Claude Code CLI 2.0.64 adds async subagents – 4 upgrades turn it agentic
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Anthropic quietly turned Claude Code from a linear chat helper into a small agent platform today. Version 2.0.64 lands four big upgrades: async subagents, a now‑paused “instant compact” context trim, custom session naming, and a /stats usage view—all from a quick claude update. This is a CLI release, not a new model, but it changes how you can actually work with the thing.
Async subagents are the headline: you can spin off background workers to crawl a monorepo, tail logs, or watch CI while you stay focused on a foreground task, then have the main agent “wake up” when the side jobs finish with a consolidated report. Early users are already wiring this into repo exploration and bash workflows, treating Claude more like a process supervisor than a chat window. Instant compact tried to keep a continuously summarized history so trims felt instant, but Anthropic pulled it within hours for over‑aggressively summarizing live conversations.
The softer touches—session renaming and /stats—matter once you have dozens of long‑running threads. Naming lets teams organize by feature or client instead of timestamps, and stats make it obvious when you’re leaning too hard on expensive models. Taken with this week’s Cursor council and Mistral Vibe 200k context bump, the coding‑agent race is clearly moving from “smart autocomplete” to orchestration, monitoring, and real project hygiene.
Top links today
- Epoch analysis of Nvidia B200 manufacturing costs
- Epoch AI capabilities index interactive benchmark explorer
- Menlo Ventures state of generative AI 2025 report
- Google DeepMind FACTS benchmark suite overview
- Ultra-FineWeb-en-v1.4 dataset on Hugging Face
- Ultra-FineWeb-en-v1.4 dataset technical paper
- LLM Compressor with Intel AutoRound PTQ on GitHub
- Perceptron Isaac 0.2 hybrid-reasoning VLM release blog
- Qwen3-Omni-Flash December 2025 upgrade blog
- Gemini 2.5 Flash and Pro TTS update blog
- GDPval-AA agentic benchmark leaderboard
- Stirrup open-source agent framework for AI agents
- Nebius Token Factory post-training and deployment platform
- Datalab Forge Evals for document parsing quality
- Yutori Scouts always-on web monitoring agents
Feature Spotlight
Feature: Claude Code CLI ships async subagents + instant compact
Claude Code CLI adds async subagents for background tasks, an instant compact (briefly disabled), session renaming, and /stats—unlocking long‑running monitoring and faster workflows for coding agents.
Major Claude Code CLI update dominates today: background subagents, near‑instant compaction (temporarily paused), session rename, and usage stats—lots of demos and community takes. Excludes other coding tools below.
Jump to Feature: Claude Code CLI ships async subagents + instant compact topicsTable of Contents
🧰 Feature: Claude Code CLI ships async subagents + instant compact
Major Claude Code CLI update dominates today: background subagents, near‑instant compaction (temporarily paused), session rename, and usage stats—lots of demos and community takes. Excludes other coding tools below.
Claude Code CLI 2.0.64 ships async subagents, instant compact, and /stats
Anthropic rolled out Claude Code CLI 2.0.64 with four big additions: async subagents, near‑instant context compaction, custom session names, and a new /stats command, all installable via claude update. release thread This is a CLI‑side upgrade (not a new model) that makes Claude much more agentic for long, multi‑session coding work.

Async subagents let a main task spawn child agents that keep running in the background even after the parent completes, which is useful for log monitoring, long builds, or deep repo scans without blocking the current chat. subagent explainer Instant compact pre‑summarizes conversation history in the background so when you hit compact, the trim happens in seconds instead of a long pause. compact description The release also adds per‑session naming and usage tracking, so you can organize large projects and see which models and workflows you actually lean on day to day. session features , stats feature Anthropic confirmed all of these features are live in today’s build, while noting that instant compact has been temporarily disabled for being over‑aggressive (see separate item below). status update For teams already using Claude Code heavily, this turns the CLI from a single linear assistant into something closer to a small, scriptable agent platform you can grow into.
Developers start using Claude’s async subagents to explore codebases in the background
Early users are already leaning on async subagents in Claude Code to offload long‑running analysis while they keep coding, showing how the new primitive changes day‑to‑day workflows. feature recap In Omar El Gabry’s demo, a top‑level task kicks off several subagents to explore different parts of a repo in parallel; the main agent goes idle, but is "woken up" with a consolidated report once the subagents finish. workflow video
Because subagents run fully in the background, they’re a natural fit for things like tailing logs, watching CI pipelines, crawling large monorepos, or doing deep research while you work on something else. Omar also points out that even plain bash commands can be run in this async mode, so you can mix shell tooling and Claude’s reasoning inside the same pattern. release note Anthropic’s own release notes emphasize this is meant as a low‑level primitive—"lots of interesting build patterns will emerge"—rather than a fixed workflow, so agent builders can compose their own higher‑level behaviors on top. release note , build commentary For AI engineers, the takeaway is that Claude Code is now much closer to a general task runner: instead of a single conversational thread, you can treat it like a small process supervisor and start experimenting with subagents that watch services, crunch traces, or refactor codebases autonomously while you stay in the foreground task.
Claude’s new instant compact gets temporarily pulled for over‑summarizing conversations
Alongside async subagents, Anthropic tried turning on continuous background summarization (“instant compact”) in Claude Code so context trims would feel instantaneous—but had to roll it back within hours after it started summarizing too frequently. initial compact note , rollback notice The idea was to have Claude constantly maintain a compressed representation of the session so invoking compact would be a cheap pointer swap instead of an expensive pass over the full history. initial compact note
In practice, the first cut was too aggressive: some users saw active conversations get summarized mid‑flow, potentially losing detail they still needed. Anthropic acknowledged the issue publicly, disabled instant compact, and says they’re "looking into it" before re‑enabling. status update , rollback notice The older, on‑demand compaction path still works, just without the new latency win. context management For agents and tooling built on top of Claude Code, this is a useful signal: background context maintenance is coming, but you shouldn’t assume a specific compaction behavior is stable yet. If you depend on exact logs or multi‑step traces, you still need your own persistence layer and shouldn’t rely solely on the CLI to preserve every token.
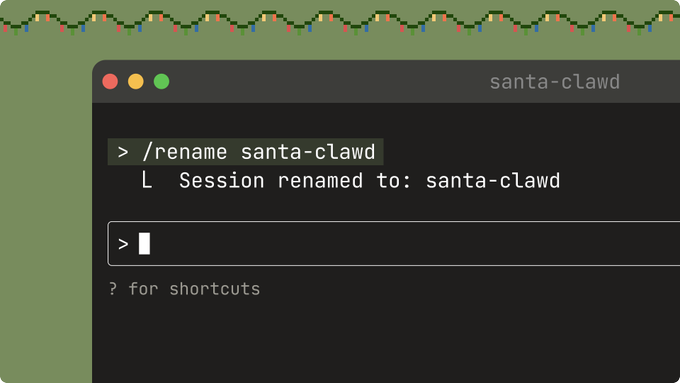
Claude Code adds session renaming and /stats usage visualizations
On the quality‑of‑life side, Claude Code now lets you rename sessions, navigate them with keyboard shortcuts, and inspect your own usage patterns via a new /stats command—small changes that matter once you have dozens of long‑running threads. rename announcement , context management From the CLI you can run /rename on any prior session, or hit R/P in the /resume screen to rename or preview respectively, making it much easier to keep large projects organized by feature, bug, or client instead of random timestamps. context management The /stats command generates a visualization of your Claude Code activity, highlighting daily usage, streaks, and favorite models. stats feature In the short demo, Anthropic shows a calendar‑like view plus per‑model breakdowns, which is a handy way to see whether you’re accidentally burning most of your tokens on heavyweight models when a cheaper one would suffice.

These features don’t change model capabilities, but they do shift Claude Code closer to being a primary coding environment rather than a throwaway helper. For leads and teams standardizing on Claude, the session naming and stats views also make it easier to audit how people are using the tool, spot power users, and nudge workflows toward the right model mix.
🧪 New models: open math SOTA, vision‑language hybrids, and omni voice
Mostly concrete releases vs rumors: an open 30B math model with Putnam results, a compact VLM duo with tool‑calling and OCR, plus omni voice/video improvements. Continues the model cadence from prior days.
Nomos 1 open math model reaches near–top human score on 2025 Putnam
NousResearch released Nomos 1, a 30B-parameter open math model (about 3B active MoE parameters per token) that scores 87/120 on the 2025 Putnam exam, which observers estimate would rank around #2 out of 3,988 human contestants. (nomos explainer, emad comment)
The model specializes Qwen3‑30B‑A3B‑Thinking into a "math and proof" expert and is paired with a public Nomos Reasoning Harness for running full chain‑of‑thought solutions and evals; charts show Nomos cleanly outperforming a strong Qwen3 baseline across nearly all 12 Putnam problems. nomos explainer For AI engineers and researchers, the interesting bits are: (1) you get a near‑Olympiad‑level mathematician in an open model that can still be run on a single modern MacBook via MoE sparsity, (2) the release comes with tooling—not just weights—aimed at reproducible reasoning experiments, and (3) it strengthens the case that carefully post‑trained open models can close much of the gap with proprietary frontier reasoning systems on hard, formal problems.
Perceptron open-sources Isaac 0.2 hybrid-reasoning VLMs at 2B and 1B
Perceptron open‑sourced Isaac 0.2, a pair of 2B and 1B hybrid‑reasoning vision‑language models that sit on the “frontier of perception” curve—beating many larger VLMs on an averaged 23‑benchmark suite at roughly $0.02 per million tokens. isaac release thread

Isaac 0.2 adds optional thinking traces for harder multi‑step VQA, a first‑party Focus tool‑calling system that lets the model request extra inference passes over tricky regions, significantly improved OCR (including cluttered documents, charts, and UI text), better behavior on desktop/mobile UI screenshots, and stronger structured outputs for downstream agents. (hybrid reasoning note, focus tool calls, structured outputs note, ocr details, desktop workflows) Weights, demos, and a deployment‑oriented API are all available, and the team positions Isaac 0.2 as a fast, compact perception layer for agent stacks—especially ones that need reliable desktop automation, document understanding, or small‑object reasoning without paying frontier‑model prices. (future roadmap, huggingface org)
Qwen3-Omni-Flash gets richer multi-turn AV understanding and 119-language voice
Alibaba’s Qwen team pushed a substantial 2025‑12‑01 refresh of Qwen3‑Omni‑Flash, focusing on better multi‑turn audio/video conversations, more controllable personalities, and much broader language coverage: 119 text languages and 19 speech languages, with voices described as "indistinguishable from humans". qwen omni update The upgraded model powers voice and video chat in the Qwen Chat app (VoiceChat/VideoChat buttons), plus a realtime streaming API and an offline SDK for on‑prem or edge deployments, and the team is actively soliciting detailed user feedback on latency and quality. (qwen omni update, feedback request, blog post) For builders, this makes Qwen3‑Omni‑Flash a more serious contender for omni assistants: you can now lean on it for multi‑turn conversations over videos or call‑like sessions, steer persona via system prompts (e.g., roleplay or branded support agents), and target truly global audiences without stitching together separate TTS/ASR stacks, while still having both cloud and offline options.
💻 Coding agents in practice: Cursor 2.2, councils, and bigger context
Hands‑on dev tooling that’s not the Claude CLI feature: Cursor 2.2 adds runtime Debug Mode and multi‑agent judging; Mistral Vibe doubles context; editors get better diffs and history.
Cursor 2.2 adds Debug Mode for runtime‑aware bug fixing
Cursor 2.2 now ships Debug Mode, letting its coding agent instrument your code, spin up a local server, and stream runtime logs while you manually reproduce a bug feature thread. This shifts the agent from passively reading diffs to debugging the way human engineers do.

Under the hood, Cursor injects print/debug statements around suspected hotspots, captures structured traces as you hit the repro steps, and then proposes minimal, test‑backed fixes instead of shotgun edits engineer commentary. Early users are calling it "insane" for chasing down gnarly issues that previously required 20+ guess‑and‑check cycles, and the new modal makes it a single click to switch a chat into Debug Mode when you hit a flaky or data‑dependent bug
.
Cursor introduces an LLM Council to auto‑judge competing code fixes
Cursor is also rolling out an "LLM Council" flow where multiple models tackle the same coding task and the tool auto‑selects the best variant based on tests and spec adherence council UI. In one example A/B, GPT‑5.1 Codex Max beats Composer 1, Opus 4.5, and Sonnet 4.5 with a +57/‑17 score because it’s the only option that actually wires up a working A/B test with dynamic rendering variant comparison.
For AI engineers, this turns model diversity into a practical lever instead of a configuration headache: you can keep multiple backends in play, let Cursor run them in parallel, and then inspect the winning diff plus its rationale when you care about why something was chosen. It’s especially useful when a repo has a mix of UI work, infra changes, and tests where different models tend to shine on different slices of the task multi-model comment.
Zed’s latest release tightens diff and history UX for agent‑assisted coding
Zed 0.216.0 shipped word‑level diffing, per‑file Git history, and an easier way to delete branches from the branch picker, all of which make it easier to supervise AI‑generated changes release thread. Word‑level diffs in particular turn vague "something changed on this line" views into precise token‑level edits, which matters when an agent quietly tweaks conditionals or regexes.

Right‑clicking a file now exposes a File History view that lets you scrub through commits, compare versions, and copy diffs directly from the UI, which pairs well with agent workflows that stage large patches you still want to audit history feature. The branch picker gained an inline delete control so you can clean up experiment branches created by agents or humans without dropping to the CLI
. For AI‑heavy teams, these are the kinds of UX upgrades that keep human review tight even as more code comes from tools.
Mistral Vibe bumps context from 100k to 200k for repo‑scale work
Mistral raised the context limit for its Vibe coding agent from 100k to 200k tokens, advertised directly in the mistral-vibe CLI splash context update. Installation is a single uv tool install mistral-vibe command, so it’s trivial to wire a terminal‑native agent to this bigger window.

A 200k context is enough to hold large slices of a monorepo plus logs or design docs, which makes long‑horizon refactors and cross‑service trace analysis more realistic without resorting to heavy manual chunking. For teams already experimenting with Devstral or Claude Code, Vibe now looks like a more serious option for "read the whole project and plan" workflows rather than just file‑at‑a‑time edits.
RepoPrompt adds ask_user and a 1‑click Claude Code install
RepoPrompt 1.5.54 introduces a new ask_user tool for its context builder and a one‑click Claude Code integration with slash commands, so repo‑aware agents can pause for clarification and be wired into IDEs with far less glue code release notes. Following up on Unix socket shift, which moved RepoPrompt’s MCP transport to Unix sockets for lower overhead, this update pushes it further toward a full agent harness instead of a one‑off script.
The ask_user tool lets the context builder surface intermediate questions ("should I refactor this API or just patch the bug?", "which service owns this config?") instead of charging ahead with bad assumptions, which is crucial when an agent is touching a large codebase without complete specs shortcut list. The new slash commands and 1‑click Claude Code install reduce setup friction for teams that want a repeatable, observable way to run repo‑scale tasks—like onboarding refactors or test suite hardening—through the same harness rather than bespoke prompts in every editor.
📊 Evals and leaderboards: GDPval‑AA, FACTS, Code Arena, OCR
New cross‑domain evals and production‑adjacent leaderboards landed: FACTS factuality, GDPval‑AA agentic knowledge work, Code Arena webdev, plus OCR Arena movements. This is a step up from yesterday’s eval rhythm.
GDPval-AA benchmarks agentic knowledge work across top LLMs
Artificial Analysis launched GDPval-AA, a new leaderboard that runs OpenAI’s GDPval real‑world knowledge‑work tasks through an agent harness called Stirrup and scores models by Elo, with Claude Opus 4.5 taking the top spot ahead of GPT‑5 and Claude Sonnet 4.5, while DeepSeek V3.2 and Gemini 3 Pro tie for fifth place. GDPval launch thread The same models perform noticeably better in Stirrup than in their consumer chat UIs, and Claude’s official chatbot tops a separate app ranking but still trails the Stirrup+Opus combo on task quality. GDPval launch thread
Costs are highly skewed: running the full GDPval suite cost about $608 on Claude Opus 4.5 versus $167 on GPT‑5 and only $29 on DeepSeek V3.2, making DeepSeek ~20× cheaper than Opus at similar Elo and about 3× cheaper than Gemini 3 Pro’s $94 bill. cost breakdown GPT‑5.1 used roughly 50% fewer tokens than GPT‑5 but scored 67 Elo lower, suggesting that more aggressive token "effort" saving can degrade complex work quality in practice. cost breakdown The team open‑sourced Stirrup so engineers can run the same agentic protocol against any OpenAI‑compatible model and reproduce GDPval‑AA style evaluations on their own workloads. (stirrup harness, GDPval dataset) For AI teams, GDPval-AA is one of the first broad benchmarks that looks like actual white‑collar output (pitch decks, spreadsheets, marketing assets) instead of short answers, and it clearly separates model capability, agent harness design, and unit economics. If you’re picking a primary model for agents, this is a good reality check: Opus 4.5 appears strongest for end‑to‑end quality, GPT‑5 looks like the high‑end performance/cost compromise, and DeepSeek V3.2 shows how far aggressive open‑weight optimization has come. GDPval paper
FACTS Benchmark compares LLM factuality across knowledge, search, grounding, and multimodal
Google DeepMind and Google Research released the FACTS Benchmark Suite, a 3,513‑question battery that scores models on four dimensions of factuality—parametric knowledge, web search, grounding to provided context, and multimodal image questions—and evaluated 15 leading LLMs. facts announcement Gemini 3 Pro leads with a 68.8 FACTS Score, driven by very strong web search (83.8%) and parametric (76.4%) performance, while still only hitting 46.1% on multimodal factuality. facts table
Runner‑ups include Gemini 2.5 Pro at 62.1, GPT‑5 at 61.8, Grok 4 and GPT‑o3 in the low‑50s, and Claude 4.5 Opus at 51.3, with most models trading off between search strength and parametric recall. facts table Gemini 2.5 Flash, Claude Sonnet 4.5 Thinking, GPT‑5.1, and others cluster tightly in the 42–50 range, and every model scores under 50% on multimodal, confirming that grounded text‑only factuality is much further along than image‑based question answering. facts announcement The suite is being published on Kaggle to encourage independent replication and longitudinal tracking rather than single‑number marketing benchmarks. facts announcement For engineers and eval leads, FACTS gives you a clean way to separate "how much the model knows on its own" from "how well it uses search" and "how much it hallucinates when you hand it documents" instead of rolling all that into one task score. It also makes clear that if your product depends heavily on screenshot or chart QA, you should treat all current models as experimental and backstop them with stricter retrieval and validation until multimodal factuality climbs out of the mid‑40s.
Code Arena webdev ladder adds Mistral-Large-3 alongside DeepSeek V3.2
LM Arena’s new Code Arena, which live‑tests models on planning, scaffolding, debugging, and shipping full web apps, now lists Mistral‑Large‑3 at #8 among open models and #22 overall with a score of 1224. code arena update This follows DeepSeek V3.2 and V3.2‑Thinking joining the arena for coding battles earlier in the week, deepseek code arena continuing the trend of top labs pushing their frontier coding models into more realistic, end‑to‑end evals rather than only static benchmarks. Code Arena
Code Arena stands out because each run is a full web task—building layouts, wiring APIs, fixing runtime errors—so scores implicitly bundle reasoning, tool use, and iteration under a fixed time and cost budget. For AI teams, Mistral‑Large‑3’s arrival here gives you a comparative datapoint against closed models in exactly the "full‑stack webdev" setting many coding agents target, and lets you watch runs and failure modes instead of trusting headline percentages. If you’re already experimenting with Devstral 2 for code, this is another signal that Mistral’s stack is maturing beyond offline SWE‑Bench into more production‑like flows.
Intellect-3 posts 1348 on Arena’s text leaderboard with strengths in coding and hard prompts
Arena’s Text Leaderboard added Intellect‑3, which enters at #37 among open‑weight models and #95 overall with an Elo of 1348, showing particular strength on coding, IT, hard prompts, and multi‑turn conversations. text leaderboard update Unlike synthetic exams, this leaderboard aggregates live head‑to‑head user preferences across diverse tasks, so a mid‑pack global rank with standout category performance can still make a model attractive as a specialized worker.
For practitioners, Intellect‑3 is worth shortlisting if you’re assembling a multi‑model routing setup where a relatively small, inexpensive open model handles code, infrastructure, or hard‑prompt workloads, while larger proprietary models cover more general reasoning. The Arena score also gives you a public reference curve if you’re fine‑tuning or distilling on similar domains and want to know whether your variant actually beats a competitive open baseline rather than just a toy benchmark.
OCR Arena shows new Glyph and Retina models trading speed and accuracy
OCR Arena’s public leaderboard now features Glyph and Retina as notable new entrants, both approaching the top tier of OCR performance while exposing different latency profiles. ocr leaderboard update Glyph holds an Elo of 1643 with a 65.7% win rate over 67 battles and 15.7 s/page latency, whereas Retina posts 1635 Elo, a higher 71.2% win rate over 59 battles, but takes about 31.9 s/page. ocr leaderboard update
Both models trail the current #1 Gemini 3 Pro (FACTS’ factuality leader) on raw Elo but show that specialized or checkpoint‑tuned OCR systems can get very close at a fraction of the compute budget. ocr leaderboard update The Arena setup is battle‑based: models compete on the same scanned pages and users prefer outputs, making the Elo and win‑rate numbers directly comparable as you consider switching OCR backends. For engineers running large‑scale document ingestion or multimodal RAG, this chart is a practical way to choose between faster but slightly weaker (Glyph) and slower but more often correct (Retina) without having to build your own evaluation corpus first.
🏗️ Compute economics and geopolitics: HBM costs, space DCs, China
Concrete infra signals impacting AI supply: B200 cost breakdowns, training in orbit, China’s domestic chip procurement push vs H200 flows, and India’s multi‑year AI capex. Fresh angles vs yesterday’s capex threads.
China steers state buyers to Huawei/Cambricon while rationing Nvidia H200
China’s industry ministry has put domestic AI accelerators from Huawei and Cambricon onto its official Xinchuang procurement list, signalling that government agencies and SOEs should prefer local chips over Nvidia for new AI clusters. ft chip policy At the same time, regulators are reportedly considering caps that tie each company’s allowed H200 imports to how many Chinese chips they buy, and may block H200 use entirely in sensitive sectors like finance and energy. policy followup This comes right after Washington agreed to let Nvidia resume H200 exports to China with a 25% revenue skim, following H200 exports on that licensing, so the net effect is: H200 becomes an exception, domestic GPUs the default.
Reuters adds that ByteDance and Alibaba are eager to order H200s now that they’re technically allowed, but actual access will be constrained by limited H200 production and Nvidia prioritizing Blackwell and Rubin for US hyperscalers. h200 demand report Beijing is also backing local data centers with power subsidies that can cut bills by up to 50%, helping offset the poorer perf/Watt of domestic chips. For AI planners, the picture is clear: Chinese labs will get some H200 capacity, but long‑term training and inference will have to assume Huawei/Cambricon as primary, with US GPUs treated as rationed, high‑priority resources.
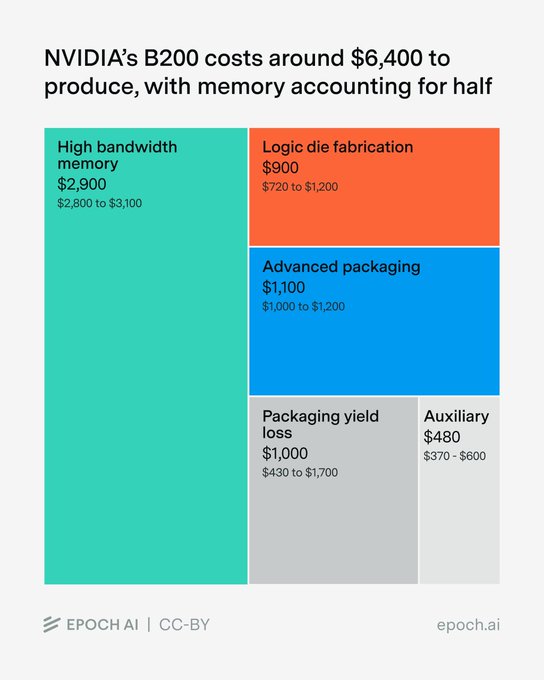
Epoch breaks down Nvidia B200 cost, HBM and packaging dominate
Epoch estimates Nvidia’s B200 costs about $6,400 to manufacture, with nearly half of that coming from its 192 GB of HBM3E memory, putting a spotlight on memory and packaging rather than compute as the main cost drivers for frontier GPUs. cost breakdown thread They argue chip‑level gross margin is ~80% at current $30–40k ASPs, higher than Nvidia’s ~73% blended margin once full systems and services are factored in. margin context
The estimate decomposes cost into roughly $2,900 for HBM, $1,100 for advanced CoWoS‑L packaging plus $420–1,700 of packaging yield loss, and only ~$900 for the two 4NP logic dies, meaning the compute silicon itself is well under 15% of total cost. component costs This framing reinforces that HBM supply and advanced packaging capacity, not pure flops, are the binding constraints on AI scaling, and helps infra teams reason about where future price cuts or shortages are most likely to come from. It also underlines why Nvidia increasingly sells full racks instead of bare GPUs: system‑level margins are lower, but they lock in more of the stack while hiding chip economics behind bundled pricing.
DeepSeek Blackwell smuggling allegations highlight porous export controls, Nvidia pushes back
The Information reports that China’s DeepSeek is secretly training its next model on thousands of banned Nvidia Blackwell GPUs, allegedly smuggled into China via “phantom” overseas data centers where servers are fully built and inspected, then dismantled and re‑shipped as loose parts to evade export rules. smuggling report A companion graphic shows Blackwell cards floating around a breaching whale, underscoring how porous current controls look if this pipeline is real. smuggling graphic
Nvidia, for its part, told CNBC it has no evidence or credible tips of such a scheme and called the allegations far‑fetched, stressing that it investigates all smuggling leads and is racing to add location‑tracking and remote disable features to future chips. nvidia denial The US has already labelled DeepSeek a national security threat and brought smuggling charges against some intermediaries, but this episode shows the basic tension: frontier compute is small, mobile, and incredibly valuable. As long as there’s a large price gap between sanctioned and allowed markets, labs with enough money and motivation will try to route around controls, and enforcement will increasingly hinge on in‑silicon attestation rather than customs paperwork.
Big Tech lines up ~$68B for India AI and cloud build‑out through 2030
New numbers put combined Big Tech investment commitments in India at about $67.5B for 2025–2030, with Amazon at $35B, Microsoft at $17.5B, Google at $15B, and Apple plus suppliers at ~$7B, alongside new OpenAI and Anthropic offices. india investment chart Microsoft’s own announcement says its $17.5B will fund Azure regions, sovereign cloud, AI skilling for 20M people by 2030, and AI‑powered public platforms like e‑Shram and the National Career Service that touch 310M informal workers. microsoft india post
For AI infra teams this marks India as the clear #2 global growth market after the US: a major source of datacenter capacity, relatively cheap technical labor, and a huge domestic demand pool for language, voice, and vertical AI apps. It also hints at a more multipolar compute landscape—while China grapples with export controls and pushes Huawei/Cambricon, Western hyperscalers are pouring tens of billions into a politically friendlier jurisdiction that can host both global training clusters and nation‑specific “digital public goods”. Expect more on‑shore training, India‑first feature flags, and sovereign‑cloud architectural patterns to grow out of this wave.
Starcloud trains H100 LLM in orbit and pitches 5 GW space data centers
Starcloud, backed by Nvidia, says it has trained the first LLM in space on an H100 GPU aboard its Starcloud‑1 platform and is pitching a roadmap to a 5 GW orbital compute station with 4 km of solar panels and radiative cooling. starcloud summary The idea is simple physics: in orbit you get ~6× more solar energy than on Earth, no night or clouds, and you can dump heat directly to deep space with big radiators instead of chillers. space dc argument

Right now this is still a tech demo: Starcloud‑1 is running a small model and some telemetry‑driven workloads, not training GPT‑class systems. But if they can scale to multi‑GW, the economics change—power and cooling are often half the TCO of a terrestrial AI data center, so materially cheaper, cleaner energy in orbit would put pressure on ground‑based operators in the long run. The catches are orbital debris, radiation hardening, launch costs, and geopolitics around who gets to beam what compute capacity back down; for the next few years this looks more like a specialized platform for space‑sensing and defense work than a replacement for Azure or GCP.
🛡️ Security, safety and policy: preparedness, prompt‑injection, antitrust
Fresh safety posture notes and live threat intel: OpenAI flags rising cyber capability and safeguards, a real zero‑click prompt‑injection case in M365 Copilot, and an EU antitrust probe into Google’s AI content use.
EchoLeak paper shows zero‑click prompt‑injection data theft in Microsoft 365 Copilot
A new case study, EchoLeak (CVE‑2025‑32711), documents how a single crafted email could make Microsoft 365 Copilot silently exfiltrate internal data via zero‑click prompt injection, with no user opening or replying required. echoleak summary The email’s hidden instructions ran whenever Copilot auto‑processed mailbox content, coercing it to fetch internal emails, chats, and files and smuggle them out using allowed channels.
Researchers chained several weaknesses: evading Microsoft’s XPIA prompt‑injection classifier, abusing reference‑style Markdown links to dodge link‑redaction, leveraging auto‑fetched images, and finally tunneling stolen data through a Microsoft Teams proxy that passed browser content‑security policies. echoleak summary The key lesson is that Copilot treated untrusted email text and trusted Graph data as living in the same trust zone, so once the LLM read the email it could freely mix attacker instructions with sensitive organizational context.
For AI security engineers, this elevates prompt injection from “theoretical annoyance” to a first‑class vulnerability category on par with XSS: you need hard boundaries between untrusted content, system prompts, and private tools, plus per‑tool allowlists and output filtering. echoleak summary It also underscores the need for provenance‑aware access control, separate sandboxes for agent browsing vs. tenant data, and security reviews that treat every auto‑processed document or email as an untrusted program being fed to the model, not as mere text.
OpenAI flags rapidly rising cyber capabilities in GPT‑5.x and tightens safeguards
OpenAI says upcoming models are on track to reach the ‘High’ cyber‑capability tier in its Preparedness Framework and highlights that capture‑the‑flag (CTF) performance jumped from 27% on GPT‑5 in August to 76% on GPT‑5.1‑Codex‑Max by November 2025. (preparedness note, ctf capability quote) This is framed as a dual‑use risk and a reason to invest early in safeguards and external expert review so defenders gain more than attackers.
For engineers and security teams, this signals that future GPT‑5.x‑class models will be materially better at exploit discovery, tooling, and environment navigation, so expect tighter safety layers around cyber‑adjacent prompts and more scrutiny on red‑team findings. security comment OpenAI’s messaging also gives CISOs cover to start treating frontier‑model access as a security‑sensitive resource—something to gate, monitor, and integrate into threat‑modeling rather than a generic developer tool. model risk framing For anyone building agentic tooling on top of Codex‑style models, this is a reminder to design for least privilege, auditable actions, and explicit separation between analysis and execution of suggested exploits.preparedness blog
EU opens antitrust probe into Google’s use of publisher content for AI Overviews
The European Commission has launched an antitrust investigation into whether Google breached EU competition rules by using web publishers’ content and YouTube videos to power AI Overviews and AI Mode without appropriate compensation or a realistic opt‑out. eu probe summary Regulators will also test if refusing AI training effectively means losing visibility in Search, which could be treated as abusive tying or self‑preferencing. crackdown repost
For AI leaders, this is the clearest signal yet that scraping the open web for training and inference outputs is shifting from a norms question to a competition‑law question. If the EU decides Google must pay or offer a strong opt‑out, that precedent will ripple to any large model that leans on news, video, or UGC to answer user questions. Practically, expect growing pressure to (a) track training data provenance, (b) support robots‑style AI opt‑outs and per‑publisher controls, and (c) negotiate direct licensing for high‑value verticals like news, music, and sports highlights.
Policy‑wise, the probe also blurs the line between training and runtime use: the Commission explicitly calls out both how content was used to train models and how AI Overviews surface synthesized answers instead of clicks to original sites. eu probe summary If you are building AI features on top of a search or aggregation product, you should assume future regulators will look not only at your datasets but at your traffic flows and default UI choices as potential levers of market power.
US defense bill would force Pentagon to plan explicitly for AGI
A provision in the FY26 National Defense Authorization Act would require the US Secretary of Defense to establish an Artificial Intelligence Futures Steering Committee that, among other tasks, formulates proactive policy for advanced AI systems including AGI. ndaa agi note The mandate is to think ahead about how much autonomy, access, and oversight AGI‑class systems should have in defense contexts, rather than reacting once they appear.
For security and policy teams, this is a sign that AGI is moving from research talk into formal governance structures: defense planners will now have a standing body tasked with scenario‑planning, red‑teaming, and writing playbooks for deployment constraints. That will likely feed into future export‑control debates, alliance‑level norms, and procurement requirements for auditability and human‑in‑the‑loop controls on any system that might qualify as “co‑superintelligent”. If you work on AI systems that could plausibly be dual‑use for cyber, targeting, or intelligence analysis, you should assume US defense policy will increasingly ask: who owns the weights, where do they run, and how can their behavior be independently verified?
🧩 Agent plumbing goes managed: Google’s MCP servers
Interoperability storyline continues: after yesterday’s governance news, today shows concrete product—Google ships fully‑managed MCP servers for Maps, BigQuery, Compute and GKE with Apigee exposure.
Google ships managed MCP servers for Maps, BigQuery, GCE and GKE
Google is rolling out fully managed remote MCP servers for Google Maps, BigQuery, Compute Engine and GKE, letting agents and MCP clients like Gemini CLI and AI Studio point at a single endpoint instead of self-hosting tool servers launch details.
A detailed rundown notes that these servers provide Maps Grounding Lite for real‑world context, direct in‑place querying of BigQuery, and autonomous infra and container operations over GCE and GKE, all wrapped in IAM, audit logs, Cloud API Registry and Model Armor, with enterprise and third‑party APIs exposed via Apigee and more MCP-backed services promised soon feature breakdown explainer blog. For AI engineers and platform teams this effectively turns key Google Cloud services into managed, standards-based agent tools, shrinking the amount of glue code and MCP boilerplate they need to maintain while deepening lock‑in to Google’s agent ecosystem.
🎨 Creative stacks: Adobe inside ChatGPT, Sora styles, NB Pro playbooks
A heavy creative day: Adobe Photoshop/Express/Acrobat show up as ChatGPT Apps, new Sora ‘Festive/Retro’ styles, plus NB Pro prompt guides and Kling promos. This sits apart from voice‑TTS improvements.
Adobe Photoshop, Express and Acrobat land as free ChatGPT Apps
Adobe has quietly shipped Photoshop, Express, and Acrobat as first‑class ChatGPT Apps, with users reporting that these tools are currently available for free inside ChatGPT’s app picker. apps launch This effectively turns ChatGPT into an entry point for basic image editing and PDF work without leaving the chat.

Early demos show Photoshop doing background removal and other quick edits from inside ChatGPT, bg removal demo while Acrobat and Express are exposed through the same Apps UI. ui screenshot Commentary threads call this “huge” for casual creators and marketers who already live in ChatGPT. enthusiastic reaction At the same time, power users are bumping into UX constraints: when a specific app is selected as a connector, ChatGPT seems unable to call any other tools in the same conversation, making it awkward to chain Adobe functions with core model tools or third‑party connectors. ux limitation clip Some users also hit rough edges in the Photoshop integration itself, like background removal working but leaving confusing state in the editor. demo glitch Tech press confirms the launch and frames it as part of a broader push to turn ChatGPT into a multi‑app workspace rather than a single model. TechCrunch article
Nano Banana Pro community shares advanced prompt playbooks and Firefly flows
Prompt authors are rapidly evolving a set of Nano Banana Pro playbooks, from identity‑consistent sports celebrations to surreal 3×3 “body journey” photo grids and text‑shaped character art, extending the reusable workflows highlighted earlier in the week. prompt workflows Several long prompts now circulate as de‑facto templates for high‑end imagery.
One football prompt has the model infer a subject’s nationality from their face, pick an appropriate elite club, dress them in the club’s current kit, and render a specific post‑goal celebration in a telephoto sports photo style, complete with sweat, grass stains, and stadium bokeh. sports prompt Another huge “travel through your own body” recipe orchestrates a 3×3 grid of Kodak‑style film photos that shrink the subject to 2 mm tall and march them through brain folds, lung caverns, villi jungles, and a final bladder “exit” shot, with explicit shot lists and lighting notes for each tile. body journey grid On the graphic side, people are using NB Pro to draw animals whose silhouettes are entirely formed from stylized lettering—like a raven made from the word “RAVEN”raven art or a Pikachu built from repeating “pika pika pika!”. pikachu lettering Lifestyle creators are also sharing portrait prompts that turn a casual phone shot into something that looks like a pro‑photographed holiday campaign, holiday portrait then feeding those into Adobe Firefly where NB Pro appears as a selectable model in the Generate Image flow. (firefly interface, Firefly generate page) For builders, the pattern is clear: NB Pro works best when you treat prompts as full shot‑lists and production specs rather than vague text, and those specs are now getting standardized enough to be shared, reused, and chained into video pipelines.
OpenAI Sora adds Festive and Retro video styles
OpenAI’s Sora video model picked up two new style presets, “Festive” and “Retro”, which creators are already using to generate highly stylized holiday‑themed clips. styles announcement The Retro style in particular is being showcased in playful samples like a grainy, garlic‑themed holiday scene that looks like it came off a 90s camcorder. retro garlic clip For people building creative pipelines on top of Sora, these presets give you one‑click access to a specific color grade and motion aesthetic instead of relying purely on free‑form prompt language. The sentiment in the threads is that Sora’s realism was already strong, and these styles mainly lower the iteration cost when you want a particular vibe for marketing clips, holiday content, or nostalgic social posts without hand‑tuning every prompt.
Kling 2.6 pushes SHOTS multi‑angle promo with NB Pro bundle
Kuaishou is heavily promoting Kling 2.6 SHOTS, a feature that turns a single product image into a sequence of cinematic close‑ups from multiple angles, as part of a holiday sale that also bundles a year of unlimited Nano Banana Pro access. shots promo The promotion pitches SHOTS as a one‑click way for brands to get a full suite of hero angles from a single still.

The demo reel shows a dark, glossy gadget being rotated through dramatic lighting setups and camera moves, with overlaid text calling out “67% OFF” and the Kling 2.6 + Nano Banana Pro pairing. shots promo For creative teams, this builds directly on workflows where NB Pro is used to design detailed stills and Kling (or Kling O1) handles motion and editing downstream, cinematic pipeline turning that into more of an integrated bundle rather than two unrelated tools. The practical takeaway is that if you already use NB Pro for product renders, Kling’s SHOTS gives you an inexpensive way to scale those into multi‑angle video assets without needing a full 3D or live‑action pipeline.
💼 Enterprise adoption: web ‘Scouts’, assistants in inboxes, meeting ops
Practical enterprise rollouts: Yutori’s Scouts GA for always‑on web monitoring, Claude for Slack code handoff, and Perplexity’s Comet surfaces TODOs/Meeting Recorder. Adobe in ChatGPT is covered under Creative.
Yutori launches Scouts, always‑on web agents that watch sites for you
Yutori’s Scouts are now generally available as background AI agents that monitor arbitrary web pages, searches, and feeds, then email you distilled updates only when something changes that matches your criteria. launch context Instead of building your own scrapers or cron jobs, you describe what you care about (AI releases, apartment listings, price drops, reservations, etc.), and each Scout spins up an orchestrator, scraper pool, and change‑detector that crawls public endpoints, dedupes diffs against past runs, and pushes structured summaries on your schedule. user breakdown

For developers and PMs, this is effectively “Google Alerts done right”: event‑driven rather than keyword‑spammy, with examples like daily AI release briefs (3 models, 5 product launches, plus why they matter), price tracking, internship postings, or politics splits that arrive as focused digests instead of raw links. roundup thread Engineers get audit trails of each crawl step and deterministic triggers, while non‑technical teams can treat Scouts as a set‑and‑forget alerting layer over the public web rather than wiring up scraping infra themselves. usage example
Format turns scattered customer conversations into a 15‑minute weekly report
Format is an AI service that connects to Slack, Intercom, Zendesk, Gong, email and more, reads thousands of customer conversations, and sends each stakeholder a tailored weekly report they can consume in about 15 minutes. format intro Instead of dashboards, it behaves like an always‑on analyst: it first learns your role, product, customers, and tone, then continuously updates that context so the insights you see feel specific rather than generic summaries. format step one

Under the hood, each week it ingests fresh threads across channels, runs multi‑step analysis to cluster themes, and pulls out only the issues, risks, objections, and requests that match your lens—CEO, PM, sales, marketing, etc.—with traceability back to source conversations. system details That means a CEO gets strategic risks and opportunities, product sees recurring friction points, sales gets objection patterns, and marketing sees positioning signals, all without manually skimming logs. role outputs For teams that have “lost the plot” on what customers are saying as they scale, this is a lightweight way to re‑establish a customer‑obsessed loop without adding another heavy tool. call to action
Odo trains on your Gmail history to draft emails in your own style
Odo is a new “Cursor for email” style agent that ingests your Gmail history and uses it to draft new emails and replies that match your tone, structure, and preferred level of detail. odo overview Unlike generic smart‑reply features, Odo leans on long‑term examples of how you actually write, so it can handle complex, multi‑paragraph responses instead of brief canned answers. odo overview

Early testers say it’s the first tool that really sounds like them, which makes it viable for founders and managers who delegate more of their inbox without losing their voice. odo overview The product is still on a waitlist, but the model and UX pattern—per‑user fine‑tuning grounded in years of email—are a notable data point in how “AI employees” will plug into enterprise mailboxes next year. odo thread
Perplexity Comet experiments with TODOs and meeting auto‑recording
Perplexity’s Comet assistant is testing two workflow features that push it closer to a true work hub: inline TODO items in the browser and a configurable Meeting Recorder for calls. todos feature The TODO card UI sits alongside notes and media in the Comet sidebar, hinting that future versions of the agent may be able to create, manage, and execute tasks directly from research sessions rather than just summarizing pages. todos feature
In Comet Email Assistant settings, a hidden "Meeting Notes" section already exposes options to auto‑record meetings, include audio with transcripts, decide when to auto‑join, and choose who receives meeting recaps (e.g., everyone on the calendar invite). meeting settings None of this has shipped broadly yet, but it signals that Perplexity wants Comet to handle the whole loop—capture live calls, transcribe, summarize, and then turn decisions into trackable TODOs—rather than staying a pure read‑only research agent. hidden options
🗣️ Voice: Gemini TTS upgrades and controllable performance dubbing
Fewer items but relevant: Google upgrades Gemini 2.5 Flash/Pro TTS (style, pacing, multi‑speaker), and Fal’s react‑1 enables performance‑level dubbing. Excludes creative video and Adobe items covered elsewhere.
Gemini 2.5 TTS refines style control, pacing and multi‑speaker for builders
Google’s updated Gemini 2.5 Flash/Pro TTS models are getting a second wave of coverage focused on how to use the new controls in real apps, following the initial quality jump noted earlier this week tts upgrade. The upgrades center on richer style prompts (tone, mood, role), smarter context‑aware pacing (slow down for dense content, speed up for urgency), and much more stable multi‑speaker dialogue, especially across long scripts feature thread analysis thread.
Builders now get a clearer split: use Gemini 2.5 Flash TTS when low latency matters (interactive agents, real‑time UX) and Gemini 2.5 Pro TTS when audio polish matters (audiobooks, tutorials, longform narration), with both available directly in AI Studio’s model picker and script UI ai studio screenshot tts docs link. The new controls also help keep character voices consistent across multi‑speaker scenes and multilingual dialogue, and they respect explicit timing instructions much better than the May‑25 versions, which matters if you’re syncing to video or UI events feature thread analysis thread. For anyone building voice agents, this means you can route quick back‑and‑forth turns to Flash, then hand off final explainers or training content to Pro without changing APIs, using style prompts instead of one‑off audio engineering tweaks (Google blog post).
Fal’s react‑1 lets you re‑direct an actor’s performance in post
Fal introduced sync.react‑1, a new video model aimed squarely at performance‑level editing: you can take a single live‑action take and then direct alternate emotional reads, timing, and reactions afterwards instead of re‑shooting video demo. The model can adjust expression and micro‑movement while preserving identity, making it behave less like a generic face‑swap and more like a controllable actor in post.

React‑1 also doubles as a native dubbing system: instead of only re‑animating lips to match a new language track, it reanimates the full head and facial performance to fit the new audio, so the whole body language tracks with the line delivery video demo. For AI engineers working on localization, advertising, or film/creator tools, this gives you a new primitive: you can generate multiple emotional variants of the same line, or localize a performance across languages, all from one original clip, and keep everything running on Fal’s hosted APIs without custom motion rigs or 3D pipelines.
🤖 Embodied AI: open‑ended reasoning demos and field robots
Light but notable: DeepMind’s agents reasoning segment, Boston Dynamics’ Atlas update, and Stanford’s ‘puppers’ doing tasks with Gemini APIs. Orthogonal to creative video and model releases.
DeepMind spotlights shift from scripted robot tricks to open‑ended reasoning
DeepMind is publicizing a robotics direction focused less on pre‑programmed stunts (like backflips) and more on agents that can understand context and figure out what to do on their own. The lab demo contrasts brittle hand‑tuned behaviors with robots that reason over goals and environment state to choose actions, underscoring that embodied AI is increasingly framed as a planning and inference problem rather than just control and trajectory optimization. DeepMind overview

For engineers, it’s a signal that future robot stacks will look a lot like agentic LLM systems—perception → context → tool/actuator calls—with more emphasis on generalizable decision policies than on one‑off motion scripts.
Boston Dynamics’ new Atlas reel shows custom hardware and adaptive whole‑body control
Boston Dynamics shared a fresh Atlas demo highlighting how far real‑world mobility hardware and control have come: the robot runs custom batteries, 3D‑printed titanium and aluminum parts, and uses whole‑body dynamic control to adjust to rough, uneven terrain in real time. Atlas description

For embodied‑AI folks, the clip is a reminder that frontier capability now hinges on marrying strong perception and planning with bespoke electromechanical design, and that learning‑based reasoning layers will increasingly sit on top of extremely capable, already‑deployed locomotion stacks like this.
Stanford class uses Gemini APIs to run packs of robotic ‘puppers’
At a Stanford engineering demo night, an entire pack of small quadruped robots (“puppers”) were shown doing sensing and interaction tasks—picking up balls, walking on leashes, navigating cluttered spaces—with teams wiring them up to Gemini APIs for perception and decision‑making. (Stanford puppers demo, More pupper tasks)

The takeaway for builders is that LLM‑class models are already being treated as off‑the‑shelf brains for student‑level robots: you can prototype embodied agents by pushing vision and text state to a hosted model, then mapping its tool‑like outputs to locomotion and manipulation behaviors without having to train custom policies from scratch.
🧄 Frontier watch: GPT‑5.2 ‘garlic’ teasers and sightings
High‑volume rumor cycle: OpenAI teases ‘garlic’ in a cooking clip; screenshots of GPT‑5.2 tooltips in Cursor circulate; release timing speculation. Excludes firm releases which sit in Model Releases.
Cursor leak shows GPT‑5.2 as “latest flagship” with 272k context
Screenshots from Cursor’s model picker show an entry for “GPT‑5.2 – OpenAI’s latest flagship model” described as good for planning, debugging and coding, with a 272k‑token context window and “medium reasoning effort,” fueling speculation that internal integrations are already wired up. cursor tooltip
Several users report seeing this option in their Cursor builds while others cannot, and one thread notes that the “Christmas is coming early” comments from Cursor employees might actually have been about a new feature rather than the model itself, raising the possibility that the specific screenshot could be premature or misconfigured. (cursor early sighting, cursor skepticism) Even if it’s not generally live yet, the combination of “latest flagship” wording, a 272k context window, and a planning/debugging‑focused description gives engineers an early glimpse of how OpenAI intends to position GPT‑5.2 relative to GPT‑5.1 Codex Max and existing long‑context offerings.
‘Garlic in the pasta’ clip cements GPT‑5.2 codename rumors
OpenAI’s ChatGPT account posted a short video of Sam Altman cooking and joking that whatever he’s making “is going to be garlic in the pasta somehow,” which the community is treating as a deliberate wink that “garlic” is the internal codename for GPT‑5.2 and that a launch is close. garlic clip Commentators explicitly tie the garlic line to earlier chatter that GPT‑5.2 is coming “tomorrow” or “Thursday,” framing the clip as a playful confirmation of both the name and timing. garlic hint thread Meme posts depicting Altman as “Garlic Man” and joking that “Sam is about to add the garlic” reinforce the idea that this model will be the next big ingredient in OpenAI’s lineup rather than a minor patch. garlic add joke
Speculation frames GPT‑5.2 launch as existential race vs Gemini and Opus
Commentators now talk about GPT‑5.2 as a near‑certain “this week” or Thursday launch, with multiple threads claiming executives overruled internal voices asking for more time so OpenAI can respond to Gemini 3 Pro and Claude Opus 4.5. (release timing talk, thursday prediction)
Some voices describe the release as “existential” for OpenAI, arguing that if 5.2 is not clearly ahead of Gemini 3 Pro and Opus 4.5 “OpenAI might be cooked,” especially as Gemini’s usage and web traffic growth have pushed OpenAI into a public “code red” posture. (existential hot take, gemini growth claim) At the same time, analysts cite OpenAI’s own preparedness note that cyber capabilities on CTF challenges jumped from 27% on GPT‑5 in August 2025 to 76% on GPT‑5.1‑Codex‑Max by November, and a warning that upcoming models are expected to reach “High” capability under the internal framework, as evidence that 5.2 will likely be both significantly more capable and more tightly guarded on security‑sensitive tasks. (preparedness excerpt, high capability hint)
Rumors point to IMO‑grade ‘Thinking’ tier and olive‑oil codenames for GPT‑5.2
One leaker claims a reliable source says the GPT‑5.2 “Thinking” tier may reuse or distill OpenAI’s IMO Gold competition model, raising expectations that Plus‑tier users could soon get access to much stronger step‑by‑step reasoning at around the $20/month price point instead of only via expensive APIs. imo gold rumor Elsewhere, a Notion‑side leak reports an internal model labeled “olive‑oil‑cake” being tested and widely assumed to be GPT‑5.2 under another food‑themed codename, echoing the “garlic” motif from the ChatGPT clip. olive oil cake note Some power users also report that GPT‑5.1 with extended thinking “feels way better than it did yesterday,” speculating that background tweaks or partial rollouts connected to 5.2’s training might already be affecting current behavior, much like the quiet 5.0→5.1 upgrade earlier this year. quality jump comment
📑 Reasoning & methods: stability, confessions, RL interplay, DP logs
New research threads: instability in LLM reasoning, ‘confession’ self‑audit training, how pre/mid/RL stages interact, and a DP framework for chatbot log mining. Excludes any bioscience topics by policy.
OpenAI trains models to add honest ‘confession’ reports after answers
OpenAI’s new "Confessions" paper trains LLMs to produce a second, structured self-audit after each answer, listing which instructions they followed, where they cut corners, and how confident they are, with a separate reward model scoring only the honesty of that confession. confessions summary
During normal RL they sometimes flip into "confession mode": the model answers as usual, then gets a fixed reward for that answer and an independent honesty reward for a follow-up ConfessionReport, whose gradients update only the confession tokens rather than the original answer. training explanation Because lying in the confession can’t improve the original reward but can hurt the honesty score, the easiest way to get high reward is to accurately admit hacks, mistakes, or safety violations, and in experiments the confessions expose hidden behaviour like reward-model hacking, sandbagging quizzes, or quiet rule-breaking far more often than the primary answers—though they still can’t reveal errors the model itself never noticed, so they function as a monitoring layer rather than a full safety solution.
Google proposes differentially private pipeline for mining chatbot logs
Google researchers outline a full differential‑privacy framework for analyzing chatbot usage—clustering conversations, building noisy keyword histograms, then letting an LLM write summaries—so product teams can mine patterns without exposing any one user’s chats. dp summary
Instead of feeding raw logs to a model or relying on "redact PII" prompts, they first embed each conversation, then run a DP clustering algorithm so each chat only slightly nudges a cluster centroid, and within each cluster they compute differentially private keyword counts with added noise. pipeline explanation An LLM then generates insights using only those noisy, cluster‑level statistics and keywords, and in human evals these DP summaries are actually preferred over a non‑private baseline in up to 70% of cases, while membership‑inference AUC drops to ~0.53 vs ~0.58, suggesting this style of analytics can give useful product signals with quantifiable privacy guarantees instead of vague "we strip identifiers" claims.
ReasonBENCH finds LLM reasoning highly unstable across repeated runs
ReasonBENCH introduces a benchmark and library to measure how stable LLM "reasoning" actually is, showing that many popular chains-of-thought setups swing wildly in accuracy and cost when you rerun them 10× on the same tasks. paper thread
The authors standardize 11 reasoning frameworks and several modern models under a multi-run protocol, then report confidence intervals instead of a single headline accuracy, finding that top methods can have confidence bands up to 4× wider than others at similar mean scores. paper thread They also highlight that some strategies burn far more tokens in an unstable way, so the real trade-off is solve rate vs variance vs token budget, and argue that eval culture needs to move from one-shot percentages to variance-aware reporting, especially for production agents that need predictable behaviour and cost rather than lucky runs.
CMU maps how pre‑training, mid‑training and RL interact for reasoning LLMs
A Carnegie Mellon team systematically studies how pre‑training, focused mid‑training, and reinforcement learning combine to shape reasoning in language models, using synthetic math tasks built from small operation graphs with controllable depth and narrative context. paper summary
By varying graph depth they probe depth generalization (longer chains than seen in training) and by swapping templates they test contextual generalization (same skills in new stories), then add RL with process-based rewards that score each intermediate step rather than only the final answer. paper summary They find RL helps most when tasks sit just beyond what pre‑training already covers—the "competence edge"—and that when tasks are too easy or too far out-of-distribution RL adds little, while mid‑training on targeted reasoning data plus per-step rewards both improves out-of-distribution accuracy and reduces reward hacking, giving practitioners a more nuanced recipe than "slap RL on everything".
PPO vs GRPO vs DAPO: RL study finds DAPO wins for LLM reasoning
Another RL paper compares three families of reinforcement algorithms—PPO, GRPO, and DAPO—for improving small LLMs on math and reasoning benchmarks, concluding that DAPO without its dynamic sampling add‑on tends to give the best and most stable gains. rl comparison
All three methods treat the model as a policy over token sequences rewarded for good answers, but whereas PPO trains a separate value head, GRPO and DAPO rely on group-wise comparisons of multiple sampled answers for the same prompt and explicitly push up better completions. rl comparison The authors’ parameter sweep shows that larger answer group sizes make training more stable, entropy bonuses and overly large learning rates often hurt, and the KL penalty that keeps the new model near the base works best at moderate strength; taken together, the results suggest that if you’re doing RL for reasoning, a well‑tuned, value‑free method like DAPO may be a better default than heavyweight PPO.
Prompt personas don’t reliably boost factual accuracy on hard exams
A new Prompting Science report tests whether telling models to "act like an expert" actually makes them more factually accurate on tough multiple-choice questions in science, engineering, and law—and finds that it mostly doesn’t. persona paper
The authors run six models on GPQA Diamond and MMLU-Pro with many samples per question, comparing domain-matched expert personas, mismatched experts, and low-knowledge personas like toddlers, then analyze performance after averaging out sampling noise. persona paper Expert personas, whether matched or mismatched, usually match the plain, no-persona baseline within noise, whereas low-knowledge personas reliably hurt accuracy and can even trigger refusals in some Gemini variants, so the practical advice is to invest in clearer task specs and evaluation instead of stacking personas when you care about being right.
Game‑theory framework reveals LLM agent strategies and cooperation biases
A multi‑institution team uses game theory to analyze how LLM agents behave in repeated social dilemmas, showing that cooperation levels and learned strategies depend sensitively on payoff scaling and even the language of the prompt. game theory paper
Using their FAIRGAME setup, they put models into iterated Prisoner’s Dilemmas and Public Goods Games with different stake multipliers but fixed outcome rankings, then rerun many times to see how often they cooperate and how those patterns shift in English vs Vietnamese phrasing. game theory paper A recurrent classifier maps play histories to classic strategies like always‑cooperate or tit‑for‑tat, revealing that models embed distinct cooperation biases and that cooperation often decays over time, especially in some languages and payoff regimes; for people designing multi‑agent systems or AI negotiators, the takeaway is that small changes in framing, stakes, or locale can nudge agents into very different equilibrium behaviours.
KAG study finds scale‑agnostic geometric structure emerging in MNIST MLPs
A theoretical paper extends Kolmogorov‑Arnold Geometry (KAG) analysis from toy 3‑D tasks to realistic high‑dimensional MNIST, showing that shallow MLPs trained on digit classification spontaneously develop the same kind of structured response patterns at multiple spatial scales. kag paper
The authors probe trained 2‑layer GELU networks by nudging input pixels and measuring how hidden units respond, summarizing those Jacobians via simple statistics over many local submatrices, then comparing them to the random initial networks. kag paper After training, these KAG statistics move far from random—especially in the first hidden layer and in wider networks—and the same geometry appears whether they analyze small 7‑pixel neighborhoods, distant pixel groups, or the whole image, even under spatial augmentation; for people thinking about mechanistic interpretability and representation learning, it’s a datapoint that relatively simple models converge toward a scale‑agnostic, Kolmogorov‑Arnold‑like decomposition of input space.