Qwen3‑Next‑80B‑A3B hits 10.6× prefill, 10× decode – 84.7 MMLU
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Alibaba’s Qwen team just dropped a speed‑first sparse MoE: Qwen3‑Next‑80B‑A3B. At 32k context it claims 10.6× prefill and 10.0× decode throughput over a dense 32B baseline while still landing ~84.72 MMLU. If you’re actually running long‑context agents on big docs, that tradeoff — dramatically faster tokens without face‑planting on accuracy — is the stuff that moves budgets from dense to sparse.
According to Qwen’s write‑up, the gains come from a “super sparse” routing recipe with gated DeltaNet, multi‑token prediction, and gated attention, plus an emphasis on training cost efficiency. Translation: you get more tokens per dollar and less latency tax when prompts balloon past 32k. Community notes suggest the architecture leans into the current best ideas in sparse expert gating rather than another brute‑force dense scale‑up, which is exactly where inference economics are headed.
Qwen’s momentum isn’t just on paper either. Its Qwen3‑VL‑235B‑A22B‑Instruct now accounts for roughly 48% of OpenRouter image processing (about 457k images), and the visual line places near the top of public leaderboards. If you’ve been waiting for a credible long‑context MoE to standardize on, this looks like the practical speed play to test first.
Feature Spotlight
Feature: Browser‑capable coding agents and plan‑mode workflows
Coding agents level up: Cursor drives the browser (screenshots, console, network), Claude Code’s Plan Mode yields near‑human patches, and MCP hooks Chrome DevTools + background agents—making multi‑step software tasks reliably automatable.
Cross‑account demos show a step‑change in practical autonomy for coding agents: Cursor now drives a real browser, Claude Code’s Plan Mode upgrades output quality, and MCP bridges Chrome DevTools and background agents. Mostly hands‑on tooling; excludes enterprise agent builders.
Jump to Feature: Browser‑capable coding agents and plan‑mode workflows topicsTable of Contents
🧰 Feature: Browser‑capable coding agents and plan‑mode workflows
Cross‑account demos show a step‑change in practical autonomy for coding agents: Cursor now drives a real browser, Claude Code’s Plan Mode upgrades output quality, and MCP bridges Chrome DevTools and background agents. Mostly hands‑on tooling; excludes enterprise agent builders.
Cursor adds live browser control for end‑to‑end testing, accessibility checks and design‑to‑code
Cursor can now drive a real browser: it takes screenshots, runs app tests, inspects console/network logs, checks accessibility, and converts designs into code—positioning the IDE to automate larger slices of the dev loop browser feature list. In practice, users are already running hands‑free test passes (“never touched the keyboard”) via its autopilot testing mode autopilot test demo, with one‑click "Fix in Cursor" deep links emerging in the ecosystem to move from code review to agent fixes seamlessly bugbot deep link.
Claude Code Plan Mode is a dramatic quality jump over ad‑hoc prompting, say users
Developers report a “night and day” difference when enabling Plan Mode: without it, the generated code is often throwaway; with it, output approaches senior‑level quality with occasional, easy‑to‑catch bugs user report. A shared five‑option implementation plan illustrates the concise, reviewable scaffolding Plan Mode proposes before writing changes, which users credit for the higher reliability plan screenshot.
Two‑command Chrome DevTools MCP hookup lets Claude Code operate your live browser
A hands‑on demo shows Claude Code attached to Chrome via MCP in two commands (launch with --remote‑debugging‑port, then add the chrome‑devtools MCP), after which the agent lists tabs and executes JavaScript—e.g., triggering alert("Hi!") on x.com attach steps. This is a practical follow‑through on MCP for real‑time debugging and automation, following debugging integration where the integration first landed.
Fan‑out for coding agents: plan, shard tasks, then spawn background workers via Cursor MCP
A workflow pattern gaining traction: spend cycles refining a global plan, split it into independent tasks, then fan out background agents through an unofficial Cursor MCP server to execute in parallel—bringing persistent, multi‑worker orchestration to day‑to‑day coding workflow outline, with setup and examples in the open repo GitHub repo.
LangCode CLI unifies Gemini, Claude, OpenAI and Ollama for safe coding with diff previews
Built on LangChain, LangCode routes coding tasks across multiple models, generates reviewable diffs before applying changes, supports ReAct and Deep modes, and can extend with MCP tools—making it a portable alternative to vendor‑specific CLIs feature overview, with install and usage in the repo GitHub repo.
RepoPrompt teases Codex‑driven context assembly to pack 60k‑token problems for GPT‑5
An upcoming RepoPrompt 1.5 feature will use a "codex" stage to assemble the most relevant code and specs into a 60k‑token context window for GPT‑5 Pro, aiming to move from small prompts to single‑shot, large‑scope problem solving on big repos planning teaser, with the author calling it a "game changer" for reasoning‑model planning feature tease.
Warp’s terminal‑agent UX is maturing into a CLI+IDE hybrid that some devs prefer
A practitioner review frames Warp as "a CLI that looks like an IDE": editor code view, project explorer, one‑click command output, agent/CLI toggle, credit tracking, task lists, and shared context (Warp Drive). The agent has ranked near the top of terminal benchmarks in recent tests, though there’s a learning curve adopting the workflow user review.
🕸️ Agent builders, connectors and MCP surfaces
Enterprise‑oriented agent orchestration and connectors: Gemini Enterprise’s Agent Builder UI and reliability notes, open‑source Agent Builder teasers, and Grok’s GitHub integration. Excludes coding‑agent autonomy (covered in the Feature).
Gemini Enterprise Agent Builder adds 15-seat free trial; $21/seat after, with more reliable outputs
Google’s enterprise Agent Builder now shows 15 seats on the free trial and then $21 per seat monthly, while testers report agent responses (Gemini 2.5 Pro) feel more reliable than personal Gemini pricing clarification, and reliability note. Following up on Agent Builder early access, the UI lets teams compose agent workflows directly in Chat, create files, and auto-select models first look thread, with details in feature overview.
Open Agent Builder set to be open-sourced next week with visual n8n‑style workflows
Firecrawl says its Open Agent Builder is “coming next week,” teasing a visual, n8n‑style workflow builder for composing multi‑step agents that can be self‑hosted and extended teaser update, and open source hint. This adds another open, configurable orchestration surface for teams standardizing on agent pipelines across tools and data sources.
🧠 Agent planning, memory and self‑learning research
Today’s papers center on reliable tool use and long‑horizon reasoning: Stanford’s AgentFlow (planner/executor/verifier/generator), Meta’s reward‑free “early experience,” meta‑awareness RL gains, DPO value scaling, and reusable reasoning templates.
AgentFlow trains planner–executor–verifier–generator in‑the‑loop, surpasses GPT‑4o on tool‑use tasks
Stanford’s AgentFlow coordinates four modules via evolving memory and Flow‑GRPO (group refined policy optimization) trained with real tool outputs; a 7B backbone beats baselines and GPT‑4o on search, math, and science tool‑use suites paper abstract. The approach decouples planning from execution and optimizes when to call tools and when to stop, improving reliability of multi‑turn workflows paper thread.
Implication: a concrete recipe for “deep agents” that closes the gap between prompt‑chaining demos and robust, instrumented tool use in production.
Meta‑awareness RL (MASA) lifts 8B reasoning by +19.3% on AIME25 and hits 1.28× faster GRPO parity
MASA trains a short “meta path” to predict pass rate, solution length, and likely concepts; rewards the meta path only when its predictions match correct‑solution stats, then uses those estimates to steer reasoning—skipping trivial/hopeless cases, trimming dead ends, and adding concise hints. Reported gains: +19.3% AIME25 on an 8B model and 1.28× faster time to match GRPO, without external data paper summary.
Takeaway: lightweight meta‑signals can materially improve both accuracy and training efficiency for math‑style reasoning.
Meta’s reward‑free “early experience” lets language agents learn from their own suboptimal actions
Meta AI proposes training agents without human rewards by interacting in environments, then learning from future outcomes of their own alternate actions. Two ingredients—implicit world modeling and self‑reflection rationales—boost generalization across eight diverse environments versus imitation learning, and improve downstream RL efficiency by seeding better priors paradigm overview.
Why it matters: this bridges static SFT and costly RL, offering a scalable path to competence without dense rewards.
DPO scaling law: ~875 samples per value (for 10 values) targets ~5% error; balance beats sheer size
A theoretical and empirical study shows Direct Preference Optimization generalizes over multiple value clusters when preference data are balanced across values. For ~10 values, ~875 preference pairs per value keep test error near ~5%, with token‑level extensions summing to whole‑response rewards; results replicate across Llama, Mistral, and Qwen variants paper abstract.
Why it matters: alignment workloads should allocate labeling budget evenly across value dimensions instead of only growing total dataset size.
ReasoningBank + test‑time scaling: parallel MaTTS reaches 55.1% SR at k=5 and cuts redundant steps
Following up on ReasoningBank, which turned agent histories into reusable strategies, Google’s memory‑aware test‑time scaling shows success rising with more rollouts: on WebArena‑Shopping, parallel MaTTS improves from 49.7% at k=1 to 55.1% at k=5, outperforming vanilla TTS at the same k (52.4%). The framework also trims steps more on successful runs, indicating less redundant exploration MaTTS results, Efficiency note, with details on how richer parallel/serial self‑contrast yields better memories over time Method details.
Why it matters: memory quality multiplies TTS gains—scaling not only boosts accuracy but also curates stronger, transferable strategies.
Reusable “thought templates” help long‑context LMs connect facts and answer multi‑hop questions
The method distills reusable thought outlines from solved examples, composes matching templates at test time (with or without retrieval), and edits weak parts via natural‑language feedback—no weight updates needed. Across four multi‑hop QA datasets and multiple model families, templates consistently boost accuracy, and optimized templates transfer to smaller open‑source models paper abstract.
Bottom line: structured, editable reasoning scaffolds make long‑context reads more deductive and less “bag‑of‑tokens.”
📊 Evals: safety, time‑horizon and creative tests
Mostly benchmark updates rather than new model launches: Spiral‑Bench v1.2 judge ensemble, METR’s time‑horizon trend, VoxelBench live ratings, and signals that LLMs now top student olympiads.
METR trend: time‑horizon doubles every ~202 days; Sonnet 4.5 hits ~1h53m at 50% success
METR’s longitudinal “time‑horizon” analysis shows the median task duration at which models succeed 50% of the time has been doubling roughly every 202 days over six years (R² ≈ 0.98). Claude Sonnet 4.5’s 50% time‑horizon is estimated at ~1 hour 53 minutes (95% CI: 50–235 minutes) across RE‑Bench, HCAST and expert‑timed tasks metr chart.
For engineering leaders, the curve implies month‑long autonomous task viability within the decade if trendlines hold, with obvious implications for agent architectures, monitoring, and safety guardrails.
Spiral‑Bench v1.2 debuts judge ensemble and tighter rubric; Sonnet‑4.5 Safety Score ~70.3
Spiral‑Bench updated to v1.2 with an ensemble of judges (Claude Sonnet‑4.5, GPT‑5, Kimi‑k2), a reworked rubric distinguishing protective vs delusion‑reinforcing behaviors, and new model entries including Qwen3‑235B and GLM‑4.6 update notes. A sample report shows Claude Sonnet‑4.5 at ~70.3 overall with detailed sub‑scores across warmth, pushback, de‑escalation, and risky behaviors like confident bullshitting and delusion reinforcement update notes.
The tighter rubric plus judge ensemble should reduce single‑model bias in safety scoring, making it more actionable for red‑teaming and model comparisons at scale.
VoxelBench live board: Gemini 2.5 Deep Think leads; GPT‑5 tiers follow
The community‑run VoxelBench, which evaluates LLMs on voxel building tasks (e.g., honoring Google’s “Nano Banana”), now shows Gemini 2.5 Deep Think in first place with a 1571 rating and an ~87.2% win rate over 1,300+ games; GPT‑5 High and GPT‑5 Medium sit second and third leaderboard stats. Earlier posts teased the benchmark and examples of builds evaluated benchmark intro.
- Gemini 2.5 Deep Think: 1571 rating, 87.2% WR, 1,332 games leaderboard stats
- GPT‑5 (High/Medium): trailing tiers on rating but strong win rates leaderboard stats
Leaderboards like this offer a live, game‑style signal on spatial reasoning and instruction‑following that complements static code/math evals.
Reports grow that LLMs now match gold‑level performance across student olympiads
Educators and researchers highlight that current frontier LLMs now meet or exceed gold‑medal performance thresholds across rigorous STEM olympiads (e.g., IMO, IOAA, IOI), expanding beyond single‑event case studies olympiads claim. This comes alongside specific claims of gold‑level IOAA theory performance by GPT‑5 and Gemini 2.5 Pro ioaa update, following up on IOAA gold where competitive parity first surfaced.
For analysts, olympiad‑grade competence is a noisy but compelling proxy for reasoning improvements that should translate into stronger scientific search, verification, and code‑as‑proof workflows.
VCBench: LLMs rival top investors on anonymized founder‑success prediction
A new benchmark (VCBench) anonymizes ~9,000 founder profiles and scores models on predicting startup success under precision‑weighted metrics. GPT‑4o shows the best balance (F0.5), with DeepSeek‑V3 leaning precision and Gemini‑2.5‑Flash leaning recall; privacy checks report ~80–92% reductions in re‑identification risk paper summary.
While domain‑specific, the setup is a useful pattern for building high‑stakes evals that measure practical judgment under strict leakage controls and calibrated error costs.
🎬 Generative media stacks and creator workflows
Heavy creator activity today: Veo 3.1 vs 3 comparisons, LTX Studio’s nano banana + Veo Fast playbooks, Grok Imagine templates on iOS, Sora’s Play Store presence, and Sora cameos boosting influencer reach.
Sora appears on Google Play with video, remix and cameo features
OpenAI’s Sora app has surfaced on the Google Play Store, advertising prompt-to-video, remixing, casting yourself or friends, and social collaboration—signaling an imminent Android rollout, following up on Android prereg opening in the US and Canada. See the listing screenshots for feature callouts and onboarding flows Play Store listing.
For media teams, this shifts Sora from closed tests to a broader mobile distribution channel, accelerating creator onboarding and cross‑app repost workflows.
Sora tightens cameo rules and watermarking while safety systems evolve
OpenAI updated Sora with cameo restrictions, watermark improvements, and safety tweaks, and fixed an account deletion issue—reflecting a push for safer, more controllable creator tooling Changelog summary. Separately, ChatGPT Pro users can download Sora videos without a watermark in certain cases, clarifying how watermarks apply across tiers Watermark policy. The UI also flags prompts/drafts that may be too similar to third‑party content, indicating stricter similarity guardrails during creation Similarity warning.
Implication: more predictable policy boundaries for brands and creators, but expect tighter checks around look‑alike content and cameo usage.
Grok Imagine for iOS adds one‑tap templates for consistent image styles
xAI is rolling out template presets in Grok Imagine on iOS, enabling one‑tap style systems for repeatable looks and faster creator workflows Templates rollout. For teams making series content, presets reduce prompt drift and shorten iteration cycles compared with free‑form prompting.
LTX Studio shows nano banana + Veo 3 Fast playbook for consistent characters with audio
A detailed LTX Studio thread demonstrates a practical creator workflow: generate stills and maintain character consistency with nano banana, then animate with Veo 3 Fast (with audio), orchestrated via concise JSON prompts for shots, dialogue, and scene control Workflow thread, JSON prompts, Dialog and audio. The examples cover building locations, reusing reference images, and multi‑shot continuity for a short story.
Takeaway: a reproducible stack that reduces style drift while speeding storyboard→animation handoffs for short‑form video.
Sora cameos supercharge influencer reach; Jake Paul racks up billions of views
Creators report that Sora’s cameo feature is translating into outsized social reach: Jake Paul’s cameo‑based AI videos drew billions of views in roughly a week, illustrating how AI‑native formats can reignite audience interest across platforms Creator reach thread. Observers note Sora as a creation tool with distribution via other apps, not necessarily a standalone social network Distribution take.
Why it matters: cameo pipelines can compress production and amplify personal brands, offering marketers a new lever for rapid‑iteration campaigns.
🛡️ IP, platform guardrails and AI media forensics
Policy + defense items: MPA’s statement criticizing Sora 2 for infringing use, user reports of Sora’s similarity guardrails, a 96%‑accurate zoom‑in forensic VLM, and NVIDIA AI Red Team’s practical LLM security advice.
OpenAI tightens Sora 2 IP guardrails with cameo limits, watermark tweaks, and stricter similarity checks
OpenAI has pushed a Sora update that adds cameo restrictions, improves watermarking, and includes safety tweaks alongside an account deletion fix safety update. Users are also seeing “similarity to third‑party content” blocks on prompts and drafts, indicating a more aggressive similarity filter at generation time guardrail warning, drafts screen.
- Watermarks: one roundup notes ChatGPT Pro users can export without a watermark under certain conditions, suggesting nuanced policy by plan and flow watermark note.
MPA urges OpenAI to curb Sora 2 infringement and assumes platform responsibility for IP
The Motion Picture Association’s Charles Rivkin issued an Oct 6 statement pressing OpenAI to “take immediate action” against Sora 2 clips that mimic member films, shows, and characters, arguing the platform—not rightsholders—bears the duty to prevent infringement MPA statement. The note also mentions OpenAI aims to give creators more control over character generation, a lever that could reduce look‑alike misuse.
ZoomIn forensic VLM hits ~96% by zooming into suspicious regions to detect AI images
Researchers propose ZoomIn, a two‑stage approach where a VLM first proposes small “suspicious” regions to inspect and then revises its real/fake judgment, achieving about 96.39% accuracy and robustness under compression, cropping, and downsampling. The team also releases MagniFake (20k images) with region boxes and natural‑language reasons to train grounded decisions paper thread.
NVIDIA AI Red Team publishes concrete mitigations for LLM RCE risks and RAG access control
NVIDIA’s AI Red Team outlines practical steps for safer LLM apps: never exec/eval model output without isolation to avoid remote code execution, route tool calls through intent parsers and safelisted functions, and enforce per‑user permissions in RAG stacks to prevent sensitive data leaks. Guidance also warns against rendering active content from untrusted sources and recommends sandboxing and least‑privilege connectors security blog, NVIDIA blog.
🧪 Model momentum: Qwen’s week (perf and share)
Model‑centric signals today skew Qwen: a new MoE 80B with large throughput gains and Qwen3‑VL’s 48% share of OpenRouter image processing. Mostly usage/tech deltas; few price notes.
Qwen3‑Next‑80B‑A3B MoE touts ~10× token throughput and ~84.7 MMLU at lower training cost
Alibaba’s new sparse MoE, Qwen3‑Next‑80B‑A3B, claims large speed gains at long context with competitive accuracy: prefill throughput ~10.6× and decode ~10.0× versus a dense 32B model at 32k context, with MMLU ~84.72 and improved training cost efficiency per their chart and blog write‑up benchmarks chart, and Qwen blog post.
- Architecture notes from community highlight “super sparse MoE,” gated DeltaNet, multi‑token prediction, and gated attention as contributors to the perf/efficiency combo architecture notes.
Qwen3‑VL tops OpenRouter images with ~48% share (457k), ahead of Gemini and Claude
Qwen reports its Qwen3‑VL‑235B‑A22B‑Instruct now handles ~48% of images processed on OpenRouter (≈457k images), leading the stack; Gemini 2.5 Flash variants and Claude Sonnet 4.5 trail in the league table snapshot usage share.
- The top‑10 also shows Qwen2.5‑VL‑32B at ~5.6% and “GPT‑5 Mini” near ~2.8%, indicating a broad multimodal mix concentrated around Qwen and Google models usage share.
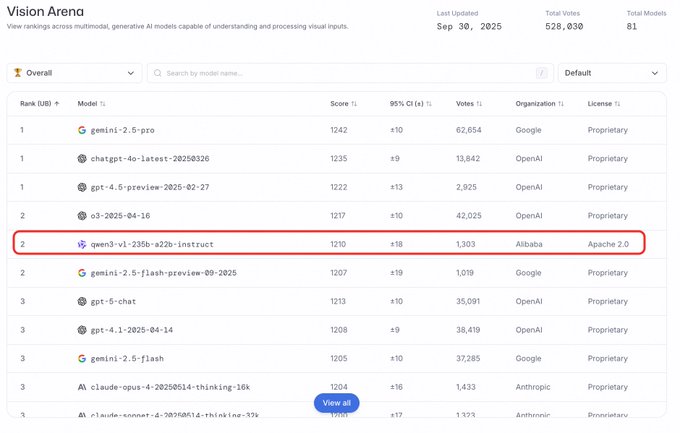
Qwen3VL places 2nd on Arena visual track, first among open‑source entries
On the Arena visual track leaderboard, Qwen3VL is cited as the overall runner‑up and the highest‑ranked open‑source model, signaling rising eval momentum alongside usage wins arena placement.
🏢 Enterprise adoption and go‑to‑market shifts
Signals from GTM and partnerships: Gemini Business priced at $21/seat for 15 seats, Anthropic’s India outreach, and teams reporting 2–3× gains from agent‑centric workflows; Gemini site MoM growth stat resurfaces.
Deloitte expands alliance to bring Claude to 470,000 employees
Deloitte and Anthropic announced an expanded alliance that will make Claude available to 470,000 Deloitte professionals globally—an unusually large top‑down enterprise enablement that could accelerate standardized AI use in consulting workflows alliance announcement, echoed in broader weekly roundups weekly recap list. Expect immediate traction in document analysis, modeling and code review within regulated client environments.
Gemini Business priced at $21/seat (15 seats) as Agent Builder lands in chat
Google is positioning Gemini for teams with a Business plan priced at $21 per seat bundled in 15-seat blocks, and early testers can build agent workflows directly from the Chat UI—following up on Agent Builder early access reports. A tester also notes the same Gemini 2.5 Pro model feels more reliable in enterprise agent responses than in personal Gemini, with the free trial reportedly including the full 15 seats enterprise walkthrough, agent reliability note, free trial detail, and details in the first‑look write‑up first look article.
For engineering leaders, the pricing clarity and in‑chat agent builder hint at a lower‑friction path to pilot agentic workflows at the team level without custom orchestration.
ChatGPT expands enterprise connectors: Slack app plus Notion, Linear, SharePoint sync
OpenAI is widening enterprise surface area with a Slack connector and a dedicated ChatGPT app for Slack slated for Enterprise customers, alongside new synced connectors for Notion, Linear, and SharePoint weekly recap list, Slack app plan, connectors rollout. This reduces integration friction for knowledge workflows and positions ChatGPT deeper inside day‑to‑day collaboration stacks.
Agent‑centric workflows deliver 2–3× gains vs 20–30% ad‑hoc use, say operators
Leaders report wide spreads in AI productivity: teams that intentionally redesign engineering workflows around agents (prompting, planning, code review, orchestration, larger task granularity) see 2–3× improvements, while ad‑hoc usage yields ~20–30% workflow gains comment. For GTM, this underscores packaging and enablement around process change—not just model access.
Anthropic meets India’s PM and IT Minister, pledges support for 2026 AI Summit
Anthropic met with Prime Minister Narendra Modi and IT Minister Ashwini Vaishnaw to discuss India’s AI roadmap and signaled intent to support the country’s AI Summit in February 2026, a move that could shape enterprise adoption and public‑sector pilots in a fast‑growing market India outreach note.
‘Clinician Mode’ strings surface in ChatGPT web app, hinting healthcare GTM
References to a new “Clinician Mode” have been spotted in the ChatGPT web app, alongside other enterprise features in the same weekly roundup clinician mode strings, weekly recap list. If formalized, a scoped healthcare mode could target compliance and workflow needs for clinical teams, expanding ChatGPT’s enterprise footprint in regulated sectors.
Claude surfaces inside Excel via add‑in for financial modeling and analysis
A Claude add‑in for Excel was spotted, aimed at building financial models and analyzing data directly within spreadsheets Excel add‑in note, also listed among this week’s updates weekly recap list. Embedding into Office‑first workflows should ease adoption for FP&A and consulting teams that live in Excel.
Gemini Enterprise testers report agent responses feel more reliable than personal Gemini
Early testers say agent responses powered by Gemini 2.5 Pro in Enterprise feel more reliable than what they observe in personal Gemini, which could reflect tuned defaults, guardrails, or context policies on the business tier agent reliability note. Combined with bundled seats and in‑chat Agent Builder, this strengthens the enterprise value proposition enterprise walkthrough.
Gemini site visits up 46.24% MoM in September per Similarweb snapshot
Traffic to gemini.google.com grew ~46.24% month‑over‑month in September 2025, outpacing peers in a snapshot chart and suggesting rising awareness ahead of the expected Gemini 3.0 wave growth chart. For product and sales teams, this is an encouraging top‑of‑funnel signal to pair with trials like Gemini Business.
Perplexity readies invite payouts via Dub to accelerate user growth
Perplexity is preparing a limited‑time invite program with cash payouts through Dub, signaling a growth‑marketing push to amplify distribution beyond organic channels payouts program leak. For rivals, expect near‑term competition on referral economics and creator affiliates rather than pure feature parity.
📄 Parsing and web data pipelines for agents
Concrete building blocks for data‑hungry agents: Microsoft’s MarkItDown (dozens of formats→Markdown with OCR/transcription) and ScrapeCraft’s AI‑assisted scraping editor on LangGraph.
Microsoft MarkItDown: one‑stop doc→Markdown (PDFs, Office, HTML, media) now at ~81k stars
Microsoft’s MarkItDown consolidates PDFs, Office files, HTML, JSON/XML, ZIPs and even YouTube/audio into clean Markdown with built‑in OCR and transcription—ideal as a drop‑in preprocessor for agent pipelines that treat Markdown as a “native” format GitHub repository.
For AI engineers, this removes brittle per‑format glue: a single tool yields structured text plus preserved tables/links/metadata, enabling consistent chunking, indexing and prompt assembly across heterogeneous corpora at scale GitHub repository.
ScrapeCraft ships a visual, AI‑assisted scraping editor built on LangGraph
ScrapeCraft combines ScrapeGraphAI with LangGraph to provide an AI‑assisted, web‑based scraping editor: design pipelines visually, scrape bulk URLs, stream results in real time, auto‑generate Python (async), and define dynamic schemas—built for agents that need reliable, reproducible web data flows Project overview, and GitHub repo.
This brings “Cursor‑style” ergonomics to data ingestion, reducing hand‑rolled scrapers and making it easier to integrate extraction steps, validation, and deployment hooks directly into agent runtimes.
🏭 Industrial robotics and the China manufacturing edge (Non‑AI exception)
Multiple charts/posts argue China now makes ~80% of industrial robots and leads advanced manufacturing categories—implications for embodied AI supply chains and cost curves. Limited to macro signals; no chip updates today.
China now produces ~80% of industrial robots, powering rise of 24/7 “dark factories”
An analysis claims China makes about 80% of the world’s industrial robots and has the highest robot density, warning that 24/7 “dark factories” could deliver a pricing and volume advantage that reshapes global manufacturing competitiveness analysis thread, with a supporting source link provided source article.
Implication for AI hardware and embodied agents: faster deployment cycles and lower unit economics for automated lines in China, with downstream effects on where robotics‑heavy AI products can be scaled first and most profitably.
China tops advanced manufacturing rankings across materials, coatings, and additive processes
A new comparative table shows China ranking first across most advanced materials and manufacturing verticals—spanning nanoscale materials, specialty coatings, smart materials, and additive manufacturing—often by wide margins over the US ranking table.
For AI builders, this strengthens the case that upstream components for robotics, sensors, and precision actuation will be cheaper and more readily sourced from Chinese supply chains, potentially tilting embodied‑AI cost curves and lead times in China’s favor as factory automation scales.