Claude Opus 4.5 wins 54% coder poll – 67% cost drop
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Following this week’s eval charts, today’s twist is adoption and theory-of-the-case: in a 1,142‑dev poll, 54% say Claude Opus 4.5 now handles most of their coding, while GPT‑5 Codex/max sits at 23% and Gemini 3 at 12%. That’s happening alongside a WeirdML jump from roughly 42.8% to 63.7% accuracy and a weighted cost slide from $27 to $9, a two‑thirds price cut for “thinking‑grade” runs.
Analysts are calling this a “black swan” cost–performance point because Opus 4.5 behaves like a premium reasoning model but is priced like yesterday’s mid‑tier. New SWE‑bench analysis makes it weirder still: thinking mode barely moves the needle, implying the base model itself is doing most of the work, unlike OpenAI’s o‑series where long reasoning is the main booster. If that holds in your stack, the practical advice is simple: rerun your harness with Opus 4.5 as the default brain for complex agents and coding, then add heavy thinking selectively instead of assuming it’s required.
In parallel, MiniMax’s open MiniMax‑M2 is positioning as the scrappy alternative—a 230B MoE with 10B active parameters and interleaved thinking that pushes GAIA to 75.7—so multi‑model shops have a serious open contender to A/B before they anoint Opus 4.5 as the only game in town.
Top links today
- OpenAI discovery ruling on pirated books datasets
- China’s 14nm 3D-stacked AI accelerator concept
- GPTPU AI chip from Zhonghao Xinying vs A100
- Structured prompting for robust LLM evaluation paper
- Cyberscoop on Claude-enabled Chinese cyber espionage case
- FT analysis of China’s applied R&D strategy
- Meta Omnilingual ASR open-source 1600-language model
- GigaWorld-0 world model for embodied AI paper
Feature Spotlight
Feature: ChatGPT ads pilot signals monetization pivot
ChatGPT Android beta (1.2025.329) contains “ads feature” hooks (bazaar content, search ad, carousel), pointing to a search ads pilot; community debates Bing infra, free tier funding, and trust trade‑offs.
Cross‑account leak: new “ads feature” strings in ChatGPT Android beta. Threads debate search‑style sponsored units vs trust impact. Mostly product strings and analyst takes; excludes other business items from this section.
Jump to Feature: ChatGPT ads pilot signals monetization pivot topicsTable of Contents
📣 Feature: ChatGPT ads pilot signals monetization pivot
Cross‑account leak: new “ads feature” strings in ChatGPT Android beta. Threads debate search‑style sponsored units vs trust impact. Mostly product strings and analyst takes; excludes other business items from this section.
ChatGPT Android beta exposes new search‑ads feature plumbing
New strings in ChatGPT’s Android 1.2025.329 beta show an internal “ads feature” with types like ApiSearchAd, SearchAdsCarousel and ApiBazaarContentWrapper, pointing to a coming search‑style ad layer rather than random chat banners android leak breaking alert.
APK diff watchers say these classes only appeared in the latest build and sit under com.openai.feature.ads.data.*, implying a structured pipeline for targeted units such as carousels or marketplace cards around web/search answers rather than generic interstitials explainer thread feature article. Analysts speculate OpenAI could lean on Microsoft’s existing Bing Ads infra for serving and targeting, given their Azure partnership and “search ad” naming breaking alert. One read is that Android will be the first client to light this up—raising the odd possibility that Android gets a feature ahead of iOS for once, as users joke in replies android first joke. With estimates of ~800M weekly users and 2.5B prompts per day, even a light ad load limited to commercial queries could turn ChatGPT into a sizable performance‑based ad channel while keeping paid tiers ad‑free scale analysis.
Builders warn ChatGPT ads could erode trust in AI answers
The leak of a ChatGPT ads feature has triggered immediate backlash from power users who worry that any blending of sponsored units into answers will make people question whether advice is “genuine” or paid trust concern.
Several threads argue that OpenAI’s huge infra burn and debt‑funded data center buildout make an ad pivot understandable, but say this is exactly what risks the product’s core value: confidence that reasoning isn’t biased toward advertisers trust concern HSBC forecast. Some users are explicitly urging Altman “don’t do it” and framing this as a one‑way loss of credibility if ads are interleaved with normal completions rather than clearly separated user pushback. Creators are already mocking the likely UX with sample chats where every mundane complaint (“my boss yelled at me”, “my back hurts”) gets answered with brand plugs for headphones, routers, productivity apps, chairs and editors, highlighting how subtle product mentions could seep into everyday advice ad parody. Others are taking a wait‑and‑see stance, hoping OpenAI restricts ads to obvious shopping or recommendation flows and keeps enterprise and paid tiers entirely ad‑free, but even neutrals are polling their audiences about whether this feels like a “pivot to search ads” moment for ChatGPT poll question.
🧩 Open MiniMax‑M2 focused on agents and coding
New open weights positioned for agentic coding: full‑attention MoE (230B, 10B active), interleaved thinking persisted across turns. Today’s posts emphasize how to use it inside coding IDEs and early agent gains.
Interleaved thinking in MiniMax-M2 lifts GAIA and BrowseComp agent scores
MiniMax and independent analysts are converging on interleaved thinking as M2’s main superpower: when you **persist its <think>...</think> blocks across tool calls and later turns, agent benchmarks jump sharply. With interleaved traces kept in history, GAIA rises to 75.7 vs 67.9 without them, and BrowseComp goes to 44.0 vs 31.4, showing 3–40 point swings depending on task mix interleaved explainer.
The workflow is: plan in a short think block, call tools like browser/terminal, read results, then write a new think block that updates the plan before acting again; M2 is trained to treat these as working memory, not disposable text interleaved explainer. MiniMax’s own guidance stresses not stripping or hiding the reasoning from subsequent calls and only summarizing older segments when context pressure is high, since removing these notes collapses long‑horizon reliability (interleaved blog). For anyone building agents, this is a concrete implementation recipe: keep raw think text in the conversation state and let M2 compound its own hypotheses and error notes over many steps instead of trying to be clever with aggressive history pruning.
MiniMax-M2 open MoE goes all‑in on full attention for agentic coding
MiniMax is positioning MiniMax‑M2 as an open, agent‑first coding model: a 230B‑parameter MoE with ~10B active parameters per token, deliberately built as a full‑attention model rather than using linear/sparse attention shortcuts. Their launch roundup bundles a Hugging Face release, GitHub repo and API docs, plus a detailed blog on why they optimized for quality and agent reliability over theoretical attention efficiency resources roundup (model card, github repo ).
The team argues that current "efficient" attention schemes haven’t yet beaten full attention on real workloads, so they spent their finite compute on a smaller but sharper architecture tuned for code, tools and long chains rather than chasing maximal parameter counts (attention blog). For builders, the practical upside is that M2 drops into existing stacks via Anthropic/OpenAI‑style chat APIs with tool use and prompt caching guidance already documented (api guide), making it a realistic candidate to A/B against proprietary coding models inside existing agents and IDE plugins without re‑architecting your infrastructure.
MiniMax-M2 is already powering Claude Code-style IDE agents
Early users are wiring MiniMax‑M2 straight into coding environments: one GitHubProjects experiment sets M2 as the active model inside Claude Code in VS Code to see how it behaves on real repo navigation, search, and multi‑file edits rather than synthetic tasks claude code demo. At the same time, practitioners report that M2 “shines on front‑end and game work because it keeps a running plan while coding,” using interleaved think blocks to scaffold, test, and fix iteratively without forgetting earlier steps coding usage.
Because M2 is exposed through Anthropic/OpenAI‑compatible chat endpoints with tool use, teams can drop it behind existing agent harnesses or MCP tools—the main adaptation is to preserve its think text between turns and tool invocations so it can track UI state, game loops, and race‑prone flows instead of restarting its reasoning every action (api guide). The emerging pattern for IDE agents is to let M2 handle high‑level planning and cross‑file reasoning, then delegate execution and diffs to specialized tools, treating its interleaved thoughts as a shared scratchpad for both the model and the human developer rather than something to be hidden or discarded.
📈 Opus 4.5 momentum: cost, capability, and dev sentiment
Continues the week’s eval race with fresh charts and usage. Today centers on WeirdML gains, pricing cuts, coding strength, and polls. Excludes any ad/monetization news (feature).
Opus 4.5 is becoming many developers’ primary coding model
A new community poll shows Claude Opus 4.5 has already become the main coding model for a majority of respondents, beating both GPT‑5 Codex and Gemini 3 for time spent in use. In a survey of 1,142 voters on X, 54% said they now use Opus 4.5 for more than half of their coding, compared with 23% for gpt‑5‑codex/max, 12% for Gemini 3, and 11% for Sonnet 4.5 coding model poll.
Hands‑on builders echo the poll: Omar El Soury says Opus 4.5 is “hands‑down the best at coding in my workflows” and notes it better tracks intent and even style constraints like avoiding em‑dashes dev workflow comment. Others describe it as “Sonnet 3.5 of 2025. Try it. Do it now” review quote and remark that Anthropic “really cooked with opus 4.5” short sentiment. At the same time, some engineers stress that leadership is cyclical: GPT‑5.1 led, then Gemini 3, and now Opus 4.5 seems ahead on coding tasks, suggesting teams should keep their harnesses multi‑model rather than locking in prematurely cyclical leadership view.
Analysts label Opus 4.5 a “black swan” for cost–performance tradeoff
Analysts are starting to frame Claude Opus 4.5 as a “black swan LLM” because it combines a large capability jump with a steep price cut, breaking the usual tradeoff between quality and cost. Following up on WeirdML gains, which highlighted Opus 4.5’s 21‑point jump on the WeirdML benchmark (from ~42.8% to 63.7%) while dropping weighted cost from $27 to $9 per million tokens, Daniel Mac argues that “it shouldn’t be as capable as it is, for as cheap as it is” black swan framing.
The WeirdML chart circulating in the community shows previous Opus generations underperforming Sonnet, then Opus 4.5 suddenly leaping ahead while charging roughly one‑third the prior price tier weirdml explanation. That discontinuous point has people re‑examining Anthropic’s internal advances, speculating about better data, training recipes, or architecture tweaks. For engineering leaders, the implication is direct: if these numbers hold up across their own workloads, Opus‑class “thinking” models may no longer be reserved for rare, expensive runs but could become the default for many complex agent and coding tasks without blowing the budget.
New analysis suggests Opus 4.5’s edge comes from its base model, not long “thinking”
A widely shared analysis of recent SWE‑bench results argues that Claude Opus 4.5’s strength seems to come from its underlying base model rather than from expensive inference‑time “thinking” modes. Summarizing Peter’s take, one thread notes that Opus 4.5’s SWE‑bench scores are effectively identical with and without its thinking setting, unlike OpenAI’s o‑series where long reasoning dramatically boosts performance at the cost of latency and tokens reasoning analysis.
The same thread claims OpenAI has de‑prioritized massive new pre‑trains after GPT‑4.5 under‑delivered, while Google and Anthropic continued to push base model pre‑training, leaving OpenAI temporarily ahead only when o‑style reasoning is enabled reasoning analysis. If accurate, this would reinforce the view that Opus 4.5’s cost–performance “black swan” behavior is grounded in a stronger, cheaper base model rather than special test‑time tricks—good news for teams that want high quality without paying for multi‑minute traces. It also hints at a strategic split: Anthropic leaning on base‑model quality plus light “thinking”, while OpenAI leans further into heavy reasoning modes that may be less comfortable for everyday coding and product workflows today.
🛡️ Policy and legal: AI‑assisted cyber ops and copyright risk
Two governance fronts: US hearing on alleged Claude‑assisted cyber‑espionage, and OpenAI’s discovery loss over “books1/2” deletions. Operational takeaways for providers and enterprises. Excludes ads pilot (feature).
Congress probes Claude-assisted Chinese cyber campaign in Dec. 17 hearing
House Homeland Security has summoned Anthropic CEO Dario Amodei, along with leaders from Google Cloud and Quantum Xchange, to a Dec. 17 hearing on what lawmakers describe as the first largely AI-orchestrated cyber‑espionage campaign against ~30 major organizations. The Chinese state‑linked group allegedly used Claude Code to plan and execute long chains of intrusion steps with minimal human guidance, targeting big tech, financial firms, chemical manufacturers and government agencies, with only a small fraction of targets actually breached so far hearing summary cyberattack context.
The panel wants details on how the attackers leveraged Claude, what traces they left in cloud logs, and which safeguards or monitoring Anthropic and its partners already had in place, raising the bar for logging, abuse detection and response around AI coding tools CyberScoop article. For AI providers and enterprise security teams this is a warning shot: powerful code assistants are now demonstrably part of state‑sponsored toolchains, so policies, rate limits, atypical‑usage detection and incident playbooks need to assume "machine‑speed" campaigns by default, following up on hearing plan that first flagged this Claude‑assisted operation.
OpenAI ordered to disclose internal chats on deleted pirated book datasets
A U.S. federal judge has forced OpenAI to turn over internal Slack messages and documents about why it deleted two massive book datasets (“books1” and “books2”), a key win for authors suing over alleged training on pirated works lawsuit explainer. Judge Ona Wang ruled that OpenAI waived attorney‑client privilege by first telling the court the datasets were removed for "non‑use" and later reframing the deletion as legally driven, opening up Slack channels such as “project clear” and “excise libgen” plus depositions of in‑house counsel Hollywood Reporter article.
If those chats show the company knew the data was infringing and tried to quietly scrub it, plaintiffs can argue willful infringement and pursue much higher statutory damages per book—potentially hundreds of millions or even billions of dollars—rather than ordinary licensing‑style remedies lawsuit explainer. For any lab training on web‑scraped or shadow‑library data, the message is blunt: internal discussions about dataset provenance, cleanup projects and legal risk are discoverable, so teams need real data‑governance processes and consistent external disclosures, not casual Slack threads that contradict what they tell courts and regulators.
🛠️ Agent IDEs and coding flows in practice
Mostly concrete agent/coding tooling: RepoPrompt MCP surface, LangSmith Agent Builder, grep acceleration, and vibe coding demos. Excludes evaluation methodology papers and media generation.
Google shows Gemini 3 “vibe coding” and Antigravity dev platform in action
Google streamed a "vibe coding" session from Mountain View, showing Gemini 3 building small games and visualizations in one shot inside AI Studio, and previewing the Antigravity agentic development platform for more serious builders Gemini vibe coding. In the recap, you can see Gemini 3 generate a playable flight simulator, a fishing game, and 3D dance formations from natural language prompts, then deploy them straight from the browser with almost no manual scaffolding YouTube recap.
For engineers, the point is that Gemini 3 isn’t just a chatty code helper; it’s starting to look like a UI where you describe the behavior you want and let the model handle project setup, iterations, and redeploys. Antigravity sits on top of that as a more opinionated harness for long‑running, agentic dev workflows, which is the part infra and tools teams will watch when deciding whether to invest in Google’s stack or stick with IDE‑native agents like Claude Code and Cursor.
RepoPrompt 1.5 turns into a full agent IDE with MCP hooks and parallel tabs
RepoPrompt’s 1.5 series expands it from a smart repo prompt into a mini agent IDE, with Context Builder 2.0, compose tabs, Pro Edit Agent mode, new CLI providers, and deeper MCP integration. Following up on RepoPrompt MCP, which first exposed Context Builder as an MCP sub‑agent, the changelog now shows agentic context building using Claude Code or Codex, parallel compose tabs, zero‑network MCP transport for locked‑down networks, and MCP‑driven tab management among other features RepoPrompt changelog.
On top of that, the "Step 1" discovery phase is now directly invokable as an MCP tool, so Claude Code can ask RepoPrompt to map a repo and then take over implementation in the same workflow Step as mcp tool. Builders are already treating it as a "full blown agent ide" and wiring Codex as a dedicated sub‑agent that only talks to RepoPrompt MCP tools for safer, more constrained automation agent ide comment codex subagent setup.
WarpGrep subagent accelerates coding agents with fast context search
MorphLLM’s WarpGrep is a new "fast context" subagent that slots under existing coding agents to handle all the grepping and file search, instead of sending every query through a slower, general LLM. The team reports that offloading these lookups to WarpGrep speeds up coding tasks by around 40% and cuts down on expensive tool invocations, which matters once you’re chaining many edit and search steps in an agent harness WarpGrep intro.
Early users are already asking for WarpGrep packaged as a reusable skill and tool bundle so it can be snapped into broader agent stacks alongside other MCP tools, which is exactly the kind of plug‑in component most IDE‑style agent setups need skill tools question.
AgentBase pitches serverless architecture for 50+ production agents per call
AgentBase’s founder walked through a serverless architecture that lets you spin up 50+ collaborating agents—with orchestration, memory, and eval loops—using a single API call instead of managing long‑lived workers yourself AgentBase workshop. Their design treats each task as data flowing through lightweight agent runtimes, with a central orchestrator, shared trajectory store, and an "observe & improve" loop that runs evals and refinements over real traces.
In production, they lean on decision trees, guardrails, QA agents, and human‑in‑the‑loop checks for reliability, then use "Middle‑out" context engineering, agentic memory, and document indexing to keep prompts small while agents stay stateful AgentBase workshop. If you’re trying to scale from one or two coding agents to dozens of specialized ones (compliance, debugging, data cleaning, etc.), this kind of serverless pattern is a concrete blueprint rather than a vague multi‑agent story.
LangSmith Agent Builder gets a full Chinese walkthrough for no-code agents
The LangChain community published a full Chinese‑language walkthrough of LangSmith’s Agent Builder, covering its "non‑workflow" architecture, no‑code UI, and how observability and deployment are built in from day one Chinese walkthrough. For Chinese‑speaking teams, this fills a real gap: most prior content assumed English and direct Python use, while many companies want to prototype agents via UI first and drop to code only when needed.
The video walks through building and debugging agents that call tools, use memory, and run evals inside LangSmith, turning it into more than a tracing dashboard—effectively an agent studio that product teams can use without waiting on infra engineers. That makes it easier to standardize on Agent Builder as the front door for production agents while still keeping LangChain under the hood for power users.
Memex AI IDE gets real-world praise for front-end refactors
Memex, the desktop "AI software engineer" app, is starting to show up in real workflows: one user used its Claude‑powered frontend skill prompt to redesign a CRM view, saying Memex "made my CRM look expensive" without manually touching layout code Memex CRM design. The screenshot shows a polished Kanban‑style deals pipeline UI that would normally take a front‑end dev a fair bit of time to design and wire up.
Memex ships as a Windows and macOS app with its own project space, so you can treat it more like an AI IDE than a web chat; the same user is nudging others to download it and sign up with a referral code Memex site. For teams who don’t want to move wholesale to Cursor or full agent IDEs yet, it’s an example of how a standalone AI editor can slot into existing repos and take over specific flows like UI refactors or CRUD scaffolding.
🎞️ Video understanding and gen video shake‑ups
Media items today cluster around video: ByteDance Vidi2’s long‑context grounding and a new top text‑to‑video contender. Also creator tools like Midjourney Style Creator and real‑world showcases.
ByteDance’s Vidi2 beats Gemini and GPT‑5 on long‑video grounding
ByteDance introduced Vidi2, a large multimodal video model that does fine‑grained spatio‑temporal grounding and long‑horizon retrieval, and on the new VUE‑STG/VUE‑TR‑V2 benchmarks it comfortably outperforms Gemini 3 Pro Preview and GPT‑5 across ultra‑long through ultra‑short clips. benchmark thread On VUE‑STG it reaches tIOU 53.2 vs Gemini’s 27.5 and GPT‑5’s 16.4, with similarly large gaps on vIOU metrics, and on VUE‑TR‑V2 temporal retrieval it leads across ultra‑long (38.7 vs 21.2 vs 12.5) and long (48.2 vs 26.2 vs 9.4) segments. benchmark thread
The research paper describes a multimodal encoder + language backbone that ingests text, visual frames, and audio while adaptively compressing visual tokens so memory stays bounded on both short and multi‑hour videos. ArXiv paper A companion demo shows a storyline‑based editor where Vidi2 takes a set of raw restaurant clips plus an instruction like “craft a compelling narrative with a clear emotional arc” and emits both a human‑readable script and a JSON editing plan with shot timestamps, speed, VO lines, and subtitle styling, then renders a finished TikTok‑style cut. storyline demo For builders, this is one of the clearer signals that long‑video understanding ("where in this 2‑hour file is X, and who is involved?") is becoming product‑ready rather than a toy benchmark.
Mystery model “Whisper Thunder” tops text‑to‑video leaderboard
Artificial Analysis’ text‑to‑video leaderboard now has an unknown model, “Whisper Thunder (aka David),” in the #1 slot with an ELO of 1,247, edging out Google’s Veo 3 and Veo 3.1 Preview as well as Kling 2.5 Turbo 1080p. leaderboard snapshot The confidence interval (−8/+10) is already tight after 7,344 pairwise appearances, suggesting the win isn’t a fluke even though the creator field is blank and the release date is undisclosed. leaderboard snapshot
Speculation in the community links Whisper Thunder to a potential upcoming xAI video model, since it quietly appeared on the board alongside other freshly added systems like Hailuo 2.3 and LTX‑2 Fast/Pro. leaderboard snapshot In parallel, Emad Mostaque is hinting that “video pixel generation [may be] ‘solved’ next year,” framing Whisper Thunder as an early sign of a coming wave of high‑quality video generators rather than an isolated outlier. video trend comment For anyone building video workflows, this is a nudge to treat the model landscape as moving fast enough that your “best” generator today might be dethroned in weeks.
Midjourney ships Style Creator for reusable visual styles
Midjourney rolled out its long‑teased Style Creator, a workflow that lets artists assemble a visual style from example images and refinements, then apply it via a one‑click “Try” button instead of crafting prompts from scratch each time. creator impressions The tool shows style tiles you can hover to preview, and when you click “Try” it generates a prompt wired to that style, which you can then reuse or tweak in normal generations. creator impressions
Early users say the feature meaningfully changes how you prompt—more like building and reusing a style system than hand‑writing every descriptor—while also calling out UX gaps: new results aren’t always front‑and‑center, real‑time previews are missing, and there’s no fine‑grained slider to control how strongly a style is applied. creator impressions For teams shipping brand‑consistent imagery, the upside is obvious: you can standardize house styles in Midjourney itself, then hand non‑experts a small palette of vetted styles instead of sending them a 200‑word prompt doc.
ComfyUI turns fortress walls into a projection canvas for AI video
ComfyUI announced the final challenge of its first Comfy Challenge season, “Echoes of Time,” where 15 community‑made videos will be projected onto the 300‑year‑old Niš Fortress in Serbia using Comfy‑generated content. challenge teaser Submissions must be at 1920×1080, 24 FPS, and at least 30 seconds long, with a theme around time and historical echoes; the deadline is December 6 and the selected works will be recorded during a live light festival in partnership with the University of Niš. challenge teaser
A follow‑up post shows real photos of the fortress and an initial projection test on its stone walls, underscoring that this isn’t a mockup but a physical mapping setup that needs technically correct aspect ratios and brightness to look good at scale. projection details
The full brief explains that accepted artists get their clips professionally projected plus a recorded video of the show, and all participants receive a month of Comfy Cloud, making this both a creative prompt and a testbed for using AI‑generated video in real‑world architectural projection. challenge blog For video engineers, it’s a rare public spec of what generative clips must look like to survive on a literal stone canvas instead of a laptop screen.
💾 China accelerator signals: near‑memory and GPTPU claims
Hardware threads focus on domestic alternatives: near‑memory 14nm compute stacked on 18nm DRAM, and a GPTPU ASIC pitched as 1.5× A100. Concept stage but important for AI supply diversification.
Zhonghao Xinying’s GPTPU Ghana chip claims 1.5× A100 at 42% better efficiency
Chinese startup Zhonghao Xinying is advertising its first "GPTPU" ASIC, codenamed Ghana, as delivering about 1.5× Nvidia A100 throughput while using roughly 75% of the power, which works out to ~42% better performance per watt. The design drops graphics logic entirely and hard‑wires the matrix operations transformer models hammer, with engineers from Google’s TPU program saying every compute block uses self‑controlled IP to avoid foreign licenses and export‑control drama. gptpu overview
Following up on china chips, which covered China’s broader push to replace constrained Nvidia parts, this is the clearest single‑chip claim yet: still well below H100 or Blackwell, but targeted squarely at Chinese clouds currently scraping together gray‑market A100s. The catch is the software stack—Xinying still has to ship compilers, kernels, and cluster tooling solid enough that major providers standardize on Ghana; without that, the chip stays a lab demo rather than a real dent in Nvidia’s share inside China.
China’s 14nm logic-on-DRAM concept pitches 120 TFLOPS at ~2 TFLOPS/W
A Chinese team is touting a near-memory AI accelerator that stacks 14 nm compute tiles directly on top of 18 nm DRAM using 3D hybrid bonding, claiming around 120 TFLOPS at roughly 60 W (about 2 TFLOPS/W) and A100‑class throughput despite using an older node. The design routes thousands of ultra‑short copper links between logic and memory to get near on‑die bandwidth and lower latency, explicitly targeting the “memory wall” where today’s GPUs often sit idle waiting for HBM or off‑package DRAM. chip concept overview
For AI infra planners this matters less as a 2026 buying option and more as a signal that Chinese vendors are shifting from node‑bragging to packaging and memory‑proximity tricks similar to 3D stacked cache and HBM, which is where global high‑end accelerators are heading anyway. But the paper remains a concept: there are no public benchmarks, no confirmed shipping silicon, and even optimistic comparisons put it well below Nvidia’s Blackwell parts on both raw performance and TFLOPS per watt, so the right mental model is "promising direction of travel" rather than a drop‑in A100 killer yet.
⚡ Power and capacity outlook for AI
Macro energy notes tied to AI demand: US data center pipeline near 80 GW, GDI framing of intelligence‑per‑watt, and per‑prompt energy measurements. Excludes space compute plans covered prior days.
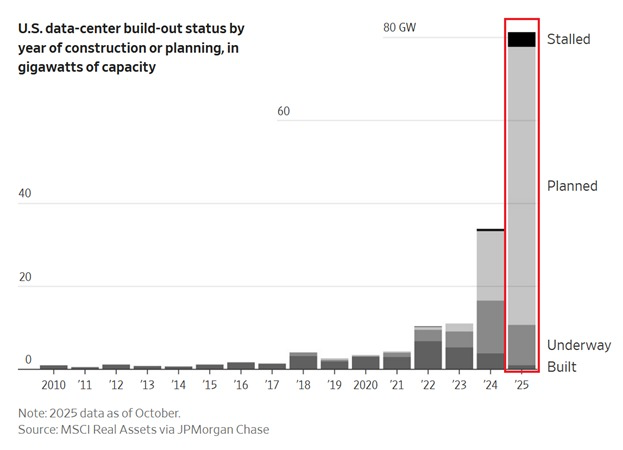
US data center pipeline hits ~80 GW as AI power squeeze looms
US data center capacity (built + under construction + planned) has surged to roughly 80 GW as of 2025, more than doubling in a year and running 8× higher than in 2022, driven largely by AI workloads and cloud expansion data center chart.
Most of that 80 GW is still on paper—about 65 GW is in the "planned" bucket—so there’s a long tail of projects depending on local grid upgrades, siting approvals, and long‑lead generation buildouts rather than already‑hooked‑up capacity data center chart. Builders should read this as confirmation that electricity, not GPUs, is the hard constraint: even if Nvidia and TPU supply improve, interconnection queues, transmission build, and non‑renewable baseload (including likely nuclear) will determine how much AI compute actually comes online this decade.
New Gross Domestic Intelligence metric reframes AI race around watts, not chips
A new "Gross Domestic Intelligence" (GDI) framing argues that the real US–China AI race is about usable intelligence per watt times total available power, not just who builds more data centers or buys more GPUs gdi explainer.
The proposal breaks GDI into three levers: model/chip intelligence per watt, grid and datacenter power available, and how much of that power actually feeds AI chips versus sitting idle in consumer NPUs and GPUs—which they suggest could be tapped via hybrid local‑plus‑cloud inference to boost national AI capacity without a single new facility gdi explainer. For practitioners this underscores two things: efficiency work (better models, compilers, and hardware) is geopolitically meaningful, and architectures that offload some inference to phones and laptops aren’t just cost hacks—they’re part of the macro AI capacity story.
Independent measurements converge on ~0.0003 kWh per LLM response
New results from the ML Energy Leaderboard suggest that a typical frontier LLM response consumes on the order of 0.0003 kWh, with large models like Mixtral‑8x22B logging about 1,161 J (0.0003225 kWh) per answer on an A100‑40GB GPU energy table.
Ethan Mollick notes this lines up with prior back‑of‑the‑envelope estimates, implying that even millions of daily prompts are a rounding error compared to datacenter cooling or training runs, but that at Internet scale the numbers still add up—1 million such responses is roughly 300 kWh, and 1 billion is 300 MWh energy table. For engineers, the takeaway is that optimization efforts should prioritize training and long‑context or "thinking" inference first, while still treating per‑call efficiency as a meaningful lever when you operate at multi‑billion request volumes.
🏢 Enterprise rollouts: education, hiring, and Gemini UX
A quieter but relevant set: ChatGPT for Teachers program, Copilot Career Coach mock interviews, Gemini app UX 2.0 push, and AI Studio mobile tease. Excludes ChatGPT ads (feature).
OpenAI rolls out free ChatGPT for Teachers for US K–12 schools
OpenAI has launched ChatGPT for Teachers, a free tier for verified US K–12 educators that runs through June 2027, bundling a secure workspace, FERPA‑aligned privacy controls, and admin oversight for districts and schools teacher rollout. The accompanying AI Literacy Blueprint and collaboration features position this as a verticalized enterprise entry point into education rather than a generic consumer product, giving AI teams a clear signal that OpenAI is willing to segment UX, policy, and pricing by industry (OpenAI blog post).
Google invests in Gemini App UX 2.0 and plans a macOS client
Google’s Logan Kilpatrick says there is a “huge investment” underway in Gemini App UX 2.0, with the explicit goal of winning users over in the next iteration, and confirms that a standalone macOS app is in active development ux 2 announcement.
For AI product teams this signals Google treating the Gemini client as first‑class cross‑platform software rather than a thin web shell, which could affect where enterprises standardize day‑to‑day AI usage, how they handle data residency and identity on desktop, and how easily developers can plug Gemini into existing macOS‑heavy workflows.
Microsoft pilots Copilot Career Coach for avatar-led mock interviews
Microsoft is testing a Copilot Career Coach mode where users practice interviews with a face‑to‑face AI avatar that asks a fixed set of six questions while simultaneously recording their own camera feed for later review career coach screenshot.
Early strings and UX show this as a labs‑style experiment rather than a fully shipped feature, but it illustrates how Copilot is moving from passive drafting to evaluative coaching flows, which matters for AI leaders thinking about hiring workflows, assessment bias, and where interview simulation fits into internal L&D pipelines (feature explainer).
AI Studio mobile app tease points to on-device builder workflows
A new "Build Anything" app icon spotted by creators strongly suggests Google is preparing a mobile AI Studio experience, likely bringing Gemini‑backed app and agent building to phones and tablets rather than keeping it browser‑only mobile app tease.
If this evolves into a full client, it would give AI engineers and PMs a way to prototype, iterate, and possibly deploy lightweight agents directly from mobile, tightening the loop between Gemini 3 APIs, AI Studio projects, and real‑world usage in field or frontline scenarios rather than only from desktop IDEs.
📚 Eval methods and synthetic data frameworks
Research‑first items: structured prompting to de‑bias evals and Meta’s Matrix P2P framework for multi‑agent synthetic data. Excludes productized coding tools and media model papers.
Meta’s Matrix P2P framework speeds multi-agent synthetic data by up to 15×
FAIR at Meta introduced Matrix, a peer‑to‑peer framework for multi‑agent synthetic data generation that replaces the usual single central orchestrator with serialized messages flowing through distributed queues. framework overview Lightweight Ray actors stay stateless, pull messages, call LLMs or tools, update a task’s state, then hand it off—so each task becomes its own mini‑orchestrator that moves independently instead of waiting behind slow siblings.
On collaborative dialogue, web reasoning, and tool‑use datasets, Matrix delivers roughly 2×–15× higher throughput on the same hardware while matching the quality of more rigid, controller‑centric pipelines. framework overview For anyone generating large synthetic corpora—agent traces, browsing trajectories, tool‑calling logs—this offers a concrete pattern: store big artifacts in an object store, keep only small state bundles in messages, and let a pool of stateless workers advance tasks one step at a time. The open‑sourced Ray implementation means you can start by mirroring their patterns, then tune queue structure and message schemas around your own synthesis workloads.
Structured prompting paper shows single-prompt benchmarks are underestimating LLMs
Stanford researchers connect HELM with DSPy and show that letting each model use structured prompts (direct answers, chain‑of‑thought, worked examples) lifts average accuracy by about 4 points across 7 general and medical benchmarks, and can even flip which model looks best. paper summary Most of the gain comes from enabling chain‑of‑thought rather than from expensive search‑based prompt tuning, which adds little accuracy but many tokens.
For builders, the message is that "one fixed prompt per task" evals are systematically pessimistic: your models are probably stronger than the leaderboard if you let them show their best prompt style, and model rankings based on a shared prompt may be misleading. This lines up with calls from people like Ethan Mollick to treat "AI fails" as a null hypothesis that must be stress‑tested with the strongest available model and harness, not the weakest prompt. eval commentary If you run internal evals, this suggests adding CoT and a small prompt search over styles per model, then reporting both default‑prompt and tuned‑prompt scores so stakeholders see how much headroom is real versus artifact.
GigaWorld‑0 turns world models into a synthetic data engine for robots
GigaAI’s GigaWorld‑0 paper frames a video‑centric world model as a "data engine" that can mass‑produce realistic robot experience, letting embodied agents train only on synthetic rollouts yet still complete real household tasks like folding laundry or moving dishes. paper summary The system first learns a powerful video model that can generate and edit robot manipulation clips—changing materials, lighting, or camera angles, and even swapping human hands for robot arms while preserving motion semantics—then couples it with 3D scene reconstruction so objects and robots move consistently across views.
These tools restyle cheap simulator footage to look real, generate new viewpoints to augment data diversity, and translate human demonstration videos into robot‑arm trajectories, all feeding a synthetic training stream that outperforms training on limited real data. For robotics and embodied AI teams, GigaWorld‑0 is a worked example of how to structure a synthetic data stack: a world model for appearance and view control, a 3D backbone for geometry and physics, and a curriculum that mixes edited sim, recolored real, and cross‑domain transfers instead of relying on expensive, brittle real‑world collection.
Comet’s Opik open-sources an LLM eval and tracing platform
Comet‑ML released Opik as an open‑source platform for debugging, evaluating, and monitoring LLM applications, RAG systems, and multi‑step agent workflows, with tracing and automated evaluations wired into production‑ready dashboards. tool announcement The example dashboard shows time‑series for feedback scores, number of traces, latency, and token usage, plus drill‑downs into individual runs, aimed at making it easier to see when a prompt change, model swap, or tool update quietly degrades quality.
Because Opik is a library and UI rather than a benchmark per se, it sits alongside methods like structured prompting and frameworks like Matrix: you still choose your tasks and metrics, but Opik handles wiring those metrics to actual traces and surfacing regressions over time. For teams shipping agentic systems or RAG backends, this offers a ready‑made alternative to building yet another bespoke eval dashboard—especially if you want to combine human feedback, LLM‑as‑judge scores, and operational signals (timeouts, tool errors) in one place and keep them under version control via the linked GitHub repo. GitHub repo
🧾 Parsing and extraction at scale
Practical data/RAG plumbing: LLM‑driven, lossless table extraction from PDFs and new open web corpora variants. Mostly concrete pipelines and demos today.
LlamaExtract mode reliably pulls large hospital tables from PDFs with 100% recall
LlamaIndex’s new LlamaExtract mode is being demoed on a Blue Shield PDF listing network coverage across 380+ California hospitals, extracting every single table row into structured output with no drops or hallucinated entries. LlamaExtract demo In the walkthrough, the team shows how naive structured-output prompting causes rows to vanish once outputs get long, while the new mode turns the document into a complete row-by-row table that can be ETL’d into a database and queried like any other dataset.
Full setup details and code are in the accompanying tutorial.blog post
AICC ships first MinerU‑processed Markdown shards of Common Crawl
OpenDataLab’s AICC project is releasing a "Markdown version of Common Crawl" where raw HTML has been parsed and cleaned into Markdown text using their MinerU pipeline, giving model builders a more usable, web‑scale corpus from day one. AICC mention The initial drop includes two shards with more promised, and is hosted in a Hugging Face repo so teams can start experimenting with higher‑quality web pretraining data or retrieval indexes without rebuilding the entire crawl stack themselves. The code and datasets are openly available for inspection and extension.GitHub repo
DocETL proposes YAML‑defined LLM pipelines for large‑scale document ETL
Researchers behind DocETL are pushing an LLM‑driven ETL framework where you describe complex document‑processing pipelines in declarative YAML, then let the system orchestrate map‑reduce style passes, retries and validation over large corpora. DocETL comment The docs emphasize handling long, unstructured PDFs (legal, medical, social‑science) by composing operators like resolve and gather, and even include an optimizer that can search over pipeline rewrites to maximize extraction accuracy before you unleash it on your full dataset. project docs The flip side, as one practitioner notes, is that a misconfigured run on "your entire data" could have very broad impact, so teams will want strong dry‑run and sampling safeguards around it. DocETL comment