OpenAI DoW deal publishes contract excerpt – 3 red lines, “all lawful purposes”
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
OpenAI published a detailed write-up of its Department of War classified-deployment agreement, quoting contract language and reiterating 3 “red lines” (mass domestic surveillance; autonomous weapons direction; high-stakes automated decisions); enforcement is framed as layered controls—cloud-only deployment, an OpenAI-controlled safety stack, cleared OpenAI personnel in the loop, plus contractual terms—rather than policy text alone. Critics point to the excerpt’s “all lawful purposes” language and human-control carveouts keyed to existing law/policy, arguing the constraints may not add much beyond “already illegal,” and that cloud hosting doesn’t prevent decision-support outputs from entering kill chains; Community Notes amplified the mismatch between clause text and Sam Altman’s messaging.
• Anthropic–DoW SCR posture: Amodei says Anthropic has seen only “tweets,” no formal notice; Anthropic claims any designation under 10 USC 3252 would scope to DoW contracts, not commercial Claude access.
• Privacy & trust ambient: Stanford HAI reviewed 28 privacy documents across 6 U.S. AI companies; concludes chat data appears used for training by default in all six, with some indefinite retention.
Altman’s AMA recast the fight as elected-government power vs private-company power; the missing artifact is a fuller, future-proofed contract view—what updates as policies change, and what gets independently audited.
Top links today
- OpenAI DoW agreement details and redlines
- Anthropic statement on Hegseth comments
- Codified Context paper on agent memory tiers
- Introduction to Ray free course
- Guide to inference ASICs beyond GPUs
- FT report on DeepSeek V4 launch plans
- FT analysis on AI power grid constraints
- Stanford HAI analysis of AI privacy policies
- Hermes Agent hooks system announcement
- Ollama OpenCode subagents launch instructions
- Readout session replay for Claude Code
- Paper testing practical value of AI skills
- CopilotKit MCP Apps middleware docs
- CBS interview with Dario Amodei
Feature Spotlight
OpenAI–DoW classified deployment deal: contract language, guardrails, and backlash
OpenAI disclosed contract language for classified DoW deployments and claimed enforceable red lines on surveillance/weapons—sparking verification-by-law vs verification-by-contract debate and immediate user/employee backlash.
High-volume story: OpenAI published details and quoted contract language for deploying models in classified environments, triggering intense debate about whether the “red lines” (surveillance, autonomous weapons, high-stakes automation) are truly enforceable. Excludes Anthropic’s court fight and SCR mechanics, which are covered separately.
Jump to OpenAI–DoW classified deployment deal: contract language, guardrails, and backlash topicsTable of Contents
🛡️ OpenAI–DoW classified deployment deal: contract language, guardrails, and backlash
High-volume story: OpenAI published details and quoted contract language for deploying models in classified environments, triggering intense debate about whether the “red lines” (surveillance, autonomous weapons, high-stakes automation) are truly enforceable. Excludes Anthropic’s court fight and SCR mechanics, which are covered separately.
OpenAI publishes contract language for its classified DoW deployment agreement
DoW classified deployment agreement (OpenAI): OpenAI published a detailed write-up of its agreement for deploying advanced AI systems in classified environments, including quoted contract language and three stated red lines (mass domestic surveillance, autonomous weapons direction, and high-stakes automated decisions), as described in the agreement thread and reiterated in the guardrails thread.
The post frames enforcement as layered—cloud-only deployment, OpenAI-controlled safety stack, cleared OpenAI personnel “in the loop,” and contractual protections—rather than relying primarily on usage policies, per the layered safeguards framing.
• What’s actually in the excerpt: The released clause includes “all lawful purposes” language plus constraints that key off existing law/policy (e.g., “where law, regulation, or Department policy requires human control”), as shown in the clause analysis screenshot.
• Why engineers care: This is a concrete example of how a frontier model vendor tries to enforce policy via deployment surface (cloud vs edge), operator-in-the-loop controls (cleared FDEs), and contract terms—not just model weights or a terms-of-service document, as described in the guardrails thread.
Community Notes dispute centers on “all lawful purposes” vs claimed red lines
Contract interpretation controversy (X Community Notes): Screenshots of Community Notes claim government officials contradicted Sam Altman’s characterization of the deal by emphasizing that DoW can use OpenAI models for “all lawful purposes,” which critics argue could still encompass surveillance and weapons-related use cases; the note is shown in the community note screenshot and repeated in the translated note screenshot.
The dispute isn’t whether the government must follow the law—it’s whether the contract adds meaningful constraints beyond “already illegal,” which is the core critique in the loopholes critique.
OpenAI publicly opposes designating Anthropic as a “supply chain risk”
Supply chain designation stance (OpenAI): OpenAI posted that it does not think Anthropic should be designated a supply chain risk and says it made that position clear to the Department of War, as stated in the OpenAI statement and echoed again in the follow-up post.
The move lands inside the same 24–48 hour window as OpenAI’s own classified-deployment agreement disclosure, which makes this a rare case where a direct competitor is publicly arguing against a government restriction on another frontier vendor, per the Q&A screenshot.
Altman AMA frames the fight as government power vs private power, raises nationalization risk
Governance framing (Sam Altman / OpenAI): Sam Altman opened an AMA about OpenAI’s DoW work, arguing there’s more debate than he expected about whether democratically elected governments or unelected private companies should have more power, as written in the AMA opener and summarized again in the AMA recap.
He also explicitly raises the question of government nationalization of OpenAI/other AI efforts and says close partnership between governments and builders is important, per the AMA recap, while adding he’ll bring in OpenAI’s national security leads to answer questions as noted in the team participation and additional help posts.
Critiques argue the deal’s surveillance language is narrow and definition-dependent
Surveillance guardrails (contract semantics): A detailed critique argues the released language only bans “unconstrained monitoring” of U.S. persons’ private information—leaving room for “constrained” large-scale monitoring, non‑U.S. person surveillance, and broad intelligence analysis under “lawful purposes,” as laid out in the loopholes critique and summarized in the mass surveillance tldr.
A separate thread also points out that the public debate is heavily centered on domestic surveillance while foreign surveillance is treated as implicitly acceptable, per the foreign surveillance comment.
Critiques dispute OpenAI’s “cloud-only” argument for autonomous weapons safety
Autonomous weapons constraints (deployment surface): Critics argue that “cloud-only” deployment is not a hard technical barrier against fully autonomous weapons or lethal autonomy because cloud systems can still feed decision-support outputs into kill chains; they also note the excerpted wording only bans autonomous weapon direction where law/policy already requires human control, per the loopholes critique and the critique summary.
In parallel, a legal-style reading flags that the excerpted constraint is policy-dependent (“where law, regulation, or Department policy requires human control”), which may not be equivalent to a categorical ban, as discussed in the clause analysis.
Backlash takes a concrete form: “Cancel ChatGPT” churn posts and how-tos
Consumer backlash signal (ChatGPT/OpenAI): Multiple posts describe a surge of users canceling ChatGPT subscriptions following the DoW agreement, including Reddit threads with step-by-step account deletion instructions shown in the Reddit cancellation screenshot and a meta-observation that cancellation posts spiked within ~16 hours per the churn anecdote.
Separate commentary frames this as a PR problem even if the deal is strategically rational, per the PR framing screenshot.
Clause-by-clause reading spotlights ambiguity in “as they exist today” claims
Contract review (public analysis): A lawyer-style thread walks through the released excerpt clause-by-clause, arguing the domestic surveillance language may be stronger than expected while questioning whether the autonomous-weapons language is as future-proof as OpenAI claims; the excerpt and reasoning are laid out in the clause analysis.
A follow-up asks OpenAI to clarify whether the contract explicitly locks referenced laws/policies “as they exist today,” since that phrasing is asserted in an FAQ but not obviously visible in the excerpted clause, per the clarification request.
Backlash escalates into calls for OpenAI employee-led resignations
Internal pressure discourse (OpenAI org dynamics): Some posts explicitly call on OpenAI employees to force Sam Altman, leadership, and the board to resign over the DoW deal, as stated in the employee callout and reinforced by follow-on pressure language like the tick tock post.
Other backlash threads separate “the models” from “the company,” arguing for continued technical excitement while rejecting institutional support, per the separating tech from org.
Mollick flags escalation and opacity as a bad pattern for future AI governance
Governance process signal (AI policy): Ethan Mollick argues that the public sequence—sudden escalations, lack of transparency, and lack of clarity—looks like a bad pattern for handling even more disruptive AI decisions ahead, as written in the governance warning.
⚖️ Anthropic vs DoW: “supply chain risk” fallout, legal posture, and CEO interviews
Continues yesterday’s government-lab standoff, but today’s tweets shift to Anthropic’s public interview posture and litigation framing (what is formal vs tweets, what gets challenged in court, and how customers/contractors interpret scope). Excludes OpenAI’s contract disclosure, covered as the feature.
Amodei says Anthropic has only seen “tweets,” calls SCR punitive, and signals court fight
Dario Amodei (Anthropic): Following up on Court challenge—Anthropic’s plan to litigate—Amodei says the company has received “no formal information whatsoever,” only posts “from the President” and “from Secretary Hegseth,” and that they’ll evaluate and challenge any formal action in court, as shown in the CBS clip shared in Formal action quote.

He also frames the designation as “retaliatory and punitive” and says it’s “never been applied to an American company,” per another interview clip in Retaliatory framing. In the same interview cycle, he leans on a civic framing—“Disagreeing with the government is the most American thing in the world”—as highlighted in Disagreeing is American. A separate recap claims he described a short negotiation window and a proposed compromise with loopholes, per Ultimatum claim.
Anthropic statement claims SCR scope is limited to DoW contracts; commercial access unaffected
Anthropic (Claude): In its written response, Anthropic says “no amount of intimidation or punishment” will change its stance on mass domestic surveillance or fully autonomous weapons, and reiterates it will challenge any “supply chain risk” designation in court, as quoted in the excerpt screenshot in Statement excerpt.
The same excerpt tries to narrow the operational blast radius for builders: it argues a designation under 10 USC 3252 can only reach use of Claude “as part of Department of War contracts,” and that individual/commercial customer access (API, claude.ai, products) is “completely unaffected,” per Statement excerpt. Anthropic’s initial “statement on the comments from Secretary of War Pete Hegseth” is also referenced via the Anthropic account in Anthropic statement link, but the most concrete scoping language circulating today is in the screenshot text.
Debate: should DoW “punish” Anthropic for red lines, or just walk away from the vendor?
Procurement norms vs retaliation: One thread crystallizes a view that the dispute should have been a straightforward vendor/customer mismatch—Anthropic can refuse constraints; the government can refuse constraints—and that “punishing them for the conflict” is unnecessary, as argued in Walk away argument.
That framing shows up alongside other commentary interpreting the SCR move as an escalation tool rather than ordinary procurement friction, which is part of what makes the “supply chain risk” label operationally scary for any AI supplier selling into government-adjacent markets.
Discourse split: “moral stand” narrative vs claims it’s mainly a readiness objection on autonomy
Autonomous weapons framing: A visible argument today is whether Anthropic’s position is best described as a categorical ethical refusal, or more narrowly as “models aren’t ready yet” for certain autonomy-linked uses; one example of the latter framing is in Readiness framing claim.
A separate counter-narrative claims Anthropic previously offered to work with DoW on fully autonomous weapons development, as alleged in Narrative violation claim, though the tweet itself doesn’t include primary documentation. The split matters because it changes how engineers and analysts interpret future red lines: immutable principle vs capability-gated constraint.
Public sentiment artifact: chalk messages outside Anthropic praising civil liberties stance
Public sentiment (Anthropic): A photo circulating from outside Anthropic’s SF office shows chalk messages thanking Anthropic “for taking a stand for Civil Liberties,” plus a patriotic framing (“Opus 3 would be proud”), as seen in Chalk outside office.
This is less about the contract text and more about how quickly the dispute is being translated into consumer-facing identity and brand signaling—useful context if you’re tracking adoption risk, reputational spillovers, or procurement sensitivity.
🧑💻 Claude product signals: Pro features, reliability hiccups, and UI affordances
Engineer-relevant Claude updates today were mostly operational/distribution signals (outages and App Store surge) plus small workflow improvements (remote control rollout, interactive pickers). Excludes policy drama tied to DoW deals (feature + Anthropic category).
Claude experiences a service disruption; status page shows recent incidents
Claude (Anthropic) reliability: Multiple users reported a temporary service disruption with an in-product “Claude will return soon” banner in Disruption screen. Another post shared Claude’s status dashboard with recent incident bars and reported 90‑day uptime figures (e.g., 99.36% for claude.ai) in Status page screenshot. This is an operational signal for anyone shipping on Claude’s web app or API.
The posts don’t pin a root cause; the visible artifact is user-facing unavailability plus a status timeline.
Claude Code Remote Control becomes available to all Pro users
Claude Code (/remote-control): Following up on Remote rollout (initial Pro rollout), reports now claim /remote-control is available to all Pro users, indicating the rollout has effectively completed as stated in Pro-wide availability. This is a distribution signal for teams relying on remote/phone-as-console workflows.
• Rollout confirmation: A separate repost about the earlier rollout aligns with the same feature name and availability track in Rolling out now note.
Xcode 26.3 ships with Claude Agent and Codex via the Mac App Store
Xcode 26.3 (Apple) distribution: A repost claims Xcode 26.3 with Claude Agent and Codex is available on the Mac App Store, positioning “advanced reasoning capabilities in Xcode” as part of the IDE experience in Mac App Store post.
No configuration details are included in the tweet text; the notable part is the channel (Mac App Store) and the pairing (Claude Agent + Codex) inside a mainstream IDE surface.
Claude hits #1 in the US App Store and gets “App of the Day” featuring
Claude iOS distribution: Following up on App Store climb (Claude reaching #2), multiple posts now claim Claude is #1 in the App Store, including a screenshot of the Free Apps chart in Ranking screenshot and a celebratory note in #1 claim. Another screenshot shows Apple’s “App of the Day” card positioning Claude as “Privacy-focused, nuanced AI chat,” as shown in App of the day card. This is a demand/load signal more than a feature change.
The same ranking screenshot also shows ChatGPT at #2 and Gemini below, which helps contextualize relative consumer pull in the moment.
Claude UI surfaces dynamic option pickers (“mini interfaces”) during tasks
Claude UI affordances: Users highlighted Claude dynamically presenting small interactive pickers (instead of pure text) for choosing options in both web flows and Claude Code, as described in Mini interface picker. A follow-up line frames this as evidence toward more dynamic, personalized UIs in agentic workflows in Personalized UI note.
This is a UX pattern shift: tool calls can return structured choices that reduce back-and-forth.
Claude subscription UI highlights $20/mo Pro and $214.99/yr option
Claude plans (pricing surface): A screenshot of the in-app upgrade flow shows Claude Pro at $20/month or $214.99 billed annually (shown as “Save 10%”), plus a visible tease of a Max tier offering “5× or 20× more usage than Pro,” as captured in Plan picker screenshot. This matters because it’s the UI many users see at the exact moment they hit limits.
The screenshot also calls out “unlimited Projects” under Pro (with “limits apply”), which is a packaging signal for how Anthropic is bundling organization/memory features.
⚡ Codex in practice: speed sentiment, real refactors, and IDE embedding
Today’s Codex content is dominated by practitioner feedback (speed, CLI ergonomics, willingness to act) and examples of real codebase improvements. Excludes DoW contract/policy discussion (feature).
Xcode 26.3 with Claude Agent and Codex lands on the Mac App Store
Xcode 26.3 (Apple): A build of Xcode 26.3 that includes “Claude Agent & Codex” is reported as shipping via the Mac App Store “today,” bringing agentic reasoning into a mainstream IDE distribution channel, as stated in the Mac App Store note. This is a practical distribution shift: it moves coding agents from separate terminals/apps into the default tool many teams already standardize on.
Codex “speed” positioning emerges as builders compare it to Claude
Codex (OpenAI): Practitioner chatter is converging on one theme—Codex is becoming synonymous with iteration speed, with multiple builders explicitly comparing it to Claude and calling it “faster” in day-to-day use, as reflected in “Codex is now starting to be associated to speed” from the Speed association note and “seems a bit faster than Claude” in the Speed comparison. Latency is the product.
A representative take is “Codex is definitely faster and probably smarter than Claude,” as written in the Builder comparison.
Uncle Bob: Codex improved performance and frame rate of a real app
Codex (OpenAI): Robert “Uncle Bob” Martin describes using Codex on a real production-ish app (a flight school board with split-flap-style visuals) and getting a concrete perf win—“massively increasing the frame rate” while cleaning things up, according to the Perf refactor anecdote. This is an example of agentic coding value that’s hard to see in benchmarks: end-to-end profiling, refactoring, and measurable UX improvement inside an existing codebase.
An OpenCode models endpoint lists “alpha-gpt-5.4,” then gets walked back
Model inventory signals (OpenCode/OpenAI): A screenshot of OpenCode’s .../zen/v1/models JSON shows an entry labeled alpha-gpt-5.4, shared in the Endpoint JSON screenshot after “GPT-5.4 … has been spotted a few times,” as claimed in the Spotting claim. Later posts suggest it was corrected back to 5.3 rather than a confirmed new model surface, per the Correction note. Treat this as a breadcrumb, not a release.
Pattern: ask Codex whether a refactor plan makes the codebase easier for Codex
Workflow pattern: One practical prompt pattern surfaced in an Uncle Bob example is to have the coding agent propose an architecture plan, then explicitly ask whether executing the plan would make the system easier for the agent itself to work with—and why; Codex responds with concrete, codebase-shaping criteria like “clear dependency direction” and “single mutation boundary,” as shown in the Clean architecture exchange. This turns “refactor for humans” into “refactor for predictable agent edits.”
Uncle Bob: Codex CLI feels cleaner and asks fewer permission questions than Claude
Codex CLI (OpenAI): Early CLI ergonomics feedback highlights reduced workflow friction versus Claude—“Cleaner CLI than Claude” and “not quite so bothersome with questions and permissions so far,” per the CLI first impressions. This is a usability signal more than a capability claim: fewer interruptions changes the edit→run→diff loop.
🧠 Agentic engineering patterns: context scaling, “factory model”, and verification as bottleneck
High-signal practitioner content on how to make agents effective in real codebases: scaling beyond single manifest files, structuring memory/context, and shifting from code writing to system orchestration. Excludes tool release notes that belong in the Claude/Codex categories.
Codified Context paper: 3-tier memory beats single AGENTS.md for 100k-line codebases
Codified Context (arXiv): A new report argues that single-file agent manifests (AGENTS.md/CLAUDE.md/.cursorrules) hit a hard ceiling as codebases grow, and documents a three-tier “codified context” stack built during a 108k-line C# distributed system across 283 sessions, as described in the paper summary thread and shown on the paper first page.
The proposed structure is: a small always-loaded “hot memory constitution” (660 lines), a set of specialized “domain expert agents” invoked per task (19 agents, 9,300 lines total), and a “cold memory” knowledge base (34 specs, ~16,250 lines) retrieved on demand via an MCP retrieval server, with the paper emphasizing that each new artifact emerged from a concrete failure mode rather than upfront design, per the implementation details.
Agent architecture signal: “own computer + filesystem” is becoming the default primitive
Agents with computers (runtime pattern): Levie claims that giving agents their own computer and filesystem is becoming a core primitive for powerful agentic systems, and that model capability has recently crossed a threshold where this architecture is now viable in practice, as asserted in the architecture take.
Spec/intent engineering: prompts split into intent + context, with legal-style controls
Spec/intent engineering (agent alignment in practice): A thread argues “prompt engineering” is bifurcating into context engineering and a more formal specification/intent layer (goals, principles, overrides), drawing analogies to how legal systems encode and amend rules over time, as discussed in the spec framing. A related “agent definition” expansion—adding intent, memory, planning, auth/trust, control flow, and tool use—shows up in the definition slide.
The “factory model” for agentic coding: orchestration scales, verification bottlenecks
Factory model (agentic engineering): Addy Osmani frames the next abstraction shift as moving from writing code to orchestrating systems that write code—treating agents like a production line with specs as blueprints and tests as quality control, while arguing the hardest unsolved piece is verification rather than generation, as laid out in the factory model thread.
Agent memory tip: preserve causal dependencies, not just summaries
Agent memory (context integrity): A concise pattern claim is that the key to better agent memory is preserving causal dependencies—i.e., retaining “why” links between decisions, constraints, and outcomes—rather than only compressing text into flat summaries, as stated in the memory note.
Agents as explanation generators: interactive/animated docs to pay down cognitive debt
Agentic Engineering Patterns (documentation): Simon Willison adds a chapter describing a workflow where coding agents build custom interactive and animated explanations—treating “teaching artifacts” as first-class outputs to reduce cognitive debt during ongoing development, as introduced in the new chapter note.
Seeing like an agent: notice modality constraints before trying to “fix” outputs
Seeing like an agent (interface constraints): A practical prompt-and-interface lesson: when a model “wants” to express something it can’t (e.g., color), it will route around the constraint (e.g., hashed Unicode approximations), and the first step is noticing that mismatch rather than over-constraining the model, as described in the constraint observation and reiterated in the follow-up post.
“Deep learning was OG vibe coding”: trial-heavy iteration as a cautionary workflow analogy
Vibe-coding analogy (iteration discipline): Jerry Liu draws a parallel between 2013–2020 deep learning practice and today’s “vibe coding”—try many variants, run lots of experiments, then rationalize the one that works—positioning it as a reminder that nonlinearity and post-hoc narratives are common failure modes without strong evaluation/verification loops, as framed in the OG vibe coding thread and qualified in the respect and caveats addendum.
🧰 Agent runners & ops: subagents, session replay tooling, and “agent computers”
Ops/coordination tooling and architecture signals: parallel subagents, replayable sessions for debugging, and the emerging standard that agents need a real filesystem/computer substrate. Excludes agent SDK/library internals (kept to agent-frameworks).
Ollama adds subagents in OpenCode to parallelize refactors, reviews, and research
OpenCode subagents (Ollama): Ollama says OpenCode can now run subagents to parallelize tasks that need longer context windows—explicitly calling out research, refactoring, and code reviews in the subagents announcement.

• Ops impact: This is a concrete shift from “one chat loop” to “fan-out/fan-in,” where you can keep a main driver agent and delegate time-consuming context-heavy branches to parallel workers, as shown in the subagents announcement.
agent-browser skill shows Slack as an action surface for agents
agent-browser Slack control (Vercel Labs): A builder demo shows an agent setup where installing vercel-labs/agent-browser with a Slack skill makes Slack controllable as part of the agent’s tool surface—highlighted as a “holy shit” moment in the Slack skill install.

• Workflow shape: The clip emphasizes that “app control” is becoming a first-class pattern: you wire a skill into the runner, then drive real work in existing SaaS UIs (here, Slack) from the agent loop, as shown in the Slack skill install.
Readout adds session replays: scrub Claude Code prompts, tool calls, and file edits
Readout session replays (Readout): Readout shipped Session Replays for Claude Code; it replays a past session as a scrub-able timeline covering prompts, tool calls, and file changes “lighting up” as edits land, according to the session replays demo.

• Debuggability: The feature is positioned like an “agent flight recorder” for post-mortems—step through changes manually or play at different speeds, as shown in the session replays demo.
Agents having a real computer and filesystem is emerging as the default architecture
Agent computers as a primitive: Box CEO Aaron Levie argues that giving agents their own computer + filesystem will be a core primitive for the most capable agentic systems, and that models “would not have been able to make this work even a year ago,” but now this looks like the dominant pattern per the architecture claim.
• Why it matters operationally: The claim reframes “agent runners” around durable state—files, workspaces, and long-lived execution context—rather than purely stateless chat calls, as stated in the architecture claim.
MiniMax launches MaxClaw, an always-on agent mode with chat app integrations
MaxClaw (MiniMax Agent): MiniMax launched MaxClaw, a mode inside MiniMax Agent pitched as a “fully operational, always-on AI agent” that comes up in “under 10 seconds” and integrates with Telegram, WhatsApp, Slack, and Discord, per the launch summary.

• Operational surface: The packaging is explicitly ops-oriented—messaging endpoints plus “10,000+ pre-built Expert templates” as a library for repeatable agent roles, as described in the launch summary.
🔒 LLM privacy & data use: Stanford policy audit and “chats used for training” defaults
Today’s privacy content is driven by a Stanford HAI audit of major AI companies’ privacy policies and renewed attention on default chat retention/training, plus secondary debate about what ‘privacy-focused’ actually means in consumer AI apps. Excludes DoW surveillance policy (feature).
Stanford HAI finds chat data is used for training by default across major AI labs
User privacy and LLMs (Stanford HAI): Stanford researchers reviewed 28 privacy documents across six major U.S. AI companies and conclude that all six appear to use user chat data to train/improve models by default, with some retaining chats indefinitely, as summarized in the [paper overview thread](t:127|Paper overview thread) and amplified by the [Stanford audit post](t:8|Stanford audit post).
The practical engineering implication is that “what happens to chat logs” is not a single-policy question; the study’s framing is that key terms are fragmented across many linked documents, which makes it hard for users (and enterprise reviewers) to reason about defaults and retention windows from just a top-level policy, per the [document-scope description](t:127|Document-scope description).
Why chat data reuse matters: health inference can leak into ads and insurance workflows
Data inference spillover: A concrete risk scenario highlighted from the Stanford HAI analysis is that seemingly benign prompts (e.g., asking for heart-healthy recipes) can let a platform infer sensitive traits and then propagate that inference when chat data is merged with broader account/ecosystem data—affecting downstream targeting and decisioning, as described in the [risk scenario write-up](t:127|Risk scenario write-up).
This is less about one model training run and more about cross-product linkage: the scenario’s harm comes from inferred attributes moving across advertising, personalization, and third-party data flows rather than staying confined to a single chat UI, per the same [Stanford thread](t:127|Stanford thread).
“Privacy-focused AI chat” marketing collides with renewed attention on training defaults
Claude (Anthropic) on the App Store: Apple’s App Store editorial card positions Claude as “Privacy-focused, nuanced AI chat,” as shown in the [App of the Day screenshot](t:7|App of the Day screenshot).
At the same time, the Stanford HAI policy audit circulating today argues that, across major AI companies, chat data is typically used to improve models by default unless users opt out, per the [policy audit thread](t:127|Policy audit thread). The tension here is not about any one app’s UX claim; it’s that “privacy-focused” is increasingly being read against specific operational questions—default training, retention duration, and human review access—that the Stanford audit tries to standardize across vendors, as described in the [audit summary](t:127|Audit summary).
🔌 MCP & agent UI plumbing: interactive tool UIs and AG‑UI middleware
Interoperability and UI-returning tools were a notable thread today, focused on rendering interactive interfaces from tool calls and syncing agent↔app state. Excludes non-MCP agent feature work (kept to agent-ops or coding assistants).
CopilotKit adds MCP Apps middleware for UI-returning tools using AG‑UI
MCP Apps middleware (CopilotKit): CopilotKit announced MCP Apps, a middleware layer that lets MCP tools return interactive UIs that render inside a host product, handling the hard plumbing—streaming tool progress, routing UI events back to the agent, and keeping agent↔app state synchronized—built around the AG‑UI protocol, as described in the MCP Apps announcement.

• What’s concretely new: the post positions MCP Apps as the missing glue for “UI-returning tools,” where the tool doesn’t just emit text but a small UI surface that the host app can render and interact with, per the MCP Apps announcement.
• Bootstrap surface: CopilotKit calls out a one-command starter—npx copilotkit create -f mcp-apps—to stand up the middleware + protocol wiring, as shown in the MCP Apps announcement.
• Interop signal: the same announcement says AG2 has “fully integrated” with the AG‑UI ecosystem (AG2 as the agentic backend; AG‑UI as the standardized event stream), which frames AG‑UI as a cross-project contract for interactive agent UX rather than a single-tool feature, according to the MCP Apps announcement.
🏗️ AI infrastructure constraints: power grid limits and inference ASIC landscape
Infra signals today center on electricity/power as the limiting reagent for US AI datacenters and a roundup of inference-specialized ASIC options as stacks diversify beyond GPUs. Excludes funding/valuation chatter (business category).
FT: US AI buildout hits an electricity wall as grid interconnect times stretch past 4.5 years
Power for AI datacenters (US): A Financial Times analysis argues the near-term ceiling for frontier-model scaling in the US is increasingly electricity and interconnect lead time, not GPUs—citing projections that AI-driven electricity demand could double by 2030, while new projects can take 4.5+ years to connect to the grid as summarized in FT power grid thread.
The same thread highlights relative capacity buildout (China adding ~1,500GW since 2021 vs the US’s ~1,373GW total capacity) and flags knock-on risks if hyperscalers lean harder on diesel backup generation (claimed 20–50% fuel price impact in a stress scenario), all per FT power grid thread.
Inference is fragmenting: a short list of notable ASICs beyond GPUs
Inference ASICs (landscape): A Turing Post roundup frames a shift away from GPU-only inference stacks and names seven ASIC lines teams are tracking—Google TPU Ironwood, AWS Inferentia2, Groq LPU, Cerebras WSE-3, d-Matrix Corsair, plus smaller/less-mainstream entrants (Taalas HC, MatX One)—as listed in Inference ASIC list.
For engineers, the practical signal is that “hardware choice” is becoming an application-level concern again (latency, cost per token, operator ecosystem, and portability), rather than a default “run it on Nvidia.”
🧬 Model pipeline watch: DeepSeek V4 timing, multimodal rumors, and China hardware optimization
Model news today is mostly forward-looking release timing (DeepSeek V4) and strategic hardware-compatibility positioning (Huawei/Cambricon), rather than confirmed GA launches. Excludes coding-assistant product rollouts (Claude/Codex categories).
DeepSeek V4 rumor adds multimodal scope and China-chip inference optimization
DeepSeek V4 (DeepSeek): Following up on multimodal rumor (next-week multimodal timing), FT-linked reporting says V4 is expected next week as a multimodal model (text + image + video generation) with much of the work aimed at inference, plus explicit optimization work with Huawei and Cambricon chips to reduce reliance on top-tier Nvidia parts, as summarized in the [FT recap](t:126|FT recap) and reiterated in a [multimodal note](t:153|Multimodal note). This is about deployability, not just a bigger model.
The operational signal is that “model quality” and “hardware compatibility” are being marketed as one package; the tweets don’t include API surfaces, pricing, or a technical report timeline beyond the claim that this is the first major update since R1, per the [release timing post](t:215|Release timing post).
Reuters claims DeepSeek gave Huawei a head start and withheld V4 from US chipmakers
DeepSeek V4 (DeepSeek): A Reuters-style exclusive claims DeepSeek did not follow the usual playbook of sharing upcoming model software early with Nvidia/AMD for performance tuning; instead it reportedly gave Huawei early access for weeks, aiming to ensure V4 runs best on domestic hardware—while a U.S. official also alleges DeepSeek trained its latest model using Nvidia Blackwell chips in mainland China, per the [Reuters screenshot summary](t:137|Reuters screenshot summary). This is a supply-chain strategy story as much as a model story.
If accurate, it implies Chinese AI labs may increasingly treat “which accelerators get first-class kernels” as a competitive lever, not a back-office optimization step.
Grok on iOS is reported to be adding voice cloning with shareable voice links
Grok Voice (xAI): A TestingCatalog leak claims xAI is working on a voice cloning feature for Grok on iOS where users can record their voice, share it as a link, and then reuse it inside Grok Voice mode, per the [feature clip](t:83|Feature clip). This shifts Grok Voice from “pick a voice” to “import a voice,” which has obvious implications for impersonation controls and consent UX. Details on rollout timing and guardrails aren’t included.

📏 Evals & measurement: contamination, “bullshit” tests, and visual benchmarks
Today’s eval chatter includes dataset integrity concerns, small benchmark leaderboard updates, and renewed emphasis on measuring model truthfulness and robustness under slight prompt changes. Excludes pure model-release rumors (model-releases category).
OpenAI deprecates SWE-bench Verified over memorization and contamination concerns
SWE-bench Verified (OpenAI): OpenAI has deprecated the widely used SWE-bench Verified eval, with the stated reason being model memorization and data contamination concerns as relayed in the deprecation claim. This matters because SWE-bench numbers have been a common go/no-go gate for agentic coding claims; removing a “trusted” public yardstick forces teams back toward internal test suites, stricter holdouts, and provenance audits (especially for regression tracking).
The tweet doesn’t include replacement guidance or a successor benchmark artifact, so treat downstream leaderboard shifts as provisional until an updated eval spec is published or adopted broadly.
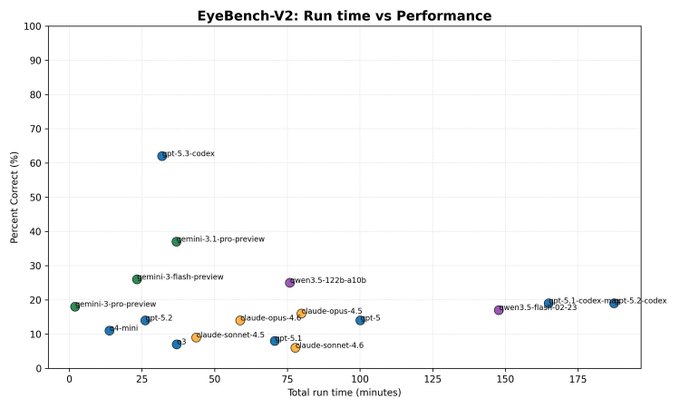
EyeBench-V2 leaderboard cites Codex-5.3 at 62% with big drop-off for older models
EyeBench-V2: A circulated “full leaderboard” snapshot claims Codex-5.3 leads at 62%, with many earlier models scoring in the low single digits, per the leaderboard recap. The practical engineering relevance is that visual/recognition-style benchmarks like this often correlate with how reliably models can read UI states, diffs-as-images, or diagrammatic specs—workflows that show up in agent runners and QA harnesses.
There’s no linked canonical eval card or reproducible run details in the tweet text, so the result should be treated as a directional signal rather than a stable metric.
Financial Times Lex spotlights Arena.ai’s “bullshit benchmark” for hallucination resistance
BullshitBench (Arena.ai): The Financial Times’ Lex column name-checks Arena.ai’s “bullshit benchmark” as a concrete way to test whether models push back on nonsensical prompts versus producing confident garbage, as shown in the FT excerpt. This is a useful framing for eval design because it targets a failure mode that standard accuracy benchmarks often underweight: whether the model refuses/qualifies instead of roleplaying certainty.
The mention is also a distribution signal: integrity-style evals are starting to show up in mainstream business commentary, not just ML circles, per the same FT excerpt.
“Change a single word and it breaks” resurfaces as a reliability critique
Robustness testing: A recurring critique argues you can’t delegate high-stakes operations to LLMs if behavior “randomly breaks down when you change a single word,” as summarized in the reliability warning. For engineers, this maps directly to eval gaps around metamorphic testing (small perturbations), sensitivity to phrasing, and measuring stability under paraphrases—especially for agent pipelines where upstream tool outputs subtly vary.
The tweet is rhetoric, not an eval result, but it reflects the growing expectation that “works on my prompt” isn’t a sufficient acceptance bar for production automation.
💼 Market & enterprise signals: OpenAI financing rumors, platform distribution, and churn/boycotts
Business news today is a mix of large financing rumors, distribution moves, and observable consumer churn signals (cancel movements, App Store rankings). Excludes contract-language specifics of the DoW deal (feature).
“Cancel ChatGPT” posts spike as a visible short-term churn signal
Consumer churn signal (ChatGPT): Several posts claim a sudden rise in cancellations in the last ~16 hours, with one account explicitly saying they’ve seen “more posts about people canceling ChatGPT” than in the prior month in the cancellation volume claim. The most concrete artifact is a Reddit screenshot showing step-by-step “delete account” instructions and multiple “I’m canceling” threads in the Reddit cancellation collage.
This matters to AI product leads because it’s a rare, observable public churn pulse tied to governance news—useful for calibrating how quickly sentiment can translate into subscription behavior, even if the absolute numbers remain unknown from the tweets alone.
Rumored OpenAI–Amazon $50B deal links capital to cloud distribution and IPO milestones
OpenAI–Amazon (rumor): Multiple tweets point at a proposed $50B Amazon investment into OpenAI, with a structure that allegedly mixes a large upfront check with IPO/convertible-style conditions—one thread summarizes it as $15B upfront + $35B conditional in the deal structure claim, while another frames Amazon as an exclusive “third‑party cloud distribution provider” in the distribution framing. This matters to product and platform leaders because it implies OpenAI’s go-to-market could increasingly be mediated by a hyperscaler channel rather than only first‑party API/app surfaces.
Treat this as unconfirmed: the tweets provide deal-shaped numbers and positioning, but no primary term sheet, filings, or joint announcement appears in the dataset.
A rumor surfaces that OpenAI agents could run through AWS Bedrock
AWS Bedrock distribution (OpenAI x AWS, unverified): A practitioner flags a distribution surprise—“OpenAI-powered agents running on AWS Bedrock”—in the Bedrock claim, framing it as something they “never thought” would happen. The point for enterprise AI teams is straightforward: if true, Bedrock becomes a procurement and governance surface for OpenAI agent workloads (billing, IAM boundaries, regional controls), not just a place to host other model providers.
No rollout details (regions, model IDs, pricing, support level) are included in today’s tweets, so this reads as early channel chatter rather than an announced launch.
Claude reaches #1 on the US App Store as ChatGPT sits at #2
App Store rankings (Claude vs ChatGPT): Following up on App Store climb (Claude at #2 earlier), multiple posts now show Claude at #1 and ChatGPT at #2 in US iOS rankings, including the ranked list screenshot in the rankings screenshot and a separate “Claude is #1” note in the #1 confirmation.
Apple’s store editorial positioning also shows up as “App of the Day” with a “Privacy-focused, nuanced AI chat” tagline in the App of the Day card. This is a market signal, not a benchmark: it mostly captures top-of-funnel demand and short-term switching behavior.
A newsletter screenshot claims an OpenAI $110B round at $730B pre-money
OpenAI financing (unverified): One newsletter-style post asserts OpenAI “secured a record-breaking $110B investment round” at a **$730B pre-money valuation,” naming SoftBank, Nvidia, and Amazon as participants in the newsletter screenshot.
This is directionally relevant to enterprise buyers because it signals continued capital availability for compute and distribution, but today’s evidence is a screenshot claim rather than a primary funding announcement or investor confirmation.
Analysis thread argues OpenAI’s usage is broad but not yet deep or sticky
Competitive positioning (OpenAI): A summarized Ben Evans argument claims OpenAI may lack durable moats despite “800–900m users,” emphasizing that engagement is “wide but shallow,” with a cited stat that 80% of users sent fewer than 1,000 messages in 2025 (averaging under three prompts/day) as captured in the moat critique summary.
For analysts, this frames a concrete question behind distribution deals and PR shocks: whether the durable value accrues to model labs, or to the apps/OS/incumbents that can turn occasional prompting into embedded workflows.
🎬 Gen media tooling: Seedance 2.0 demos and Nano Banana 2 prompt workflows
Generative media content today is mostly workflow demos and prompt pipelines (image/video consistency, stylized transformations), not new core model releases. Excludes non-media personal agents (kept out unless directly media-creation).
Nano Banana 2 prompt shows consistent Pokémon-style UI scene generation
Nano Banana 2: A prompt example demonstrates generating a coherent game UI world across two related frames—battle scene → overworld scene—while matching the same location vibe and adding a following Pokémon, as shown in the Pokémon UI prompt.
This is a practical prompt pattern for anyone prototyping UI-heavy visuals: describe the “next screen” relative to a reference (“same area,” “fit the vibe,” “one follower”) rather than re-specifying the whole scene.
Seedance 2.0 demo turns a rough sketch into a cinematic sequence
Seedance 2.0: A widely shared demo shows sketch-to-cinematic conversion—starting from a rough, handheld sketch setup and jumping to a stabilized, film-like car-stunt shot, framed as “100K film sequence” quality in the Seedance demo post. This is a concrete workflow signal for teams doing previz/storyboards who want faster iteration without hand-animating every beat.

The clip itself is the point: it’s showing continuity (same scene intent) across a very low-fidelity input to a high-production-looking output, which is the part that tends to break in real pipelines.
A repeatable console-to-car pipeline uses Leonardo NB Pro then Kling
Leonardo (NB Pro) + Kling 3.0: A multi-step recipe for consistent “console reimagined as a car” outputs is shared as a short pipeline: generate an interior first, reuse it as reference for exterior shots, add a magazine-cover framing, then animate with Kling, per the console-to-car examples and follow-up steps in interior-first step and animate step.

• Reference chaining: The workflow emphasizes carrying a strong reference (interior → exterior → magazine layout) so later generations inherit design cues instead of drifting, as described in the reference step.
• Video closure: The final “interior to magazine” transition is framed as an I2V step in Kling, according to the animate step.
Constraint-first prompts help Nano Banana 2 lock a stylized look
Nano Banana 2: A prompt exploration shows that adding hard constraints (e.g., “use only 4 triangles to make the animal”) can produce repeatable, graphic stylized characters and gives a stable starting point for iteration, per the constraint prompt examples.
This is a simple technique for art-direction: constrain form language early (shapes, palette, texture cues), then iterate details after you’ve locked the silhouette.
Nano Banana 2 and Seedance 2.0 get chained into a single transition
Nano Banana 2 × Seedance 2.0: A short “hand swap” transition clip explicitly tags a two-model chain—using Nano Banana 2 on the image side and Seedance 2.0 for the motion/transition side—per the NB2 and Seedance clip.

The operational takeaway is that people are treating image models as keyframe generators and video models as transition engines, rather than expecting one model to own the whole workflow.
Seedance 2.0 gets used for stylized “Ghibli” remixes
Seedance 2.0: A separate example focuses on style transfer / stylization, with a dance clip rendered in a recognizable hand-drawn animation aesthetic, shared in the stylization clip. It’s less about camera realism and more about whether the system can hold a coherent style across motion.

This is another data point that Seedance usage is drifting toward “edit/transform this into a look,” not only text-to-video generation.
🧑🏫 Work & labor reality: AI intensifies work, not reduces it
The culture/management thread today is about how AI changes workload and expectations (more hours, more coordination) and the scale of job exposure estimates—useful context for leaders planning org design around agents.
AI adoption anecdotes keep converging on longer hours, not leisure
Workload reality (knowledge work): A repeated on-the-ground claim is that heavy AI users are logging more hours rather than fewer, with the blunt summary “Everybody I know using AI is working more hours not less,” as echoed via More hours quote and More hours repost. The same frame is being reinforced by people circulating an HBR writeup that “AI does not reduce work. It intensifies it,” per HBR study repost, suggesting the day-to-day pain point is less about task completion time and more about throughput expectations and coordination/review overhead.
The signal today isn’t a new metric; it’s a growing consensus among practitioners that AI shifts the constraint to human attention (review, integration, decision-making), which keeps total work hours elevated even when per-task execution gets faster.
A high-end “AI exposure” estimate resurfaces: 93% of US jobs, $4.5T labor value
Labor exposure stats (research claim): A widely shareable headline number is circulating again—“93% of US jobs and $4.5 trillion in labor value are exposed to AI,” as stated in Exposure estimate repost. For engineering and product leaders, the practical implication is that organizational planning conversations are being anchored to “exposure” framing (tasks touched by AI) rather than immediate automation, which can affect hiring plans, reskilling budgets, and how teams justify added review/coordination layers.
This is a reposted claim without the underlying methodology in the tweet, so treat it as a directional narrative signal rather than an operational forecast.