GLM‑5 open weights debut at 744B – $1 input per 1M tokens
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Z.ai launched GLM‑5 (“Pony Alpha”), a text‑only MoE flagship at 744B params trained on 28.5T tokens; it ships with 200K context and up to 128K output, plus MIT‑licensed weights on Hugging Face (BF16 footprint ~1.5TB). Z.ai’s chart claims 77.8 on SWE‑bench Verified and 56.2 on Terminal‑Bench 2.0; Artificial Analysis pegs it at 50 on its Intelligence Index and 63 on its Agentic Index, with the lowest AA‑Omniscience hallucination rate attributed to more abstention; independent eval artifacts aren’t bundled. Distribution is unusually fast: OpenRouter publicly lists it; Ollama Cloud, Modal, vLLM, and SGLang posted day‑0 routes/recipes; W&B Inference offered $20 credits, then users reported the endpoint disappearing.
• Z.ai rollout ops: traffic up ~10×; compute “very tight”; phased access and Coding Plan price changes set for Feb 11.
• Codex in production: OpenAI describes a 3‑engineer harness steering ~1,500 PR merges; NVIDIA rollout targets ~30k engineers with US‑only processing.
The open‑weights story is colliding with serving reality: FP8 endpoints and tensor‑parallel configs show up immediately, while throughput limits and capacity constraints may dominate long‑horizon agent runs more than token pricing.
Top links today
- OpenAI agent primitives reliability tips
- How OpenAI shipped with Codex agents
- GLM-5 model weights on Hugging Face
- GLM-5 official launch blog
- Artificial Analysis page for GLM-5
- vLLM day-0 GLM-5 FP8 serving recipe
- Karpathy self-contained fp8 training code
- DeepWiki Q&A for GitHub repos
- Claude free plan feature upgrades
- Claude compaction feature overview
- Reuters on ByteDance AI inference chip
- Stanford study on AI-exposed job declines
- Epoch AI report on robot deployment tasks
Feature Spotlight
GLM‑5 revealed: open weights frontier model + rapid ecosystem availability
GLM‑5 (744B/40B active, MIT) lands as the new top open‑weights contender with strong agentic/coding evals and fast provider rollout—meaning cheaper near‑frontier capability and more viable self/third‑party deployment paths now.
Dominant story today: Z.ai’s GLM‑5 ("Pony Alpha") drops with open weights, strong agentic/coding benchmarks, aggressive pricing, and day‑0 availability across multiple providers. This category includes GLM‑5 rollout, benchmarks, pricing, and where you can run it; other categories exclude GLM‑5 to avoid duplication.
Jump to GLM‑5 revealed: open weights frontier model + rapid ecosystem availability topicsTable of Contents
🐎 GLM‑5 revealed: open weights frontier model + rapid ecosystem availability
Dominant story today: Z.ai’s GLM‑5 ("Pony Alpha") drops with open weights, strong agentic/coding benchmarks, aggressive pricing, and day‑0 availability across multiple providers. This category includes GLM‑5 rollout, benchmarks, pricing, and where you can run it; other categories exclude GLM‑5 to avoid duplication.
Artificial Analysis crowns GLM‑5 the top open‑weights model and highlights abstention-driven low hallucination
GLM‑5 (Artificial Analysis): Artificial Analysis reports GLM‑5 reaches 50 on its Intelligence Index—making it the new open‑weights leader—and posts a large jump on agentic benchmarks plus a major reduction in hallucinations via more frequent abstention, according to the full AA breakdown and the updated score note in score update.
• Agentic positioning: AA puts GLM‑5 at 63 on the Agentic Index, near top proprietary systems, as shown in the agentic index chart.
• Hallucination framing: GLM‑5 shows the lowest hallucination rate on AA‑Omniscience among models displayed, per the hallucination chart.
AA also notes ~110M output tokens were used to run their full suite vs ~170M for GLM‑4.7, as shown in the token usage chart, which is a practical “how expensive is evaluation” signal even if it’s not a perfect proxy for real workload efficiency.
Z.ai launches GLM‑5 with open weights and a 200K context window
GLM‑5 (Z.ai): Z.ai formally launched GLM‑5—a new flagship MoE model scaling to 744B total params (40B active) and 28.5T pretraining tokens, positioned for long-horizon agentic work, as described in the launch thread and detailed in the Tech blog; it’s already selectable in the Z.ai chat UI per the Z.ai model picker.
The release also pins down operational specs that matter for builders—text-only, 200K context, and 128K max output, as shown in the Context and output card. Following up on architecture hints (DeepSeek-style sparse attention + MoE scaffolding), the public release makes GLM‑5 a concrete option rather than a rumor.
GLM‑5 weights land on Hugging Face under MIT license
GLM‑5 (Hugging Face): The zai-org/GLM‑5 weights are now public on Hugging Face under an MIT License, with community notes emphasizing the native BF16 release size (roughly 1.5TB) and day‑0 compatibility with common tooling, according to the HF availability note and the official Model card.
This matters because MIT licensing makes downstream packaging (agents, fine-tunes, internal deployment) much simpler than research-only terms, but the BF16 footprint sets a high bar for self-hosting unless you rely on FP8 provider endpoints (which show up repeatedly elsewhere in today’s threads, such as the provider availability summary).
Z.ai says traffic jumped 10×; GLM‑5 rollout is gated by tight compute and plan repricing
Z.ai (GLM‑5 rollout ops): Z.ai says user traffic increased roughly tenfold and it’s actively scaling capacity, per the scaling note and the standalone traffic update.
It also warns “compute is very tight” and describes a phased rollout (starting with certain paid tiers) plus GLM Coding Plan pricing adjustments effective Feb 11, 2026, as laid out in the pricing and rollout post. The net for teams is that “open weights exist” doesn’t automatically mean “unconstrained capacity,” especially for long-context agent runs.
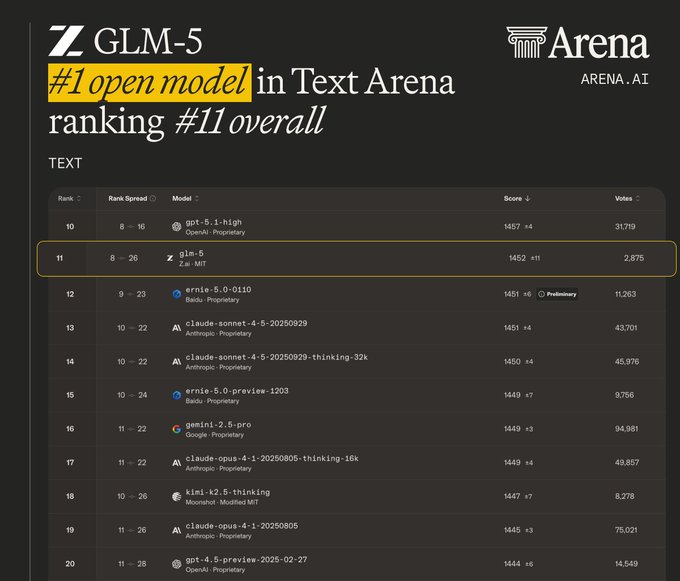
Arena shows GLM‑5 as the top open model in Text, landing near #11 overall
GLM‑5 (Arena): Arena reports GLM‑5 is now the #1 open model on the Text leaderboard and sits around #11 overall, with a displayed score near 1452 and a still-growing vote count, according to the leaderboard announcement and the screenshot in the rank evidence.
This is a different kind of signal than benchmark charts: it’s a preference-driven arena score with wider noise sources, but it’s also a direct read on how humans are experiencing the model in head-to-head comparisons.
Early GLM‑5 user reports: long-running agent workflows look strong; UI polish is mixed
GLM‑5 (early usage): Early practitioner posts describe GLM‑5 as a noticeable jump over prior GLM releases—one summary says “GLM‑5 feels like a big update” in the voxel comparison, while another frames it as “competitive…level with Opus 4.5” in the vibe check.

• Long-horizon agent behavior: Z.ai is explicitly leaning into “long-task era” narratives, including a reported 24+ hour single-agent run with 700+ tool calls in the long-task clip, which is more representative of real agent harness stress than single-turn codegen.
• Frontend/design taste: The same vibe checks that praise agentic performance also call out “taste” gaps in visual/frontend outputs (for example voxel scene completeness) per the voxel comparison—a common pattern when models are tuned primarily for tool-use and long workflows.
Separate threads also flag practical throughput constraints (tens of tokens/sec across providers) as a limiting factor for “agentic” use, as shown in the throughput comparison, even when per-token pricing is aggressive.
Ollama Cloud hosts GLM‑5:cloud and wires it into popular coding agent CLIs
Ollama (GLM‑5): Ollama announced GLM‑5 on Ollama’s cloud with ollama run glm-5:cloud and explicit ollama launch commands that let you point tools like Claude Code, Codex, OpenCode, and OpenClaw at GLM‑5 as the backend, per the Ollama launch thread and the command list shown in app launch list.
Ollama also said it’s increasing capacity due to demand, according to the capacity update, which lines up with the broader “compute is tight” theme across GLM‑5 surfaces.
SGLang posts a GLM‑5‑FP8 server launch recipe with EAGLE speculative decoding
SGLang (GLM‑5): LMSYS/SGLang announced day‑0 support for GLM‑5 and published a launch_server command targeting zai-org/GLM‑5‑FP8, including EAGLE speculative decoding and the same GLM tool/reasoning parsers seen across other stacks, according to the SGLang cookbook post.
The launch recipe bakes in --tp-size 8 and a fixed memory fraction (--mem-fraction-static 0.85), which are the knobs teams typically end up rediscovering the hard way when trying to stabilize throughput under long-context workloads.
Modal publishes a GLM‑5 endpoint and makes it free for a limited time
Modal (GLM‑5): Modal announced GLM‑5 availability via a hosted endpoint and says it will be free for a limited time, positioning it as a plug-in backend for agent frameworks like OpenClaw/OpenCode, per the Modal announcement and the accompanying writeup in the Modal blog.

The practical angle here is reduction in “bring-your-own-serving” friction for a model whose raw BF16 footprint would otherwise push most teams toward managed FP8 providers.
W&B Inference adds GLM‑5 day‑0 with tracing and credits, but availability looks fluid
W&B Inference (GLM‑5): Weights & Biases announced GLM‑5 is live on W&B Inference, describing an OpenAI-compatible API and Weave tracing integration in the W&B launch post, then offered $20 inference credits for early users per the credits offer.
One follow-on note suggests the endpoint may have been pulled or temporarily unavailable (“it’s gone”), per the availability note, which is a reminder that “day‑0” distribution can still be operationally unstable even when the model weights are public.
🧰 Codex in production: harness engineering + enterprise rollouts
What’s new today is less about model hype and more about operationalizing Codex: OpenAI describes the harness (tests/linters/observability/UI automation) that makes agent output mergeable, plus enterprise rollout details. Excludes GLM‑5 (covered as the feature).
OpenAI details a Codex harness that merged ~1,500 PRs with zero manual coding
Codex harness engineering (OpenAI): OpenAI described how a 3‑engineer team “steering Codex” shipped a product by opening and merging ~1,500 PRs into a ~1M‑line repo without writing code by hand, by building a tight harness around the agent—tests/linters, repo-specific instructions, isolated environments, UI automation, and observability loops, as outlined in the case study post and the article screenshot.
The practical shift is that throughput comes from automatic, repeatable validation (the harness), not from longer prompts; OpenAI’s writeup calls out patterns like using a concise AGENTS.md that points into a docs/ knowledge base (kept honest via CI), spinning up per‑git‑worktree app environments, driving UI checks via Chrome DevTools Protocol, and exposing logs/metrics/traces so agents can query systems (e.g., LogQL/PromQL) during iteration, per the Harness engineering post.
OpenAI rolls Codex to ~30k NVIDIA engineers with enterprise controls
Codex at NVIDIA (OpenAI): OpenAI says Codex is rolling out company-wide at NVIDIA to ~30k engineers, with cloud-managed admin controls plus US-only processing and fail-safes, according to the enterprise rollout note.
The operational detail here is the emphasis on jurisdictional processing and admin control surfaces—features teams typically need before they can standardize an agent in a regulated engineering org—as echoed in NVIDIA’s rollout reactions in the rollout graphic.
OpenAI publishes 10 operational tips for multi-hour agent workflows
Shell + Skills + Compaction (OpenAI Devs): OpenAI published a set of practical reliability patterns for multi-hour agent runs—explicitly aimed at long workflows that keep making progress without babysitting—following up on Server compaction (server-side context compression) with more concrete runbook-style guidance in the tips announcement.
Their framing is that you combine a hosted shell for real execution, reusable skills as packaged capabilities, and compaction to keep context stable over hours; the detailed writeup lives in the Tips post.
Codex Alpha desktop app opens Windows waitlist (Linux build also listed)
Codex Alpha app (OpenAI): An early access waitlist for the Codex Alpha desktop app surfaced with Windows as a target OS and Linux also listed as an option, per the waitlist screenshot.
This is a concrete distribution signal that Codex’s “agent app” UX is moving beyond macOS-heavy early adopters into broader enterprise workstation coverage.
Harvey: Codex helps engineers run parallel approaches, then converge on design
Codex at Harvey (OpenAI): OpenAI shared a usage pattern from Harvey—engineers use Codex to explore multiple approaches in parallel and converge faster, shifting human time toward system design and harder decisions, as shown in the Harvey workflow clip.

The notable workflow claim is “parallel exploration then converge,” which fits the harness-first theme: agents generate options, while humans arbitrate architecture and tradeoffs.
Altman signals Codex is “winning” faster than expected
Codex adoption (OpenAI): Sam Altman wrote that he expected Codex to “eventually win” but is “pleasantly surprised” it’s happening so quickly, explicitly crediting builders for the acceleration in the Altman comment.
This aligns with broader (if anecdotal) chatter that “nearly all of the best engineers… are switching from claude to codex,” as quoted in the switching claim, and with blunt preference statements like “no idea why people would still be using Claude” in the preference repost.
Codex CLI 0.99 ships /statusline and better concurrent shell execution
Codex CLI 0.99 (OpenAI): A new Codex CLI release adds /statusline to customize the TUI footer metadata and changes shell command handling so direct commands no longer interrupt an in-flight turn, as shown in the release notes screenshot.
These are small, workflow-level improvements, but they target the two things that tend to break “agent as daily driver”: situational awareness (statusline) and terminal concurrency.
OpenAI’s Atlas browser team says Codex wrote over half the codebase
Atlas built with Codex (OpenAI): A long interview clip describes the team building OpenAI’s agentic browser Atlas and claims “more than half of Atlas’s code was written by Codex,” with Codex also used for navigating Chromium, prototyping UI, and learning implementation techniques, per the podcast segment.

This is another concrete “Codex in production” datapoint: not a benchmark claim, but a statement about how senior engineers are using it inside a large, legacy codebase.
OpenAI presents Codex steering practices at Pragmatic Summit
Pragmatic Summit (OpenAI DevRel): OpenAI’s developer team posted from Pragmatic Summit, pitching what it means to “steer an engineering team in an agent-first world” based on internal Codex usage, with a public demo invite in the summit session clip and follow-up logistics in the demo invite.

This mainly reads as field-positioning: Codex is being framed as an org-level system with steering, not a single-user coding assistant.
🟤 Claude product updates: free plan upgrades + Claude Code in Slack
Anthropic expanded free-tier capabilities and pushed more “work OS” features into Claude/Claude Code surfaces (connectors, skills, compaction, Slack workflows). Excludes GLM‑5 and Codex harness story (feature + Codex category).
Claude Code can run in an open-source sandbox runtime with isolation controls
Claude Code (Anthropic): Claude Code can opt into an open-source sandbox runtime via /sandbox, with both file and network isolation; the post notes Windows support “coming soon,” as described in Sandboxing tip with the runtime linked in Sandbox runtime repo.
This is about fewer permission prompts while keeping containment.
Claude Code plugins can install LSPs, MCPs, and skills via marketplaces
Claude Code (Anthropic): Claude Code’s /plugin flow can install LSPs, MCP servers, skills, and other components; the post also calls out the ability to run company/private marketplaces and check settings into version control, as described in Plugins tip with docs in Plugin marketplace docs.
This is an ops surface. It’s how teams standardize toolchains.
Anthropic’s advanced tool use framing resurfaces: tools as determinism, not browsing
Claude Developer Platform (Anthropic): An Anthropic engineering write-up on “advanced tool use” is being recirculated, framed around saving time/tokens and improving determinism when sites expose bespoke tools, as referenced in Advanced tool use link with details in Engineering post.
This aligns with the broader “tool interfaces beat UI automation” direction, but the tweets don’t include new metrics.
Claude Code exposes Low/Medium/High effort levels via /model
Claude Code (Anthropic): Claude Code supports an explicit effort level selection via /model; the thread frames it as a speed/cost vs quality dial (Low/Medium/High), as outlined in Effort level tip.
This is a product-level acknowledgement that “same model” is not one behavior.
Claude Code Slack app install link is live
Claude Code in Slack (Anthropic): Anthropic shared an install entry point for the Slack app in Install link post, pointing to setup documentation in Slack app docs.
Distribution is the change here. It’s no longer “internal beta only” vibes.
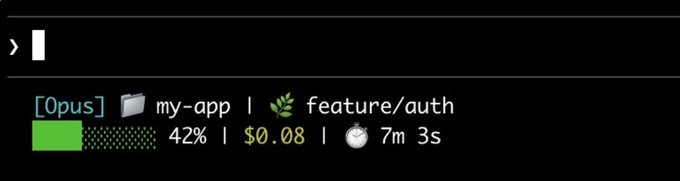
Claude Code status lines let you surface model, context, and cost inline
Claude Code (Anthropic): Claude Code supports custom status lines shown below the composer; the thread calls out showing model, directory, remaining context, and cost, with setup via /statusline, as described in Status line tip and detailed in Status line docs.
This is small but operational. It reduces “what state am I in?” confusion.
Claude Code terminal setup adds shift+enter newlines across more terminals
Claude Code (Anthropic): The customization thread highlights /terminal-setup for enabling shift+enter newlines (avoiding backslash line continuation) when running in IDE terminals and apps like Warp/Alacritty, as described in Terminal config tip and detailed in Terminal setup docs.
This targets a real papercut. It’s about writing multi-line prompts faster.
Claude Code keybindings are fully remappable with live reload
Claude Code (Anthropic): Claude Code allows customizing every keybinding via /keybindings, with settings hot-reloading so you can feel changes immediately, as described in Keybindings tip and documented in Keybindings docs.
This matters for teams standardizing a workflow across editors and terminals.
Plan Mode gets pushback from builders who want a persistent plan artifact
Plan Mode workflows (Claude Code): Alongside the Slack Plan Mode announcement in Plan Mode announcement, a counterpoint argues “plan mode sucks” and describes keeping the plan in a dedicated doc that doesn’t get compacted, as shown in Plan Mode debate screenshot.
This is an emerging split: embed planning in the agent loop vs keep a long-lived human-readable artifact.
Claude Code CLI benchmark shows claude --version ~15× faster in next build
Claude Code CLI (Anthropic): A benchmark claims the next Claude Code version makes claude --version ~15× faster—about 12 ms vs 180 ms—as shown in the hyperfine output shared in CLI benchmark.
It’s small, but it signals continued focus on CLI responsiveness.
🧑💻 Cursor & editor copilots: higher limits and model routing ergonomics
Tactical shipping updates for people using Cursor-style IDE agents: quota/limit changes and practical model allocation decisions. Excludes GLM‑5 (feature).
Routing heuristic: Composer/Opus for live iteration, Codex for background work
Model routing (practice): A practical allocation pattern is circulating: use Composer 1.5 + Opus 4.6 for “sync work” (interactive, fast feedback loops) and switch to GPT‑5.3 Codex for “async work” (longer, background-style tasks), as described in the Routing heuristic post—notably framed as a workflow choice, not a benchmark race.
The same post ties into Cursor’s temporary quota headroom—individual plans get 3× more Composer 1.5 than Composer 1, with a limited-time bump to 6× through Feb 16, as stated in the Limits increase note—which makes “use the faster/cheaper model while you’re present” a more viable default for day-to-day iteration.
🔷 Google Gemini developer surfaces: AI Studio UX + NotebookLM styles + Gemini 3.1 signals
Google’s builder UX got multiple small-but-real workflow updates today (AI Studio navigation/omnibar, design tooling modes) alongside renewed Gemini 3.1 preview chatter. Excludes GLM‑5 (feature).
Gemini 3.1 Pro Preview reference appears in public model listings
Gemini 3.1 Pro Preview (Google): Multiple watchers report seeing “Gemini 3.1 Pro Preview” referenced in model lists, suggesting an upcoming release or staged rollout; one example is a listing screenshot shared in the Artificial Analysis screenshot, with additional sightings echoed in the Model list highlight.
Treat this as a “surface signal,” not a spec drop: the tweets don’t include context window, pricing, or API availability details—only the name appearing in listings, as documented in the Artificial Analysis screenshot.
Google AI Studio redesign focuses on fast resume and an Omnibar
Google AI Studio (Google): A redesigned home page is rolling out that makes it easier to jump back into prior chats and “vibe-coded apps,” check usage, and start new work from a central Omnibar, as shown in the Homepage walkthrough and reiterated in the Build for speed clip.

• Navigation and retrieval: The emphasis is “get back to past chats” and “jump back to a past vibe coding session,” with a global keyboard shortcut (Ctrl + /) called out in the Build for speed clip.
• Ops visibility: The new surface highlights usage and project entry points, with a concrete view of the “Jump back in” list and usage panel visible in the UI screenshot.
NotebookLM adds infographic style presets in testing
NotebookLM (Google): NotebookLM is testing infographic customization with an auto-selection mode plus nine explicit styles—sketch, kawaii, professional, anime, 3D clay, editorial, storyboard, bento grid, and bricks—as shown in the Styles preview video.

This is a small UX change, but it matters for teams using NotebookLM outputs in external docs: it turns “same content, different visual treatment” into a first-class control, per the Styles preview video.
Stitch adds direct export to Figma with editable layers
Stitch (Google): Stitch now supports direct export of generated designs to Figma with editable layers, framed as a long-requested capability in the Export demo.

This changes the handoff path for teams: it turns Stitch output into a native design artifact rather than a screenshot-to-rebuild step, as shown in the Export demo.
Stitch introduces an Ideate mode for solution exploration
Stitch (Google): Stitch gained an Ideate mode positioned as “Bring a problem to solve and see solutions,” expanding beyond redesign-style workflows; the mode picker and prompt framing are visible in the Ideate mode screenshot.
The same UI capture also shows an “Export to Figma” callout in-product, but the tweet’s concrete change is the new Ideate workflow and its intent (“problem → solutions”), as documented in the Ideate mode screenshot.
🧑✈️ Agent orchestration & ops tooling: cloud runners, registries, memory, and multi-session UX
Ops-layer tooling for running many agents reliably: cloud agent platforms, registries, agent memory, and multi-session management in editors/terminals. Excludes GLM‑5 provider rollout (feature).
Devin Review hits 40k+ daily runs and adds one-click fixes, merge, and REVIEW.md
Devin Review (Cognition): Two weeks after launch, Devin Review is reportedly running 40,000+ times per day; the team added one-click apply fixes, a merge button, REVIEW.md support, and comment mentions, per the feature update demo.

This is a clear scaling signal for agent ops: PR-level automation is moving from “demo” to “high-volume workflow surface,” and the shipped features are aimed at collapsing the loop from review → edits → merge.
Warp open-sources the Oz Skills pack used for coding-agent automations
Oz Skills (Warp): Following up on cloud agents launch, Warp open-sourced the set of Skills they built into Oz—packaged automations for agentic chores like accessibility audits, docs updates, and test-coverage improvements, as announced in the skills open-source thread.

• What changes for teams: instead of re-creating “house style” automations per harness, you can install/inspect the same Skill definitions and reuse them across agent runners, per the skills open-source thread and the GitHub repo.
This is another data point that “skills as artifacts” is becoming the portability layer between agent products.
RepoPrompt 2.0 adds built-in agent mode and Codex app-server integration
RepoPrompt 2.0 (RepoPrompt): RepoPrompt shipped v2.0 with a built-in Agent mode that uses its MCP tools more fully, plus first-class support for Codex via its app server, while also supporting Claude Code and Gemini CLI, per the release notes and the changelog link.
This is part of a wider ops trend: “context builder + execution harness” tools are converging into products that sit between your repo and whichever agent you run.
Warp agent adds Skills: save to .agents, browse with /skills, edit with /edit-skill
Warp agent (Warp): Warp’s built-in agent now supports Skills stored in a local .agents/ folder; you can search them with /skills and modify them via /edit-skill in a rich viewer, as shown in the skills support demo.

The operational impact is that teams can treat Skills as versionable repo artifacts (reviewable diffs) rather than ad-hoc prompts floating in chat history.
Warp ships an /oz Skill to let other agents manage Oz cloud runs
/oz Skill (Warp): Warp released an /oz Skill that lets other coding agents (Claude Code, Codex, OpenCode, etc.) query Oz cloud-agent runs, update schedules, and modify Docker environment dependencies, as demonstrated in the oz skill demo.

This is a concrete interoperability move: orchestration state (runs, schedules, env) becomes tool-callable from whichever harness your team prefers.
Zed v0.223 adds URL-launched Agent Panel and terminal-to-thread capture
Zed v0.223 (Zed): Zed shipped deep multi-session UX improvements for agent workflows: you can open the Agent Panel via a custom URL (zed://agent?prompt=...) and send terminal selections into an agent thread via a context-menu action, as shown in the release demo.

These are small primitives, but they reduce the friction of “turn output into context” when you’re running multiple agent threads and iterating fast.
agent-browser crosses 500k weekly downloads a month after launch
agent-browser (open source): The agent-browser project crossed roughly 500,000 weekly downloads about one month after being launched and open-sourced, according to the downloads screenshot.
For ops-minded teams, that adoption curve suggests “agent-capable browser primitives” are becoming standard dependencies—raising the bar on reliability, observability, and safety defaults for web-task execution.
LangSmith Agent Builder explains its memory system for repeatable autonomous tasks
LangSmith Agent Builder memory (LangChain): LangChain shared how they designed memory into Agent Builder from the start—storing reusable instructions and learning from feedback, with portability via Markdown/JSON formats, as described in the memory deep dive.

The practical ops angle is that memory becomes an artifact you can migrate across harnesses (and review), instead of a proprietary per-app toggle that behaves unpredictably.
Zed’s ACP Registry adds Junie (JetBrains) and Kimi CLI agents
ACP Registry (Zed): Zed highlighted growing agent availability via its ACP Registry—calling out new installables including Junie (JetBrains) and Kimi CLI (Moonshot), per the registry screenshot.
The immediate value is operational: “agent choice” moves from per-tool setup to a registry install step, which matters once teams are running multiple specialized agents in parallel.
🔎 Codebase intelligence & context extraction: Q&A over repos, ripping dependencies, and doc parsing
Tools and patterns for turning repos/docs into agent-ingestible context: repo Q&A, targeted code extraction, diagram-to-graph conversion. Excludes GLM‑5 (feature).
DeepWiki MCP plus GitHub CLI is being used to extract small, self-contained modules from large deps
DeepWiki MCP (Context-to-code extraction): Karpathy reports a workflow where an agent uses DeepWiki via MCP plus GitHub CLI to locate the real implementation details inside a dependency, then re-implements only the needed slice with tests—he describes getting ~150 lines of self-contained FP8 training code that let him drop torchao and even run ~3% faster in one case, per his DeepWiki MCP workflow. The point is less “read the repo” and more “give the agent a repo-explainer API, then ask it to carve out a minimal equivalent.”
DeepWiki URL swap turns any GitHub repo into an instant Q&A surface
DeepWiki (Context extraction): A lightweight trick—swap github.com to deepwiki.com—creates auto-generated wiki pages plus repo-grounded Q&A, which Karpathy says often beats stale library docs because “the code is the source of truth,” as described in his DeepWiki usage thread. This is showing up as a practical way to answer implementation questions (e.g., internal FP8 details) without first finding the “right” doc page.
Diagram-to-Mermaid parsing turns dense PDFs into LLM-ingestible graphs
LlamaCloud (LlamaIndex): A diagram parsing feature is being demoed that converts complex diagrams inside PDFs/PowerPoints into Mermaid plaintext so LLMs can reason over structure without “burning” extra vision tokens; the before/after is shown in the Diagram to mermaid example, alongside a pointer to Anthropic’s multi-agent architecture diagram in the Agent architectures report.
This is a direct bridge from visual documentation into graph-shaped context that can be versioned, diffed, and fed into agents.
Agent-assisted code extraction is pushing a ‘bacterial code’ philosophy for libraries and deps
Software malleability (Design signal): Following the same DeepWiki MCP experience, Karpathy argues agents make it economical to “rip out the exact part you need,” which could change how software is written—favoring self-contained, stateless, easy-to-extract modules (“bacterial code”) over tangled dependency graphs, as framed in his Malleable software argument. Scott Wu echoes that as agents write less code directly, interfaces that help humans and agents ask precise questions against reality (code + surrounding context) become the new bottleneck, per his Interface matters take.
Doc Q&A agents are using a virtualized filesystem plus bash to harvest context deterministically
Doc ingestion pattern (agent-browser, json-render): ctatedev describes “Ask AI” endpoints that spin up a virtualized filesystem and run deterministic bash commands to traverse docs, extract relevant files, and assemble context for answers—positioned as a fast, inspectable alternative to black-box browsing, per the Just-bash doc search example.
The same pattern is being applied across multiple doc sites, including the surfaces cited in Project docs and Agent-browser docs.
opensrc CLI adds a one-command “give my agent the source” flow
opensrc (ctatedev): A new CLI flow—npx opensrc <package|repo>—clones the resolved upstream repo at a detected version into a local directory, explicitly positioned as a way to “give it the source” when agents need deeper context, as shown in the CLI output screenshot.
This is a concrete alternative to doc-only context packing: pull the exact source snapshot first, then point tools/agents at a stable filesystem path.
A single repo tries to standardize “Generative UI” building blocks for agentic apps
Generative UI (CopilotKit): CopilotKit published a consolidated resource repo that frames “GenUI” as agentic UI specs and groups three implementation patterns—MCP Apps (sandboxed iframe apps), Google’s A2UI (declarative JSON UI), and CopilotKit’s AG‑UI (state/protocol sync), as captured in the Repo screenshot.
It reads like an attempt to make UI artifacts as portable and inspectable as prompts/tools—so agents and frontends can share a common schema.
Property-based testing is being pitched as the safety rail for dependency extraction refactors
Equivalence testing pattern: A recurring tactic for ripping functionality out of a dependency is to keep a thin bridge to the original implementation and use property-based tests to assert behavioral equivalence across many generated inputs, as suggested in the Property-based testing tip. This pairs naturally with agent-written re-implementations: fast extraction, then high-coverage behavioral checks.
🦞 OpenClaw ecosystem: power-user workflows, scaling pains, and trust issues
OpenClaw remains a high-signal community harness, but today’s tweets are about operational friction (usability, rate limits) and trust boundaries (scraping/stargazer spam). Excludes GLM‑5 (feature).
OpenClaw power-user walkthrough shows a “Codex + Opus” operating setup
OpenClaw (open source): A detailed power-user walkthrough shows how OpenClaw gets used as the “glue layer” across daily knowledge work—personal CRM, KB, content pipeline, X search, analytics tracking, automations, backups, and memory—while routing execution across GPT‑5.3 Codex and Opus 4.6, as demonstrated in the Workflow video rundown.

The author also published the exact prompts behind those workflows in a public artifact, as linked in the Prompt pack follow-up and captured in the Prompt pack gist. For teams evaluating agent harnesses, this is a concrete “here’s the scaffolding” example rather than a generic endorsement.
OpenClaw maintainer signals workload pressure and steps back briefly
OpenClaw (open source): The project’s creator publicly said they “need a break,” signaling maintainer bandwidth as a real constraint when a community harness scales quickly, per the Maintainer comment.
The surrounding replies also show users explicitly asking for roadmaps and more features, which frames the “scaling pains” as expectation management as much as engineering throughput, as captured in the Roadmap pressure screenshot.
OpenClaw stargazers reportedly targeted via GitHub scraping for cold email
OpenClaw (open source): A complaint alleges a startup scraped the list of users who starred OpenClaw and emailed them (“I noticed that you starred OpenClaw”), raising a practical trust issue for open-source adoption funnels and the privacy surface of GitHub’s API, per the Stargazer email report.
The post frames this as both a growth tactic and an ecosystem problem—if “who starred what” is easily extractable at scale, dev tools with large star counts become easy outbound targets, as argued in the same Stargazer email report.
ClawHub gets blunt usability feedback: “unusable”
ClawHub (OpenClaw ecosystem): A user posted a short clip calling ClawHub “unusable,” highlighting day-to-day friction in the ecosystem UI layer even when the underlying agent harness is popular, as shown in the ClawHub complaint.

The critique is about operational UX (interaction lag and control issues), not model quality—useful context for leaders tracking whether agent adoption is being limited by tooling ergonomics rather than capability, per the same ClawHub complaint.
OpenClaw builds a Game Boy Snake clone via a local emulation feedback loop
OpenClaw (open source): A builder reports using OpenClaw with Gemini 3 Flash to generate a Game Boy Snake clone that runs on an emulator—explicitly calling out a “local emulation feedback loop” during development, per the Game Boy build report.

This is a crisp example of an agent workflow that benefits from tight run-verify-iterate cycles in a constrained environment (emulator), as described in the same Game Boy build report.
OpenClaw vs Claude Code/Cowork: people ask what’s uniquely enabled
OpenClaw (open source): A thread prompt asks what people do with OpenClaw that they can’t already do with Claude Code or Claude Cowork, which is a useful framing for evaluating whether a third-party harness is adding unique orchestration primitives (scheduling, hooks, multi-tool automation) versus being “just another chat surface,” per the OpenClaw comparison question.
A follow-up question pushes for specifics on “cron jobs and hooks,” implying the differentiator might be operational automation patterns rather than raw coding assistance, as asked in the Cron jobs and hooks ask.
Community claim: OpenClaw passed VS Code in GitHub stars
OpenClaw (open source): A retweeted claim says OpenClaw has surpassed VS Code in GitHub stars (and multiples of other projects), which is a pure adoption-signal datapoint—more about community scale than feature capability—per the Stars comparison claim.
No independent verification artifact is included in the tweet thread, so treat it as directional sentiment about momentum rather than a confirmed metric, based on the same Stars comparison claim.
OpenClaw “sub-agent swarms” demo gets livestreamed and shared
OpenClaw (open source): A livestream/demo shows “sub-agent ready swarms” running via OpenClaw with Orgo, positioning OpenClaw as a coordination harness for multiple concurrent agent threads, per the Swarms livestream note.
A replay link is provided via the same thread’s follow-up, pointing to the YouTube replay.
OpenClaw project builds a prompt library and vector search for better image prompting
OpenClaw (open source): A builder describes using OpenClaw and Gemini 3 Flash to build a system that writes its own image prompts (avoiding “keyword slop”), including a vector search index over 500+ prior prompts for inspiration, per the Prompt generation project.
The artifact shown includes a generated prompt card and an example output, implying the workflow is “retrieve past style → generate new prompt → render,” as documented in the same Prompt generation project.
Honolulu OpenClaw meetup gets scheduled for Feb 13
OpenClaw (community): A local OpenClaw meetup is scheduled in Honolulu, with details shared via the Meetup announcement and the linked Meetup page.
It’s a small but concrete signal that OpenClaw is forming in-person user groups, which tends to correlate with sustained tool adoption beyond online novelty, as implied by the same Meetup announcement.
✅ Quality, review, and safety rails for agent-written code
Engineering hygiene to keep agent throughput from breaking production: test harnesses, review bottlenecks, sandboxing and flags, and practical verification patterns. Excludes Codex harness engineering details (covered in the Codex category).
Vercel Sandbox adds network egress controls to limit agent data exfiltration
Vercel Sandbox (Vercel): Vercel added network isolation and explicit egress policies, so agent-run code can be constrained to an allowlist of outbound domains; the CLI supports an --allowed-domain flow, as shown in Allowed-domain demo.

The rollout is also reflected in the Vercel changelog, which describes “advanced egress firewall filtering,” as detailed in Changelog announcement and the linked Changelog post. The practical impact is that teams can move from “ask forgiveness” network access to “prove necessity” network access for agent sandboxes.
Claude Code in Slack ships Plan Mode, and the “plan artifact” debate follows
Claude Code in Slack (Anthropic): Anthropic added Plan Mode to Claude Code’s Slack experience—Claude asks clarifying questions and proposes an implementation plan before proceeding, per the product demo in Slack plan mode demo.

There’s already pushback that “plan mode sucks,” with an alternative workflow of keeping a persistent plan doc outside compaction and iterating against that artifact, as captured in the discussion screenshot in Plan mode critique.
Slack installation and docs are linked in Slack app install and the Slack app docs, which matters for teams trying to standardize how plans are reviewed before agent execution.
Review throughput emerges as the limiting factor as code generation gets cheap
Code review throughput: A recurring claim is getting stated bluntly—“the bottleneck isn’t compute, it’s biology”—arguing that code generation is approaching machine speed while review remains human-speed, leading to teams “drowning in PRs,” as framed in Review bottleneck post. The same post reframes the skill shift as auditing code quickly (often with LLMs) rather than writing it.
This is less about any single tool and more about an org-level failure mode: agent adoption increases the cost of quality gates unless review workflows and test signals scale with it.
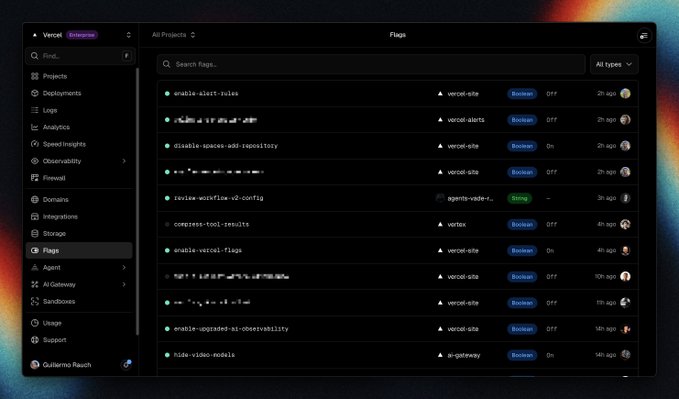
Vercel launches Vercel Flags as a safety valve for agentic shipping
Vercel Flags (Vercel): Vercel shipped Vercel Flags and explicitly frames flags as a way to “de-risk agentic engineering” as teams scale via agents, per the product note in Vercel Flags announcement; docs are live in the Flags docs. The operational point is familiar but newly urgent: when PR throughput spikes, flags become a first-line containment tool for shipping partial agent output without exposing it to everyone.
Vercel also claims heavy internal dogfooding for velocity in the Vercel Flags announcement, which is a useful signal that rollout/rollback is being treated as a default posture rather than an edge-case process.
Zed hard-blocks dangerous shell commands even in chained expressions
Zed Agent permissions (Zed): Zed added hardcoded safety guards that block dangerous commands like rm -rf /, including when they’re buried in chained shell expressions (e.g., ls && rm -rf /), as described in Hardcoded guardrails note. This is a distinct posture from allow/deny lists alone: it’s an invariant that can’t be relaxed via settings.
Property-based equivalence tests as a guardrail for agent refactors
Property-based testing as a safety rail: A practical technique is resurfacing for “rip out dependency / reimplement locally” work—write a bridge that calls the old code and assert equivalence across generated cases, per the suggestion in Property-based testing tip. This pairs well with agent-generated rewrites because it gives a deterministic pass/fail signal that doesn’t rely on subjective review.
📏 Benchmarks & measurement: coding arenas, time-horizon plots, and evaluation gaps
Measurement chatter today is about coding agent leaderboards, model selection signals, and the widening eval gap—not GLM‑5’s scores (those are in the feature).
Windsurf Arena Mode leaderboard points to speed as the winning UX metric
Windsurf Arena Mode (Windsurf): A week in, Arena Mode logged ~40,000 votes and surfaced a consistent preference for “fast but good enough,” with several notable “upsets” called out in the Leaderboard highlights and contextualized in the Leaderboard blog post. This is a measurement signal, not a benchmark claim: it’s explicitly optimizing for human-in-the-loop coding ergonomics rather than pure frontier accuracy.
• Upset pattern: The same post highlights Gemini 3 Flash beating 3 Pro, Grok Code Fast beating Gemini 3, and Claude Haiku 4.5 beating GPT-5.2, all as “major upsets” in this arena’s objective function per the Leaderboard highlights.
It’s an early datapoint that “model choice” in IDE workflows is drifting toward latency/iteration-loop preference, even when engineers believe a slower model is smarter.
Code Arena adds multi-file app builds to evaluate agentic web-dev workflows
Arena Code (Arena): Code Arena added multi-file apps, positioning it as a closer proxy for production web-dev agent workflows (project structure, cross-file edits, integration points) rather than single-prompt snippets, as announced in the Multi-file apps announcement.

• Workflow surface: The rollout framing emphasizes “production-ready projects” and “real-world, agentic coding tasks,” which changes what’s being measured versus single-file codegen, as stated in the Multi-file apps announcement.
• Where it lives: The entry point is the Code Arena UI at the Code Arena destination, which the follow-up post uses as the canonical surface for trying multi-file comparisons.
METR time-horizon debate shifts from “when” to “how to measure” multi-hour tasks
METR time-horizon plot (METR): A new poll asks whether the METR-style curve hits ~20-hour tasks by Jan 1, 2027 or ~50-hour tasks by 2028, alongside the more operational question: “What would be the right way to measure tasks of that scope?” as posed in the Time-horizon poll.
The core measurement problem being surfaced is scoping: multi-hour “tasks” are rarely single-threaded, and evaluation design needs to decide what counts as success (handoffs, partial credit, tool failures, retries) rather than only extrapolating from shorter task distributions.
OpenHands agentic coding index highlights score vs cost vs runtime tradeoffs
OpenHands agentic coding index (OpenHands): A leaderboard snapshot shows Claude Opus 4.6 leading on average score, but with closely tracked average cost and runtime comparisons that make it harder to treat “#1” as a single dimension, as shown in the OpenHands index post.
• What engineers can actually infer: The table format (Average Score / Average Cost / Average Runtime) makes explicit that model selection for agentic coding is a three-way trade (quality, dollars, wall-clock), not a single scalar, as shown in the
.
Open Benchmarks Grants signal more money and coordination for harder evals
Open Benchmarks Grants (SnorkelAI + partners): A partnership announcement frames the core bottleneck as measurement—“the world needs more hard benchmarks”—and points at new funding/coordination mechanisms in the Grants partnership note.
• Follow-on signal: Separately, there’s a claim that “a large eval company is starting a task force” to launch something in 1–2 years, as stated in the Eval task force claim.
No specific benchmark spec is described in the tweets, but the combined signal is that eval infrastructure is becoming an organized, staffed effort rather than a community side-project.
⚙️ Inference & serving engineering: throughput, long-context scheduling, and hybrid attention
Serving-side engineering updates beyond the GLM‑5 rollout: cache-aware scheduling, long-context efficiency, and new attention architectures aimed at faster inference. Excludes GLM‑5 day‑0 serving posts (feature).
Cache-aware CPD adds a third tier for long-context serving and claims +40% sustainable throughput
Cache-aware scheduling (Together Research): Together describes cache-aware prefill–decode disaggregation (CPD) as a scheduling fix for long-context inference—separating cold requests that need full prefill from warm follow-ups that can reuse KV cache; they report up to ~40% higher sustainable throughput without changing model weights or hardware, per the CPD thread and the linked technical writeup.
• Three-tier serving shape: CPD introduces pre-prefill nodes for cold contexts that write KV state into a distributed cache, while warm requests fetch cached KV blocks via RDMA and skip recomputation—keeping decode isolated and latency-focused, as described in the tier breakdown.
The point is that, as context windows stretch into 100K+ tokens, KV reuse and queueing policy start to dominate TTFT and tail latency under load, which is the core claim in the throughput results.
MiniCPM-SALA claims 3.5× faster 256K inference via sparse+linear hybrid attention
MiniCPM-SALA (OpenBMB): OpenBMB announced MiniCPM-SALA, a 9B model trained with a hybrid Sparse-Linear Attention (SALA) architecture—75% linear attention for global flow and 25% sparse attention for recall; they claim 3.5× inference speedup vs Qwen3-8B at 256K context and support up to 1M context on edge GPUs, per the release thread and the linked model card.
• Positional and length generalization: the release highlights a hybrid positional encoding (HyPE) intended to keep behavior stable across varying sequence lengths, as described in the release thread.
• Inference-optimization pressure test: OpenBMB also launched the SOAR optimization contest targeting SGLang acceleration for this architecture (single/multi-batch, ultra-long context on consumer VRAM, low latency), per the competition details.
vLLM passes 70K GitHub stars and spotlights Blackwell multi-node serving primitives
vLLM (vLLM Project): vLLM crossed 70K GitHub stars and used the milestone to highlight recent work on large-scale serving—especially production multi-node support on NVIDIA Blackwell with WideEP and expert parallelism, plus broader async scheduling and multimodal streaming work, as summarized in the 70K stars post.
• Serving focus: the post frames recent engineering as making “the biggest models” practical to serve at scale (multi-node + expert parallelism), alongside real-time streaming for speech/audio and a “growing multimodal story,” per the 70K stars post.
• Ecosystem signal: it also notes the founding of Inferact by core maintainers (inference cost/latency focus), which matters if you’re tracking where vLLM’s production roadmap might concentrate next, per the 70K stars post.
BaseTen’s Kimi K2.5 speed recipe leans on EAGLE-3 speculation and NVFP4 on Blackwell
Kimi K2.5 inference (BaseTen): BaseTen published a concrete recipe for speeding up Kimi K2.5 inference using a custom EAGLE-3 speculator trained on synthetic queries plus INT4→NVFP4 conversion to unlock NVIDIA Blackwell inference, per the performance roundup and the linked technical post.
The engineering takeaway is that they’re stacking speculative decoding plus new low-precision paths (NVFP4) as a combined latency/throughput lever, rather than treating quantization and decoding tricks as separate optimizations, as described in the performance roundup.
Crush adds multi-process management for running multiple agent and serving loops in parallel
Crush (Charm): Crush can now run and manage multiple background processes—multiple web servers, docker swarms, or other long-running jobs inside the terminal UI—shown in the feature demo.

This is a pragmatic fit for local inference + eval setups where you’re often juggling several services (gateway, tracing, cache, model server) and want them controllable from one interface, as demonstrated in the feature demo.
🛡️ Security, safety, and platform abuse signals (spam, privacy, and cyber risk)
Today’s security signal is about agent misuse risk, privacy surfaces, and automation flooding—plus governance/safety-org churn. Excludes AI-infrastructure power commitments (covered under infrastructure).
Embedding vectors aren’t “irreversible” anymore: Jina AI inverts embeddings back to text
Embedding inversion (Jina AI): A new demo shows recovering original text from embedding vectors using conditional masked diffusion, challenging the common assumption that stored embeddings are “safe” because they’re non-human-readable; Jina claims ~80% token recovery with a 78M parameter inversion model against Qwen3-Embedding and EmbeddingGemma vectors, as described in the demo overview and method details. This is a privacy and security issue. Embeddings can carry secrets.

• Why this is different: Instead of autoregressive vec2text plus iterative re-embedding, they condition a denoiser on the target embedding via AdaLN-Zero and refine all positions in parallel, as explained in the method details.
• Operational implication: Any product logging or sharing embeddings (telemetry, vector DB backups, vendor “debug traces”) may need to treat them like sensitive plaintext, given the inversion capability shown in the demo overview and the linked live demo.
Bot automation is expected to overwhelm more channels within ~90 days
Platform abuse (automation & spam): A circulated prediction argues that in <90 days “all channels we thought were safe from spam & automation” will be flooded, as amplified in the spam prediction RT. This is a direct product risk. It hits support inboxes, community channels, and even internal tooling.
The point is scaling “agentic” posting changes the baseline. Moderation load and trust signals become core infrastructure, not a side feature, per the framing in the spam prediction RT.
Dual-use anxiety rises as builders call Claude-based work “cyber-weapon level”
Dual-use (Claude Opus 4.6): A developer claims a principal threat researcher told them their Opus‑4.6-driven project can’t be open-sourced because it’s a “nation‑state‑level cyber weapon,” as stated in the cyber weapon comment. That’s a strong signal. The details aren’t provided.
This illustrates the widening gap between “can a model write code?” and “can it produce operational exploit chains,” and it’s part of why teams are increasingly treating model access, logging, and sharing policies as security controls, not just compliance paperwork, as suggested by the tone in the cyber weapon comment.
Signal’s founder repeats: Telegram isn’t a private messenger
Messaging security (Telegram vs Signal): A quote attributed to Signal founder Moxie Marlinspike is resurfacing, stating “Telegram’s not a private messenger,” as shared in the Telegram privacy RT. This matters if teams use chat apps to move model outputs, credentials, incident info, or customer data.
It’s not a new technical disclosure. It’s a reminder about threat models and what “private” means in practice, per the Telegram privacy RT.
🔌 Compute, power, and hardware supply chain for AI buildout
Concrete infra moves affecting capacity and cost: power pricing commitments, custom inference silicon, and datacenter power delivery experiments. Excludes funding/valuation chatter (business category).
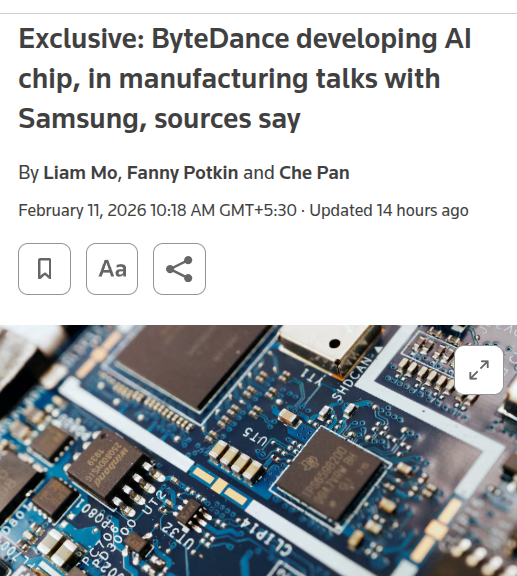
ByteDance plans an in-house inference chip and targets 100k units in 2026
ByteDance (Reuters via rohanpaul_ai): ByteDance is reportedly developing an in-house AI inference chip and is in talks with Samsung for manufacturing; the report says ByteDance is targeting at least 100,000 chips in 2026, with a possible ramp toward 350,000, and that access to scarce memory (HBM/DRAM) is part of the discussions, per the Reuters excerpt.
This matters because it reinforces a supply-chain reality builders already feel: GPU availability isn’t the only limiter—memory supply can bottleneck deployments even when compute silicon exists. It also signals more vertical integration pressure on NVIDIA-alternatives and on memory allocation across hyperscalers and large AI buyers.
Anthropic says it will pay 100% of grid upgrade costs tied to its data centers
Anthropic (AnthropicAI): Anthropic says it will cover electricity price increases attributable to its data centers by paying 100% of grid upgrade costs, working to bring new power online, and investing in systems that reduce grid strain, as laid out in the policy post and detailed in the Policy post. This is a direct attempt to pre-empt “AI data centers raise my rates” backlash and permitting friction.
For engineering and infra leads, the practical implication is that power contracts and interconnection work are becoming a first-class part of AI delivery, not a back-office detail; this kind of pledge can shift how projects get approved, where capacity is available, and how costs get allocated across tenants and regions.
Microsoft tests superconducting power cables to move more MW into AI data centers
Power delivery (Microsoft): Microsoft is testing high-temperature superconductor (HTS) cables for AI data centers, citing a factory test and demo around a 3MW superconducting cable; the pitch is much higher power density (claims of ~10× smaller/lighter delivery) by eliminating resistive losses once cooled to around −200°C, as described in the HTS cable thread.
The trade-off highlighted in the same thread is operational: HTS shifts constraints from copper losses to cryogenic cooling reliability, maintenance, and failure handling. If it works, it’s a plausible lever for faster site power-ups and denser rack footprints without needing the same right-of-way and trenching as conventional transmission.
xAI “Macrohard” recirculates as a GW-scale power-and-GPU buildout signal
xAI infrastructure: Posts are recirculating stats about xAI’s “Macrohard” compute site—framed as 1+ GW scale with 12 data halls, 27,000 GPUs, and 200,000+ fabric connections, as shown in the cluster tour clip.

A separate graphic making the rounds claims an even larger snapshot—“330K+ GPUs,” “>1GW nameplate power,” and “558 Megapacks = 2,293 MWh,” as shown in the stats graphic.
The numbers conflict across sources, so treat them as directional rather than audited; the consistent throughline is that power delivery and on-site energy storage are being discussed as core scaling primitives, not secondary facilities work.
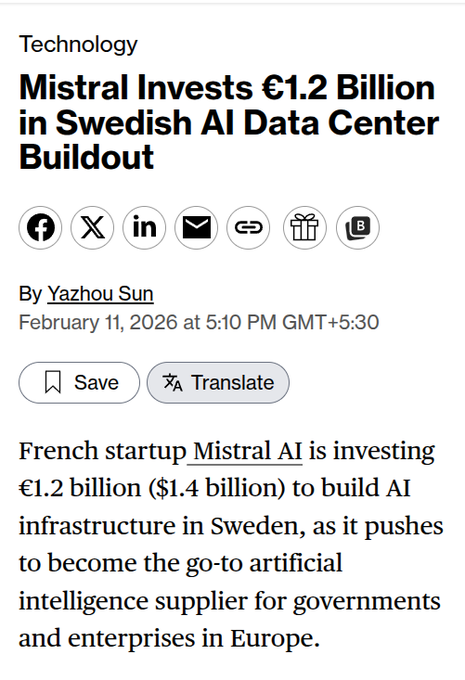
Mistral plans a €1.2B AI infrastructure buildout in Sweden for 2027
Mistral (Bloomberg via rohanpaul_ai): Mistral AI is reported to be planning a €1.2B AI infrastructure facility in Sweden targeting 2027 operations, positioning for European government and enterprise demand, per the Bloomberg snippet.
For AI platform leaders, this is a “sovereign compute” signal: Europe is still trying to secure domestic capacity and procurement pathways, which can affect where models are trained/served (data residency) and how quickly regional inference capacity grows relative to US hyperscalers.
💼 Enterprise adoption & capital signals around AI tools
Buyer behavior and capital flows relevant to engineering leaders: who’s paying for which models, overlap/churn, and large strategic investments. Excludes infra buildouts (infrastructure category).
Ramp AI Index shows Anthropic growth is mostly within existing OpenAI customers
Ramp AI Index (enterprise adoption): Ramp spend data shows Anthropic reached 19.5% of U.S. businesses with paid AI subscriptions (up from 16.7%) while OpenAI is at 35.9%; a key nuance is that 79% of Anthropic customers also pay OpenAI and churn is ~4% for both, per the Ramp index analysis.
• Buyer behavior: this reads less like vendor displacement and more like “second provider added” inside the same org, as argued in the Ramp index analysis.
• Planning implication: multi-model procurement looks normalizing (budgets split across vendors), which tends to push engineering leaders toward routing/benching and vendor redundancy rather than single-stack commitments, per the same Ramp index analysis.
Blackstone reportedly increases Anthropic stake to about $1B at a ~$350B valuation
Anthropic funding signal (Blackstone): Blackstone is reportedly increasing its Anthropic investment to about $1B, with an estimated $350B valuation, according to a Reuters item shared in the Reuters screenshot.
This fits as an incremental datapoint on the broader late-stage funding appetite for frontier model providers—especially relevant for engineering leaders forecasting medium-term pricing stability, enterprise support capacity, and long-term model roadmap continuity.
🎬 Generative video, image, and voice models: quality jumps and workflow stacks
High volume of creative-model evidence: Seedance 2.0 clips, realtime world/video claims, and voice latency improvements—useful for teams shipping media features. Excludes drug design/biomed topics.
SeeDance 2.0 clips dominate “text-to-video feels solved” chatter
SeeDance 2.0 (ByteDance): Following up on Hype questions (consistency/bias concerns), today’s feed is packed with “one-shot” anime-style outputs—people are explicitly calling it “passed the video Turing test” while highlighting the economics (a 10-minute clip taking ~8 hours and costing ~$60) in posts like Cost breakdown and Long clip example.

• Range of prompts: examples span manga→anime adaptation in a single go per Manga to anime claim, plus short comedic/character acting setups (otter sitcom variants) shown in Prompted sitcom clip.
• Production signal: users are framing this as a compute-demand shock (“explosion of demand for compute”) in Manga to anime claim, but there’s no official provider/SDK surface in the tweets to validate workflows beyond demos.
The dominant mood is excitement; the main missing piece is trustworthy access and repeatable tooling outside China.
ElevenLabs adds Expressive Mode to ElevenAgents for more human calls
ElevenLabs ElevenAgents (ElevenLabs): ElevenLabs shipped “Expressive Mode” for its agent voice stack—positioned as more emotional, context-aware delivery and real-time turn-taking across 70+ languages in Expressive mode details. Separately, builders keep fixating on latency (“voice but especially latency”) in reactions like Latency reaction, and the company is doubling down on “voice replaces outdated interfaces” messaging in its summit keynote clip Summit keynote clip.

The engineering takeaway is that speech agents are getting judged less on raw fidelity and more on conversational timing and interruption behavior (where most stacks still feel brittle).
SeeDance 2.0 access gets messy: scam warnings and “wrapper” claims
SeeDance 2.0 (ByteDance): Continuing Access notes (BytePlus+VPN access chatter), creators are now explicitly warning that “wrapper” platforms may falsely claim exclusive access and that people can get scammed, as argued in Wrapper scam warning. A recurring theme is that the model is “not currently available outside China,” while third parties advertise “unlimited access” anyway, per Wrapper site promo.

• Operational risk: the guidance is to wait for “trusted platforms” in Wrapper scam warning, which matters because the same workflows that make the clips look real also make phishing/fake-hosting easy.
Net: even if the model quality is real, distribution uncertainty is a practical blocker for teams trying to ship features with predictable uptime and terms.
Local video generation stack: Nano Banana stills → LTX-2 animation
Local video workflow (LTX-2 + ComfyUI): A concrete “consumer GPU” stack is being shared: generate stills, then animate with LTX-2 locally, with reported generation times of ~6–10 minutes on a 4070 Ti in Local consumer GPU demo. The thread frames it as a repeatable loop—iterate on frames, reuse references, then run i2v—rather than a single prompt-and-pray approach.

This is the kind of workflow detail that matters more than headline model quality: it’s about how you actually amortize prompt/search time across multiple shots on local hardware.
PixVerse R1 surfaces as a “real-time interactive worlds” video model
PixVerse R1 (PixVerse): A new model branded as “real-time interactive worlds in 720P” is being circulated via a launch claim in RT launch blurb, with additional detail that it targets near-instant response by cutting sampling to 1–4 steps using an “Instantaneous Response Engine,” per the summary in Realtime pipeline notes.
This reads like an attempt to make video generation feel more like a game loop (latency-first), but the tweets don’t include a technical report, evals, or reproducible demos—so performance/quality tradeoffs vs longer-sample models are still unclear.
Prompting pattern: shorter prompts can beat constraint-heavy ones in image editing
Prompt discipline (image models): A long practitioner note argues that adding many constraints to an image-edit prompt often makes results worse—producing “face-in-hole” artifacts—while a short schematic instruction can yield more natural outputs, based on a Nano Banana-style identity swap scenario in Prompt minimalism essay.
The core claim is that modern models already have strong defaults, and over-specification forces the model to optimize for satisfying every clause rather than realism; it’s framed as analogous to over-directing a skilled chef.
Grok adds multi-reference image blending and web image display in voice
Grok (xAI): Two image-surface updates are being spotted: Grok web can combine 3 reference images into a new image per Three-reference feature, and Grok voice mode can display “real-time images from the internet” as shown in Voice web images.
This is a product signal that xAI is trying to collapse “search + show + speak” into one loop; the open question for builders is whether these are powered by a stable tool API or remain UI-only behaviors that can’t be integrated into agent workflows reliably.
Qwen Chat patches a Qwen-Image 2.0 bug affecting ordering and consistency
Qwen-Image 2.0 (Alibaba/Qwen): Qwen says it patched a Qwen Chat bug that affected (1) ordering for classical Chinese poem image generation and (2) character consistency during image editing, with the fix announced in Bugfix announcement.
This kind of “small” fix matters operationally: it targets two common production pain points for image features—layout/sequence fidelity and identity consistency across edit passes—without implying a new model release.
📄 Research & technical writeups: agents for math, tiny GPTs, UI world models, and interpretability
Paper-and-implementation heavy posts today: math/science agents, minimal GPT implementations, GUI world modeling, and interpretability methods. Excludes bioscience/drug discovery items.
DeepMind’s Aletheia shows a verifier-driven loop for research-level math work
Aletheia (Google DeepMind): DeepMind shared results and workflows around an internal math research agent powered by an “advanced version of Gemini Deep Think,” emphasizing a generator→verifier loop (with reviser feedback) for research problems, as introduced in the DeepMind research post and the Aletheia paper announcement. This matters because it’s a concrete reference design for “research agents” that couple long-horizon search with explicit verification, not just prompting.
• Workflow pattern: The agent architecture is explicitly framed as generator/candidate solution→verifier with branches for “critically flawed” (loop back) vs “minor fixes” (reviser), as diagrammed in the DeepMind research post.
• Reported math performance: A shared leaderboard screenshot claims Aletheia 91.9% on IMO‑ProofBench Advanced with a breakdown that includes 100% on IMO 2024+, as shown in the leaderboard screenshot. Treat this as provisional until DeepMind publishes a canonical eval artifact, since the most detailed numbers in the feed are secondary commentary.
• Primary artifact: The Aletheia writeup is available via the Aletheia paper PDF, which is the cleanest place to verify the “open problems / publishable outputs” claims summarized in the Aletheia paper announcement.
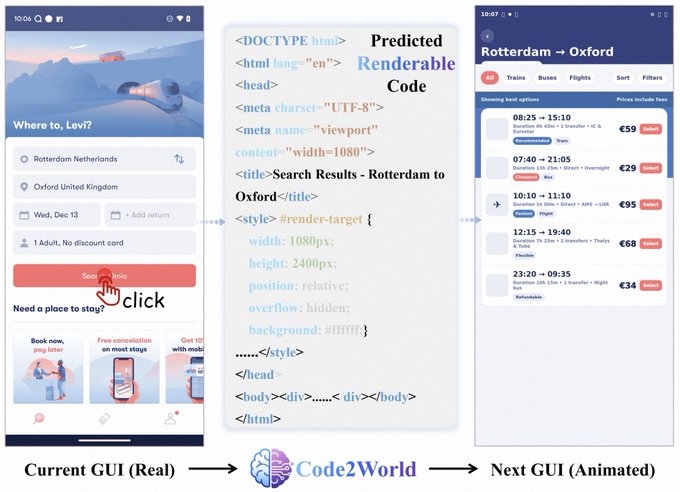
Code2World predicts next UI state by generating renderable code
Code2World (paper): A “GUI world model” approach that predicts the next UI state by generating renderable code (e.g., HTML/CSS) rather than emitting pixels directly, as highlighted in the paper share. The engineering implication is a more testable interface for UI prediction: you can diff, lint, and even run a renderer to validate state transitions.
The paper can be accessed via the paper page, and the figure in the paper share shows the core loop: current GUI → code generation → next GUI.
Karpathy’s microgpt distills GPT training + inference into ~243 lines
microgpt (Andrej Karpathy): A minimal, dependency-free Python implementation trains and runs a GPT in ~243 LOC, framing “everything else” in modern stacks as efficiency scaffolding, as described in the microgpt gist intro and reiterated in the math ops breakdown. It strips the architecture and loss down to primitive ops (+, *, **, log, exp) and uses a tiny scalar autograd engine (micrograd) plus Adam, per the microgpt gist intro.
For the reference implementation, see the GitHub gist, with a single-page mirror in the microgpt page.
UI-Venus-1.5 report benchmarks GUI grounding and navigation for agents
UI‑Venus‑1.5 (technical report): A benchmark-heavy report on GUI agents covering grounding and navigation tasks (Android/web), with scores shown across multiple suites, as posted in the report share. This matters for teams evaluating “computer use” agents because it provides a comparable set of tasks/metrics (grounding vs navigation) rather than collapsing everything into one aggregate.
The report entry point is the technical report page, while the report share includes navigation bars for AndroidWorld/AndroidLab/WebVoyager-style tasks and radar plots for grounding.
LatentLens maps visual tokens to human descriptions for interpretability
LatentLens (paper): A method for making visual tokens in LLM/VLM stacks more interpretable by retrieving the most similar contextualized text descriptions to a given visual token, positioned as a practical “what does this token mean?” probe, per the paper share. This is aimed at interpretability workflows where you want human-legible concepts without training a bespoke concept classifier.
The paper entry point is the paper page, with the diagram in the paper share showing the pipeline: precompute text reps → encode visual tokens → top‑k text descriptions → VLM judge feedback.
OPUS proposes iterative data selection to improve pretraining efficiency
OPUS (paper): A data-selection method for LLM pretraining that argues for selecting training data every iteration (not a one-time filter) to improve sample efficiency and downstream performance, as shared in the paper post. For teams doing large-scale pretraining, this is a concrete proposal for shifting optimization effort from architecture tweaks to continual dataset curation.
The paper landing page is the paper page, and the paper post is the main claim artifact shown in the feed (performance vs tokens, with an “8× efficiency” annotation).
🤖 Robotics & embodied AI: deployment reality vs hype
Embodied AI updates span real deployment constraints (navigation vs manipulation) and fast-moving surgical/teleop robot claims. Excludes any wet-lab or bioscience research content.
Epoch AI: navigation is deployed; manipulation transfer is the bottleneck
Robot deployment reality (Epoch AI Research): A new review breaks robot autonomy down into 14 concrete task areas and lands on an unglamorous split—navigation is already in broad commercial use, while manipulation is mostly stuck in narrow, engineered settings, as summarized by task capability review and extended in navigation deployment examples and warehouse picking caveat. The repeated constraint is transfer: many systems work when the environment is designed around the robot, but evidence for generalizing to new objects/homes is thin, per transfer bottleneck note and household transfer framing.
The review also flags that pretrained robot foundation models are becoming the default for harder manipulation regimes, with Toyota Research Institute results cited in pretrained model results and a task-by-task classification linked in full report link.
TeleAI TextOp: streaming text commands for humanoid control with balance policy
TextOp (TeleAI): A new framework turns natural-language commands into real-time humanoid motion while letting you change instructions mid-action; it uses a two-level setup where a high-level model streams motion trajectories and a low-level policy maintains balance, according to TextOp summary.

This is a practical design point for embodied agents: “instruction following” becomes a continuously updated control signal, not a one-shot plan, which is closer to how interactive robot deployments get supervised in the real world.
5G teleop surgery demo claims ~5,000km remote operation in ~1 hour
Remote surgery demo (China): A reported teleoperation case had surgeons in Shanghai operate on a patient in Kashgar—nearly 5,000km away—using a China-made 5G surgical robot, with the procedure described as taking about 1 hour and having minimal blood loss/no complications in teleop surgery clip.

For robotics teams, the operational question is less “can it move precisely” and more the full stack: network guarantees, failure modes, fallback procedures, and how much autonomy vs. strict teleop is actually in play.
Fei-Fei Li: embodied, spatial intelligence is the missing gap
Embodied intelligence framing (Fei-Fei Li): Fei-Fei Li argues that human intelligence is fundamentally physical—built on navigating 3D space, anticipating motion, and dealing with friction and consequences—unlike current AI systems that are primarily linguistic, as quoted in embodied intelligence clip.

This maps cleanly onto what robotics teams see in practice: the hard part is not producing text plans, it’s grounding them in perception, control, and uncertainty.
Surgery-on-a-grape demo resurfaces as a benchmark for fine manipulation
Surgical manipulation signal: A short clip of a robot performing a very high-precision procedure on a grape is circulating as a visceral “dexterity” benchmark, via grape surgery demo.

It’s a reminder that impressive micro-dexterity demos don’t automatically translate to robust manipulation in unstructured settings—especially when sensing, tooling, and task variance change.
Optimus surgery timeline claims spread, with little operational detail
Optimus speculation (Tesla): A prediction that Tesla’s Optimus will outperform human surgeons “in 3 years at scale” is being reshared, alongside a clip attributed to Elon Musk dismissing medical school as “pointless,” per Optimus surgeon claim.
There’s no accompanying evidence in the tweet about validation protocols, deployment constraints, or regulatory path, so it reads more like timeline signaling than an engineering update.

















![➜ code hyperfine "./claude-new --version" "./claude-old --version"
Benchmark 1: ./claude-new --version
Time (mean ± σ): 12.1 ms ± 1.6 ms [User: 3.8 ms, System: 2.2 ms]
Range (min … max): 7.0 ms … 15.4 ms 123 runs
Benchmark 2: ./claude-old --version
Time (mean ± σ): 179.9 ms ± 7.7 ms [User: 179.9 ms, System: 20.0 ms]
Range (min … max): 170.4 ms … 200.0 ms 15 runs
Summary
./claude-new --version ran
14.91 ± 2.03 times faster than ./claude-old --version](https://pbs.twimg.com/media/HA5N_UNbsAIzRLe?format=jpg&name=small)