Xcode 26.3 brings Claude Agent SDK + Codex – MCP tool surface
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Apple shipped Xcode 26.3 with “agentic coding” as a first-class IDE workflow; agents can traverse projects, consult Apple docs, and iterate against SwiftUI Previews inside Xcode. Anthropic says the Claude Agent SDK now embeds “full Claude Code” functionality in the IDE, while OpenAI says Codex is available in the Xcode 26.3 release candidate; both pitch higher-autonomy task decomposition plus project-level navigation, not inline autocomplete. Apple frames Model Context Protocol (MCP) as the standard way to expose Xcode capabilities, with demos showing MCP-style CLIs driving simulator/build flows; exact permissioning and audit surfaces aren’t fully specified.
• Anthropic/Claude Code: API reliability wobble triggers widespread 500s; CLI 2.1.30 adds PDF page ranges and cuts --resume memory ~68%; 2.1.31 hardens limits (100 pages, 20MB) and fixes sandbox/PDF lockups; Slack connector lands for Pro/Max; session sharing adds public/private links with private-repo leak warnings.
• Open models + serving: Qwen3-Coder-Next drops as an 80B MoE with 3B active; vLLM 0.15.0 and SGLang publish day-0 tool-call parsing recipes; Together hosts it with 99.9% SLA at $0.50/$1.20.
Net: IDEs are being repositioned as agent runtimes; MCP/ACP-style control planes and shareable run traces are becoming the integration battleground, but reliability and data-leak edges are now shipping alongside the features.
Top links today
- Qwen3-Coder-Next model on Hugging Face
- Anthropic Claude Constitution on GitHub
- Agent Client Protocol specification and docs
- WEF talk on AI agents and payments
- CL-bench context learning benchmark repo
- ARC-AGI-2 leaderboard and reproduce links
- LangChain guide to evaluating deep agents
- LangSmith observability for agent evaluation
- Claude Agent SDK Xcode integration details
- Claude Slack integration setup and docs
- GPT-5.2 inference latency improvements
- Xcode 26.3 release notes with Codex
- vLLM 0.15.0 release with Qwen support
- ACE-Step v1.5 open-source music model
- GLM-OCR model page and technical details
Feature Spotlight
Xcode 26.3 goes agent-native: Claude Agent SDK + Codex inside the IDE
Xcode 26.3 embeds Claude Agent SDK and Codex so agentic coding happens where iOS/macOS engineers already work—project-aware edits + docs lookup + Previews feedback loops—shifting IDEs into the primary agent harness.
High-volume story across Apple/Anthropic/OpenAI: Xcode 26.3 adds native “agentic coding” integrations so agents can navigate projects, consult Apple docs, and iterate with Previews directly in Xcode. This is the day’s biggest workflow change for iOS/macOS teams.
Jump to Xcode 26.3 goes agent-native: Claude Agent SDK + Codex inside the IDE topicsTable of Contents
🧩 Xcode 26.3 goes agent-native: Claude Agent SDK + Codex inside the IDE
High-volume story across Apple/Anthropic/OpenAI: Xcode 26.3 adds native “agentic coding” integrations so agents can navigate projects, consult Apple docs, and iterate with Previews directly in Xcode. This is the day’s biggest workflow change for iOS/macOS teams.
Xcode 26.3 ships “agentic coding” with Claude and Codex integrations via MCP
Xcode 26.3 (Apple): Apple’s Xcode 26.3 release positions “agentic coding” as a first-class IDE workflow—agents can break down tasks, search Apple docs, traverse project structure, and iterate with UI Previews, as described in the Xcode 26.3 newsroom post Newsroom post.

This matters because it turns Xcode into an agent runtime (not just an editor): the IDE itself becomes the tool surface agents can call into, with Apple explicitly framing Model Context Protocol (MCP) as the standard way to expose those Xcode capabilities Newsroom post.
Codex is now available inside Xcode 26.3 RC with higher-autonomy workflows
Codex in Xcode 26.3 (OpenAI): OpenAI says Codex is now available in Xcode 26.3 (release candidate); the pitch is higher autonomy for complex tasks—task decomposition, Apple docs search, file-structure exploration, and Preview capture while iterating, as outlined in the Xcode 26.3 Codex post.

• Workflow framing: The goal is to let you specify an outcome and have the agent find the right files/settings to change, rather than step-by-step edits, per the Xcode 26.3 Codex post.
• Naming signal: One internal nickname for the integration is “xcodex,” as mentioned in the Internal nickname note.
A separate OpenAI comment suggests subscription-based entitlement is meant to carry into Xcode (“take your ChatGPT subscription directly into Xcode”), as stated in the Subscription note.
Xcode 26.3 adds direct Claude Agent SDK integration for in-IDE Claude Code workflows
Claude Agent SDK in Xcode 26.3 (Anthropic): Xcode 26.3 now directly integrates the Claude Agent SDK, bringing “the full functionality of Claude Code” into Xcode for Apple-platform development, per Anthropic’s integration announcement Integration announcement and the accompanying feature writeup Integration post.
• UI verification loop: Claude can use Xcode Previews to visually verify SwiftUI output and fix issues while iterating, as Anthropic highlights in the Integration post.
• Agentic project navigation: The integration is framed as project-level reasoning (file tree + framework boundaries) and autonomous multi-file edits, rather than “inline autocomplete,” as described in Integration announcement.
Some community re-tellings go further—e.g., “subagents, background tasks, and plugins” inside Xcode—building on the same integration surface shown in Xcode superpowers clip.
XcodeBuildMCP demo shows how MCP can drive simulator workflows from agents
MCP tooling around Xcode 26.3: A demo clip shows Xcode 26.3 using an XcodeBuildMCP-style CLI to interact with the simulator (via xcodebuild-like flows), which is a concrete example of how “Xcode capabilities via MCP” can become automation primitives for agents, as shown in the Simulator MCP clip.
The same direction—MCP as the bridge between agents and Xcode’s native affordances—is also the framing Apple uses in its Xcode 26.3 announcement Newsroom post.
🛠️ Claude Code: connectors, CLI releases, sharing, and reliability incidents
Continues the Claude Code beat with concrete shipping deltas: Slack connector availability, new Chrome automation path, and CLI 2.1.30/2.1.31 changelog items. Also includes widespread reports of Claude API 500s and Sonnet 5 deployment speculation.
Claude API shows elevated 500s, impacting Claude Code sessions
Reliability incident (Anthropic): Anthropic’s status page flags an “elevated error rate on API across all Claude models,” as shown in the screenshot in status page capture, while developers report Claude Code returning 500s in active terminal sessions in the CLI error screenshot.
• On-the-ground signal: Builders explicitly call out “Anthropic's API is 500-ing” in the API failing report, suggesting a broad outage rather than a single-client regression.
Claude Code CLI 2.1.30 adds PDF page ranges and MCP OAuth credentials
Claude Code CLI 2.1.30 (Anthropic): v2.1.30 ships a dense batch of workflow fixes and quality-of-life changes—most notably a PDF reading change that avoids stuffing whole docs into context, plus improved MCP auth ergonomics—summarized in the release thread and detailed in the changelog.
• PDF handling: Read now supports pages: "1-5"; PDFs over 10 pages return a lightweight reference when @ mentioned instead of being inlined (with a 20-page cap noted in prompt guidance), per the release thread and the full changelog.
• MCP OAuth: Adds pre-configured OAuth client credentials for MCP servers without Dynamic Client Registration (notably Slack), using --client-id and --client-secret with claude mcp add, as described in the release thread.
• Debug + resume reliability: Adds /debug and cuts --resume memory usage by ~68% for many-session users; also fixes prompt-cache invalidation behavior and several session corruption / login edge cases, per the release thread and the changelog.
Claude adds a Slack connector on Pro and Max plans
Slack connector (Claude): Claude can now connect to Slack on Pro and Max plans, letting you search channels/threads/files, prep for meetings, and draft + send Slack messages without leaving the Claude chat, as announced in the connector launch.
• Workflow impact: This effectively turns Slack into a first-party context source (and an outbound action surface) inside the Claude UI, per the connector launch and the setup details on the connector page.
Claude Code can now drive Chrome via the VS Code extension
Claude Code in Chrome (Anthropic): The VS Code extension can now connect Claude to Chrome so it can debug frontend apps, collect data, and automate the browser; usage starts by typing @browser, as shown in the browser attach demo.

• Rollout detail: Anthropic points to the extension install/update path in the install instructions, which links to the VS Code marketplace page.
Claude Code CLI 2.1.31 tightens session resume and sandbox behavior
Claude Code CLI 2.1.31 (Anthropic): v2.1.31 follows quickly with session continuity tweaks, sandbox correctness fixes, and clearer size-limit errors, per the release thread and the changelog.
• Session continuity: Adds an exit hint showing how to resume the conversation later, per the release thread.
• Sandbox and PDF fixes: Fixes sandbox-mode bash commands incorrectly failing with “Read-only file system” and resolves PDF-too-large errors permanently locking sessions; error messages now include explicit limits (100 pages, 20MB), as listed in the release thread.
• Prompt guidance change: Updates instructions so “Agent Teams” limitations are only disclosed if the user explicitly asks, according to the prompt diff note and the linked diff view.
Claude Code introduces shareable session links with private-repo warnings
Session sharing (Claude Code): Claude Code now lets users share an agent session via a private or public link, and it explicitly warns when the conversation originated from a private repository—highlighted in the UI screenshot shared in the share modal screenshot.
• Practical effect: This makes an agent run reviewable out-of-band (similar to linking a build log), but the product is calling out leakage risk directly in the modal, per the share modal screenshot.
Claude Code MCP stdio servers show intermittent connect failures and process leaks
MCP stability (Claude Code): Some builders report their MCP stdio server fails to connect reliably in Claude Code while working in Claude Desktop and Codex, and they suspect sessions aren’t tearing down processes cleanly (“zombie processes that pile up”), per the stdio server report and the follow-up in zombie process theory.
• Debugging clue: A separate screenshot shows multiple long-running Claude Code CLI instances discovered as “orphaned processes,” including one annotated “This is me,” in the process table screenshot.
Sonnet 5 speculation intensifies as Claude outages cluster around deploy timing
Sonnet 5 watch (Anthropic): Following up on version string leak—Sonnet 5 timing rumors—builders now tie today’s Claude API instability to a potential failed Sonnet 5 deploy; one hypothesis is that Anthropic “ran into technical issues and had to roll it back,” as speculated in the rollback guess.
• What’s actually observable: There’s confirmed service degradation via the status page capture and repeated user reports of model unavailability (e.g., Opus/Sonnet selection failing) visible in the Claude error screenshot.
No official Sonnet 5 release note appears in the tweet set; all Sonnet 5 causality claims remain inference from outage timing.
Developers report Claude Code terminal UI lag as a usability regression
Claude Code UX signal (Anthropic): At least one developer reports the Claude Code terminal UI “literally lags” despite being a CLI, framing it as a speed tradeoff versus Codex, in the lag complaint.
The tweet set doesn’t include profiling data or an upstream issue reference, so it’s a qualitative but actionable reliability/UX datapoint rather than a confirmed regression ticket.
🧠 Codex app: adoption telemetry, workflow feedback, and team enablement
Non-Xcode Codex developments: first-day adoption numbers, user-reported friction (Windows/perf/battery/worktrees), and OpenAI-hosted training content. Excludes Xcode 26.3 integration (covered as the feature).
Codex app crosses 200k day-one downloads and collects pain-point feedback
Codex app (OpenAI): Following up on Codex app launch (multi-agent macOS workspace), Sam Altman says 200k+ people downloaded the Codex app in the first day and “they seem to love it” per the download milestone. A separate telemetry screenshot shows 205,308 production users, alongside a call for the biggest gripes—Windows support, performance/battery, and worktree workflow confusion—per the feedback request.
This is the first hard adoption number in the wild; it also names the specific UX/portability issues likely to dominate near-term fixes.
Automations in Codex app used as cron-style background agents
Codex app (OpenAI): A detailed user thread describes using Automations like “check repo for security vulnerabilities” to run daily in the background across multiple repos, describing this as the scaling unlock (one automation can cover many repos) in the automation pattern.
This is the clearest “agents while you sleep” pattern tied specifically to Codex app primitives (Automations + review queue), rather than external cron + CLI glue.
Codex app workflow shifts from “many worktrees” to “projects” for multi-repo work
Codex app (OpenAI): A practitioner report argues the bigger unlock isn’t “hundreds of worktrees,” but projects/workspaces (multiple directories) for juggling several repos calmly; they describe stacking ideas “into the queue,” then having the agent research feasibility and produce an exec plan, as shared in the projects workflow note and framed more broadly as a hub experience in the field report opener.
This is a concrete alternative to the “one worktree per PR” mental model: treat the app as a queueable multi-repo cockpit, then review output when ready.
OpenAI Devs announces a live Codex app workshop focused on Skills and Automations
Codex app (OpenAI): OpenAI Devs is hosting a live workshop where the team will “build apps end to end” using the Codex app, including setup plus Skills and Automations in the workflow, as described in the workshop announcement.
This is one of the few official “watch us actually use it” artifacts, which tends to surface the real gotchas (auth, repo layout, review/approval loops) that docs skip.
Codex app as a “command center” reduces IDE/terminal switching for some builders
Codex app (OpenAI): One 10-day usage report says they “have not opened” a terminal or VS Code during most work, describing the app as a calm multi-thread hub that made complex codebases feel simpler, per the editor/terminal avoidance note.
This is a concrete adoption signal: the app is functioning as the primary interaction surface, not a thin wrapper around CLI sessions.
Codex app users describe Skills as pre-bundled capability packs
Codex app (OpenAI): A practitioner calls out Skills integration as unusually usable: recommended Skills “out of the box” are framed like “packs” (bundles of functionality) that avoid doc-diving or copy/paste setup, as described in the skills integration note and contextualized inside a broader 10-day report in the experiences thread.
The practical takeaway is that Skills are being used as the primary on-ramp for tool/API usage inside the app, not a power-user-only feature.
Codex speedup clarified as API-only, with app parity noted
Codex app (OpenAI): After OpenAI Devs said GPT-5.2 and GPT-5.2-Codex are now 40% faster for API customers in the latency update, an OpenAI team member clarified that the change “was specifically for API customers,” while also claiming Codex via “Sign in with ChatGPT” and via API already run “at roughly the same speed,” with “further good news coming soon” per the staff clarification.
The key operational detail is that the announced latency win targets the inference stack for API traffic; the app experience may shift separately.
⚡ OpenAI performance + budget shifts: faster APIs, lower “thinking” caps
Infra signal cluster centered on OpenAI: API latency improvements and observed reductions in ChatGPT “reasoning effort/Juice” tiers. This directly impacts cost/perf planning for teams shipping on OpenAI APIs and using ChatGPT plans as dev tooling.
OpenAI speeds up GPT-5.2 and GPT-5.2-Codex by ~40% for API users
GPT-5.2 / GPT-5.2-Codex (OpenAI): OpenAI says API latency dropped ~40% after inference-stack optimizations—explicitly “same model, same weights, lower latency,” per the Speedup announcement.
This is an infra change (not a model refresh), so teams should expect identical behavior with faster wall-clock tool loops—especially noticeable in agent-style flows where many short calls dominate end-to-end time.
ChatGPT reportedly halves “thinking Juice” budgets across multiple paid tiers
ChatGPT Thinking (OpenAI): Multiple users report updated “reasoning effort / Juice” values in ChatGPT; Plus & Business show Standard 64→32 and Extended 256→128, while Pro shows Light 16→8, Standard 64→16/32, and Extended 256→128, with region/experiment variance called out in the Juice values report.
The practical impact is a lower ceiling for long “thinking” runs inside the consumer app, which changes expectations if teams were using ChatGPT tiers as a quasi-dev tool for heavier reasoning prompts.
Speculation grows that OpenAI shifted compute from ChatGPT thinking to API throughput
Compute allocation chatter: Posts argue the reduced ChatGPT “thinking” budgets and the API speedup look like a deliberate compute rebalance; one claim ties it to Codex access/influx and calls it “getting less for your money,” per the Customer value complaint and the more pointed Compute shift take.
A separate thread explicitly attributes the shift to “200k new users” and temporary Codex access while calling for customer notification, as alleged in the Compute rebalance claim. The underlying attribution is unverified, but the sentiment signal is consistent: performance wins for API builders are being read as a trade against consumer-tier reasoning ceilings.
ChatGPT “Juice” experiments coincide with new policy-flag friction for test prompts
ChatGPT policy friction (OpenAI): Alongside the reported “Juice” changes, at least one tester says previously-used measurement prompts now trigger “flagged as potentially violating our usage policy,” suggesting either new filters or experiment-specific policy tuning, as described in the Policy flag note.
This matters if you have internal eval prompts (or regression harness prompts) that are “meta” about system behavior—some of those may become brittle under plan/region experiments.
OpenAI staff clarifies the 40% speed boost targeted API customers
Codex / API surfaces (OpenAI): An OpenAI staff reply says the 40% speed change was specifically for API customers, adding that Codex via “Sign in with ChatGPT” and via API already run at roughly the same speed and teasing “further good news coming soon,” according to the Staff clarification.
This is a useful constraint for incident reviews and performance tracking: if you saw latency shifts, they may differ by surface even when the model name is the same.
🧰 Skills ecosystem: `.agents/skills` standard push + new skill packs
Skills/plugins remain a high-churn surface: a cross-tool push for .agents/skills, plus new vendor skill repos and “npx skills add …” distribution patterns. Excludes MCP protocol items (covered separately).
.agents/skills is emerging as the portability target for coding-agent “skills”
.agents/skills (Skills directory standard): A cross-tool push is forming around reading skills from a shared .agents/skills directory to avoid per-assistant folders, per the Open call for builders and follow-on adoption rollups like Support list so far. The loudest gap is Anthropic/Claude Code—a public petition is asking Claude Code to adopt the same directory layout that other CLIs/editors already read, as listed in the Claude Code petition.
The practical implication is a more “git-friendly” portability layer for org conventions (PRD templates, lint rules, API usage recipes) that can be reused across multiple agent frontends without duplicating files.
ElevenLabs launches a Skills repo installable via npx
ElevenLabs Skills (ElevenLabs): ElevenLabs shipped a distributable Skills pack aimed at making coding assistants more reliable at using ElevenLabs APIs for audio and agent workflows, with installation via npx skills add elevenlabs/skills as shown in the Skills announcement.

The repo itself is published as a reusable asset (speech/music/STT/TTS primitives), per the GitHub repo.
Firecrawl v2.8.0 ships a Skill for “live web context” and parallel agent runs
Firecrawl Skill (Firecrawl): Firecrawl v2.8.0 adds a Skills-distributed integration that lets agents pull live web context, alongside “Parallel Agents” for running large numbers of /agent queries concurrently, as introduced in the v2.8.0 release note. The detailed rollout (including the npx skills add firecrawl/cli install path and the Spark model ladder for fast→deep extraction) is spelled out in the Changelog.
Agentic image generation: a “skill” wrapper around iterative image workflows
Image Generator skill (workflow pattern): A concrete “skill-first” approach to image generation is being shared as a repeatable loop: drive generation and refinement through a coding agent (Claude Code), with a dedicated Image Generator skill and a Playground plugin for tighter annotation/iteration, as demonstrated in the Image Generator skill demo.

The notable angle for engineers is the framing: treat image generation as an executable, iterated pipeline (code + annotations), not a one-shot prompt.
Hugging Face adds “hf skills add --claude” to teach assistants the hf CLI
huggingface_hub hf skills (Hugging Face): Hugging Face is distributing “CLI know-how” as a Skills bundle, advertising a one-command install—hf skills add --claude—to teach an assistant how to use the hf CLI, per the hf skills add callout. This is part of the broader trend of packaging operational expertise (not just prompts) into installable, versionable skill units.
Personal “skill stacks” are becoming a repeatable way to steer agents
Skill authoring practice (personal stack): Matt Pocock shared the concrete “skills” he runs day-to-day—write-a-prd, make-refactor-request, tdd, design-an-interface, and write-a-skill—as composable building blocks for agent workflows, per the Skills list. He’s also signaling a distribution pattern (release via newsletter first) in the Newsletter note, pointing at skills becoming shareable artifacts rather than one-off prompts, with the signup link living in the Newsletter signup.
🔌 Agent interoperability: ACP + connector plumbing
Orchestration layer news focused on protocols/connectors rather than model/tool launches: Agent Client Protocol (ACP) positioning and cross-editor integration hooks. Excludes .agents/skills packaging (covered under Skills).
Agent Client Protocol proposes a shared JSON-RPC layer for editor↔agent integration
Agent Client Protocol (ACP): A new open spec frames “agent ↔ editor” interoperability as JSON-RPC 2.0 with transports over stdio (local subprocess agents) or HTTP (remote agents), aiming to standardize file access, terminal execution, permission prompts, and streaming session updates, as described in the protocol explainer.
For tool builders, the practical implication is a single integration surface for editors (Zed/JetBrains/Neovim-style clients) to talk to multiple agent backends, with the core verbs (fs read/write, terminal create/run, permission gating, session/update streaming) spelled out in the same place per the protocol explainer.
Cline CLI 2.0 adds ACP support to pair terminal agents with editors
Cline CLI 2.0 (Cline): The new Cline terminal app adds Agent Client Protocol wiring so a CLI agent can be attached to ACP-compatible editors; the integration is called out in the release post as ACP support (alongside parallel agents and a redesigned TUI) in the release announcement, and the pairing path is explicitly described as using --client-acp in the ACP flag snippet.

This is specifically about connector plumbing: Cline is positioning its CLI as a backend that can reuse editor UIs/permissions/file tooling via ACP instead of building bespoke integrations per editor, as stated in the ACP flag snippet.
MCP vs Skills: a practical framework for choosing deterministic tools vs instruction packs
Skills vs MCP tools (LlamaIndex): A new write-up argues that “Skills” (local markdown/instructions) are fast to stand up but can be ambiguous and drift, while MCP provides deterministic API-style execution with schemas but adds auth/transport overhead and network latency; the comparison is summarized in the tradeoff table and expanded in the blog post.
• Where this lands operationally: The post highlights different failure modes—MCP tends toward wrong tool selection, while Skills stack “misinterpretation + wrong tool selection,” as laid out in the tradeoff table.
The net is a clearer decision rubric for teams trying to keep “connector complexity” bounded as they mix local agent behavior steering with networked tool execution, per the blog post.
🧑✈️ Agent runners & multi-agent ops: CLIs, plugins, sharing, and model routing
Operational tooling for running agents in parallel: new/updated CLIs, plugin marketplaces, session sharing surfaces, and multi-model routing usage signals. Excludes first-party Codex/Claude releases (covered in their own categories).
Cline CLI 2.0 adds parallel agents, ACP IDE pairing, and a rebuilt terminal UI
Cline CLI (Cline): Cline released Cline CLI 2.0 as a ground-up rebuild of its terminal experience—bringing a redesigned TUI, parallel agent running, and an Agent Client Protocol (ACP) bridge so the CLI can pair with editors like Zed/Neovim/Emacs, as announced in the Release announcement.

• Parallel agents in the terminal: the new UI is explicitly built to run multiple Cline instances at once while keeping per-agent status visible, as shown in the Parallel agents clip.
• ACP integration: pairing is exposed via a --client-acp flag so the CLI can drive ACP-capable IDE clients, as shown in the ACP pairing demo.
• Automation + model access: Cline highlights more scriptable/headless usage (including skipping permission prompts and structured output), as described in the Headless automation note, and it temporarily includes free access to Kimi K2.5, per the Free model access note.
Agent Client Protocol pushes a standard interface for editor↔agent tool access
Agent Client Protocol (ACP): A new push for ACP frames it as a JSON-RPC 2.0 standard to connect agents (e.g., Claude Code, Gemini CLI) with editors (e.g., Zed, JetBrains, Neovim), standardizing file reads/writes, terminal execution, permissions, and session updates, as described in the Protocol overview.
The diagram in the Protocol overview is explicit about transport options (stdio for subprocesses; HTTP for remote agents) and about streaming session updates—suggesting the protocol is meant to support long-running, tool-using “agent runner” loops rather than one-shot completions.
FactoryAI Droid adds plugins and a marketplace install flow
Droid CLI (FactoryAI): FactoryAI says Droid now supports plugins, where a plugin can bundle skills, commands, and agents into a shareable package; they’re also rolling out a “Factory Plugins Marketplace” install flow, as shown in the Plugins announcement.

• Marketplace distribution: the marketplace is added via a CLI command (droid plugin marketplace add …), as described in the Marketplace details.
• Claude plugin ecosystem compatibility: FactoryAI claims Droid’s plugin system is compatible with Claude Code’s plugin ecosystem, as stated in the Compatibility claim, with setup details in the Plugin docs.
Gemini CLI rolls out Skills and Hooks support in its extension system
Gemini CLI (Google): Gemini CLI rolled out an extension framework that can package skills, hooks, MCP servers, custom commands, and context files, with a claim of 300+ extensions available, as summarized in the Extension framework update.

The key operational angle is that “hooks” implies lifecycle interception (pre/post steps, approvals, logging, routing) rather than only tool registration—useful for teams trying to make CLI agents behave consistently across projects.
Kilo CLI 1.0 launches with 500+ models for terminal-native agentic engineering
Kilo CLI (Kilo): Kilo shipped Kilo CLI 1.0, positioning it as a terminal-first agent runner that can access “500+ models” and is tightly integrated with the Kilo platform, as stated in the Kilo CLI launch note.
The release frames the CLI as rebuilt “from scratch on a proven open-source foundation,” with more detail in the Launch blog, but today’s tweets don’t include a public changelog-style list of flags/behavior changes beyond the headline features.
A practical multi-model loop: scan with subagents, critique skeptically, then fix
Multi-model agent workflow: One practitioner describes a repeatable loop for larger codebases—spawn n subagents on Claude Opus 4.5 to scan for smells/issues, then switch to GPT‑5.2 for a skeptical “is this accurate and worth fixing?” critique, and finally use Codex to apply changes, as outlined in the Workflow writeup.
The workflow is notable because it explicitly separates “broad, parallel discovery” from “single-threaded judgment” before edits land—trying to reduce wasted refactors driven by overconfident first-pass findings.
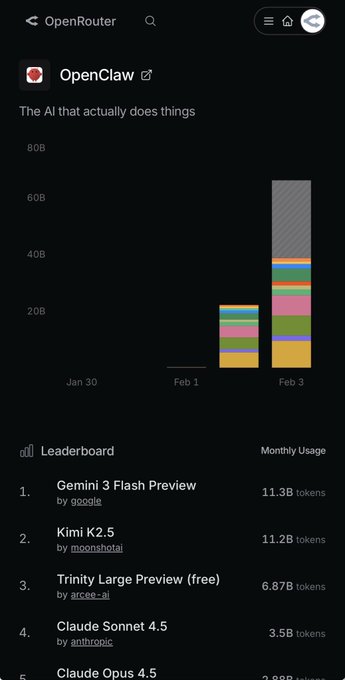
OpenRouter posts OpenClaw’s top resolved models as a usage signal
OpenRouter (OpenRouter): OpenRouter shared a snapshot of the “top models being used by OpenClaw” via OpenRouter, emphasizing that it shows the resolved models behind openrouter/auto, as stated in the Usage leaderboard callout.
While the tweet points to a full leaderboard, the most concrete artifact in the dataset is the OpenClaw app listing on OpenRouter, which is linked in the OpenClaw app page and frames this as an ongoing usage signal rather than a one-off benchmark.
Warp adds weblink sharing for agent conversations with planning docs
Warp (Warp): Warp added the ability to share an agent conversation as a weblink that can be viewed in Warp or on the web, and it includes access to the agent’s planning documents for review, as shown in the Sharing demo.

This is a concrete “attach the agent trail to a PR” workflow surface: the shared artifact is the conversation + plan, not just a diff or a pasted transcript.
RepoPrompt previews a new agent UI focused on file actions and history
RepoPrompt (RepoPrompt): RepoPrompt shared a WIP preview of a new agent UX that foregrounds thread history, explicit file actions, and diff visibility—essentially treating “agent run traces” as a first-class review surface, as shown in the UX preview.
The screenshot in the UX preview shows the core interaction pattern: user request → tool/file reads → an explicit Edit diff → a summarized “File Action: Done!” outcome, which aligns with the broader shift toward runner UIs that make agent execution legible for review/hand-off.
🧪 Agentic engineering practices: scaling dev work, tests, and context discipline
Practitioner patterns for making agents reliable: parallelism as leverage, stronger acceptance-test boundaries, and harness/context engineering as an emerging discipline. Excludes tool-specific changelogs (Claude/Codex).
Acceptance tests the agent cannot edit to reduce “fragility”
Acceptance-test boundary (pattern): When agents refactor, unit tests don’t reliably prevent regressions because the model will often “fix” the tests too; Uncle Bob’s workaround is human-readable acceptance tests (BDD-style specs) that the agent is not allowed to modify, then have the agent compile those specs into executable tests, as outlined in Fragility and acceptance tests.
He shares an example of a concrete GIVEN/WHEN/THEN scenario that asserts visible behavior (“fighter refuels at player city”) in plain text, per Acceptance test example. The point is to create a non-negotiable contract that survives implementation churn.
Parallel CLI agents as “horizontal scalability” for developers
Parallel agent execution (workflow): Treat coding agents as horizontal scale—run multiple terminal agents in parallel via splits/tabs/tmux sessions, then steer them with Skills/MCP and push work into sandboxes for near-infinite concurrency (overnight PRs, incident follow-ups), as described in Parallel agent framing.
The core claim is that the job shifts from “writing code” to automating the full product-development loop—assigning goals, supervising diffs, and routing tasks to the right environment (local vs sandbox) while the agents run continuously, per Parallel agent framing.
Context-length plateau (200k–1M) framed as a VRAM/bandwidth constraint
Context discipline (constraint signal): Despite big capability gains, context windows have largely stayed in the ~200k to 1M range; Simon Willison argues this is likely a hardware bottleneck—context needs VRAM and memory bandwidth more than raw compute, as stated in Context length stagnation and reinforced in Hardware limitation guess.
For agent builders, the implied direction is that improvements will come from context-management tactics (compaction, retrieval, selective state) as much as from waiting on bigger windows, given the bandwidth-bound nature of long-context inference described in Context length stagnation.
Scan wide with subagents, then run a skeptical critique pass before fixes
Two-phase review loop (workflow): Spawn N subagents to scan a repo for smells/issues, then switch to a more skeptical model pass to critique whether findings are accurate and worth fixing before paying the cost of edits—then apply fixes with a coding agent, as described in Subagent scan then critique workflow.
The concrete example uses ~10 subagents for the initial sweep and explicitly separates “find” from “change,” aiming to reduce wasted diffs and model-driven churn, per Subagent scan then critique workflow.
Agent-amplified dev feedback loops: logs/observability/debug tests run 50×/day
Feedback-loop compounding (workflow): A recurring pattern is investing in better debug/test/observability loops because agents can run them repeatedly at very high frequency; the claim is that loops that used to take weeks to pay off can now be executed “50×/day,” making the ROI more immediate, as described in Feedback loops run frequently.
A concrete example mentions using a tmux-oriented skill to click through e2e flows in a CLI while building the CLI itself, highlighting that automation plus tight loop design changes what teams bother to instrument, per Feedback loops run frequently.
Ask the agent to restate intent to catch wrong assumptions early
Intent alignment (prompting practice): A lightweight guardrail is asking the agent to explain its understanding of your goal before it starts changing code; the claim is that many modern agent mistakes are no longer syntax errors but “subtle conceptual errors” driven by wrong assumptions, and restating intent surfaces misalignment early, per Intent restatement tip.
This sits alongside a broader warning that models don’t reliably ask clarifying questions or “manage their confusion,” so the explicit check becomes a practical substitute for that missing behavior, as quoted in Intent restatement tip.
Harness engineering reframed as “environment engineering” for useful work
Harness/environment design (community signal): One framing shift is “prompt → context → harness → environment engineering,” arguing that the general question is how to design an Agent+Environment system that reliably does useful work—pulling in decades of RL ideas as agents increasingly run inside sandboxes/containers, as argued in Environment engineering framing.
The post positions this as a current “community explosion” around harness design rather than model-only progress, emphasizing that environment control (tools, sandboxes, constraints) is becoming a primary lever, per Environment engineering framing.
📦 Model releases (open + closed): coding MoEs, OCR, and omni-modal
Today is heavy on open-weight drops and lightweight specialists: Qwen3-Coder-Next dominates the conversation, alongside compact OCR and omni-modal releases. Excludes serving/runtime recipes (covered under Inference Runtimes).
Qwen3-Coder-Next ships as an open-weight, agent-trained coding MoE (80B total, 3B active)
Qwen3-Coder-Next (Alibaba Qwen): Qwen shipped Qwen3-Coder-Next, an open-weight coding model aimed at agentic workflows and local dev; it’s an 80B total-parameter MoE with 3B active, trained with 800K verifiable agent tasks and executable environments, per the Launch thread.

• Benchmarks claimed: Qwen highlights >70% SWE-Bench Verified using the SWE-Agent scaffold and reports strong SWE-Bench Pro results for its size/activation profile, as shown in the Launch thread charts.
• Release artifacts: weights and variants are organized in the Model collection, with additional training/architecture detail linked via the Tech report.
• Early builder read: some third-party reactions call it “performance equivalent to Sonnet 4.5” for certain coding workloads in the Comparison claim, while others report it’s “not bad… far from Sonnet 4.5 level” in quick local tests per the Early local test.
GLM-OCR follow-on: speed and real-doc parsing claims start to dominate
GLM-OCR (Z.ai): Following up on initial release (0.9B OCR VLM), today’s chatter is less “it exists” and more “can it run production workloads fast”; LlamaParse reports it dethroned PaddleOCR-VL-1.5 on OmniDocBench and is 50–100% faster in their testing, per the Speed claim thread.
• Where it seems to shine: the comparison table in the Benchmark table screenshot shows strong scores on doc parsing/text/formula/KIE benchmarks despite the 0.9B size.
• Field timing snippets: one user compares GLM-OCR to Gemini 3 Flash Thinking (medium) on messy docs (e.g., “doctor notes (13.5s)”) and concludes GLM-OCR is faster, as shown in the Timing comparison screenshots.
Most of the evidence is still third-party and tool-context-dependent (parsing-to-markdown vs raw OCR makes a big difference), but the performance conversation is now anchored in concrete timings and throughput claims rather than leaderboard scores alone.
MiniCPM-o 4.5 launches as a full-duplex omni-modal 9B model for local use
MiniCPM-o 4.5 (OpenBMB): OpenBMB released MiniCPM-o 4.5, positioning it as an open-source full-duplex omni-modal model (seeing, listening, and speaking concurrently) at 9B params, with a reported 77.6 OpenCompass vision-language score, per the Release post.

• Realtime interaction focus: the pitch is “no mutual blocking” during live streaming conversations plus more proactive behaviors (e.g., initiating reminders), as described in the Release post.
• Local deployment story: the team emphasizes “experience it on your PC” with broad engine support (llama.cpp, ollama, vLLM, SGLang), per the Deployment note and the linked Model card.
Holo2-235B-A22B claims #1 GUI localization with “agentic localization” refinement
Holo2-235B-A22B (H Company): H Company released Holo2-235B-A22B, a GUI localization VLM that claims #1 on ScreenSpot-Pro (78.5%) and #1 on OSWorld-G (79.0%), as stated in the Release announcement.
• Iterative refinement as the product: the team frames “agentic localization” as the key trick—running multiple localization steps to net 10–20% relative gains, as described in the Release announcement and expanded in the Technical post.
• Access and licensing nuance: the model is available on Hugging Face, per the Hugging Face listing, and is described as a research-only release for the larger variants in the Model card.
There’s no independent reproduction in these tweets, but the release is notable for packaging iterative, multi-step refinement as part of the benchmark story rather than a separate agent scaffold.
WorldVQA debuts to measure memorized visual world knowledge separately from reasoning
WorldVQA (Moonshot/Kimi): Moonshot introduced WorldVQA, a 3,500-pair VQA benchmark across 9 categories designed to measure “what the model memorizes” (vision-centric world knowledge) separately from reasoning, per the Benchmark announcement.
• Why this benchmark exists: the stated goal is to stop conflating visual knowledge retrieval with reasoning—WorldVQA is explicitly framed as an “atomic world knowledge” test, as explained in the Benchmark announcement.
• Early comparative numbers: swyx notes results where Gemini-3-pro scores 47% while GPT-5.2 scores 28% on this benchmark, and highlights calibration metrics as under-discussed, in the Results and calibration notes.
The dataset structure and the calibration emphasis are the new ingredients here; treat model-vs-model scores as provisional until there’s a single canonical eval artifact and prompt protocol widely replicated.
📏 Benchmarks & evals: ARC-AGI, time-horizons, search and context learning
Multiple eval streams land today: ARC-AGI submissions, time-horizon measurements, search leaderboards, and context-learning benchmarks. Useful for leaders tracking capability vs cost and reliability in agent settings.
ARC-AGI-2 gets a new top public refinement submission built on multi-model ensembles
ARC Prize (ARC-AGI-2): A new public “refinement” submission built around GPT-5.2 reports 72.9% on ARC-AGI-2 at $38.99 per task, with a second variant listed as 94.5% at $11.4 per task, per the submission announcement; the authors describe a pipeline that runs tasks through GPT-5.2, Gemini-3, and Claude Opus 4.5 in parallel, then has models write Python transform functions and executes them in a sandbox before a judge-model vote, as outlined in the method thread.
• Mechanism shift: Instead of predicting grids directly, the system pushes models toward executable hypotheses (Python functions) and uses runtime validation plus multi-candidate selection, per the method thread.
• Cost-per-performance visibility: The ARC-AGI-2 leaderboard framing makes the cost tradeoff explicit—see the plotted point for “GPT-5.2 (Refine.)” in the leaderboard screenshot, with official references linked from the leaderboard links.
Tencent HY and Fudan release CL-bench to measure “context learning,” not recall
CL-bench (Tencent HY + Fudan): Tencent HY announced CL-bench as a benchmark for “context learning” (learning from provided context vs pretraining recall), describing 500 complex contexts, 1,899 expert-curated tasks, and 31,000+ validation rules, while reporting that evaluated frontier models solve only ~17.2% on average in the benchmark launch and dataset scale note.
• Failure taxonomy: The shared breakdown shows high rates of context ignored and context misused across models (often ~55–66%), plus non-trivial format errors, as shown in the error breakdown screenshot.
• Why it’s different: The benchmark claims every task is solvable from in-context information alone (“pure contextual reasoning”), which makes low scores more diagnostic of ingestion/usage failures than missing world knowledge, per the dataset scale note.
METR reports Gemini 3 Pro around 4h at 50% success, ~43 min at 80%
METR (software task time horizons): Gemini 3 Pro is being reported at a 50% time horizon of 236 minutes (3h56m) in the exact minutes note, with comparisons claiming it’s close to GPT‑5.1‑Codex‑Max at 3h57m in the comparison post; multiple posts also cite an 80% horizon just over ~40 minutes, as stated in the 80% horizon comparison.
• Leaderboard movement: One charted datapoint suggests Gemini 3 Pro barely edges prior entries on the “80% horizon” plot, as shown in the METR chart share.
• Interpretation caveat: These are horizon estimates over a task suite (not a single benchmark), so small deltas may be within noise unless replicated across more runs, as implied by the close clustering referenced in the 80% horizon comparison.
WorldVQA launches to test memorized visual world knowledge separately from reasoning
WorldVQA (Moonshot/Kimi): Moonshot introduced WorldVQA, a 3,500-pair benchmark across 9 categories designed to isolate “what the model memorizes” in vision-centric world knowledge—separating knowledge retrieval from reasoning per the benchmark announcement.
• Early comparisons + calibration: Shared results show Gemini‑3‑pro around 47.4/50 and Kimi‑K2.5 around 46.3/50, while Claude‑opus‑4.5 is shown near 36.8/50 and GPT‑5.2 near 28.0/50, along with calibration metrics like ECE and slope highlighting overconfidence, as captured in the results and calibration charts.
• Dataset intent: The taxonomy (Culture/Objects/Transportation/etc.) and emphasis on linguistic/cultural diversity are part of the core design claim in the benchmark announcement.
Arena’s image Pareto charts push “score vs price” model selection for generation and edit
Arena (Image leaderboards): Arena is promoting Pareto frontier views for image models—plotting Arena score vs price per image—to help teams pick models that are either best-quality or best-efficiency for a given use case, as described in the text-to-image frontier and image-edit frontier.
• Text-to-image frontier callouts: The post lists frontier candidates including OpenAI (GPT‑Image‑1.5‑High‑Fidelity, GPT‑Image‑1‑Mini), Black Forest Labs (Flux‑2 variants), Google (Nano‑Banana), and Tencent (Hunyuan‑Image‑3.0), per the text-to-image frontier, with the underlying board reachable via the text-to-image leaderboard.
• Image edit frontier callouts: For single-image edit, the post highlights OpenAI (ChatGPT‑Image‑High‑Fidelity), Bytedance (Seedream), Google (Nano‑Banana), BFL (Flux‑2 variants), and Reve (Reve‑V1.1‑Fast) in the image-edit frontier, with drill-down boards linked from the image-edit leaderboard.
Search Arena adds new frontier entrants; Gemini 3 Flash Grounding leads
Search Arena (Arena): The search leaderboard update puts gemini‑3‑flash‑grounding at #1, adds gpt‑5.2‑search‑non‑reasoning at #5, and places claude‑opus‑4.5‑search at #7 and claude‑sonnet‑4.5‑search at #13, with the evaluation framed around real-time queries and citation/source quality in the leaderboard update.
• What’s measured: The benchmark explicitly calls out citation quality and “real-time search queries,” and it points to the live testing surface in the Search arena.
• Product signal: A non-reasoning search model landing in the top 5 is called out as notable directly in the leaderboard update, suggesting latency/grounding tradeoffs are being rewarded on this board.
🏎️ Inference runtimes & training efficiency: fp8, serving support, throughput
Serving and efficiency work shows up via day-0 runtime support for new open models and practical precision experiments (fp8). Compared to yesterday, more emphasis is on speed/throughput and deployment commands.
Karpathy reports fp8 GPT-2 repro at 2.91 hours and explains why gains are modest
fp8 training (Karpathy): Andrej Karpathy reports enabling fp8 training for a GPT‑2 reproduction run, improving “time to GPT‑2” by +4.3% down to 2.91 hours, and notes a rough cost of ~$20 using 8×H100 spot pricing, all detailed in the fp8 training notes.
He also documents why fp8 can under-deliver at small scale (extra scale conversions; GEMMs not large enough; step quality drops), and describes a practical tradeoff he saw between rowwise vs tensorwise scaling—ending up with ~5% net speedup after adjusting training horizons.
vLLM 0.15.0 ships day-0 serving for Qwen3-Coder-Next with tool-call parsing
vLLM (vLLM Project): vLLM 0.15.0 adds day-0 support for serving Qwen3-Coder-Next, including a dedicated --tool-call-parser qwen3_coder path and --enable-auto-tool-choice, as shown in the Serve command recipe that uses vllm serve Qwen/Qwen3-Coder-Next with tensor parallelism.
This matters for teams trying to run agent harnesses against Qwen locally or on their own GPUs, because correct tool-call parsing is usually where “works in chat” turns into “works in production” for coding agents.
SGLang posts day-0 server launch command for Qwen3-Coder-Next
SGLang (LMsys): SGLang announced day-0 support for Qwen3-Coder-Next, emphasizing its hybrid attention + sparse MoE design and long-context focus, and showing a concrete python -m sglang.launch_server recipe with --tool-call-parser qwen3_coder and --tp 2, according to the SGLang serving post.
For inference engineers, the key detail is that tool-call parsing is wired directly into the runtime invocation, which reduces glue-code drift between agent scaffolds and the served model.
vLLM + NVIDIA improve gpt-oss-120B throughput on Blackwell; lower latency too
vLLM (vLLM Project): The vLLM community and NVIDIA report improved gpt-oss-120B inference on Blackwell GPUs, claiming +38% max throughput and +13% min latency, driven by FlashInfer integration, torch.compile kernel fusions, async scheduling, and stream-interval tuning, as described in the Perf update.
This is a concrete example of “runtime engineering beats weights changes” for production deployments: same model class, better Pareto frontier on interactivity vs tokens/sec.
Together AI hosts Qwen3-Coder-Next with 99.9% SLA and posted pricing
Together AI (Together): Together is hosting Qwen3-Coder-Next as an “agentic coding backbone,” advertising 99.9% SLA and quoting pricing as $0.50/$1.20, per the Hosting announcement; the productized endpoint details are also visible on the Model API page.
This is a distinct deployment surface versus self-hosting: teams get a stable endpoint for coding-agent workloads without needing to maintain MoE serving and tool-call parsing infrastructure themselves.
🛡️ Safety & governance: preparedness hires, constitutions, and sharing risks
Security/safety news today is governance-forward: OpenAI preparedness staffing, Anthropic’s constitution publication, and emerging risk surfaces from shareable agent sessions and instruction-following as marketing/prompt-injection vectors.
OpenAI appoints Dylan Scand as Head of Preparedness
OpenAI (Preparedness): OpenAI hired Dylan Scand as its new Head of Preparedness; Sam Altman frames it as a response to “extremely powerful models soon” and says safeguards need to scale accordingly, with Scand leading severe-risk mitigation across the company as stated in the Hiring announcement.
The hiring reads as a governance signal that OpenAI expects capability jumps on a short timeline, and that internal “preparedness” work is being treated as an exec-level function rather than a part-time research/ops responsibility.
Anthropic publishes Claude’s Constitution as a public artifact
Claude’s Constitution (Anthropic): Anthropic’s Claude Constitution is now publicly accessible, per a community callout that it’s “public on GitHub” in the GitHub publication note, with the canonical text available on the Constitution page.
A separate summary thread claims the newer constitution emphasizes explanatory principles (“why,” not just rules) and is released under CC0, as described in the Constitution summary. Treat interpretation details as secondhand unless you’ve reviewed the primary text.
OpenAI says it’s nearing “Cybersecurity High” under its preparedness framework
OpenAI (Capability gating): A screenshot of Altman’s post claims OpenAI expects to reach the Cybersecurity High capability level “soon” under its preparedness framework, alongside “exciting launches related to Codex” starting next week as shown in the
.
This matters because the “High” label implies internal thresholds that can trigger new safeguards (access controls, monitoring, eval requirements, or rollout constraints), even if the specific measures aren’t enumerated in the post.
Claude Code session sharing surfaces a new code-leak footgun
Claude Code (Anthropic): Claude Code now supports sharing full sessions via link with Private/Public options; the share flow explicitly warns that sessions from private repositories may expose code to anyone with the link, as shown in the Share modal screenshot.
This shifts “agent traces as documentation” into a real data-governance surface: shared transcripts can include diffs, file paths, and other sensitive context depending on how the harness logs tool output.
Prompt-like ads may become both growth channel and security risk
Agent instruction attacks (Ecosystem): Ethan Mollick highlights a pattern where a tweet can double as “the instructions for the agent to set itself up,” suggesting plain-English, agent-readable marketing could become a distribution primitive—and “a security nightmare,” per the Marketing prompt-injection risk.
The core issue is that natural-language onboarding and “call-to-action” content can be indistinguishable from operational instructions to an agent with tool access, especially if the agent is configured to follow external text verbatim.
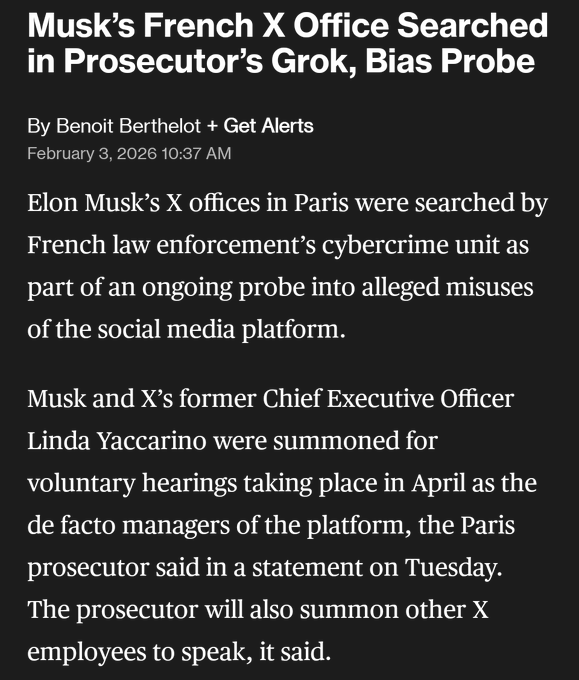
France escalates enforcement pressure around Grok outputs
Grok (xAI) / X (Regulation): A report says French cybercrime investigators searched X’s Paris office as part of a probe into Grok’s alleged biases and platform misuse, per the Raid report.
If accurate, it’s a near-term operational signal for EU-facing deployments: model output issues are being treated as enforceable platform risk, not just “content moderation discourse.”
🏢 Enterprise & market signals: agents vs SaaS, payments rails, and adoption playbooks
Business-side discussion clusters around agent-driven market structure changes and enterprise adoption tactics. This is lighter on hard numbers than tool/infra beats, but high-signal for leaders tracking where budgets move next.
Circle CEO predicts “billions of AI agents” will need payment rails in 3–5 years
AI agent economy (Circle): Circle CEO Jeremy Allaire argued that “in 3–5 years” there could be billions of AI agents conducting economic activity, and that they’ll need an economic/financial/payment system, as shown in the WEF clip. This frames payments not as “fintech later,” but as core infrastructure for agentic workflows that buy APIs, place orders, and reconcile costs.

The claim is directional (no concrete timeline commitments), but it’s a crisp enterprise signal: if agents become first-class “actors,” budgeting, identity, and transaction primitives become product requirements—not compliance afterthoughts.
A concrete rubric for picking AI coding and AI code review tools at companies
Enterprise adoption (Pragmatic Engineer): A deepdive describes how ~10 companies evaluate AI coding and AI code-review tools using a rubric that separates value density from noise density (and tracks signal-to-noise), with one example scorecard shown in the vendor scorecard. The piece positions this as a procurement-friendly alternative to “developer vibes” when rolling tools out across teams.
The public artifact is the longform writeup linked in the Full report, while the vendor scorecard image captures the key mechanic: treat AI review comments as measurable output you can sample, categorize, and compare vendor-to-vendor.
a16z marketplace advice shifts toward “AI as ops team” and instant pricing
Marketplace playbook (a16z): A marketplace-focused memo lays out tactics for 2026 that treat AI as the scalable operations layer—voice agents doing intake/vetting, reasoning agents enabling instant pricing, and “high-coordination” categories as the best wedge, as summarized in the tips snapshot. It’s not claiming the marketplace math changes; it’s arguing AI makes previously-unviable categories operationally feasible.
• Ops substitution: Tasks that used to require humans (interviewing both sides, doc processing, matching) get reframed as voice/agent workflows, per the tips snapshot.
• Distribution bet: The memo explicitly says “ChatGPT and Claude app stores are worth investing in now,” treating agent platforms as future top-of-funnel, per the tips snapshot.
It’s a pattern writeup rather than a case study—no conversion numbers or CAC deltas are provided in the tweet itself.
🎛️ Generative media tooling: motion design, playable media, and open music gen
Generative media is a meaningful share of today’s feed: prompt-to-motion tooling, “software as content” bots, and fast local music generation. Kept separate so creative stack updates don’t get dropped on agent-heavy days.
ACE-Step v1.5 lands in ComfyUI: open music gen with low-VRAM runs
ACE-Step 1.5 (ComfyUI): ComfyUI added ACE-Step 1.5 with claims of generating full songs “in under 10 seconds” and fitting into “<4GB VRAM” workflows, as shown in the ComfyUI announcement clip.

The accompanying writeup says the system uses an LM to plan song structure and a diffusion transformer for audio synthesis, with more details in the Comfy blog post and reiterated in the Architecture note.
Higgsfield ships Vibe-Motion: prompt-to-motion design with real-time canvas control
Vibe-Motion (Higgsfield): Higgsfield launched Vibe-Motion, positioning it as an AI motion-design tool where one prompt generates an animated design and you can refine parameters live on the canvas, as shown in the Launch demo.

The rollout is also being framed as Claude-powered agentic workflows embedded into a motion/video toolchain, per the Workflow claim and the Video editor demo.
Sekai’s X bot turns replies into playable browser software with remix loops
Sekai (Playable media): Sekai is getting attention for an X bot workflow where replying with an idea (tagging the bot) yields an interactive experience in-browser within ~30 seconds, as described in the Playable media thread and demonstrated in the In-browser build demo.

• Remix loop: The pitch is “software as content”—people clone and modify each other’s tiny apps/games, not just consume them, per the Software as content framing.
A concrete example of what’s being built is visible via the Example game.
Gemini 3 Flash + code execution in AI Studio: cheap background removal and stickers
Gemini in AI Studio (Workflow): A practical pattern showing up is using Gemini 3 Flash with code execution to turn generative images into deterministic assets—generate/edit with Nano Banana, then run OpenCV in the sandbox for transparency + bounding boxes, with a stated per-run cost of ~$0.006, per the Workflow breakdown.

The same approach is also being packaged as a “sticker lab” UI that can ground on search and output transparent PNGs, as shown in the Sticker generation UI; a longer walkthrough is linked in the Dev.to tutorial.
Riverflow 2.0 (Sourceful) is available on Replicate after topping image leaderboards
Riverflow 2.0 (Sourceful/Replicate): Replicate is promoting hosted access to Riverflow 2.0 Pro for image generation/editing, per the Replicate listing.
A separate thread claims it recently took #1 on Artificial Analysis “All listings” leaderboards for both text-to-image and image editing and notes pricing at $150 per 1,000 images, as shown in the Leaderboard screenshot.
Arena publishes image Pareto frontiers for text-to-image and image editing models
Arena (Image evaluation): Arena posted Pareto frontier snapshots plotting Arena score vs price to highlight which image models are “best quality” vs “efficient at scale,” naming frontier sets for both text-to-image and image edit in the Text-to-image frontier post and the Image edit frontier post.
The underlying leaderboards are accessible via the Text-to-image leaderboard and the Image edit leaderboard, which makes the price/quality tradeoffs queryable beyond the static frontier lists.
🧭 Dev sentiment & labor narratives around agents
Discourse itself is news here: recurring claims about job displacement/UBI, “turning point” narratives, and shifting norms around what it means to ‘ship’ with agents. Kept tight to avoid mixing in product updates.
Developer work gets reframed as orchestrating parallel agents
Agent labor reframing (Vercel): A post frames “the new engineering” as building agents that scale individual developer output horizontally—parallel CLI agents (tmux/splits), steered by skills/MCPs, with sandboxes enabling overnight/background execution across PRs and incidents in the horizontal scalability post.
The core claim is that the job shifts toward automating the full product-development loop, with implementation becoming “supervision + orchestration” more than keystrokes.
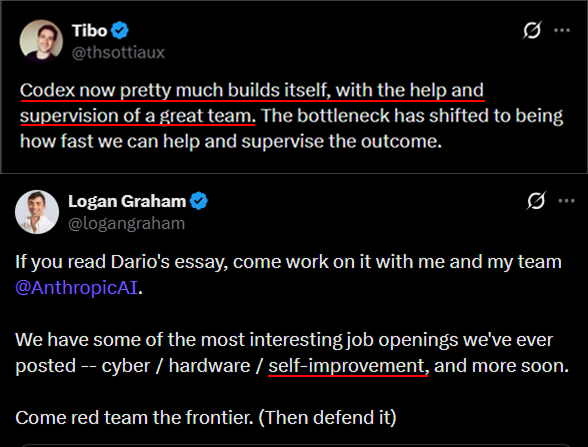
Recursive self-improvement talk moves from theory to product anecdotes
Self-improvement narrative: One thread points to internal quotes like “Codex now pretty much builds itself” and “Claude Code builds the next version of itself” as early signs of recursive tool improvement—while noting “the loop isn’t fully closed yet,” as shown in the recursive self-improvement claim.
This is largely discourse (not a benchmark), but it’s increasingly how builders describe day-to-day work: bottleneck as supervision speed, not typing speed.
“2026 is the turning-point” narrative spreads around autonomous iteration
Dev labor narrative: A post claims we’re entering a phase where frontier labs “largely write the code for the next iteration autonomously,” while CEOs focus on macroeconomic effects and reduced white‑collar labor demand, calling 2026 an inflection year in the turning-point post.
It’s a sentiment signal more than a shipped capability claim; the concrete part is the assumption that autonomy is moving from “assist” to “iterate on itself” as a default expectation.
Coding-tool mindshare shifts: Gemini seen as missing vs Claude Code and Codex
Competition discourse: A thread argues “Gemini [is] not being in the conversation at all” compared with Claude Code and Codex, calling that the real “code red” for Google’s coding footprint in the coding mindshare take.
The follow-on claim is that Chinese open-weight labs’ coding plans are getting disproportionate mindshare on X—“those vibes can become real habits,” per the follow-up note.
Debate: AI may plateau in real-world impact even if models improve
Impact vs capability: A clip summarizes a view that AI progress could plateau in practical, day-to-day transformation—tools become “nice helpers” (coding, shopping, math) but not universally disruptive, partly because training/running costs remain high and benefits can be niche, per the impact plateau discussion.

It’s a useful counterweight to “everything changes this quarter” narratives; the claim is specifically about impact diffusion, not raw model metrics.
Circle CEO: billions of agents will need payments infrastructure within 3–5 years
Agent economy narrative (Circle): A WEF clip quotes Circle CEO Jeremy Allaire predicting “billions of AI agents conducting economic activity” in 3–5 years, explicitly calling out the need for an economic/financial/payment system to support them, as shown in the WEF quote clip.
This is more macro than tooling, but it’s increasingly used to justify agent identity, compliance, and transaction primitives as first-class product requirements.
Open-weight labs get cast as the new open-source standard-bearers
Open vs closed narrative: A post lists DeepSeek, Qwen, GLM, Kimi, Mistral, and MiniMax as the open-source / open-weight ecosystem that’s “becoming what Meta was supposed to be,” in the open-models take.
This is less about a specific release and more about perceived leadership in open distribution and fast iteration cadence.
Vibe coding gets re-scored as “useful but imperfect”
Vibe coding maturity: One reflection says vibe coding has improved markedly over a year—basic tasks feel easy now, complex tasks are feasible, but reliability still isn’t perfect, as described in the vibe coding reflection.
It’s a sentiment marker that “vibe coding” is shifting from meme to an evaluated workflow, with quality judged against real project complexity.
“No one has pulled ahead” becomes a recurring AI race frame
Competition framing: A post argues the AI race has “only just started,” citing shifting leadership across labs over time as evidence the space will stay competitive, in the race competitiveness take.
This is analyst-style narrative, but it tends to influence how teams justify multi-model strategies and hedge vendor risk.
Some devs predict code wrappers become disposable in agent workflows
Labor/value claim: A post asserts the economic value of a 10K‑line Python library is “close to $1” in 2026 because agents can synthesize bespoke wrappers on demand; the prediction is that wrappers as durable artifacts “will disappear,” per the wrappers disappear claim.
It’s a provocative valuation framing that often comes up in build-vs-buy conversations when agents can generate integration glue quickly.
📅 Workshops, meetups, and office hours for agent builders
Events/learning surfaces that help teams operationalize agent tooling: live Codex training, LangChain evaluation/observability education, and local builder meetups. Excludes product announcements unless the primary artifact is the event.
LangChain publishes evaluation patterns for “deep agents” (single-step to multi-turn)
Evaluating deep agents (LangChain): LangChain shared a field guide for testing long-horizon agents, arguing you need per-datapoint success logic plus single-step, full-turn, and multi-turn evals, and clean reproducible environments; the five-part framework is summarized in the Deep agent eval patterns and expanded in the Blog post.
• Why it matters: This treats agent evaluation more like scenario testing than LLM scoring—regressions often happen at individual decision points, not just in the final answer, per the Deep agent eval patterns.
OpenAI Devs announces a live Codex app workshop (Skills + Automations)
Codex app workshop (OpenAI): OpenAI Devs is hosting a live, end-to-end build session showing Codex app setup plus real usage of Skills and Automations during an app build; the run-of-show ("build apps end to end", "show how we use it") is laid out in the Workshop announcement.
This is explicitly about operational workflow—how to wire the app up, then lean on Skills/Automations while shipping—rather than model capabilities.
LangChain announces SF meetup on troubleshooting agents via traces
SF troubleshooting meetup (LangChain): LangChain is running an in-person San Francisco event focused on diagnosing agent failures using traces (reasoning goes off-track without a crash), with limited spots and food/drinks; the positioning and RSVP link are in the Meetup invite.
This is the same theme as their recent eval push, but aimed at live ops: what to look at when a long tool-calling run ends wrong.
LangChain schedules webinar on observability primitives for agent evaluation
Agent observability webinar (LangChain): LangChain announced a webinar on how debugging shifts from stack traces to inspecting an agent’s trajectory—covering observability primitives like runs, traces, and threads, plus how production traces enable offline/online eval; details and RSVP are in the Webinar announcement.
The framing is directly about where failures show up in multi-step tool use (“nothing crashed; the reasoning failed”), which is the operational pain point teams hit once agents are doing hundreds of steps.
OpenClaw “Unhackathon” in SF: curated build/debug day (40 cap)
OpenClaw Unhackathon (Work OS): A small, curated SF build day is scheduled (40 attendee cap) for people actively shipping OpenClaw/ClawdBot projects—explicitly optimized for deep work (peer debugging, infra setup) rather than pitches/prizes; the constraints and intent are described in the Event registration and the Event page.
The event format is notable because it’s selection-based around concrete tasks, not “anyone can show up and demo.”
Zed hosts “New User Office Hours” for live workflows and Q&A
New user office hours (Zed): Zed announced its first office hours session (Feb 5) to walk through live workflows and answer questions directly in the editor; the invite is in the Office hours post, with registration in the Signup page.
This is one of the few recurring formats where teams can get hands-on help integrating an editor into their agent workflow (especially as CLIs/ACPs become the interface layer).