilities and retail back‑rooms.
Biped robot aces a golf hole‑in‑one
A bipedal robot lands a hole‑in‑one on a full green, showcasing repeatable swing planning, balance, and contact control under uncertainty (turf, club‑ball impact) stunt video.

So what? It’s a showpiece, but it hints at tighter whole‑body control and real‑world perturbation handling—skills that transfer to warehouse pick‑place on uneven floors, door opening, or tool use.
Robotic cones secure crash scenes in <10 seconds
Field tests in China show robotic traffic cones fanning out and securing an incident scene in under 10 seconds, following up on robotic cones which first flagged the sub‑10s deployment claim test update.
Why it matters: this is a practical, embodied safety workflow (autonomous pathing, collision avoidance, timing guarantees). Municipal buyers will care about response time and reliability in rain, night, and mixed traffic.