Anthropic alleges 24,000 fake accounts and 16M Claude exchanges – distillation crackdown
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Anthropic publicly alleged “industrial-scale distillation attacks” against Claude attributed to DeepSeek, Moonshot AI, and MiniMax; the company claims 24,000+ fraudulent accounts generated 16M+ Claude exchanges to copy agentic tool use, coding, and even reasoning-trace reconstruction prompts. Anthropic paired the disclosure with tighter auth language: OAuth tokens from Claude Free/Pro/Max are now stated as for Claude.ai and Claude Code only, with third-party tooling directed to API keys; it also argues this kind of output-extraction strengthens the case for export controls, though attribution and impact are tweet-level and not independently benchmarked.
• DoD access pressure: Reuters/Axios-style reporting says the Pentagon is pushing Anthropic to run Claude on classified networks “without safety filters,” with talks reportedly near collapse.
• OpenAI Responses API: WebSockets mode ships for long-running, tool-heavy agents; OpenAI claims 20%–40% speedups; Cline reports ~39% on complex workflows; Cursor cites up to ~30%.
• Coding eval norms: OpenAI deprecates SWE-bench Verified reporting; community audit chatter cites 16.4% “technically unsolvable” tasks and ID leakage concerns.
Top links today
- Responses API WebSockets guide
- Realtime API docs for voice agents
- Why OpenAI is deprecating SWE-bench Verified
- Anthropic report on distillation attacks
- Anthropic AI Fluency Index research
- Anthropic persona selection model post
- OpenRouter OAuth documentation
- OpenRouter effective pricing dashboard
- Intelligent AI Delegation paper
- Think fast and slow for LLM agents paper
- LLM-designed multi-agent learning algorithms paper
- NVIDIA and SGLang long-context inference benchmarks
Feature Spotlight
Distillation attacks go public: fraud at scale, ToS tightening, and national‑security stakes
Anthropic publicly attributes large-scale Claude distillation via fraud (24k accounts, 16M chats), triggering immediate ToS lock-downs and policy escalation. For builders, this foreshadows stricter auth, monitoring, and data-exfil defenses across AI APIs.
Anthropic alleges industrial-scale distillation campaigns (24k fake accounts, 16M+ Claude exchanges) attributed to DeepSeek, Moonshot, and MiniMax—plus follow-on debate about IP, safeguards removal, export controls, and enforcement. Includes new Claude OAuth token restrictions and US DoD pressure reports; excludes unrelated API/perf updates covered elsewhere.
Jump to Distillation attacks go public: fraud at scale, ToS tightening, and national‑security stakes topicsTable of Contents
🛡️ Distillation attacks go public: fraud at scale, ToS tightening, and national‑security stakes
Anthropic alleges industrial-scale distillation campaigns (24k fake accounts, 16M+ Claude exchanges) attributed to DeepSeek, Moonshot, and MiniMax—plus follow-on debate about IP, safeguards removal, export controls, and enforcement. Includes new Claude OAuth token restrictions and US DoD pressure reports; excludes unrelated API/perf updates covered elsewhere.
Anthropic says DeepSeek, Moonshot, MiniMax ran industrial-scale Claude distillation
Claude distillation attacks (Anthropic): Anthropic says it identified “industrial-scale distillation attacks” attributed to DeepSeek, Moonshot AI, and MiniMax—claiming 24,000+ fraudulent accounts and 16M+ exchanges used to extract Claude capabilities for training competing models, as stated in the opening allegation.
The company frames “distillation” as sometimes legitimate (e.g., compressing models) but argues these campaigns were illicit and risk removing safeguards—raising concern about downstream military/intelligence/surveillance uses per the distillation framing and the opening allegation.
Anthropic updates terms: bans Claude subscription OAuth tokens in third-party tools
Claude authentication policy (Anthropic): A terms/documentation update says OAuth tokens from Claude Free/Pro/Max accounts are “intended exclusively for Claude Code and Claude.ai,” and using them in “any other product, tool, or service” (including the Agent SDK) violates the Consumer Terms; developers are directed to use API key auth via Claude Console or supported cloud providers, as shown in the policy screenshot.
Operationally, this draws a bright line between consumer logins and developer routing/aggregation—explicitly disallowing “Claude.ai login” as a third-party auth surface, per the policy screenshot.
Anthropic: distillers targeted tool use, coding, and reasoning-trace extraction
Attack playbook (Anthropic): In the same disclosure, Anthropic describes what it claims the campaigns were trying to copy: agentic reasoning/tool use, coding, and even reasoning-trace reconstruction—including prompts that asked Claude to “write out step by step” internal reasoning, as shown in the attribution breakdown.
• Scale by lab: the breakdown cites roughly MiniMax ~13M, Moonshot ~3.4M, and DeepSeek ~150k exchanges, as shown in the attribution breakdown.
• Operational signals: Anthropic claims coordinated traffic patterns (shared payment methods/timing) and rapid pivots when Anthropic shipped a new model, per the attribution breakdown.
The key technical implication is that “model stealing” is being described less as one-off scraping and more as an end-to-end post-training data factory, per the opening allegation.
Anthropic argues distillation attacks strengthen the case for export controls
Export controls argument (Anthropic): Anthropic claims distillation attacks “undermine” US export controls by transferring capability from American frontier models without fully reproducing the training pipeline, arguing that executing such extraction “at scale requires access to advanced chips,” as excerpted in the export controls excerpt.
The point is that the public might read rapid capability gains as evidence export controls are ineffective, but Anthropic frames the gains as partially dependent on access to US model outputs, per the export controls excerpt and the opening allegation.
Report: Pentagon presses Anthropic to run Claude on classified networks without filters
Military deployment pressure (Axios/Reuters via posts): A report summarized on X says Defense Secretary Pete Hegseth summoned Anthropic CEO Dario Amodei for talks about using Claude on top-secret networks; the Pentagon is described as pushing for access “without the safety filters,” with negotiations reportedly near collapse, as relayed in the Reuters summary.
This lands in the same week as Anthropic’s distillation allegations, creating a parallel thread about who gets “unrestricted” capability access and under what controls, per the Reuters summary.
Backlash theme: “you trained on everyone’s data—why complain about distillation?”
Ecosystem backlash (community): A large share of replies and quote-tweets argue Anthropic is being inconsistent—framing API distillation outrage as rich coming from labs accused of training on copyrighted/public internet data; this theme shows up as both jokes and pointed critiques, including the meme contrast in the cartoon meme and the more direct line in the inconsistent evil quote.
The practical upshot for builders is that policy enforcement and data provenance are getting treated as competitive levers, not just ethics debates, as reflected in the angry reaction thread and the pile-on sentiment.
Distillation allegations hit mainstream: WSJ frames it as “siphoning data from Claude”
Mainstream amplification (WSJ): The allegations quickly propagated into major outlets; a WSJ headline screenshot describes “Anthropic Accuses Chinese Companies of Siphoning Data From Claude” and notes parallels to earlier OpenAI claims about distillation, as shown in the WSJ screenshot.
Alongside that, several commentators frame the public attribution as an escalation step—“cyberwars started”—based on the same 24k/16M claim set from Anthropic, per the viral summary and the opening allegation.
Legal framing: pretraining fair use claims vs API distillation as ToS breach
Contract vs copyright (legal framing): One thread argues the key legal distinction is that model pretraining on published works can be litigated under copyright/fair use, but API distillation using Claude outputs in violation of Terms of Service is a straightforward breach-of-contract theory (because a contract exists between user and provider), as laid out in the fair use vs ToS explanation.
This is a narrower argument than “who copied whom,” but it’s likely to matter in how providers design enforcement, account controls, and remedies, per the fair use vs ToS explanation.
🔌 Agents get faster: WebSockets land in OpenAI Responses API (persistent context)
OpenAI adds WebSockets mode for the Responses API aimed at low-latency, long-running, tool-heavy agents by avoiding full-context round-trips. Includes early third-party measurements (Cline/Cursor) showing double-digit speedups; excludes the Anthropic distillation story (feature).
Responses API gets WebSockets for persistent, low-latency agent runs
Responses API WebSockets (OpenAI): OpenAI added a WebSockets connection mode to the Responses API for “low-latency, long-running agents with heavy tool calls,” keeping a persistent connection so clients send incremental inputs instead of round-tripping the full context each turn, as described in the launch thread. OpenAI claims this avoids repeated work by maintaining in-memory state across interactions and can speed up runs with 20+ tool calls by 20%–40%, per the performance detail.

The practical impact is concentrated in agent harnesses that do many tool calls (browsing, repo scans, multi-step code edits) where “resend context, wait, repeat” is the main wall-clock cost, as framed in the launch thread.
Cline reports sizable speedups from Responses API WebSockets on multi-file work
Cline (benchmarks): The Cline team reports early measurements integrating OpenAI’s Responses API WebSockets: about 15% faster on simple tasks and about 39% faster on complex multi-file workflows (with best cases hitting 50%), based on their Codex 5.2 testing, as detailed in the benchmark results.
• Trade-off: They note the WebSocket handshake adds slight time-to-first-token overhead on short tasks, but it amortizes quickly on heavier workloads with many tool calls, per the benchmark results.
The main engineering takeaway is that for agent loops dominated by tool-call latency, transport choices can produce double-digit wins without changing model choice or prompts, as evidenced by the benchmark results.
Cursor upgrades OpenAI traffic to WebSockets and advertises up to 30% speedups
Cursor (Anysphere): Cursor is rolling out WebSockets for OpenAI models via the Responses API, with messaging that this makes model responses “up to 30% faster,” as stated in the Cursor rollout claim. The claim is repeated in the parallel repost in the Cursor rollout repost.
For teams already standardized on Cursor, this is a “free speedup” at the integration layer (assuming it’s enabled by default for all users as implied), and it aligns with OpenAI’s broader positioning of WebSockets as a tool-call latency lever in the launch thread.
OpenAI points to early team usage patterns for WebSockets in Responses API
Responses API WebSockets (OpenAI): After the initial release, OpenAI highlighted that teams are already using WebSockets in the Responses API to speed up agentic workflows, pointing to follow-up material in the usage note. A further reference post reiterates that the transport change is specifically targeted at tool-heavy, long-running runs rather than short single-turn requests, as echoed in the follow-up link post.
This reads as an “agent runtime primitive” move: shifting performance work from prompt/compaction tricks to connection semantics, consistent with the usage note framing.
Developers start treating the transport layer as first-class for agent speed
Transport layer as performance surface: Developers are explicitly calling out that persistent channels change agent performance profiles—“no full-context resend, just incremental updates,” so latency savings compound in tool-heavy runs—per the transport summary. A parallel sentiment is that “the transport layer can do” more than many teams assume, as reflected in the transport layer comment.
This is a shift in optimization attention: rather than only debating models and prompting, builders are pointing at connection semantics as something worth instrumenting and benchmarking, as captured in the transport summary and transport layer comment.
📏 Coding eval reset: SWE-bench Verified deprecated, Pro recommended
OpenAI and the community shift away from SWE-bench Verified due to contamination and broken/underspecified tasks, pushing SWE-bench Pro and stronger evaluation standards. This is about benchmark integrity and reporting norms, not model launches.
OpenAI stops reporting SWE-bench Verified, citing saturation and contamination
SWE-bench Verified (OpenAI): OpenAI now recommends reporting SWE-bench Pro instead, and says it will stop reporting SWE-bench Verified as a frontier coding metric because Verified is showing saturation from test-design issues plus contamination from public repos, as described in the [eval standards note](t:25|eval standards note).
The practical impact is that “Verified %” becomes a less trustworthy single-number comparison across frontier models, and public benchmark claims will increasingly shift to Pro (or other evals) rather than trying to squeeze marginal gains out of a leaky leaderboard.
SWE-bench Verified audit highlights task-ID leakage and unsolvable-by-spec problems
SWE-bench Verified (Audit details): Community discussion around OpenAI’s decision emphasizes two failure modes—frontier-model regurgitation from identifiers (models can recite setups/solutions from a Task ID) and a non-trivial slice of tasks that appear underspecified or effectively unsolvable as written, as laid out in the [swyx breakdown](t:229|swyx breakdown) and echoed by the [OpenAI announcement](t:25|OpenAI announcement).
• Spec integrity failure: swyx claims at least 16.4% of Verified problems should be “technically unsolvable” given their descriptions, and that solving them often implies leakage, according to the thread.
• Norms shift: the same commentary frames this as a warning shot for other benchmarks (“what else is hiding”), reinforcing the move away from Verified-style public-repo tasks, as discussed in the [follow-up post](t:477|follow-up post).
SWE-bench Pro gets the nod: structured tasks and private codebases to curb leakage
SWE-bench Pro (Next standard): OpenAI’s recommendation to report Pro, not Verified, is paired with a clearer rationale for why Pro exists—more structured/executable task definitions and curation intended to reduce contamination compared to public-repo benchmarks, as stated in the [OpenAI guidance](t:25|OpenAI guidance) and expanded in the [SWE-bench Pro note](t:612|SWE-bench Pro note).
Proponents also point toward what comes after Pro—rubric-based evaluation and more agent-like environments beyond unit tests—per the [same SWE-bench Pro post](t:612|same SWE-bench Pro post).
Meridian Labs forms to build open evaluation tooling around Inspect and Petri
Meridian Labs (Eval tooling): A new nonprofit is positioning itself around open tooling for evaluating and analyzing model/agent behavior—highlighting Inspect AI, Inspect Scout, and Petri as core projects, as shown in the [Meridian site capture](t:301|Meridian site capture).
This lands in the same week as the SWE-bench Verified deprecation narrative, suggesting more emphasis on eval infrastructure and transcript/trace analysis alongside benchmark score reporting.
🎙️ Realtime voice stacks: gpt-realtime-1.5 bumps tool-calling + multilingual reliability
Voice-agent builders focus on OpenAI’s new gpt-realtime-1.5 and how partners are wiring it into production. Emphasis is on instruction following, tool calling, transcription accuracy, and end-to-end audio task robustness.
OpenAI releases gpt-realtime-1.5 for speech-to-speech agents in the Realtime API
gpt-realtime-1.5 (OpenAI): OpenAI shipped gpt-realtime-1.5 in the Realtime API, positioning it as a voice-agent upgrade with better instruction following, tool calling, and multilingual accuracy, as announced in the release thread.

The rollout is also visible in the model picker UI where gpt-realtime-1.5 shows up as a selectable audio-session model, as captured in the model picker screenshot.
gpt-realtime-1.5 internal evals show gains in audio reasoning and transcription
gpt-realtime-1.5 (OpenAI): OpenAI reports internal eval lifts for the new realtime model—+5% on Big Bench Audio (reasoning), +10.23% on alphanumeric transcription, and +7% on instruction following, as stated in the internal eval snippet and reiterated in the release thread.
The demo narrative being shared is end-to-end robustness on messy audio inputs, including correctly capturing and repeating a 7-character mixed order identifier, per the benchmarker commentary.
Dictation quality becomes the practical UX bottleneck for everyday AI use
Dictation workflows (WisprFlow): One concrete usage pattern getting repeated is replacing typed replies with dictation now that some products claim high accuracy—Wispr is cited at ~85% “zero edit rate” and described as a daily driver for Slack/email/text, including hardware-style triggers like a foot pedal, per the dictation workflow note.
Broader sentiment is that transcription quality is nearing “errorless” in practice and that this shifts input ergonomics (keyboard displacement), as claimed in the transcription comment and echoed by Android-specific enthusiasm in the Android dictation remark.
Partner implementations start to standardize around gpt-realtime-1.5 voice workflows
gpt-realtime-1.5 integrations (OpenAI): OpenAI is explicitly framing partner usage as part of the release story—sharing examples of how teams are applying gpt-realtime-1.5 in real voice workflows, as teased in the partner usage thread.
The surrounding discussion from voice-agent benchmarkers emphasizes that the model’s value shows up in full-pipeline tasks (audio understanding → tool use → spoken response), as described in the benchmarker writeup.
Builders call voice models an under-covered surface area
Voice model discourse: Alongside the gpt-realtime-1.5 drop, developers are explicitly calling out that “we don’t talk enough about voice models,” using the release as a prompt to treat realtime audio stacks as a first-class area of engineering focus, as in the dev reaction.
🧠 Claude Code churn: CLI prompt diffs, worktree tooling, and speed experiments
Claude Code users track rapid CLI/system-prompt changes (2.1.51/2.1.52) and practical speed modes (e.g., Chrome extension Quick Mode). This category is about specific workflow-affecting deltas and regressions, not the distillation allegations (feature).
Claude Code 2.1.51 adds remote-control, stream-json I/O, and TodoWrite planning
Claude Code (Anthropic): 2.1.51 tightens the “agent session as a workflow” loop—TodoWrite is now required for planning/tracking tasks, and the CLI gains flags like --print, --session-id, plus --input-format/--output-format for stream-json style automation, as summarized in the [release highlights](t:302|release highlights).
The same build also introduces a claude remote-control subcommand for external builds/local environment serving, and changes how large tool outputs are persisted to disk (now 50K chars) to reduce context pressure, as detailed in the [CLI changelog](t:813|CLI changelog).
AGENTS.md guidance: keep only non-discoverable landmines; use a directory hierarchy
AGENTS.md (repo steering): A practical framing is to treat AGENTS.md as a living list of “codebase smells you haven’t fixed yet,” and to avoid auto-generated files because they duplicate what an agent can already discover and inflate costs, according to the [AGENTS.md note](t:270|AGENTS.md note).
The same guidance argues a single root file doesn’t scale; a hierarchy of AGENTS.md files scoped to directories/modules better matches how agents work when they’re assigned to a subset of the repo, as described in the [hierarchy proposal](t:270|hierarchy proposal).
Claude Code 2.1.51 hardens hooks: allowedEnvVars, workspace trust gating, sandbox proxy
Claude Code (Anthropic): 2.1.51 includes multiple hook-related security fixes—HTTP hooks can no longer interpolate arbitrary env vars unless explicitly allowlisted via allowedEnvVars, and interactive hook execution is better gated on workspace trust, according to the [CLI changelog](t:813|CLI changelog).
It also routes HTTP hooks through the sandbox network proxy when sandboxing is enabled (so the domain allowlist applies), which changes assumptions for teams using hooks as glue in agent runs, as described in the same [changelog entry](t:813|CLI changelog).
Claude Code 2.1.51 prompt changes: EnterWorktree tool added; skill invocation guidance removed
Claude Code (Anthropic): 2.1.51 changes the system prompt in a way that affects day-to-day ergonomics—ClaudeCodeLog reports that explicit guidance for /slash skill invocation was removed, which may reduce how often the agent self-routes to skill docs, as shown in the [prompt diff note](t:809|prompt diff note).
A new EnterWorktree tool was also introduced for explicit worktree sessions (triggered when the user says “worktree”), per the [worktree tool summary](t:772|worktree tool summary) and the [system prompt change recap](t:771|system prompt recap).
Claude in Chrome adds Quick Mode experiment for faster responses; pairs with Opus 4.6 fast
Claude in Chrome (Anthropic): The Chrome extension now has a Quick Mode experiment intended to make Claude “significantly faster,” and the same thread notes it can be paired with Opus 4.6 fast for lower-latency use, per the [Quick Mode announcement](t:102|Quick Mode announcement).

The demo shows the lightning-button toggle flow inside the extension UI, as captured in the [activation clip](t:336|activation clip).
Workflow pattern: enforce max 500 lines per file to keep agent edits reviewable
Repo hygiene for coding agents: One concrete way teams are constraining agent sprawl is an ESLint max-lines rule (e.g., 500 lines, skipping blanks/comments) to keep files small enough for search, review, and incremental edits, as shown in the [ESLint config screenshot](t:186|ESLint config screenshot).
The same post frames this as part of a broader shift in whether CLAUDE.md/AGENTS.md steering files should be kept at all, with lint as a backstop when they aren’t.
Claude Code 2.1.52 ships request-path behavior tweaks; no CLI surface deltas detected
Claude Code (Anthropic): 2.1.52 is framed as a small behavior-only update—ClaudeCodeLog calls out request-path handling tweaks (e.g., delete/POST targeting the specified path; POST indicating when data is already archived) in the [2.1.52 release note](t:729|2.1.52 release note).
Snapshot-based diffing also reports “no CLI surface deltas detected,” despite ~91 prompt/string changes, as stated in the [surface check post](t:843|surface check post).
User sentiment: Claude Code with Opus 4.6 is “thinking WAY TOO long”
Claude Opus 4.6 (Anthropic): A user report flags a usability regression where Claude Code with Opus 4.6 is “thinking WAY TOO long” with little perceived value, as written in the [complaint post](t:710|user complaint).
This matters operationally because longer deliberation directly increases wall-clock time for tool loops and human waiting time, even when output quality is unchanged; the thread is a single data point, but it matches the broader theme of builders chasing “fast mode” toggles when latency becomes the bottleneck.
Pattern: automated reminders to re-read AGENTS.md at the start of Claude Code sessions
Claude Code (workflow glue): One builder reports adding an automated “reminder to read AGENTS.md” at the start of each Claude Code conversation and says it’s saving time in practice, per the [automation note](t:382|automation note).
It’s a small pattern, but it’s aimed at a real failure mode: long-running projects where agent behavior drifts because conventions and sharp edges aren’t reloaded into working context early enough.
🧑💻 Codex/Cursor in practice: multi-agent toggles, harness co-design, and user switching
Builders compare Codex vs Claude for day-to-day shipping, highlight multi-agent operation modes, and surface how Codex is being paired with IDE surfaces like Cursor. Excludes transport/WebSocket mechanics (covered separately) and the distillation feature story.
Codex CLI multi-agent mode can be enabled via config.toml and /experimental
Codex CLI (OpenAI): Users report a hidden/experimental multi-agent mode that’s enabled by setting [features] multi_agent = true in ~/codex/config.toml and then flipping it on inside the CLI via /experimental, which exposes three default agents (explorer, worker, general helper) as shown in the multi-agent instructions.
This is one of the clearest “power user” switches surfaced today, since it changes how you structure work (parallel exploration vs implementation) without changing models.
Codex leadership frames a shift from code review to plan review
Codex (OpenAI): A clip attributed to Codex co-lead Alexander Embiricos frames a “delegation phase” where reviewing an agent’s plan matters more than reviewing its code, and claims “nearly all code at OpenAI is reviewed by Codex automatically,” as shown in the delegation clip.

The practical implication is that orgs will likely formalize plan/spec artifacts (and their review) as a first-class step, since that’s where the bottleneck shifts when output code volume stops being scarce.
GPT-5.3 Codex shows up inside Cursor
Cursor (Anysphere): GPT-5.3 Codex is reported as available inside Cursor and framed as “noticeably faster than 5.2,” per a Cursor update callout amplified in the Cursor availability repost.
This matters mainly because it normalizes Codex-as-an-IDE-default rather than “Codex app vs IDE,” which is the decision boundary many teams are currently sitting on.
Builders report switching to Codex for precision and instruction following
Codex app + GPT-5.3 Codex (OpenAI): A prominent thread argues Codex is now the best choice for getting dev work done—“precise, accurate and excellent at following instructions,” with the claim that OpenAI is co-designing “the model and the harness together,” as described in the Codex endorsement.
• Subscription switching: The same post explicitly mentions moving from Claude Max back to ChatGPT Pro due to Codex performance, while noting a more “machine-like” personality tradeoff in the Codex endorsement; similar “model-merry-go-round” switching behavior shows up in the subscription switching note.
• Ongoing adoption signal: Short, repeated praise for the Codex app continues in the Codex app praise, suggesting the app surface itself (not only the model) is compounding usage.
This is mostly sentiment and anecdote; there’s no independent benchmark artifact in these tweets tying the claim to a specific eval run.
Codex compaction is being described as “near infinite context”
Codex (OpenAI): Multiple posts point to compaction/auto-summarization as a key differentiator: one claims Codex “auto-summarise[s] when the max context limit has been reached,” giving “near infinite context memory” vibes, per the auto-summarize claim; similar takes describe compaction as unusually strong in the compaction praise and as hard to reason about behaviorally in the compaction chatter.
No concrete interface screenshot or setting name is provided today; treat this as user-perceived behavior rather than a documented feature surface.
Codex used for a full infra migration (Railway to Hetzner) in about an hour
Codex (OpenAI): A developer reports migrating an app off Railway to a Hetzner VPS in ~1 hour—“all data, users, skills,” plus a claimed cost reduction from ~$150/mo to ~$30/mo—crediting Codex’s familiarity with Docker and the Hetzner hcloud CLI in the migration anecdote.
This is a concrete example of using coding agents for ops-heavy, multi-step changes (data move + deploy + cutover), not just code generation.
Cursor founder hints at an upcoming product change
Cursor (Anysphere): Cursor’s founder teases “launching something new” and claims it “has changed how I work,” without details yet, in the Cursor teaser.
Treat it as pre-announcement signal; no artifact (release notes, screenshots, or feature description) is included in the tweets today.
Some teams are splitting work: Codex for code, Opus for browser/planning
Model selection in practice: One workflow report says codex-5.3-xhigh handles “essentially all” coding usage, while Opus 4.6 remains preferred for browser automation and the first draft of big-feature planning in the workflow split note.
This reinforces a pragmatic division of labor between “write/modify code reliably” and “navigate messy UIs / draft high-level plans,” rather than expecting one agent/model to dominate every part of the loop.
🧪 Agentic engineering patterns: TDD guardrails, context hygiene, and planning artifacts
Hands-on workflow patterns for keeping coding agents reliable: test-first loops, agent planning discipline, and scoping context (AGENTS.md hierarchy, ADRs). This is practitioner playbooks, not product releases.
Red→Green→Refactor becomes the go-to “anti-cheat” loop for coding agents
Red→Green→Refactor (workflow): Practitioners are re-centering test-first development as the simplest reliability lever for coding agents—write a failing test, implement until it passes, then refactor—because it reduces “looks right” code and forces observable progress, as shown in Matt Pocock’s walkthrough for Claude Code in the video walkthrough and reinforced by his note that RGR is “pretty hard to cheat for an LLM” in the confidence note.

• Why it changes day-to-day work: The loop turns agent output into a sequence of verifiable deltas (red test → green test), which shifts attention from judging long diffs to judging whether the harness is proving correctness, as described in the guide excerpt and echoed by Matt’s “move fast” framing in the confidence note.
• Where it helps most: Multi-file refactors and bug-fixes where the agent might otherwise skip edge cases; the technique is framed as “20 years old” but newly high-leverage with Claude Code in the video walkthrough.
AGENTS.md as “landmines only,” and split it by directory
AGENTS.md (practice): Addy Osmani argues AGENTS(.md) should be treated as a living list of non-discoverable traps (tooling gotchas, conventions, landmines), not a permanent dumping ground; auto-generated steering files add noise, inflate costs, and degrade agent performance, as explained in the AGENTS.md guidance.
• Structure change: A single repo-root file doesn’t scale; the proposal is a hierarchy of AGENTS(.md) files scoped to modules/directories so agents get context matched to where they’re working, as called out in the AGENTS.md guidance.
• Connection to “keep files small” discipline: One concrete way teams are enforcing readability for agent-edited code is lint constraints like file-size caps, as shown in the max-lines lint example—useful when AGENTS.md is intentionally minimal and code must remain searchable.
Agentic engineering: when code is cheap, specs and review discipline matter more
Agentic engineering (concept): Simon Willison’s new “Agentic Engineering Patterns” guide frames the central shift as: code generation cost collapsing while the cost of steering, verifying, and integrating becomes the limiting factor, as laid out in his guide announcement in the chapters announcement and the “writing code is cheap now” chapter description in the chapter summary.
• Team-level implication: The day-to-day bottleneck moves toward shared artifacts that reduce ambiguity—clear task definitions, acceptance criteria, and reviewable plans—rather than relying on raw agent throughput, which is the core challenge described in the chapter summary.
• What’s new here: The guide treats “agentic engineering” as its own practice area (not prompting), pairing planning discipline with verification loops, as introduced in the chapters announcement.
Compaction edge-cases are becoming a first-class worry in long agent sessions
Context compaction (risk pattern): Simon Willison flags a “compaction edge-case” that he hadn’t previously considered, highlighting that long-running agent sessions can fail in subtle ways even when the tool claims it can summarize and continue, as noted in the compaction edge-case note.
• Related user behavior: Separate chatter about compaction tooling treating summarization as “voodoo” suggests people are changing habits around when to reset context windows, as described in the compaction habit note.
Today’s tweets don’t include the full reproduction details for Simon’s edge-case, so treat it as a watch-item rather than a pinned mitigation.
Max-lines linting as an “agent constraint” for maintainable diffs
Lint constraints (workflow): A concrete pattern emerging in agent-heavy repos is enforcing a max file length so agent edits stay localized and reviewable; one example is an ESLint max-lines rule set to 500 lines to keep components “small and easily searched/understood,” as shown in the max-lines lint example.
• Why it matters with agents: When an agent can generate a lot of code quickly, constraints that force smaller files create natural “checkpoints” for humans and for follow-up agent edits, which is the motivation described in the max-lines lint example.
• Where it can backfire: Hard caps can cause churny file-splitting if the team doesn’t pair it with clear module boundaries—something implied by the “scope context to module/dir” argument in the AGENTS.md guidance.
“Understand your tools” becomes the lightweight safety rail for agent work
Docs-first delegation (practice): A recurring meta-pattern is pushing back on “skip the thinking with AI” by explicitly prioritizing understanding: read docs, ask questions, and build your own mental model before delegating, as stated in the docs-first note.
• Why engineers care: This shows up as a practical response to tool misuse and incorrect assumptions about what a system was designed for; one example is a maintainer asking users to read the security model docs instead of forcing an agent tool into adversarial multi-user use cases, as described in the maintainer warning.
ADRs with coding agents: are teams actually using them, and what changes?
ADRs (planning artifact): Matt Pocock is explicitly asking teams how ADRs (architectural decision records) are working with coding agents—what people notice, what breaks, and whether ADRs improve consistency across longer agent runs, as posed in the ADR question.
• Why this is surfacing now: As more code is cheap to produce, durable decision artifacts (like ADRs) become a way to keep agents aligned to why a design exists, which matches the “writing code is cheap now” framing in the chapter summary.
What’s missing in today’s tweets is outcomes—no shared transcript yet showing a clear “ADRs prevented X failure.”
Automated “read AGENTS.md” reminders as a low-effort context hygiene hack
AGENTS.md reinforcement (workflow): One concrete tactic for keeping sessions aligned is automating a reminder to read AGENTS.md at the start of conversations (or early in a run); Doodlestein reports it’s “saving me time” after using it for a while, as described in the reminder pattern note.
• Why it pairs well with good AGENTS.md hygiene: If AGENTS.md is kept to non-discoverable landmines and scoped guidance (not noise), reminders are cheap and usually helpful—matching the “landmines only” framing in the AGENTS.md guidance.
Today’s thread doesn’t show the exact implementation hook, so the transferable idea is the reminder itself rather than a specific script.
🦞 OpenClaw ops & security posture: personal-assistant threat model, providers, and local runners
OpenClaw/OpenClaw-adjacent tooling discussions focus on correct threat modeling (single-user assistant vs multi-tenant), provider integrations, and local running via Ollama. Excludes the Antigravity account-ban drama (covered in coding-ecosystem).
OpenClaw threat model: treat it as a personal assistant, not shared multi-user infra
OpenClaw (security posture): Peter Steinberger reiterates that OpenClaw’s security model is one user with one-to-many agents, and that attempts to stretch it into adversarial multi-user infrastructure (“a bus”) create needless complexity and bugs, per the Threat model clarification. He says he closed ~20 reports from people trying to force multi-user semantics, and points anyone needing adversarial separation to per-user gateways (one VPS or machine per user) as the simpler boundary, as described in the Threat model clarification.
The framing matters because many “agent gateway” designs accidentally turn a local/personal trust model into a shared service without rethinking isolation, credentials, and abuse handling.
Ollama 0.17 adds a one-command path to run OpenClaw with local open models
Ollama (0.17) + OpenClaw: Ollama 0.17 makes local usage simpler by introducing a dedicated flow to run OpenClaw via ollama launch openclaw, as announced in the Launch announcement.

This is a workflow-level change for teams trying to keep sensitive tasks local: it reduces the integration friction between a “Claw-style” agent harness and local model runners, with setup shown in the Launch announcement.
OpenClaw beta ships security+bugfix work plus Kilo provider and Kimi vision/video
OpenClaw (beta release): A new OpenClaw beta is out with an explicit focus on security and bugfixes, while also adding a new Kilo provider and Kimi vision + video support, according to the Beta release note.
The delta is operational rather than “new agent ideas”: provider surface area expands, and the maintainer is prioritizing hardening and regression cleanup over broadening the multi-user feature set, consistent with the threat-model stance in the Threat model clarification.
NanoClaw positions “auditable minimalism” as a security response to Claw complexity
NanoClaw (OpenClaw alternative): A “NanoClaw” write-up frames it as a smaller, container-isolated personal assistant with OpenClaw-like capabilities (web access, scheduled tasks, swarms) but a codebase meant to be understandable quickly, according to the NanoClaw overview.
The notable stance is architectural: isolate agents in Linux containers and extend behavior through “skills” rather than growing the core surface area—an explicit trade toward auditability and simpler threat boundaries, as outlined in the NanoClaw overview.
Together models become selectable in OpenClaw (Kimi K2.5, MiniMax M2.5, more)
OpenClaw (providers) + Together: Together says its models are now officially supported in OpenClaw, including Kimi K2.5 and MiniMax M2.5, per the Provider support announcement.
This expands OpenClaw’s provider matrix beyond the “single lab” default and makes multi-provider routing a more normal operational posture for Claw-style personal agents.
OpenClaw expands “stop/abort” trigger coverage to reduce runaway sessions
OpenClaw (safety UX): Steinberger shared a test suite for abort-trigger detection that recognizes multiple natural-language stop phrases (e.g., “stop”, “abort”, “please stop”), arguing that broader coverage is better under stress, as shown in the Abort trigger tests.
This is a small but practical control-plane detail: if an agent UI’s “stop” path is brittle, users resort to killing processes or revoking credentials, which is higher-risk operationally.
OpenRouter shares a drop-in skill for “Sign in with OpenRouter” OAuth wiring
OpenRouter (auth plumbing): OpenRouter shared a minimal “Sign in with OpenRouter” skill install snippet—npx add-skill OpenRouterTeam/agent-skills—positioned as reusable OAuth wiring, as shown in the Skill snippet.
For OpenClaw-style assistants that rely on skills/plugins as extension points, this is a concrete building block for standardizing login flows without re-implementing auth per tool.
🧰 Agent SDK plumbing: tracing, interaction retention, and delegation frameworks
Framework-level building blocks for agents: tracing integrations (LangSmith/OTel), Google Interactions API retention features, and research-backed delegation frameworks that aim to formalize task handoff and verification.
DeepMind proposes a formal framework for delegating tasks to AI agents
Intelligent AI Delegation (Google DeepMind): A DeepMind paper proposes an adaptive delegation framework that treats handoff as a sequence of decisions—whether to delegate, how to specify, how to validate—explicitly modeling authority/responsibility/accountability transfer and trust calibration, as summarized in paper overview.
• Market-style delegation: The paper summary highlights a possible “market where agents bid on tasks” with smart-contract-like mechanisms and cryptographic monitoring, as described in paper overview.
• Verification emphasis: It frames output acceptance around validation mechanisms rather than simple ratings, including confidence-aware acceptance and fallback plans, per the description in paper overview.
The paper details appear anchored to the titled PDF shown in paper overview, including the “Intelligent AI Delegation” framing and Google DeepMind authorship.
LangSmith adds native tracing for Google ADK agents
LangSmith (LangChain): LangChain shipped native tracing for Google ADK agents with a click-through setup flow, positioning it as part of LangSmith’s growing “works natively with 25+ frameworks/providers” surface while also calling out OpenTelemetry compatibility in the same announcement, as shown in native tracing post.

The practical shift is that ADK-based agent runs can land in the same trace store and UI teams already use for other stacks (LangGraph, etc.), instead of requiring custom instrumentation first—per the product framing in native tracing post.
Gemini Interactions API adds include_input=True with tiered retention
Gemini Interactions API (Google): Google’s Gemini Interactions API now supports include_input=True to retrieve previous interactions including their inputs, with retention called out as 1 day TTL on free and 55 days on paid, as described in include_input announcement.
The concrete engineering implication is improved eval/audit workflows: you can reconstruct what users actually sent (not only model outputs) for analysis and regression tracking, with the retention window differing by plan per include_input announcement.
LangSmith updates trace filtering for faster debugging
LangSmith (LangChain): LangChain updated the trace filtering experience so it’s easier to apply filters, edit filters, and see active filters at a glance, according to the UI walkthrough in filtering UX update.
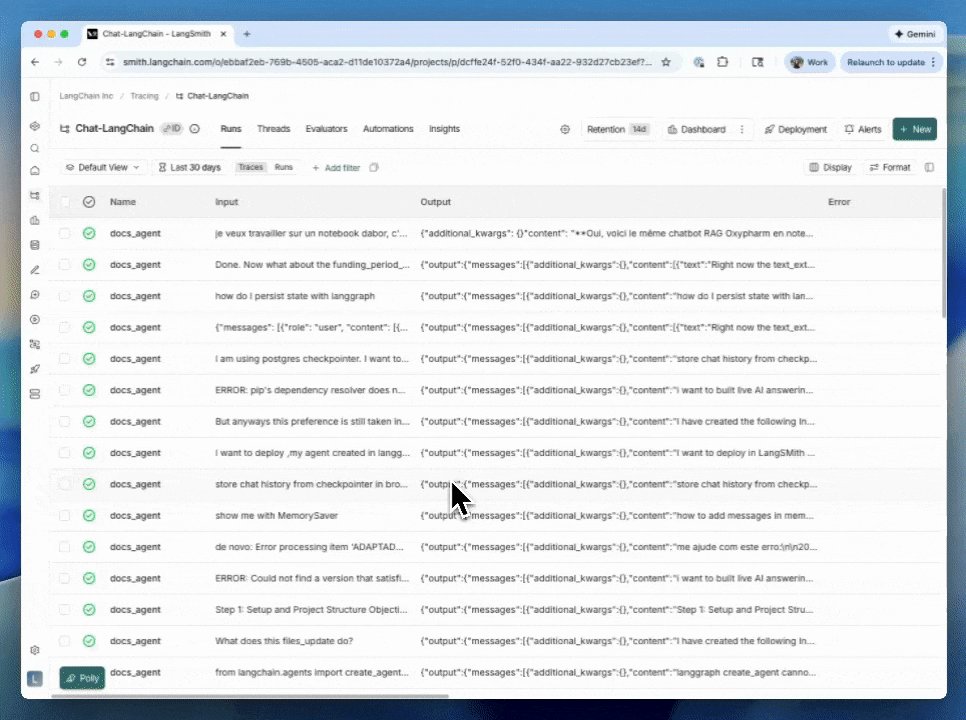
This lands as a pure debugging/ops improvement: less time spent wrangling query state when you’re scanning agent runs for failures, regressions, or high-cost traces—matching what’s shown in filtering UX update.
🧩 Antigravity ↔ AI Studio ↔ OpenClaw: access enforcement and reliability fallout
Continues yesterday’s platform-risk storyline: Antigravity/AI Studio reliability upgrades and bans intersect with third-party OAuth routing via OpenClaw. This beat is about ecosystem coupling and operational risk, not model capability.
Antigravity bans after abuse detection ripple into OpenClaw OAuth Gemini routing
Antigravity ↔ OpenClaw OAuth (Google/OpenClaw): A reported incident chain ties degraded Antigravity performance to Google detecting malicious usage and banning accounts, with many affected users having connected Gemini through OpenClaw OAuth, after which OpenClaw’s maintainer says they plan to remove Gemini OAuth support per the Incident chain summary.
• Operational coupling: The thread frames this as an enforcement action (malicious backend usage → bans) that cascaded into third-party routing via OAuth, as summarized in the More context follow-up.
It’s a concrete example of how agent platforms and “bring your own surface” integrations can share blast radius when identity and routing are intertwined.
Google AI Studio Build upgrade caused slowness; Google says fixes underway
Google AI Studio (Google): Google AI Studio says it’s rolling out “major updates” to the Build experience and acknowledges weekend slowness/unexpected behavior, with fixes already in progress per the Build upgrade note. A follow-up from a Google account says the issue “should be resolved now,” asking users to keep reporting problems in the Resolved status reply.
This reads like a platform-layer change that can alter end-to-end agent build latency and reliability even when model performance is unchanged.
AI Studio shows Antigravity integration UI for full-stack app building
Google AI Studio + Antigravity (Google): A screen recording shows an “Antigravity” panel sliding into AI Studio, positioned as an integration to build production-ready full-stack apps, per the Integration demo clip.

This is the product-surface side of the same coupling story: when AI Studio becomes a front door to Antigravity workflows, any Antigravity enforcement/reliability changes can show up as AI Studio build friction as well.
Gemini 3.1 Pro “not available on this version” blocks Antigravity use
Gemini 3.1 Pro in Antigravity (Google): A screenshot shows an error stating “Gemini 3.1 Pro is not available on this version. Please upgrade to the latest version,” with the user saying they’re already on the latest build and can’t switch back to Gemini 3.0, per the Version mismatch screenshot.
This is a straightforward availability gate: builders can have a working model elsewhere but be blocked by the Antigravity client/version handshake.
Antigravity users report “Waiting” stalls and approval friction despite settings
Antigravity (Google): A user report describes Antigravity getting stuck on “Waiting” and requiring restarts; it also claims that even with settings enabled to “always proceed,” the product still asks to run/reject actions in the loop, per the Waiting and approval report.
This is more about agent UX and reliability than model quality: the platform can become the limiting factor for tool-heavy, iterative builds.
🛠️ Dev tools shipping around agents: dashboards, review surfaces, and browser sandboxes
New tools and repos that support agent-driven development: local environment dashboards, PR review surfaces that apply fixes, and agent-browser ergonomics. Excludes agent SDKs/MCP and first-party coding assistant releases.
Devin Review adds one-click inline code fixes for issues it flags in PRs
Devin Review (Cognition): Devin Review can now generate inline code changes to fix issues it found in a PR, and you can apply them with a click; the workflow is triggered by swapping github → devinreview in a PR link and it works without an account, as shown in the [product demo](t:261|Product demo).

• Review-to-fix loop: This collapses “diagnose → patch → re-run CI” into a single review surface, reducing the back-and-forth of copying suggestions into an IDE, per the [URL swap instructions](t:261|URL swap instructions).
Readout proposes a local dev dashboard that tracks Claude Code usage and repo hygiene
Readout (benjitaylor): A new native macOS app prototype aims to give a single dashboard over your local dev environment—Git status and hygiene warnings, running processes, deps/worktrees/env files, MCP servers, plus Claude Code setup/usage and spend tracking, as shown in the [Readout screenshot](t:27|Readout screenshot).
In the preview, the app surfaces repo-level “ahead/uncommitted” alerts alongside cost rollups (including a per-model breakdown) and recent agent sessions, which maps directly to the operational pain point of “where did the tokens go?” when multiple agents are running in parallel, as illustrated in the [dashboard details](t:27|Dashboard details).
agent-browser v0.14 ships a keyboard command and hardens Chrome DevTools plumbing
agent-browser v0.14 (ctatedev): The release adds a keyboard command for sending keystrokes/shortcuts without needing a selector, plus a --color-scheme flag and several stability fixes around CDP reconnection and backpressure-aware IPC writes, as listed in the [v0.14 release note](t:320|v0.14 release note).
This is mostly about making browser-driving agents less brittle when DOM selectors aren’t reliable, while also reducing run failures caused by transport/state issues, as detailed in the [fix list](t:320|Fix list).
OpenRouter adds “Effective Pricing” to compare providers using cache hit rates
Effective Pricing (OpenRouter): OpenRouter shipped an “Effective Pricing” view that estimates real average costs per model/provider by factoring in cache pricing and observed cache hit rates over time, instead of showing only sticker token prices, as described in the [feature announcement](t:108|Feature announcement).
The feature is explicitly positioned as useful for closed models too (where cache behavior differs materially by provider), with an example callout to Gemini 3.1 Pro Preview in the [model pricing note](t:108|Model pricing note).
Liveline adds candlestick charts with animated transitions
Liveline (benjitaylor): Liveline shipped a QoL update adding candlestick charts with smooth line/candle transitions—installed via npm i liveline per the [release post](t:110|Release post).

This expands the UI primitives available for agent-facing dashboards or eval/telemetry frontends that need financial-style time series visualization, as shown in the [animation clip](t:110|Animation clip).
📚 Research refresh: multi-agent algorithm discovery, long-CoT structure, and retrieval models
A cluster of research posts: DeepMind on LLM-generated multi-agent learning algorithms, papers on delegation and cognitive depth adaptation, plus retrieval model improvements and long-CoT structure analyses. This is primarily paper-driven content rather than product releases.
DeepMind uses LLMs to automatically discover multi-agent learning algorithms
AlphaEvolve for MARL (Google DeepMind): DeepMind researchers report using LLMs as an iterative search engine over algorithm space—generate pseudocode, evaluate on game-theoretic benchmarks, then refine—to discover new multi-agent learning algorithms that perform competitively with hand-designed baselines, as described in their paper summary in Paper overview.
• What they claim was discovered: Novel variants including Volatility-Adaptive Discounted CFR (VAD-CFR) and Smoothed Hybrid Optimistic Regret PSRO (SHOR-PSRO), with competitive results across multiple domains, according to the Paper overview.
• Why engineers care: It’s a concrete loop for “LLM as optimizer” in algorithm design—prompt → eval → prompt—rather than using models only for implementation help; the paper frames LLMs as a reusable mechanism for proposing and iterating on procedures, not just code.
ColBERT-Zero revives late-interaction retrieval with multi-vector pretraining
ColBERT-Zero (LightOn): LightOn claims a new late-interaction retrieval model, ColBERT-Zero, reaches 55.43 nDCG@10 on BEIR while training only on public data by doing contrastive pre-training directly in the multi-vector setting, as announced in Launch thread.
• Compute/cost angle: The thread says skipping an expensive unsupervised phase and adding a supervised contrastive step hits 55.12 nDCG@10 (99.4% of full) at ~10× lower compute (40 vs 408 GH200-hours), per Compute comparison.
• Release posture: It states intermediate checkpoints/configs are released under Apache 2.0, with the strongest model at lightonai/ColBERT-Zero, according to Release details.
For engineers, this is a retrieval-side signal that “RAG quality” can still move via embedding+index training recipes, not only via bigger generators—treat the BEIR number as provisional until you’ve validated on your own corpus.
Tencent CogRouter routes “fast vs slow” thinking per step to cut agent tokens
CogRouter (Tencent Hunyuan / Fudan): A new paper proposes step-level “cognitive depth” selection for LLM agents—choosing among multiple reasoning intensities per action to avoid overthinking easy steps—reporting 62% fewer tokens while maintaining strong success on interactive tasks, per the writeup in Paper summary.
• Reported numbers: The thread cites an 82.3% success rate for a 7B model on interactive tests and “62% fewer tokens,” while comparing against larger/closed baselines, as summarized in Paper summary.
• Training recipe (as described): Two stages—Cognition-aware supervised fine-tuning (COSFT) followed by cognition-aware policy optimization (COPO)—with the selection objective tied to action confidence, according to Paper summary.
ByteDanceOSS models long CoT as structured transitions, not length
Long-CoT structure (ByteDanceOSS): A research summary argues that strong long chain-of-thought traces have a stable internal topology—deep reasoning, self-reflection, and self-exploration behaving like different “bonds”—and that naively copying long traces (or mixing traces across models) can destabilize training, as outlined in Research summary and expanded in Mole-Syn details.
• Key training claim: Mixing reasoning traces from different models can be incompatible even when answers match (“semantic isomers”), and long reasoning quality comes from the structure of transitions rather than verbosity, per Mole-Syn details.
• Proposed approach: Mole-Syn aims to learn the transition pattern (reason → reflect → explore) and generate new training data that matches the structure without copying text, according to Mole-Syn details.
Generated Reality explores interactive video generation with hand and camera control
Generated Reality (research demo): A paper/demo presents “human-centric world simulation” via interactive video generation where the user can influence actions with hand control and camera control, as shown in the demo clip shared in Paper and demo.

The practical angle for builders is less about cinematic output and more about controllable, interactive generation loops (inputs → environment update → new frames), which is a recurring requirement for agent evaluation and simulation-style workflows—though the tweet doesn’t provide benchmark numbers or system constraints beyond the demo in Paper and demo.
VESPO proposes an off-policy RL objective for more stable LLM training
VESPO (training method): A new paper proposes “Variational Sequence-Level Soft Policy Optimization” aimed at stabilizing off-policy training for language models, as shared in Paper link.
The tweets don’t include experimental results or implementation details beyond the title/link in Paper link, but the positioning is squarely in the space of RL/RLHF-style post-training where off-policy instability (replay, distribution shift) is a recurring engineering constraint.
🏗️ Compute & capex reality: Stargate stalling, burn projections, and GPU scarcity
Infra signals: reports of Stargate (OpenAI/Oracle/SoftBank) stalling, revised compute spend/cash-burn projections, and ongoing GPU scarcity anecdotes. Focus is on capacity, strategy shifts (own DCs vs cloud), and cost trajectories.
OpenAI forecast chatter points to $665B cash burn through 2030
OpenAI (Financial/compute trajectory): A widely shared summary claims OpenAI has revised projections to a cumulative cash burn of about $665B through 2030, with inference costs quadrupling in 2025 and margins pressured; the same thread pegs 2025 revenue at $13.1B and references 910M weekly active users, as described in the Forecast summary and echoed in the Compute spend screenshot.
The engineering-relevant reading is that the constraint is no longer “can we train?” but “can we serve at scale without inference cost exploding,” with cash-flow positivity pushed out to 2030 per the Forecast summary.
OpenAI’s Stargate venture reportedly stalls after SoftBank disagreements
Stargate (OpenAI/Oracle/SoftBank): Reporting circulating today says the $500B Stargate data-center JV has stalled after OpenAI/SoftBank disagreements and leadership gaps; OpenAI also missed a 10 GW contracted-capacity target for 2025 and is leaning more on cloud-heavy partnerships instead of first-party campuses, per the Stargate stall summary and the Compute power scramble excerpt.
OpenAI is also publicly reframing Stargate as an umbrella compute program rather than a single build-out, as reflected in the Compute strategy quote. The operational question this raises for infra leaders is whether “capacity commitments” shift from owned build plans to a portfolio of long-term cloud contracts and partners.
GPU scarcity sentiment spikes again among dev-tool builders
GPU supply (Builder sentiment): Founders are again posting that they’re “sick of not having enough GPUs,” paired with on-the-ground NVIDIA proximity signaling, as shown in the NVIDIA lobby photo.
This is a soft but persistent capacity signal: even teams already deep in the inference ecosystem still describe GPU access as a day-to-day limiter, rather than a solved procurement problem.
Altman downplays orbital data centers for this decade
Orbital data centers (OpenAI): Sam Altman argues space-based data centers aren’t practical right now because launch costs outweigh power savings and in-space maintenance/hardware failures make the idea unrealistic this decade; he frames ground facilities as the near-term growth path in the Orbital data center clip.

This is a constraints-first statement about power, reliability, and serviceability, not model capability—useful context for anyone modeling long-run capex options.
GB300 racks show up in long-context open inference benchmarks
Blackwell Ultra GB300 (NVIDIA/LMSYS): A reposted benchmark callout claims LMSYS results show Blackwell Ultra GB300 racks raising the bar for long-context open-source inference, per the GB300 benchmarks repost.
The main practical implication is serving capacity for long-context workloads (memory bandwidth, interconnect, and sustained throughput), though the tweet doesn’t include full methodology details beyond the headline claim in the GB300 benchmarks repost.
Local compute setups are expanding past “one Mac mini”
Local compute (Andrej Karpathy): Karpathy describes building a “home compute fabric” and finding that a Mac mini still isn’t enough compute even after adding a DGX Spark, per the Home compute fabric note.
The meta-signal for infra teams is that local/edge experimentation is scaling up in parallel with cloud usage—people are increasingly treating compute as a pool to be expanded and orchestrated, not a single dev box.
🏢 Enterprise commercialization: consulting alliances and “agents in the org chart”
Enterprise go-to-market and adoption signals: OpenAI’s consulting partnerships to deploy Frontier, plus narratives about AI agents collapsing SaaS middlemen and repricing software. Excludes pure infra capex (covered in infrastructure).
OpenAI signs multi-year “Frontier Alliances” with major consultancies to ship agents
Frontier Alliances (OpenAI): OpenAI is formalizing an enterprise go-to-market channel by signing multi-year partnerships with Accenture, BCG, Capgemini, and McKinsey to deploy its Frontier enterprise platform through workflow redesign, system integration, and change management, as summarized in the CNBC recap shared in deal summary.
• Delivery model: The partnership pitch is “consultants handle the messy org-layer,” while OpenAI’s forward-deployed engineering team collaborates and certifies partner teams, as described in the partner program text and echoed in the enterprise rollout summary.
• Commercial signal: The CNBC thread claims enterprise is already ~40% of OpenAI revenue and is expected to reach ~50% by end of 2026, as stated in the deal summary.
AI adoption is still shallow: 84% never used AI; paid power users are tiny
AI adoption distribution: A widely shared chart claims ~84% of people (~6.8B) have never used AI; ~16% are free chatbot users; only ~15–25M (~0.3%) pay ~$20/mo; and ~2–5M (~0.04%) use “coding scaffolds,” as shown in the adoption breakdown visualization.
This is being used as a correction to “everyone already has AI” narratives—see the simpler restatement in still early framing—and as a demand-side lens for why enterprise rollout work (training, workflow integration, governance) still matters as much as model quality.
Agent feature upgrades are being framed as wiping out thin SaaS middlemen
Agent-driven disintermediation: Multiple posts claim that when general assistants gain a new vertical capability, “middleman” SaaS products can see abrupt demand shocks—one anecdote reports a startup’s close rate dropping from 70% to 20% after a Claude/Manus feature release, as described in close-rate anecdote.
A second retelling generalizes the pattern to ad-tech tooling (“bots can connect directly to the ad platforms”), again using the 70%→20% drop as the concrete metric, as stated in middleman bypass story.
Legacy modernization narratives: Claude+COBOL claims get tied to IBM repricing
COBOL modernization (Anthropic/market narrative): A circulating claim says IBM stock fell ~10%–13% after Anthropic discussed Claude’s ability to analyze/optimize legacy COBOL, with investors extrapolating that AI could shrink the human-heavy “modernization” services model, as described in COBOL impact thread and summarized with a market blurb in IBM victim claim.
This is being bundled into broader “per-seat software breaks when AI is the worker” framing, as asserted in the per-seat model thesis thread; the tweets don’t include a primary Anthropic artifact, so treat the causality as reported commentary rather than confirmed attribution.
Pika introduces “AI Selves” as persistent digital twins for work
AI Selves (Pika): Pika is describing an internal operating model where “every employee works with an AI Self,” and is productizing that as personalized, autonomous digital twins with persistent memory and configurable personality traits, as stated in internal adoption claim and expanded in the product description shared in product summary.

The public rollout includes a roster of “AI Self” accounts and a prompt to interact with them, as shown in team roster thread.
🚀 Model radar: DeepSeek V4 imminence, Grok 4.20 beta, and on-device-ish coders
Model-focused chatter: imminent DeepSeek V4 rumors, Grok 4.20 beta rollout on X, and popular open-weight coding models packaged for local running. Excludes benchmark-policy changes (covered in coding-evals).
DeepSeek V4 “imminent” rumor cycle resurfaces via CNBC screenshot
DeepSeek V4 (DeepSeek): A CNBC PRO screenshot claims DeepSeek is “set to release a new AI model” with timing framed as imminent, and posters are explicitly linking that to renewed Nasdaq/AI-stock volatility narratives, as shown in the CNBC screenshot recap.
The technical takeaway for engineers is limited (no specs, API surface, or eval artifacts in these tweets), but the coordination signal is clear: builders and analysts are treating “DeepSeek V4 soon” as a near-term planning variable, echoed again in the release imminent post and the challenge frontier models framing.
Grok 4.20 (Beta) appears on X with a dedicated “SuperGrok” surface
Grok 4.20 (xAI): xAI is shown rolling out Grok 4.20 (Beta) inside X, with a “SuperGrok” UI that exposes a model/version selector labeled “Grok 4.20 Beta,” as shown in the rollout UI screenshot.
• Follow-on build rumor: A separate thread claims “beta 2” is expected this week, per the beta 2 timing claim.
From an adoption standpoint, the only concrete datapoint in these tweets is the surface-level productization (a visible version toggle), not new capability or benchmark evidence.
DeepSeek release-cadence tables become the community’s V4 countdown
DeepSeek release tracking (DeepSeek): A community-maintained table enumerates DeepSeek’s 2024–2025 release intervals and pegs “DeepSeek-V4 (expected)” at roughly a ~78-day training window estimate, as shown in the release cadence table.
This kind of cadence monitoring is increasingly being used as a forecasting primitive (when to schedule eval runs, re-run internal bakeoffs, and watch for new open-weight drops), even when there’s no corresponding first-party release note yet.
Qwen3-Coder-Next 80B GGUF gets positioned as “Mac-runnable” coding base
Qwen3-Coder-Next (Unsloth): Unsloth says Qwen3-Coder-Next GGUF is now its most-downloaded model, and claims the 80B coding model can run on a ~36GB RAM Mac/device and be used via Claude Code and Codex locally, per the download and RAM claim.
The main engineering signal here is packaging, not a new model release: GGUF distribution plus “fits on a beefy laptop/desktop” positioning is continuing to compress the gap between frontier coding workflows and local/offline-ish setups.
Gemini app adds Veo 3.1 video templates for guided generation
Veo 3.1 templates (Gemini app): Google says new Veo 3.1 templates are rolling out in the Gemini app’s “Create videos” tool; the flow is template selection plus optional reference photo and/or text description, per the template rollout note.
No latency, pricing, or API-surface details are included in these tweets, but it’s a concrete product shift toward templated, parameterized video generation rather than fully free-form prompting.
🎬 Generative media: Seedance heat, video-template rollouts, and image/video leaderboards
Creative-model activity remains high: Seedance 2.0 quality/guardrail debates, Google Veo templates, and Arena-style media leaderboards. Kept separate so creative-tool news doesn’t get lost in coding/agent updates.
Seedance 2.0 global API launch postponed after copyright and deepfake blowback
Seedance 2.0 (ByteDance): Following up on Seedance demos (viral cinematic clips), ByteDance reportedly postponed the planned Feb 24 global API launch with no new date, attributing the delay to copyright and deepfake controversies plus cease-and-desist pressure from Hollywood studios and unions, as summarized in the delay report.
The immediate engineering implication is that any integration plan that assumed near-term, stable public API access now has timeline risk; the same report claims ByteDance is prioritizing stricter filtering and compliance monitoring before opening it up more broadly, per the delay report.
Seedance 2.0 clips drive “post-uncanny” talk as creators brace for guardrails
Seedance 2.0 (ByteDance): Creators are posting cinematic sequences and arguing outputs “don’t look like AI,” with a prominent example in the quality claim and another viral “New Silicon Valley” montage in the showcase clip.

• Guardrails expectations: As API scrutiny rises, some users are already framing a before/after experience where “unrestricted” behavior gets “nerfed,” as shown in the nerf meme.
The main signal is mixed: high confidence in visual realism, and rising skepticism that those capabilities will ship unfiltered at scale.
Gemini app rolls out Veo 3.1 video templates with reference-photo workflows
Veo 3.1 (Gemini app): Google is rolling out new template-driven video creation for Veo 3.1 inside the Gemini app; the flow is “pick a template, then customize with a reference photo and/or description,” as described in the template rollout.
This matters for teams that rely on repeatable creative formats (ads, explainers, social loops): templates shift prompting from one-off composition to a more constrained “style + slot-filling” workflow, per the template rollout.
Grok Imagine video claims #1 on Image-to-Video Arena (1402)
Grok Imagine video (xAI): A leaderboard screenshot claims grok-imagine-video-720p is ranked #1 on an Image-to-Video Arena with a score of 1402, narrowly ahead of multiple Veo 3.1 variants, as shown in the leaderboard screenshot.
Treat the ranking as directional rather than definitive (single screenshot, no methodology in the tweet), but it’s a concrete signal that xAI’s video stack is being evaluated head-to-head with Veo in public arenas, per the leaderboard screenshot.
fal ships Wan Motion: motion transfer API priced at $0.06/s for 720p
Wan Motion (fal): fal launched an optimized motion-transfer API (“Wan 2.2 Animate” variant) that transfers motion from a driving video to a single reference image; pricing is advertised at $0.06/s for 720p, as shown in the launch post.

• Identity preservation option: The product framing includes optional identity enhancement (“Flux 2 Edit”) and built-in retargeting for different body proportions, per the launch post.
This is a clean, API-first motion layer for teams building composable video pipelines rather than end-to-end generators.
Prompting pattern: describe camera effort to control multi-shot Kling videos
Kling 3.0 (Kling): A creator workflow argues that multi-shot control improves when prompts describe what the camera does (and struggles with) rather than only what it sees—e.g., “trucking… struggling to keep up,” “crash zoom,” “shaky ground-level,” as demonstrated in the camera effort prompts thread.

The underlying idea is that camera-behavior tokens act like a control channel for dynamism and continuity across cuts; the same thread pairs it with an explicit “wide → medium → close” multi-cut structure in the multi-cut formula.
🗣️ Culture & comms: bot slop, “AI fluency,” and agency without direction
Discourse itself is the news: rising frustration with AI-generated reply spam, attempts to define/measure “AI fluency,” and debates about how much oversight humans still need as agents scale. Excludes policy enforcement around distillation (feature).
“Reply guy tools” become shorthand for AI reply spam on X
Social spam (X): Builders are increasingly calling out AI-generated replies as a platform-quality problem, with people asking whether it’s mostly “packaged solutions” or custom reply bots, and noting the category term “reply guy tools” is now common shorthand in the discussion, as captured in Reply bot question and Category name callout.
Social network health: The concern is less “bad takes” and more volume—one thread describes replies as “post-meaning… botslop” and frames “unfilterable inanity” as a potential failure mode for social networks, as argued in Botslop replies critique.
Anthropic publishes an AI Fluency Index based on 11 behaviors in Claude chats
AI Fluency Index (Anthropic): Anthropic introduced an “AI Fluency Index” that measures 11 observable behaviors across large volumes of Claude conversations—e.g., how often people iterate and refine—to quantify how effectively users collaborate with AI, as described in AI Fluency Index intro.
• What it recommends: The lab’s own summary emphasizes iteration, skepticism toward polished outputs, and explicitly setting collaboration terms (only ~30% do), as shown in AI fluency critique.
• Open question on framing: At least one prominent analyst says they’re “not convinced” this is the right way to think about fluency long-term, while still endorsing the practical advice, per AI fluency critique.
As agents get cheaper, “what to do” becomes the bottleneck
Problem selection (Practice): A recurring theme is that AI makes execution cheap, but doesn’t pick worthwhile work by itself; one widely shared warning is to “collect your hard problems and good ideas now” because undirected “do stuff” behavior is increasingly wasteful or harmful, as argued in Agency without direction and reiterated in Problem choice matters.
The practical implication is cultural more than technical: teams can scale output, but still need a shared sense of what’s worth building and why.
A three-pass rewrite loop to reduce “AI slop” in writing
Slop reduction (Workflow): One concrete technique circulating is a three-step pipeline for cleaning up AI-generated emails: generate a draft, have a model identify “slop patterns,” then feed those patterns back in and request a rewrite, as outlined in Three-step slop pipeline.

The claim is that splitting steps into separate context windows makes the critique-and-rewrite phase more consistent than a single-shot “make it better” request, per Three-step slop pipeline.
X incentives appear to reward LLM slop over careful posts
Distribution incentives (X): Multiple posts complain that the platform’s reach seems to favor low-effort AI-written content—one example contrasts a “slop post” hitting ~1M impressions while a thoughtful tweet gets ~2K, as stated in Impressions gap claim.
Observed symptom: The same thread describes a feed example where “the entire thing is slop” and “not one word… is written by a human,” reinforcing the idea that spammy automation is being amplified rather than filtered, as shown in Feed slop example.
“Fully Human Written” claims become a new trust friction
Provenance and trust (Discourse): A separate comms thread focuses on authenticity signals getting muddy—even for influential writing—after a viral essay was described as “Fully Human Written” while simultaneously being framed with an absurd authorship story, with the broader takeaway being “I don’t know who you can trust anymore,” as described in Authenticity confusion post and echoed again in Trust skepticism repeat.
The practical subtext is that “human-written” labels are turning into contested marketing claims rather than reliable provenance, per Authenticity confusion post.
🤖 Robotics & embodied scaling: 24/7 fleets, open humanoid platforms, and swarms
Robotics posts concentrate on deployment scaling and open platforms: Figure’s 24/7 operations loop, China’s humanoid platform open-sourcing, and logistics robots in the wild. This is operational/market signal, not LLM API news.
Figure pitches 24/7 robot shifts via charging swaps and self-triage
Figure (Figure AI): Figure describes an ops loop aimed at true 24/7 deployment—a depleted robot heads to a charging dock, signals a fully charged unit to swap in, and routes itself to a “triage area” when it hits hardware/software issues, per the operational description in 24/7 operation details.

The mechanism details matter for robotics teams because they define the real throughput limiter (fleet orchestration, charging logistics, failure-handling), not model quality; Figure also claims inductive charging via coils in the feet at up to 2 kW with a roughly 1 hour full charge, as stated in 24/7 operation details.
X-Humanoid’s TienKung 3.0 pushes an open humanoid platform play
Embodied TienKung 3.0 (X-Humanoid): X-Humanoid is positioning TienKung 3.0 as a general-purpose humanoid “base kit,” pairing hardware plus an interoperable software stack—and explicitly open-sourcing building blocks (motion control, perception/planning components, world-model/VLM/VLA pieces, and training toolchains/datasets) as described in Platform overview.

The practical implication is ecosystem formation: an open, composable robotics stack can lower time-to-demo for labs and integrators, but it also puts more pressure on standard interfaces (sensors, joints, control APIs) to stay stable across deployments, per the interoperability rationale in Platform overview.
Autonomous delivery trucks in rural China show last-mile scaling signal
Autonomous delivery trucks (rural China): Footage circulating today shows small autonomous delivery vehicles operating in rural village environments, suggesting last-mile autonomy is moving beyond test geofences into routine delivery contexts, per the clip shared in Rural delivery footage.

This is an embodied-systems deployment signal: navigation, remote ops, and maintenance logistics matter as much as perception when vehicles are running in dispersed, low-infrastructure areas.
Figure posts “5 buildings in 15 months” as a scaling signal
Figure (Figure AI): Figure is signaling manufacturing and deployment ramp via a “5 buildings in 15 months” claim, framed as evidence of industrial-scale expansion rather than lab demos, as shown in Facility scaling clip.

This is an ops-side indicator for embodied AI: the constraint shifts from model iteration to how fast you can stand up production lines, test capacity, and service infrastructure.
Toyota hiring “7 Digit humanoids” surfaces as a deployment datapoint
Digit humanoids (Toyota): A robotics roundup claims Toyota has hired 7 Digit humanoids, positioning it as a concrete enterprise adoption datapoint amid broader 2026 deployment chatter, as listed in Robotics roundup.
The detail is thin in the tweets (no contract terms or sites cited), but the “count of units deployed” framing is a useful filter for separating PR from real operations, per the roundup context in Robotics roundup.
Unitree stages a high-visibility robot swarm coordination demo
Unitree (G1 swarm demo): Unitree showed a large robot “swarm performance” in a public setting, emphasizing synchronized group motion and choreography as a coordination-at-scale demo, as seen in Swarm performance clip.

For engineers, this is less about single-robot capability and more about the stack needed for fleet-level timing, localization robustness, and failure tolerance in dense multi-robot behaviors.




























































