Qwen3.5 Small 0.8B–9B ships – ~7GB local footprint, multimodal tools
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
Alibaba’s Qwen team released open-weights Qwen3.5 Small in 0.8B/2B/4B/9B sizes (plus Base variants), positioning “more intelligence, less compute”; the launch emphasizes native multimodal training, tool-calling, and fast day‑0 packaging across local runtimes. Distribution landed immediately: Ollama added qwen3.5:{0.8b,2b,4b,9b} with “tool calling, thinking, multimodal”; Unsloth shipped GGUFs and a local run/fine-tune guide; LM Studio lists Qwen3.5‑9B with a ~7GB local footprint; an MLX demo shows Qwen3.5‑2B running on an iPhone 17 Pro at 6‑bit quantization.
• Qwen3.5 eval chatter: a circulating collage cites 81.7 GPQA Diamond and 87.7 OmniDocBench v1.5 for 9B; mappings/settings vary across retellings, so no single auditable artifact yet.
• Cursor business signal: Bloomberg-reported $2B ARR in February; up from $1B three months prior; ~60% enterprise mix.
• BullshitBench v2: adds 100 questions and reports 70+ model variants; claims more “reasoning” tokens correlate with worse nonsense detection.
Taken together, the day reads as “local-first weights + agent UX + eval skepticism”: small multimodal models get installed everywhere fast, while reliability/measurement artifacts lag behind the rollout velocity.
Top links today
- Qwen 3.5 Small models on Hugging Face
- Qwen 3.5 models on ModelScope
- Qwen 3.5 on Ollama model page
- ActionEngine paper on GUI agents
- Codified Context paper for coding agents
- AgentConductor paper for multi-agent coding
- BullshitBench v2 benchmark GitHub repo
- BullshitBench v2 results explorer
- Claude memory settings and import
- Vercel Marketplace integration add via CLI
- Anthropic web search tool docs
- ActionEngine arXiv PDF
- AGENTS.md study paper link
Feature Spotlight
Qwen 3.5 Small open-weights: edge-ready multimodal models (0.8B–9B) land everywhere
Qwen3.5 Small (0.8B–9B) compresses “agent-capable” multimodal performance into laptop/phone-sized open weights, immediately impacting local deployment, offline agents, and cost/perf tradeoffs.
High-volume cross-account release of Qwen3.5 Small (0.8B/2B/4B/9B) with strong benchmark claims, multimodal + tool-calling support, and rapid day-0 availability across local runtimes (Ollama/LM Studio/MLX/GGUF guides).
Jump to Qwen 3.5 Small open-weights: edge-ready multimodal models (0.8B–9B) land everywhere topicsTable of Contents
🪶 Qwen 3.5 Small open-weights: edge-ready multimodal models (0.8B–9B) land everywhere
High-volume cross-account release of Qwen3.5 Small (0.8B/2B/4B/9B) with strong benchmark claims, multimodal + tool-calling support, and rapid day-0 availability across local runtimes (Ollama/LM Studio/MLX/GGUF guides).
Qwen ships Qwen3.5 Small (0.8B–9B) plus Base weights
Qwen3.5 Small (Alibaba Qwen): The hinted “small Qwens” are now a full release following up on early hint—Qwen3.5-0.8B, 2B, 4B, and 9B, with Base variants also published; positioning is “more intelligence, less compute” with native multimodal training and scaled RL called out in the launch thread launch thread.
The public packaging emphasis is migration-to-production friendliness (multiple sizes; Base + post-trained), with the canonical entry point being the Hugging Face collection linked as the model collection in Model collection.
Qwen3.5-2B runs on iPhone 17 Pro via MLX (6-bit quant)
On-device inference (MLX + Qwen3.5-2B): A demo shows Qwen3.5 2B running on an iPhone 17 Pro with MLX optimization and a 6-bit quantization setup, framed as a practical edge-deployment milestone on-device demo.

The surrounding chatter treats this as the “edge-ready multimodal” storyline becoming tangible for consumer hardware, with one post explicitly calling 2B-on-phone the “breakthrough that was needed” for local edge models on-device reaction, and Qwen’s account separately noting the small series is “already on MLX” MLX note.
Qwen3.5-9B/4B benchmark collage sets aggressive “small beats big” narrative
Qwen3.5 Small eval claims: A benchmark collage is circulating that compares Qwen3.5-9B and Qwen3.5-4B across instruction following, reasoning, multilingual knowledge, and several multimodal evals; one widely-shared chart shows scores like 81.7 on GPQA Diamond and 87.7 on OmniDocBench v1.5 for Qwen3.5-9B, alongside baselines including gpt-oss variants, GPT-5 nano, and Gemini Flash-Lite benchmarks screenshot.
• What’s consistent across posts: The official announcement frames 4B as a “strong multimodal base for lightweight agents” and 9B as “closing the gap with much larger models,” as stated in the launch thread.
• What’s still messy: Community retellings vary on details (context length, exact model mappings, and which “GPT-OSS” versions are used), so treat the collage as directional until the underlying eval scripts/settings are clearly pinned down in a single artifact claims thread.
Ollama ships Qwen3.5 Small runners with tool calling and multimodal support
Ollama (Qwen3.5 Small): Ollama added day‑0 runners for the four small models—ollama run qwen3.5:{0.8b,2b,4b,9b}—and says the builds support native tool calling, thinking, and multimodal capabilities inside Ollama run commands.
The follow-up post repeats the same contract (“all models support native tool calling, thinking, and multimodal capabilities”) and links to the consolidated library page as the Ollama model page in Ollama model page, with the short command list again in Ollama details.
Unsloth publishes Qwen3.5 Small GGUFs, pitching phones and 6–7GB RAM laptops
Unsloth (Qwen3.5 Small GGUF): Unsloth released GGUF variants and a how-to guide, pitching 0.8B/2B/4B for phones and 9B for low-RAM laptops; they also claim the set supports long context (cited as 256K) and a mix of “thinking” and non-thinking variants in their writeup GGUF release post.
The distribution angle is the point: GGUF format plus a single-page run guide tends to collapse local testing time, and Unsloth is explicitly framing these as models that can be embedded into edge and agent workflows local GGUF note.
Hugging Face shows fast uptake for Qwen3.5 variants and GGUF packaging
Hugging Face distribution signal (Qwen3.5): The Qwen3.5 family is showing rapid public uptake on Hugging Face, including a screenshot where Unsloth’s Qwen3.5-35B-A3B-GGUF hits #3 trending (with large download counts visible) trending screenshot.
This isn’t limited to the 0.8B–9B set, but it’s relevant because it indicates the “local-first” packaging layer (GGUF + runtimes) is compounding demand beyond the official weights list shown in model list screenshot.
Qwen3.5-0.8B/2B early benchmark table fuels “tiny models plateau” talk
Tiny-model reality check (Qwen3.5-0.8B/2B): A shared benchmark table comparing Qwen3.5-2B and Qwen3.5-0.8B against prior small Qwen3 variants argues that capability gains at the smallest sizes look uneven; the accompanying take is that “progress on tiny models has come to a stop” tiny benchmarks table.
The same table also shows “thinking” mode lifts many scores relative to non-thinking for both models, which is consistent with how many small models now rely on inference-time compute to recover capability at low parameter counts tiny benchmarks table.
Qwen3.5-9B is available in LM Studio, marketed as ~7GB to run local
LM Studio (Qwen3.5-9B): Qwen’s account says Qwen3.5-9B is available in LM Studio and calls out a “~7GB to run locally” footprint LM Studio availability.
This is an “installation surface” update more than a model spec change; it matters mainly because LM Studio tends to be a default on-ramp for local evaluation and quick GUI-based model switching.
Early bet: Qwen3.5 Small becomes a base for OCR and computer-use agents
Ecosystem reaction (Qwen3.5 foundation): A builder expectation popping up is that Qwen3.5’s small, multimodal weights will seed a wave of OCR-focused models and agentic computer-use variants downstream downstream prediction.
That prediction is plausibly driven by the combination of “native multimodal” framing in the release messaging and the low-compute deployment surfaces (GGUF, MLX, Ollama) that make fine-tuned derivatives cheaper to iterate on launch thread.
🧑💻 Claude Code shipping week: voice input, remote control UX, skills/plugins, and Cowork tasks
Claude Code dominates builder chatter with concrete workflow changes (voice mode rollout, new skills/plugins/connectors, Cowork scheduled tasks, quick mode) alongside reliability hiccups and usage UI changes. Excludes Qwen3.5 Small (feature).
Claude Opus 4.6 web search tool reaches #1 on Arena Search
Claude web search tool (Anthropic): Claude Opus 4.6 plus the web search tool is reported as #1 on Arena’s Search Arena; the API tool’s newer version uses code execution to filter intermediate search results for token savings and relevance, according to the Search Arena claim and the linked API docs.
One operational implication is that search-result post-processing can happen outside the model’s main context window (via code execution) rather than spending model tokens on long result lists, as described in API docs.
Builders are using Claude Code Voice Mode for hands-free CLI work
Claude Code (Anthropic): One early user reports writing “much of my CLI code” via Voice Mode over the last week, framing it as a practical way to stay in-flow while navigating terminal coding tasks, per the Week of voice coding note.
This is a different usage pattern than dictating long prompts: short voice bursts to drive iterative shell-and-edit loops, aligned with the Voice Mode UX shown in the Voice mode rollout clip.
Claude Code calls out auto-memory as a shipped feature
Claude Code (Anthropic): “Auto-memory in Claude Code” is highlighted as one of the week’s shipped items, per the Auto-memory mention post and the surrounding ship list context in Shipping week list.
The tweets don’t include storage format or toggles; they only confirm the existence and shipping timeframe of the feature in Auto-memory mention.
Claude Code Remote Control is being used as a phone-to-server control plane
Claude Code Remote Control (Anthropic): A practitioner describes using Remote Control to edit via the Claude app (MacOS or iOS) against a production server “from anywhere,” per the Remote control anecdote mention, building on Remote control (feature becoming available broadly).
The practical shift here is treating the Claude app as the front-end while the code environment stays remote, rather than pairing the agent UI with the local workstation.
Claude for Open Source Program offers Max 20x for 6 months
Claude for Open Source Program (Anthropic): An invite email screenshot shows acceptance into the program with “Claude Max 20x free for 6 months” and an activation flow, as captured in Program invite email.
This reads as a distribution lever aimed at maintainers/contributors rather than a general pricing change; the only concrete terms visible in the email are the 6‑month duration and the “Max 20x” entitlement in Program invite email.
Claude usage page reportedly drops weekly/session stats view
Claude app (Anthropic): Users report the Usage page no longer shows weekly or per-session usage stats and instead surfaces “Extra usage” spend controls (toggle + monthly spend limit + balance), as seen in the screenshot shared in Usage UI screenshot.
The visible fields in Usage UI screenshot suggest the remaining UI is focused on post-limit continuation (“extra usage”) rather than historical consumption breakdown.
Claude Code ships new Skills
Claude Code (Anthropic): Anthropic staff highlight “New skills in Claude Code” as part of the week’s ship list, per the Skills mention post and the consolidated roundup in Shipping week list.
No specific skill names are listed in the tweets, but the change signal is that the Skills catalog/content changed, not just docs.
Claude Cowork adds scheduled tasks
Claude Cowork (Anthropic): Scheduled tasks are called out as a newly shipped capability in Cowork, per the Scheduled tasks mention post and the broader “shipped this past week” roundup in Shipping week list.
The tweets don’t include configuration details; they only confirm the feature exists and was shipped in the last week via Shipping week list.
Claude expands plugins and connectors surfaced in the UI
Claude integrations (Anthropic): Anthropic staff call out “a bunch of new plugins and connectors” as shipped this week, per the Plugins and connectors post and the weekly roundup context in Shipping week list.
The tweets don’t enumerate which connectors; they indicate integration surface area expanded in the same shipping window referenced by Shipping week list.
Claude for Chrome highlights a new Quick mode
Claude for Chrome (Anthropic): “Quick mode in Claude for Chrome” is called out as a shipped item this week in the Anthropic product roundup, per the Quick mode mention post and the broader list in Shipping week list.
The tweets don’t specify triggers/keys; they only confirm the feature exists via Quick mode mention.
🧠 Claude Memory expands: free-plan availability + import/export portability
Memory becomes a mainstream product surface: now available on Claude free plan, with an explicit import flow from other providers and export controls—positioned as reducing switching costs during the current app-store churn. Excludes Claude Code tooling updates (separate category).
Claude makes Memory free, adds import/export so you can switch assistants without losing context
Claude Memory (Anthropic): Following up on Memory migration (copy/paste memory transfer for paid users), Anthropic says Memory is now available on the free plan, with a streamlined way to import saved memories into Claude and the ability to export them whenever you want, as described in the memory announcement and reiterated in the settings pointer; the import entrypoint is explicitly called out in the import guide.
The practical workflow change is that Memory is no longer a paid-only retention feature: the same settings surface (“Settings → Memory”) now serves as the control plane for enabling Memory, running the import flow, and retaining an exit hatch via export, per the memory announcement.
Builders frame Claude’s Memory import as an explicit switching mechanic during churn
Migration narrative (Claude Memory): Posts argue the new import flow is timed to make migration from ChatGPT/Gemini “frictionless,” positioning Memory as a direct switching-cost reducer rather than a passive personalization feature, as shown in the migration explainer and its migration explainer.

• Demand signal being cited: The same threads connect importability to claims that Claude “dethroned ChatGPT” in mobile charts, using the app store claim as the concrete artifact.
Treat the app-rank linkage as directional: the tweets attribute causality to Memory/import plus controversy-driven switching, but they don’t provide a clean attribution breakdown between product changes and the surrounding news cycle.
🧰 Codex product signals: outages, Windows tease, hackathons, and fast-mode breadcrumbs tightening
Codex chatter shifts from rumor to operational signals: brief outages and resets, community hackathons, Windows app teaser, and a notable change where GPT‑5.4 coupling text gets scrubbed from CLI help strings. Excludes OpenAI–DoW policy terms (separate category).
OpenAI teases Codex for Windows and opens an interest form
Codex for Windows (OpenAI): OpenAI is teasing a Windows build of the Codex app in a short Windows-logo clip shown in the teaser video.

The campaign includes a BSOD-style splash screen with “Codex app for Windows is coming soon” and an early access flow pointing to the [signup form](link:700:0|Signup form), as shown in the BSOD mock.
No release date is stated in the teaser assets; this is signal rather than a shipped build.
Codex incident briefly blocked requests as “high cyber risk,” fixed in ~8 minutes
Codex (OpenAI): A production issue caused Codex requests to be blocked/rejected as “high cyber risk,” and OpenAI says it was resolved in ~8 minutes as described in the incident note; the team also said they’ll reset rate limits after the disruption, per the same incident note.
This is operationally relevant because it’s a distinct failure mode (security-risk gating) versus normal rate limiting or model errors.
Codex CLI trims “GPT‑5.4” from the /fast command description
Codex CLI fast mode (OpenAI): Following up on Fast mode PR (the earlier /fast-mode breadcrumb), a new commit removes the explicit “toggle Fast mode for GPT‑5.4” wording and replaces it with “toggle Fast mode,” as shown in a diff screenshot.
This looks like tightening the leak surface around model/version naming in user-facing CLI strings, without changing the existence of the /fast command itself.
Codex hits all-time high RPS; team signals capacity ready
Codex traffic (OpenAI): A Codex team member says Codex hit an all-time high in requests/second “yesterday,” with more releases pending, and that “GPUs are on standby,” per the capacity comment. A second post frames repeated request spikes as a sign that “the alternative to agentic coding isn’t coding by hand anymore,” per the usage pattern note.
This is one of the clearer near-real-time demand signals for cloud coding agents, because it’s tied to service-side load rather than app-store rank or anecdotal adoption.
Builder reports Codex Xhigh taking 33+ minutes on a task Opus did in 3
GPT‑5.3 Codex Xhigh latency (OpenAI): A builder reports running the same prompt on Claude Opus 4.6 and “GPT 5.3 Codex Xhigh,” claiming Opus finished in ~3 minutes while Codex was still running after 33 minutes, with the ongoing trace shown in the terminal screenshot.
This is a user-facing performance signal about long “thinking” runs (and their ergonomics), not a benchmark; there’s no repro artifact in the tweet beyond the screenshot.
Codex’s APAC hackathon: 100+ devs, 50+ projects; meetups directory goes live
Codex community (OpenAI): Following up on Hackathon results (the first APAC Codex hackathon), OpenAI now adds concrete scale numbers—“100+ developers” and “50+ projects” built in a day in Singapore—per the event recap.
• Winners snapshot: The announced winners include an iOS AR studio app in the 1st place note, a Codex “computer user agent” to hunt illegal gambling sites in the 2nd place note, and a multi-agent policy simulator in the 3rd place note.
• Local organizing surface: OpenAI also points people to a Codex meetups/hackathons directory, per the meetups callout and the linked [meetups directory](link:485:0|Meetups directory).
The project list itself isn’t published in these tweets, but the meetups page is a concrete distribution channel for future events.
Codex CLI 0.107 reportedly hits 503s; rollback behavior emerges
Codex CLI (OpenAI): A user reports Codex “0.107 runs into 503 errors” and says they reverted to 0.105 as captured in the version regression note. Short-term reliability issues also showed up at the service layer earlier, with OpenAI describing a separate “high cyber risk” block incident in the incident note.
These are different failure classes (client build vs service-side gating), but they’re landing in the same week of heavy Codex usage.
GPT‑5.3‑Codex‑Spark starts rolling out to engaged Codex users on Plus
GPT‑5.3‑Codex‑Spark (OpenAI): OpenAI is rolling out a “GPT‑5.3‑Codex‑Spark” variant to “most engaged Codex subs on ChatGPT Plus,” according to the rollout note. A separate builder comment describes Spark as useful for “researching, asking code base questions and quick UI edits,” per the Spark usage comment.
No public model card, pricing, or capability deltas are included in these tweets; the signal here is the product segmentation (Spark as a distinct Codex flavor) and the distribution path (Plus → engaged Codex users).
📈 Cursor & agentic coding market: revenue milestones and “third era” autonomous agents
Business + workflow signals around Cursor and the broader coding-assistant market: ARR milestones, the shift from tab→agent→autonomous cloud agents, and discussion of what developers review when agents ship artifacts instead of diffs. Excludes Codex/Claude specific release notes.
Cursor reportedly hits $2B ARR, doubling in three months
Cursor (Anysphere): A Bloomberg report screenshot shared by builders says Cursor’s annual recurring revenue hit $2B in February, up from $1B three months earlier, with ~60% coming from enterprise customers per the Bloomberg screenshot and the matching recap in ARR recap.
The same source is linked directly in the Bloomberg article, which is the cleanest artifact in this set; no Cursor-side confirmation appears in the tweets provided.
Cursor’s “third era”: autonomous cloud agents that return artifacts, not diffs
Cursor (workflow shift): A circulated summary of Cursor CEO commentary argues dev tooling is moving from tab autocomplete → interactive agents → autonomous cloud agents that run longer tasks and return reviewable artifacts (previews, videos, logs) rather than code diffs, with Cursor claiming 35% of merged PRs already come from these autonomous cloud agents per the Cursor CEO summary.
This frames the engineering bottleneck as artifact review and environment reliability (e.g., flaky tests) rather than typing speed, as described in the same Cursor CEO summary.
AI coding assistants get a $7.5–10B market size estimate
AI coding assistants (market signal): One synthesis thread pegs the current AI coding market at $7.5–10B, citing Cursor’s acceleration and adding rumors that Codex is at ~$1B and a next tier (Cognition/Copilot/Lovable/Replit) at $300–600M per the Market sizing estimate.
The Cursor revenue milestone used as an anchor for those comparisons is the same Bloomberg-screenshot claim that Cursor reached $2B ARR per the Bloomberg screenshot.
Cursor Plan mode uses Mermaid diagrams as a planning aid
Cursor (Plan mode UX): A builder calls out that Cursor’s Plan mode can emit Mermaid diagrams during planning, which they find easier to scan than terminal-only plans—see the concrete “Data Flow” diagram example in the Mermaid plan diagrams.
This is a narrow UX edge, but it maps to a broader pattern: planning outputs that are visual artifacts can be faster to review than long text blocks, as illustrated in Mermaid plan diagrams.
🦞 OpenClaw ecosystem: rapid releases, ACP/subagents, multi-channel adapters, and community scaling
OpenClaw remains a major agent-runner ecosystem topic: big beta drops, ACP agent plumbing, multi-platform messaging/streaming, and community governance/moderation issues. Excludes Qwen model release details (feature) even when mentioned alongside OpenClaw.
OpenClaw beta v2026.3.2 adds a first-class PDF tool and expands adapters
OpenClaw 2026.3.2-beta.1 (OpenClaw): A new beta release adds a first-class pdf tool (native providers for Anthropic/Google with fallbacks), expands SecretRef coverage across credential surfaces, and broadens outbound adapters (Discord/Slack/WhatsApp/Zalo) per the Beta install command, with implementation details in the Release notes.
• Doc and file pipelines: The new pdf tool formalizes “PDF as a primitive” in agent workflows (model/provider selection, page/byte limits, extraction fallback), as described in the Release notes.
• Credential handling: SecretRef support is extended and unresolved refs “fail fast” on active surfaces, according to the Release notes.
• Multi-channel delivery: Shared sendPayload support and chunk-aware text fallback land across messaging adapters, as listed in the Release notes.
OpenClaw documents ACP Agents for running Claude Code/Codex as external runtimes
ACP Agents (OpenClaw): OpenClaw’s Agent Client Protocol (ACP) is documented as the path to run external harnesses (Claude Code, Codex, OpenCode, Gemini CLI) via /acp session management, including thread-bound routing and persistent sessions, as laid out in the ACP Agents docs.
• Enablement and rollout: Discussion around “ACP subagents” suggests the feature may require explicit enabling today per the ACP subagents question, with a maintainer noting it will be “on by default” in an upcoming release in the Default-on note.
Telegram response streaming lands, and TeleClaw shows streaming OpenClaw agents
TeleClaw on Telegram: Telegram bots now support response streaming, and a TeleClaw demo shows OpenClaw agents emitting token-by-token replies inside Telegram chats, as shown in the Streaming demo.

• Accessibility and UI semantics: There’s immediate discussion about how well streaming chat UIs work with screen readers, raised in the Accessibility question.
OpenClaw crosses 1,000 contributors on GitHub
OpenClaw community (OpenClaw): The project reached 1,000 contributors, a scale signal for ongoing maintenance capacity and ecosystem growth, as celebrated in the Contributors milestone.
OpenClaw maintainer bans a PR copier and retroactively repairs credits
OpenClaw governance (community ops): The maintainer reports banning a user for copying others’ PRs, then fixing credits and retroactively updating the changelog, per the Maintainer ban note and follow-up in the Credits repair note.
OpenClaw’s meetup calendar shows a fast-growing multi-city builder circuit
OpenClaw meetups (community): A published events calendar lists OpenClaw meetups and workshops across many global cities (including multiple sold-out/waitlist events), indicating sustained organizer and builder throughput, as compiled in the Events calendar.
OpenClaw users ask for per-channel instruction injection without spinning up new agents
Per-thread configuration (OpenClaw): A user asks for a way to inject custom instructions per Telegram topic / Discord channel at the start of a new session—without creating a separate agent with separate memory—suggesting demand for a “per-channel constitution” layer beyond global settings, per the Feature request question.
Vercel signals OpenClaw support as a deployment surface
Vercel + OpenClaw (deployment signal): Vercel publicly highlights support for OpenClaw, framing it as a first-class target for hosted agent frontends and community projects, as shown in the Support post.
✅ Code quality pressure: reviews breaking under agent throughput + evaluation tactics
As PR volume explodes, tweets focus on keeping code mergeable: arguments that traditional human code review is dying, plus practical evaluation heuristics (deterministic graders, lean context files) to prevent agent thrash. Excludes model benchmarks (separate category).
AGENTS.md can cut worst-case agent thrash, per a 124-PR study
AGENTS.md efficiency (Empirical study): Researchers ran identical PR tasks twice across 10 repos / 124 PRs with Codex—once with an AGENTS.md context file and once without—and found median runtime dropped 28.64% and output tokens fell 16.58% while task completion stayed comparable, as summarized in AGENTS.md impact results.
A key nuance in the summary is that the gains were not uniform: the file mainly reduced cost in a small number of very expensive runs, acting as a “guardrail” against worst-case looping rather than a universal speedup.
Manual code review is buckling under agent PR volume
Code review throughput (Latent.Space): A Latent.Space guest post argues that PR volume/size is rising fast enough that “read the diff” reviews don’t scale, and proposes replacing them with a 5-step layered playbook for quality control, as introduced in Guest post announcement and detailed in the Essay.
The core claim is not that quality gates go away, but that teams shift from line-by-line reading toward layered checks (automation + rollout controls) because the review workload is now the bottleneck.
A lightweight evaluation stack for agents: deterministic first, LLM judge later
Agent evaluation (Practical heuristics): A compact checklist lays out how to evaluate agents without overbuilding infra: define success up front (outcome/process/style), start with 20–50 real failures, use deterministic graders first (tests, file existence, command success), then add LLM judges for style, and grade the produced artifacts rather than the path, as written in Evaluation tips and captured in the
.
Use a fail-off/pass-on feature flag to keep long agent runs honest
Long-run agent control (Red/green loop): A concrete steering technique for long-running coding agents is to require a new feature flag where the same workflow must fail when the flag is off and succeed when it’s on, forcing a tight “red/green” cycle that exposes partial fixes and regressions, as described in Feature-flag trick.

This is framed as a guardrail against hours-long thrashing: you get a deterministic fail state first, then a deterministic pass state—so progress is measurable mid-run.
AGENTS.md guidance: encode repeatable corrections, avoid dumping the wiki
AGENTS.md authoring (Rule hygiene): A suggested structure for AGENTS.md emphasizes writing down repeatable corrections, unique preferences, and intentional constraints—while explicitly avoiding massive info dumps, outdated workflows, and generic mega-prompts, as summarized in AGENTS.md do and don't.
This is basically treating AGENTS.md as a “worst-case thrash preventer” rather than a documentation mirror.
Open-source maintainers are flagging AI-written issue overhead
Maintainer workload (Issue quality): An OSS maintainer reports seeing issues that look AI-generated—verbose, heavily formatted, and longer than the underlying question—arguing that this increases triage/review burden even when the core problem is legitimate, as stated in AI issue critique.
This is a “code quality pressure” cousin: it’s not PR review, but it’s still human attention becoming the limiting factor under higher throughput.
Banning stock phrases is becoming a quality control tool for AI writing
AI writing review hygiene: One practitioner shared a “banned phrases” list for their writing agent (e.g., avoiding filler like “hard truth” and “here’s the thing”) to reduce generic copy and make edits/review more about substance, as shown in Banned phrases list.
This pattern shows up as a cheap way to tighten output distribution when the failure mode is “sounds plausible but says nothing.”
🔌 MCP + agent integrations: skills vs tools, marketplace procurement, and batch learning
Interoperability and integration surfaces: MCP vs Skills framing, agent-driven procurement/install flows, and tools to learn/attach multiple skills in parallel. Excludes OpenClaw core releases (separate category).
Vercel’s CLI becomes an agent procurement path for Marketplace integrations
Vercel CLI for Marketplace (Vercel): Vercel says agents can now autonomously discover and install Marketplace integrations from the CLI—positioning “procurement” (choosing and wiring third-party services) as a first-class agent action surface, per the agent procurement demo and the associated changelog post.

• How it’s invoked: the flow combines installing a Vercel CLI skill (npx skills add vercel/vercel --skill vercel-cli) with an agent executing vercel integration add <provider>, as shown in the agent procurement demo and reiterated in the CLI command example.
• Why it’s notable: the framing from Vercel leadership is that agents can stop re-building common infra and instead attach existing vendors by command, as argued in the procurement framing.
Weaviate ships Agent Skills repo and a crisp MCP vs Skills mental model
Weaviate Agent Skills (Weaviate): Weaviate published a concrete “MCP vs Agent Skills” distinction—MCP as deterministic JSON-RPC tool interfaces to external systems vs Skills as local, markdown-based behavioral playbooks—and paired it with a new Skills repo you can install via npx skills add weaviate/agent-skills plus a /weaviate:quickstart entrypoint, as laid out in the MCP vs skills explainer.
• What changes for agent builders: the post’s framing makes it explicit when to reach for Skills (repeatable reasoning/workflow guidance) vs MCP (API-grade operations and live data), including the “Skill guides the reasoning, MCP performs the action” pattern in the MCP vs skills explainer.
• Packaging signal: the install surface (npx skills add …) matches the broader “skills as portable add-ons” workflow that Vercel is also leaning on for agent-driven integrations, as shown in the Marketplace install flow.
Hyperbrowser shows “/learn batch” to teach agents multiple skills in parallel
Hyperbrowser skill learning (Hyperbrowser): Hyperbrowser is demoing /learn batch, a single command that learns multiple skills concurrently—aimed at reducing the setup/iteration cost of making a coding agent “multi-tool capable,” as described in the learn batch announcement and shown in the HyperPlex demo.

• Where it sits: the command is presented as part of HyperPlex, an open-source research agent that “spawns agents, browses, reads, extracts, and returns a cited answer,” according to the HyperPlex demo.
• Workflow implication: it treats skills as an installable, learnable layer you can refresh in parallel, rather than a one-at-a-time interactive setup loop, as shown in the learn batch announcement.
📊 Benchmarks & evals: BS detection, repo-level tests, ARC scores, and search arena rankings
Evaluation news clusters around BullshitBench v2, repo-level benchmarks (Repo Bench), ARC-AGI semi-private international model scores, and tool+model leaderboard movement. Excludes release announcements (separate category).
BullshitBench v2 expands to 100 questions and 70+ model variants
BullshitBench v2 (petergostev): The benchmark refresh adds 100 new “nonsense detection” questions split across coding/medical/legal/finance/physics and reports results for 70+ model variants (model + reasoning levels), with replication scripts and judgments published alongside the dataset, per the Release summary and the linked GitHub repo.

The headline result is that Anthropic models separate sharply from the pack, while Qwen is the other consistent strong performer; the thread also argues that increasing “reasoning” effort often reduces nonsense pushback rates, as summarized in the Release summary.
A compact view of the per-model detection breakdown is shown in the Detection rate chart.
The full interactive breakdown is available in the Data explorer, but the tweets don’t include a single canonical “one-number” score definition beyond the green/amber/red rates.
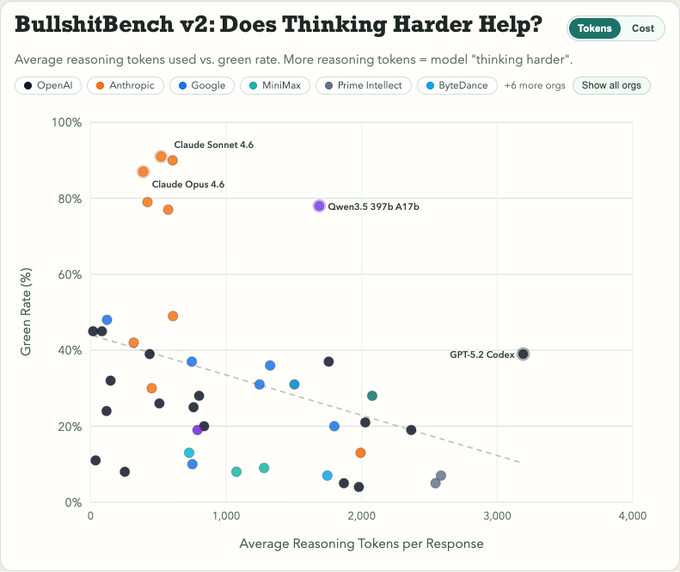
BullshitBench v2 plots suggest “think harder” can backfire on nonsense prompts
BullshitBench v2 (petergostev): A follow-on analysis plots average reasoning tokens vs. “green rate” and finds a visible negative slope—models that spend more tokens “thinking” tend to accept more nonsense, as visualized in the Reasoning tokens scatter.
• Reasoning-mode failure hypothesis: The post notes a plausible mechanism that reasoning models may “try to get to an answer no matter what,” which could reduce refusal/challenge behavior on ill-posed prompts, as discussed in the Reasoning tokens scatter.
• Size vs. sparsity: Another set of plots suggests green-rate tracks total parameters more than active parameters (MoE sparsity), based on the Parameter scaling plots.
• Over-time comparison: A time-series view shared in the Detection over time chart claims Anthropic’s line rises across releases while Google/OpenAI are flatter on this benchmark.
Treat these correlations as benchmark-specific; the tweets don’t establish whether the “reasoning tokens” metric is normalized across providers or decoding settings.
ARC-AGI-2 Semi-Private posts low scores for non-frontier providers (with costs)
ARC-AGI-2 Semi-Private (ARC Prize Foundation): ARC Prize posted “international model” results with both score and approximate cost per evaluation—Kimi K2.5: 12% ($0.28), MiniMax M2.5: 5% ($0.17), GLM-5: 5% ($0.27), DeepSeek V3.2: 4% ($0.12)—as listed in the Scores and costs post.
The foundation also states Semi-Private testing is limited to providers with trusted data retention agreements, and says Qwen 3 Max Thinking is excluded on that basis, per the Testing policy note.
GLM-5 posts a 76% points rate on Repo Bench (shared run)
Repo Bench (RepoPrompt ecosystem): A shared run shows Z.ai GLM-5 hitting 130.5/170 points (76%) with a 70% pass rate, according to the Repo Bench result screenshot.
The post frames this as “GLM-5 is now #3 on Repo Bench” and even claims it edges Opus 4.6, per the Repo Bench result screenshot; the artifact shown is a single run UI snapshot, not a full reproducible report dump.
Claude Opus 4.6 web search ranks #1 on Arena Search; API docs highlight code-filtering
Claude web search (Anthropic): A post claims Claude Opus 4.6 + the web search tool is now #1 on Arena’s Search Arena, and notes the API tool can use code execution to filter intermediate search results (token/quality trade), per the Search arena ranking note.
Implementation details for web_search_20260209, including “dynamic filtering” requirements and model compatibility, are described in the linked API docs.
WeirdML: GPT‑5.3 Codex (xhigh) reportedly takes the lead over Opus 4.6
WeirdML (community benchmark): A circulating leaderboard claim says GPT‑5.3 Codex (xhigh) scores 79.3%, ahead of Opus 4.6 (77.9%), and mentions “less than half the prize,” per the WeirdML score claim.
No primary benchmark artifact (run logs, dataset spec, grading script) is included in the provided tweets, so this should be read as a headline comparison rather than a fully auditable eval.
🗺️ Practical agentic engineering patterns: exploration, specs/plans, context resets, and prompt variables
Hands-on workflow discussions about getting better outputs from coding agents: forcing global exploration vs “local view,” using SPEC.md/PLAN.md conventions, iterative Figma→code patterns, and variable-driven prompt templates. Excludes CI/review mechanics (separate category).
Being too “local” with coding agents leads to inconsistent changes
Agent scope (coding workflow): Over-specifying changes by only feeding the agent the exact files you want edited can suppress curiosity—no repo search, no prior art—so the agent makes the “easiest possible change” that doesn’t match existing patterns, as described in the Local vs global scope thread.
A practical reframing from the same post is to treat “Explore” as mandatory context gathering (global view) before requesting edits, so the model can align with existing architecture and conventions instead of patching the nearest file.
A concrete Figma-to-code stack: Gemini 3.1 Pro + MCP + browser + rules + resets
Figma-to-code workflow (Gemini): A field-tested stack pairs Gemini 3.1 Pro, the Figma MCP server, and a browser tool, then adds project-specific “Figma Rules,” with an emphasis on frequent context resets and small commits, per Figma MCP to code steps.
The thread links directly to rule authoring guidance and MCP setup docs—see the Custom rules docs and MCP server docs—and also calls out a preferred browser agent implementation in the Browser agent repo.
SPEC.md as destination and PLAN.md as journey for multi-agent work
SPEC/PLAN docs (session hygiene): A lightweight convention is to separate the immutable target from the mutable execution path—“SPEC.md is the destination, PLAN.md is the journey,” as captured in Spec vs plan metaphor.
This tends to reduce rework in longer agent runs because the “what” stays stable while the “how” can be revised without losing alignment.
Use prompt variables to keep outputs consistent while iterating
Prompt variables (prompt discipline): A repeatable technique is to lock the recurring part of a prompt and expose only a small structured “variable block” (e.g., subject/location/style fields) so iteration doesn’t drift, as shown in the Variables prompt tip tutorial.
A more formal example template (with fields like STRUCTURE/COLORS/MATERIALS/LIGHTING/ANGLE) is shared in 3D asset prompt template, illustrating how this approach can keep style stable while swapping specifics.
When agents loop on ideas, try the opposite approach
Brainstorming with agents (creative throughput): When a group of humans plus agents keeps revisiting the same options, one proposed intervention is to explicitly notice the loop and “break the frame” by attempting the opposite of the current approach, as summarized in Break the frame heuristic.
The longer writeup adds concrete “frame-breaking” moves (e.g., dropping scaffolding and shifting to an entirely different angle), detailed in the Break the frame playbook.
📑 Doc parsing & retrieval plumbing: PDF reality, layout data, and parsing toolchains
Document AI shows up as a practical pain point: why PDFs are hard to parse, how teams approach layout/figures, and tooling that turns parsing into a first-class primitive. Excludes model benchmarks (separate category).
Why PDF parsing breaks: display coordinates aren’t document structure
PDF parsing (LlamaIndex): PDFs are a rendering format first—internals often look like “draw this glyph at (x,y) with font F,” not “this is a paragraph/table,” which forces parsers to reconstruct semantics from scattered coordinates and sometimes missing Unicode/font mappings, as explained in the [PDF parsing breakdown](t:53|PDF parsing breakdown).
VLM-based approaches help by screenshotting pages and reading pixels, but they also discard useful metadata and still struggle on accuracy/cost tradeoffs, per the same [PDF parsing breakdown](t:53|PDF parsing breakdown). The thread also notes Word/PPTX are usually easier because the source formats are closer to structured text, not pure display instructions, as described in the [PDF parsing breakdown](t:53|PDF parsing breakdown).
OpenClaw beta adds a first-class pdf tool with provider backends
OpenClaw v2026.3.2-beta.1 (OpenClaw): The beta introduces a first-class pdf tool with native support for Anthropic and Google PDF providers plus extraction fallback for non-native models, as detailed in the [beta release post](t:55|Beta release post) and the linked [release notes](link:55:1|Release notes).
It also ships knobs for defaults (model, max bytes, pages) alongside docs/tests, according to the [beta release post](t:55|Beta release post). This frames PDF handling as a tool-level primitive inside the agent runtime, rather than something every project re-implements, as described in the [release notes](link:55:1|Release notes).
LlamaParse exposes layout data for figures and charts
LlamaParse (LlamaIndex): When parsing documents, LlamaParse can return layout data for non-text elements (figures/charts), not just extracted text, as noted in the [layout data mention](t:639|Layout data mention).
That’s a practical enabler for retrieval and downstream UX: you can link citations back to page regions, drive figure-aware chunking, or render “where this came from” overlays instead of treating the PDF as a flat text blob, as implied by the [layout data mention](t:639|Layout data mention).
🛠️ Reliability & infrastructure shocks: outages, failover, and conflict-linked cloud incidents
Today’s infra signal is reliability under stress: Claude outages and recovery notes, plus continued reporting of cloud-region incidents tied to broader conflict, with practitioners emphasizing multi-region failover habits. Excludes model release distribution (feature).
Claude hits elevated errors; API mostly OK, web login/logout impacted
Claude Status (Anthropic): Claude saw “elevated errors” across claude.ai, console, and Claude Code, with Anthropic indicating the API was working as intended while the claude.ai login/logout paths were a major driver of user-facing failures, per the incident notes shown in Status incident timeline and Status banner screenshot.
• Timeline detail: the status thread shows an investigate→identify→fix sequence over ~2 hours, including a note that “some API methods are not working” later in the incident, as captured in Status incident timeline.
• Recent uptime context: the 90-day view flags a “partial outage” lasting 2 hrs 45 mins, per the tooltip in Uptime tooltip screenshot.
The tweets don’t specify root cause; the only concrete scope called out is auth path instability on the web app.
AWS confirms objects struck UAE data center, triggering fire and AZ disruption
AWS ME-CENTRAL-1 (Amazon Web Services): AWS said “objects” struck its UAE region and caused sparks/fire, impacting one Availability Zone and impairing some services; AWS also emphasized redundancy for customers operating across multiple zones, as reported in Reuters screenshot and echoed in Incident recap.
The tweets don’t provide an official attribution for the “objects,” but they do establish an AWS-confirmed physical incident and a concrete operational impact at the AZ level.
Vercel dxb1 outage becomes multi-AZ; platform excludes Dubai from new deployments
Vercel (dxb1 region): Vercel reported the dxb1 incident worsened into a multi-AZ outage, and they began excluding Dubai from new Function and Routing Middleware creations (Node.js middleware first, then edge runtimes), as described in Multi-AZ outage update.
The update also calls out a temporary compatibility workaround—switching deployments to the recommended Node.js runtime if teams are seeing deploy issues—per Multi-AZ outage update.
Codex falsely blocked requests as high cyber risk; fixed in ~8 minutes
Codex (OpenAI): Codex requests were blocked/rejected after a change flagged traffic as “high cyber risk”; the issue was fixed in ~8 minutes, and the team said they would reset rate limits afterward, per Incident note.
This reads like a classification/abuse-protection regression rather than capacity exhaustion, but the tweet doesn’t include the specific control or threshold that triggered it.
📄 Research papers to track: agent GUI memory, multi-agent topology, diffusion LMs, and transformer theory
A dense research-paper day: agent GUI execution paradigms, multi-agent communication/topology, diffusion language modeling, and scaling theory for Transformers—mostly shared as arXiv links and paper screenshots. Excludes productized tools and benchmarks.
ActionEngine proposes state-machine memory for one-shot GUI automation
ActionEngine (Microsoft + Georgia Tech): A new paper frames a shift from reactive “VLM-per-click” web agents to a programmatic approach: crawl/explore a site to build a persistent state machine (memory graph), then generate an executable script in one shot; the thread claims ~95% success on complex tasks while cutting cost ~11.8× and reducing latency by ~50% compared to iterative screenshot+LLM loops, as described in the Paper screenshot.
• Why it’s different: It explicitly separates exploration from execution (planner once, then deterministic code), which aims to reduce failure compounding across 50-step tasks, per the Paper screenshot.
The post doesn’t include the full experimental setup or datasets in-tweet, so treat the metrics as paper-claims until you’ve read the full methods section.
AgentConductor adapts multi-agent communication graphs per task and failure
AgentConductor (paper): A new multi-agent coding framework proposes generating a task-specific communication graph (instead of fixed “5 agents always talk the same way”), then evolving that topology across turns when execution fails; the shared summary claims accuracy gains on competition-style programming while cutting token cost by ~68%, as outlined in the Paper screenshot.
• Core mechanism: A “manager” agent picks an initial topology based on perceived difficulty, then rewrites the graph using runtime error feedback, according to the Paper screenshot.
• Practical implication: The paper positions topology as a first-class tuning knob (who talks to whom, when), rather than only role assignment, per the Paper screenshot.
The tweet summary doesn’t specify the baseline topologies or the evaluation harness details, so the magnitude of the 68% claim depends heavily on experimental controls.
dLLM revisits diffusion as a “simple” language modeling recipe
dLLM (diffusion language modeling): A new paper pitch argues for diffusion-style generation as an alternative to autoregressive next-token decoding, positioning it as a simplified diffusion LM recipe rather than a heavily engineered hybrid system, as linked in the Paper page.
The share itself is light on details (no results tables or ablations are shown in-tweet), but it’s a clean pointer to track if you’re watching for non-transformer or non-AR inference paths—especially where parallel denoising steps might trade off latency, controllability, or decoding stability differently than token-by-token generation.
Memory Caching: recurrent models that grow memory with cached checkpoints
Memory Caching (RNNs with growing memory): A new arXiv paper proposes “Memory Caching” to give recurrent models an effectively growing memory by checkpointing and reusing past hidden states, aiming to bridge the gap between fixed-state RNN memory and attention’s expanding context; the share points to the full paper PDF in the ArXiv PDF.
The claim is directionally relevant to long-context efficiency debates: it’s an attempt to get scaling memory capacity without paying full attention’s quadratic cost. The tweet doesn’t include benchmark tables, so the real question is where it lands on recall-heavy tasks versus modern attention variants.
Meta’s transformer “effective theory” paper gets recirculated for scaling guidance
Effective theory of wide and deep Transformers (Meta): A longform theory paper is resurfacing in feeds as a practical reference for how forward/backward signal propagation behaves in residual attention networks, and what that implies for width scaling, initialization, and training hyperparameter scaling; the recap cites NTK analysis plus optimizer behavior (SGD vs AdamW) and empirical validation on vision/language Transformers in the Thread summary, with the canonical preprint linked in the ArXiv abstract.
This is less about new SOTA results and more about having a principled checklist for “why did my deep Transformer blow up or go flat?” across depth/width regimes.
💼 Business & enterprise signals: model commoditization, private-market pricing, and platform growth
Business/market tweets cluster on revenue/ARR milestones, private-market pricing proxies, and strategic moats (data, feedback loops, distribution) as agents spread beyond engineering into org-wide workflows. Excludes tool release notes and benchmarks.
AI coding market sizing thread pegs the category at $7.5–$10B
AI coding market (sizing): One thread estimates the overall AI coding market at $7.5–$10B, citing rumors of Codex at ~$1B and a second tier (Cognition/Copilot/Lovable/Replit) at $300–$600M each, per the Market sizing post.
The same narrative anchors the top end with a Bloomberg-reported Cursor $2B ARR figure and ~60% enterprise mix, as shown in the Bloomberg screenshot share. These are directional numbers with no primary financial filings in the tweets.
Claude download spike coincides with reported 295% ChatGPT uninstall surge
Consumer distribution (Claude vs ChatGPT): A chart attributed to Appfigures shows late-February first-time downloads rising sharply for Claude while ChatGPT declines, with a claim that “ChatGPT uninstalls surged by 295%” after the DoW deal, following up on Cancel wave (early churn/cancellation posts) as echoed in the Download and uninstall chart.
A separate post also claims Claude hit #1 on the U.S. App Store during the same period, as stated in the App Store rank claim.
The AI moat debate shifts from data to feedback and distribution loops
AI moats (Ellison debate): A resurfacing claim attributes model commoditization to shared public internet data, pushing “proprietary datasets” as the moat, as summarized in the Ellison moat quote.
A counter-argument in the Moat counterpoint shifts the defensibility away from raw data toward proprietary feedback, distribution, and proprietary environments that generate reinforcement signals and keep improving systems. It’s a clean articulation of “model weights are less defensible than the loops around them.”
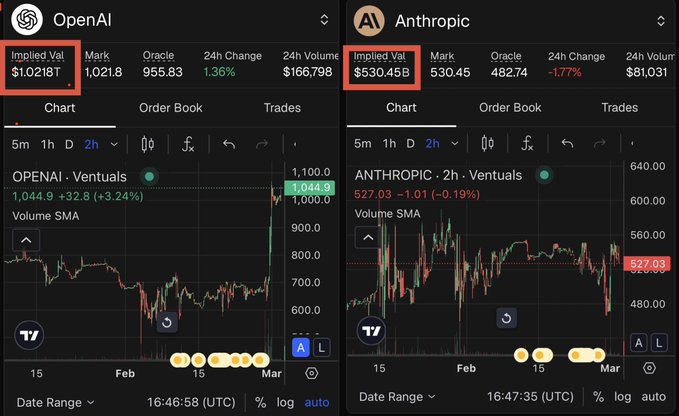
Ventuals perps imply $1.02T OpenAI and $530B Anthropic valuations
Ventuals perps (Ventuals): A synthetic perps market is quoted as implying OpenAI at $1.02T and Anthropic at $530B, framed as ~40% above last-round pricing; the key caveat is that it’s “exposure to private assets” without owning the underlying equity, as described in the Perps valuation post.
• Mechanics and limitations: The follow-up thread points to how these contracts work (cash-settled perps on Hyperliquid infra), along with “many issues,” via the Perps docs referenced in the How perps work thread.
Liquidity and mark-setting still look hard to assess from the tweets alone.
McKinsey projects $3T–$5T commerce mediated by shopping agents by 2030
AI commerce agents (McKinsey): A McKinsey projection is summarized as AI agents mediating $3T–$5T of global consumer commerce by 2030, moving from “compare products” to “assemble and execute carts,” as described in the McKinsey summary thread.
The same post describes a six-stage ladder up to agent-to-agent negotiation, and argues that machine-readable catalogs/returns via APIs become a competitive requirement in that framing from the McKinsey summary thread.
Meta reportedly tests shopping inside Meta AI, with product cards and flows
Meta AI (shopping): Meta is described as testing shopping features inside Meta AI in the U.S., positioning it against other AI-commerce efforts, according to the Feature test claim.

A related write-up claims some requests are routed to Gemini “under the hood,” but that detail is only asserted in the Routing claim alongside the Feature write-up.
MiniMax reports $79M 2025 revenue and a shift from models to platform
MiniMax (HKEX): MiniMax posted its first earnings as a public company, reporting $79M revenue (+159% YoY), gross margin improvement from 12.2% to 25.4%, and 236M+ users plus 214K enterprise clients & developers, as stated in the Earnings snapshot.
It also outlined a 2026 positioning change from “model company” to an “AI platform,” with emphasis on coding, workplace productivity, and multimodal creation in the same Earnings snapshot.
xAI reportedly repays $3B of debt early ahead of a market debut
xAI (finance): Reuters is cited as reporting xAI will repay $3B of debt early, framed as balance-sheet cleanup ahead of a potential public-market debut, in the Reuters screenshot thread.
The post ties the move to data-center buildout financing (prior $5B debt package mentioned) and interest-cost savings, but those details are only asserted in the same Reuters screenshot thread.
Z.ai opens a startups program offering credits and early API access
Z.ai (startup program): Z.ai announced a startups program offering free API credits, “priority rate limits,” and “early API access,” with an application link in the Program announcement and details on the Program page.
A follow-up says there are “issues with the Startup account” and directs applicants to email support, per the Signup issue note.
🎥 Gen media & vision tools: Nano Banana 2 workflows, video leaderboards, and creator pipelines
Creative/vision chatter stays high: DeepMind’s Nano Banana 2 positioning around fast high-quality image creation and editable outputs, plus video-model leaderboard updates and practical prompting workflows. Excludes robotics demos.
Nano Banana 2 pushes aspect ratios, text-in-image, and 2K/4K upscales
Nano Banana 2 (Google DeepMind): DeepMind is positioning Nano Banana 2 around controllable output specs—multiple aspect ratios and upscaling from 521px to 2K/4K—as shown in the Aspect ratio post. It’s also being marketed as faster/cheaper visual creation with “accurate writing directly into images” and on-the-fly localization, per the Product positioning.

The pitch here is less “new style” and more “treat images like assets you can ship” (iterate sizes, keep text legible, reuse across channels), as described in the Aspect ratio post.
Kling 3.0 leads Artificial Analysis text-to-video leaderboard (with audio)
Kling 3.0 (KlingAI): A shared Artificial Analysis leaderboard screenshot shows Kling 3.0 1080p (Pro) ranked #1 for text-to-video “with audio” at ELO 1,094, with multiple Kling variants clustered in the top spots, per the Leaderboard screenshot.
The same table lists per-minute API pricing (e.g., $20.16/min for Kling 3.0 1080p Pro and $13.44/min for an Omni 720p Standard variant), as shown in the Leaderboard screenshot.
Nano Banana 2 edit prompting: background swaps and attribute transfer from refs
Nano Banana 2 editing (ProperPrompter): A reference-driven edit workflow is circulating for precise image modifications (swap background to a reference photo; transfer hairstyle/outfit onto a subject), demonstrated in the Editing workflow demo.

• Prompt minimalism: The shared prompts are intentionally short (e.g., “swap out the background to the reference photo”), as shown in the Prompt examples.
• Reference set quality: The thread includes side-by-side reference photos and resulting edits, visible in the Prompt examples.
From Nano Banana 2 image to animated 3D model, then into a game prototype
Creator pipeline (techhalla): A workflow demo shows taking a 2D Nano Banana 2 output and turning it into an animated 3D model, then dropping it into a simple playable game scene, per the 2D to 3D demo.

Nano Banana 2 pixel-art recipe: reference the style, then isolate the card art
Nano Banana 2 workflow (ProperPrompter): A repeatable prompt pattern is being shared for turning Pokémon card art into dithered pixel art—attach reference images for both the target style and the card, then instruct the model to “isolate and convert” the character while keeping the background, as shown in the Pixel art example and clarified in the Prompt and references.
The thread notes the model may blend references; adding negative constraints like “no charizard” is suggested to reduce that failure mode, per the Prompt and references.
Runway Gen-4.5 hits #15 in Arena Video with ELO 1218
Runway Gen-4.5 (Arena Video): Arena reports Runway Gen-4.5 tied around #15 in its text-to-video rankings at ELO 1218, stated in the Arena ranking, with the note that the board is driven by side-by-side blind votes rather than a fixed benchmark suite.
Arena also points to an explanation of why this methodology differs from static benchmarks in the Methodology explainer, and it links directly to the public board at the Leaderboard page.
A reusable variables template for image generation prompts (low‑poly asset spec)
Prompt templating (techhalla): A structured “variables + fixed directive” pattern is being shared for image generation—define a small JSON-like block for STRUCTURE/COLORS/MATERIALS/LIGHTING/ANGLE, then keep a long invariant spec for consistency, per the Prompt template.
The examples are tuned for low‑poly 3D game assets (white background, sharp silhouettes, AO/flat shading), with the variable block doing most of the customization, as shown in the Prompt template.
Pollo AI adds Nano Banana 2 as an image model option
Nano Banana 2 distribution (Pollo AI): TestingCatalog says Nano Banana 2 is now usable inside Pollo AI, framed as a fast image model with subject consistency, multilingual text rendering, and wide-format support in the Integration note.
The same thread also shares example prompts (e.g., “Space Banana”) in the Prompt example and a long-form infographic prompt in the Infographic prompt, while separately mentioning a “50% off” promotion in the Discount post.
🏛️ Safety & policy turbulence: DoW contract language, surveillance limits, and government offboarding
The OpenAI/Anthropic–DoW saga continues with new contract-language claims, criticism of loopholes, and government-wide offboarding/retaliation narratives—plus app-store churn and “cancel” sentiment as measurable demand signals. Excludes pure product updates.
OpenAI says it will amend DoW deal to bar domestic surveillance and NSA use
DoW agreement amendment (OpenAI): OpenAI CEO Sam Altman says OpenAI and the Department of War are amending their agreement to add explicit language that the AI system “shall not be intentionally used for domestic surveillance of U.S. persons,” including via “commercially acquired” personal/identifiable information, as laid out in his internal post repost in Altman internal update.
• Surveillance limit, spelled out: The added clause cites the Fourth Amendment plus the National Security Act of 1947 and FISA (1978), then adds a “for the avoidance of doubt” sentence about banning deliberate tracking/monitoring including via purchased personal data, as shown in the excerpt image shared in Contract excerpt screenshot and echoed in a summary thread in Summary of key clauses.
• Intelligence agencies carve-out: Altman says the DoW affirmed OpenAI services will not be used by DoW intelligence agencies (example: NSA) unless a follow-on contract modification occurs, per Altman internal update.
• Process correction: Altman explicitly says the Friday rollout was rushed and “looked opportunistic and sloppy,” and he frames the update as iterative deployment with future refinement, as written in Altman internal update.
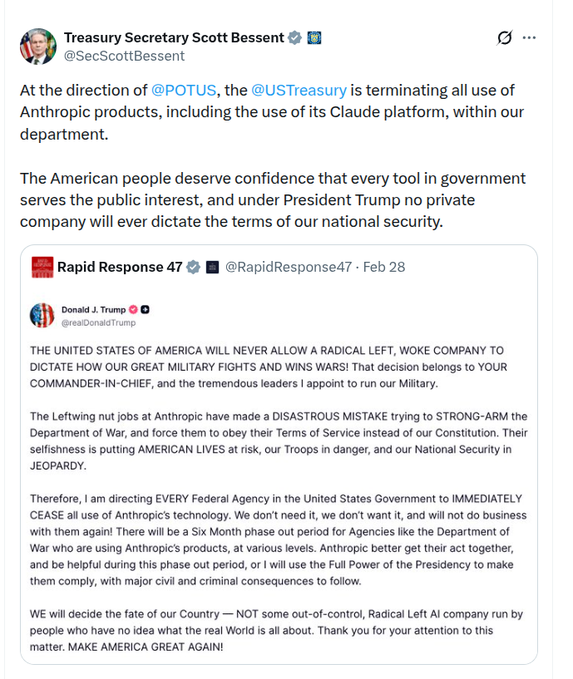
U.S. Treasury says it is terminating Anthropic/Claude use under presidential direction
Treasury offboarding (U.S. government): Treasury Secretary Scott Bessent says Treasury is “terminating all use of Anthropic products, including…Claude,” explicitly attributing it to presidential direction, as captured in the screenshot thread in Bessent termination post.
The same screenshot bundle embeds Trump’s statement ordering every federal agency to cease Anthropic use and calling out a “six month phase out period” for agencies like the DoW, which makes this an operational offboarding timeline rather than an overnight cutover, as shown in Bessent termination post.
Backlash signals: posts claim ChatGPT uninstalls +295% and Claude hits #1 in US downloads
Backlash metrics (ChatGPT vs Claude): Multiple posts claim a demand shock after the DoW deal—one says “ChatGPT uninstalls surged by 295%,” while another points to Claude overtaking ChatGPT as the #1 U.S. app, as framed in Uninstall surge claim and App Store headline.
The chart shown in Uninstall surge claim attributes its data to Appfigures and notes it tracks first-time downloads (not reinstalls); it shows Claude’s line sharply rising late Feb as ChatGPT dips. Separately, posts describe “Cancel ChatGPT” trending and “thousands unsubscribing,” but those claims are presented without a shared primary dataset in Backlash narrative.
DoW contract language debate centers on “intentionally used” and what loopholes remain
Contract wording debate: The amended line “shall not be intentionally used for domestic surveillance” is drawing both loophole-hunting and lawyerly pushback—critics focus on edge cases like “unintentional” surveillance, non-identifiable data, and non-commercially acquired data in Wording loopholes critique, while another take argues “intentional use for domestic surveillance” is already broad but still depends on unreleased defined terms in Defined-term concern.
Both sides converge on the same missing artifact: the full contract text (including any definitions of “domestic surveillance”), which is explicitly called out as unknown in Defined-term concern.
Claim: Congress moving to block federal retaliation against AI companies and address surveillance/weapons
Congress response (U.S.): One update claims Congressman Sam Liccardo plans an amendment to the Defense Production Act to prohibit federal agencies from retaliating against AI companies, and separately claims Senate Democrats are preparing legislation targeting AI-powered mass surveillance and autonomous weapons, as reported in Legislation claim.
No bill text, docket, or statutory language is provided in the tweet, so the concrete scope and enforcement mechanism remain unspecified based on the material in Legislation claim.
OpenAI researcher Aidan McLaughlin posts: “I don’t think this deal was worth it”
OpenAI internal dissent signal: Aidan McLaughlin posts “i personally don’t think this deal was worth it,” a critique of the DoW agreement that’s getting significant attention (one repost screenshot shows 335K+ views), as shown in Deal criticism and amplified via a screenshot in Screenshot repost.
The post is notable mainly as a visible, individual-level objection from someone others describe as working on core models, as stated in Screenshot repost.
Open letter asks DoW and Congress to reverse Anthropic “supply chain risk” designation
Open letter on “supply chain risk”: An open letter is circulating that asks the Department of War and Congress to rescind the “supply chain risk” designation applied to Anthropic, arguing the designation is being used as punishment in a contract dispute rather than for foreign-adversary risk, as promoted in Letter circulation and hosted on the linked Open letter site.
The public artifact here is the letter itself (a signature-gathering page), while the tweets don’t include an official DoW response or a count of signatories at the time captured in Letter circulation.
🎙️ Voice agents beyond the IDE: network-integrated calling + build stacks
Voice-related items that are not “coding assistant voice mode”: carrier/network call assistants, and infrastructure stacks for building and scaling real-time voice agents (models + hosting + WebRTC/SIP adjacent tooling).
Deutsche Telekom shows a network-integrated AI call assistant (ElevenAgents)
Magenta AI Call Assistant (Deutsche Telekom / ElevenLabs): Deutsche Telekom demoed a network-integrated voice assistant (“Magenta AI Call Assistant”) powered by the ElevenAgents platform, positioning it as an assistant that lives in the carrier network rather than in a phone app, per the event note in MWC announcement. It’s described as working on any device that can place a call—including “decades-old landlines”—and offering in-call translation (up to 50 languages), summarization, and action-taking, as stated in Capability details.
• Deployment surface: The key engineering claim is that the assistant is embedded into network infrastructure (not an on-device or over-the-top app flow), as described in MWC announcement.
• Capabilities called out: Translation (50 languages), intelligent summaries, and in-call actions are explicitly listed in Capability details.
No public API surface, latency targets, or data-retention model are detailed in today’s tweets.
Modal, NVIDIA, and Daily schedule a Nemotron voice-agent build/scaling livestream
Voice agent build stack (Modal + NVIDIA + Daily): Modal announced a livestream for March 3 at 2pm EST on building and scaling “real-team” voice agents with NVIDIA’s open-source Nemotron models plus Modal hosting and Daily’s realtime calling stack, as posted in Livestream invite. A second announcement frames it as a code walkthrough plus a GPU infrastructure deep dive, explicitly name-checking Pipecat-style architectural patterns, as described in Infra focus note.
See the YouTube livestream in YouTube livestream for the stated agenda and timing.