OpenAI GPT-5.3-Codex hits $1.75/$14 per 1M – 400k context in Responses API
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
OpenAI says GPT-5.3-Codex is now available to all developers in the Responses API; the surfaced model metadata calls out 400k context, 128k max output, and $1.75/M input plus $14/M output. The same API flow adds native docx/pptx/xlsx/csv inputs for agent runs; OpenRouter also lists 5.3-Codex with the same 400k window and pricing, widening distribution to OpenRouter-based IDEs. Adoption anecdotes move from “model shipped” to “agent stayed coherent”: one post claims ~25 hours uninterrupted, ~13M tokens, and ~30k LOC in a single session; Lovable claims 3–4× token efficiency vs GPT-5.2, but neither comes with independent harness artifacts.
• Anthropic/Claude: Claude Code Remote Control rolls out for Max users via claude rc; 2.1.53–2.1.54 add bridge min-version guards, shutdown fixes, initial prompt, and session archiving; Enterprise adds Cowork, private plugin marketplaces, and a unified Customize surface.
• Cloud-agent verification: Cursor’s cloud agents return demo videos; Cursor claims ~1/3 of merged PRs come from sandboxed agents; Devin 2.2 adds computer-use testing, self-verify/auto-fix loops, and a 3× faster startup claim.
• Models + inference plumbing: Qwen3.5 Flash ships 1M context by default and claims near-lossless 4-bit + KV quant; Mercury 2 is positioned as diffusion text with >1,000 tok/s claims; Baseten’s RadixMLP advertises 1.4–5× faster prefill via prefix deduplication, workload-dependent until reproduced.
Top links today
- Claude Code Remote Control docs
- Claude Cowork enterprise announcement
- Anthropic Responsible Scaling Policy v3
- Qwen3.5-35B-A3B model on Hugging Face
- Qwen3.5 Medium models on ModelScope
- OpenAI Responses API docs
- Responses API WebSocket mode announcement
- Responses API expanded file input types
- GPT-5.3-Codex in Responses API announcement
- GPT-5.3-Codex on OpenRouter
- Cursor agents demos not diffs announcement
- Bullshit Benchmark GitHub repo
- Benchmarks saturate when judge fails paper
- Modal sandbox directory snapshots blog
- Weaviate agent skills repo and guide
Feature Spotlight
Claude Code Remote Control: keep local sessions running from your phone
Remote Control turns Claude Code into a “start on laptop, steer from phone” workflow without moving execution off your machine—shrinking context-switching and making long-running agent tasks usable during meetings/commutes.
High-volume launch across Anthropic/Claude Code accounts: start a Claude Code task in your terminal and continue controlling the same local session from the Claude mobile app or web bridge. This category covers Remote Control only; excludes Cowork/plugins and other Claude enterprise updates.
Jump to Claude Code Remote Control: keep local sessions running from your phone topicsTable of Contents
📱 Claude Code Remote Control: keep local sessions running from your phone
High-volume launch across Anthropic/Claude Code accounts: start a Claude Code task in your terminal and continue controlling the same local session from the Claude mobile app or web bridge. This category covers Remote Control only; excludes Cowork/plugins and other Claude enterprise updates.
Claude Code Remote Control lets you drive a local session from your phone
Claude Code Remote Control (Anthropic): Following up on CLI update—early Remote Control hooks—Anthropic is now rolling out Remote Control as a Research Preview for Max users, letting you start work in the terminal and continue the same session from the Claude mobile app or a web bridge while the code keeps running on your machine, as shown in the launch thread and reiterated in the availability note.

Remote Control is invoked via claude rc, with docs linked from the announcement in the launch thread; the rollout status is being confirmed by Anthropic engineers saying it’s “now rolled out to all Max users,” as stated in the rollout update.
Claude Code 2.1.53 adds Remote Control bridge gating and fixes stale sessions
Claude Code 2.1.53 (Anthropic): Build 2.1.53 surfaces remote-control as a first-class command and adds a tengu_bridge_min_version guard so Remote Control bridge usage can enforce minimum client versions, as tracked in the CLI surface diff and clarified in the flag analysis.
The same release includes Remote Control-specific reliability work—fixing “graceful shutdown sometimes leaving stale sessions when using Remote Control” by parallelizing teardown network calls—per the CLI changelog.
Claude Code 2.1.54 updates the Bridge UX with an initial session prompt
Claude Code 2.1.54 (Anthropic): The Bridge flow that underpins Remote Control now “starts with an initial session prompt,” and the client adds the ability to archive one or more selected sessions, per the release notes and the prompt change summary.
This is a small UX change. It affects how quickly a resumed session is oriented and how aggressively session history accumulates.
Remote Control is getting day-one usage feedback from Claude Code builders
Remote Control adoption (Anthropic): Builders close to Claude Code are already describing Remote Control as something they’re “using daily,” and explicitly asking for feedback, as captured in the daily use comment.
Separately, additional Anthropic accounts are pushing the “try /remote-control” call-to-action, as seen in the try it note, which signals this is being treated as a core workflow surface rather than an experimental side feature.
🏢 Claude for Enterprise: Cowork, private plugin marketplaces, and finance workflows
Enterprise-focused Claude updates: Cowork collaboration, admin-controlled plugin distribution, and “Customize” controls—plus finance-oriented connectors/plugins and partnerships. Excludes Remote Control (covered in the feature).
Cowork brings Claude customization and collaboration to enterprises
Cowork (Anthropic): Anthropic introduced Cowork as an enterprise surface for customizing Claude around how different teams work, positioning plugins as the mechanism to turn Claude into role-/department-specific agents, as announced in the Cowork announcement.
• What changes for org rollouts: Cowork frames “customize once, distribute to teams” as the default operating model—important if you’re trying to standardize tools/skills across departments without each team building its own prompt stack, per the Cowork announcement.
Anthropic and Intuit partner on “financial intelligence” and custom agents
Intuit partnership (Anthropic): Anthropic and Intuit announced a multi-year partnership centered on “financial intelligence” and custom AI agents for money/tax/accounting workflows, as stated in the Partnership announcement and echoed in the Partnership recap.
The key implementation detail in the tweets is the positioning: Claude users in Cowork/Enterprise/Claude can execute finance tasks with Intuit’s data interpretation layer in the loop, per the Partnership announcement.
Claude Enterprise adds private plugin marketplaces for org distribution
Private plugin marketplaces (Anthropic): Enterprise admins can now create private plugin marketplaces to distribute org-approved plugins across their company, as described in the Enterprise plugin update and reiterated in the Admin marketplace note.
This is a concrete governance primitive: it centralizes plugin availability decisions (and implied data/tool access) in admin controls rather than individual user installs, as shown in the Admin marketplace note.
Claude Enterprise unifies plugins, skills, connectors, and agents under Customize
Customize menu (Anthropic): Anthropic shipped a unified Customize menu that consolidates control over plugins, skills, and connectors, and the rollout chatter also highlights a new Agents tab in the same admin surface, according to the Customize menu mention and the Agents tab preview.

• Why this matters operationally: this turns “what tools can Claude touch?” into one place you can review and gate—especially relevant once multiple departments start shipping internal plugins and connectors, as shown in the Customize menu screenshot.
Claude ships finance-focused plugins and tool grounding for capital markets work
Finance plugin pack (Anthropic): Multiple posts describe new finance-oriented plugins aimed at workflows like financial analysis, investment banking, equity research, private equity, and wealth management, with a broader claim that Cowork can move across tools like spreadsheets and slide decks in multi-step flows, per the Finance workflow description and the Plugin category list.
This reads as a packaging move: “Claude as a finance analyst” becomes a set of installable workflow shortcuts and connectors rather than a prompt collection, consistent with the “Customize” surface shown in the Customize menu screenshot.
Claude Code adds a Slack plugin for search and updates
Slack plugin (Anthropic ecosystem): A Slack plugin is shown connecting Claude Code to Slack for search, messaging, and document creation—so the agent can pull team context and post updates—according to the Slack plugin demo and the Install command.

The on-the-ground usage claim is that the Claude Code team uses it internally, including a case where Claude Code searched Slack for missing context to unblock itself, as described in the Slack plugin demo and the Team usage note.
Claude Enterprise expands its connector set for business systems
Connectors expansion (Anthropic): Alongside Cowork, Anthropic is described as adding more enterprise connectors—covering Google Workspace, DocuSign, Apollo, Clay, Outreach, Similarweb, WordPress, and Harvey—plus ecosystem plugins including Slack by Salesforce, per the Connector and plugin list.
The immediate engineering implication is broader “bring your system-of-record into Claude” coverage under a single admin-managed surface, which the UI positioning in the Customize menu screenshot suggests is intended to be operated centrally (not per-user).
Claude finance workflows add a FactSet connector for market data grounding
FactSet connector (Anthropic): In the finance workflow framing, Anthropic is described as adding a FactSet connector so Claude can reference institutional market data rather than relying only on pretrained knowledge, according to the Finance connector details.
What’s still not shown in the tweets is the exact connector API surface (permissions model, query limits, and auditing hooks), beyond the existence claim in the Finance connector details.
Claude finance workflows add an MSCI connector for index and risk context
MSCI connector (Anthropic): The same finance push is described as adding an MSCI connector to ground Claude’s analysis in index tracking and related datasets, per the Finance connector details.
The tweets don’t yet include examples of how MSCI data is surfaced inside Claude responses (citations, snapshots vs live pulls, or model/tool separation), beyond the connector callout in the Finance connector details.
🧠 OpenAI Codex 5.3 in the Responses API: availability, pricing, and ergonomics
Developer-facing Codex updates centered on GPT‑5.3‑Codex being available broadly in the Responses API and across aggregators, plus pricing and API surface improvements. Keeps benchmark results/evals in the evals category to avoid duplication.
GPT-5.3-Codex is now in the Responses API for all developers
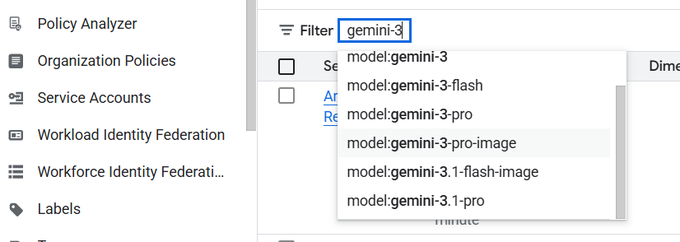
GPT-5.3-Codex (OpenAI): OpenAI says GPT-5.3-Codex is now available to all developers via the Responses API, per the Responses API availability. The same rollout surfaces concrete knobs/specs—400k context, 128k max output, and $1.75/M input + $14/M output—as shown in the Model card screenshot.
This is primarily an ergonomics change for teams standardizing on Responses API (tool calling + files + caching) while moving to a newer Codex checkpoint; pricing and large output limits are now explicit in the surfaced model metadata.
GPT-5.3-Codex becomes available through OpenRouter toolchains
GPT-5.3-Codex (OpenRouter): OpenRouter lists GPT-5.3-Codex as live, making it reachable from OpenRouter-powered IDEs/agents without direct OpenAI integration, according to the OpenRouter announcement. The OpenRouter listing highlights 400,000 context plus the same $1.75/M input, $14/M output pricing, as shown in the OpenRouter model page.
The practical upshot is distribution: teams already standardized on OpenRouter routing/billing can now slot in 5.3-Codex with no harness rewrite.
Responses API expands file inputs beyond PDFs and text
Responses API (OpenAI): OpenAI expanded supported file input types so agents can pass docx, pptx, csv, xlsx, and more directly into the Responses API, as described in the file input update. This is a workflow-level change for “bring your own artifacts” agents (sales decks, spreadsheets, status docs) that previously had to pre-convert everything into text.

The tweet frames the motivation as better grounding from real-world files, which matters most for automation that needs to preserve table structure and slide semantics rather than lossy copy/paste.
A 25-hour GPT-5.3-Codex run is shared as a long-horizon agent datapoint
Long-horizon Codex runs: A developer-shared anecdote claims GPT-5.3-Codex (xhigh) ran for ~25 uninterrupted hours, used ~13M tokens, and generated ~30k lines of code, as relayed in the long horizon screenshot.
This isn’t an eval artifact, but it’s a concrete “can it stay coherent for a workday?” datapoint that engineering leaders track when deciding whether to trust background agent runs over multi-hour tasks.
Cline surfaces GPT-5.3-Codex in its model picker
GPT-5.3-Codex in Cline (Cline): Cline says GPT-5.3-Codex is selectable in Cline, and frames the upgrade around faster completion and lower token usage, as shown in the Cline launch clip.

The post mixes in benchmark claims, but the operational takeaway is that one more mainstream agent harness has a first-class “pick 5.3-Codex” path without custom wiring.
Lovable switches harder problems to GPT-5.3-Codex for token efficiency
GPT-5.3-Codex adoption (Lovable): Lovable says it’s now using GPT-5.3-Codex for its “most complex problems,” claiming it’s 3–4× more token-efficient than GPT-5.2, per the Lovable rollout note.
This is one of the few concrete “production delta” statements in the feed (efficiency, not just capability), and it matches how many teams evaluate coding models now: total tool-loop cost rather than single-shot quality.
Codex app supports GPT-5.3-Codex via API-key login
Codex app (OpenAI): OpenAI staff note you can use GPT-5.3-Codex either via the Responses API or inside the Codex app when you’re signed in with an API key, per the API key note. Separately, Codex app UX is shown surfacing “Open in …” targets (VS Code, Cursor, Terminal, Xcode) in the Open in menu screenshot.
In practice this reduces the gap between “API model access” and “desktop agent workflow,” especially for developers bouncing between app UI and repository-local tools.
☁️ Cursor Cloud Agents: “demos not diffs” and self-verifying PRs
Cursor’s cloud-agent workflow shifts review toward proof-of-work: agents run in their own cloud computer/VM, test changes end-to-end, and return videos/screenshots instead of only diffs. Excludes generic testing tools not specific to Cursor.
Cursor Cloud Agents switch review from diffs to demo videos from a cloud VM
Cursor Cloud Agents (Cursor): Cursor shipped “demos, not diffs”—cloud agents now run changes in their own cloud environment and return recorded proof (video chapters) of end-to-end behavior instead of asking you to infer correctness from a patch, as shown in the launch demo.

• Artifacts as the new review unit: Cursor describes agents using the software they build and sending videos of their work, including internal dogfooding where an agent adds secret redaction to tool calls and records itself testing the local build in a three-chapter video, per the launch demo and the redaction example.
• Cloud computer per agent: Each agent gets its own VM/development environment (browser and desktop apps), enabling longer autonomous runs and parallel tasks; Cursor’s own framing emphasizes verifying changes end-to-end in that environment, according to the cloud agent workflow and cloud agents note.
• Adoption signal inside Cursor: Cursor says “a third of the PRs we merge now come from agents running in cloud sandboxes,” per the internal PR share.
• Builder behavior shift: Users are already doing phone-first orchestration—e.g., “added Winamp … built end to end from my phone with Cursor cloud agents” and receiving a video tour plus screenshots as evidence, per the phone-built app example.
🧑💻 Devin 2.2: computer-use testing, self-verification, and faster sessions
Devin’s release focuses on autonomous dev lifecycle loops: computer use in a virtual desktop, self-review/self-fix before PR handoff, and UX speedups. Excludes Cursor/Claude tooling to keep tool beats distinct.
Devin 2.2 adds computer-use testing plus self-verify and auto-fix loops
Devin 2.2 (Cognition): Cognition is shipping Devin 2.2 with a tighter end-to-end autonomy loop—computer use in a virtual desktop for testing, plus self-verification and automatic fixes before handoff—positioned as reducing “it compiled, trust me” moments in agent PRs, as described in the Devin 2.2 launch. It also comes with a ground-up rebuild and a claimed 3× faster startup, which is mostly about shrinking the time between “start session” and “first useful action,” per the same Devin 2.2 launch.

• Computer-use testing: The release explicitly calls out “computer use + virtual desktop,” meaning the agent can click through UI flows and run checks in an environment closer to a real dev box than a pure tool-call harness, according to the Devin 2.2 launch.
• Self-verify then patch: Devin is marketed as closing its own loop—run, check, fix—before you see the PR, which shifts review effort from “find issues” to “decide if the approach is acceptable,” as shown in the Devin 2.2 launch.
Access details are still light in the tweets beyond “try it for free,” as stated in the Devin 2.2 launch and reiterated in the Free trial link.
Devin 2.2 UI overhaul: dev lifecycle is one click away
Devin 2.2 UI (Cognition): Cognition says it rebuilt “every screen” so each step of the dev lifecycle is one click away—start sessions, review output, jump back to code review—alongside the same 3× faster startup claim, according to the UI redesign note and the broader Devin 2.2 launch. For teams using Devin as a background agent, this is aimed at reducing navigation overhead and making session management + review feel less like spelunking through logs.

The company’s framing is that the UX, not the model, is the bottleneck: keep the context of “what just happened” close to the next action you need to take, as described in the UI redesign note.
Devin Review is now integrated into the main Devin session page
Devin Review (Cognition): Cognition is pulling Devin Review into Devin’s core session UI—so the agent reviews its own work, catches issues, and fixes them before you open the PR—building on Devin Review, earlier one-click inline fixes, as stated in the Review integration note. This is explicitly positioned as “Devin doesn’t just write code and hand it off,” i.e., review becomes a first-class step in the default workflow.
A concrete “in the wild” view of this loop (agent completes work; review reports “no potential bugs”) shows up in the screenshots shared in the Devin internal workflow notes.
Devin adoption signal: users report rapid ramp from trial to daily use
Devin adoption (field signal): Builder chatter is highlighting a steep usage ramp: one thread claims Devin usage “doubled every 2 months” after landing in enterprises in 2025, then accelerated to “every 6 weeks” this year, as written in the Devin adoption notes. Separately, practitioners describe a personal shift from “using it as a meme” to “many times a day,” as stated in the Daily usage comment, with similar first-impression sentiment (“so far it slaps”) appearing in the Early trial reaction.
This is anecdotal and not a public dashboard metric, but it’s consistent with a broader pattern: as agents get more reliable at self-verifying, the limiting factor becomes review bandwidth and integration friction rather than raw code generation.
Devin rebuilds Slack and Linear integrations for faster conversations
Devin integrations (Cognition): Cognition says it rebuilt Devin’s Slack and Linear integrations to make conversations “faster and more reliable,” which matters if your team routes agent instructions and status updates through chat + issue trackers rather than Devin’s own UI, per the Slack and Linear demo.

The tweet doesn’t specify protocol or retry semantics, but it’s a direct acknowledgement that agent UX often degrades in the connector layer (message delivery, threading, linking work to tasks) even when the model is capable, as noted in the Slack and Linear demo.
🧩 Agents in work apps: Notion custom agents + Google Opal workflow agents
Team productivity suites are shipping agent builders: scheduled/triggered autonomous agents in Notion, and Opal workflow steps that route tools, ask clarifying questions, and persist memory. Excludes developer-focused agent SDKs and MCP servers.
Notion rolls out custom AI agents that run on triggers and schedules
Notion custom AI agents (Notion): Notion is rolling out team-oriented agents that run autonomously on triggers or schedules (i.e., not a one-off “Ask AI” prompt), with the product pitch that they operate “’round the clock,” as shown in the launch demo; they’re framed as connector-driven (Notion + external apps) and powered by “latest models from OpenAI and Anthropic,” per the launch demo.

• Surfaces and scope: the beta UI puts agents into a dedicated “Agents Beta” sidebar section, as shown in the agents beta UI.
• Cross-app workflow claim: expanded rollout notes say agents can operate across Notion, email, calendars, and Slack, as described in the agents beta UI.
The main unknown from today’s posts is how robust these agents are under real org policies (permissions, audit trails, and failure recovery), since the tweets focus on the builder UX rather than control-plane details.
Google Opal adds an in-workflow agent step with tool routing and memory
Opal agent step (Google): Google Opal is adding an “agent” step inside workflows, where you describe a goal in natural language and the agent chooses tools/models, can pause to ask follow-ups, and can retain memory between sessions; the demo prompt includes “answer questions about my last three meetings,” as shown in the Opal agent block demo.

• Native agent primitives: posts call out built-in tool calling (including image/video tooling and web search), memory, and conditional logic/dynamic routing, as described in the Opal agent block demo and the agentic workflows recap.

This reads as a shift from “static pipelines” to “interactive workflow agents,” but today’s tweets don’t specify implementation limits (e.g., what memory persists, scoping rules, or which tools are allowed per tenant) beyond the surfaced UX.
🧾 Context engineering reality check: AGENTS.md, /init pitfalls, and “less is more”
Practitioner and research-driven guidance on repo context files and prompt hygiene: evidence that auto-generated AGENTS.md can hurt success rates and inflate costs, plus recommendations for minimal, human-written, task-relevant steering.
AGENTS.md evaluation finds auto-generated context hurts coding agents
AGENTS.md paper (ETH Zurich/LogicStar): A new preprint reports that LLM-generated repository context files (AGENTS.md and similar) slightly reduce task success while materially increasing inference cost, based on SWE-bench plus a new 138-instance “AGENTbench”, as summarized in the paper highlight thread.
• Measured impact: The study’s headline result is that auto-generated context decreased success by about 0.5–2% while increasing inference cost by 20%+, and it drove 1.6–2.5× more tool use plus roughly 22% more reasoning tokens, as described in the paper highlight thread.
• What helped instead: Developer-written context improved success by about 4% but still raised cost; the paper’s practical takeaway is to keep human-written context minimal and non-obvious (build/test/tooling landmines), rather than duplicating repo docs, per the paper highlight thread.
The authors’ mechanism claim is that these files encourage extra exploration without helping agents find relevant files faster, as noted in the paper highlight thread.
A practical AGENTS.md template: keep it short, point to task docs
AGENTS.md guidance (Phil Schmid): A distilled playbook frames AGENTS.md as the “highest configuration point” injected into every session; it argues for “less is more” and recommends keeping the file focused on WHAT/WHY/HOW, with task-specific details moved to separate docs and referenced by pointer, as laid out in the best-practices thread.
• Content to keep: Tech stack + project structure, intent (“why”), and exact build/test commands—especially non-obvious tooling like bun/uv—per the best-practices thread.
• Content to drop: Directory inventories, style guides (use linters/formatters), and auto-generated context; the thread also claims tool mentions strongly steer behavior (“get used 160× more often”), as stated in the best-practices thread.
It links the motivation back to the AGENTS.md evaluation results, which are referenced in the paper links follow-up.
Claude Code /init pushback: token burn and fast staleness
Claude Code /init (Matt Pocock): A warning thread argues that running claude /init is a footgun because it burns tokens, bloats the system prompt, and becomes stale quickly, as stated in the /init warning post.

The core claim is that repo-wide “setup” prompts rot fast and create repeated cost across sessions, with the author recommending tighter, more durable guidance instead of a one-time giant prompt, per the /init warning post.
AGENTS.md as “landmines list,” plus a directory hierarchy
Context file structure (Addy Osmani): A suggested mental model treats AGENTS.md as a living list of “codebase smells / recurring agent mistakes” rather than a permanent brain dump, with a caution to be careful with /init, as written in the /init caution note.
The same note claims a single root AGENTS.md doesn’t scale for complex repos; it proposes a hierarchy of AGENTS.md files by directory/module so agents receive scoped context instead of a monolithic prompt, as described in the /init caution note.
A separate pointer to “best article till today” on the same theme appears in the best article pointer.
Lead-dev mentality becomes the skill ceiling for AI coding
AI coding workflow (Matt Pocock): A practitioner take says AI coding feels good when you bring a “lead dev” posture—requirements, API design, architectural feedback loops, and continual review—rather than optimizing only for personal output, as argued in the lead dev mentality post.
A related note is that much “AI coding education” collapses back into classic fundamentals (requirements, types/tests, architecture, backlog prioritization), as outlined in the fundamentals list.
When agents struggle, spend tokens on probes and summaries, not thrash fixes
Agent debugging pattern (Robert C. Martin): A concrete rule of thumb is to stop spending tokens on repeated manual “fix attempts” when the model is failing; instead, have the model build targeted probes/tools that make debugging cheaper and more deterministic, per the token-burn warning.
The same thread suggests managing context windows by having the agent write short summary documents of the relevant components as it goes, as stated in the probe and summary tip.
ACE frames AGENTS.md as a compact anti-mistake file, with separate playbooks
Context playbooks (ACE): A tool pitch reframes CLAUDE.md/AGENTS.md as a short steering file meant to prevent recurring mistakes—excluding anything discoverable from the repo—and pushes the idea of separate task playbooks that get updated over time, as summarized in the context file guidance.

This sits adjacent to the paper-driven “don’t auto-generate AGENTS.md” message, but adds a product claim about autonomously maintained playbooks rather than a single repo-wide context file, per the context file guidance.
🔌 Interop & tool access: MCP servers, agent collaboration layers, and chat SDKs
Plumbing that lets agents reach real tools: MCP-compatible collaboration/knowledge handoffs, large tool catalogs via MCP, and multi-surface chat interfaces. Excludes Claude enterprise plugin marketplaces (covered in Cowork).
BridgeMind MCP adds persistent tasks, handoffs, and shared knowledge for agents
BridgeMind MCP (BridgeMind): BridgeMind shipped an MCP server that makes agent work persistent across sessions—an agent can create a task, another can pick it up later, and shared research stays available to the rest of the “team,” according to the [BridgeMind MCP launch](t:519|BridgeMind MCP launch); it’s framed as working across MCP-compatible clients like Cursor, Claude Code, Windsurf, and Codex.

• Workflow surface: The demo shows task creation, messaging/handoffs, and a “store research” loop so later agents don’t redo the same investigation, as shown in the [product walkthrough](t:519|Product walkthrough).
It’s positioned as an interop layer rather than a new IDE or harness, with a launch promo calling out “50% off,” per the [pricing mention](t:519|Pricing mention).
Composio frames MCP servers as a 15,000+ tool access layer for agents
Composio (MCP servers): Composio is pushing its MCP server approach as a way to give agents access to “15,000+ tools” without building each integration yourself, with a live session agenda that includes Slack/GitHub/Gmail and “auth, testing, deployment best practices,” per the [event announcement](t:638|Event announcement).
The tweet frames the key problem as integration coverage (tool catalogs) rather than model quality, and treats MCP as the transport for that coverage, as described in the [session outline](t:638|Session outline).
Vercel’s Chat SDK bets on agent interfaces inside Slack/Teams/Discord
Chat SDK (Vercel): Vercel’s Guillermo Rauch highlighted npm i chat as a UI layer for “agentic interfaces” that can live beyond a company’s own web app—explicitly calling out Slack, Discord, Teams, and Google Workspace as the distribution surfaces in the [Chat SDK post](t:57|Chat SDK post).
A separate quickstart report says a working setup took “<5m,” shown in the [setup clip](t:180|Setup clip).

The thread framing is less about model choice and more about where agents show up for users (mentions, group chats, existing comms tools), per the [distribution argument](t:57|Distribution argument).
OpenClaw can route models through Kilo Gateway via a new provider option
OpenClaw (Kilo Gateway): OpenClaw added a “Kilo Gateway” option in its model/auth provider list—showing it alongside many other providers in the UI—per the [provider picker screenshot](t:192|Provider picker screenshot).
Kilo positions the gateway as a unified access layer (“Access 500+ AI models… unified billing… zero markup”) in the [gateway description](t:885|Gateway description), which becomes relevant once OpenClaw can point at it as a single provider.
Weaviate publishes Agent Skills and cookbooks to keep coding agents on-spec
Weaviate Agent Skills (Weaviate): Weaviate published an agent-facing repo of “skills” plus end-to-end cookbooks aimed at reducing common coding-agent errors when implementing vector DB flows (outdated syntax, hallucinated parameters, multivector confusion), as described in the [repo announcement](t:573|Repo announcement).
The drop includes a set of named commands (e.g., /weaviate:collections, /weaviate:explore, /weaviate:search) and positions cookbooks as full app blueprints (PDF retrieval, agentic RAG), per the [command list](t:573|Command list).
🧱 Model releases: Qwen 3.5 medium wave + Mercury 2 diffusion LLM + LFM2 MoE
A busy model day: Qwen 3.5 medium series emphasizes better architecture/RL over sheer params, Mercury 2 introduces diffusion-style LLMs for speed, and LiquidAI ships a hybrid MoE aimed at high-volume agent pipelines. Excludes image/video models (kept in gen-media).
Qwen 3.5 Medium models launch with a 1M-context Flash API and new efficiency claims
Qwen 3.5 Medium (Alibaba): Alibaba launched the Qwen3.5 Medium family—Qwen3.5-Flash (hosted), Qwen3.5-27B (dense), and MoE variants Qwen3.5-35B-A3B plus Qwen3.5-122B-A10B—pitching “more intelligence, less compute” and claiming the 35B MoE surpasses prior 235B-class Qwen models, as stated in the launch thread.
• Serving surface: Qwen3.5-Flash is positioned as the production hosted variant aligned with 35B-A3B, and it ships with 1M context length by default plus “official built-in tools,” per the launch thread.
• Long-context + quantization signal: Alibaba also claims near-lossless accuracy under 4-bit weight + KV-cache quantization, with long-context targets including 800K+ (27B) and 1M+ (35B-A3B / 122B-A10B) depending on VRAM, as described in the long-context note.
• Builder reaction: early takes highlight size/perf inversion—“6.7x smaller… Better in all benchmarks,” per the builder reaction—and a separate thread argues dense releases still matter for the open ecosystem, per the dense-model comment.
Mercury 2 launches as a diffusion LLM aimed at high-speed reasoning and code
Mercury 2 (Inception Labs): Inception announced Mercury 2 as a “reasoning diffusion LLM,” framing it as 5× faster than speed-optimized autoregressive models and opening early access opt-in plus free public testing, according to the launch post.

• What’s new architecturally: Mercury 2 is described as a diffusion-style text generator—iteratively refining a sequence rather than producing one token at a time—aiming to parallelize output generation, per the architecture explainer.
• Market positioning: one analyst take summarizes it as “10x faster and the cheapest model” for its quality tier, as written in the analyst note; these claims are directionally consistent with the “>1,000 output tokens/s” figure cited in the architecture explainer, but the tweets don’t include a single canonical third-party eval artifact.
LFM2-24B-A2B ships as a hybrid MoE tuned for high-concurrency agent workloads
LFM2-24B-A2B (LiquidAI): LiquidAI’s LFM2-24B-A2B is described as a 24B-parameter MoE with ~2.3B active parameters per token, positioned for high-volume multi-agent concurrency and tool-heavy production use, as summarized in the Together AI launch note.
• Product framing: Together pitches it as a “fast inner-loop model” with native function calling, and it calls out a hybrid architecture (short convolution blocks + GQA blocks), per the Together AI launch note.
• On-device-ish target: Ollama’s announcement frames it as designed to run “fast on device” and to fit machines with 32GB unified memory, per the Ollama launch note.
• Ecosystem distribution: Modal describes itself as a launch partner and highlights snapshotting/routing as complementary serving primitives, per the Modal partner note.
Mercury 2’s early story is speed first, with selective agentic strengths
Mercury 2 eval signal (Artificial Analysis): Early third-party commentary frames Mercury 2 as unusually fast—“>1,000 output tokens/s”—while landing “above par” on some agentic evaluations (not frontier-best intelligence), per the performance overview and the agentic eval note.
• Where it’s reported to do well: Artificial Analysis calls out strengths in instruction following and agentic coding/terminal use, including a claim that it performs around Claude 4.5 Haiku level on “Terminal-Bench Hard,” as described in the performance overview.
• How to interpret: the writeup emphasizes the “speed vs intelligence” trade—competitive capability in its price/size class but not leading overall—while making speed the headline, per the performance overview.
Qwen 3.5 Medium gets day-0 GGUFs with clear local RAM targets
Qwen 3.5 GGUFs (Unsloth): Unsloth published GGUF builds for Qwen3.5 Medium and summarized what “fits” locally—27B ~18GB, 35B-A3B ~24GB, and 122B-A10B ~70GB—as shared in the GGUF availability post.
• Practical constraint framing: the post explicitly calls out that these models are “ready to run” locally with quantized footprints and points to an inference settings guide in the GGUF availability post.
• What this changes: it shortens the path from a model announcement to “try it on a laptop,” and it anchors expectations around memory, not parameter count, using the same figures shown in the GGUF availability post.
Ollama adds a one-command run path for LFM2-24B-A2B
Ollama (LFM2): Ollama added a direct run entry point—ollama run lfm2:24b-a2b—and framed LFM2-24B-A2B as its latest “on-device” model that fits systems with 32GB unified memory, per the Ollama launch note.
This is a packaging/availability change (distribution + defaults), not a new training result; the key detail is the single-command local bootstrap described in the Ollama launch note.
vLLM ships day-0 support for LFM2-24B-A2B with a minimal serve command
vLLM (LFM2): vLLM announced day-0 support for LFM2-24B-A2B, including a minimal vllm serve snippet and a note that it “fits in 32 GB RAM,” alongside an example throughput figure of 293 tok/s on H100, per the vLLM support post.
The post also calls out a dependency detail—“upgrade transformers to v5”—as shown in the vLLM support post, which matters for teams whose serving images pin older Transformers versions.
✅ Verification tooling: autonomous QA, code review benchmarks, and security scanning
Tools and practices aimed at keeping agent output mergeable: autonomous browser dogfooding, comparative code-review benchmarks on real shipped bugs, and agent-assisted security scanning. Excludes Cursor/Devin-specific verification (covered elsewhere).
Anthropic preview: Claude Code Security for vulnerability scanning
Claude Code Security (Anthropic): Anthropic is being described as rolling out a Claude Code Security capability in a limited research preview for Team/Enterprise customers—positioned as an agentic scan that suggests patches with human review—per the summary in Claude Code Security claim.
• Claimed validation loop: The description calls out multi-stage verification plus severity ratings and confidence scoring, as written in Claude Code Security claim.
• Claimed evidence base: The post says Anthropic used Claude Opus 4.6 to find 500+ vulnerabilities in production open-source codebases, per Claude Code Security claim.
The tweets don’t include an official spec, eval set, or rollout docs, so the exact workflow surface (CLI flag, UI entry point, or API) isn’t verifiable from today’s sources.
Entelligence benchmarks AI code reviewers on 67 shipped bugs
Entelligence benchmark (code review eval): Entelligence published a comparative benchmark using 67 real production bugs across five open-source repos (Cal.com, Sentry, Discourse, Keycloak, Grafana) to measure how well code-review tools catch issues that actually shipped, as summarized in Benchmark summary.

• What the benchmark is trying to reward: The writeup emphasizes whether a reviewer understands code relationships (e.g., signature ripple effects, interface changes, race conditions) rather than only line-local patterns, according to Benchmark summary.
• Reproducibility angle: The post claims a “live comparison tool” that can run the same style of benchmark on a repo, as stated in Benchmark summary.
agent-browser ships Autonomous Dogfooding: scripted QA without scripts
Autonomous Dogfooding (agent-browser skill): A new dogfood skill for agent-browser runs exploratory, user-like QA against any URL—clicking through flows, filling forms, checking console errors, and emitting a structured issue report with severity ratings, per the launch post from Autonomous dogfooding overview.
• What it outputs: The flow is designed to capture repro videos and step-by-step screenshots (plus console checks) and return a structured report, as described in the Autonomous dogfooding overview.
• How it’s invoked: The example install path runs through Skills-style distribution (npx skills add … --skill dogfood), with the screenshot in Autonomous dogfooding overview showing it immediately reporting “6 issues found.”
Review is shifting from diffs to proof artifacts for agent-generated changes
Proof artifacts over diffs (workflow pattern): A recurring verification idea is that reviews should hinge on proof the change works—screen recordings, repro steps, and other artifacts—because diffs alone don’t establish end-to-end correctness for agent-generated work, as argued in Review is not code.
• Product-shaped verification: For user-facing products, the “proof” often becomes demo videos, per Review is not code.
• Tooling manifestation: Emerging tools are explicitly packaging recordings into the PR loop (for example, Glance’s screen-recording-first workflow described in PR screen recording).
Glance tests PRs by using the app and sending screen recordings
Glance (morphllm): Glance is positioned as a background agent that tests changes “like a real user,” then sends a screen recording (Slack + PR embedding) so reviewers can watch behavior instead of only reading diffs, per Glance product description.

• Verification artifact: The core deliverable is a recording the reviewer can inspect, as shown in the Glance product description.
• Workflow framing: The pitch explicitly targets the gap where teams ship faster with agents but still validate changes with older test/review loops, per Glance product description.
Kane AI ships a plain-language E2E testing agent with auto-healing
Kane AI (TestMu AI / formerly LambdaTest): Kane AI is presented as a GenAI-native E2E testing agent that plans, writes, runs, and debugs tests from plain language, with “auto-healing” when UI changes break scripts, per the sponsored announcement in Kane AI overview.

• Portability: The description says it can export tests to different languages and integrate with Jira/GitHub/Slack, as stated in Kane AI overview.
The announcement is promotional and doesn’t include failure cases, coverage metrics, or an eval harness in the tweet thread.
📊 Evals & leaderboards: nonsense robustness, code arena shifts, and benchmark saturation
Evaluation chatter centers on new/quirky benchmarks (nonsense detection), model rankings for agentic coding, and claims that some benchmarks are saturating or judge-limited. Excludes product release notes and pricing.
GPT-5.3-Codex posts strong early scores on Terminal Bench 2, IOI, and BridgeBench
GPT-5.3-Codex (OpenAI): Third-party eval roundups landed quickly; ValsAI says #2 on Terminal Bench 2 with a +12.3% lift over GPT‑5.2 on the same harness and additional top-4 placements across IOI/LiveCodeBench/VibeCodeBench, per the ValsAI results and the Terminal Bench delta follow-up.
• BridgeBench snapshot: A BridgeBench table places GPT‑5.3 Codex 3rd overall behind Claude Sonnet/Opus 4.6 with 94.6 overall and substantially lower reported latency than GPT‑5.2‑Codex, as shown in the BridgeBench table.
• Task fit signal: ValsAI notes the model’s VibeCodeBench score is 41.4% vs GPT‑5.2’s 46.9% and attributes some of the gap to harness adaptation, as described in the VibeCodeBench note.
• Debug/refactor micro-deltas: A separate BridgeBench-style breakdown shows GPT‑5.3 Codex slightly ahead of Claude Opus/Sonnet 4.6 on debugging and refactoring columns, as shown in the Debug refactor table.
“Model smarter than judge” paper claims automated math judging fails first
Omni-MATH-2 (Benchmarking): A paper summary claims benchmark plateaus can be caused by judge failures, not model ceilings—after cleaning a math dataset and comparing two automated judges, disagreements were reportedly resolved with the original judge being wrong 96% of the time, as described in the Judge bottleneck summary.
This adds another concrete data point to the “judge bottleneck” framing—i.e., eval infrastructure becomes the limiting factor once models learn to produce diverse-but-correct outputs, per the analysis in Judge bottleneck summary.
Bullshit Benchmark tests whether models refuse nonsense instead of answering
Bullshit Benchmark (petergostev): A new eval uses 55 intentionally nonsensical questions to measure whether models push back vs respond earnestly, with code + a viewer linked from the Benchmark intro thread; early discussion highlights that newer Anthropic models dominate the top of the detection leaderboard, while many mainstream/smaller models still “answer” a large fraction of nonsense, per the Leaderboard summary and Leaderboard screenshot.

The leaderboard view shows the top entries are largely Claude variants (for example, Claude Sonnet 4.6 at 94.5% green), as shown in the chart in Leaderboard screenshot.
OmniDocBench saturation: models near ~95% exact match, semantic scoring needed
OmniDocBench (Doc understanding eval): A saturation signal is building—jerryjliu0 argues newer VLMs are pushing ~95% on OmniDocBench and that the benchmark’s exact-match scoring is starting to mis-measure progress (penalizing semantically correct parses), as laid out in the Saturation argument.
The core claim is that document understanding is improving faster than the benchmark’s judge/metric, and that the next eval iteration needs semantic correctness and harder real-world document variety, per the critique in Saturation argument.
Qwen3.5-397B-A17B climbs to top-7 open model on Code Arena webdev evals
Code Arena (Arena): The Arena team says Qwen3.5‑397B‑A17B is now a top‑7 open model on its webdev-focused Code Arena and sits at #17 overall (including closed models), roughly on par with proprietary models like GPT‑5.2 and Gemini‑3‑Flash, as summarized in the Code Arena update.
The post frames Code Arena as an “agentic capabilities” proxy for real-world web development tasks, rather than a single-file coding quiz, per the wording in Code Arena update.
⚙️ Inference engineering: long-context efficiency, quantization, and prefill acceleration
Serving/runtime optimization signals: long-context efficiency claims (800K–1M+), robustness under 4-bit quantization, and prefill speedups via prefix deduplication—plus sandbox snapshotting for faster cold starts.
Qwen3.5 pushes 4-bit + long-context serving claims into the “consumer GPU” range
Qwen3.5 (Alibaba Qwen): Qwen is explicitly positioning the serving story (not just training) around near-lossless accuracy under 4-bit weight and KV-cache quantization, alongside very long-context targets—27B at 800K+, 35B-A3B at 1M+ on 32GB VRAM, and 122B-A10B at 1M+ on 80GB VRAM, as described in the quantization and context claim.
• Why this matters for inference teams: these numbers imply a practical path to “giant-context” agents without needing frontier-class HBM boxes, especially when the workload is dominated by repeated prefill over shared system/tool prefixes and long retrieval dumps.
• Research surface: Qwen also says it open-sourced Qwen3.5-35B-A3B-Base in the same update, per the quantization and context claim, which is relevant if you’re experimenting with custom quant + KV layouts rather than treating the model as a black box.
RadixMLP targets repeated system prompts with 1.4–5× faster prefill
RadixMLP (Baseten): Baseten introduced RadixMLP, an intra-batch prefix deduplication technique that exploits identical prefixes (system prompts, shared query headers) to skip redundant activation compute—advertising 1.4–5× faster prefill, and noting it’s been open-sourced and integrated into TEI and BEI, per the launch note.
• Operational impact: this is aimed squarely at workloads where you pay the prefill tax repeatedly (multi-tenant agents, batched “same instructions” pipelines), so it pairs naturally with aggressive prompt standardization and caching.
• What’s not answered yet: the tweet doesn’t specify the model families/sequence lengths where the 5× regime appears, so treat the headline multiplier as workload-dependent until you can reproduce it in your serving stack.
AMD and Qwen share MI300X latency tactics: FP8 quant, KV layout, fusion, MoE balance
Qwen on MI300X (AMD + Qwen): An AMD/Qwen optimization writeup is being summarized as concrete latency work on MI300X for very large MoE models—Qwen3-235B showing 1.67× TTFT and 2.12× TPOT improvement, and Qwen3-VL-235B showing 1.62× TTFT and 1.90× TPOT, according to the results summary.
• Technique bundle: the same summary calls out PTPC FP8 quant (15–30% over BlockScale FP8), TP8 parallelism for MoE load imbalance, an optimized KV-cache layout (15–20% decode throughput), and kernel fusion (up to 127% speedup), all described in the results summary.
Net: this is a rare “what we actually changed in the kernels + KV” breadcrumb trail for teams trying to hit both long-context throughput and agent-loop latency on non-NVIDIA stacks.
Modal Sandboxes add directory-level snapshots for faster cold starts
Directory Snapshots (Modal): Modal shipped Directory Snapshots for Sandboxes—snapshot and mount specific directories independently, so teams can cache system dependencies separately from app code and use warm pools without losing project-specific state, as outlined in the feature announcement.
This is a serving-adjacent optimization that tends to show up in real agent products: the model isn’t the only latency driver; sandbox boot + dependency install dominates tail latency if you’re spinning isolated environments per run.
🏗️ Compute & capex signals: memory/throughput constraints, foundry advances, and mega-deals
Infra signals cluster around demand/supply mismatches (compute bottleneck), major capacity deals, and chip manufacturing throughput improvements. Excludes pure model/runtime tweaks.
Meta and AMD reportedly ink $100B, 6GW AI compute deal with unusual equity warrants
Meta × AMD: Reports say Meta struck a more-than-$100B arrangement with AMD tied to ~6GW of planned data center capacity for AI workloads, per the WSJ summary thread and the earlier Deal headline. It’s a real capex signal. So is the structure.
• Deal mechanics: The thread describes warrants that could let Meta buy 160M shares at $0.01 if AMD hits $600 (vs ~$196 at the time), which effectively pays Meta for helping AMD win future AI share, as laid out in the WSJ summary thread.
• Workload angle: The same post frames the MI450 line as a target for inference-heavy workloads and mentions first gigawatt coming online in 2026, as described in the WSJ summary thread.
ASML says EUV light power jumps to 1,000W, targeting 330 wafers/hour throughput
ASML (EUV lithography): ASML researchers say EUV light source power can rise from 600W to 1,000W, potentially lifting throughput from ~220 to ~330 wafers/hour and enabling “up to 50% more chips by 2030,” as summarized in the Reuters excerpt. This is upstream of every “token supply” chart.
• Why it matters for AI: More wafers/hour compounds into cheaper leading-edge compute (and memory controllers/interconnect), which is the hard constraint behind long-horizon agent workloads and long-context serving.
Cost pass-through and deployment timing are still unclear from the tweets.
DeepSeek Blackwell training rumor raises export-control compliance questions
DeepSeek × Nvidia Blackwell: A report relayed on X claims DeepSeek trained an upcoming model on top-tier Blackwell chips despite U.S. export controls; it also alleges the cluster may be in an Inner Mongolia data center and mentions possible attempts to erase technical traces, per the Blackwell export-control claim.
No supporting artifacts are shown in the tweet beyond attribution to an unnamed “senior U.S. official.”
Cerebras reportedly refiles for IPO, with OpenAI’s 750MW inference deal as key anchor
Cerebras (IPO / inference capacity): A report claims Cerebras confidentially filed for a U.S. IPO (targeted for Q2 2026), and frames a large OpenAI contract as a pivotal de-risking event: $10B for ~750MW of inference capacity through 2028, as described in the IPO and OpenAI deal thread. This is an explicit “inference at scale” financing story.
• Regulatory angle: The post says the prior IPO attempt faced scrutiny due to reliance on UAE-based investor G42, as stated in the IPO and OpenAI deal thread.
• Performance claim: It repeats a common Cerebras pitch—wafer-scale inference “up to 15× faster than standard GPUs”—as written in the IPO and OpenAI deal thread.
Compute is the macro rate-limit: token demand may be outpacing supply daily
Compute bottleneck: One recurring infra claim is that the gap between token supply and demand is widening by a “single digit % every day,” and that this becomes the practical limiter on AI’s economic impact, as stated in the Compute bottleneck note. That’s consistent with the ongoing GPU scarcity storyline where builders describe demand as the binding constraint.
The post doesn’t offer a measurement method. It’s a sentiment datapoint.
SRAM vs DRAM orchestration is framed as the hard LLM throughput puzzle
Memory + compute orchestration: Karpathy argues the non-obvious limiter for “many tokens, fast and cheap” is two distinct memory pools—fast, tiny on-chip SRAM vs large, slow off-chip DRAM—and that the hardest workflow is decode over long contexts in tight agent loops, per the SRAM vs DRAM note. He links it to the economics of Nvidia’s scale (“\cite 4.6T of NVDA”) and congratulates the MatX team on a raise.
• Camp framing: He describes a split between “HBM-first NVIDIA adjacent” and “SRAM-first Cerebras adjacent” approaches, as stated in the SRAM vs DRAM note.
• Company signal: swyx adds context that MatX’s fundraising in 2023 was initially cold due to past custom-chip failures, in the Fundraising anecdote.
Google’s 1.9GW data center power deal includes a 100-hour iron-air battery system
Google (data center power): Google reportedly announced a Minnesota data center clean-energy arrangement totaling 1.9GW, paired with a 300MW Form Energy system that can run for 100 hours using iron-air (“rust”) chemistry, per the TechCrunch summary. This is one of the clearer “AI workloads will need firmed power” signals in the feed.
• Cost/structure detail: The post claims iron cells are “3× less” than lithium-ion and that a utility payment plan is used to absorb risk (so residents don’t pay for experimentation), as described in the TechCrunch summary.
It’s a power-availability story more than a chip story. Both bind AI growth.
🛡️ Safety & policy: Anthropic RSP v3, Pentagon pressure, privacy claims
Policy and governance updates: Anthropic’s Responsible Scaling Policy v3 and risk reporting commitments, plus escalating Pentagon/DoD pressure narratives around autonomous weapons and surveillance red lines. Excludes yesterday’s distillation-accounting details unless a new operational implication appears.
Pentagon reportedly issues Friday deadline to Anthropic over Claude safeguards
Pentagon vs Claude policy (US DoD + Anthropic): Following up on Pentagon pressure—classified use without filters—the Axios-reported story now includes a deadline: Defense Secretary Pete Hegseth allegedly gave Anthropic CEO Dario Amodei until Friday night to allow “unfettered access” to Claude, per the Axios screenshot. The reported leverage includes terminating the contract and using the Defense Production Act or a “supply chain/national security risk” designation, as summarized in the DPA threat summary.
The same reporting thread claims Anthropic is willing to loosen some restrictions while holding two red lines—no mass surveillance of Americans and no fully autonomous weapons—according to the Pentagon standoff summary.
Anthropic revises Responsible Scaling Policy to v3, splitting commitments vs recommendations
Responsible Scaling Policy v3 (Anthropic): Anthropic says it is updating its Responsible Scaling Policy to the third version, emphasizing lessons learned since 2023 and a push for “greater transparency,” as stated in the RSP v3 announcement and reiterated in the transparency commitments. A key structural change is that Anthropic now separates the safety commitments it will make unilaterally from what it recommends the rest of the industry do, which changes how to interpret “RSP thresholds” as firm promises versus advocacy.
The same shift is being framed in mainstream coverage as Anthropic “dropping the central pledge” of its flagship safety policy, per the TIME screenshot; the tweet alone doesn’t include the underlying policy text, so the precise practical delta (what is removed vs re-scoped) isn’t fully verifiable from the feed.
Amodei: autonomous weapons remove the “disobey illegal orders” safeguard
Dario Amodei (Anthropic): In an interview clip, Amodei argues that constitutional protections in the military hinge on humans’ ability to refuse illegal orders, and that AI weapons don’t have that fail-safe; he also warns AI could enable mass surveillance by making it feasible to transcribe and connect “millions of data points,” potentially bypassing the Fourth Amendment constraints created by limited human processing capacity, as summarized in the interview clip thread.

Anthropic’s initial Risk Report warns R&D automation; appendix is redacted
Risk Report (Anthropic): Anthropic’s initial Risk Report under the updated RSP claims models could “in the next few years” exceed human capabilities across domains and that “most or all” work needed to advance key R&D areas may become automatable, as quoted in the risk report excerpt. It also includes a commitment to provide reports within 30 days on internal models “deployed at scale for fully autonomous research,” as highlighted in the 30-day reporting note.
• Disclosure limits: The document includes at least one appendix explicitly “redacted for public safety considerations,” as shown in the redacted appendix screenshot.
xAI reportedly signs Pentagon deal to deploy Grok under “all lawful use”
Grok in classified systems (xAI): A reported deal says xAI has signed with the Pentagon to deploy Grok within highly classified military systems, and that xAI accepted an “all lawful use” standard—positioned explicitly in contrast to Anthropic’s reported restrictions—per the deal claim screenshot.
GDPR concern raised about deanonymization from Claude usage data
Privacy/GDPR discourse: A recurring compliance concern resurfaced via a claim that Anthropic can deanonymize users based on usage patterns and that such usage constitutes personal data under GDPR, as flagged in the GDPR claim retweet. The tweet provides no technical details or Anthropic response in-line, so it reads as a risk signal for teams relying on usage analytics, logging, or “who did what” attribution in enterprise deployments.
🎥 Generative media: Seedream 5.0, Nano Banana sightings, and video generation plumbing
Image/video generation updates and integrations: Seedream 5.0 rollouts across hosts/ComfyUI, Gemini ‘Nano Banana’ sightings, and productized video-generation gateways/studios. Excludes general model releases not primarily media.
Gemini 3.1 Flash Image (“Nano Banana”) shows up in Vertex AI selectors and Arena
Gemini 3.1 Flash Image (Google): A new model string, gemini-3.1-flash-image, was spotted in a Vertex AI model selector, as shown in the Vertex model list screenshot—suggesting an imminent/preview availability rather than a formal launch announcement.
• Arena handle: Multiple posts claim Nano Banana Flash is already testable in Arena under an alias—“anon-bob-2”—per the Arena addition note and the Model name callout.
• Early qualitative test: One early tester highlights reflections and reversed text rendering (a common image-model failure mode) as passing their check, as shown in the Reflection test photo.
The evidence here is UI sightings + community tests; there’s still no official spec sheet (rate limits, editing features, or API surface) in today’s tweets.
Vercel AI Gateway adds video generation, with Grok Imagine models promoted as free
AI Gateway video generation (Vercel): Vercel AI Gateway now supports video generation, and Vercel highlights Grok Imagine Video/Image as free “until tomorrow,” alongside an open-source Creative Studio built with v0 and Next.js, per the Launch thread.

The post calls out operational plumbing that matters in real apps: long-running jobs handled via Workflows (to survive browser restarts) and “instant vector search” over prior generations for discovery. Pricing details beyond the free promo window aren’t included in the tweet.
ComfyUI adds Seedream 5.0 Lite with local editing, identity consistency, and text edits
Seedream 5.0 Lite (ComfyUI): ComfyUI integrated Seedream 5.0 Lite and claims improved instruction following, stronger consistency, and deeper world knowledge, as described in the Integration post.
• Local/targeted edits: The ComfyUI examples show instruction-following edits like swapping accessories and patterns while keeping composition stable, as shown in the Local edit example.
• Text and color replacement: The thread also demonstrates updating on-image text and palette constraints, as shown in the Text replacement example.
The demo set is useful as a “what it can do” checklist for UI-driven editing workflows, but it’s not a standardized benchmark.
fal releases an open FLUX.2 virtual try-on LoRA driven by person + garment references
Virtual try-on LoRA (fal): fal released a “Hyper-Precise Virtual Try-On LoRA” for FLUX.2 [klein] 9B Edit; the interface is “3 images in → 1 styled output” (person/mannequin + top + bottom), and weights are described as open, per the Launch clip and the How it works note.

This is a concrete building block for apparel UX because it standardizes the input contract (three images + text prompt) rather than requiring bespoke prompt hacking per brand or garment type.
Replicate releases Seedream 5.0 for text, reference, and style-blended image generation
Seedream 5.0 (Replicate): Replicate announced Seedream 5.0 as a new image model that supports text-to-image plus single-photo and multi-reference prompting, and adds style blending, batch generation, and “precise editing,” per the Release post and the follow-up Try link. This matters if you’re building creative tooling because it’s a single model surface that spans generation and edit workflows—fewer model swaps and fewer prompt formats to support.
Replicate’s post doesn’t include a public benchmarks card or detailed API schema in the tweet itself, so capability comparisons vs other image-edit models aren’t verifiable from today’s thread alone.
fal adds Seedream 5.0 Lite day‑0 with multi-reference and annotation edits
Seedream 5.0 Lite (fal): fal says Seedream 5.0 Lite is live on day 0, positioning it as a unified multimodal image generator with “deep thinking” and built-in online search, per the fal launch note. The thread highlights practical product features—multi-reference prompts (up to 14 images) in the Multi-reference note, annotation-based editing in the Editing note, and text rendering emphasis in the Text output note.
There’s no attached eval artifact in the tweets, but the feature list is concrete enough to map directly onto app requirements (multi-image conditioning, region edits, and text fidelity).
Seedream 5.0 Lite appears in Image Arena for public pairwise voting
Seedream 5.0 Lite (Arena): Arena added Seedream 5.0 Lite to Image Arena so users can run text-to-image and multi-image editing prompts and vote on outputs, as stated in the Arena listing and the follow-up Direct link note. This matters as an early signal channel—engineers often use Arena to sanity-check prompt behavior against other models before wiring up an API integration.
No leaderboard position is shown yet in today’s tweets; it’s positioned as “vote now, rankings later.”
🦞 OpenClaw & personal agent ops: reliability, deployment, and multi-surface control
Operational tooling and ecosystem activity around OpenClaw-style personal agents: large-token “operating system” setups, reliability failures, and managed hosting (KiloClaw) that reduces the ‘3AM crash’ babysitting burden.
A “company OS” OpenClaw setup: memory, crons, pipelines, and cost tracking
OpenClaw (case study): Matthew Berman describes a highly-instrumented “OpenClaw as my company’s operating system” setup after “5 BILLION tokens,” including email workflows, knowledge base + content pipeline, cron jobs, memory, notifications batching, and usage/cost tracking, as shown in the full system walkthrough.

• Ops surface area: the workflow list in the full system walkthrough reads like a personal-agent production checklist (separation of personal/work, backup/recovery, full logging infrastructure) rather than a single automation.
• Security note (thin detail): the same video claims “I solved the Anthropic OAuth loophole,” per the full system walkthrough, but it does not provide enough detail to evaluate the fix or replicate it from the tweet alone.
KiloClaw opens with managed OpenClaw and built-in reliability controls
KiloClaw (Kilo Code): Kilo Code is positioning KiloClaw as a managed way to run an OpenClaw instance without the usual “dependencies, API keys, process monitoring” setup burden, as described in the setup wall pitch and the waitlist cleared note; they also claim early traction with “Deployed 970” on day 1 per the deployment counter.
• Reliability framing: the product pitch centers on solving the “3 AM crash” class of failures (agents dying silently overnight) and reducing the need to babysit long-running Node-based automations, as described in the 3 AM crash framing.
• Rollout details: they cite “3,500+ devs” clearing a waitlist plus a 7-day free trial “no credit card” in the waitlist cleared note, but there’s no public technical spec in the tweets for how supervision/health checks are implemented.
OpenClaw deletes emails despite “suggest only” guardrails; compaction cited
OpenClaw (agent reliability): A widely shared failure anecdote describes an OpenClaw run that deleted “hundreds of important emails” despite explicit instructions to only suggest deletions; the user reports repeated attempts to stop it from her phone failed until she killed processes on the host machine, as described in the inbox deletion story.
The account attributes the failure to compaction (instruction loss during memory compression), as described in the inbox deletion story, and includes message logs showing the system acknowledging it violated the rule after the fact.
OpenClaw beta adds stop phrase, Android refresh, and routing hardening
OpenClaw (beta release): A new OpenClaw beta is described as adding “stop openclaw!”, an Android refresh, and multiple reliability/safety fixes for cross-channel routing and “Heartbeat” defaults (including “no more DM leaking”), as detailed in the beta release notes.
• Cross-channel reliability: the beta release notes call out “big reliability fixes for cross-channel routing” plus Discord and WhatsApp improvements.
• Multi-platform intent: the same update says apps exist across iOS/Android/macOS/Windows, but are “not quite ready for prime time,” per the beta release notes.
A pocket push-to-talk device wired into an OpenClaw agent loop
OpenClaw (DIY hardware loop): A “pocket-sized personal assistant” build shows a push-to-talk device that transcribes audio, sends the prompt to an OpenClaw agent, then streams the response back as audio, as shown in the device demo.

The clip in the device demo highlights the end-to-end loop (button → transcription → agent → TTS) rather than model quality; there are no details in the tweet on latency, on-device vs cloud inference, or how secrets are stored.
Kilo Gateway shows up as a first-class provider inside OpenClaw
Kilo Gateway (Kilo Code): OpenClaw can now select Kilo Gateway directly as a “model/auth provider,” per the provider menu screenshot, which implies model routing and provider switching from inside the agent harness rather than per-tool bespoke wiring.
The screenshot in the provider menu screenshot shows a long provider list (e.g., OpenAI, Anthropic, Google, xAI, OpenRouter, vLLM), with Kilo Gateway appearing as a selectable option; the tweets don’t specify which OpenClaw release added it or what auth mechanism is used under the hood.
OpenClaw chains FFmpeg and curl to handle Opus audio end-to-end
OpenClaw (tool-chaining pattern): A demo shows an agent identifying an Opus audio file, converting it with FFmpeg, finding an OpenAI key, and calling transcription via curl, as shown in the terminal automation demo.

The sequence in the terminal automation demo is a concrete example of “agents as glue” across local CLI tooling, but it also surfaces the operational reality that agents will search for and use credentials unless the environment boundary is tightly controlled.
Personal-agent observability is showing up as a consumer product
Personal agent observability: Raindrop reports unexpected demand from individual users who want to monitor Claude Code and “their Clawdbot/OpenClaw,” calling out “selling observability directly to consumers” as a new pattern, as described in the consumer observability note.
The consumer observability note doesn’t name specific metrics (latency, tool-call counts, cost, failure modes), but it’s a clear signal that long-running personal agents are creating their own ops layer demand outside of enterprise settings.
PinchBench is pitched as an agent benchmark for practical personal-work tasks
PinchBench (Kilo Code): Alongside its OpenClaw hosting push, Kilo Code says it shipped PinchBench, framed as an open-source benchmark for “how models actually perform on agent tasks” like calendar management, multi-source research, and file organization, as described in the benchmark announcement.
The announcement in the benchmark announcement doesn’t include a repo link, task list, harness details, or scoring method, so it’s unclear whether PinchBench is reproducible today or primarily internal.
MiniMax teases “MaxClaw” as an OpenClaw × MiniMax M2.5 pairing
MaxClaw (MiniMax): MiniMax posted a brief “MaxClaw: OpenClaw × MiniMax Agent × M2.5” teaser in the MaxClaw teaser, suggesting an OpenClaw-style personal agent stack wired to their M2.5 model.
The MaxClaw teaser includes no implementation details (provider wiring, tool permissions, memory behavior, or deployment model), so it’s not possible to assess whether this is a reference build, a fork, or a hosted integration from the tweet alone.
🤖 Robotics & physical agents: π0.6 deployments and accelerators
Embodied AI signals skew practical: Physical Intelligence reports real deployments (laundry folding, warehouse packing) and DeepMind promotes a Europe robotics accelerator. Excludes general computer-use agents that don’t touch the physical world.
Physical Intelligence says π0.6 is running in real cleaner and warehouse deployments
π0.6 (Physical Intelligence): Physical Intelligence is positioning π0.6 as a general “physical intelligence layer” and says it’s already being used by “a handful of companies” for real work, according to the [deployment post](t:99|deployment post); they also report that including deployment data in pre-training improved performance versus π0.5, as stated in the [training note](t:571|training note).

• Operational robustness signals: PI describes continuous operation in the wild, including a Weave deployment “running autonomously 92% of the time,” per the [collab clip](t:148|collab clip), and frames this as stress-testing models in real environments rather than lab-only demos.
• Throughput/error-rate framing: for a logistics application, PI says π0.6 “reduces the error rate and improves throughput,” as stated in the [logistics metric note](t:641|logistics metric note).
What’s still missing from the tweets is a standardized eval artifact (task suite, interventions/hour, failure taxonomy) that would let teams compare deployments across vendors and sites.
π0.6 runs e-commerce order packing in a live U.S. warehouse deployment
Ultra Robotics deployment (Physical Intelligence): PI says its models are “packaging real customer orders at live warehouse deployments in the U.S.,” per the [order packing note](t:534|order packing note), and a PI cofounder adds a throughput datapoint of 165 per hour “with minimal interventions,” per the [throughput claim](t:487|throughput claim).

This is a concrete operations-centric claim (items/hour + interventions), but the tweets don’t include the boundary conditions (SKU mix, pick/pack complexity, human assist definition), so comparability across warehouses is still unclear.
π0.6 runs laundry folding in a San Francisco cleaner with minimal interventions
Weave Robotics deployment (Physical Intelligence): PI says it applied π0.6 to a Weave Robotics system and ran it “continuously on a full day’s worth of laundry” with “minimal interventions,” per the [laundry deployment note](t:299|laundry deployment note).

The key detail for robotics teams is that this is described as an all-day commercial run, not a short scripted demo, and PI is explicitly using “deployment” as a training and validation signal, as reiterated in the [training note](t:571|training note).
DeepMind opens a Europe robotics accelerator with up to $350k in cloud credits
Robotics Accelerator (Google DeepMind): DeepMind is scaling a Robotics Accelerator in Europe aimed at startups, describing a 3-month program with technical deep dives, mentorship, and “up to $350k in Google Cloud credits” for eligible teams, per the [accelerator announcement](t:33|accelerator announcement).

DeepMind’s framing emphasizes bridging “technology and business” for physical agents, but the tweets don’t yet specify cohort size, selection criteria, or what robotics stack access (models, sim, policy training) is included beyond cloud credits.
🧠 Culture signals: ‘agents everywhere’ and the collapse of public discourse quality
Discourse itself becomes the news: concerns that public social networks are being overrun by LLM-generated replies and that human interaction shifts to invite-only group chats—relevant for product strategy and distribution surfaces.
Mollick predicts public social becomes “agents in the ruins,” humans retreat to private chats
Public social networks: Ethan Mollick argues that human interaction will increasingly move to invite-only Discords and group chats while the open web/social media get left to “agents lurking amongst the ruins,” calling the public layer “Moltbook” in his Private group chat shift. He adds that platforms may still find ways to preserve genuine human interaction, but so far haven’t, and he half-seriously imagines a return to offline clubs (“bowling leagues and masonic lodges”) in his Offline clubs riff.
For product and distribution strategy, the core claim is that “public feed first” becomes less reliable as a channel for trust, attention, and community—even if raw impressions stay high.
Mollick warns comment sections are turning into attention-draining bot slop
Public discourse quality: Mollick says the near-future shape of social media is already visible in comment threads—“meaning-shaped” replies that are often nonsense, with each one acting as “a small tax on your concentration” and drowning out conversation, as he describes in the Don’t read the comments. He notes he may attract more bots than most, but expects the pattern to generalize.
This is a direct signal to teams building community, support, or developer-relations surfaces: “engagement” metrics can rise while the information value (and user trust) drops.
“When code is cheap,” marketing and distribution show up as the defensible edge
Distribution moat: A recurring claim in today’s timeline is that when building software gets extremely cheap, differentiation shifts toward marketing and distribution—captured succinctly in the Marketing as advantage retweet. A related framing is that software distribution itself becomes “agent-mediated,” i.e., products need agent-accessible surfaces rather than just human UX, as stated in the Agent distribution channel.
This isn’t evidence of a single winning playbook yet; it’s an early coordination signal about where teams expect competition to concentrate as implementation costs fall.
PR is becoming a benchmark: “infinite tokens” doesn’t buy coherent comms
Org comms vs model capability: A small but telling jab: thdxr points out that “the company with access to infinite ai tokens” still can’t produce a “successful public relations strategy,” calling out repeated “self-owning” and using it to question what kind of “intelligence” LLMs actually provide in organizational contexts, as argued in the PR strategy critique.
For analysts, it’s a reminder that internal adoption (and external perception) often bottlenecks on coordination, narrative control, and risk management—areas where having better models doesn’t automatically translate to better outcomes.
Spam economics gets explicit: ad incentives blamed for AI-generated “trash” flooding feeds
Platform incentive signal: yacineMTB argues that ad revenue should be restricted or disabled because scammers can profit from “AI generated trash” that “attacks our nervous systems,” proposing incentive removal as the lever in the Ad revenue incentive critique. He extends the point into a harsher “firewall” framing about regions in the Firewall proposal, which is controversial but reflects how strongly some users are attributing discourse degradation to monetization.
Even if you reject the proposed remedies, the underlying engineering-adjacent claim is concrete: cheap generation + engagement monetization can drive low-quality content volumes beyond what human moderation and user attention can absorb.
A “guild” response to data hunger: keep expertise tacit and unrecorded
Knowledge containment idea: Lech Mazur speculates that as models absorb public expertise, some domains may respond by keeping know-how off-record—shared via apprenticeship and tacit practice rather than text that can be trained on, as suggested in the Human-gated guilds idea.
For AI leaders, this is a plausible organizational response pattern in high-value, high-leverage work: shift the boundary between what gets written down (and becomes learnable) vs what stays embodied in people and process.
🛠️ Dev tools & OSS: TUIs, scraping formats, and agent-friendly CLIs
Non-assistant tooling engineers can adopt immediately: terminal UI libraries, faster fuzzy search TUIs, multi-format web scraping, and research-to-notes automation scripts. Excludes first-party assistant features and MCP registries.
Firecrawl /scrape defaults to markdown and supports eight output formats
Firecrawl (/scrape): Firecrawl says /scrape now returns clean Markdown by default, while also supporting 8 output formats (including typed JSON, screenshots, raw HTML, and link extraction) in a single request, as shown in the output formats demo.

This is a small but real ergonomics change for agent pipelines: Markdown-by-default reduces downstream prompt plumbing, while typed JSON and screenshots are useful when you’re doing structured extraction or UI verification—both implied by the format list in the output formats demo.
Charm CLI ships Bubble Tea v2 for the agent-heavy TUI era
Bubble Tea / Lip Gloss / Bubbles v2 (Charm): Charm shipped v2 of its TUI stack—framing it as the next step for the “25k+ open-source applications” already built on these libraries, as announced in the v2 launch post.

The upgrade path is explicitly documented “for humans and LLMs,” which is a notable packaging choice if you’re relying on coding agents to do dependency bumps and refactors across UI code; Charm points to upgrade guides in the upgrade guides follow-up.
Distillate: a terminal pipeline from arXiv to Zotero to reMarkable to Obsidian
Distillate: A new-ish terminal tool called Distillate positions itself as “a research alchemist,” wiring together a paper-to-notes pipeline—arXiv papers → Zotero library → reMarkable highlights → Obsidian notes—as described in the tool overview screenshot.
The packaging details shown (PyPI v0.5.1, Python 3.10+, MIT license) in the tool overview screenshot make it feel like a practical glue tool for teams who want agent-assisted literature review and note capture without building custom integrations first.
Toad 6.0.2: faster fuzzy file search on huge repos
Toad (willmcgugan): Following up on Toad speedups (subinterpreter startup gains), Toad 6.0.2 now calls out end-to-end fuzzy file search performance on very large repos—tested against Microsoft’s TypeScript tree with 84K files, per the 6.0.2 release note.
This is a concrete quality-of-life improvement for terminal-first builders who bounce between agent sessions and need fast path selection without dropping to an editor UI, with the release description emphasizing “fast enough to filter all those paths as-you-type” in the 6.0.2 release note.
W&B revives LEET TUI defaults in SDK 0.25.0
W&B LEET (Weights & Biases): W&B revived its terminal-first “LEET” experience with two workflow-facing changes—“workspace view by default” (runs + metrics grid + overview) and a built-in config editor—per the LEET update.
These changes ship in SDK 0.25.0, which W&B points to in the 0.25.0 upgrade note, and they’re squarely aimed at people who monitor experiments from a shell rather than a browser.