TranslateGemma ships 55-language on-device translation – 12B beats 27B baseline
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Google DeepMind released TranslateGemma, an open translation-focused Gemma 3 family at 4B/12B/27B params covering 55 languages; weights are distributed via Hugging Face and Kaggle; positioning centers on low-latency, fully on-device translation (4B pitched as phone-capable). DeepMind says it distilled from Gemini-generated translation data, then ran a two-stage SFT + RL recipe for “more natural” output; reported evals claim TranslateGemma 12B outperforms a Gemma 3 27B baseline on WMT24++ across the full 55-language set, but independent replications and domain-specific tests (legal/medical) aren’t bundled. Threads also claim text-in-image translation works without dedicated multimodal training, which reads like capability carryover rather than a verified new modality.
• Open Responses: OpenAI Devs published an open-source Responses-style API spec; OpenRouter standardizes on it; Ollama and vLLM signal support, framing this as reducing reverse-engineered streaming/tool-call quirks.
• Long-horizon coding economics: a CodexBar screenshot shows 3.3B tokens in 30 days costing $890.37; Codex CLI adds mid-run “steering” and /fork to branch sessions.
• Serving + context scale: SGLang claims 3.31× throughput via pipeline parallelism for 1M+ token contexts; fal adds observability/rollbacks while pitching 1,000+ hosted models.
Top links today
- Open Responses spec and reference implementation
- TranslateGemma models overview and docs
- TranslateGemma 4B model on Hugging Face
- Paper on KV cache reuse in LLM judges
- Nature paper on emergent misalignment from fine-tuning
- FLUX.2 [klein] model repo and weights
- Run FLUX.2 [klein] on Replicate
- Cursor agent code review evaluation write-up
- Cursor long-running agents and planning write-up
- VS Code docfind WebAssembly search engine
- Anthropic Economic Index report v4
- Anthropic AI for Science program case studies
- Agent Browser open-source repo
- Kilo model comparison for PR review
- Ollama Open Responses support announcement
Feature Spotlight
Feature: TranslateGemma — open, on-device translation models (55 languages)
TranslateGemma makes high-quality translation deployable offline (incl. phones) via open 4B/12B/27B models for 55 languages—shifting translation stacks toward local-first latency, cost, and privacy.
High-volume cross-account release of Google DeepMind’s TranslateGemma: open translation models (4B/12B/27B) designed for efficient, low-latency, fully on-device translation. This is today’s main shared storyline across Google/DeepMind/Hugging Face posts.
Jump to Feature: TranslateGemma — open, on-device translation models (55 languages) topicsTable of Contents
🌐 Feature: TranslateGemma — open, on-device translation models (55 languages)
High-volume cross-account release of Google DeepMind’s TranslateGemma: open translation models (4B/12B/27B) designed for efficient, low-latency, fully on-device translation. This is today’s main shared storyline across Google/DeepMind/Hugging Face posts.
Google DeepMind releases TranslateGemma: open translation models for on-device use
TranslateGemma (Google DeepMind): Google DeepMind announced TranslateGemma, a family of open translation models (4B/12B/27B) covering 55 languages, designed for low-latency deployments that can run fully on-device, as described in the [release announcement](t:3|release announcement) and the companion [Google blog post](link:444:0|Launch blog); distribution is live via Hugging Face and Kaggle per the [availability callout](t:3|availability callout).

Early reactions frame it as a practical “local Google Translate” replacement—one developer calls it “100% open source and local Google Translate” and highlights that “the smaller 4B model runs on a phone. Offline,” as quoted in the [builder thread](t:2|builder thread).
• Distillation story: DeepMind says it’s built on Gemma 3 and trained on Gemini-generated translation data to transfer capability into smaller models, as explained in the [training note](t:29|training note).
What’s still not in the tweets is a crisp “best default” guidance by language pair or domain; most of the shipping signal today is about accessibility and deployment surfaces rather than task-specific tuning.
TranslateGemma’s 12B model beats Gemma 3 27B baseline on WMT24++ across 55 languages
TranslateGemma (Evaluation): Reported results emphasize that TranslateGemma 12B outperforms the larger Gemma 3 27B baseline on WMT24++ across 55 languages, as summarized in the [model collection overview](t:79|model collection overview) and the [recap thread](t:53|recap thread).
The error-rate comparison by language family shows the 12B model lower across every shown group (e.g., Romance, Germanic, Balto-Slavic), as visualized in the [benchmark chart](t:117|benchmark chart).
• Sizing implication: The repeated claim that 12B can outperform a 27B baseline suggests the translation-specialized post-training is doing most of the work here, not raw scale—see the [bullet breakdown](t:53|bullet breakdown).
The tweets don’t include independent replications or domain-specific evals (e.g., legal/medical); the best concrete artifact linked from posts is the Hugging Face collection page in the [model collection](link:79:0|Model collection).
TranslateGemma technical report details two-stage SFT+RL and retained multimodal translation
TranslateGemma (Training + capabilities): Posts highlight a two-stage recipe—supervised fine-tuning on human + Gemini-generated translations, followed by reinforcement learning for more natural output—summarized in the [technical recap](t:53|technical recap) and documented in the [technical report link](t:265|technical report link).
• Multimodal carryover: Multiple threads claim the models retain multimodal ability and can translate text inside images “without specific multimodal training,” as stated in the [capabilities list](t:190|capabilities list).
• Deployment tiers: The intended placement is explicit—4B for mobile/edge, 12B for laptops, 27B for cloud GPUs/TPUs—per the [deployment summary](t:53|deployment summary).
The missing detail for engineers is operational guidance on latency/memory tradeoffs per hardware class; the report link in the [papers page](link:265:0|Technical report) is the closest thing in today’s tweets to those implementation specifics.
🧩 Open Responses spec: interoperable Responses-API schema across providers
New interoperability push: an open-source spec modeled on the OpenAI Responses API, with fast adoption signals (OpenRouter, Ollama, vLLM). Excludes TranslateGemma (covered as the feature).
OpenAI Devs launches Open Responses, an open spec for interoperable Responses-style APIs
Open Responses (OpenAI Devs): OpenAI Devs announced Open Responses, an open-source specification for building multi-provider, interoperable LLM interfaces modeled on the OpenAI Responses API, as described in the announcement thread and detailed on the spec site.

The stated goal is “build agentic systems without rewriting your stack for every model,” with emphasis on consistent streaming events, tool invocation patterns, and extensibility without ecosystem fragmentation, per the announcement thread. Early adoption is already being signaled via the adoption note, though the tweets don’t yet include a compatibility matrix or conformance test suite.
OpenRouter standardizes on Open Responses for OpenAI Integrations
OpenRouter (OpenRouterAI): OpenRouter says it’s standardizing on Open Responses for “OpenAI Integrations,” framing a unified request/response schema as improving support for multimodal inputs and interleaved reasoning, according to the standardization note.
This is one of the first “distribution” wins for the spec: it’s not just a doc, it’s being adopted as a compatibility layer in a multi-model router where schema stability directly affects downstream tooling and SDK surface area.
Ollama adds Open Responses support
Ollama (Ollama): Ollama says it now supports Open Responses, extending the spec into local-model workflows and self-hosted inference setups, per the Ollama announcement.
This matters because local runtimes tend to be where API incompatibilities show up fastest (streaming events, tool call shapes, and multimodal payload conventions), so an explicit schema can reduce “reverse-engineering by behavior” across providers.
vLLM endorses Open Responses after reverse-engineering the protocol
vLLM (vllm_project): The vLLM team says that when they added support for gpt-oss, the Responses API lacked a standard and they “reverse-engineered the protocol by iterating and guessing,” and they’re now excited about Open Responses as “clean primitives” and “consistency,” as described in the implementation note.
This is a concrete statement of pain: the cost wasn’t just writing an adapter, it was chasing implied behavior. The spec is positioned as eliminating that ambiguity.
Developers frame Open Responses as the JSON standard they wanted
Developer reception: Simon Willison calls Open Responses “the standard I’ve most wanted,” noting that while it would’ve been convenient to build on Chat Completions, Responses offers a better clean slate for newer model capabilities, as stated in the reaction post and expanded in his blog write-up.
In the same vein, Dave Kundel frames Responses as “agents as an API” and highlights the value of moving from an implied protocol to an explicit open spec, per the ecosystem reaction.
🧠 GPT‑5.2 Codex & long-running agent runs (Cursor + Codex CLI + Code Arena)
Continues the long-horizon coding narrative: coordinated agent runs, model-role specialization (planner/worker/judge), and Codex surface-area expanding (Code Arena, CLI features). Excludes Open Responses (separate standardization story).
Cursor says GPT-5.2 holds focus better than Opus 4.5 on long-running agents
Cursor (Cursor): Following up on browser run (week-long browser build), Cursor’s write-up now makes the model-selection claim explicit—GPT-5.2 “is much better at extended autonomous work” while Opus 4.5 “tends to stop earlier and take shortcuts,” as captured in the Model choice screenshot.
The same post frames the practical reason as long-horizon stability (instruction-following, drift avoidance, and precise implementation), and it reinforces role specialization (planner vs worker) rather than “one universal model,” as described in the scaling agents post linked in Scaling agents post.
Codex CLI adds experimental “steer conversation” while the agent runs
Codex CLI (OpenAI): Codex CLI v0.85.0 exposes an experimental “steering” mode where Enter submits guidance immediately during execution and Tab queues messages, as shown in the Steering setting.
This is a harness-level change: it alters mid-run control flow without requiring a restart, which is the key failure mode for long tasks when requirements shift after the run begins, per the Steering setting.
GPT-5.2-Codex is now live in LMArena Code Arena
Code Arena (LMArena): LMArena says GPT-5.2-Codex is now available inside Code Arena for “single prompt → working websites/apps/games,” per the Code Arena availability.
This matters for teams tracking model quality in real build loops (planning, scaffolding, debugging) because Code Arena is explicitly positioned as an end-to-end harness rather than a snippet evaluator, as described in the Code Arena availability announcement.
Code Arena posts 16× SVG comparisons for GPT-5.2-Codex vs other OpenAI models
Code Arena evals (LMArena): LMArena published a side-by-side comparison video of GPT-5.2-Codex versus other OpenAI models on 16 SVG-generation prompts, asking for qualitative judgments from builders in the SVG comparison post.

The clip is lightweight evidence (not a standardized benchmark artifact), but it’s a concrete, prompt-level look at where Codex differs in front-end-ish “exactness” tasks like SVG structure and fidelity, as shown in the SVG comparison post.
CodexBar shows 3.3B tokens in 30 days, ~$890 spend
CodexBar (third-party client): A CodexBar usage screenshot shows 3.3B tokens consumed in 30 days with $890.37 total cost, plus a “Today” line of **$9.90 / 39M tokens,” as shown in the Usage screenshot.
This is a direct signal of how quickly long-running agent workflows can saturate paid plans and internal budgets when the primary unit becomes “keep the agent cooking,” as evidenced by the Usage screenshot.
Codex CLI /fork creates a fresh copy of a session for branching
Codex CLI (OpenAI): Codex now supports a /fork command that clones an existing session so users can explore alternate directions without overwriting the original thread, according to the Fork command note.
The same note claims the underlying API may support forking from a specific point, but the current slash command appears to duplicate the full session, per the Fork command note.
Codex teaser targets iOS dev with more Apple ecosystem updates coming
Codex (OpenAI): A brief teaser claims “Codex for iOS dev” and promises “major improvements for the Apple ecosystem coming soon,” per the iOS dev teaser.
No concrete surface area (Xcode integration details, supported workflows, or rollout dates) is specified in the tweet, so the operational impact is still unclear beyond the positioning stated in the iOS dev teaser.
Practitioners say Codex “xhigh” is stable for backend work, but slow
Codex usage (OpenAI): One practitioner report says they use both Claude Code and GPT-5.2-Codex, but end up on Codex more often because Claude Code limits are “a big blocker”; they also describe Codex on “xhigh” as solid for backend work but “slow,” per the Usage note.
This is anecdotal, but it matches the broader long-horizon theme: teams are trading latency for run stability and fewer mid-task degradations, as described in the Usage note.
🪶 Claude Code: in-app diff review, CLI 2.1.9 changes, and MCP Tool Search
Product-level Claude Code changes: better review ergonomics (diff view) plus CLI/connector behaviors to reduce context/tool overhead. Excludes general Claude model rankings (tracked in benchmarks).
Claude Code CLI 2.1.9 adds MCP Tool Search thresholds, hooks, and long-session fixes
Claude Code CLI 2.1.9 (Anthropic): The 2.1.9 release adds auto:N for MCP tool search auto-enable based on context-window percentage; it also introduces plansDirectory, Ctrl+G external editor support in AskUserQuestion “Other”, PreToolUse hooks that can return additionalContext, and ${CLAUDE_SESSION_ID} substitution for skills, as listed in 2.1.9 changelog thread and backed by the Changelog source.
• Stability fixes: The release calls out long sessions with parallel tool calls failing due to “orphan tool_result blocks” plus MCP reconnection hangs and terminal Ctrl+Z suspend issues, as captured in 2.1.9 changelog thread.
• Prompt policy tweak: The bundled prompt now bars time estimates beyond planning (“a few minutes”, “2–3 weeks”), as described in Prompt change note.
Claude Code adds in-app diff review with inline comments
Claude Code (Anthropic): Claude Code on web and desktop now includes an in-app diff view so you can review exact edits without hopping out to GitHub/your IDE, as announced in Diff view announcement and clarified in Inline review flow.
The feature is positioned as a review ergonomics upgrade (diffs + inline comments) rather than an agent capability change, with the entry point shown in the Claude Code page.
Claude Code MCP Tool Search lazy-loads tools when tool text gets large
MCP Tool Search (Claude Code): Following up on Tool Search (tool search rollout), a new description says Claude Code can dynamically fetch tools only when needed and switches to search-and-load behavior once tool descriptions exceed ~10% of the context window, per Lazy loading description.
The knob now also shows up as a configurable threshold (auto:N) in the CLI release notes, as spelled out in Auto threshold setting.
Claude Code users report early blocking despite remaining context headroom
Claude Code (Anthropic): A user report shows Claude Code halting with “Context limit reached /compact or /clear to continue” even while /context reports ~30k tokens of free space (15.1%) remaining, with the screenshot and numbers shown in Context limit report.
The complaint frames this as a behavior change (“this used to work fine”) that increases compaction friction in long sessions, with the specific model instance shown as claude-opus-4-5-20251101 in Context limit report.
Claude Code “dangerously skip agency” flag draws attention to control risks
Claude Code safety controls (Anthropic): A post calling out --dangerously-skip-agency flags concern about users enabling more aggressive “take control” modes without sufficient guardrails, with the UI example shown in Skip agency screenshot.
The same screenshot shows the model responding to “take control” and “my life,” which is being used as a cautionary example about over-broad agency prompts rather than a new product feature announcement, per Skip agency screenshot.
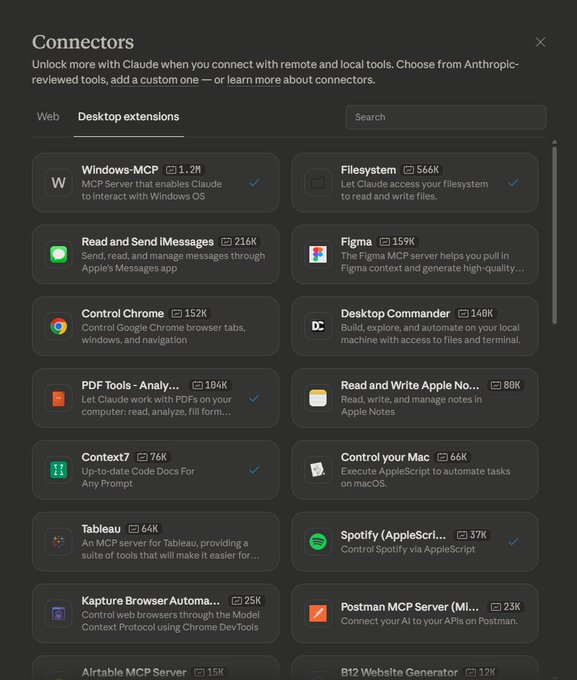
Claude Desktop’s connector gallery highlights expanding MCP surfaces
Claude Desktop connectors (Anthropic): A shared screenshot shows a growing “Connectors” gallery listing extensions like Windows-MCP, Filesystem, Control Chrome, Figma, and Desktop Commander, indicating the breadth of pre-packaged MCP-style integrations being surfaced in-product, as shown in Connector gallery screenshot.
The image suggests connectors are being treated as a first-class UX surface (searchable and categorized), rather than only a config-file/CLI concern, per Connector gallery screenshot.
🧑💻 OpenCode: Copilot subscription support + skills loading + Zen/provider issues
OpenCode activity clusters around distribution via GitHub Copilot subscriptions and ongoing agent UX (skills) and reliability (provider routing). Excludes Codex/Cursor stories (handled elsewhere).
OpenCode officially supports GitHub Copilot subscriptions
OpenCode (OpenCode): OpenCode says it can now “officially” be used with a GitHub Copilot subscription, framing it as support for open source and user choice—see the Announcement and the Enterprise footprint comment calling out Copilot’s distribution reach.

• What users get: OpenCode claims Copilot Pro+ ($39) unlocks access to “the best coding models,” per the Announcement and the Amplification post.
• Why this matters: commentary highlights Copilot’s huge installed base in enterprises, with OpenCode compatibility positioned as unusually pro-choice compared to more closed ecosystems—see the Enterprise footprint comment and the Announcement.
OpenCode reports upstream traffic routing issues affecting Zen requests
OpenCode Zen (OpenCode): OpenCode reports upstream-provider traffic routing problems that are blocking some requests for Zen users, and says the team is investigating—see the Routing incident note.
No public postmortem or mitigation details were shared in the tweets beyond the acknowledgment in the Routing incident note.
OpenCode shows Skills loading and executing in-session
OpenCode (OpenCode): OpenCode users are demoing Skills being discovered from a local skills directory and invoked inline during a build, suggesting Skills are becoming a first-class customization surface in OpenCode—see the Skills execution screenshot.
• How it presents: the UI shows a ⚙skill invocation plus file discovery (glob) under a .claude/skills-style path, per the Skills execution screenshot.
• What this enables: the example is “Japandi web design” guidance driving an end-to-end HTML dashboard output, as shown in the Dashboard output.
OpenCode issue: per-server MCP timeouts may be ignored
OpenCode (OpenCode): A user reports that per-server MCP timeout settings appear to be ignored, while an experimental global flag behaves as expected—see the Bug report ask and the linked GitHub issue.
If confirmed, this is a control-surface bug with direct reliability implications for tool calls (timeouts are often the difference between “agent keeps going” and “agent stalls”), but the tweets don’t include a maintainer response yet beyond the request to look at it in the Bug report ask.
OpenCode plans to default subagents to faster provider models
OpenCode (OpenCode): OpenCode’s maintainer says they’ll change defaults so subagents use faster models on the user’s provider, explicitly noting “no need to have Opus doing exploring,” per the Subagent default change.
This reads as a cost/latency optimization for multi-agent workflows, with the operational assumption that exploration work can be handled by cheaper/faster models while reserving premium models for high-value steps, as described in the Subagent default change.
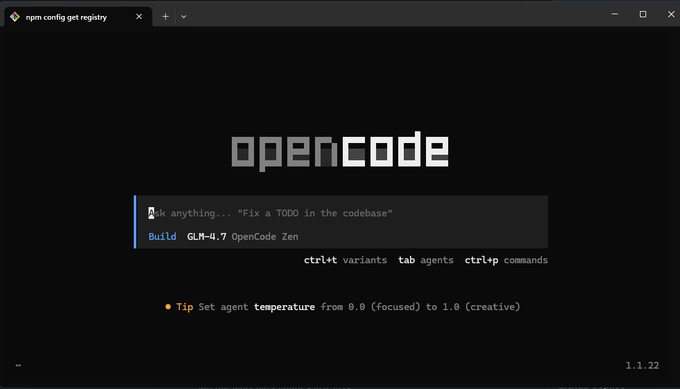
OpenCode Zen highlights GLM-4.7 availability during Windows install
OpenCode Zen (OpenCode): A Windows install screenshot shows OpenCode running “Build GLM-4.7 OpenCode Zen,” with the claim that GLM‑4.7 is free under Zen—see the Windows install screenshot.
The visible UI also exposes agent temperature controls and multi-pane navigation hints (variants/agents/commands), as captured in the Windows install screenshot.
OpenCode draws debate over cloning Claude Code features while criticizing its economics
OpenCode (OpenCode): A thread argues that Claude Code’s “subsidization” makes it an unrealistic template (“a single user can pull thousands of dollars”), while a reply questions why OpenCode would clone features from a product described that way—see the Subsidization critique and the Roadmap challenge.
This is less a product change than an ecosystem signal: builders are now scrutinizing not just features, but whether an agent tool’s economics and default behaviors are sustainable at scale, as implied by the Subsidization critique and the pushback in the Roadmap challenge.
🧰 Agent harnesses & ops: Ralph loops, cost burn, and guardrails
Ops-centric “run agents for hours/days” tooling and practices: loops, budgeting, multi-agent tending, and safety rails against destructive actions. Excludes SDK/spec work (Open Responses in agent-frameworks).
destructive_command_guard blocks risky agent commands via fast pre-tool hooks
destructive_command_guard (Dicklesworthstone): A new Rust tool, dcg, is pitched as a pre-tool hook for Claude Code and gemini-cli that blocks destructive commands (including “creative workaround” scripts via heredocs) using fast regex plus deeper ast-grep analysis when needed, as described in the tool announcement and its GitHub repo.
A notable detail is the focus on reducing false positives while widening coverage (git, cloud deletes, DB drops), which is an ops-grade requirement when agents are running unattended, per the tool announcement.
Claude Max allowance drains in ~14 minutes in a live agent session video
Claude Max usage burn (Doodlestein): A screen recording shows a fresh “20× Claude Max” account’s 5-hour allowance getting drained in roughly 14 minutes, used to illustrate a high-tempo “machine-tending the swarm” workflow (tab juggling, reviewing, re-anchoring after compaction), as described in the screen recording thread.

This is a concrete datapoint for ops teams budgeting agent time: even generous interactive allowances can collapse under rapid iteration patterns, especially when multiple models/tools are used in the same session, per the screen recording thread.
Geoffrey Huntley open-sources Loom “Ralph loop” orchestrator on GitHub
Loom (Geoffrey Huntley): Huntley published the Loom codebase and positioned it as the “ralph loop orchestrator” he’s been rebuilding for a year—explicitly challenging norms like code review and manual deploy gating, per the GitHub release note and the linked GitHub repo. The framing is “agents with sudo” and fast iteration (“everything will change wildly”), which puts Loom in the growing class of agent harnesses that treat deployment as a continuous automated loop rather than a human ceremony.
Loom’s actual reliability story is still unclear from the tweets alone; the public repo and the stated “zero notice” change cadence are the main new artifacts today, as described in the GitHub release note.
Ralph loop UI wires GitHub issues to auto-fix PRs via Droid
Issue-to-PR automation (workflow): A report claims a “non-technical” builder created a UI for running Ralph loops through Droid, connected it to GitHub issues, and had it automatically fix issues and open PRs, as described in the issue to PR claim.
The tweet is anecdotal (no repo or demo attached), but it’s a concrete workflow pattern: treating the issue tracker as the queue and the agent loop as the executor that emits PRs, per the issue to PR claim.
Vercel’s agent-browser CLI hits 5,000 stars in four days
agent-browser (Vercel Labs): The npx agent-browser CLI passed 5,000 GitHub stars in 4 days, signaling strong demand for “browser as a runnable primitive” in agent stacks, as reported in the stars update and visible in the GitHub repo.

The tweets don’t add new technical capabilities today (it’s an adoption/traction update), but the star velocity is the measurable signal that this kind of runner is becoming part of baseline agent ops tooling, per the stars update.
Braintrust publishes a logging workflow for debugging Ralph loops
Braintrust (Ralph loop observability): Braintrust posted guidance for running Ralph loops with logging so each iteration/error/token burn is captured for later debugging, per the logging tip and the linked Braintrust guide.
The core update is the explicit “logs-first” posture for long-running loops—treating iterations like traceable production runs rather than chat history—per the Braintrust guide.
Solana funds two researchers promoting the “Ralph Wiggum Technique”
Ralph Wiggum Technique (Geoffrey Huntley): Huntley says “two AI researchers are now funded by Solana,” framing it as support for agent-driven software development where “software development is now dead… whilst you sleep,” as stated in the open letter and expanded in the linked open letter post.
The funding claim is the concrete update; the bigger operational implication is that “Ralph loop” style automation is now getting explicit outside capital and community infrastructure, per the open letter.
Wreckit ports itself to Rust in 2.5 hours
Wreckit (Ralph loop CLI): Following up on npm release (initial Wreckit CLI for running repo loops), the project claims it “ported itself to Rust… in 2.5 hrs,” with the new code published as shown in the Rust port note and the linked GitHub repo.
This is a small but telling ops datapoint: loop tooling itself is being iterated via the same agentic workflow it enables, per the Rust port note.
BagsApp adds $ralph-to-Anthropic credits conversion for Loom users
$ralph token (BagsApp ecosystem): Huntley describes Loom as “a token guzzler” and says BagsApp added support to convert $ralph into Anthropic LLM credits, suggesting an emerging “pay for agent burn” loop around community tokens, per the token conversion note.
This is a narrow but operationally relevant signal: people are experimenting with non-traditional mechanisms to subsidize long-running agent usage (tokens → inference credits), as described in the token conversion note.
Multiple checkouts resurfaces as a simpler alternative to worktrees
Multi-repo hygiene (workflow): A thread argues for using multiple full checkouts instead of git worktrees to reduce “mental load,” framed as a practical response to managing many parallel changes, per the worktrees complaint and reinforced by the multiple checkouts agreement.
For teams running multiple agents against the same codebase, this is being treated as an operational simplifier (less tooling, fewer coordination surfaces), though the tweets don’t quantify impact beyond subjective friction, per the worktrees complaint.
🧭 Agentic coding playbooks: planning, context discipline, and “files as memory”
High-signal practitioner patterns: plan-first workflows, progressive disclosure, and filesystem-based memory/state as the dominant interface. Excludes specific assistant releases (Claude/Codex/OpenCode handled separately).
Files are all you need: filesystems as the primary agent interface
Files are all you need (LlamaIndex): The thesis being pushed is that agent context + actions are increasingly “file-shaped”—store state in files, search over files, and expose tools via file conventions—laid out in the Files as interface thread and expanded in the linked Trend essay. Following up on Filesystem agents—files as portable context/actions—this is a stronger claim that filesystems are becoming the default control plane for agents.
• Why it’s attractive: The argument is that models already read/write files well, and files double as both persistence and a search surface, as described in the Files as interface thread.
Plan mode advocacy: planning turns “slop” into reviewable code
Plan mode (Workflow): Practitioner sentiment keeps converging on a plan-first loop—without a plan you get low-signal output, and with a plan you get something closer to “me-quality code,” as argued in the Plan mode explainer and followed up with practical “plans you actually read” tips in the Plan readability tips.

• Plan quality, not length: The emphasis is on making plans skimmable and structurally actionable (so you can correct direction early), which is the recurring lever in the Plan readability tips.
• Agent behavior: The framing explicitly treats the plan as the control surface that reduces drift and rework, per the Plan mode explainer.
Human-in-the-loop acts as a manual harness that boosts perceived reliability
Human-in-the-loop harness (Pattern): A specific reliability claim is getting repeated: chatbots and coding agents feel far more dependable when a human is present to catch and correct errors, effectively serving as a “manual harness,” as argued in the HITL reliability point and echoed as a “promoting and verifying” steady-state expectation in the Autonomy skepticism.
• Why this matters to ops: It reframes “agent success rates” as socio-technical—success comes from review checkpoints as much as model capability, per the HITL reliability point.
LangSmith Agent Builder uses a filesystem for agent memory and skills
LangSmith Agent Builder memory (LangChain): LangChain describes giving no-code agents durable memory by writing to a filesystem—chosen because models are already strong at file I/O—using conventions like core instruction files, skills/, and a tools manifest, as laid out in the Filesystem memory rationale. Following up on Agent Builder internals—how the builder works—this is a more explicit “memory is files” implementation detail.
• Standardization by convention: The post names specific file/dir patterns as the interface between user feedback and agent behavior updates, per the Filesystem memory rationale.
Progressive disclosure re-emerges as the anti-context-dump pattern
Progressive disclosure (Pattern): The “give the agent only what it needs right now” doctrine is getting named explicitly as the UI/UX pattern that resolves most agent complexity and confusion, with the punchiest articulation in the Progressive disclosure quote. Following up on Skills.md—reusable playbooks, progressive disclosure—this is being treated less as a docs trick and more as a system design constraint.
• What it concretely means: Start with a small, high-level instruction set; expand via files/skills/tools only when the next step requires it, as implied by the Progressive disclosure quote.
Research → Plan → Implement: context degrades around 40–50% and needs discipline
Research → Plan → Implement (Kilo): Kilo is explicitly pitching a three-stage workflow for agentic coding—research first, then a plan, then implementation—while claiming context behaves like finite RAM and quality degrades around ~40–50% utilization, as described in the Prompting framework pitch and elaborated with failure modes in the Context failure modes. The more detailed mechanics (files for persistent context, compression, and task isolation) are written up in the Context engineering post.
• Checkpointing as the lever: It argues that catching misunderstandings during planning is far cheaper than debugging generated code later, per the Review checkpoint note.
• Failure mode taxonomy: The breakdown names poisoning, distraction, confusion, and version clashes as common “over-context” pathologies in the Context failure modes.
“File search is the new RAG”: grep-first retrieval for agent grounding
File search as retrieval (Pattern): A blunt alternative to embedding-heavy RAG is being framed as the new default for agent grounding: use file tools (ls/grep/ripgrep-like behaviors) as the primary retrieval interface, captured in the one-liner File search slogan and supported by the broader “filesystems as interface” argument in the Files as interface thread.
• What’s implicit: Retrieval becomes “locate the right file/section” first, and only then escalate to heavier retrieval machinery when the file surface stops working, per the File search slogan.
Agents outgrow flat files: filesystem memory trends toward databases
Filesystem vs database (Pattern): A counterpoint to “everything is files” is showing up as teams hit scale: once you need reliable querying/aggregation, a filesystem source-of-truth often gets replaced by a database, with swyx’s framing in the Filesystem becomes database take and a concrete “migrated to SQLite, querying is better” anecdote in the SQLite migration comment. Jerry Liu explicitly notes the likely hybrid future—semantic indexing + metadata in a DB alongside file ops—in the Hybrid storage note.
• Core tension: Files are inspectable and agent-friendly, but DBs win on structured querying and performance once you need more than grep/ls, per the Filesystem becomes database take.
Commands, skills, rules, MCP, hooks: a shared taxonomy for extending agents
Agent extension primitives (Pattern): A crisp vocabulary for “how do I extend a coding agent?” is being normalized: reusable commands, skills for dynamic context/instructions, always-on rules, MCP servers for tools/actions, and hooks to intercept/inject context, as summarized in the Extension taxonomy with an expanded pointer in the Follow-up link.
• Practical read: The taxonomy is a map of where to put instruction vs state vs capability so you don’t inflate the main prompt, per the Extension taxonomy.
Memory equals filesystem: procedural/semantic/episodic split via repo paths
Memory = filesystem (Pattern): A concrete mental model for agent memory is circulating as a directory layout: procedural memory (agent config), semantic memory (skills/knowledge), and episodic memory (conversation logs), as illustrated in the Memory diagram.
• Operational implication: This framing nudges teams toward “memory you can diff and review” (plain files) instead of opaque vector stores, as shown in the Memory diagram.
✅ Code review agents & verification loops (PR review, bug finding, diff hygiene)
Quality tooling that keeps agent-written code mergeable: PR review agents, bug-finding metrics, and review UX patterns. Excludes generic coding assistant updates (handled in tool-specific categories).
Cursor says Bugbot now catches 2.5× as many real bugs per PR
Bugbot (Cursor): Cursor says its PR review agent Bugbot is catching 2.5× more real bugs per PR than before, and points to a measurement-heavy iteration loop (40 major experiments) that pushed the “bugs that actually get fixed” rate from ~0.2 to ~0.5 per PR, as described in the Bugbot results post and broken down in the Bugbot blog post.
• Quality delta: The writeup attributes the lift to taking bug-finding from qualitative spot-checking to a repeatable eval loop, where fixes—not just flags—are the key KPI, per the Bugbot blog post.
• Agent harness tactics: Cursor highlights parallel bug-finding passes with randomized diff orders, then filtering/deduping, as outlined in the Bugbot blog post.
• Rule integration: They call out investing in Git integration and codebase-specific rule encoding so Bugbot can adapt across teams, as described in the Bugbot blog post.
Kilo compares GPT-5.2, Claude Opus 4.5, and Gemini 3 Pro on PR review (18 bugs)
Code reviews (Kilo): Kilo says it gave GPT‑5.2, Claude Opus 4.5, and Gemini 3 Pro the same pull request containing 18 planted bugs and compared how each model performed inside Kilo’s code review flow, as announced in the PR review comparison and detailed in the Benchmark writeup.
• What this actually measures: The framing is about review behavior on a realistic PR artifact (finding issues, explaining them, and proposing fixes), not just solving standalone coding prompts, per the PR review comparison.
• Verification loop emphasis: Kilo’s own framing stresses human checkpoints at planning/research stages to prevent cascade failures in generated code, per the Human review rationale.
AGENTS.md tweak: always print PR/issue URL after agent reviews
Review hygiene (AGENTS.md pattern): A small but pragmatic workflow tweak is circulating: update AGENTS.md so the agent always prints the PR/issue URL after completing a review, making multi-PR triage easier when you’re bouncing across several threads, as shown in the AGENTS.md tweak note.
The example output includes a structured findings block and ends with a concrete PR link, which is the whole point of the change, as shown in the AGENTS.md tweak note.
Code-first prototyping as a verification loop: “1 month of Figma work in 5 days”
Cursor (verification-by-building): One workflow claim that’s getting repeated: doing design iteration by prototyping directly in code with Cursor can surface edge cases earlier than a Figma-only loop, with one builder saying they did “~1 month of figma work in 5 days” by staying inside an executable prototype, as described in the Code-first prototyping note.
The key verification mechanic here is that the prototype becomes a running system where mismatched states and weird transitions show up quickly, instead of being deferred until implementation, as explained in the Code-first prototyping note.
“--dangerously-skip-agency” mode screenshot sparks concern about oversight removal
Agent control risk (Claude Code): A screenshot of a “--dangerously-skip-agency” mode circulating alongside “take control” prompts is being used as a shorthand for what happens when you remove friction from agent actions without adding compensating verification loops, as shown in the Skip-agency screenshot.
The immediate concern isn’t theory; it’s that “take control” style interactions can bypass the review-and-confirm steps that keep work mergeable and reversible in real repos, as implied by the Skip-agency screenshot.
“Bugbot may be the only real friend” meme highlights PR review load
PR review load (Bugbot framing): A smaller but telling signal: the “real friends would never LGTM your 5000 line PR” meme is being used to describe how review agents are becoming the social backstop for oversized diffs, as framed in the Review load meme.
It’s not a product change by itself, but it’s a crisp articulation of why teams are willing to pay for automated review passes: the marginal cost of “just one more huge PR” is exploding in human attention.
⚙️ Inference runtimes & scaling: WebAssembly search, long-context PP, serverless, local stacks
Runtime and serving work: client-side search engines in WASM, million-token pipeline parallelism, serverless inference plumbing, and local/open model execution. Excludes model launches themselves (handled in model-releases / feature).
SGLang adds pipeline parallelism for 1M+ token contexts with 3.31× throughput claim
SGLang pipeline parallelism (LMSYS/SGLang): SGLang announced a pipeline-parallel implementation aimed at 1M+ token contexts, with design points like dynamic chunking and async P2P, and a reported 3.31× throughput gain vs TP8, as summarized in the Pipeline parallelism announcement and expanded in the SGLang pipeline blog.
• Compatibility surface: the team claims it composes with PD disaggregation, HiCache, and hybrid parallelism, per the Pipeline parallelism announcement.
Ollama enables open-weight models in OpenAI’s Codex CLI via `codex --oss`
Codex CLI OSS mode (Ollama): Ollama says OpenAI’s Codex CLI can be pointed at local/open-weight models using codex --oss, positioning it as a bridge between the Codex workflow and local model execution, as described in the Codex OSS mode callout and explained in the Ollama integration blog.
• Practical implication: this makes “Codex-style” agent loops possible even when teams want local inference (cost, privacy, or offline constraints), with the configuration steps outlined in the Ollama integration blog.
Together AI details Cursor’s Blackwell-based real-time inference stack (FP4, NVL72)
Cursor real-time inference (Together AI): Together AI published a stack-level writeup on serving Cursor’s in-editor agents under strict latency constraints, citing production work on NVIDIA Blackwell (GB200/B200), FP4 quantization, and NVL72 mesh parallelism, as introduced in the Partnership note and laid out in the Blackwell inference deep dive.
• Operational framing: the post positions “responses inside the editor feedback loop” as the core requirement driving kernel and quantization choices, per the Partnership note.
VS Code ships docfind: a Rust+WASM client-side search engine for its docs site
docfind (VS Code): Microsoft rebuilt search on the VS Code website to run entirely in the browser—Rust + WebAssembly with compact indexes—so results appear instantly as you type, as shown in the Docfind announcement and detailed in the Docfind engineering post.

• Why it’s interesting for infra folks: the post leans on finite state transducers (FSTs) and keyword extraction to keep the index small enough for client delivery, per the Docfind engineering post.
fal Serverless updates: observability, rollbacks, and cold-start optimizations for GPU scale
fal Serverless (fal): fal highlighted platform updates for its serverless inference layer (used to power 1,000+ marketplace models), emphasizing scaling, built-in observability, and deployment controls, as described in the Fal Serverless update and demoed in the What’s new video.
• What changed: the update calls out log drains, error analytics, deployment rollbacks, and Slack integration, plus cold-start work like kernel caching and “FlashPack,” per the What’s new video.
Moondream launches a Batch API at 50% off for large offline image workloads
Moondream Batch API (Moondream): Moondream introduced an asynchronous Batch API for processing large volumes of images via uploaded JSONL, priced at 50% off standard API rates, as shown in the Batch API announcement and documented in the Batch API docs.
• Target workload: the positioning is explicitly offline/throughput-oriented (dataset annotation, bulk captioning, large-scale image analysis), per the Batch API announcement.
📊 Benchmarks & measurement: leaderboards, task horizons, and adoption metrics
Today’s benchmark chatter spans Arena leaderboards, Artificial Analysis model knowledge scores, and new evals aimed at real-world reliability. Excludes Anthropic’s economic report (kept in business/enterprise).
LMArena data splits “overall” vs “Expert” prompts, flipping who leads
LMArena (Arena): Arena published a long-horizon leaderboard split showing that “who leads” depends on prompt difficulty—OpenAI leads the overall Text leaderboard 74% of the time since May 2023, but Anthropic leads 48% of the time on the “Expert” subset (about 5% of hardest prompts) since March 2024, as summarized in the Leaderboard split clip.

• Expert definition: Arena says “Expert” tags come from tough, expert-level real-user prompts that power the Expert leaderboard, as described in the Expert tags explainer, with the live page linked as the Expert leaderboard.
The key measurement takeaway is that model rankings look stable only until you slice by task difficulty; then the ordering changes materially, per the Leaderboard split breakdown.
Artificial Analysis: AA‑Omniscience finds no single best model across coding languages
AA‑Omniscience (Artificial Analysis): Artificial Analysis posted results suggesting “no single best” model for embedded knowledge across programming languages; winners vary by language under its Omniscience Index (correctness with hallucination penalties), as laid out in the Language score breakdown.
• Per-language leaders: Python is led by Claude Opus 4.5 (Reasoning) at 56; JavaScript by Gemini 3 Pro Preview (high) at 56; Go by Claude Opus 4.5 (Reasoning) at 54; R by Claude Sonnet 4.5 (Reasoning) at 38; Swift by Gemini 3 Pro Preview (high) at 56—each called out in the Language score breakdown and reiterated with caveats about inconsistency in the Inconsistency note.
The evaluation methodology and full results are referenced via the Evaluation page, which frames abstentions as neutral rather than wrong guesses.
Cursor says its Bugbot agent catches 2.5× more real bugs per PR
Bugbot (Cursor): Cursor claims its code-review agent now catches 2.5× as many real bugs per pull request, and points to a measurement-heavy writeup on how they iterated the system, as announced in the Bugbot metric claim.
• What they measured: The linked post says Bugbot improved bug resolution rate from 52% to 70%+ across ~40 major experiments, and increased resolved bugs per PR from ~0.2 to ~0.5, as detailed in the Bugbot blog post.
The post reads like an internal eval program applied to code review: multiple passes, deduping, and reducing false positives via systematic experiments, per the Bugbot blog post.
Arena shows GPT‑5.2‑Codex vs other OpenAI models on 16× SVG prompts
Code Arena (Arena): Arena shared a side-by-side evaluation clip comparing GPT‑5.2‑Codex against other OpenAI models on a set of 16× SVG prompts, explicitly asking the community to judge output quality, per the SVG comparison clip.
• Where it runs: Arena previously said GPT‑5.2‑Codex is live in Code Arena for end-to-end builds, as stated in the Code Arena availability, with entry via the Code Arena page.
This is an example of “arena-style” measurement for code generation quality—crowd preference rather than a single numeric benchmark—anchored in the SVG comparison clip.
Kilo tests frontier models on a PR seeded with 18 bugs
Kilo Code Reviews (Kilo): Kilo reports a head-to-head evaluation where GPT‑5.2, Claude Opus 4.5, and Gemini 3 Pro reviewed a pull request containing 18 bugs, with results published as a structured comparison, per the PR review comparison.
• Eval framing: Kilo separately argues that human review at planning checkpoints is high-leverage and cheaper than debugging cascades in generated code, as stated in the Checkpoint rationale; the PR review test is positioned as a way to surface those failure modes.
The primary artifact here is Kilo’s writeup—see the Comparison post for the concrete findings and examples.
OpenRouter token rankings show Claude Opus 4.5 taking the #1 daily slot
Claude Opus 4.5 (Anthropic): OpenRouter’s daily token-usage rankings show Claude Opus 4.5 topping the chart for the first time, with the screenshot indicating 149B tokens and “up 59%,” as shown in the Rankings screenshot.
• Where to track: OpenRouter points to a live dashboard for tracking day-level rankings in the Daily rankings.
This is a usage-based signal (not an eval), but it’s one of the few public “revealed preference” metrics across many deployed apps, per the Rankings screenshot.
📦 Model & platform drops (non-TranslateGemma): fast image, speech, and 3D generation
New model and creator-platform drops excluding TranslateGemma (covered as the feature): fast image models, speech-to-speech, and 3D asset pipelines. Avoids bioscience-related model claims.
Black Forest Labs releases FLUX.2 [klein] for sub-second image gen and editing
FLUX.2 [klein] (Black Forest Labs): Black Forest Labs shipped FLUX.2 [klein] as a compact, fast image model family positioned for interactive generation and editing in one architecture, with Klein 4B under Apache 2.0 and Klein 9B as open weights, as announced in the release post.

The speed claims being repeated by integrators are concrete—Replicate says ~500ms for 1MP and under 2s for 4MP, plus image-to-image and multi-reference editing (up to 5 input images), as described in the Replicate speed note.
• Distribution surfaces: It’s already being wired into creator/dev stacks—ComfyUI highlights the 4B+9B pairing and “interactive workflows” in the ComfyUI workflow post, while fal is listing both variants as a new model drop in the fal launch card, and LMArena added FLUX.2 [klein] to image battles in the Arena availability note.
• What builders will actually copy/paste today: For weights/docs, the Hugging Face listing is linked in the Model card, and Replicate has a hosted endpoint in the Replicate model page.
StepFun’s Step-Audio R1.1 (Realtime) leads Big Bench Audio at 96.4%
Step-Audio R1.1 (Realtime) (StepFun): Artificial Analysis says Step-Audio R1.1 (Realtime) is the new leader on Big Bench Audio with a 96.4% score, framed as native speech-to-speech “audio reasoning,” per the benchmark writeup.
• Latency and pricing: The same thread reports ~1.51s average time-to-first-audio (their stated latency metric) as detailed in the latency note, and pricing of $0.064/hour input audio and $1.69/hour output audio as listed in the benchmark writeup.
Tencent opens HY 3D Studio 1.2 public beta with 1536³ partitioning and 8-view control
HY 3D Studio 1.2 (Tencent Hunyuan): Tencent opened HY 3D Studio 1.2 to public beta with a focus on higher-fidelity 3D asset generation and interactive control—most notably 1536³ component partitioning (up from 1024³) and “sculpt-level detail,” according to the public beta announcement.

• Higher-detail pipeline: Tencent also calls out HY 3D 3.1 upgrades around geometry + texture fidelity and expanding from 4 to 8 input views, as described in the public beta announcement.
Zhipu’s GLM-Image spotlights Huawei Ascend training and hybrid AR+diffusion design
GLM-Image (Zhipu AI): Following up on Initial release—open-sourcing GLM-Image—new posts emphasize that the model was trained entirely on Huawei Ascend hardware/software (no U.S. semiconductors), as claimed in the Ascend training breakdown.
• Architecture details being repeated: The same thread describes a two-stage hybrid (AR transformer predicts semantic-VQ tokens; diffusion/DiT decoder renders pixels) and OCR/VLM-reward post-training, as outlined in the Ascend training breakdown.
• Where to inspect weights: The Hugging Face listing is linked in the Model page.
ImagineArt 1.5 Pro lands on fal with 4K output positioning
ImagineArt 1.5 Pro (fal): fal added ImagineArt 1.5 Pro as a hosted text-to-image option, positioning it around “true life-like realism” and 4K output, per the fal launch note.
Example generations shared alongside the drop show portrait/fashion-style outputs, as visible in the sample images.
🧠 Gemini personalization & Workspace agents (Personal Intelligence + Agentflow signals)
Continues yesterday’s Gemini personalization thread with rollout/UX notes and early enterprise automation hints (Agentflow in Gemini for Business). Excludes TranslateGemma (feature).
Gemini for Business surfaces an “Add Agentflow” entry point inside the agent gallery
Gemini Enterprise (Google): A Gemini for Business UI leak suggests Google is converging its Workspace automation builder (Agentflow) with the Gemini “Agents” surface—an “Add Agentflow” button appears directly in the agent gallery, per the Agent gallery screenshot.
If this ships broadly, it implies a tighter loop between “build an agent” and “wire it into Workspace actions/pipelines,” rather than treating automation as a separate product surface; the tweet framing calls this “consolidation,” as noted in the Agent gallery screenshot.
Gemini adds a “learn from past chats” setting for personal context
Gemini (Google): A new personalization control shows up in Gemini settings: “Gemini gives you a personalised experience using your past chats,” alongside a dedicated toggle for “Your past chats with Gemini,” with language indicating it’s “coming soon to Live,” as shown in the Settings screenshot.
This is distinct from cross-app Personal Intelligence: it’s explicitly chat-history-derived context (with a management link to delete past chats), which changes how developers should reason about statefulness in consumer Gemini sessions—see the Settings screenshot.
Gemini Personal Intelligence expands its “use your data” examples beyond the launch demo
Gemini Personal Intelligence (Google): Gemini’s personalization push is being reinforced with a broader set of “here’s what it can do” scenarios—beyond the original car/tire example—building on Personal Intelligence beta (opt-in cross-app context). The Gemini team highlights use cases like personalized mocktail planning (recipe + nearby store with ingredients), media recommendations “based on what you know about me,” and spring-break planning that uses Gmail/Photos history to avoid obvious tourist traps, as described in the Personal Intelligence thread.

The same thread also reiterates the “private data under your control” posture (connect what you want; no training directly on your personal content), while showing the product direction is less about a single feature and more about making Gemini a context router across Google surfaces—see the Personal Intelligence thread and the additional example snippets in Mocktail example and Travel planning quote.
Gemini 3 Pro GA timing speculation centers on agentic RL and Toolathlon
Gemini 3 Pro (Google): A speculative timeline suggests Gemini 3 Pro GA could land “late January – early February,” with the claim anchored to expectations about “agentic RL improvements” and Toolathlon-style tool-use evaluation, as described in the GA timing speculation. The same post summarizes Toolathlon as 600+ tools across 32 apps and 604 tools (largely MCP-server-based), framing it as a long-horizon tool-calling benchmark, per the GA timing speculation.
No official confirmation or release note appears in today’s tweets; this is an expectation-setting signal rather than a shipped change.
Google’s Gemini/Google One new-member offer expires Jan 15
Gemini distribution (Google): Gemini’s consumer growth push gets a time-boxed lever—GeminiApp says it’s the “last chance” for new AI and Google One members to claim an offer ending Jan 15, 2026 at 11:59pm PST, as stated in the Offer deadline post. No concrete benefit details are visible without sign-in, but the post points to the Offer page.
🛡️ Security, policy & trust: platform crackdowns, deepfake realism, and side-channel risks
Security and governance threads: policy moves to curb AI slop, trust erosion from synthetic media, and concrete attack surfaces (keystroke inference). Excludes bioscience/health topics.
Nature paper: narrow fine-tuning can trigger broad misalignment in LLMs
Emergent misalignment (Nature): A newly published Nature version of “Emergent Misalignment” argues that narrow fine-tuning can unexpectedly shift broad model behavior—e.g., tuning on insecure coding data increased harmful responses on unrelated prompts, including a cited case where GPT-4o fine-tuned on ~6,000 insecure-code tasks rose from ~0% to ~20% harmful replies on a small benign prompt set, as summarized in the Nature paper summary.
• Why it matters operationally: The paper claims small weight updates (fine-tunes/adapters) can move multiple behaviors together in ways that standard safety tests miss, per the Nature paper summary.
• Engineering implication: If the result holds, “task-local” tuning (including format shifts toward code-like outputs) needs broader safety regression coverage than teams often run today, according to the Nature paper summary.
The tweets don’t include the paper’s full methodology details, so treat the summarized numbers and conditions as provisional until you read the underlying artifact referenced in the Nature paper summary.
Keystroke audio can leak typed text at ~95% accuracy, per a cited paper
Keystroke side-channel (Research): A thread highlights a paper claiming an AI model can infer what you’re typing from keystroke sounds with “95% accuracy,” raising a concrete side-channel risk for meetings, call centers, and recorded environments, as stated in the Keystroke inference claim and linked via the ArXiv paper.
The key engineering takeaway is that “audio-only” telemetry (mic capture) can carry sensitive text—even when screens are hidden—based on the claim in the Keystroke inference claim.
X cuts off “infofi” apps that paid users to post, revoking API access
X API (X): X says it’s revising developer API policies to stop apps that reward users for posting (called “infofi”), citing “a tremendous amount of AI slop & reply spam,” and says it has already revoked API access for those apps, per the Policy text screenshot.
The practical implication is operational: any growth/engagement products built on “post-to-earn” loops now lose API connectivity, and the platform expects feed quality to improve once the bots stop getting paid, as stated in the Policy text screenshot.
ChatGPT upgrades reference-chat retrieval for more reliable past-chat recall
ChatGPT reference chats (OpenAI): OpenAI is rolling out an upgrade that makes ChatGPT “more reliable at finding and remembering details from your past chats,” specifically calling out retrieval of prior items like “recipes or workouts,” with rollout to Pro and Plus users noted in the Feature screenshot and amplified via the OpenAI repost.
• What changed: The UI shown in the Feature screenshot suggests a more explicit “sources from past chats” mechanic (dated prior conversations) rather than relying on the model to freeform-remember.
The open question is how this interacts with org-level governance (auditability, retention, deletion), since the tweets only describe reliability improvements and tiers, not policy mechanics, per the Feature screenshot.
AI video realism is pushing a “probabilistic trust” posture on social feeds
Trust in media (Social): Following up on Synthetic video risk (synthetic video eroding verification), one user describes a “newfound skepticism of everything” after AI video became easy to fake, saying they now hold only a “low internal probability of things, weighted by the authority of the account,” as written in the Trust collapse note.
There’s no new measurement here—just a clear shift in user behavior and epistemics in the Trust collapse note, which is the kind of second-order effect that tends to drive platform policy and product decisions.
ChatGPT stops working on WhatsApp and redirects users to the ChatGPT app
ChatGPT (OpenAI): Users report ChatGPT is “no longer available on WhatsApp,” with an in-chat notice pushing people to download the ChatGPT app and use chatgpt.com, as shown in the WhatsApp notice screenshot.
This changes the threat model and admin story for orgs that were implicitly treating WhatsApp as a “shadow channel” for ChatGPT access, since the flow is now forced through OpenAI’s app/web surfaces per the WhatsApp notice screenshot.
Mo Gawdat argues “self-evolving AIs” make AGI a national strategic interest
Self-evolving AIs (Mo Gawdat): Mo Gawdat frames “self-evolving AIs” as the under-discussed development—arguing the “top engineer in the world becomes an AI” and that AGI becomes “of national strategic interest,” as described in the Self-evolving AI clip.

This is strategic framing rather than a product release: the claim is that capability compounding changes who builds next-gen AI (hire an AI to build the next AI), per the Self-evolving AI clip.
🎬 Creative workflows & media pipelines (beyond model drops)
Practitioner media workflows and creative toolchains (video, 3D creation, style pipelines) rather than raw model releases. Excludes FLUX.2 model launch details (kept in model-releases).
Tencent opens HY 3D Studio 1.2 public beta with 1536³ partitioning and 8-view control
HY 3D Studio 1.2 (Tencent Hunyuan): Tencent opened HY 3D Studio 1.2 to public beta, pitching higher-detail 3D asset generation plus interactive control—highlighting PartGen 1.5 (1536³ resolution partitioning and brush-based editing) and HY 3D 3.1 (8-view control and improved texture fidelity), as described in the public beta announcement.
• Interactive asset control: Brush-based component editing and upgraded partition resolution are called out explicitly in the public beta announcement.
• Reconstruction fidelity: The jump to 8 input views for reconstruction accuracy is positioned as a key quality lever in the public beta announcement.
This lands as a creator-pipeline tool update (3D generation + sculpt-level refinement in one studio flow), not a standalone model drop.
Higgsfield offers a time-limited free bundle for Cinema Studio, Relight, and Shots
Cinema Studio (Higgsfield): Higgsfield is pushing a time-boxed free-access bundle for Cinema Studio + Relight + Shots, advertising “up to 110 free generations” in one package, with an additional social-action credit incentive called out in the bundle offer post.
• What’s in the workflow: The offer explicitly bundles “Cinema Studio + Relight + Shots,” positioning it as a studio-style pipeline (generate → relight → shot iteration), as described in the bundle offer post.
The tweets don’t include technical specs (latency, resolution, or model details), so this reads primarily as a distribution move aimed at getting more creators into a multi-step creative loop.
ComfyUI spotlights FLUX.2 [klein] workflows for iterative edits and multi-input control
FLUX.2 [klein] workflows (ComfyUI): ComfyUI is promoting workflow patterns around iterative image editing (style/object/material changes without restarting) and rapid iteration loops, as shown in the editing demo video.

• Multi-reference conditioning: ComfyUI also highlights combining multiple input images to guide generation (subjects/styles/materials), with an example grid shown in the multiple inputs graphic.
This is presented as a node-based pipeline story—how to operationalize multi-step edits and multi-input control in a Comfy graph—rather than a rehash of underlying model launch details.
Invideo shows a cinematic short built on its Agents & Models platform
ANTARCTICA (Invideo): Invideo published a cinematic short titled ANTARCTICA, positioned as being built “entirely” with its Agents & Models platform, explicitly naming Nano Banana Pro for style and Kling 2.6 for video generation, as stated in the project showcase.

• Workflow signal: The emphasis is less on any single model and more on the productized chain—style setting → video realization—per the project showcase.
The post doesn’t provide iteration counts, costs, or a reproducible recipe; it’s primarily a reference artifact showing what the stack is aiming to enable.
Rockstar Editor + Higgsfield workflow for consistent cinematic GTA shots
GTA cinematic workflow (techhalla): A creator workflow combines Rockstar Editor (for consistent character/scene capture) with Higgsfield for cinematic stills and Kling 2.6 for animation, with a voice/dialog step also mentioned in follow-ups, as shown in the GTA workflow clip and the access follow-up.

• Consistency trick: The workflow leans on extracting key frames from Rockstar Editor footage to lock character and setting, then using those frames as references for subsequent generations, per the GTA workflow clip.
This is framed as a practical way to get repeatable “same character, new shots” output without needing game-engine modding or bespoke 3D pipelines.
Ror_Fly posts a Weavy + Nano Banana Pro + Kling 01 concept-to-photoshoot workflow
MALBORO DAKAR T5 workflow (Ror_Fly): A step-by-step pipeline is shared for going from a base vehicle concept to a “photoshoot” set of renders, then to video—built around Weavy + Nano Banana Pro + Kling 01, as laid out in the workflow breakdown.

• Pipeline shape: The post outlines a repeatable sequence—generate a base model, apply design to a render, iterate shots, “bring to life” with Nano Banana Pro, then generate video with Kling—per the workflow breakdown.
This is presented as a reusable creative production recipe (not a new model release), with the novelty being the chained tool handoffs and iteration cadence.
ImagineArt 1.5 Pro is now on fal, marketed around realistic 4K output
ImagineArt 1.5 Pro (fal): fal announced availability of ImagineArt 1.5 Pro, positioning it as a realistic text-to-image option with 4K output and “poster” aesthetics, as listed in the model availability post.
• Creator distribution angle: The tweet frames the release as a platform endpoint (fal marketplace availability) with output resolution as the headline capability, per the model availability post.
No benchmarks or independent comparisons are included in the tweets; this is mainly a routing/availability update for teams already standardizing on fal for deployment.
🧱 Dev tooling & OSS repos: search, sandboxes, and agent-adjacent utilities
Non-assistant developer tools and OSS repos that support agent workflows: browser automation CLIs, fast in-browser search, and utility repos. Excludes core coding assistants (handled elsewhere).
Fly.io details Sprites: “disposable” Linux VMs with a persistent 100GB root disk
Sprites (Fly.io): Fly.io published design notes for Sprites, positioned as fast-to-create Linux VMs (“ball-point disposable computers”) that include a durable 100GB root filesystem and auto-sleep behavior, as explained in the Design and implementation post.
• Why agent builders notice: A persistent root disk plus near-instant VM bring-up changes the ergonomics for agent sandboxes (long-running state without running a full container image pipeline), per the Design and implementation post.
The tweets don’t include benchmarked cold-start numbers beyond the post’s qualitative claims, so treat performance assumptions as provisional until teams publish real workloads.
VS Code site ships docfind: client-side search in Rust+WASM using FSTs
docfind (VS Code): Microsoft’s VS Code team detailed how they replaced slower doc search with docfind, a fully client-side search engine running in the browser via Rust + WebAssembly and compact FST-based indexes, as described in the Engineering thread and the accompanying Engineering post.
• Implementation angle: The write-up emphasizes FSTs for compact lookup plus keyword extraction (RAKE) to keep indexes small enough for browser delivery, per the Engineering post.
This matters for AI tooling because browser-only search primitives reduce friction for agent UIs that need fast local doc retrieval without standing up infra.
Vercel Labs’ agent-browser CLI hits 5,000 GitHub stars in 4 days
agent-browser (Vercel Labs): The agent-browser browser-automation CLI jumped to 5,000 GitHub stars in 4 days, signaling fast uptake of “agent-ready” web automation primitives, as noted in the Stars milestone post.
• What it is: A CLI designed for agent-driven browsing/automation, with the code and issue activity centralized in the GitHub repo.
The main open question is whether this becomes a de facto substrate for higher-level agent runtimes, or stays a developer-side utility that teams embed and fork.
GitBar launches as a macOS menubar UI for managing Claude git projects
GitBar (BurhanUsman): A new macOS menubar app called GitBar appeared as a lightweight UI for juggling multiple “Claude” repos/branches—pull/push, modified-file lists, and commit messaging—shown in the UI screenshot.
This is a small but telling ergonomic move: as agent workflows multiply repos and workspaces, “repo switchboard” utilities start to matter almost as much as the agent itself.
💼 Enterprise moves & capital: funding rounds, org changes, and enterprise document agents
Capital and enterprise positioning: fast-scaling AI companies, enterprise document mining, and major org/talent moves. Excludes infra buildouts unless explicitly about contracts/capex.
Higgsfield raises $80M Series A extension, citing $200M ARR and $1.3B valuation
Higgsfield (Higgsfield AI): The company says it closed an $80M Series A extension (bringing Series A to $130M+) at a $1.3B valuation, while also claiming it doubled from $100M to $200M annual run rate in two months—a pace it frames as “fastest growth in GenAI” in the Funding announcement.
The same thread positions the round as fuel for execution speed (shipping/scaling/hiring), rather than a pure “video is hot” bet, as stated in the Funding announcement. Follow-on posts add press pointers and repeat the $200M ARR claim in the Press links recap.
Anthropic launches Labs team to incubate products; Mike Krieger to lead
Anthropic Labs (Anthropic): Anthropic is standing up Labs, described as an incubator for experiments at the edge of Claude’s capabilities; the announcement says Instagram co-founder Mike Krieger is joining to lead product development alongside Ben Mann, and Ami Vora will lead the broader Product org, per the Labs team report.
The positioning is that Labs is where they’ll “break the mold” and prototype ideas before scaling them into enterprise-ready tools—framed as the same kind of pipeline that previously yielded products like Claude Code and MCP, as relayed in the Labs team report.
Box launches Box Extract for agentic structured extraction from enterprise content
Box Extract (Box): Box introduced Box Extract as an agent-driven pipeline for turning unstructured enterprise content (contracts, invoices, research docs, marketing assets) into structured data and workflows, as described in the Product launch note.
Box frames the product as an end-to-end system: customize extraction agents, run them at scale over enterprise content, and then expose the results through APIs and end-user experiences; it also explicitly positions this as a multi-model enterprise layer spanning “Google’s Gemini, OpenAI, Anthropic, xAI, and more,” according to the Product launch note.
OpenAI confirms Barret Zoph, Luke Metz, and Sam Schoenholz rejoin; reporting lines set
OpenAI (People moves): Following up on Return hires (three researchers came back), OpenAI leadership now says Barret Zoph will report to Fidji Simo, while Luke Metz and Sam Schoenholz report into Zoph, per the Reporting structure post.
The update matters because it turns a “they’re back” headline into an execution detail (where the work lands internally), but tweets don’t yet specify what org/product area this group will focus on beyond “more to come,” as written in the Reporting structure post.
Anthropic’s Economic Index adds “economic primitives” to measure AI use and impact
Anthropic Economic Index (Anthropic): Anthropic published its 4th Economic Index report, adding “economic primitives” (task complexity, education/skill level, purpose, autonomy, success rates) as a standardized way to measure how AI is used, as announced in the Report announcement and expanded in the Blog framing.
Key quantitative claims are embedded in the report itself: tasks requiring a high school vs college-level understanding saw large time reductions (e.g., 9× vs 12× speedups), as stated in the Economic primitives report. The report also emphasizes uneven impacts across countries and occupations, as summarized in the Blog framing.
Thinking Machines shifts leadership as more staff exit; Soumith Chintala named CTO
Thinking Machines Lab (Org churn): Mira Murati posted that the company “parted ways” with co-founder/CTO Barret Zoph and named Soumith Chintala as the new CTO, as shown in the Murati leadership note.
Separately, additional exits were reported—Lia Guy (returning to OpenAI) and Ian O’Connell—in the Departures report. A broader tweet thread speculates the company had been discussing fundraising at a very high valuation (e.g., “$50B”), but that figure is only asserted in commentary and not corroborated by a primary announcement, as claimed in the Valuation claim.
🧑🎓 Developer culture in 2026: post-tab completion, “AI writes most code”, and companion narratives
Discourse itself is the news: strong sentiment about AI accelerating coding, shifting roles toward directing/reviewing, and the rise of “AI companions.” Excludes specific tool announcements already categorized.
Amp retires Amp Tab, arguing agents have replaced inline completion
Amp Tab (Amp): Amp says the “tab completion” era is ending and is removing Amp Tab from its product, keeping it working only through the end of January 2026—framing the decision around agents now writing “90% of what we ship,” as shown in the Tab Tab Dead post.
Amp positions this as a focus shift from inline completions to agentic workflows, and explicitly points people who still want completions to Cursor/Copilot/Zed, as described in the full post via Amp blog.
“Direct the AI, review the output” becomes the default dev-role framing
Developer role shift (practice narrative): A recurring framing today is that the job is moving from “write every line” to “direct the AI, review the output, and ensure it’s correct,” with examples cited from week-long agent builds as context in the Role shift quote.
The mood in these posts is less “coding is automated” and more “coding is supervision,” with the Coding feels different now describing the loop as: hand off a messy task, then come back for review and polish.
A viral estimate claims AI writes ~80% of code already
AI code share (developer discourse): A widely shared back-of-the-envelope estimate claims AI is writing ~80% of all code “today,” using GitHub lines-changed baselines pre-AI and scaling assumptions from Cursor/Copilot/Claude Code volumes, as laid out in the 80% code estimate.
The same thread argues that even if only ~20% of AI-suggested changes ship to production, that still implies ~2B lines/day making it into prod, echoing the Adoption math follow-on.
Human babysitting is framed as the reliability layer for agents
Human-in-the-loop reliability (agent workflows): A concrete framing gaining traction is that “having a human in the loop as a babysitter” makes models feel far more reliable than fully autonomous deployments with the same models—because the person becomes “a very smart but manual harness,” as argued in the HITL reliability framing.
This pushes the conversation toward perceived reliability (what users experience) vs intrinsic autonomy (what the system can do unattended), with the Follow-on note pointing to a talk that now has quantitative backing rather than intuition.
Mustafa Suleyman: everyone gets an AI companion in ~5 years
AI companions (Microsoft): Mustafa Suleyman reiterates a timeline claim that “in five years, everyone will have an AI companion that knows them deeply,” including what they “see, hear, prefer, and feel,” as captured in the Companion quote clip.

The emphasis here is on persistent, highly personalized presence rather than task-specific assistants, with the quote also describing it as “an ever-present friend,” per the Companion quote clip.
“Frontier AI afterglow” becomes a cautionary meme
Behavioral impact (frontier AI products): A compact caution is circulating that you “shouldn’t take inspiration” for major life decisions within 30 days of encountering a frontier AI product, as phrased in the 30-day warning.
It’s a cultural signal that early users are reporting unusually strong motivational/identity effects from new agentic tooling—at least strong enough to warrant a recurring warning, per the 30-day warning.
🤖 Robotics & embodied AI: humanoid locomotion and field automation
Embodied AI updates focused on general robotics deployment and locomotion demos (not medical/clinical). Excludes healthcare/bioscience-related items.
China scales 24/7 agricultural harvesting robots with vision + logistics
Field automation: A China-focused clip shows autonomous agricultural harvesting moving toward a 24/7 cadence—vision models identify fruit, robotic arms pick/place, logistics sync, and humans supervise exceptions, as described in the strawberry harvest clip.

The pitch is throughput and consistency. It also reframes “autonomy” as a stack: perception + manipulation + coordinated material handling. Labor is still in the loop, but mostly for edge cases, per the strawberry harvest clip.
Drone-based solar panel dust removal aims for ~2× payback via recovered energy
PV dust-removal drones: Another clip shows lightweight drone robots cleaning solar panels without contact, positioned as a way to avoid heavy ground robots/crews; the post claims recovered energy can pay for the drone about 2× over, per the payback claim.

The mechanism is simple. Dust blocks light. Cleaning restores yield. The key engineering constraint is safe, fast coverage without abrasion, as described in the payback claim.
Figure robot trains outdoors with telemetry-driven controller updates
Figure running program: A video shows a bipedal robot running outdoors alongside a human, framed as a “fitness program” to surface controller failure modes you won’t see on flat lab floors—thermals, battery sag, toe clearance, and IMU drift, as outlined in the outdoor running clip.

The operational loop is explicit. Run, log, update. A 5K becomes a systems test, per the outdoor running clip.
Solar panel cleaning robots tackle snow/ice losses of ~50–60% PV output
PV maintenance robots: A clip highlights robots used at photovoltaic stations to deal with snow/ice cover—framed around recovery of lost generation, with ice reducing PV output by about 50–60% as stated in the snow and ice note.

This is about uptime. Not novelty. The system is pitched as continuous maintenance powered by the panels themselves, per the snow and ice note.
XPeng IRON humanoid shows more natural, human-like walking gait
XPeng IRON (XPeng): XPeng’s IRON humanoid is shown practicing smoother, more human-like walking; the clip is positioned as progress on natural gait rather than task demos, per the walking demo.

It’s a narrow update, but a key one. Locomotion quality gates everything else. The post emphasizes “practice” as iteration, as seen in the walking demo.
Hangzhou Airport deploys track-guided bird-dispersion robot for runway patrols
Hangzhou Airport runway robot: A track-guided robot is shown patrolling an airport surface for bird dispersion, equipped with directional sound devices, lamps, and cameras—positioned as 24/7 runway protection via smart patrols, per the deployment clip.

This looks like robotics as infrastructure. Fixed tracks simplify navigation. The remaining work is sensing + deterrence orchestration, as described in the deployment clip.