GPT‑5.2‑Codex hits 56.4% SWE‑Bench Pro – gated cyber access
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
OpenAI’s week is about agents, not chat: GPT‑5.2‑Codex is now the default coding brain in Codex and paid ChatGPT, tuned for long‑horizon refactors, tighter Windows/tool use, and context compaction so multi‑hour sessions don’t blow your token budget. On OpenAI’s own numbers it edges GPT‑5.2 and 5.1‑Codex‑Max on real‑world suites, hitting 56.4% on SWE‑Bench Pro and 64.0% on Terminal‑Bench 2.0, which map much closer to “did this actually fix the repo?” than to toy LeetCode.
The twist is cyber. 5.2‑Codex sits at the top of their internal professional CTF evals with pass@12 clustered around 85–90%, so OpenAI is turning it on inside Codex but slow‑rolling API access and spinning up an invite‑only “trusted access” track for defensive teams. That follows a recent CVE‑2025‑55183 React exploit that a researcher co‑developed with 5.1‑Codex‑Max, and it’s clear they don’t want that workflow in every random pentest bot.
Codex CLI 0.74 makes 5.2‑Codex the default with per‑run reasoning effort knobs and a configurable sandbox; devs report “medium” effort covering ~85% of work and x‑high rescuing gnarly bugs Opus 4.5 couldn’t crack in an hour. But 5.2‑Codex underperforms 5.1‑Codex‑Max on MLE‑Bench‑30, and repo hints of a “caribou” flagship suggest a 5.2‑Codex‑Max tier is already brewing. Treat this as your new baseline model—then keep workload‑specific evals and routing in the loop.
Top links today
- OpenAI GPT-5.2-Codex launch and system card
- Agent Skills open standard overview
- Agent Skills open standard GitHub repository
- Gemini 3 Flash in Google AI Studio
- Mistral OCR 3 technical blog and API
- LlamaParse v2 document parsing release blog
- Audio MultiChallenge benchmark paper for speech agents
- Audio MultiChallenge spoken dialogue leaderboard
- Arena-Rank paired-comparison ranking library repo
- SGLang Ollama-compatible API quickstart guide
- OpenRouter JSON response healing feature blog
- vLLM wide expert-parallel MoE benchmark
- Braintrust Brainstore AI observability database
- Exa People Search evals GitHub repository
- Google Agent Development Kit for TypeScript agents
Feature Spotlight
Feature: GPT‑5.2‑Codex lands for agentic coding and cyber
OpenAI ships GPT‑5.2‑Codex in Codex: SOTA agentic coding with 56.4% SWE‑Bench Pro and 64.0% Terminal‑Bench 2.0, context compaction for long runs, stronger Windows/vision, and an invite‑only cyber program.
Cross‑account launch with docs, CLIs and early dev reports. Focus is long‑horizon coding (context compaction), better Windows/tool use, vision‑aided code reading, and a new trusted‑access path for defensive cybersecurity.
Jump to Feature: GPT‑5.2‑Codex lands for agentic coding and cyber topicsTable of Contents
🧠 Feature: GPT‑5.2‑Codex lands for agentic coding and cyber
Cross‑account launch with docs, CLIs and early dev reports. Focus is long‑horizon coding (context compaction), better Windows/tool use, vision‑aided code reading, and a new trusted‑access path for defensive cybersecurity.
OpenAI turns on GPT-5.2‑Codex for long‑horizon agentic coding
OpenAI has launched GPT‑5.2‑Codex as the new default agentic coding model inside Codex for all paid ChatGPT users, positioning it as their best option so far for complex, long‑running software work and defensive security tasks, with API access promised “soon.” launch tweet dev launch
The model is a GPT‑5.2 variant tuned specifically for coding and terminal use, adding native context compaction so multi‑hour sessions don’t blow past context limits, stronger long‑context reasoning, better Windows support, and improved tool‑calling for shells, editors, and test runners. gdb launch note This also extends to vision: GPT‑5.2‑Codex can parse screenshots, diagrams, and UI layouts more reliably, which matters for folks who debug from error dialogs or design mocks. OpenAI blog post In practice, you invoke it via the Codex CLI as codex -m gpt-5.2-codex, or pick it in the Codex model menu, where it’s now the top option and wired to multiple reasoning‑effort levels (low→x‑high) for different workloads. (cli usage, cli picker screenshot) For now it’s strictly available through Codex and ChatGPT for paying users, with OpenAI explicitly saying they’ll roll the API out more slowly than prior Codex models due to the model’s higher cybersecurity capability. (cli usage, cyber capability)
GPT‑5.2‑Codex posts SOTA on SWE‑Bench Pro and Terminal‑Bench 2.0
OpenAI’s launch benchmarks show GPT‑5.2‑Codex edging out GPT‑5.2 and GPT‑5.1‑Codex‑Max on real‑world coding suites, with 56.4% on SWE‑Bench Pro (up from 55.6% for GPT‑5.2 and 50.8% for GPT‑5.1) and 64.0% on Terminal‑Bench 2.0 (vs 62.2% and 58.1%). benchmarks tweet release page
Those numbers matter because both benchmarks measure end‑to‑end behavior: SWE‑Bench Pro scores if the patch actually fixes the bug in a live repo, and Terminal‑Bench 2.0 scores whether an agent can drive a realistic shell session through compiles, migrations, and service management, not just emit code snippets. For teams already running 5.1‑Codex‑Max agents, the gains are incremental rather than explosive, but they land on exactly the painful edge cases: larger refactors and longer, more stateful terminal sequences. benchmarks summary There are also early signs that performance is not uniformly better everywhere. On an MLE‑Bench‑30 chart, GPT‑5.2‑Codex scored 10% pass@1 against tuning/optimization problems, below 17% for GPT‑5.1‑Codex‑Max and even the 16% of GPT‑5.2‑thinking.
mle-bench tweet And a scenario‑based CTF table shows mixed results across specialized security challenges, with GPT‑5.2‑thinking failing more scenarios than 5.1‑Codex‑Max while 5.2‑Codex recovers some but not all of that loss. scenario table For AI leads, this all says: treat GPT‑5.2‑Codex as the new default starting point, but keep per‑workload evals in your loop instead of assuming it’s strictly dominant.
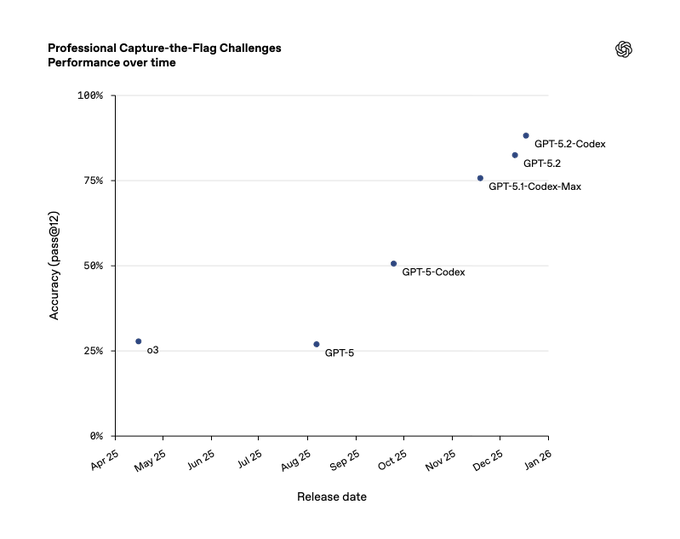
GPT‑5.2‑Codex pushes cyber skills, OpenAI adds trusted‑access track
OpenAI says GPT‑5.2‑Codex is “more cyber‑capable” than GPT‑5.1‑Codex‑Max and now sits at the top of their internal professional CTF evals, with pass@12 accuracy clustered near 85–90% on advanced multi‑step challenges in a Linux environment. (ctf chart summary, cyber capability)
The company is explicitly tying that capability to real‑world outcomes: a security researcher using GPT‑5.1‑Codex‑Max plus the Codex CLI recently helped uncover and responsibly disclose CVE‑2025‑55183, a React Server Components vulnerability that could expose source code and cause denial‑of‑service, by having the model scan a repo, propose attack surfaces, build a harness, then fuzz and refine until the exploit stuck. (ctf chart summary, workflow summary) Because the same skills can be misused, OpenAI is splitting things into two tracks. Regular paid users get GPT‑5.2‑Codex in Codex today, benefiting from the stronger bug‑finding and hardening behavior in everyday work, while a separate invite‑only “trusted access” program will expose the most powerful cyber workflows to vetted defensive teams and researchers, particularly those inside enterprises and open‑source communities. (trusted access note, rollout details) For security engineers and CISOs, the message is that Codex is now a serious co‑analyst for vuln research and hardening pipelines—but getting the full power will require going through an onboarding and accountability process rather than just flipping a flag.
Codex CLI 0.74 makes GPT‑5.2‑Codex the default and exposes sandbox tuning
Codex 0.74 has shipped with GPT‑5.2‑Codex as the new default model in the CLI, along with a proper “Select Model and Effort” picker that lets you choose between low, medium, high, and extra‑high reasoning effort for each run. cli update
From a workflow point of view, that means you can stay on gpt-5.2-codex but dial up x‑high for multi‑hour refactors, then flip to low or medium for quick edits or test fixes without changing the model ID. People are already doing exactly that, with one engineer noting they now use medium effort “85% of the time” for speed, reserving x‑high for the genuinely gnarly tasks. (cli usage, reasoning effort usage) On the harness side, Codex’s sandbox remains intentionally strict by default, which has frustrated some users who find xcodebuild or other heavy commands blocked even though they’re core to their daily loop. sandbox complaint To address that, OpenAI now documents a local-config rules file where you can loosen or tighten sandbox permissions per project, giving you a way out of “xcodebuild hell” without turning Codex loose on your entire machine. (sandbox customization, sandbox docs) For infra owners, the take‑away is that Codex is treating model choice and execution policy as first‑class configuration knobs; you’ll want to standardize those per team the same way you do linting or CI settings.
Builders report GPT‑5.2‑Codex fixing bugs faster with a terser personality
Early users describe GPT‑5.2‑Codex as unusually terse and willing to push back, but also as the first model that reliably solves some long‑standing bugs and refactors that other frontier LLMs struggled with. (personality comment, dev sentiment)
One OpenAI engineer highlighted that they “like the terseness” and showed a playful exchange where the model insists its original emoji count was correct and then replies “Count them next time, bestie.” personality comment That tone might be annoying for some, but it maps to a deeper behavior: the model is more confident about its intermediate reasoning and will argue when you miscount or mis‑specify something, which can be helpful when you’re staring at a subtle logic bug.
More importantly, there are concrete wins. In one report, a 5.2 xHigh Codex run fixed a nasty streaming bug in an iOS transcript/token counting pipeline in about five minutes—after Opus 4.5 had spent an hour trying and failing to land a working patch.
bugfix anecdote Other developers are using 5.2‑Codex to one‑shot risky changes like swapping xterm for libghostty in a production TUI, describing the result as “works… perfect? lol” and calling the model “ridiculously good.” terminal migration short launch note
People are also learning to lean on the new reasoning‑effort controls. One practitioner says medium reasoning feels as smart as high for most work while being much faster, and that low effort gives “about 90% as good” results at a huge latency savings, which lines up with the idea that you should reserve x‑high for only the most complex or security‑sensitive edits. reasoning effort usage For AI leads rolling Codex out to teams, the pattern emerging is: standardize on 5.2‑Codex, teach engineers when to bump effort, and expect a more opinionated partner than prior models.
Caribou presets hint at a GPT‑5.2‑Codex‑Max follow‑on
GitHub activity and config snippets from OpenAI’s Codex repo show a new caribou model preset being wired in, described as the “latest Codex‑optimized flagship for deep and fast reasoning,” strongly suggesting a forthcoming GPT‑5.2‑Codex‑Max‑style variant. (caribou pr, config snippet)
The preset defines caribou with a default medium reasoning effort and support for low, high, and x‑high modes, mirroring how 5.1‑Codex‑Max is exposed today but with more explicit descriptions like “extra high reasoning depth for complex problems.”
That’s led a number of observers to argue that “caribou” is the internal codename for a next‑step Codex model tuned even more aggressively for long‑horizon work, effectively a 5.2‑Codex‑Max.
Commentators tracking the repo note that this code landed within hours of the public 5.2‑Codex launch, speculating that “the next iterative release is on the horizon: GPT‑5.2‑codex‑max, project name ‘Caribou’,” and wondering out loud whether 5.3 will even fit into the 2025 calendar at this pace. (release speculation, caribou branch spotted) A write‑up by TestingCatalog walks through the PR and reinforces that this is more than a refactor: it’s a dedicated preset with its own description and reasoning settings, not just an alias. testingcatalog blog For engineering leaders, the important part isn’t the name so much as the pattern: OpenAI is clearly carving out a two‑tier Codex story again—a more general 5.2‑Codex that most people touch, and a “flagship” profile with higher reasoning budgets that will likely come with tighter controls and higher costs. Planning your harnesses and routing logic around that split now will make it easier to adopt Caribou‑class models once they surface in the public API.
🛠️ Coding agents and dev tooling in practice
Non‑OpenAI updates to daily coding stacks: Claude Code’s browser control, stabilization rollbacks, repo agents and review flows. Excludes the GPT‑5.2‑Codex launch (covered in the feature).
RepoPrompt 1.5.57 adds full CLI and MCP slash commands for repo-scale agents
RepoPrompt shipped v1.5.57 as its last big 2025 release, adding a fully featured CLI that agents can call without the MCP server, plus MCP slash commands that auto‑surface structured workflows like rp-build and rp-investigate in compatible clients. It also explicitly supports the latest coding models (GPT‑5.2‑Codex and Gemini 3 Flash) for discovery and implementation loops. Following repo agent, which emphasized research→plan→execute patterns, this release is about making those flows easier to wire into any harness. release thread
The new CLI lets you run discovery, planning, and implementation steps from any shell, which is handy when your main editor doesn’t yet speak MCP or when you want agents to orchestrate RepoPrompt as a sub‑tool. The MCP slash commands mean Claude Code, Codex, and other ACP/MCP‑aware clients can expose opinionated prompts like rp-build directly in their UIs, turning “fix this feature” into a guided multi‑step workflow instead of ad‑hoc chat. slash commands note On top of that, the Context Builder continues to focus on high‑signal retrieval by having agents explore the repo, refine the task description, and assemble dense, ranked context windows—reducing the usual slop of dumping half the codebase into the model. context builder screenshot , docs update If you’re already using RepoPrompt as a planning brain, this release makes it much easier to share that brain across multiple agents and environments.
Amp editor adds review agent as teams call code review the new bottleneck
The Amp editor extension now ships with a dedicated review agent aimed at tackling what Sourcegraph’s team calls the bottleneck in agentic coding: getting trustworthy feedback on big diffs instead of dumping untested AI patches on colleagues. review agent note
The idea is that your coding agent can do the bulk of implementation, and Amp’s review agent then analyzes the change—reasoning about async behavior, streaming bugs, hangs, and other subtle issues—before you hit “merge.” In one shared example, a Codex‑backed run took five minutes at extra‑high reasoning effort but located and fixed a thorny async bug Opus 4.5 couldn’t solve in over an hour. bugfix example That’s exactly the kind of “slow but smart” pass you want a machine doing, not a human sweating over traces. Timely feedback matters here: one engineer says he now uses this agent for “~80% of my diffs,” which tells you people are comfortable letting it be the first reviewer before they step in for final judgment. usage comment For teams leaning into agentic coding, this is a concrete way to shift human time from raw code review to higher‑level design and risk checks.
Toad becomes a universal ACP terminal for Claude, Codex, Gemini and more
Will McGugan launched Toad, a terminal UI that speaks the Agent Client Protocol (ACP) and can sit in front of multiple AI coding agents—OpenHands, Claude Code, Gemini CLI, Codex and others—so you get one consistent interface instead of juggling a dozen bespoke CLIs. launch post

Toad treats AI agents like TV channels: you install and configure them once, then flip between them inside a single, keyboard‑driven terminal app, without each vendor double‑charging you for tokens or forcing separate UIs. It already supports slash‑style commands, session views, and logs; the roadmap calls out sessions, multi‑agent support, a model picker (once ACP standardizes it), and even a UI for managing MCP servers, which would make it a genuine hub for agent tooling. launch post , feature tease Early users are enthusiastic about the ergonomics (“beautiful terminal interface”), and Hugging Face is sweetening the deal with $10 in Inference credits to experiment with open models through Toad. early review , HF credit promo If you’re feeling overwhelmed by separate CLIs for Claude, Codex, Gemini, etc., this is an appealing way to consolidate without giving up flexibility.
LangChain’s Deepagent-CLI leans on reflection to update agent memory over time
LangChain is sketching out how its Deepagent-CLI should handle long‑term memory: either via direct instruction (“remember this rule”) or by reflecting over past sessions and writing new rules into files like AGENT.md and CLAUDE.md. A diagram from the team shows a loop where a code agent runs, LangSmith traces are collected, a reflection pass distills patterns, and the resulting memories are written back into the agent’s config. memory loop diagram
The goal is to make memory a first‑class primitive rather than an ad‑hoc blob in a vector store. In this design, agents are explicitly told what they’ve learned (new rules, preferences, gotchas), and those changes are version‑controlled alongside code, so you can understand why an agent behaves differently after a week of use. memory overview For coding agents in particular, this approach lets you encode things like “never run xcodebuild in this sandbox,” “always use our logging helper,” or “prefer this testing pattern” as durable, inspectable instructions instead of hoping RAG fetches the right internal doc at the right time. It’s still early, but it’s a concrete blueprint for making agent behavior more debuggable and less mystical over months of use.
Notte’s Demonstrate Mode turns recorded browser sessions into automation code
Notte introduced a "Demonstrate Mode" that records your actions in the browser—clicks, scrolls, form fills—and then converts that trace into executable automation code, instead of making you describe the workflow in a long natural‑language prompt. One early user calls it "the perfect tool" for making precise workflows that prompts routinely mangle. feature summary The key idea is that some tasks are much easier to demonstrate than to specify: multi‑step CRUD flows, dashboards with odd DOM structures, login gates, or sites where selector stability really matters. Demonstrate Mode captures that behavior once and gives you editable code you can tweak, reuse, or plug into a larger agent pipeline, which is far more dependable than having an LLM hallucinate a Playwright script from scratch. feature summary For coding agents, this is a natural companion: let the agent call into these recorded scripts for brittle UI work, while it focuses its reasoning on higher‑level orchestration and error handling.
Warp adds Python and Node environment chips to cut debugging friction
Warp shipped new "environment chips" that show your active Python virtualenv path or Node version directly in the terminal UI, with a quick toggle to switch Node versions via nvm. It’s a small quality‑of‑life update, but one that removes a common source of "why does it work in my shell but not in CI" confusion. feature demo

For Python projects, the chip surfaces the full path to the .venv directory, so you can instantly confirm whether you’re running against the project’s local environment or some system/global install. For JavaScript, it shows the current Node version and lets you flip versions inline—helpful when you’re bouncing between projects on different runtimes or reproducing a bug on an older LTS. feature demo For AI‑heavy stacks where you juggle GPU‑enabled Python envs and multiple Node CLIs (CLI agents, dev servers, dashboards), having this ambient context in the terminal reduces the back‑and‑forth "which env is this?" conversations and makes reproducing agent failures much easier.
WarpGrep positions itself as a specialized MCP search agent for Claude Code
Morph’s WarpGrep project is being wired into Claude Code via MCP, turning it into a high‑throughput, code‑aware search subagent that coding agents can call instead of issuing naive rg or grep commands. The recommended setup installs WarpGrep as an MCP server and lets Claude invoke it through slash commands inside the code harness. Claude WarpGrep demo , Warpgrep docs

The pitch is that retrieval itself has become an inference task: rather than treating search as “just a vector DB query,” you give the LLM a dedicated tool optimized for scanning large repos and log outputs, with its own heuristics and GPU‑accelerated guts. In one shared flow, a developer shows Claude Code calling /warp-grep to locate relevant files and context before planning an implementation, which keeps the main model from burning tokens on broad scans. Claude WarpGrep demo This fits a broader pattern of "specialized subagents" doing one thing well—search, planning, testing—while the main agent orchestrates, and it’s a good option if your current MCP toolchain still relies on slow, generic shell commands for codebase exploration.
Claude Code experiments with shareable sessions for showcasing agent runs
Anthropic is prototyping a "Share session" feature in Claude Code that would let you publish an entire coding session—commands, thoughts, and results—either privately for yourself or publicly via a link, so others can review or continue the work. A leaked modal shows options for Private vs Public sharing, plus a warning when the session touches a private repository. share UI
This would make it much easier to show teammates how Claude solved something (or got stuck) instead of summarizing after the fact, and it’s a natural fit for debugging agent harnesses as well: you could share a broken run with a vendor or open‑source maintainer without having to screen‑record your terminal. The safety warning about private repos suggests Anthropic is at least aware of the risk of accidentally leaking source code via public links, but you’ll still want governance guardrails before anyone is allowed to make sessions public from sensitive monorepos. share UI If it ships, expect to see "vibe coding" transcripts become a standard artifact for code reviews and agent tuning.
Cline partners with LG CNS to build an “AI-native” enterprise dev flow
Agentic code editor Cline announced a partnership with LG CNS to build an "AI-Native Development" solution that covers the full software lifecycle—from requirements to code to testing—using agents as first‑class citizens rather than bolt‑ons. partnership post , partnership blog The framing here is that big enterprises don’t just want an AI pair programmer; they want a harness that can interact with Jira, design docs, monorepos, CI, and testing infrastructure, then hand humans reviewed diffs and reports. Cline’s role is to be that orchestrating layer in the editor, speaking to multiple models and tools while respecting enterprise constraints. partnership post For engineers, this kind of integration matters more than any single model upgrade: if LG CNS starts standardizing on agentic flows inside Cline, you’re likely to see patterns, conventions, and internal tooling emerge that others can copy, in the same way GitHub’s PR model quietly standardized how we ship code.
Yutori Scouts adds suggested query tweaks and privacy controls for web agents
Yutori’s Scouts—browser agents that monitor the web for topics you care about—now surface suggested improvements for your queries and a privacy toggle when you create a new Scout. Following Scouts GA, which focused on moving from preview to general availability, this is an early quality‑of‑life pass for people running agents over their timelines and niche sources. Scouts update

Suggested query tweaks matter because most users think they’ve written clear tracking rules when they actually haven’t; letting the system propose refinements (e.g., narrower terms, excluding noisy sites) should lead to more precise, less spammy alerts. The new privacy setting clarifies whether a Scout is private to you or can be discovered/shared, which is important when agents are effectively codifying your monitoring strategy for markets, competitors, or emergent research topics. Scouts update For AI engineers using Scouts to feed coding agents, this is a gentle reminder that observability and governance start at the data‑collection layer, not only inside the model harness.
🧩 Interoperability: Agent Skills and AG‑UI momentum
Standards traction for cross‑platform skills and UI orchestration. New open Skill catalogs, enterprise rollout controls, and protocol bridges. Excludes model launches; focuses on portability and ops.
Anthropic publishes Agent Skills open standard and enterprise Skills Directory
Anthropic has turned its Claude Skills format into Agent Skills, an open standard for packaging procedures and domain knowledge so they work across different AI platforms, and rolled it out to Claude Team and Enterprise customers with a managed Skills Directory and org‑wide controls. (standard announcement, claude skills blog)

Agent Skills are just folders of markdown instructions, scripts, and resources that agents can discover and load on demand, so you can write a skill once and reuse it in multiple products instead of maintaining separate prompt DSLs. Anthropic is shipping this with:
- A Skills Directory that already includes partner skills from Notion, Figma, Atlassian, Canva and others, plus internal org skills you define yourself. skills directory video - Org‑wide deployment and policy controls so admins can roll skills out to all users or specific groups from a central console. admin rollout - Immediate availability on Claude Team and Enterprise plans, not just labs or beta tiers. team enterprise note The standard itself lives at agentskills.io, with a spec and rationale that make it easy for other vendors to adopt the same on‑disk format instead of inventing yet another prompt packaging scheme. spec overview Anthropic’s own post makes it explicit they expect Skills to "work across AI platforms" and not be Claude‑only, which is why you’re already seeing frameworks and other agents start to pick it up. (claude skills blog, skills blog)
Open-source frameworks and agents quickly adopt the Agent Skills standard
Within hours of the Agent Skills spec going public, several independent agent frameworks and tools started wiring it in as their preferred way to package procedures and domain knowledge. The pattern is clear: builders want a shared skill format they can point any model or harness at. (opencode plans, openskills launch) Stirrup, a lightweight agent framework, now lets you point it at a directory of skill markdown files and have agents load them dynamically, so the same skills you wrote for Claude Code or Codex can be reused without translation. (stirrup support, stirrup details) OpenSkills, an open project launched the moment Skills went public, is aiming to be a network‑addressable catalog of skills that other agents can query and mount remotely instead of bundling everything locally. (openskills launch, skills workshop) Letta AI is already listed alongside Claude Code and OpenCode as a first‑party Agent Skills supporter, which means its agents can discover and invoke the same procedures you define for Claude. letta skills And on the IDE side, the author of OpenCode (opcode) says they held off on their own skills system once they heard a standard was coming, and have now committed to supporting Agent Skills with a planned ship next week. opencode plans The net effect for engineers is that you can start investing in skill files as durable assets—"knowledge modules" that survive model swaps, harness changes, and even vendor changes—rather than throwing away work every time you change where your agent runs. Omar from Dair AI summed it up: "Skills will start to show up everywhere." skills prediction
Oracle’s Open Agent Spec adopts AG‑UI protocol via CopilotKit
Oracle’s Open Agent Spec has been wired into the AG‑UI protocol through CopilotKit, so agents defined once in Oracle’s JSON spec can now be rendered as full interactive UIs with tracing and observability using the same open client runtime. (oracle ag-ui brief, oracle thread)

CopilotKit describes AG‑UI as the "glue" that turns structured agent definitions into working frontends: JSON in, live UI out, with built‑in logging, inspection, and experiment control. a2ui tutorial The Oracle integration means:
- Agent Spec focuses on portability and standardizing what an agent can do, while AG‑UI handles how users see and steer it, including controls, intermediate state, and tool traces. oracle ag-ui brief - Teams can go from a declarative agent JSON to a usable web UI in minutes, which makes it much faster to try new multi‑tool or multi‑step agents without writing bespoke frontends each time. a2ui tutorial - The same AG‑UI client can now talk to Oracle‑defined agents alongside other AG‑UI compatible systems, making it a plausible cross‑vendor UI layer rather than yet another proprietary playground. oracle thread CopilotKit has shipped a starter project plus docs that show AG‑UI taking care of layout, state, and telemetry while Agent Spec and the backend handle the actual planning and tool calls. starter project blog post For AI teams, the interesting part is that this turns "agent UX"—the knobs, traces, and affordances around your model—into something you can standardize and swap, much like Agent Skills is doing for procedures.
📊 Leaderboards and eval suites: cost, tools, and rankings
Fresh third‑party measurements and open tooling. Gemini 3 Flash climbs new boards; Arena and Toolathlon updates; open‑sourced ranking code. Excludes Codex’s launch metrics (in feature).
Arena Search leaderboard adds GPT‑5.2‑Search and Grok‑4.1‑Fast‑Search
LMArena’s Search leaderboard now features OpenAI’s GPT‑5.2‑Search at #2 with a score of 1211 and xAI’s Grok‑4.1‑Fast‑Search at #4 with 1185, both beating their own prior search‑tuned models by 10–17 Elo points. search arena update If you’re building RAG or answer engines, this is a concrete third‑party signal that both vendors’ search‑specialized variants are worth testing against your current stack rather than relying on generic chat models for retrieval-heavy tasks.
Gemini 3 Flash consolidates its lead across multiple third-party eval suites
Today’s wave of third‑party evals—Toolathlon tool use toolathlon chart, Vals AI’s SWE‑bench/MMMU results vals benchmarks, Epoch’s ECI eci chart and AA price‑vs‑Elo plots elo-vs-price scatter—all converge on the same picture: Gemini 3 Flash is now consistently in the top tier of frontier models when you factor in cost.
For AI leads setting 2026 defaults, it’s time to assume 3 Flash (or whatever Google ships next under that pricing) will be one of the main axes in any serious evaluation plan, not a side experiment, even if you still hedge with Opus, GPT‑5.2‑high, or DeepSeek on specific workloads.
GPT‑5.2 and Olmo‑3.1‑32B‑Think join Arena’s text model rankings
Arena has added OpenAI’s GPT‑5.2 (standard, non‑high) to its Text leaderboard at #17 with an Elo of 1439, two points above GPT‑5.1 and one point behind GPT‑5.2‑high. arena text update At the same time, AI2’s Olmo‑3.1‑32B‑Think debuts as a new open‑weights reasoning entry, giving teams another strong non‑proprietary option to A/B against the closed labs. olmo arena For anyone routing traffic by Arena Elo instead of vendor marketing, this is a nudge to start experimenting with 5.2 as a default conversational model and to test Olmo‑3.1‑32B‑Think where openness or self‑hosting matter.
GSO-Bench: GPT‑5.2‑high + OpenHands leads optimization speedup rankings
On the new GSO benchmark for optimization problems, OpenHands paired with GPT‑5.2‑high achieves a 27.4% OPT@1 score (26.5% hack‑adjusted), topping Claude 4.5 Opus + OpenHands at 26.5% and Gemini 3 Pro + OpenHands at 18.6%. gso leaderboard
If you’re using agents to tune hyperparameters, compile constraints, or solve contest‑style tasks, this suggests a 5.2‑high + OpenHands stack is currently the most reliable at finding true improvements over a human baseline on a first attempt, though the benchmark authors also highlight how sensitive these results are to agent design, not just the base model.
K2‑V2 tops Artificial Analysis openness index with competitive intelligence
MBZUAI’s new K2‑V2 70B reasoning model debuts tied for #1 on Artificial Analysis’s Openness Index—matching OLMo 3 32B Think—by releasing weights, pre‑ and post‑training data, and Apache‑licensed code, while scoring 46 on their Intelligence Index in high‑reasoning mode. k2-v2 summary
The model’s medium reasoning mode cuts token usage ~6× for only a 6‑point intelligence drop, and intriguingly performs better on their hallucination‑sensitive AA‑Omniscience test, making K2‑V2 a strong candidate if you want an open model that’s both capable and thoroughly documented for downstream fine‑tuning. k2-v2 analysis
Scale AI releases Audio MultiChallenge for multi-turn spoken-dialogue evals
Scale’s MAI team has open‑sourced Audio MultiChallenge, a 452‑conversation benchmark across four tasks (Inference Memory, Instruction Retention, Self‑Coherence, Voice Editing) designed to stress‑test speech‑native, multi‑turn dialogue models on real, noisy audio. audio benchmark They report that even top models like Gemini 3 Pro only reach ~55% pass rate, with performance dropping 36.5% when answers depend on audio cues (background sounds, prosody) rather than transcript text, and that text‑output modes still outperform speech‑to‑speech generations—highlighting how immature voice‑first agents remain compared with their text counterparts. benchmark paper dataset page
Vals and AA paint a mixed but clearer eval picture for Gemini 3 Flash
Taken together, Vals AI’s index, Toolathlon, Epoch’s ECI and AA‑Omniscience now show a fairly consistent story: Gemini 3 Flash is frontier‑tier on many reasoning, coding and multimodal tasks vals overview toolathon chart but has noticeably worse hallucination behavior on knowledge‑heavy QA. hallucination chart If you’ve already adopted 3 Flash as your default fast model, the practical takeaway is to segment its usage: lean on it heavily for tool‑driven coding, search and UI‑rich workflows, but keep slower, more fact‑reliable models in the loop for anything that looks like long‑form factual judgment or compliance work.
Arena open-sources Arena-Rank, the paired-comparison ranking engine behind LMArena
LMArena has open‑sourced Arena‑Rank, the exact Bradley–Terry and contextual Bradley–Terry implementation they use in production to turn head‑to‑head votes into Elo‑style model rankings, including confidence intervals and utilities for messy real‑world datasets. (arena-rank release, github repo) This means you can now run the same math on your own internal pairwise evals—whether for models, prompts, or agents—instead of bolting together ad‑hoc scoring scripts, and you can audit how Arena’s public leaderboards are computed rather than treating them as a black box. arena-rank blog
Exa publishes People Search benchmark for role- and location-aware profile retrieval
Exa has released an open People Search benchmark that evaluates how well search APIs retrieve the right LinkedIn‑style profiles by role, location and seniority, using 1,400 synthetic queries across nine job‑function categories. people-search brief
They track recall@1, recall@10 and precision over a de‑identified corpus of ~1B profiles, making this a useful yardstick if you’re building GTM tools, recruiting products, or internal people‑search features and want to compare your retrieval stack—including LLM‑reranked hybrid search—against a standardized, task‑aligned suite. (benchmark blog, github benchmark)
MLE-Bench-30 shows GPT‑5.2-Codex underperforming 5.1-Codex-Max on ML engineering tasks
Early MLE‑Bench‑30 results suggest GPT‑5.2‑Codex scores only 10% pass@1 on a 30‑task ML engineering suite, versus 17% for GPT‑5.1‑Codex‑Max and 16% for GPT‑5.2‑thinking without browsing. mle-bench chart
For teams tempted to assume the new Codex variant dominates everywhere, this is a cautionary datapoint: at least on this particular benchmark of end‑to‑end ML workflows, the older 5.1‑Codex‑Max still looks stronger, so you may want to A/B both before flipping your default model for infra and data‑science agents.
⚙️ Serving and runtime: MoE scaling, hybrid APIs, embedded media
Runtime engineering notes: MoE throughput, Ollama‑compatible backends, and microcontroller media SDKs. Mostly systems updates; few core model notes today.
vLLM wide-EP MoE hits ~2.2k tok/s per H200 GPU on multi-node runs
vLLM shared new community benchmarks showing its wide expert-parallel (wide-EP) MoE inference stack sustaining ~2.2k tokens/sec per H200 GPU on multi-node clusters, using DeepEP all‑to‑all, dual‑batch overlap, and expert parallel load balancing with KV‑efficient MLA routing. vllm wide ep thread Following up on Blackwell tuning, this extends their earlier single‑GPU speedups to a realistic cross‑node setting by disaggregating prefill/decoding paths and keeping expert imbalance from stalling whole EP groups.

For infra engineers, the point is: you can now treat DeepSeek‑style MoE as a first‑class serving pattern instead of a research toy, but only if you adopt the full recipe (wide‑EP flag, DeepEP all‑to‑all, KV‑cache affinity, and separate prefill/decode deployments) rather than naïve expert parallelism that gets dominated by collectives and stragglers.
SGLang adds Ollama-compatible API to bridge local and cloud inference
LMSYS released an Ollama‑compatible API for SGLang, so you can point the standard ollama CLI or Python client at an SGLang server by changing OLLAMA_HOST, and get high‑performance inference plus smart routing between local and remote models. ollama api thread This builds on their earlier compact server work mini SGLang and effectively lets you prototype with true Ollama on a laptop, then swap the backend to an SGLang cluster for production without rewriting client code. usage guide For teams already invested in Ollama tooling, this turns SGLang into a drop‑in backend: keep your ollama run workflows, but gain parallel decoding, better batching and a cleaner story for mixing cheap local models with bigger cloud models behind the same API.
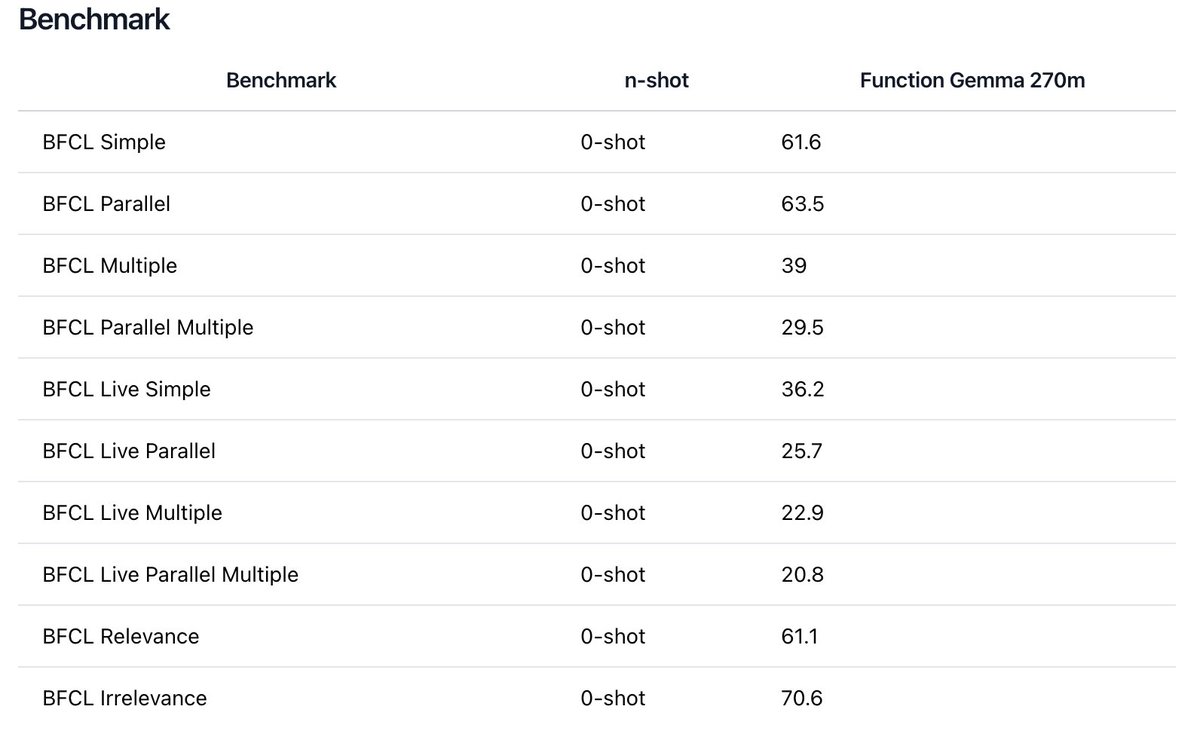
FunctionGemma lands in Ollama for tiny on-device function-calling agents
Google’s new 270M‑parameter FunctionGemma, a function‑calling‑focused Gemma 3 variant, is now available as functiongemma in Ollama v0.13.5, so you can pull and run it locally with ollama pull functiongemma and bind it to tools on laptops or edge boxes. ollama functiongemma tweet The model is designed for low‑latency, offline agent workflows (smart home, mobile, system actions) and ships with examples for JSON‑schema tools in the Ollama model card. model page

For runtime architects, this means you can keep heavyweight reasoning models in the cloud while delegating fast, private function‑calling (like OS automation or home control) to a tiny local model that runs fully on‑device, with the same Ollama tool API you already use for bigger LLMs.
LiveKit and Espressif ship ESP32 SDK for realtime AV on microcontrollers
LiveKit announced a full SDK for Espressif’s ESP32 microcontrollers, using their EXO 1.0 stack to stream realtime audio and video from very resource‑constrained devices into the LiveKit cloud. esp32 sdk tweet The demo shows wearables, smart cameras and avatar intercoms pushing media straight from an ESP32 into LiveKit rooms, with unified APIs across mobile, web and now microcontrollers.blog post
If you’re building embedded agents or on‑device perception, this gives you an off‑the‑shelf way to turn tiny ESP32 boxes into first‑class participants in your AV pipelines, instead of having to bolt on a Raspberry Pi or phone as a relay.
Warp adds Python and Node environment chips for quicker debug context
Warp terminal added "environment chips" that automatically surface your active Python virtualenv path and current Node.js version, plus a toggle to switch Node versions via nvm, directly in the prompt UI. warp env update The short demo shows Warp detecting a .venv for Python projects and letting you flip Node versions without retyping shell incantations before you run tests.
This is a small but practical runtime quality‑of‑life improvement: agents and humans both get an at‑a‑glance view of which interpreter they’re about to use, cutting a bunch of "why is this using system Python" and "wrong Node version" bugs before they waste cycles.
🏗️ AI infrastructure build‑out and power economics
Concrete moves linking national labs and vendors, plus power stack visibility. Signals on where capacity and efficiency will come from; not a funding roundup.
DOE’s Genesis Mission signs AI lab MOUs to double scientific output
The US Department of Energy’s Genesis Mission is now formally partnering with OpenAI, Google DeepMind, Anthropic, NVIDIA and Groq to pair frontier models with national‑lab supercomputers and target roughly a 2× boost in scientific productivity by 2030. (deepmind genesis summary, openai mou quote, anthropic partnership note, groq mission thread, nvidia genesis blog) This follows OpenAI’s own framing of 2026 as a “Year of Science” and its push to get frontier models closer to real research environments. (openai year-of-science, compute flywheel)

The MOUs set up information‑sharing and follow‑on agreements so labs can run things like fusion plasma simulations, climate models, and materials discovery directly on DOE machines using vendor models and tooling, with OpenAI already testing GPT‑5‑series reasoning on Los Alamos’s Venado system and in a 1,000‑scientist “AI Jam”. openai mou quote openai science blog DeepMind is pitching Gemini 3 for physics and chemistry workloads, while NVIDIA is bringing its full accelerated stack plus open domain models like Apollo and Nemotron into the program, explicitly tying its hardware roadmap to US‑led scientific compute. (deepmind genesis summary, nvidia genesis blog) nvidia genesis blog Groq’s role is to pilot energy‑efficient, deterministic inference for lab‑side agents and simulations, aiming to cut power per unit of reasoning, not just add more GPUs. groq mission thread Anthropic commits Claude plus a dedicated engineering team across energy, biosecurity and basic research so that lab groups get help building actual workflows, not just API keys. anthropic partnership note
For teams building on top of these vendors, the signal is that a lot of near‑term capacity and optimization work will be skewed toward scientific and national‑lab workloads, not just consumer chat. It also means the reference architectures coming out of DOE—how to wire models into HPC codes, safety reviews, and high‑assurance workflows—are likely to filter back into commercial best practice over the next 12–24 months, especially for companies trying to justify big AI capex to regulators and boards.
Epoch: GPUs only ~40% of AI datacenter power once overheads included
Epoch AI broke down where electricity actually goes in a frontier AI datacenter and estimates that GPUs account for only about 40% of total power once you include server overhead, networking fabric, and cooling plus power‑conversion losses. (epoch power thread, power tweet followup) That complements their earlier grid‑level work on how much AI load the US system can absorb by 2030. grid study The group models three big multipliers on top of raw GPU draw: servers use roughly 1.5× more power than the accelerators alone once you add CPUs, fans, storage and local interconnect; non‑server IT like top‑of‑rack and spine switches adds another 1.14×; and then cooling plus power‑conversion and other facility overhead piles a further 1.4× on top. (epoch power thread, power tweet followup, power usage article) In other words, a rack full of GPUs that nominally needs 1 MW at the chip level ends up closer to 2.4 MW at the wall. That ratio matters when you’re planning substations, transformers and long‑lead equipment, not just ordering more accelerators.
For infra engineers and AI leads, the point is: efficiency gains on any one layer (cooling, networking, server design) compound across the stack, while sloppy design in one place can wipe out GPU‑level efficiency wins. It also means power‑aware scheduling and model placement—e.g. co‑locating latency‑sensitive work on more efficient pods—has real room to move the needle on both cost and environmental footprint, even if you can’t touch model architectures directly.
64 GB DDR5 kit spikes from ~$150 to ~$800 in three months
Retail pricing for a popular Crucial 64 GB DDR5 kit has climbed from roughly $150 to nearly $800 in about three months, according to a widely shared price‑history chart. ddr5 price chart
The chart shows the kit hovering in the low‑$200 range through September before a steep, almost vertical run‑up into the high‑$700s by mid‑December, with the current new price around $640 and recent peaks near $798. ddr5 price chart There’s no hard attribution baked into the data, but the timing lines up with mounting AI workstation builds, rapidly densifying inference servers, and OEMs hoarding high‑capacity DIMMs for Blackwell and similar GPU nodes rather than letting them hit consumer channels. For individual engineers, the impact is direct: upgrading local dev rigs to 64–128 GB is suddenly a lot more expensive, and for smaller shops trying to stretch on‑prem clusters, memory—not GPUs—may become the next visible bottleneck.
For infra and procurement teams, this is one more signal that AI demand doesn’t just stress GPU supply; it also distorts adjacent components like DRAM and power gear. Locking in memory contracts or designing models and serving stacks that can tolerate lower per‑node RAM (through sharding or more aggressive KV eviction) may be as important as chasing the latest accelerator SKU over the next year.
📥 Data plumbing: OCR, parsing tiers and robust JSON
Document intelligence and data extraction saw multiple concrete upgrades; also pragmatic guardrails for structured outputs. Useful for RAG and ETL pipelines.
Mistral OCR 3 pushes SoTA document understanding at $1–2 per 1k pages
Mistral released OCR 3, a new document-understanding model that clearly beats major enterprise OCR systems from AWS, Azure, Google DocAI and DeepSeek on forms, invoices, handwriting, complex tables and historical scans, with scores like 95.9% on forms and 88.9% on handwriting versus competitors in the low‑70s or 80s benchmark recap. It’s exposed as mistral-ocr-2512 via the API and a Document AI playground in Mistral Studio, priced at $2 per 1,000 pages (or $1 per 1,000 via batch mode), and returns both clean text and rich structure such as markdown with HTML‑style table reconstruction including row/col spans, which is exactly what RAG and ETL pipelines need to keep schema alignment on messy real‑world PDFs studio launch pricing summary.
For AI engineers, this means you can probably rip out a lot of brittle custom parsing around invoices, forms, handwritten notes and low‑quality scans, and let OCR 3 handle both recognition and layout so your downstream indexers just consume markdown/tables rather than PDFs or ad‑hoc JSON capability overview Mistral blog post.
Firecrawl launches /agent for autonomous web navigation and dataset extraction
Firecrawl unveiled /agent, a research‑preview API that takes a natural‑language description (optionally with a starting URL) and then autonomously searches, clicks, paginates and scrapes the web to return structured data, rather than raw HTML agent launch. In their examples, the agent accomplishes in minutes what would normally be hours or days of manual browsing and copy‑pasting, targeting use cases like building large domain‑specific datasets, multi‑site aggregation, or deep research for downstream RAG capability summary agent docs.

For AI engineers, this is effectively a programmable "web ETL" layer: instead of writing one‑off scrapers per site, you describe the schema or fields you want and let the agent handle navigation and anti‑scraping quirks, then feed the resulting JSON or rows straight into your index, warehouse, or labeling pipeline scale example.
OpenRouter ships Response Healing to auto‑repair malformed JSON from LLMs
OpenRouter introduced Response Healing, a plug‑in that automatically fixes malformed JSON from any upstream model—handling things like trailing commas, missing brackets and bad escaping—before the response hits your app, based on observations from over 5M structured requests last week feature launch. Their benchmarks show defect rates dropping by 80%+ across a mix of OpenAI, Google, Anthropic and open models, with sub‑millisecond latency overhead and zero changes required to your prompts or schema tooling overhead note defect stats.
Today it only repairs syntax, not schema validity, but for any production system that depends on response_format=json or tool‑calling outputs this is an immediate reliability win—you toggle it on in OpenRouter settings and start burning fewer retries, writing fewer regex band‑aids, and filing fewer “LLM forgot a quote” bug tickets healing blog.
NotebookLM adds Data Table artefact and one‑click export to Sheets
Google’s NotebookLM quietly added a Data Table artefact type that lets the model turn unstructured notes and reports into structured tables, which you can then export directly into Google Sheets; notes and longform reports can also now be exported into Docs and Sheets for further processing feature screenshot. This matters if you use NotebookLM as a research scratchpad: instead of manually rebuilding tables from prose summaries, you can have the model synthesize a proper tabular view once, ship it to Sheets, and plug it into your existing analytics or ETL flows upgrade tease.
It’s not a replacement for heavy‑duty OCR or schema‑aware parsers, but it does give product teams a fast path from raw source material inside NotebookLM to CSV‑like structure that other tools can consume without extra glue code export reminder.
💼 Capital flows and enterprise platform moves
Material financing rumors and enterprise distribution updates. Mostly OpenAI financing chatter and app platform news; includes a notable Series B.
OpenAI explores tens of billions in new funding at ~$750B valuation
OpenAI is reportedly in early talks to raise tens of billions of dollars at a valuation around $750B, with internal figures citing roughly $19B annualized revenue as of late 2025. valuation summary Following up on compute flywheel, where they tied multi‑GW data center buildout to revenue growth, this cements OpenAI as one of the most valuable private companies on earth and signals how aggressively they plan to finance future compute and model training.
For AI leaders, this implies OpenAI expects continued demand for frontier models at a scale that justifies both the capital and the power buildout, and it gives a rough revenue benchmark for what "winning" looks like in consumer and enterprise AI right now. Analysts should read this as confirmation that the capital flywheel—money → compute → better models → more money—is still spinning, with valuations now being justified on the back of real revenue rather than only expectations. funding analysis
Amazon in talks to invest ≥$10B in OpenAI and supply Trainium chips
Bloomberg and others report that Amazon is in initial talks to invest at least $10B in OpenAI, in a deal that would also see OpenAI adopt Amazon’s Trainium accelerators for some workloads. amazon talks This would build on the earlier $38B cloud agreement and, if completed, value OpenAI north of $500B, effectively deepening a compute‑for‑equity style partnership similar to Microsoft’s and Google’s arrangements with other labs, and extending the story from Amazon funding.
For infra and strategy teams, the takeaway is that Amazon seems determined to make Trainium a first‑class alternative to NVIDIA in large‑scale inference and training, and OpenAI is happy to multi‑home if it reduces GPU dependence. deal rumor If this closes, expect Trainium support to show up on OpenAI’s internal stack, which matters if you’re betting on specific hardware ecosystems for on‑prem or hybrid deployments that need to stay compatible with leading models.
Lovable raises $330M Series B at $6.6B to scale no‑code AI app platform
Lovable announced a $330M Series B at a $6.6B valuation, led by CapitalG and Menlo’s Anthology fund, with strategic checks from NVentures (NVIDIA), Salesforce Ventures, Databricks, Deutsche Telekom, Atlassian, HubSpot and others. series b thread The company positions itself as an AI‑native builder tool for "the 99%"—non‑coders inside startups and large enterprises—so this war chest is aimed squarely at turning their AI app‑builder into a mainstream platform.
For AI teams, this is a signal that investors see durable value not just in frontier models but in verticalized "AI OS" layers where non‑technical staff assemble workflows, internal tools, and small apps without writing code. The strategic investor mix (NVIDIA, Databricks, Atlassian, HubSpot) suggests Lovable will keep leaning into deep integrations with existing SaaS, making it easier for enterprises to standardize on a single AI app‑building surface instead of a sprawl of bespoke agents and internal tools. (investor breakdown, founder reflection)
Amazon restructures AI into unified AGI division under Peter DeSantis
Amazon is restructuring its AI efforts into a single AGI division that combines frontier model research, custom silicon (Trainium) and quantum computing under longtime AWS leader Peter DeSantis, while current AGI chief Rohit Prasad departs. amazon agi reorg Robotics veteran Pieter Abbeel will oversee the frontier model team, and the group reports directly to CEO Andy Jassy.
For AI engineers and infra planners, this means Amazon is now set up more like a focused AI lab inside a cloud giant: model research, chips, and infra in one org. That should reduce the friction between model needs and silicon roadmaps, and it raises the odds that Trainium and future ASICs are tightly co‑designed with the models they’ll run. It also signals Amazon intends to compete head‑on with OpenAI/Microsoft and Google/DeepMind not just as a cloud for AI, but as a first‑party model and agent provider.
OpenAI sells 700k+ ChatGPT licenses across ~35 US public universities
Documents cited by Techmeme show OpenAI has sold 700,000+ ChatGPT licenses to roughly 35 US public universities, with students and faculty using it more than 14M times so far. university licenses These are paid institutional seats, not just casual free usage, so this is one of the first concrete adoption snapshots for AI assistants in higher education.
For AI product people, this highlights universities as a serious early enterprise vertical: they are willing to buy at scale for students if you can bundle access, governance, and usage reporting. For leaders, it’s also a reminder that competing education‑focused tools need to be positioned either as safer, more controllable layers on top of ChatGPT, or as domain‑specific assistants that can justify their own license line item against OpenAI’s already‑embedded seat counts.
Morningstar and PitchBook ship financial data apps into ChatGPT
Morningstar and PitchBook launched official apps inside ChatGPT, letting users query equity and private‑market data using natural language rather than flipping between terminals. morningstar pitchbook The deal plugs two of the most widely used investing datasets straight into OpenAI’s new Apps framework, so any ChatGPT user on supported plans can pull fundamentals, valuations, and deal data inline while they chat.
This follows Apps directory, where OpenAI opened the ChatGPT Apps directory to third parties, and shows the kind of "serious" integrations that can live there beyond consumer search and creativity. For fintech and analytics teams, it’s a preview of how vertical data vendors will defend their moats: by becoming first‑class ChatGPT apps, not just external dashboards, and by letting AI agents orchestrate their APIs under the hood.
Perplexity launches desktop‑grade iPad app for AI research and browsing
Perplexity released a new iPad app that brings the full desktop feature set—Labs, Deep Research, Finance, Spaces and more—to iPadOS, optimized for split‑screen and Stage Manager workflows. perplexity ipad app The app is pitched as a serious productivity surface, not just a mobile wrapper, so power users can keep long research sessions and structured outputs on tablet hardware.

For AI product teams, this is another data point that "AI browsers" are trying to live everywhere people work, not just on laptops. If your users already sit in an iPad‑heavy environment (field work, education, healthcare), Perplexity just became a more credible default assistant there, and you may want to think about whether your own agents integrate with, compete with, or piggyback on that usage pattern.
Sora video app rolls out across 10 Latin American countries
OpenAI’s Sora video app is expanding beyond its original markets into 10 Latin American countries, including Mexico, Argentina, Chile, Colombia and Peru. sora launch tweet The official announcement frames this as the start of a broader international rollout, inviting local creators to start using Sora for short‑form video.
For platform strategists, this matters because Sora now competes more directly with regional creator tools and with model‑backed video products from Meta and Google in fast‑growing markets. If you operate in media, education or marketing in LATAM, you should expect an uptick in Sora‑generated content and consider how to accept, flag, or verify these videos inside your own products.
🎙️ Realtime voice stacks: accuracy, controls and hosting
Voice‑to‑voice APIs and production hosting updates. Pricing/latency and enterprise posture in focus; fewer creative audio items today.
Grok Voice Agent tops speech reasoning benchmark and posts strong latency profile
xAI’s Grok Voice Agent now has detailed public evals from Artificial Analysis, confirming it as the top speech‑to‑speech model on the Big Bench Audio reasoning suite at 92.3% accuracy while staying among the fastest models to first audio output. Following up on Grok launch, which introduced the flat $0.05/min API, the new charts show Grok ahead of Gemini 2.5 Flash Native Audio (92.1%) and Nova Sonic (87.1%) on reasoning, with ~0.78s time‑to‑first‑audio—just behind the fastest Gemini 2.5 Flash variants and ahead of GPT Realtime tiers. benchmarks thread
For infra teams, the more interesting angle is pricing and operating envelope: Grok charges $3/hour for both input and output audio, landing near the middle of the pack on raw cost but at the very top of the quality charts. benchmarks thread It also supports tool calling and SIP telephony integrations (e.g. Twilio, Vonage) out of the box, which makes it viable as a drop‑in backend for phone agents and call centers where reasoning accuracy, not only speed, determines business value. capability overview For 2026 voice stacks, this positions Grok as a premium‑quality but still straightforwardly priced option when you care about hard questions, not small‑talk bots.
Scale AI releases Audio MultiChallenge benchmark for multi‑turn voice reasoning
Scale AI’s MAI team open‑sourced Audio MultiChallenge, a new benchmark for evaluating spoken conversational intelligence in realistic, noisy, multi‑turn settings. benchmark overview It extends their earlier text‑only MultiChallenge suite into audio, covering 452 multi‑turn conversations from 47 speakers across four task families: inference memory, instruction retention, self‑coherence, and a new Voice Editing axis that checks whether models can handle in‑utterance repairs like “two… no, make it six apples.”
Early results show that even frontier models top out at around a 55% pass rate, with a sharp drop‑off when tasks require recalling background audio cues or paralinguistic signals instead of just transcript text—Scale reports a 36.5% accuracy hit on these audio‑cue tasks. benchmark overview For anyone building speech‑first agents, this provides a much more realistic yardstick than casual chat demos and will likely become a go‑to regression suite for testing new end‑to‑end voice stacks and realtime routing policies. The team also released the paper, dataset, and leaderboard so infra groups can plug their own systems into the same evaluation harness.benchmark paper dataset repo
Together AI hosts Rime Arcana v2 and Mist v2 for production TTS
Together AI is now hosting Rime Labs’ Arcana v2 and Mist v2 text‑to‑speech models, giving teams a production‑grade, centrally managed voice layer with deterministic control and compliance guarantees. hosting announcement Arcana v2 focuses on expressive, human‑like voices trained on over a billion real conversations, while Mist v2 adds deterministic pronunciation controls so you can define how a word should sound once and have that rendering reused consistently across 40+ voices—critical for names, brands, and domain jargon. model capabilities Arcana and Mist are already powering tens of millions of calls per month in Rime’s own stack, and Together brings them into a cloud that’s SOC 2, HIPAA‑ready, and PCI compliant, which matters if you’re putting these behind healthcare or fintech contact flows. hosting announcement For voice‑agent builders already using Together for LLMs or STT, this reduces latency and cross‑cloud complexity by co‑locating all three layers—LLM, speech recognition, and speech synthesis—on one provider, while still letting you swap in open‑weight or other commercial models where needed via the same account.Together blog post
ElevenLabs adds Versioning control plane for voice agents
ElevenLabs introduced Versioning for its Agents platform, a control layer that tracks every configuration change, supports diff views, and lets teams stage rollouts of new agent versions. versioning launch Each agent now carries a version history with editor‑level attribution and timestamps, so you can see exactly who changed prompts, tools, or routing rules and when.

The system also adds traffic controls so you can canary new versions—routing only a slice of calls to a fresh configuration before promoting it to 100% if metrics hold up. versioning launch That’s especially important in voice, where a bad update can instantly affect thousands of live phone conversations. Compliance teams get reproducible records of which version handled which calls, simplifying audits and incident investigations. history modal For anyone running multi‑channel voice agents on ElevenLabs (web, phone, WhatsApp), Versioning turns previously ad‑hoc prompt and tool tweaks into something closer to a proper release pipeline.
LiveKit and Espressif ship ESP32 SDK for tiny realtime AI voice endpoints
LiveKit partnered with Espressif to ship a full LiveKit SDK for ESP32 microcontrollers, bringing realtime media and AI‑ready connectivity to very small, low‑power devices. sdk announcement The SDK is optimized for streaming audio and video from wearables, intercoms, and smart cameras into LiveKit rooms where LLMs, STT, and TTS can run on servers, while the devices handle only capture, playback, and minimal logic.
From a voice‑stack perspective, this is a way to push the “edge” of your system all the way down to $5–$10 hardware without rewriting transport or NAT traversal logic. You get the same signaling, SFU, and session semantics as web and mobile LiveKit clients, which means you can test and host one set of AI voice agents while swapping front‑ends between browser, phone, and embedded endpoints. For teams designing hardware companions or kiosk‑style assistants, this removes a lot of the bespoke WebRTC and TLS plumbing that usually slows down experiments.
🎬 Creative media pipelines and layered edits
A dense stream of practical gen‑media releases and comparisons—video modification, cinema‑style workflows, layered image decomposition, and community A/Bs.
Qwen-Image-Layered auto-splits images into editable RGBA layers
Alibaba’s Qwen-Image-Layered work tackles one of the biggest pain points in AI art workflows: getting clean layers. The model decomposes a flat image into multiple semantically disentangled RGBA layers—background, subject, logos, text blocks, decorative elements—so you can recolor, resize, remove or move each part independently without re‑rendering the whole scene. paper highlight
The paper demo shows a busy promo poster being split into background burst, character, title text, callouts and logo, then edited by recoloring the backdrop, swapping the shirt color, deleting lemons, resizing a badge, and repositioning labels without harming other content. ArXiv paper For production design and marketing teams, that’s the holy grail: take a single master render, then localize it for markets and formats like you would a Photoshop PSD. The obvious next step is wiring this into tools like Figma, Photoshop, or Comfy graphs so you can treat model outputs as true layered assets instead of dead-end bitmaps.
Bria Video Eraser lands on fal for object and person removal
Bria’s Video Eraser is now live on fal, offering a practical “content‑aware fill for video” that can remove objects or people while preserving background realism and temporal consistency. launch summary You can drive it three ways: natural‑language prompts (“remove the red car”), manual masks, or sparse keypoints for fine control. prompt eraser

For creative shops, this slots neatly into existing pipelines as the clean‑up stage: erase boom mics, bystanders, license plates, or logos without rerunning a full generation model or hand‑painting every frame. Because it’s on fal, you also get REST + SDK access and can script batch passes across a library. The main thing to test is how well it handles hard shots—motion blur, fast pans, or occluded limbs—before you trust it in a fully automated loop.
GPT-Image-1.5 plus Kling 2.5 emerges as a character-consistent video stack
Creators are converging on a two‑stage pipeline where GPT‑Image‑1.5 handles stills and Kling 2.5 handles motion: use GPT‑Image‑1.5 in ImagineArt to generate consistent keyframes of a character or scene, then feed those stills into Kling 2.5 for smooth animated shots, following up on earlier reports of sharper, identity‑preserving edits with OpenAI’s new image model. (edit gains, workflow thread)

ImagineArt wired GPT‑Image‑1.5 in on day one and is even offering a week of unlimited usage, which lowers the barrier to experimenting with multi‑shot sequences and camera moves. free week note What you get in practice is total character consistency plus cinematic transitions: the still model locks in faces, outfits and props, while Kling handles timing, interpolation and scene motion. If you’re building creative tooling, this is a strong pattern to copy: specialize one model for images, another for motion, and design your UX around stitching them rather than waiting for a single monolithic video model to do everything.
Higgsfield Cinema Studio brings camera, lens and move presets to browser video
Higgsfield’s new Cinema Studio product went live, packaging six pro camera bodies, eleven lenses, 15+ director-style camera moves, and 4K output into a browser UI aimed at film‑style AI shots. launch thread It’s designed so you describe the scene, then pick cameras, glass and movements like you would on a set, rather than fiddling with raw CFG knobs. workflow breakdown The upshot is that you can build repeatable cinematography pipelines: grid out multiple angles of the same scene, lock in a virtual kit (say, ARRI body + 35mm lens + dolly in), then re‑use that template across campaigns. Creators are already using it to rapidly iterate looks, then handing chosen stills off to animation tools. creator reaction For teams who’ve been hacking together storyboard → stills → video flows, Cinema Studio gives you something closer to a proper shot list and lens package sitting on top of the model.
LMArena spins up community A/Bs of GPT-Image-1.5 vs Nano Banana Pro
Arena turned the ongoing GPT‑Image‑1.5 vs Nano Banana Pro debate into a structured, community‑driven compare lab, following up on earlier one‑off tests of the two image models. vs Nano Banana Their image arena now serves paired outputs for the same prompt—everything from “hand with 7 fingers + clock at 8:22 + full glass of wine” to Feynman polaroids, Einstein selfies and detailed GDP slides—and lets people vote on which side wins. arena intro
Because every prompt is fixed and the UI hides which model is which, this gives a more honest signal than cherry‑picked Twitter grids. Over time, those votes feed into Arena’s image leaderboard, so you can see if, say, Nano Banana really dominates on infographics and text rendering while GPT‑Image‑1.5 wins on multi‑character realism, or whether that impression holds up. For teams choosing a default image backend, this is an easy place to send your own prompts, inspect artifacts (hands, text, small objects), and decide when to route different asset types to different models instead of picking a single winner. prompt catalog
Luma launches Ray 3 Modify for character swaps in existing videos
Luma quietly shipped Ray 3 Modify, a video model that edits existing clips by swapping in new characters from reference images, rather than generating footage from scratch. This is pitched as "inject yourself everywhere now" and is currently available on Luma’s paid plans. launch note

For builders, this is a practical video-mod pipeline: you keep camera motion, lighting, and timing from the source video, and only change who appears in-frame. That’s ideal for UGC remixes, ad localization, and character testing without rebuilding shots. The main questions to probe now are temporal consistency (does the identity stay stable across frames?), edge cases like occlusions, and how well it handles multi-person scenes versus solo subjects. If you’re already using Ray 3 for generation, this is the obvious second tool in that stack for post-hoc edits instead of re-renders.
ComfyUI adds Template Library of real-world workflows and open-source graphs
ComfyUI introduced a new Template Library: a curated set of graph workflows aimed at concrete creative tasks (stylized portraits, product shots, multi‑step video chains), rather than bare model demos. template overview The templates are fully open‑source and can be downloaded to run in local ComfyUI installs, following up on Comfy’s earlier Manager UI work to tame big graphs. manager ui

Each template encodes a full pipeline—models, samplers, control nets, post‑processing—so instead of wiring from scratch, you start from a proven node graph and tweak. A follow‑up note confirmed that all templates live in a public repo, and that the team plans clearer tags for which ones depend on custom nodes, to avoid environment conflicts for local users. local usage note If you’re building your own internal Comfy graphs, this is a useful pattern: share them as tasks (“stylize product shot”, “erase background and relight”) rather than as abstract model playgrounds so non‑experts can actually adopt them.
Gamma bakes Nano Banana Pro into its deck builder with sharp in-slide text
Presentation tool Gamma is now leaning on Nano Banana Pro for all its in‑slide imagery, and has made NB Pro free to use regardless of tier. gamma overview The pitch is simple: NB Pro finally renders logos, UI mockups and tiny product labels cleanly enough that you can trust AI images inside slides, not just as mood boards.
In practice, Gamma’s flow looks like: generate the outline and layout in their AI deck builder, then call Nano Banana Pro for the visuals that sit alongside text, charts and code samples. usage note If you ship any product where images and dense text share the same canvas—pitch decks, spec docs, marketing one‑pagers—this is a good reference pattern: pair a layout engine with an image model whose typography and small glyphs are actually legible.
Runway Gen-4.5 video model appears inside Adobe Firefly Boards
Adobe’s Firefly Boards picked up support for Runway’s Gen‑4.5 video model, letting Firefly users call Gen‑4.5 from within Adobe’s own storyboard‑style interface. integration note The short clip shows Firefly Boards invoking Gen‑4.5 to produce high‑fidelity video snippets directly in a board, instead of exporting prompts to a separate Runway UI.

For teams already entrenched in Adobe’s ecosystem, this matters more than raw model news: it means you can keep your planning, asset management and review inside Firefly, but still tap into a state‑of‑the‑art third‑party generator for final motion. It also hints at a future where creative tools become model routers, swapping in different backends per shot while preserving one UX, rather than forcing editors to pick sides between Gen‑4.5, Veo, Sora or Wan.
Seedance Pro 1.5 claims new SOTA lip-sync for character video
Seedance Pro 1.5 was highlighted as “the AI lip‑sync problem is officially solved,” with the model positioned as the new state of the art for matching mouth movements, character expressions and audio in video. model announcement The demo shows native lip shapes, emotions and head motion keeping tight sync with the spoken track, even under camera motion.
For creative media pipelines, this kind of model slots in after image or video generation: you generate a talking head or character animation with rough mouth movement, then run Seedance Pro 1.5 to correct phonemes and timing. That reduces how often you need to regenerate entire clips just to fix a few bad syllables, and opens up workflows like localizing dialogue across languages while keeping a consistent performance.
📑 Methods and agents: memory, long‑context and hybrid decoding
A strong wave of new papers: constant‑memory agents, long‑context test‑time tuning, draft‑then‑verify decoding, video RL, and AR→diffusion adaptation. Practitioner‑leaning summaries.
MEM1 trains constant‑memory long‑horizon agents with 3.5× better performance
MEM1 is a reinforcement‑learning framework that teaches agents to keep a single compact internal state across arbitrarily long tasks, instead of appending every observation into context. On a 16‑objective multi‑hop QA benchmark, a 7B MEM1 agent delivers 3.5× higher task success while using 3.7× less peak memory than Qwen2.5‑14B‑Instruct, and on WebShop navigation it beats AgentLM‑13B with 2.8× lower token usage. paper thread
Instead of external memory modules or growing prompts, MEM1 uses PPO with masked trajectories: after each turn the model updates its internal state and discards all prior states, observations, and actions, so inference cost stays effectively constant even as horizon length increases. paper thread For builders, this is a concrete recipe for turning today’s LLM agents into always‑O(1) memory systems on long‑running tasks without changing the base model architecture, which is exactly the failure mode many current agent stacks hit first.
Meta’s qTTT test‑time training boosts long‑context Qwen3‑4B by 12–14 points
Meta and collaborators propose query‑only test‑time training (qTTT) for long‑context models, arguing that “just putting more in context” causes score dilution as attention spreads over many similar tokens. paper overview Instead of fine‑tuning the whole model, they cache keys/values once and update only the query weights at test time so the model learns to lock onto the truly relevant parts of a huge prompt.
On LongBench‑v2 and ZeroScrolls, qTTT lifts Qwen3‑4B by +12.6 and +14.1 points respectively, while leaving the base weights unchanged. paper overview For anyone fighting degraded accuracy at 100k+ tokens, this points to a new knob: spend a little extra compute adapting the query to the current document, instead of spending a lot more compute on longer prompts or full fine‑tunes.
CANOE uses synthetic QA + RL to cut RAG hallucinations and beat GPT‑4o
CANOE reframes contextual faithfulness as a synthetic RL problem: it auto‑generates millions of short‑form QA examples from Wikidata and then trains a model to stick to provided context using a Dual‑GRPO objective. method summary The result is a 7B model that outperforms GPT‑4o and o1 across 11 faithfulness benchmarks, without a single human‑labeled example.
By supervising both short answers and longer rationales, CANOE learns to quote and reason from sources instead of free‑associating, and its rewards explicitly penalize unsupported claims. method summary For people building RAG systems, this is a concrete template: generate cheap synthetic QA from your own KB, then run RL on top to make your model “allergic” to going off‑script.
CANOE’s Dual‑GRPO RL unifies memory and reasoning for faithful long‑context use
(This topic is merged into the earlier CANOE entry for contextual faithfulness; see that summary for details.)
DEER proposes draft‑with‑diffusion, verify‑with‑AR decoding for language models
DEER (Draft with Diffusion, Verify with Autoregressive Models) introduces a hybrid decoding scheme where a diffusion‑style model proposes candidate text blocks and a conventional autoregressive LM scores and filters them. teaser clip That way you get diffusion’s ability to refine whole chunks at once, while using the AR model as a familiar “truth oracle.”

The paper positions this as a way to escape the strict one‑token‑at‑a‑time autoregressive bottleneck without throwing away existing AR models and their tooling. ArXiv paper For practitioners, DEER is more a pattern than a product today, but it is worth watching if you care about decoding speed vs. controllability: you can imagine swapping in your production AR model as the verifier while experimenting with different draft‑time samplers.
NBDiff‑7B adapts AR LLMs into block‑diffusion models with 78.8 avg score
The NBDiff work treats classic autoregressive generation as a one‑token special case of block diffusion, then shows you can gradually morph an AR LLM into a block‑diffusion model without starting from scratch. thread summary They keep past tokens causal across blocks, allow bidirectional attention within each block, train all blocks in parallel, and add an auxiliary AR loss so the model doesn’t forget what it already knows.
Instead of training a diffusion LM from zero, they adapt a pre‑trained 7B AR model into NBDiff‑7B‑Instruct, which jumps from a 64.3 to 78.8 average score across their task suite. thread summary That’s a sizable gain for a modest extra training budget, and it suggests a practical path toward block‑level diffusion decoders that still behave like your existing LLM. ArXiv paper
IC‑Effect shows precise video effects editing with pure in‑context learning
IC‑Effect tackles video effects editing—adding or modifying effects at precise times and regions—using only in‑context learning, no task‑specific fine‑tuning. paper link Given a few example clips showing the desired effect behavior, the model learns to apply similar edits to new videos with fine temporal and spatial control.
The interesting part for method‑minded folks is the pattern: complex, structured video transformations are framed as “few‑shot programs” embedded in the prompt, which the model then imitates. ArXiv paper If you’re working on multimodal agents, IC‑Effect is a strong data point that prompt‑as‑program can extend well beyond text and images into time‑based media.
Model‑first reasoning agents cut hallucinations by forcing explicit world models
The Model‑First Reasoning LLM Agents paper argues that many agent failures are representation errors, not planning errors: the model is improvising on a fuzzy understanding of the task. paper abstract Their fix is to force agents to first write down an explicit, symbolic problem model—objects, actions, preconditions, effects, and constraints—before planning any steps.
Across scheduling, routing, resource allocation and logic puzzles, this “world‑model then plan” setup yields more consistent, constraint‑respecting plans and fewer silent hallucinations. paper abstract If you’re already using tools and JSON schemas in agents, this paper is a push to go further: make the agent synthesize and maintain a checkable problem model as a first‑class artifact, not just a hidden chain‑of‑thought.
SAGE trains any‑horizon video agents that beat baselines by ~6–8%
SAGE (Smart Any‑horizon aGEnts) is a reinforcement‑learning recipe for long video reasoning: instead of treating every frame equally, the agent learns policies for when to look, what to remember, and when to stop. tweet summary It’s explicitly designed so the same agent can handle short and very long clips without architectural changes.
On curated long‑video benchmarks, SAGE‑7B improves accuracy by about 6–8 percentage points over strong baselines, while using a bounded number of reasoning steps per clip. tweet summary For anyone experimenting with video‑centric agents—surveillance, sports analysis, or lecture QA—this is a concrete template for policy‑driven glimpsing and memory management rather than brute‑force frame processing.
🛡️ Safety, monitoring and content provenance
New monitoring work and platform guardrails. Today centers on CoT monitorability, controlled cyber rollout, and watermark checks in consumer tools.
GPT‑5.2‑Codex boosts cyber capabilities as OpenAI gates access to defenders
OpenAI’s new GPT‑5.2‑Codex significantly improves on previous Codex models for professional capture‑the‑flag (CTF) style security challenges and vulnerability discovery, prompting the company to roll it out cautiously with a trusted‑access program for defensive teams. codex cyber note The launch blog notes that the model beats GPT‑5.1‑Codex‑Max on a proprietary professional CTF eval while still sitting below their internal “High” cyber‑capability threshold under the Preparedness Framework, so it is enabled in Codex for paid ChatGPT users now while API access will follow more slowly. codex launch blog
OpenAI highlights a recent case where a security researcher used GPT‑5.1‑Codex‑Max with the Codex CLI to help find and responsibly disclose a React Server Components vulnerability (now CVE‑2025‑55183) that could expose source code, via an expert‑guided loop of repository scanning, harness construction, fuzzing and human verification. sama ctf chart The GPT‑5.2‑Codex blog doubles down on this pattern by publishing a detailed workflow diagram for using Codex in vuln research, but pairs it with an invite‑only program for vetted defensive security teams so that powerful exploit‑finding behavior is channeled toward patching and audits rather than broad self‑serve use. trusted access note For AI leads, the message is clear: Codex is now potent enough in security domains that you must treat it like dual‑use tooling, with access control, logging, and policy guardrails if you point it at production codebases.
OpenAI publishes chain-of-thought monitorability evals across 24 environments
OpenAI released a dedicated framework and benchmark suite for measuring how well models’ chain-of-thought (CoT) traces can be monitored, covering 13 evaluations across 24 environments and comparing CoT‑only monitoring to watching actions or final answers. cot announcement The study finds that inspecting CoT is substantially more effective for catching problems than monitoring actions/outputs alone, and that longer reasoning traces increase monitorability rather than hiding intent. openai cot blog
For GPT‑5, “all messages” and “CoT‑only” monitors reach g‑mean² around 0.8 at long CoTs, versus ~0.5 when monitoring actions only, and similar trends appear across o3/o3‑mini and other reasoning models. monitoring charts That matters for safety work that wants models to think in the open: it gives quantitative backing to the idea that encouraging explicit reasoning makes oversight easier, not harder. The work also benchmarks multiple model families, showing that newer reasoning‑optimized models like o3‑mini and GPT‑5 have the most monitorable CoTs, which is useful input for teams choosing a “default” model where internal supervision will matter.
Reasoning‑style poisoning paper shows style-only attacks and RSV monitors
A new paper on “Reasoning‑Style Poisoning” (RSP) demonstrates that you can derail LLM agents not by changing facts, but by rewriting retrieved text into harmful styles like “analysis paralysis” or overconfident haste, and that standard prompt‑injection and content filters mostly miss it. rsp summary The authors introduce Generative Style Injection (GSI), which rewrites supporting documents into different reasoning tones, leading an agent to either loop excessively (up to 4.4× more reasoning steps) or jump to wrong answers faster, even though the underlying factual content is untouched.arxiv paper
To defend, they propose Reasoning Style Vectors (RSV) that summarize process patterns—like repeated tool calls, hesitation language, or sudden confidence spikes—and a lightweight runtime monitor (RSP‑M) that flags abnormal RSV trajectories for human or automated intervention. rsp summary The point is: many agent safety systems today focus on what text says (instructions, obvious jailbreaks) or final actions, but this work argues you also need to watch how the model is reasoning over time, because style‑level perturbations can steer long‑horizon agents into failure modes without tripping traditional guards.
Gemini app now checks SynthID watermarks in images and video segments
Google shipped a SynthID-based provenance checker into the Gemini app and web UI, so you can upload an image or video and have Gemini report whether any segment was created or edited with Google AI. gemini synthid post The tool distinguishes between audio and visual tracks and returns time‑stamped spans such as “SynthID detected within the audio between 10–20 secs. No SynthID detected in the visuals,” which is much more granular than a single yes/no flag. segment example

This builds on SynthID watermarks that Google already embeds into its own generative models, now exposing a consumer‑facing way to verify content authenticity for things like political clips, influencer ads, or suspicious voiceovers. google synthid blog For AI teams shipping media tools, it’s an example of how provenance checks can live inside the assistant UX rather than as a separate forensic lab: the assistant becomes both the generator and the authenticity checker. It also quietly sets a bar that other labs using watermarks will be compared against—segment‑level reporting, clear separation of modalities, and consumer‑grade ergonomics instead of raw forensic APIs.
OpenAI updates Model Spec with explicit under‑18 safety principles
OpenAI quietly updated its public Model Spec—the “intended behavior” guide for its models—with a new Under‑18 (U18) section that spells out how systems should respond when they detect a child or teen user. u18 spec update The update is framed as part of the living spec, and Greg Brockman resurfaced it alongside other behavior guidance, reinforcing that this document is meant to inform both internal training and how third‑party builders think about acceptable responses. model spec mention The U18 principles focus on things like avoiding sexualized conversation with minors, steering users toward trusted adults and professional help for self‑harm or abuse topics, and refusing requests that would put a young person at risk, while still being empathetic and helpful. For AI product teams, this is a concrete, referenceable baseline you can align your own guardrails with: if you’re wrapping OpenAI models, your policies and fine‑tuning should not undercut, and ideally should extend, these U18 constraints rather than ignoring them.
Anthropic details Claude’s approach to emotional support and crisis safety
Anthropic published a deep dive on how Claude is shaped to handle emotionally charged conversations—especially around self‑harm and suicide—with explicit system prompts, reinforcement learning, and product‑level safeguards. anthropic safeguards The post describes a suicide and self‑harm classifier that can trigger a crisis banner and route users to human helplines via ThroughLine when language suggests acute risk, plus behavioral policies that push Claude to be compassionate but clear that it is not a human or a therapist. anthropic safety blog For engineers and policy leads, this write‑up is useful because it sketches a full stack: high‑level behavior goals in prompts, reward modeling for “good” crisis responses, and runtime detection that sits outside the model and can evolve independently. It also highlights a design tension that many apps will face: supporting users who are looking for emotional help without crossing into pretending to be a professional, which is increasingly likely to be regulated and audited in healthcare‑adjacent products.
🤖 Affordable humanoids and open desktop robots
Embodied datapath news: low‑cost humanoid aimed at scaling interaction data collection, plus community arrivals of Reachy Mini kits.
LimX’s $6.8k TRON2 humanoid targets large‑scale real‑world data collection
LimX Dynamics’ new TRON2 humanoid is being positioned as a low‑cost workhorse for collecting large volumes of real‑world interaction data, with a reported starting price around $6,800 and specs tuned for everyday manipulation and locomotion tasks. tron2 overview It combines a bipedal base with a full upper body, can walk at up to ~3 m/s and switch to a wheel‑foot configuration for ~5 m/s, and is specced to carry ~30 kg on flat ground and ~20 kg on stairs while keeping each arm’s working payload around 3–5 kg. tron2 overview A separate demo from the company highlights highly reconfigurable, modular morphologies (legs to wheels and back), reinforcing that the platform is meant less as a one‑off demo bot and more as a chassis for diverse data‑gathering setups.

For AI engineers and robotics teams, the point is: this is a relatively cheap way to generate the messy “try something, feel what happens, adjust” streams that vision‑language‑action models need but synthetic data can’t fully provide. tron2 overview Because TRON2 is being pitched with ROS support, onboard compute options and an EDU variant, it slots into existing research and startup stacks rather than demanding a proprietary toolchain, and it hints at a near‑future where hundreds or thousands of similar humanoids are deployed primarily as data capture appliances instead of factory showpieces. tron2 overview
Reachy Mini kits hit builders’ desks via Hugging Face tie‑in
Pollen Robotics’ Reachy Mini desktop robot is now showing up on developer desks worldwide, with a noticeable wave of unboxings and early experiments tied to Hugging Face’s distribution partnership. reachy-mini box The kit arrives as a compact, desk‑friendly biped with a co‑branded box (Pollen + Hugging Face) and is already being driven by a polished desktop control app that lets users script motions and interactions without diving immediately into low‑level robotics code.

Anthropic, HF and the broader community are leaning into it as an on‑ramp for embodied AI tinkering: people are assembling Reachy Mini with their kids, family build post bringing units to holiday parties,

and asking for custom apps like Christmas‑carol performances and classroom demos. carols request For AI engineers, the appeal is a physically safe, relatively affordable robot you can keep next to your monitor while you prototype vision‑language‑action loops, MCP‑style control stacks, or voice‑driven behaviors—using the same HF ecosystem you already use for models and data. reachy-mini box It’s less about industrial payloads and more about building intuition and tooling for everyday robot behaviors in a form factor that fits in a home office or lab bench.