Google Veo 3.1 adds 9:16 output and 4K upscaling – SynthID verification
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Google is rolling out Veo 3.1 across Gemini app, Flow, AI Studio, Gemini API, and other surfaces; the update pushes native 9:16 portrait generation (not a landscape crop), 1080p output plus an explicit 4K upscaling path, and an upgraded “Ingredients-to-Video” workflow aimed at reducing character/scene drift across multi-shot sequences; availability is framed as paid-tier gated (Plus/Pro/Ultra). Google also says Veo 3.1 embeds SynthID watermarks, with Gemini-side verification to check provenance; it’s an integrity feature more than a quality claim, and independent robustness tests aren’t shown.
• Anthropic/Claude Code 2.1.7: MCPSearch auto-mode turns on by default; tool descriptions are deferred when they exceed 10% of the context window; Explore/Plan subagents become read-only by removing edit/write tools; wildcard permission rules tighten around shell-operator compounds.
• Vercel Labs/agent-browser: v0.5.0 adds CDP mode, extensions, and “serverless ready” support; a field report claims ~70% lower token burn vs a Chrome DevTools MCP setup, but it’s a single comparison.
Across the feed, “agents as products” is converging on packaging and routing: Veo ships as distinct SKUs (including “fast”); OpenRouter surfaces privacy/ZDR settings as routing eligibility rather than hidden failures.
Top links today
- Anthropic $1.5M support for Python and OSS security
- Anthropic Labs hiring for Claude Code and MCP
- MedGemma 1.5 model docs and download
- Veo 3.1 video generation in Gemini API docs
- GLM-Image model card on Hugging Face
- GLM-Image GitHub repo
- EvoRoute paper on agent model routing
- iMIST paper on tool disguised jailbreaks
- Goal Force paper for physics conditioned planning
- iReasoner paper for self evolving multimodal reasoning
- Anchored Reference jailbreak evaluation paper
- Self consuming performative loop bias paper
- OpenRouter provider routing and privacy eligibility
- Firecrawl agent endpoint on Zapier integrations
- Every Vibe Code Camp event page
Feature Spotlight
Feature: Google’s Veo 3.1 update rolls out (portrait video, 4K upscaling, Ingredients-to-Video consistency, SynthID)
Veo 3.1’s rollout makes Google’s video stack more production-ready: portrait-native generation, improved identity/scene consistency, 1080p/4K upscaling, and SynthID verification—key for creators and enterprise pipelines.
High-volume cross-account story: GeminiApp, GoogleDeepMind, and others highlight Veo 3.1 upgrades—native vertical video, improved Ingredients-to-Video consistency, higher resolutions (1080p/4K), and verification via SynthID. Excludes other video/image tools and non-Google gen-media (covered elsewhere).
Jump to Feature: Google’s Veo 3.1 update rolls out (portrait video, 4K upscaling, Ingredients-to-Video consistency, SynthID) topicsTable of Contents
🎬 Feature: Google’s Veo 3.1 update rolls out (portrait video, 4K upscaling, Ingredients-to-Video consistency, SynthID)
High-volume cross-account story: GeminiApp, GoogleDeepMind, and others highlight Veo 3.1 upgrades—native vertical video, improved Ingredients-to-Video consistency, higher resolutions (1080p/4K), and verification via SynthID. Excludes other video/image tools and non-Google gen-media (covered elsewhere).
Google rolls Veo 3.1 updates across Gemini, Flow, AI Studio and APIs
Veo 3.1 (Google): The Veo 3.1 upgrade is rolling out across the Gemini app plus developer surfaces (Gemini API, AI Studio) and product surfaces (Flow/Shorts), bundling portrait support, higher-res outputs, and a refreshed Ingredients-to-Video workflow, as summarized in the rollout recap clip and the Gemini app rollout. Access appears gated to paid tiers, with Gemini positioning it for AI Plus/Pro/Ultra accounts in the availability note.

The distribution detail matters because it determines whether teams can ship via API now (paid key + model selection) versus only experimenting inside the consumer app, with the rollout cadence framed directly in the rollout note.
Veo 3.1 adds native portrait (9:16) video generation without cropping
Veo 3.1 (Google): Native portrait output is now a first-class path—Gemini can generate 9:16 videos directly (not a landscape crop), with the consumer workflow shown in the portrait workflow demo and the API framing called out in the API feature bullets. Gemini also pitches "less prompting" for acceptable results in the Gemini app rollout, which is a quiet but important shift for creator iteration speed.

This is specifically positioned as aspect-ratio preservation: upload a vertical image and Gemini keeps orientation and ratio, as described in the portrait workflow demo.
Veo 3.1 adds 1080p and 4K upscaling for higher-fidelity exports
Veo 3.1 (Google): Upsampling is now part of the supported workflow, with Google calling out 1080p and 4K options in the API and Studio update and reiterating “state-of-the-art upscaling” in the upscaling callout. Developer-facing framing also appears in the API feature bullets, which lists improved 1080p outputs and a new 4K resolution path.

While some surfaces may gate the highest output settings, the existence of an explicit 4K path changes what teams can reasonably export into real edit timelines versus treating generations as preview-only.
Veo 3.1 upgrades Ingredients-to-Video for stronger identity and scene consistency
Ingredients-to-Video (Veo 3.1): Google is pushing a more controllable “ingredients” workflow—reference images drive better character identity and background stability across scenes, as introduced in the Ingredients update thread and described more concretely in the consistency explanation. A second axis is compositional control: combining disparate elements (characters/objects/textures/stylized backgrounds) is highlighted in the consistency explanation and demonstrated in the mixing ingredients demo.

The change here is less about raw generation and more about reducing drift across multi-shot sequences, which is what makes short-form “clips” composable into a story.
Veo 3.1 embeds SynthID watermarks and enables Gemini-side verification
SynthID verification (Google): Veo 3.1 outputs embed SynthID watermarks for provenance, and Gemini can verify whether a clip is AI-generated via Google’s tooling—both points are explicitly listed in the API feature bullets and summarized in the broader rollout list in the rollout recap clip.

This is a product-level integrity feature rather than a model-quality claim: it changes how generated video can be labeled/checked downstream, especially when clips move between consumer sharing surfaces and developer pipelines.
AI Studio model picker shows Veo 3.1 and Veo 3.1 Fast as paid video models
AI Studio (Google): The AI Studio UI now lists Veo 3.1 and a separate “Veo 3.1 fast” option as paid models that require linking a paid API key, with model IDs visible in the picker screenshot shared in the model picker screenshot.
This is a concrete packaging signal: Google is presenting “Veo 3.1” vs “Veo 3.1 fast” as distinct SKUs (quality vs latency/cost tradeoffs implied), rather than only shipping a single monolithic video model.
🦞 Claude Code: 2.1.7 release details, subagent tool restrictions, and desktop mode UX
Continues the Claude Code tooling drumbeat with concrete new release notes (2.1.7) and prompt/tooling changes that affect how subagents behave, plus ongoing discussion of permission-prompt friction. Explicitly excludes Cowork launch recap (covered previously).
Claude Code CLI 2.1.7 ships MCPSearch auto-mode, Windows fixes, and permission hardening
Claude Code CLI 2.1.7 (Anthropic): The 2.1.7 CLI drop focuses on operational polish—less noisy UX, safer permission matching, and less context waste from MCP tool descriptions—per the detailed Changelog highlights.
• MCP context pressure: MCP tool search auto mode is now enabled by default, deferring tool descriptions when they exceed 10% of the context window via MCPSearch, as described in the Changelog highlights.
• Security and permissions: Wildcard permission rules no longer match compound commands containing shell operators, tightening a class of “too broad allow” behavior as noted in the Changelog highlights.
• Quality-of-life + Windows: Adds showTurnDuration to hide “Cooked for …” messages; improves task notifications with inline final responses; fixes Windows false “file modified” errors from timestamp-touching tools and temp-path escape issues, all called out in the Changelog highlights.
Claude Code 2.1.7 makes Explore and Plan subagents read-only by removing edit tools
Claude Code 2.1.7 subagents (Anthropic): The Explore/Plan task subagents now lose file-mutating capabilities—pushing them toward “read and reason” instead of “act and change the repo”—as described in the Prompt change note with details in the Tool access summary.
• Tool access reduction: Explore/Plan subagents no longer have Edit/Write/Task/ExitPlanMode (and related notebook editing), which blocks nested agents from directly changing files or toggling plan mode, as explained in the Tool access summary and linked via the Diff view.
Claude Code desktop users report permission-prompt fatigue as a skip option is teased
Claude Code permissions UX (Anthropic): A recurring pain point is the volume of allow/deny prompts during interactive workflows—described as repetitive “Always allow” clicking in the Permission prompt screenshot—with a “skip permissions” option hinted as coming soon in the Skip permissions tease.
The immediate issue is friction in long sessions (especially when commands like git operations repeatedly trigger prompts), while the teased skip option suggests Anthropic is considering a more global trust posture for projects rather than per-command approvals, as implied by the Skip permissions tease.
Claude Code 2.1.7 adds Chrome auto-enable and code diff CLI flags
Claude Code 2.1.7 (Anthropic): Alongside the CLI changes, 2.1.7 introduces several internal flag flips—including Chrome enablement and a code-diff CLI path—summarized in the Flag list and reiterated in the Release note.
• Flags added: enhanced_telemetry_beta, tengu_chrome_auto_enable, tengu_code_diff_cli, and tengu_compact_streaming_retry, as listed in the Flag list.
• Flag removed: tengu_opus_default_pro_plan is removed in the same Flag list.
Claude Code expands Vim motion support and cleans up complex movements
Claude Code editor ergonomics (Anthropic): Vim-mode users get more coverage of the motion spec and improved handling of complex motions, with the change described as “support for more of the spec” in the Vim motion update.
The same update thread frames missing motions as an ongoing backlog (“holla at me and I’ll add them”), per the Vim motion update.
🧠 OpenAI Codex & GPT‑5.2 in the wild: long runs, productivity claims, and debugging tradeoffs
Practitioner reports on Codex/GPT‑5.2 usage for real work: long-running autonomous sessions, perceived productivity changes vs Claude, and “thinking level” tradeoffs during iterative debugging. Excludes unverified model-launch rumors (captured in model releases).
Security workflow: Codex-assisted Node.js DoS find (CVE-2025-59466)
Codex (OpenAI): A report claims a contributor and OpenAI Codex 5.1/5.2 helped find a Node.js denial-of-service issue, tracked as CVE‑2025‑59466, with details in the Node.js security release notes linked from the CVE mention. The concrete anchor is the upstream advisory—see the Security advisory for the “uncatchable maximum call stack size exceeded” crash via async_hooks.
Switching from Claude Code to Codex: “productivity doubled” claim
Codex vs Claude Code: A practitioner says their output roughly doubled after moving from Claude Code to Codex, after an initial learning curve, as stated in the Productivity stats claim; they add that Claude Code remains strong as a general “computer agent,” but “not for code,” per the Claude Code caveat. The implied takeaway is harness/model fit: Codex for code-heavy throughput, Claude Code for broader tool use.
Codex long-run sessions: “cooked 6 hours” while code still worked
GPT‑5.2 Codex (OpenAI): A developer report describes GPT‑5.2 Codex running autonomously for ~6 hours and still producing a working result, framed as making formerly “unthinkable” levels of accumulated changes feel promptable, per the 6-hour session claim and the follow-on Tech debt framing. The signal here isn’t a benchmark; it’s that people are treating multi-hour agent runs as a normal unit of work when the repo is structured enough for the agent to keep passing its own checks.
GPT‑5.2 Codex thinking levels: Extra High vs Medium for iterative debugging
GPT‑5.2 Codex (OpenAI): A builder experimenting with a complex Linear coding-agent orchestration says they’ve been defaulting to “Extra High” thinking for outcome certainty, but found it can become counterproductive during iterative debugging (more deploy/check loops), prompting a shift toward Medium thinking paired with a plan + to-do list, as described in the Thinking level tradeoff. This is a very specific workflow claim: the “best” thinking setting can be the wrong one when feedback cycles are short and frequent.
Codex Extra High: works best with clear instructions and a structured codebase
GPT‑5.2 Codex Extra High (OpenAI): A recurring practitioner note is that the model performs best when tasks are well-scoped and repos are organized—because it’s “more agentic and execution-focused,” per the Xhigh workflow guidance. A separate comparison list emphasizes Codex being “systematic and evidence-based” (citing code locations/logs/docs) rather than adding product/architecture judgment, as shown in the Codex vs me comparison.
Cursor + GPT‑5.2 Codex: macOS app built in under 20 minutes from one plan
Cursor + GPT‑5.2 Codex (OpenAI): One developer says they built a small macOS app (app switcher) in <20 minutes using Cursor with “1 plan, 100% GPT‑5.2 Codex,” motivated by existing App Store alternatives crashing/bugging, as stated in the 20-minute build claim. The artifact screenshot shows a simple hotkey-to-app mapping UI, which is the kind of “scratch your own itch” tool that’s increasingly getting built ad hoc.
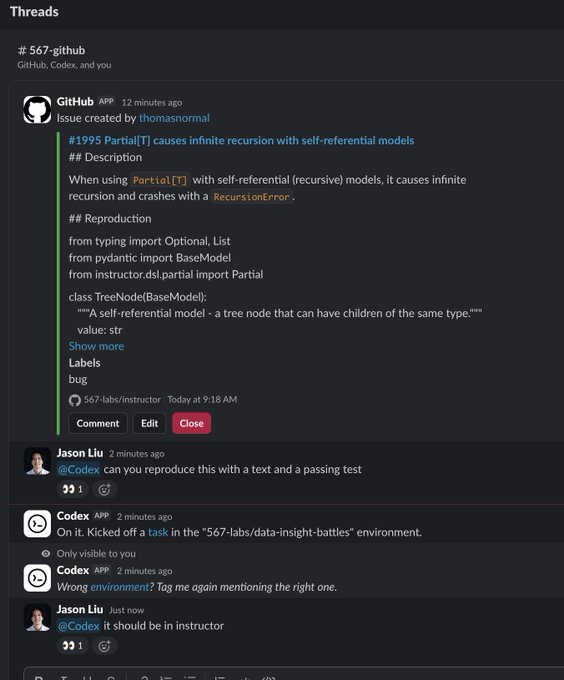
Codex GitHub app workflow: task kickoff + “wrong environment” handoff friction
Codex in GitHub: A GitHub-thread screenshot shows a maintainer tagging @Codex to reproduce a bug “with a test,” followed by the Codex app kicking off a task in a different environment and then warning “Wrong environment? Tag me again mentioning the right one,” as shown in the GitHub thread screenshot. This is small, but it’s a real-world failure mode: agent actions are gated by correct repo/workspace routing metadata, not just prompt quality.
🧰 OpenCode: plan mode experiments, workflow UX improvements, and ecosystem integrations
OpenCode-specific updates and adoption signals: experimental plan mode flows, UI “interview” questions, and integrations into other CLIs. Excludes generic coding advice (covered in workflows) and broader agent runners (covered elsewhere).
OpenCode v1.1.18 ships an experimental plan-first flow behind a feature flag
OpenCode (OpenCode): OpenCode v1.1.18 introduces a more structured “plan then execute” loop modeled after Cursor/Claude Code-style planning, but keeps it behind OPENCODE_EXPERIMENTAL_PLAN_MODE=1 while the team gauges whether it should be default, as shown in the Plan mode walkthrough and reinforced by the Feature flag note.

In the demo, a user issues a fairly involved build request and OpenCode responds with a multi-step implementation plan before generating code, which is the core UX shift compared to ad-hoc single-turn coding, as shown in the Plan mode walkthrough. Feedback-seeking and “not 100% sure yet” language suggests they’re treating this as an experiment rather than a finalized interface, per the Plan mode walkthrough and Feature flag note.
Ralph CLI merges OpenCode agent support, including a runner security fix
Ralph CLI (Ralph): Ralph’s CLI merged OpenCode as a first-class agent option alongside Codex/Claude, including new command templates, install prompts, and an explicitly called-out fix for a shell injection issue in the agent runner, as shown in the Merged PR summary.
The change list includes OpenCode skill install paths and “server mode” variants, suggesting the integration is meant to work across different OpenCode setups (local vs server), per the Merged PR summary.
OpenCode plan mode grows a dedicated “interview” phase for clarifying questions
OpenCode (OpenCode): A new OpenCode pull request adds a plan “interview” phase plus navigation options in the AskUserQuestion flow, indicating the plan UX is moving toward more explicit, stepwise clarification rather than freeform chat, as shown in the PR screenshot.
The PR is shown as “Open” and ready to merge, suggesting this is imminent but not necessarily released to all users yet, per the PR screenshot.
OpenCode’s plan questions shift toward multiple-choice, tabbed prompts
OpenCode (OpenCode): Early user feedback highlights a new “questions” UX that looks closer to a guided interview: tabbed sections and multiple-choice options for conventions (e.g., testing patterns), reducing ambiguity before execution, as shown in the Questions UI praise.
The screenshot shows a structured selection interface (tabs like Parallel/Integration/HTTP Tests) with rationale text per option, implying OpenCode is standardizing how it gathers repo-specific preferences up front, as shown in the Questions UI praise.
🧪 Coding with agents: plan-mode hygiene, concise specs, and orchestration debates
Hands-on practices for getting reliable results from coding agents: plan-mode configuration, keeping prompts/specs short, when to restart threads, and how to structure long tasks. Excludes tool-specific release notes (covered in product categories).
Tool-call subagents hit a ceiling; symbolic recursion is the alternative
Recursive decomposition limits (RLMs): A detailed critique argues that “subagents as tool calls” break down for massive inputs because the model can’t explicitly emit O(N) sub-prompts and also can’t reliably compact huge prompts; the workaround is symbolic access to the prompt through code/pointers rather than verbatim tool-call expansion, as explained in the [subagent expressiveness note](t:131|Subagent expressiveness note) and illustrated in the [RLM architecture diagram](t:500|RLM architecture diagram).
The core idea is treating the prompt as an addressable object and using code to recurse over it, instead of trying to spell out the recursion in natural language.
CLAUDE.md tweak makes plan outputs readable again
CLAUDE.md plan hygiene (community): A widely shared config snippet appends two constraints—“make the plan extremely concise” and “end with unresolved questions”—to reduce the common failure mode of unreadably long plans, as shown in the [CLAUDE.md snippet](t:8|CLAUDE.md snippet) and explained in the [AGENTS.md guide](link:8:0|AGENTS.md guide).
This pattern is showing up as a practical “defaults file” layer for agent sessions: it doesn’t change the model, but it changes the plan’s shape so humans can actually approve it quickly.
No consensus yet on how to orchestrate agent work
Agent orchestration debate (practice): There’s still no clear “right way” to structure long tasks—serial skills, parallel subagents, hierarchical managers, or agent-as-judge checkpoints—and builders are openly describing the space as unsettled, per the [orchestration uncertainty post](t:161|Orchestration uncertainty post) and the follow-up list of [open orchestration questions](t:234|Open orchestration questions).
This is surfacing a meta-problem: orchestration choices are becoming as important as prompting, but evidence is thin and patterns are still in flux.
Plan-first approval loop for coding agents spreads
Plan-first workflow (Cursor): A concrete loop is being repeated as a reliability baseline—enter plan mode, let the agent gather context and ask clarifying questions, then approve before execution—as described in the [best practices thread](t:83|Best practices thread) and reiterated with the [Shift+Tab plan mode step](t:505|Shift+Tab plan mode step).
The key operational detail is the explicit “wait for approval” gate; it’s being used as the control point that separates quick chat iteration from longer-running agent execution.
Revert-and-refine beats endless follow-ups
Failure recovery pattern (Cursor): When an agent veers off, the suggested move is to revert the change and refine the plan rather than “patching” via follow-up prompts, which tends to accumulate inconsistent constraints over time; this is called out directly in the [revert guidance](t:505|Revert guidance) and sits inside the broader [agent workflow guide](t:83|Agent workflow guide).
This is essentially treating the plan as the single source of truth and using git reverts as the reset mechanism when the plan is wrong.
Rules vs skills becomes a shared mental model
Rules vs skills distinction (Cursor): A recurring framing draws a bright line between static, always-on repo constraints (“rules”) and dynamic, task-triggered capabilities (“skills”), aiming to keep global context small while still enabling specialized behavior; the split is described in the [rules vs skills note](t:578|Rules vs skills note) and reinforced by the [developer habits list](t:529|Developer habits list).
The practical implication is that teams are trying to avoid putting everything into a single ever-growing system prompt, instead pushing optional behavior behind skills that only load when needed.
Token-burner automation gets pushback on cost grounds
Cost-aware agenting (workflow): A pointed critique targets heavily automated “token burner” approaches that minimize human work by spending an amount of tokens people wouldn’t normally pay for—and notes subscription businesses are seeing economics break as average spend rises, per the [token burner critique](t:35|Token burner critique).
The claim isn’t that automation is useless; it’s that many tasks can be done with materially fewer tokens if the human does a small amount of upfront structure and scoping.
“Could this org be markdown files?” becomes an agent-ready pattern
Plain-English org specs (workflow): A pattern gaining airtime is to describe what an organization does in detailed, plain-English markdown files so agents can ground their actions in durable documentation, as suggested in the [markdown files post](t:30|Markdown files post) and repeated in the [meeting vs markdown prompt](t:237|Meeting vs markdown prompt).
This is effectively pushing “context engineering” into repo-like docs: stable, diffable, and reviewable.
⚖️ Agent coding economics & ecosystem tensions: tokens, subscriptions, and “MCP vs CLI” arguments
Meta-level dynamics shaping agent adoption: token-cost blowups, subscription economics, and debates about whether heavy automation approaches are viable at scale. Excludes specific product releases (covered in their categories).
Epoch AI chart: top-end model token prices falling ~900× per year
Token pricing (Epoch AI): A widely shared cost curve claims token prices are collapsing fastest at the frontier—about 9×/year for low-end, 40×/year mid-tier, and 900×/year for “most capable” models—per the Pricing collapse post citing Epoch AI.
The thread explicitly ties this to Jevons-style demand expansion (“billionfold improvement → explosion of applications”), as argued in the Pricing collapse post.
Agent-browser vs Chrome DevTools MCP: claimed ~70% lower token burn
agent-browser (Vercel Labs): A field comparison claims browser automation via the agent-browser CLI can cut token consumption by ~70% versus a Chrome DevTools MCP setup, largely by replacing long tool descriptions with a short CLI instruction + --help discoverability, as measured in the Token burn comparison and expanded in the Breakdown follow-up.

• Token accounting: The write-up reports ~4k tokens just to load MCP tool descriptions plus ~38k tokens for a test prompt, versus ~95 tokens of CLI instruction and ~12k tokens for the same task, per the Breakdown follow-up.
The argument escalates into an ecosystem claim (“CLI instead of MCP”), with the concrete comparison anchored in the Token burn comparison and the implementation pointing to the GitHub repo.
Manus adds Similarweb access: 12 months of traffic history bundled into agent plans
Manus + Similarweb: Manus is bundling access to 12 months of Similarweb traffic history (versus 1 month on Similarweb’s free plan), positioning it as context an agent can use while doing tasks, per the Feature comparison demo and the Partnership announcement.

This is an early, concrete example of “agent subscription = proprietary data entitlement,” with the 12‑month claim demonstrated in the Feature comparison demo.
Token-heavy “autopilot” agent loops get blamed for breaking subscription economics
Angle/Theme: Some builders are pushing back on highly automated “token burner” workflows, arguing they often minimize human work by spending an amount of tokens users wouldn’t normally pay for—and that this is showing up as broken subscription unit economics, per the Cost critique thread.
The same critique frames the sweet spot as narrower than the hype: large migrations (like porting a codebase) can justify the spend, but for many tasks “20% more effort” in planning or scoping can cut cost/time dramatically, as described in the Cost critique thread.
MCP tool-call timeouts: push for “heartbeat” streaming to reduce false timeouts
MCP protocol ergonomics: A practical complaint is that MCP tool calls need a heartbeat/keepalive mechanism because many clients default to ~60s timeouts, and today there’s no clean way to distinguish “still running” from “hung,” as argued in the Heartbeat request.
The same post frames this as a systemic reliability issue (“slop servers bring down the rest”), with the failure mode described directly in the Heartbeat request.
“What did your agents get done this week?” starts showing up as a perf-review lens
Org dynamics: A meme-like reframing of performance reviews is circulating: “What did your agents get done this week?” as the new weekly check-in question, as quoted in the Perf review quote.
While not tied to a specific product release, it captures a real budgeting/management shift: output attribution moves from individual effort to agent throughput, as implied by the Perf review quote.
Payroll vs tokens budgeting: “$200k in payroll or $200k in Claude tokens” framing spreads
Cost framing: A blunt budgeting line is being repeated: founders choosing between “$200k in payroll expenses” and “$200k in Claude tokens,” per the Payroll vs tokens quote.
It’s not a metric, but it’s a signal that teams are starting to talk about agent usage as a first-class line item comparable to headcount, as reflected in the Payroll vs tokens quote.
🧩 Installables & wrappers for agentic coding: Ralph loops, TUIs, and repo tooling
What builders are installing or wiring into their agent workflows: Ralph-loop wrappers, TUIs/CLIs, and repo-specific helper tools that augment coding assistants. Excludes core assistant releases (covered in their own categories).
wreckit CLI ships to research, plan, and run Ralph loops from a repo
wreckit (mikehostetler): A new npm-installable CLI called wreckit packages a repeatable “research → plan → run loop → open PR” workflow for Ralph-style agent loops, starting from inside your codebase as described in the Launch post. It’s installable via npm install -g wreckit, then run as wreckit in-repo, per the Install instructions, with the implementation published in the GitHub repo.
• Workflow wrapper: The tool frames Ralph as something that “needs guidance,” and positions wreckit as the harness that turns a pile of ideas into a long-running loop that ends in a PR, as stated in the Launch post.
• Practical surface area: The repo is presented as a CLI-first wrapper (not a model), so the “unit of work” is reproducible in git history, with the project entry point and docs living in the GitHub repo.
The open question is how opinionated wreckit is about planning artifacts (file layout, plan schema) versus being a thin runner around existing Ralph repos.
xf Rust CLI turns your X archive into a fast local searchable knowledge base
xf (doodlestein): A new Rust CLI, xf, indexes your downloaded X/Twitter archive zip into a searchable local store so agents (or you) can query your own past tweets/DMs/likes quickly, as described in the Tool overview. The project is open-sourced in the GitHub repo.
It’s pitched as “free” in the sense that it leverages data you already generated on X. That’s the point.
• Agent-friendly personal context: The framing in the Tool overview is that an agent can consult your “sacred texts” (your archive) before taking actions like replying to issues or drafting content.
The tweets don’t include a benchmark, but they do claim sub-millisecond querying via Tantivy/SQLite and a workflow that starts from X’s built-in archive export.
peky 0.0.29 adds split/resize/drag panes for agent-friendly terminal UX
peky 0.0.29 (kevinkern): The peky terminal UI shipped v0.0.29 with pane splitting, resizing, and drag support, plus improved mouse handling and bug fixes, as listed in the 0.0.29 release.
• Multi-pane workflows: The core change is treating “multiple views at once” (project overview, prompt/reply area, terminal focus) as a first-class TUI primitive, which fits the agent-era terminal workflow shown in the
.
• Where to get it: Source and install entry points are in the GitHub repo.
This is a UX-layer tool, not a model integration; its value is in reducing terminal friction when you’re running long agent sessions.
🧱 Agent frameworks & workflow builders: LangSmith GA, blueprint runners, and sandboxes
Framework/SDK layer updates for building and running agents: no-code/low-code builders, durable workflow runners, and sandbox security knobs. Excludes MCP-only artifacts (covered in orchestration).
LangSmith Agent Builder reaches general availability
LangSmith Agent Builder (LangChain): LangChain is shipping Agent Builder as generally available, positioning it as a no/low-code path to define an agent goal, pick tools, and share agents with a team, as announced in the [GA launch post](t:73|GA launch post) and detailed in the [launch blog](link:73:1|Launch blog).

The launch message emphasizes lowering the floor on “agent engineering” (including the tongue-in-cheek “Even a VC can do it” line in the [launch thread](t:73|Launch thread)), while the GA writeup highlights teams already using the flow to deploy agents for recurring work (briefings, research, project tracking), as described in the [launch blog](link:73:1|Launch blog).
Vercept launches Blueprints (beta) for modular multi-step agent runs
Blueprints (Vercept): Vercept introduced Blueprints (Beta) as a way to break a long task into modular steps you can test in isolation, then execute together either sequentially or in parallel, per the [Blueprints announcement](t:674|Blueprints announcement).

The pitch is explicitly about longer-running work where single-prompt, single-thread agents get brittle; Blueprints frames the “unit” as a step graph with reusable blocks and templates, as shown in the [product walkthrough video](t:674|Product walkthrough video).
E2B adds domain-based firewall controls for sandbox egress
Domain-based firewall (E2B): E2B added a sandbox control to restrict outbound internet access to specific hostnames or wildcard patterns, aiming to give teams tighter control over what external services an agent workload can talk to, per the [feature note](t:344|Feature note).
The change is framed as “granular control over outbound traffic” for sandboxed execution, with a small rollout acknowledgment in the [ship callout](t:776|Ship callout).
Memex Web launches data-app builder backed by Modal Sandboxes
Memex Web + Modal Sandboxes (Modal): Memex’s new web experience turns uploaded data (e.g., a CSV) into an interactive dashboard/app, and Modal publicly called out Modal Sandboxes as the execution backend in its [launch congrats](t:589|Launch congrats).

The Memex demo shows ingestion and visualization flowing straight from a dataset upload, as shown in the [dashboard video](t:653|Dashboard video), with setup and constraints documented in the [Memex Web preview docs](link:852:0|Memex web preview docs).
🕹️ Running agents as systems: browser agents, task runners, and multi-session ops
Operational layer stories: agentic browsing/automation, running tasks asynchronously, and agent runners that coordinate tools/browsers. Excludes SDKs/libraries (agent frameworks) and assistant-specific changelogs (coding assistants).
agent-browser v0.5.0 adds CDP mode, extensions, and serverless support
agent-browser v0.5.0 (Vercel Labs): The CLI-based browser automation tool shipped a feature-heavy update—CDP mode to connect to an existing browser, extension loading, “serverless ready” support (e.g., Vercel), custom headers, and improved error handling as listed in the v0.5.0 feature list.
• Operational angle: It’s being positioned as a lower-context, CLI-driven alternative to tool-description-heavy browser MCP setups, with one user reporting ~70% lower token usage in a side-by-side comparison in the Token comparison claim and the Breakdown thread.
Gemini UI leak shows “Auto browse” mode for agentic web browsing
Gemini Auto browse (Google): A new “Auto browse” entry is showing up in Gemini’s UI, suggesting an agentic mode that can autonomously navigate the web (likely via Chrome control) rather than only answering with text—evidence comes from a Gemini UI screenshot in the Auto browse UI and a separate DevTools/source-code string find in the Source string snippet.
The leaked labeling frames this as a browser-agent surface inside the consumer Gemini experience, not just an API feature; details like rollout scope, permissions, and tool limits are still unclear from the tweets.
Browser Use launches BU beta as a Manus-style web agent alternative
BU (browser_use): browser_use announced BU in beta, explicitly positioning it against Manus and pushing a waitlist signup in the BU beta announcement with a follow-up link in the Waitlist post.

The product framing is “web agent of the future,” but the tweets don’t include technical details about the execution model (local vs remote browser), security boundaries, or evaluation methodology—only the comparison demo and positioning.
Conductor 0.30 adds Chrome browsing for Claude Code plus agent plan handoff
Conductor 0.30 (Conductor): The release adds Chrome-based browsing/testing/screenshot capabilities for Claude Code inside Conductor, fixes error spikes tied to async subagents/background tasks, and introduces “handoff” so a plan can be passed to a different agent in the same workspace, per the 0.30 release notes.

• Browser execution: A live demo shows Claude controlling Chrome to solve Wordle in the Chrome demo.
• Task routing: The UI for handing a plan to a new chat is shown in the
.
caam workflow targets Claude Max account swapping during in-progress sessions
caam (coding_agent_account_manager): A practical ops pain point surfaced around juggling multiple Claude Max accounts when usage limits hit mid-session; the author describes why token swapping doesn’t help “in-process sessions” and shares a longer design/problem writeup for fixing the workflow in the Account swapping writeup, with supporting context in the linked doc at Redacted prompt doc.
The emphasis is less on a new agent capability and more on account/session continuity as an operational constraint when running long coding-agent sessions.
Clawdbot v2026.1.12 adds vector memory search and restores voice calling
Clawdbot v2026.1.12 (clawdbot): A new release adds vector-search over agent memories (SQLite-backed), restores voice-call plugins, and extends scheduling/cron features, as described in the release page linked from the Release announcement and detailed in the Release notes.
• Field signal: A user report shows the new “vector-powered recall” pulling context across dates while running embeddings locally (embeddinggemma-300M), as shown in the Memory recall message.
📏 Benchmarks & evals: aligned coding agents, SWE-bench positioning, and prediction leaderboards
Measurement-centric posts: new benchmarks/datasets and leaderboard updates relevant to evaluating agents and coding models. Excludes model-release announcements unless they come with a distinct benchmark artifact.
MiniMax releases OctoCodingBench for evaluating aligned coding agent behavior
OctoCodingBench (MiniMax): A new benchmark dataset targets “aligned behavior” in coding agents—cases where tests can pass while the agent violates system constraints, repo conventions, or tool protocols, as described in the [launch post](t:342|Launch description) and spelled out in the [dataset rationale](t:342|Why this benchmark).
The focus is behavioral compliance over multi-turn work, not just functional correctness; the dataset framing explicitly calls out system-level constraints, CLAUDE.md/AGENTS.md conventions, and tool-call sequencing as first-class failure modes, as shown in the [why OctoCodingBench image](t:764|Why OctoCodingBench).
Full artifact is on Hugging Face—see the [dataset page](link:342:0|Dataset page).
MiniMax claims #1 open source on SWE-Bench Pro, citing Scale AI benchmark
SWE-Bench Pro (MiniMax): MiniMax claims it is the #1 open-source model on SWE-Bench Pro—“ahead of Gemini 3 Flash” and “level with Haiku 4.5”—and attributes the benchmark source to Scale AI, per the [ranking claim](t:120|SWE-Bench Pro claim).
This is a leaderboard positioning signal rather than a full eval write-up. No score table or run configuration is included in the tweet thread, so the evidence is limited to the public claim in the [MiniMax post](t:120|SWE-Bench Pro claim).
PredictionBench posts 24-hour PnL snapshot: Mystery Model Alpha leads, GPT‑5.2 trails
PredictionBench (ArcadaLabs/Kalshi): Following up on Kalshi stake (models given $10K to trade), the 24-hour snapshot says “no one’s in the green”; Mystery Model Alpha leads at $9,999.6, while GPT‑5.2 sits at $9,660.83, as shown in the [leaderboard clip](t:296|Leaderboard update).

The project also posted a fraud-prevention note saying it “does not support any tokens” and “will not accept any funds,” per the [token disclaimer](t:348|No token statement). Live tracking is linked via the [site](link:296:0|Leaderboard site).
🛠️ Developer tools & repos: durable workflows, search stacks, and agent-friendly utilities
General-purpose developer tooling (not a coding assistant itself): data frameworks, search pipelines, and utilities that teams can adopt to support agents. Excludes agent frameworks and assistant-specific tooling.
Exa details exa-d: typed dependencies and sparse updates for “web as database” pipelines
exa-d (Exa): Exa described exa-d, its internal data framework for “storing the web as a database,” focusing on declarative typed dependencies and sparse, granular recomputation (rather than full reprocessing) as outlined in the [framework intro](t:214|framework intro) and the accompanying [exa-d blog post](link:214:0|exa-d blog post).

The same release was positioned as part of Exa’s broader search stack work—see the [search stack framing](t:317|search stack framing)—with the blog emphasizing scale constraints (hundreds of billions of pages / petabytes) and why dependency-aware orchestration matters when downstream artifacts (parses, metadata, embeddings) constantly change, as described in the [exa-d blog post](link:214:0|exa-d blog post).
Mux ships durable AI video workflows by resuming failed runs with Vercel Workflow DevKit
Workflow DevKit (Vercel) + @mux/ai (Mux): Mux described shipping its AI video SDK with durable execution so long-running steps resume after timeouts/rate limits instead of restarting, as summarized in the [launch note](t:266|launch note) and explained in the [Workflow DevKit case study](link:266:0|Workflow DevKit case study).
This is framed as an “opt-in durability” pattern (same code can run in plain Node, but gains persistence/retries/observability when run under Workflow DevKit), per the [Workflow DevKit case study](link:266:0|Workflow DevKit case study).
🔌 Orchestration & MCP plumbing: interoperability friction and routing surfaces
Interoperability and orchestration signals: MCP reliability pain points and “routing” UX that affects which providers/models you can call. Excludes agent runners and non-MCP CLIs (covered in ops/tools).
OpenRouter adds “Provider routing eligibility” UI tied to privacy settings
OpenRouter (OpenRouterAI): OpenRouter shipped a new “Provider routing eligibility” view that previews how privacy toggles—explicitly including ZDR—change which models/providers you can use, and shows the result immediately in the UI as demonstrated in the Eligibility UI demo.

• Routing surface: The feature turns what used to be “why can’t I call this model?” debugging into a first-class eligibility check, with the underlying knobs living in the Privacy settings page shown in Privacy settings link and accessible via Privacy settings.
OpenRouter promotes Claude Code integration as a transport layer option
Claude Code via OpenRouter (OpenRouterAI): OpenRouter published a “Claude Code takeoff” integration post, positioning OpenRouter as a backend/transport layer for Claude Code usage, as announced in the Claude Code takeoff.
This is about plumbing, not a new model.
• Interoperability angle: When paired with OpenRouter’s eligibility/routing controls (including privacy constraints), it frames Claude Code as a front-end that can sit on top of multiple provider options, with the gating logic now surfaced in-product per the Routing eligibility UI.
🗂️ Retrieval & knowledge plumbing: file search vs vector search, chunking, and web grounding
Retrieval mechanics and “agent-ready” knowledge access: comparisons of filesystem exploration vs vector search, chunking tradeoffs, and web-grounding integrations. Excludes full agent frameworks (covered separately).
Vertex AI previews Gemini grounding via Parallel web search integration
Grounding with Parallel (Google Vertex AI): Google added a preview integration that lets Gemini models ground responses using Parallel’s web search API, positioning it as web-connected retrieval for agents with token-efficient excerpts and enterprise controls, as announced in preview announcement and documented in the Vertex AI docs.
• Operational posture: Parallel emphasizes compressed snippets for token efficiency plus compliance signals like SOC-2 Type 2 and ZDR options, per preview announcement and the product positioning.
Filesystem search vs vector search benchmarks show crossover after ~1K files
Retrieval trade-off (LlamaIndex): A new benchmark writeup contrasts agentic filesystem exploration with vector search—finding similar speed up to ~100 files, but showing vector retrieval wins strongly from ~1K files onward for “first answer” latency, as summarized in benchmark takeaway.
• Why agents still like file search: the post argues filesystem tools let agents do dynamic, multi-hop linking across docs (not just nearest-neighbor snippets), while hybrid setups tend to work best in practice, per benchmark takeaway and the accompanying blog post.
Weaviate shares a “chunking strategy matrix” framing precision vs richness
Chunking (Weaviate): A “chunking strategy matrix” frames the core tension as retrieval precision vs contextual richness—small chunks are findable but context-poor; large chunks are rich but noisy; the practical target is semantically complete paragraphs, as laid out in chunking matrix explainer.
The guidance is explicitly “no universal best chunk size,” with chunking choice depending on document structure and query complexity, per chunking matrix explainer and the referenced context engineering ebook.
🏗️ AI infrastructure & supply chain: datacenters, fabs, and compute-cost dynamics
Infra-level signals that directly affect AI capability and economics: datacenter buildouts and chip manufacturing capacity. Excludes general macro/politics not tied to AI supply/demand.
Epoch AI chart: top-tier LLM token prices falling ~900× per year vs ~40× mid-tier
Inference economics (token pricing): A circulated Epoch AI chart claims token prices are collapsing fastest at the high end—about 9×/year for low-tier models, 40×/year for mid-tier, and ~900×/year for the most capable tier, as summarized in the cost curve post. That’s a steep compute-cost dynamic.
The tweets frame this through Jevons paradox—cheaper tokens driving more total usage—but don’t break out the drivers (hardware cost, model efficiency, competition, or subsidy) beyond the plotted trend.
TSMC reportedly commits to 5+ additional Arizona fabs tied to U.S.–Taiwan trade deal
TSMC (semiconductor supply chain): A report claims a pending U.S.–Taiwan trade agreement would cut tariffs on Taiwanese exports to 15% and include a commitment from TSMC to build at least five additional semiconductor fabs in Arizona, effectively doubling its U.S. footprint as described in the trade-deal screenshot. This is a capacity signal.
Any leading-edge wafer capacity in the U.S. tends to flow into AI accelerators and their upstream components over time; the tweets don’t include node details, timelines, or capex, so treat it as directional rather than schedulable.
Microsoft says it will expand AI datacenters and cover grid costs amid U.S. backlash
Datacenter buildout (Microsoft): Microsoft says it will build more AI data centers while promising residents won’t see higher power bills because it will cover grid costs; TechCrunch reporting cited in the datacenter backlash summary also notes 142 activist groups across 24 states pushing back on datacenter impacts. This is a permitting and power-availability story.
The practical implication is less about Microsoft’s intent and more about whether utility commissions, water constraints, and local permitting become the limiting factor for near-term inference capacity.
🧬 Model releases & credible rumors (non-bio): open image models, real-time world models, and frontier leaks
Model drops and credible rumor traffic across text/image/video models (non-medical). Includes early “how it feels” comparisons when present. Excludes Veo 3.1 (feature) and robotics hardware deployment (robotics category).
Z.ai open-sources GLM-Image, a hybrid autoregressive+diffusion image model
GLM-Image (Z.ai/Zhipu): Z.ai announced GLM-Image as an open-source image generator built with a hybrid autoregressive (9B) + diffusion decoder (7B) stack, positioning it as competitive with mainstream diffusion quality while being notably strong at text rendering and “knowledge-intensive” images, as described in the launch thread and expanded in the tech blog.
Distribution is already broad: the model is up on Hugging Face per the model page link, and fal is advertising hosted access with the same architecture breakdown in its availability post. The key open question from today’s material is practical parity versus top closed TTI systems—there’s plenty of architectural detail, but not a shared, standardized eval set in the tweets yet.
PixVerse R1 debuts as a “real-time world model” with infinite streaming
PixVerse R1 (PixVerse): PixVerse R1 is being presented as a “first real-time world model” with infinite, continuous generation and 1080p output, framed as moving video gen from offline rendering to a live simulator-like loop, as outlined in the release explainer and teased as “Infinite. Continuous. Alive.” in the PixVerse R1 teaser.

The most specific technical claims being circulated today include a unified multimodal token stream and memory-augmented attention for long-horizon consistency, plus latency workarounds to keep frame time low, according to the R1 details thread. What’s still missing in the public chatter here is a clean breakdown of controllability (inputs/actions) and reproducible benchmarks for “world model” behavior beyond the promo demos.
DeepSeek V4 rumor: mid‑February with “coding” and “lite” variants
DeepSeek V4 (DeepSeek): Leak chatter says DeepSeek V4 is expected mid‑February 2026 and may ship in two variants—a coding-focused version and a smaller “lite” version—per the V4 leak post and the similar two-variant claim.
Nothing in today’s tweets pins down benchmarks, pricing, or distribution surfaces; the main actionable detail is the asserted split between long coding sessions and faster responses, as described in the V4-lite framing.
Rumor mill points to a ChatGPT 5.3/5.5 release in 1–2 weeks
ChatGPT next model (OpenAI): Following up on Garlic rumor—prior claim of “GPT‑5.3 Garlic”—a new leak thread says the next ChatGPT model could be 5.3 or 5.5, targeted for 1–2 weeks, with “access to the IMO model” and “significantly intensified pre-training,” according to the leak bullets.
A separate post continues to push the “GPT‑5.3” codename “Garlic” narrative, but without additional technical substantiation beyond source confidence in the codename repost. This remains unverified; today’s incremental signal is the tighter timeline and the “IMO model” access claim rather than any concrete eval artifact.
Grok 4.20 “Pearl checkpoint” demos circulate for code and animation
Grok 4.20 “Pearl” (xAI): Demo posts claim a “Pearl checkpoint” of Grok 4.20 can generate runnable single-file HTML/SVG outputs and short animations from one prompt, shown via an animation demo and an SVG skyline output.

The evidence today is experiential and community-posted rather than a first-party release note; what’s concrete is the style of prompts being used (single-shot, “paste into one HTML file”) and the multimodal outputs people are sharing in the SVG example and the solar system demo.
📄 Research papers: long-context architectures, routing agents, and evaluation methods
Non-product research highlights discussed today—especially long-context reasoning architectures, agent routing, and evaluation methodology. Excludes medical/healthcare research entirely.
Recursive Language Models propose symbolic access to 10M-token prompts
Recursive Language Models (MIT CSAIL): A new inference-time architecture called RLMs treats the full prompt as a Python REPL variable and lets the model “peek” and decompose it via code, aiming to scale beyond 10 million tokens without retraining, as outlined in the [RLM overview](t:500|RLM overview).
A key implementation nuance is that naive “subagents as tool calls” won’t express true recursion at this scale, because the recursion has to be symbolic through code/pointers rather than explicit tool-call prompts, as argued in the [tool-call critique](t:131|tool-call critique).
EvoRoute routes LLM agents per step to cut cost up to 80%
EvoRoute (research): A self-routing agent approach called EvoRoute picks a different LLM per step using similarity to past steps, reporting cost cuts up to 80% and latency reductions over 70% while keeping accuracy close to fixed-model baselines, per the [EvoRoute summary](t:310|EvoRoute summary).
• What’s actually new here: The routing signal is experience-driven at the step level (log of prior steps), rather than hard-coding “planner uses model X, executor uses model Y,” as described in the [trilemma discussion](t:310|trilemma discussion).
Anchored-reference jailbreak eval reduces “scary looking” false positives
Jailbreak evaluation (research): A paper proposes an “anchored reference” checklist approach that classifies jailbreak outputs into fine-grained buckets (refusal/off-topic/vague/wrong/success) and reports that common evaluators overstate jailbreak success by about 27%, as summarized in the [evaluation thread](t:468|evaluation thread).
The point is intent-match scoring: it separates “contains harmful text” from “actually followed the harmful request,” which is the failure mode highlighted in the [judge overcount note](t:468|judge overcount note).
BabyVision benchmark targets visual reasoning beyond language priors
BabyVision (benchmark): A new benchmark aims to test visual reasoning independent of language knowledge, reporting 388 tasks across 22 subclasses and showing a large gap between top MLLMs and human baselines (e.g., adults ~94 vs Gemini3-Pro-Preview ~49.7), according to the [paper listing](t:244|paper listing) and the linked [ArXiv paper](link:244:0|ArXiv paper).
Dr. Zero trains search agents without seed data
Dr. Zero (research): A “data-free” self-evolution loop for multi-turn search agents trains a proposer and solver (initialized from the same base model) to generate and answer an increasingly difficult curriculum without external training data, per the [paper listing](t:174|paper listing) and the accompanying [ArXiv paper](link:174:0|ArXiv paper).
VideoDR benchmarks open-web deep research for video agents
VideoDR (benchmark): A proposed “video deep research” benchmark evaluates video QA that requires cross-frame visual anchors plus interactive web retrieval and multi-hop verification, and it reports that “agentic” setups don’t reliably beat workflow baselines unless the model can hold onto the initial visual anchors, per the [paper link](t:460|paper link) and the linked [ArXiv paper](link:460:0|ArXiv paper).
🛡️ Security, safety & policy: military deployments, account compromises, and ToS enforcement
Security/policy-relevant AI developments today, including government deployments and platform enforcement. Excludes healthcare/medical AI policy topics.
Pentagon reportedly adopts Grok for work on classified and unclassified data
Grok (xAI): Reports claim the Pentagon is bringing Grok inside its network and intends to use it across classified and unclassified workflows, as summarized in the Hegseth statement and amplified by the Pentagon Grok claim.

The same thread frames this as Grok joining Google’s generative AI engine inside the Pentagon environment, per the Pentagon Grok claim. Details like scope, accreditation, and concrete operational boundaries are not specified in these tweets.
Anthropic reportedly cracks down on unauthorized Claude usage via third-party harnesses
Claude (Anthropic): A VentureBeat report says Anthropic is cracking down on “unauthorized Claude usage” via third‑party harnesses and rivals, as shown in the VentureBeat screenshot.
A related signal is that Cowork is described as supporting only the official Max subscription (and not third‑party APIs), which is part of why developers are recreating Cowork-like tooling outside Anthropic’s app surface, per the Cowork API limitation.
MiniMax says its official account was hacked
MiniMax (MiniMax): The company’s official account says both @MiniMax_AI and @SkylerMiao7 “got hacked,” with no additional incident details shared in the post itself, per the Hack acknowledgment.
This is a reminder that model capability gains don’t remove basic account-security failure modes; there’s no info here yet about impact radius (API keys, repos, customer systems) or remediation steps.
Prompt copyrightability resurfaces as a legal uncertainty for agent workflows
Prompt IP (Legal/policy): A developer thread raises the question of whether prompts might become copyrightable (or otherwise protectable) and notes uncertainty about current protectability—suggesting someone will likely test it in court, per the Prompt copyright question.
This matters because reusable prompt assets (skills/rules/agent playbooks) increasingly function like product IP, but the tweets provide no jurisdictional framing or existing case references.
💼 Enterprise & GTM moves: ARR milestones, funding, partnerships, and workplace agents
Business-side signals with concrete adoption/capital metrics and enterprise rollouts. Excludes infrastructure buildouts (covered separately) and avoids healthcare/medical business items.
Genspark claims $100M ARR in 9 months and teases AI Workspace 2.0
Genspark.ai (Genspark): Genspark says it hit $100M ARR in 9 months and says “AI Workspace 2.0 arrives in 2 weeks,” per the [ARR announcement](t:117|ARR announcement).
The claim is presented as a growth milestone rather than a product spec drop; today’s tweet doesn’t include customer count, retention, or expansion numbers, and “Workspace 2.0” details are still unspecified beyond timing, as stated in the [same post](t:117|ARR announcement).
Manus adds Similarweb access for 12 months of web traffic history
Manus + Similarweb (Partnership): Manus is adding Similarweb data access directly inside Manus, expanding from 1 month on Similarweb’s free plan to 12 months for Manus users, as shown in the [comparison demo](t:36|Plan comparison demo) and reiterated in the [integration post](t:150|Integration demo).

This is one of the clearer examples in today’s feed of an “agent subscription” bundling proprietary, normally paywalled data—see the [plan comparison](t:36|Plan comparison demo) for how it’s framed in-product.
Slackbot becomes an AI agent on Business+ with Canvas creation and org context
Slackbot (Slack): Slack is rolling out a “new AI Slackbot” for Business+ that can create Slack Canvases and pull context from org discussions, as shown in the [product demo](t:211|Canvas creation demo).

This is a concrete workplace-agent surface (not just a chat UI): it’s positioned as taking an intent like “create a Canvas for next steps” and turning it into an artifact inside Slack, per the [same clip](t:211|Canvas creation demo).
Anthropic commits $1.5M to the Python Software Foundation and open source security
Python Software Foundation (Anthropic): Anthropic says it is investing $1.5 million to support the Python Software Foundation and open source security, per the [announcement](t:6|Funding announcement) and amplified in the [news screenshot](t:34|News screenshot).
The framing is dependency-driven—“Python powers so much of the AI industry”—and the tweet doesn’t specify the breakdown between PSF support vs broader “open source security,” beyond the combined figure in the [same statement](t:6|Funding announcement).
Deepgram announces $130M raise with a “10-year overnight success” framing
Deepgram (Funding): Deepgram announced $130 million in funding, with the moment framed as a “ten year overnight success,” as described in the [funding note](t:380|Funding note).
The tweet’s business angle is paired with a product thesis: Deepgram has long optimized for low-latency speech recognition (called out as foundational for voice agents) and is now pushing into broader “audio Turing test” components like intent/emotion/tone/context, according to the [same post](t:380|Funding note).
Firecrawl launches an /agent endpoint on Zapier for web data gathering
Firecrawl + Zapier (Integration): Firecrawl’s /agent endpoint is now live on Zapier, positioning it as an embedded web-research/navigation step inside Zaps, as shown in the [launch demo](t:226|Zapier launch demo).

The pitch is “describe what web data you need” and the agent searches/navigates/gathers automatically within Zapier, per the [same announcement](t:226|Zapier launch demo).
Firecrawl launches creator affiliate program with 20% rev share
Creator affiliate program (Firecrawl): Firecrawl launched an affiliate program offering creators a free Standard plan plus commissions—20% of subscription revenue for 6 months on smaller plans, or 50% of the first sale—with a 5k+ followers eligibility threshold and a 24-hour “apply now” window, as stated in the [program post](t:253|Program terms).
This is a straightforward GTM move aimed at developer/AI-tool content channels rather than an enterprise procurement motion, per the [same announcement](t:253|Program terms).
🖼️ Generative media (non‑Veo): creator tools, upscalers, motion control, and styling stacks
Everything gen-media today that’s not Veo 3.1: creator platforms, motion control, upscaling, and style transfer tooling. Excludes the Veo 3.1 rollout (feature).
ComfyUI adds a Kling 2.6 Motion Control node for reference-video motion transfer
Kling 2.6 Motion Control (ComfyUI): ComfyUI shipped a Kling 2.6 Motion Control integration that transfers motion from a reference video onto a character image—aiming at full-body movement, gesture fidelity, and consistent animation, as shown in the Node announcement.

• Workflow shape: the basic pipeline is “reference video + character image → motion-applied output,” per the Node announcement, with more specifics pointed to in the ComfyUI blog.
This is a concrete bridge from a motion-control feature into node-graph pipelines, which tends to matter most when teams need repeatable, inspectable compositions rather than app-only generation, as demonstrated in the Node announcement.
fal adds ByteDance Seedance 1.5 Pro: 1080p video generation with native audio (12s)
Seedance 1.5 Pro (fal): fal says ByteDance Seedance 1.5 Pro is live with 1080p generation and native audio, supporting clips up to 12 seconds, as stated in the Model availability post.

• Access surfaces: fal points to separate endpoints for text-to-video and image-to-video in the Try it links.
The key technical unlock being marketed is synchronized audio at full-HD output in short-form durations, with the hard constraint (12s) specified in the Model availability post.
fal ships LTX-2 Trainer for custom video LoRA training (including video-to-video)
LTX-2 Trainer (fal): fal launched LTX-2 Trainer for training custom LoRAs for video models—positioned for style transfers, effects, and “video-to-video transformations,” as announced in the Trainer launch.
• Two training modes: fal also points to separate trainer entry points (standard and video-to-video) in the Trainer links, with detailed pricing and defaults exposed on the Training page and the Video-to-video training page.
This is a clear move toward creator-controlled personalization loops (dataset → LoRA → repeated reuse), with the availability framed directly in the Trainer launch.
fal launches Crystal Video Upscaler to upscale videos to 4K with text/face detail focus
Crystal Video Upscaler (fal): fal released Crystal Video Upscaler for boosting video to 4K, with the product copy emphasizing sharper results for text on products and facial details, as announced in the Upscaler launch.

The tweet focuses on the “professional portraits / product text” niche rather than cinematic upscaling, which implies the model is tuned for high-frequency legibility artifacts (logos, typography, facial features), per the Upscaler launch.
Higgsfield runs “Go All-In” promo: unlimited Kling 2.6, free Kling Motion, unlimited Nano Banana Pro
Go All-In promo (Higgsfield): Higgsfield is running a time-boxed promo that removes usage limits across multiple gen-media tools—pitching unlimited Kling 2.6, free Kling Motion, and unlimited Nano Banana Pro, with a social action flow that grants 220 credits per the Promo offer and reiterated in the Countdown reminder.

• What’s actually being sold: the offer is framed as unlimited windows (e.g., “7 days unlimited” for Kling 2.6 and “365 unlimited” for Nano Banana Pro) as specified in the Countdown reminder.
The tweets are promo-forward (no quality metrics or sample outputs), but they’re a clear signal of aggressive credit/limits experimentation in creator tool distribution, as shown in the Promo offer.
Replicate previews Riverflow v2 for consistent on-brand image generation and editing
Riverflow v2 (Replicate + Sourceful): Replicate is offering a preview of Riverflow v2 aimed at consistent “on-brand” image generation plus precise editing, with the full model expected “in the next couple of weeks,” per the Preview announcement.
The examples emphasize brand consistency across multiple shots (packaging label, lifestyle shot, and kitchen context) rather than single-image aesthetics, as shown in the Preview announcement.
Higgsfield pushes Mixed Media as “vibe editing” with 30+ cinematic 4K looks
Mixed Media (Higgsfield): Following up on initial launch (one-click 4K stylization), Higgsfield is now positioning Mixed Media explicitly as “vibe editing,” emphasizing 30+ cinematic 4K looks and rapid transformations “in seconds,” as described in the Vibe editing pitch.

The new detail here is the breadth claim (30+ looks) and the stronger “replace manual stylization” framing, both called out in the Vibe editing pitch.
Midjourney user sentiment: “still the GOAT for aesthetics”
Midjourney (Midjourney): A creator post argues Midjourney remains the strongest for aesthetics—shared via a set of cinematic-looking stills—capturing ongoing user perception even as video workflows and agent tooling accelerate elsewhere, as stated in the Aesthetics claim.
This is qualitative signal only (no benchmarks or controlled comparisons in the tweet), but it’s a reminder that “best-looking stills” remains a distinct axis from controllability and pipelines, per the Aesthetics claim.
🤖 Robotics & embodied AI: humanoid production, video-pretrained world models, and physical AI push
Robotics and embodied intelligence updates that matter to AI strategy: production scale signals and world-model approaches for robots. Excludes healthcare robotics and non-AI geopolitics.
Boston Dynamics moves Atlas from demo to production scale
Atlas (Boston Dynamics/Hyundai): Atlas “mass production has begun,” with Hyundai aiming to deploy tens of thousands of robots and produce up to 30,000 units annually, according to the Atlas production post and the company’s own rollout timeline in the Product Atlas blog. The spec claims circulating alongside the announcement include 56 degrees of freedom, ~50 kg lift, and autonomous battery swapping, as listed in the Atlas production post.
The key signal for strategy teams is that Atlas is being framed as an industrial product with a ramp plan (not another lab prototype), with initial deployments called out for 2026 in the Product Atlas blog.
AGIBOT’s shipment share claim surfaces as a scale signal for humanoids
AGIBOT (China): A circulating claim (citing Omdia) says AGIBOT led global humanoid robot shipments in 2025 with ~39% share and >5,100 units shipped, with early deployments concentrated in factories and entertainment, as described in the Shipment share claim.

Treat the market-share figure as directional until you’ve read the underlying report; the tweet does not include primary tables or methodology beyond attribution in the Shipment share claim.
Nvidia tees up “physical AI” as a 2026 priority
Physical AI (Nvidia): Nvidia is increasingly framing 2026 around “physical AI,” i.e., models and stacks aimed at embodied systems rather than purely digital copilots, as stated in the Physical AI clip.

This slots into a broader industry shift toward world models + control in real environments, but the tweet itself provides positioning rather than concrete product specs or benchmarks—see the Physical AI clip for the exact framing.
🎙️ Voice agents & speech workflows: customer interviews, STT challenges, and conversation timing
Speech/voice-agent building and deployment stories (non-medical): automated interviews, STT tooling, and turn-taking models. Excludes creative audio generation and healthcare speech claims.
ElevenLabs says Agents ran 230 customer interviews in under 24 hours
ElevenLabs Agents (ElevenLabs): ElevenLabs says it used ElevenLabs Agents to conduct 230+ customer interviews in <24 hours for the ElevenReader app, reporting 85% of calls were on-topic with ~10 minutes average duration, and that insights shipped the next day, as shown in the Interview results summary.

• What changed operationally: This is positioned as a replacement for the “live interviews don’t scale / surveys lose nuance” tradeoff, by using conversational calls at high volume, per the Interview results summary.
• Follow-up signal from their analysis: ElevenLabs reports ~95% of respondents engaged without acknowledging it was an AI interviewer, and that fiction readers disproportionately asked for multi-character dialogue, per the Additional findings thread.
ElevenLabs launches a $1,111 Scribe v2 build challenge focused on advanced STT
Scribe v2 (ElevenLabs): ElevenLabs’ dev team announced a $1,111 challenge for developers building with Scribe v2, explicitly asking entrants to use advanced features like keyterm prompting and entity detection, as described in the Challenge announcement.
• How it’s structured: Submissions opened Jan 13 with a Jan 20 deadline and Jan 23 winners announcement, per the Timeline post.
• Submission mechanics: Entry requires building with the API and submitting via the Submission form, alongside posting a demo video with a hashtag, as described in the How to enter steps.
• Where to look for the STT surface area: The most direct starting points are the Transcription docs and the Speech-to-text quickcquickstart.
Tavus describes Sparrow-1 for real-time turn detection and floor transfer
Sparrow-1 (Tavus): Tavus published details on Sparrow-1, a model for real-time conversational timing (turn detection / “floor transfer”), described as continuously analyzing streaming audio and adapting to user behavior, per the Sparrow-1 overview.

• Why it’s distinct: The thread emphasizes handling overlapping speech and predicting when someone will stop talking before they do—capabilities framed as central to “human-level” timing, per the Sparrow-1 overview.
• Primary artifact: The technical writeup is linked as the Sparrow-1 blog.
Deepgram announces $130M and doubles down on low-latency speech for voice agents
Deepgram (Deepgram): Deepgram announced $130 million in funding, with commentary framing the company as a “ten year overnight success” and reiterating a core product thesis that speech recognition latency is foundational for voice agents, per the Funding announcement.
• Scope of the stated roadmap: The same post claims recent Deepgram releases aim at broader “audio Turing test” components—intent, emotion, tone, and context—rather than ASR alone, as described in the Funding announcement.
🎓 Events & learning: agent engineering conferences, live build sessions, and workshops
Distribution and learning mechanisms (events, livestreams, meetups) for agentic engineering and building with AI tools. Excludes product announcements unless the event itself is the artifact.
Every sets Jan 22 for an all-day Vibe Code Camp livestream
Vibe Code Camp (Every): An all-day livestream is scheduled for January 22, 2026, with a lineup of builders showing their live “vibe coding” workflows, as announced in the [event post](t:95|event post) and reinforced in the [follow-up invite](t:419|follow-up invite).
The guest list called out includes Logan Kilpatrick, Ryan Carson, Ben Tossell, and others, with “free and open to everyone” positioning in the [announcement](t:95|guest lineup). Additional details and signup live on the [event page](link:95:0|Event page).
Vercel schedules v0 Studio in San Francisco for Jan 29
v0 Studio (Vercel): Vercel is hosting an in-person v0 Studio session in San Francisco on 01.29.26, framed as “open studio” plus “live builds” and “surprise guests,” per the [teaser post](t:160|teaser post).

Registration is routed through the [event page](link:392:0|Event page), which repeats the open-studio format in the [follow-up post](t:392|registration post).
CASE Conf Berlin runs Jan 14 with agentic software engineering talks
CASE Conf (Conference): A Berlin event focused on “agentic software engineering” is set for January 14, 2026, with speakers and attendees coordinating in public threads like the [Berlin check-in](t:507|Berlin check-in).
The conference framing—agents as collaborators, plus practical sessions for building with agents—is described on the [conference site](link:507:0|Conference site).
Google AI Studio ran a “vibe coding” workshop at Berkeley Haas
Google AI Studio (Google): A hands-on workshop at Berkeley Haas had participants build and deploy an application on Google Cloud by the end of the session, per the [workshop recap](t:444|workshop recap).
The post positions this as a shift in classroom expectations (“build and deploy an application … by end of this class”), and it’s explicitly tied to Google AI Studio tooling in the [same update](t:444|deployment claim).
Vercel hosts a v0 Power Hour on building an agent (Jan 14, 2pm PT)
v0 Power Hour (Vercel): A live session is scheduled for Jan 14 at 2pm PT, featuring Relevance AI walking through how they built a website-generation agent with v0, as described in the [session announcement](t:368|session announcement).
The format is billed as a structural teardown—how the agent is “structured, connected, and iterated on”—with attendance routed via the [live link](link:368:0|Live link) and repeated in the [follow-up](t:623|format note).
🧑💻 Work and careers in the agent era: displacement fears, new “comparative advantage,” and org change
When the discourse is the news: how engineers/founders interpret agent impacts on jobs, titles, and productivity expectations. Excludes pure product updates.
“JIRA → develop → test → PR” agent pipeline raises layoff fears for junior CRUD work
Ticket-to-PR automation pattern: A Reddit screenshot circulating on X describes an internal effort to encode domain knowledge into “Claude skills,” then run an automated loop from JIRA tickets → implementation → tests → PRs, with the author explicitly asking if this could drive layoffs in a 300-developer org, as described in the Reddit pipeline worry.
This is one of the clearest “agent replaces the queue” narratives: it’s not speculative AGI talk; it’s an explicit proposal to mechanize the exact middle of the software factory for routine app work.
Claim that Claude Code wrote 100% of Cowork fuels “engineers won’t have jobs” talk
Claude Code (Anthropic): A viral thread claims Claude Code wrote “all of” Claude Cowork—reportedly shipped in “a week and a half”—and frames it as a sign that software engineering jobs are at risk, per the 100% claim and the corroborating Engineer quote recap.
The new element today is less about Cowork features and more about the labor narrative: the quote “All of it” is being treated as evidence that teams can ship user-facing products with dramatically fewer engineers, at least for greenfield internal tools.
Jensen Huang reiterates “everybody’s jobs will change; some will disappear”
Jobs-changing narrative (Nvidia): Jensen Huang is cited saying AI will change every job and that “some jobs will disappear,” with the follow-on question being what new jobs remain that AI/robotics can’t do, as captured in the Huang job quote.

This continues the pattern of top AI infrastructure CEOs leaning into labor-market disruption as a near-term certainty, not a distant AGI hypothetical.
Wage polarization thesis: automation eats junior tasks, senior judgment captures surplus
Workforce economics (Baumol/Jevons): A post argues AI will “deflate anything that scales with compute” while inflating work gated by scarce humans, predicting wage polarization within the same job title—junior tasks automated, senior judgment paid more—per the Wage polarization note.
The concrete implication is org design pressure: roles may split into high-throughput “agent wrangling” and higher-status decision rights (product/architecture/risk acceptance) rather than a uniform SWE ladder.
“If everyone can vibecode anything, what’s my advantage?” becomes a recurring career frame
Comparative advantage framing: The “if everyone can Google anything, what’s my comparative advantage?” meme is now being re-skinned for coding agents (“if I can vibecode anything…”), as shown in the Comparative advantage quote and the Vibecode advantage cartoon.
This framing is showing up as a practical career question: when implementation becomes cheap, differentiation shifts toward taste, scoping, verification discipline, and distribution—not typing speed.
“Single pane of glass” SaaS is predicted to fail as agents replace dashboards
Dashboard displacement thesis: One post predicts any SaaS whose core value prop is “a single pane of glass for [X]” is “dead in 2026,” arguing agentic interfaces will subsume dashboards as the primary interaction pattern, per the Single pane claim.
This is less about a specific product and more about a go-to-market warning: if your UI is mainly aggregation, the defensible layer likely becomes workflow ownership, data rights, and execution primitives—not visualization.
Counter-signal: founders say the startups doing well are hiring aggressively anyway
Hiring behavior signal: In contrast to replacement narratives, one founder claims “every startup founder I know that is doing well is hiring like crazy,” per the Hiring like crazy post.
The takeaway for org planners is the divergence: some teams talk about automating ticket flow end-to-end, while others are responding to the same tooling wave by expanding headcount—presumably to ship faster, cover more surface area, or compete on distribution/quality rather than raw implementation speed.
“What did your agents get done this week?” shows up as a new performance-review meme
Managerial metric shift: A widely shared line frames the new performance review as “What did your agents get done this week?”, per the Perf review meme.
This is a small meme with a real organizational hook: it implies evaluation moving from individual throughput to agent throughput + supervision quality (task selection, review rigor, and system design that keeps agents productive).