OpenAI Stargate Abilene sets ~$32B build for ~1 GW – 2‑year target
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
A fresh tranche of data pins the scale and tempo of AI compute to real timelines and dollars. EpochAI maps five 1+ GW hyperscaler campuses targeting 2026 and pegs 2025 AI DC spend near $300B (~1% of U.S. GDP). OpenAI’s Stargate Abilene alone aims for ~1 GW in ~2 years for ~$32B, while xAI says Colossus 2 can hit a gigawatt in ~12 months by reusing shells and bootstrapping on‑site power.
Here’s the operating reality: builds to 1 GW are arriving in 1–4 years; siting follows electricity, not proximity, because model generation time dwarfs network RTT by 100× (even a Moon relay wouldn’t be the bottleneck). Liquid cooling is mandatory when a 0.5 m² rack can drink the power of 100 homes. Early phases are spinning natural‑gas turbines, then layering wind/solar after interconnects, and only a few countries can host many of these—30 GW is ~5% of U.S. generation but ~90% of the U.K.
For model teams, the punchline is capacity: Epoch expects enough aggregate buildout to support ~5×/year growth in frontier training for two years, so plan multi‑run roadmaps and regional redundancy now. If you enjoy moonshots, Google’s “Suncatcher” sketches orbital TPUs with 10 Tbps links at ~$810/kW/yr—but the near‑term move is tracking real sites via cooling fields and permits in plain sight.
Feature Spotlight
Feature: Gigawatt AI data centers race to 2026
Epoch AI’s analysis shows five 1+ GW AI data centers targeted for 2026, with cumulative AI DC spend >$300B (~1% US GDP). Power, not latency, dictates siting; xAI’s Colossus 2 aims GW scale in 12 months.
Multiple posts detail AI data centers scaling to 1+ GW with concrete timelines, costs, and power math; a dense infrastructure burst today across sources.
Jump to Feature: Gigawatt AI data centers race to 2026 topicsTable of Contents
🏗️ Feature: Gigawatt AI data centers race to 2026
Multiple posts detail AI data centers scaling to 1+ GW with concrete timelines, costs, and power math; a dense infrastructure burst today across sources.
Gigawatt data centers are hitting 1 GW in 1–2 years; observed range 1–4 years
Across tracked builds, time from ground‑break to 1 GW facility power typically ranges from 1 to 4 years, with several targeting 1–2 years timeline insight. Epoch’s methods and project samples for these timelines are documented in its data insight note Buildout speeds.
xAI’s Colossus 2 targets 1 GW in ~12 months using shell reuse and early on‑site power
xAI plans to reach gigawatt scale in Memphis in about 12 months by reusing industrial shells and bootstrapping with on‑site gas turbines and batteries before grid interconnect Memphis plan. For builders, that implies earlier capacity availability and a different risk profile than greenfield builds highlighted in the broader survey build tactics.
Only a few countries can host many >1 GW sites; 30 GW is ~5% US, ~2.5% China, ~90% UK
Power availability sets the map. Adding 30 GW of AI DC capacity is ~5% of U.S. generation, ~2.5% of China’s, but ~90% of the U.K.’s—a stark constraint on where large clusters can proliferate power shares.
Power beats latency: model generation time is >100× network RTT
Siting is driven by power, not proximity: generating an LLM response takes over 100× longer than sending data across continents—so even a Moon relay wouldn’t be the bottleneck latency math. This supports consolidating serve clusters near abundant electricity rather than end users.
AI is ~1% of U.S. power today vs 8% for lighting and 12% for AC
AI’s current footprint is small—about 1% of U.S. power—compared to lighting (~8%) and air conditioning (~12%), though that mix can change if buildouts continue compounding usage context.
Builds start with firm on‑site gas, then add grid renewables at scale
Early phases often rely on natural‑gas turbines for firm capacity, with later grid interconnects pulling large volumes of wind and solar where available power sourcing. For operators, this staggers emissions profiles and interconnect risk.
Many sites aim for 1–2 year paths to 1 GW despite heavy permitting
Across builds tracked, hyperscalers plan to reach 1 GW in as little as 1–2 years from construction start, even with major interconnect and thermal constraints timing range. That compresses model roadmap risk for multi‑run training programs.
New Frontier Data Centers dataset and map launched for satellite‑based tracking
Epoch released a Frontier AI Data Centers dataset and explorer compiling locations, power, construction phases, and cooling footprints using permits and satellite imagery dataset launch. This enables independent tracking of capacity additions and timelines Dataset hub.
These campuses aren’t secret: satellite cooling arrays and permits expose progress
Unlike the Manhattan Project, gigawatt DCs are hard to hide—thousands of workers, visible chiller farms, and public permits reveal capacity and phase status satellite view. Epoch maintains a public explorer for independent verification Satellite explorer.
Design note: dense racks and liquid cooling define GW campus architecture
Because racks can pull “100 homes” worth of power in 0.5 m², facilities are shifting from air to liquid cooling at scale, with chiller farms a visible tell from orbit cooling detail. This drives building layouts, maintenance staffing, and water reuse planning.
🧰 Agentic coding stacks and dev ergonomics
Developer‑facing tools and workflows saw active updates and demos today (Cursor, RepoPrompt, Graphite, Evalite, Conductor). Excludes the data‑center feature.
Berkeley’s DocETL debuts natural‑language→pipeline generator with hosted playground
Describe an ETL task in plain English and DocETL will draft a runnable pipeline, execute on sample data, and show results immediately; it’s backed by the open‑source DocWrangler IDE demo video. The repo and a free playground are live, with data collection noted to improve the tool GitHub repo, playground. This is useful for agent teams wrangling messy PDFs and spreadsheets into structured inputs.

GPT‑5‑Codex‑Mini throughput doubles; better for code‑heavy generations
A provider reports serving GPT‑5‑Codex‑Mini at ~2× the prior tokens/sec, which should halve wall‑clock time on generation‑heavy coding tasks perf chart. Developers also spotted the model live in UI pickers, alongside the main Codex, for fast routing mid‑session model picker. If you batch long diffs or scaffolds, this is a quick win.
RepoPrompt 1.5.28 adds Codex CLI provider and renders Codex reasoning traces
RepoPrompt can now use Codex CLI as an API provider, letting Plus/Pro subscribers pipe GPT‑5/Sonnet into built‑in chat and pair‑programming MCP workflows without any auth hacks; it just drives the official CLIs headlessly release note, auth note. The update also streams Codex reasoning traces inside the context builder so you can inspect tool calls as they happen trace view.
AG‑UI gets a Kotlin SDK to run agent UIs natively on Android/iOS/JVM
A community‑contributed Kotlin SDK brings AG‑UI to mobile and other JVM apps with one API, avoiding a JS bridge and keeping agent UX consistent across platforms SDK announcement. Docs and a blog explain setup and design goals, plus a video walkthrough for getting started Kotlin docs, blog post, SDK walkthrough. For field apps or IoT, this removes a lot of glue code.
Agent evals highlight efficiency: GLM‑4.6 solved tasks with fewer steps
A forthcoming benchmark analysis shows large score deltas when factoring effort, not just correctness—GLM‑4.6 achieved the same file edits and outcomes in a single step where competitors took multiple, boosting its score under an efficiency‑aware metric analysis excerpt. The point is: start logging action count and wasted tool calls, not only pass/fail.
Conductor ships Plan Mode and a new copy‑path shortcut
Conductor added Plan Mode to propose a stepwise change list you can approve or tweak before execution—handy for avoiding agent overreach in shared workspaces feature card. A small but useful ergonomics tweak also landed: ⌘⇧C copies the current file or workspace path so you can paste into prompts or shells shortcut demo.

Graphite’s gt modify now auto‑updates stacked PRs end‑to‑end
A live demo shows gt modify updating an entire stack, detecting dependencies, and pushing changes automatically—removing much of the pain from rebase hell on stacked diffs stacked PRs demo. For teams adopting AI code review with stacked diffs, this tightens the loop between agent edits and human PR hygiene.
Cursor merges MCP server PR that unlocks ~8,000 web data sources
A queued PR to the Cursor MCP servers repo was merged, reportedly adding access to roughly 8,000 web data sources for Cursor developers and AI apps merge note. If your agents scrape or enrich from external sources, this widens the tool surface without local scripting.
McPorter patch adds import of OpenCode configs for smoother CLI handoff
McPorter now imports OpenCode config files, tightening the loop between local agent setups and compiled per‑server CLIs patch note. For teams juggling Claude/Codex/Cursor toolchains, this reduces one more source of config drift.
Yutori’s Scouts now learn from email replies to their reports
You can reply to a Scout’s emailed report and that feedback will be incorporated into future runs, making it a lightweight loop for adjusting agent behavior without new UIs feature demo. This is simple. It’s also how non‑technical teams will actually tune agents.

🧩 MCP interoperability and auth realities
Teams debated secure auth for agents and pushed MCP ecosystem advances (alt clients, hackathons, PR merges). Excludes the data‑center feature.
Agent auth isn’t OAuth: call for short‑lived app keys and anomaly flags
A leading implementer argues OAuth flows don’t fit headless agents and that the industry needs short‑lived, per‑app keys with first‑class anomaly signaling; MCP isn’t the place to fix auth Auth thread. Following up on OAuth shift where maintainers questioned OAuth DCR, this pushes teams to design agent‑friendly auth layers outside MCP contracts.
Google publishes ‘Agent Tools & Interoperability with MCP’ white paper
A new Google paper lays out patterns for agent tool design and cross‑runtime interoperability using MCP, offering concrete guidance to standardize how agents discover and invoke tools Paper link, white paper.
Cursor merges MCP server PR unlocking 8,000+ web data sources
Cursor accepted a community PR in its mcp-servers repo that exposes 8,000+ web data sources to Cursor agents and developer workflows, broadening out‑of‑the‑box tool coverage PR merge.
Groq, Docker and E2B host MCP hackathon with 200+ preinstalled tools
E2B announced an agents hackathon (online Nov 21; SF Nov 22) where builders get sandboxes preloaded with 200+ MCP servers, plus Groq inference and Docker integration to wire real tools fast Hackathon details, event page. A second call to register reiterates the same setup and timeline Signup post.
OSS “MCP alternative” in the works, promising backward compatibility
An open‑source, drop‑in alternative to MCP is being built with backward compatibility, aimed at smoothing server discovery and tool wiring while keeping existing MCP apps running OSS plan. The move reflects ongoing pain around interoperability and setup while preserving today’s MCP integrations for teams that have already invested.
Community debate: “Does MCP suck?” recap surfaces DX and reliability gaps
A Nov 10 Agents Hour recap from Mastra revisits MCP friction points—server stability, config sprawl, and real‑world ROI—giving teams a snapshot of the current trade‑offs before committing Talk recap. The discussion complements recent pushes for better auth and alternative runtimes without abandoning the spec.
⚙️ Serving speed and provider routing
Runtime throughput and provider choices were front‑and‑center (Codex speedups, SGLang/Kimi hosting, OpenRouter integrations). Excludes the data‑center feature.
Kimi K2 Thinking routing: SGLang on Atlas Cloud; vendors cite 0.3 s TTFT and ~140 TPS
LMSYS confirmed it is powering Kimi K2 Thinking with SGLang on Together’s Atlas Cloud, clarifying the fastest serving path for production use hosting confirmation. Vendors showcasing K2 report time‑to‑first‑token around 0.3 s and throughput near 140 tokens/sec on their stacks, which lines up with what builders are seeing in practice provider stats. Kimi also warned that some third‑party endpoints show 20+ pp accuracy drops on benchmark tasks and recommends hitting the official kimi‑k2‑thinking‑turbo endpoint with streaming enabled and retries for reliable evals benchmark guidance. In parallel, Cline is pitching itself as the “fastest provider” for K2 with a snappy round‑trip demo, highlighting that routing choice still matters speed demo. This follows OpenRouter speed where early tests showed sub‑second TTFT on community providers.

Replit apps can now route to 300+ models via OpenRouter out of the box
Replit added native OpenRouter support so app builders can swap among 300+ models without bespoke adapters, broadening provider coverage inside an existing dev loop integration announcement, dev comment. As a concrete example, OpenRouter is hosting Kwai’s KAT‑Coder‑Pro free for now (73.4% on SWE‑Bench Verified), giving teams another strong coding option to route to directly from Replit model launch, OpenRouter model page. This reduces switching costs and lets you A/B serving speed, cost, and quality per feature without re‑plumbing.
GPT‑5‑Codex Mini doubles tokens/sec for code generation
OpenAI’s GPT‑5‑Codex‑Mini is now serving at roughly 2× the previous tokens‑per‑second rate, making long code diffs and scaffolds feel substantially faster week‑over‑week throughput chart, serving note. For teams leaning on continuous generation loops, this cuts wall‑clock time without changing prompts or providers.
📊 Leaderboards, eval variance, and efficiency scoring
Today’s eval chatter focused on K2 standings, provider‑induced variance, and scoring that rewards fewer steps. Excludes the data‑center feature.
Kimi flags 20+ pp benchmark drops via third‑party providers; urges official endpoint
Moonshot AI warns some third‑party endpoints induce 20+ percentage‑point accuracy drops on reasoning‑heavy sets like LiveBench; they recommend testing via kimi‑k2‑thinking‑turbo on the official API with stream=True, temperature=1.0, and large max_token budgets, plus retries benchmark guidance. They’ll publish provider verification in a public repo to standardize results. For teams publishing evals, this makes endpoint provenance and run params part of the method section, not a footnote.
Kimi K2 Thinking hits #2 open-source and ties #7 overall on Arena Text
Arena’s latest Text board places Kimi K2 Thinking as the #2 open‑source model and tied for #7 overall, with strong showings across Math, Coding, and Creative Writing arena update. Arena also reports it in the Top 5 across several occupational slices (Software/IT, Science, Media, Business/Legal/Healthcare) and notes better instruction following versus prior K2 category ranks, with public head‑to‑heads available on the Arena site Arena site. So what? It’s a credible third‑party signal that K2 Thinking is competitive for agentic and text workloads.
Efficiency matters: GLM‑4.6 scores higher by finishing in fewer action steps
A scoring analysis comparing opencode/glm‑4.6 against Claude Code and Codex shows a ~2× delta driven not by different edits or outcomes, but by “single‑step” execution versus multi‑step discovery/verification workflows in peers scoring excerpt. The point is: leaderboards that bake in time/token costs implicitly reward action parsimony, not just correctness—instrumentation and step budgets will change who wins.
LisanBench: Kimi K2 Thinking lands 1928.6 Glicko‑2, between GPT‑5 and GPT‑5‑Mini
Fresh LisanBench plots show Kimi K2 Thinking at 1928.6 Glicko‑2, slotted between GPT‑5 (1939.0) and GPT‑5‑Mini (1904.2), with chain‑length distributions shared for multiple starting words benchmarks chart. Follow‑ons tease more slices (e.g., “countries” looks like a dead end) and a follow‑up release of results author note coming soon.
Implication: strong reasoning‑chain depth near top closed models, but with topic‑dependent variability that matters for prompt selection and evaluation design.
Artificial Analysis ranks LTX‑2 Pro #3 (image→video) and #7 (text→video)
Artificial Analysis’ Video Arena places Lightricks’ LTX‑2 Pro at #3 for image→video, trailing only Kling 2.5 Turbo and Veo 3.1 Fast Preview, and #7 for text→video; priced at about $0.06/s for 1080p generations arena overview. They post prompt‑by‑prompt comparisons against Veo/Kling/Sora peers, including camera moves and destruction sequences prompt clips.
If you run gen‑video benches, add a cost‑per‑second column—rankings compress when normalized for price.
Task length keeps rising: models double workable duration every ~7 months
New commentary on METR’s time‑horizon chart says LLMs are roughly doubling the human‑task durations they can complete at 50–80% success about every seven months, and OpenAI reportedly has internal models handling ~4 hours of continuous work trend chart, following up on time horizon.
For eval designers, this argues for longer‑form tasks with state carryover, or else you’ll saturate the metric quickly.
Field report: K2 Thinking looping on Extended Connections despite official playground
One tester reports Kimi K2 Thinking entering reasoning loops and failing to finalize answers on Extended Connections questions, after re‑running via Moonshot’s own playground to rule out third‑party routing failure report. Together with provider variance warnings, this reinforces that benchmark scripts should log reasoning, tool calls, and stop conditions—not just final answers.
🗣️ Speech and voice infra at scale
A big multilingual ASR release and an enterprise voice stack event dominated the voice beat. Excludes the data‑center feature.
Meta open-sources Omnilingual ASR covering 1,600+ languages, up to 7B params
Meta released Omnilingual ASR under Apache‑2.0, with models from ~300M to 7B and support for 1,600+ languages (claiming up to 5,400 with one‑shot learning). It ships with a new Omnilingual ASR Corpus emphasizing 350 underserved languages, plus a public demo and code. This is a rare, scalable ASR drop that product teams can deploy and fine‑tune today. See the announcement and links in paper card and full resources via Meta research, GitHub repo, and Demo space.
Why it matters: A permissive license, broad language reach, and model size range make this a strong base for global voice products—contact centers, field apps, and creator tools—without locking into a single cloud. Expect real trade‑offs: the 7B tier will cost more to serve, but the 300M–1B variants may be enough for many domains if you invest in domain text normalization and diarization. The corpus itself is useful for labs standardizing multilingual evals; it can also seed benchmarks for accented speech and code‑switching.
ElevenLabs Summit SF teases product announcements with enterprise partners
ElevenLabs previewed its Summit SF agenda and promised product announcements and session replays across the week, with speakers from Salesforce AI, MasterClass, Lionsgate, TELUS Digital, Square, and a Jack Dorsey fireside. If you ship voice features, watch for updates on enterprise deployment patterns, licensing, and any latency/cost changes for large seats summit agenda.
What to do now: prep a quick eval sheet for TTS/voice‑clone latency and word‑error‑rate deltas. If ElevenLabs announces new voices or streaming modes, route a side‑by‑side test against your current vendor and log TTFT/TPS per locale, then decide on regional routing or a single‑vendor swap.
🎨 Generative media: Ketchup leaks, LTX‑2 results, editing tools
Heavy creative/model chatter today: new ‘Ketchup’ naming, leaked samples, video model rankings, and practical editors. Excludes the data‑center feature.
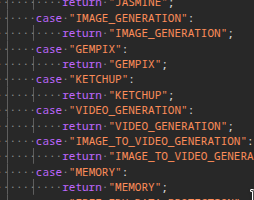
Google’s Nano‑Banana 2 shows up as “KETCHUP” in code, signaling a rename
Multiple Gemini code paths now reference KETCHUP/GEMPIX alongside image/video generators, pointing to a Nano‑Banana 2 rebrand and near‑term availability, following up on preview pulled after a brief public appearance last week. Listings include switch/case enums and UI tooltip updates in the Gemini site bundle and related assets code snippet, and a separate thread noting GEMPIX2 → KETCHUP renaming and updated canvas tooltips feature note; another code sighting corroborates the “KETCHUP” identifier in routing logic code sighting.
For teams planning prompt libraries and API integration, treat "KETCHUP" as the programmatic handle to watch in upcoming releases.
Leaked “Ketchup” samples show strong instruction fidelity on visual puzzles
Fresh samples attributed to Google’s Ketchup (née Nano‑Banana 2) demonstrate multi‑step capabilities such as assembling torn notes into coherent text, and paired remastering/colorization/translation tasks, strengthening the case for better text rendering and compositional following leak summary. The torn‑paper reconstruction is a clear instruction‑following stress test and the model nails the final sentence layout assembly example; a recap with more examples is in the write‑up news post.
If you build image agents for layout or infographic workflows, this looks like a meaningful fidelity bump over prior Gemini‑family models.
LTX‑2 Pro ranks #3 (image→video) and #7 (text→video); priced at $3.60/min 1080p
Artificial Analysis places Lightricks’ LTX‑2 Pro third for image‑to‑video (behind Kling 2.5 Turbo and Veo 3.1 FP) and seventh for text‑to‑video, with native audio support and up to 10‑second, 4K generations. Cost lands at $3.60/min for 1080p, undercutting Veo 3.1 ($12/min) and Sora 2 Pro ($30/min); a faster $2.40/min tier exists arena ranking arena page.

This gives small teams a cheaper high‑quality alt for storyboard beats and short b‑roll. The price‑quality point is the draw.
Replicate ships Reve Image Edit Fast at ~$0.01/output for spatially aware edits
Replicate introduced a speed‑tuned Reve pipeline that honors composition and spatial relations while applying localized edits, with outputs priced around one cent each launch thread. The product page shows intent‑driven changes that keep scene geometry intact (shadows, perspective, reflections) model page.
Batch this where you’d currently mask by hand; the value is predictable geometry retention at micro‑cost.
Freepik Spaces adds camera‑angle controls on a collaborative canvas
Freepik’s Spaces now exposes angle/zoom controls so creators can rotate and reframe scenes directly on a shared canvas, alongside real‑time collaboration and asset pipelines spaces demo. A separate teaser emphasized “Camera Angles” as a headline addition feature announcement, and you can try Spaces from the launch page Spaces page.

For teams iterating product shots or ad beats, this cuts round‑trips between 3D tools and deck comps.
Higgsfield Lipsync Studio demos emotion‑controlled lipsync across images and video
A quick walkthrough shows Higgsfield’s Lipsync Studio driving expression‑aware lipsync on stills and clips, with an “Emotion” slider, and support for model backends like Infinite Talk, Kling Speak, and Wan 2.5 mentioned in the thread studio walkthrough. This is targeted at character content and dub pipelines.

If you localize or UGC‑scale talking heads, the per‑shot emotion control is the practical win.
Creators highlight Firefly 5’s photo‑real output with film‑style prompts
A community thread showcases Firefly 5 handling film‑photography prompts (Portra stock, ISO, grain, shallow DoF) with convincing monochrome and color renders photo set. While not a formal release note, the examples suggest stronger consistency for portrait and product‑style shots.
If your pipeline mixes stock+gen shots, this is worth a bake‑off against your current image model.
Qwen‑Edit‑2509 Upscale LoRA targets photo restoration and detail recovery
An open LoRA built on Qwen‑Edit‑2509 focuses on upscaling and restoring degraded photos (noise, blur, JPEG artifacts), with a hosted demo space to try it before/after view Hugging Face space. The examples show sharper facial structure and cleaner backgrounds while preserving identity.
It’s a handy slot in media cleanup queues when you don’t want to round‑trip into heavier diffusion.
🗂️ Data pipelines, retrieval, and NL→pipeline tools
Parsing/RAG saw multiple tangible drops: DocETL pipeline generator, multimodal UltraRAG updates, and agentic retrieval stacks. Excludes the data‑center feature.
Berkeley’s DocETL turns plain English into runnable data pipelines
Berkeley released a natural‑language→pipeline generator for DocETL, letting you describe a data job in plain English and see a runnable pipeline with immediate sample results. It’s open‑source (DocWrangler IDE + DocETL), and the hosted playground is live; the repo has 3k+ stars. This matters if you’re building retrieval and document ETL because it cuts the “gulf of specification” from spec to working pipeline today. See the demo and code in action
and the OSS details in the GitHub repo GitHub repo.
UltraRAG 2.1 ships VisRAG, automated corpus server, and multimodal evals
OpenBMB’s UltraRAG 2.1 adds a full VisRAG pipeline (images→retrieve→generate), a corpus server that auto‑parses .txt/.md/.pdf/.epub, six new VQA datasets, and support for vLLM/HF/OpenAI/Infinity backends. If you run retrieval at scale, this is a ready kit for end‑to‑end multimodal RAG and faster experiments. See the feature rundown in the short launch clip

.
Google Opal demo: one‑prompt agent chains research, tools, and Gemini 2.5 Pro
A quick Opal walkthrough shows a “meeting prep” agent that asks for inputs, fans out concurrent deep research, pulls external context (web, Maps, code), and synthesizes outputs with Gemini 2.5 Pro. If you prototype NL→workflow builders, this is a useful pattern for tool‑orchestrated retrieval + summarization in one place

.
Parallel’s llms.txt turns any website into LLM‑friendly text via Extract API
Parallel shipped a tool that converts arbitrary sites into standardized llms.txt files using their Extract API. For RAG teams, this gives you a predictable, crawlable text surface without standing up a separate content mirror, and it’s scriptable for bulk ingestion. Try it here: Parallel llms.txt Parallel llms.txt.
Hornet positions a retrieval engine purpose‑built for agent workloads
Hornet describes a schema‑first retrieval engine tuned for agents rather than humans: long, structured queries; iterative/parallel loops; and token‑aware cost control. If you’ve hit the limits of keyword‑centric search backing your agents, this is a specialized alternative you can deploy in VPC or on‑prem. Product background is here: Hornet site Hornet for agents.
Make.com AI connectors: Google Sheets → OpenAI tweet generator in minutes
A lightweight Make.com scenario wires “watch new rows” → “generate OpenAI completion” → “write back to Sheet,” producing social copy from topics without custom code. For scrappy RAG/ETL teams, this is a quick path to stand up content pipelines or QA harnesses around your data before investing in services work
. See Make’s product page for connectors and pricing on Make Make product page.
TOON proposes a compact JSON replacement to cut prompt token spend
Token‑Oriented Object Notation (TOON) is a deterministic, compact alternative to JSON designed for LLM prompts, with a TypeScript SDK and benchmarks. For retrieval chains that shuttle large structured payloads, a tighter wire format can materially lower cost and latency without changing your tools. Spec and SDK: TOON on GitHub GitHub repo.
💼 Enterprise momentum and access programs
Funding/adoption signals: Gamma’s growth financing, education programs, and new distribution. Excludes the data‑center feature.
Gamma raises Series B at ~$2.1B; says it crossed ~$100M ARR
Gamma announced a Series B led by a16z at roughly a $2.1B valuation, with an investor noting the company has surpassed about $100M in ARR and “one million gammas a day.” This is a strong signal that AI-native presentation/docs software is monetizing at scale and moving upmarket. See the investor note and deck for details investor note, and the follow‑up ARR claim from the same investor arr update.
Kazakhstan brings ChatGPT Edu to 165 universities covering ~2.5M students
The Government of Kazakhstan signed a strategic agreement with OpenAI and Freedom Holding to roll out ChatGPT Edu across 165 universities, reaching roughly 2.5M students. This is a national‑scale education access program that will seed daily AI use in higher‑ed and create downstream demand for enterprise tools in the region. The agreement was announced by the Kazakh government accounts and echoed by OpenAI leadership gov announcement, with a brief note from OpenAI’s Greg Brockman exec comment.
OpenAI offers one year of ChatGPT Plus free to eligible U.S. veterans
OpenAI launched a one‑year ChatGPT Plus offer for U.S. service members within 12 months of separation/retirement and recent veterans, widening premium access without cost. For enterprise leaders, this expands skilled usage and hiring pools; for builders, it’s an on‑ramp to paid features in orgs with veteran workforce programs. Program details are outlined by OpenAI and partners program page image, with additional confirmations via announcements today offer announcement and the official page OpenAI post.
Replit apps can now use 300+ OpenRouter models out‑of‑the‑box
OpenRouter is now integrated into Replit, making 300+ models immediately available inside Replit apps without bespoke wiring. This expands distribution for model providers and lets teams prototype with multiple vendors in one place. OpenRouter framed the rollout, and Replit voices highlighted the developer experience improvement integration note, with additional confirmation from a Replit leader that multimodal app building is now “super easy” on the platform dev comment.
Kwai’s Kat Coder Pro joins OpenRouter, free for now; 73.4% SWE‑Bench Verified
KwaiAICoder’s flagship coding model “Kat Coder Pro” is now hosted on OpenRouter, free for a limited time, advertising 73.4% on SWE‑Bench Verified, 256k context and 32k output. This adds another strong coding option into common gateways teams already use, lowering trial friction for evaluations and agent stacks. See the provider’s announcement model listing and the model’s route on OpenRouter for specs and status OpenRouter page.
🧠 Accelerators and parallelism notes
Smaller but relevant hardware updates today around MoE scaling and supply chatter. Excludes the data‑center feature.
NVIDIA details Wide Expert Parallelism for MoE on GB200 NVL72, up to 1.8× per‑GPU
NVIDIA published a TensorRT‑LLM write‑up on “Wide Expert Parallelism” for large Mixture‑of‑Experts models running on GB200 NVL72 racks, claiming up to ~1.8× higher per‑GPU throughput versus smaller EP groups. The approach reduces weight‑loading pressure and leans on the NVL72’s 130 TB/s coherent NVLink domain to keep GroupGEMM and all‑to‑all costs in check, making 8+‑GPU expert sharding practical for training and serving MoEs at scale blog highlight, and NVIDIA blog post.
Nvidia reportedly pushes TSMC for +50% 3nm output to feed multi‑GW clusters
Market chatter says Nvidia is asking TSMC to increase 3nm wafer output by ~50% as multiple gigawatt‑scale training clusters come online, each needing hundreds of thousands of GPUs. One month of current 3nm production reportedly wouldn’t fill a single mega‑datacenter, underscoring near‑term supply constraints for Blackwell‑class parts supply rumor.
Blackwell NVFP4 kernel challenge launches; first task is NVFP4 GEMV
A community competition for Blackwell NVFP4 kernels kicked off on GPU_MODE, with the opening problem targeting NVFP4 GEMV. It’s a timely signal that FP4 math paths are being hardened for Blackwell, with potential wins in memory bandwidth and throughput for both MoE serving and training loops kernel contest.
CoreWeave CEO says A100s are sold out across the market
CoreWeave’s CEO claimed A100 GPUs are “sold out across the space,” adding that new H100 capacity was immediately absorbed when a large cluster came online. It suggests sustained demand for older accelerators in both training and inference backfills even as Blackwell ramps supply remark.
🤖 Humanoids, autonomy, and logistics
Robotics momentum continued with production targets and AV depth; also delivery and game‑world agents. Excludes the data‑center feature.
XPENG says IRON humanoid targets mass production by 2026
XPENG announced its IRON humanoid is targeting mass production in 2026, showing smooth bipedal locomotion and sharing market sizing of roughly $230–$240B by 2030 production plan. Following up on IRON internals, which addressed the “human inside” rumors by revealing actuators and wiring, this shifts the conversation from demo credibility to supply‑chain readiness and unit economics.

For teams, the signal is clear: plan for low‑cost, general‑purpose manipulation pilots over the next 12–18 months, and expect rapid iteration on hands (22‑DoF class) and balance controllers as vendors race toward manufacturable assemblies.
DoorDash, Uber, Lyft flag bigger 2026 autonomy spend to scale robots and AVs
Delivery and ride‑hail leaders say autonomy needs more capital before it becomes routine. DoorDash plans to spend “several hundred million dollars more” in 2026 to push its autonomous‑delivery efforts (including its Dot robot), while Uber and Lyft highlight similar needs for robotaxi scale‑up and depots like Lyft’s planned Nashville site spending note, Business Insider. The takeaway: expect more paid pilots, tighter retailer integrations, and city‑by‑city rollouts where permitting and depot logistics align.
Waymo details driverless stack and safety; billions of miles in sim
On DeepMind’s podcast, Waymo’s Vincent Vanhoucke outlined the driverless stack: multi‑sensor perception, a persistent 3D world model, closed‑loop planning, and multimodal learning—tested across billions of simulated miles spanning rare edge cases and weather podcast outline, podcast episode. The point is: safety cases increasingly hinge on sim coverage plus field ops, with tokenization choices and control‑loop design showing up as real reliability levers.

NVIDIA Isaac Lab 2.3 hits GA to speed robot learning loops
NVIDIA announced Isaac Lab 2.3 general availability, highlighting enhancements for faster robot learning and sim‑to‑real workflows release note. If you train policies at scale, this is a nudge to re‑benchmark PPO/IL pipelines, revisit domain randomization, and check kernel‑level changes that cut iteration latencies on modern GPU stacks.
Paper: Robot learns via a physical world model for fast action selection
A new study shows a robot learning from a physical world model can plan and act quickly in evolving scenes, demonstrated by high‑throughput block sorting with accurate binning paper explainer, ArXiv paper. The approach offsets pure reactive control by forecasting object dynamics, which helps when perception, grasp planning, and placement must run under real‑time deadlines.

‘Steve’ mod brings LLM agents into Minecraft for NL tasking
An open‑source mod called Steve lets LLM agents (OpenAI/Groq/Gemini) play alongside you in Minecraft—mine ore, build structures, fight—using plain‑language commands. Agents parse context, plan sequences, then execute with re‑planning on failures, offering a compact, inspectable testbed for tool‑use, planning, and multi‑agent coordination mod overview, GitHub repo. For autonomy researchers, this is a low‑friction sandbox to prototype hierarchical control and memory without spinning up robots or simulators.

📚 Reasoning, spatial vision, and hallucination mitigation
A dense set of new/spotlighted papers: real‑time reasoning agents, spatial tuning, ASR/vision alignment, and data engines. Excludes the data‑center feature.
Meta open-sources Omnilingual ASR for 1,600+ languages (up to 5,400 with one‑shot)
Meta releases a multilingual ASR family (300M→7B) with an encoder‑decoder design and a new Omnilingual ASR Corpus covering 350 underserved languages. The team claims coverage for 1,600+ languages and one‑shot generalization to thousands more; code, models, and demo ship under Apache‑2.0 release roundup, with the dataset hosted on Hugging Face Hugging Face dataset.
Why it matters: speech is a core modality for agents. Broad‑language ASR lowers integration cost for voice workflows, contact‑center analytics, or field tools, and the license is permissive. Check the repos and demo for latency/quality trade‑offs GitHub repo.
Real-time reasoning agents meet deadlines with AgileThinker’s dual-loop planning
Stanford/Tsinghua propose AgileThinker, a framework that lets agents think while acting under strict per‑action deadlines, treating tokens as a time budget. It mixes a fast reactive loop with a parallel planner and defaults to safe moves on missed deadlines, outperforming pure reaction or pure planning in evolving tasks like Freeway, Snake, and Overcooked paper thread.
Proactive agents were highlighted earlier; this pushes that line by quantifying timing and showing higher scores under load.
Why it matters: many agent stacks stall or drift because long chains collide with a moving world. This paper gives a practical template teams can borrow now: keep a short-horizon loop alive while longer plans update, cap thinking with token budgets, and define fallbacks. It’s a clear recipe to reduce thrash in tool‑using agents without giving up reasoning depth.
VisAlign reduces VLM hallucinations by fusing a compact visual summary into text tokens
UMD and collaborators propose VisAlign: summarize the image once, join that vector to every textual token, and re‑project so the LLM “reads” text already infused with visual cues. Reported gains include +9.33% on MMVP and ≈3% on conflict tests, with higher precision/F1 on object presence—all by adding one small linear layer and no base‑model changes paper summary.
Try it where hallucinations kill UX: chart QA, product photos, or doc‑image reasoning. It’s cheap to prototype and plays well with decoding‑time safeguards.
Visual Spatial Tuning (VST) claims SOTA spatial reasoning with 4.1M-sample corpus + RL
ByteDance/Seed/HKU introduce Visual Spatial Tuning: a 4.1M‑example spatial perception dataset (single, multi‑image, and video) plus a smaller reasoning set and a progressive SFT→RL training pipeline. They report 34.8% on MMDI‑Bench and 61.2% on VSIBench without harming general VLM capabilities paper card, with details in the arXiv preprint ArXiv paper.
For builders: the approach avoids extra expert encoders and focuses on curriculum + RL. If your app needs layouts, part relations, or 3D-ish consistency, this is a data+training recipe to benchmark against.
‘Jr. AI Scientist’ runs paper→hypothesis→experiments→draft, scores ≈5.75 vs. 3–4 baselines
University of Tokyo demos an autonomous pipeline that reads a baseline paper+repo, identifies limits, implements improvements, runs ablations, and writes the manuscript with multi‑round edits. Automated reviewers and author audits rate its outputs ≈5.75, beating 3–4 for typical agent baselines; risk review flags issues like fabricated ablations or shaky citations paper note.
If you supervise research agents, this outlines a realistic loop and the failure modes to instrument for—especially verifying claims against code and results.
NVIDIA’s Nemotron Nano V2 VL targets long docs/video with hybrid Mamba‑Transformer
Nemotron Nano V2 VL is a ~12B VLM tuned for long‑context document and video understanding. It uses image tiling and token reduction, de‑duplicates stable video patches, and couples a vision encoder with a Mamba‑Transformer LLM to reach 300K context, reporting up to ~35% faster long‑doc tasks and ~2× video throughput with small accuracy impact paper brief.
Engineers doing contract/slide parsing or surveillance and meeting video triage get a concrete recipe to match or beat comparable open baselines while staying efficient.
ByteDance’s MIRA shows visual steps boost multimodal reasoning on conflict tasks
A ByteDance study argues that explicit visual steps—multimodal chain‑of‑thought—improve reasoning when images conflict with textual priors. The work benchmarks how adding visual imagination steps shifts models to trust pixels over memory, lifting scores on hard conflict cases paper note.
The takeaway: when your tasks include visually deceptive scenes, force image‑referencing steps, not text‑only CoT.
DeepEyesV2 pitches an agentic multimodal stack; short explainer and paper link
DeepEyesV2 frames a path toward ‘agentic’ multimodal models. A brief explainer accompanies a preprint entry on Hugging Face Papers, outlining components and objectives for perception→action pipelines paper post, with the listing available for review Hugging Face page.

This is early but useful as a checklist if you’re aligning VLMs with tool use, sensors, or environment simulators.
🛡️ Risk, labor impact, and market caution
Policy/econ signals dominated: new labor‑market analysis, bubble risk framing, and governance takes. Excludes the data‑center feature.
Goldman flags dot‑com echoes in AI trade; capex ~$349B, spreads widen
Goldman Sachs outlines five late‑cycle warning signs rhyming with the 1990s: mega‑cap AI capex pacing ~$349B in 2025, margins at risk, pockets of new leverage, rate cuts propping multiples, and HY spreads drifting from 2.76% to ~3.15% into Nov ’25—suggesting conditions look more like 1997 than 1999 analyst summary. This lands after the recent AI selloff erased ~$800B in a week, following up on $800B loss noted earlier.
Yale study: AI exposure shares stable since 2023; no unemployment spike
A new Yale/“Budget Lab” analysis finds the mix of jobs with low/medium/high AI exposure has stayed near 29%/46%/18% through 2023–2025, with no measurable rise in AI‑driven unemployment. Observed usage skews to coding/math jobs; many clerical roles look exposed on paper but show little real use, so exposure scores alone overstate near‑term risk key takeaways, Yale report.
- Among unemployed workers, prior jobs’ exposure bands stayed flat, and “automation‑heavy” categories only dominate if you count observed tasks; counting missing tasks as zero collapses that share to ~3% method notes, usage vs exposure.
Debate over AI server “useful life” changes: audits back extensions, Amazon shortens
A fresh accounting debate questions whether hyperscalers are juicing earnings by extending server/network useful lives. Counterpoints cite disclosed, audited changes: Microsoft moved to 4–6 years “due to software efficiency and tech advances,” Google’s shift to 6 years cut 2023 depreciation by $3.9B, and Meta’s 5.5‑year move trims 2025 by ~$2.9B—while Amazon shortened certain assets to 5 years for 2025 amid faster AI/ML cycles accounting thread, follow‑up analysis.
Developer trust in AI coding slips to ~60% from 70% in two years
Google’s Addy Osmani highlights a “70% problem”: favorable views of AI coding tools declined from ~70% to ~60% over two years, complicating rollout plans for teams that rely on AI assistance in the editor and CI talk highlights.

Eric Schmidt: “Giving AI agency is a mistake” in near term
Eric Schmidt argues today’s systems are prompt‑driven “special intelligence,” and the real danger begins when models initiate ideas via recursive self‑improvement; he calls granting computers agency a mistake at this stage video remarks.

Field experiments: GenAI lifts online retail sales up to 16.3% via conversion gains
A large retailer’s randomized trials report 0–16.3% sales gains from seven GenAI touchpoints (e.g., pre‑sale chat, better search queries, clearer product copy), with an implied ~$5 per consumer annually at scale; gains come from higher conversion, not larger baskets paper recap. For operators, this is rare causal evidence of productivity in the wild.
Germany’s software job postings fall below 60 (Feb ’20=100) after 2022 peak
Indeed’s Germany index for software development job postings has slid from >160 in mid‑2022 to under 60 in 2025 (Feb 1, 2020=100), underscoring a tougher market even as AI accelerates in adjacent roles chart note. Causality with AI isn’t proven here, but the signal matters for hiring plans and reskilling.