Qwen3‑VL 4B/8B launch FP8 builds – approach 72B performance
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Alibaba just shrunk its flagship‑style VLM into laptop‑friendly sizes: Qwen3‑VL arrives in 4B and 8B “Instruct” and “Thinking” variants with FP8 builds and low‑VRAM footprints. Why this matters: the team claims these compact models beat Gemini 2.5 Flash Lite and GPT‑5 Nano across STEM, VQA, OCR, video, and agent tasks, and often approach Qwen2.5‑VL‑72B quality—bringing near‑flagship vision to everyday hardware without a data‑center bill.
The rollout nails developer ergonomics. Day‑0 support in MLX‑VLM and LM Studio means Apple silicon users can run dense and MoE locally on NPU/GPU/CPU, while vLLM adds a production‑grade serving path with strong JSON‑structured outputs and high throughput, according to early adopters. The 8B variants are already battling on LMArena in both Text and Vision modes, a timely public read after Qwen’s strong visual standings last week. Cookbooks ship with task‑level recipes for OCR, grounding, multi‑image/video, and agent loops, and TRL notebooks show SFT/GRPO fine‑tuning on the 4B model in a free Colab—plus Hugging Face Spaces and a lightweight in‑browser app to poke the models fast. Kaggle entries round out quick benchmarking.
If you need a bigger yardstick, Ollama Cloud now offers Qwen3‑VL‑235B for free, making it easy to compare footprint vs capability before standardizing a tier.
Feature Spotlight
Feature: Qwen3‑VL goes compact (4B/8B) with near‑flagship VLM
Qwen3‑VL 4B/8B deliver near‑flagship multimodal ability at a fraction of VRAM, with FP8, cookbooks, and day‑0 ecosystem support—pushing serious VLMs onto laptops/phones and enabling agentic vision at edge costs.
Cross‑account launch dominates today: Alibaba’s Qwen3‑VL 4B/8B (Instruct/Thinking) lands with low VRAM, FP8, cookbooks, MLX/LM Studio support, and leaderboard exposure—mostly model release + developer enablement coverage.
Jump to Feature: Qwen3‑VL goes compact (4B/8B) with near‑flagship VLM topicsTable of Contents
🧩 Feature: Qwen3‑VL goes compact (4B/8B) with near‑flagship VLM
Cross‑account launch dominates today: Alibaba’s Qwen3‑VL 4B/8B (Instruct/Thinking) lands with low VRAM, FP8, cookbooks, MLX/LM Studio support, and leaderboard exposure—mostly model release + developer enablement coverage.
Qwen3‑VL 4B/8B launch: compact, FP8-ready models rival larger VLMs
Alibaba released Qwen3‑VL in 4B and 8B "Instruct" and "Thinking" variants that run in lower VRAM while retaining full capabilities, with FP8 builds for efficient deployment. The team claims the compact models beat Gemini 2.5 Flash Lite and GPT‑5 Nano across STEM, VQA, OCR, video and agent tasks, and often approach Qwen2.5‑VL‑72B performance release thread.
Hugging Face and ModelScope collections, API docs, and cookbooks are live for immediate use Hugging Face collection, ModelScope collection, Thinking API docs, Instruct API docs, Cookbooks. A Kaggle entry rounds out access for benchmarking and demos Kaggle models.
Cookbooks, TRL notebooks and Spaces shorten time‑to‑value for Qwen3‑VL
Developer cookbooks cover OCR, object grounding, multi‑image/video, and agent workflows, with the GitHub README pointing straight to task templates cookbook note, GitHub readme. Community notebooks show day‑0 fine‑tuning (SFT/GRPO) on the 4B model in free Colab, plus a Hugging Face Space to compare against moondream3 with object detection hf fine‑tune, Colab notebook, HF Space demo. A lightweight Hugging Face app for the 4B Instruct model offers a quick way to poke the compact VLM in‑browser hf app.
Day‑0 Apple silicon path: MLX‑VLM and LM Studio run Qwen3‑VL locally
Qwen3‑VL (Dense & MoE) is now supported in MLX‑VLM, with maintainers noting optional devices (MLX‑CUDA, CPU) and on‑device readiness; community reports LM Studio + MLX runs on Apple silicon as well mlx release, mac usage. Alibaba amplified the "day‑0 on NPU, GPU, CPU" positioning, signaling a practical local dev loop for Mac users npu support.
vLLM adds Qwen3‑VL, signaling production‑grade serving path
vLLM highlighted Qwen3‑VL as one of its most popular multimodal models, making the compact VLMs easy to serve at scale in existing Python inference stacks vLLM note. Early adopters also point out strong JSON‑structured outputs and high throughput, useful for API‑style multimodal pipelines json claim.
Qwen3‑VL‑235B free on Ollama Cloud complements compact family
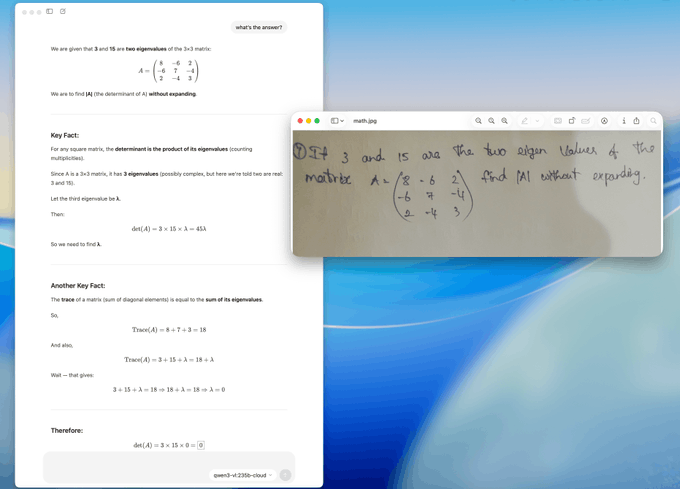
Ollama made the 235B Qwen3‑VL available free on its cloud with ready‑to‑copy examples (OCR on menus, math with image context), and says smaller models and full on‑device runs are coming soon cloud launch, Ollama blog. This provides a large‑model counterpart to Alibaba’s new compact 4B/8B releases for teams testing capability vs. footprint trade‑offs.
Qwen3‑VL‑8B joins LMArena’s Text & Vision battles
The 8B Thinking and Instruct variants are now live in LMArena’s Text and Vision modes for head‑to‑head prompting and community voting arena entry, arena listing. This comes after Qwen3‑VL’s strong standing on visual tracks, providing a lighter option for side‑by‑side comparisons Arena standing.
🆕 Search models: GPT‑5 web stack lands in the API
Fresh model release focused on web search in dev workflows; excludes Qwen3‑VL compact launch which is covered as the feature.
OpenAI ships gpt‑5‑search‑api: 60% cheaper web search in Chat Completions with domain filtering
OpenAI added a dedicated web search model (gpt‑5‑search‑api) to Chat Completions, priced at $10 per 1,000 calls—about 60% lower than before—and it supports domain filtering like the Responses tool pricing update. The updated docs outline three modes—non‑reasoning lookups, agentic search with reasoning, and deep research—with copy‑paste snippets for JS, Python, Bash and C# OpenAI docs.
Engineers are already seeing both the undated and dated variants (“gpt‑5‑search‑api‑2025‑10‑14”) in the platform model selector, confirming availability beyond docs model list screenshot. Third‑party trackers also flagged the new IDs surfacing across the ecosystem, reinforcing the rollout signal model finder alert.
- Endpoint parity means domain allowlists/blocks now work the same in Chat Completions as in Responses, simplifying agent plumbing for grounded search.
- The 60% price drop encourages broader use of agentic and deep‑research traces; teams should still watch token budgets and throttle strategies in long sessions.
🛠️ Agentic coding: Codex, sub‑agents, and end‑to‑end delegation
Heavy practitioner activity today: Codex CLI education, plan‑mode previews, Claude Code sub‑agents, Cursor long‑run build, and Factory 1.8 integrations.
Claude Code sub‑agents emerge as a best practice for deep repository work
Practitioners report big quality and speed wins by orchestrating Claude Code sub‑agents—repo mappers, analyzers, API readers, writers—in parallel, then merging their outputs, outperforming single‑loop agents on codebase mapping and authoring subagent demo. The broader “Deep Agents” pattern emphasizes structured planning, orchestrator + specialist sub‑agents, agentic search, hybrid memory, and verification to tackle multi‑hour tasks design blueprint.
Takeaway: split concerns, keep each agent’s context clean, and compose results—especially for docs generation, migrations, and new feature scaffolding.
Factory 1.8: delegate Linear tickets, spin headless “droid exec”, and close incidents via Sentry×Linear
Factory’s 1.8 release plugs Droids into more of the dev stack: assign Linear issues for end‑to‑end completion release thread, mention @Factory in Slack threads to spin a headless session and track progress Slack hand‑off, run non‑interactive batch jobs with droid exec for large refactors/tests headless mode, and loop incidents through Sentry with fixes handed back into Linear incident flow. Release notes outline autonomy controls and output formats for CI/CD use release notes. A just‑in‑time permissions prompt in terminal tightens safety for file edits and reads permission UI.
Net: Factory is evolving from a chat‑agent to a delegatable dev assistant embedded across planning, code, and on‑call.
OpenAI kicks off Codex video series and CLI how‑to for GPT‑5‑Codex
OpenAI Developers launched a multi‑part video series to help teams get productive with the Codex CLI and GPT‑5‑Codex, including install and usage patterns (npm i -g @openai/codex) series intro, with a mirrored post reiterating the CLI workflow install recap. For broader context on how Codex is used across real products and events, see OpenAI’s behind‑the‑scenes write‑up on using Codex to run DevDay demos and tooling DevDay blog, and the central docs hub for deeper guides and examples Codex hub.
Anthropic’s code_execution tool lands in the AI SDK with typed I/O for bash and text edits
A new Anthropic code_execution_20250825 tool with bash execution and text editing is being wired into the AI SDK, with fully typed inputs/outputs to simplify UI surface creation and safer agent loops feature brief. A companion example shows the typed schema intended to streamline frontends and logging typed I/O.
Implication: agent builders can give Claude more reliable, auditable action surfaces for repo ops, scripts, and patching—without bespoke adapters.
Codex “Plan Mode” preview surfaces with iterative planning and planner model toggle
A Plan Mode PR shows read‑only, iterative planning (Shift+Tab), a configurable planner model (/plan-model), and checklisted plan updates—hinting at a first‑class planning pass before code edits PR details. Although that PR was later closed without merge, maintainers signal Plan Mode is still coming PR status note. This lands as teams double down on planning‑first loops, following up on plan mode adoption in Cursor that cut back‑and‑forth and spawned background jobs.
Expectations: a dedicated planner improves long‑horizon tasks (refactors, migrations) and lets orgs standardize plan quality independently of the coding model.
Codex CLI v0.45 trims tokens by ~10% at equal quality; new usage videos share workflows
OpenAI engineers said Codex CLI v0.45 made interactions ~10% more token‑efficient at the same result quality efficiency note. A senior IC also shared a personal walkthrough on day‑to‑day usage workflow video, and the DevDay write‑up details broader Codex applications across stage demos and app development DevDay blog. Teams shipping with Codex can expect lower cost per loop and clearer patterns for multi‑tab, multi‑task workflows.
Cursor agent runs 24 hours straight to ship a working project management app
A developer ran Cursor’s agent in a continuous loop with Sonnet 4.5 (CLI), minimal seed context, and autonomous progress tracking until “completed,” yielding a functional PM app and surprisingly navigable code structure overnight run, with notes on minimal upfront scope and what improved with a bit more initial context run notes. Screens show the resulting UI and repo layout app snapshot.
Why it matters: end‑to‑end feasibility for greenfield apps is crossing from demo to practice; the next frontier is hardening—tests, security, and production CI/CD.
Vercel ships a Slack Agent Template and Bolt library to build agents inside Slack
Vercel demonstrated v0 running directly in Slack at Dreamforce and released a Slack Bolt library plus a starter template, letting teams query data, build dashboards, and ship agent actions without leaving chat stage demo, with a template to scaffold Slack agents quickly agent starter.
This reduces “glue code” to bring LLM agents where work already happens—channels, threads, and DMs—with a path to production deploys on Vercel.
• Resources: Slack Bolt library, and Agent template.
Braintrust adds remote evals so you can benchmark local agents without moving workloads
Braintrust showed how to hook locally running agents to remote evaluations, so teams can iterate on tasks, datasets, and scorers without redeploying infrastructure how‑to guide. This is useful when you want reproducible evals (goldens, regressions) while keeping heavy data and tooling on your box or VPC.
Vercel AI SDK adds Anthropic memory tool integration for agent state management
Vercel noted it is shipping support for Anthropic’s memory tool in the AI SDK, making it easier to persist, inspect, and version agent memories in product UIs memory support. For coding agents, this reduces prompt bloat and gives users recovery points when long sessions meander or break.
🚀 Serving speed: GB200 tokens/sec and adaptive speculation
Runtime perf stories concentrate on Blackwell throughput and spec‑decoding; mostly systems knobs rather than silicon announcements.
SGLang hits ~26k input / 13k output tok/s per GPU on GB200 NVL72
LMSYS reports SGLang sustaining ~26K input and ~13K output tokens per GPU per second on NVIDIA GB200 NVL72, with up to 4× generation speedups over Hopper in InferenceMAX runs and SGLang set as the default DeepSeek engine on both NVIDIA and AMD. Following up on tokens per MW lead, GB200’s efficiency story now comes with concrete per‑GPU throughput measurements. benchmarks overview LMSYS blog post
These results reflect joint system‑level optimizations (prefill/decode disaggregation, expert parallelism, FP8 attention, NVFP4 GEMMs) and Blackwell’s higher‑bandwidth interconnects. The adoption as the default engine in the SemiAnalysis InferenceMAX benchmark underlines runtime maturity beyond a single hardware stack. collaboration note
Together AI’s ATLAS speculator delivers up to 4× faster inference and ~500 TPS on DeepSeek‑V3.1
Together AI unveiled ATLAS, an adaptive speculative decoding system that learns from live traffic to accelerate inference; they show up to 4× faster throughput vs baseline and around 500 TPS on DeepSeek‑V3.1, nearly 2× faster than their prior Turbo speculator. results overview ATLAS blog post
Because ATLAS adapts to workload acceptance rates and latency profiles at runtime, it avoids static speculator brittleness and continues improving under production mixes—relevant for teams pushing long‑context and multi‑turn agent workloads where token budgets dominate cost and latency.
DGX Spark runtime clarified: read vs generation speeds, and where it lands vs 5090/M4 Pro
Simon Willison updated his DGX Spark notes to separate token read (prefill) from token generation speeds, highlighting early‑ecosystem wrinkles on ARM64 CUDA and containers for inference workflows. blog update hands‑on notes
Independent charts circulating today place Spark’s output tokens/sec close to Apple’s Mac Mini M4 Pro and below RTX 5090/5080 desktop GPUs; at ~$4,000, it targets small‑model local serving rather than top‑end desktop cards. This framing helps teams choose hardware based on actual decode throughput rather than mixed prefill+decode numbers. benchmarks chart
🧱 Desktops and racks: DGX Spark and AMD Helios
Concrete hardware updates span desktop Blackwell boxes and rack‑scale MI450 systems; excludes runtime perf which sits under Serving speed.
DGX Spark lands on desks: 1‑PFLOP Blackwell box ~$4k, early buyers flag ARM64 gaps
NVIDIA’s DGX Spark is now in customers’ hands—Jensen Huang even hand‑delivered a unit—with users calling out ~1 PFLOP in a tiny form factor and an expected ~$4,000 price bracket, following up on early runtime coverage that focused on capability demos. OpenAI’s Greg Brockman highlighted the size‑to‑compute leap, while a community review details 128 GB RAM, ~3.7 TB NVMe, and an ARM64 stack that works best today via NVIDIA’s official containers as the CUDA-on‑ARM ecosystem matures hand delivery and blog post. A comparative chart situates Spark near Apple’s Mac Mini M4 Pro on smaller models yet below RTX 5090 class boards for raw headroom, framing Spark as a developer desktop rather than a training rig comparison chart.
For engineers, the takeaway is clear: strong local prototyping hardware, but plan on containerized toolchains and watch for fast‑moving ARM64 library support as the ecosystem catches up update note.
Oracle to deploy 50,000 AMD MI450 GPUs on OCI from Q3 2026
Oracle Cloud Infrastructure will roll out 50,000 AMD Instinct MI450 accelerators starting in Q3’26, with further expansion in 2027+, giving enterprises a sizable non‑NVIDIA public cloud option for training and inference. The deployment uses AMD’s Helios rack design—MI450 + next‑gen EPYC + Pensando networking—offering pre‑wired rack blocks that target scale and serviceability deployment plan.
For AI platform teams, this strengthens a multi‑vendor strategy: OCI’s MI450 footprint could improve supply diversification and pricing leverage while testing the maturity of ROCm‑based toolchains at rack scale; evaluation should include memory‑bound workloads that benefit from MI450’s HBM4 capacity and bandwidth.
AMD Helios racks: 72 MI450s, ~1.4 exaFLOPS FP8 and 31 TB HBM4 per cabinet
AMD’s new Helios rack‑scale platform packages 72 Instinct MI450 GPUs into a serviceable cabinet with quick‑disconnect liquid cooling, delivering roughly 1.4 exaFLOPS FP8 and ~31 TB of HBM4 per rack. Each MI450 pairs 432 GB HBM4 with ~19.6 TB/s bandwidth, with UALink for in‑node scale‑up and UEC Ethernet for cross‑rack scale‑out; the design follows Open Rack Wide conventions to simplify deployment and field service platform details.
For leaders scoping non‑NVIDIA capacity, Helios’ emphasis on memory capacity per GPU, open fabrics, and rack‑level serviceability is the notable angle; it positions AMD’s stack as a credible alternative for large training and high‑context inference footprints.
🏗️ AI factories and demand math
Macro infra signals today are investment and usage economics; few pure capex filings, but meaningful scale commitments and token‑demand curves.
Hidden “thinking tokens” push usage to ~1.3 quadrillion per month even as unit prices fall
Usage is exploding while price per token drops: WSJ highlights that models’ hidden reasoning traces (“thinking tokens”) are swelling tokens per answer, driving spend despite cheaper rates WSJ analysis. The ecosystem view shows monthly usage jumping to roughly 1,300T tokens (~1.3 quadrillion) by Oct ’25, up from ~9.7T in May, as deep inference and self‑checking take hold ecosystem map.
For AI leaders, the economics bifurcate into quick vs deep inference. Capacity planning now hinges on acceptance rates for speculative decoding, tool‑use loops, and explicit “thought budgets,” not just list prices.
OpenAI’s compute roadmap now totals ~26 GW across Nvidia, Broadcom and AMD
OpenAI’s disclosed arrangements add up to roughly 26 GW of data‑center capacity equivalents: a 10 GW Broadcom custom‑accelerator program, a 10 GW Nvidia systems LOI (with an anticipated ~$100B Nvidia investment as rollouts happen), and 6 GW of AMD capacity paired with a warrant for up to 160M AMD shares at $0.01 tied to deployments compute summary, following up on 10 GW term sheet.
The plan targets first racks shipping in 2H‑2026 and multi‑year build‑outs through 2029, implying a full‑stack bet (silicon, memory hierarchy, compiler/runtime) to raise perf/W and reduce cost per token at scale.
Google to build $15B AI hub in India with gigawatt-scale data center and subsea landing
Google will invest $15B from 2026–2030 to stand up its first AI hub in India (Visakhapatnam), including a gigawatt‑scale AI data center built with AdaniConneX and Airtel and a new subsea cable landing that ties into Google’s global network announcement recap.
This adds multi‑GW‑class capacity in South Asia and shortens latency paths for India’s fast‑growing AI workloads. The bundle (DC, subsea, and "full AI stack") signals a vertically integrated approach that can insulate critical AI services from regional power and network bottlenecks.
Oracle to deploy 50,000 AMD MI450s on OCI starting Q3 2026, expanding in 2027+
Oracle Cloud Infrastructure will add 50,000 AMD Instinct MI450 GPUs beginning in Q3‑2026, with further expansion planned into 2027 and beyond deployment note. The move strengthens a non‑Nvidia public‑cloud lane for large‑scale training and inference and offers enterprises vendor diversification during a supply‑constrained cycle.
Expect customers to weigh ROCm maturity, cluster fabrics, and model portability alongside price/perf as they evaluate multi‑vendor pipelines.
AMD unveils Helios rack: 72 MI450s, 31 TB HBM4 and ~1.4 exaFLOPS FP8 per cabinet
AMD’s Helios rack aims to simplify serviceability at AI‑factory scale: 72 MI450 GPUs per cabinet, ~31 TB of HBM4 and ~1.4 exaFLOPS FP8, with UALink for in‑node GPU memory sharing, UEC Ethernet for scale‑out, and quick‑disconnect liquid cooling platform brief.
Helios’ memory‑heavy design targets throughput on memory‑bound training and large‑context inference while leaning on open fabrics, a useful counterweight to proprietary interconnect stacks.
Brookfield commits up to $5B to Bloom Energy to finance fuel‑cell AI data centers
Infrastructure financier Brookfield Asset Management will provide up to $5B to Bloom Energy to fund fuel‑cell‑powered AI data centers, expanding on‑site generation options beyond grid ties and traditional PPAs funding update.
Fuel cells can reduce interconnect delays, cut transmission risk, and improve siting flexibility for AI factories, though cost curves will hinge on fuel pricing and fleet‑scale deployment economics.
AI is lifting GDP via investment before productivity, says WSJ
WSJ reports that AI’s contribution is showing up first in capex, not broad productivity gains: roughly two‑thirds of U.S. GDP growth in early 2025 came from software and compute investment, while measured worker productivity impacts remain mixed; about 10% of firms report AI use WSJ summary.
For AI planners, this implies near‑term demand will keep tracking capex cycles (chips, racks, power, data) even as productivity dividends arrive more slowly and unevenly across sectors.
🛡️ Well‑being guardrails, age‑gating and privacy signals
Policy/safety moves dominate discourse: OpenAI’s well‑being council and adult‑content stance; California’s one‑click privacy control. Excludes model launches.
OpenAI will relax mental‑health refusals and allow erotica for verified adults in December
Sam Altman said ChatGPT’s conservative stance on mental‑health topics will be eased as new safeguards mature, and that erotica will be permitted for verified adults starting in December as age‑gating rolls out broadly Altman thread. The shift emphasizes user choice (“treat adult users like adults”) and optional, more expressive personalities, while maintaining crisis protections for at‑risk users.
OpenAI creates Expert Council on Well‑Being and AI to inform youth safeguards and product design
OpenAI introduced an eight‑member Expert Council spanning psychology, psychiatry, and HCI to guide ChatGPT and Sora on healthy interactions across age groups, building on prior work like parental controls and teen distress notifications OpenAI announcement, and outlining scope and members in detail OpenAI blog post. The council is intended to continuously advise on features that affect emotions, motivation, and mental health.
California AB566 mandates one‑time browser “do not sell/share” signal and statewide deletion system
California approved AB566 requiring browsers to ship a built‑in privacy control that broadcasts a one‑click “do not sell/share” signal, plus a statewide data‑broker deletion request flow law details.
- Browser signal deadline: mandatory by Jan‑2027; deletion system begins Jan‑2026 with 45‑day broker checks thereafter law details.
- Practical impact: cross‑site ad targeting and broker feeds will face wider opt‑outs by default, tightening data available to train and target AI‑powered ad systems.
California signs first U.S. chatbot law requiring safeguards; enables lawsuits for harms
Governor Newsom signed SB 243, billed as the first U.S. law regulating AI chatbots, mandating operator safeguards for vulnerable users and allowing lawsuits when failures cause harm news coverage, following up on SB243 that required bots to disclose non‑human status and address self‑harm protocols. The signature moves the mandate from passage to enforceable law, raising compliance stakes for AI assistants deployed at scale.
🎬 Video/3D tools: Sora 2 vs Veo 3.1, deflicker, and image→3D
Large creative stack chatter today (video arena moves, deflicker tool, ComfyUI workflows, image→3D). Separate from the Qwen VLM feature.
Sora 2 Pro ties Veo 3 for #1 on Video Arena; Sora 2 (with audio) ranks #3
LMArena’s organizers added OpenAI’s Sora 2 and Sora 2 Pro to their Text‑to‑Video leaderboard, noting Sora 2 Pro is the first to tie Veo 3 variants for the top spot while Sora 2 lands at #3 and is praised for synchronized audio generation leaderboard update.
This is the first broad, head‑to‑head signal that Sora’s audio+video pipeline is competitive with Veo 3 on overall quality, and it raises the bar for integrated sound in T2V workflows (see the invite for direct prompting and voting in Discord) Discord invite.
Gemini UI surfaces Veo 3.1 banners and a “fast” model, pointing to imminent release
Screenshots show “New! Video generation just got better with Veo 3.1” banners in Gemini with a Try Now entry point, and a Model Finder card listing veo‑3.1 and veo‑3.1‑fast preview endpoints; one user notes availability appears limited to the U.S. for now Gemini banner, model finder card, UI screenshot. This follows yesterday’s third‑party endpoint sightings without Google confirmation Veo 3.1 hint.
If this ships as indicated, expect longer durations and better motion consistency to narrow gaps vs Sora 2 on multi‑scene coherence (and give Gemini Studio users a native path for video+audio).
Higgsfield launches Enhancer to kill flicker; adds Sora 2 MAX/Pro MAX and a free‑run promo
Higgsfield introduced Enhancer, a universal deflicker that cleans up AI‑generated and legacy footage, alongside Sora 2 MAX (higher fidelity) and Sora 2 Pro MAX (multi‑scene at MAX quality), plus a 1080p Upscale Preview—available with “Unlimited” usage through the end of the week release thread. Creators are already pushing teaser workflows on the platform and highlighting the unlimited window for Ultimate/Creator plans creator promo.
Image→3D in ~2–5 minutes: Hitem3D cuts modeling to ~$0.30–$1.40 per asset with watertight meshes
Hitem3D—built atop Sparc3D geometry and ULTRA3D speed—turns one or a few reference photos into studio‑ready, watertight meshes (up to 1536³ detail) in about 2–3 minutes per view, with typical jobs completing in ~2–5 minutes and costing roughly $0.30–$1.40 per model feature breakdown, ArXiv paper. A follow‑up thread walks through the view expansion, alignment, triangulation, and texturing path, and calls out a faces/hair variant for character‑centric assets how-to thread, official note.
Runway debuts Apps for everyday video work: remove, reshoot, add dialogue, upscale to 4K, restyle
Runway released a set of five AI video Apps—Remove from Video, Reshoot Product, Add Dialogue (with tone), Upscale Video (one‑click to 4K), and Change Image Style (incl. relighting/retexturing)—rolling out on the web with more coming weekly and an open call for ideas apps overview, feature list. For production teams, this bundles common cleanup and repurposing tasks without leaving the browser, potentially reducing round‑trips to NLEs or specialized plugins.
ComfyUI’s 3‑minute guide to WAN 2.2 Animate and a new character replacement workflow
For creators assembling animation pipelines in nodes, ComfyUI shared a concise WAN 2.2 Animate tutorial to get character motion running fast, plus a separate walkthrough on character replacement inside the same graph tutorial, character replacement. The team is soliciting feedback on the workflow ergonomics to refine defaults and examples feedback request.
📊 Leaderboards and puzzlers (non‑video)
Smaller eval pulse today: coding/vibe arena standings and NYT Connections deltas. Excludes Qwen leaderboard items (covered in the feature) and video arena (in Media).
DeepSeek-V3.2-Exp leads new Vibe Coding Arena
DeepSeek‑V3.2‑Exp now tops the BigCodeArena “vibe coding” board, reflecting execution‑first, user‑voted preferences; following up on execution evals that introduced the arena’s run‑and‑judge method, today’s snapshot shows a clear pecking order driven by real usage. See the board preview in leaderboard image.
- Top 3 today: DeepSeek‑V3.2‑Exp (≈1107), DeepSeek‑V3.1‑Terminus (≈1080.9), and qwen3‑235b‑a22b‑instruct‑2507 (≈1069.8), all based on raw head‑to‑head user votes and execution outcomes leaderboard image.
NYT Connections update: GPT‑5 Pro 83.9; DeepSeek V3.2 Exp 59.4
A fresh NYT Connections snapshot (last 100 puzzles) puts GPT‑5 Pro at 83.9, with DeepSeek V3.2 Exp at 59.4; Claude Sonnet 4.5 Thinking 16K rises to 48.2 while its non‑reasoning mode reaches 46.1; GLM‑4.6 sits at 24.2. The update also notes GPT‑5 Pro trails an earlier o3‑pro marker (87.3) in this cut score rundown, and confirms the scope is the most recent 100 puzzles method note, with the benchmark and scripts available in the maintainer’s repo GitHub repo.
💼 Enterprise moves: funding, assistants and commerce apps
Notable GTM signals span a large Series B, Salesforce+OpenAI/Slack integrations, a Walmart ChatGPT app, and AI‑driven layoffs commentary.
Salesforce brings Agentforce 360 into ChatGPT; $100M support savings cited
Salesforce expanded its OpenAI partnership so Agentforce 360 apps can run inside ChatGPT, alongside deeper Slack and Codex tie‑ins shown at Dreamforce partnership summary, integration graphic, and a Salesforce post company update. Internally, Salesforce says AI support agents are saving ~$100M annually and Reddit reports 84% faster resolution (46% deflection, 8.9→1.4 min) savings stats. Full partner details are in Salesforce’s release Salesforce press release, following up on Slack apps which shipped ChatGPT for Slack.
For enterprises, this tightens the loop between CRM data, Slack workflows, and ChatGPT distribution—lowering friction to deploy agentic flows where users already work.
Goldman Sachs signals job cuts as AI adoption accelerates under “OneGS 3.0”
Goldman told staff it will constrain headcount growth and make limited reductions this year as part of an AI‑driven efficiency push (“OneGS 3.0”), even as overall headcount remains above 2024 levels ai plan memo, bloomberg snapshot.
For AI leaders and HR, it’s a visible example of large‑bank operational redesign around automation in onboarding, compliance, lending, and vendor flows—shifting workforce mix while scalability improves.
Walmart launches a shopping app inside ChatGPT
Walmart rolled out a ChatGPT app that lets users browse and buy across Walmart and Sam’s Club assortments directly in ChatGPT, signaling mainstream retail’s move into agentic commerce walmart details, Bloomberg report, deal roundup.
For commerce leaders, this tests conversion in conversational channels and sets a template for catalog search, bundling, and checkout flows embedded in general‑purpose assistants.
Reducto raises $75M Series B, surpasses 1B pages processed
Document AI startup Reducto closed a $75M Series B led by a16z, taking total funding to $108M, and says it has now processed 1B+ pages (~6× since its Series A) with plans to double down on model research and production‑grade tooling funding note.
For AI leaders, this marks accelerating enterprise demand for high‑accuracy OCR+VLM pipelines in regulated workflows (charts, tables, multi‑page docs) and a well‑funded competitor in the document automation stack.
Slack turns Slackbot into a full AI assistant with private AWS processing
Slack is piloting a revamped Slackbot that plans meetings, summarizes threads, finds files via natural language, and coordinates calendars (Google/Outlook), with AI running in a private AWS environment and wider rollout targeted by end‑2025 product brief.
This positions Slack’s native assistant as an enterprise option alongside third‑party bots—important for CIOs weighing data residency, privacy, and change‑management for knowledge work assistants.
Vercel ships Slack Agent Template and Bolt library to build agents inside Slack
Vercel released a Slack Agent Template plus a Bolt library to quickly build, test and deploy Slack agents, complementing the growing wave of agentic enterprise workflows showcased at Dreamforce template link, slack demo.
For platform teams, this lowers the integration cost to embed RAG, approvals, and code actions directly in Slack with CI/CD‑friendly scaffolding.
🧪 Reasoning, RL and long‑horizon methods
Dense research day: diffusion guidance, chain robustness, dynamic context windows, memory‑driven agents, overthinking control, KV compression, and AI peer review.
Deep search agents with sliding context hit ~33.5%
A sliding window that retains assistant thoughts, elides older tool dumps, and preserves latest tool outputs lets agents reason over ~100 turns within 32k, reaching ~33.5% on a tougher multi‑page benchmark—without external summarizers paper abstract.
- Training mirrors the runtime view (tool calls replaced by placeholders), followed by RL that rewards only correct final answers, stabilizing long multi‑step sessions paper abstract.
MUSE learns on the job to set new TAC SOTA
An experience‑driven loop—plan, execute, reflect, store—writes hierarchical memories (strategic notes, sub‑task SOPs, tool tips) and reuses them across tasks and models, pushing TAC to 51.78% with Gemini‑2.5 Flash paper overview.
- A separate reflect agent blocks false success, proposes retries, and distills new SOPs; plain‑language memories transfer to other LLMs without retraining paper overview.
RL finds the heads that matter for reasoning
A tiny gate per attention head mixes a short sliding window with full history; RL raises gates for heads that improve correctness. High‑gate heads keep full KV while others get trimmed, preserving chain integrity and saving ~20–50% KV with near‑lossless (or better) accuracy on math/coding paper title page.
- On a tough math set, the compressed policy even beats the full‑cache baseline by focusing memory where it counts paper title page.
TAG diffusion guidance trims steps and hallucinations
Tangential Amplifying Guidance (TAG) amplifies the tangential component of each diffusion update to keep samples near high‑probability regions, reducing semantic drift; in tests, ~30 TAG steps surpass 100‑step classifier‑free guidance on quality without extra model calls paper thread.
- Methodologically, TAG keeps the radial (noise) part fixed while modestly boosting the tangential (content) component, improving likelihood and text‑image alignment on standard samplers paper recap.
R‑Horizon: RL improves long‑chain reasoning
New details show reinforcement learning on composed chains lifts chain accuracy and yields roughly +7.5 on AIME24, addressing early stopping and format breaks that crater long sequences paper update. This builds on R‑Horizon, which introduced breadth‑and‑depth chaining to stress long‑horizon reasoning.
- Gap analysis finds real chain scores fall below independent‑trial expectations as chain length grows; verifiable rewards and GRPO reduce error accumulation paper summary.
Reasoning shaping curbs overthinking
Group Relative Segment Penalization (GRSP) supervises at the step level: it detects step boundaries (keywords or confidence dips) and penalizes choppy, short segments that correlate with wrong answers, yielding shorter outputs with stable accuracy on math and RL setups paper details.
- Larger bases still benefit, compressing steps better and stabilizing training versus token‑level penalties paper details.
AI metareview nears human accept/reject accuracy
An ensemble of reviewer personas (empiricist, theorist, pedagogical) plus a metareviewer achieves ~81.8% accept/reject accuracy on 1,963 submissions, close to the ~83.9% human average; AI excels at fact/literature checks but lags on novelty/theory paper summary.
- Rebuttals can over‑sway agents, so humans stay in the loop; ensembles reduce persona bias versus single reviewers paper summary.
MPO co‑optimizes words and visuals for MLLMs
Treating prompts as paired text+cue (image/video/molecule) and updating both after single‑note feedback improves MLLM answers while slashing trial budgets by ~70% compared to text‑only optimizers; strong parents are warm‑started to explore efficiently paper summary.
- Visual cues are created, edited, or mixed to align attention on the right details, with wins across images, videos, and molecular tasks paper summary.