Mistral Devstral 2 hits 72.2% SWE‑Bench – 24B laptop coder rivals giants
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Mistral showed up to the coding race with receipts, not vibes. Devstral 2 (123B params) and Devstral Small 2 (24B) both ship as open‑weight coders with 256K context and FP8 checkpoints, posting 72.2% and 68.0% on SWE‑Bench Verified—within a few points of proprietary staples like Claude 4.5 Sonnet and GPT‑5.1 Codex Max. The twist: the 24B Small model is roughly 28× smaller than some DeepSeek‑class flagships yet lands in the same accuracy band, and it’s Apache 2.0, laptop‑deployable, and very privacy‑friendly.
What’s new versus yet another open model drop is the stack around it. Mistral shipped Vibe CLI as an open, repo‑aware terminal agent—plan → read → edit → run → summarize—where all prompts and tools live in Markdown, begging to be forked. Day‑zero support from vLLM (with a dedicated tool‑calling parser), Zed’s new Vibe Agent Server, AnyCoder’s model picker, and Kilo Code’s IDE (free Devstral usage all December, after quietly running a pre‑release “Spectre” build) means you can trial this in real workflows without writing glue.
Builders are already tagging Devstral Small 2 as “SOTTA” (state of the tiny art) and treating it as the default self‑hosted coder, while grumbling about the big model’s revenue cap for $20M+/month companies. Net effect: if you’ve been leaning on DeepSeek or closed coders, Devstral is now a serious, open toggle in your production dropdown.
Top links today
- OpenAI and Anthropic agent standards overview
- Missing Layer of AGI coordination paper
- Omega system for trusted cloud agents
- Excessive chain-of-thought training study
- M4-RAG multilingual multimodal RAG benchmark
- World models with calibrated uncertainty paper
- GRAPE unified transformer position encoding
- Verifier-driven LLM reasoning and diversity paper
- LUNE efficient LLM unlearning via LoRA
- LLM failure modes in agentic simulations
- LLMs vs time-series models for forecasting
- GenAI.mil Pentagon platform using Gemini
- FT on Nvidia H200 export deal to China
Feature Spotlight
Feature: Mistral’s Devstral 2 + Vibe CLI push open‑source coding to SOTA
Mistral ships Devstral 2 (123B) and Devstral Small 2 (24B) plus the Vibe CLI—open SOTA coding with 72.2%/68.0% SWE‑bench Verified, 256K context, FP8 weights, and a repo‑aware terminal agent.
Biggest cross‑account story today. New open‑weight coding models (123B, 24B) with 256K context and a native terminal agent. Multiple third‑party benchmarks, tools, and day‑0 serving surfaced in the sample.
Jump to Feature: Mistral’s Devstral 2 + Vibe CLI push open‑source coding to SOTA topicsTable of Contents
🛠️ Feature: Mistral’s Devstral 2 + Vibe CLI push open‑source coding to SOTA
Biggest cross‑account story today. New open‑weight coding models (123B, 24B) with 256K context and a native terminal agent. Multiple third‑party benchmarks, tools, and day‑0 serving surfaced in the sample.
Devstral 2 hits 72.2% SWE‑Bench and pushes tiny‑model efficiency
On SWE‑Bench Verified, Devstral 2 scores 72.2% and Devstral Small 2 68.0%, putting them at or near the top of all open-weight coding models and close to proprietary coders like Claude 4.5 Sonnet (77.2%) and GPT‑5.1 Codex Max (77.9%).
benchmark chart That 68.0% from the 24B Small model is particularly notable, matching or beating much larger open models while remaining realistically laptop‑deployable.
A separate “SWE‑Bench vs model size” scatterplot shows Devstral 2 and Small 2 clustered in the top-left—high accuracy but trained on far fewer tokens than rivals like Kimi K2 or DeepSeek V3.2—earning the community nickname “SOTTA” (state of the tiny art).
efficiency plot Third‑party evals using the Cline framework report Devstral 2 winning or tying DeepSeek V3.2 in about 71% of coding tasks, though Claude Sonnet 4.5 still wins more than half the time while costing up to ~7× more per solved task in those tests. (cost comparison, cline comparison) For teams, the message is clear: Devstral isn’t the single best coder on earth, but its accuracy‑per‑parameter and accuracy‑per‑dollar make it a very strong default for open, self‑hosted coding agents.
Mistral launches Devstral 2 coding family with 123B and 24B models
Mistral has released its Devstral 2 coding family: a 123B-parameter Devstral 2 model under a modified MIT license and a 24B Devstral Small 2 model under Apache 2.0, both with 256K context and FP8 weights for long-horizon coding and agents. launch thread The smaller 24B model is being highlighted as “laptop class” yet hitting top-tier coding scores, offering a Western open-source alternative that’s ~28× smaller than DeepSeek’s flagship while preserving privacy via local deployment. community overview

For AI engineers this means you can now self-host a frontier-level coding model with a clear license split: the big 123B for clusters and the 24B for on-prem or even single-GPU setups, both tuned for agentic tool use. The launch blog and Hugging Face collection spell out FP8 checkpoints, 256K context, and intended use as the backbone for coding agents rather than a general chat model. (launch blog, model collection) The main trade-off is that Devstral 2’s modified MIT license caps usage for companies above a $20M/month revenue line, which some see as constraining adoption in larger orgs. license concern
Devstral lands in vLLM, Zed, AnyCoder and Kilo on day one
Within days of launch, Devstral 2 is already wired into key tools: vLLM exposes a serve recipe with Mistral’s tool parser, Zed ships a Mistral Vibe Agent Server, AnyCoder surfaces Devstral in its model picker, and Kilo Code makes both Devstrals free for December. (vllm serve snippet, zed integration, anycoder screenshot, kilo announcement)
For AI engineers this quick ecosystem uptake reduces the friction of evaluating Devstral in real workflows: you can try it as a backend in vLLM, as an IDE agent in Zed or Kilo, or as an app‑builder brain in AnyCoder without writing glue code. The pattern is similar to how GLM‑4.6V or DeepSeek models spread: strong open‑weight performance plus permissive tooling means the model becomes a standard option in editors and agent frameworks rather than a one‑off experiment. This widespread support is what will decide whether Devstral ends up as a go‑to coding backend or another short‑lived leaderboard spike.
Mistral Vibe CLI turns Devstral into a repo-aware coding agent
Alongside the models, Mistral shipped Vibe CLI, a Python/Textual-based terminal app that wraps Devstral into a full coding agent which can scan a repo, plan work, edit multiple files, run commands, and even open a local game as a test task. launch thread The core prompts, tools (bash, grep, file ops, search/replace, TODOs), and conversation summarizer live in markdown, making it easy for developers to inspect and fork the agent’s behavior. Vibe writeup
Early demos show Vibe being asked to "make a fun game and run a server" and then generating a full HTML/JS Snake game plus a dev server, all from the terminal. snake game example For AI engineers, this is a reference implementation of an agentic coding loop—plan → read → edit → run → summarize—that’s both open-source and already wired for long-context Devstral, useful as a starting point for custom internal agents or for studying prompt and tool design at scale. Vibe blog post
Community touts Devstral Small 2 as laptop‑class ‘state of the tiny art’
Early community reaction is that Devstral Small 2 hits a sweet spot: at 24B parameters it can run locally on a decent laptop but still hits 68% on SWE‑Bench Verified, making it competitive with much larger models for real coding work. community overview Commentators frame it as everything you need for “100% privacy and unlimited vibe coding,” with Western open source “so back” after a lull. (shipping praise, fp8 praise)
People are also picking up on the “SOTTA” framing from the scatterplot—Devstral 2 and Small 2 live in the high‑performance, low‑token corner—which reassures teams that these aren’t just benchmark‑tuned curiosities but efficient workhorses. efficiency plot The main caveats bubbling up are around Devstral 2’s more restrictive license for large companies and some concern that yet another CLI coding agent (Vibe) increases fragmentation, but overall the mood from builders is that Devstral has put Mistral “so back” into the serious coding race. (license concern, cli fatigue)
Kilo Code makes Devstral 2 and Small 2 free for December
Kilo Code confirmed that its previously “stealth” Spectre model was a pre‑release Devstral variant and is now swapping it for the official Devstral 2 and Devstral Small 2, both free for all Kilo users through December. kilo announcement The IDE’s model selector already lists “Devstral 2512 (free)” and “Devstral Small 2512 (free)” as options for coding assistance.
For developers who don’t want to manage their own serving stack, this is one of the easiest ways to get hands‑on time with Devstral in a production‑grade coding environment and compare it to GitHub Copilot‑style flows. It also hints that Kilo had enough positive results from the pre‑release weights to bet their default experience on Devstral for at least a month, which is a useful endorsement if you’re considering it for your own agent stack. kilo commentary
vLLM ships day‑0 Devstral‑2‑123B serving recipe with tool parser
vLLM now supports serving the Devstral‑2‑123B‑Instruct model out of the box, including a --tool-call-parser mistral flag and auto‑tool selection, making it easy to drop Devstral into existing tool‑calling stacks. vllm serve snippet The recommended config uses FP8 weights with tensor parallelism across 8 GPUs, targeting high‑throughput agent workloads rather than single‑GPU hobby use.
If you’re already using vLLM for tools or agents, this means Devstral 2 is one CLI away from production experiments, with no custom backends required. You get Mistral’s tool‑calling conventions interpreted correctly by the parser, which matters for multi‑step coding agents that juggle file edits, shell commands, and web fetches. This is also a good reference for others wiring FP8 100B‑scale models into vLLM, since the snippet shows the practical parallelism and flags needed.
AnyCoder exposes Devstral Medium as a selectable build model
AnyCoder’s “Build with AnyCoder” UI now offers “Devstral Medium 2512” in its model dropdown alongside Gemini 3, DeepSeek, Qwen, Grok and others, giving users a one‑click way to route app‑generation requests through Devstral. anycoder screenshot
This matters less as a technical milestone and more as a distribution one: tools like AnyCoder normalize Devstral as a peer to the big frontier models in real coding workflows. For teams comparing models inside the same front‑end, this will make it easier to A/B Devstral against proprietary options on identical tasks instead of relying on isolated benchmarks.
Zed exposes Mistral Vibe as a plug‑and‑play coding agent
The Zed editor now lists “Mistral Vibe” as an Agent Server extension, meaning you can point Zed at a Devstral‑backed coding agent by just installing the extension and pasting in a Mistral API key. zed integration That turns Vibe into a first‑class companion inside Zed’s UI, rather than a separate terminal window.
For engineers already living in Zed, this is a low‑friction way to trial Devstral‑powered agentic coding without rebuilding their environment: the extension wraps prompts, tool use, and repo context for you. It’s also a signal that Devstral is quickly joining the short list of models editors ship direct support for (alongside things like Claude Code and Gemini CLI), which will influence which models teams standardize on for day‑to‑day development.
🔌 Open agent standards: MCP donated to Linux Foundation’s AAIF
Standards and interop took center stage today. Anthropic donates MCP to the Agentic AI Foundation (with OpenAI and Block), and builders show MCP Apps and new MCP tools. Excludes Mistral Devstral which is covered as the feature.
MCP moves under Linux Foundation’s Agentic AI Foundation
Anthropic is donating the Model Context Protocol (MCP) to the new Agentic AI Foundation (AAIF), a directed fund under the Linux Foundation co‑founded with OpenAI and Block, with support from Google, Microsoft, AWS, Cloudflare, and Bloomberg. anthropic announcement This shifts MCP’s governance to a neutral, open‑source home while the original maintainers keep running the spec and SDKs.
Alongside MCP, OpenAI is contributing AGENTS.md (a standard repo‑level instruction file for agents) and Block is contributing goose (an on‑device agent framework) so the foundation starts with three core building blocks for cross‑vendor agents. (openai aaif post, goose and agentsmd) The first‑year MCP timeline shows how much is already in play: 10k+ active public MCP servers, enterprise hosting from Google Cloud, Azure, and Cloudflare, plus ~97M monthly SDK downloads across Python and TypeScript. mcp metrics graphic In practice MCP is already wired into Claude, ChatGPT, Gemini, and Microsoft Copilot, and AAIF formalizes that into something closer to “HTTP for tools” rather than yet another proprietary plugin system. (community reaction, timeline commentary) For engineers and platform leads, this makes it much safer to invest in MCP servers (tools) knowing they’ll work across agents from multiple labs and be steered by a shared standards body instead of one vendor’s roadmap.
MCP Apps spec adds a shared UI layer for agent tools
A new proposal, SEP‑1865 "MCP Apps", lands in the MCP repo to standardize how servers expose interactive UIs—think HTML dashboards or control panels—alongside tools. spec pull request The draft introduces a ui:// URI scheme and an HTML-based resource type (text/html+mcp), plus a JSON‑RPC bridge so an agent host can render a server‑provided UI and send user interactions back over the same MCP connection. github proposal Anthropic is already experimenting with this idea in Claude’s web UI, where an MCP Apps toggle surfaces recipe‑like interfaces (e.g. a pixel‑avatar generator with prompt + examples) instead of raw tool calls. claude apps leak For builders, this moves MCP beyond “CLI‑style tools only” toward portable mini‑apps: the same server could show a configuration panel or workflow view inside Claude, ChatGPT, or any future AAIF‑compatible client without each vendor inventing a bespoke plugin UI format. It also creates a natural place to put richer affordances (previews, form validation, multi‑step flows) while keeping the underlying protocol and tool semantics shared.
Browser Use turns Skills into MCP tools and automates Instacart shopping
Browser Use has turned its “Skills” into first‑class MCP tools, effectively shipping an MCP server that can drive almost any website—including a new Instacart workflow. skills as tools In the Instacart example, the server exposes two MCP tools, Instacart: Search and Instacart: Add Item to Cart, so an agent like Claude can search local inventory, add items, and build a cart directly from natural‑language instructions.

You can clone those skills and point them at your own MCP client, turning grocery shopping into a standard tool‑call sequence instead of custom browser automation. instacart skills thread This is a concrete glimpse of how AAIF‑era standards play out at the edge: independent projects wrap real‑world web flows behind MCP servers, and any compliant agent—Claude Code, Codex, or future AAIF‑aligned runtimes—can reuse those tools without bespoke integrations. For AI teams, it suggests a pattern: describe repeatable web tasks as Skills, expose them via MCP, and let different agents orchestrate them rather than hard‑coding Selenium‑style scripts per app.
👩💻 Agent SDKs and coding ops: sandboxes, forks, and cloud workers
Practical agent engineering updates for teams shipping code: SDK safety and context scale, CLI/terminal UX, and remote agent runtime. Excludes Devstral/Vibe specifics (feature).
Claude Agent SDK adds 1M‑token Sonnet, sandboxing, and simpler TS v2 API
Anthropic upgraded the Claude Agent SDK with support for the 1M‑context Sonnet 4.5 variant, built‑in filesystem and network sandboxing, and a much simpler TypeScript v2 interface that reduces async/yield plumbing to send()/receive()/done() calls. (sdk launch thread, context window note) This matters if you’re trying to ship robust agents: you can now point Sonnet 4.5 at full codebases or hundreds of docs via the SDK, run tools in a locked‑down environment, and wire up agents in TS without juggling async generators or custom coordination loops. Anthropic also calls out that sandboxing is configurable (filesystem and network isolation), which gives you a concrete knob for production risk reduction instead of shelling out blindly. sandbox docs Builders are already saying the new TS surface is “so good” and planning migrations, which is a good sign that this won’t stay a niche API. (ts v2 praise, sdk reference)
Claude Code mishap nukes a user’s home directory, highlighting agent safety gaps
A Claude Code user on Reddit reports that a coding session issued rm -rf tests/ patches/ plan/ ~/, which wiped their entire home directory after they ran with --dangerously-skip-permissions. Anthropic’s own log view later calls this “really bad,” explicitly pointing out that ~/ means “your entire home directory.” reddit incident
For agent builders, this is the nightmare failure mode: a shell‑capable agent plus a bypassed permission system equals irreversible data loss. The lesson is not that Claude Code is uniquely unsafe, but that any tool‑calling agent with file or shell access must default to conservative guardrails, clear the separation between production and scratch repos, and never encourage flags like --dangerously-skip-permissions for everyday use. People are now advising explicit backups, running agents inside throwaway worktrees or containers, and treating privileged modes as you would sudo in prod—not as a performance tweak. (reddit link, nuke anecdote)
Kilo Code Cloud Agents let devs run coding agents from any device
Kilo Code introduced Cloud Agents, a hosted runtime that lets you run its coding agent from a phone, borrowed laptop, or any browser, with every change auto‑committed back to your repo. cloud agents launch

Following up on Kilo’s earlier push to benchmark itself against GitHub Copilot and expose model choices in the IDE Kilo adoption, this is the next step toward treating the agent as a remote coworker: no local environment setup, no half‑applied edits, and a clean commit history by default. You authenticate in the web UI, choose the model stack (now including Devstral‑backed variants), and let the agent handle edits and commits from the cloud while you supervise. For teams, this makes it much easier to standardize on one agent runtime and avoid the “works on my laptop” problem when people connect from different machines or thin clients. sign in page
Warp adds agent-friendly forking and Git-style diff viewer in the terminal
Warp shipped two quality-of-life features for people leaning on coding agents: conversational "forking" of an agent session and a GitHub-style diff viewer built right into the terminal. (forking demo, diff viewer demo)

Forking lets you right‑click anywhere in a messy agent conversation, spawn a new branch from that point, and continue from the earlier, still‑good state—useful when an agent has gone off the rails but you don’t want to lose context. The diff viewer then gives you a one‑shot view of all file changes (or a diff vs master) with PR‑style previews, and you can even attach those diffs as context when you question an agent before pushing, which tightens the loop between code, review, and automation. This is the kind of UX that makes long‑running agent sessions feel less brittle and more like a tool you can safely explore with.
OpenCode gains MCP OAuth support through a community PR
OpenCode 1.0.37 quietly picked up full MCP OAuth support, and the maintainer notes the best part is they "didn't have to do anything"—a community contributor wired it up and even fixed bugs in an upstream library. oauth update This matters for anyone running a serious MCP tool stack: instead of baking API keys into config, you can now rely on proper OAuth flows when agents talk to external services, which is both safer and easier to rotate. It’s also a good example of the ecosystem effect around MCP: as more OSS tools adopt the protocol and auth patterns, you get a broader menu of plug‑and‑play servers without having to hand‑roll credentials and glue every time.
Droid adds `/review` command for branch and diff-aware code reviews
Factory’s Droid coding agent picked up a /review command that can inspect a branch, commit, or uncommitted changes and focus on custom instructions during the review. droid review feature The idea is straightforward: instead of manually pasting diffs or explaining what changed, you point /review at the right target and let the agent walk the patch, raise issues, and summarize risks. Early users are already calling Droid “best” among their options for this kind of workflow, which suggests the review UX is hitting a practical sweet spot for day‑to‑day use in real repos. (review announcement, user endorsement)
📊 Leaderboards and eval hygiene: Arena shifts, OCR bake‑off, context tests
Today’s sample leans into eval culture—new model entries, live feeds, and methodology explainers. Continues yesterday’s leaderboard narrative but with fresh entries and infra. Excludes Devstral metrics (feature).
Arena shares 2025 top‑10 lab trends and invites harder prompts
Arena published an end‑of‑year view of how the top 10 labs have moved on its leaderboards since early 2025, highlighting which providers are rising or slipping and asking users to submit their hardest prompts to keep pressure on the rankings.

Following up on occupational ranks where they introduced job‑style evals, this pushes the story from individual models to lab‑level performance over time, which is exactly the lens infra and product teams care about when picking a default stack.
For builders, the takeaway is that Arena is drifting from a one‑off benchmark into a longitudinal eval surface: you can now use it not only to A/B models, but to track vendor momentum and prioritize where to spend integration effort next. arena call for prompts
Context Arena MRCR shows Qwen3‑Next Thinking helps at 8K, hurts at 128K
Context Arena added qwen3‑next‑80b‑a3b and its :thinking variant to the MRCR multi‑needle retrieval tests, revealing a sharp trade‑off between short‑ and long‑context performance. On 2‑needle tasks at 8K, the Thinking model jumps to 81.0% vs 48.7% for Base, and on 4‑needle at 8K it’s 58.6% vs 33.1%, but by 128K the Base model retains more needles (e.g. 46.2% vs 41.5% on 2‑needle, 25.0% vs 18.0% on 4‑needle). mrcr thread So the pattern is: reasoning‑tuned decoding clearly helps focused, short‑context retrieval, yet doesn’t generalize to very long context windows where the vanilla model actually forgets less. If you’re building context‑heavy agents on Qwen3‑Next, this suggests routing short, tricky lookups to the Thinking variant while keeping Base for 64K–128K MRCR‑style workloads instead of assuming the "smarter" model is strictly better. context arena site
Datalab launches OCR benchmark and eval service over ~8K multilingual pages
Datalab introduced an OCR benchmark and evaluation service that compares leading document‑vision models on roughly 8,000 real pages across many layouts, scripts, and languages, using an LLM‑as‑judge plus Bradley–Terry/ELO aggregation instead of raw token accuracy.
The public benchmark covers models like Chandra, Chandra small, olmOCR, DeepSeek, dots.ocr, and RolmOCR, and exposes both scores and page‑level outputs so you can inspect how models behave on messy scans, receipts, and low‑resource scripts. ocr breakdown They also launched "Datalab evals", a closed beta that runs the same pipeline on your own documents: you upload a corpus, they run pairwise matchups on shared H100/vLLM infra, and you get an ELO‑style ranking plus qualitative outputs per page. evals teaser For teams whose products live or die on OCR (IDP, RAG over PDFs, back‑office automation), this is a much healthier pattern than eyeballing a single leaderboard number—use the public benchmark to shortlist models, then pay for a one‑off eval on your own doc mix before committing. datalab blog
ERNIE‑5.0‑Preview‑1103 cracks Text Arena’s top 20 with strong coding scores
Baidu’s ERNIE‑5.0‑Preview‑1103 has landed on the Arena Text leaderboard with an overall score of 1431, entering the top 20 in the most competitive arena. ernie overview It scores 1471 in the Software & IT Services occupational slice and 1464 on Coding, roughly on par with GPT‑5.1‑high and chat‑gpt‑4o respectively according to Arena’s breakdown. ernie overview For people routing workloads, this is a concrete signal that ERNIE’s preview build isn’t just a regional curiosity: it’s competitive on Western‑style professional and coding tasks, and now lives in the same eval surface you already use for OpenAI, Anthropic, Google, and others. Arena also exposes per‑field scores, so you can decide whether ERNIE belongs in a router for software/IT tasks without blindly trusting a single aggregate metric. arena compare link
LM Arena adds live per‑model creation feed for qualitative comparisons
LM Arena quietly shipped a per‑model live feed: you can now click any model and see a scrolling stream of recent user creations for that model, alongside its win‑rate stats.

The Gemini 3 Pro card, for example, shows its maintained lead on Website Arena plus real generated sites flowing in, which gives a much richer sense of "feel" than aggregate scores alone. feed announcement This matters for anyone choosing defaults for creative or UI‑heavy tasks—leaderboard edges of a few points don’t tell you whether a model’s style, failure modes, or latency match your product. The live feed turns Arena into something closer to a gallery plus scoreboard, making it easier to notice, say, that two models with similar ELOs actually have very different UX for the kinds of prompts your users send.
Hamel Husain drops an eval explainer video and companion meme gallery
Hamel Husain released a short video walking through LLM eval basics—what evals are for, why naive benchmarks mislead, and how to think about test sets and metrics when you’re shipping products, not papers.

It’s explicitly aimed at practitioners who need a mental model before diving into tooling.
He paired it with a tongue‑in‑cheek "eval memes" page that captures common pitfalls, like overfitting to a favorite benchmark or misreading a 100% pass rate as anything but a data problem, making the deeper points easier to remember and share internally. eval memes If you’re the person trying to convince a team to stop cargo‑culting leaderboards and start designing realistic evals, this duo is a lightweight resource you can circulate to reset the conversation.
💼 Enterprise GTM: CRO hire, telco pact, Accenture scale, and $140M for gen‑media
Clear signals on enterprise adoption and go‑to‑market: senior hires, multi‑year partnerships, and a sizable media infra raise. Builds on yesterday’s enterprise usage stats with concrete org moves.
Accenture and Anthropic build a 30k‑person Claude practice to move pilots into production
Anthropic and Accenture are expanding their partnership into a dedicated "Accenture Anthropic Business Group" that will train roughly 30,000 Accenture staff on Claude and package offerings to help enterprises move from AI pilots to full production accenture deal. Claude Code—Anthropic’s coding assistant which it says holds over half of the AI coding market—will be a core pillar, with a specific product aimed at helping CIOs scale coding agents safely across their organizations accenture press release.
For AI leaders, this matters because it addresses the real bottleneck: not models, but organizational plumbing. Accenture is effectively productizing Claude as a "full‑stack" enterprise platform—consulting, integration, governance, and pre‑built vertical solutions in regulated sectors like finance, healthcare, and the public sector. If you’re competing with them, you now have to beat a combined GTM where Anthropic provides the models and Accenture provides the change‑management machine.
The agreement also says something about Anthropic’s enterprise ambition. Rather than try to build a 30k‑person services org themselves, they’re hitching to a global SI that already owns executive relationships and transformation budgets. For engineers inside large enterprises, this is a preview of your next few years: third‑party consultants showing up with pre‑canned Claude patterns, guardrail libraries, and "reference architectures" that will strongly influence which tools you can use internally.
If you’re an independent vendor selling around Claude, treat this as both threat and opportunity: threat because Accenture+Anthropic can displace you from some greenfield deals; opportunity because you can target the long tail of cases they won’t custom‑build.
Menlo Ventures report pegs 2025 gen‑AI enterprise spend at $37B, with Anthropic leading
Menlo Ventures published a 12‑page survey of ~500 US enterprise execs estimating that generative AI has reached about $37B in annual software spend—roughly 6% of all software budgets in 2025, growing ~3.2× year‑over‑year menlo overview menlo report. Within that pie, they say Anthropic is now the #1 model provider in the enterprise with roughly 40% share of spend, pushing OpenAI to #2 menlo overview.
Beyond market share, the report sketches where the money is going. Off‑the‑shelf horizontal tools like ChatGPT Enterprise, Claude for Work, Microsoft Copilot, and Glean dominate, while "departmental" tools such as Cursor and GitHub Copilot make coding by far the largest functional category spend breakdown. On the vertical side, healthcare leads AI spending, followed by legal, creator tools, and government coding and healthcare. Meanwhile, the share of enterprises training their own models has dropped from roughly half to about a quarter, suggesting most buyers prefer to rent intelligence rather than build it.
Menlo also pushes back on the meme that “95% of gen‑AI pilots fail.” Their data shows the opposite pattern: buyers are coming in with high intent in 2025 and converting at roughly twice the rate of typical SaaS deals, driven by bottoms‑up adoption through product‑led tools like Cursor and Gamma pilot conversion. That lines up with what many teams are seeing on the ground: once one team proves value with AI, adjacent teams pile in.
If you sell AI into enterprises, this report is your cheat‑sheet for 2025. It says the easiest money is still in coding and horizontal productivity, that vertical AI in healthcare is heating up fast, and that winning vendors are the ones who package frontier models into workflows—not the ones telling CIOs to hire a big ML team and train from scratch.
Commonwealth Bank of Australia rolls out ChatGPT Enterprise to nearly 50,000 staff
Commonwealth Bank of Australia (CBA) is partnering with OpenAI to make ChatGPT Enterprise available to almost 50,000 employees, treating AI as a core capability rather than a niche pilot cba deployment article. CEO Matt Comyn frames it as using "a high‑quality product" to improve customer outcomes and embed AI into everyday workflows across the bank cba case study.
Unlike many experiments limited to one department, this is an org‑wide deployment in a heavily regulated industry. CBA plans to use ChatGPT Enterprise for internal knowledge search, drafting, analysis, and productivity tasks, while exploring higher‑stakes use cases like customer service and fraud support with appropriate controls. It’s the same pattern you see in other early adopters: start with internal productivity, then graduate into workflow‑critical roles once governance is in place.
For other banks and financial institutions, CBA’s move lowers the perceived risk of going big on AI. Regulators and boards will look at this as precedent: if one of Australia’s biggest banks can deploy ChatGPT Enterprise to its entire workforce, you can at least justify a structured rollout. For AI engineers inside those orgs, this means more pressure to integrate with the standardized tooling the enterprise has chosen, rather than hand‑crafting isolated pilots.
The takeaway: we’ve crossed from "a few power users" to "entire banks" integrating AI into how they work. That shifts the questions from "should we use AI?" to "how do we standardize and measure it?".
Deutsche Telekom taps OpenAI alpha‑model access and ChatGPT Enterprise in multi‑year deal
Deutsche Telekom and OpenAI have signed a multi‑year collaboration that gives the telco early access to an alpha‑phase OpenAI model and rolls ChatGPT Enterprise out across the organization as a core productivity tool telekom partnership. First pilots are targeted for Q1 2026, with a focus on customer care, network operations, and everyday communication for Telekom’s hundreds of millions of subscribers telekom press release.
The key detail for AI engineers and GTM folks is the alpha‑model access. Telekom isn’t just buying today’s models; it’s reserving a seat at the table for the next frontier generation, and shaping how those models are productized for telco‑specific workflows. Internally, Telekom will adopt ChatGPT Enterprise broadly, signaling that AI chat is moving from "tool some teams use" to baseline infrastructure—like email or Office—for tens of thousands of employees.
For anyone building in telecom or adjacent industries (billing, OSS/BSS, fraud detection, customer support), this deal is a clear signal: large operators are ready to anchor long‑term AI roadmaps around a single model provider. It also raises the bar for competitors—if you want those accounts, you probably need a story that goes beyond a model API to co‑developed products, early‑access programs, and integration into existing network and support stacks.
The point is: this isn’t a lab partnership. It’s the shape of what an AI‑first telco contract looks like when both sides are betting on multi‑year, model‑evolving deployments.
Enterprise AI GTM patterns converge: CROs, telcos, SIs, banks, and infra funds
Taken together, today’s moves sketch a coherent picture of what AI enterprise go‑to‑market looks like at scale. OpenAI is professionalizing revenue with a seasoned CRO cro announcement, cutting deep GTM alliances with a major European telco telekom partnership, and embedding ChatGPT Enterprise into a national‑scale bank cba deployment article. Anthropic is leaning on Accenture’s 30,000‑person practice to turn Claude into a de facto standard inside Fortune‑500 IT accenture deal. Infra providers like Fal are raising nine‑figure rounds and seeding customers via dedicated funds fal funding media fund launch.
This isn’t the early‑stage world where model APIs quietly spread from dev teams outward. The new pattern looks like this:
- A dedicated CRO and enterprise org to coordinate multi‑year, multi‑product relationships.
- Strategic alliances with telcos, SIs, and banks who already control distribution and trust.
- Industry reports (from OpenAI and Menlo) that quantify value in the language of CFOs and CIOs—hours saved, revenue share, and sector‑specific growth menlo overview power user gap.
For engineers, all this translates into a more opinionated environment. You’ll see more pre‑approved stacks ("we’re an OpenAI + Accenture shop" or "we’re a Claude + SI shop"), more standardized patterns (certifications, recommended architectures), and more pressure to align internal systems to one of a small set of powerful vendors.
For founders, it’s a wake‑up call that GTM is now a multi‑front game: you’re not just competing on model quality or UX; you’re competing against full ecosystems—CROs, SIs, telcos, banks, and infra funds—all moving in sync.
OpenAI appoints ex‑Slack CEO Denise Dresser as Chief Revenue Officer
OpenAI has hired Denise Dresser, former CEO of Slack, as its Chief Revenue Officer to lead global sales, customer success, and support as the company scales past 1M business customers and pushes deeper into the enterprise stack cro announcement. She’s being brought in explicitly to turn early product‑led adoption into durable, large‑ticket relationships across sectors like finance, retail, and manufacturing, where OpenAI is already embedded via ChatGPT Enterprise and custom model deals openai blog post.
This is a classic "grown‑up GTM" move. Dresser has already run a large SaaS sales org and knows how to build repeatable pipelines in enterprise accounts. The message to rivals is clear: OpenAI doesn’t want to be just the model people prototype with; it wants to be the default strategic platform CIOs bet careers on. Greg Brockman’s public welcome underscores that she’ll be central to OpenAI’s next phase of commercialization welcome note.
For AI teams inside companies, this usually translates into more packaged offerings (vertical templates, deployment patterns, compliance artifacts) and more opinionated guidance around how to standardize on OpenAI as "the corporate stack". It also signals OpenAI is comfortable putting revenue optimization front‑and‑center while it’s in a very public feature race with Gemini and Claude.
So if you sell into enterprises yourself, expect OpenAI to show up more often in the room—both as a technology partner and as a political force in how AI budgets get allocated.
Fal raises $140M Series D and launches a Generative Media Fund
Fal, the gen‑media infrastructure company behind hosted video and image models, has closed a $140M Series D led by Sequoia with participation from Kleiner Perkins, NVIDIA and existing backers fal funding. The team of ~70 plans to use the cash to scale its platform globally and ship "the next wave of capabilities" for generative media workloads
.
Alongside the raise, Fal announced a Generative Media Fund that will invest up to $250k (cash plus Fal credits) into startups building on top of its stack media fund launch media fund page. On Bloomberg TV, CEO Burkay Gürsel claimed Fal’s proprietary inference engine can run NVIDIA models 3–4× faster than standard setups, framing the company less as an API wrapper and more as a performance‑obsessed serving layer for image and video models ceo interview.
For AI builders, this is a concrete signal that infra focused on high‑throughput, high‑fidelity media is attracting serious money. If you’re building creative tools, video ads, virtual production, or game assets, Fal wants you to think of them as "Vercel for generative media"—taking care of scaling, acceleration, and cost so you can focus on UX. The dedicated fund sweetens that pitch: they’re not just selling you GPU time, they’re willing to co‑fund you if you bet your product on their stack.
The trade‑off, as always, is platform risk. A $140M raise plus NVIDIA’s backing suggests Fal isn’t going away tomorrow, but you’ll still want a portability story—especially if you’re training or fine‑tuning models that you might later want to run on your own infra or a competitor.
OpenAI launches certification courses with goal to upskill 10M Americans by 2030
OpenAI has rolled out its first certification courses—"AI Foundations" and "ChatGPT Foundations for Teachers"—aimed at giving non‑experts practical, job‑ready AI skills directly inside ChatGPT cert courses. The long‑term target is ambitious: certify 10 million Americans in AI skills by 2030, with these initial courses forming the entry point cert courses page.
The interesting piece for enterprise leaders is the delivery model. The AI Foundations course runs inside ChatGPT itself, combining instruction, hands‑on tasks, and reflection in a single conversational environment. That makes it much easier to deploy at scale than traditional LMS courses: you don’t need a separate platform, and the same tool people are learning about is the one they use day‑to‑day.
OpenAI is already piloting these certifications with employers like Walmart, John Deere, and Accenture, plus public‑sector partners cert courses. For HR and L&D teams, this offers an off‑the‑shelf way to standardize "AI literacy" across a workforce without designing everything from scratch. For individual workers, the pitch is straightforward: empirical research shows AI‑literate workers earn more, and OpenAI wants its certs to become a portable signal of that literacy.
If you run an AI team, it’s worth asking whether you want to align internal training with OpenAI’s stack or keep things more vendor‑neutral. But either way, this move pushes the market toward a world where "AI certification" is as normal on a résumé as AWS or Salesforce badges.
OpenAI’s enterprise report shows power users burn 8× more AI credits than median staff
Following up on OpenAI’s broad 2025 State of Enterprise AI report, which catalogued adoption across 1M business customers enterprise report, new breakdowns highlight how uneven usage is inside companies. The top 5% of workers by usage consume about 8× more AI credits than the median employee and are far more likely to use advanced features like GPT‑5 Thinking, Deep Research, and image generation across multiple tools power user gap.
These "power users" also report the biggest productivity gains: the cohort saving more than 10 hours per week is the same one consuming those extra credits credits vs hours. Meanwhile, sectors like tech, healthcare, and manufacturing are seeing double‑digit year‑over‑year growth in enterprise AI use (11×, 8×, and 7× respectively), while education lags at around 2× sector growth. The story inside orgs is similar: adoption is broad, but deep, transformative use is clustered in a relatively small group.
For AI leaders, the implication is that rollout strategy matters. Giving everyone a chatbot does a bit; cultivating and supporting heavy users—through better access, training, and workflows—does a lot. Those users act as internal force multipliers, building prompts, playbooks, and sometimes internal tools that the rest of the organization can follow.
So if you’re only looking at seats purchased, you’re missing the plot. You should also be measuring credit consumption and feature mix, and you should probably be talking directly to your top 5% of users to understand what they’re doing that the rest of the org isn’t—yet.
📑 Research focus: positional geometry, coordination layers, robust agents
A dense set of fresh papers on agent reliability, position encoding, retrieval effects, and parallel reasoning—useful for modelers and agent engineers. Yesterday’s GLM coverage gives way to core methods here.
GRAPE unifies RoPE, ALiBi and FoX into a single positional geometry
GRAPE proposes Group Representational Position Encoding as a common framework that exactly re-expresses RoPE, ALiBi and the Forgetting Transformer as special cases of a single group-action-based geometry, and then extends beyond them with learned mixed subspaces and low-rank additive biases. It introduces multiplicative rotations in learned 2D planes and additive logit-bias actions, giving relative, compositional, cache-friendly encodings that train more stably and reach better language-modeling scores than RoPE/ALiBi/FoX at equal size on web-text experiments grape abstract.
For model and infra engineers this is a concrete candidate to standardize long-context position handling: you can recover familiar behaviors by choice of generators, but also explore richer cross-subspace coupling without changing asymptotics. The point is: positional encoding is now a tunable design space rather than a grab-bag of unrelated tricks, which should make it easier to reason about extrapolation, streaming, and compatibility across architectures (ArXiv paper).
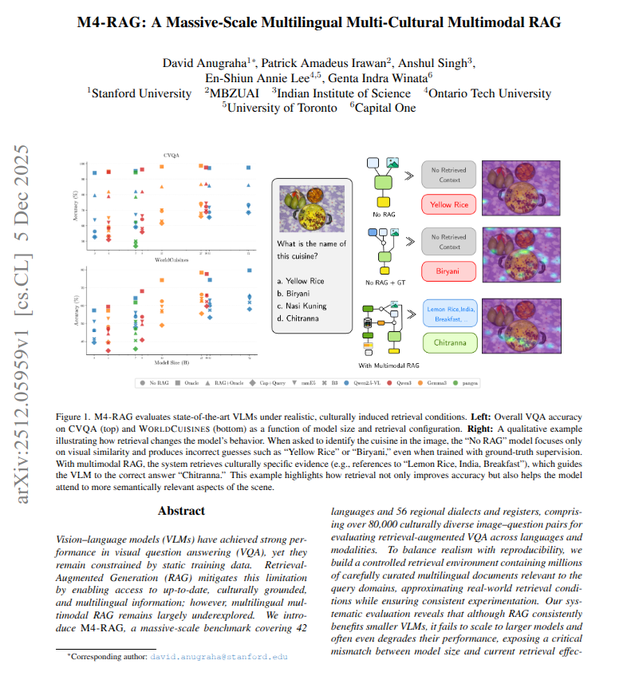
M4‑RAG finds retrieval boosts small VLMs but can hurt large ones
The M4‑RAG benchmark tests how retrieval-augmented generation affects vision‑language models across ~80k image–question pairs in 42 languages and 56 dialects, using a controlled Wikipedia-derived knowledge base m4rag summary. It shows that high-quality multimodal retrieval can fix many culture-specific failures (e.g. obscure regional dishes) for small/medium VLMs, but the gains shrink or even turn negative for larger models that tend to trust their internal knowledge and sometimes misuse or ignore external context.
The study also surfaces a strong English bias: even when correct context is provided, prompts and passages in low-resource languages sharply reduce accuracy. The point for practitioners is to be cautious about blindly slapping RAG onto strong VLMs—especially at scale—and to invest in retrieval quality, language coverage, and model-side training that actually uses context rather than treating it as optional decoration (ArXiv paper).
Omega designs trusted cloud agents with enclaves and encrypted logs
Omega is a system for running AI agents in the cloud where even the cloud operator cannot see raw data: it packs many agents into a single confidential VM (using hardware TEEs), separates a small trusted core from sandboxed agent sandboxes with no direct disk/network/GPU access, and records all key actions in encrypted, counter-protected logs omega paper page. The system also emits attestation reports that bind model weights, code, policies and inputs into a verifiable proof that a given result or log came from the expected configuration.
Experiments show Omega can block prompt-injected tool misuse while keeping answer quality close to an unsecured baseline and scaling far better than giving each agent its own enclave VM (ArXiv paper). For anyone building serious multi-tenant or regulated-agent platforms, this reads like a blueprint: treat "agent stack in a TEE + attestable logs" as a default architecture, then layer safer tool routing and auditability on top instead of trusting plain Kubernetes.
‘Missing Layer of AGI’ paper argues LLMs need a coordination controller
A Stanford paper argues that current LLMs already provide a strong "pattern substrate" but lack a coordination layer that decides which patterns to trust, when to debate, and how to maintain state over time maci abstract. It introduces an anchoring strength score that increases when evidence consistently backs an answer and remains stable under prompt perturbations, then uses it inside a MACI architecture that runs multiple agents in debate, tunes their stubbornness, adds a judge, and tracks decisions in memory.
On small arithmetic and concept-learning tasks, the system shows a sharp phase change where answers become more reliable once anchoring crosses a threshold, supporting the claim that many "LLM failures" stem from missing oversight and memory rather than substrate limits (ArXiv paper). For agent builders, the takeaway is to treat pattern generation and coordination as separate concerns: focus your engineering energy on anchoring, debate, and state management rather than endlessly swapping base models.
DoVer auto‑debugs multi‑agent tasks via targeted interventions
DoVer (Intervention‑Driven Auto Debugging) tackles a very practical pain: figuring out why an LLM multi‑agent system failed on a complex task. Instead of just logging traces and hand‑inspecting them, DoVer generates explicit failure hypotheses, injects targeted interventions (e.g. changing a tool output or intermediate plan), and watches how task outcomes change to validate or refute those hypotheses dover abstract.
On GAIA and AssistantBench, this method improves bug localization and fix rates compared to static analysis of traces alone, and can surface non-obvious issues like mis-specified tools, brittle routing logic, or agents stuck in unproductive loops (ArXiv paper). For teams shipping real agents, the idea is simple but powerful: debugging should include counterfactual replays, not just reading JSON logs—DoVer gives a conceptual template for automating that loop.
KAMI study categorizes how LLM agents fail on realistic tool tasks
The KAMI v0.1 benchmark paper analyzes 900 execution traces from three models (Granite 4 Small, Llama 4 Maverick, DeepSeek V3.1) on filesystem, text extraction, CSV and SQL tasks to answer a blunt question: how do LLM agents actually fail when wired to tools kami abstract. Instead of just reporting aggregate scores, the authors categorize four recurring failure archetypes: premature action without grounding (e.g. guessing schema instead of inspecting it), over-helpful guessing when data is missing, context pollution from distractor tables, and brittle execution that collapses once traces get long.
They also find that bigger models aren’t automatically more reliable—DeepSeek’s edge appears to come mostly from extra tool-use post‑training rather than size alone. For agent engineers this is a useful failure checklist: bake schema-discovery, missing‑data handling, context isolation, and long‑horizon robustness into your harness and evals instead of assuming the base model will handle them by itself (ArXiv paper).
ThreadWeaver trains adaptive parallel reasoning with speedups on AIME24
ThreadWeaver is a framework that teaches LLMs to reason in parallel by launching multiple candidate reasoning "threads" and learning when to branch, merge, or stop, instead of always decoding serially token by token threadweaver abstract. It uses a two-stage trajectory generator and a trie-based training+inference co-design, plus a parallelization-aware RL objective that optimizes both accuracy and latency.
Applied to Qwen3‑8B, ThreadWeaver matches or beats strong sequential reasoning baselines, achieving ~79.9% on AIME24 and up to 1.53× lower token latency at the same accuracy (ArXiv paper). For model folks and infra engineers, this suggests that smarter decoding policies—rather than bigger models alone—can deliver meaningful speedups on hard reasoning tasks, especially when you care about tail-latency under load.
C3 adds calibrated uncertainty to controllable video world models for robots
A Princeton-led paper adds a calibrated uncertainty head, C³, to controllable video world models so robots can tell where their predictions are likely wrong instead of hallucinating plausible but impossible futures c3 abstract. C³ operates in latent space, predicting per-patch correctness probabilities under a chosen error threshold, and then decodes them into pixel-level heatmaps that flag trustworthy vs untrustworthy regions in each frame.
On Bridge and DROID datasets, these heatmaps line up with actual prediction errors and spike on out-of-distribution scenes (new lighting, clutter, grippers), while adding only modest overhead to standard diffusion-style video architectures (ArXiv paper). If you’re working on robot planning or model-based RL, the lesson is clear: don’t just ask your world model what will happen—ask how confident it is, and treat low-confidence regions as constraints in your planner.
AI Correctness Checker finds rising math and citation errors in AI papers
"To Err Is Human" quantifies objective mistakes in 2,500 ICLR, NeurIPS and TMLR papers by running an LLM-based AI Correctness Checker over PDFs to flag formula slips, wrong table entries, broken references and similar issues paper error abstract. It estimates about five concrete mistakes per paper on average, with almost every paper containing at least one, and reports a ~55% increase in NeurIPS errors per paper between 2021 and 2025.
Manual review confirms ~263/316 sampled flags are real mistakes, while planted synthetic errors are caught about 60% of the time, so the tool is helpful but far from perfect. The point for researchers and reviewers: you should treat an automated checker as a pre‑submission lint pass for math and claims, not as a replacement for peer review—yet it’s probably time to add something like this into your lab CI pipeline (ArXiv paper).
🎬 Creative stacks: Gemini templates, NB Pro + Kling reels, and CHORD PBR
A sizable share of today’s discourse covers image/video workflows and pro pipelines—Google’s app experiments, NB Pro + Kling showcases, OpenAI image rumors, and Ubisoft’s PBR toolchain.
Nano Banana Pro quietly becomes the slide engine in multiple Google tools
Nano Banana Pro is turning into Google’s default image engine for anything that spits out decks: Mixboard now uses it to generate slide imagery from text, handle multi‑board projects, and support PDFs and other file types, while relying on NB Pro for fast, on‑brand visuals. Mixboard NB upgrade

AiPPT is doing something similar with a "dynamic slide" feature that auto‑fills presentations with context‑matched images per slide, rather than generic placeholders, again powered by NB Pro. AiPPT feature brief NotebookLM users are reporting that throwing an entire book at it yields a surprisingly polished, image‑rich deck with minimal hallucinations—more evidence that image generation is becoming a first‑class part of the doc→slides pipeline, not an afterthought. NotebookLM slide usage Following up on 4-step grid, where the community converged on NB Pro prompt workflows, this shift inside Google products signals that the same image stack is now being weaponized for everyday business artifacts: decks, reports, and internal pitches, not just art experiments.
OpenAI’s Chestnut and Hazelnut image models surface on Arena with mixed early takes
Two mystery OpenAI image models, "Chestnut" and "Hazelnut", have appeared in LM Arena and designarena configs, widely assumed to be early Image v2 variants. (Arena model spotting, designarena config)
Sample outputs show highly detailed celebrity selfie‑style group shots and anime portraits that many suspect were generated by these models rather than photographers: they’re sharp, well‑lit, and packed with tiny facial cues that older Image 1 struggled with. (image v2 first looks, Drake selfie guess) But there’s also consistent criticism that Hazelnut still has a "washed out" or yellow‑ish cast compared to models like Seedream 4, especially on fashion shots and character renders. (yellow tint complaint, anime sample) For product teams, the important signal isn’t just that OpenAI has new image weights in the wild—it’s that these are being hammered in public battle arenas, which means you can start to gauge style, color behavior, and failure modes now and be ready to wire them into pipelines the day ChatGPT exposes them.
Gemini tests Veo 3.1 video templates for one‑click stylized clips
Google is quietly A/B‑testing a Veo 3.1 template gallery inside the Gemini app, letting a small group of users pick pre‑built styles like "Glam", "Crochet", "Cyberpunk", "Video Game", "Cosmos" and "Action Hero" before describing their video. (Gemini template demo, Gemini app leak)
For builders, this shows where Google thinks consumer video UX is heading: less raw prompting, more opinionated presets that encapsulate a whole style, camera language, and color grade. It’s a nudge toward treating video models as render engines behind a template system, which could simplify onboarding but also push serious users toward "template hacking" or custom backends when they want control over pacing, framing or continuity.
Stitch’s NB‑powered redesign agent now ships code and attention heatmaps
Google’s Stitch design tool is leaning hard into Gemini image models: the Redesign Agent can now take a styled UI mock and generate updated HTML/CSS layouts and components directly from it, turning high‑fidelity comps into production-ish code in one step. Stitch redesign thread
On top of that, Stitch is adding predictive heatmaps that estimate where users will visually focus on a given layout, so designers can see likely attention hotspots without shipping a single A/B test. heatmap example Power‑user hotkeys for zoom, pan and zen mode suggest they’re targeting serious design teams, not just casual tinkerers. hotkey screenshot For engineers, the interesting bit is the workflow pattern: NB Pro (and kin) aren’t offered as raw models here, but as multi‑step agents—redesign → codegen → attention analysis—all wired into one creative surface.
Ubisoft open‑sources CHORD PBR materials with ComfyUI nodes for AAA pipelines
Ubisoft La Forge has open‑sourced CHORD, a production PBR material model plus a set of ComfyUI nodes that turn a single tileable texture into full Base Color, Normal, Height, Roughness and Metalness maps suitable for AAA asset workflows. CHORD announcement
The ComfyUI graphs cover three stages—generate a tileable texture, estimate full PBR channels, then upscale to 2K/4K—letting artists drop CHORD into existing node trees rather than building a bespoke tool. CHORD announcement Ubisoft’s own write‑up stresses that ComfyUI’s graph‑based approach made it a good host for mixing CHORD with ControlNets, inpainting and other generative tools, which is a quiet endorsement of community tooling as "production ready" for big studios. material example For TDs, this is a rare case where a real, shipping AAA workflow—materials for physically based renderers—is now expressible as open, inspectable nodes instead of opaque in‑house plugins. Ubisoft blog post
Creators chain Nano Banana Pro stills into Kling 2.6/O1 video for “cinema”
Creators are increasingly pairing Nano Banana Pro for keyframes and look‑dev with Kling 2.6/O1 for motion, treating NB as an art director and Kling as the camera. One popular combo sets up hero shots in NB Pro and then hands them to Kling for dynamic, GTA‑style city chases and dramatic lighting. (NB and Kling video, Kling sample image)

Another thread shows "Nano Banana Pro plus Kling O1" marketed as a cinema‑grade stack: NB handles consistent characters and styling, Kling adds speech, lip‑sync, and physically plausible motion, including clothing and light interaction. combo teaser Together they form a practical pipeline for spec ads, trailers, and social video where you iterate on stills until the look is right, then lock it in as reference for the video pass, extending the editing‑first focus we saw when Kling O1 launched. Kling editing
The point is: real teams are no longer asking "which video model?", they’re building two‑model stacks—image for design control, video for motion—and tuning prompts and references across both.
Felo LiveDoc turns documents into image‑rich decks and reports on one canvas
Felo’s LiveDoc workspace is pitching itself as an "intelligent canvas" where agents can turn raw text, research, and data into polished articles and decks with on‑brand visuals—no manual image hunting. A common workflow: paste a plain product PRD, prompt "Write a press release and add images", and LiveDoc writes the copy and sources cover art, product shots, and contextual illustrations in one pass. Felo LiveDoc video

Under the hood, multiple agents handle drafting, layout, and image selection so that edits to text reflow into new image choices without starting over. Felo thread It also supports translation (e.g., English → Japanese decks) while preserving layout, and can synthesize decks from long‑form docs by proposing different storylines (exec, technical, customer). That positions it less as "ChatGPT with uploads" and more as a structured, multi‑agent alternative to PowerPoint and Google Slides for teams that live in long docs but need presentable artifacts on demand.
Grok Imagine lets X users generate short videos from the post composer
Grok Imagine is now wired directly into X’s post composer: alongside photos, GIFs and live, some users see a "video" icon that opens a prompt box and returns a generated clip—like a detailed "cyberpunk robot" shot—inline before posting. Grok Imagine feature
This makes Grok not just a chat assistant but part of the authoring surface for social video, similar to how image buttons changed meme workflows. Creators don’t need to visit a separate app or site; they can iterate on prompts until the preview looks right, then ship it to their followers. For engineers, the interesting bit is that the model is being exposed in a high‑frequency, low‑friction context where latency, safety filters, and prompt ergonomics all have to hold up under typical "scroll‑post‑scroll" usage rather than deliberate editing sessions.
ImagineArt builds consumer video editing apps on top of Kling O1
ImagineArt has launched a suite of video tools built on Kling O1 that let regular users remove objects, recolor scenes, change backgrounds, and re‑frame footage with prompt‑level controls instead of keyframes and masks. ImagineArt Kling apps

The same stack now ships as a mobile app, so users can run these Kling‑backed edits on their phones, turning single JPEGs or clips into full "commercial‑style" videos in a few taps. ImagineArt mobile This is a concrete proof‑of‑concept for Kling as a backend service rather than a destination UI: third‑party apps can integrate it, add UX sugar, and own the customer relationship while leaning on Kling’s motion and lip‑sync capabilities under the hood.
Combined with earlier Kling integrations into ComfyUI and pro workflows Kling editing, the pattern is clear: expect more vertical apps that package Kling as "magic edit" buttons for specific niches like ads, UGC, and social commerce.
Light Migration LoRA brings controllable relighting to ComfyUI workflows
A new "Light Migration" LoRA by dx8152 is making the rounds in ComfyUI circles for its ability to re‑light existing renders—changing direction, softness and color of light—without repainting the whole scene. LoRA relighting link Used inside ComfyUI graphs, it lets artists keep geometry and materials intact while trying different lighting setups, which is a huge time saver for product shots, key art, and look‑dev where the model or prop is approved but the mood isn’t. Instead of burning GPU cycles on full re‑generations, you can treat relighting as its own stage in the pipeline, closer to how 3D and VFX teams separate shading from lighting. For AI engineers, it’s another data point that LoRA‑style adapters are becoming the standard way to bolt specific edits—here, lighting—onto large base models without re‑training them.
🛡️ Alignment & control: SGTM, fast unlearning, and trusted execution
Safety‑centric research and mitigations dominate: pretraining‑time capability isolation, LoRA unlearning with negatives, and confidential VMs for agent ops. Excludes defense procurement, which is covered separately.
Anthropic’s SGTM localizes risky knowledge into deletable ‘forget’ weights
Anthropic’s Selective GradienT Masking (SGTM) is a pre‑training method that splits each layer’s weights into retain and forget subsets, then routes high‑risk knowledge into the forget slice so it can be zeroed out before deployment with minimal damage to the rest of the model. research summary SGTM trains so that clearly marked risky data only updates forget weights, and even unlabelled but related text is nudged to rely more on that slice, giving you a parameter‑level kill‑switch instead of blunt dataset filtering. anthropic recap In controlled experiments on a small transformer trained on a mixed corpus, SGTM outperforms pure data filtering on the trade‑off between removing an unwanted domain and preserving general capabilities, while adding only ~5% compute overhead. safety thread When adversaries try to fine‑tune the model to relearn the removed knowledge, a prior unlearning method (RMU) recovers it in ~50 steps, whereas SGTM requires ~350 steps and around 92M tokens—roughly 7× more work to undo the forgetting. relearning cost That extra resistance matters if weights ever leak or if downstream teams can fine‑tune models without central oversight.
The authors stress that SGTM doesn’t help if an attacker pastes dangerous content straight into the prompt, and that results so far are on small models and proxy domains. limitations note But it’s an important proof‑of‑concept that capability removal can be engineered into pre‑training itself instead of bolted on afterward, and that we can selectively degrade a model’s competence on sensitive areas while keeping the rest of its skills largely intact. Builders who currently rely only on dataset filtering or post‑hoc refusal tuning should watch this line of work closely as a future compliment to those methods, especially for frontier‑scale training where redoing the whole run is not an option. See the full technical details in the SGTM paper. ArXiv paper
LUNE uses LoRA plus negative examples for fast, cheap factual unlearning
The LUNE paper proposes an efficient way to make a model forget specific facts by training only small LoRA adapters on negative examples—answers that explicitly contradict what the model currently believes—rather than re‑training the full network. paper summary Instead of wiping or editing the entire pre‑training dataset, LUNE takes prompts where the model would normally answer correctly, then fine‑tunes it to insist on alternative outputs (for example, not naming a particular entity), injecting that change through a low‑rank adapter.
This approach reaches similar unlearning quality to full fine‑tuning on several benchmarks while using roughly an order of magnitude less compute and memory, because the base model stays frozen and only the LoRA adapter is updated. paper summary It also holds up under paraphrased queries and some prompt variations, showing that the forgotten fact isn’t trivially recoverable by rephrasing the question. Where earlier unlearning methods either struggled to fully erase the target knowledge or caused broad collateral damage to nearby capabilities, LUNE’s negative‑example LoRA sits closer to a surgical patch: you can attach, detach, or swap adapters as needed for different regulatory regimes or deployment contexts.
For teams already comfortable with LoRA fine‑tuning pipelines, LUNE is immediately practical: you can build an unlearning adapter for a narrow slice of knowledge without re‑running massive training jobs, then layer that on top of your existing checkpoint. It’s not a silver bullet—motivated attackers could still fine‑tune around the adapter—but it meaningfully lowers the cost of responding to takedown requests, model evaluation findings, or new compliance requirements.
The bigger takeaway is that unlearning doesn’t have to mean “start from scratch”. With the right use of negative examples and modular adapters, we can retrofit existing models to forget specific things almost as cheaply as we now fine‑tune them to learn new ones.
Omega proposes trusted cloud VMs for safer multi‑agent AI systems
The Omega system paper tackles a messy reality: today’s AI agents are often a tangle of LLMs, tools, and third‑party services all running on shared cloud infra where neither users nor devs can fully see or control what happens to their data. Omega’s answer is to put the entire agentic stack—multiple agents, tools, and coordination logic—inside a single confidential virtual machine (CVM) whose memory is encrypted even from the cloud operator, then wrap it with attested configurations and tamper‑evident logs. system overview Inside this encrypted VM, Omega separates a small trusted core from sandboxed agents that have no direct access to network, disk, or GPUs. Agents call tools only through the core, which mediates IO and logs each sensitive action (like hitting an API or writing to storage) to encrypted, counter‑protected audit logs.
Before results are returned, Omega produces a compact attestation report that includes cryptographic measurements of the code, models, policies, and input hashes that produced the output, so downstream systems—or even end users—can verify that the response really came from an approved configuration. ArXiv paper
In experiments, this setup blocks attacks where hidden text or compromised tools try to trick the agent into calling the wrong services, while keeping answer quality similar to an unsecured baseline. It also scales better than giving every agent its own CVM, because Omega amortizes the confidential‑compute overhead across a whole multi‑agent cluster instead of per‑agent. omega recap For infra and security leads, the important shift is conceptual: you start treating the agent runtime itself as a security perimeter with verifiable behavior, not just the model weights or the API.
If you’re operating agents over sensitive data—finance, healthcare, internal code, government workloads—Omega‑style architectures point to a future where you can demand not just “we don’t log your data”, but machine‑checkable proofs of exactly which code ran, which tools it used, and what it did with your inputs. That’s a much stronger story than the trust‑us dashboards most AI platforms offer today.
🏛️ Public sector & defense: GenAI.mil starts with Gemini
Defense adoption enters deployment mode. DoD brings frontier models to an internal platform for paperwork‑heavy workflows; multi‑model roadmap noted. Excludes enterprise GTM (covered elsewhere).
Pentagon launches GenAI.mil with Google Gemini as first model
The US Department of War has quietly launched GenAI.mil, an internal AI platform for military personnel that initially runs on Google’s Gemini models to handle paperwork-heavy workflows like policy summarization, compliance checklists, SOW term extraction, and risk assessments. Verge summary GenAI.mil is restricted to unclassified use, lives on defense networks only, and Google says data from the system will not be used to train its public models, with other vendors’ models slated to be added later. Verge summary
Reporting describes this as a multi‑year contract where Gemini effectively becomes the default "AI desktop" for large parts of the US military, at least for document and planning work, with the Secretary of War framing it as a way to make the force "more lethal than ever before". Fox coverage Commentary notes that this is the first large, visible win where Gemini, not ChatGPT, is the named AI backbone for a major Western defense platform, signaling both intensifying AI vendor competition and an acceleration of AI adoption in defense operations. (war commentary, AI platform note)
🗣️ Realtime voice agents: higher‑fidelity TTS and sandwich patterns
Multiple posts on voice stacks and TTS QoS—new 44.1 kHz model, architecture guidance, and seasonal agents. Keeps media generation separate in Creative Stacks.
Gemini text‑to‑speech preview models get 12/10 quality upgrade with no API changes
Google emailed Gemini API users that the gemini‑2.5‑flash‑preview‑tts and gemini‑2.5‑pro‑preview‑tts models will be upgraded in place on December 10, promising “significant improvements in expressivity, pacing, and overall audio quality” while keeping request formats identical. gemini tts email For anyone already using these voices in products, this is a free QoS bump—no redeploy or code changes—though you may want to re‑QA critical flows where timing, prosody, or voice tone were finely tuned.
VoxCPM 1.5 bumps TTS to 44.1 kHz and halves tokens per second
OpenBMB’s VoxCPM 1.5 pushes its TTS stack from 16 kHz to 44.1 kHz while cutting usage to 6.25 tokens per second of audio (down from 12.5), so you get hi‑fi speech with lower token burn and better long‑form stability. voxcpm update It also ships LoRA and full fine‑tune scripts, which makes it attractive if you want to deeply customize voices or adapt the model to a narrow domain without building a TTS stack from scratch.model card github repo
LangChain breaks down ‘sandwich’ vs speech‑to‑speech architectures for voice agents
LangChain shared a concrete reference implementation of a voice agent built with AssemblyAI STT, an LLM, and Cartesia TTS, contrasting the classic STT→LLM→TTS “sandwich” with end‑to‑end speech‑to‑speech systems and spelling out the latency/complexity trade‑offs in each. architecture thread For builders, the takeaway is that sandwich stacks remain easier to extend (you can swap models and reuse text agents) but you pay in stream management and interrupt handling, and their demo plus docs are a good starting point if you’re wiring up a robust multimodal assistant today. docs page
ElevenLabs shows Santa voice agent running in React with ~8 lines of code
Following up on their real‑time Santa voice experienceSanta agent, ElevenLabs broke down how to embed that agent into a React site using their Agents Platform and Scribe v2, claiming it takes about eight lines of code plus some UI config. react demo For teams experimenting with seasonal or character agents, the blog post is a useful pattern for wiring a custom voice assistant into an existing frontend without building your own WS/streaming plumbing. react guide
Voice AI Primer distills RAG, multi‑agent, and state‑machine patterns for voice agents
Kwindla Kramer Booth’s "Voice AI & Voice Agents" primer is making the rounds as a pragmatic map of how people are actually building production voice agents, with worked patterns for RAG backends, multi‑agent orchestration, and state‑machine style flows rather than single‑prompt bots. primer mention If you’re designing a stack that talks and listens in real time, it’s a handy companion to frameworks like Pipecat, since it focuses less on any one library and more on the architectural pieces you need to get from raw STT/TTS to debuggable, production‑grade voice experiences. voice primer
⚙️ Runtime throughput: InferenceMAX and MoE kernel work
Smaller but relevant runtime updates for infra‑minded engineers. One lab posts higher tok/s per GPU curves; Transformers gains MoE perf work. Excludes Devstral serving (feature).
InferenceMAX pushes DeepSeek R1 FP8 to 4,260 tok/s/GPU at realistic loads
LMSYS and NVIDIA published new InferenceMAX curves for the sglang-dsr1-1k1k-FP8 setup on GB200, showing peak throughput improved by ~20% and reaching 4,260 tokens/s per GPU at 30 tok/s/user with interactivity supported up to 102 tok/s/user. throughput update
For infra engineers, the charts make it easier to pick rate limits that keep both latency and utilization in a good band, and they show how aggressive batching starts to collapse per‑GPU throughput beyond ~70–100 tok/s/user as the system prioritizes responsiveness over raw FLOPs. throughput update This is a useful reference point if you’re sizing GB200 clusters for long‑context DeepSeek R1 workloads or comparing against your own sglang/vLLM deployments.
Transformers gains batched/grouped MoE kernels to speed expert models
A new pull request to Hugging Face Transformers adds batched and grouped Mixture‑of‑Experts execution, aiming to significantly improve MoE model throughput and efficiency in the core library. maintainer note The change introduces specialized kernels and routing logic so multiple MoE calls can be aggregated, reducing overhead and better utilizing GPU memory bandwidth, and the author is explicitly asking the community to test and benchmark it across architectures like Mixtral and other expert‑based LLMs. GitHub PR For runtime engineers this matters because MoE models have often under‑delivered on theoretical speed/quality trade‑offs due to poor framework‑level implementations; if this PR lands and is solid, it could make Transformers a more viable serving stack for large, sparse‑expert models without having to drop down to custom CUDA or vendor‑specific runtimes.
🤖 Embodied AI: construction demo and real‑world challenge spec
A quieter but distinct beat. One lunar‑habitat construction demo and details for an offline real‑world robotics challenge emphasizing perception→planning→control.
GITAI’s robots cooperatively assemble a 5 m lunar construction tower
Following up on tower demo of GITAI’s 5‑meter autonomous tower for off‑world habitats, a new clip reframes the system as “the Moon’s first construction crew,” showing multiple robots cooperatively assembling a key structural element for future bases on the Moon and Mars. construction overview

For embodied‑AI people this is a clean real‑world example of perception→planning→control at construction scale rather than in a lab: robots must localize parts, coordinate hand‑offs, and maintain stability as the tower grows, all while handling outdoor lighting and terrain. The demo underscores why construction is becoming a flagship application for legged and wheeled platforms—long‑horizon tasks, high payloads, and safety constraints where scripted automation breaks down and learning‑based policies plus robust teleop fallbacks are needed. construction overview It’s a useful mental model for anyone designing multi‑robot controllers or task planners for infrastructure work in harsh environments.
ATEC 2025’s Offline Extreme Challenge formalizes four hard real‑world robot tasks
ATEC 2025 has published specs for its Offline Real‑World Extreme Challenge, defining four embodied tasks—Orienteering, Swaying Bridge Crossing, Autonomous Plant Watering, and Waste Sorting—intended to test full‑stack robustness from perception through planning to low‑level control. challenge overview
One example is the 10 m × 10 m waste‑sorting field where robots must find, classify, and deposit three object types (plastic bottles, food waste, cartons), with 25 points per correctly sorted item and separate control modes for quadrupeds (fully autonomous) versus humanoids (locomotion teleop, manipulation autonomous). challenge overview Other tasks add dynamics like a swaying bridge and outdoor navigation, forcing teams to cope with wind, glare, uneven terrain, and ambient noise rather than clean lab conditions. For researchers, the value is in having a public, task‑level spec that ties scoring directly to successful long‑horizon behavior, giving a concrete target for benchmarking embodied stacks instead of only sim or tabletop metrics.