OpenAI Sora 2 brings physics‑accurate video – 95.1–99.7% unsafe blocks
Stay in the loop
Free daily newsletter & Telegram daily report
Executive Summary
OpenAI rolled out Sora 2 alongside an invite‑only iOS app, instantly turning its video model into a social creation platform. The upgrade tightens physics and world‑state consistency for multi‑shot prompts and now generates synchronized speech and sound effects. Access starts free in a two‑country rollout (US/Canada), with ChatGPT Pro users prioritized for Sora 2 Pro quality and an API on the roadmap. The safety posture is unusually concrete: every export carries visible watermarks and C2PA credentials, and internal evals claim 95.1–99.7% block rates on unsafe categories.
What’s new is control and consent baked into the core loop. Cameos let you verify your face and voice once and then decide who can use your likeness, with draft notifications and one‑click revoke or delete. Reports suggest copyrighted characters and styles are allowed by default unless rights holders opt out, while public figures remain blocked without consent. The app’s feed is tuned for creation over passive scrolling, with mood checks and teen safeguards, and OpenAI’s Peebles, Sahai, and Dimson demoed physically plausible motion and stylized shots live. If the promised API lands soon, expect Sora 2 to become the default building block for video‑first agents and creator workflows.
Feature Spotlight
Feature: OpenAI Sora 2 and the Sora app
OpenAI ships Sora 2 and an invite-only social app: physics-accurate video with synced audio, multi-shot control, and consented cameos. Early US/CA rollout and Pro-tier access position it to set the bar for AI video & distribution.
Cross-account, high-volume story. OpenAI unveils Sora 2 plus an invite-only iOS social app. Focus is on physics-accurate video+synced audio, multi-shot control, and "cameos" with consent controls; US/CA rollout, Pro-tier Sora 2 Pro, API later.
Jump to Feature: OpenAI Sora 2 and the Sora app topicsTable of Contents
🎬 Feature: OpenAI Sora 2 and the Sora app
Cross-account, high-volume story. OpenAI unveils Sora 2 plus an invite-only iOS social app. Focus is on physics-accurate video+synced audio, multi-shot control, and "cameos" with consent controls; US/CA rollout, Pro-tier Sora 2 Pro, API later.
OpenAI launches Sora 2 with physics‑accurate video and synchronized audio
OpenAI unveiled Sora 2, a major upgrade to its video model that better adheres to real-world physics, maintains world state across multi‑shot prompts, and generates synchronized speech and sound effects. This follows app rumor that a Sora 2 launch and social experience were imminent.
- The launch post details improved instruction following, object permanence, and failure modeling (e.g., missed shots rebound) alongside audio generation model post, and the full write‑up expands technical claims and examples OpenAI blog post.
- A formal system card outlines capability bounds and mitigations for synthetic media risks system card.
- Leadership framed this as a "ChatGPT for creativity" moment, emphasizing speed from idea to result and new social dynamics Sam Altman blog.
- A physics demo reel highlights challenging dynamics and animation styles physics demo.
Cameo: Verified likeness insertion with granular sharing and revocation
Sora’s new Cameo feature records a short verification clip (face+voice) once, allowing the model to place your likeness in generated videos while giving you strict control over who can use it and the ability to revoke access—and even flag drafts.
- The feature is described as a highlight of the new experience with heavy emphasis on character consistency and social uses Sam Altman thread.
- Consent mechanics include per‑person sharing, ability to delete any video you’re featured in, and export blocks for others’ likenesses cameo controls.
- The system card details liveness checks and additional safeguards around likeness misuse system card.
- UI flows show a cameo prompt (“close‑up, say your name”) used to verify identity before insertion cameo prompt.
Sora app debuts invite‑only in US/Canada with creation‑first feed
OpenAI released a standalone iOS app for Sora, starting in the US and Canada with invite‑only access. It’s free with generous limits initially; ChatGPT Pro users are prioritized for higher‑quality generation (Sora 2 Pro), and an API is planned.
- App onboarding and invite workflow are live in the App Store listing and initial UI app screenshots.
- OpenAI confirms geo rollout, access queue, and prioritization for Pro subscribers app explainer and reiterates access notes during the staged rollout access note.
- The core model announcement underscores the same capabilities inside the app, with API access on the roadmap model post.
- A live page and event teed up the debut and demos livestream page.
Sora ships creation‑centric ranking, wellbeing prompts, and watermarked exports
OpenAI says Sora’s feed is tuned to prioritize creation over passive consumption, with steerable preferences, periodic mood checks, and parental controls for teens. All exports include visible watermarks and C2PA credentials.
- The system card documents watermarks, C2PA metadata, stricter teen defaults, and other guardrails at launch system card.
- App rollout notes reiterate invite gating, content checks, and teen protections while the system scales access note.
- Product principles posted by leadership emphasize long‑term satisfaction, user‑controlled feeds, and creation priority Sam Altman blog.
Free Sora access now, Sora 2 Pro for Pro users, API to follow
OpenAI confirms free initial Sora access with generous limits, elevated quality via Sora 2 Pro for ChatGPT Pro subscribers, and an API in the pipeline.
- Access and prioritization specifics are called out in rollout threads app explainer and access note.
- The model announcement and system documents point to future API availability alongside the app model post.
- Public posts from users note the invite gating and credits behavior during early usage waves usage note.
Live demo showcases Sora 2 physics and multi‑shot control
OpenAI hosted a livestream to walk through Sora 2’s capabilities and the app experience, with leadership and researchers demonstrating physics, multi‑shot narratives, and audio sync.
- The livestream was promoted on OpenAI’s site and YouTube; the replay page lists presenters and schedule livestream page livestream replay.
- Supplementary clips highlight physically plausible motion and anime stylization physics demo.
- The launch thread and blog offer fuller examples and technical framing release thread OpenAI blog post.
Report: Sora’s default includes copyrighted IP unless rights holders opt out
Multiple reports indicate Sora’s default policy will allow copyrighted characters and styles unless rights holders request exclusion, while public figures remain blocked without consent. This would shift monitoring to rights holders while keeping cameo identity checks for private likenesses.
- WSJ and Reuters describe an opt‑out posture for copyrighted content, with notable exceptions for public figures and consent requirements WSJ report Reuters write‑up.
- Community summaries discuss how this interacts with the app’s consent and watermarking stack policy analysis system card.
- Cameo controls (grant/revoke, draft notifications) remain separate from copyrighted IP handling cameo controls.
🧪 New Models: GLM‑4.6 and open reasoning baselines
Model updates relevant to engineers. Excludes Sora 2 (covered as the feature). Mostly coding/agentic models and an open small-model baseline.
GLM‑4.6 benchmark roundup: near Claude Sonnet 4, fewer tokens, stronger tool use
Across internal and third‑party summaries, GLM‑4.6 reports a 48.6% win rate vs Claude Sonnet 4 in real‑world dev scenarios and ~15% token savings vs GLM‑4.5, with consistent gains in agentic tasks. benchmarks chart summary charts
- Leaderboard snapshots and vendor plots highlight long‑context coding, browse/search tasks, and tool‑using agents. arena post
- Following up on SWE‑bench SOTA, this is the first open competitor in days to publicly narrow the gap on coding tasks while reducing token budgets. benchmarks chart
Zhipu’s GLM‑4.6 launches with 200K context and leaner token use
Zhipu released GLM‑4.6, a flagship update focused on agentic coding and long‑context work: 200K tokens of context, tighter tool use, and about 15% fewer tokens per task than GLM‑4.5. First‑party docs and weights are live alongside a technical blog and product pages. launch details tech blog developer docs Hugging Face model
- Real‑world coding performance improves while reducing total token footprint (cost/latency) vs 4.5. dataset page
- API, subscription and weights are all linked from the GLM site; multiple downstream tools announced support today. launch details
Coding agents roll in GLM‑4.6: Cline, Claude Code, Roo, Kilo add support
Major coding agents integrated GLM‑4.6 on day one, citing stronger agentic coding and fewer tokens per task. cline update
- Cline: 200K context (up from 131K), 15% fewer tokens than GLM‑4.5 across tasks; available via subscription/provider switch. cline update
- Claude Code & others expose GLM‑4.6 as a selectable backend for plan/act loops and parallel tool calls. agent roundup
- OpenRouter availability simplifies multi‑provider routing into existing agent stacks. provider page
GLM‑4.6 becomes default for Coding Plan; pricing still starts at $3/month
Z.AI set GLM‑4.6 as the default for all Coding Plan tiers without changing pricing; existing subscribers are auto‑upgraded. pricing update
- Lite/Pro/Max tiers remain, with first‑month discounts and usage multipliers; Pro/Max promise faster throughput/SLA perks. pricing update
- Subscription portal highlights GLM‑4.6 advantages (200K context, agentic tools) with same entry price. subscribe page
ServiceNow releases Apriel‑v1.5‑15B‑Thinker (open weights) scoring 52 on AAI Index
ServiceNow shipped an open‑weights 15B reasoning model with a 128k context window that scores 52 on the Artificial Analysis Intelligence Index—competitive with much larger closed models on instruction following and tool‑use tracks. model overview
- Strong multi‑turn + tool behaviors (e.g., 68% on τ²‑Bench Telecom; 62% IFBench) and enterprise‑friendly MIT license. model overview
- Noted verbosity: ~110M tokens consumed across the full AAI Index run; model card and repo are live. token usage note Hugging Face model
OpenRouter lists GLM‑4.6 with 200K context and 128K max output tokens
OpenRouter added GLM‑4.6, exposing provider routing, context controls (128k/200k), and a raised max output to 128k (default 64k). provider page
- Devs can hit GLM‑4.6 through OpenAI‑compatible APIs across multiple providers. OpenRouter page
- Listing emphasizes broad improvements (reasoning, coding, long‑context) and quick trial via the provider UI. provider page
Ring‑1T‑preview (open) posts 92.6 on AIME ‘25 with natural‑language reasoning
InclusionAI’s trillion‑parameter Ring‑1T‑preview shares early results: AIME’25 92.6 (NL reasoning), strong LiveCodeBench and Codeforces ELO, and competitive ARC‑AGI‑v1—all in a community release. model overview
- RLVR‑style post‑training and MoE routing underpin math/coding gains; open Transformers support invites replication. model overview
- Known issues include identity mix‑ups and reasoning loops; maintainers seek community fixes in this preview. model overview
Anycoder sets GLM‑4.6 as default model for vibe‑coding space
The Anycoder space on Hugging Face flipped its default to GLM‑4.6 so users get the larger 200K context and upgraded coding behavior by default. anycoder space
- Zhipu confirms GLM‑4.6 as default across partner tools and coding plans, reinforcing ecosystem support. integration note
📈 Evals: Day‑2 Sonnet 4.5 results and leaderboards
Fresh evals/debates since yesterday; focuses on new numbers. Excludes Sora 2 launch. Mix of ARC‑AGI, creative writing, and long-horizon coding.
Sonnet 4.5 scales to 63.7% on ARC‑AGI‑1 and 13.6% on ARC‑AGI‑2 at 32k thinking
ARC Prize’s semi‑private evals show Anthropic’s Sonnet 4.5 climbing with larger reasoning budgets: 63.7% on ARC‑AGI‑1 and 13.6% on ARC‑AGI‑2 at 32k tokens, with per‑task costs of ~$0.52 and ~$0.76 respectively ARC results.
- Shorter budgets trade accuracy for cost: ARC‑AGI‑1 reaches 31.3% (1k), 46.5% (8k), 48.3% (16k); ARC‑AGI‑2 reaches 5.8%, 6.9%, 6.9% at the same budgets ARC results.
- Cost/performance plots circulating today show Sonnet 4.5 competitive with GPT‑5 variants along the spend curve on ARC‑AGI‑2 cost plot.
- Additional charts highlight that Sonnet 4.5 gains continue with more “thinking” tokens on ARC‑AGI‑2 rather than saturating early ARC scaling chart.
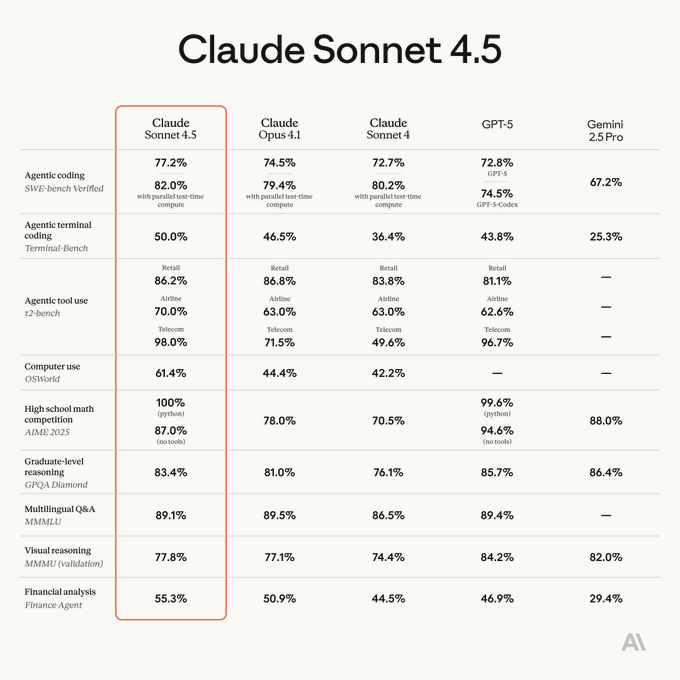
Computer use: Sonnet 4.5 posts 61.4% on OSWorld while leading SWE‑bench Verified at 77.2%
Anthropic’s charted results show Sonnet 4.5 at 61.4% on OSWorld computer‑use tasks and 77.2% on SWE‑bench Verified (n=500), reinforcing its long‑horizon and agentic coding strengths beyond static unit tests Software engineering chart.
- The same snapshot situates Sonnet 4.5 ahead of GPT‑5 on the coding benchmark while remaining competitive across other applied categories Software engineering chart.
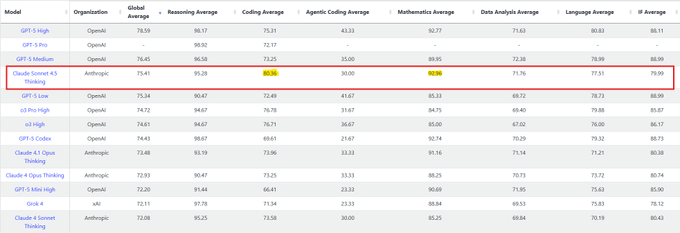
LiveBench: Sonnet 4.5 ranks #4 overall, #1 in Coding and Mathematics
LiveBench’s latest table places Sonnet 4.5 at #4 overall while taking the top spots in Coding and Mathematics sub‑scores, extending its leaderboard momentum following LisanBench rank where it debuted at #3 LiveBench table.
- The published breakdown highlights Sonnet 4.5’s edge on developer‑centric tasks without sacrificing broad performance across categories LiveBench table.
Sonnet 4.5 leads the Deep Research Bench with ~0.577 score
On Deep Research Bench (DRB), Sonnet 4.5 sits at the top with an aggregate score near 0.577, outperforming rivals on sourcing, validation, and dataset compilation categories visible on the shared radar DRB leaderboard.
- DRB focuses on multi‑step web research and evidence‑backed synthesis rather than single‑turn QA, aligning with agentic use cases DRB leaderboard.
Lab test shows Sonnet 4.5 leading real‑world code edit success over Claude 4 and GPT‑5
A team’s internal benchmark on real repository edits reports Sonnet 4.5 with the highest success rate, edging out Claude 4 Sonnet and GPT‑5 on applied code change tasks (bar chart provided) Edit study.
- The comparison targets practical code fixes rather than synthetic patch tasks, suggesting stronger planning + tool use loops in Sonnet 4.5 Edit study.
Sonnet 4.5 tops Creative Writing v3 and Longform Writing leaderboards
Creative writing benchmarks swung Anthropic’s way: Sonnet 4.5 is #1 on Creative Writing v3 (Elo) and #1 on Longform Writing, with strong rubric and low‑slop scores shared alongside sample lengths Writing boards.
- Creative Writing v3 shows Sonnet 4.5 leading ahead of o3/GPT‑5 in rubric/Elo head‑to‑heads Writing boards.
- Longform results include per‑run text length and degradation metrics, indicating stability across multi‑kiloword outputs Writing boards.
🛠️ Agentic coding stacks and IDE updates
Developer tooling momentum. Excludes model launches unless directly about tooling adoption. Hooks, routing, and IDE agents dominate today.
Claude Agent lands in JetBrains IDEs, expanding beyond VS Code
Anthropic rolled out Claude Agent inside JetBrains IDEs with a native agent selector and UX hooks—extending beyond the previously announced VS Code integration, following up on Claude Code 2.0 (checkpoints, UI refresh, VS Code). JetBrains rollout
- In‑IDE menu exposes Claude Agent and other assistants with quick switching.
- Complements Claude Code 2.0 features like /rewind and checkpoints from the prior release.
Cursor 1.7 adds agent lifecycle hooks, team-wide rules, deeplinks and menubar status
Cursor shipped a sizeable IDE update aimed at controlling and observing agent behavior end-to-end. Hooks let teams script the agent lifecycle (audit, block, redact), and Rules can now be enforced org‑wide. release note
- Hooks: Observe/override actions across plan/act steps; see examples in the docs hooks docs.
- Team rules: Centralize guardrails like Bugbot rules for automated PR reviews team rules note.
- Deeplinks: Share prompts and set up reproducible runs via links share prompts brief.
- Menubar: Monitor running agents from the OS menubar menubar status.
- Changelog covers image‑file reading in workspace and other polish changelog page.
Cline publishes practical routing blueprint: direct, aggregator, and local model paths
Cline laid out a clear strategy for routing agent requests across providers, including when to prefer direct APIs, aggregators, or local LLMs, and how to split Plan vs Act modes. routing overview
- Direct connections: Lowest latency, latest features; trade‑off is managing multiple keys direct provider brief.
- Aggregators: One account, usage analytics, easy model trials; good for experimentation aggregator options.
- Local models: Full privacy, zero per‑token cost, version control; requires GPUs local models brief.
- Strategy: Hybrid routing by task—fast local for planning, premium providers for execution; config guide included config flexibility and routing guide.
Open coding agents adopt GLM‑4.6 (200K context) across Cline, Roo, Kilo, Claude Code
Zhipu’s GLM‑4.6—now the default for Coding Plan users—landed across popular coding agents, bringing a 200K context window and ~15% token efficiency vs 4.5 into day‑to‑day agent loops. coding plan update cline integration
- Cline support plus benchmarks against prior GLM versions and peers cline integration.
- Multi‑agent availability: Claude Code, Roo Code, Kilo Code, and more report plug‑in support agent support.
- Also available via OpenRouter with updated context/max tokens settings openrouter page.
Claude Agent SDK live session shows subagents, rewind, and project scaffolds
Anthropic hosted a hands‑on session for the new Claude Agent SDK, highlighting how to spin up agents, attach tools, and compose sub‑agents for complex tasks. getting started session replay
- Subagents: Dynamically add specialist agents via --agents for parallel or staged work feature list.
- Recovery: Use /rewind to roll back conversation and undo code changes during long runs feature list.
- Dev flow: Live Q&A on structuring projects, checkpoints, and traceability for audits.
MCP security playbook highlights poisoned tools, rug pulls, and cross‑server exploits
A focused workshop dissected real‑world MCP attack patterns against agent stacks—poisoned tool manifests, post‑approval behavior flips, conversation theft—and the defensive checks teams should add. workshop invite
- Checklist: Tool validation, version pinning, sandboxing, and provenance logging recommended.
- Incident response: Detect, isolate, and rotate credentials across servers when compromise is suspected.
- Materials and registration page are available for teams to operationalize learnings course page.
AmpCode’s Build Crew streams agent planning and execution internals
Amp/AmpCode showcased live “Build Crew” sessions focused on transparent agent planning, deterministic tool calling, and approval gates for risky steps. Build Crew live
- Plan/act traces: Inspect long‑running plans and interleave with human approvals when needed.
- Safety gates: Stop‑the‑world validation for shell/API actions reduces YOLO failure modes.
- Prompt hygiene: Keep system prompt, plan, and execution transcript visible for debugging. agent session snapshot
🔌 MCP in practice and security
Interoperability and safety of Model Context Protocol. New dev wins and red-team thinking; separate from general coding tooling.
Claude Code spins up an MCP server to auto‑build n8n workflows from plain English
In a hands‑on demo, Claude Code was prompted to design and ship an MCP server that programmatically creates n8n workflows—end‑to‑end in roughly 10 minutes demo claim. The same flow now supports issuing natural‑language requests to generate and edit workflows inside n8n, positioning MCP as the control plane for real tool‑using agents rather than just chat wrappers natural language build.
- A growing repository of agentic workflow templates and MCP test scripts is being curated to scale reuse and harden reliability over time repo and tests.
- For teams adopting this pattern, a companion curriculum walks through context engineering, evaluation, and deployment of agentic apps (useful scaffolding if you’re standardizing MCP at work) course link course page.
- Why it matters: MCP turns LLMs into deterministic tool orchestrators—here, n8n becomes a controllable action space with provenance, retries, and audit trails rather than opaque “do X” prompts.
MCP exploit playbook: poisoned tools, rug pulls, and cross‑server shadowing go mainstream
A live workshop is cataloging real‑world MCP attacks—poisoned tools, post‑approval “rug pulls,” stolen conversation histories, and cross‑server shadowing—along with concrete detection and defense patterns security workshop event page. The session targets teams already rolling out MCP in production, following up on MCP servers list which highlighted how quickly the ecosystem is standardizing.
- Threat model updates: attackers can flip behavior after initial approval or pivot across servers to exfiltrate session context; the playbook covers policy checks, trust boundaries, and isolation strategies security workshop.
- Operator guidance: attendees get incident‑response checklists and validation patterns (e.g., schema pinning, signature checks, out‑of‑band attestations) to reduce blast radius security workshop.
- Takeaway for leads: treat MCP endpoints like third‑party code—enforce versioned contracts, rotate credentials, and monitor post‑approval deltas to catch drift early.
🏗️ AI economics: cash burn, GPUs and storage demand
Non‑model, non‑tooling economics with direct AI impact. OpenAI’s P&L, GPU cloud capacity, and NAND/SSD demand for AI inference. Excludes Sora feature.
OpenAI posts ~$4.3B H1’25 revenue, $7.8B operating loss, and $2.5B cash burn
OpenAI generated about $4.3B revenue in the first half of 2025 but recorded a $7.8B operating loss and burned $2.5B of cash, according to internal results seen by reporters numbers recap.
- Cash and securities stood at ~$17.5B at Q2 end; +$10B arrived in June, with another ~$30B sought in July numbers recap The Information report.
- Cost of revenue was ~$2.5B H1, largely for Nvidia‑powered servers rented via Microsoft; Microsoft takes a 20% revenue share. An LOI with Nvidia pegs capacity at ~$10B per 1 GW up to $100B numbers recap.
- R&D spend hit ~$6.7B H1 (on pace to double 2024); stock comp ~$2.5B H1 (targeting ~$6B FY); sales & marketing ~$2B (including a Super Bowl ad) numbers recap.
- Management scenarios include ~$8.5B full‑year cash burn, a tender at ~$500B valuation, and a 2030 target of ~$200B revenue numbers recap.
- A Reuters recap adds a $13B 2025 revenue target and a goal of 1B weekly ChatGPT users by year‑end Reuters recap.
CoreWeave inks up to $14.2B deal to supply Meta GPU cloud capacity
Meta is locking in multi‑year GPU supply with CoreWeave in a contract valued up to $14.2B—signaling persistent demand and a strategic pivot to multi‑vendor capacity deal overview.
- The deal reduces vendor concentration risk for CoreWeave (Microsoft made up ~71% of revenue last quarter) and smooths utilization across years deal overview.
- For Meta, the agreement secures early access to top‑tier silicon without owning every rack, supporting model training and inference scale‑up deal overview.
Kioxia: AI to more than double NAND demand to 2,044 EB by 2029; inference grows 69% CAGR
A new Kioxia outlook says AI‑related NAND usage will rise from 970 EB in 2025 to 2,044 EB in 2029 (20% CAGR), with inference workloads expanding at 69% CAGR—outpacing training at 26% demand summary.
- Data‑center NAND is projected to grow from 253→668 EB (27% CAGR) over the same period demand summary.
- Smartphones: avg storage climbs 265→474 GB per unit by 2029 as AI phones reach ~61% share smartphone figures.
- PCs: SSD density per unit increases 657→1,083 GB; AI PCs reach ~39% share by 2029 smartphone figures.
- Why flash matters: SSDs balance capacity, performance, and power versus HBM/DRAM/HDD for AI training and inference pipelines server overview.
- Inference relies on SSDs for fast model loads, KV caching, and RAG stores; training uses SSDs for large datasets, snapshots, and logs inference drivers.
⚙️ Runtime efficiency and reasoning‑training advances
Today’s speed/quality deltas outside of benchmarks. Decoding speedups, numeric formats, and RL/training recipes. Excludes Sora and eval leaderboards.
NVFP4 4‑bit pretraining matches FP8 accuracy; 2–3× matmul throughput on Blackwell
NVIDIA details training a 12B Mamba Transformer on 10T tokens in NVFP4 with near‑FP8 loss and similar task scores, while Blackwell FP4 matmuls hit ~2× (GB200) to ~3× (GB300) the FP8 rate. This follows 4-bit pretraining that previewed NVFP4’s aim to cut compute and memory. See highlights and the paper. paper summary
- Accuracy: MMLU‑Pro 62.58% (NVFP4) vs 62.62% (FP8); small late‑stage loss gap largely removed by brief BF16 finishing. paper summary
- Efficiency: ~50% lower memory; FP4 matmuls 2–3× faster on Blackwell generations. paper summary
- Stability tricks: block‑wise scaling + tensor scale; stochastic rounding for gradients; ablations show each component matters. paper summary
Diffusion LLMs decode up to 22× faster (57× with KV cache) using Learn2PD
A new decoding scheme for diffusion-style LLMs flags "done" tokens per step and stops on End‑of‑Text, cutting wasted remasking/padding while keeping accuracy nearly intact on GSM8K. See method details in the paper summary and full preprint. paper thread ArXiv paper
- Per‑token “done” filter prevents reprocessing correct tokens, shrinking denoising iterations. paper thread
- Early EoT halts generation when outputs finish, eliminating padding-heavy tails. paper thread
- Reported speedups: ~22× at 1,024 tokens; up to 57× when combined with KV cache reuse. paper thread
- GSM8K accuracy is maintained within noise despite large decoding cuts. paper thread
dParallel learns parallel decoding for dLLMs, slashing steps 256→30 on GSM8K
A learnable parallel decoder for diffusion LLMs drives certainty on masked tokens, enabling big step reductions without retraining the base model. The team reports 8.5–10.5× speedups on GSM8K/MBPP with minimal quality loss. paper note Hugging Face paper
- Certainty‑forcing distillation accelerates convergence on uncertain tokens in a few post‑hoc passes. paper note
- GSM8K steps cut 256→30 (≈8.5×); MBPP 256→24 (≈10.5×), with near‑baseline accuracy. paper note
- Method keeps model weights, learning only a parallel decoding policy; no base retraining required. paper note
TruthRL uses ternary rewards (correct/abstain/hallucinate) to cut hallucinations with GRPO
A reinforcement recipe directly optimizes truthfulness by rewarding correct answers, penalizing hallucinations, and positively scoring safe abstentions when uncertain. Authors report strong reductions on knowledge‑intensive tasks. Overview and paper link below. paper link Hugging Face paper
- Trains the policy to prefer “I don’t know” over confident guesses when evidence is missing. paper link
- Built on GRPO, avoiding proxy metrics (e.g., length) that can be gamed. paper link
- Evaluated across multiple open‑domain knowledge datasets with consistent hallucination drops. paper link
VERL replaces token‑entropy heuristics with hidden‑state signals, boosting RL for reasoning
A hidden‑state controller (Effective Rank and its velocity) rebalances exploration and exploitation without relying on token entropy. Integrated into GRPO/PPO, VERL reports +21.4% on Gaokao’24 and +10.0% on AIME’24. Paper summary and figure here. paper summary
- ER/ERV reveal exploration and progress can rise together, unlike token‑level proxies that force a trade‑off. paper summary
- Plug‑in bonus is clipped and computed from final‑layer states; easy to drop into existing RLVR loops. paper summary
- Gains show up across math/logic tasks and improve pass@k while maintaining stability. paper summary
Constrained‑MDP distillation improves student reasoning while keeping it close to the teacher
Reframing LLM distillation as a constrained Markov Decision Process sets an explicit divergence budget from the teacher while training for task reward. On math reasoning, students stayed within bound more often and solved better than KL‑weighted baselines. Paper highlights here. paper summary
- Avoids brittle KL‑weight tuning by enforcing a hard proximity constraint during optimization. paper summary
- Improves chain quality without forcing students to copy teacher traces they can’t reliably execute. paper summary
- Demonstrated on math tasks; authors report higher constraint satisfaction and answer quality. paper summary
🏢 Enterprise assistants and agentic productivity
What large org users will actually use. Excludes model launch news. Copilot agent capabilities and agentic browsers lead the day.
Microsoft 365 Copilot adds Agent Mode; scores 57.2% on SpreadsheetBench and auto-builds dashboards
Agent Mode is rolling out in Microsoft 365 Copilot with measurable task execution: 57.2% accuracy on SpreadsheetBench’s 912 Excel tasks, plus one‑prompt dashboard/report generation. Word gains conversational drafting, and Office Agent in Copilot Chat can research and build slides end‑to‑end. See the early capability rundown in copilot update.
- SpreadsheetBench score: 57.2% across 912 tasks, with spreadsheet‑native “speaks Excel” behaviors copilot update
- Excel: Builds full financial reports and calculators from a single prompt (formulas, charts, layout) copilot update
- Word + PowerPoint: Live research → slide deck creation via Office Agent in Copilot Chat copilot update
- Availability: Rolling out to US personal subscribers (Frontier program) now; Excel/commercial support next copilot update
Microsoft brings Anthropic Claude to Copilot Studio and 365 Copilot
Model choice arrives in Microsoft’s Copilot stack: customers can pick Anthropic’s Claude Sonnet family in Copilot Studio (and for Office workflows) in addition to OpenAI defaults—reducing vendor lock‑in and letting teams align models to task and policy needs. The update lands alongside a broader Azure catalog that already spans 1,800+ models, including DeepSeek R1, per the rollout note in copilot models.
- Default remains OpenAI, but admins can select Claude per agent/app policy copilot models
- Enterprise impact: Easier A/B of planning vs. tool‑use models, and policy routing by data sensitivity copilot models
- Azure model catalog: Microsoft flags growing third‑party coverage (e.g., DeepSeek R1) for specialized tasks copilot models
Opera launches Neon: a privacy‑first, on‑page agentic browser
Opera’s Neon introduces a browser‑native agent that acts directly on the page DOM to fill forms, compare data across sites, and even draft code—without screen recording or shipping session data to external clouds. Work is organized as Tasks with Reusable Cards (prompt components), and a Make mode builds artifacts on EU‑hosted VMs, returning source files on completion. Feature overview in product page.
- On‑page actions: “Neon Do” executes flows locally, keeping cookies/history on‑device product page
- Tasks & Cards: Self‑contained workspaces plus reusable prompt blocks for repeatable workflows product page
- Make mode: Generates sites/games/reports server‑side (EU VMs), ships code back to the user product page
- Developer angle: DOM‑level understanding improves speed and reliability vs screen‑based agents product page
🛡️ Safety, copyright and robot conduct
Policy and safety angles. Excludes Sora 2 product launch details (feature). Focuses on consent, copyright, and embodied agent safety.
OpenAI’s Sora 2 sets opt‑out copyright default; public figures remain blocked
Sora 2 will allow copyrighted characters and IP in user videos by default unless rights holders opt out, shifting the monitoring burden to studios and labels WSJ report. Public figures are still blocked without explicit consent per early access tests and briefings Reuters note.
- Studios and agencies are being briefed on the policy ahead of broader rollout, with no blanket catalog blocks at launch Reuters note.
- The app restricts uploads to in‑app creations (no external video ingests), which simplifies provenance and takedown handling feature brief.
- Users report blocks on real‑person likeness prompts (e.g., politicians/celebrities), consistent with consent‑first rules guardrail screenshot.
Sora 2 safety stack: C2PA credentials, visible watermarks, teen safeguards, and consented cameos
OpenAI details a multi‑layer safety design for Sora 2: every export carries C2PA content credentials plus visible watermarks; a liveness check and consented Cameos govern likeness use; and teen defaults curb infinite scroll and DMs system card PDF.
- Draft notifications alert you if your verified cameo appears in any work, with granular revoke/delete controls cameo safeguards.
- App creation happens in‑app only; photo uploads are restricted (no video‑to‑video), reducing deepfake vectors at launch feature brief.
- OpenAI cites internal evals showing 95.1–99.7% block rates on unsafe content classes (policy categories) feature summary.
Unitree G1 security: shared‑key BLE root and silent 5‑minute telemetry raise red flags
New analysis finds Unitree’s G1 humanoid can be rooted over BLE due to a universal hidden key and unsafe credential handling, while the robot uploads audio/video/system data to remote servers roughly every 300 seconds—often without user awareness security analysis. This follows earlier reporting on weaknesses in its config protection and messaging stack G1 risks.
- Attackers within BLE range can inject Wi‑Fi credentials that include shell commands, enabling full takeover BLE details.
- The study argues for adaptive, cyber‑physical AI defenses on‑device to detect misuse and contain compromise paths security brief.
Cloudflare launches AI Index so sites can gate, meter, and monetize AI crawlers
Cloudflare introduced an AI‑oriented indexing layer that lets domains publish llms.txt policies, expose MCP servers, and stream pub/sub updates—enabling pay‑per‑crawl, usage analytics, and permissioned access for model training and agent use product blog.
- An aggregated Open Index offers a permissioned feed of multi‑site content for search, agent workflows, and training pipelines product blog.
- For rights holders, the model creates clearer levers to allow/deny and meter AI usage—complementing app‑level watermarking and provenance elsewhere.
DeepMind outlines layered safety for embodied agents: from risk reasoning to collision avoidance
Google DeepMind described a multi‑layer framework for safe robot behavior that chains high‑level risk reasoning with conversational norms, pre‑act risk checks, and low‑level controllers like collision avoidance safety thread.
- A shown prototype labels hazards (e.g., electric shock from outlet misuse), timestamps likely contact, and suggests interventions, with JSON outputs for downstream policy hooks injury detection demo.
🖼️ Creative video/image tools (non‑Sora)
Dedicated creative stack coverage given high volume today. Excludes Sora 2 (feature). Focus on alternative T2V and editing models/workflows.
Luma Ray 3 climbs to #2 on Text‑to‑Video leaderboard with 1080p, 10s, and 16‑bit HDR
Luma’s Ray 3 now ranks second on Artificial Analysis’ Text‑to‑Video arena, with a chain‑of‑thought iteration loop that evaluates and refines generations, plus native 16‑bit HDR and 1080p up‑to‑10‑second outputs model rundown, and a public board to compare models side‑by‑side video arena.
- Ranks #2 in T2V and #7 in I2V on the Video Arena model rundown.
- Supports 10‑second 1080p generations; HDR enables SDR→HDR conversions and true HDR T2V model rundown.
- Uses iterative self‑critique to improve prompt adherence and quality model rundown.
Rodin Gen‑2 one‑click image→3D arrives with PBR textures and enterprise procurement path
fal’s Rodin Gen‑2 converts a single image (or multi‑view set) into a high‑quality 3D mesh with T/A‑pose support and PBR textures—now easy to try directly and purchasable through Google Cloud Marketplace model release model page blog post.
- Multi‑view→3D, PBR textures, and one‑click flows target game, VFX, and ecommerce pipelines model release.
- Self‑serve pricing from ~$0.40 per generation on the hosted model page (production‑ready assets) model page.
- Marketplace listing enables SOC2/SSO, private endpoints, and consolidated cloud billing for enterprises blog post.
From single image to full video: reproducible Weavy + multi‑model pipeline goes public
A creator published a step‑by‑step pipeline that turns a single image into a polished video by chaining Weavy for orchestration with Reve, Nano Banana, Luma Ray 3, Kling, Minimax, and Suno v5 for music—showing a repeatable path to production‑ready clips workflow overview.
- Keyframe tactic: extract and rotate frames, match object details, then extend with Ray 3 for motion consistency keyframes step.
- An in‑flow prompt generator converts ideas into structured prompts per video model prompt generator.
- Public Weavy flows are shared for cloning and modification by other teams image workflow.
- Stack includes Minimax for shots, Ray 3 for detail, Kling for dynamics, and Suno v5 for synced audio workflow overview.
HunyuanImage 3.0 shows precise text rendering and layout in new creative set
Tencent highlighted HunyuanImage 3.0’s UI fidelity and accurate text rendering via themed ‘historical social posts,’ reinforcing its strength for typography‑heavy composites—following up on fal pricing where a public playground went live image showcase.
- Examples span Marie Curie, Newton, Einstein, and Da Vinci with tight alignment of captions, icons, and layouts image showcase.
Qwen Image Edit 2509 livestream showcases new local editing upgrades today
Qwen’s Image Edit 2509 gets a live multi‑platform demo at 6pm ET/3pm PT, with hosts previewing a "powerful update" to the popular local editor and how it slots into common ComfyUI workflows livestream info comfyui notice.
- Watch on YouTube, X, and Twitch; VOD expected on the YouTube event page YouTube livestream.
- Expect focus on precise region edits and style controls based on the event brief livestream info.
Higgsfield keeps WAN “Unlimited” for one more week with Full HD and ready‑to‑go audio
Higgsfield says WAN remains unlimited for one more week, highlighting Full HD video output, built‑in audio, and diverse style presets for creators shipping fast plan update.
- Platform menu shows active models (e.g., Higgsfield DOP for VFX/camera control), confirming breadth of generation options available to users platform view.
- Useful for short‑form prototyping where throughput and audio pairing matter (e.g., ads, reels).