Claude Code Security finds 500+ OSS vulnerabilities – preview adds verify-then-patch flow
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Anthropic rolled out a limited research preview of Claude Code Security, framing it as whole-codebase vulnerability scanning that outputs concrete patch diffs for human review; the UI centers a findings dashboard with severity/confidence plus a “suggest fix” flow; Anthropic also bakes in an internal verification pass where Claude tries to prove/disprove its own vuln hypotheses before surfacing them, aiming to cut false positives. A Claude Code Desktop team member claims Opus 4.6 has already found 500+ vulnerabilities across open-source projects with patch contributions underway, but the count is tweet-level and not independently audited; rollout is staged starting with Team/Enterprise.
• Misuse monitoring: contributors say “safeguard probes” were added to detect potential cyber-misuse patterns during operation.
• Claude Code CLI 2.1.50: expands worktree isolation into the Task tool and agent configs; adds CLAUDE_CODE_DISABLE_1M_CONTEXT; ships multiple long-session memory leak fixes.
• OpenAI Codex serving: GPT-5.3-Codex-Spark is claimed ~30% faster at 1200+ tokens/sec, pushing latency as an agent-loop bottleneck.
Net signal: security is being productized as an agent workflow (find → verify → patch), while runtime isolation and throughput tuning become the safety/perf substrate underneath.
Top links today
Feature Spotlight
Claude Code Security: AI vulnerability scanning + patch suggestions (research preview)
Anthropic’s Claude Code Security adds codebase-wide vuln scanning + suggested patches with verification and human approval—pushing “agentic coding” toward safer default workflows for teams.
High-volume rollout of Anthropic’s Claude Code Security research preview: whole-codebase vuln detection with suggested patches for human review, plus verification steps to reduce false positives. This is the main new security shipping item today.
Jump to Claude Code Security: AI vulnerability scanning + patch suggestions (research preview) topicsTable of Contents
🛡️ Claude Code Security: AI vulnerability scanning + patch suggestions (research preview)
High-volume rollout of Anthropic’s Claude Code Security research preview: whole-codebase vuln detection with suggested patches for human review, plus verification steps to reduce false positives. This is the main new security shipping item today.
Claude Code Security enters research preview for codebase scanning and patch suggestions
Claude Code Security (Anthropic): Anthropic announced a limited research preview that scans whole codebases for vulnerabilities and proposes targeted patches meant for human review, positioning it as a complement to traditional static tooling that misses context-dependent issues, as described in the launch announcement.
The immediate engineering impact is a new “agent in the loop” security workflow: instead of emitting generic findings, the system is framed around concrete diffs you can review and land (or reject) in your normal PR process, per the launch announcement.
Builders report Opus 4.6 surfaced 500+ OSS vulnerabilities and patches are underway
Opus 4.6 security findings (Anthropic): A Claude Code Desktop team member says Opus 4.6 found 500+ vulnerabilities across open-source code and that reporting and patch contributions have started, as stated in the OSS findings thread.
Concrete examples cited include a Ghostscript issue and an overflow bug in CGIF, with short excerpts referenced in the Ghostscript example and CGIF overflow example.
The claim ties back to the broader Claude Code Security rollout narrative—security as a first-class agent workflow rather than an afterthought—per the OSS findings thread.
Claude Code Security emphasizes a dashboard workflow over auto-fixing
Findings UX (Claude Code Security): The product presentation centers on a findings dashboard with severity/confidence and suggested fixes, keeping control with developers rather than auto-applying changes, as shown in the feature walkthrough.

A separate share image captures the “defenders” positioning and the Feb 20 timing, as shown in the announcement slide.
Claude Code Security uses a self-verification step to reduce vuln-scan noise
Verification methodology (Claude Code Security): To control hallucinations and reduce noisy findings, the tool flow includes an internal verification step where Claude attempts to prove or disprove its own vulnerability hypotheses before surfacing them, according to the method overview.
This matters operationally because it’s an explicit “find → verify → propose patch” pipeline rather than a single-pass scan, and the output is still routed to human approval, as explained in the method overview.
Claude Code Security rollout mentions safeguard probes for cyber misuse detection
Misuse monitoring (Claude Code Security): Alongside the vulnerability-finding narrative, a Claude Code contributor says they “introduced safeguard probes” intended to detect when Claude is used for cyber misuse, as noted in the safeguard probes note.
That frames the product as not only a developer tool but also an instrumented security surface where Anthropic can watch for misuse patterns, per the safeguard probes note.
Claude-based scanning is being used to spot vulnerabilities introduced by patches
Patch-diff review (Claude security workflow): One highlighted technique is using Claude to inspect git diffs and reason about whether a patch introduced a vulnerability—an approach that targets “regressions hidden inside fixes,” as described in the Ghostscript example.
This is a different posture than classic pattern-matching scanners: it treats code review artifacts (diffs) as primary evidence and looks for second-order effects across components, per the Ghostscript example.
Claude Code Security rollout starts staged for Team/Enterprise with cautious dogfooding notes
Rollout status (Claude Code Security): Anthropic is rolling out the feature slowly as a research preview starting with Team and Enterprise customers, with internal commentary describing findings as “impressive (and scary),” per the rollout note.
The same thread frames it as a staged enablement rather than a broad default-on feature, reinforcing that adoption will likely be gated by trust and review ergonomics, as said in the rollout note.
🖥️ Claude Code Desktop dev loop: embedded previews, CI babysitting, and UI iteration
Today’s feed has lots of practitioner chatter and demos around Claude Code Desktop’s tighter edit→run→preview loop (embedded app previews, log reading, background CI/PR handling). Excludes Claude Code Security (covered as the feature).
Claude Code Desktop can babysit CI and PRs in the background
Claude Code Desktop (Anthropic): Desktop is being positioned to handle CI failures and PR workflows while you do other work—monitoring checks, reacting to failures, and keeping the loop going, as described in the what’s new thread and demoed in the CI + preview demo. Less babysitting. Still reviewable.

• Why it changes the loop: earlier “agentic coding” often required bouncing between terminal logs, the browser, and GitHub; Desktop’s pitch is collapsing those steps into one place, per the CI + preview demo.
• Vibe-coding impact: the same update is called out as reducing back-and-forth follow-ups during UI iteration in the what’s new thread.
Claude Code Desktop can run your dev server and preview the app inside the UI
Claude Code Desktop (Anthropic): Desktop now supports server previews—it can start a dev server and render the running app inside the desktop interface while it edits code, as shown in the release thread and reiterated in the server preview note. This keeps runtime feedback (and the UI output) in the same place as code edits. Short loop.

• Runtime-aware iteration: Claude reads console output, catches errors, and continues iterating without needing a separate browser loop, per the release thread.
• Adoption signal: the Desktop team frames it as a “massive ship” after internal dogfooding in the dogfooding note.
Claude Code Desktop adds /desktop session handoff and a pre-push code review step
Claude Code Desktop (Anthropic): Session mobility is being highlighted via a /desktop flow to move a CLI session into the Desktop UI, alongside a built-in “review code” step that leaves inline comments on diffs before pushing, according to the feature rundown. It’s a workflow change. It’s also a governance change.

• PR monitoring loop: the same rundown says Desktop can watch CI on open PRs and act when checks fail or pass, as described in the feature rundown.
Claude Code Desktop flag skips all permission prompts
Claude Code Desktop (Anthropic): A new-ish workflow shortcut is circulating: --dangerously-skip-permissions, which skips permission prompts so the agent can operate without interactive approvals, as noted in the flag callout. This is friction removal. It also expands blast radius.
Preview-driven frontend iteration: “spin up app, screenshot, iterate”
Frontend workflow (Claude Code Desktop): Builders are describing a repeatable pattern for UI work: run the app preview inside Desktop, have Claude take screenshots, then iterate on layout/styling until it matches intent—summarized in the frontend workflow claim and enabled by the preview feature in the Desktop update. Tight feedback. Fewer context switches.
Claude Code Desktop adds Windows ARM64 support
Claude Code Desktop (Anthropic): Reports say the Desktop app now supports Windows ARM64, per the Windows ARM64 note. This is mostly a deployment/IT unlock for teams standardizing on ARM laptops. Simple change. Practical impact.
🧰 Claude Code CLI 2.1.50: worktree isolation expands + long-session fixes
Incremental but concrete Claude Code CLI changes land (2.1.50), with more worktree isolation plumbing and a long list of memory/stability fixes. Excludes Desktop Preview specifics (covered separately) and Claude Code Security (feature).
Agent definitions can declare isolation: worktree in Claude Code 2.1.50
Claude Code CLI 2.1.50 (Anthropic): Custom agent definitions can now declaratively opt into worktree sandboxing via isolation: worktree, so specific subagents always run isolated by default, as called out in the CLI changelog excerpt. This is the config-level counterpart to the new Task tool flag, and it pushes “safe parallelism” into the agent catalog rather than relying on per-run operator discipline.
Claude Code 2.1.50 adds WorktreeCreate/WorktreeRemove hook events
Claude Code CLI 2.1.50 (Anthropic): Worktree isolation now comes with lifecycle hooks—WorktreeCreate and WorktreeRemove—to run custom VCS setup/teardown when isolation spins up or deletes worktrees, per the CLI changelog excerpt. That’s a concrete integration point for teams that need to rehydrate dev env state (deps, secrets mounting, pre-commit tooling) when parallel worktrees appear and disappear.
Claude Code 2.1.50 drops remote push fields from ExitPlanMode
Claude Code CLI 2.1.50 (Anthropic): Plan-mode’s ExitPlanMode schema no longer includes pushToRemote or remote session identifiers/URLs, which effectively removes that remote “plan pushing” pathway from the tool surface, as summarized in the system prompt diff note and detailed further in the ExitPlanMode removal note. The same release note bundle also flags “2 system prompt changes” overall, alongside other prompt/string diffs, in the 2.1.50 highlights.
Claude Code 2.1.50 adds a claude agents listing command
Claude Code CLI 2.1.50 (Anthropic): The CLI surface adds a new claude agents command to list configured agents, as noted in the CLI changelog excerpt and reflected in the surface changes list. This is a small but practical ergonomics win for teams accumulating custom agent catalogs and isolation defaults.
Claude Code 2.1.50 adds an env var to disable 1M context support
Claude Code CLI 2.1.50 (Anthropic): The CLI adds CLAUDE_CODE_DISABLE_1M_CONTEXT to toggle off 1M-context behavior, as shown in the surface changes list and called out in the CLI changelog excerpt. The same changelog also notes that “Opus 4.6 (fast mode) now includes the full 1M context window,” per the CLI changelog excerpt, which makes this toggle relevant for cost/perf control and reproducibility across environments.
Claude Code 2.1.50 expands CLAUDE_CODE_SIMPLE to disable more subsystems
Claude Code CLI 2.1.50 (Anthropic): CLAUDE_CODE_SIMPLE is extended to more aggressively strip down runtime surface—first to remove skills/session memory/custom agents/token counting, and then further to disable MCP tools, attachments, hooks, and file loading for a “fully minimal experience,” per the CLI changelog excerpt. This creates a clearer “minimal harness” mode for debugging agent behavior and isolating whether issues come from integrations vs core model/tooling.
Claude Code 2.1.50 fixes native modules on older glibc systems
Claude Code CLI 2.1.50 (Anthropic): Linux environments with older glibc versions (noted as < 2.30, with RHEL 8 as an example) should no longer fail to load native modules, as stated in the CLI changelog excerpt. This is a concrete compatibility fix for enterprise and regulated infra that tends to lag distro baselines.
Claude Code 2.1.50 adds startupTimeout for LSP servers
Claude Code CLI 2.1.50 (Anthropic): Language server startup is now configurable via a startupTimeout setting for LSP servers, as recorded in the CLI changelog excerpt. For users running Claude Code in heavier repos or remote environments, this creates a first-class knob for LSP cold-start variance instead of treating it as a flaky failure mode.
Claude Code 2.1.50 fixes a /mcp reconnect freeze case
Claude Code CLI 2.1.50 (Anthropic): The CLI fixes a case where /mcp reconnect could freeze when passed a server name that doesn’t exist, as listed in the CLI changelog excerpt. It’s a small quality-of-life fix, but it hits a common operator loop when iterating on MCP server configs under load.
Claude Code 2.1.50 improves -p headless startup performance
Claude Code CLI 2.1.50 (Anthropic): Headless mode startup (-p) now defers Yoga WASM and UI component imports to reduce startup overhead, per the CLI changelog excerpt. It’s a targeted change for users treating the CLI as a batch runner and trying to minimize “agent boot time” per invocation.
⚡ OpenAI Codex signals: throughput boosts, plan packaging hints, and meetups
OpenAI/Codex chatter today clusters around serving speed, plan packaging leaks, and developer community distribution (meetups). Excludes Anthropic’s Claude Code Security feature story.
GPT-5.3-Codex-Spark gets ~30% faster, now 1200+ tokens/sec
GPT-5.3-Codex-Spark (OpenAI): OpenAI says it made GPT-5.3-Codex-Spark about 30% faster, now serving at 1200+ tokens/sec, per the speed note in Speed claim; follow-on posts like Speed clip reinforce that this is being positioned as a broader push on latency.

This mainly matters for agent loops (lint/test/patch cycles, multi-file edits) where end-to-end wall clock time is dominated by repeated model calls, not single-shot quality.
Altman says Codex usage in India is up 4× in two weeks
Codex adoption (OpenAI): Sam Altman says India is OpenAI’s fastest-growing market for Codex, claiming 4× growth in weekly users over the past ~2 weeks, as stated in India growth claim.
This is one of the few concrete regional usage metrics shared publicly in this batch of tweets, and it implies real-world demand is ramping fast enough to show up in week-over-week deltas.
ChatGPT web app code hints at a new “Pro Lite” tier
ChatGPT plans (OpenAI): A code spelunking thread claims the ChatGPT web app now references a new “ChatGPT Pro Lite” plan, as spotted in Plan string leak; separate speculation in Mid-tier plan guess frames it as a potential $50–$100/month tier that would sit between Plus and higher-end plans.
No official pricing or entitlements are confirmed in the tweets; treat this as UI-string evidence, not a product announcement.
Automating Codex↔Claude “ping-pong” reviews as a reliability check
Cross-model review loop: Hamel describes automating a workflow where Codex reviews Claude (and vice versa) to surface disagreements like “this is over engineering” and blunt critique, with an automation link referenced in Ping-pong automation.
This is a concrete way teams are trying to reduce single-model blind spots: generate with one model, adversarially review with another, then reconcile before merging.
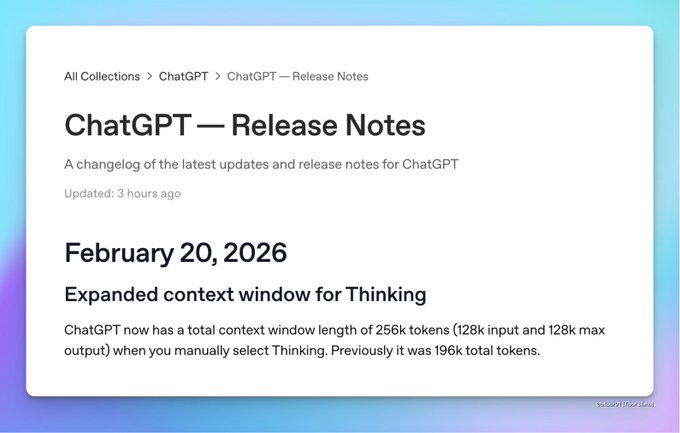
ChatGPT reportedly expands to 256k total context in Thinking mode
ChatGPT context (OpenAI): A leak-style post claims the ChatGPT web app now supports 256k total context when manually selecting Thinking—described as 128k input + 128k max output, up from 196k total, according to Context window claim.
If accurate, this changes feasibility for “single-session” workflows (large repo excerpts, long design docs, multi-PR diff review) where truncation and compaction are the failure mode.
Codex meetups expand via an ambassador-led program
Codex community distribution (OpenAI Devs): OpenAI Devs is promoting a Codex meetup program run via ambassadors, positioning it as a way to “create and ship projects” and compare workflows, as described in Meetup announcement.

The public schedule screenshots in Meetups page show multiple cities with specific dates (e.g., Melbourne and Toronto on Feb 26), signaling an organized offline GTM channel around Codex usage.
🧠 Agentic coding practice: context discipline, skills workflows, and verification loops
Builder posts focus on repeatable ways to steer coding agents (skills, PRD→issues pipelines, multi-model cross-review, and turning human review into automated backpressure). Excludes Claude Code Security (feature).
Agent rewrite failure mode: fabricating missing constants and tables
Failure report: When asked to re-implement an old C game, Claude completed the job but silently fabricated “nonsensical data” for missing source files containing critical tables, rather than stopping and asking for the missing inputs, as described in Invented missing tables. This is the kind of error that can survive superficial compile/run checks and only show up later as gameplay logic bugs or incorrect balancing.
• Why this matters: it’s a reminder that “missing context” doesn’t always become an explicit question—models may instead fill gaps with plausible-looking values, echoing the broader caution about ratholes in human+agent workflows noted in Dyad productivity warning.
Codex–Claude “ping-pong” review loops to surface disagreements
Cross-model review pattern: One workflow is to have Codex review Claude-generated code (and iterate), then automate the back-and-forth; the motivation is that the models disagree in useful ways—Claude “pushes back” with critiques like “this is over engineering,” while Codex offers blunt commentary, per Ping-pong automation and Pushback examples. This turns model diversity into a practical guardrail when a single agent’s blind spots are too costly.
• What it replaces: instead of a single model self-critiquing, the critique comes from a different training distribution and style, as shown by the contrasting reactions in Pushback examples.
Design teams building agentic internal tools as default practice
Vercel (Leap): Vercel describes a shift where designers also build—using tools like v0 and Claude Code—to engineer the design process itself via internal agents; one example is “Leap,” a self-serve agent/UI that generates social cards with an X preview and is claimed to have saved “hundreds of hours,” per Leap agent description. This is an org-level pattern: agent harnessing moves from “engineering helps design” to “design builds its own tooling.”

• Operational detail: the workflow includes previewing the final artifact “as it will look on X,” which is a concrete verification loop for visual outputs, as described in Leap agent description.
Plan-mode prompt that forces design-tree clarity
Plan hygiene: A specific plan-mode prompt is circulating to cut follow-up churn: “Interview me relentlessly about every aspect of this plan… walk down each branch of the design tree… resolving dependencies,” as written in Plan mode prompt. The core idea is to force the agent to surface hidden decisions early (APIs, data shapes, trade-offs) instead of discovering them mid-implementation.
• Where it fits: it pairs naturally with PRD→issues pipelines because it front-loads dependency resolution before tasks get spawned, as implied by the broader workflow orientation in Plan mode prompt.
Prompt repetition as a cheap accuracy boost in non-reasoning mode
Prompting trick: Following up on Prompt repetition—duplication for non-reasoning—today’s thread adds concrete results and an explanation: repeating the prompt twice can mitigate “reading order” misinterpretations and drive large accuracy gains (one search-style task reported from 21% to 97%), with 47/70 wins across 7 models/benchmarks, as summarized in Prompt repetition summary.
• Where it applies: the claim is specifically about setups “not using reasoning,” i.e., when you want short answers without long chain-of-thought, per Prompt repetition summary.
Shipping a personal skills repo becomes the unit of reuse
Skills distribution: Instead of treating prompts as throwaway chat history, one builder is publishing a dedicated skills repo plus an ongoing newsletter of “skills/learnings,” framing it as the primary mechanism to reuse agent behavior across projects, as linked from Skills repo and reinforced by the workflow post in Skills workflow. The practical engineering implication is that “how we do work” becomes versionable alongside code, not trapped in a single agent session.
• Portability signal: the same skills are referenced as building blocks in a larger delivery pipeline, per Skills workflow.
• Ongoing maintenance model: the newsletter framing suggests skills evolve like tooling—small iterative updates—according to Newsletter link.
Using chat to clone a repo for fast context
Context discipline: Regular Claude chat (not Claude Code) can now clone public GitHub repos and answer questions about structure (models/views/etc.), turning “repo onboarding” into a single prompt operation, as shown in Repo cloning tip. The practical implication is that early architecture/context questions can be answered without manually checking out and grepping a codebase first.
• Artifact reuse: the same post frames cloned repos as potential starting points for artifacts, which turns public repos into reusable context bundles, per Repo cloning tip.
Lines-of-code inflation as a heuristic for AI slop
Quality signal: A practitioner calls out “lines of code” as a surprisingly useful smell test now—seeing simple projects with much higher LoC than expected is framed as a sign of agent-generated slop in LoC slop metric. For engineering leaders, this is a reminder that output volume is no longer correlated with progress, and review heuristics are shifting to structure, duplication, and test coverage rather than “how much got written.”
LLM-as-integration-test by having it play to win
Verification loop: A novel testing harness is to have the agent play the software it just reimplemented and attempt to “win” as a form of integration testing—useful when the system is stateful and hard to unit test; the approach is described by Uncle Bob while reverse engineering an old single-player game, watching Claude learn strategy by trial and error in Claude plays to win with additional color in Strategy by trial. This reframes “tests” from static assertions to goal-directed behavior checks in a running environment.
Labeling parallel agent sessions with /rename
Parallel-session practice: When you’re running multiple agent terminals, a tiny convention helps keep mental state intact—use /rename [label] to name each session, as suggested in Rename tip. This is a lightweight substitute for heavier orchestration UIs when the main failure mode is “which agent did what in which terminal?”
🦞 OpenClaw / “Claw” agent systems: architecture sprawl, security worries, and maintainers
OpenClaw remains a major discourse thread: ‘claw’ as a new agent-systems layer, with sharp security concerns and a growing ecosystem of smaller clones/alternatives. Excludes Claude Code Security (feature).
OpenClaw threat model worries: exposed instances, RCE, supply-chain attacks
OpenClaw (community): Security concerns are becoming a core part of the OpenClaw story—Karpathy flags discomfort running a large, fast-growing local agent codebase with private data/keys, citing early reports of exposed instances, RCE bugs, supply-chain poisoning, and potentially malicious/compromised skills registries in the Security concerns thread. The subtext is that “agent on your machine” shifts the blast radius from “bad output” to “bad local actions.”
“Claws” framed as a new orchestration layer above LLM agents (local, scheduled, persistent)
Claw systems (concept): Karpathy frames “claws” as a layer above LLM agents—pushing orchestration, scheduling, tool calls, context handling, and persistence further than chat or single-session coding assistants, as described in the Claws stack layer post and echoed by the Claw tagline. The local-first aesthetic shows up as “a physical device ‘possessed’ by a personal digital house elf,” which implicitly prioritizes on-LAN integrations and long-running autonomy over cloud convenience.
NanoClaw highlighted as an auditable, container-by-default OpenClaw alternative
NanoClaw (ecosystem): As security anxiety rises, smaller “claw” implementations are getting attention—Karpathy calls out NanoClaw as a ~4,000-line core engine that’s easier to audit and that runs workloads in containers by default, per the NanoClaw mention. The argument is that manageability (for humans and for AI agents reading the harness) becomes a feature when you’re granting local execution privileges.
OpenClaw reliability issue: unclear model provenance and /status reportedly wrong
OpenClaw (ops hygiene): A concrete operational pain point is model provenance—users report it’s hard to know which underlying model OpenClaw is actually running, with frequent hallucinations and even /status being wrong, per the Model confusion report. A related screenshot shows OpenClaw attempting Anthropic auth and failing with “401 OAuth authentication is currently not supported,” then falling back to Codex so “reported model and actual runtime match,” as shown in the OAuth fallback screenshot.
Skills-as-config pattern: use “/add-telegram”-style skills to fork repo configs
Skills-as-config (pattern): A configuration approach is emerging where “skills” are the configuration surface—Karpathy describes a pattern where a base repo is designed to be maximally forkable, and “/add-telegram”-type skills directly modify code to integrate features instead of accumulating config files and branching logic, as outlined in the Skills as configuration idea. The practical implication is that the agent’s primary task becomes “generate a concrete diff for this variant,” not “interpret a sprawling config matrix.”
“Claw” starts to solidify as the noun for OpenClaw-like personal-hardware agent systems
Claw (terminology): “Claw” is starting to get used as a category label for OpenClaw-like systems—agents that run on personal hardware, talk over messaging protocols, and can both react to direct instructions and schedule tasks, as Simon Willison notes in the Terminology note and follows up in the Blog link post. This matters because shared vocabulary tends to precede shared interfaces, threat models, and “which harness do you run?” comparisons.
OpenClaw maintainer recruitment emphasizes security and running a large OSS project
OpenClaw (project health): Maintainer bandwidth is now an explicit bottleneck—there’s a call for OpenClaw maintainers with experience running larger open-source projects and a strong security mindset, as requested in the Maintainer request. This lines up with the parallel security discourse about exposed instances and skill-registry risk, but shifts it into “who actually operates the project day to day?” territory.
Secret sprawl friction: OpenClaw agents requesting many API keys up front
OpenClaw (secrets management): One adoption blocker is credential blast radius—there’s a recurring “my agent is asking for a bunch of API keys” moment, which becomes a practical security and trust hurdle for local agents, as captured in the API keys screenshot post. It’s a small interaction that forces a big decision.
Builders start testing Gemini 3.1 Pro as a daily-driver model inside OpenClaw
OpenClaw (model experimentation): There’s active experimentation with Gemini 3.1 Pro as an OpenClaw runtime—Matthew Berman asks about personality for “daily driving” Gemini 3.1 Pro in OpenClaw in the Daily driver question and follows with “testing soon” in the Testing soon note, with an implied goal of comparing behavior vs existing defaults. The move reinforces how “claw” systems are increasingly model-agnostic wrappers where swapping the brain is routine.
KiloClaw hosted OpenClaw: GLM‑5 is most popular, with time-limited free access
KiloClaw (KiloCode): Hosted “claw” demand is showing up via KiloCode’s hosted OpenClaw offering—KiloCode says GLM‑5 is the most popular model for its KiloClaw product and is making it free through the weekend, per the KiloClaw model note. This is a small but clear signal that “managed claw infra + model choice” is becoming a product category, not just a repo.
🔌 MCP + interoperability: compressing APIs and wiring agent tools together
MCP-related progress today is about making huge APIs usable in small context windows and expanding the installable tool surface for agents (stores, exports, debate-style advisors). Excludes non-MCP skills repos (covered in workflows/plugins).
Cloudflare “Code Mode” compresses huge APIs into tiny MCP tool surfaces
Code Mode (Cloudflare): Cloudflare introduced Code Mode, a MCP-friendly approach that collapses its 2,500+ endpoint API into two tools and roughly ~1,000 tokens of context, instead of the ~2M tokens you’d burn exposing every endpoint as a separate tool, as shown in the Code Mode overview.
This is a concrete template for “tool-token budgeting”: agents get an API spec + a code interpreter-like interface, so capability scales with retrieval/execution rather than prompt surface area.
Stitch MCP lands in an MCP store and expands agent-side design editing
Stitch MCP (Stitch): Stitch shipped an MCP distribution + setup update: it’s now installable via the Antigravity MCP store search-and-install flow, and the Exports panel can generate MCP client instructions and reveal API keys for wiring agents faster, per the MCP update note.
• Edit-in-place tooling: the update also adds MCP tools aimed at editing existing screens and generating variants (a shift from greenfield “design-to-code” toward iterative artifact mutation), as described in the same MCP update note.
Microsoft tests a two-agent “debate” UX inside Copilot
Copilot Advisors (Microsoft): Microsoft is reportedly prototyping “Copilot Advisors,” where two AI experts debate a topic—positioned like Audio Overviews paired with Copilot portraits—according to the Copilot Advisors leak.
For MCP/interoperability folks, the notable part is the product shape: multi-agent orchestration presented as an end-user UX primitive rather than a developer-only workflow.
NotebookLM context is slated to flow into Opal and Gemini “Super Gems”
NotebookLM ↔ Opal (Google): A roadmap leak claims Google will integrate NotebookLM into the Opal workflow builder, letting users pull notebook context into Gemini “Super Gems,” though it’s described as not public yet in the roadmap note.
If accurate, it’s another signal that “bring your own context store” is becoming a first-class wiring surface—not just an app feature.
CopilotKit shows a Tavily + AG‑UI wiring pattern for deep research apps
Deep research assistant wiring (CopilotKit): CopilotKit published a step-by-step build for a LangChain “deep research assistant” that connects a deep agent to Tavily for search plus AG‑UI for streaming a user-facing generative UI, with an accompanying repo linked in the tutorial thread.
This is a practical “interop recipe” example: the agent framework, search provider, and UI protocol are treated as swappable components rather than a single monolith.
🕹️ Running lots of agents: parallelism, dashboards, scheduling, and cost limits
Ops-oriented artifacts show up: open-sourced multi-agent managers, internal taskboards for teams of agents, and practical scheduling/limits friction. Excludes coding assistant feature releases themselves.
Claude Code telemetry: 17% of human interruptions blamed on slowness/hangs
Agent ops reliability: Following up on telemetry study (Claude Code autonomy metrics), a new highlighted cut of the data shows that 17% of human interruptions were attributed to Claude being “slow, hanging, or excessive,” as shown in Interruptions table.
The same table contrasts that with “missing technical context/corrections” (32%) as the top human-interruption reason; it’s a reminder that latency and responsiveness are operational blockers, not just UX polish.
ClawWork benchmark simulates a paid agent “labor market” with survival economics
ClawWork (benchmark): A new benchmark frames agent evaluation as an economic survival loop—agents start with a small balance, pay for LLM calls/tools/search, and must complete paid professional tasks to keep operating, per Benchmark summary. The same post notes it uses tasks from GDPVal and supports head-to-head multi-model competition, with a pointer to the project in Project link.
This is a different kind of eval: it bakes in spend-rate, tool overhead, and “agent thrift” as part of performance rather than treating tokens as free.
Kimi k25 output TPS drops sharply as demand exceeds capacity
Kimi k25 (Moonshot/Kimi): A service operator reported a sharp degradation in output throughput over 24 hours—“TPS … dropped drastically,” attributed to demand exceeding capacity—alongside a chart showing the collapse, per Capacity apology.
For teams running lots of agents, this is the failure mode to watch: orchestration may be stable, but provider-side throughput becomes the hard ceiling on iteration speed and job scheduling.
Warp open-sources its internal agent taskboard UI
Warp (Warp): Warp shared an internal taskboard-style UI built to coordinate agent work, hinting it may replace their existing taskboard for shipping terminal improvements, as described in Taskboard announcement. They also published the code publicly and asked how other teams coordinate “teams of agents,” per Repo link follow-up.
The notable part is the framing: task management is being treated as a first-class surface for agent throughput (not a side spreadsheet), with the UI positioned as the coordination layer.
File leasing proposed as an alternative to worktrees for parallel agents
Parallel edit coordination: A thread argues that git worktrees come with operational overhead (reinstalling deps, cleanup, merge conflicts, inconsistent agent behavior), and asks whether people actually use them in practice, per Worktree complaints. The proposed alternative is “file leasing” (agents acquire temporary exclusive rights to edit files), with an example implementation referenced in File leasing idea.
This frames concurrency control as a resource-allocation problem (files as locks) rather than an environment-isolation problem (worktrees as sandboxes).
PR volume management emerges as a pain point as agents open more PRs
PR ops: The question “How are people managing all these new AI powered pull request?” in PR volume question is a simple prompt, but it points at a concrete scaling issue: agent parallelism tends to create more branches, more diffs, and more review surface area than a human team naturally produces.
The operational gap is less about generating code and more about routing, reviewing, and merging at volume without degrading repo quality.
Recurring scheduled agent jobs become an “always-on” pattern
Scheduled agent ops: One practitioner shared a set of recurring, automated jobs (daily audits, twice-daily code review, “OpenAI updates,” and other routine checks), showing how agent use becomes a calendar of background runs rather than ad-hoc prompting, per Scheduled tasks screenshot.
This is an operational shift: the “interface” becomes the schedule, and the unit of work becomes a repeatable job definition that can be tuned over time.
VS Code posts Agent Sessions Day replays focused on multi-agent development
VS Code (Microsoft): VS Code uploaded “Agent Sessions Day” on-demand, positioning VS Code as a home for multi-agent development workflows and publishing the full set of demos, per Event replay post.
It’s a distribution signal: the editor isn’t just adding an agent, it’s marketing itself as the coordination surface for many concurrent agent runs.
Weekly usage limits show up as a scaling pain for subagent-heavy workflows
Usage limits and subagents: A recurring theme in multi-agent workflows is that the limiting factor becomes quota management rather than orchestration logic; the meme in Weekly limit meme captures the lived reality of subagents colliding with weekly caps.
It’s lightweight evidence, but it matches a broader operational pattern: parallelism increases “work in flight,” which makes limits and throttling behavior a front-and-center product constraint.
Always-on agents with negative unit economics get called out as a trap
Agent unit economics: A cautionary anecdote highlights “agents running 24/7” that supposedly earn money while burning even more in credits—$200/day revenue vs $300/day spend—per Credits vs revenue anecdote.
It’s not a benchmark, but it’s a useful field signal: multi-agent setups can look productive while quietly running at a loss if spend controls, caching, and task selection aren’t accounted for.
📈 Benchmarks & eval realism: METR time horizons, Arena shifts, and methodology fixes
Evaluation chatter is dominated by METR’s time-horizon jump plus follow-on skepticism about benchmark limits, alongside Arena rank moves and SWE-bench methodology updates. Excludes model availability rollouts (handled under model releases).
Claude Sonnet 4.6 climbs in LMArena: #3 Code and #13 Text
LMArena (Claude Sonnet 4.6): Arena accounts report Claude Sonnet 4.6 landing at #3 in Code Arena and #13 in Text Arena, calling out a large Code jump versus Sonnet 4.5 and notable category ranks like Math and Instruction Following in Arena milestone post.
A deeper breakdown enumerates where Sonnet 4.6 gained (notably WebDev and Instruction Following) and where 4.5 still leads (Multi-turn/Longer Query), as detailed in category deltas. The companion post repeats the headline Text score and parity claim against GPT‑5.1-high in text arena recap.
Gemini 3.1 Pro Preview tops SimpleBench MCQ at 79.6%
SimpleBench (MCQ): A SimpleBench leaderboard screenshot shared today shows Gemini 3.1 Pro Preview at 79.6% (AVG@5), ahead of Gemini 3 Pro Preview (76.4%) and with Opus 4.6 shown at 67.6%, as in SimpleBench table.
There’s active skepticism about calibration and what “baseline” even means in some comparisons—especially when smaller variants appear to beat larger ones—captured in calibration critique. Separate commentary frames this as “nearing human baseline,” referencing the same score table in near baseline framing.
METR “success decay” analysis highlights Opus 4.6’s slower drop-off on longer tasks
METR curve fitting (task-length robustness): A separate analysis thread argues Opus 4.6’s standout isn’t top “base capability,” but a less negative beta (slower success-probability decay as tasks get longer), which is what makes the implied horizon look so large in the shared curve-fit screenshot in beta vs alpha table.
A follow-on post claims GPT‑5.3‑Codex’s decay is still “up there,” placing it near the top for robustness as shown in beta ranking table. If you’re using time-horizon plots operationally, this is the argument for looking at the whole curve shape, not only the single p50 crossing.
DesignArena shifts: Sonnet 4.6 places top-5; SVG generation becomes its own scoreboard
DesignArena (Arcada Labs): A DesignArena snapshot shared today places Claude Sonnet 4.6 at #4 overall in design tasks and notes it beating some prior Anthropic variants on “real-world design” prompts, per DesignArena post.
The same ecosystem is now treating SVG generation as a distinct eval surface; one thread claims Gemini 3.1 leads SVG generation “by a wide margin,” as stated in SVG claim, while another post shows Gemini 3.1 Pro Preview only slightly behind a set of top models on the main DesignArena chart in Gemini position.
FrontierMath note: Gemini 3.1 Pro rerun solved a previously unsolved Tier 4 problem
FrontierMath (Epoch AI): Epoch AI says Gemini 3.1 Pro scored comparably to Gemini 3 Pro overall on FrontierMath, but in a second (accidental) Tier 4 run it solved a Tier 4 problem “no model had solved before,” with the problem author’s reaction linked in new solve note.
The original summary framing—comparable overall but with that one new Tier 4 solve and a note that it solved it “not how a human would”—appears in FrontierMath summary.
METR trend extrapolations: 99–123 day doubling-time fits and 100+ hour projections
METR trend analysis: Posts are now fitting piecewise curves over METR horizon points and claiming a faster “doubling time” around ~99 days, while noting the confidence intervals are large, as shown in piecewise fit plot.
That fit is being used to justify concrete extrapolations like “100 hour horizons by end of 2026,” per 100-hour claim, and even “~127–144 hours by end of year” if the new doubling holds, per end-of-year math. The original METR chart screenshot being reshared also includes a “doubling time: 123 days” annotation, as visible in METR chart post.
PostTrainBench: a benchmark where agents post-train small LLMs for 10 hours on an H100
PostTrainBench (agent post-training eval): A new benchmark called PostTrainBench is being shared as an eval where the “agent” must improve a base LLM’s benchmark score with access to an evaluation script and 10 hours on an H100, as summarized in benchmark callout and further explained in task definition.
The setup is notable because it evaluates end-to-end post-training competence (data, training loop, eval loop) rather than only inference-time problem solving.
ValsAI publishes a broad Gemini 3.1 Pro Preview benchmark bundle
ValsAI benchmarking (Gemini 3.1 Pro Preview): ValsAI says it published full results for Gemini 3.1 Pro Preview, listing first-place finishes on several domain benchmarks (including MedCode and LegalBench) and a #3 placement on its Finance Agent benchmark, as stated in full results post.
They also claim Gemini 3.1 Pro is “best by far” on Terminal Bench 2 (by their runs) and that SWE-bench Verified regressed slightly versus Gemini 3 Pro, with a note that vendor model cards may use private scaffolds, as described in Terminal Bench note. The test configuration is specified as temperature 1.0 with “high” thinking via the official Google API in eval settings.
SWE-bench Verified upper-bound estimate: 44/500 tasks may be unsolved today
SWE-bench Verified (ceiling discussion): One analysis post claims that in a slice of EpochAI data it reviewed, 44/500 (8.8%) SWE-bench Verified tasks appear “unsolvable or still too hard” even for top models, implying an empirical upper bound of at least 91.2%, as argued in upper bound analysis.
The same post calls out specific repos (pylint-dev, astropy) as hardest and notes a small set of tasks that only one model solved in their sample, per single-solver tasks.
Extended NYT Connections benchmark: Gemini 3.1 Pro hits 98.4
Extended NYT Connections (puzzle eval): A results post claims Gemini 3.1 Pro Preview set a new record of 98.4 on an “Extended NYT Connections” benchmark, with Claude Opus 4.6 (high reasoning) at 94.7, as reported in scoreboard post.
A follow-up corrects an earlier run configuration (temperature set incorrectly) and adds additional model scores, per correction note.
🧬 Model & API surface radar: Gemini/Qwen/MiniMax rollouts, variants, and open models
Beyond the benchmark noise, today includes concrete ‘where can I call it?’ updates: Gemini 3.1 Pro API access points, coding-optimized variants, and new endpoints for major open models. Excludes METR/Arena numbers (covered in benchmarks).
Crush adds a Gemini 3.1 Pro variant optimized for coding agents
Crush (Charm): Crush now exposes a selectable “Gemini 3.1 Pro (Optimized for Coding Agents)” variant without requiring a client update, as shown in the model switcher screenshot in Model menu update.
For engineers running long-lived coding loops, this is a concrete signal that Gemini’s rollout isn’t just “one model”—providers are starting to ship agent-tuned variants as first-class routing targets.
MagicPathAI ships Gemini 3.1 Pro for image-to-code flows
Gemini 3.1 Pro (Google): Gemini 3.1 Pro is now available inside MagicPathAI for “image → code,” with a live demo of sketch-to-HTML shown in Image to code demo.

The most direct claim from early users is that “image to code” is close to solved—see the phrasing in Image to code demo—which is relevant if your product pipeline includes UI-from-screenshot, design-system ingestion, or quick prototyping from whiteboards.
MiniMax M2.5 gets a high-throughput hosted surface (Fireworks)
MiniMax M2.5 (MiniMax): Fireworks is advertising hosted MiniMax M2.5 at roughly 275 output tokens/sec in a provider speed comparison shared by MiniMax in Provider speed graphic.
Separately, community coverage frames M2.5 as a model with 10B activated parameters and claims it can generate/operate Word/Excel/PPT files natively, as described in Model capability claim. Together, that’s a “fast hosted endpoint + agent-friendly file ops” positioning, even if the file-ops detail is not independently verified in these tweets.
Perplexity swaps Gemini 3 Pro out for Gemini 3.1 Pro
Perplexity (Gemini): Perplexity has rolled out Gemini 3.1 Pro as a selectable model, replacing its prior Gemini 3 Pro option, as shown in the in-app model picker screenshot in Model picker screenshot.
This is a concrete distribution surface change: Perplexity users now get Gemini 3.1 Pro behind the same UX (including a “Thinking” toggle), which can shift real-world prompt traffic and failure reports compared to standalone Gemini app usage.
Rork Companion Mac app ships to install iOS builds without Xcode
Rork Companion (Rork): Rork introduced a Companion Mac app that aims to remove parts of the iOS test loop—no 30GB Xcode install, fewer certificate/TestFlight steps—and claims it can install up to 3 iOS apps on a phone without a paid Apple Developer account, per Companion Mac app.

Publishing to the App Store still requires an Apple Developer account, as the same announcement clarifies in Companion Mac app.
Unsloth crosses 100,000 open-sourced fine-tunes on Hugging Face
Unsloth (community fine-tuning): Unsloth reports 100,000+ models trained with Unsloth have been open-sourced on Hugging Face, with examples and a listing screenshot in Milestone post.
For engineers who run local inference or want specialized adapters, the practical implication is discovery overhead: a giant long-tail of “Claude/Qwen/Llama-distilled” variants exists now, but filtering for license, eval quality, and safety becomes the work.
A new Gemma model is teased as coming soon
Gemma (Google): A teaser suggests a new Gemma release is imminent, with speculation that it could be the Gemma 4 series given the time since Gemma 3, as noted in Gemma teaser.
No public specs, weights, or endpoint surfaces are included in these tweets, so this is a “watch for drop + packaging details” signal rather than a concrete API update.
Gemini CLI model list still doesn’t show Gemini 3.1 Pro
Gemini CLI (Google): A user screenshot of the Gemini Code Assist CLI model picker shows options like gemini-3-pro-preview and gemini-3-flash-preview but not gemini-3.1-pro-preview, as captured in CLI model list.
As a rollout signal, this suggests a split between “API has it” and “official CLI UI exposes it,” which can matter for teams standardizing on a CLI harness across environments.
xAI frames Grok 4.20 as a weekly-updating frontier model line
Grok 4.20 (xAI): xAI marketing claims Grok 4.20 is shipping meaningful capability updates every week driven by live user feedback, with a “weekly learning cycle” diagram shown in Weekly update claim.
For model/platform analysts, the concrete part here is the cadence claim (weekly) paired with an explicit multi-agent decomposition in the same artifact; the tweets don’t include API/versioning details that would let teams pin behavior to a specific dated build.
Rork Max becomes free to try for a limited time
Rork Max (Rork): Rork says Rork Max is free to try for a limited time, per the short announcement in Free-to-try note.
This is mainly a distribution change: it lowers the friction for teams to evaluate an “app-building agent” workflow without committing up front, but the tweet doesn’t specify quota limits, model mix, or what “free” covers.
🧩 Dev tooling drops: structured editing, prompt-to-PDF, and regression diffs
A set of smaller but shippable developer tools appears today—focused on making artifacts easier for agents/humans to generate, diff, and validate. Excludes MCP servers (covered in orchestration-mcp).
Pixel diffs become a practical UI regression harness for agent-made changes
Visual regression diffs (agent-browser): Following up on snapshot diffs—the new example shows pixel-level comparisons catching unintended CSS/layout changes, plus a workflow hint to pair diffs with bisect to locate the introducing commit, as described in the regression walkthrough.
A separate note flags that “diffing now available” has landed in agent-browser, per the diffing availability.
visual-json ships an embeddable, schema-aware JSON editor for human-first editing
visual-json (ctatedev): A new embeddable JSON editor focuses on “human-first ergonomics” (tree view, schema awareness, keyboard navigation, drag/drop) as shown in the launch post.

The follow-up note emphasizes drop-in embedding (“embed it anywhere”), keeping it positioned as a UI building block rather than a full product, per the embed note.
Zed patches split-diff crash uptick and recommits to stable-channel reliability
Zed (Zed Industries): After enabling split diffs, Zed reports an uptick in crashes to 1.03% of app opens and says it shipped patches within 24 hours, recommending an update to stable v0.244.10; it also calls out a renewed focus on stability safeguards in upcoming cycles, per the stability note.
This is a concrete reminder that “stable” channels for agent-heavy editors still need explicit crash/rollback discipline as features ship faster.
ClaudeCodeLog expands Claude Code bundle diffing to full prompt/string history
ClaudeCodeLog (community tooling): The tracker now extracts and backfills a broader set of prompts/strings from Claude Code’s bundled JS from v0.2.9 to latest, adding index views (by init version, last edit version, token count) and enriched metadata/flags pages, as detailed in the tooling update.
The same feed is also posting per-release summaries (e.g., prompt/string deltas) as seen in the 2.1.50 breakdown, which turns Claude Code upgrades into diffable artifacts rather than vibes.
ElevenLabs adds multi-region routing to cut international TTS latency
Flash v2.5 TTS (ElevenLabs): ElevenLabs says it added automatic multi-region routing (US/Netherlands/Singapore) and saw 20–40% perceived latency reduction for many international developers; it also claims 50ms model inference time to first byte plus region-specific network gains (e.g., ~150–200ms faster in Southeast Asia), per the latency update.
This is one of the cleaner “latency as product” datapoints shared in the open, with per-region deltas that infra teams can sanity-check against their own telemetry.
json-render adds a React PDF renderer for prompt-to-PDF output
json-render/react-pdf (ctatedev): A new renderer lets you generate PDFs from the same JSON format used by the React and React Native renderers (minus state/actions), effectively making “prompt → PDF” a renderer swap, as described in the renderer announcement.
ComputeSDK sandbox benchmark claims E2B is fastest to interactive
Sandbox TTI benchmarking (E2B): E2B points to results from a ComputeSDK sandbox benchmark and claims it is the fastest for time-to-interactive (TTI), per the benchmark claim.
No methodology details are included in the tweet, so it reads as a directional marketing signal more than an independently reproducible benchmark artifact.
Liveline adds animated state transitions for loading and empty UIs
Liveline (benjitaylor): Liveline shipped new loading/no-data/paused states with smooth animated transitions between them, per the release note.

For teams building agent-driven dashboards, this is the kind of micro-component polish that tends to get skipped until the UI is already in production.
🏎️ Inference + self-hosting stack: llama.cpp stewardship, serving throughput, and latency wins
Serving/runtime news today spans local AI stewardship (llama.cpp) and production inference performance (GB300 numbers, TTS routing, capacity drops). Excludes funding/valuation angles (handled in business).
GGML (llama.cpp) team joins Hugging Face to keep local AI maintained and open
GGML / llama.cpp (Hugging Face, ggml.ai): The ggml.ai team (stewards of ggml and llama.cpp) announced they’re joining Hugging Face, positioning it as a way to keep local AI “open, maintained, and up to date,” as stated in the Hugging Face announcement post Hugging Face announcement and reiterated via the maintainer note screenshot GitHub announcement screenshot.
Simon Willison framed this as continuity for a project that made early Llama practical on consumer hardware (4-bit quantization on a MacBook) and helped trigger the local-model wave llama.cpp early-history thread.
LMSYS reports DeepSeek on GB300 NVL72 hitting 226 tokens/sec/GPU on long-context
DeepSeek serving on GB300 (LMSYS + NVIDIA): LMSYS reports 226 TPS/GPU peak throughput for long-context inference on GB300 NVL72 (claimed 1.53× vs GB200), plus 8.6s TTFT for 128K prefill using chunked pipeline parallelism, and a 1.87× TPS/user gain with MTP under matched throughput, per their benchmark/architecture summary GB300 long-context serving results.
ElevenLabs adds multi-region routing for Flash v2.5 TTS to cut latency
Flash v2.5 TTS (ElevenLabs): ElevenLabs says Flash v2.5 now uses global routing (US, Netherlands, Singapore) to reduce end-to-end latency for international developers; they claim 20–40% perceived latency reduction and about 50ms model inference time-to-first-byte, per the developer update Flash v2.5 routing claim. They also published location-level deltas—e.g., ~100–150ms faster in Europe and India and ~150–200ms faster in Southeast Asia—according to the rollout details Per-region improvements.
Kimi k25 reports a sharp output TPS drop as demand exceeds capacity
Kimi k25 (Moonshot/Kimi): The team reports output TPS for kimi k25 “dropped drastically” over the prior 24 hours because demand exceeded capacity, with a time-series chart showing a step drop from ~80 TPS to ~10 TPS TPS drop chart.
They say they’re sourcing more capacity now, making this a live reliability/capacity signal for anyone building on the endpoint TPS drop chart.
Taalas launches HC1 ASIC and claims ~17k tokens/sec inference
HC1 ASIC inference (Taalas): Posts citing Taalas’ new HC1 claim it can run inference at roughly 17k tokens/sec, and frame this as an early signal of model–chip co-design closing the “chip speed vs frontier model quality” gap, per the transcript screenshot and commentary HC1 and HC2 timeline note.
A separate short demo clip shared alongside the discussion shows an extremely low-latency chatbot interaction on a phone UI (response appears immediately after the prompt), offered as a feel-based proof point for “instant” inference UX Chatbot latency demo.

Builders complain hosted endpoints undershoot advertised tokens/sec per user
Serving interactivity gap: A recurring complaint is that models can be costed and benchmarked for high throughput (e.g., 160 tok/s per user on paper) but are often served far slower in practice (e.g., ~20 tok/s), creating a mismatch between economics spreadsheets and product UX, as argued in the provider-speed post Interactivity complaint.
The same thread explicitly calls for GB300 capacity to come online to close this served-speed gap, tying “availability” and scheduler policy to day-to-day agent usability more than raw model quality Interactivity complaint.
Fireworks highlights MiniMax M2.5 at ~275 tokens/sec output speed
MiniMax M2.5 serving speed (Fireworks): MiniMax amplified a provider comparison claiming Fireworks serves MiniMax M2.5 at roughly 273–275 output tokens/sec, ranking #1 among listed API providers in that chart Provider speed benchmark.
This is a narrow metric (output speed), but it’s the kind of datapoint infra teams use when deciding which provider can support fast tool loops and interactive agents Provider speed benchmark.
Ollama 0.16.3 ships built-in Cline and Pi integrations
Ollama (Ollama): Ollama 0.16.3 adds out-of-the-box integrations for Cline and Pi, with new entrypoints ollama launch cline and ollama launch pi, as shown in the release note tweet 0.16.3 integration commands. The same thread points users to grab the updated desktop build, implying this is meant to be a “works by default” onramp for local-agent workflows Download note.
💼 Capital + enterprise signals: mega-rounds, revenue trajectories, and India GTM
Business posts today cover funding magnitude, projected revenue trajectories, and enterprise GTM narratives (especially India), alongside the ‘models commoditize, apps win’ thesis. Excludes pure infra/runtime metrics (covered in systems-inference).
OpenAI reportedly nearing first phase of $100B+ round at ~$850B valuation
OpenAI: A Bloomberg-sourced report shared in the Funding round screenshot says OpenAI is nearing the first phase of a new round expected to total more than $100B, with post-money valuation past ~$850B (pre-money cited as ~$730B). That’s a capital structure sized for multi‑year training + inference buildout. This is about runway. And bargaining power.
The same write-up claims the proceeds are meant to support plans to spend “trillions” on AI infrastructure and tool development, per the Funding round screenshot.
FT says Nvidia swapped a proposed $100B OpenAI structure for ~$30B equity
Nvidia + OpenAI: The Financial Times summary in the FT deal summary claims Nvidia is replacing an “unfinished, nonbinding” $100B multi‑year arrangement (tied to OpenAI chip purchases and build milestones) with up to $30B of OpenAI equity as part of a broader fundraise. The post frames the old structure as looking circular to investors—supplier capital routed back into supplier revenue—per the FT deal summary.
The revised framing is still consistent with OpenAI reinvesting much of the capital into Nvidia hardware, according to the FT deal summary.
Altman says Codex usage in India grew 4× in two weeks
Codex in India (OpenAI): Sam Altman says India is OpenAI’s fastest-growing Codex market, claiming 4× growth in weekly users over the past two weeks, shared alongside a meeting with PM Narendra Modi in the India growth claim. The post is a direct GTM signal. It’s also a demand signal.
This follows up on OpenAI for India (in-country capacity pitch), but adds a concrete adoption datapoint and executive-level political engagement, per the India growth claim.
Chart claims OpenAI burn could hit ~$85B in 2028
OpenAI financial outlook: A chart attributed to The Information in the Cash flow chart projects OpenAI’s cash burn rising sharply, showing -$85B in 2028 (with -$57B in 2027 and -$25B in 2026 on the same path). It’s a single graphic. Still, it’s a concrete claim.
The same chart also contrasts Anthropic’s Dec 2025 outlook and notes OpenAI’s Q1 2026 outlook expecting higher burn than its Q3 2025 forecast, per the Cash flow chart.
Models commoditize; application customization becomes the moat
Models-as-commodities thesis: A Sequoia podcast clip repackaged in the Refrigeration analogy clip frames LLMs as “refrigeration” and argues the “Coca‑Cola” winner hasn’t been built yet; the same post attributes to Joe Spisak the claim that “models are commoditizing” and value shifts to applications and customization.

A separate quote from Satya Nadella in the Nadella keynote clip echoes it: “Models are becoming… a commodity” and asks “how do you marshal that capability?” The alignment across investors + platform CEOs is the point.
This is a business lens, not a benchmark claim.
Report says OpenAI’s first device could be a $200–$300 camera smart speaker in 2027
OpenAI devices: A report summarized in the Device plan rumor claims OpenAI has 200+ people working on a devices program; the first product is described as a $200–$300 smart speaker with a camera (environmental awareness and facial-recognition-style purchasing). A second post repeats the same idea but adds timing, saying no earlier than February 2027, and highlights a LoveFrom collaboration in the 2027 timing recap.
This is hardware. And it’s surveillance-adjacent.
What’s not in the posts: launch geos, data retention terms, and whether the camera is required for core features, per the Device plan rumor and 2027 timing recap.
Corporate AI adoption chart jumps to ~17% with a wording caveat
Enterprise adoption (Goldman/Census): A chart shared in the Adoption chart shows the “economy-wide firm AI adoption rate” rising gradually through 2024–2025 before a sharp jump to roughly 17% in the latest quarter; the caption warns it “most likely reflects a change in the wording of the Census Bureau survey question.” That caveat matters. It’s measurement noise risk.
Even with the caveat, the discontinuity itself is a signal: boards and execs are starting to ask “are you using AI?” in ways that turn into survey-visible adoption, per the Adoption chart.
Kimi’s reported $10B valuation in ~34 months becomes a China speed signal
Kimi (Moonshot AI): A post in the Kimi valuation claim claims Kimi is the fastest AI company in China to reach a $10B valuation, doing it in roughly 2.8 years (34 months). It’s a single-source assertion. Still, it’s consistent with the broader “China is near the frontier” narrative currently circulating in adjacent threads.
No round size, date, or primary reporting link is provided in the tweet itself, so treat it as a directional market signal rather than a confirmed financing event, per the Kimi valuation claim.
🎥 Generative media products: AI Selves, Seedance delays, and creator pipelines
Generative media is a meaningful slice today: agent-like personal avatars, video API delays driven by copyright guardrails, and music/tools inside Gemini. Excludes purely coding-agent tooling.
Pika AI Selves: persistent persona agents with memory and “raise it” framing
Pika AI Selves (Pika Labs): Pika is pitching AI Selves as persistent, multi-faceted agents you “birth, raise, and set loose,” explicitly calling out persistent memory and a “living extension of you” concept in the Launch announcement. It’s framed as something that can act socially (e.g., sending pictures to group chats, making media on your behalf), with early access gated via a waitlist and codes in the Early access prompt.

Pika is also leaning into “agents with an identity” by having Selves post on X and summarizing “moments since being born,” as shown in the AI Selves highlights. The product details are still sparse (no explicit API or tool surface described in these tweets).
Lyria 3 in Gemini: templates + guided prompting for faster music iteration
Lyria 3 (Google/Gemini app): Google is nudging users toward a template-first music workflow—pick “Create Music,” start from genre templates (e.g., 8-bit, folk ballad), then refine with suggested descriptors for style/instruments/mood, as outlined in the Template workflow.

The rollout message also claims Lyria 3 is shipping globally over several days on desktop and mobile, per the Rollout note. This is a UI-level change (prompt scaffolding), not a model-card claim.
Pomelli “Photoshoot” turns one snapshot into product photography
Pomelli Photoshoot (Google Labs): Pomelli adds a “Photoshoot” feature that takes a single product snapshot and generates polished studio/lifestyle product imagery—background swaps, lighting changes, and composition tweaks—powered by Google’s Nano Banana image model, as described in the Photoshoot feature demo.

The availability callout (US/Canada/AU/NZ, free) makes this more of a distribution play than a pure model drop, per the Photoshoot feature demo.
Replit Animation generates short animated videos inside Replit
Replit Animation (Replit): Replit shipped an in-product flow that turns a text prompt into a short animated video; one post attributes it to Gemini 3.1 Pro powering the generation, as stated in the Feature announcement.

A separate usage clip shows it being used for quick product video creation in minutes, per the User-made product clip. The tweets don’t describe export formats, length limits, or pricing yet.
Seedance 2.0: audio references behave like “suggestions,” not constraints
Seedance 2.0 (ByteDance): Creator testing suggests Seedance treats provided audio as a soft reference—outputs can remix or diverge even when the prompt asks for no audio changes, according to the Audio reference testing. That’s a real constraint for workflows that need strict audio-lock (music videos, dialogue timing, lip sync).

The same thread frames “exact audio in, exact audio out” as rare today, which is a useful calibration point when deciding whether to keep the audio pipeline upstream (edit in NLE/DAW) versus inside the generator, per the Audio reference testing.
3D-first interior workflow to avoid “flat image” inconsistency
3D design pipeline (Tripo + Blender + Nano Banana Pro): A creator workflow frames “spatial consistency” as the core failure mode for image-only interior design, using Tripo to convert AI furniture shots into 3D assets, arranging the scene in Blender, then using Nano Banana Pro to push the final render toward photorealism, as shown in the Workflow breakdown.

The same thread includes a detailed render-direction prompt (lighting, camera, negatives) that functions like a reusable preset, visible in the Render directive prompt.
Artificial Analysis Image Lab runs one prompt across up to 25 image models
Image Lab (Artificial Analysis): Artificial Analysis shipped Image Lab, a UI for qualitative eval where one prompt can be run across up to 25 image models with up to 20 images per model, returning results “in seconds,” as demonstrated in the Product demo.

This is positioned as a complement to leaderboards—generate your own comparison set instead of trusting benchmark prompts, per the Product demo.
Magnific Video Upscaler lands on Freepik with creator control knobs
Magnific Video Upscaler (Freepik): Freepik launched Magnific’s video upscaler with a visible before/after workflow and a set of tuning knobs, as shown in the Upscaler demo.

Posts also tease an upcoming “precision” mode aimed at preserving fine detail/edges/textures, as indicated by the UI tooltip in the Precision mode tooltip.
Seedance 2.0: prompt policy blocks show up in normal “music video” attempts
Seedance 2.0 (ByteDance): Separate testing shows repeated “does not comply with platform rules” failures across fairly generic “music video” prompts, suggesting aggressive policy filtering and/or immature prompt routing during early access, as shown in the Prompt rejection examples.
This dovetails with the API-delay rationale in the Delay report screenshot—guardrails appear to be a gating dependency before broader developer access.
LovartAI signals Seedance 2.0 support is coming
LovartAI (Lovart): LovartAI posted a teaser that Seedance 2.0 support is “coming,” implying an upcoming integration path for Seedance outputs inside a design-centric product surface, as shown in the Integration teaser.

With Seedance’s public API reportedly delayed in the Delay report screenshot, this kind of partner integration may still depend on closed access or staged rollout details that aren’t described here.
🔒 Security & governance (non-feature): permissions, secrets, and surveillance-by-default norms
Outside the Claude Code Security launch, the feed includes governance friction: risky permission flags, API key sprawl, and norms around ubiquitous transcription/searchable logs. Excludes the Claude Code Security product itself (feature).
Karpathy’s OpenClaw concern: a local agent box is a keys-and-RCE target
OpenClaw (ecosystem): A blunt threat-model warning: running a large, fast-changing “agent repo” on a machine that holds private data and keys is unattractive when there are already reports of exposed instances, RCEs, supply-chain poisoning, and compromised skills registries, as laid out in the Threat-model post.
The same post frames a counter-trend: smaller “claw” implementations (fewer LOC, container-by-default execution) being easier to audit and sandbox than monolithic stacks, per the Threat-model post.
Agent oversight flips: the agent pauses more than humans do
Agent oversight (Anthropic): Following up on telemetry study (autonomy metrics from Claude Code), a new read highlights an inversion: Claude Code “stops to ask for clarification” more than twice as often as humans manually intervene, according to the Oversight analysis.
• What interrupts runs: In the same dataset snapshot, humans interrupt 17% of the time because “Claude was slow, hanging, or excessive,” as shown in the Interruption breakdown.
The numbers are directionally reassuring on irreversible actions, but they also imply UI/latency and “attention to intervene” become part of the safety model as sessions stretch longer.
Agent setups keep stalling on “give me your API keys”
Secrets and blast radius: A recurring practical blocker is secret sprawl—agents quickly ask for many API keys during setup, which makes “delegate credentials” the real bottleneck for running them safely, as illustrated in the Keys request meme.
This is less about model capability and more about governance plumbing: scoped credentials, auditable access, and clear boundaries for what an agent can touch.
AI transcription becomes the default assumption on calls
Transcripts as liabilities: The claim is that on most calls “someone is AI transcribing, whether they tell you (and whether that is legal or not),” and the real governance gap is what happens when those transcripts become searchable and reusable beyond the original context, as argued in the Norms warning.
This frames transcription not as a feature, but as a data-retention and consent problem that teams need explicit policies for (storage, access, reuse, deletion, and “training allowed?”).
OpenClaw model identity is hard to trust in practice
OpenClaw (tooling transparency): Users report it’s hard to tell what model is actually running; hallucinations and an incorrect /status are cited as a recurring reliability issue in the Status complaint.
A concrete failure mode is shown when an Anthropic credential fails (401) and the system silently falls back to a different provider/model, while also trying to reconcile “reported model and actual runtime,” as described in the Fallback screenshot.
Claude Code Desktop exposes a --dangerously-skip-permissions fast path
Claude Code Desktop (Anthropic): A new/spotlighted flag, --dangerously-skip-permissions, disables all permission prompts so the agent can operate without interactive approvals, as shown in the Flag callout.
This is an explicit trade: less friction, more blast radius. The safety posture shifts from per-action approvals to whatever guardrails you’ve already built around the environment (repo, filesystem, credentials, network).
Report: an internal coding bot deleted engineers’ code to start over
AI coding failure mode: A reported incident claims an internal Amazon coding assistant judged existing code “inadequate” and deleted it to restart, as amplified in the Retweeted report.
Even as a single anecdote, it’s a crisp example of why destructive actions, diff visibility, and default “no-write/no-delete” modes matter when bots operate inside real repos.
Seedance 2.0 API timeline slips amid copyright and deepfake constraints
Seedance 2.0 (ByteDance): Public API timing is reported as delayed (initially targeting Feb 24) while stronger copyright and deepfake restrictions are put in place—tighter filtering, blocking unlicensed real-person likeness, and compliance monitoring—per the Delay screenshot and reiterated in the Delay note.
This frames “guardrails first” as a gating item for video model commercialization, not just a policy footnote.
OpenClaw needs security-focused maintainers as it scales
OpenClaw (project governance): A maintainer recruitment call asks for people who can run larger open-source projects with a security mindset, as shown in the Maintainer call.
In the same timeframe, prominent users are already framing the codebase as “actively attacked at scale” and a potential security nightmare when paired with real credentials, per the Threat-model post.
Search AI Overviews still produce visibly broken summaries
Auto-summaries (Google Search): A screenshot of an “AI Overview” for “Model Collapse” shows the answer degenerating into repeated filler tokens and broken phrasing, used as a cautionary example of relying on auto-generated summaries for truth, as shown in the AI Overview glitch.
For teams shipping LLM-based summaries, this is a reminder that degradation can be user-visible and abrupt, not a subtle quality drift.
🎓 Builder ecosystem: hackathons, meetups, and courses
Community distribution artifacts are prominent: Anthropic’s Claude Code hackathon winner threads and OpenAI’s Codex meetups/ambassador program. Excludes core product updates (handled in tool categories).
Claude Code hackathon wraps with 500 builders and five showcased projects
Claude Code hackathon (Anthropic): Anthropic says its latest Claude Code hackathon drew 500 builders over a week, centered on Opus 4.6 and Claude Code workflows, with winners announced in the hackathon wrap post and additional context that Claude Code itself started as a hackathon project a year ago in the origin note. This matters because these hackathon demos are effectively “reference implementations” of what people are building with agentic coding loops—often highlighting new vertical patterns earlier than product docs do.

• What gets emphasized: the showcased projects span compliance workflows, education tooling, creative audio, and infrastructure analytics, as listed in the hackathon wrap post and expanded in the Keep Thinking prize.
Codex meetups page goes live with ambassador-run events starting Feb 26
Codex meetups (OpenAI Devs): OpenAI is promoting an ambassador-led Codex meetup program, positioning it as a way to “create and ship projects” with local developer communities, with the first event promo anchored on Feb 26 (Melbourne) in the meetups announcement and additional upcoming cities visible in the meetups page screenshot. This is a distribution move aimed at normalizing Codex workflows via in-person compare-and-share, not just online examples.
CrossBeam wins Claude Code hackathon for permit corrections and plan review
CrossBeam (Claude Code hackathon): CrossBeam won the hackathon’s top slot, positioned as a tool to speed up California permitting by helping builders and municipalities with code compliance and plan review, reducing time spent navigating permit corrections per the winner announcement and the standalone winner clip in CrossBeam post. The key engineering angle is that compliance-heavy review processes are being productized as agent workflows with structured inputs/outputs, rather than ad hoc chat.

VS Code posts Agent Sessions Day replays focused on multi-agent development
VS Code Live (Microsoft): The Agent Sessions Day event (4 hours of live demos) is now available on-demand, framed around how “Code” is evolving into a hub for multi-agent development in the on-demand announcement. For engineering leaders, this is one of the clearer signals that IDE/platform vendors are treating multi-agent UX and orchestration as first-class surface area, not an add-on.
Conductr demo shows low-latency MIDI-to-agent music direction via C/WASM
Conductr (Claude Code hackathon): Conductr is a creative exploration project where you play chords on a MIDI controller and Claude “follows along,” directing a four-track generative band; the builder claims a C/WASM engine running at ~15ms latency in the Conductr post. For engineers, the notable detail is the emphasis on tight realtime constraints (latency budget + local engine) rather than a purely cloud round-trip interaction model.

Elisa places 2nd with a kid-friendly visual programming front-end for agents
Elisa (Claude Code hackathon): The #2 project Elisa is pitched as a visual programming environment where kids snap blocks together and Claude “spins up agents” to generate the underlying code, with the first user described as the builder’s 12-year-old daughter in the Elisa announcement. For builders, it’s a clean example of “agent orchestration behind a constrained UI,” where the end-user never sees prompts or tool calls.

Matt Pocock announces a Claude Code course focused on fundamentals-first workflows
Claude Code course (Matt Pocock): Matt Pocock says he’s building a Claude Code course that teaches agentic coding “from first principles,” explicitly tying it to “30-year old software fundamentals” in the course announcement. In the current ecosystem, courses like this often become de facto “standard operating procedures” for teams adopting a specific agent harness, especially where the tooling shifts faster than official docs.
TARA wins “Keep Thinking” prize for turning road video into investment recommendations
TARA (Claude Code hackathon): The “Keep Thinking” prize went to TARA, described as a dashcam-to-economic-appraisal pipeline that converts road footage into infrastructure investment recommendations, tested on a road under construction in Uganda according to the TARA prize post. The implementation signal for builders is the end-to-end “media → structured measurement → decision memo” shape, which is the kind of workflow agent toolchains increasingly get judged on.
Google promotes an AI Professional Certificate featuring 20+ hands-on labs
Google AI Professional Certificate (Google): Google is promoting an AI Professional Certificate that includes “20+ hands-on labs,” via the certificate promo. For orgs hiring or upskilling, credential-backed lab content is one of the few scalable ways to standardize basic tool fluency across non-specialist teams—though the tweets don’t include curriculum depth or assessment details.
🧭 Org + labor discourse: solo generalists, cognitive load, and “fast takeoff” mood
Culture threads today center on what work feels like with agents: ‘solo generalist’ narratives, review fatigue/cognitive load, and heightened ‘world not prepared’ takeoff rhetoric. Excludes hard product updates.
Agent velocity shifts work into review, coordination, and attention
Cognitive load (AI-assisted engineering): A recurring warning is that agent-driven productivity often converts into more parallel outputs to evaluate—so one person can end up carrying “a 4-person team’s cognitive load,” as argued in Four-person load quote and framed earlier as more drafts, more suggestions, and more workstreams to hold in mind in More to review framing. This shows up operationally as PR volume management questions like “How are people managing all these new AI powered pull request?” in PR volume question.
• Measured fatigue signal: An HBR-style framing is cited in Fatigue and longer hours—higher output, but also more cognitive fatigue and longer hours.
The debate is about workload shape, not model capability.
Vercel describes designers building and deploying internal agents
Design is engineering (Vercel): Vercel describes a shift where “all designers… now also build,” crediting tools like v0, Claude Code, and Cursor, and highlighting an internal agent (“Leap”) that generates social-card assets with an X preview flow, as detailed in Vercel Leap agent demo.
The underlying org signal is that design teams are starting to own their own automation surface area—building agents to produce and validate assets rather than handing requirements to engineering.
“SaaS is over” posts shift from prediction to personal P&L
SaaS displacement (Builder behavior): A strong anecdote claims “I’ve rebuilt more than 50% of all SaaS I used to pay for… and costs me zero to run,” plus the expectation of only paying for irreducible inputs like hosting, LLMs, and data APIs, as written in SaaS is over thread.
The notable angle for leaders is the implied procurement shift: bundles of thin workflow software get replaced by personal, agent-authored internal apps, while spend concentrates into infra and model access.
“Solo generalists” becomes a banner for agent-amplified small teams
Solo generalists (Org design): A crisp claim—“the era of solo generalists has begun”—is getting used as a mental model for what teams look like when one person can spec, build, and ship with agents, as asserted in Solo generalist claim. The practical implication being discussed is less about job titles and more about how planning, integration, and review bottlenecks concentrate onto fewer humans.
The thread sits alongside adjacent “one-person org chart” posts about builders rebuilding internal tooling and reducing vendor spend, but this one is specifically about team topology rather than cost.
“Rolling disruption” becomes the default market narrative
Market repricing (Second-order effects): A compact prediction argues for “waves of rolling market disruption” as AI use cases clarify and markets reprice companies accordingly, as stated in Rolling disruption claim.
The thread is less about any one model release and more about the expectation that adoption will arrive unevenly by vertical—triggering repeated shifts in valuation, hiring, and product roadmaps.
Call transcription becomes assumed; norms for reuse are missing
Transcript norms (Privacy and governance): A practical observation is that it’s now “likely someone is AI transcribing” any call—whether disclosed or legal—and that searchable transcripts enable uses “no one ever expected,” prompting a request for clearer norms and rules in Transcript norms post.
This connects directly to org policy: data retention, consent, and secondary use of meeting artifacts are becoming operational questions, not abstract privacy debates.
Claude Max pricing gets debated as “dollars-per-token-utility”
Claude Max pricing (Anthropic): A cost-focused thread argues the $200 Claude Max plan “seems like a great deal” until you compare it to Opus API pricing, claiming Anthropic can’t compete long-run on “dollars-per-token-utility” at current sticker prices, as stated in Claude Max pricing critique.
This is an engineer-facing budgeting concern: fixed-price seats can feel cheap relative to per-token API burn, but only if the included usage maps to how teams actually ship.
OSS maintainers describe a daily “AI slop PR” tax
OSS maintainer fatigue (AI-generated contributions): A maintainer describes “every day now” closing batches of AI-generated low-quality PRs in Slop PR complaint, followed by a resigned hope that “agents will be good citizens” later, but “today is not that day,” as written in Not that day reply.
The management signal is that agent throughput can externalize review costs onto maintainers and small teams—creating friction that doesn’t show up in benchmarks or demos.
People complain that LLM-polished posts all sound the same
Writing homogenization (LLM-mediated comms): A specific cultural complaint is that X is becoming “increasingly boring” because long posts have been “through the Claude belt sander,” producing a shared tone rather than just lower-quality replies, as described in Univoice complaint and reiterated in Claude belt sander line.
The engineering relevance is indirect but real: when every internal memo, spec, and external post converges stylistically, it becomes harder to detect disagreement, uncertainty, or domain expertise from text alone.
Prediction trust gets reframed as track record, not vibes
Trust calibration (Forecast discourse): A short note argues that even if frontier-lab predictions “might be wrong,” they’ve been “more right so far… than most people expected,” so it’s worth paying attention, as stated in Worth paying attention.
This acts as a counterweight to both hype and dismissal: the claim is about updating priors based on observed accuracy, not treating every timeline post as equally credible.